Embed Size (px)
Citation preview

THE ABSTRACT OBJECT RELATIONSHIP BROWSER (absORB)
COS 333 Project DemoThursday, May 7th, 2009
Laura Bai ’10Natasha Indik ’10Ryan Bayer ’09Tsheko Mutungu ’09
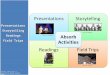
We lack user-friendly interfaces for concept-based search:
Concept-based Information Retrieval

Topic-based information retrieval is attractive: uses term co-occurrence patterns to decompose electronic corpora into sets of topics topics reveal multiple meanings of given terms in some cases, topics can handle synonymity don’t need to know exactly what you’re looking for (easier to browse through a general set of topics than a set of documents)
Concept-based Information Retrieval

A good interface should
a) Capture the multi-dimensionality of the relationships in the data. termstopics documentstopics documentsdocuments topicstopics
b) Convey differences in relevance among the set of topics/documents that match a query
c) Be navigable and intuitive for general users
Interface Requirements

100-topic model of the Journal Science. (Blei & Lafferty)
Example Topic Model Interface

100-topic model of the Journal Science. (Blei & Lafferty)
Example Topic Model Interface

This interface is browsable, but it isn’t searchable.
And the front page doesn’t directly show us which topics are related to one another.
Capturing Relationships

With super-category districts of similar topics and topics of similar documents. This gives the user:
a) A coherent overview of the topic space.
b) Relevance reporting by snapping directly to districts that contain the highest scoring topics and color coding topics accordingly.
Our Solution: Represent Topic Space as City
Anyone with a university MySQL test database and some flat file of documents for which they want to build a search engine or interface.
The first step is to register for an account.
Who can use our solution?

Anyone with a university MySQL test database and some flat file of documents for which they want to build a search engine or interface.
The first step is to register for an account.
The next step is to upload some data.
Who can use our solution?

Anyone with a university MySQL test database and some flat file of documents for which they want to build a search engine or interface.
The first step is to register for an account.
The next step is to upload some data.
Who can use our solution?

Anyone with a university MySQL test database and some flat file of documents for which they want to build a search engine or interface.
The first step is to register for an account.
The next step is to upload some data.
This prompts our system to schedule your data for topic modeling using the LDA algorithm from Blei et al.
Who can use our solution?

Anyone with a university MySQL test database and some flat file of documents for which they want to build a search engine or interface.
The first step is to register for an account.
The next step is to upload some data.
This prompts our system to schedule your data for topic modeling using the LDA algorithm from Blei et al.
Who can use our solution?

Anyone with a university MySQL test database and some flat file of documents for which they want to build a search engine or interface.
The first step is to register for an account.
The next step is to upload some data.
This prompts our system to schedule your data for topic modeling using the LDA algorithm from Blei et al.
Who can use our solution?

The output from the LDA algorithm is: a lexicon of terms from the document set a file showing termtopic relationship scores a file showing documenttopic relationship scores a file showing documentdocument relationship scores
Extracting Super-Category Districts

To determine topic super-categories, we wrote a C++ program that:parses the termtopic relationship score file to generate topic-specific term vectorsuses a centroid clustering heuristic to decompose the associated topic-term matrix into districts
Our particular solution clusters uses a cluster centroid similarity scoring function that integrates similarity (significance of correlation) with balance (similarity of size) to determine which pairs of clusters to merge.
In practice, our solution works really fast and really well, producing coherent districts that don’t vary so much in size.
Extracting Super-Category Districts

The districting program outputs: a file containing districttopic pairs districtterm relationship scoresa file containing per-district topic interactions; this is an input file for the city map generator
The limitation of this solution is that districts are completely disjoint: have no overlap in topic members.
The upside is that we can easily relate districts to one another.
Extracting Super-Category Districts
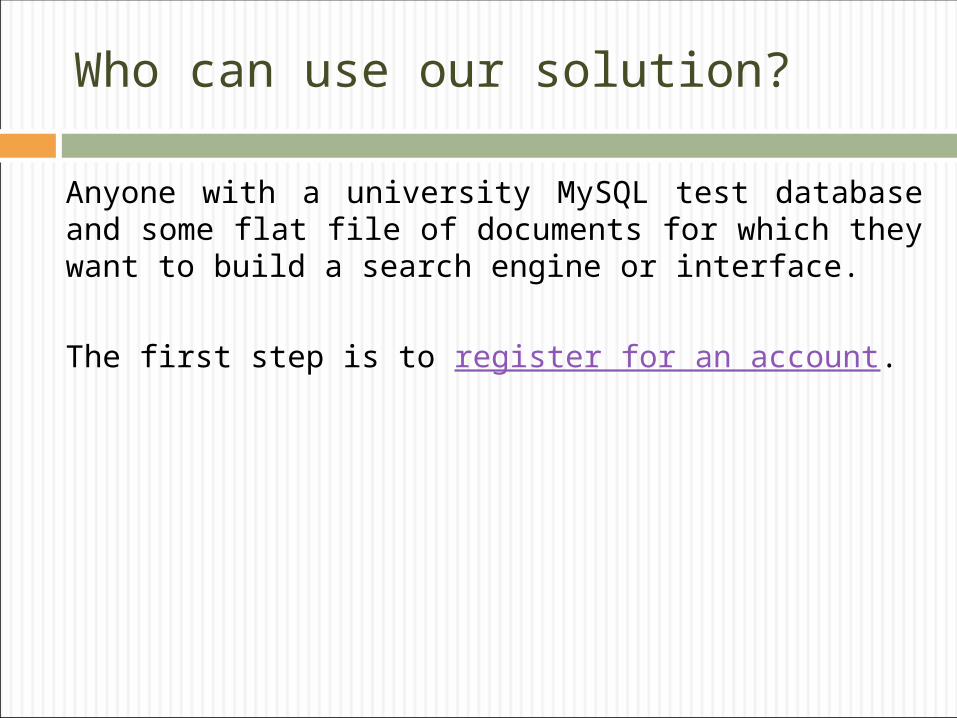
The district-specific topic interactions file is passed to a Python script that builds a force-directed graph of the district and then imposes a rectangular grid-structure on it to simulate city blocks.
Generating district maps