Embed Size (px)
Citation preview

TopX 2.0 TopX 2.0 at the INEX 2009 at the INEX 2009
Ad-hoc and Efficiency tracksAd-hoc and Efficiency tracks
Martin TheobaldMax Planck Institute Informatics
Ralf SchenkelSaarland University
Ablimit AjiEmory University

Outline
Query rewriting Data & scoring model Distributed indexing (new for 2009!) Query processing Results
Ad-hocEfficiency
Ad-h
oc F
ocus
edEffi
cien
cy F
ocus
ed
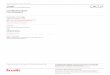
Query Rewriting I (NEXI/XPath-FT) CAS Queries
– //article//(sec|p)[(about(.//header, “Yoga Lessons” ) or about(.//title, +Yoga -history)) and about(.//figure, exercise) ]
• Query DAGs– tag-term pairs as leafs– navigational tags as support elements
• Discard all Boolean constraints, “andish” mode for both CO and CAS
articlearticle
secsec pp
header$yoga
header$yoga
header$lesson
header$lesson
title$yoga
title$yoga
figure$exercisefigure$exercise
////
////
selfself

Query Rewriting II (NEXI) CO Queries– “Yoga Lessons” +Yoga -history exercise– //*[about(., “Yoga Lessons” +Yoga -history exercise)]
– Virtual * tag, fully pre-computed and materialized in inverted lists as *-term pairs
– Can be generalized to specific tag classes(e.g. <article|sec|p>)
*$yoga*$yoga *$lesson*$lesson *$exercise*$exercise
selfself selfself
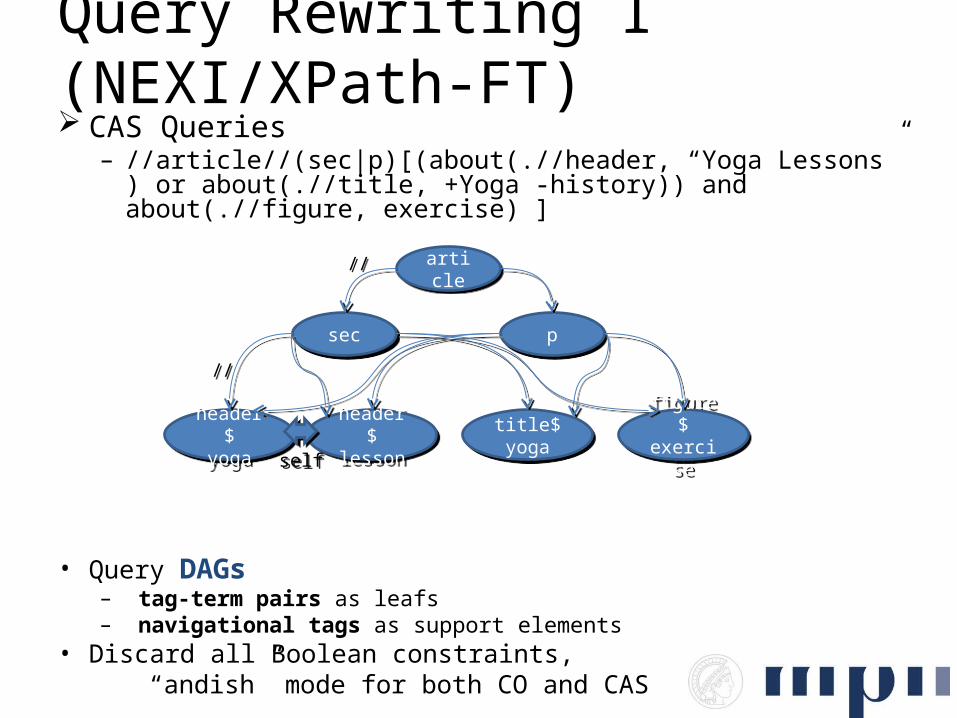
Data Model
XML Trees (no XLink/ID/IDRef) Pre-/post-order ranges for the structure Redundant full-content text nodes
<article>
<title>XML Data Management </title> <abs>XML management systems vary widely in their expressive power. </abs> <sec> <title>Native XML Data Bases. </title> <par>Native XML data base systems can store schemaless data. </par> </sec></article>
“xml data manage xml manage system vary wide expressive power native xml data base native xml data base system store schemaless data“
“native xml data base native xml data base system store schemaless data“
“xml data manage”
articlearticle
titletitle absabs secsec
“xml manage system vary wide
expressivepower“
“native xml data base”
“native xml data base system store schemaless data“
titletitle parpar
1 6
2 1 3 2 4 5
5 3 6 4
“xml data manage xml manage system vary
wide expressive power native xml native
xml data base system store schemaless data“
ftf (“xml”, article1 ) = 4ftf (“xml”, article1 ) = 4
ftf (“xml”, sec4 ) = 2ftf (“xml”, sec4 ) = 2
“native xml data base native xml data base system store schemaless data“

Scoring Model [TopX @ INEX ’05–’09]
XML-specific variant of Okapi BM25 (aka. E-BM25, Robertson et al. [INEX ‘05])
with k1 = 2.0, b=0.75decay factor for ftf of 0.925
Content Index (Tag-Term Pairs) Element Freq. Element Statistics
author[“gates”]vs.
section[“gates”]
author[“gates”]vs.
section[“gates”]

How to create a full CAS index for a large XML collection efficiently?
TopX index statistics for Wikipedia 2009 (55 GB XML sources)
Go distributed!

tag$term1
tag$term3
…
tag$term1
tag$term3
…
File[(f/p)+1]
… File[2f/p]
File[(p-1)(f/p)+1]
… File[f]
File[1]
…File[f/p]
tag$term2
tag$term4
…
tag$term2
tag$term4
…
tag$term4
tag$term5
…
tag$term4
tag$term5
…
…
…
…
Node1 Node2 Nodep
Docs[1, …, n/p] Docs[(n/p)+1, …, 2n/p] Docs[(p-1)/(n/p)+1, …, n]
Distributed Indexing ITop-k EngineTop-k Engine Two-level hashing:
At query processing time:
hash(ti) NodeId|FileId|ByteOffset (64-bit dictionary)
At Indexing Time:
FileId(ti) = hash(ti) mod f NodeId (ti) = FileId(ti) mod p

Distributed Indexing II
Shared dictionary is mapping 64-bit keys 64-bit values– Using hash(ti) as keys– Using 8 bits/NodeId, 12 bits/FileId, 44 bits/ByteOffset
as values Max. distributed index size:
4,096 x 244 bytes = 16 Terabytes
(Dictionary itself takes ~4 GB for 200 million keys)

Group element blocks with similar Max-Score into document blocks of fixed length (e.g. 256KB)
Sort element blocks within each document block by Doc-ID
Supports Sequential (“sorted”) access by
descending max(Max-Score) Merge-joins by Doc-ID
Dynamic top-k pruning, efficient merge-joins over large blocks
Index Files: Inverted Block Structure for CAS Queries
sec[“xml”]
0
title[“xml”]
122,564L
Doc-ID 1
Doc-ID 5
Doc-ID 2
…
…
Doc-ID 3
Doc-ID 6
Doc
umen
t Blo
ck ≤
256
KB
Max-Sore
Max-Sore
ElementBlock
SASA
pre post score

Merging BlocksIncrementally
sec[“xml”]
2
1
5
…
3
6
…
par[“retrieval”]
4
2
7
5
6
//sec[about(.//, “XML”)] //par[about(.//, “retrieval”)]
SASA
1.0
0.8
Max(Max-Score): 0.9
0.6
Sorted access and efficient merge-joins on top of large document blocks from disk

Some more tricks… Dump leading histogram blocks directly into index list headers
Histograms only for index lists that exceed one document block (<5% of all lists) Supports probabilistic pruning and cost-based index access scheduling [Prob-
Top-K, VLDB ’04; IO-Top-K, VLDB ’06] Efficient on-the-fly index decompression (S16), internal caching of
decompressed index lists
Incrementally read & process precomputed memory images for fast top-k queries on top of large disk blocks
~36
byte
s

Runs
• Ah-hoc Track (Article-Only, CO & CAS)– Focused– Best-In-Context– Thorough
• Efficiency– Type (A) Focused (same as Ad-Hoc Focused)• Top-15, Top-150, Top-1500, Article-Only, CO & CAS
– Type (B) Focused, CO only • Top-15 only, but up to 96 keywords/query
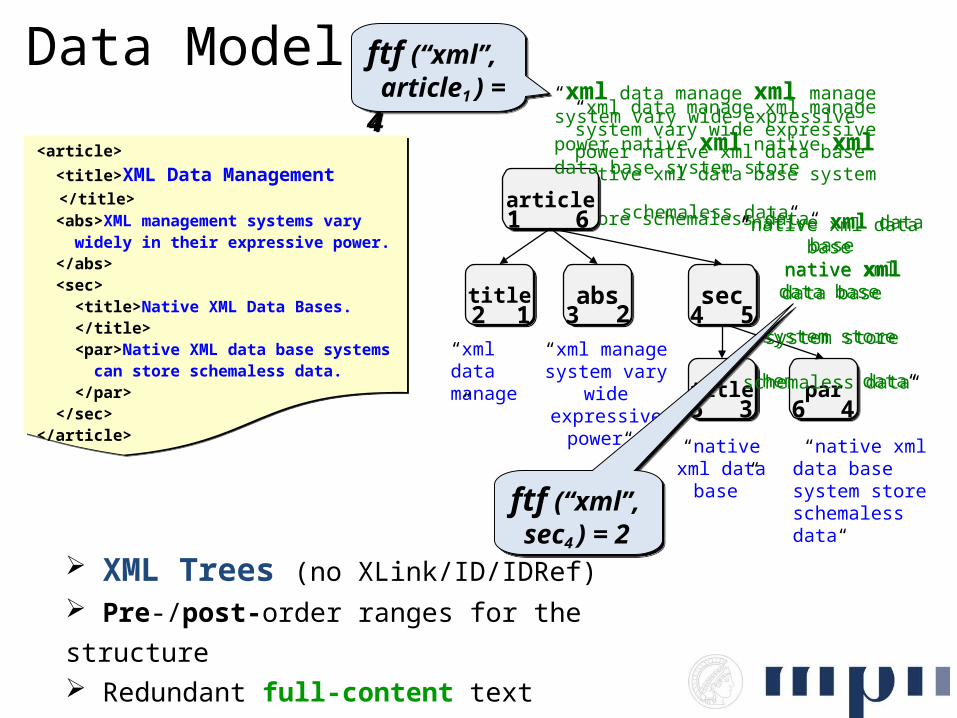
Results – Ad-hoc, Focused

Results – Ad-hoc, Best-In-Context

Results – Ad-hoc, Thorough

Results – Efficiency, Focused (Type A)

Results – Efficiency, Focused (Type A)

Results – Efficiency, Focused (Type B)

Results – Efficiency, Focused (Type B)

Future Work
• Phrase-matching & proximity ranking(non-monotonic!)• “Holistic” Top-k for XQuery – Multiple XPaths per XQuery– Efficient inter-document retrieval– Complex Boolean constraints among paths
• Updates!
Full-fledged open-source platform for W3C XQuery Full-Text