Embed Size (px)
Citation preview

Tugas Individu Anova (Hikmah Sujana)
NAMA : HIKMAH SUJANANIM : 080621KELOMPOK : 7 (Analisis Faktor)
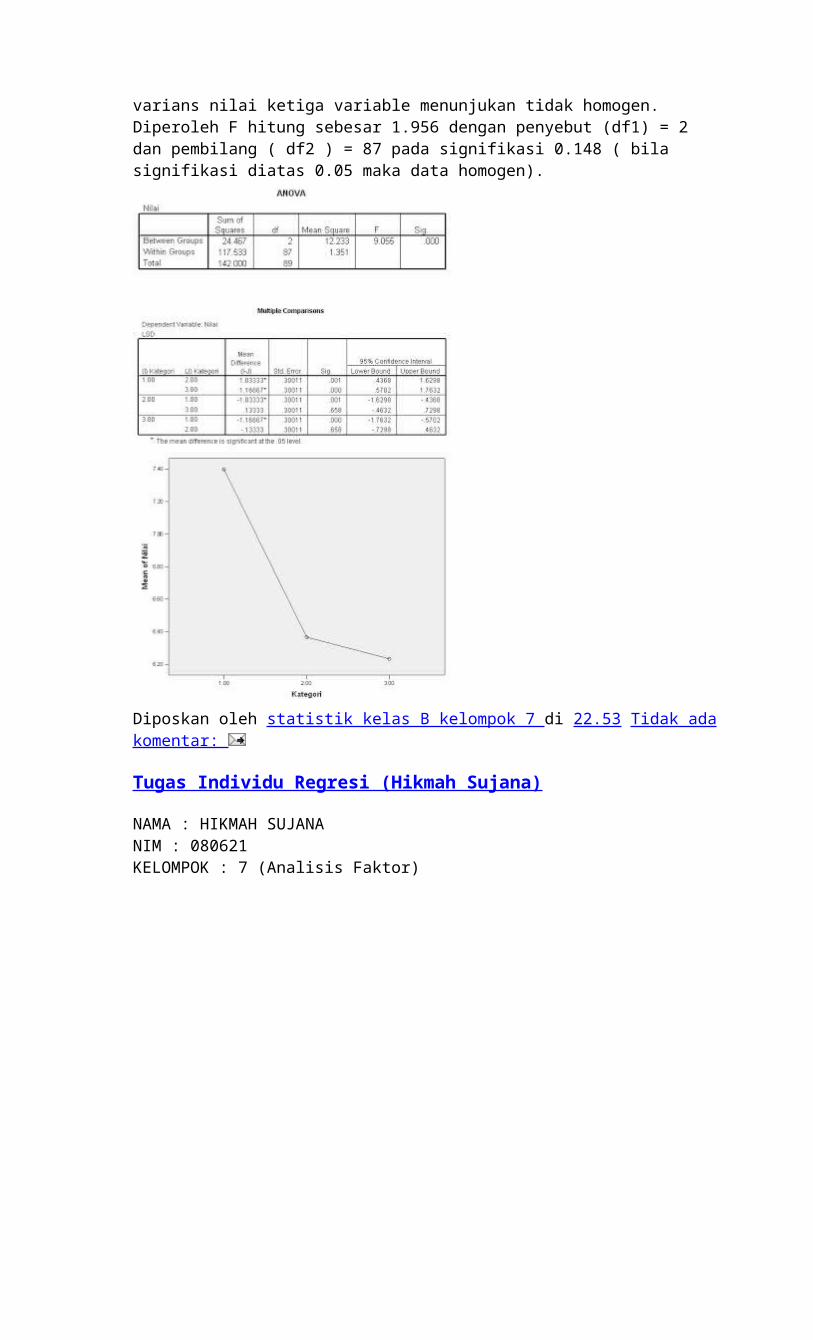
Analisis Output :Statistic deskriptif merupakan deskripsi variabel-variabel yang dianalisis.Variabel 1 sebanyak 30 orang dengan rata-rata 7.4000, standard deviasi 1.32873, tingkat kesalahan 0.24259 dengan nilai minimum 6.9038 dan nilai maksimum 1.8962.Variabel 2 sebanyak 30 orang dengan rata-rata 6.3667, standard deviasi 1.12903, tingkat kesalahan 0.20613 dengan nilai minimum 5.9451 dan nilai maksimum 6.7883.Variabel 3 sebanyak 30 orang dengan rata-rata 6.2333, standard deviasi 1.00630, tingkat kesalahan 0.18372 dengan nilai minimum 5,8576 dan nilai maksimum 6.6091.Total variabel 90 orang dengan rata-rata 6.6667, standard deviasi 1.26313, tingkat 1.21083 dengan nilai minimum 6.4021 dan nilai maksimum 6.9312.
Analisis Output :Tabel Test of Homogeneity of Variances menunjukan nilai Sig ( 0,398 ) > α ( 0,05 ). Hal tersebut mengidentifikasikan varian antar kelompok adalah sama ( homogen ).Test homogenitas varians nilai ketiga variable menunjukan tidak homogen. Diperoleh F hitung sebesar 1.956 dengan penyebut (df1) = 2 dan pembilang ( df2 ) = 87 pada signifikasi 0.148 ( bila signifikasi diatas 0.05 maka data homogen).
Diposkan oleh statistik kelas B kelompok 7 di 22.53 Tidak ada komentar:
Tugas Individu Regresi (Hikmah Sujana)
NAMA : HIKMAH SUJANANIM : 080621KELOMPOK : 7 (Analisis Faktor)
Analisis Output:Tabel di atas merupakan gambaran umum tentang data yang diinput

Analisis Output: 1. Dengan mengunakan korelasi Pearson diperoleh r= 0.346.Itu berarti hubungan antara nilai UTS terhadap nilai KUIS sangat kuat. Dari koefesien korelasi yang bertanda + diperoleh arti adanya hubungan searah.2. Sig (1-tailed)= 0.031, artinya memiliki tingkat kesalahan sebesar 3.1%, jadi kita dapat percaya bahwa terdapat hubungan yang signifikan antara nilai UTS dengan Kuis sebesar 96.9%.3. N=30, artinya jumlah dat yang valid dari UTS dan Kuis sebanyak 30 data.
Analisis Output:Koefisien determinasi persamaan garis dan nilai P dapat dilihat dari tabel Model Summary pada kolom R Squere bernilai 0.346 artinya persamaan garis regresi yang diperoleh dapat menerangkan 34.6 % variasi nilai UTS atau persamaan garis linier yang diperoleh cukup baik untuk menjelaskan variasi nilai Kuis.
Analisis Output:Dari table ANOVA dapat terlihat bahwa nilai F hasil perhitungan adalah 3.804 dengan probabilitas 0.000 yang lebih kecil dari 0.05 karena itu dapat disimpulkan bahwa model regresi valid atau sesuai dengan data yang ada dan dapat digunakan untuk memprediksi.

Analisis Output:Table Coefificients menggambarkan besar konstanta dan koefisien yang digunakan untuk membuat fungsi regresi yaitu pada kolom B, dapat dilihat bahwa nilai konstanta (nilai a) = 34.66 dan nilai koefisien (nilai b)= 0.33Untuk mengetahui apakah koefisien dan konstanta regresi linier signifikan atau tidak, perlu di ketahui hipotesis yang digunakan H0 : koefisien tidak signifikan, H1 : koefisien signifikan, H0 ditolak pabaila t > tα/2 n-1 atau apabila t negatif, maka H0 ditolak apabila t< - tα/2 n-1Diposkan oleh statistik kelas B kelompok 7 di 22.40 Tidak ada komentar:
Tugas Individu Korelasi (Hikmah Sujana)
NAMA : HIKMAH SUJANANIM : 080621KELOMPOK : 7 (Analisis Faktor)
Analisis Output :
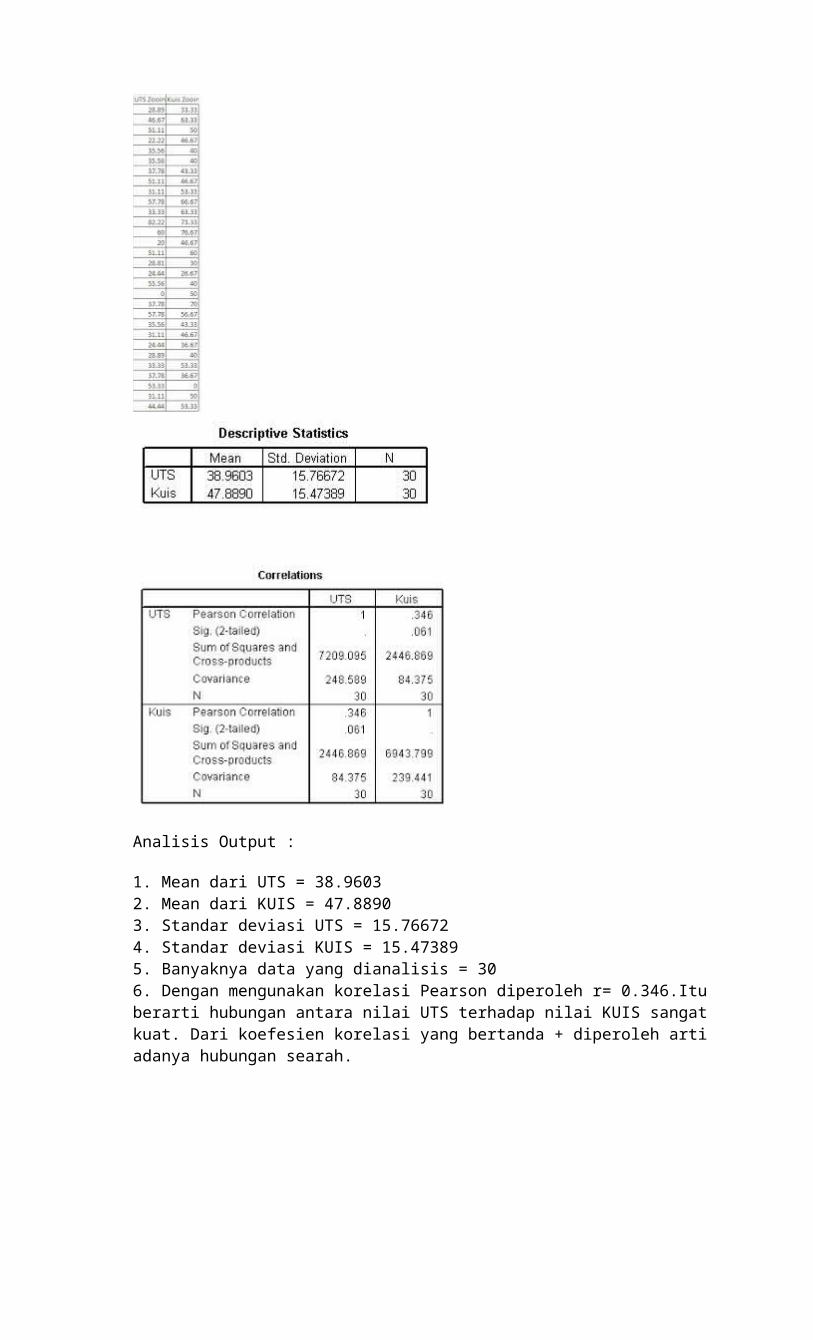
1. Mean dari UTS = 38.96032. Mean dari KUIS = 47.88903. Standar deviasi UTS = 15.766724. Standar deviasi KUIS = 15.473895. Banyaknya data yang dianalisis = 306. Dengan mengunakan korelasi Pearson diperoleh r= 0.346.Itu berarti hubungan antara nilai UTS terhadap nilai KUIS sangat kuat. Dari koefesien korelasi yang bertanda + diperoleh arti adanya hubungan searah.
Analisis Output:
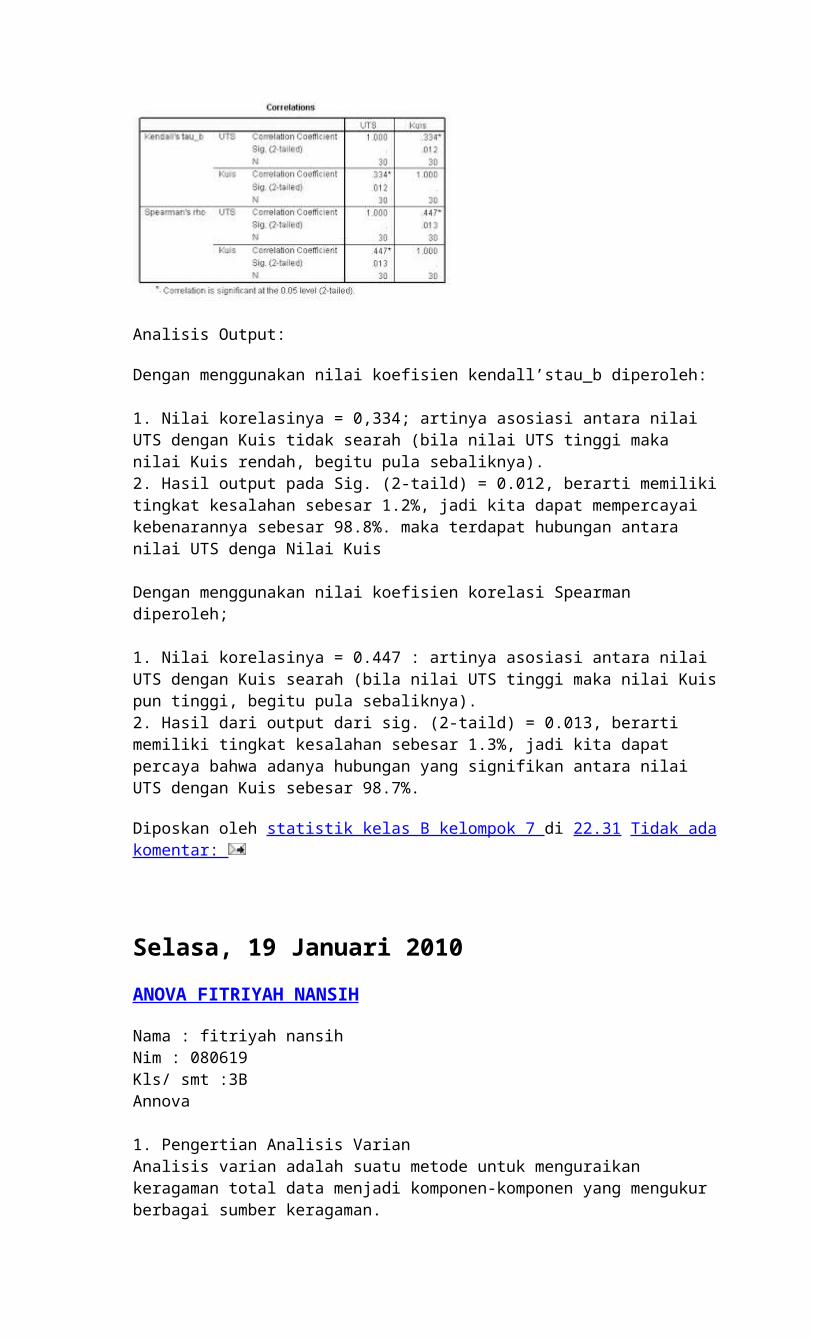
Dengan menggunakan nilai koefisien kendall’stau_b diperoleh:
1. Nilai korelasinya = 0,334; artinya asosiasi antara nilai UTS dengan Kuis tidak searah (bila nilai UTS tinggi maka nilai Kuis rendah, begitu pula sebaliknya).2. Hasil output pada Sig. (2-taild) = 0.012, berarti memiliki tingkat kesalahan sebesar 1.2%, jadi kita dapat mempercayai kebenarannya sebesar 98.8%. maka terdapat hubungan antara nilai UTS denga Nilai Kuis
Dengan menggunakan nilai koefisien korelasi Spearman diperoleh;
1. Nilai korelasinya = 0.447 : artinya asosiasi antara nilai UTS dengan Kuis searah (bila nilai UTS tinggi maka nilai Kuis pun tinggi, begitu pula sebaliknya).2. Hasil dari output dari sig. (2-taild) = 0.013, berarti memiliki tingkat kesalahan sebesar 1.3%, jadi kita dapat percaya bahwa adanya hubungan yang signifikan antara nilai UTS dengan Kuis sebesar 98.7%.
Diposkan oleh statistik kelas B kelompok 7 di 22.31 Tidak ada komentar:
Selasa, 19 Januari 2010
ANOVA FITRIYAH NANSIH
Nama : fitriyah nansihNim : 080619Kls/ smt :3BAnnova
1. Pengertian Analisis VarianAnalisis varian adalah suatu metode untuk menguraikan keragaman total data menjadi komponen-komponen yang mengukur berbagai sumber keragaman.2. Tujuan Analisis Varian- Untuk menempatkan variabel-variabel bebas penting di dalam suatu studi- Untuk menentukkan bagaimana mereka berinteraksi dalam mempengaruhi jawaban (Mendel hell dan reinmuth, 1982. hal: 542)3. Tipe Analisis varianAnalisis Varian memiliki dua tipe yaitu :1. Analisis varian 1 arahAnalisis varian 1arah yaitu suatu metode untuk menguraikan keragaman total data menjadi komponen-komponen yang mengukur berbagai sumber keragaman dengan menggunakan One-Way ANOVA dengan satu perlakuan.2. Analisis varian 2 arahAnalisis varian 2 arah yaitu suatu metode untuk menguraikan keragaman total data menjadi komponen-komponen yang mengukur berbagai sumber keragaman dengan menggunakan One-Way ANOVA dengan dua perlakuan.Untuk hipotesis nol pada analisis varian dua arah interaksi antarvariabel perlakuannya sebagai berikut.• Pengujian hipotesis nol bahwa nilai tengah baris µi adalah sama:Ho : αi = 0H1 : minimal satu αi tidak sama dengan nol• Pengujian hipotesis nol bahwa nilai tengah kolom µj adalah sama :Ho : βj = 0H1 : minimal satu βj tidak sama dengan nol• Pengujian hipotesis nol bahwa nilai tengah interaksi antara baris dan kolom adalah sama.Ho : (αβ)ij = 0Hi : minimal satu (αβ)ij tidak sama dengan nol.
Dari data tersebut dilakukan uji perbandingan, dengan menggunakan Prosedur One-Way Anova. Tombol Option pada prosedur One-Way ANOVA dapat kita gunakan untuk menampilkan nilai-nilai statistic dengan memberikan tanda centang pada pilihan Descriptipe dan untuk menguji homogenitas varian (kesamaan varian). Sehingga dari analisis dengan menggunakan SPSS tersebut diperoleh output sebagai berikut:
Oneway

Hipotesis :Ho : ó²nilai matdas 1 = ó² nilai fisdas 1= ó² nilai kimdas 1Ho : Nilai variansinya tidak semua sama.Dari table di atas terllihat bahwa taraf signifikansi = 0,335 Karena nilai ini lebih besar dari taraf signifikansi 0,05 maka kita menerima Ho. Artinya varians dari populasi nilai statistik tersebut adalah sama.
Output anovaHo : µ nilai matdas 1 = µ nilai fisdas 1 =µ nilai kimdas 1(tidak ada perbedaan daya tahan rata-rata dari ketiga nilai tersebut)H1 : µ nilai matdas 1 ≠ µ nilai fisdas 1 ≠ µ nilai kimdas 1(minimal 3 nilai dengan kualitas rata-rata yang berbeda) Dalam pengujian kali ini di gunakan tingkat signifikasi 0,026 ( α = 0,026) atau dengan kata lain tingkat kepercayaannya sebesar 0,95 (95%)Penarikan kesimpulan:Fhit > Ftable → tolak HoFhit< >Nilai statistic Ftable adalah (2;87;0,05) = 0,459 (dari table distribusi F)Terlihat dari table ANOVA bahwa nilai Fhit = 3.186 yang mana nilai ini lebih besar dari nilai Ftable sehingga dapat di simpulkan bahwa dapat menolak Ho, yang artinya ada perbedaan antara nilai dari ketiga mata kuliah tersebut.Di atas sudah di jelaskan bila Ho diterima uji perbandingan mean dalam Post Hoc tidak berguna lagi, hal ini bise kita lihat bahwa tingkat signifikasi semuanya di atas 0,05.Dengan analisi LSD pada Post Hoc terlihat bahwa :Nilai matdas dan nilai kimdas berbeda ( karena nilai sig.> 0,05)
Post Hoc Tests

ANALISIS OUTPUTDengan analisis LSD pada Post Hoc terlihat bahwa: nilai matdas 1 dan nilai fisdas 1 (karena nilai Sig. > 0,05) nilai matdas 1 dan nilai kimdas 1 (karena nilai Sig. > 0,05Selanjutnya dilakukan uji kehomogenan varians populasi jumlah.Adapun hipotesisnya adalah sebagai berikut :Ho : ó1² = ó2 ² = ó3 ² = … = ók²H1 = Nilai varian tidak semuanya sama.
Means Plots
Diposkan oleh statistik kelas B kelompok 7 di 20.46 Tidak ada komentar:
REGRESI FITRIYAH NANSIH
nama : fitriyah nansihnim : 080619kel/smt :3bPengertian regresiUntuk mengukur besarnya pengaruh variabel bebas terhadap variabel tergantung dan memprediksi variabel tergantung dengan menggunakan variabel bebas. Gujarati (2006) mendefinisikan analisis regresi sebagai kajian terhadap hubungan satu variabel yang disebut sebagai variabel yang diterangkan (the explained variabel) dengan satu atau dua variabel yang menerangkan (the explanatory). Variabel pertama disebut juga sebagai variabel tergantung dan variabel kedua disebut juga sebagai variabel bebas. Jika variabel bebas lebih dari satu, maka analisis regresi disebut regresi linear berganda. Disebut berganda karena pengaruh beberapa variabel bebas akan dikenakan kepada variabel tergantung.
Tujuan Tujuan menggunakan analisis regresi ialah• Membuat estimasi rata-rata dan nilai variabel tergantung dengan didasarkan pada nilai variabel bebas.• Menguji hipotesis karakteristik dependensi• Untuk meramalkan nilai rata-rata variabel bebas dengan didasarkan pada nilai variabel bebas diluar jangkaun sample.AsumsiPenggunaan regresi linear sederhana didasarkan pada asumsi diantaranya sbb:• Model regresi harus linier dalam parameter• Variabel bebas tidak berkorelasi dengan disturbance term (Error) .• Nilai disturbance term sebesar 0 atau dengan simbol sebagai berikut: (E (U / X) = 0• Varian untuk masing-masing error term (kesalahan) konstan• Tidak terjadi otokorelasi• Model regresi dispesifikasi secara benar. Tidak terdapat bias spesifikasi dalam model yang digunakan dalam analisis empiris.• Jika variabel bebas lebih dari satu, maka antara variabel bebas (explanatory) tidak ada hubungan linier yang nyataPersyaratan Penggunaan Model RegresiModel kelayakan regresi linear didasarkan pada hal-hal sebagai berikut:a. Model regresi dikatakan layak jika angka signifikansi pada ANOVA sebesar < 0.05

b. Predictor yang digunakan sebagai variabel bebas harus layak. Kelayakan ini diketahui jika angka Standard Error of Estimate < Standard Deviationc. Koefesien regresi harus signifikan. Pengujian dilakukan dengan Uji T. Koefesien regresi signifikan jika T hitung > T table (nilai kritis)d. Tidak boleh terjadi multikolinieritas, artinya tidak boleh terjadi korelasi yang sangat tinggi atau sangat rendah antar variabel bebas. Syarat ini hanya berlaku untuk regresi linier berganda dengan variabel bebas lebih dari satu.e. Tidak terjadi otokorelasi. Terjadi otokorelasi jika angka Durbin dan Watson (DB) sebesar < 1 dan > 3f. Keselerasan model regresi dapat diterangkan dengan menggunakan nilai r2 semakin besar nilai tersebut maka model semakin baik. Jika nilai mendekati 1 maka model regresi semakin baik. Nilai r2 mempunyai karakteristik diantaranya: 1) selalu positif, 2) Nilai r2 maksimal sebesar 1. Jika Nilai r2 sebesar 1 akan mempunyai arti kesesuaian yang sempurna. Maksudnya seluruh variasi dalam variabel Y dapat diterangkan oleh model regresi. Sebaliknya jika r2 sama dengan 0, maka tidak ada hubungan linier antara X dan Y.g. Terdapat hubungan linier antara variabel bebas (X) dan variabel tergantung (Y)h. Data harus berdistribusi normali. Data berskala interval atau rasioj. Kedua variabel bersifat dependen, artinya satu variabel merupakan variabel bebas (disebut juga sebagai variabel predictor) sedang variabel lainnya variabel tergantung (disebut juga sebagai variabel response)RingkasanAnalisis regresi berbeda dengan analisis korelasi. Jika analisis korelasi digunakan untuk melihat hubungan dua variable; maka analisis regresi digunakan untuk melihat pengaruh variable bebas terhadap variable tergantung serta memprediksi nilai variable tergantung dengan menggunakan variable bebas. Dalam analisis regresi variable bebas berfungsi untuk menerangkan (explanatory) sedang variable tergantung berfungsi sebagai yang diterangkan (the explained). Dalam analisis regresi data harus berskala interval atau rasio. Hubungan dua variable bersifat dependensi. Untuk menggunakan analisis regresi diperlukan beberapa persyaratan yang harus dipenuhi.
Regression
Tabel di atas merupakan gambaran umum tentang data yang diinput

1. Dengan mengunakan korelasi Pearson diperoleh r= 0.041.Itu berarti hubungan antara nilai pancasila terhadap nilai Kwn sangat kuat. Dari koefesien korelasi yang bertanda + diperoleh arti adanya hubungan searah. 2. Sig (1-tailed)= 0.416, artinya memiliki tingkat kesalahan sebesar 4.1%, jadi kita dapat percaya bahwa terdapat hubungan yang signifikan antara nilai pancasila dengan nilai KWN sebesar 95.9%.3. N=30, artinya jumlah dat yang valid dari nilai panacasila dan nilai kwn sebanyak 30 data.
Variables Entered/Removed(b)
Koefisien determinasi persamaan garis dan nilai P dapat dilihat dari tabel Model Summary pada kolom R Squere bernilai 0,002 artinya persamaan garis regresi yang diperoleh dapat menerangkan 0,2 % variasi nilaipancasila atau persamaan garis linier yang diperoleh cukup baik untuk menjelaskan variasi nilai Kwn.
Dari table ANOVA dapat terlihat bahwa nilai F hasil perhitungan adalah 0,046 probabilitas 0.831 yang lebih besar dari 0.05 karena itu dapat disimpulkan bahwa model regresi valid atau sesuai dengan data yang ada dan dapat digunakan untuk memprediksi.
Coefficients(a)

Residuals Statistics(a)
Analisis: Table Coefificients menggambarkan besar konstanta dan koefisien yang digunakan untuk membuat fungsi regresi yaitu pada kolom B, dapat dilihat bahwa nilai konstanta (nilai a) = 34.66 dan nilai koefisien (nilai b)= 0.33 Untuk mengetahui apakah koefisien dan konstanta regresi linier signifikan atau tidak, perlu di ketahui hipotesis yang digunakan H0 : koefisien tidak signifikan, H1 : koefisien signifikan, H0 ditolak pabaila t > tα/2 n-1 atau apabila t negatif, maka H0 ditolak apabila t< - tα/2 n-1
Charts

Diposkan oleh statistik kelas B kelompok 7 di 19.52 Tidak ada komentar:
KORELASI FITRIYAH NANSIH
NAMA : FITRIYAH NANSIHNIM : 080619KLS/SMT: 3BKorelasi merupakan teknik analisis yang termasuk dalam salah satu teknik pengukuran asosiasi / hubungan (measures of association). Pengukuran asosiasi merupakan istilah umum yang mengacu pada sekelompok teknik dalam statistik bivariat yang digunakan untuk mengukur kekuatan hubungan antara dua variabel. Diantara sekian banyak teknik-teknik pengukuran asosiasi, terdapat dua teknik korelasi yang sangat populer sampai sekarang, yaitu Korelasi Pearson Product Moment dan Korelasi Rank Spearman. Selain kedua teknik tersebut, terdapat pula teknik-teknik korelasi lain, seperti Kendal, Chi-Square, Phi Coefficient, Goodman-Kruskal, Somer, dan Wilson.Pengukuran asosiasi mengenakan nilai numerik untuk mengetahui tingkatan asosiasi atau kekuatan hubungan antara variabel. Dua variabel dikatakan berasosiasi jika perilaku variabel yang satu mempengaruhi variabel yang lain. Jika tidak terjadi pengaruh, maka kedua variabel tersebut disebut independen.Korelasi bermanfaat untuk mengukur kekuatan hubungan antara dua variabel (kadang lebih dari dua variabel) dengan skala-skala tertentu, misalnya Pearson data harus berskala interval atau rasio; Spearman dan Kendal menggunakan skala ordinal; Chi Square menggunakan data nominal. Kuat lemah hubungan diukur diantara jarak (range) 0 sampai dengan 1. Korelasi mempunyai kemungkinan pengujian hipotesis dua arah (two tailed). Korelasi searah jika nilai koefesien korelasi diketemukan positif; sebaliknya jika nilai koefesien korelasi negatif, korelasi disebut tidak searah. Yang dimaksud dengan koefesien korelasi ialah suatu pengukuran statistik kovariasi atau asosiasi antara dua variabel. Jika koefesien korelasi diketemukan tidak sama dengan nol (0), maka terdapat ketergantungan antara dua variabel tersebut. Jika koefesien korelasi diketemukan +1. maka hubungan tersebut disebut sebagai korelasi sempurna atau hubungan linear sempurna dengan kemiringan (slope) positif. Jika koefesien korelasi diketemukan -1. maka hubungan tersebut disebut sebagai korelasi sempurna atau hubungan linear sempurna dengan kemiringan (slope) negatif. Dalam korelasi sempurna tidak diperlukan lagi pengujian hipotesis, karena kedua variabel mempunyai hubungan linear yang sempurna. Artinya variabel X mempengaruhi variabel Y secara sempurna. Jika korelasi sama dengan nol (0), maka tidak terdapat hubungan antara kedua variabel tersebut.Dalam korelasi sebenarnya tidak dikenal istilah variabel bebas dan variabel tergantung. Biasanya dalam penghitungan digunakan simbol X untuk variabel pertama dan Y untuk variabel kedua. Dalam contoh hubungan antara variabel remunerasi dengan kepuasan kerja, maka variabel remunerasi merupakan variabel X dan kepuasan kerja merupakan variabel Y.
1.2 KegunaanPengukuran asosiasi berguna untuk mengukur kekuatan (strength) hubungan antar dua variabel atau lebih. Contoh: mengukur hubungan antara variabel:• Motivasi kerja dengan produktivitas• Kualitas layanan dengan kepuasan pelanggan• Nilai pancasila dan nilai Kewarganegaraan

Pengukuran ini hubungan antara dua variabel untuk masing-masing kasus akan menghasilkan keputusan, diantaranya:• Hubungan kedua variabel tidak ada• Hubungan kedua variabel lemah• Hubungan kedua variabel cukup kuat• Hubungan kedua variabel kuat• Hubungan kedua variabel sangat kuatPenentuan tersebut didasarkan pada kriteria yang menyebutkan jika hubungan mendekati 1, maka hubungan semakin kuat; sebaliknya jika hubungan mendekati 0, maka hubungan semakin lemah.
Correlations
1. Mean dari nilai pancasila = 3.60002. Mean dari nilai kwn = 3.53333. Standar deviasi nilai pancasila = 0.498274. Standar deviasi nilai kwn = 0.681455. Banyaknya data yang dianalisis = 306. Dengan mengunakan korelasi Pearson diperoleh r= 0.041.Itu berarti hubungan antara nilai pancasila terhadap nilai kwn sangat kuat. Dari koefesien korelasi yang bertanda + diperoleh arti adanya hubungan searah.
Nonparametric Correlations

Dengan menggunakan nilai koefisien kendall’stau_b diperoleh:
1. Nilai korelasinya = -0,009; artinya asosiasi antara nilaipancasila dengan nilai KWN tidak searah (bila nilai pancasila tinggi maka nilaiKWN rendah, begitu pula sebaliknya).2. Hasil output pada Sig. (2-taild) = 0.96, berarti memiliki tingkat kesalahan sebesar 9,6%, jadi kita dapat mempercayai kebenarannya sebesar 91,4%. maka terdapat hubungan antara nilai pancasila denga Nilai kwn
Dengan menggunakan nilai koefisien korelasi Spearman diperoleh;
1. Nilai korelasinya = 0.009 : artinya asosiasi antara nilai nilaipancasila dengan kwn searah (bila nilai pancasila tinggi maka nilai KWN pun tinggi, begitu pula sebaliknya).2. Hasil dari output dari sig. (2-taild) = 0.961, berarti memiliki tingkat kesalahan sebesar 9,61%, jadi kita dapat percaya bahwa adanya hubungan yang signifikan antara nilai pancasila dengan nilai kwn sebesar 98.7%. Diposkan oleh statistik kelas B kelompok 7 di 18.55 Tidak ada komentar:
Rabu, 13 Januari 2010
MUHAMMAD DERI GUSTIMAN 22 24 080629
ANOVA
DATA MENTAH

Analisis Output :Statistic deskriptif merupakan deskripsi variabel-variabel yang dianalisis.
Nilai Mortum sebanyak 30 orang dengan rata-rata 73.4517, standard deviasi 8.71104, standard kesalahan 1.59041 dengan nilai minimum 57.00 dan nilai maksimum 88.00.
Nilai matdas 1 sebanyak 30 orang dengan rata-rata 75.3000, standard deviasi 12.32365, standard kesalahan 2.24998 dengan nilai minimum 46.00 dan nilai maksimum 97.00.
Nilai pai 1 sebanyak 30 orang dengan rata-rata 68.4000, standard deviasi 12.28007, standard kesalahan 2.24202 dengan nilai minimum 34.00 dan nilai maksimum 88.00.
Total nilai Mortum, matdas I, dan pai I sebanyak 90 orang dengan rata-rata 72.3839, standard deviasi 11.48694, standard kesalahan 1.21083 dengan nilai minimum 34.00 dan nilai maksimum 97.00.
Analisis Output :Tabel Test of Homogeneity of Variances menunjukan nilai Sig ( 0,398 ) > α ( 0,05 ). Hal tersebut mengidentifikasikan varian antar kelompok adalah sama ( homogen ).Test homogenitas varians nilai Mortum, Matdas I, dan PAI I menunjukan homogen. Diperoleh F hitung sebesar 0.930 dengan penyebut (df1) = 2 dan pembilang ( df2 ) = 87 pada signifikasi 0.398 ( bila signifikasi diatas 0.05 maka data homogen).
Dalam pengujian kali ini menggunakan tingkat signifikasi 0,05 (=5%) atau dengan kata lain tingkat kepercayaan 0,95 (95%).
Nilai Statistik F adalah F (2: 87 : 0,05) = 0,459 (dari table distribusi F)
Penarikan kesimpulan :
F hitung > F table → tolak Ho
F hitung <>o
Terlihat dari table ANOVA bahwa nilai statistic F adalah 3.033 yang berarti lebih besar dari F table = 0,459. Jadi dapat disimpulkan bahwa Ho di tolak. Itu berarti ada perbedaan rata-rata pilihan bacaan. (Hal ini bisa dilihat pada Sig. = 0,053, yang lebih kecil dari taraf signifikasi = 5%).

Dengan analisis LDS pada Post Hoc terlihat bahwa :
Matdas dengan Pai berbeda (karena nilai Sig.<>
Mortum dengan Pai berbeda (karena nilai Sig. > 0,05) Mortum dengan Matdas berbeda (karena nilai Sig. > 0,05























