Embed Size (px)
Citation preview

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 1/59
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
Uông Huy Long
GIẢI PHÁP MỞ RỘNG THÔNG TIN NGỮ CẢNHPHIÊN DUYỆT WEB NGƯỜI DÙNG NHẰM NÂNGCAO CHẤT LƯỢNG TƯ VẤN TRONG HỆ THỐNG
TƯ VẤN TIN TỨC
KHOÁ LUẬN TỐT NGHIỆP ĐẠI HỌC HỆ CHÍNH QUY
Ngành: Công nghệ thông tin
HÀ NỘI - 2010

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 2/59
Lời cảm ơn
Trước tiên, tôi xin gửi lời cảm ơn và lòng biết ơn sâu sắc nhất tới Phó Giáo sư Tiến sĩ
Hà Quang Thụy và Thạc sĩ Trần Mai Vũ, người đã tận t ình chỉ bảo và hướng dẫn tôi
trong suốt quá tr ình thực hiện khoá luận tốt nghiệp.
Tôi chân thành cảm ơn các thầy, cô đã tạo những điều kiện thuận lợi cho tôi học tập và
nghiên cứu tại trường Đại Học Công Nghệ.
Tôi cũng xin gửi lời cảm ơn tới các anh chị và các bạn sinh viên trong nhóm “Khai phá
dữ liệu” đã giúp tôi rất nhiều trong việc hỗ trợ kiến thức chuyên môn để hoàn thành tốt
khoá luận.
Cuối cùng, tôi muốn gửi lời cảm vô hạn tới gia đ ình và bạn bè, những người thân yêu
luôn bên cạnh và động viên tôi trong suốt quá tr ình thực hiện khóa luận tốt nghiệp.
Tôi xin chân thành cảm ơn!
Sinh viên
Uông Huy Long
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
Uông Huy Long
GIẢI PHÁP MỞ RỘNG THÔNG TIN NGỮ CẢNHPHIÊN DUYỆT WEB NGƯỜI DÙNG NHẰM NÂNG
CAO CHẤT LƯỢNG TƯ VẤN TRONG HỆ THỐNG TƯ
VẤN TIN TỨC
KHOÁ LUẬN TỐT NGHIỆP ĐẠI HỌC HỆ CHÍNH QUY
Ngành: Công nghệ thông tin
Cán bộ hướng dẫn: Th.S Trần Mai Vũ
HÀ NỘI - 2010

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 3/59

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 4/59

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 5/59
iii
Mục lục
Mở đầu .......................................................................................................................... 1 Chương 1. Khái quát về các hệ thống tư vấn .................................................................. 3
1.1. Bài toán tư vấn ............................................................................................... 3 1.2. Các k ĩ thuật tư vấn .......................................................................................... 5
1.2.1. K ĩ thuật tư vấn dựa tr ên nội dung .................................................. ........... 5 1.2.2. K ĩ thuật tư vấn cộng tác ........................................................................... 8 1.2.3. K ĩ thuật tư vấn lai................................................................................... 11
1.3. Sơ lược về hệ thống tư vấn tin tức của khóa luận .......................................... 13 1.3.1. Đặc trưng của tư vấn tin tức. .................................................................. 13 1.3.2. Hướng tiếp cận của khóa luận ................................................................ 14
Chương 2. Mô h ình hóa sở thích người dùng cho các hệ tư vấn dựa tr ên nội dung. ...... 16 2.1. Tiến tr ình mô hình sở thích người dùng ......................................... ............... 16 2.2. Thu thập thông tin về người dùng ................................................................. 17
2.2.1. Phương pháp định danh người dùng ....................................................... 17 2.2.2. Các phương pháp thu thập thông tin ....................................................... 18
2.3. Xây dựng mô h ình sở thích người dùng ........................................................ 21 2.3.1. Phương pháp dựa tr ên từ khóa có trọng số.............................................. 21 2.3.2. Phương pháp dựa tr ên mạng ngữ nghĩa ................................................ .. 22 2.3.3. Phương pháp dựa tr ên cây phân cấp khái niệm ....................................... 23
Chương 3. Mô h ình .................................................................... ............................ ...... 24 3.1. Cơ sở lý thuyết ............................................................................................. 25
3.1.1. Phân tích thông tin chủ đề dựa tr ên mô hình chủ đề LDA. ...................... 25 3.1.2. Nhận dạng các thực thể trong tài liệu dựa tr ên từ điển ............................ 27
3.2. Phân tích sở thích người dùng ............................... ........................................ 28 3.2.1. Thông tin trong phiên duyệt web người dùng ......................................... 28 3.2.2. Mô hình sở thích người dùng ................................................................. 29
3.3. Áp dụng mô h ình môi quan tâm người dùng vào tư vấn tin tức ..................... 30 3.3.1. Pha phân tích dữ liệu tư vấn ................................................................... 30 3.3.2. Pha tư vấn trực tuyến ............................................................................. 33
3.4. Đánh giá kết quả tư vấn. ............................................................................... 36 Chương 4: Thực nghiệm và đánh giá ........................................................................... 37

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 6/59
iv
4.1. Môi trường thực nghiệm ............................................................................... 37 4.2. Dữ liệu và công cụ........................................................................................ 37
4.2.1. Dữ liệu ................................................................................................... 37 4.2.2. Công cụ.................................................................................................. 38
4.3.
Thực nghiệm ................................................................................................ 39
4.3.1. Ví dụ về phân tích tin tức ....................................................................... 39 4.3.2. Ví dụ phân tích sở thích người dùng ....................................................... 40 4.3.3. Tư vấn tin tức......................................................................................... 42
4.4. Kết quả thực nghiệm và đánh giá.................................................................. 43 Kết luận ....................................................................................................................... 46 Tài liệu tham khảo ....................................................................................................... 48

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 7/59
v
Danh sách hình
Hình 1. Các thành phần chính của hệ thống tư vấn......................................................... 4
Hình 2. Tiến tr ình mô hình hóa sở thích người dùng. ................................................... 16
Hình 3. Các hệ thống tư vấn dựa tr ên thông tin phản hồi hiện. ..................................... 19 Hình 4. Mô hình mối quan tâm người dùng dựa tr ên từ khóa. ...................................... 22 Hình 5. Mô hình mối quan tâm người dùng dựa tr ên mạng ngữ nghĩa .......................... 22 Hình 6. Mô hình mối quan tâm người dùng dựa tr ên mạng khái niệm .......................... 23 Hình 7. Tài liệu với K chủ đề ẩn. ................................................................................. 25 Hình 8. Biểu diễn đồ họa LDA..................................................................................... 26 Hình 9. Ước lượng tham số tập dữ liệu văn bản. .......................................................... 26 Hình 10. Suy diễn chủ đề sử dụng tập dữ liệu VnExpress ............................................ 27 Hình 11. Mô hình sở thích người dùng dựa tr ên chủ đề ẩn và thực thể. ........................ 29 Hình 12. Mô hình pha phân tích dữ liệu tư vấn ............................................................ 31 Hình 13. Mô hình pha tư vấn trực tuyến....................................................................... 33 Hình 14. Biểu diễn tin tức theo chủ đề và thực thể. ...................................................... 39 Hình 15. Kết quả phân tích cho thấy các thông tin liên quan đến chủ đề 19.................. 42

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 8/59
vi
Danh sách các bảng
Bảng 1. Đánh giá theo thang điểm về một số bộ phim đã xem. ............... ....................... 5
Bảng 2. Các kĩ thuật thu thập thông tin ẩn. ................................................................... 20
Bảng 3. Ví dụ về một hồ sơ sở thích người dùng. ......................................................... 24 Bảng 4. Thông tin trong phiên duyệt web..................................................................... 28 Bảng 5. Môi trường thực nghiệm. ................................................................................ 37 Bảng 6. Công cụ. ......................................................................................................... 38 Bảng 7. Một số chủ đề ẩn............................................................................................. 39 Bảng 8. Ví dụ về phân tích sở thích người dùng. .......................................................... 40 Bảng 9. Đánh giá mô h ình phân tích sở thích. .............................................................. 44 Bảng 10. Độ chính xác của mô h ình dựa vào đánh giá của người sử dụng.................... 44

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 9/59
1
Mở đầu
Từ khi những bài báo đầu tiên về lọc công tác được công bố từ những năm 90 của
thế kỉ trước, hệ tư vấn đã chứng tỏ được vai tr ò quan trọng của m ình trong cả hai khía
cạnh nghiên cứu và ứng dụng. Chúng ta có thể dễ dàng tiếp cận với các bài báo khoa học
liên quan đến từ khóa “Recommender System” trong hơn 8600 kết quả trả về từ máy t ìm
kiếm GoogleScholar 1 với hơn 1100 kết quả cho riêng năm 2009 hoặc sử dụng các ứng
dụng tư vấn nổi tiếng như sách trên Amazon2, phim trên NetFlix3.
Các hệ tư vấn hoạt động như một bộ lọc thông tin [8], nhằm cố gắng đưa ra các
thông tin về nội dung hoặc thông tin về sản phẩm (như phim, sách, website, tin tức,…) có
nhiều khả năng thuộc được người dùng quan tâm. Thông thường, một hệ tư vấn so sánh
mối quan tâm của người dùng (trong khóa luận, hai khái niệm mối quan tâm người dùng
hay sở thích người dùng có thể được sử dụng thay thế cho nhau) với một vài đặc trưng
tham chiếu để đưa ra các ước lượng đánh giá cho các sản phẩm. Các đặc trưng này có thể
đến từ các thông tin của sản phẩm (hướng tiếp cận lọc dựa tr ên nội dung) hoặc từ môi
trường xã hội người dùng (hướng tiếp cận lọc cộng tác).
Mặc dù các hệ thống tư vấn đã được nghiên cứu từ khá lâu, và đã có nhiều ứng
dụng chứng minh được tính hiệu quả của các hệ thống tư vấn trên thế giới, các nghiên cứu
về lĩnh vực này ở Việt Nam còn hạn chế. Mong muốn phát triển một hệ thống tư vấn,
khóa luận tập trung vào xây dựng một hệ thống tư vấn các tin tức tiếng Việt.
Ngày nay, khái niệm “báo điện tử” cũng như việc đọc tin tức điện tử đã không còn
xa lạ với đa số người dân Việt Nam. Những thống k ê trong gần đây tr ên BaoMoi4 về số
lượ t người sử dụng internet để xem các tin tức điện tử hiện nay đang cho thấy nhu cầu
ngày một tăng của xã hội trong lĩnh vực truyền thông này. Tuy nhiên, một vấn đề còn tồn
tại hiện nay đó là trong khi có quá nhiều tin tức mỗi ngày được cập nhật, người dùng
giường như bị ch ìm ngập trong biển thông tin mà vẫn không t ìm ra được các thông tin
phù hợp, đó chính là môi trường cho các lĩnh vực liên quan đến tư vấn tin tức phát triển.
Nắm bắt được nhu cầu này, khóa luận đề xuất một giải pháp tư vấn các nội dung thông tin
liên quan đến ngữ cảnh tiếp nhận thông tin hiện tại của người sử dụng, qua đó mong
1 http://www.scholar.google.com2 http://www.amazon.com3 http://www.netflix.com4 http://www.baomoi.com/Statistics/Report.aspx

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 10/59
2
muốn cung cấp được những chỉ dẫn đúng, nhanh chóng, và không có các phiền toái từ
việc phải đăng kí hay cung cấp các thông tin cá nhân.
Nội dung chính của khóa luận được chia làm 4 phần:
Chương 1. Các hệ thống tư vấn: Trình bày các khái niệm, các thuật ngữ, các kĩ
thuật liên quan đến hệ thống tư vấn. Các ưu và nhược điểm của các k ĩ thuật này
cũng được tr ình bày chi tiết hơn trong các mục 1.2 và 1.3.
Chương 2. Mô hình hóa sở thích người dùng cho các hệ tư vấn dựa trên nội
dung: Giới thiệu về bài toán xây dựng sở thích người dùng, các thông tin được
sử dụng để phân tích và một số kĩ thuật mô h ình sở thích người dùng.
Chương 3. Mô hình: Trình bày đề xuất xây dựng sở thích người dùng dựa tr ên
phân tích chủ đề ẩn phổ biến và các thực thể, và áp dụng của mô h ình này vào hệthống tư vấn tin tức.
Chương 4. Thực nghiệm và đánh giá: Trình bày một số kết quả đánh giá ban
đầu.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 11/59

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 12/59
4
Trong các hệ thống tư vấn, mức độ phù hợp của sản phẩm thường được biểu diễn
theo đánh giá thang điểm (rating), phụ thuộc vào từng ứng dụng, các đánh giá này có thể
được thực hiện trực tiếp bởi người dùng hoặc được tính toán bởi hệ thống.
Mỗi người dùng thuộc không gian ngươi dùng U được xác định bởi một hồ sơ (user profile), những thông tin lưu trong hồ sơ này có thể bao gồm các thông tin như giới tính,
tuổi, quốc gia, tính trạng hôn nhân, … hay cũng có thể bao gồm các thông tin về sở thích,
mối quan tâm của họ. Tương tự như vậy, mỗi sản phẩm cũng được mô tả bởi tập hợp các
đặc trưng của chúng. Ví dụ, trong hệ thống tư vấn phim, các đặc trưng của một bộ phim
có thể là tên phim, thể loại, đạo diễn, diễn viên chính,…
Một cách khát quát tiến tr ình tư vấn có thể được mô tả như sau:
Hình 1. Các thành phần chính của hệ thống tư vấn.
Đầu tiên, bộ phận học hồ sơ người dùng phân tích các sở thích ngươi dùng. Một khi
hệ thống hiểu được người dùng quan tâm đến điều g ì, nó thực thi một thuật toán tư vấn,
so sánh, tổ hợp giữa các hồ sơ người dùng hoặc giữa hồ sơ người dùng với các đặc trưng
sản phẩm, sau đó chọn ra tập hợp những sản phẩm người dùng có thể ưa thích.
Vấn đề chính của hệ tư vấn là hàm g không được xác định trên toàn không gian
× mà chỉ tr ên một miền nhỏ của không gian đó. Điều này dẫn tới việc hàm g phải
được ngoại suy trong không gian này. Thông thường, độ phù hợp được thể hiện bằng
điểm và chỉ xác định tr ên tập các sản phẩm đã từng được người dùng đánh giá từ trước

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 13/59
5
(thường khá ít). Ví dụ, bảng 2 là đánh giá của một số người dùng với các phim mà họ đã
xem (thang điểm từ 0-10, kí hiệu ∅ ngh ĩa là bộ phim chưa được người dùng cho điểm).
Từ những thông tin đó, hệ thống tư vấn phải dự đoán (ngoại suy) điểm cho các bộ phim
chưa được người dùng đánh giá, từ đó đưa ra những gợi ý phù hợp nhất.
Bảng 1. Đánh giá theo thang điểm về một số bộ phim đã xem.
Spartacus Back to the
Future 3
HarryPotter 6 Up
A 2 ∅ 8 9
B 8 7 ∅ ∅
C ∅ ∅ 6 5
D ∅ 4 ∅ 7
1.2. Các k ĩ thuật tư vấn
Có rất nhiều cách để dự đoán, ước lượng hạng/điểm cho các sản phẩm như sử dụng
học máy, lí thuyết xấp sỉ, các thuật toán dựa tr ên kinh nghiệm… Các hệ thống tư vấn
thường được phân thành ba loại dựa trên cách nó dùng để ước lượng các đánh giá về sảnphẩm:
Dựa tr ên nội dung (content- based): người dùng được gợi ý những sản phẩm
tương tự như các sản phẩm từng được họ đánh giá cao.
Cộng tác (collaborative): người dùng được gợi ý những sản phẩm mà những
người cùng sở thích với họ đánh giá cao.
Lai ghép (hybrid): kết hợp cả hai phương pháp trên.
1.2.1. K ĩ thuật tư vấn dựa trên nội dung
Hệ tư vấn dựa tr ên nội dung đưa ra các tư vấn dựa tr ên phỏng đoán rằng một người
có thể thích các sản phẩm có nhiều đặc trưng tương tự với các sản phẩm mà họ đã từng ưa
thích. Theo đó, độ phù hợp g(u,i) của sản phẩm i với người dùng u được đánh giá dựa

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 14/59
6
trên độ phù hợ p g(u, i j), trong đó i j ∈ và tương tự về nội dung i. Ví dụ, để gợi ý một bộ
phim cho người dùng u, hệ thống tư vấn sẽ nhận ra sở thích của u qua các đặc điểm của
những bộ phim từng được u đánh giá cao (như thể loại, tên đạo diễn…); sau đó chỉ những
bộ phim tương đồng với sở thích của u mới được giới thiệu.
Hướng tiếp cận dựa tr ên nội dung bắt nguồn từ những nghiên cứu về thu thập thôngtin (IR - information retrieval) và lọc thông tin (IF - information filtering). Do đó, rất
nhiều hệ thống dựa tr ên nội dung hiện nay tập trung vào tư vấn các đối tượng chứa dữ liệu
text như văn bản, tin tức, website… Những tiến bộ so với hướng tiếp cận cũ của IR là do
việc sử dụng hồ sơ về người dùng (chứa thông tin về sở thích, nhu cầu…). Hồ sơ này
được xây dựng dựa trên những thông tin được người dùng cung cấp trực tiếp (khi trả lời
khảo sát) hoặc gián tiếp (do khai phá thông tin từ các giao dịch của người dùng).
Để cụ thể hơn, đặt Content(i) là tập thông tin (hay tập các đặc trưng) về sản
phẩm i. Do hệ thống dựa tr ên nội dung được thiết kế chủ yếu để dành cho các sản phẩmdạng văn bản hoặc có các mô tả nội dung (metadata) dạng văn bản nên phương pháp biểu
diễn thường được lựa chọn là mô hình không gian vector (Vector Space Model ). Theo
đó, nội dung sản phẩm được biểu diễn bởi các từ khóa: Content(i) = (wi1,wi2,…,wik), với
wi1,..wik là trọng số của các từ khóa (như TF-IDF) từ 1 tới k trong không gian từ khóa
được xây dựng từ trước. Ví dụ điển h ình cho hệ thống dạng này là các hệ tư vấn trang web
như Fab[5], biểu diễn nội dung các trang web bằng 100 từ quan trọng nhất hay Syskill &
Webert [23] sử dụng 128 từ có trọng số cao nhất.
Đặt Profile(u) là hồ sơ về người dùng u, bao gồm các thông tin về sở thích của u.Những thông tin này có được bằng cách phân tích nội dung của các sản phẩm từng được u
đánh giá (cho điểm) trước đó. Phương pháp được sử dụng thường là các k ĩ thuật phân
tích từ khóa của IR, do đó, Profile(u) cũng có thể được định nghĩa như một vector trọng
số: Profile(u) = (wu1, …,wuk) với xuj biểu thị độ quan trọng của từ khóa j với người dùng
u.
Trong hệ thống tư vấn dựa tr ên nội dung, độ phù hợp g(u,i) được xác định bởi công
thức:
g(u,i) = Score(Profile(u), Content(i))
Cả Profile(u), Content(i) đều được biểu diễn bằng vector trọng số từ TF-IDF (tương
ứng là các vector ⃗ ,⃗ ) nên ta có thể sử dụng một công thức tính độ tương tự như độ đo
cosin:

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 15/59
7
g(, ) = cos(⃗ ,⃗ )= ⃗ . ⃗
‖⃗ ‖×‖⃗ ‖
Bên cạnh các phương pháp IR, hệ tư vấn dựa tr ên nội dung còn sử dụng nhiều
phương pháp học máy khác như: phân lớp Bayes, cây quyết định, mạng nơron nhântạo… Các phương pháp này khác với các phương pháp của IR ở chỗ nó dựa tr ên các mô
hình học được từ dữ liệu nền. Ví dụ, dựa tr ên tập các trang web đã được người dùng
đánh giá là “thích” hay “không thích” có thể sử dụng phân lớp Bayes để phân lớp các
trang web chưa được đánh giá.
Một số hạn chế của hệ thống tư vấn dựa trên nội dung:
Theo công trình khảo sát các hệ tư vấn của Adomavicius và Tuzhulin[2], các hệ
thống tư vấn dựa trên nội dung có một vài hạn chế sau đây:
Sự phân tích nội dung bị hạn chế (Restricted content analysis): Tính hiệu quả của
hệ tư vấn này phụ thuộc vào việc mô tả một cách đầy đủ các đặc trưng nội dung
của sản phẩm. V ì vậy, nội dung sản phẩm phải hoặc có thể được trích xuất tự
động bởi máy tính hoặc dễ dàng được trích xuất bằng tay. Có nhiều trường hợp,
yêu cầu này rất khó thực hiện, ví dụ trong miền ứng dụng tư vấn dữ liệu đa
phương tiện như ảnh đồ họa, phim, âm thanh,… Trích xuất tự động đặc trưng nội
dung của các đối tượng dữ liệu này là một bài toán khó, và việc trích xuất bằng
tay là không khả thi do chi phí lớn.
Sự lạm dụng nội dung chuyên môn (Content over-specialisation): Sự tư vấn chỉ
được tạo ra từ phân tích nội dung các sản phẩm đã từng được người dùng ưa
thích, trong khi các những đánh giá của người dùng khác có thể được sử dụng để
tư vấn những sản phẩm mới (thậm chí khác loại), những tư vấn dựa tr ên nội
dung chỉ có thể đưa ra những sản phẩm tương tự với những g ì họ đã từng đánh
giá cao trước đây. Trong nhiều trường hợp, những sản phẩm không nên được tư
vấn nếu nó quá giống với các sản phẩm đã được đánh giá từ trước. Một ví dụ
điển h ình là trong các hệ thống tư vấn tin tức, những tin tức tư vấn được đánh giá
cao hơn nếu nó không phải là một bản trích dẫn hoặc có nội dung thông tin tr ùng
lặp.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 16/59
8
Vấn đề người dùng mới (new user problem): Người dùng cần đánh giá một
lượng sản phẩm đủ lớn trước khi hệ thống tư vấn có thể thực sự hiểu sở thích của
họ, và đưa ra những tư vấn đáng tin cậy.
1.2.2. K ĩ thuật tư vấn cộng tác
Theo Adomavicius và cộng sự [2], không giống như phương pháp tư vấn dựa tr ên
nội dung, hệ thống cộng tác dự đoán độ phù hợp g(u,i) của một sản phẩm i với người
dùng u dựa trên độ phù hợp g(u j, i) giữa người dùng u j và i, trong đó u j là người có cùng
sở thích với u. Ví dụ, để gợi ý một bộ phim cho người dùng u, đầu ti ên hệ thống cộng tác
tìm những người dùng khác có cùng sở thích với u, ví dụ cùng thích các bộ phim hành
động. Sau đó, những bộ phim được họ đánh giá cao sẽ được dùng để tư vấn cho u.
Có rất nhiều hệ thống cộng tác đã được phát triển như: Grundy, GroupLens (tintức), Ringo (âm nhạc), Amazon.com (sách), Phoaks (web)… Các hệ thống này có thể chia
thành hai loại: dựa tr ên kinh nghiệm (heuristic-based hay memory-based) và dựa tr ên mô
hình (model-based).
Hệ thống cộng tác dựa trên kinh nghiệm
Các thuật toán dựa tr ên kinh nghiệm dự đoán hạng của một sản phẩm dựa tr ên toàn
bộ các sản phẩm đã được đánh giá trước đó. Nghĩa là, độ phù hợp của sản phẩm in với
người dùng um, g(um, in) được tổng hợp từ đánh giá của những người dùng khác về in (thường là N người có sở thích tương đồng nhất với um).
Theo đó, hướng tiếp cận lọc cộng tác này tổ hợp các đánh giá người dùng cùng sở
thích này:
Trong đó, m là tập các người dùng cùng sở thích với um.
Một số ví dụ về hàm tổ hợp [2]:

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 17/59
9
Trong đó, d là hệ số chuẩn hóa
Giá trị trung b ình các đánh giá của người dùng u j
Có nhiều cách để tính độ tương đồng (về sở thích) giữa hai người dùng, nhưng trong
hầu hết các phương pháp, độ tương đồng chỉ được tính dựa tr ên các sản phẩm được cả hai
người cùng đánh giá. Hai phương pháp phổ biến nhất là dựa trên độ tương quan(correlation-based) và dựa tr ên cosin (cosine-based).
Biểu diễn những đánh giá quá khứ của hai người dùng um và u j tương ứng như sau:
Độ tương đồng dựa tr ên cosin:

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 18/59
10
Độ tương quan:
Hệ thống cộng tác dựa trên mô hình
Khác với phương pháp dựa tr ên kinh nghiệm, phương pháp dựa tr ên mô hình
(model-based) sử dụng kĩ thuật thống k ê và học máy tr ên dữ liệu nền (các đánh giá đã
biết) để xây dựng nên các mô hình. Mô hình này sau đó sẽ được dùng để dự đoán hạng
của các sản phẩm chưa được đánh giá.
Breese [10] đề xuất hướng tiếp cận xác suất cho lọc cộng tác (collaborative
filtering), trong đó công thức sau ước lượng đánh giá của người dùng u về sản phẩm i
(thang điểm đánh giá từ 0 đến n):
r u,i = , = ∑ × Pr , = , ́ , ́ ∈
Billsus và Pazzani [9] đề xuất phương pháp lọc cộng tác tr ên nền học máy, trong đó
rất nhiều các kĩ thuật học máy (như mạng nơron nhân tạo) và các k ĩ thuật trích chọn đặc
trưng (như SVD – một kĩ thuật đại số nhằm làm giảm số chiều của ma trận) có thể đượcsử dụng.
Ngoài ra còn nhiều hướng tiếp cận khác như mô h ình thống k ê, mô hình bayes, mô
hình hồi quy tuyến tính, mô h ình entropy cực đại…
Hệ thống tư vấn cộng tác khắc phục được nhiều nhược điểm của hệ thống dựa tr ên
nội dung. Một điểm quan trọng là nó có thể xử lý mọi loại dữ liệu và gợi ý một loại sản
phẩm, kể cả những sản phẩm mới, khác hoàn toàn so với những g ì người dùng từng xem.
Một số hạn chế của hệ thống tư vấn lọc cộng tác
Một số hạn chế của các hệ tư vấn lọc cộng tác có thể được liệt kê như sau:
Vấn đề của sự đánh giá thưa thớt: vấn đề số lượng các đánh giá từ người dùng
quá ít để tạo ra các dự đoán đủ tin cậy. Mức độ thành công của các hệ thống tư

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 19/59
11
vấn phụ thuộc nhiều vào những đánh giá nhận được từ khách hàng, và sự tư vấn
cộng tác được thực hiện dựa tr ên sự chồng lấn của những đánh giá này. Vì vậy,
rất khó để có thể đưa ra những tư vấn chính xác khi không gian đánh giá là thưa
thớt. Ví dụ như một vài sản phẩm chỉ được nhận được ít đánh giá từ người dùng,
chúng có thể rất ít có cơ hội được tư vấn, thậm chí cả khi được đánh giá cao. Vấn đề người dùng mới: Chiến lược cộng tác học sở thích người dùng từ chính
những đánh giá trong quá khứ của họ. Đối với những người dùng mới chưa thực
hiện đánh giá nào, không có một sự tư vấn nào có thể được tạo ra.
Vấn đề sản phẩm mới: tương tự như vấn đề người dùng mới, đối với những sản
phẩm mới, chưa nhận được đánh giá nào từ phía người dùng, không thể có sự tư
vấn nào về chúng.
Vấn đề chú cừu xám: Đối với người dùng có sở thích khác biệt với số đông, sự
tư vấn đôi khi không mang lại kết quả.
Vấn đề thiếu tính đa dạng: V ì tri thức của hệ thống về nội dung chỉ dựa tr ên các
lựa chọn từ phía người dùng, nên sự tư vấn thường có xu hướng lệch về những
sản phẩm đã được chọn trong quá khứ, kết quả là trong khi phải xử lý lượng lớn
dữ liệu, phần lớn những tư vấn được tạo ra lại chỉ tập trung vào những sản phẩm
phổ biến nhất. Ví dụ điển h ình cho những cản trở của vấn đề này là ở các hệ
thống tư vấn tin tức, trong khi những tin tức mới hơn có thể mang nhiều giá trị
hơn, những tin tức được nhiều người đọc trước đây lại thường xuyên được tư
vấn.
1.2.3. K ĩ thuật tư vấn lai
Một vài hệ tư vấn kết hợp cả phươ ng pháp cộng tác và dựa trên nội dung nhằm
tránh những hạn chế của cả hai. Có thể phân thành bốn cách kết hợp như sau:
Cài đặt hai phương pháp riêng rẽ rồi kết hợp dự đoán của chúng.
Tích hợp các đặc trưng của phương pháp dựa trên nội dung vào hệ thống cộngtác.
Tích hợ p các đặc trưng của phươ ng pháp cộng tác vào hệ thống dựa trên đặc
trưng.
Xây dựng mô hình hợp nhất, bao gồm các đặc trưng của cả hai phươ ng pháp.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 20/59
12
Kết hợp hai phương pháp riêng rẽ
Có hai kịch bản cho trường hợp này:
Cách 1: Kết hợp kết quả của cả hai phương pháp thành một kết quả chung duy
nhất, sử dụng cách kết hợp tuyến tính (linear combination) hoặc voting scheme.
Cách 2: Tại mỗi thời điểm, chỉ chọn phương pháp cho kết quả tốt hơn (dựa tr ên
một số độ đo chất lượng tư vấn nào đó).
Thêm đặc trưng của mô h ình dựa trên nội dung vào mô hình cộng tác
Một số hệ thống lai (như Fab[5]) dựa chủ yếu trên các k ĩ thuật cộng tác nhưng vẫn
duy trì hồ sơ về người dùng (theo dạng của mô hình dựa trên nội dung). Hồ sơ này được
dùng để tính độ tương đồng giữa hai người dùng, nhờ đó giải quyết được trường hợp có
quá ít sản phẩm chung được đánh giá bở i cả hai người. Một lợi ích khác là các gợi ý sẽ
không chỉ giớ i hạn trong các sản phẩm được đánh giá cao bởi những người cùng sở
thích (gián tiếp), mà còn cả với những sản phẩm có độ tươ ng đồng cao với sở thích của
chính người dùng đó (trực tiếp).
Thêm đặc trưng của mô hình cộng tác vào mô hình dựa trên nội dung
Hướng tiếp cận phổ biến nhất là dùng các k ĩ thuật giảm số chiều trên tập hồ sơ củaphương pháp dựa trên nội dung. Ví dụ, Soboroff và Nicholas [29] sử dụng phân tích
ngữ ngh ĩa ẩn (latent semantic analysis) để tạo ra cách nhìn cộng tác (collaborative
view) với tập hồ sơ người dùng (mỗi hồ sơ được biểu diễn bởi một vector từ khóa).
Mô hình hợp nhất hai phương pháp
Trong những năm gần đây đã có khá nhiều nghiên cứu về mô hình hợp nhất. Basu
và cộng sự [5] đề xuất kết hợp đặc trưng của cả hai phương pháp vào một bộ phânlớp dựa trên luật (rule-based classifier). Popescul và cộng sự [25] đưa ra phươ ng pháp
xác suất hợp nhất dựa trên phân tích xác suất ngữ ngh ĩa ẩn (probabilistic latent
semantic analysis). Ansari và cộng sự [4] giới thiệu mô hình hồi quy Bayes sử dụng
dây Markov Monte Carlo để ước lượng tham số.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 21/59
13
Độ chính xác của hệ thống tư vấn lai ghép có thể được cải tiến bằng cách sử dụng
các k ĩ thuật dựa trên tri thức (knowledge-based) như case-based reasoning. Ví dụ, hệ
thống Entrée dùng những tri thức về nhà hàng, thực phẩm (như: đồ biển không phải là
thức ăn chay).. để gợ i ý nhà hàng thích hợp cho người dùng. Hạn chế chính của hệ thống
dạng này là nó cần phải thu thập đủ tri thức, đây cũng là nút thắt cổ chai (bottle- neck)của rất nhiều hệ thống trí tuệ nhân tạo khác. Tuy nhiên, các hệ thống tư vấn dựa trên tri
thức hiện đang được phát triển trên các l ĩnh vực mà miền tri thức của nó có thể biểu diễn
ở dạng mà máy tính đọc được (như ontology). Ví dụ, hệ thống Quickstep và Foxtrot sử
dụng ontology về chủ đề của các bài báo khoa học để gợi ý những bài báo phù hợp cho
người dùng.
1.3. Sơ lược về hệ thống tư vấn tin tức của khóa luận
Mô hình hệ tư vấn do khóa luận đề xuất không được triển khai một cách độc lập mà
tích hợp vào hệ thống cung cấp tin tức. Với việc phân tích những đặc trưng của đối tượng
tư vấn này, khóa luận đề xuất ý tưởng ban đầu cho giải pháp tư vấn được triển khai.
1.3.1. Đặc trưng của tư vấn tin tức.
Tư vấn tin tức là một lĩnh vực giàu tiềm năng bởi số lượng các sản phẩm tư vấn, số
lượng người dùng và số lượt sử dụng cao hơn nhiều so với các đối tượng tư vấn khác. Tuy
nhiên, đi kèm theo đó là các thử thách về các đặc trưng riêng có của miền đối tượng tintức cũng như các đặc trưng chung của người sử dụng tư vấn.
Tin tức là một đối tượng tư vấn đặc biệt, các đặc trưng sau của tin tức giúp đưa ra
các giải pháp hữu hiệu hơn trong xây dựng giải pháp tư vấn:
Tính không đồng nhất giá trị: Giá trị của tin tức chỉ có thể được xác định bằng
cách kết hợp các yếu tố: nội dung thông tin của bản tin, nguồn tin, thời điểm xuất
bản, nhà xuất bản, tác giả, người nhận tin,…
Tính dễ sinh ra: một số lượng lớn tin tức có thể nảy sinh xung quanh một sựkiện, hiện tượng.
Tính dễ tàn lụi: hiện tượng tin tức đánh mất giá trị khi vấn đề nó đề cập không
còn tính thời sự.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 22/59
14
Khi xem xét đến yếu tố phù hợp giữa đối tượng tư vấn và mối quan tâm người dùng,
các đặc trưng về mối quan tâm của người dùng cũng cần được xem xét.
Tính đa quan tâm: Tại một thời điểm, người dùng có thể có nhiều mối quan
tâm khác nhau. Ví dụ: họ có thể quan tâm đến cả các thông tin về cả thể thao v à
chính trị.
Tính thay mới: Mối quan tâm của họ có thể phân chia thành 3 loại chính: các
mối quan tâm dài hạn, các mối quan tâm trung hạn và các mối quan tâm ngắn
hạn. Tính thay mới có thể diễn ra ở cả ba loại mối quan tâm này, tuy nhiên tốc độ
thay mới của các mối quan ngắn hạn là nhanh nhất và nó cũng có ưu thế hơn khi
dùng để tư vấn các tin tức, vốn liên tục được sinh ra.
1.3.2.
Hướng tiếp cận của khóa luận Để vượt qua các thử thách này, chúng tôi tập trung vào các tiếp cận lọc dựa tr ên nội
dung với thông tin về mối quan tâm ngắn hạn thông qua các chủ đề ẩn. Các lý do có thể
được nêu ra là:
Thứ nhất: Lọc dựa tr ên nội dung không gặp phải các vấn đề rất khó giải quyết
của lọc cộng tác tr ên miền đối tượng tin tức: (i) vấn đề những đánh giá đầu: các
tin tức liên tục được sinh ra và cần dễ dàng tiếp cận trong khi quá tr ình lọc cộng
tác không thể tạo ra các sản phẩm chưa từng được đánh giá bởi người dùng khác
hoặc những người dùng chưa từng đánh giá một sản phẩm nào; (ii) vấn đề matrận thưa: Khó t ìm ra được các sản phẩm đã được đánh giá bởi một lượng đủ
người dùng vì số lượng quá lớn các tin tức mới và đặt gánh nặng cung cấp thông
tin đánh giá lên người dùng [11].
Thứ hai: Biểu diễn thông tin ở mức chủ đề có mô tả rõ ràng hơn tập hợp các
mối quan tâm hay sở thích của người dùng. Sử dụng phương pháp này còn có thể
khắc phục được hạn chế tư vấn các sản phẩm quá giống các sản phẩm đã được
ưa thích trước đó (ví dụ như vấn đề trùng lặp tin tức).
Thứ ba: Các dữ liệu thu thập dựa tr ên những tin tức được truy cập gần nhất cho
phép mô tả chính xác hơn đặc tính thay mới mối quan tâm.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 23/59
15
Theo đó, hệ thống đề xuất giải quyết hai vấn đề cơ bản của tiến tr ình tư vấn:
Đầu tiên là dựa tr ên khảo sát về các phương pháp xây dựng mô h ình hóa sở thích
người dùng dựa tr ên các dữ liệu văn bản thường được áp dụng cho hướng tiếp
cận lọc nội dung, đề xuất giải pháp mô h ình sở thích người dùng dựa tr ên phân
tích chủ đề ẩn phiên duyệt web người dùng (ngữ cảnh đọc tin tức).
Sau đó, dựa tr ên mô hình sở thích này của người dùng, những tin tức liên quan
được thực hiện thông qua đối chiếu chủ đề và thực thể của chúng với những chủ
đề và thực thể người dùng từng quan tâm.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 24/59
16
Chương 2. Mô hình hóa sở thích người dùng cho các hệ tư
vấn dựa trên nội dung.
Trong chương một, khóa luận đã trình bày sơ bộ về các khái niệm liên quan đến hệ
tư vấn. Qua đó, chúng ta biết rằng chất lượng của những tư vấn cá nhân phụ thuộc v àokhả năng học sở thích người dùng của hệ tư vấn (hay xây dựng hồ sơ sở thích ngươi
dùng). Hồ sơ sở thích người dùng càng phản ảnh đúng mối quan tâm của họ, th ì càng có
nhiều k hả năng có được những tư vấn tốt.
Các k ĩ thuật tư vấn dựa tr ên nội dung thường dựa tr ên các hồ sơ sở thích được xây
dựng thông qua một quá tr ình phân tích các tài liệu dạng văn bản.
Trong chương này, khóa luận tr ình bày sâu hơn về các khái niệm và k ĩ thuật liên
quan đến quá trình mô hình hóa sở thích người dùng nói chung và cho các hệ tư vấn dựa
trên nội dung nói riêng.
2.1. Tiến tr ình mô hình sở thích người dùng
Theo Gauch và các cộng sự [14], một tiến tr ình mô hình hóa sở thích người dùng
cho các ứng dụng hướng cá nhân (như các hệ tư vấn hướng cá nhân, các hệ thống web
thích nghi, …) bao gồm 2 pha cơ bản như minh họa sau.
Hình 2. Tiến tr ình mô hình hóa sở thích người dùng.
Trong pha đầu tiên, một tiến tr ình thu thập thông tin được sử dụng để thu thập các
dữ liệu từ người dùng, có thể chia các dữ liệu này thành hai loại cơ bản: các thông tinngười dùng hiện (hay thông tin người dùng rõ) và các thông tin người dùng ẩn. Những
thông tin này sau đó được tổng hợp để xây dựng mô h ình sở thích người dùng trong pha
còn lại, pha xây dựng hồ sơ người dùng.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 25/59

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 26/59
18
người dùng sử dụng nhiều máy tính, tương tự như hai giải pháp tr ên, nó yêu cầu người
dùng tham gia bằng cách đăng kí cùng một địa chỉ proxy cho tất cả các máy họ sử dụng.
Hai phương pháp sau, cookie và phiên duyệt web không yêu cầu bất cứ sự tham gia
nào từ phía người dùng. Trong lần đầu tiên trình duyệt máy khách truy cập vào hệ thống ,
một userid được tạo ra, id này sẽ được lưu trong cookie máy người dùng. Một người dùngtruy cập vào cùng một trang web được xác định là duy nhất nếu cùng một userid được sử
dụng. Tuy nhiên, nếu người dùng sử dụng nhiều hơn một máy tính, hay một loại tr ình
duyệt, sẽ có những cookie khác nhau, và tương ứng là những hồ sơ người dùng khác
nhau. Hơn nữa, giải pháp này cũng gặp vấn đề khi có nhiều hơn một người dùng cho một
máy, hoặc trường hợp người dùng xóa, hay tắt cookie. Đối với phiên duyệt web, trở ngại
cũng tương tự khi có nhiều hơn một người dùng cho một máy hay có sử dụng nhiều hơn
một máy, một trình duyệt, nhưng nó không lưu trữ userid giữa những lần duyệt. Một
người dùng bắt đầu với một phiên duyệt web mới, thông tin trong phiên duyệt web lưu lại
vết các hành vi người dùng tương tác với hệ thống trong một lần duyệt web của họ ví dụ
danh sách các pageview, thời gian giành cho mỗi pageview, địa chỉ IP,…
Ưu điểm quan trọng của giải pháp định danh dựa tr ên phiên duyệt web là nó không
đặt bất cứ gánh nặng nào về phía người dùng, không gặp những nghi ngại về tính riêng tư
(tức là không lưu lại bất cứ thông tin nào về người dùng) và cũng không yêu cầu bật
cookie ở tr ình duyệt.
2.2.2. Các phương pháp thu thập thông tin
Thông thường, các kĩ thuật thu thập thông tin được phân theo tính chất của dữ liệu
thu thập được. Theo đó, tương ứng với hai kiểu thông tin người dùng ẩn và hiện, có hai
phương pháp thu thập thông tin người dùng.
2.2.2.1. Phương pháp thu thập thông tin người dùng hiện
Phương pháp thu thập thông tin người dùng hiện (hay thông tin phản hồi hiện) thu
thập những thông tin được nhập trực tiếp bởi người dùng, thông thường qua các HTMLForm. Dữ liệu thu thập có thể là các là các thông tin như ngày sinh, t ình trạng hôn nhân,
nghề nghiệp, sở thích,…
Một trong các hệ tư vấn sớm nhất Syskill & Webert [23] tư vấn các trang web dựa
vào các phản hồi hiện. Nếu người dùng đánh giá cao một vài liên kết từ một trang, Syskill

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 27/59
19
& Webert sẽ tư vấn các trang liên kết khác. Thêm vào đó, hệ thống còn có thể tạo một
truy vấn tới máy t ìm kiếm Lycos1 để trích xuất các trang web có thể người dùng sẽ ưa
thích.
Một vấn đề với các thông tin phản hồi hiện đó là nó đặt gánh nặng cung cấp thông
tin về phía người dùng. Vì vậy, nếu người dùng không muốn phải cung cấp các thông tinriêng tư, họ sẽ không tham gia hoặc không cung cấp thông tin chính xác. Hơn nữa, v ì các
hồ sơ được duy tr ì t ĩnh trong khi tồn tại các đặc điểm có thể thay đổi như sở thích, thói
quen,…khiến cho những hồ sơ này có thể trở nên không chính xác nữa theo thời gian.
Một lý lẽ cho những hệ thống sử dụng thông tin phản hồi hiện là trong một vài trường hợp
người dùng thích cung cấp, chia sẻ thông tin của họ.
2.2.2.2. Phương pháp thu thập thông tin người dùng ẩn
Hồ sơ người dùng trong phương pháp này được xây dựng dựa tr ên các thông tin
phản hồi ẩn. Ưu điểm của phương pháp này là không yêu cầu bất cứ sự xen vào nào của
người dùng trong suốt tiến tr ình xây dựng và duy trì các hồ sơ người dùng. Công trình của
Kelly và Teevan [20] cung cấp một cái nh ìn tổng quát về các kĩ thuật phổ biến để thu thập
thông tin phản hồi ẩn và các thông tin về người dùng có thể suy diễn từ hành vi của họ.
Theo đó, Gauch và các cộng sự [14] thống k ê tóm tắt các cách tiếp cận của kĩ thuật
thu thập thông tin phản hồi ẩn.
1 http://www.lycos.com/
Hình 3. Các hệ thống tư vấn dựa trên thông tin phản hồi hiện.
8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 28/59
20
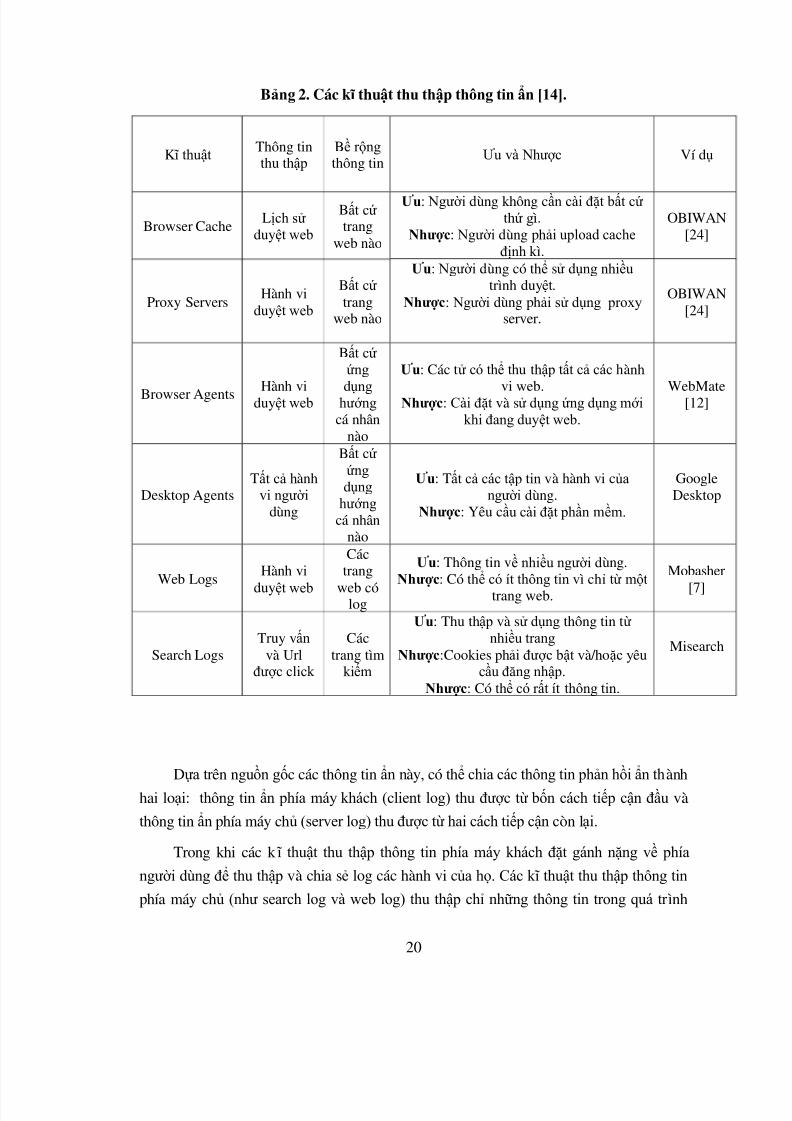
Bảng 2. Các k ĩ thuật thu thập thông tin ẩn [14].
K ĩ thuật Thông tinthu thập
Bề rộngthông tin
Ưu và Nhược Ví dụ
Browser CacheLịch sử
duyệt web
Bất cứtrang
web nào
Ưu: Người dùng không cần cài đặt bất cứthứ g ì.
Nhược: Người dùng phải upload cacheđịnh k ì.
OBIWAN[24]
Proxy ServersHành vi
duyệt web
Bất cứtrang
web nào
Ưu: Người dùng có thể sử dụng nhiều trình duyệt.
Nhược: Người dùng phải sử dụng proxyserver.
OBIWAN[24]
Browser Agents Hành viduyệt web
Bất cứứng
dụnghướngcá nhân
nào
Ưu: Các tử có thể thu thập tất cả các hành
vi web.Nhược: Cài đặt và sử dụng ứng dụng mớikhi đang duyệt web.
WebMate[12]
Desktop AgentsTất cả hành
vi ngườidùng
Bất cứứngdụng
hướngcá nhân
nào
Ưu: Tất cả các tập tin và hành vi củangười dùng.
Nhược: Yêu cầu cài đặt phần mềm.
GoogleDesktop
Web LogsHành vi
duyệt web
Cáctrang
web cólog
Ưu: Thông tin về nhiều người dùng.Nhược: Có thể có ít thông tin v ì chỉ từ một
trang web.
Mobasher
[7]
Search LogsTruy vấn
và Urlđược click
Cáctrang tìm
kiếm
Ưu: Thu thập và sử dụng thông tin từnhiều trang
Nhược:Cookies phải được bật và/hoặc yêucầu đăng nhập.
Nhược: Có thể có rất ít thông tin.
Misearch
Dựa tr ên nguồn gốc các thông tin ẩn này, có thể chia các thông tin phản hồi ẩn thành
hai loại: thông tin ẩn phía máy khách (client log) thu được từ bốn cách tiếp cận đầu và
thông tin ẩn phía máy chủ (server log) thu được từ hai cách tiếp cận còn lại.
Trong khi các k ĩ thuật thu thập thông tin phía máy khách đặt gánh nặng về phía
người dùng để thu thập và chia sẻ log các hành vi của họ. Các kĩ thuật thu thập thông tin
phía máy chủ (như search log và web log) thu thập chỉ những thông tin trong quá tr ình

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 29/59

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 30/59
22
Hình 4. Mô hình mối quan tâm người dùng dựa trên từ khóa.
2.3.2. Phương pháp dựa trên mạng ngữ nghĩa
Mối quan tâm được mô tả bằng tập các node (từ khóa hoặc khái niệm) v à các cạnh
liên kết. Đầu tiên, các từ khóa cũng được trích xuất từ dữ liệu người dùng. Khái niệm có
thể bao gồm một hoặc nhiều từ khóa liên kết với nhau ( ví dụ như: quan hệ đồng nghĩa
suy diễn từ WordNet ). Trọng số giữa cạnh được xác định dựa tr ên sự xuất hiện đồng thời
của hai node hoặc các từ khóa thuộc vào hai node trong cùng một văn bản. Điển h ình cho
mô hình này là hệ thống InfoWeb [15], mỗi hồ sơ người dùng được biểu diễn bởi một
mạng ngữ nghĩa các khái niệm. Ban đầu, mạng ngữ nghĩa chứa một tập các node khái
niệm không liên kết gọi là các node hành tinh với một trọng số. Càng nhiều thông tin thu
thập được, hồ sơ về người dùng càng được làm giàu thông qua các từ khóa có trọng số
liên kết với các khái niệm. Các từ khóa được biểu diễn như các node vệ tinh xung quanh
các khái niệm chính, trọng số liên kết giữa các khái niệm tương ứng cũng được thêm vào.
Hình 5. Mô hình mối quan tâm người dùng dựa trên mạng ngữ nghĩa[15].

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 31/59
23
2.3.3. Phương pháp dựa trên cây phân cấp khái niệm
Mối quan tâm người dùng được mô tả tập các khái niệm có trọng số. Ban đầu, các
khái niệm không trích ra từ văn bản mà được định nghĩa trước từ cây phân cấp các mục
mở ODP (The Open Directory Project)[30]. Dữ liệu người dùng được phân lớp vào một
trong các nhánh của cấu trúc phân cấp này. Vấn đề của phương pháp này là mức độ chitiết của mục có thể làm mất thông tin về các mối quan tâm chung và sự phụ thuộc vào độ
chính xác của các cây phân cấp khái niệm. Một trong các dự án đầu tiên sử dụng phương
pháp này là OBIWAN [24]. Ban đầu, họ dùng cấu trúc phân cấp khái niệm từ 3 mức đầu
tiên của ODP[30]. Dữ liệu người dùng được tự động phân lớp để t ìm ra các các khái niệm
phù hợp nhất, các trọng số khái niệm tương ứng được tăng lên.
Hình 6. Mô hình mối quan tâm người dùng dựa trên mạng khái niệm [24].

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 32/59

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 33/59
25
3.1. Cơ sở lý thuyết
3.1.1. Phân tích thông tin chủ đề dựa trên mô hình chủ đề LDA.
Phân tích chủ đề cho văn bản nói chung và cho dữ liệu Web nói riêng có vai tròquan trọng trong việc “hiểu” và định hướng thông tin tr ên Web. Khi ta hiểu một trang
Web có chứa những chủ đề hay thông tin g ì thì dễ dàng hơn cho việc xếp loại, sắp xếp, và
tóm tắt nội dung của trang Web đó. Trong phân lớp văn bản, mỗi văn bản thường được
xếp vào một lớp cụ thể nào đó. Trong phân tích chủ đề, chúng ta giả sử mỗi văn bản đề
cập đến nhiều hơn một chủ đề (K chủ đề) và mức độ liên quan đến chủ đề được biểu diễn
bằng phân phối xác suất của của tài liệu đó tr ên các chủ đề.
Hình 7. Tài liệu với K chủ đề ẩn.
Có rất nhiều phương pháp phân tích thông tin chủ đề từ văn bản, điển h ình là mô
hình LDA [13]. LDA là một mô h ình sinh (generative model) và thực hiện phân tích chủ
đề từ các tập dữ liệu văn bản hoàn toàn phi giám sát (fully unsupervised). Về mục tiêu,
tươ ng tự với LSA, LDA đưa ra một kĩ thuật mô tả thu gọn các tập dữ liệu rời rạc (như tập
văn bản). Về mặt trực quan, LDA t ìm những cấu trúc chủ đề (topics) và khái niệm
(concepts) trong tập văn bản dựa tr ên thông tin về đồng xuất hiện (co-occurrence) của các
từ khóa trong văn bản, và cho phép mô hình hóa các khái niệm đồng nghĩa (synonymy) và
đa nghĩa (polysemy). Về mặt mô h ình hóa, LDA hoạt động tương đối giống với pLSA(probabilistic LSA) [19]. Tuy vậy, LDA ưu việt hơn pLSA ở một vài điểm như tính đầy
đủ và tính khái quát cao hơn [13][17].

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 34/59
26
Hình 8. Biểu diễn đồ họa LDA[13].
Ước lượng giá trị tham số cho mô h ình LDA.
Hình 9. Ước lượng tham số tập dữ liệu văn bản.
Ước lượng tham số cho mô h ình LDA bằng phương pháp cực đại hóa hàm
likelihood trực tiếp và một cách chính xác có độ phức tạp thời gian rất cao và không khảthi trong thực tế. Người ta thường sử dụng các phương pháp xấp xỉ như Variational
Methods [13] và Gibbs Sampling [17]. Gibbs Sampling được xem là một thuật toán
nhanh, đơn giản, và hiệu quả để huấn luyện LDA.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 35/59
27
Sử dụng mô h ình LDA để suy diễn chủ đề.
Theo Nguyễn Cẩm Tú [22], với một mô h ình chủ đề đã được huấn luyện tốt dựa tr ên
tập dữ liệu toàn thể (Universial Dataset) bao phủ miền ứng dụng, ta có thể thực hiện một
tiến tr ình quá trình suy diễn chủ đề cho các tài liệu mới tương tự như quá tr ình ước lượng
tham số (tức là xác định được phân phối tr ên các chủ đề của tài liệu qua tham số theta).Tác giả cũng chỉ ra rằng sử dụng dữ liệu từ VnExpress1 huấn luyện được các mô h ình có
ưu thế hơn trong các phân tích chủ đề tr ên dữ liệu tin tức, trong khi các mô h ình được
huấn luyện bởi dữ liệu từ Wiki2 tốt hơn trong phân tích chủ đề các tài liệu mang tính học
thuật.
Dựa tr ên những nghiên cứu đó, chúng tôi lựa chọn mô h ình được chủ đề được huấn
luyện bởi tập dữ liệu toàn thể thu thập từ trang Vnexpress cho phân tích chủ đề. Một tiến
trình phân tích chủ đề tổng quát được minh họa như sau:
Hình 10. Suy diễn chủ đề sử dụng tập dữ liệu VnExpress[22].
3.1.2. Nhận dạng các thực thể trong tài liệu dựa trên từ điển
Đối với một đối tượng văn bản, nội dung của nó liên quan nhiều đến các thực thể
chứa trong văn bản đó. Đối tượng thực thể có thể là tên người, tên một địa điểm hoăc mộttổ chức,…Phương pháp nhận dạng các thực thể dựa tr ên từ điển đơn giản chỉ xem xét đến
sự hiện diện của các thực thể thuộc vào một tập từ điển thực thể trong văn bản đang tiến
1 www.vnexpress.net 2 www.wikipedia.org

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 36/59
28
hành phân tích. Thuật toán đối sánh xâu Aho-Corasick [3] là phương pháp nhận dạng thực
thể dựa tr ên từ điển điển h ình. Ý tưởng cơ bản của phương pháp này khá đơn giản này,
các thực thể trong từ điển được xem là các mẫu, một ôtômát hữu hạn trạng thái xây dựng
từ các mẫu này sẽ được sử dụng để xác định sự hiện diện của các mẫu trong văn bản.
3.2. Phân tích sở thích người dùng
3.2.1. Thông tin trong phiên duyệt web người dùng
Một phiên duyệt web là một chuỗi các pageview của một người dùng đơn trong một
lần duyệt đơn [7]. Trong đó, các pageview là tập hợp các đối tượng web hiển thị tới người
dùng. Mỗi pageview có thể được xem như một tập hợp các đối tượng web hay các tài
nguyên biểu diễn cho một hành vi người dùng cụ thể như đọc một trang tin tức, xem
thông tin một sản phẩm hoặc thêm một sản phẩm vào giỏ hàng,…Mô hình sử dụng phiênduyệt web là danh sách các url tương ứng với các trang web người dùng truy cập vào hệ
thống.
Bảng 4. Thông tin trong phiên duyệt web.
Session ID (Profile ID) Url
1 www.bestnews4u.com?newsid=102
1 www.bestnews4u.com?newsid=82 1 www.bestnews4u.com?newsid=11
1 www.bestnews4u.com?newsid=1021
2 www.bestnews4u.com?newsid=102
2 www.bestnews4u.com?newsid=144

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 37/59
29
3.2.2. Mô hình sở thích người dùng
Trong mô hình này, sở thích của người dùng được biểu diễn bởi hai thông tin: Tập
các chủ đề ẩn người dùng quan tâm nhất và tập các thực thể liên quan.
Xác định tập chủ đề ẩn người dùng quan tâm được thực hiện qua 3 bước
Bước 1: Từ tập tài liệu mô tả sở thích người dùng, các chủ đề và phân phối của
chúng vào từng tài liệu được tính toán.
Ứng với mỗi tài liệu di thuộc vào tập D các tài liệu mô tả mối quan tâm người sử
dụng, sử dụng phân tích chủ đề ẩn ta được kết quả là tập các topic của tài liệu di,
kí hiệu là các TP j thuộc vào tập các topic TP, với trọng số wtpj.
Topics(di) = {(TP j, wtpj),…}
Bước 2: Xếp hạng chủ đề dựa tr ên thống k ê tính phổ biến
Rank (TP j) = Số lần xuất hiện của TP j trong ma trận D x TP với wtpj lớn hơn một
ngưỡng
Bước 3: Xác định Top N chủ đề ẩn có hạng cao nhất được sử dụng để biểu diễn
mô hình người dùng.
Các thực thể liênquan
Các tin tứcngười dùng
quan tâm trongphiên
Các chủ đề ẩn phổbiến
Hình 11. Mô hình sở thích người dùng dựa trên chủ đề ẩn và thực thể.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 38/59
30
Xác định tập thực thể qua 2 bước
Bước 1: Xác định tài liệu cần phân tích thực thể. Các tài liệu được sử dụng đề
phân tích các thực thể biểu diễn sở thích người dùng thỏa mãn hai điều kiện
sau:
o Là các tin tức thuộc phiên duyệt web người dùng
o Là các tin tức có nội dung liên quan đến chủ đề người dùng quan tâm đ ã
xác định ở quá tr ình xác định chủ đề ẩn phổ biến.
Bước 2: Trích xuất các thực thể từ các văn bản tin tức.
3.3. Áp dụng mô h ình sở thích người dùng vào tư vấn tin tức
Nghiên cứu của chúng tôi phát triển một mô h ình hệ thống tư vấn sử dụng mô h ình
mối quan tâm đề xuất ở phần trước. Trong đó, ý tưởng chung của việc tư vấn dựa tr ên
xem các tin tức tư vấn tiềm năng là các tin tức mang thông tin về chủ đề và các thực thể
người dùng từng quan tâm. Ứng dụng tư vấn được tích hợp trong một hệ thống quản lý
nội dung (Content Management System). Vì vậy, giải pháp được đưa ra là xác định chủ đề
và các thực thể nằm trong mỗi tin tức được thực hiện ngay sau khi dữ liệu tin tức được
nhập vào cơ sở dữ liệu các tin tức của hệ thống. Khóa luận xem giai đoạn này là pha xử lý
phân tích dữ liệu tư vấn. Sau pha này, mỗi tin tức sẽ tương ứng với hai danh sách một
danh sách các chủ đề và một danh sách các thực thể. Pha tư vấn trực tuyến thực hiện thu
thập thông tin về sở thích người dùng thông qua thống k ê các chủ đề phổ biến trong phiênduyệt web, sau đó tự động sinh các truy vấn cho cơ sở dữ liệu, kết quả đạt được là dữ liệu
tư vấn liên quan thuộc về nhiều chủ đề và chứa các thông tin về các thực thể người dùng
từng quan tâm.
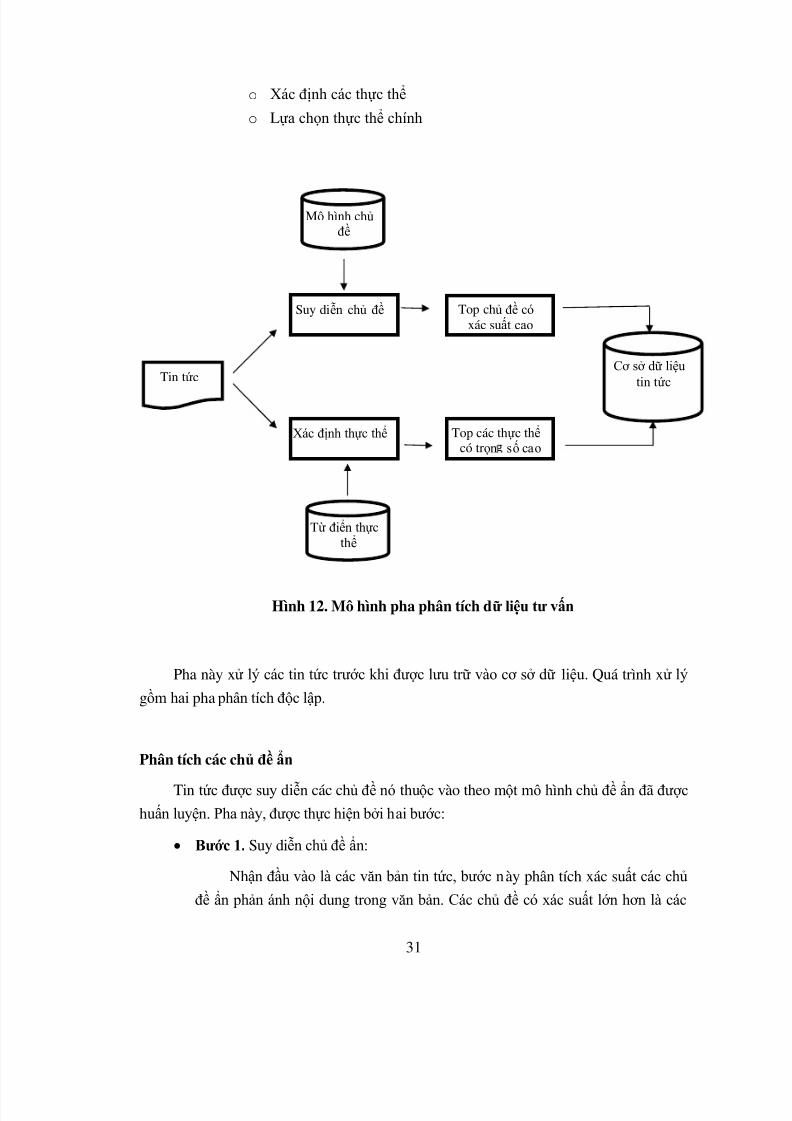
3.3.1. Pha phân tích dữ liệu tư vấn
Input: Mỗi văn bản tin tức.
Output: Phân tích chủ đề và thực thể của từng tin tức.
Pha phân tích chủ đề ẩn.
o Suy diễn chủ đề ẩn
o Lựa chọn chủ đề chính
Pha phân tích thực thể liên quan.
8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 39/59
31
o Xác định các thực thể
o Lựa chọn thực thể chính
Pha này xử lý các tin tức trước khi được lưu trữ vào cơ sở dữ liệu. Quá trình xử lý
gồm hai pha phân tích độc lập.
Phân tích các chủ đề ẩn
Tin tức được suy diễn các chủ đề nó thuộc vào theo một mô h ình chủ đề ẩn đã đượchuấn luyện. Pha này, được thực hiện bởi hai bước:
Bước 1. Suy diễn chủ đề ẩn:
Nhận đầu vào là các văn bản tin tức, bước này phân tích xác suất các chủ
đề ẩn phản ánh nội dung trong văn bản. Các chủ đề có xác suất lớn hơn là các
Top chủ đề cóxác suất cao
Top các thực thểcó trọn số cao
Mô hình chủđề
Từ điển thựcthể
Tin tức
Suy diễn chủ đề
Xác định thực thể
Cơ sở dữ liệutin tức
Hình 12. Mô hình pha phân tích dữ liệu tư vấn

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 40/59
32
chủ đề mà nội dung chính của tin tức hướng tới. Chú ý rằng số lượng các chủ đề
ẩn là không đổi, và mỗi chủ đề đều có một xác suất phản ánh nội dung của văn
bản. Ví dụ, nếu ta chọn mô h ình với 100 chủ đề ẩn để phân tích, mỗi văn bản
được xác định bởi một vector 100 chiều, với mỗi chiều là một chủ đề và mỗi giá
trị trong các chiều là trọng số xác suất của chủ đề tương ứng.
Bước 2. Xác định top các chủ đề có phân phối cao:
Từ các vector phân phối chủ đề của văn bản tin tức, ta cần xác định đâu là
các chủ đề có thể đại diện cho nội dung thông tin của tin tức. Các chủ đề này có
thể được nhận ra bởi hai r àng buộc:
o Số lượng chủ đề có thể biểu diễn nội dung cho một văn bản phải nằm
trong một giới hạn.
o Xác suất của chủ đề đó phải lớn hơn một ngưỡng cho trước.
Phân tích các thực thể liên quan.
Vì giá trị của tin tức còn liên quan đến các thực thể mà nó đề cập tới, ví dụ như tin
tức về k ì nghỉ của tổng thống có giá trị hơn tin tức về k ì nghỉ của một người b ình thường.
Pha này xác định các thực thể nằm trong văn bản tin tức. Các thực thể có thể được trích
xuất từ văn bản thông qua hai bước:
Bước 1: Xác định tất cả các thực thể trong nội dung tin tức.
Nếu coi văn bản tin tức tương ứng với một xâu và mỗi thực thể trong từ điển
là một mẫu, ta có thể áp dụng một thuật toán đối sánh xâu để nhận ra tất cả các
thực thể nằm trong nội dung của tin tức. Kết quả của bước này là một danh sách
các thực thể với trọng số là số lần xuất hiện của nó trong văn bản.
Bước 2: Lựa chọn các thực thể có trọng số cao để lưu trữ.
Những thực thể được nhận định là liên quan nhiều hơn tới nội dung của văn
bản nếu nó được nhắc tới hơn một số lần nào đó, bước này thực hiện lọc bớt các
thực thể xuất hiện quá ít (nhỏ hơn một ngưỡng). Các thực thể được lưu trữ như
biểu diễn một phần giá trị của tin tức.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 41/59
33
3.3.2. Pha tư vấn trực tuyến
Input: Tập Url lưu trong phiên duyệt web.
Output: Tập các tin tức tư vấn.
Pha tiền xử lý tập Url trong phiên.
o Đưa các Url về một chuẩn thống nhất, xác định các tin tức trong phiên.
Pha phân tích mối quan tâm người dùng.
o Xác định tin tức trong phiên và các chủ đề tương ứng.
o Phân tích chủ đề ẩn phổ biến.
o Xác định tập thực thể liên quan trong phiên.
Pha xác định các tin tức tư vấn.
o Lọc ra danh sách các tin có cùng chủ đề phổ biến ẩn.
o Xếp hạng lại các tin có liên quan đến nhiều thực thể.
Tập url các tintức trong phiên
Tiền xử lý CSDL tin
tức
Tập các tin tứctrong phiên vớicác chủ đề ẩn.
Thống k ê các chủ
đề phổ biến
Các thực th ngườidùng quan tâm
trong phiên
Truy vấn 1 Truy vấn 2
Các tin tức có chủđề là chủ đề phổ
biến.
Truy vấn 3
X p hạng lại cáctin tức
Top các tin tứcgiành cho tư vấn
Hình 13. Mô hình pha tư vấn trực tuyến.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 42/59

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 43/59
35
(có thể có những tin tức không thuộc về chủ đề phổ biến). V ì vậy, truy vấn thực
hiện trích xuất các thực thể cần thỏa mãn hai ràng buộc (truy vấn 2 như minh họa
hình 14):
o Thuộc vào các tin tức trong phiên.
o Thuộc vào các tin tức có chủ đề là chủ đề phổ biến.
Tư vấn tin tức
Giai đoạn cuối cùng của tiến tr ình tư vấn là tìm ra những tin tức phù hợp nhất với
sở thích người dùng. Vì vậy, sự tư vấn có thể đạt được theo hai bước sau:
Bước 1: Xác định các tin tức ứng viên từ tập các tin tức có thể tin vấn.
Hệ thống lọc ra các tin tức thuộc vào cùng chủ đề với mối quan tâm người
dùng, thông qua đối sánh chủ đề ẩn của các tin tức trong cơ sở dữ liệu và chủ đề ẩn
được phân tích là được người dùng quan tâm phổ biến (truy vấn 3 minh họa h ình
14).
Bước 2: Xếp hạng lại các tin tức.
Kết quả của bước 1 là một lớp các tin tức có thể người dùng quan tâm ở mức
chủ đề, có thể có quá nhiều tin tức như vậy, do vậy cần có một giải pháp xếp hạng
lại các tin tức này. Một giải pháp có thể triển khai dựa tr ên ý tưởng một phần tiêu
chí ra quyết định của người dùng phụ thuộc ở việc xem xét tin tức đó có liên quanđến các thực thể đang được họ quan tâm hay không.
Từ tập thực thể của các tin tức tư vấn tiềm năng, hạng của một tin tức được
xác định bằng số thực thể nó đề cập tới thuộc vào danh sách các thực thể người
dùng quan tâm trong phiên duyệt web đã được phân tích trong pha trước.
Bước 3: Tư vấn top các tin tức xếp hạng cao nhất.
Quá trình xếp hạng cho ra một danh sách các tin tức được sắp xếp theo thứ tự
giảm dần về mức độ liên quan tới các thực thể người dùng đang quan tâm. Bước
này, hệ thống chọn ra N tin tức tiềm năng nhất để tư vấn tới người đọc.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 44/59
36
3.4. Đánh giá kết quả tư vấn.
Việc đánh giá chất lượng của tin tức tư vấn trả về bởi hệ thống là một bài toán khó,
vì không có một độ đo ngữ nghĩa đánh giá chính xác được sự phù hợp giữa người dùng và
tin tức hệ thống trả lại.
Herlocker [18] đưa ra hai nguyên nhân chủ yếu dẫn tới việc đánh giá các hệ thống
tư vấn là khó khăn. Nguyên nhân đầu tiên là chất lượng của hệ tư vấn phụ thuộc vào tập
dữ liệu sử dụng. Một hệ tư vấn tin tức có mô h ình tốt chưa chắc đã tư vấn tốt hơn một hệ
tư vấn có dữ liệu tốt (như một cơ sở dữ liệu tin tức phong phú). Nguyên nhân thứ hai là
việc đánh giá hệ tư vấn có thể hướng tới các mục tiêu khác nhau. Trong một số hệ thống,
các đánh giá có thể dựa tr ên số lần tư vấn dẫn đến quyết định đúng và sai. Trong một số
khác, các đánh giá có thể dựa trên xem xét người dùng hài lòng hoặc không hài lòng đối
với các kết quả tư vấn.
Do các nguyên nhân này, để đánh giá tính đúng đắn của mô h ình tư vấn đã được
đề xuất, chúng tôi chủ yếu dựa vào việc thu thập ý kiến người sử dụng về kết quả tư vấn.
Bên cạnh đó, dựa vào kết quả nghiên cứu về phân tích sở thích của người sử dụng
thông qua lịch sử tr ình duyệt (history browser) được chúng tôi đề xuất trong công tr ình
nghiên cứu sinh viên 2010 [1], chúng tôi đưa ra một phương pháp đánh giá tự động mô
hình phân tích sở thích dựa vào sự tương đồng giữa sở thích nổi trội trong phiên duyệt
web với sở thích nổi trội của lịch sử duyệt web của người sử dụng trong c ùng một thời
điểm. Phương pháp đánh giá này sẽ xem xét sự tương đồng giữa sở thích của người sử
dụng tr ên nhiều trang và sở thích người sử dụng tr ên hệ thống để đưa ra sự đánh giá.
Chúng tôi so sánh 2 loại sở thích tr ên bằng cách lấy 3 chủ đề ẩn phổ biến nhất của 2 loại
sở thích ra làm đại diện, nếu giữa chúng có sự xuất hiện của 1 chủ đề cụ thể nào thì xem
như chúng tương đồng. Kết quả đánh giá sẽ được thể hiện trong phần tiếp theo.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 45/59
37
Chương 4: Thực nghiệm và đánh giá
4.1. Môi trường thực nghiệm
Bảng 5. Môi trường thực nghiệm. Thành phần Thông số
CPU Core 2 Duo 2.0 GHz
RAM 2 GB
HDD 320 GB
OS Windows 7 Ultimate
4.2. Dữ liệu và công cụ
4.2.1. Dữ liệu
Dữ liệu tư vấn
Để xây dựng bộ dữ liệu tư vấn của hệ thống, chúng tôi thu thập dữ liệu từ 3 trang
web là: Dantri, Vnexpress, 24h. Sau quá trình tiến hành tiền xử lý như bóc tách lấy nội
dung chính của tin tức, chúng tôi thu được 4333 tin : 2060 tin trên website Dantri.com.vn
1291 tin trên website Vnexpress.net
982 tin trên website 24h.com.vn
Dữ liệu phiên duyệt web của người sử dụng
Chúng tôi tiến hành thu thập 30 phiên duyệt web của 30 người sử dụng tr ên các
website Dantri và Vnexpress thông qua việc phân tích các history.
Dữ liệu lịch sử tr ình duyệt của người sử dụng
Thu thập 30 dữ liệu lịch sử tr ình duyệt (history browser) của chính nhưng người sử
dụng ở tr ên có thời gian trong khoảng 15 phút trước và sau của 30 phiên duyệt web đã lấy.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 46/59
38
4.2.2. Công cụ
Bảng 6. Công cụ.
Công cụ Mô tả
SessionRecommendation Tác giả: Uông Huy Long
Mô tả: Bộ công cụ phân tích sở thích duyệt web của người sử
dụng thông qua Session và tư vấn tin tức dựa tr ên sở thích đã
được phân tích
JGibbLDA Tác giả: Nguyễn Cẩm Tú và Phan Xuân Hiếu
Mô tả: Công cụ phân tích chủ đề ẩn cho tài liệu viết tr ên nền
Java
Website: http://jgibblda.sourceforge.net
VutmDic Tác giả: Trần Mai Vũ
Mô tả: Bộ từ điển thực thể gồm 6479 thực thể thuộc 4 loại
thực thể: địa danh trong nước, địa danh nước ngoài, tên người,
tên tổ chức.
Vnexpress 100topics Tác giả: Nguyễn Cẩm Tú và Phan Xuân Hiếu
Mô tả: Bộ dữ liệu 100 chủ đề ẩn được phân tích từ Vnexpressdùng để phân tích chủ đề ẩn
Website: http://jgibblda.sourceforge.net/vnexpress-
100topics.txt
Crawler4j Tác giả: Yasser Ganjisaffar
Mô tả: Công cụ thu thập dữ liệu từ các website báo điện tử
Website: http://code.google.com/p/crawler4j/

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 47/59
39
4.3. Thực nghiệm
4.3.1. Ví dụ về phân tích tin tức
Bảng 7. Một số chủ đề ẩn
Topic 86 Topic 23 Topic 94
du_lịch tourthái_landu_kháchđẹp kháchsingapore
phố cổ điểm_đến bãi_biển sinh_tháide_france
việt_namvàngthể_thaohcchạythế_giớivn
sea_gamesđiền_kinhvđvgiànhnội_dungasiad
học_sinh quốc_tế emthitốt_nghiệp giáo_viênquốc_gia
lớp thpttổ_chức giỏi kỳ_thi olympic
Du lịch Bắc Kinh dịp Olympic cực khó28/07/2008 08:17 Theo các hãng lữ hành Hà Nội,hiện nay nhu cầu khách đi du lịch Bắc Kinh vàothời điểm diễn ra Olympic 2008 tăng cao songcác công ty không thể đáp ứng được. Vào thờiđiểm này, giá phòng khách sạn tại Bắc Kinh tănggấp 5 lần so với trước kia, lượng xe vận chuyểnkhách du lịch không thể đặt được do đã được huyđộng phục vụ Olympic.Mặt khác, vào thời điểm này, thủ tục xin cấp visavào Trung Quốc cũng gặp nhiều khó khăn. Do vậy,không chỉ giá tour đến Bắc Kinh tăng đột biến màcác hãng lữ hành tại Trung Quốc còn từ chối khiphía Việt Nam đề nghị đưa khách sang…
Danh sách các chủ đề: - Topic 86- Topic 23- Topic 94
Danh sách các thực thể: - Bắc kinh - Hà Nội
- Olympic- Trung Quốc - Việt Nam
Hình 14. Biểu diễn tin tức theo chủ đề và thực thể.
8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 48/59
40
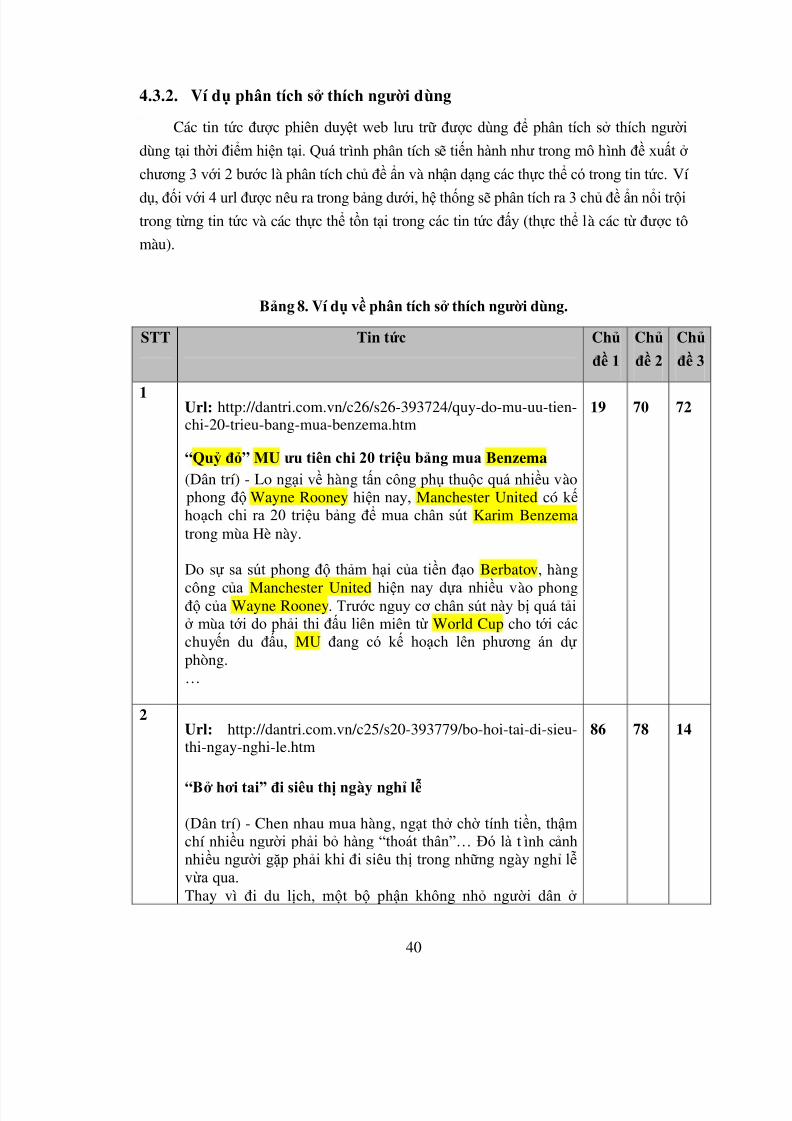
4.3.2. Ví dụ phân tích sở thích người dùng
Các tin tức được phiên duyệt web lưu trữ được dùng để phân tích sở thích người
dùng tại thời điểm hiện tại. Quá tr ình phân tích sẽ tiến hành như trong mô h ình đề xuất ở
chương 3 với 2 bước là phân tích chủ đề ẩn và nhận dạng các thực thể có trong tin tức. Ví
dụ, đối với 4 url được nêu ra trong bảng dưới, hệ thống sẽ phân tích ra 3 chủ đề ẩn nổi trộitrong từng tin tức và các thực thể tồn tại trong các tin tức đấy (thực thể là các từ được tô
màu).
Bảng 8. Ví dụ về phân tích sở thích người dùng.
STT Tin tức Chủ
đề 1
Chủ
đề 2
Chủ
đề 3
1 Url: http://dantri.com.vn/c26/s26-393724/quy-do-mu-uu-tien-chi-20-trieu-bang-mua-benzema.htm
“Quỷ đỏ” MU ưu tiên chi 20 triệu bảng mua Benzema(Dân trí) - Lo ngại về hàng tấn công phụ thuộc quá nhiều vào phong độ Wayne Rooney hiện nay, Manchester United có kếhoạch chi ra 20 triệu bảng để mua chân sút Karim Benzematrong mùa Hè này.
Do sự sa sút phong độ thảm hại của tiền đạo Berbatov, hàng
công của Manchester United hiện nay dựa nhiều vào phongđộ của Wayne Rooney. Trước nguy cơ chân sút này bị quá tảiở mùa tới do phải thi đấu liên miên từ World Cup cho tới cácchuyến du đấu, MU đang có kế hoạch lên phương án dựphòng.…
19 70 72
2Url: http://dantri.com.vn/c25/s20-393779/bo-hoi-tai-di-sieu-thi-ngay-nghi-le.htm
“Bở hơi tai” đi siêu thị ngày nghỉ lễ
(Dân trí) - Chen nhau mua hàng, ngạt thở chờ tính tiền, thậmchí nhiều người phải bỏ hàng “thoát thân”… Đó là t ình cảnhnhiều người gặp phải khi đi siêu thị trong những ngày nghỉ lễvừa qua. Thay vì đi du lịch, một bộ phận không nhỏ người dân ở
86 78 14

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 49/59
41
TPHCM lại vung tiền cho mua sắm trong dịp nghỉ lễ dài ngày30/4 - 1/5 vừa qua. Đáp lại, các siêu thị cũng có nhiều chươngtrình khuyến mãi hấp dẫn để tạo sức hút với người dân…
3Url: http://dantri.com.vn/c26/s26-394037/wayne-rooney-tiep-tuc-boi-thu-danh-hieu-ca-nhan.htm
Wayne Rooney tiếp tục bội thu danh hiệu cá nhân (Dân trí) - Với phong độ chói sáng trong mùa giải năm nay,Wayne Rooney một lần nữa lại ẵm về các danh hiệu cá nhâncao quý. Mới đây anh đã đoạt thêm 2 giải thưởng Cầu thủxuất sắc nhất do các CĐV MU và các đồng đội b ình chọn.
Với tỷ lệ phiếu bầu áp đảo 83% Rooney đã vượt qua các đồngđội Patrice Evra và Antonio Valencia để trở thành Cầu thủxuất sắc nhất năm 2010 của MU (Sir Matt Busby Player of the Year). Giải thưởng do các CĐV của Qu ỷ đỏ khắp nơi trênthế giới b ình chọn thông qua website ManUtd.com. Đây là lầnthứ hai chân sút người Anh có được vinh dự này sau thànhcông lần đầu vào năm 2006.
19 4 70
4Url: http://dantri.com.vn/c26/s26-381415/owen-rooney-giup-mu-bao-ve-thanh-cong-carling-cup.htm
Owen, Rooney giúp MU bảo vệ thành công Carling Cup(Dân trí) - Dù để Aston Villa vượt lên dẫn trước ngay đầu trận
nhưng với bản lĩnh của m ình, “Quỷ đỏ” đã lội ngược dòng đểgiành chiến thắng 2-1 nhờ hai pha lập công của Owen vàRooney, qua đó lần thứ hai liên tiếp vô địch Carling Cup.Trận chung kết tại Wembley tối nay, 28/2, diễn ra cởi mở vàhấp dẫn ngay sau tiếng còi khai cuộc. Aston Villa bất ngờ mở tỷ số ngay phút 4 sau cú sút penalty thành công của JamesMilner. Bị dội “gáo nước lạnh” từ sớm nhưng MU không hềnao núng và nhanh chóng quân bình tỷ số chỉ sau đó 9 phút,với pha chớ p thời cơ của Owen.
Dù sau đó cựu tiền đạo Newcastle phải rời sân ở cuối hiệp 1
do bị đau nhưng người vào thay anh, Wayne Rooney tiếp tụchoàn thành xuất sắc nhiệm vụ. Tiền đạo đang có phong độ ghibàn “cực khủng” này chính là tác giả bàn thắng ấn định tỷ số2-1 ở phút 74, giúp MU đăng quang chức vô địch CarlingCup lần thứ hai liên tiếp...
19 39 37

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 50/59
42
Hệ thống nhận ra điểm tương đồng chủ đề giữa các tin tức mới được đọc. Như trong
ví dụ, chủ đề phổ biến là : 19 (3 lần), 70 (2 lần) (ví dụ một số từ khóa có trọng số cao
trong 2 chủ đề 19 và 70 được nêu trong bảng dưới) và các thực thể nổi trội như: MU,
Wayne Rooney, Newcastle, Carling Cup, Owen,...
Phân phối tr ên các từ của chủ đề 19 Phân phối tr ên các từ của chủ đề 70
giảivô_địchcầu_thủ độimùabóngvòng
trậnhạng bóng_đáđấuthi_đấu …
0.069964952081788170.0289545249625525330.0251734217529776160.0218285996829690360.019356339892093130.0149935284964297640.014266393263819203
0.0115032793798990720.0112124252868548490.0112124252868548490.0109215711938106240.010485290054244287
đồnghàngtiềntriệutỷ chiếmlừa
trămchụcgiả chiếm_đoạtnghìn…
0.075845301135310.038345043578596010.034636226897162750.031339500958110970.022273504625718580.0117651906949910370.008674510127129994
0.0082624193847485210.0066140564152226320.0064080110440318960.006201965672841160.0053777841880782145
4.3.3. Tư vấn tin tức
Các tin tức được xem là liên quan nếu nó thuộc vào cùng chủ đề phổ biến trong
các tin tức người dùng quan tâm, ví dụ với các tin tức được liệt k ê trong bảng 8. Các tin
tức liên quan là các tin tức có chủ đề thuộc vào 19 hoặc 70.
Hình 15. Kết quả phân tích cho thấy các thông tin liên quan đến chủ đề 19.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 51/59
43
Tuy nhiên, nếu chỉ tư vấn các tin tức thuộc cùng chủ đề th ì có thể có quá nhiều tin
tức được lựa chọn, cần có một giải pháp để sắp xếp lại các tin tức này, khóa luận sử dụng
những thực thể nằm trong các tin tức đã được xem thuộc về chủ đề được quan tâm phổ
biến (như MU, Wayne Rooney, Newcastle, Carling Cup, Owen,...) để xếp hạng lại những
kết quả thu được.Top N các tin tức thu được sẽ được sử dụng để đưa ra tư vấn với người dùng. Ví dụ,
tin tức có thể được tư vấn.
Garry Neville và 10 sự kiện đáng nhớ trong sự nghiệp ở MU - Bóng đá - Tin bênlề. Score: 4
Gary Neville, tên đầy đủ là Gary Alexander Neville, hiện nay đang là người đứng thứ 5 trongdanh sách những cầu thủ khoác áo nhiều nhất của MU với 597 trận đấu tr ên tất cả các đấutrường. Xếp tr ên anh là Paul Scholes với 641 lần ra sân và Ryan Giggs đang là người dẫn đầudanh sách này với 836 lần. Neville cũng là 1 trong 9 cầu thủ trong top hơn 500 lần xuất hiện
trong màu áo đỏ của MU.
Neville là sản phẩm của lò đào tạo trẻ MU những năm 90 và đã có vinh dự được đeo băng độitrưởng trong đội h ình Manchester United đoạt cúp vô địch FA dành cho các đội trẻ năm1992. Mùa bóng đó chứng kiến sự ra đời của lứa cầu thủ tài năng như David Beckham, Ryan
4.4. Kết quả thực nghiệm và đánh giá
Chúng tôi tiến hành đánh giá độ chính xác của mô h ình dựa vào 2 phương pháp
đánh giá đã được nêu ở mục 3.4:
Đánh giá mô h ình phân tích sở thích dựa vào tính tương đồng chủ đề giữa mối
quan tâm người dùng nhận ra từ lịch sử duyệt web lưu trong máy khách và mối
quan tâm người dùng nhận ra từ phiên duyệt web lưu tại máy chủ.
Đánh giá độ chính xác của mô h ình dựa vào đánh giá của người sử dụng: thống
kê các đánh giá trực tiếp của người dùng qua việc kiểm tra thông tin tư vấn là
phù hợp hay không phù hợp. Kết quả đo độ chính xác là độ chính xác trung bình
tính trên 30 người sử dụng.
8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 52/59
44
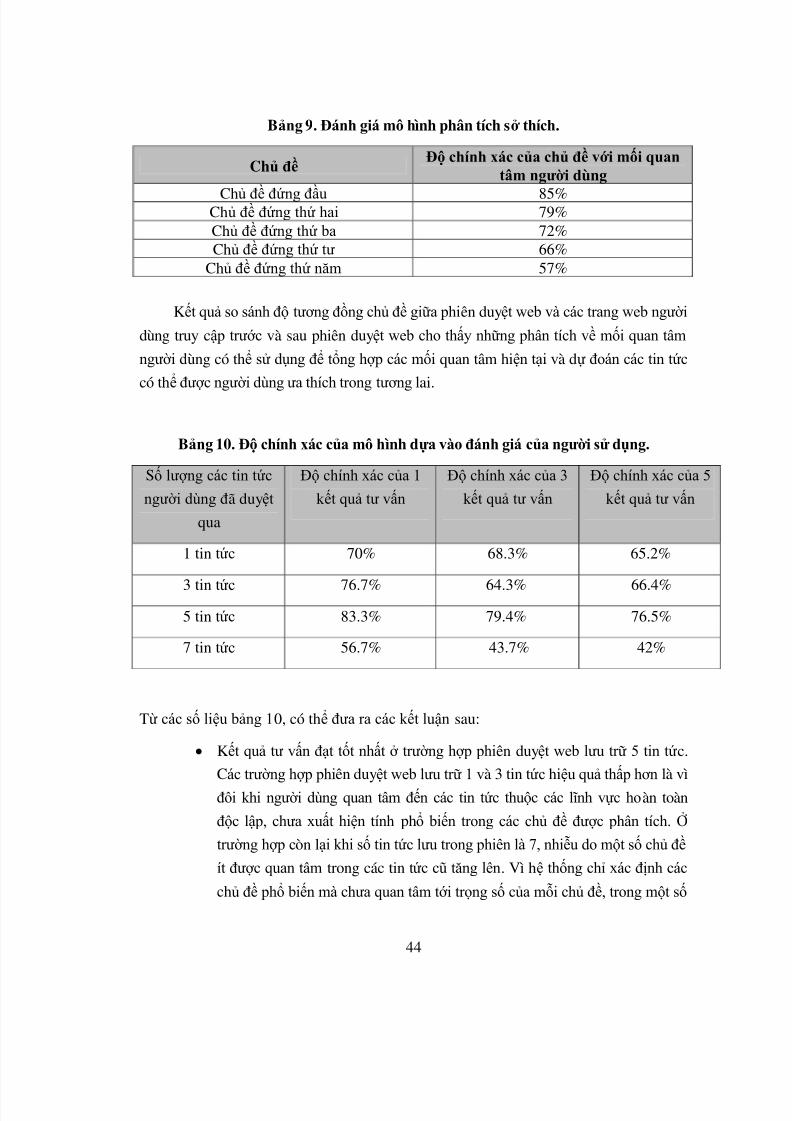
Bảng 9. Đánh giá mô h ình phân tích sở thích.
Chủ đề Độ chính xác của chủ đề với mối quan
tâm người dùng
Chủ đề đứng đầu 85%Chủ đề đứng thứ hai 79%Chủ đề đứng thứ ba 72%Chủ đề đứng thứ tư 66%
Chủ đề đứng thứ năm 57%
Kết quả so sánh độ tương đồng chủ đề giữa phiên duyệt web và các trang web người
dùng truy cập trước và sau phiên duyệt web cho thấy những phân tích về mối quan tâm
người dùng có thể sử dụng để tổng hợp các mối quan tâm hiện tại và dự đoán các tin tức
có thể được người dùng ưa thích trong tương lai.
Bảng 10. Độ chính xác của mô h ình dựa vào đánh giá của người sử dụng.
Số lượng các tin tức
người dùng đã duyệt
qua
Độ chính xác của 1
kết quả tư vấn
Độ chính xác của 3
kết quả tư vấn
Độ chính xác của 5
kết quả tư vấn
1 tin tức 70% 68.3% 65.2%
3 tin tức 76.7% 64.3% 66.4%5 tin tức 83.3% 79.4% 76.5%
7 tin tức 56.7% 43.7% 42%
Từ các số liệu bảng 10, có thể đưa ra các kết luận sau:
Kết quả tư vấn đạt tốt nhất ở trường hợp phiên duyệt web lưu trữ 5 tin tức.
Các trường hợp phiên duyệt web lưu trữ 1 và 3 tin tức hiệu quả thấp hơn là vì
đôi khi người dùng quan tâm đến các tin tức thuộc các lĩnh vực hoàn toàn
độc lập, chưa xuất hiện tính phổ biến trong các chủ đề được phân tích. Ở
trường hợp còn lại khi số tin tức lưu trong phiên là 7, nhiễu do một số chủ đề
ít được quan tâm trong các tin tức cũ tăng lên. Vì hệ thống chỉ xác định các
chủ đề phổ biến mà chưa quan tâm tới trọng số của mỗi chủ đề, trong một số

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 53/59
45
trường hợp, những chủ đề ít được quan tâm trở thành phổ biến, làm giảm độ
chính xác của mô h ình.
Nhìn chung, độ chính xác của mô h ình tư vấn giảm dần theo số lượng các tin
tức được tư vấn. Tuy nhiên việc đưa ra nhiều tư vấn cung cấp cho người
dùng nhiều lựa chọn hơn.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 54/59
46
Kết luận
Các hệ thống tư vấn đã nhận được nhiều quan tâm từ cộng đồng nghiên cứu và các
tổ chức kinh tế vì những đóng góp của nó trong giải quyết vấn đề tr àn ngập thông tin và
cung cấp các dịch vụ hướng cá nhân. Tuy nhiên, đối với lĩnh vực tư vấn tin tức, các hướng
tiếp cận hiện nay vẫn còn nhiều vấn đề cần giải quyết. Nắm bắt được nhu cầu đó, khóa
luận tiến hành nghiên cứu, khảo sát một số hướng tiếp cận giải quyết bài toán tư vấn đã
có. Sau đó, dựa tr ên các khảo sát này, khóa luận đề xuất một giải pháp tư vấn cho các hệ
thống cung cấp tin tức.
Các kết quả chính đạt được
Khóa luận đã tìm hiểu các khái niệm, thuật ngữ, kĩ thuật liên quan đến các hệ thốngtư vấn. Dựa vào khảo sát các đặc trưng của tư vấn tin tức, phân tích ưu nhược điểm của
các phương pháp xây dựng hai thành phần chính của hệ tư vấn là mô hình sở thích người
dùng và các thuật toán tư vấn, khóa luận đề xuất một giải pháp tư vấn tin tức dựa tr ên khai
phá ngữ cảnh sử dụng hiện tại của người dùng. Trong đó, hệ thống thực thi một thuật toán
tư vấn dựa tr ên phân tích chủ đề ẩn và các thực thể trong nội dung của những tin tức
người dùng vừa truy cập (hướng tiếp cận dựa tr ên nội dung). Hướng tiếp cận này có nhiều
tiềm năng và đã được chứng minh thông qua một số số liệu thống k ê kết quả ban đầu.
Một số vấn đề cần tiếp tục giải quyết
Tuy mô hình đã bước đầu đạt được một số kết quả khả quan, nhưng vẫn còn tồn tại
nhiều vấn đề cần giải quyết. Đầu tiên, vì chưa có các độ đo ngữ ngh ĩa cho các hệ thống tư
vấn tương tự, các đánh giá chủ yếu dựa tr ên các nhận định chủ quan về tính phù hợp hay
không phù hợp của kết quả tư vấn. Thêm vào đó, hạn chế về số lượng và chất lượng của
kho dữ liệu tin tức cũng ảnh hưởng xấu đến chất lượng của sự tư vấn. Cuối cùng, do hệ
thống sử dụng dữ liệu từ phiên duyệt web người dùng, kết quả tư vấn khi người dùng mới
truy cập một vài tin tức đầu còn chưa cao.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 55/59
47
Hướng nghiên cứu tiếp theo
Trong thời gian tới, ngoài việc tiếp tục giải quyết các vấn đề còn tồn tại, chúng
tôi định hướng một số nghiên cứu tiếp theo:
- Nghiên cứu thêm về các yếu tố ngữ cảnh và ảnh hưởng của chúng đến quyết
định của người dùng.
- Nghiên cứu các hướng áp dụng của giải pháp mở rộng thông tin ngữ cảnh người
dùng như cung cấp các thông tin quảng cáo phù hợp với ngữ cảnh sử dụng.

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 56/59
48
Tài liệu tham khảo
Tiếng Việt
[1] Uông Huy Long, Nguyễn Đạo Thái, Trần Xuân Tứ . Mô hình tư vấn dựa trênviệc phân tích chủ đề ẩn sự quan tâm của ngườ i dùng, Công trình sinh viên nghiên
cứ u khoa học, Đại học Công Nghệ, ĐHQGHN, 2009.
Tiếng Anh
[2] G.Adomavicius, A.Tuzhilin. Towards the Next Generation of Recommender
Systems:A Survey of the State-of-the-Art and Possible Extensions, IEEE
Transactions on Knowledge and Data Engineering, 2005.
[3] Aho, Alfred V.; Margaret J. Corasick. "Efficient string matching: An aid to
bibliographic search". Communications of the ACM 18 (6): 333–340, June 1975.
[4] Ansari, A., S. Essegaier, and R. Kohli. Internet recommendations systems.
Journal of Marketing Research, pages 363-375, 2000.
[5] Basu, C., H. Hirsh, and W. Cohen. Recommendation as classification:
Using social and content-based information in recommendation. In Recommender Systems. Papers from 1998 Workshop. Technical Report WS-98-08. AAAI Press, 1998.
[6] Balabanovic, M. and Y. Shoham. Fab: Content-based, collaborative
recommendation. Communications of the ACM, 40(3):66-72, 1997.
[7] Bamshad Mobasher: Data Mining for Web Personalization. The Adaptive
Web 2007:90-135.
[8] Belkin, N.J., Croft, W.B.: Information filtering and information retrieval: two
sides of the same coin?. Communications of the ACM 35(12), 29–38 (1992).
[9] Billsus, D. and M. Pazzani. Learning collaborative information filters.
In International Conference on Machine Learning, Morgan Kaufmann Publishers,

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 57/59
49
1998.
[10] Breese, J. S., D. Heckerman, and C. Kadie. Empirical analysis of predictive
algorithms for collaborative filtering. In Proceedings of the Fourteenth Conference on
Uncertainty in Artificial Intelligence, Madison, WI, 1998.
[11] Burke, R. Hybrid Recommender Systems: Survey and Experiments. User
Modeling and User-Adapted Interaction 12, 4 (Nov. 2002), 331-370.
[12] Chen, L., Sycara, K.: A Personal Agent for Browsing and Searching. In:
Proceedings of the 2nd International Conference on Autonomous Agents,
Minneapolis/St. Paul, May 9-13, (1998) 132-139.
[13] David M. Blei, Andrew Y. Ng, Michael I. Jordan: Latent Dirichlet Allocation. Journal of Machine Learning Research (JMLR) 3:993-1022 (2003).
[14] Gauch, S., Speretta, M., Chandramouli, A., Micarelli, A. User profiles for
personalized information access , In: Brusilovsky, P., Kobsa, A., and Neidl, W., Eds.
The Adaptive Web: Methods and Strategies of Web Personalization. Springer- Verlag,
Berlin Heidelberg New York, 2007, 54-89.
[15] Gentili, G., Micarelli, A., Sciarrone, F.: Infoweb: An Adaptive InformationFiltering System for the Cultural Heritage Domain. Applied Artificial Intelligence
17(8-9) (2003) 715-744.
[16] Guarino, N., Masolo, C., Vetere, G.: OntoSeek: Content-Based Access to the
Web. IEEE Intelligent Systems, May 14(3) (1999) 70-80.
[17] Heinrich, G., “Parameter Estimation for Text Analysis”, Technical Report.
[18] Herlocker, .L., Konstan, J.A., Terveen, L.G., Riedl, J.T.: Evaluating
Collaborative Filtering Recommender Systems. ACM Transactionson Information
Systems 22(1), 5–53(2004).
[19] Thomas Hofmann. Probabilistic latent semantic indexing. In Proceedings of

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 58/59
50
SIGIR-99, (1999) 35–44.
[20] Kelly, D., Teevan, J.: Implicit feedback for inferring user preference: a
bibliography. ACM SIGIR Forum 37(2) (2003) 18-28.
[21] Le Dieu Thu. Online context advertising, Undergraduate Thesis, College of
Technology, Vietnam National University, Hanoi, 2008.
[22] Nguyen Cam Tu. Hidden Topic Discovery toward Classification and Clustering
in Vietnamese Web Documents, Master Thesis, College of Technology, Vietnam
National University, Hanoi, 2008.
[23] Pazzani, M., Muramatsu, J., Billsus, D.: Syskill & Webert: Identifying
Interesting Web Sites. In: Proceedings of the 13th National Conference On Artificial
Intelligence Portland , Oregon, August 4–8 (1996) 54-61.
[24] Pretschner, A.: Ontology Based Personalized Search. Master’s thesis. University
of Kan- sas, June (1999).
[25] Popescul, A., L. H. Ungar, D. M. Pennock, and S. Lawrence. Probabilistic
Models for Unified Collaborative and Content-Based Recommendation in Sparse-
Data Environments. In Proc. of the 17th Conf. on Uncertainty in Artificial Intelligence, Seattle, WA, 2001.
[26] R.Baeza, F.Silvestri. Web Query Log Mining, ACM SIGIR Conference tutorial,
2009.
[27] G. Salton, A. Wong, C.S. Yang. A Vector Space Model for Automatic Indexing,
Communication of the ACM , 18 (11), 1975.
[28] Sieg, A., Mobasher, B., Burke, R.: Inferring users information context:
Integrating user profiles and concept hierarchies. In: 2004 Meeting of the
International Federation of Classification Societies, IFCS, Chicago, July (2004).
[29] Soboroff, I. and C. Nicholas. Combining content and collaboration in

8/3/2019 Uong Huy Long-KLTN2010
http://slidepdf.com/reader/full/uong-huy-long-kltn2010 59/59
text filtering. In 43 IJCAI'99 Workshop: Machine Learning for Information Filtering,
1999.
[30] The Open Directory Project (ODP), http://dmoz.org
[31] Widyantoro, D.H., Yin, J., El Nasr, M., Yang, L., Zacchi, A., Yen, J.: Alipes:
A Swift Messenger In Cyberspace. In: Proc. 1999 AAAI Spring Symposium Workshop
on Intelli- gent Agents in Cyberspace, Stanford, March 22-24 (1999) 62-67.


























![[Www.foodnk.com]Bao Cao Thuc Hanh Do Uong Full](https://img.pdfslide.net/doc/110x75/55cf9b8c550346d033a6802d/wwwfoodnkcombao-cao-thuc-hanh-do-uong-full.jpg)


