Embed Size (px)
Citation preview

Zaven Akopov (DESY -L-)For the INSPIRE Collaboration
DESY Computing Seminar

Joint Project of CERN, DESY, Fermilaband SLACSPIRES: wonderful system, largest HEP database, best-curated content, but..oldengine (>30 years):
need a modern open-source multimedia digital library
Unify SPIRES content with Invenioplatform
Invenio = Open source digital library○ http://invenio-software.org
SPIRES + Invenio = InSpire

InvenioIntegrated digital library system
written largely in PythonMySQL databasemodular built
Navigable collection treeDocuments organized in collectionsRegular and virtual collection trees Customizable portal-boxes for each collection
Powerful search engineSpecially designed indexes to provide fast search speed for repositories of up to 2,000,000 recordsCustomizable simple and advanced search interfaces
Flexible metadataStandard metadata format (MARC)Handling articles, books, theses, photos, videos, museum objects and more
User personalizationBaskets, e-mail notifications, comments, etc.

DESY participationInput of Journal/Article DataHEP Ontology (Keywords) InputHierarchy of HEP concepts based on DESY HEP ThesaurusDESY assigns keywords and classification to HEP Articles since 1964SPIRES/InSPIRE mirror website

Where are we?First Beta site released April 2010Production Beta released a week ago
http://inspirebeta.netLive NowPopulated with SPIRES content dailyAdditional features
Bugs are getting ironed out, but already:
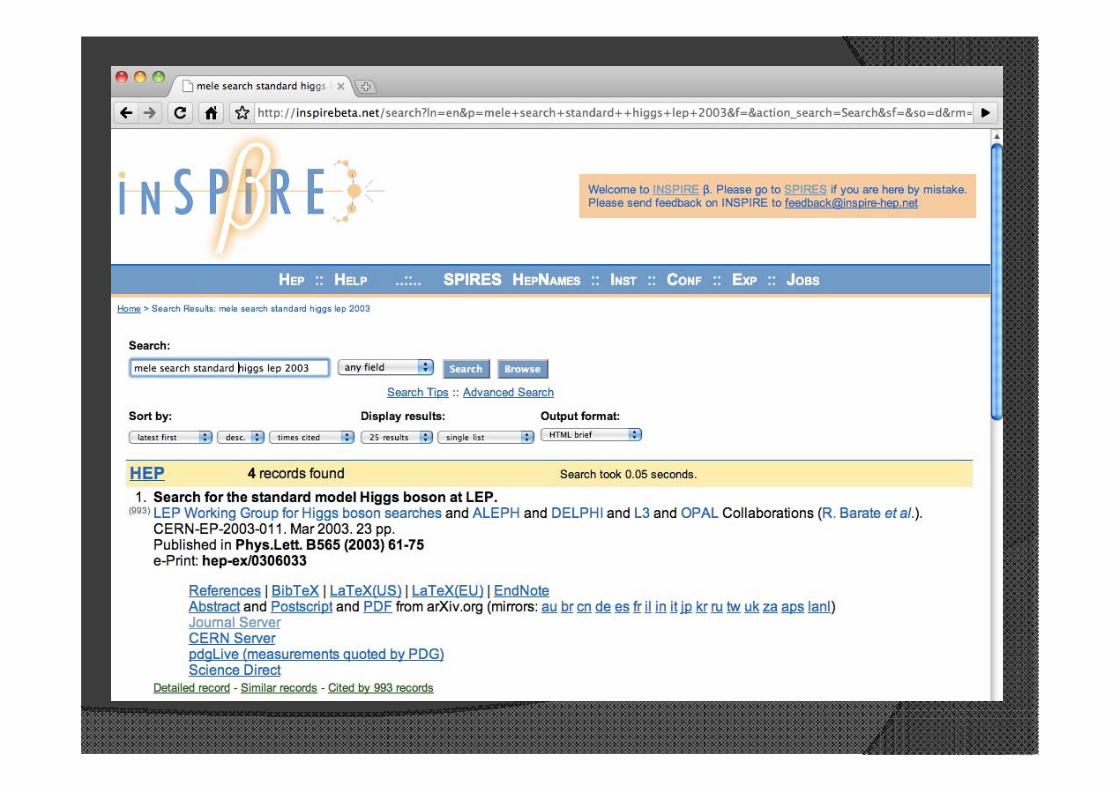
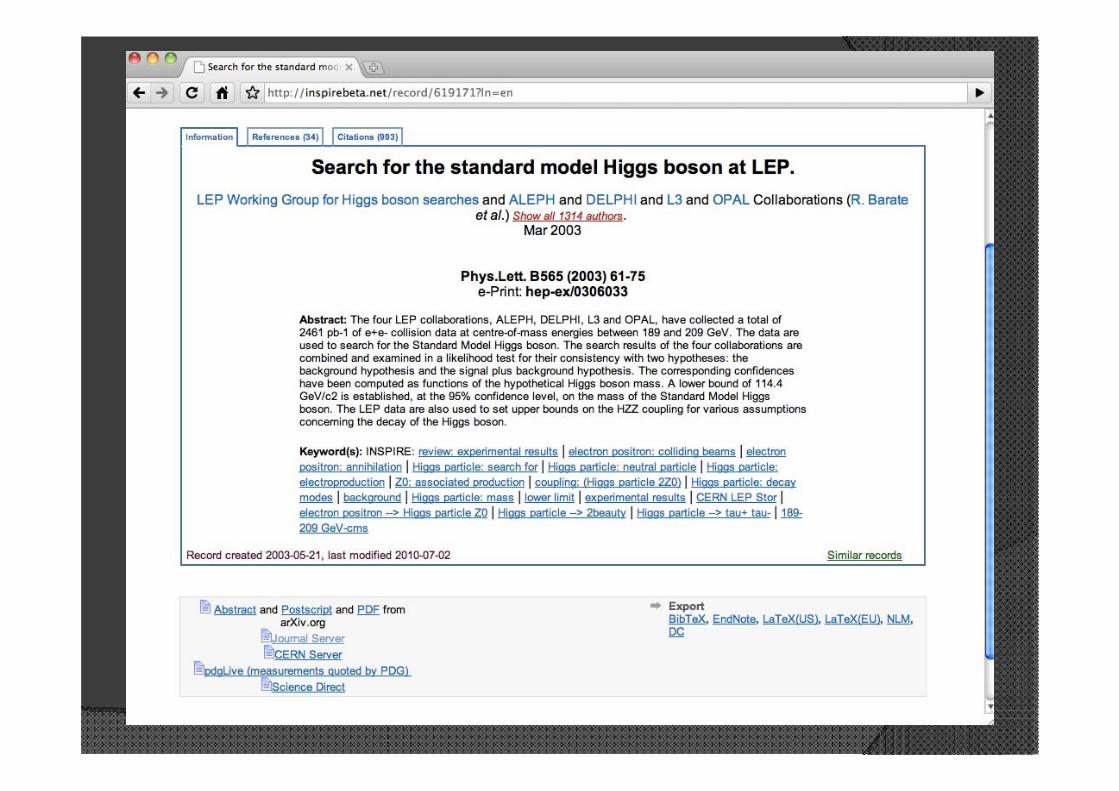
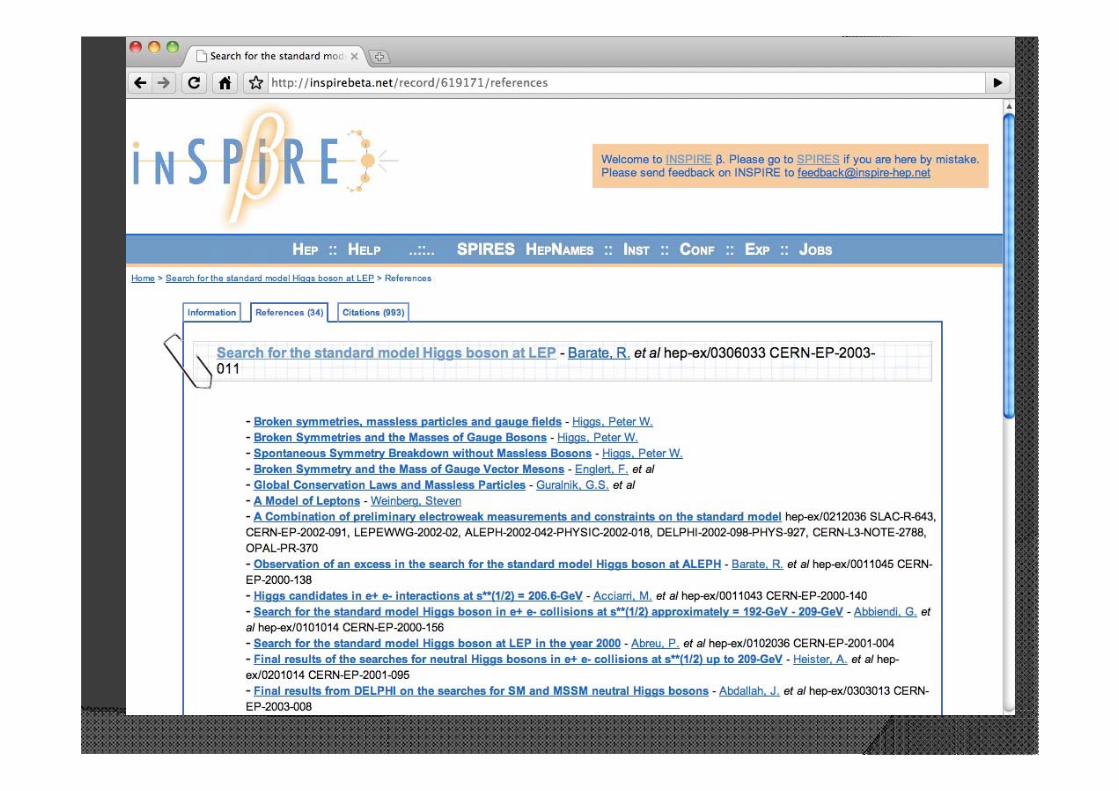
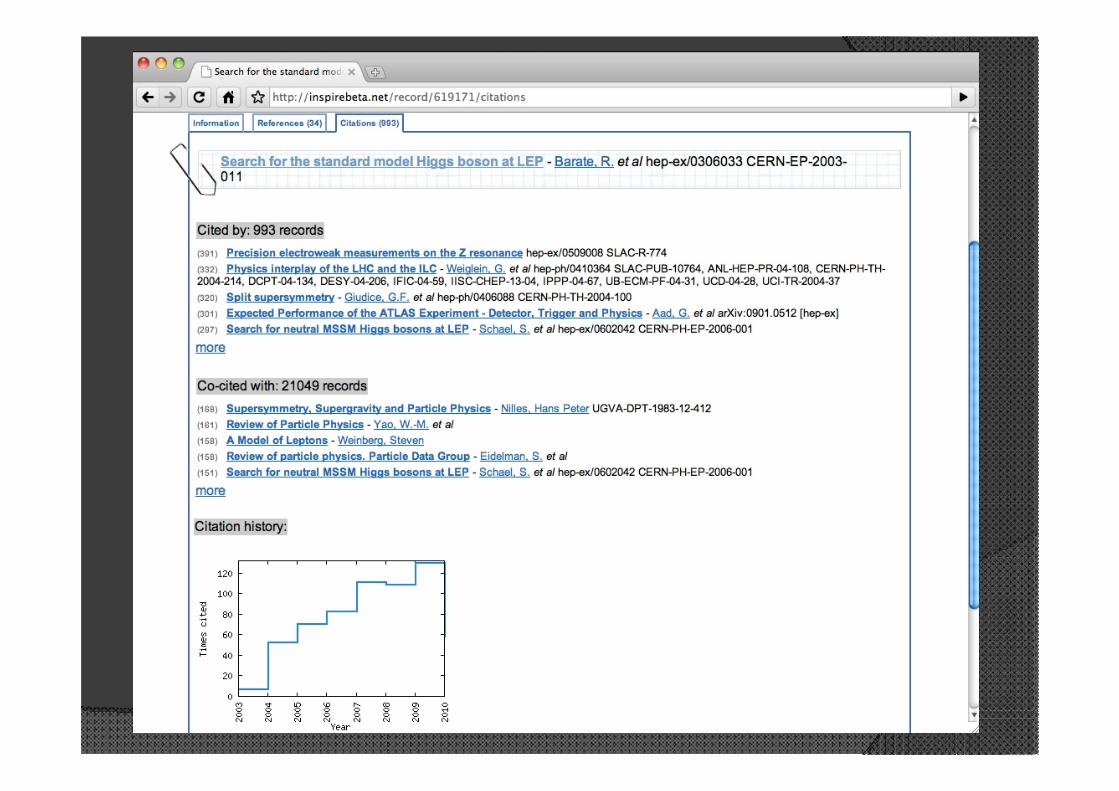




Figures/Plots extraction

Full-text search

More to comePersonal libraries, alertsClaim my papers (with arXiv and ORCID (Open Researcher and Contributor ID))Submit theses and old non-arXivmaterialAttach non-text materialOCR of older materialsEven better feeds (with ADS, arXiv, Publishers)

Automatic DisambiguationHenning Weiler - PhD student@CERN
On 963 documents, 21 real authors could be identified for the query "Chen, G".
22 orphans remain98% identified

User Accounts
Tied to academic affiliation
Ability to correct information and claim papers
Corrections still vetted by staff
Add “corporate accounts” for collaborations

Data - SoonPartnership and interlinking with HEPData
HepData reloaded: reinventing the HEP data archive.Andy Buckley, Mike Whalley. Jun 2010. e-Print: arXiv:1006.0517 [hep-ex]http://hepdata.cedar.ac.uk/HEPData+INSPIRE working with LHC and other experiments to ease submission process and interlinkingMove towards citation/tracking use – reputation…
Storage for other objects like ROOT, Mathematica, etc.

Non-text material

Full-cycle of a publicationUp to now, we've captured product:
PapersConsidering Data
Currently, through DPHEP, opportunity to build infrastructure for capturing the process:
Internal NotesTechnical/Software DocumentationLogbooks

WikisIncreasingly popular central place to aggregate documentationUsers structure the data for usBackups and 'dumps' are generally easy to make
And usually in an easily digestible format (like XML)

ToolsFor MediaWiki, most of the essential tools already exist.
Wikimedia Foundation (Wikipedia) is interested in seeing what we do with them.From discussions with them, they are supportive of what we're trying to do

Nascent BaBar WikiMediaWiki Instance with:
162 content pages201 total pages (talk, redirects, etc.)22 registered usersSimple script can easily produce dumps.

ScenariosLevel 0 Service: Basic Preservation
Index and store wiki snapshot data as if it were a scientific publication (with many authors)
Level 1 Service: Readable SnapshotsLevel 0 + read-only final version respecting formatting, etc.
Level 2: Multiple SnapshotsLevel 0 + Level 1 for each of multiple wiki“release points”, with full(?) metadata Linking with Papers

Publication/Drafting History: H1 Example
A publication history includes:Set of preliminary results (typically, prepared for/as conference reports), short papers with associated figures.Actual publication process which begins with a pre-T0 report, which goes then through T0 talk to First/Second/… draft.Each draft stage has it’s set of answers (comments by collaboration and answers to them); typically a referee reportAnd a final version that goes to the journal.

Mock-Up


How does it work?External Users can see the links from Conference talks to final papers, but nothing in betweenAccess control – must be registered and validated (e-mail ping): already planned
“Corporate” accounts for collaboration to update pageIndividual access via connection with collaboration…(Any paper? Current membership? What about long-term?)
In development

AccessMain challenge: Access policies and their technical implementationNeed input from collaborations to create policies. One size does not fit all.
Easy – master access file maintained by coll. But not long-term…Medium – Computation based on author lists (not always correct?)Harder – Individual access lists depending on date of object and date of access
OAIS (ISO standard) etc. can help us implement these in line with archival best practices

Questions?For more information on INSPIRE see
http://www.projecthepinspire.net
Just try it out!
http://inspirebeta.net





























