
Fall 2011
Foreword
The seminar at Aalto University, School of Electrical Engineering, Department of Signal Processing and Acoustics is devoted to changing current topics in audio signal process-ing. In fall 2011, the topic of the seminar was mobile audio programming on popular platforms.
The seminar topics were organized according to the background and learning goals of the par-ticipants (left). The learning objectives were:
• to read and understand technical literature• develop scientific writing and presentation skills• understand the fundamentals of audio program-ming, and their utilization on mobile platforms• compare different control protocols, such as MIDI, OSC, and TUIO• tackle more advanced topics, such as streams, threads, and multimedia frameworks.
During the keynotes, invited experts have introduced the architecture and application programming interfaces relevant for interactive mobile audio applications. Meanwhile, each participant has prepared a manuscript on a selected topic and presented it at the final event of the seminar, on December 9, 2011. This report is a compilation of the seminar papers by the participants.
Each contribution is an open-access article distributed under the terms of the Creative Commons Attribution License 3.0 Unported, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source (Proceedings of Mobile Audio Programming Seminar Fall 2011, by edited by Cumhur Erkut, Antti Jylhä, and Jussi Pekonen) are credited.
I hope you enjoy the content as much as we do.
Cumhur Erkut
January 8, 2013
Mobile Audio Programming Seminar 2011
S-89.3580 Audio Signal Processing Seminar (3 cr) V S-89.4820 Postgraduate Course in Audio Signal Processing (8 cr) PV
Mobile Audio Programming SeminarProceedings

Fall 2011
Table of Contents
R.Albrecht, Mobile audio-based environment recognition ... 1F.Belveze, Recognition of musical content using audio fingerprinting ... 13S. D’Angelo, Pure Data on mobile devices: approaches and perspectives ... 21S. Delikaris-Manias, Way-finding and navigation assistance in mobile devices . 34F. Delord, The accelerometer in mobile phone: from physics to programming ... 44T. Jugé, Into the vocoder: digital filters ... 54C.-H. Lai, Mobile Music in Performance Context ... 64A. Pakarinen, Procedural audio in mobile games ... 73J. Parker, Mobile instrument construction with MoMu ... 87A. Politis, Collaborative and networked music approaches on mobile platforms . 103R. Pugliese, Audio-driven mobile music applications: a design perspective ... 120M. Valtonen, Mobile game audio effects ... 131R. C. D. de Paiva, Mobile application of audio-based activity recognition ... 141
S-89.3580 Audio Signal Processing Seminar (3 cr) VS-89.4820 Postgraduate Course in Audio Signal Processing (8 cr) PV
Mobile Audio Programming Seminar 2011

Mobile Audio-Based Environment Recognition
Robert AlbrechtAalto University School of ScienceDepartment of Media Technology
Abstract
Context recognition systems may use different types of data available on a mobile device,e.g., audio and acceleration, to infer the environment the device is located in. A contextrecognition system typically uses a set of pre-classified training data and machine-learning algorithms to classify the new data given. For an audio-based system, certainfeatures, such as Mel-frequency cepstral coefficients, are extracted from raw audio data,and used by the classification algorithms. Suitable machine-learning algorithms includehidden Markov models and k-nearest-neighbours classifiers. The choice of training data,features, classes, and classification algorithms not only affects the recognition accuracy,but also the resources required. On mobile devices, a balance must thus be found betweentime and power consumption, and accuracy.
Keywords — Context recognition, environment, mobile audio
1 Introduction
Knowing the environment the user of a mobile device is located in can be useful information.Based on the surrounding environment, the mode of operation of the device could be adjusted,or information relevant to the current environment could be presented. One potential usecase for environment recognition is audio-augmented-reality applications, where the virtualsounds presented could vary depending on the environment. With microphone-hear-throughhardware (Lindeman et al., 2007), the level at which the environment is heard can also beadjusted based on this information, e.g., attenuating it when the user sits in a disturbinglynoisy environment.
When implementing a system for context recognition, there are several different aspectsto consider. Probably the first question that should be asked, is for what purpose theinformation about the context will be used. Based on this, different context classes can bedefined and appropriate training data representing these classes may be acquired. Choosingan appropriate classifying algorithm is important, but equally important is the choice of theset of low-level features that is used by the algorithm.
Context recognition can be performed using different types of data. Many mobile phonessupply applications with information about the acceleration and the orientation of the device.The GPS device in mobile phones can also provide valuable data. Preferably, information
1

from many different types of sensors could be fused. This paper, however, concentrates onusing audio to extract the environmental context.
In Section 2, different features that can be extracted and used as data for classificationalgorithms are discussed. Studies on how classification using different features compareare presented. In Section 3, two different classification algorithms are discussed. Theseare the commonly used hidden-Markov-model classification and the k-nearest-neighbourclassification. Examples of implementations and their results are presented, including acomparison between these two classification methods.
In Section 4, some aspects related to mobile applications of environment recognition arediscussed. The time needed for performing accurate recognition is studied, as well as waysto adapt the recognition process to only use the computational resources available. Section 5concludes and summarizes the paper.
2 Feature extraction
The task of a context recognition system is to use a set of data given, and based on thisprovide an educated guess of the context where the data was recorded. In an audio-basedcontext recognition system, the data given is raw audio. However, this raw audio datacontains several different types of information which can be used to give clues about thecontext, but this information is not in a form that can be used by the classification algorithmsas such. The raw audio data thus needs to be processed to extract the relevant features thatcan be used by these algorithms.
Eronen et al. (2006) investigated using several different features as data for their classifi-cation algorithms. All features were measured in short analysis frames, typically with alength of 30 milliseconds and an overlap of 15 milliseconds between consecutive frames. Thefeatures used are listed below.
• Zero-crossing rate is the number of times the signal crosses zero within a frame.
• Short-time average energy is calculated as the sum of squared amplitudes within aframe.
• Mel-frequency cepstral coefficients (MFCC) are short-term spectral features (Logan,2000). These are obtained by chopping the signal into frames and applying a windowfunction on each frame. The spectrum of each frame is then obtained with the discreteFourier transform and only the logarithm of the amplitude spectrum is retained.These spectral components are collected into frequency bins equally spaced on the Melfrequency scale. Finally, the obtained Mel-spectral vectors are decorrelated using, e.g.,principal component analysis (PCA) or the discrete cosine transform (DCT), producingthe MFCCs.
• Mel-frequency delta cepstral coefficients are an approximation of the first time deriva-tive of each cepstral coefficient.
• Band energy is the energy of a subband of the signal normalized with the total energy.
• Spectral centroid is the barycenter of the spectrum.
2

• Bandwidth is an estimate of the bandwidth of the signal.
• Spectral roll-off is the frequency below which a certain amount of the total energyresides.
• Spectral flux is the difference between the amplitude spectra of consecutive frames.
• Linear prediction coefficients are used for predicting the future values of signals as alinear combination of previous values (O’Shaughnessy, 1988). They are suitable fordescribing a slowly-varying linear filtering process.
• Linear prediction cepstral coefficients are obtained from the linear prediction coeffi-cients through recursion.
The recognition accuracy obtained with the different features is shown in Fig. 1. For allfeatures, the context recognition is performed using both nearest neighbour and hiddenMarkov model classifiers. The different classifiers are discussed in more detail in Section 3.
Eronen et al. (2006) divided the training data into a total of 27 contexts. The contextswere grouped into six high-level categories: outdoors, vehicles, public/social places, of-fices/meetings/quiet places, home, and reverberant places. As an example, the outdoorscategory consisted of the following contexts: street, road, nature, construction, marketplace,and fun park.
The best recognition rates are acquired using Mel-frequency cepstral coefficients, bandenergy, and linear prediction cepstral coefficients. Not surprisingly, the features containinglimited or no spectral information give poorer accuracy. Fig. 1 also shows that differentclassifiers using the same feature can perform very differently.
In their work, Korpipää et al. (2003) used descriptors defined in the MPEG-7 standard(ISO/IEC 15938-4, 2002): harmonicity ratio, spectral centroid, spectral spread, spectralflatness, and fundamental frequency. In addition to these, they also used transient detectionand low-energy ratio. A naive Bayesian network was used to classify samples into sevenaudio-related contexts: speech, rock music, classical music, other sounds, car, elevator, andrunning tap water. Korpipää et al. also used other sensors to extract an additional sevencontexts. For all contexts, they achieved a true positive recognition accuracy of 87 %, and atrue negative accuracy of 95 %.
The best recognition accuracy of audio-related contexts was achieved with the car, elevator,and running tap water contexts. For these contexts, a small amount of features could be usedto distinguish them from other contexts. For example, running tap water could be recognizedbased on the low level of harmonicity ratio and the high spectral centroid. Korpipää et al.mostly used one-second-long analysis windows. The large variation between consecutivewindows made recognition of classical music, rock music, and speech difficult.
Zeng et al. (2008) used linear prediction and Mel-frequency cepstral coefficients as featuresfor context recognition with hidden Markov model classification. They extracted a totalnumber of 25 features and compared the recognition accuracy when varying the number offeatures used, choosing the features giving the best result in each case. As illustrated inFig. 2, the error rate drastically drops as the number of features used is increased from one
3

Figure 1: Recognition accuracy with different features using a nearest-neighbour classifier(1-NN) and one-state hidden Markov models (GMM). From Eronen et al. (2006).
Figure 2: Recognition error using different numbers of linear prediction and Mel-frequencycepstral coefficients as features with a hidden Markov model classifier. From Zenget al. (2008).
4

to three. After that, there is only a small decrease in error rate when increasing the numberof features. Unfortunately, Zeng et al. do not specify which exact set of features gave thebest recognition accuracy for each number of features used.
To implement an adaptive classification model, Zeng et al. (2008) chose three levels of featuresets. The coarse model used 3, the medium model 8, and the fine model 15 features. Theiradaptive model first used the coarse model, then if necessary, the medium model, and finallythe fine model, until the desired recognition accuracy was reached. On average, the adaptivemodel reached the same level of accuracy as the fine model, but using only slightly morethan half of the time that the fine model needed for the task.
3 Classification algorithms
This section looks in more detail at two classification algorithms: the k-nearest-neighboursalgorithm and the more commonly used hidden Markov models. Studies on implementationsof these algorithms are presented.
3.1 K nearest neighbours
The k-nearest-neighbours (k-NN) classification algorithm determines the k classified neigh-bours which are nearest to the sample to be classified in some metric space (Cover andHart, 1967). Based on this, it decides that the sample has the class that is representedby the largest number of the k neighbours. The nearest-neighbour (1-NN) classificationthus assigns the class of the single nearest neighbour to the sample. Fig. 3 illustrates thek-nearest-neighbours algorithm.
Figure 3: An example of k-nearest-neighbour classification, where a sample represented ina metric space by a star should be classified. Using 1-NN classification, the star isassigned the same class as the rectangles, since a rectangle is closest to the starin the space. If, instead, 3-NN classification is used, the three nearest neighboursare a rectangle and two circles. As the majority of neighbours are circles, the staris assigned the same class as the circles.
5

3.2 Hidden Markov models
A hidden Markov model (HMM) is a stochastic process that is not directly observable (andthus hidden), but instead observed through another set of stochastic processes (Rabiner andJuang, 1986). The model involves a set of states, each with probabilites for a transition tothe other states. There is also a number of possible observations, which can be done withdifferent probabilites while in different states. An example of a hidden Markov model isgiven in Fig. 4.
X1 X2 X3
y1 y2
t12 t23
t21t32
p11p21
p31
p12
p22 p32
t31
t13
t11 t33
t22
Figure 4: An example of a hidden Markov model with three states. X1, X2, and X3 are thestates, while y1 and y2 are the possible observations. tnm is the probability for atransition from state Xn to state Xm. pnm is the probablity of the observationbeing ym while in the state Xn.
3.3 Examples
For their work, Ma et al. (2003) used a HMM classifier with Mel-frequency cepstral coeffi-cients. These were augmented with their velocity and acceleration derivatives to improveclassification accuracy. Only three second-long audio samples were used for the training andevaluation. Ma et al. expected that this would be a likely length of data that a practicalsystem would operate on, and that the length of the data would be enough to provide atypical example of the noise associated with a specific environment.
A left-to-right topology was used for the model, with a varying number of states between 3and 21. A comparison between the different number of states used when recognizing thecontext among ten different scenes is illustrated in Fig. 5. The accuracy increases from 3up to 11 states, but decreases when the number of states goes above 15. Based on theseresults, optimizing the number of states used by HMM-based classification systems can berecommended.
6

Figure 5: The overall recognition accuracy among 10 different scenes when varying thenumber of states used by a HMM classifier. After Ma et al. (2003).
Ma et al. (2003) also performed listening tests to compare the recognition rate of their HMMclassifier with that of human listeners. The listeners heard the same three-second-longsamples as the HMM classifier used in the task. While the overall accuracy achieved by theclassifier was 91.5%, the listeners on average only recognized 35.0% of the samples correctly,with the maximum accuracy, 71.4%, for an office scene and the minimum accuracy, 9.5%, fora street scene. This indicates that human listeners have difficulty to identify environmentalnoise from short samples and to distinguish between the different types of noise in thescenes.
In their work, Eronen et al. (2006) used both nearest neighbour and hidden Markov modelclassifiers, and compared using different features with these classifiers, as discussed inSection 2. For the nearest neighbour classifier, the feature vectors were decorrelated usingprincipal component analysis (PCA) and the class was assigned to that of the single nearestneighbour (1-NN), based on the Euclidean distance in the transformed space. For the HMMclassifier, a one-state hidden Markov model was trained for each class, and the class withthe largest posterior probability was selected for a sample that should be classified.
As shown in Fig. 1, the highest recognition rate is achieved with the HMM classifier usingMel-frequency-cepstral-coefficient features. Using band-energy features, the 1-NN classifierhas almost as high a recognition rate. When looking at all the features, the 1-NN classifierperforms better than the HMM classifier on average. For many of the features, the HMMclassifier produces a poor result compared with the 1-NN classifier.
Eronen et al. (2006) also compared a maximum-likelihood training algorithm, using theBaum-Welch method (Baum et al., 1970), with a discriminative training algorithm, proposedby Ben-Yishai and Burshtein (2004). Where maximum-likelihood training aims at describingthe training data associated with a class as well as possible, discriminative training instead
7

aims at maximizing the ability to distinguish between different classes. Eronen et al. notethat, where processing resources are limited and computationally simpler models should beused, maximum-likelihood training may not provide a good representation of the trainingdata, and other training algorithms, such as discriminative training, may produce betterresults.
For the comparison of maximum-likelihood and discriminative training, Eronen et al. (2006)used Mel-frequency delta cepstral coefficients as features. Hidden Markov models with oneto four states were used. In this comparison, the discriminatively-trained models achievedthe same recognition rate as the computationally more intense maximum-likelihood-trainedmodels.
To obtain a performance baseline Eronen et al. (2006) performed listening tests to gainknowledge about the recognition rate of humans on the same sample set. The test subjectsmade their decision about the context of a sample after listening to it, on average, for 13seconds, while the context recognition system was given 30 seconds of each sample. Thecontext recognition system achieved an overall recognition rate of 58% for the contexts, and82 % for the high-level classes. The test subjects achieved 69% and 88% accuracies for thecontexts and high-level classes, respectively.
4 Making it mobile
There are many aspects to consider when making a context recognition system for mobiledevices. The most obvious aspect is how to make a system that works with the limitedresources on these devices. This chapter looks in more detail at how fast recognition can beperformed and what kind of adaptive algorithms can be applied to improve the results.
4.1 How long does it take to recognize the context?
Eronen et al. (2006) studied the effect of the test length sequence on the recognition rate.For this test, Mel-frequency delta cepstral coefficients were transformed using independentcomponent analysis (ICA), and used as features for two-state hidden Markov models. Fig. 6shows the results for a test sequence length up to 160 seconds.
After about 60 seconds of test signal, there is only slight improvement when increasing thetest sequence length. A satisfactory recognition rate can be achieved after about 20 seconds.As the test sequence is shortened below this, the recognition rate drops rapidly. Still, cruderecognition can be done with a test sequence only one second long.
In Fig. 6, the classification into 24 contexts or six higher level classes (presented in Section 2)can be compared. The samples were classified into the higher level that the context theywere classified as belonged to. The figure reveals that recognition accuracy can be increasedconsiderably by using well-chosen higher-level classes for the classification, instead of lowerlevel contexts. The choice of classes and the level of the classes of course depends on theintended application.
8

Figure 6: Recognition accuracy versus test sequence length. The classification was donewith two-state HMMs using ICA-transformed Mel-frequency delta cepstral coeffi-cients. From Eronen et al. (2006).
4.2 Adaptation
As discussed in Section 2, Zeng et al. (2008) used an adaptive recognition system, wherethe classification model used was gradually changed from course to fine, until the desiredrecognition accuracy was reached. Another approach is to adapt the recognition system inreal time based on the resources available, as investigated by Dargie (2009). Dargie proposesan adaptation component consisting of two subcomponents, a platform-performance monitorand a complexity control.
The performance of a platform has a static and a dynamic aspect. The static aspect is definedby the maximum resources available on the platform: processor speed, networking capability,storage and random access memory size and speed, and maximum available power. Thedynamic aspect refers to the resources available at a point in time. The platform-performancemonitor provides the complexity control with this information.
The complexity control has the role of considering the trade-off between recognition accuracyand processing time. The application provides upper and lower thresholds for both theseparameters to the complexity control, which dynamically adjusts the complexity level ofthe classification algorithm based on the available resources. If the processing time neededto perform the classification is below the lower threshold, the complexity can be increasedto provide better recognition accuracy. If, on the other hand, the higher threshold for theprocessing time is exceeded, the complexity is reduced.
Table 1 presents an example of the time distribution of a context-recognition process. The fivestages of the process are the pre-processing, the fast Fourier transform (FFT), calculating theMel-frequency cepstral coefficients, performing vector quantization (VQ) on them, and finally
9

performing the hidden Markov model classification. The largest amount of processing timeis spent doing the FFT, and not the feature extraction or actual classification. Varying thenumber of hidden states of the HMMs did not have a considerable effect on the processingtime.
Table 1: Relative time distribution of a context-recognition process. From Dargie (2009).
Recognition process Time [ms] Relative time [%]
Pre-processing 65 20.2FFT 192 59.813 MFCC 25 7.8VQ code-book size 256 5 1.6HMM classification 34 10.6
Total 321 100.0
Dargie (2009) thus considers adapting the sampling rate, with a lower threshold of 8 kHzand a higher threshold of 22.05 kHz. Other parameters that can be modified are the framesize and the percentage of frame overlapping. The results from a test investigating theeffect of frame length on recognition accuracy is presented in Table 2. The effect of frameoverlapping on accuracy is presented in Table 3. Reducing the frame overlapping reducesthe amount of raw audio data that needs to be processed.
Table 2: Effect of frame length on context-recognition accuracy, when using a HMM classifierwith MFCC features at the sampling rate of 22 050 Hz. From Dargie (2009).
Sample size [samples] 128 256 512 1024 2048
Length [ms] 5.80 11.61 23.22 46.44 91.02Recognition accuracy [%] 58.75 80.17 83.46 80.49 77.20
Table 3: Effect of frame overlapping on context-recognition accuracy. The number of audioframes a sample is divided into increases as the percentage of overlapping increases.From Dargie (2009).
Overlapping [%] 0 12.5 25 50
Number of audio frames 43 49 57 86Recognition accuracy [%] 78.37 79.85 83.46 82.12
5 Conclusions
Information about the environment a mobile device is located in may be useful for manyapplication, either adjusting their behaviour based on this or providing tailored information
10

to the user. A typical mobile device, the mobile phone, can supply audio, acceleration,orientation, and location data to applications. It is the purpose of context recognition systemsto use this information and to infer the actual context based on this data.
The classification algorithms in context recognition systems work on features extracted fromthe raw sensor data. Different features work well with some classifiers, but not necessarilywith others. For example, band-energy features can give good recognition accuracy togetherwith k-nearest-neighbours classifiers, but not with hidden Markov models. Mel-frequencycepstral coefficients, possibly together with their velocity and acceleration derivatives, seemto be better suited for hidden-Markov-model classifiers, and this also seems to be a popularcombination in many implementations.
Several different parameters of the classification and the feature extraction can be modified,affecting the recognition accuracy. For hidden Markov models, the number of hidden statescan be varied, but more is not always better in this case. The number of states should beoptimized for each use case and system. The size and overlapping of the audio frames alsoaffects the accuracy.
Modifying the different feature extraction and classification parameters not only affects therecognition rate, but also the processing time. On mobile devices and in mobile situations,the resources are limited as is the time in which the recognition should be performed. Oneapproach is for each sample to be analyzed to gradually increase the complexity of theclassification algorithm until the desired level of accuracy is achieved. Another approach isto monitor the available resources, and adjust the complexity to keep the time needed for therecognition task within some chosen limits.
Although there are many studies on the feature extraction and classification algorithms tohelp in choosing a good setup for implementing a context recognition system, the choice ofthe context classes and the appropriate training data representing these classes is up to theimplementer. These building blocks, together, well chosen for the application, will compose asuccessful environmental context recognition system.
6 References
L. Baum, T. Petrie, G. Soules, and N. Weiss. A maximization technique occurring in thestatistical analysis of probabilistic functions of Markov chains. The annals of mathematicalstatistics, 41(1):164–171, 1970.
A. Ben-Yishai and D. Burshtein. A discriminative training algorithm for hidden Markovmodels. Speech and Audio Processing, IEEE Transactions on, 12(3):204–217, 2004.
T. Cover and P. Hart. Nearest neighbor pattern classification. Information Theory, IEEETransactions on, 13(1):21–27, 1967.
W. Dargie. Adaptive audio-based context recognition. Systems, Man and Cybernetics, Part A:Systems and Humans, IEEE Transactions on, 39(4):715–725, 2009.
A. Eronen, V. Peltonen, J. Tuomi, A. Klapuri, S. Fagerlund, T. Sorsa, G. Lorho, andJ. Huopaniemi. Audio-based context recognition. Audio, Speech, and Language Pro-cessing, IEEE Transactions on, 14(1):321–329, 2006.
11

ISO/IEC 15938-4. Information technology – multimedia content description interface – part4: Audio, 2002.
P. Korpipää, M. Koskinen, J. Peltola, S. Mäkelä, and T. Seppänen. Bayesian approach tosensor-based context awareness. Personal and Ubiquitous Computing, 7(2):113–124, 2003.
R. Lindeman, H. Noma, and P. de Barros. Hear-through and mic-through augmented reality:Using bone conduction to display spatialized audio. In 6th IEEE and ACM InternationalSymposium on Mixed and Augmented Reality, pages 173–176. IEEE, 2007.
B. Logan. Mel frequency cepstral coefficients for music modeling. In International Symposiumon Music Information Retrieval. ISMIR, 2000.
L. Ma, D. Smith, and B. Milner. Context awareness using environmental noise classification.In 8th European Conference on Speech Communication and Technology, pages 2237–2240.ISCA, 2003.
D. O’Shaughnessy. Linear predictive coding. Potentials, IEEE, 7(1):29–32, 1988.
L. Rabiner and B. Juang. An introduction to hidden Markov models. ASSP Magazine, IEEE,3(1):4–16, 1986.
Z. Zeng, X. Li, X. Ma, and Q. Ji. Adaptive context recognition based on audio signal. In 19thInternational Conference on Pattern Recognition. IEEE, 2008.
12

Recognition of musical content using audio fingerprinting
Francois BelvezeAalto University School of Electrical EngineeringDepartment of Signal Processing and Acoustics
Abstract
An audio fingerprint is a compact content-based signature that summarizes an audiorecording. It is interesting in the context of mobile applications, since the audio fileswhich are being processed do not need to be in particular format, and no metadata isneeded, only a phone with a recorder. In this paper, different techniques leading to songidentification using audio fingerprinting are reviewed. A focus will be put especially onthe Shazam application, which is one of the most popular application for song recognitionon smartphones nowadays.
1 Introduction
The concept of song identification can be defined by the situation in which a potential useris listening to an audio excerpt, and wants to access content information relating to thatexcerpt. The kind of information the user may want to access can be as diverse as actualcontent describing the audio, such as rhythmic, timbrical, melodic or harmonic descriptions.It can also be metadata information, such as the song name, the name of the composer, yearof composition, performer, date of performance, or studio recording/live performance.In nowadays mobile applications related to song identification, two applications especiallystand out. Shazam proposes to the user to record a song, for example using a radio broad-cast, for a short period of time, and then extract a feature from the song known as audiofingerprinting (a major concept discussed further later), and then compares it with a largeaudio fingerprints database to find the right match (Wang, 2003).SoundHound is quite similar to Shazam, and differs from it since the input is provided bythe user; indeed, this systems is based on query-by-humming, which means that the userhas to hum the melody of the song whose name he wishes to know. Once recorded, an audiofingerprint will be extracted from that humming, and compared with a database, similarlyto Shazam.The use of audio fingerprinting enables to lower the size of the database (which only containsfingerprints with the corresponding metadata) since fingerprints are designed to be small interm of data size, and thus provide results at a faster rate than systems that would use themultimedia content itself.
1

2 Audio fingerprinting
2.1 Definition
An audio fingerprint is basically a compact content-based signature, that summarizes anaudio recording. Such content-based retrieval systems usually need to extract relevantacoustic characteristics from recordings, and then store them in a database (Cano et al.,2005).The main principle behind music recognition systems is thus that, by using the fingerprint ofan unknown audio excerpt as a query on a fingerprint database, the unknown audio excerptcan be identified. The characteristics of the excerpt, which have been previously calculated,are matched against those stored in the database. The general framework for the fingerprintextraction and audio matching is presented in Figure 1.
Figure 1: General framework for the extraction + matching task, (Cano et al., 2005)
Once a list of matches is returned, the candidates are subsequently evaluated for correctnessof match.It is also important to notice that other terms for audio fingerprinting are used in the litera-ture, for example Haitsma and Kalker (2002) and Wang (2003) use the term of perceptualhashing. This way, they are drawing a parallel between audio fingerprinting and cryptogra-phy, which uses hash functions in order to map a usually large object X, to a usually smallhash value, H(X). It is then easier, in order to compare 2 objects X and Y, to just compare therespective hash values, H(X) and H(Y) and it also decreases the probability of error.
2.2 Properties
The requirements of the fingerprints depend heavily on the type of application targeted. Inmost of the publications, the usual requirements are (Haitsma and Kalker, 2002)
2

• Robustness: an audio excerpt should still be identifiable after severe signal degrada-tion. In order to achieve high robustness the fingerprint should be based on perceptualfeatures that are invariant (at least to a certain degree) with respect to signal degrada-tions. These degradations include mostly compression and distortion or interferencein the transmission channel. Other sources of degradation are due to equalization,background noise, D/A-A/D conversion, audio coders (such as GSM and MP3). Inthe context of mobile phone application, it is thus especially important to select afingerprinting method that isn’t affected by GSM compression.
• Reliability: This property determines the ability of the system to correctly identifya song, or audio file. There are indeed two main type of errors : the false negative,which means that the system doesn’t recognise a song which is actually part of thedatabase, and the false positive, which means that the system recognises a song whichisn’t actually in the database.
• Granularity : This property determines how many seconds of audio is needed to identifyan audio clip.
• Scalability : This property determines how long it takes to find a fingerprint in afingerprint database.
3 Extraction of features
3.1 Overview of the framework
Figure 2. proposes the same kind of overview as does Figure 1, but at a lower level ofdescription. It thus appears that the fingerprint extraction block can be separated into twodifferent sub-blocks : the first one, called Front-end by Cano et al. (2005) consists basically inoutputting a relevant description of the signal, which will then be used in the next sub-blockto obtain the fingerprints.
Figure 2: Framework for the content-based identification, (Cano et al., 2005)
3

3.2 Principle
Most fingerprint extraction algorithms are based on the following approach. First the audiosignal is segmented into frames. For every frame a set of features is computed. Preferably thefeatures are chosen such that they are, to a certain degree, invariant to signal degradations.Such features can be for example Fourier coefficients, Mel Frequency Cepstral Coefficients(Cano et al., 2002), spectral flatness, sharpness , Linear Predictive Coding (LPC) coefficientsand others. Also derived quantities such as derivatives, means and variances of audiofeatures are used.
4 Fingerprint Models
4.1 Different approaches
The fingerprint modeling block usually receives a sequence of feature vectors calculatedframe by frame. A first form of fingerprint is achieved by summarizing the multidimensionalvector sequences of the audio excerpt in a single vector. It often requires to record at least30s of audio in order to get the bit vector. Thus, this kind of fingerprinting technique is usedmostly for applications like linking mp3 files to meta-data and aims more at low complexityrather than robustness (Cano et al., 2005).
Fingerprints can also be sequences (like traces, or trajectories) of features. This fingerprintrepresentation is found in Haitsma and Kalker (2002), where the signal is first segmentedinto overlapping frames. Then, the goal is to extract a 32-bit sub-fingerprint for each frame,which will finally be gathered into one fingerprint. In order to extract a 32-bit sub-fingerprintvalue for every frame, 33 non-overlapping frequency bands are selected. These bands lie inthe range from 300Hz to 2000Hz, which represent the most relevant band for the humanauditory system (HAS), and have a logarithmic spacing. Experimentally, they verified thatthe sign of energy differences (simultaneously along the time and frequency axes) is aproperty that is very robust to many kinds of processing. By denoting the energy of band mof frame n by E(n,m) and the m-th bit of the sub-fingerprint of frame n by F(n,m), the bits ofthe subfingerprint are formally defined as :
F(n,m)={
1 if E(n,m)−E(n,m+1)− (E(n−1,m)−E(n−1,m+1))> 00 if E(n,m)−E(n,m+1)− (E(n−1,m)−E(n−1,m+1))≤ 0
Wang (2003) use a 64-bit structure, with 32 bits for the hash (i.e the part obtained from thefeature extraction step), and 32 bits for the time offset of the feature, and track ID, in orderto perform the fingerprinting of a song.
Another method exploits global redundancy of songs (Cano et al., 2002) . That techniquedraws inspiration from speech processing. Indeed, in speech processing, an alphabet of soundclasses, the phonemes, can be used to segment a collection of raw speech data into text, thusachieving a great redundancy reduction without much information loss. Similarly, a corpusof music can be viewed as a set of sentences constructed by concatenating sound classes of afinite alphabet.
4

For example, there are some sounds in music recordings which can be considered "percep-tually equivalent". For instance, the hit-hat sound of drum kit is typically present in mostof the contemporary popular music recordings. This approximation yields a fingerprintwhich consists in sequences of indexes to a set of sound classes representative of a collectionof recordings. The sound classes are modeled with Hidden Markov Models. Statisticalmodeling of the signal’s time evolution allows local redundancy reduction. The fingerprintrepresentation as sequences of indexes to the sound classes contains the information on theevolution of audio through time.
5 Searching and scoring
5.1 Similarity measure
Similarity measures are very much related to the type of fingerprint model chosen. Whencomparing vector sequences, a correlation metric is common. In the systems where the vectorfeature sequences are quantized into bit strings, for example in Haitsma and Kalker (2002),a hamming distance (which is the number of positions at which the corresponding bits aredifferent) is computed.
5.2 Searching Methods
A fundamental issue for the usability of a fingerprinting system is how to efficiently do thecomparison of the unknown audio against the possibly millions of fingerprints. A directapproach that computes the similarities between the unknown excerpt fingerprint and thosestored in the database can be prohibitory in term of computation. A very efficient searchingmethod is the use of inverted files indexing. Haitsma and Kalker (2002) proposed an index ofpossible pieces of a fingerprint that points to the positions in the songs. Instead of doing thematching process for each fingerprint of the database, only do the matching for candidateswhich contains with very high probability the best matching position.
6 A detailed example : Shazam
6.1 Fingerprint model
Shazam, which principle was developed firstly by (Wang, 2003) uses peaks of the spectrogramas candidate feature to be extracted, as they are quite robust in the presence of noise.A point in the time-frequency plan can be considered as a peak if its energy is the highestamong a neighbourhood centered around it. After that, a constellation map is obtained, withpoints of significant energy only. Hence, two similar audio segments should have a matchingpattern of dots in the constellation map. The constellation map can be seen in Figure 3.
Fingerprint hashes are formed from the constellation map, in which pairs of time-frequencypoints are combinatorially associated. Anchor points are chosen, each anchor point having atarget zone associated with it. Each anchor point is sequentially paired with points within itstarget zone, each pair yielding two frequency components plus the time difference between
5

Figure 3: Generation of combinatorial hashes - Constellation map (Wang, 2003)
the points. Each hash is also associated with the time offset from the beginning of therespective file to its anchor point.
The scheme relies on just a few landmarks being common to both query and reference items.A landmark is basically an array consisting of the start time of an onset or peak in thespectrogram, its end time, and the corresponding frequencies.
6.2 Matching process
There are several ways to perform the matching step, (Wang, 2003) proposes a quite easilyunderstandable criteria, based on a graph. The idea is that each hash from the audio excerptto identify is used to search in the database for matching hashes. Then, for each matchinghash found in the database, the corresponding offset times from the beginning of the sampleand database files are associated into time pairs. The time pairs are distributed into binsaccording to the track ID associated with the matching database hash.
After all sample hashes have been used to search in the database to form matching timepairs, the bins are scanned for matches. Within each bin, the set of time pairs represents ascatterplot of association between the audio excerpt and database sound files, which is whatwe can see in Figure 4.
If the files match, matching features should occur at similar relative offsets from thebeginning of the file (i.e a sequence of hashes in one file should also occur in the matchingfile with the same relative time sequence). The problem of deciding whether a match hasbeen found reduces to detecting a significant pattern of points forming a diagonal line withinthe scatterplot.
6

Figure 4: Match criteria : Diagonal pattern (Wang, 2003)
6.3 Algorithmic description
Ellis (2009) proposes a Matlab inplementation of Shazam. Firstly, spectral features of thesignal are computed. The log-magnitude spectrogram is computed first, it is then filteredby a high-pass filter, accentuating onsets and limiting the influence of slow-varying terms.Then, all the local prominent peaks of the spectrogram have to be found.
For each column of the spectrogram time-frequency matrix, the local maxima of the currentfrequency vector as to be found, then we have take up to 5 largest peaks, store those peaksand update the information about decay envelope. Then, for each element of the column, wehave to check if it is above a decay threshold, which will be updated afterwards. Finally, a setof maxes is obtained, which correspond to the constellation map concept in section discussedin 6.1. The maxes have to be packed into nearby pairs to get landmarks.
Finally, a set of landmarks is obtained, which will form the audio fingerprint of an audio file,and will then be compared with landmarks from database files, in order to look for a match.
7 Conclusion
In this paper, a limited (in terms of different techniques presented) review of the researchcarried out in the area of audio fingerprinting has be presented, and the principles behindShazam have been introduced . An audio fingerprinting system generally consists of twocomponents: an algorithm to generate fingerprints from recordings, and algorithm to searchfor a matching fingerprint in a fingerprint database. Features are extracted from each frameof an audio excerpt to be recognized. Subsequently these features are transformed into afingerprint. A searching then finds the best matching fingerprint among a database. Themain applications, in the case of mobile audio programming, are undoubtedly Shazam andSoundHound, which were presented briefly in the introduction of this paper. Other importantdomains include broadcast monitoring, and the automatic organisation of music libraries, bygathering missing metadata on an artist or a song.
7

8 References
S. Baluja and M. Covell. Audio fingerprinting: Combining computer vision and data streamprocessing. In International Conference on Acoustics, Speech, and Signal Processing(ICASSP), pages 213–216, 2007.
P. Cano, E. Batlle, H. Mayer, and H. Neuschmied. Robust sound modeling for song detectionin broadcast audio. In in Proc. AES 112th Int. Conv, pages 1–7, 2002.
P. Cano, E. Batlle, T. Kalker, and J. Haitsma. A review of audio fingerprinting. Journal ofVLSI Signal Processing, 41:271–284, 2005.
D. Ellis. Robust landmark-based audio fingerprinting. http://labrosa.ee.columbia.edu/matlab/fingerprint/, 2009. Accessed November 30, 2011.
J. Haitsma and T. Kalker. A highly robust audio fingerprinting system automatic identifi-cation of sound recordings. In International Symposium on Music Information Retrieval(ISMIR), pages 107–115, October 2002.
A. Wang. An industrial-strength audio search algorithm. In Proc. 2003 ISMIR InternationalSymposium on Music Information Retrieval, pages 7–13, October 2003.
8

Pure Data on mobile devices: approaches and perspectives
Stefano D’AngeloAalto University School of Electrical EngineeringDepartment of Signal Processing and Acoustics
stefano.d’[email protected]
Abstract
This paper investigates the usage of the Pure Data (PD) real-time graphical dataflowenvironment on mobile platforms. The system is first evaluated by its ability to cope withfive different classes of problems that are typically faced when doing audio programming.The available methods to run PD on mobile devices are then analyzed, and PD’s ability tohandle some issues of high relevance to mobile development, such as user interaction andnetworking, is examined. We conclude that PD already provides a viable option for manymobile audio programming tasks.
1 Introduction
While mobile audio programming certainly has its own peculiarities, reusing already existingand well-established desktop sound technologies can be still regarded as desirable for severalpractical reasons, such as interoperability, easy adaptation of already existing applicationsto mobile platforms, and reduced need of learning platform-specific programming skills.
This in turn pushes many desktop audio technology providers to strive for getting theirproducts into the ever growing mobile market, to the point that, if this trend keeps itscurrent pace, it is likely that the future of these products depends, at least in part, on theirability to fit into mobile environments.
Therefore, it is natural to ask which kind of audio development tools have better chances tobe successful on mobile platforms. It is obviously hard to find a comprehensive answer tosuch a question, yet it is not hazardous to state that those systems which better respond todeveloper needs and better integrate with the usual mobile development workflow have aclear advantage in this sense.
Thus, from a purely technical point of view, we can make a rough evaluation of the suitabilityof an audio programming tool for mobile development by investigating how well it is able tocope with five common but somewhat distinct problems:
• DSP programming, where the use of the tool should result in highly efficient algorithmswith at least sample-level accuracy and the possibility to control every aspect of thecomputation;
1

• interconnection of DSP modules, where the tool should be able to handle arbitraryinterconnection topologies at least with a temporal accuracy that buffer-level accuracyand to let the user control at least a set of predefined parameters, possibly also allowingdynamic changes to the processing graph itself;
• interfacing with externally developed code, that is the possibility to reuse DSP moduleswritten using other tools;
• embedding, that is the possibility to use the tool itself or its outcome into a genericapplication;
• interfacing with the outside world, that is the possibility to use specific hardwareand/or software APIs and control protocols.
In this paper the use of PD (PD website) on mobile platforms is evaluated. Section 2 containsan essential overview of PD describing its main features and modes of operation, as well aspointing out some of the limitations of its internal processing engine. Section 3 examines theavailable solutions for using PD on mobile platforms. Section 4 evaluates the suitability ofPD for handling user interaction, that is acquiring and processing data from input sensors ofvarious kinds. Section 5 makes some considerations on the usage of networking facilities andcontrol protocols and how they can be used in PD. In the end, section 6 looks at the licensingissues.
2 An overview of PD
PD is a real-time graphical environment for media processing that belongs to the familyof so-called patcher programming languages (Puckette (1988)). Its development startedin 1996 (Puckette (1996)) as an attempt to apply the Max paradigm to process MIDI andaudio signals on the host CPU rather than offloading the audio processing part to externalhardware, and soon extended (Puckette (1997)) to also allow networking and processing ofvideo and graphics through the Gem graphical environment (Danks (1997)).
The patcher paradigm is nowadays emplyed by most modular audio processing systems (e.g.,SuperCollider website; Ingen website) since it is flexible, rooted into the history of electricaudio equipment and easily understood even by non-experienced users. Using PD terminol-ogy, the user defines so-called patches, i.e., sound processing units, by simply interconnectingnatively coded modules called externals or objects1, subpatches and/or abstractions. Eventhough PD is mainly operated through the GUI that it supplies, it is still possible to codepatches textually. Figure 1 shows a patch implementing subtractive synthesis as displayedby the PD GUI.
Subpatches and abstractions are the foundation of PD’s encapsulation mechanism, by whichit is possible to reuse patches inside other patches as if they were regular objects. Theycontain one or more inlet and/or outlet objects that represent, respectively, their inputs andoutputs. The difference between them is that the subpatches are local copies of a patch,while abstractions are references, thus modifications to a subpatch will only affect the patch
2

Figure 1: Subtractive synthesis patch contained in the Pd-extended distribution (filename3.audio.examples/J08.classicsynth.pd).
(a) Main patch (b) Subpatch
Figure 2: Simple subpatching example, where the subpatch defined in (b) is used in thepatch shown in (a).
it belongs to, while modifications to an abstraction propagate everywhere it is invoked.Figure 2 shows a simple subpatching example.
Objects, including subpatches and abstractions, communicate with each other by sendingaudio signals and/or messages that can transport various kind of information. Messagescan be classified in three different groups: atomic messages, carrying at most one value,list-messages, carrying two or more values, and meta-messages, containing other kindsof control data. PD also supports arbitrarily nested structured data representations, notunlikely to C’s struct construct.
Data flowing through the PD engine has usually either audio rate, i.e., the sample rate ofaudio I/O signals, or message rate, that is by default 1/64 of the audio rate. Dealing withsignals at different sample rates (e.g., oversampling) is possible internally within a patchusing block~ externals, but it is not straightforward to do and the mechanism has somelimitations.
A public API is offered to develop custom externals in C or, through some additional devel-opment layers, in other languages like Python (py/pyext web page), Scheme (PD-Scheme
1Strictly speaking, the “object” term indicates instances, while “external” indicates a class – i.e., more objectsof the same external class can be instantiated.
3

website), Java (pdj website), Lua and Tcl (the last two external loaders are part of thePd-extended distribution). This allows to interface it with externally developed code, such asLADSPA and VST plugins (plugin web page), as well as potentially using any native featurethat the operating system may expose and interfacing with any accessible data that flows atany level through the system. This is, indeed, the core mechanism used by Gem to work inthe PD environment.
Another option for developing externals is to use a special purpose programming languagefor which a source-to-source compiler is available that compiles to one of the supportedlanguages, and then write a minimal amount of glue code interfacing the generated codewith PD. Such an approach becomes a lot easier if the compiler has support for generating PDexternals, as in the case of the FAUST programming language (Gräf (2007), Smith (2010)).
One thing that can be regarded as a lack in the PD engine is the impossibilty to explictlydefine feedback loop paths for audio rate signals. This can be achieved by using the specialsend~ and receive~ objects, which however inevitably introduce a one buffer-long delay in thefeedback branch. On the other hand, since the PD engine has no understanding of the innerworkings of externals, it would be extremely unlikely for such a system to reach substantiallybetter results when feedbacks are involved without compromising irremediably executionperformance.
The discussion up to this point only scratches the surface of what PD does and how it works.Since the PD engine dynamically handles all of its abstraction, interconnection and messagepassing logic while it is processing audio, it is easy to understand that the flexibility offeredby the system implies a performance penalty in terms of achievable throughput. In manycases this does not constitute a problem, especially on desktop platforms, but there is stillthe possibility that complex patches may require more processing power than available ifimplemented in PD while not being the case if they were developed in a compiled language.
In summary, PD provides an interactive and extensible environment for audio programming,trading some efficiency and accuracy for design compactness and ease of use. It is thereforebest suited for implementing relatively simple sound processing units and for prototypingpurposes, while more complicated setups are still possible but generally require real-timecoding in some general purpose or DSP programming language. However, improvementsin hardware capabilities and development tools in the mobile arena are likely to make itslimitations less problematic in the long run.
3 PD and mobile platforms
The first documented attempt to adapt PD to mobile devices is the PDa port to PocketPChandheld devices (Geiger (2003); PDa website). Since these devices provide CPUs that donot support hardware-level floating point operations, being rather emulated in software, thisport required to substitute all externals with versions using fixed-point arithmetic, thusintroducing API incompatibility with the desktop version when it comes to externals. Thisport also included the PD GUI, but it proved to be cumbersome to use because of the lack aproper keyboard and the small screen size. Figure 3 shows PDa running on a Compaq iPaqhandheld. The PDa engine was later used with custom UIs to better exploit the potential oftouch screen interfaces (Geiger (2006)).
4

Figure 3: PDa running on a Compaq iPaq. Image taken from Geiger (2003).
A completely different approach was applied by Schiemer and Havryliv (2005) for the PocketGamelan project: a desktop Java application called pd2j2me was developed to compile PDpatches into Java code to be run on the Java 2 Micro Edition runtime that is often foundon mobile devices. Such a solution does not rely on PD being ported to the mobile device,but requires a port for all the externals used in the patch being compiled, thus making itsubstantially more difficult to reuse DSP modules developed with other tools.
Although these early attempts had severe limitations, they were however useful to showthat it was possible to port PD to mobile devices and that performance issues and real-timeprogramming constraints have to be taken very seriously, hence the need for using tools thatallow to control these aspects and/or make some guarantees in this sense.
Later ports of PD on mobile devices were carried out to be completely integrated, andsometimes “hidden”, into other software. Two well-known examples are the RjDj applicationfor iPhone (RjDj website) and the Spore videogame, that was ported to iPhone and iPod,among other platforms.
The former is perhaps more interesting, since it basically is a GUI-less player of PD patchesthat can be developed directly in PD and downloaded on an iOS device. RjDj does onlyrecognize a limited set of externals, namely those in the standard PD distribution (alsoknown as “PD vanilla”) and some others that are specific to RjDj and that are accessiblethrough the abstractions included in a library called RjLib. It is however possible to useabstractions and subpatches as in PD. Such a configuration makes it natural to suspect thata similar approach to PDa is used.
Another interesting bit regarding RjDj concerns several specific externals accessible throughRjLib’s abstractions. These externals allow to get data from the device sensors such as theaccelerometer, gyroscope, compass, GPS, touch screen and the system time/date. They areheavily used by the PD patches developed for RjDj, so that the performance is affected bythe environment around the listener.
5

3.1 Embedding PD
Nowadays, all major mobile platforms allow native coding and most devices have supportfor hardware floating point operations, thus finally allowing for pure ports of the PD engine.The libpd wrapper (Brinkmann et al. (2011)) was indeed created with this use case in mind,among others. It consists of an audio library that allows to embed the PD engine intogeneric applications and a set of convenience language bindings (Java, Processing, Python,Objective-C). It does also support Android and iOS.
The libpd API essentially exposes a central processing callback for different sample types(short, float, double), a set of functions to send messages to the PD engine and another toreceive messages from it. PD’s audio and MIDI drivers, its timing facilities and the PDGUI were discarded completely in order to simplify embedding, so that the host applicationcan provide custom replacements that better suit its needs. Since libpd’s engine is almostidentical to PD’s, it typically takes little effort to port and use custom externals.
On the other hand, the possibility of embedding PD into other applications with ease is alsouseful on the desktop in a number of different context, and especially in the development ofmedia-intensive and potentially interactive applications such as videogames. This could inturn result into an enlargement of PD’s user base.
libpd, however, still has some limitations that need to be addressed, two of which areparticularly relevant for the development of real applications: the library is not thread-safe, thus requiring external locking in multi-threaded contexts that might cause seriousperformance degradation, and it is not possible to create multiple PD instances within thesame process.
The influence that libpd might have on the whole PD ecosystem is potentially enormous,since future versions of PD itself could be restructured as a libpd-based application withseparate modules for audio and MIDI drivers and user interfaces. For our purposes, however,it is safe to state that libpd is the preferred and most viable way to use PD on mobileplatforms as of today.
4 User interaction
A central topic in mobile audio programming is how the user interacts with the underlyingaudio processing system. What is peculiar of mobile devices is that they allow for a variety ofdifferent interaction methods, ranging from touch screen interfaces to microphone input tovarious sensors that are usually available, such as accelerometers or proximity and ambientlight sensors.
We have, indeed, already seen in section 3 how RjDj makes this information available tothe patches it runs for the purpose of altering the performance based on the environmentaround the listener. However, this section is rather concerned with forms of interaction inwhich the user is more actively involved.
Geiger (2006) describes proof of concept interaction methods for using the touch screen ofPDAs as a controller for virtual instruments implented with PDa. In the first place, thepaper furnishes very good reasons to focus more on the touch screen than on other available
6

inputs: it has relatively high precision and the haptic feedback and its limited size make itpossible to use it without seeing it but rahter haptically remembering positions.
Two touch screen-based user interfaces are described, one for a virtual guitar, where verticallines on the screen represent strings that can be plucked or strummed, and another for avirtual drum set, in which the screen is split in four areas, each representing a percussion.Figure 4 shows the screen layout for these two virtual instruments. The analysis proceedsby examining the virtual theremin case and concluding that two-dimensional data is notsufficient for good playability.
Figure 4: Virtual guitar and virtual drum set screen layout in Geiger (2006).
The paper concludes by making some considerations on the importance of feedbacks, yetrelegating visual feedback to a secondary role, and indicates a possible solution to the inputdata shortage problem in the design of a jacket around the device having extra input buttonsto be used by the hand holding it.
Tahiroglu (2011) investigates a more realistic approach to solve this last problem: PD is usedto apply a 4-point dynamic adaptive mapping strategy to two-dimensional control interfaces.In other words, the two-dimensional position data from the touch screen is translated into4 values computed as the distances from 4 points on the screen, and the coordinates ofthese points change accordingly to the touch screen input itself in a feedback fashion, thusresulting in a variety of possible outcomes. These 4 values can be then used as control inputsfor a PD patch. Figure 5 shows a PD abstraction implementing this kind of 4-point adaptivemapping.
The paper does also illustrate PD abstractions to get accelerometer data and to controlthe vibration module and RGB color range of the LED display on Nokia N900 devices byreading/writing from/to the Sysfs virtual filesystem provided by the Linux kernel. The PDabstractions operating on the accelerometer data and RGB color range of the LED displayare shown in Figure 6.
While user interaction for mobile audio processing is still an open research topic and whilePD-related research is at the moment concentrating mostly on touch screen input, it is worthnoticing that the ability of PD to handle structured data and to interface arbitrarily with theunderlying system allows to seamlessly use it also for the processing of input control data.It is however likely that the main interaction mean will remain the touch screen in mostapplications, at least as long as the arguments given in Geiger (2006) remain valid.
7

Figure 5: PD abstraction implementing the 4-point adaptive mapping module in Tahiroglu(2011).
(a) Accelerometer (b) LED display
Figure 6: PD abstractions for: (a) receiving N900 accelerometer data and (b) controllingRGB color range of the N900 LED display in Tahiroglu (2011).
5 Networking and control protocols
Mobile devices offer networking possibilities that are rare to find on desktop computers. Itis indeed common for mobile devices to offer one or more adaptors for short-range wirelessnetworking technologies such as WiFi, Bluetooth, ZigBee or NFC, along with the usuallong-range wireless communication technologies like GSM, UMTS, HSPA or LTE.
The increased networking abilities of these devices, together with their mobility and userinteraction features, allows for previously unknown and yet to be explored ways of usingmultiple devices for collaborative musical performance. It is therefore very important for thesuccessfulness of any audio processing system on mobile platforms to work well in this kindof scenarios.
In order for devices to “talk to each other” in a musically meaningful way, special controlprotocols are needed. While the MIDI protocol (MIDI website) is nowadays being also usedover the network, it cannot be anymore considered a sustainable solution in the long run,given its evident limitations. The OSC protocol (OSC website), instead, seems to be the bestalternative to date, both because of its extensibility and its network-friendliness.
OSC is actually more of a content format than a protocol, i.e., it defines the syntax andsemantics of messages but does not define any particular message type, which, as a sideeffect, makes it suitable also for other applications than musical instrument control. This
8

lack of standardization, however, has long been a problem in practice for the adoption of thisstandard, and indeed the most common usage of the OSC protocol for musical applicationsconsisted in encapsulating MIDI-equivalent data inside OSC messages. This phase, however,seems about to be overcome, given the latest efforts in defining OSC-based protocols such asthe TUIO protocol of the TUIO framework (TUIO website).
On the communication side, OSC is transport-independent. It defines so-called OSC packetsto be sent over any kind of network and distinguishes the roles of applications sending OSCpackets, called OSC clients, from those receiving them, called OSC servers. Therefore OSCstreams are inherently monodirectional. Once again, such a generic arrangement allowsgreat flexibility but does not provide standard solutions for many practical issues, e.g., deviceand service discovery.
A concrete example of research in this direction is described in Malloch et al. (2007), inwhich a complete framework allowing collaborative design and performance of digital musicinstruments is introduced. The paper covers many different aspects related to the usage,development and deployment of collaborative systems: from gesture mapping to networkingand automatic discovery of devices to implementation issues. It uses OSC as its messagingprotocol and Zeroconf for the device discovery part.
An interesting aspect of this work is the definition of four network entitiy types havingspecific roles: controllers, that are OSC clients translating input sensor data to OSC messages,syntehsizers, that are OSC servers using controller data to handle synthesis parameters,routers, that perform networking-related tasks such as address translation, and the mappinginterface, that performs higher-level administrative tasks such as handling mappings andconnections. Figure 7 shows two examples of topologies that can be created with thisframework. It is therefore natural to envision mobile devices acting as controllers in asimilar scenario.
(a) Centralized topology (b) Decentralized topology
Figure 7: Examples of network topologies given in Malloch et al. (2007).
It is also worth pointing out that networking through the usage of a common and technology-agnostic protocol abstracts away implementation details, thus enabling higher degrees ofinteroperability. In other words, it would be possible to e.g. use PD only for the implementa-tion of one controller, while the rest of the network might be implemented with arbitrarytechnology.
9

In any case, PD already excels in support for networking and control protocols: MIDI- andnetworking-related externals have been available since its early days (Puckette (1997)) andOSC support is provided by the routeOSC, packOSC and unpackOSC externals. Figure 8shows example patches using OSC-related externals. Once again, PD’s extensibility and itsability to handle structured data are the keys enabling this. The current implementation ofthese features might not fulfill advanced requirements (e.g., there is no external providing fullOSC pattern matching), yet there seems to be no architectural limit preventing improvement.
(a) Sending patch (b) Receiving patch
Figure 8: Example patches that send/receive OSC messages over UDP: (a) sends two differ-ent OSC messages (/test/voice and /test/mute), while (b) receives these messagesto control an oscillator. Taken from http://en.flossmanuals.net/pure-data/ch065_osc/.
6 Licensing issues
The PD vanilla distribution comes with a permissive BSD-style license that is GPL-compatible,non-copyleft, OSI and FSF approved. It allows redistribution ad libitum, either with modifi-cations or not, as long as existing copyright notices are retained in all copies and the licensingnotice is included verbatim in any distributions. Modifications can be released under anylicensing term and the redistribution of source code is not mandatory. Such licensing termsavoid having to deal with many potential legal issues when modifing PD and/or using it tocreate new software.
The Pd-extended distribution, however, also incorporates code under other more restrictivelicenses such as the GPL. The developer willing to use it must then pay careful attention towhich licensing terms apply to each part of the distribution used. This is even more relevantin the mobile market since copyleft licenses seem to be incompatible with Apple’s App Storedistribution policies.
10

7 Conclusions
PD provides a mature and flexible environment for audio programming and its latestdevelopments make it a safe and viable option for mobile platform development today. Theopenness of its architecture already proved to be a key feature for its suitability in differentcontexts and for different purposes and is likely to be so in the future as well.
It is not, however, a one-size-fits-all solution for audio programming and its limitationsshould be kept well in mind before deciding to use it for a given task. It should be ratherregarded as one out of many tools available. In particular, it should not be used for theimplementation of DSP algorithms whose behavior is highly dependent on feedback effectsand for devices that do not support hardware floating point operations.
The availability of an embedding solution such as libpd and its bindings makes it relativelyeasy to integrate it into the usual mobile development workflow for today’s major mobileplatforms.
While no pre-packaged standard solution that also integrates user interaction methods,networking and/or control protocols seems to be available as of today, there should be noarchitectural limit preventing PD from being used as the core foundation of such a framework.On the contrary, it does already offer the bulding blocks for a potential implementation.This is indeed an interesting possibility that has yet to be explored and that could on oneside increase the popularity of PD on mobile platforms and on the other provide mobiledevelopers even easier means for developing musical applications.
8 References
P. Brinkmann, P. Kirn, R. Lawler, C. McCormick, M. Roth, and H. C. Steiner. EmbeddingPure Data with libpd. http://www.uni-weimar.de/medien/wiki/PDCON:Conference/Embedding_Pure_Data_with_libpd:_Design_and_Workflow, August 2011. 4th Inter-national Pure Data Convention. Accessed October 7, 2011.
M. Danks. Real-time image and video processing in Gem. In Proceedings of the InternationalComputer Music Conference (ICMC), pages 220–223, Thessaloniki, Greece, 1997.
G. Geiger. PDa: Real time signal processing and sound generation on handheld devices. InProceedings of the International Computer Music Conference (ICMC), Singapore, Septem-ber 2003.
G. Geiger. Using the touch screen as a controller for portable computer music instruments. InProceedings of the 2006 International Conference on New Interfaces for Musical Expression(NIME ’06), pages 61–64, Paris, France, June 2006.
A. Gräf. Interfacing Pure Data with Faust. In Proceedings of the Linux Audio Conference,pages 24–31, 2007.
Ingen website. drobilla :: Ingen. URL http://drobilla.net/software/ingen/. AccessedNovember 1, 2011.
11

J. Malloch, S. Sinclair, and M. M. Wanderley. A network-based framework for collaborativedevelopment and performance of digital musical instruments. In Computer Music Modelingand Retrieval. Sense of Sounds, 4th International Symposium (CMMR 2007), pages 401–425, Copenhagen, Denmark, August 2007.
MIDI website. MIDI manufacturers association - the official source of information aboutMIDI. URL http://www.midi.org/. Accessed November 15, 2011.
OSC website. opensoundcontrol.org. URL http://www.opensoundcontrol.org/. AccessedNovember 15, 2011.
PD-Scheme website. PD-Scheme. URL http://www.westnet.com/~lt/pd/pd-scheme.html. Accessed December 1, 2011.
PD website. Pure Data – PD community site. URL http://puredata.info/. AccessedNovember 1, 2011.
PDa website. Pure Data for PDA’s. URL http://pd-anywhere.sourceforge.net/. Ac-cessed November 18, 2011.
pdj website. java plug-in for pure-data. URL http://www.le-son666.com/software/pdj/.Accessed December 1, 2011.
plugin web page. plugin~ – PD community site. URL http://puredata.info/community/projects/software/plugin. Accessed December 1, 2011.
M. S. Puckette. The patcher. In Proceedings of the 1986 International Computer MusicConference (ICMC), pages 420–429, San Francisco, USA, 1988.
M. S. Puckette. Pure Data: another integrated computer music environment. In Proceedingsof the Second Intercollege Computer Music Concerts, pages 37–41, Tachikawa, Japan, 1996.
M. S. Puckette. Pure Data: Recent progress. In Proceedings of the Third IntercollegeComputer Music Festival, pages 1–4, Tokyo, Japan, 1997.
py/pyext web page. py/pyext - Python scripting objects – PD community site. URL http://puredata.info/Members/thomas/py/. Accessed December 1, 2011.
RjDj website. We don’t do apps. We craft sonic experiences! – RjDj. URL http://rjdj.me/.Accessed November 4, 2011.
G. Schiemer and M. Havryliv. Pocket Gamelan: a Pure Data interface for mobile phones. InProceedings of the 2005 International Conference on New Interfaces for Musical Expression(NIME ’05), pages 156–159, Vancouver, Canada, May 2005.
J. O. Smith. Signal processing in Faust and Pd. https://ccrma.stanford.edu/realsimple/faust/, 2010. Online article. Accessed November 3, 2011.
SuperCollider website. SuperCollider » About. URL http://supercollider.sf.net/.Accessed November 1, 2011.
12

K. Tahiroglu. An exploration on mobile interfaces with adaptive mappingstrategies in Pure Data. http://www.uni-weimar.de/medien/wiki/PDCON:Conference/An_Exploration_on_Mobile_Interfaces_with_Adaptive_Mapping_Strategies_in_Pure_Data, August 2011. 4th International Pure Data Convention.Accessed October 7, 2011.
TUIO website. TUIO. URL http://www.tuio.org/. Accessed November 15, 2011.
13

Way-finding and navigation assistance in mobile devicesusing audio spatialization
Symeon Delikaris-ManiasDepartment of signal processing and acoustics
Aalto UniversityPOBox 13000, 00076 Aalto
December 6, 2011
Abstract
Recent advances in mobile electronic devices have made it possible to use minimal equipment innavigation applications. This seminar paper deals with an overview of navigation application for mobiledevices using audio guidance. There is a variety of applications using audio as feedback for navigatingin a closed or open space. Most of these applications take advantage of binaural synthesis algorithms asthe main auditory display. Generic head related transfer functions are used to generate binaural signalsand update the filters for each new position of the head or the source that is to be projected.
1 IntroductionNavigation is an assistive technology for wayfinding applications. It consists of two main compo-nents: sensing-understanding-exploring the environments that surrounds the user and provide informa-tion about obstacles and hazards and navigating to a remote location beyond the surrounding environ-ment. Navigation from point A to point B or in other words a journey planner is a complex process whichinvolves updating the user’s position and orientation and in the event that the user becomes lost, updateroute to point B. The most important positioning methods that are used in navigation are presented. Thistype of data can be projected to a user in different ways which can be visual, tactile and aural. This studyfocuses on the audio feedback that navigation applications can provide. In order to understand this typeof feedback it is important to understand how humans localize sounds and what type of audio systemscan be used in mobile devices. The main part of this paper are the example designs of applicationsthat use audio feedback and the evaluation. Due to the limited capabilities of the mobile devices mostapplications share the common feature that audio is reproduced through headphones.
2 BackgroundRecent mobile devices and especially mobile phone consist of many components which can be used toretrieve and projecting positioning data. This section describes briefly the various methods that can beused for obtaining this data.
2.1 Positioning Methods• GPS (Global Positioning System) is a satellite based positioning system. This is the most popular
navigation system for vehicles in open air conditions. It is not efficient enough for pedestrianuse due to the week signal strength which makes it also impossible to use it indoors. The signalstrength is also affected by the so called urban canyons which are the skyscraper-style buildings in
1

urban landscapes. For pedestrian navigation the accuracy of a positioning system must be at leastfive meters which is not the case when using a GPS [10]
• RFID (Radio Frequency Identification) are radio chips that, in passive mode, can reflect radiosignals and while in active mode project radio signals. These chips can have an accuracy of up ahundreds of meters and have minimal power requirements. The advantages of this technology isthat they are very accurate for vehicle and pedestrian navigation but the greatest drawback is thatRFID equipment needs to be placed on every object that is to be tracked
• Infra-red are sensors that can be used mainly in indoor positioning systems. They have a greataccuracy of a few centimetres but the path between the emitter and transmitter needs to be clear ofobstacles.
• Acoustic Location is the process of transmitting sounds in an environment, receiving the reflectionsand reconstructing the environment. Radars operate in a similar way.
• Cell ID can be obtained through the communication between a mobile phone and the radio tower.The signal strength depends on the number of radio tower that can be connected. This is a helpfultechnique for remote positioning but it lacks accuracy as the error can reach up to a few kilometres.
• Electro Magnetism can provide accurate position information in an environment with where elec-tromagnetic emitters exist. This is the case of a city environment.
• WLAN Positioning uses LAN networks and triangularization methods in order to obtain accurateposition. For a mobile device to use this type of data obviously needs to be connected in a LANnetwork which is not the case in an everyday use.
2.2 Main data displays• Visual. This is the most common projection of positioning data in any devices. The drawback
is that the user needs to be concentrated to the screen. This is not safe especially when the useroperates a vehicle or moving inside a busy environment
• Tactile feedback is the projection of data using sensors that send vibration messages to the user.A representative example is a belt with vibrators that indicates directions and deviations from themain path. [7]
• Auditory (Why not just use our ears!) Easy in in-car navigation, more challenging in pedestriannavigation
Figure 1: Visual feedback Figure 2: Tactile feedback Figure 3: Audio feedback
3 Sound localisation basicsIn principle, localisation can be described as the relation between a specific position in the three dimen-sional environment and the auditory space. There are various definitions of human sound localisation inthe literature. Localisation can be defined as the law or rule by which the location of an auditory eventis correlated to a specific attribute of a sound event and vice versa.
Humans have the ability to localise sounds by using a variety of cues including the relative inten-sity and timing and the spectrum of the signals reaching the two ears. Relying on these psychological
2

and physical functions of spatial hearing, the human brain recreates a three dimensional image of theacoustical environment. Extensive studies on sound localisation by humans can be found in [12]. An upto date description of the interaural, spectral and dynamic cues that are involved in the localisation ofsound is given by Hartman [14].
Interaural Cues The human auditory system determines the location of sound sources on the basisof interaural differences in signal intensity and interaural differences in the arrival times of a sound. Eachear perceives the same sound source with a different effect, which includes the phase (or time) and leveldifference. Lord Rayleigh’s duplex theory reveals that low frequencies are localised by using phase cueswhile high frequencies are localised using intensity cues. The experiments of Rayleigh also reveal thatinteraural phase changes in pure tones, of frequency below 500 Hz, result in changes in the perceivedlocation of the source of the tone. For tones above 1500 Hz interaural phase differences do not affect thelocalisation of the sound source. These intensity and phase cues are the principal means for localisationin the azimuthal plane [13]. The intensity difference between the left and the right ear is known asthe interaural level difference (ILD). The interaural level difference is a function of frequency and itoccurs due to the shadowing effect of the head. Specifically, sounds below 500 Hz, with wavelengthfour times the diameter of the average human head, do not create a large enough ILD that can contributein the localisation in the azimuthal plane. Since the auditory nerve is the only path from the inner earto the central nervous system, the use of the ILD depends on the sensitivity of this nervous system.Psychoacoustic experiments show that the central nervous system is approximately equally sensitiveacross all the frequency spectrum. The threshold of ILD is approximately 0.5 dB at all frequencies.Therefore, the ILD is a potential localisation cue at any frequency where it is greater than one decibel[14]. The interaural time difference (ITD) is the arrival time difference of a sound wave between theleft and the right ear. The importance of this cue is the contribution to the localisation of sound below1.5 KHz. The ITD can be expressed as the a function of the azimuthal angle by using the formula fordiffraction on a sphere.
Spectral cues Localisation of sounds in the azimuthal plane can be achieved with the use of the ILDand ITD. When a source is placed at the median plane it is impossuble to achieve localization only byusing ITD and the ILD and the introduction of another type of cue is necessary. The filtering of a sourcesspectrum caused by a the listeners torso, head and pinna can be collectively described as the head relatedtransfer function (HRTF). Mathematically, the HRTF can be described as the ratio of the sound pressureat the eardrum of each ear, and the free field sound pressure level at the position of the centre of thehead with the head absent. Given the spherical symmetry of the free field pressure measurement thefree field SPL should be considered independent of the azimuthal angle and elevation angle. The HRTFcan provide useful information to judge vertical directions and for resolving problems of front-backconfusions.
4 Auditory displays for mobile devicesLimitation of mobile devices and the lack of multiple speakers limit the sound reproduction system totwo channel system. These system can either use the speakers of the mobile device or headphones. Lowpower of the speakers that are built in recent mobile devices makes the headphone option ideal. Binauralaudio reproduction provides the impression of an immersive environment and can make sounds appearto appear from specific locations. Studies on the perception and localisation of sounds with two ears,know as binaural hearing, led to the development of systems that are based on human listening abilities.Binaural audio reproduction can either used real life binaural recording or by synthesizing mono sourcesand placing them in specific direction using HRTF information.
Binaural recording is the process of capturing an auditory event in the same way that humans receiveit. These are made with two microphones in an arrangement similar to that of the human ears. The easierway achieved this is with a dummy head. The main idea of binaural technology is to to give listeners theperception of an auditory experience by presenting sound signals at the listeners ears that approximatethe sound signals of a real auditory environment.
Binaural synthesis utilises head related transfer functions, which contain the interaural and locali-sation cues. A system based on the binaural technology can produce an accurate illusion of a virtual
3

acoustic space, including direction and distance. Figure 4 show a binaural synthesis example. A monosignal is filtered through a pair of HRTF for a predefined position in order to produce the binaural signals.These signals are then projected to the user and give the impression of virtual source at that predefinedposition.
Figure 4: Binaural Synthesis: a mono source signal is being convolved with a pair of HRTF or HRIRs(Head Related Impulse Response) in order to produce a two channel signal for binaural reproduction [15].
5 Auditory events in navigationThis section introduces a list of the different types of auditory events. An extended version of this listcan be found in [8]
• Speech. The most common form for communication when using sound. The greatest advantageis that it is reliable and can provide accurate and analytical information for any type of event.Unfortunately the disadvantages outnumber the advantages. Language is a barrier, as the userneeds to know the specific language. There is also a delay before the user can react. Speechinformation is not instant as the user needs to received the entire message first. This means thatanother event might occur before the first message is complete. If the information transmitted fromthe first message overlaps with another event, that information might be misleading or confusing.Hence it is difficult to be interactive in a rapid changing environment where fast messages needto be exchanged. Speech intelligibility is affected by background noise. Especially in outdoorenvironments background noise tends to be unstable and therefore short sound events instead ofspeech signal are more useful.
• Augmented Reality Audio. A definition for this term is over-layered reality. In contrary withvirtual reality, where the real world is replaced by a virtual, augmented reality enhances-replacesspecific objects from the real world. New sound images are generated without preventing the userfrom perceiving existing real objects. A typical application for music synthesis and environmen-tal sound augmentation is RjDj [11]. Special designed earphones can enhance the sound that theenvironment generates but also layer new sounds on top of the existing ones. Keeping real envi-ronment sounds is important especially in a navigation application. For example in a wayfindingapplication in a busy environment can be dangerous when the user is isolated with headphones.
4

• Musical Cues. Music can vary from complex forms to minimal sounds. It consist of two com-ponents, the rhythm and the melody. People find music intriguing and it can be used as a wayto provide information. People can also pay attention to the two different components of musicwithout finding that confusing or annoying. Hence it can be used a way to provide various typesof information and in contrast to speech the user can perform other tasks in parallel as it is notintrusive.
• Earcons are short musical events that are easy to understand. They consists of a fixed rhythmand pitch but they vary in timbre and dynamics. Sound synthesis is commonly used for creatingearcons. An earcon in order to be understood, needs to be assigned to an event. In contraryto speech that means that the user needs to be trained in order to receive the message from theearcon. There are four basic categories of earcons. One element earcons consist of only one bitof information and cannot be decomposed further. Compound earcons are formed by summingshorter earcons and are analogous to sentences created by combining different words. The lasttwo types are Hierahical and Transformational earcons which are based around a grammar and areconstructed as a node in a tree.
• Soundmarks are analogues to the word landmark which indicates to a location which is recog-nized visually. In a navigation application soundmarks are used to position a user in an area byunderstanding the surrounding.
• Auditory Icons are analogues to pictures. These auditory events indicate certain actions tha a useris performing.
• Movement sonification. Perceptual and motional mechanism can benefit from additional acous-tic information. Sonification, analogues to visualization could provide information by renderingsounds under a well structured method. It is data representation with auditory events. A largedataset can be easily described by projecting various sounds in different directions.
6 Designs and Evaluation
6.1 Sonic Torch - Binaural GlassesOne of the most basic design with audio in mobile devices. Both of those were engineered by Dr. LeslieKay during the 60’s (REF) The sonic torch utilizes an ultrasonic echolocation to measure distances. Ithas been used for blind people to navigate indoors and to avoid obstacles. Binaural glasses use the sametechnique as the sonic torch but they are fitted as normal glasses. The audio feedback that the user wasreceiving in both cases is a pitch shifting between low and high frequencies for near and far obstacles.This is one of the simplest implementation of mobile audio interface for navigation. Only pilot studieshas been performed with this project and commercial projects have been also manufactured.
Figure 5: Sonic Torch Figure 6: Binaural Glasses
5

6.2 Navigation aid for blind individualsAn electronic travel aid system for blind individuals has been developed by Choudhurry et al. [3]. Thissystem is able to detect surrounding obstacles and travel direction. The surround obstacles are beingdetected by using ultrasonic range sensors and the direction can been calculated with the assistance of anelectronic compass. The recreated virtual environment is been presented to the user through headphonesand spatialized sounds so that the user can perceive surrounding obstacles and the direction of the earth’smagnetic north. This system present two important challenges: as its use will be blind individualsthe positioning information must be presented in an non visual form and the navigational informationmust be updated in real time. In addition to that the auditory information must not interfere with theuser’s auditory activities. The system operates by performing two main tasks in real time. These arethe information retrieval and projection. The components used in this system are sensors, control andcomputation sotfware and communication and sequencing.
The 3D sound spatialization is based on Head Related Transfer Function Based. HRTFs are widelyused for synthesizing binaural signals which can give a listener the impression of a sound at a positionwhere no real source exists. In this system a single channel sound is processed by the HRTFs in order togenerate two signals for the left and right ear and give the impression to the listener of a virtual soundsource coming from a specific direction.
6.3 AudioGPSAudioGPS is an audio user interface for a global positioning system with minimal attention design toallow a user to carry out other demanding tasks simultaneously [1]. Its design is based on the principlethat the user should be able to interact with the real world by having limited attention to the navigatingdevice. The audio representation of direction and distance consists of two essential elements that haveto transfer tha navigational data to the user. These are the distance to the destination and the direction tothe destination relative to the current direction.
The first approximation to present the sound events with headphones to a user is a simple panningof a sound source representing the destination in stereo sound image. Recent advances in computationalpower allow more complex panning techniques and a 3D sound image can be represented to the user.The sound source used is a briefly repeated tone. The use of generalized HRTFs may cause problemrelated to front-back confusions [12] which means that user will not be able to distinguish betweensources presented in the front and the back hemisphere. A feasible way to overcome this problem is topresent to the user more realistic sounds is to used sharp tones for the frontal hemisphere while muffledsounds when sources are behind. This simulates also the filtering process of the pinna in a human ear.
Harpsichord sounds were chosen to suggest destinations that are ahead of the user while trombonesounds for sources that are behind. Harpsichord sounds consists of high amount of energy in highfrequencies if compared to the trombone in which most of the energy is gathered to the low frequency.The specific system uses also silence when there is no useful data to present.
The Distance is coded based on the Geiger counter (hot/cold counter). When the user approachesthe waypoint the pulses of sound and their speed give an indication of how far the next waypoint is. Ata predermited distance from the destination the system generated an arrival tone which will indicate tothe user its position compared to the destination. Distance can also be coded in a way that metric unitsare calculated in clicks, meaning that one click is a predefined measured distance in metre.
Pilot user trials have been performed in to evaluate the audio representation of direction and distanceand if the system works under real field conditions. It has been found that users are able to distinguishdirection of sound sources in any direction. Real field performance has been tested at night and insidea car. The aim was to find the time that the AudioGPS needs to provide navigational information andhow responsive it is. The system has been found usable in target finding in pedestrian application butin in-car navigation the delay of the system was causing problems as messages were received after aspecific task was complete.
6.4 SWAN: System for Wearable Audio NavigationSWAN is a project developed at the Sonification Lab, Department of Psychology [5]. The idea behindthis project is to compile auditory navigation displays based on virtual environments. The SWAN in-
6

terface utilizes a collection of non speech sounds and annotations within a specifc framework to allowusers navigate in an environment.
Different kind of objects in an environment are assigned to different kind of sounds. Beacon soundsare used for guiding a user in a predefined route. Object sounds for object declaration such as a obstacleand in general to convey knowledge about the features of surrounding world. Surface sounds to indicatechange in the walking path, location sounds or earcons to indicate the environment that the user islocated: indoors , outdoors and what kind of building it is. Annotations can also be recorded by theuser to indicate special objects or locations. The complete route that a user wishes to travel is dividedinto shorter paths that are separated by waypoints. Beacon sounds are used to indicate each differentwaypoint. A crucial element is the ability of the user to localize these beacon sounds. Similar with theprevious projects, HRTFs are also used in this design to spatialize sounds.
The sound design also needs to be easily noticed and effective. Each beacon sound was designedseperately in order to motivate the user to continue to the next beacon at a higher speed. All the beaconsounds were one second long each with a center frequency of 1kHz and equal loudness. First beacon wasa broadband burst, second a pure sine and thirds a sonar impulse. At the start of the route the beaconswere presented in an on-off mode. As the listener moved to closer to each waypoint the specific beaconwas increasing tempo (the on-off mode). Each beacon sound creating a different navigation pattern forthe listener. Different radius that indicate the user is approaching a beacon were used. Figure 5 showsnavigation patterns for different combination of beacon sounds in different maps. Non-speech auditoryinterface is proven to be successful in this application. The performance of system was significantlyimproved with the noise beacon followed by pure tones as it has received greater attention by the user.Paths with small and large radius resulted to a more hunting behaviour.
The audio interface consisted of earphones and borephones. Borephones are the headphones that areattached at the part of the skull directly behind the ears and they are able to project sounds to listeneronly by bone conduction. The two advantages of borephones compared to the earphones that theydo not block the ear canal and that they can work also for users with outer-ear disorders. The maindisadvantage is the minimal audio range that they operate. Front back confusions remains a problemfor audio navigation interface where there is lack of individualization and headtracking. This typicallyarises from the differences between the individualized and generalized HRTFs.
6.5 Reittiopas API - AudioReititReittiopas is an mobile audio application for navigation purposes that uses tha official Journey planner ofHelsinki, Finland [8]. The block diagram of this design is show in Figure 8. The input of the applicationare departure point, destination point, origin, time and target. These are the data the API of the journeyplanner requires to generate the navigation data. This data is then transmitted back to the mobile device.Location, time services, route map and weather conditions (using the Google Weather API) are projectedto the listener through audio and video. The key point of this design in this application are: minimalattention interface, the way the information is retrieved, threading, spatial and time information andperformance. The user interface is able to provide feedback for different events. The importance of thisstudy is the selection of the specifc earcons in addition with the reasoning for this selection.
6.6 Auditory display design for environment exploration and navigationThere are a number of studies which evaluate the performance of audio navigation assistance in wayfind-ing applications. Previous studies lack of systematic and repeatable user experience evaluation and for-mal methodology on how to evaluate, analyze and interpret user data tha is not quantitative. The aim ofthis design was to explore these issues and focus on performance of an mobile audio augmented realitydisplay using both qualitative and quantitative criteria [4].
Navigation without earcons and without spatial audio This first case focuses on the evaluationof audio navigation assistance with the absence of earcons, proximity zone sounds and the absence ofspatial audio. In this case mono audio clips have been activated when the user entered in a specificarea. Hence the exporation application transposed into an exploration of landmarks. Users reported thatsounds were appropriate but also sudden. Navigation through the environment has been found easy. But
7

Figure 7: Movement traces in each combination of beacon sound (noise, pure tone, and sonar sound, inrows) and capture radius (small, medium, and large, in columns) while in different maps. Participants wereable to complete the course with little practice and instruction. Some overshoots and bouncing are noted,and this differed across conditions of capture radius and beacon sounds [5].
again the instabilities of the GPS and the dealy in the response resulted in sounds been played to the userwhen an event already has happened.
Navigation with earcons but without spatial audio In this case animals sounds have been usedas earcons in addition to the environmental sounds. Earcons were played to the user each time heentered an activation zone. Users have reported that these kind of sounds were clear and blended wellwith environment. They were not very realistic which could make the users not to observe them.
Navigation with earcons and spatial audio This case included audio spatialization of earcons.That means that when the user enter the activation zone the earcone was projected to the correspond-ing location in order to alert the user of its presence. The earcone increased in loudness as the userapproached the item. The level of the earcone dropped normally over distance: 6dB per doubling theinitial distance to the sound source. Users reported the distance perception and source amplitude wasuseful and appropriate but it has been difficult to determine the exact distance to a particular landmark.
Navigation with earcons and spatial audio (3D) This last case includes the use of earcons withaudio spatialization. The difference with the previous case is that sources not only varied in amplitudefor different distances but also the direction was changing. The changing in direction of the source in
8

22
4 Implementation
This section describes the components, functionality, and design decisions of themobile application created in this work. Commonly when sound is used to deliverinformation in user interaction, it is a direct response to a user action, such as pressinga button. In this application, much of the auditory information is prompted by thecombination of the user location and time. Even many of the more direct responsesto a user pressing a button will also have a significant delay in the response time dueto information, such as current weather and bus routes, being retrieved from serverson the internet. Therefore, they often act more as notifications rather than directresponses. The user can start a route search and put the device in his pocket whilethe search is being performed. The relevant and selected information will then bedelivered by sound after it is retrieved and the time for the cue is appropriate.
Figure 4: A flowchart illustrating the usage of the application.
The flowchart in Figure 4 represents the basic operation of the application from
Figure 8: Flowchart of the Reittiopas application [8].
addition to the amplitude changes result to an immersive experience where the user could rely only inhearing. Earcons that overlapped with varying loudness also resulted in benefits as the user has beenfamiliarizing with the surroundings even before reaching the specific activation zones.
7 DiscussionIssues of Auditory Displays One of the challenges in using virtual auditory displays in navigationapplication is the accuracy of localization and the realism. Sound source positioning which indicatesthe destination or different waypoints, is performed by convolving the mono sound source with a pairof HRTF for the predefined direction. Guidance of a user along a predefined route can be accomplishedby indicating the next waypoint. If the position of the virtual sound source can be localized by the userin the median plane then it is straightforward to move on to the next waypoint. This type of directionlocalization is easily accomplished with a simple binaural synthesis algorithm provided that head rotationare tracked and used to modify the binaural signals. Binaural synthesis with generic HRTFs producesartifacts such as the lateralization (in head positioning of sources and). Externalization is already a verycomplex process that is not easy to solve in a mobile audio application. The most challenging problemthough is to solve distance perception: the ability to present to the user realistic auditory events with theeffect of the distance.
9

8 ConclusionA collection of wayfinding application with audio assistance has been presented in this seminar paper.Evaluation results have show that the techniques used nowdays for sending and receiving data can beaccurate and efficient. Navigation using spatial audio feedback, in contrary with visual or tactile feed-back, provides a minimum attention interface that can be used in a variety of wayfinding applications.Visual interfaces require the user to be concentrated to the screen which in some application as drivingor walking in busy environments can become dangerous. Tactile feedback interfaces from the otherhand require a relatively large amount of extra equipment such as vibrating belts. So far spatial audiofeedback is provided through a pair of headphones or bearbones and binaural synthesis. Future researchon spatial audio assistance in navigation application should aim to overcome the problems of binauralreproduction such as the laterization effect, front back confusion (by using individualized or syntheticHRTF databases) and distance perception.
References[1] Simon Holland, David R. Morse, and Henrik Gedenryd Audiogps: Spatial audio navigation with a minimal
attention interface. Personal and Ubiquitous Computing, Vol 6, pp. 253-259, 2002.
[2] Jack M. Loomis, Reginald G. Golledge and Roberta L. Klatzy Navigation system for the Blind: Auditorydisplay modes and guidance. Presence, Vol 7, No. 2, April 1998, 193-203.
[3] Maroof H. Choudhurry, Daniel Aguerrevere and Armando B. Barreto A pocket-PC based navigation aid forblind individuals. IEEE International conference on Virtual environments, Human-Computer interfaces admeasurement systems, Boston, MA, USA, 12-14 July 2004.
[4] Yolanda Vanquez-Alvarez, Ian Oakley, Stephen A. Brewster Auditory display design for explration in mobileaudio/augmented reality. Personal and Ubiquitous Computing, Sep, 2011.
[5] Walker, B. N., and Lindsay, J. Navigation performance with a virtual auditory display: Effects of beaconsound, capture radius, and practice. Human Factors, 48(2), 265-278, 2006.
[6] Harald K. Jansson Pedestrian Navigation and Context Awareness using Tactile Feedback and Sonification ofSpatial Data. M.Sc. Thesis, Halden, Ostfold University College, Mobile Application Group, Norway, 2011.
[7] Wilko Heuten, Niels Henze, Susanne Boll, Martin Pielot Tactile Wayfinder: A Non Visual Support Systemfor Wayfinding. , .
[8] Juho Kostiainen Mobile Auditory Guidance for Public Transportation. M.Sc. Thesis, Department of SignalProcessing and Acoustics, School of Electrical Engineering, Aalto University, 2011.
[9] Tappio Lokki and Matti Grohn Navigation with Auditory Cues in a Virtual Environment. Multimedia, IEEE, Volume: 12 Issue:2, 2005.
[10] Jean-Baptiste Prost, Baptiste Godefroy, and Stephane Terrenoir Navigation with Auditory Cues in a VirtualEnvironment. Accuracy for Urban Pedestrians. GPS World, August 200.
[11] http://rjdj.me/
[12] Jens Blauert Spatial Hearing: The. Psychophysics of Human Sound Localization. Cambridge, MA: MITPress, 1983.
[13] WIlliam Gardner 3D Audio Using Loudspeakers. School of Architecture and Planning, MIT, 1997.
[14] WIlliam Hartman How we localize sounds. Physics Today, Volume 52, Issue 11,, November 1999.
[15] http://en.wikipedia.org/wiki/3D audio effect
10

The accelerometer in mobile phone: from physics toprogramming.
Florent DelordAalto University School of Electrical EngineeringDepartment of Signal Processing and Acoustics
Abstract
Accelerometers are becoming key components in mobile phones. Everyone knows theyallow to catch the tilt, the displacement of the phone, and all between. But do you knowhow an accelerometer works, what is the physical design inside the phone, or how tocompute the rotation thanks to the acceleration. The aim of this article is to bring readerall these information, and more related to accelerometer. In addition of informationabout the other side of programming, basis to program this device have been sum up.
1 Introduction
Mobile devices and smartphones, equipped with various sensors, are wide-spread in indus-trialized countries. But since this device is no longer self-sufficient, engineers are trying tofind new ways to use it. After camera, video camera, tactile screen or internet connection,the accelerometers have been integrated for few years as a whole part of mobile phones. Asa consequence, development of smartphones is paralleled by this one of accelerometers. Foryears, accelerometers have been become a main component in many smartphone applica-tions, and also directly in the mobile operating systems. The most common use in mindshould be picture rotation.
As microelectronics industry are manufacturing smaller and smaller chips, as operatingsystems are updating as fast as possible; conception and implementation of accelerometersstay in constant evolution. Even if accelerometers are expanded, it is important to under-stand how these device works. The goal of this paper is to provide the reader an overview ofthe fabrication of this widespread sensors and to introduce basics of mobile phone program-ming using accelerometer. First of all, the physical phenomenon will be explained accordingto a model [1]. Then, microelectromechanical Systems (MEMs) design will be introduced tolink model with microelectronics manufacture. All of these topics will be developed by show-ing how to compute accelerometer characteristics thanks to model equations. After that, itwill be demonstrated how to use these equations to make the link between external informa-tion of phone (such as rotation) and accelerometer. Finally, it will be shown how to developapplications using accelerometers in Android platform [2], and what is ShaMUS project [3].
1

2 What is an accelerometer ?
The accelerometer measures the speed or g-forces created when a device accelerates acrossmultiple planes. As a result of used of MEMs in smartphone, this part will focus on themicromachined accelerometer.
2.1 Basic principle
This part explains a model of an one-axis accelerometer. Even if it is a model, equationsare closed to the reality. After understanding the problem for one axis, the reader will beable to understand the problem in three-axis devices. Nevertheless, a common way used toknow the 3-D position is to combine three one-axis accelerometer, hence the knowledge ofone-axis accelerometer is sufficient.
An accelerometer is composed of three key components which are linked with beams. Thesecomponents are the proof mass, the spring and the damper; as shown on Figure 1. Themass has a mass M, the constant spring is K and the damping factor is called D.
Figure 1: Accelerometer scheme [4]
According to Newton’s second law and the model described above, the mechanical transferfunction is [1]
H(s)= x(s)a(s)
= 1s2 + wr
Q s+w2r
, (1)
where a is the acceleration undergone by the device , x is the relative position of the proof
mass, wr =√
KM is the pulse of resonance frequency and Q =
pK MD the quality factor. Notice
that adjust K and M will change the characteristics of the system. According to equation1, it is possible to derive acceleration if we know the mass displacement. The concept of allaccelerometers is to measure the displacement of the proof mass to derive acceleration ofthe phone. A good way to measure this displacement is explained in section 2.2.
Some noise may be taken into account with this model. The main source of noise is theBrownian motion related to the proof mass: gas molecules and anchors. The total noiseequivalent acceleration (TNEA) is
TNEA =√
4KBTwr
QM,
where KB is the Boltzmann constant and T is the temperature in Kelvin.
2

2.2 Specific design: micro-electromechanical system
A huge variety of accelerometers have been spread the market over the years, such aspiezoelectric, piezoresistive, capacitive, and so on. Assuming accelerometers used in mobilephones are MEMs devices, this design is explained in this part.
The main principle of these devices is to use capacitors as a sensor. Capacitance may changewhen the geometry of the capacitor is changing. Under some realistic simplifications, theexpression of capacitance is expressed as following:
C0 = ε0εAd
= εA
d,
where ε0εA = εA and A is the area of the electrodes, d the distance between them, ε0 thereference electric permittivity and ε the permittivity of the material separating them. Achange of a previous parameters lead to a change of capacitance. Accelerometer designuses the variant parameters d and A.
Figure 2: MEMs design
Figure 2 illustrates a design of MEMs accelerometer, where two neighboured plates repre-sent one capacitor. Acceleration applied on the chip will move the proof mass. CapacitancesC1 and C2 are functions of the respective relative displacement x1 and x2. The balance po-sition is called x0, associated to the capacitance C0, and the displacement of the proof massis named x.
Then,
x1 = x0 + x; x2 = x0 − x
C1 = εA1x1
= C0 −∆C; C2 = εA1x2
= C0 +∆C .
The capacitance difference is now given by
C2 −C1 = 2∆C = 2εAx
x02 − x2 .
3

Measuring ∆C, the displacement x is the solution of second order equation
∆Cx2 +εA x−∆Cd2 = 0 . (2)
For a small displacement, the second order of x may be neglected, hence the solution ofEquation 2 is
x ≈ d2
εA∆C = d
∆CC0
. (3)
This reasoning shown that the displacement is approximatively proportional to the capaci-tance difference. The measure of the capacitance difference will give us the correspondingdisplacement. The common way to measure capacitance difference is to measure the poten-tial between C1 and C2. And using Equation 1, acceleration is derived from the displace-ment.
2.3 Characteristics of accelerometers
As we have shown in Section 2.1 , accelerometers may be design according to differentcharacteristics, such as resonance frequency or quality factor. These values are adjustedby changing the mass, or the constant spring. A specific design has been explained inSection 2.2. This part provides to link required specifications with characteristics design.Appellations and notations are the same than in Section 2.1 and 2.2.
The specifications of an accelerometers are listed below [4], where g is the acceleration unit,corresponding to Earth’s acceleration:
• Bandwidth (Hz)
• Sensitivity (pF/g)
• Dynamic range (g)
Bandwidth The bandwidth is not limited by mechanical phenomenon, but by electricalone. As electrical study will no be present here, we do not take care of this parameter.
Sensitivity The sensitivity is defined by
S = A∗m∗εk∗d2 .
The gap between the electrode d should be as small as possible in order to increase thesensibility. The idea to grow A or m is not the best one because for MEMs, components haveto be as small as possible.
4

Dynamic range The maximum acceleration amax corresponds to the maximum mass dis-placement, called dmax, following this formula:
amax = k∗dmax
m.
Now, the gap d should be high enough to provide a good dynamic range. But it is againstthe previous idea, so a compromise has to be found.
2.4 Some characteristics
The Table 1 is here to give the reader an idea of some values relative to accelerometer chip.It is based on the LIS331DL chip [6], used in new generation of iPhone.
Table 1: Technical specifications of LIS331DL accelerometer
hhhhhhhhhhhhhhhhhhhhhhCharacteristic
Reference of accelerometerLIS331DL
Size 3*3*1 mmWeight 20 mgram
Supply voltage 2.16 V to 3.6 VPower consumption < 1 mWTemperature range -40 °C to +85 °CMeasurement range ± 2.3 or ± 9.2
Sensitivity 18 mg/digitMaximum acceleration 10000 g for 0.1 ms
3 How to use it in a mobile phone
This part will explain some basic concepts of using data from accelerometer. We will notsee yet how to programming but the way to use acceleration of the phone to derive othersproperties such as the position, the speed or the tilt. According to the previous part, theacceleration of the phone is supposed to be known in each instant. Let us see how to usethis information to derive the other.
3.1 Drift correction
Accelerometer gives an access to the acceleration of the phone, but it may be fine to alsoknow the speed and the relative position of it. The problem is to know the value of con-stant integration which appeared from acceleration to speed, or from speed to position. Themethod to find the good constant is called drift correction.
Accelerometer can be associated with gyroscope to evaluate the current position [7], but thissolution will not be discussed here.
5

We suppose to know the previous (or initial) velocity and position, and current acceleration.If x(t) is the position, v(t) the velocity and a(t) the acceleration, then
x(t0 +∆t)= 12∗a(t0)∗ (t0 +∆t)2 +v(t0)∗ (t0 +∆t)+ x(t0) .
∆t should be as small as possible to give the best result, and theoretically this equationshould give a good result. But if acceleration bias error is ab, error in position is 1
2 ∗ab ∗ t2,which increases quadratically in time. To conclude, a(t0) , v(t0) and x(t0) have to be updatedfor every new computation, and the bias has to be taken into account in the implementation.
3.2 Computation of tilt
Another interesting value is the tilt. Indeed, this value is used in a lot of applications, or inphone menu to change between portrait or landscape view.
It is possible to measure tilt between 0° and 90° with one-axis accelerometer. To measurethe tilt from 0° to 360°, three-axis accelerometer is needed.
The main idea is to compare output voltage with the zero g offset, to determine if it is apositive or negative acceleration. Figure 3 shows how acceleration is used.
Figure 3: Scheme of tilt computation [8]
Let us write some equations to explain the computation.
VOUT =VOFFSET + ∆V∆g
∗ g∗ sin(θ) ,
whereVOUT = Accelerometer Output (V)VOFFSET = Accelerometer reference (0g Offset, V )∆V∆g = Accelerometer sensitivityg = Earth’s gravity (9.8 m/s−2 )θ = Angle of tilt (degrees)
The solution for θ is
θ = arcsin
(VOUT −VOFFSET
∆V∆g ∗ g
).
We have shown it is possible with this small trick to compute tilt from acceleration.
6

4 Implementation
The aim of this section is not to explain specifics and difficult examples, but the basis ofprogramming with accelerometer. Android platform [2] has been chosen as an example.This part may seem trivial but it is a good start to understand how access to data fromaccelerometer. It is not sufficient to write an application straight after the reading but themost important concepts are related here.
4.1 Main class
The higher class giving access to sensor is SensorManager. An instance of this class isobtained by calling Context.getSystemService() with the argument SENSOR_ SERVICE.The second step is to register to SensorEventListener. It can be done using the followingfunction.public boolean regis terListener ( SensorEventListener l i s tener , Sensor sensor , int
rate , Handler handler )
Parameters• listener is an object SensorEventListener• sensor is the sensor to register to• rate is explain in section 4.2• handler
4.2 Sensor rate
It is possible to get information from accelerometer with different delivering rate. Herethere is the list of different possible rate.
1. SensorManager.SENSOR_ DELAY_ FASTEST : as fast as possible2. SensorManager.SENSOR_ DELAY_ GAME : rate suitable for game3. SensorManager.SENSOR_ DELAY_ NORMAL : normal rate4. SensorManager.SENSOR_ DELAY_ UI : rate suitable for UI Thread
This parameter is used when a listener is created. Choose the most appropriate rate maybe economically interesting in terms of battery consumption for example.
4.3 Access to the value
As soon as the step 4.1 is done, it is possible to read data from accelerometer. When thereis an event, the following function is called.
public abstract void onSensorChanged ( SensorEvent event )
As a consequence, developer has to implement this function in his or her class using datafrom accelerometer. The argument event represent an event of the sensor. We have tobe careful here because this function is not only called when there is an event from theaccelerometer. This is why the type of the event has to be checked. It is done by this line:i f ( event . sensor . getType ( ) ==Sensor .TYPE_ACCELEROMETER) {/ / Action}
7

5 Case study: ShaMUS
ShaMus [3] is a sensor-based approach to turning mobile devices into musical instruments.This should allow mobile devices to be self-sufficient as a musical instrument. The goal ofthis project is to use accelerometer and magnetometer to create an interactive music mobileinstrument close to the user.
G. Essl and M. Rohs, for Shamus project, implemented few basic gestures of the phone us-ing accelerometer and magnetometer, but we will explain in this section examples relatedto accelerometer. These gestures come from the use of the phone as a musical instrument. Ifthe phone is considered to be quasi-static, measuring acceleration from 3-D axis accelerom-eters gives earth’s gravity. Figure 4 shows mobile phone with its associated axis. Tiltingthe device forward will increase acceleration in x-axis, and by knowing the new value, it ispossible to compute the associated tilt. Other gestures will be briefly explained.
Figure 4: Orientation of tilt detection [3]
5.1 Striking
Some musical instruments need to be hit, such as piano, drums, djembe, and the like. Thisis why striking is an interesting gesture to simulate. If phone angle overtake zero degreerelatively to horizontal plan, either from negative to positive or the opposite, we supposethat the striking movement had been done. Moreover, a measurement of amplitude of themovement can be computed with |αn−1 −αn| where n is the discrete time of impact and αnis the tilt angle at time n .
5.2 Shaking
This movement may come from tambourines or rattles. We suppose again that the phoneis quasi-static. That is means that in every moment, the acceleration applied in the phoneis only earth’s gravitational field. According to Newton’s 2nd law F = ma, strength is pro-portional to acceleration. Hence shaking is known by measuring acceleration amplitude.If shaking gesture is done at time instant n, the phone was quasi-static at n−1. Henceacceleration is computed as
|a| =√
(xn − xn−1)2 + (yn − yn−1)2 + (zn − zn−1)2 ,
where xn, yn, zn are accelerometer readings at discrete times n.
8

6 Conclusion
Accelerometers are interesting devices for both physics and programming. Based on thereader’s background, this article provided a starting point either on the physics of the de-vice, or on its programming. We introduced along this article the use of accelerometer fromphysics to programming, assuming the reader had not yet the background on this topic.The first step has been to explain general model and MEMs design. It was logical to studyMEMs design because in mobile phones, accelerometers chip are made with this technique.Moreover, design has been completed by some characteristics that can be computed thanksto model equations. Indeed, there are links between accelerometer specifications and phys-ical characteristics which are used to design the device.
In the second part, it has been shown how to get information derived from acceleration,such as the tilt or the position. This information is useful in order to use mobile phone as aninteractive device (picture rotation or acceleration in games applications) or to implementbasic gestures which can be useful for reader’s applications, such as ShaMUS project. Tofinish, a basic tutorial of programming has been explained.
The tutorial sums up the main steps to follow when using accelerometer sensor during ap-plications development. Now, the reader is able to implement basis but varied applicationsusing accelerometer as a sensor. It may be interesting to develop more the implementationbut it is not the main point of this article. To implement difficult apps, reader may have alook at the API of his or her choice and keep in mind this article.
9

7 References
[1] N. Yazdi, F. Ayazi, and K. Najafi, “Micromachined inertial sensors,” Proceedings of theIEEE, vol. 86, no. 8, pp. 1640–1659, 1998.
[2] “Android api.” http://developer.android.com/reference/android/hardware/SensorManager.html.
[3] G. Essl and M. Rohs, “ShaMus-A Sensor-Based Integrated Mobile Phone Instrument,”in Proc. ICMC’07, Copenhagen, Denmark, 2007.
[4] MEMSuniverse, “Accelerometers.” http://www.memsuniverse.com/mems-accelerometers/.
[5] T. Gabrielson, “Mechanical-thermal noise in micromachined acoustic and vibration sen-sors,” Electron Devices, IEEE Transactions on, vol. 40, no. 5, pp. 903–909, 1993.
[6] STMicroelectronics, “Lis331dl,”
[7] E. Foxlin, M. Harrington, and Y. Altshuler, “Miniature 6-DOF inertial system for track-ing HMDs,” in Proceedings of the SPIE, vol. 3362, pp. 214–228, 1998.
[8] M. Clifford and L. Gomez, “Measuring tilt with low-g accelerometers,” AN3107,Freescale Semiconductors, 2005.
10

1
Into
th
e v
oco
der
: d
igit
al
filt
ers
Th
ibau
lt J
ugé
TK
K, S
cho
ol
of
Ele
ctri
cal
Eng
inee
rin
g
Ab
stra
ct
The
voco
der
is
a m
odula
ting d
evic
e w
hic
h w
as
crea
ted i
n 1
939.
Eve
n t
hough i
ts i
nve
nti
on
is n
ot
rece
nt,
its
appli
cati
ons
rem
ain
quit
e appea
ling n
ow
adays
. T
he
vers
ion p
ropose
d
her
e m
odif
ies
slig
htl
y th
e ori
gin
al
des
ign
whic
h
was
under
goin
g
som
e del
ays
and
com
puta
tional
effi
cien
cy
issu
es.
The
pre
sent
vers
ion
is
base
d
on
a
filt
er
bank
only
com
pose
d b
y in
finit
e im
puls
e re
sponse
(II
R)
filt
ers.
It
als
o h
as
the
adva
nta
ge
to r
eali
ze
both
th
e fi
lter
ing
and
the
enve
lop
e tr
ack
ing
part
s si
mult
aneo
usl
y.
This
ve
rsio
n
is
a
com
puta
tional
impro
vem
ent
since
it
is b
ase
d o
n I
IR f
ilte
rs.
In a
ddit
ion,
it i
s co
mpati
ble
wit
h m
oder
n s
yste
ms.
No
net
hel
ess,
this
is
a p
rosp
ecti
on v
ersi
on r
eali
zed w
ith M
atl
ab a
nd
it d
oes
not
insu
re t
hat
the
ove
rall
sys
tem
is
reali
zable
. Som
e n
eces
sary
des
ign
ret
ouch
es
shall
be
appli
ed t
o t
ack
le t
his
tra
deo
ff a
nd p
rovi
de
the
vers
ion w
ith a
ppli
cati
ons
in m
obil
e
dev
ices
.
1
INT
RO
DU
CT
ION
An i
mport
ant
par
t of
the
purp
ose
of
mobil
e ap
pli
cati
ons
is f
un.
It i
s an
asp
ect
that
is
usu
ally
lef
t out
of
consi
der
atio
n.
How
ever
, fu
n p
revai
ls o
ver
uti
lity
in p
ract
ice.
Thus,
who
has
no
t ev
er d
ream
ed o
f sp
eakin
g l
ike
infa
mous
Dar
th V
ader
? T
he
voco
der
(sh
ort
fo
r
VO
ice
enC
OD
ER
) w
as i
nven
ted a
t B
ell
Lab
ora
tori
es i
n 1
939.
Ev
en i
f it
init
iall
y h
ad
tele
com
munic
atio
ns
purp
ose
s, i
t has
tak
en a
pla
ce i
n t
he
musi
c en
vir
onm
ent
most
ly,
but
also
in t
he
movie
indust
ry.
This
is
talk
ing a
bout
fun p
urp
ose
s but
it h
as t
o b
e re
mem
ber
ed
that
the
init
ial
purp
ose
of
the
voco
der
is
to s
ynth
esiz
e a
voic
e si
gn
al.
Sin
ce t
his
pro
cess
incl
udes
ste
ps
that
can
var
y f
rom
IIR
fil
teri
ng t
o m
ixed
fil
ter
ban
ks,
this
stu
dy d
iscu
sses
a
pro
cess
or
imple
men
tati
on f
or
dig
ital
fil
ters
wit
h p
ersp
ecti
ves
to a
big
ger
appli
cati
on:
the
voco
der
. T
his
pap
er f
irst
intr
oduce
s so
me
bac
kgro
und o
n d
igit
al s
ignal
pro
cess
ing a
nd t
he
mobil
e w
orl
d.
Then
, th
e ver
y n
oti
on o
f fi
lter
s w
ill
be
def
ined
, re
stri
ctin
g t
he
dis
cuss
ion
to
the
use
ful
kin
ds
of
filt
ers
for
the
pu
rpose
. A
fter
rap
idly
bro
wsi
ng s
om
e al
read
y e
xis
ting
appli
cati
ons
on
mobil
e pla
tform
s an
d
involv
ing
dig
ital
fi
lter
s,
the
core
id
ea
wil
l be
intr
oduce
d:
the
filt
erin
g p
art
of
a poss
ible
voco
der
appli
cati
on.
An i
dea
l fi
lter
ban
k w
ill
be
use
d t
o s
imula
te t
he
beh
avio
r of
a voco
der
.
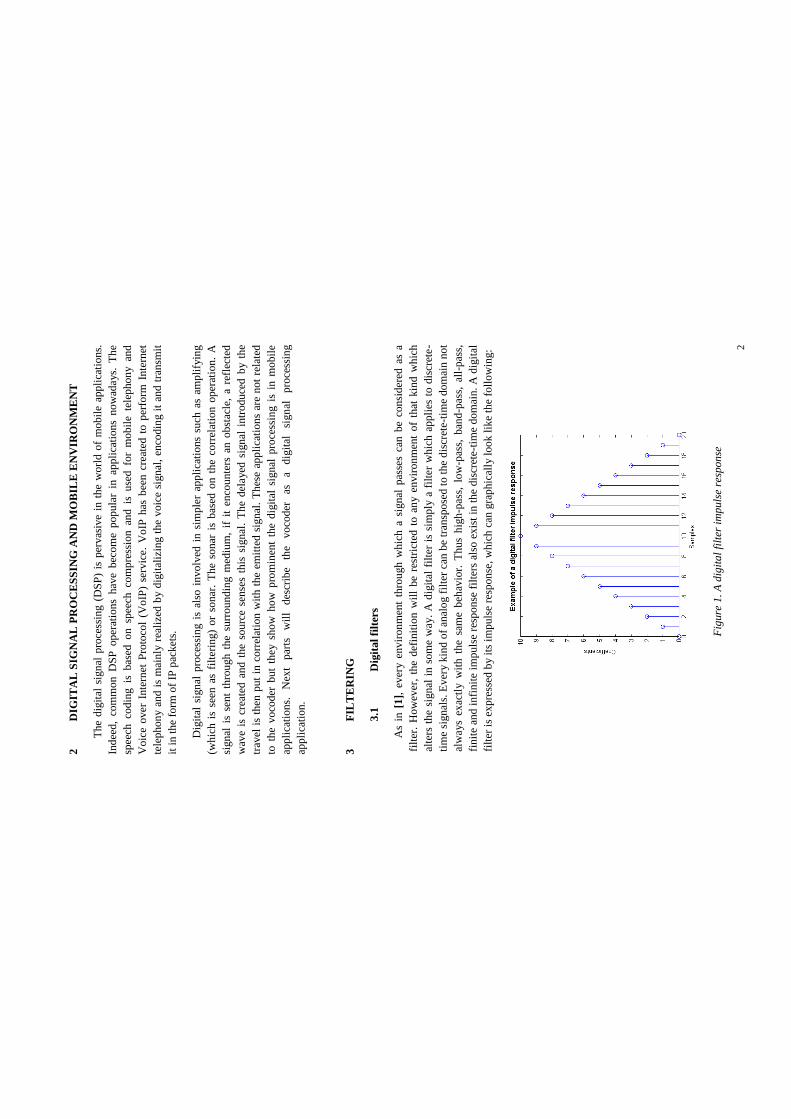
2
2
DIG
ITA
L S
IGN
AL
PR
OC
ES
SIN
G A
ND
MO
BIL
E E
NV
IRO
NM
EN
T
The
dig
ital
sig
nal
pro
cess
ing
(D
SP
) is
per
vas
ive
in t
he
worl
d o
f m
obil
e ap
pli
cati
ons.
Ind
eed,
com
mon D
SP
oper
atio
ns
hav
e bec
om
e popula
r in
appli
cati
ons
now
adays.
Th
e
spee
ch co
din
g i
s bas
ed on s
pee
ch co
mpre
ssio
n an
d i
s use
d f
or
mobil
e te
lephon
y an
d
Voic
e over
Inte
rnet
Pro
toco
l (V
oIP
) se
rvic
e.
Vo
IP h
as b
een c
reat
ed t
o p
erfo
rm I
nte
rnet
tele
phon
y a
nd i
s m
ainly
rea
lize
d b
y d
igit
aliz
ing t
he
voic
e si
gnal
, en
codin
g i
t an
d t
ransm
it
it i
n t
he
form
of
IP p
acket
s.
Dig
ital
sig
nal
pro
cess
ing i
s al
so i
nvolv
ed i
n s
imple
r ap
pli
cati
ons
such
as
ampli
fyin
g
(whic
h i
s se
en a
s fi
lter
ing)
or
sonar
. T
he
sonar
is
bas
ed o
n t
he
corr
elat
ion o
per
atio
n.
A
signal
is
sent
thro
ugh t
he
surr
oundin
g m
ediu
m,
if i
t en
counte
rs a
n o
bst
acle
, a
refl
ecte
d
wav
e is
cre
ated
and t
he
sourc
e se
nse
s th
is s
ignal
. T
he
del
ayed
sig
nal
intr
oduce
d b
y t
he
trav
el i
s th
en p
ut
in c
orr
elat
ion w
ith t
he
emit
ted s
ignal
. T
hes
e ap
pli
cati
on
s ar
e not
rela
ted
to t
he
voco
der
but
they s
how
how
pro
min
ent
the
dig
ital
sig
nal
pro
cess
ing i
s in
mobil
e
appli
cati
ons.
N
ext
par
ts
wil
l des
crib
e th
e vo
coder
as
a
dig
ital
si
gn
al
pro
cess
ing
appli
cati
on.
3
FIL
TE
RIN
G
3.1
D
igit
al
filt
ers
As
in [
1],
ev
ery e
nvir
on
men
t th
rou
gh w
hic
h a
sig
nal
pas
ses
can
be
consi
der
ed a
s a
filt
er.
How
ever
, th
e def
init
ion w
ill
be
rest
rict
ed t
o a
ny e
nvir
onm
ent
of
that
kin
d w
hic
h
alte
rs t
he
signal
in s
om
e w
ay.
A d
igit
al f
ilte
r is
sim
ply
a f
ilte
r w
hic
h a
ppli
es t
o d
iscr
ete-
tim
e si
gnal
s. E
ver
y k
ind o
f an
alo
g f
ilte
r ca
n b
e tr
ansp
ose
d t
o t
he
dis
cret
e-ti
me
dom
ain
not
alw
ays
exac
tly w
ith t
he
sam
e b
ehav
ior.
Thus
hig
h-p
ass,
low
-pas
s, b
and
-pas
s, a
ll-p
ass,
finit
e an
d i
nfi
nit
e im
puls
e re
sponse
fil
ters
als
o e
xis
t in
the
dis
cret
e-ti
me
dom
ain.
A d
igit
al
filt
er i
s ex
pre
ssed
by i
ts i
mpuls
e re
sponse
, w
hic
h c
an g
raphic
ally
look l
ike
the
foll
ow
ing:
Fig
ure
1. A
dig
ital
filt
er i
mpuls
e re
sponse

3
It c
an b
e se
en t
hat
this
is
dis
cret
e re
pre
senta
tion.
The
pre
vio
us
impuls
e re
sponse
would
then
be:
H[n
] =
{0,1
,2,3
,4,5
,6,7
,8,9
,10,9
,8,7
,6,5
,4,3
,2,1
,0}
This
giv
es u
s an
ex
pre
ssio
n i
n t
erm
s of
z-t
ransf
orm
(fr
equen
cy-d
om
ain):
10
9
0
)2
0(
10
zz
zk
zH
k
kk
Dig
ital
fil
ters
are
inte
rest
ing f
or
audio
sig
nal
pro
cess
ing i
n t
he
sense
the
sound p
ath i
s
star
ting w
ith a
n a
nal
og
-to-d
igit
al c
onver
ter
usu
ally
. M
ore
ov
er,
in d
iscr
ete-t
ime
dom
ain,
it
is
pro
ven
th
at
filt
erin
g
com
es
to
be
a dis
cre
te
convolu
tion
whic
h
is
sim
ply
a
mult
ipli
cati
on/a
ccum
ula
tion p
roce
ss a
nd n
ot
a co
nti
nuous
inte
gra
tion,
thus
mak
ing t
he
dig
ital
fil
ters
chea
per
to i
mple
men
t th
an t
he
anal
og o
nes
. In
addit
ion,
they d
o n
ot
chan
ge
over
tim
e an
d t
hey a
re o
f co
urs
e co
mp
atib
le w
ith m
oder
n c
om
puta
tional
syst
ems.
3.2
F
ilte
r b
an
ks
A f
ilte
r ban
k i
s a
gro
up o
f ban
d-p
ass
filt
ers
that
are
sep
arat
ed i
n b
ranch
es.
A g
ener
al
blo
ck d
iagra
m i
s giv
en b
elow
:
Fig
ure
2. E
xam
ple
of
filt
er b
ank
[2]
Fil
ters
index
ed b
y 0
are
low
-pas
s fi
lter
s an
d t
hose
index
ed b
y 1
are
hig
h-p
ass
filt
ers.
The
blo
ck d
iagra
m a
bov
e st
ands
for
a 4
-bra
nch
fil
ter
ban
k.
Ind
eed,
usi
ng n
oble
iden
titi
es,
i.e.
sw
appin
g d
ow
n-s
amp
lers
and f
ilte
rs,
fou
r ban
d-p
ass
filt
ers
can b
e is
ola
ted:
)(
)(
)(
)(
)(
)(
)(
)(
)(
)(
)(
)(
4
0
2
00
00
0
4
1
2
00
00
1
2
10
01
1
zH
zH
zH
zH
zH
zH
zH
zH
zH
zH
zH
zH
The
plo
t of
thei
r fr
equen
cy r
esponse
s is
the
foll
ow
ing (
this
is
gen
eral
rep
rese
nta
tion;
the
freq
uen
cy r
esponse
of
H0 a
nd H
1 a
re n
ot
expli
citl
y d
efin
ed h
ere)
:

4
Fig
ure
3. F
requen
cy r
esp
onse
s of
the
band
-pass
fil
ters
const
ituti
ng t
he
filt
er b
ank
It i
s in
tere
stin
g t
o n
oti
ce t
hat
the
asso
ciat
ion o
f ea
ch s
ubban
d a
llow
s co
ver
ing t
he
whole
ban
dw
idth
[0,
π]
and i
sola
ting d
iffe
rent
ban
dw
idth
s m
eanw
hil
e.
Th
is p
roper
ty w
ill
be
use
ful
for
the
voco
der
pri
nci
ple
as
it w
ill
be
seen
furt
her
in t
his
do
cum
ent.
It
has
to b
e
men
tioned
th
at th
e dif
fere
nt
sub
-fil
ters
ca
n be
des
ign
ed se
par
atel
y w
ithout
usi
ng tw
o
“mai
n”
filt
ers
H0 a
nd H
1.
3.3
II
R v
s. F
IR f
ilte
rs
The
pro
ble
m w
het
her
ch
oosi
ng f
init
e im
puls
e re
sponse
(F
IR)
filt
ers
or
infi
nit
e im
puls
e
resp
onse
(II
R)
filt
ers
is t
horn
y.
Indee
d,
IIR
fil
ters
involv
e le
ss c
om
puta
tio
n r
esourc
es b
ut
the
trad
eoff
is
they
could
suff
er f
rom
inst
abil
ity i
ssues
. M
ore
over
, it
is
usu
ally
tri
cky t
o
des
ign a
dig
ital
IIR
fil
ter.
Des
ignin
g a
n a
nal
og I
IR f
ilte
r (B
utt
erw
ort
h f
or
inst
ance
) is
requir
ed a
nd t
hen
, a
tim
e-dis
cret
izat
ion t
echniq
ue
is t
o b
e ap
pli
ed t
o r
eali
ze t
he
dig
ital
ver
sion o
f it
. F
IR f
ilte
rs a
re i
n p
ract
ice
lon
ger
th
an I
IR f
ilte
rs w
hic
h m
eans
they
involv
e
more
tap
s, t
hus
lead
ing t
o m
ore
del
ays.
Nev
erth
eles
s, s
ince
this
pro
ject
is
only
fo
cusi
ng o
n M
atla
b s
imula
tions
and n
ot
on
ph
ysi
cal
imple
men
tati
on,
this
would
be
easy
to d
esig
n I
IR f
ilte
rs p
rop
erly
in o
rder
to g
et
rid o
f th
e in
stab
ilit
y r
isks
and t
o a
ppre
ciat
e th
e le
ss-d
eman
din
g n
ature
. In
dee
d,
man
y g
ood
des
ign t
ools
are
avai
lable
to a
void
inst
abil
ity a
nd p
has
e is
sues
. T
he
IIR
fil
ters
opti
on i
s
chose
n f
or
its
conv
enie
nce
in t
erm
s of
com
puta
tio
ns
and e
ffic
iency.
4
EX
IST
ING
AP
PL
ICA
TIO
NS
Tw
o
appli
cati
ons
hav
e to
be
men
tioned
in
th
is
dis
cuss
ion:
Dir
ac-m
obil
e (f
rom
TheD
SP
Dim
ensi
on,
[3])
and I
Am
T-P
ain
(fr
om
Sm
ule
, [4
]).
The
firs
t is
an a
ppli
cati
on
that
al
low
s m
anip
ula
ting
pit
ch
of
audio
si
gn
als
dir
ectl
y
wit
h
a m
obil
e dev
ice.
It
is
avai
lable
on i
OS
. T
he
appli
cati
on i
s re
gula
rly u
pdat
ed a
nd i
s now
able
to e
xec
ute
the
foll
ow
ing
oper
atio
ns:
pit
ch
det
ecti
on,
exte
rnal
pit
ch
contr
ol,
ti
me-s
tret
chin
g,
pit
ch
shif
ting,
and m
any o
ther
use
ful
audio
sig
nal
pro
cess
ing a
lgo
rith
ms.
It
is d
efin
itel
y w
ort
h
to m
enti
on i
n t
he
per
spec
tive
of
a vo
coder
. It
does
not
incl
ude
a voco
der
in i
tsel
f but
pro
vid
es t
he
use
r w
ith u
sefu
l fu
nct
ions
for
auto
-tu
ne
for
exam
ple
.

5
The
seco
nd a
ppli
cati
on,
I A
m T
-Pai
n,
is r
eali
zing t
he
auto
-tun
e oper
atio
n.
Auto
-tune
was
init
iall
y r
eferr
ing t
o t
he
soft
war
e dev
eloped
by A
nta
res
Audio
Tec
hno
logie
s in
1997.
The
auto
-tune
effe
ct i
s cl
ose
to t
hat
of
the
voco
der
and
the
theo
ry beh
ind i
s si
mil
ar.
Ind
eed,
auto
-tune
can b
e se
en a
s a
phas
e voco
der
, as
[5]
expla
ins,
whic
h m
eans
it u
ses
the
phas
e in
form
atio
n t
o a
ct b
oth
on f
requen
cy a
nd t
ime
dom
ains.
It
is b
ased
on t
he
short
-tim
e
Fouri
er t
ransf
orm
(S
TF
T)
algori
thm
, w
hic
h i
s co
mm
only
com
pute
d u
sing f
ast
Fouri
er
tran
sform
s (F
FT
). A
uto
-tune
use
s pit
ch c
orr
ecti
on
and c
an b
e use
d t
o d
isto
rt t
he
hum
an
voic
e if
the
pit
ch i
s ra
ised
and w
hit
ened
dra
stic
ally
.
5
CO
RE
ID
EA
5.1
T
he
spee
ch s
ign
al
The
spee
ch s
ignal
is
som
ehow
spec
ific
in t
he
sense
form
ants
and p
honem
es a
re b
ein
g
isola
ted i
n i
t. A
spee
ch s
ignal
spec
tro
gra
m i
s li
ke
the
foll
ow
ing:
Fig
ure
4. Spec
trum
of
the
stri
ng “
pyö
rrem
yrsk
yist
ä”
The
abov
e sp
ectr
ogra
m
is a
tim
e-fr
equen
cy r
epre
senta
tion w
ith x
-ax
is b
eing t
he
tim
e
and y
-ax
is b
eing t
he
freq
uen
cy o
f th
e so
unds.
In o
ther
word
s, t
o e
ach t
ime
inst
ant
t is
asso
ciat
ed i
ts f
requ
ency s
pec
trum
. A
s it
has
bee
n s
aid b
efore
, phon
emes
and
form
ants
hav
e to
be
dis
tinguis
hed
in t
his
spec
trogra
m.
The
phonem
es a
re t
ypic
al s
ou
nds
(of
a giv
en
langu
age)
an
d ar
e re
pre
sente
d b
y a
cert
ain sp
ectr
um
at
a
cert
ain ti
me
inst
ant
t. T
he
form
ants
are
the
ener
gy m
axim
a of
the
spee
ch s
ignal
spec
trum
.
Fin
ally
, it
has
to b
e know
n,
acco
rdin
g t
o [
6],
that
the
freq
uen
cy r
ange
of
the
hum
an
voic
e is
conven
tional
ly [
60H
z, 7
000
Hz]
, in
cludin
g t
he
extr
eme
freq
uen
cies
of
scre
ams,
laughs,
cri
es a
nd s
o o
n.
How
ever
, th
e voic
e ban
dw
idth
is
conven
tional
ly r
epre
sente
d b
y
[0, 4kH
z] f
or
com
puta
tions
and r
estr
icts
to t
he
spee
ch s
ign
al i
tsel
f.

6
5.2
D
escr
ipti
on
The
foll
ow
ing b
lock
dia
gra
ms
are
illu
stra
ting t
he
gen
eral
work
ing o
f a
“cla
ssic
al”
voco
der
as
the
one
from
Bel
l L
abora
tori
es [
7]:
Fig
ure
5. G
ener
al
pri
nci
ple
of
the
voco
der
as
in [
7]
“B
P F
ilte
r” s
tand
s fo
r B
and
-Pass
Fil
ter
and “
VC
A”
for
Volt
age-
Contr
oll
ed
Am
pli
fier
.
The
pri
nci
ple
is
fair
ly s
imple
. T
wo d
iffe
rent
signal
s ar
e ap
pli
ed a
t th
e in
put:
fir
st a
voic
e si
gnal
(not
nec
essa
rily
sp
eech
sig
nal
, but
vo
ice-
bas
ed s
ignal
) w
hic
h i
s co
nsi
der
ed a
s
the
“contr
ol
signal
” an
d s
econd a
“m
odula
ting s
ignal
” or
“car
rier
sig
nal
” w
hic
h i
s oft
en a
musi
cal
inst
rum
ent
or
bas
ical
ly a
synth
esiz
er.
Thes
e tw
o s
ign
als
are
spli
t w
ith m
ult
iple
ban
d-p
ass
filt
ers.
T
he
num
ber
of
filt
ers,
th
us
the
num
ber
o
f ban
ds,
is
to
be
chose
n
acco
rdin
g
to
what
th
e use
r w
ishes
. In
oth
er
word
s,
the
bunch
of
freq
uen
cy
ran
ges
intr
oduce
d b
y t
he
filt
ers
must
cover
th
e voic
e fr
equen
cy r
ange,
but
the
use
r in
terv
enes
in
the
sense
he
can i
nfl
uen
ce t
he
outp
ut
qual
ity.
Ho
wev
er,
the
hig
her
the
nu
mber
of
filt
ers
is,
the
nar
row
er t
hei
r re
spec
tive
ban
dw
idth
s ar
e.

7
Aft
er t
he
filt
er b
ank
ste
p,
an e
nvel
op
e tr
acker
is
then
appli
ed t
o e
ach b
and o
f th
e voic
e
signal
. T
his
ste
p a
ims
at g
ener
atin
g a
n e
volv
ing f
unct
ion w
hic
h i
s re
pre
senta
tive
of
the
ampli
tude
of
the
voic
e si
gnal
in
th
e dif
fere
nt
ban
dw
idth
s co
ver
ed b
y th
e fi
lter
s. T
he
envel
ope
trac
ker
s‟ o
utp
uts
are
then
em
plo
yed
as
contr
ol
input
for
VC
As
(as
man
y V
CA
s
as t
he
num
ber
of
ban
d-p
ass
filt
ers)
giv
ing t
he
nam
e of
“contr
ol
sign
al”
to t
he
voic
e si
gnal
.
The
purp
ose
of
the
VC
As
is t
o s
et t
he
gai
n o
f th
e ca
rrie
r si
gn
al i
n t
he
dif
fere
nt
sub
-ban
ds
intr
oduce
d b
y t
he
filt
ers.
Fin
ally
, w
hen
the
VC
A s
tep i
s pas
sed,
the
dif
fere
nt
outp
uts
are
mix
ed a
gai
n t
o c
reat
e a
tota
lly s
ynth
esiz
ed v
oic
e si
gnal
res
ult
ing f
rom
the
modula
tion m
enti
oned
, re
sult
ing i
n t
he
char
acte
rist
ic v
oco
der
so
und.
Indiv
idual
ban
d-p
ass
filt
ers
can e
ither
be
FIR
or
IIR
fil
ters
and i
t has
to b
e know
n t
hat
the
all
filt
er b
ank c
an b
e re
pla
ced b
y a
sin
gle
IIR
fil
ter
usi
ng l
inea
r pre
dic
tion t
o f
it i
t to
the
spec
tral
env
elope
of
the
voic
e si
gn
al.
One
advan
tage
of
this
met
hod,
whic
h i
s th
e one
com
monly
use
d n
ow
aday
s, i
s th
at t
he
spec
tral
pea
ks
of
the
linea
r pre
dic
tor
can
be
as
pré
cise
d a
s per
mit
ted b
y t
he
tim
e dura
tion o
f th
e si
gnal
to b
e fi
lter
ed.
The
trad
eoff
is
this
met
hod i
s li
mit
ed t
o s
ignal
s w
hose
num
ber
of
freq
uen
cy c
om
ponen
ts d
oes
not
exce
ed t
he
max
imum
num
ber
of
freq
uen
cies
that
are
cov
ered
by t
he
linea
r pre
dic
tion f
ilte
r.
6
IMP
LE
ME
NT
AT
ION
6.1
D
escr
ipti
ve
This
stu
dy a
ims
at i
mple
men
ting t
he
blo
ck d
iagra
m s
how
n i
n F
ig 5
. A
dig
ital
fil
ter
ban
k i
s use
d f
or
the
spli
ttin
g o
f th
e si
gnal
s in
mu
ltip
le s
ubban
ds.
In a
ddit
ion,
to s
impli
fy
the
work
and i
mpro
ve
the
resu
lts
in t
erm
s of
com
puta
tional
eff
icie
ncy a
nd
res
ponse
tim
es,
idea
l ban
d-p
ass
filt
ers
hav
e bee
n i
mple
men
ted.
Th
is m
eans
thei
r fr
equen
cy r
esponse
s lo
ok
like
Fig
. 6
:
Fig
ure
6. F
requen
cy r
esp
onse
s of
the
filt
er b
ank

8
The
figu
re a
bov
e pre
sents
fre
quen
cy r
esponse
s an
d i
t ca
n b
e se
en t
hat
the
idea
l ban
d-
pas
s fi
lter
s ar
e sq
uar
e-fu
nct
ions.
Thus,
thei
r in
ver
se F
ouri
er t
ransf
orm
is
a si
ne
card
inal
whic
h is
not
finit
e in
ti
me.
T
he
filt
ers
use
d ar
e in
co
nse
qu
ence
qual
ifie
d as
in
finit
e
impuls
e re
sponse
(I
IR)
filt
ers.
S
ince
th
e im
ple
men
tati
on is
fo
cuse
d o
n M
atla
b,
idea
l
des
ign o
f ban
d-p
ass
filt
ers
can b
e af
ford
ed.
Note
that
the
rect
angula
r sh
ape
of
the
spec
tra
may
lea
d t
o e
dge
effe
cts
(whic
h w
ill
be
noti
ceab
le e
spec
iall
y b
ack i
n t
ime
dom
ain).
It c
an a
lso b
e noti
ced t
hat
the
freq
uen
cy r
esponse
s of
the
ban
d-p
ass
filt
ers
use
d a
re
over
lappin
g e
ach
oth
er.
This
over
lap
fac
tor
allo
ws
a b
ette
r ac
cura
cy i
n t
he
final
rem
ixin
g
whic
h le
ads
to th
e outp
ut
and it
in
sure
s th
e w
hole
voic
e fr
equ
ency
-ran
ge
is co
ver
ed
wit
hout
gap
s. F
ig.
6 s
ho
ws
a to
tal
freq
uen
cy-r
ange
of
[900H
z, 1
700H
z].
This
is
of
cours
e
not
the
actu
al f
requen
cy r
ange
use
d t
o r
epre
sen
t th
e hum
an v
oic
e [6
] but
in o
rder
to
illu
stra
te c
lear
ly t
he
filt
er b
ank u
sed,
sim
pli
fica
tions
hav
e b
een
mad
e fo
r th
e ex
ample
. T
he
final
ver
sion d
oes
cover
[0,
4kH
z] w
ith 2
5 (
twen
ty-f
ive)
idea
l ban
d-p
ass
filt
ers
whic
h
spli
ts both
in
put
signal
s in
25 su
bban
ds
also
. T
he
idea
l b
and
-pas
s fi
lter
s pre
sent
the
advan
tage
to e
xec
ute
sim
ult
aneo
usl
y t
he
filt
erin
g p
art
and t
he
env
elo
pe
trac
kin
g p
art.
In o
rder
to r
epre
sent
the
volt
age-
contr
oll
ed a
mpli
fier
(V
CA
), a
sim
ple
pro
duct
of
the
spec
tra
(car
rier
sig
nal
and m
odula
tor
sign
al)
has
bee
n o
per
ated
in e
ach
subban
d.
Then
,
each
of
thes
e su
bban
d p
roduct
is
inver
ted b
ack i
nto
tim
e dom
ain u
sing i
nver
se F
ou
rier
tran
sform
. F
inal
ly,
the
rem
ixin
g i
s m
ade
by a
butt
ing e
ach
of
thes
e ti
me-
do
mai
n s
ub
-outp
ut
and n
orm
aliz
ing t
he
final
outp
ut.
6.2
S
imu
lati
on
an
d r
esu
lts
To p
erfo
rm t
he
sim
ula
tion,
a ca
rrie
r si
gn
al c
alle
d „
guit
ar.w
av‟
and a
modula
tor
signal
call
ed „
spee
ch.w
av‟
wer
e use
d. T
he
firs
t is
a r
eco
rdin
g o
f a
vid
eo o
f an
ele
ctri
c guit
ar s
olo
.
The
seco
nd i
s ra
ndom
sen
tence
s pro
nounce
d i
n F
rench
by a
mal
e sp
eaker
. T
he
foll
ow
ing
figure
pre
sents
the
two i
nput
signal
s an
d t
he
outp
ut
signal
in t
ime
dom
ain:
Fig
ure
7. T
ime
repre
senta
tion o
f ca
rrie
r, m
odula
tor
and o
utp
ut
signals

9
It c
an b
e se
en o
n F
ig.
7 t
hat
the
resu
ltin
g o
utp
ut
signal
do
es s
tron
gly
lo
ok l
ike
the
input
voic
e si
gn
al.
This
phen
om
enon i
s due
to t
he
nat
ure
of
the
carr
ier
signal
whic
h l
ooks
like
a nois
e in
ter
ms
of
tim
e pro
per
ties
, ev
en t
hou
gh t
his
is
not
a nois
e st
rict
ly s
pea
kin
g.
In
fact
, w
hen
lis
tenin
g t
o i
t, a
whit
e nois
e ca
n b
e ea
sily
per
ceiv
ed i
n t
he
bac
kgro
und.
Its
pre
sence
is
due
to t
he
fact
that
this
wav
efil
e w
as r
eali
zed b
y r
eco
rdin
g a
noth
er r
ecord
ing
wit
h
an ex
tern
al
mic
rophone.
If
an
oth
er te
st sa
mple
of
inst
rum
ent
(car
rier
si
gn
al)
is
pro
vid
ed t
o t
he
voco
der
and i
s re
cord
er i
n b
ette
r co
ndit
ions,
the
resu
lt s
hould
be
of
a bet
ter
qual
ity.
In t
erm
s of
hea
ring q
ual
ity,
it s
ounds
like
a s
low
ed v
oic
e si
gnal
wit
h d
iffe
rent
tonal
itie
s due
to t
he
carr
ier
signal
whic
h i
s an
in
stru
men
t (t
o w
hic
h w
hit
e nois
e is
added
unfo
rtunat
ely).
7
CO
NC
LU
SIO
N
This
dis
cuss
ion h
as s
how
n t
he
dif
fere
nt
conce
pti
ons
of
a voco
der
in t
erm
s of
dig
ital
filt
ers
imple
men
tati
on an
d pro
vid
ed a
revie
w o
f th
e gen
eral
pri
nci
ple
of
this
popula
r
syst
em.
Voco
der
s ar
e oft
en u
sed i
n b
oth
musi
c an
d f
ilm
indust
ry e
ven
tho
ugh t
hes
e w
ere
not
its
init
ial
targ
et a
udie
nce
. A
chan
nel
voco
der
has
tw
o i
nputs
: a
contr
ol
signal
fo
r w
hic
h
hum
an v
oic
e is
oft
en u
tili
zed a
nd a
n i
nst
rum
ent
sign
al r
epre
sente
d b
y a
ric
h h
arm
onic
conte
nt
such
as
a sy
nth
esiz
er o
r a
musi
cal
trac
k.
The
poin
t of
the
voco
der
is
to m
odula
te
the
inst
rum
ent
signal
wit
h t
he
contr
ol
sign
al a
nd l
ead t
o t
his
char
acte
rist
ic e
ffec
t th
at i
s so
popula
r. T
his
stu
dy h
as t
aken
a d
etai
led l
ook a
t th
e dif
fere
nt
poss
ibil
itie
s to
rea
lize
the
filt
erin
g p
art
of
a ch
ann
el v
oco
der
. E
ven
though
sev
eral
alt
ernat
ives
wer
e pre
sente
d,
the
IIR
fil
ter
ban
k w
as c
hose
n f
or
its
com
puta
tional
eff
icie
ncy a
nd t
he
poss
ibil
ity t
o a
void
a
linea
r pre
dic
tion.
Sin
ce t
he
whole
stu
dy w
as b
ased
on M
atla
b,
idea
l ban
d-p
ass
filt
ers
hav
e
bee
n r
eali
zed.
A s
imula
tion w
as p
erfo
rmed
to p
ut
in e
vid
ence
the
modula
tion o
per
ated
by
this
ver
sion o
f th
e ch
ann
el v
oco
der
, th
ou
gh i
t w
as r
estr
icte
d t
o g
raphic
al i
llust
rati
ons
for
the
dis
cuss
ion.
A p
oss
ibil
ity o
f im
pro
vin
g t
he
model
would
be
to u
se a
sin
gle
IIR
fil
ter
whose
coef
fici
ent
should
be
det
erm
ined
by l
inea
r pre
dic
tion.
This
ver
sion i
s th
e m
ost
com
monly
use
d a
t th
e ti
me.
How
ever
, th
e vo
cod
er a
ppli
es t
o h
um
an v
oic
e, a
sig
nal
whic
h
pre
sents
a l
ot
of
dif
fere
nt
freq
uen
cy c
om
ponen
ts w
hose
num
ber
can
ex
ceed
the
num
ber
of
freq
uen
cies
that
may b
e co
ver
ed b
y t
he
linea
r pre
dic
tion f
ilte
r. I
n t
his
way,
the
linea
r
pre
dic
tion w
ould
not
be
a good o
pti
on i
f one
wan
ts t
o c
over
the
who
le h
um
an v
oic
e
freq
uen
cy r
ange.

10
8
RE
FE
RE
NC
ES
[1]
Sm
ith,
Juli
us
O., 2
007,
Intr
oduct
ion
to D
igit
al
Fil
ters
wit
h A
udio
Appli
cati
ons,
Juli
us
Sm
ith,
460 p
[2]
Mit
ra,
San
jit
K.,
1998,
Dig
ital
signa
l pro
cess
ing,
a c
om
pute
r-base
d a
ppro
ach
, N
ew-
York
, N
Y, M
cGra
w-H
ill,
864 p
[3]
The
DS
PD
imen
sion,
Sig
nal
Pro
cess
ing
Tuto
rials
&
Soft
ware
–
DIR
AC
-mobil
e,
htt
p:/
/ww
w.d
spdim
ensi
on.c
om
/tec
hnolo
gy-l
icen
sing/d
irac
2-i
phone,
04/1
0/2
011
[4]
Sm
ule
Inc.
, I
Am
T-P
ain
, htt
p:/
/iam
tpai
n.s
mule
.com
/, 0
6/1
0/2
011
[5]
Den
g L
, O
‟Shau
ghn
essy
D,
2003,
Spee
ch P
roce
ssin
g:
A D
yna
mic
an
d O
pti
miz
ati
on
-
Ori
ente
d A
ppro
ach
, M
arce
l D
ekk
er, pp. 41
-48
[6]
Tit
ze, In
go R
., 1
994,
Pri
nci
ple
s of
Voic
e P
rod
uct
ion
, N
J, P
renti
ce H
all,
354 p
[7]
Dec
amp
P.,
Kli
eger
U
.,
McP
her
son
A.,
2
003,
Voca
l H
arm
oniz
er
and
Voco
der
,
(avai
lable
onli
ne
at h
ttp:/
/andre
wm
cph
erso
n.o
rg/m
edia
/voco
der
.pd
f), 01/1
1/2
011

Mob
ile D
evic
es in
Per
form
ance
Con
text
Chi
-Hsi
a La
i D
epar
tmen
t of M
edia
, Aal
to S
choo
l of A
rt an
d D
esig
n
A
bstr
act
Ther
e ha
s bee
n a
grow
ing
rese
arch
inte
rest
s in
mak
ing
use
of m
obile
dev
ices
in
mus
ic p
erfo
rman
ce c
onte
xt. T
his p
aper
revi
ews s
elec
ted
case
s tha
t util
ised
m
obile
dev
ices
to
mak
e m
usic
with
foc
us t
o di
scus
s th
e pe
rfor
man
ce
pers
pect
ive.
Thi
s pa
per
also
ope
ns s
ome
chal
leng
es fa
ced
in m
obile
mus
ic
perf
orm
ance
, as
wel
l as
colla
bora
tive
mus
ic a
ppro
ach
tow
ards
cre
atin
g an
al
tern
ativ
e pe
rfor
man
ce sp
ace
as w
ell a
s aud
ienc
e pa
rtic
ipat
ion.
1.
INT
RO
DU
CT
ION
The
adve
nt o
f tec
hnol
ogy
over
the
last
few
dec
ades
has
influ
ence
d th
e w
ay m
usic
is
crea
ted,
per
form
ed, a
nd s
hare
d. T
he in
tegr
atio
n of
ele
ctro
nics
, com
putin
g te
chno
logy
, so
und
and
mus
ic h
as le
d us
to w
itnes
s the
tran
sfor
mat
ion
of m
usic
ent
erin
g in
to a
dig
ital
real
m w
here
new
com
posi
tiona
l app
roac
hes
and
new
mus
ical
inst
rum
ents
took
pla
ce in
co
ntem
pora
ry m
usic
pra
ctic
e. I
n re
cent
yea
rs,
the
incr
easi
ng a
vaila
bilit
y an
d th
e co
ntin
uous
tech
nolo
gica
l dev
elop
men
t of m
obile
dev
ices
hav
e op
ened
up
a ne
w p
ath
for
mus
ic a
nd te
chno
logy
to in
tegr
ate
furth
er. M
obile
dev
ices
hav
e no
t onl
y en
hanc
ed it
s m
ain
func
tion
as a
com
mun
icat
ive
tool
with
oth
ers
in e
very
day
life,
but
they
hav
e al
so
been
dev
elop
ed a
nd u
tilis
ed a
s a d
evic
e to
mak
e m
usic
in c
once
rt pe
rfor
man
ce.
Th
e gr
owin
g in
tere
st i
n m
usic
mak
ing
with
mob
ile d
evic
es h
as e
mer
ged
sinc
e th
e la
st d
ecad
e. O
ne a
ppro
ach
to m
ake
mus
ic w
ith m
obile
dev
ices
is
to t
urn
them
int
o w
irele
ss r
emot
e co
ntro
llers
to
man
age
diff
eren
t m
usic
al p
aram
eter
s in
a n
etw
orke
d en
viro
nmen
t. A
noth
er a
ppro
ach
is e
mbe
ddin
g so
und
gene
ratio
n on
the
mob
ile d
evic
es
with
out e
xter
nal c
ompu
ters
to c
oupl
e so
und
with
dat
a ob
tain
ed fr
om th
e in
put c
apac
ities
su
ch t
he t
ouch
scr
een
and
the
onbo
ard
sens
ors.
One
oth
er a
ppro
ach
take
s a
diff
eren
t di
men
sion
in
mob
ile m
usic
by
mak
ing
use
of i
ts m
obili
ty a
nd n
etw
ork
capa
bilit
y fo
r co
llect
ive
mus
ic p
erfo
rman
ce.
This
pra
ctic
e ga
ined
muc
h at
tent
ion
in t
he r
esea
rch
com
mun
ity o
f th
e N
IME1 , a
nd w
ithin
whi
ch, G
aye,
Hol
mqu
ist,
Beh
rend
t and
Tan
aka
have
als
o in
dica
ted
that
the
pot
entia
l of
mob
ile m
usic
is
beyo
nd t
he p
orta
bilit
y to
em
erge
asp
ects
of u
biqu
itous
com
putin
g, p
orta
ble
audi
o te
chno
logy
and
NIM
E (G
aye
et
al.,
2006
).
This
pap
er c
onsi
ders
var
ious
cas
es o
f m
obile
mus
ic i
n pa
rticu
lar
to p
erfo
rman
ce
scen
ario
s. It
also
aim
s to
disc
uss s
ome
chal
leng
es fa
ced
in m
obile
mus
ic.
1 International Conference on New Interfaces for M
usical Expression. http://www.nime.org/

2.
MO
BIL
E M
USI
C
Usi
ng m
obile
dev
ices
in p
erfo
rman
ce c
onte
xt is
not
a n
ew th
ing.
One
of t
he e
arlie
st
perf
orm
ance
s of
suc
h w
as G
olan
Lev
in’s
Dia
ltone
s (a
tel
esym
phon
y) t
hat
used
the
au
dien
ce’s
per
sona
l mob
ile p
hone
s as
the
soun
d so
urce
of t
he p
erfo
rman
ce. I
t was
firs
t pr
esen
ted
at th
e A
rs E
lect
roni
ca in
200
1 (L
evin
, 200
1). A
n in
tere
stin
g fe
atur
e of
this
w
ork
was
tha
t th
e pe
rfor
mer
s w
ere
on t
he s
tage
, bu
t th
e so
unds
cam
e fr
om t
he
audi
ence
’s a
rea
whe
n th
eir
phon
es w
ere
dial
led
up b
y th
e liv
e pe
rfor
mer
s. A
noth
er
exci
ting
char
acte
ristic
was
it
crea
ted
poly
phon
ic-li
ke m
usic
with
the
pho
nes
that
ge
nera
lly o
nly
supp
ort m
onop
honi
c rin
gton
es. T
his i
dea
not o
nly
refle
cted
the
emer
ging
te
chno
logy
in a
n ar
tistic
con
text
, but
it a
lso
expl
ored
furth
er a
ltern
ativ
es a
nd d
isco
vere
d no
vel f
orm
s of p
erfo
rman
ce c
onte
xts t
o br
oade
n th
e co
ntem
pora
ry m
usic
pra
ctic
e.
In t
he l
ast
deca
de,
conc
ert
perf
orm
ance
s fe
atur
ing
mob
ile m
usic
has
con
tinue
d to
gr
ow,
and
rapi
dly
whe
n sm
art
phon
es t
hat
com
e w
ith t
he o
nboa
rd s
enso
rs b
ecom
e w
idel
y av
aila
ble.
Ess
l and
Roh
s ha
ve g
iven
a d
etai
led
anal
ysis
of t
he s
enso
r cap
aciti
es
of m
obile
pho
nes,
and
exem
plifi
ed h
ow th
ese
sens
ors
can
be u
tilis
ed in
des
igni
ng a
n in
tera
ctiv
e pe
rfor
man
ce (
Essl
and
Roh
s, 20
09).
In th
eir
pape
r, in
tera
ctiv
ity fo
r m
obile
m
usic
-mak
ing,
they
dis
cuss
ed th
e de
sign
spa
ce o
ffer
ed b
y th
e se
nsor
cap
aciti
es w
as a
n im
porta
nt p
oint
to c
onsi
der f
rom
a c
once
ptua
l per
spec
tive
as th
e co
mpo
ser w
ould
nee
d kn
ow th
e ca
pabi
litie
s an
d lim
itatio
ns o
f or
ches
tral i
nstru
men
ts (
Essl
and
Roh
s, 20
09).
They
cla
ssifi
ed th
e ch
arac
teris
tics
of th
e on
boar
d se
nsor
s, in
clud
ing
the
once
to d
etec
t st
atic
pos
ition
and
orie
ntat
ion,
vel
ocity
of a
ccel
erat
ion,
into
a d
esig
n sp
ace
of li
near
and
ro
tatio
nal g
roup
s w
ith a
bsol
ute
and
rela
tive
mea
sure
s (E
ssl a
nd R
ohs,
2009
). M
oreo
ver,
they
fur
ther
ext
ende
d th
e di
scus
sion
on
the
phys
ical
ran
ge i
n de
sign
spa
ce t
hat
max
imum
ve
loci
ty
and
reac
h w
ere
parti
cula
r im
porta
nt
in
parti
cula
r to
m
usic
pe
rfor
man
ce c
onte
xt, b
ecau
se it
repr
esen
ted
the
diff
eren
t ran
ge b
etw
een
the
tech
nolo
gy
dete
ctio
n an
d th
e bo
dy o
f pe
rfor
mer
(Es
sl a
nd R
ohs,
2009
). Th
ese
cons
ider
atio
ns i
n th
eir
desi
gn s
pace
hav
e sh
own
a co
mpr
ehen
sive
ove
rvie
w in
bui
ldin
g m
obile
mus
ical
in
stru
men
ts.
2.1
A
s Mus
ical
Con
trol
lers
Mob
ileCo
mpu
ter
Out
put:
Soun
dAu
dio
Proc
essin
gIn
put:
Sens
or
Soun
d Sy
stem
Fi
gure
1. M
obile
dev
ice
as a
con
trol
ler f
or m
usic
al a
pplic
atio
ns
A
cla
ssic
con
figur
atio
n of
turn
ing
mob
ile d
evic
es in
to m
usic
al d
evic
es is
usi
ng th
em
as m
usic
al c
ontro
llers
to
man
age
audi
o pa
ram
eter
s on
the
com
pute
r th
roug
h w
irele
ss
netw
orks
(Fi
gure
1).
Inpu
t m
odal
ities
det
ecte
d by
sen
sors
and
tou
ch s
cree
n ar
e co
nver
ted
into
dat
a an
d se
nd t
o ne
twor
ked
com
pute
rs t
hat
com
mun
icat
e vi
a O
SC
prot
ocol
. The
dat
a is
read
and
par
sed
with
pro
gram
s su
ch a
s Pu
re D
ata2 , S
uper
colli
der3
and
OSC
ulat
or4 , a
nd th
en it
is u
sed
to c
ontro
l mus
ical
eve
nts.
Man
y m
obile
app
licat
ions
2 Pure Data. http://puredata.info/
3 Supercollider. http:// www.audiosynth.com
4 OSCulator. http://www.osculator.net/

such
as T
ouch
OSC
5 , mrm
r6 , OSC
Rem
ote7 a
nd O
SCem
ote8 a
llow
such
inte
ract
ion.
Th
is ty
pe o
f in
tera
ctio
n ca
n be
trac
ed to
the
wid
e ap
plic
atio
ns o
f th
e N
inte
ndo
Wii
Rem
ote9 , w
hich
is a
gam
e co
ntro
ller t
hat h
as b
een
used
as
a w
irele
ss m
usic
al c
ontro
ller
thro
ugh
com
mun
icat
ion
with
Blu
etoo
th p
roto
col.
The
thre
e-ax
is a
ccel
erom
eter
and
bu
ttons
bui
lt in
the
Wii
Rem
ote
shar
es s
ome
sim
ilar
inte
ract
ive
grou
nds
with
mob
ile
devi
ces
usin
g th
e ac
cele
rom
eter
sen
sor
and
touc
h sc
reen
to
cont
rol
soun
ds r
emot
ely.
K
iefe
r, C
ollin
s an
d Fi
tzpa
trick
eva
luat
ed t
he W
ii R
emot
e fu
nctio
ned
as a
mus
ic
cont
rolle
r, an
d sh
ared
fin
ding
s on
thei
r us
er s
tudi
es, i
n w
hich
two
inte
rest
ing
them
es,
virtu
ality
and
exp
ress
ion,
em
erge
d (K
iefe
r et
al.,
200
8).
They
men
tione
d th
at t
he
virtu
ality
was
one
of
stre
ngth
s of
the
Wii
Rem
ote
as i
t he
ld f
lexi
bilit
y fo
r m
ultip
le
cont
exts
, but
the
abst
ract
nat
ure
of th
e in
tera
ctio
n oc
curr
ed in
this
virt
ualit
y le
d to
the
lack
of
feed
back
, vi
sual
ly a
nd p
hysi
cally
; th
is b
roug
ht s
ome
cont
rol
issu
es f
or s
ome
user
s; o
n th
e ot
her
hand
, Wii
Rem
ote
was
pre
ferr
ed f
or a
n ex
pres
sive
con
text
, whi
ch
wou
ld b
e a
parti
cula
r at
tract
ive
feat
ure
for
mus
icia
ns (
Kie
fer
et a
l., 2
008)
. Th
ese
obse
rvat
ions
sha
re s
ome
sim
ilarit
y in
the
case
of m
obile
dev
ices
, as
the
root
of t
his
type
of
inte
ract
ions
aris
es fr
om th
e us
e of
acc
eler
omet
er se
nsor
s.
Usi
ng m
obile
dev
ices
as m
usic
al c
ontro
llers
is p
erha
ps th
e ea
sies
t met
hod
in te
rms o
f th
e so
und
synt
hesi
s de
sign
and
net
wor
ked
data
man
agem
ent.
The
adva
ntag
e of
this
is
that
mor
e so
phis
ticat
ed s
ound
pro
cess
ing
can
be m
ade
thro
ugh
the
wire
less
con
nect
ion
to e
xter
nal c
ompu
ters
. How
ever
, the
use
of e
xter
nal c
ompu
ters
is a
lso
a lim
itatio
n as
the
mob
ile m
usic
con
trolle
r he
re a
s th
e au
dio
outp
ut c
ould
onl
y be
pla
yed
thro
ugh
the
spea
kers
tha
t ar
e se
tup
in a
fix
ed p
lace
d, t
hus
rest
rictin
g ot
her
crea
tive
pote
ntia
l th
at
mob
ile d
evic
es c
ould
go
beyo
nd p
orta
bilit
y. N
onet
hele
ss,
this
met
hod
is a
lso
ofte
n ap
plie
d fo
r ear
ly st
age
of d
evel
opm
ent f
or o
ther
app
roac
hes d
iscu
ssed
in th
e fo
llow
ings
.
2.2
As M
usic
al In
stru
men
ts
Fi
gure
2. M
obile
dev
ice
as a
con
trol
ler f
or m
usic
al a
pplic
atio
ns
Th
e co
ntin
uous
adv
ance
on
mob
ile te
chno
logi
es h
as b
roug
ht h
igh
qual
ity C
PU a
nd
inpu
t/out
put
capa
citie
s to
ext
end
the
crea
tive
use
with
mob
ile d
evic
es i
n co
ncer
t pe
rfor
man
ce
cont
exts
. M
obile
de
vice
s ha
ve
been
us
ed
as
stan
dalo
ne
mus
ical
in
stru
men
ts,
in w
hich
aud
io r
ende
ring
coul
d be
pro
cess
ed i
nter
nally
, an
d th
is m
eans
m
obile
dev
ices
hav
e fu
nctio
ned
as s
mal
l co
mpu
ters
(Fi
gure
2).
The
mai
n si
gnifi
cant
ad
vant
age
to p
roce
ss s
ound
syn
thes
is in
tern
ally
is th
at n
o ex
tern
al c
ompu
ter
wou
ld b
e re
quire
d fo
r m
usic
mak
ing.
Thi
s en
able
s fu
rther
mus
ical
act
iviti
es t
o ta
ke p
lace
5 TouchOSC. http://hexler.net/software/touchosc
6 mrmr. http://poly.share.dj/projects/#m
rmr
7 OSCRem
ote. http://nr37.nl/OSCRem
ote/
8 OSCemote. http://pixelverse.org/iphone/oscemote/
9 Wii Remote. http://www.nintendo.com/wii/console/controllers
Mob
ile
Inpu
t: Se
nsor
Audi
o Pr
oces
sing
Out
put:
Soun
d
Soun
d Sy
stem
Prot
able
Sp
eake
r

anyw
here
, ev
en i
n th
e su
bway
s10,
as m
obile
dev
ices
hav
e be
com
e em
bodi
ed i
n ou
r ev
eryd
ay li
ves.
Ther
e is
not
onl
y a
vast
sel
ectio
n of
mus
ical
ins
trum
ents
as
mob
ile a
pplic
atio
ns
avai
labl
e co
mm
erci
ally
for
dow
nloa
d, b
ut it
als
o ga
ve r
ise
to a
new
res
earc
h di
rect
ion
and
new
mus
ic p
ract
ice,
suc
h as
mob
ile p
hone
orc
hest
ra,
whi
ch h
as b
een
deve
lope
d ex
tens
ivel
y by
the
Stan
ford
Mob
ile P
hone
Orc
hest
ra (M
oPho
)11. T
his
sect
ion
disc
usse
s so
me
mob
ile m
usic
inst
rum
ents
and
its p
erfo
rman
ce sc
enar
ios.
2.2.
1 K
eypa
d
One
of t
he p
ione
erin
g w
orks
usi
ng m
obile
pho
nes f
or so
und
synt
hesi
s was
the
Pock
et
Gam
elan
pro
ject
by
Gre
g Sc
hiem
er a
nd M
ark
Hav
ryliv
(Sch
iem
er a
nd H
avry
liv, 2
005)
.
For
thei
r pr
ojec
t, th
ey i
mpl
emen
ted
a lib
rary
pd2
j2m
e on
the
mob
ile p
hone
s th
at
allo
wed
com
posi
tions
to w
ritte
n in
the
Pure
Dat
a en
viro
nmen
t, an
d th
en e
xpor
ted
to th
e ja
va e
nviro
nmen
t (S
chie
mer
and
Hav
ryliv
, 20
06).
In t
heir
perf
orm
ance
sce
nario
s, B
luet
ooth
pro
toco
l was
em
ploy
ed to
allo
w c
omm
unic
atio
n be
twee
n se
rver
pho
ne a
nd
clie
nt p
hone
; so
me
play
ers
cont
rol
mus
ical
par
amet
ers
by p
ress
ing
the
keyp
ad, w
hile
ot
hers
sw
ing
phon
es t
hat
wer
e at
tach
ed t
o a
cord
, w
hich
pro
duce
d au
dio
chor
usin
g (S
chie
mer
and
Hav
ryliv
, 200
6). A
lthou
gh th
e ac
tion
of p
ress
ing
keyp
ad to
ope
rate
new
m
usic
al e
vent
s was
a n
ot so
app
aren
t for
con
trolli
ng so
und
chan
ging
from
an
audi
ence
’s
pers
pect
ive,
the
perf
orm
ance
act
ion
to in
clud
e sw
ingi
ng p
hone
s br
ough
t an
alte
rnat
ive
perf
orm
ance
inte
ract
ion
not o
nly
visu
ally
, but
als
o so
nica
lly.
2.2.
2 M
ore
than
key
pad
Man
y re
cent
res
earc
h in
tere
sts
have
inc
lude
d us
ing
sens
ors
embe
dded
in
mob
ile
devi
ces
for
mus
ic p
erfo
rman
ce c
onte
xt. A
mon
g al
l ki
nds
of o
nboa
rd s
enso
rs, m
otio
n se
nsor
s su
ch a
s ac
cele
rom
eter
s, gy
rosc
opes
, or
ient
atio
n se
nsor
s, ar
e in
par
ticul
ar
inte
rest
ing
as t
hese
sen
sors
ena
ble
furth
er g
estu
re-b
ased
act
ion
tow
ard
mak
ing
an
inte
ract
ive
perf
orm
ance
. How
ever
, mot
ion
sens
ors
are
usua
lly u
sed
in c
onju
nctio
n w
ith
mul
titou
ch sc
reen
in a
mus
ical
con
text
per
haps
for a
mor
e ab
solu
te re
fere
nce.
O
ne e
xam
ple
of tu
rnin
g m
obile
dev
ice
into
per
form
ance
inst
rum
ent t
hat u
tilis
ed su
ch
sens
ors
was
the
wor
k by
Ada
m P
arki
nson
and
Ata
u Ta
naka
(Ta
naka
, 20
10).
They
tu
rned
mob
ile d
evic
es in
to h
and-
held
per
form
ance
inst
rum
ents
that
impl
emen
ted
Pure
D
ata
(PD
)12 p
atch
for
RjD
j13 s
cene
run
ning
on
iPho
ne, a
s a
duo,
they
hol
d on
e of
the
inst
rum
ents
in
each
han
d. I
n or
der
to g
ain
one-
hand
con
trol
over
a n
umbe
r of
aud
io
para
met
ers,
they
use
d to
uchs
cree
n as
act
ivat
ion
of i
ndiv
idua
l so
unds
, sl
ider
s to
set
gr
anul
ar s
ynth
esis
gra
in s
ize,
and
acc
eler
omet
er f
or th
e ex
pres
sive
map
ping
s of
pitc
h an
d tim
e st
retc
hing
(Tan
aka,
201
0). E
ach
inst
rum
ent w
as a
lso
conn
ecte
d to
a fo
ot p
edal
fo
r vo
lum
e co
ntro
l, an
d th
e au
dio
outp
ut o
f th
e in
stru
men
t was
con
nect
ed to
a s
ound
sy
stem
.14 A
noth
er m
obile
mus
ical
ins
trum
ent
utili
sed
mot
ion
sens
ors
as i
nput
for
m
appi
ng o
f th
e re
al-ti
me
gene
rate
d sy
nthe
sis,
was
Ess
l an
d R
ohs’
Sha
Mus
, in
whi
ch
soun
ds w
ere
gene
rate
d w
ith s
triki
ng, s
haki
ng a
nd s
wee
ping
ges
ture
s (E
ssl
and
Roh
s,
10 http://bits.blogs.nytimes.com/2010/10/15/a-‐subw
ay-‐4-‐iphones-‐and-‐a-‐little-‐serendipity/
11 M
oPho. http://mopho.stanford.edu/
12 Pure Data. http://puredata.info
13 RjDj. http://rjdj.m
e/
14 Adam & Atau. http://www.ataut.net/site/IMG/pdf/Adam
Atau-‐technicalrider.pdf

2007
). O
ne o
ther
wel
l-kno
wn
mob
ile in
stru
men
t is t
he iP
hone
Oca
rina
by S
mul
e a
win
d in
stru
men
t for
iPho
ne th
at c
ombi
ned
vario
us o
nboa
rd te
chno
logi
es s
uch
as m
icro
phon
e,
mul
titou
ch s
cree
n, a
ccel
erom
eter
, GPS
, and
mor
e (W
ang,
200
9). T
he a
ctio
n of
mak
ing
soun
d w
ith O
carin
a co
uple
d cl
osel
y w
ith th
e w
ay o
f pla
ying
aco
ustic
win
d in
stru
men
ts.
It ge
nera
tes
soun
ds b
y br
eath
ing
air
gent
ly in
to th
e m
icro
phon
e, p
ress
ing
keys
of
the
GU
I on
the
mul
titou
ch sc
reen
with
fing
ers,
and
mov
ing
the
iPho
ne fo
r vib
rato
var
iatio
ns
(Wan
g, 2
009)
. The
se e
xam
ples
show
ed a
rang
e of
diff
eren
t way
s to
inte
ract
with
mob
ile
devi
ces w
hen
they
wer
e m
ade
into
mus
ical
inst
rum
ents
. Tu
rnin
g m
obile
dev
ices
into
sta
ndal
one
mus
ical
inst
rum
ents
ena
bles
mus
ic m
akin
g ta
king
pla
ce a
nyw
here
with
out
the
setu
p of
com
preh
ensi
ve s
ound
sys
tem
. In
a
perf
orm
ance
con
text
, the
sta
ge o
f pe
rfor
man
ce is
als
o tra
nsfo
rmed
into
a f
lexi
ble
form
as
the
adva
ntag
e of
this
app
roac
h al
low
mul
tiple
per
form
ers
to f
reel
y w
alke
d ar
ound
, ho
wev
er it
is n
ot th
e ca
se in
Tan
aka’
s pe
rfor
man
ce, w
hich
took
a tr
aditi
onal
ens
embl
e se
tting
con
text
. Als
o, b
y co
lloca
ting
the
actio
n ap
plie
d to
the
devi
ces
and
soun
d ou
tput
, it
impr
oves
the
actio
n-so
und
coup
ling.
2.3
As A
ugm
ente
d D
evic
es
A d
iffer
ent a
ppro
ach
of m
akin
g us
e of
mob
ile d
evic
es in
mus
ic p
erfo
rman
ce c
onte
xt
was
Dan
Ove
rhol
t’s O
verto
ne F
iddl
e, in
whi
ch th
e iP
od T
ouch
atta
ched
to th
e O
verto
ne
Fidd
le i
s ru
nnin
g D
SP t
o co
ntro
l a
mou
nted
tac
tile
soun
d tra
nsdu
cer
to s
timul
ate
reso
nant
qua
lity,
and
the
aug
men
ted
bow
con
nect
ed t
o th
e m
obile
dev
ice
also
gav
e fu
rther
ges
ture
-bas
ed p
hysi
cal
inte
ract
ion
(Ove
rhol
t, 20
11).
As
desc
ribed
, ne
w s
onic
po
ssib
ilitie
s w
ere
mad
e as
the
inte
rnal
act
uato
r co
uld
caus
e ne
w b
ehav
iour
s to
cha
nge
the
timbr
e, e
ven
if th
ere
was
no
cabl
e co
nnec
ted
to a
com
pute
r no
r to
rem
ote
loud
spea
kers
(Ove
rhol
t, 20
11).
Mor
eove
r, th
is in
stru
men
t hel
d si
mila
r phy
sica
l fea
ture
s as
an
acou
stic
vio
lin, i
f com
pare
d to
oth
er n
ewly
inve
nted
inst
rum
ents
.
The
mob
ile d
evic
e us
ed h
ere
is m
ore
or l
ess
func
tione
d as
a m
ini-c
ompu
ter
to
inte
rpre
t the
dat
a of
the
bow
and
mot
ion
sens
ors
of th
e iP
od T
ouch
to c
ontro
l the
tact
ile
soun
d tra
nsdu
cer.
One
adv
anta
ge o
f th
is d
esig
n is
tha
t it
mai
ntai
ned
the
tradi
tiona
l fid
dle-
play
ing
tech
niqu
es,
and
embr
aced
a
new
pe
rfor
man
ce
tech
niqu
e w
ithou
t ex
clud
ing
the
pre-
exis
t te
chni
que.
Th
eref
ore
the
pote
ntia
l ch
alle
nge
betw
een
actio
n-so
und
rela
tions
hips
is le
ss a
n is
sue.
One
of t
he li
mita
tions
wou
ld b
e th
e va
riatio
n of
sou
nd th
at th
e tra
nsdu
cer c
ould
off
er, b
ut th
e fo
cus
of th
is p
roje
ct w
as to
acu
ate
the
acou
stic
bod
y of
the
fid
dle,
and
not
the
com
pute
r m
usic
app
roac
h. N
onet
hele
ss,
this
al
tern
ativ
e ap
proa
ch to
incl
ude
mob
ile d
evic
es a
s an
aug
men
ted
unit
as a
par
t of a
new
in
stru
men
t stil
l giv
es th
e m
obile
dev
ices
a n
ew ro
le in
exp
erim
enta
l mus
ic d
esig
n.
2.4
Mak
ing
Mus
ic C
olla
bora
tivel
y
Ther
e is
an
incr
easi
ng in
tere
st in
mak
ing
mus
ic c
olla
bora
tivel
y w
ith m
obile
dev
ices
. In
fact
, man
y of
the
sele
cted
wor
ks d
iscu
ssed
in th
is p
aper
feat
ures
mak
ing
mus
ic in
a
colla
bora
tive
man
ner b
y co
nnec
ting
mul
tiple
dev
ices
for t
he p
erfo
rmer
s to
use
. As
mos
t of
the
cur
rent
mob
ile d
evic
es o
ffer
eas
y es
tabl
ishe
d ne
twor
k co
mm
unic
atio
n, i
t fa
cilit
ates
gro
up c
olla
bora
tion
with
wire
less
pro
toco
l th
roug
h B
luet
ooth
and
WiF
i. M
oreo
ver,
this
gro
up c
olla
bora
tion
in m
obile
mus
ic p
erfo
rman
ce n
ot o
nly
is se
en w
ithin
pe
rfor
mer
s as a
n en
sem
ble
cont
ext,
but i
t als
o ex
tend
s to
incl
ude
audi
ence
par
ticip
atio
n.
The
follo
win
g se
ctio
n ex
empl
ified
thes
e tw
o pr
actic
es.

2.4.
1 E
nsem
ble
Mob
ile m
usic
has
app
eare
d in
man
y en
sem
ble
perf
orm
ance
con
text
s. So
me
mob
ile
perf
orm
ance
wor
ks d
iscu
ssed
ear
lier,
such
as
Schi
emer
’s P
ocke
t G
amel
an,
Ada
m
Park
inso
n an
d A
tau
Tana
ka’s
duo
(A
dam
& A
tau)
and
Sta
nfor
d M
obile
Pho
ne
Orc
hest
ra (M
oPho
), w
ere
carr
ied
out i
n su
ch a
form
. One
of t
he s
igni
fican
t diff
eren
ces
betw
een
the
two
wor
ks w
as th
e ch
oice
of
spea
ker
type
s th
at p
rovi
ded
varie
d m
usic
al
expe
rienc
es. I
n A
dam
& A
tau,
the
soun
d sy
stem
was
setu
p in
a fi
xed
loca
tion
conn
ecte
d to
the
mob
ile d
evic
es, t
hus
the
phys
ical
mov
emen
t ran
ge o
f the
per
form
ers
hold
ing
the
devi
ces
wer
e bo
unde
d to
the
leng
th o
f con
nect
ed c
able
s. O
n th
e ot
her h
and
in M
oPho
’s
audi
o ou
tput
of
the
mob
ile d
evic
e w
as c
onne
cted
to w
eara
ble
(glo
ve)
spea
kers
, whi
ch
enab
led
the
perf
orm
ers
to w
alk
arou
nd t
he p
erfo
rman
ce s
pace
. Ea
ch a
ppro
ach
to
ampl
ify s
ound
s ho
lds
diff
eren
t adv
anta
ge a
nd li
mita
tions
, but
this
cho
ice
relie
s cl
osel
y on
th
e in
tent
ion
of
the
mus
ical
co
ntex
t. A
dam
&
A
tau’
s pe
rfor
man
ce
took
a
com
para
tivel
y tra
ditio
nal m
usic
ens
embl
e ap
proa
ch to
a c
once
rt pe
rfor
man
ce s
etup
and
ga
ve a
bet
ter
qual
ity a
mpl
ified
sou
nd, w
here
as
MoP
ho’s
per
form
ance
set
up e
xplo
red
anot
her
dire
ctio
n in
con
side
ring
each
mob
ile d
evic
e as
mor
e of
an
acou
stic
inst
rum
ent
in t
erm
s of
sou
nd g
ener
atio
n by
wea
ring
the
spea
kers
on
the
hand
s to
col
loca
te t
he
inst
rum
ent a
nd th
e so
und.
2.4.
2 A
udie
nce
Part
icip
atio
n
Ano
ther
app
ealin
g ap
proa
ch in
mak
ing
mob
ile m
usic
was
to in
vite
the
audi
ence
to
parti
cipa
te. I
nvol
ving
aud
ienc
e to
par
ticip
ate
in m
usic
per
form
ance
is
certa
inly
not
a
new
con
cept
, an
d it
can
be t
race
d to
mid
-20th
cen
tury
esp
ecia
lly i
n pe
rfor
man
ce a
rt pr
actic
e. N
onet
hele
ss, e
mer
ging
per
form
ance
wor
ks w
ith m
obile
dev
ices
furth
er s
how
n th
e co
llabo
rativ
e po
tent
ial t
o in
clud
e pl
anne
d au
dien
ce p
artic
ipat
ion.
Jie
un O
h an
d G
e W
ang
prov
ided
a
revi
ew
of
wor
ks
that
m
obile
de
vice
s w
ere
used
in
va
rious
pe
rfor
man
ce sc
enar
ios e
nabl
ing
audi
ence
par
ticip
atio
n (O
h an
d W
ang,
201
1).
Luke
Dah
l, Jo
rge
Her
rera
, and
Car
r Wilk
erso
n’s
Twee
tDre
ams
was
one
of t
he w
ork
that
ena
bled
rea
l-tim
e so
nific
atio
n an
d vi
sual
izat
ion
of t
wee
ts p
oste
d by
aud
ienc
e m
embe
rs w
ith th
eir o
wn
pers
onal
mob
ile p
hone
s (D
ahl,
Her
rera
and
Wilk
erso
n, 2
011)
. Th
e au
diov
isua
l out
com
es in
Tw
eetD
ream
s w
as q
uite
abs
tract
as
it w
as b
ased
on
the
idea
of a
ssoc
iatio
n, in
whi
ch tw
eets
wer
e gr
oupe
d in
to re
late
d tw
eets
and
giv
en s
imila
r m
elod
ies
(Dah
l, H
erre
ra a
nd W
ilker
son,
201
1).
Hav
ing
been
the
re a
s an
aud
ienc
e m
embe
r of o
ne o
f the
per
form
ance
, the
aut
hor w
as a
ble
to o
bser
ve th
at a
larg
e nu
mbe
r of
aud
ienc
e w
ere
activ
ely
parti
cipa
ting
durin
g th
e pe
rfor
man
ce. A
lthou
gh th
e co
uplin
g of
act
ion-
soun
d w
as n
ot c
lear
to p
erce
ive,
it s
till p
rovi
ded
an e
ngag
ing
com
mun
icat
ive
chan
nel
that
add
ed t
o th
e w
hole
mus
ical
exp
erie
nce.
Wha
t w
as p
artic
ular
int
eres
ting
was
usi
ng m
obile
dev
ice
to c
hang
e th
e pe
rfor
man
ce c
onte
xt a
s it e
mbr
aced
a w
hole
new
pe
rfor
man
ce a
nd a
udie
nce
expe
rienc
e. I
t no
t on
ly e
ngag
ed t
he a
udie
nce
furth
er w
ith
soci
al m
usic
al in
tera
ctio
n, b
ut it
als
o ex
pand
ed th
e de
velo
pmen
t of t
he c
onve
rgen
ce o
f em
ergi
ng te
chno
logy
and
per
form
ance
pra
ctic
e.
Mak
ing
mus
ic c
olla
bora
tivel
y w
ith m
obile
dev
ices
is a
n at
tract
ive
dire
ctio
n to
furth
er
expl
ore
the
inte
ract
ivity
in
a pe
rfor
man
ce s
pace
. B
y w
earin
g th
e sp
eake
rs i
n th
e en
sem
ble
mus
ic c
onte
xt, t
he p
erfo
rmer
s ca
rry
the
soun
ds w
ith th
em, t
hus
soun
d tra
vels
th
roug
h sp
ace.
It n
ot o
nly
is a
non
-trad
ition
al m
usic
al e
xper
ienc
e fo
r the
aud
ienc
e, b
ut
the
char
acte
ristic
of t
he a
udito
ry a
spec
t pro
vide
d an
alte
rnat
ive
perf
orm
ance
spa
ce th
at
is s
onic
ally
int
eres
ting
too.
Als
o, t
he p
orta
ble
adva
ntag
e of
mob
ile d
evic
es f
acili
tate
s m
ultip
le p
erfo
rmer
s to
fre
ely
mov
e ar
ound
and
inte
ract
with
oth
ers
thro
ugh
netw
orke
d

wor
ld, a
nd a
lso
phys
ical
ly. F
urth
erm
ore,
the
ide
a of
col
labo
rativ
e m
usic
with
mob
ile
devi
ce p
rovi
des
a fr
iend
ly p
latfo
rm f
or i
nviti
ng t
he a
udie
nce
to p
artic
ipat
e in
the
pe
rfor
man
ce. I
n th
e ca
se o
f Tw
eetD
ream
s, th
e au
dien
ce m
embe
rs h
ave
optio
ns to
eith
er
stay
pas
sive
to e
xper
ienc
e an
d al
tern
ativ
e m
usic
al a
ctiv
ity o
r to
cont
ribut
e to
the
mus
ic
perf
orm
ance
with
thei
r per
sona
l mob
ile p
hone
s by
app
lyin
g an
alre
ady-
fam
iliar
act
ion,
po
stin
g a
twee
t15. T
he c
onte
xt c
reat
ed a
fun
expe
rienc
e th
at h
eld
pote
ntia
l to
prod
uce
an
enga
ging
per
form
ance
by
brin
gs n
ew in
tera
ctiv
e m
usic
al e
xper
ienc
e to
the
audi
ence
by
gent
ly in
vitin
g th
e au
dien
ce to
par
ticip
ate.
3.
PER
FOR
MA
NC
E C
ON
TE
XT
It is
fair
to a
ssum
e th
at c
reat
ing
expr
essi
ve m
usic
al in
stru
men
ts w
ith m
obile
dev
ices
ha
s be
en t
he i
nten
tion
of t
he m
obile
mus
ic w
orks
dis
cuss
ed h
ere
as m
ost
of t
he
refe
renc
es s
how
ed c
once
rns
in d
esig
ning
an
expr
essi
ve i
nstru
men
t. Th
e de
finiti
on o
f ex
pres
sivi
ty in
mus
ic p
erfo
rman
ce a
rgua
ble
varie
s in
som
e de
gree
s, as
it r
elie
s on
the
desi
gn g
oals
and
arti
stic
inte
ntio
ns. A
s Es
sl a
nd R
oh a
rticu
late
d, to
des
ign
inte
ract
ion
with
mob
ile d
evic
es, i
t was
impo
rtanc
e to
kno
w th
e ca
paci
ties
and
limita
tion
of (
Essl
an
d R
ohs,
2009
). N
onet
hele
ss, i
t is
also
impo
rtant
to c
onsi
der
who
m a
re w
e de
sign
ing
the
inst
rum
ents
for
, w
hat
kind
of
cont
ext
is i
t de
sign
ed f
or,
and
perh
aps
also
wha
t ch
arac
teris
tics
of m
obile
dev
ices
cou
ld c
ontri
bute
to
furth
er t
he m
usic
al e
xper
ienc
e.
Taki
ng
all
thes
e co
nsid
erat
ions
du
ring
the
conc
eptu
al
deve
lopm
ent
wou
ld
have
in
fluen
ces
to t
he e
xpre
ssiv
ity o
f a
mob
ile m
usic
ins
trum
ent.
How
ever
, to
app
roac
h ex
pres
sivi
ty w
ith m
obile
dev
ices
is st
ill c
onsi
dere
d as
a c
halle
nge.
4.
INN
OV
AT
IVE
APP
RO
AC
H A
ND
CH
AL
LE
NG
ES
One
par
ticul
ar is
sue
that
hav
e oc
curr
ed in
mob
ile m
usic
per
form
ance
is th
e co
uplin
g be
twee
n ac
tion
and
soun
d. W
hat
gest
ure
shou
ld b
e m
appe
d to
wha
t ki
nd o
f so
und?
Je
nsen
ius
rem
inde
d us
that
this
cha
lleng
e is
als
o fa
ced
in im
mob
ile m
usic
tech
nolo
gy
(Jen
seni
us, 2
008)
. He
prov
ided
an
obse
rvat
ion
stud
y on
the
ide
a ba
sed
on e
mbo
died
m
usic
cog
nitio
n, a
nd h
ow p
eopl
e m
ove
to m
usic
(Jen
seni
us, 2
008)
.
In th
e ex
ampl
es d
iscu
ssed
ear
lier i
n Se
ctio
n 2.
2, a
ppro
ache
s of
per
form
ance
ges
ture
ge
nera
ting
soun
d w
ith
mob
ile
devi
ces
wer
e di
scus
sed.
A
s th
e na
ture
of
th
ese
inst
rum
ents
usi
ng o
nboa
rd m
otio
n se
nsor
s, m
akin
g so
unds
nat
ural
ly r
equi
red
bigg
er
gest
ures
mad
e w
ith h
and
and
arm
mov
emen
ts i
f co
mpa
red
to t
he m
ost
used
pre
ssin
g ac
tion
with
m
obile
de
vice
s. U
tilis
ing
mot
ion
sens
ors
certa
inly
en
hanc
ed
the
perf
orm
ance
attr
actio
n fr
om a
n au
dien
ce p
oint
of
view
as
the
gest
ure
was
ext
ende
d fr
om sm
alle
r act
ions
of p
ress
ing
keyp
ad to
war
ds g
estu
re-b
ased
inte
ract
ion.
A
noth
er c
halle
nge
is t
he c
ause
-eff
ect
issu
e th
at h
olds
sig
nific
ant
influ
ence
s to
the
co
mm
unic
atio
n flo
w b
etw
een
perf
orm
er a
nd t
he a
udie
nce
in a
per
form
ance
con
text
. Th
ese
two
ques
tions
sha
re s
ome
com
mon
gro
unds
in
the
field
of
desi
gnin
g a
NIM
E/D
MI.
One
rea
son
why
the
se c
halle
nges
are
con
cern
ed w
ould
be
that
the
pe
rfor
mer
s ai
m t
o en
gage
with
the
aud
ienc
e. H
owev
er,
inst
ead
of t
ryin
g to
ide
ntify
w
hich
ges
ture
wou
ld b
e m
ost
effe
ctiv
e, i
t m
ight
als
o be
ben
efic
ial
to l
ook
at o
ther
ad
vant
ages
th
at
mob
ile
devi
ces
have
, su
ch
as
colla
bora
tive
mus
ic
mak
ing
and
ubiq
uito
us c
ompu
ting
to e
nhan
ce a
udie
nce
enga
gem
ent a
s wel
l as b
ringi
ng n
ew m
usic
al
expe
rienc
es w
ith e
mer
ging
mob
ile te
chno
logi
es a
s dis
cuss
ed in
Sec
tion
2.4.
15 Twitter. http://twitter.com/

5.
CO
NC
LU
SIO
N
This
pap
er h
as p
rovi
ded
som
e ba
ckgr
ound
s in
mob
ile m
usic
and
rev
iew
ed s
elec
ted
mob
ile m
usic
al i
nstru
men
ts i
n pe
rfor
man
ce c
onte
xt.
It ha
s al
so b
riefly
dis
cuss
ed
chal
leng
es fa
ced
in m
obile
mus
ic.
A
n al
tern
ativ
e w
ay
look
ing
at
thes
e is
sues
is
to
ch
ange
th
e fo
cus
to
the
com
mun
icat
ion
adva
ntag
e th
at m
obile
dev
ices
pro
vide
d to
war
d cr
eatin
g an
eng
agin
g pe
rfor
man
ce w
as p
ropo
sed.
Fut
ure
wor
k w
ill i
ncor
pora
te s
ome
of t
he c
once
pts
and
tech
niqu
es m
entio
ned
in th
is p
aper
and
look
into
dev
elop
ing
a m
usic
pie
ce th
at in
vite
s au
dien
ce p
artic
ipat
ion
with
mob
ile d
evic
es, i
n ad
ditio
n to
loo
k at
a b
road
er r
esea
rch
scop
e on
the
top
ics
asso
ciat
ing
aspe
cts
of d
igita
l m
usic
al i
nstru
men
t de
sign
and
co
mpa
re so
me
shar
ed is
sues
to m
obile
mus
ic.
RE
FER
EN
CE
Dah
l, L.
, Her
rera
, J.,
and
Wilk
erso
n, C
. (20
11).
Twee
tDre
ams:
Mak
ing
mus
ic w
ith
the
audi
ence
and
the
wor
ld u
sing
rea
l-tim
e Tw
itter
dat
a. P
roce
edin
gs o
f 20
11
Inte
rnat
iona
l Con
fere
nce
on N
ew In
terf
aces
for M
usic
al E
xpre
ssio
n, O
slo,
Nor
way
.
Essl
, G.,
and
Roh
s, M
. (20
09).
Inte
ract
ivity
for
Mob
ile M
usic
-Mak
ing.
Org
anis
ed
Soun
d, 1
4(02
), pp
.197
-207
.
Essl
, G.,
and
Roh
s, M
. (20
07).
ShaM
us -
A S
enso
r-B
ased
Int
egra
ted
Mob
ile P
hone
In
stru
men
t. Pr
oc.
of t
he I
nter
natio
nal
Com
pute
r M
usic
Con
fere
nce,
Cop
enha
gen,
D
enm
ark.
Essl
, G
., W
ang,
G.,
and
Roh
s, M
. (2
008)
. D
evel
opm
ents
and
Cha
lleng
es t
urni
ng
Mob
ile P
hone
s in
to G
ener
ic M
usic
Per
form
ance
Pla
tform
s. Pr
oc. o
f the
Mob
ile M
usic
W
orks
hop,
Vie
nna,
Aus
tria.
Gay
e, L
., H
olm
quis
t, L.
, B
ehre
ndt,
F. a
nd T
anak
a, A
. (2
006)
. M
obile
Mus
ic
Tech
nolo
gy:
Rep
ort
on a
n Em
ergi
ng C
omm
unity
. Pr
oc.
of t
he 2
006
Inte
rnat
iona
l C
onfe
renc
e on
New
Inte
rfac
es fo
r Mus
ical
Exp
ress
ion,
Par
is, F
ranc
e, p
p. 2
2-25
.
Jens
eniu
s, A
. (20
08).
Som
e C
halle
nges
Rel
ated
to M
usic
and
Mov
emen
t in
Mob
ile
Mus
ic T
echn
olog
y. P
roc.
of t
he M
obile
Mus
ic W
orks
hop,
Vie
nna,
Aus
tria.
Kie
fer,
C.,
Col
lins,
N.
and
Fitz
patri
ck,
G.
(200
8).
Eval
uatin
g th
e W
iimot
e as
a
Mus
ical
Con
trolle
r. Pr
oc.
of t
he I
nter
natio
nal
Com
pute
r M
usic
Con
fere
nce,
Bel
fest
, Ir
elan
d.
Levi
n, G
. (20
01).
Dia
ltone
s -
a te
lesy
mph
ony.
ww
w.fl
ong.
com
/tele
sym
phon
y, S
ept.
2, 2
001.
Ret
rieve
d on
Nov
. 18,
201
1.
Oh,
J., W
ang,
G. (
2011
). A
udie
nce-
Parti
cipa
tion
Tech
niqu
es B
ased
on
Soca
il M
obile
C
ompu
ting.
Pro
c. o
f th
e In
tern
atio
nal
Com
pute
r M
usic
Con
fere
nce,
Hud
ders
field
, En
glan
d.
Ove
rhol
t, D
. (20
11).
The
Ove
rtone
Fid
dle:
an
Act
uate
d A
cous
tic In
stru
men
t. Pr
oc. o
f th
e 20
11 I
nter
natio
nal
Con
fere
nce
on N
ew I
nter
face
s fo
r M
usic
al E
xpre
ssio
n, O
slo,
N
orw
ay, p
p.4-
7.
Roh
s. M
., Es
sl,
G.
and
Rot
h, M
. (2
006)
. C
aMus
: Li
ve M
usic
Per
form
ance
usi
ng
Cam
era
Phon
esan
d V
isua
l Grid
Tra
ckin
g. P
roc.
of t
he 2
006
Inte
rnat
iona
l Con
fere
nce
on N
ew In
terf
aces
for M
usic
al E
xpre
ssio
n, P
aris
, Fra
nce.

Schi
emer
, G
., A
lves
, B
., Ta
ylor
, S.
J.,
& H
avry
liv,
M.
(200
3).
Pock
et g
amel
an:
deve
lopi
ng t
he i
nstru
men
tariu
m f
or a
n ex
tend
ed h
arm
onic
uni
vers
e. P
roc.
of
2003
In
tern
atio
nal C
ompu
ter M
usic
Con
fere
nce,
Mon
treal
, Can
ada.
Schi
emer
, G. a
nd H
avrd
yliv
, M. (
2006
). Po
cket
Gam
elan
: a P
ure
Dat
a in
terf
ace
for
mob
ile p
hone
s. Pr
oc.
of t
he 2
005
Inte
rnat
iona
l C
onfe
renc
e on
New
Int
erfa
ces
for
Mus
ical
Exp
ress
ion,
Van
couv
er, B
C, C
anad
a. p
p. 1
56-1
59.
Schi
emer
, G. a
nd H
avrd
yliv
, M. (
2006
). Po
cket
Gam
elan
: Tun
eabl
e Tr
ajec
torie
s fo
r Fl
ying
Sou
rces
in
Man
dala
3 a
nd M
anda
la 4
. Pr
oc. o
f th
e 20
06 c
onfe
renc
e on
New
In
terf
aces
for M
usic
al E
xpre
ssio
n, P
aris
, Fra
nce.
Tana
ka, A
. (20
04).
Mob
ile M
usic
Mak
ing.
Pro
c. o
f th
e 20
04 C
onfe
renc
e on
New
In
terf
aces
for M
usic
al E
xpre
ssio
n, H
amam
atsu
, Jap
an. p
p. 1
54–1
56.
Tana
ka, A
. (20
10).
Map
ping
out
inst
rum
ents
, aff
orda
nces
, and
mob
iles.
Proc
. of t
he
2010
Int
erna
tiona
l C
onfe
renc
e on
New
Int
erfa
ces
for
Mus
ical
Exp
ress
ion,
Syd
ney,
A
ustra
lia. p
p. 8
8–93
. W
ang,
G
. (2
009)
. D
esig
ning
Sm
ule’
s iP
hone
O
carin
a.
Proc
. of
th
e 20
09
Inte
rnat
iona
l C
onfe
renc
e on
New
Int
erfa
ces
for
Mus
ical
Exp
ress
ion,
Pitt
sbur
gh,
PA,
USA
.

1
Proc
edur
al a
udio
in m
obile
gam
es
Ant
ti Pa
karin
en
Aal
to U
nive
rsity
, Dep
artm
ent o
f Sig
nal P
roce
ssin
g an
d A
cous
tics
A
bstr
act
Proc
edur
al a
udio
is
inve
stig
ated
in
gene
ral
and
in t
he c
onte
xt o
f m
obile
ga
me
envi
ronm
ents
. Pr
oced
ural
so
und
gene
ratio
n is
co
mpa
red
to
trad
ition
al m
etho
ds a
nd it
s po
ssib
ilitie
s an
d ch
alle
nges
are
eva
luat
ed. T
he
inve
stm
ents
in d
evel
opin
g ne
w m
etho
ds in
aud
io g
ener
atio
n ha
ve b
een
smal
l in
the
gam
es i
ndus
try.
New
way
s to
util
ize
com
mon
sou
nd t
ools
dir
ectly
w
ithin
gam
e en
gine
s ar
e em
ergi
ng a
nd t
hat
can
boos
t th
e in
tere
st i
n pr
oced
ural
aud
io a
mon
g de
velo
pers
. A
thor
ough
exa
mpl
e is
giv
en i
n im
plem
entin
g a
proc
edur
al so
und
effe
ct o
n An
droi
d pl
atfo
rm u
sing
a li
brar
y ca
lled
libpd
. Util
izin
g pr
oced
ural
aud
io is
pos
sibl
e in
mob
ile g
ames
with
a
reas
onab
le e
ffort
.
1 IN
TR
OD
UC
TIO
N
Aud
io te
chno
logy
in g
ames
has
bee
n m
ostly
sta
tic in
rece
nt y
ears
whi
le th
e gr
aphi
cs
have
bee
n de
velo
ping
rap
idly
. Sa
mpl
e-ba
sed
audi
o ca
n of
fer
a hi
ghly
aut
hent
ic
soun
ding
exp
erie
nce
in a
gam
e, b
ut t
he s
ound
env
ironm
ent
can
lack
var
iety
and
the
so
und
mat
eria
l ha
s to
be
pre-
reco
rded
. In
pro
cedu
ral
audi
o, s
ound
is
gene
rate
d sy
nthe
tical
ly
in
real
tim
e,
base
d on
en
viro
nmen
t-dep
ende
nt
para
met
ers.
Thes
e pa
ram
eter
s m
ight
incl
ude
gam
e pl
ay a
ctio
ns, g
ame
engi
ne s
tate
s or
bas
ical
ly a
nyth
ing
that
the
deve
lope
r wan
ts to
con
trol t
he so
unds
with
. M
ost
mod
ern
gam
e co
nsol
es
and
mob
ile
devi
ces
incl
ude
posi
tion-
depe
nden
t co
ntro
llers
, su
ch a
s an
acc
eler
omet
er o
r a
gyro
scop
e. T
here
fore
pro
vidi
ng u
ser
with
fe
edba
ck
of
obje
cts’
or
ient
atio
n be
com
es
mor
e im
porta
nt.
In
term
s of
au
dito
ry
feed
back
, the
opt
imal
sol
utio
n w
ould
be
to m
ake
an o
bjec
t sou
nd e
xact
ly a
s it
soun
ds in
re
al (
or f
ictio
nal)
wor
ld, t
akin
g in
to a
ccou
nt th
e ob
ject
’s o
rient
atio
n in
rel
atio
n to
the
play
er.
This
is
poss
ible
with
sam
ple-
base
d au
dio
to s
ome
degr
ee b
y th
e m
eans
of
equa
lizat
ion
and
usin
g m
ultip
le s
ampl
es, b
ut a
s th
e co
mpl
exity
of
obje
cts
incr
ease
this
be
com
es d
iffic
ult.
One
pos
sibi
lity
to a
ppro
ach
this
pro
blem
is
to u
tiliz
e pr
oced
ural
au
dio
and
crea
te s
ound
det
ails
dyn
amic
ally
, con
cent
ratin
g on
the
esse
ntia
l com
pone
nts
that
rela
te to
the
obje
ct’s
stat
e in
the
gam
e.
If th
e so
unds
are
cre
ated
syn
thet
ical
ly in
the
clie
nt d
evic
e, th
e st
orag
e sp
ace
take
n by
th
e ap
plic
atio
n is
red
uced
. Th
is i
s ad
vant
ageo
us e
spec
ially
in
mob
ile p
latfo
rms.
For
exam
ple,
app
s di
strib
uted
ove
r-th
e-ai
r of
ten
have
a f
ixed
upp
er-li
mit
for
file
size
s an
d th
eref
ore
it is
im
porta
nt t
o m
inim
ize
the
raw
dat
a th
at i
s em
bedd
ed i
n an
app
. A
s a
draw
back
for p
roce
dura
l aud
io, i
t req
uire
s pro
cess
ing
pow
er a
nd th
at c
an b
e pr
oble
mat
ic
in m
obile
env
ironm
ents
. As
oppo
sed
to g
ame
cons
oles
or
desk
top
com
pute
rs, t
here
is
usua
lly o
nly
one
proc
esso
r tha
t has
to h
andl
e bo
th g
raph
ics a
nd a
udio
pro
cess
ing.

2
In th
is s
emin
ar p
aper
, pro
cedu
ral a
udio
is in
vest
igat
ed in
gen
eral
and
in th
e co
ntex
t of
mob
ile g
ame
envi
ronm
ents
. A
fter
gene
ral
disc
ussi
on a
bout
the
sub
ject
, so
me
prac
tical
tec
hnol
ogie
s ar
e pr
esen
ted
that
cou
ld b
e us
ed t
o cr
eate
pro
cedu
ral
audi
o in
m
obile
pla
tform
s. In
add
ition
, a p
ract
ical
pro
gram
min
g ex
ampl
e is
giv
en f
or A
ndro
id
plat
form
.
2 D
EFI
NIT
ION
OF
PRO
CE
DU
RA
L A
UD
IO
2.1
Bac
kgro
und
Dig
ital
devi
ces
such
as
com
pute
rs a
nd m
obile
pho
nes
repr
oduc
e so
und
by f
eedi
ng
suita
ble
digi
tal d
ata
thro
ugh
a D
A-c
onve
rter i
nto
a lo
udsp
eake
r. Th
is d
igita
l dat
a ha
s to
co
me
from
som
ewhe
re, a
nd in
man
y ca
ses,
the
data
has
bee
n ac
quire
d at
som
e po
int b
y re
cord
ing
audi
o m
ater
ial u
sing
a m
icro
phon
e an
d an
AD
-con
verte
r. A
noth
er p
ossi
bilit
y to
cre
ate
such
dat
a is
to c
ompu
te it
mat
hem
atic
ally
with
in th
e de
vice
itse
lf.
Proc
edur
al a
udio
stan
ds fo
r thi
s kin
d of
alg
orith
mic
app
roac
h to
the
crea
tion
of a
udio
co
nten
t [4]
. Ano
ther
, mor
e co
mpr
ehen
sive
def
initi
on is
giv
en in
[1]:
“Pro
cedu
ral a
udio
is
non
-line
ar,
ofte
n sy
nthe
tic s
ound
, cr
eate
d in
rea
l tim
e ac
cord
ing
to a
set
of
prog
ram
mat
ic ru
les
and
live
inpu
t.” T
his
mea
ns th
at in
add
ition
to b
eing
alg
orith
mic
ally
ge
nera
ted,
pro
cedu
ral a
udio
is a
lso
mea
nt to
be
play
ed b
ack
inst
anta
neou
sly.
Aud
io c
an
be c
onsi
dere
d as
pro
cedu
ral e
ven
if it
inco
rpor
ates
sam
ples
. One
suc
h si
tuat
ion
aris
es
whe
n sa
mpl
e da
ta i
s us
ed t
o co
nstru
ct n
ew, r
eal-t
ime
soun
ds r
athe
r th
an p
layi
ng t
he
reco
rded
sam
ples
dire
ctly
. Thi
s is o
ften
refe
rred
to a
s gra
nula
r syn
thes
is [1
].
In a
dditi
on t
o in
trodu
cing
pos
sibi
litie
s to
var
y si
mila
r so
und
even
ts i
n a
virtu
al
envi
ronm
ent s
uch
as a
gam
e, p
roce
dura
l aud
io h
as c
erta
in o
ther
adv
anta
ges
as w
ell.
The
need
for a
udio
rela
ted
data
sto
rage
dec
reas
es a
s th
ere’
s no
nee
d to
sto
re th
e pr
oced
ural
au
dio
data
afte
r it
has
been
use
d. P
erha
ps t
he b
igge
st a
dvan
tage
, es
peci
ally
in
gam
e co
ntex
ts is
inte
ract
ivity
. Uni
que
soun
d sc
enar
ios
that
dep
end
on th
e pl
ayer
’s a
ctio
ns a
re
vita
l to
the
aut
hent
icity
of
the
gam
ing
expe
rienc
e. W
ith p
roce
dura
l au
dio
tech
niqu
es,
inte
ract
ivity
can
be
expa
nded
from
tim
ings
of d
iffer
ent s
ound
s to
the
char
acte
ristic
s an
d re
latio
ns b
etw
een
indi
vidu
al so
und
sour
ces.
Pr
oced
ural
aud
io h
as so
me
maj
or d
raw
back
s as w
ell a
nd it
shou
ldn’
t be
thou
ght a
s an
abso
lute
alte
rnat
ive
to c
onve
ntio
nal,
sam
ple
base
d au
dio.
Aud
io-r
elat
ed C
PU c
ost
incr
ease
s an
d it
can
also
be
hard
to p
redi
ct a
nd n
on-li
near
[5]
. For
exa
mpl
e, if
sou
nd
obje
cts
inte
ract
with
eac
h ot
her,
the
num
ber
of r
elat
ions
bet
wee
n ob
ject
s in
crea
ses
rapi
dly
as th
e nu
mbe
r of o
bjec
ts g
row
s. Fu
rther
mor
e, c
reat
ing
soun
d al
gorit
hms
that
are
ab
le to
pro
duce
con
vinc
ing
soun
d in
stan
ces
is n
ot e
asy.
It m
ay re
quire
hou
rs o
f wor
k to
im
plem
ent a
syn
thes
is e
ngin
e fo
r a ra
ther
sim
ple
soun
d so
urce
. In
the
begi
nnin
g, re
sults
ar
e us
ually
not
ver
y co
nvin
cing
whe
n co
mpa
red
to re
cord
ed sa
mpl
es.
On
the
othe
r han
d, th
e w
ork
done
with
syn
thes
is a
lgor
ithm
s is n
ot so
met
hing
that
has
to
be
done
all
over
aga
in e
very
tim
e. N
ew s
ound
cre
atio
n al
gorit
hms
can
be m
ade
by
com
bini
ng a
nd e
nhan
cing
pre
viou
s wor
k.
2.2
Gam
e co
ntex
t
The
choi
ce b
etw
een
proc
edur
al a
nd s
ampl
e ba
sed
audi
o is
a m
atte
r of
ava
ilabl
e re
sour
ces
and
the
leve
l of
inte
ract
ivity
that
a g
ames
sou
nd e
nviro
nmen
t nee
ds to
hav
e.
For
exam
ple,
if a
gam
e co
nsis
ts o
f ev
ents
that
are
mai
nly
pred
eter
min
ed a
nd s
tatic
in
natu
re, s
ampl
e-ba
sed
audi
o ap
proa
ch is
def
inite
ly th
e be
st c
hoic
e in
the
curr
ent s
tate
of

3
gam
e au
dio
engi
nes.
The
tool
s ar
e re
adily
ava
ilabl
e an
d m
akin
g so
unds
in
real
-tim
e do
esn’
t off
er m
uch
adva
ntag
es c
ompa
red
to th
e ef
fort
need
ed. T
he p
roce
dura
l way
of
audi
o co
nten
t cre
atio
n be
com
es a
rele
vant
cho
ice
if so
me
or a
ll of
the
follo
win
g ap
plie
s. 1.
The
gam
e or
oth
er a
pplic
atio
n in
trodu
ces
lots
of
poss
ibili
ties
for
diff
eren
t typ
es o
f ac
tions
. 2. T
he e
nviro
nmen
t is
such
that
new
, une
xpec
ted
soun
ds a
re n
eede
d. 3
. Use
of
sam
ples
is n
ot p
ossi
ble
beca
use
of d
ata
stor
age
limita
tions
. The
pre
viou
s si
tuat
ions
are
ju
st e
xam
ples
, th
ere
are
lots
of
othe
r ap
plic
atio
ns t
hat
coul
d be
nefit
fro
m p
roce
dura
l au
dio
as w
ell.
Furth
erm
ore,
com
plet
ely
new
kin
d of
gam
e id
eas
coul
d ar
ise
from
the
po
ssib
ilitie
s of
rea
l-tim
e so
und
crea
tion.
Diff
eren
ces
on w
orkf
low
bet
wee
n sa
mpl
e-ba
sed
and
proc
edur
al a
udio
pro
duct
ion
have
bee
n sk
etch
ed in
figu
re 1
.
Figu
re 1
: Con
cept
ual w
orkf
low
dia
gram
of s
ampl
e-ba
sed/
proc
edur
al a
udio
.
3 PR
OC
ED
UR
AL
AU
DIO
IN G
AM
ES
Usi
ng p
roce
dura
l aud
io g
ener
atio
n is
not
a n
ew c
once
pt. I
n th
e ea
rly d
ays
of g
amin
g,
a so
und
chip
of
som
e ki
nd w
as u
sual
ly in
clud
ed th
e in
the
hard
war
e th
at w
as u
sed
to
gene
rate
sou
nds
at r
untim
e. A
t som
e po
int,
it be
cam
e po
ssib
le to
use
rec
orde
d di
gita
l au
dio
and
sam
ples
as
prim
ary
sour
ces
for a
udio
. Sin
ce th
en, p
roce
dura
l aud
io h
as b
een
mos
tly a
band
oned
by
the
gam
e in
dust
ry. T
he re
ason
for t
his
has
mai
nly
been
the
shea
r qu
ality
and
eas
e of
use
of s
ampl
e-ba
sed
audi
o co
mpa
red
to p
roce
dura
l met
hods
. [2]
3.1
Con
sole
s and
PC
’s
Som
e de
velo
pmen
t in
tere
st f
or p
roce
dura
l au
dio
has
emer
ged
in t
he c
onso
le a
rea.
N
icol
as F
ourn
el f
rom
Son
y En
terta
inm
ent E
urop
e m
entio
ned
a lo
t of
oppo
rtuni
ties
for
proc
edur
al a
udio
in h
is s
peec
h at
GD
F 20
11 (G
amin
g D
evel
oper
s’ C
onfe
renc
e). T
hese
op
portu
nitie
s in
clud
ed, f
or e
xam
ple,
redu
cing
mem
ory
foot
prin
t and
gen
erat
ing
soun
ds
for
user
-def
ined
obj
ects
. H
e al
so d
iscu
ssed
cha
lleng
es a
nd r
easo
ns t
hat
expl
ain
the
min
imal
use
of
proc
edur
al a
udio
in
popu
lar
gam
es.
In a
dditi
on t
o th
e pr
oble
ms
disc
usse
d in
the
pre
viou
s ch
apte
r, he
men
tione
d th
at t
here
’s a
lac
k of
tra
ined
sou
nd
desi
gner
s, pr
ogra
mm
ers
and
test
ers
and
colla
bora
tion
with
in t
he g
ame
indu
stry
. H
e pr
esen
ts t
hat
the
lack
of
mod
els
(for
bui
ldin
g sy
nthe
tic s
ound
s) l
eads
to
a “v
icio
us
circ
le”.
As
ther
e’s n
ot m
any
good
mod
els a
vaila
ble,
peo
ple
tend
to th
ink
that
pro
cedu
ral

4
audi
o so
unds
bad
. Th
is a
gain
lea
ds t
o la
ck o
f in
tere
st i
n de
velo
pmen
t an
d la
ck o
f m
odel
s. [5
] In
the
past
, a fe
w c
omm
erci
al g
ames
hav
e be
en re
leas
ed th
at u
tiliz
e pr
oced
ural
aud
io
crea
tion.
In
2008
, a g
ame
title
d “S
pore
” w
as r
elea
sed
by E
lect
roni
c ar
ts. I
t int
rodu
ces
dyna
mic
mus
ic c
onte
nt th
at is
con
trolle
d by
the
play
er’s
act
ions
. The
mus
ical
scr
ipts
for
the
gam
e w
ere
writ
ten
in P
ure
Dat
a, a
nd th
e de
velo
pers
use
d a
cust
omiz
ed v
ersi
on o
f PD
em
bedd
ed i
n th
e ga
me.
[6]
Aud
io e
ffec
ts i
n th
e ga
me
wer
e m
ade
usin
g m
ostly
tra
ditio
nal s
ampl
e-ba
sed
met
hods
.
Ano
ther
exa
mpl
e of
a m
oder
n ga
me
utili
zing
pro
cedu
ral a
udio
tech
niqu
es is
Roc
ksta
r G
ames
’ tit
le “
Red
Dea
d R
edem
ptio
n”. T
he g
ame
take
s pl
ace
in th
e w
ild w
est a
nd th
e pl
ayer
can
mov
e fr
eely
in th
e vi
rtual
wes
tern
sce
nes.
Am
bien
t sou
nds
in th
e ga
me
are
cont
rolle
d us
ing
proc
edur
al a
ppro
ach.
As
in “
Spor
e”,
mos
t of
the
aud
io c
onte
nt i
s sa
mpl
e-ba
sed.
[7]
The
situ
atio
n in
des
ktop
gam
ing
plat
form
s se
ems
to b
e su
ch th
at th
e po
ssib
ilitie
s an
d th
e be
nefit
s of
pro
cedu
ral
audi
o ar
e kn
own
amon
g au
dio
prog
ram
mer
s. St
ill,
the
chal
leng
es r
elat
ed t
o im
plem
entin
g pr
oced
ural
aud
io i
n th
e ga
me
audi
o pi
pelin
e ar
e m
akin
g it
diff
icul
t to
act
ually
util
ize
thos
e be
nefit
s. A
noth
er m
ajor
pro
blem
in
deve
lopi
ng m
ore
adva
nced
aud
io t
echn
ique
s is
tha
t in
the
gam
ing
indu
stry
, au
dio
usua
lly c
omes
last
in th
e pr
iorit
ies [
7].
3.2
Mob
ile g
ames
Mob
ile g
ames
hav
e ex
perie
nced
roug
hly
the
sam
e ki
nd o
f evo
lutio
n as
con
sole
s an
d de
skto
p co
mpu
ters
in te
rms
of a
udio
. Alth
ough
mob
ile d
evic
es a
re s
till c
lear
ly b
ehin
d de
skto
p ga
min
g pl
atfo
rms
on t
he e
volu
tiona
l ar
c, t
he s
peed
of
adva
ncem
ent
is f
ast.
Smar
t pho
nes
have
bee
n ta
king
the
field
alre
ady
for a
few
yea
rs n
ow a
nd m
obile
gam
es
have
bec
ome
an im
porta
nt p
art o
f th
e ga
mes
indu
stry
. Thi
s ha
s le
d to
inve
stm
ents
and
ne
w s
tartu
p co
mpa
nies
in m
obile
gam
e de
velo
pmen
t. M
obile
dev
ices
are
net
wor
ked
by
natu
re a
nd t
he p
oten
tial
for
soci
ally
lar
ge a
nd h
ighl
y in
tera
ctiv
e ga
me
wor
lds
is w
ell
know
n. A
s m
entio
ned
earli
er, w
hen
the
leve
l of u
ser-
crea
ted
cont
ent r
ises
, the
nee
d fo
r ne
w a
nd fl
exib
le a
udio
ass
ets a
lso
rises
. Thi
s is o
ne re
ason
why
inve
stig
atin
g pr
oced
ural
au
dio
is re
leva
nt in
mob
ile e
nviro
nmen
ts a
lso.
B
ecau
se C
PU p
ower
of
mob
ile d
evic
es i
s lim
ited,
the
ext
ra c
ompu
tatio
nal
cost
of
real
-tim
e so
und
algo
rithm
s ca
n ca
use
prob
lem
s. N
ever
thel
ess,
the
proc
essi
ng p
ower
of
mob
ile d
evic
es i
t ex
pect
ed t
o co
ntin
ue r
isin
g. I
t is
pos
sibl
e th
at i
n a
few
yea
rs,
that
pr
oble
m d
imin
ishe
s. A
lso,
not
all
gam
es c
onsu
me
as m
uch
proc
essi
ng p
ower
, fo
r ex
ampl
e th
e on
es t
hat
are
grap
hica
lly m
ild.
How
ever
, m
obile
gam
es t
hat
utili
ze
proc
edur
al a
udio
hav
e no
t yet
em
erge
d.
Ther
e ar
e so
me
mus
ical
app
licat
ions
read
ily a
vaila
ble
that
em
ploy
pro
cedu
ral a
udio
. R
jDj i
s an
app
for t
he iP
hone
that
use
s th
e da
ta f
rom
the
acce
lero
met
ers
to c
ontro
l the
m
usic
that
is g
ener
ated
in a
pro
cedu
ral f
ashi
on. T
he m
usic
al p
iece
s in
RjD
j are
cal
led
scen
es, a
nd it
is p
ossi
ble
to e
dit o
r cre
ate
thes
e sc
enes
in P
d. [8
]
4 R
EA
LIZ
ING
PR
OC
ED
UR
AL
AU
DIO
IN M
OB
ILE
EN
VIR
ON
ME
NT
In o
rder
to c
reat
e so
unds
on
runt
ime,
the
gam
e ha
s to
hav
e an
aud
io s
ynth
esis
eng
ine
embe
dded
to
it. T
here
are
a n
umbe
r of
pop
ular
ope
n so
urce
aud
io s
ynth
esis
too
ls
avai
labl
e fo
r de
skto
p co
mpu
ters
, suc
h as
CSo
und,
STK
, Pur
e D
ata,
Sup
erC
ollid
er a
nd
othe
rs. C
urre
ntly
, a l
ot o
f de
velo
pmen
t is
goi
ng o
n to
dev
elop
por
ts o
f th
ese
tool
s to

5
mob
ile p
latfo
rms.
In th
is c
hapt
er, a
n ov
ervi
ew o
f tw
o su
ch p
orts
for A
ndro
id is
giv
en. I
n th
e ne
xt c
hapt
er,
a si
mpl
e pr
actic
al e
xam
ple
for
And
roid
-pla
tform
usi
ng l
ibpd
is
pres
ente
d.
4.1
Lib
Pd
LibP
d is
a p
rogr
amm
ing
libra
ry,
orig
inal
ly c
reat
ed b
y Pe
ter
Brin
kman
n fo
r th
e pu
rpos
e of
get
ting
Pure
Dat
a’s
softw
are
engi
ne f
unct
ion
as a
DSP
lib
rary
fro
m t
he
prog
ram
mer
’s p
oint
of v
iew
. Thi
s co
uld
be u
tiliz
ed to
cre
ate
proc
edur
al a
udio
eve
nts
in
a m
obile
gam
e. W
ith li
bPd,
the
gam
e ev
ents
can
con
trol t
he P
ure
Dat
a pa
tch
by s
endi
ng
bang
s, pa
ram
eter
s an
d ot
her
mes
sage
s. Fo
r ex
ampl
e, w
hen
a ga
me
char
acte
r sh
oots
a
gun,
a b
ang
mes
sage
cou
ld b
e se
nt to
the
Pd p
atch
and
the
soun
ds re
late
d to
the
shoo
ting
wou
ld b
e sy
nthe
size
d in
Pd.
Li
bpd
is d
eriv
ed f
rom
the
orig
inal
Pd
in a
sub
tract
ive
way
. Th
is m
eans
tha
t th
e de
velo
pers
hav
e re
mov
ed u
ser
inte
rfac
e, t
imin
g, a
nd t
hrea
ding
cap
abili
ties
from
Pd.
Th
is a
llow
s Pd
to fu
nctio
n as
an
embe
ddab
le li
brar
y, ra
ther
than
a st
and-
alon
e to
ol. T
hat
libra
ry c
an th
en ru
n in
the
cont
ext o
f oth
er a
pplic
atio
ns, s
uch
as p
rovi
ding
an
inte
ract
ive
mus
ic o
r sou
nd e
ffec
ts e
ngin
e fo
r a g
ame.
Thi
s w
ay it
can
als
o fu
nctio
n m
ore
easi
ly o
n m
obile
pla
tform
s lik
e iO
S an
d A
ndro
id. [
9]
The
deve
lope
rs s
tate
that
with
libp
d, a
sep
arat
ion
of c
once
rns
can
be a
chie
ved.
Wha
t th
ey m
ean
by t
his
is e
xpla
ined
in
[9]:
“Sou
nd d
esig
ners
, m
usic
ians
, an
d co
mpo
sers
do
n’t
have
to
know
abo
ut p
rogr
amm
ing,
and
pro
gram
mer
s do
n’t
have
to
know
abo
ut
soun
d de
sign
. Th
e so
und
desi
gner
can
sta
y w
ithin
the
con
fines
of
Pd’s
gra
phic
al
data
flow
use
r in
terf
ace,
with
out
need
ing
to w
ork,
for
ins
tanc
e, w
ith a
gam
e co
ded
in
C++
. The
gam
e de
sign
er, l
ikew
ise,
can
use
thei
r too
l of c
hoic
e an
d ne
ed n
ot u
nder
stan
d ho
w to
use
Pd.
”
Bui
ldin
g a
patc
h fo
r lib
pd is
sim
ilar
to b
uild
ing
a pa
tch
for
the
norm
al, s
tand
-alo
ne
vers
ion
of P
d. E
xist
ing
Pd p
atch
es c
an a
lso
be u
sed
with
libp
d. In
ord
er to
pre
pare
the
patc
h fo
r us
e in
libp
d, th
e so
und
desi
gner
onl
y ha
s to
ass
ign
the
appr
opria
te s
end
and
rece
ive
sym
bols
tha
t ar
e ne
eded
to
cont
rol
the
desi
red
para
met
ers.
In t
he t
arge
t ap
plic
atio
n, t
he c
lient
cod
e w
ill c
omm
unic
ate
with
the
se s
end
and
rece
ive
sym
bols
pr
ogra
mm
atic
ally
. Thi
s is d
one
by se
ndin
g m
essa
ges t
o th
e pa
tch
from
for e
xam
ple
GU
I ev
ents
or s
enso
rs. T
he a
pplic
atio
n ca
n th
en u
pdat
e its
ow
n G
UI i
n re
spon
se to
mes
sage
s fr
om th
e Pd
pat
ch. B
asic
ally
this
mea
ns th
at th
e ap
plic
atio
n pr
ogra
mm
er c
an s
impl
y us
e a
Pd p
atch
as a
“bl
ack
box”
.
4.2
Supe
rCol
lider
Supe
rCol
lider
is
a po
pula
r en
viro
nmen
t an
d pr
ogra
mm
ing
lang
uage
orig
inal
ly
rele
ased
in
1996
by
Jam
es M
cCar
tney
for
rea
l-tim
e au
dio
synt
hesi
s an
d al
gorit
hmic
co
mpo
sitio
n. I
n th
e st
anda
rd v
ersi
on o
f Su
perC
ollid
er,
clie
nt p
rogr
ams
com
mun
icat
e w
ith th
e Su
perC
ollid
er sy
nthe
sis s
erve
r (sc
synt
h) u
sing
OSC
(Ope
n So
und
Con
trol).
Th
e A
ndro
id p
ort f
or S
uper
Col
lider
is e
arly
on
deve
lopm
ent.
It ha
s so
me
diff
eren
ces
com
pare
d to
the
nor
mal
ver
sion
. For
tra
nsfe
rrin
g O
SC m
essa
ges,
in a
dditi
on to
UD
P an
d TC
P, A
ndro
id p
rovi
des
an i
nter
faci
ng s
yste
m c
alle
d A
IDL.
Gen
eral
ly,
it al
low
s A
ndro
id p
roce
sses
to p
ass
mes
sage
s be
twee
n ea
ch o
ther
. Thi
s is
util
ized
in th
e A
ndro
id
port
for S
uper
Col
lider
. [1
0]
Supe
rCol
lider
-And
roid
em
beds
Sup
erC
ollid
er’s
“na
tive”
cod
e in
to a
Jav
a-ba
sed
appl
icat
ion,
so
it ca
n be
use
d w
ithin
an
And
roid
app
. In
that
sen
se, i
t doe
s ro
ughl
y th
e sa
me
to S
uper
Col
lider
that
libp
d do
es to
Pur
e D
ata.

6
5 E
XA
MPL
E: P
RO
CE
DU
RA
L S
OU
ND
EFF
EC
T W
ITH
AN
DR
OID
In th
is c
hapt
er, a
pra
ctic
al e
xam
ple
is g
iven
in c
reat
ing
a si
mpl
e A
ndro
id a
pplic
atio
n th
at u
ses
libpd
to
embe
d Pu
re D
ata-
engi
ne a
s m
eans
to
prod
uce
a pr
oced
ural
sou
nd
effe
ct. T
he e
ffec
t tha
t will
be
impl
emen
ted
is a
car
eng
ine
whi
ch h
as a
n ad
just
able
rpm
. In
an
actu
al g
ame,
acc
eler
atio
n pa
ram
eter
s of
raci
ng c
ar o
bjec
t cou
ld b
e us
ed to
con
trol
the
soun
d ge
nera
tion.
In th
is s
impl
e ex
ampl
e, a
use
r-co
ntro
llabl
e sl
ider
is u
sed
for t
hat
purp
ose.
5.1
Eng
ine
soun
d m
odel
The
hear
t of t
he P
d pa
tch
used
in th
is e
xam
ple
is a
mod
el o
f a fo
ur-c
ylin
der e
ngin
e.
The
basi
c co
mpo
nent
s of
the
mod
el a
re a
sin
e w
ave
gene
rato
r an
d a
whi
te n
oise
ge
nera
tor.
The
sine
wav
e is
squ
ared
and
inve
rsed
to g
ener
ate
a se
ries
of im
puls
es th
at
rese
mbl
e th
e in
divi
dual
igni
tions
that
take
pla
ce in
the
engi
ne’s
cyl
inde
rs. T
here
are
four
si
ne w
ave
gene
rato
rs th
at re
pres
ent t
he fo
ur c
ylin
ders
. Whi
te n
oise
is u
sed
as m
eans
to
rand
omiz
e ph
ase
and
ampl
itude
of
the
gene
rate
d pe
aks.
This
hel
ps m
akin
g th
e so
und
less
sta
tic a
nd m
ore
like
a re
al e
ngin
e. O
utpu
t sig
nal c
reat
ed b
y th
e pa
tch
is s
how
n in
fig
ure
3.
Fig
ure
3: O
utpu
t sig
nal o
f the
eng
ine
mod
el.
The
patc
h w
as o
rigin
ally
pre
sent
ed b
y A
ndy
Farn
ell
in [
3].
It is
ava
ilabl
e fo
r do
wnl
oad
at h
ttp://
mitp
ress
.mit.
edu/
desi
gnin
gsou
nd/c
ars.a
sp.
5.2
Prep
arin
g a
Pure
Dat
a pa
tch
The
mos
t ess
entia
l par
t tha
t aff
ects
the
soun
d th
at th
e up
com
ing
app
will
pro
duce
is
the
actu
al P
d pa
tch
that
was
des
crib
ed a
bove
. In
orde
r to
mak
e it
avai
labl
e fo
r the
app
, it
will
be
embe
dded
to th
e co
de. B
efor
e th
at, t
he p
atch
has
to b
e m
odifi
ed b
y ad
ding
a
rece
ive
obje
ct t
hat
will
lat
er h
andl
e in
com
ing
mes
sage
s w
ithin
the
And
roid
app
. The
ne
eded
add
ition
al o
bjec
t is s
how
n in
figu
re 2
.

7
Figu
re 2
: Pd
patc
h w
ith th
e ad
ded
rece
ive
obje
ct “
r gas
posi
tion”
and
its c
onne
ctio
ns.
It
has
to b
e co
nnec
ted
in th
e sa
me
way
that
the
exis
ting
slid
er “
engi
ne-s
peed
”, a
s it
will
re
plac
e th
e sl
ider
’s f
unct
iona
lity
in t
his
libpd
-targ
eted
ver
sion
. Th
e sl
ider
can
be
rem
oved
as
it is
not
nee
ded
anym
ore.
Afte
r sav
ing
the
patc
h, it
is re
ady
to b
e em
bedd
ed
in th
e up
com
ing
And
roid
pro
ject
.
5.3
Con
figur
ing
deve
lopm
ent e
nvir
onm
ent
In th
is e
xam
ple,
Ecl
ipse
is u
sed
as a
n ID
E fo
r cre
atin
g th
e ap
p. E
clip
se is
a p
opul
ar,
open
so
urce
en
viro
nmen
t th
at
can
be
used
to
de
velo
p ap
plic
atio
ns
in
mul
tiple
pr
ogra
mm
ing
lang
uage
s. Fo
r A
ndro
id,
an S
DK
is
prov
ided
tha
t is
com
patib
le w
ith
Eclip
se.
In o
rder
to h
ave
the
And
roid
SD
K ru
nnin
g, th
e Ec
lipse
env
ironm
ent a
nd J
ava
have
to
be d
ownl
oade
d an
d in
stal
led
first
. Th
e la
test
ver
sion
of
Java
is
avai
labl
e at
ht
tp://
java
.com
/en/
dow
nloa
d/in
dex.
jsp
and
Eclip
se
dow
nloa
ds
are
foun
d in
ht
tp://
ww
w.e
clip
se.o
rg/d
ownl
oads
/. Fo
r A
ndro
id d
evel
opm
ent,
the
“Ecl
ipse
Cla
ssic
” ve
rsio
n is
reco
mm
ende
d [1
1]. M
oreo
ver,
libpd
requ
ires
an E
clip
se v
ersi
on 3
.7 o
r lat
er.
Whe
n Ja
va a
nd E
clip
se a
re p
rope
rly in
stal
led,
the
tool
s fo
r And
roid
dev
elop
men
t can
be
inst
alle
d.
Dow
nloa
d lin
ks
for
the
And
roid
SD
K
are
foun
d at
ht
tp://
deve
lope
r.and
roid
.com
/sdk
/inde
x.ht
ml.
Th
e A
ndro
id S
DK
cou
ld a
lso
be u
sed
inde
pend
ently
, bu
t as
thi
s ex
ampl
e us
es
Eclip
se a
s th
e ID
E, a
plu
gin
calle
d A
ndro
id A
DT
has
to b
e in
stal
led.
Ins
truct
ions
on
dow
nloa
ding
an
d se
tting
up
th
e pl
ug-in
ar
e w
ell
docu
men
ted
in
http
://de
velo
per.a
ndro
id.c
om/s
dk/e
clip
se-a
dt.h
tml#
inst
allin
g, a
nd w
ill n
ot b
e re
peat
ed
here
. Onc
e th
e A
ndro
id A
DT
is in
stal
led,
Ecl
ipse
is re
ady
to c
ompi
le A
ndro
id a
pps.
5.4
Inst
allin
g lib
pd
Libp
d re
posi
torie
s ar
e fo
und
in h
ttp://
gito
rious
.org
/pdl
ib. T
his
exam
ple
requ
ires
two
of th
e lis
ted
pack
ets
liste
d on
the
site
, lib
pd (c
ore
libra
ry) a
nd p
d-fo
r-an
droi
d (A
ndro
id
and
Eclip
se sp
ecifi
c fil
es).
Whe
n th
e do
wnl
oade
d pa
ckag
es a
re lo
cate
d at
a k
now
n pl
ace
in t
he h
ard
driv
e, t
he l
ibpd
cor
e lib
rary
fol
der
has
to b
e m
oved
to
resi
de i
n pd
-for
-an
droi
d fo
lder
PdC
ore\
jni\.
W
hen
the
fold
ers
of l
ibpd
-for
-and
roid
are
set
, the
lib
rary
for
And
roid
can
now
be
impo
rted
in E
clip
se.
This
is
done
by
sele
ctin
g “F
ile-I
mpo
rt-Ex
istin
g pr
ojec
ts i
nto
wor
kspa
ce”.
In th
e fo
llow
ing
dial
og, l
ibpd
-for
-and
roid
fold
er h
as to
be
adde
d as
a ro
ot
fold
er.
Afte
r ad
ding
the
roo
t fo
lder
, a
list
of p
roje
cts
will
app
ear
in t
he d
ialo
g. I
t co
ntai
ns s
ever
al e
xam
ple
proj
ects
and
the
cor
e lib
rary
pro
ject
, PdC
ore.
The
exa
mpl
e pr
ojec
ts c
an b
e un
chec
ked
so th
e on
ly p
roje
ct th
at re
mai
ns c
heck
ed in
the
list i
s PdC
ore.
A
fter c
licki
ng fi
nish
, the
libr
ary
proj
ect i
mpo
rt is
com
plet
e.

8
5.5
Ecl
ipse
pro
ject
5.5.
1 Pr
ojec
t set
ting
At
this
poi
nt,
the
PdC
ore
libra
ry p
roje
ct h
as a
lread
y be
en i
mpo
rted
to E
clip
se’s
w
orks
pace
. The
nex
t st
ep i
s to
cre
ate
the
actu
al A
ndro
id p
roje
ct t
hat
will
be
used
to
build
the
app
. A
new
pro
ject
is
crea
ted
by s
elec
ting
in E
clip
se,
“File
-New
-And
roid
Pr
ojec
t”. W
hen
the
proj
ect i
s cr
eate
d, it
will
app
ear
in th
e w
orks
pace
with
the
PdC
ore
libra
ry p
roje
ct. N
ow th
e Pd
Cor
e lib
rary
has
to b
e in
clud
ed in
the
new
pro
ject
. Thi
s is
do
ne b
y m
odify
ing
the
prop
ertie
s of
the
new
pro
ject
. In
the
prop
ertie
s di
alog
of t
he n
ew
proj
ect,
in th
e A
ndro
id ta
b, a
new
libr
ary
proj
ect i
s inc
lude
d by
clic
king
“A
dd”.
Bec
ause
th
e Pd
Cor
e lib
rary
pro
ject
has
bee
n im
porte
d to
the
wor
kspa
ce, i
t sho
uld
appe
ar in
the
list
in t
he “
Proj
ect
sele
ctio
n” d
ialo
g. A
fter
sele
ctin
g Pd
Cor
e an
d cl
icki
ng “
Ok”
, th
e lib
rary
has
bee
n in
clud
ed in
the
new
pro
ject
. Not
e th
at th
e em
pty
chec
kbox
“Is
libr
ary”
sh
ould
n’t b
e ch
ecke
d. It
refe
rs to
the
proj
ect o
f whi
ch p
rope
rties
are
bei
ng m
odifi
ed, i
n th
is c
ase,
the
new
pro
ject
. For
exa
mpl
e, i
n th
e pr
oper
ties
of t
he P
dCor
e pr
ojec
t, th
is
optio
n w
ould
be
sele
cted
. Th
e Pd
pat
ch h
as to
be
adde
d to
the
proj
ect a
nd th
at c
an b
e do
ne a
t thi
s po
int.
For
that
, a n
ew fo
lder
“ra
w”
is c
reat
ed in
the
proj
ect f
olde
r und
er “
res\
”. T
he p
atch
that
was
cr
eate
d ea
rlier
now
has
to
be c
opie
d to
“re
s\”
as a
.zi
p fil
e. T
his
is b
ecau
se t
he
initi
aliz
atio
n co
de is
des
igne
d to
han
dle
mul
tiple
pat
ches
, and
if th
ere
wer
e m
ore
than
on
e, th
ey c
ould
all
be in
serte
d vi
a th
e sa
me
.zip
file
. In
this
exa
mpl
e, th
e .z
ip fi
le a
nd th
e pa
tch
itsel
f is
nam
ed “
engi
ne”.
In
othe
r w
ords
, in
the
pro
ject
fol
der,
ther
e sh
ould
be
“\re
s\ra
w\e
ngin
e.zi
p”, w
hich
con
tain
s a fi
le n
amed
eng
ine.
pd.
5.5.
2 In
itial
izat
ions
Whe
n th
e pr
ojec
t is c
reat
ed a
nd th
e Pd
Cor
e lib
rary
has
bee
n in
clud
ed, t
he n
ext s
tep
is to
add
som
e co
de to
initi
aliz
e th
e Pd
eng
ine.
The
fol
low
ing
code
is a
dded
to th
e .ja
va
file,
loc
ated
in
the
proj
ect
fold
er,
insi
de “
src\
” an
d th
e na
mes
pace
fol
der
that
was
de
fined
am
ong
proj
ect c
reat
ion.
Firs
t, a
initP
d()
met
hod
is a
dded
that
initi
aliz
es a
ll th
e ne
cess
ary
parts
of l
ibpd
for t
his e
xam
ple.
Con
tent
s of t
his f
unct
ion
are
liste
d be
low
.
private void initPd() throws IOException {
if (AudioParameters.suggestSampleRate() < SAMPLE_RATE) {
throw new IOException("required sample rate not available");
}
int nOut = Math.min(AudioParameters.suggestOutputChannels(), 2);
if (nOut == 0) {
throw new IOException("audio output not available");
}
PdAudio.initAudio(SAMPLE_RATE, 0, nOut, 1, true);
File dir = getFilesDir();
File patchFile = new File(dir, "engine.pd");
IoUtils.extractZipResource(getResources().openRawResource(R.raw.engine),
dir, true);
PdBase.openPatch(patchFile.getAbsolutePath());
}

9
The
first
sev
en l
ines
of
the
initP
d()
–met
hod
test
whe
ther
the
aud
io s
yste
m o
f th
e ta
rget
pla
tform
can
han
dle
the
sugg
este
d pa
ram
eter
s. Th
e ac
tual
ini
tializ
atio
n of
Pd
engi
ne i
s do
ne w
ith P
dAud
io.in
itAud
io()
-met
hod.
The
rem
aini
ng l
ines
han
dle
the
unpa
ckin
g an
d op
enin
g of
the
Pd p
atch
that
has
bee
n co
pied
to th
e pr
ojec
t fol
der e
arlie
r. A
fter a
ddin
g th
e co
de, E
clip
se w
ill n
otic
e th
at so
me
pack
ets a
re m
issi
ng. T
he p
acke
ts
can
be im
porte
d by
hov
erin
g th
e m
ouse
ove
r the
pie
ce o
f cod
e th
at n
eeds
a p
acke
t and
by
acc
eptin
g th
e su
gges
ted
Qui
ckFi
x. A
noth
er p
ossi
bilit
y is
to im
port
all t
he n
eces
sary
pa
cket
s by
add
ing
the
impo
rt co
des
man
ually
. The
y ca
n be
foun
d in
App
endi
x A
, whi
ch
cont
ains
the
sour
ce c
ode.
5.5.
3 G
raph
ical
Use
r Int
erfa
ce
Nex
t, so
me
UI e
lem
ents
are
add
ed to
pro
vide
use
r with
con
trols
ove
r the
Pd
patc
h. A
sw
itch
will
be
adde
d th
at w
ill tu
rn th
e en
gine
sou
nd o
n or
off
and
a s
lider
will
be
adde
d to
con
trol t
he a
ccel
erat
ion
of th
e en
gine
. The
gra
phic
al e
dito
r pro
vide
d by
the
And
roid
A
DT
will
be
used
to c
onst
ruct
the
visu
al c
ontro
l ele
men
ts o
f the
app
. The
edi
tor c
an b
e ac
cess
ed b
y op
enin
g th
e m
ain.
xml f
ile a
nd c
hoos
ing
the
“Gra
phic
al la
yout
” ta
b.
Mai
n.xm
l con
tain
s th
e la
yout
dat
a of
the
proj
ect a
nd it
can
als
o be
edi
ted
with
a te
xt
edito
r. Fo
r th
e en
gine
sou
nd to
ggle
sw
itch,
an
info
rmat
ive
text
will
als
o be
add
ed. I
n or
der t
o se
t the
se tw
o el
emen
ts s
ide
by s
ide,
a h
oriz
onta
l lin
ear l
ayou
t ele
men
t is
adde
d by
dra
ggin
g it
from
“Pa
lette
\Lay
out”
into
the
blan
k sc
reen
. Now
, fro
m “
Pale
tte\F
orm
W
idge
ts\”
, a te
xt fi
eld
and
a to
ggle
but
ton
can
be a
dded
to th
e lin
ear l
ayou
t ele
men
t tha
t w
as a
dded
ear
lier.
The
mar
gins
of t
he e
lem
ents
can
be
adju
sted
to se
t the
ir po
sitio
ns in
a
desi
red
way
. Th
e sl
ider
for t
he g
as p
ositi
on a
nd a
n in
form
ativ
e te
xt fo
r it w
ill b
e ad
ded
next
. Fro
m
“Pal
ette
\For
m W
idge
ts\”
, a
text
fie
ld a
nd a
See
kBar
are
dra
gged
to
the
scre
en,
unde
rnea
th t
he p
revi
ous
elem
ents
, ou
tsid
e th
e lin
ear
layo
ut e
lem
ent.
As
abov
e, t
heir
mar
gins
can
be
adju
sted
for
a b
ette
r vi
sual
loo
k. F
or t
he S
eekB
ar,
its l
eft
and
right
pa
ddin
g va
lue
shou
ld b
e in
crea
sed
in o
rder
to a
void
clip
ping
of t
he g
raph
ics.
Nex
t, so
me
mod
ifica
tions
will
be
mad
e di
rect
ly to
mai
n.xm
l. Ea
ch e
lem
ent t
hat w
as
adde
d in
the
gra
phic
al l
ayou
t ed
itor
now
has
a t
ag. T
ags
cont
ain
all
the
data
for
the
el
emen
ts.
For
the
Seek
Bar
and
the
tog
gle
butto
n, u
niqu
e id
’s a
re g
iven
man
ually
(“@+id/seekBarGasPosition”
an
d "@+id/toggleEngine")
by
editi
ng
the
resp
ectiv
e lin
es. T
his
is b
ecau
se th
ese
id’s
will
be
used
late
r in
the
java
cod
e. D
ispl
ay
text
s fo
r the
text
vie
ws
can
also
be
edite
d di
rect
ly f
rom
thei
r res
pect
ive
tags
. Afte
r the
m
odifi
catio
ns, t
he la
yout
of t
he a
pp sh
ould
be
clos
e to
the
one
show
n in
figu
re 3
.
Figu
re 3
: Gra
phic
al la
yout
of t
he a
pp e
xam
ple.

10
5.5.
4 Th
e co
de
Whe
n th
e gr
aphi
cal
elem
ents
and
the
lay
out
is f
inis
hed,
the
fun
ctio
nalit
ies
of t
he
cont
rol e
lem
ents
nee
d to
be
code
d. T
his
is d
one
agai
n in
the
.java
file
. Writ
ing
the
code
fo
r han
dlin
g th
e U
I act
ions
for t
he S
eekB
ar a
nd th
e To
ggle
But
ton
are
wel
l doc
umen
ted
in [1
2] a
nd c
an a
lso
be se
en in
App
endi
x A
.
Insi
de th
e To
ggle
But
ton
hand
ler,
a pi
ece
of c
ode
is a
dded
that
will
sta
rt ru
nnin
g th
e Pd
pat
ch v
ia li
bpd.
In
this
exa
mpl
e, it
will
sta
rt th
e so
und
of a
n en
gine
. The
cod
e fo
r st
artin
g th
e au
dio
whe
n th
e To
ggle
But
ton
is sw
itche
d on
is sh
own
belo
w.
PdAudio.startAudio(getParent());
PdBase.sendFloat("gasposition", (float) ((float)(gasControl.getProgress() /
100.0)));
The
first
line
sta
rts ru
nnin
g th
e pa
tch
in th
e Pd
eng
ine.
Bec
ause
in th
is e
xam
ple,
the
call
occu
rs f
rom
ins
ide
the
Togg
leB
utto
n ha
ndle
r, a
poin
ter
to t
he p
aren
t ac
tivity
is
need
ed a
s a
para
met
er. I
n th
e se
cond
lin
e, a
mes
sage
is s
ent t
o th
e Pd
eng
ine.
It
is a
flo
atin
g po
int n
umbe
r tha
t is
addr
esse
d to
the
“r g
aspo
sitio
n” o
bjec
t sho
wn
in fi
gure
2.
The
num
ber (
scal
ed to
0...
1.0)
to b
e se
nt is
obt
aine
d fr
om th
e po
sitio
n of
the
Seek
Bar
. In
the
Seek
Bar
han
dler
, a s
imila
r cod
e is
add
ed to
sen
d a
mes
sage
to th
e Pd
eng
ine
ever
y tim
e th
at th
e Se
ekB
ar h
as b
een
adju
sted
. Fi
nally
, a c
ode
to s
top
the
Pd e
ngin
e is
add
ed to
the
Togg
leB
utto
n ha
ndle
r. Th
e co
de
show
n be
low
is to
be
exec
uted
whe
n th
e To
ggle
But
ton
is sw
itche
d of
f.
PdAudio.stopAudio();
The
last
thin
gs th
at n
eed
to b
e ad
ded
are
the
lines
PdAudio.release();
PdBase.release();
Thes
e lin
es s
houl
d be
exe
cute
d w
hen
the
app
is c
lose
d to
mak
e su
re th
at a
ll re
sour
ces
are
free
d. W
hen
the
code
is
read
y, t
he a
pp c
an b
e ru
n in
a s
imul
ator
or
in a
n ac
tual
A
ndro
id d
evic
e. N
ote
that
in th
e si
mul
ator
, onl
y a
sam
ple
rate
of
8000
Hz
is p
rovi
ded.
C
ompl
ete
sour
ce c
ode
for t
he .j
ava-
file
is sh
own
in A
ppen
dix
A.
6 C
ON
CL
USI
ON
Proc
edur
al a
udio
refe
rs to
mak
ing
soun
ds in
com
pute
r env
ironm
ents
alg
orith
mic
ally
at
run
time.
It o
ffer
s an
alte
rnat
ive
to s
ampl
e-ba
sed
audi
o. I
t al
so m
akes
it p
ossi
ble
to
furth
er e
nhan
ce th
e qu
ality
of
perc
eive
d so
und
in v
irtua
l env
ironm
ents
suc
h as
gam
es.
Ach
ievi
ng r
esul
ts t
hat
wou
ld o
utdo
sam
ple-
base
d au
dio
in q
ualit
y w
ith p
roce
dura
l te
chni
ques
is
not
sim
ple.
The
refo
re,
ther
e ha
s be
en a
gen
eral
lac
k of
int
eres
t in
the
ga
mes
indu
stry
tow
ards
pro
gres
sive
aud
io m
etho
ds. A
lthou
gh m
obile
pla
tform
s co
uld
bene
fit fr
om u
sing
pro
cedu
ral a
udio
, the
re a
re c
urre
ntly
no
com
mer
cial
gam
es a
vaila
ble
in w
hich
it
wou
ld h
ave
been
util
ized
. O
ne o
f th
e m
ost
impo
rtant
rea
sons
for
litt
le
inte
rest
in p
roce
dura
l aud
io se
ems t
o be
the
lack
of g
ood
soun
ding
mod
els.
Met
hods
to
incl
ude
com
mon
aud
io d
esig
n/re
sear
ch t
ools
suc
h as
Pur
e D
ata
or
Supe
rCol
lider
to
a ga
me
audi
o en
gine
hav
e st
arte
d to
em
erge
. Th
ere
are
libra
ries
avai
labl
e th
at c
an b
e us
ed to
em
bed
the
audi
o en
gine
s of
thes
e to
ols
dire
ctly
in a
gam
e

11
or o
ther
app
licat
ion.
Thi
s w
ay th
e so
und
algo
rithm
s ca
n be
des
igne
d w
ith to
ols
that
are
al
read
y fa
mili
ar t
o de
sign
ers.
In o
ther
wor
ds,
prot
otyp
es o
f so
und
algo
rithm
s ca
n be
us
ed in
app
licat
ions
with
out t
he n
eed
to im
plem
ent t
hem
sep
arat
ely
in w
hate
ver
audi
o en
gine
is u
sed.
Thi
s ki
nd o
f app
roac
h po
ssib
ility
cou
ld e
ncou
rage
mor
e in
tere
st to
war
ds
usin
g pr
oced
ural
aud
io in
gam
es, i
n bo
th d
eskt
op a
nd m
obile
env
ironm
ents
. Li
bpd
is a
libr
ary
that
can
be
used
with
out m
uch
effo
rt to
impl
emen
t Pur
e D
ata
as a
fu
nctio
nal
audi
o en
gine
for
And
roid
. It
is s
traig
htfo
rwar
d to
use
and
allo
ws
a m
obile
ga
me
to u
se P
d pa
tche
s as s
ound
sour
ces o
r pro
cess
ors.
RE
FER
EN
CE
S
1.
Farn
ell,
A. 2
007.
“An
int
rodu
ctio
n to
pro
cedu
ral
audi
o an
d its
app
licat
ion
in
com
pute
r ga
mes
.”
Onl
ine
artic
le.
[Cite
d 5
Oct
20
11]
Ava
ilabl
e at
: ht
tp://
obiw
anna
be.c
o.uk
/htm
l/pap
ers/
proc
-aud
io/p
roc-
audi
o.pd
f
2.
Col
lins,
K.
2009
. “A
n In
trod
uctio
n to
Pro
cedu
ral
Mus
ic i
n Vi
deo
Gam
es.”
C
onte
mpo
rary
Mus
ic R
evie
w, S
peci
al I
ssue
on
Alg
orith
mic
Gen
erat
ive
Aud
io.
[Ele
ctro
nic
jour
nal]
Vol
. 28
:1.
P. 5
-15.
[C
ited
6 O
ct 2
011]
. A
vaila
ble
at:
http
://w
ww
.tand
fonl
ine.
com
/doi
/abs
/10.
1080
/074
9446
0802
6639
83.
ISSN
074
9-44
67.
3.
Farn
ell,
A.
2010
. “D
esig
ning
Sou
nd.”
Cam
brid
ge,
Mas
sach
uset
ts,
USA
: M
IT
Pres
s. 69
0 p.
ISB
N 0
-262
-014
41-6
.
4.
V
ener
i, O
.; G
ros,
S.;N
atki
n, S
. 200
8. “
Proc
edur
al A
udio
for G
ame
usin
g G
AF.”
O
nlin
e ar
ticle
. [C
ited
3 N
ov 2
011]
Ava
ilabl
e at
: ht
tp://
cedr
ic.c
nam
.fr/P
UB
LIS/
RC
1568
5.
Four
nel,
N. 2
011.
“Pr
oced
ural
Aud
io C
halle
nges
& O
ppor
tuni
ties.”
Key
note
. In
: Gam
e D
evel
oper
s Con
fere
nce
2011
. San
Fra
nsis
co, C
alifo
rnia
, USA
. [C
ited
20 O
ct 2
011]
Ava
ilabl
e at
: http
://w
ww
.pro
cedu
ral-
audi
o.co
m/p
aper
s/G
DC
%20
2011
%20
-%20
Aud
io%
20B
oot%
20C
amp.
6.
Kos
ak, D
. 200
8. “
The
Beat
Goe
s on:
Dyn
amic
Mus
ic in
Spo
re.”
Onl
ine
artic
le.
[Cite
d 20
Oct
201
1] A
vaila
ble
at:
http
://uk
.pc.
gam
espy
.com
/pc/
spor
e/85
3810
p1.h
tml
7.
Paul
, L. J
. 201
0. “
Proc
edur
al S
ound
Des
ign.
” K
eyno
te. I
n: G
ame
Soun
d C
onfe
renc
e 20
10. S
an F
rans
isco
, Cal
iforn
ia, U
SA. [
Cite
d 20
Nov
201
1]
Ava
ilabl
e at
: http
://vi
deog
amea
udio
.com
/Gam
eSou
ndC
on-
Nov
2010
/Gam
eSou
ndC
on20
10-S
anFr
an-P
roce
dura
lSou
ndD
esig
n-Le
onar
dJPa
ul.p
df

12
8.
Rea
lity
Jock
ey L
td.
2011
. “S
cene
mak
ing”
The
RjD
j w
ebsi
te.
[Cite
d 20
Nov
20
11] A
vaila
ble
at: h
ttp://
blog
.rjdj
.me/
page
s/pd
-util
ities
9.
Brin
kman
n, P
. et a
l. 20
11. “
Embe
ddin
g Pu
re D
ata
with
libp
d” O
nlin
e ar
ticle
. In:
4t
h in
tern
atio
nal P
ure
Dat
a C
onve
ntio
n 20
11. W
eim
ar, B
erlin
, Ger
man
y. [C
ited
10 N
ov 2
011]
Ava
ilabl
e at
: ht
tp://
netto
yeur
.noi
sepa
ges.c
om/fi
les/
2011
/08/
libpd
fullp
aper
10. S
haw
, Ale
x. 2
011.
“Su
perC
ollid
er-A
ndro
id w
iki.”
Web
site
. [C
ited
23 N
ov
2011
]. A
vaila
ble
at: h
ttps:
//gith
ub.c
om/g
last
onbr
idge
/Sup
erC
ollid
er-
And
roid
/wik
i
11. G
oogl
e In
c. 2
011.
“In
stal
ling
the
SDK
”. A
ndro
id d
evel
oper
s’ w
ebsi
te. [
Cite
d 10
N
ov 2
011]
Ava
ilabl
e at
: http
://de
velo
per.a
ndro
id.c
om/s
dk/in
stal
ling.
htm
l
12. G
oogl
e In
c. 2
011.
“Fo
rm S
tuff”
. And
roid
dev
elop
ers’
web
site
. [C
ited
10 N
ov
2011
] Ava
ilabl
e at
: http
://de
velo
per.a
ndro
id.c
om/re
sour
ces/
tuto
rials
/vie
ws/
hello
-fo
rmst
uff.h
tml

13
APP
EN
DIX
A.
Sour
ce c
ode
for
the
impl
emen
tatio
n ex
ampl
e
package procAudioDemo.namespace;
import java.io.File;
import java.io.IOException;
import org.puredata.android.io.AudioParameters;
import org.puredata.android.io.PdAudio;
import org.puredata.core.PdBase;
import org.puredata.core.utils.IoUtils;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.SeekBar;
import android.widget.ToggleButton;
public class Audio_seminar_demoActivity extends Activity {
private static final int SAMPLE_RATE = 8000;
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
try {
initPd();
} catch (IOException e) {
finish();
}
setContentView(R.layout.main);
final ToggleButton engineControl=(ToggleButton)findViewById(
R.id.toggleEngine);
final SeekBar gasControl=(SeekBar)findViewById(R.id.seekBarGasPosition);
engineControl.setOnClickListener(new OnClickListener(){
public void onClick(View v) {
// Perform action on clicks
if (engineControl.isChecked()) {
PdAudio.startAudio(getParent());
PdBase.sendFloat("gasposition",(float)
((float)(gasControl.getProgress() / 100.0)));
} else {
PdAudio.stopAudio();
}
}
});
gasControl.setOnSeekBarChangeListener(new SeekBar.OnSeekBarChangeListener(){
@Override

14
public void onProgressChanged(SeekBar arg0, int progress,
boolean arg2) {
// TODO Auto-generated method stub
if(engineControl.isChecked())
PdBase.sendFloat("gasposition",(float) ((float)progress /100.0));
}
});
}
@Override
protected void onDestroy() {
cleanup();
super.onDestroy();
}
private void initPd() throws IOException {
if (AudioParameters.suggestSampleRate() < SAMPLE_RATE) {
throw new IOException("required sample rate not available");
}
int nOut = Math.min(AudioParameters.suggestOutputChannels(), 2);
if (nOut == 0) {
throw new IOException("audio output not available");
}
PdAudio.initAudio(SAMPLE_RATE, 0, nOut, 1, true);
File dir = getFilesDir();
File patchFile = new File(dir, " engine.pd");
IoUtils.extractZipResource(getResources().openRawResource(
R.raw.engine),dir, true);
PdBase.openPatch(patchFile.getAbsolutePath());
}
private void cleanup() {
// make sure to release all resources
PdAudio.release();
PdBase.release();
}
}

Mobile Instrument Construction with MoMu
Julian ParkerAalto University School of Electrical EngineeringDepartment of Signal Processing and Acoustics
Abstract
The new generation of mobile computing devices embodied by modern smartphones andtablet computers offer interesting new possibilities for mobile instrument construction,due to their relatively large computational resources and plurality of built-in sensors. Inthis work, we explore the history, challenges and design approaches of mobile instrumentconstruction. We also examine the MoMu framework, which is designed to make construc-tion of these types of instruments easier and quicker for potential designers. We show howMoMu can be applied to construct mobile instruments, and present case-studies of twocommercial instruments which have been constructed using MoMu.
Keywords — Mobile audio, sound synthesis, audio DSP, musical interaction
1

1 Introduction
Electronic instruments are generally composed of two main features - a sound generationmechanism, and a control mechanism that allows them to be played. Whilst at first glancethey may seem to be an unusual choice, modern smart-phones are in many ways an idealplatform for developing new electronic instruments. They provide a relatively great amountof computational power which can be used for sound-generation, and they provide manysensors such as touch-screens, accelerometers, gyroscopes etc which can be used to controlthe sound-generation. Smart phones also provide a new, unforeseen, benefit - accessibility.With the arrival of Apple’s iPhone and its rivals, an extremely large group of people nowhave in their pocket a device which can easily be used as an electronic instrument. Thismakes the potential user-base of an appealing instrument very large.
In Section 2, we review the history of mobile electronic instrument design and the challengeswhich it presents. In Section 3 we discuss MoMu, giving a general overview of its structurein Sections 3.1 and 3.2, and a short example of some MoMu code in Section 3.3. In Section 4,we describe three projects which have utilised MoMu, two being commercial iOS applicationsand one being a performance project based around custom designed instruments softwarerunning on iOS devices. In Section 5, we conclude.
2 The History of Mobile Instrument Design.
The history of mobile instruments and music making on mobile devices can roughly beseparated into three overlapping eras. The pre-touchscreen era, the era of early single-touchPDA devices and the era of modern multitouch smartphones.
2.1 Pre-touchscreen mobile music
Constructing an expressive instrument on a mobile device which posses only buttons asan input device is a difficult task. Therefore, early mobile musical instruments generallyconsisted of sequencer-like applications which allowed programming of musical phrasesthat could be played back by the device’s internal sound-chip. Some applications of thistype existed for mobile phones, but mainly as a method of allowing the user to producetheir own ring tones rather than as a tool for music production or performance. The mostfertile platform for early mobile music applications was the Nintendo Gameboy. One of themost popular early music applications was Nanoloop (Witchow (1998)), designed by OliverWitchow. This was a simple 16-step sequencer for the 4 channels of the Gameboy’s sound-chip, which allowed for expressive manipulation of patterns and parameters. Nanoloopproved very popular for live performance. Another significant mobile music applicationfor the Gameboy was Little Sound DJ (LSDJ)(Kotlinski (2000)), programmed by JohanKotlinski. LSDJ provided users with a complete music-making environment on the Gameboy,built around the structure of a popular type of computer music production program called a’tracker’.
2

2.2 Early touchscreen mobile music
Parallel to the developments for the Nintendo Gameboy described above, musical applicationswere also being developed for early touch-screen portable computing devices of the late 1990s -notably the Palm Pilot series of PDAs. Whilst the expressive potential of the Palm Pilot serieswas greater than the Nintendo Gameboy due to its touchscreen, early models lacked thecomputational power to synthesize sound and also lacked a dedicated sound-chip. Therefore,early applications mainly consisted of controllers or sequencers designed to interact withan external sound generation device via MIDI (Whitman (1999)). Some true self-containedinstruments were produced, mainly following the paradigm of an x-y pad on the touch screencontrolling 2 parameters (generally pitch and volume) of a very simple synthesis algorithmconsisting of a single oscillator (Mealey (1999)).
Later Palm Pilot devices possessed greater computational power, and consequently somemore advanced instruments and sequencers appeared, notably Bhaji’s Loops by Olivier Gillet(Gillet (2004)). This program appeared in 2004, and offered sequencing, sampling, synthesis,effects and instrument features well beyond anything available previously on a mobile device.This particular program was unsurpassed in capability until the arrival of applications foradvanced modern smartphones based on iOS and Android.
2.3 Modern mobile instruments
The field of mobile instrument design moved forward greatly when, in the late 2000s, mobilephones started to become available that both had a reasonable amount of computing power,and also had interesting new sensors such as multi-touch screens and accelerometers. Thesimultaneous arrival of easily accessible distribution networks for software for these devices,such as the Apple App Store and the Android Marketplace, lead to a huge proliferationof mobile instrument software for the platforms. Perhaps the most well-known modernmobile instrument is the Ocarina described by Wang (2009), and released by Smule. Smuleis a company entirely dedicated to the development of mobile music applications, whosemanifesto for the design of such instruments is presented by Wang et al. (2009).
In the literature, the current mobile instrument design paradigm was anticipated by Tanaka(2004), who described a control interface based on a PDA augmented by additional sensors(accelerometers etc). Complex sound generation on a mobile device was first discussed byGeiger (2003), who later went on to write about the use of touch-screens for interaction withsuch sound generation (Geiger (2006)). Several authors explored the idea of specifically usingmobile phones (rather than a general portable computing device) as instruments, notablyEssl et al. (2008) and Wang et al. (2008). However, recently this distinction has disappearedwith the convergence of mobile phone and mobile computing technology in ’smartphone’devices.
3 MoMu
MoMu is an attempt to make the implementation of mobile instruments more accessible andfaster. It was produced as a collaboration between Stanford University’s CCRMA, and theiroffshoot mobile development company Smule. A high-level overview of MoMu is given byBryan et al. (2010), but more detailed information must be inferred from it’s source-code andthe documentation thereof.
3

3.1 Approach & Structure
The purpose of MoMu is to abstract away much of the peripheral complexity that is inherentin developing software (specifically audio software) for a general purpose mobile device. Thisapproach is useful for two reasons. Firstly, because it allows potential instrument designersto concentrate on the important elements of instrument design, rather than expend timeand effort on the implementation of mundane technical functions. Secondly, it providessome level of portability, by hiding platform specific functionality behind its abstractions.In theory, an instrument written with the MoMu SDK could be compiled for a number ofplatforms by providing implementations of the MoMu API for each of these platforms. Thecurrent release of MoMu is designed to work with Apple’s iOS, which powers their iPhone,iPod Touch and iPad.
MoMu is provided as an SDK consisting of a collection of APIs and utility classes that handlea variety of useful functions:
• Audio input and output.
• Input from the device’s various sensors (touch screen, accelerometer etc).
• Input from outside the device (networking, location data etc).
• Sound synthesis and processing.
• Graphics.
Figure 1 shows a schematic overview of the structure of MoMu.
MoMu implements most of these facilities as static classes, which means that a single globalinstance of each is created when the program is run. The way these classes are interactedwith is discussed in more detail in Section 3.2, but follows a number of broad patterns. Eachsensor has a class associated with it. This class can be polled by calling a method of the classwhich returns the latest sensor value. Alternatively, one or many callbacks can be defined tospecify what should occur when the sensor updates its data. A callback is a special functionthat is registered with the class in question, and which then runs automatically wheneverthe sensor receives new data. Processing and routing of audio input and output is handledby a single callback. In general, the design of MoMu encourages the use of a callback basedstructure wherever possible.
Utility classes provided for facilities such as digital filtering, synthesis and audio process-ing follow a slightly different paradigm (they are not static, and generally do not employcallbacks), as is obviously necessary for their general use.
MoMu utilises a number of other open-source libraries for certain functions. Notably, STK(described by Cook and Scavone (1999); Scavone et al. (2005)) for synthesis and audio effects,CARL (Moore (1980)) for FFT calculations and oscpack (Bencina (2006)) for Open SoundControl (Wright and Freed (1997)) facilities.
4

MoMu: A Mobile Music Toolkit
Nicholas J. Bryan, Jorge Herrera, Jieun Oh, Ge WangCenter for Computer Research in Music and Acoustics (CCRMA)
Stanford University660 Lomita Drive
Stanford, CA, USA{njb, jorgeh, jieun5, ge}@ccrma.stanford.edu
ABSTRACTThe Mobile Music (MoMu) toolkit is a new open-sourcesoftware development toolkit focusing on musical interac-tion design for mobile phones. The toolkit, currently im-plemented for iPhone OS, emphasizes usability and rapidprototyping with the end goal of aiding developers in cre-ating real-time interactive audio applications. Simple andunified access to onboard sensors along with utilities forcommon tasks found in mobile music development are pro-vided. The toolkit has been deployed and evaluated in theStanford Mobile Phone Orchestra (MoPhO) and serves asthe primary software platform in a new course exploringmobile music.
Keywordsinstrument design, iPhone, mobile music, software develop-ment, toolkit
1. INTRODUCTIONMotivated by the newly blossoming field of mobile music [4,3, 13, 7, 2, 16, 15], the Mobile Music (MoMu) toolkit offers acollection of application programming interfaces (API) andutilities focusing on mobile music development and design.The initial MoMu release focuses on usability and rapidprototyping for the iPhone OS with a particular emphasistoward unifying audio input/output, synthesis, and graph-ics with the onboard sensors now available on commoditymobile phones including accelerometer, compass, location,and multi-touch as seen in Fig. 1. More specifically, thefundamental design goals of MoMu include:
• Real-time audio, synthesis, and control
• Consistent conventions for external sensor access
• Unified common functionality for mobile music
• Focus on ease of use, setup, and installation
• Open source C, C++, and Objective-C code
The design focus enables programmers with little or noprior mobile development experience to rapidly develop in-teractive audio applications, while concentrating on musi-cal and aesthetic considerations. MoMu builds upon theiPhone OS SDK as well as several open source software
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.NIME2010, June 15-18, 2010, Sydney, AustraliaCopyright 2010, Copyright remains with the author(s).
Figure 1: MoMu Overview.
packages including the Synthesis ToolKit (STK) for soundsynthesis and processing [11, 12], OSCpack [1] for network-ing via Open Sounds Control [17], and a Fast Fourier Trans-form (FFT) implementation adapted from the CARL soft-ware distribution [9]. To maximize performance on currentmobile hardware, MoMu has been implemented largely ina low-level language (C/C++). The open-source nature al-lows for custom modifications or additions for productionlevel applications. As far as our experience has shown, suchan approach tends to be more familiar to computer musi-cians and audio developers alike, easier to learn, and lendsitself to greater code reuse for future platforms. To encour-age academic researchers and commercial developers to fo-cus on more musical and interactive applications, MoMu isreleased under a BSD-like license. In the remaining paper,we discuss the components of MoMu and evaluate its use ina mobile phone orchestra [15] and classroom setting.
2. APIThe design of MoMu can be divided into two general top-ics involving mobile music development: access to onboardsensors and other useful programming abstractions. Theincredibly diverse onboard sensors now available on cur-rent smartphones include audio input/output, accelerome-ter, compass, location, networking, and multi-touch. Forour purposes of mobile music, such sensors have a trans-formative effect on the gamut of new musical experiences.
Figure 1: Schematic overview of the structure of MoMu, adopted from Bryan et al. (2010)
3.2 Classes
3.2.1 MoAudio
MoAudio is one of the most important classes provided by MoMu, as it handles audioinput and output. It is based on the structure of RtAudio, as described by Scavone (2002).It greatly simplifies the use of the device’s audio system by abstracting the lengthy setupusually needed, and by transparently handling changes in audio routing (such as dynamicallyswitching between headphone and speaker output etc).
MoAudio requires that a single callback function be used to carry out audio processing.Methods are provided to register and unregister the callback, as well as to set properties ofthe audio system such as sampling rate, frame size and number of channels. The callbackshould be built following this prototype:
void <AudioCallback> (Float32 * buffer, Uint32 numFrames, void * userData){\\ processing code};
The first parameter provides a pointer to a section of memory containing floating point audiodata. At the start of the callback, this section of memory contains the latest audio inputsamples. At the end of the callback, MoAudio expects the same section of memory to be filledwith the samples intended for audio output. Therefore, if the callback function is left empty,audio will pass through from the input to output. The last parameter, userData, provides afacility for passing data in and out of the callback from other parts of the program.
5

3.2.2 MoAccel
MoAccel is the class dedicated to dealing with the accelerometer. It provides methods whichallow polling of the accelerometer in the x, y and z directions, or all simultaneously. Methodsare provided to set the update interval of the accelerometer. It also contains two methods forregistering and unregistering callbacks which will trigger when the accelerometer updates.Callbacks are constructed according to the prototype:
void <AccelCallback> (double x, double y, double z, void * userData){\\ processing code};
The fourth parameter, userData, can point to any data the user likes and is used to passinformation out of the callback.
3.2.3 MoCompass
MoCompass is the class dedicated to interfacing with digital compasses. It is structured in avery similar way to MoAccel. Compass heading data can be retrieved by using polling meth-ods. Again, two methods for registering and unregistering callbacks which will trigger whenthe compass updates are provided. Callbacks are constructed according to the prototype:
void <CompassCallback> (CLHeading * heading, void * userData){\\ processing code};
The first parameter contains the compass heading whilst the userData parameter is againused to communicate data to other parts of the program.
3.2.4 MoLocation
MoLocation is the class dedicated to receiving information about the device’s geographiclocation. It abstracts away the underlying CoreLocation Framework, and provides theinstrument designer with a simple interface to location data. CoreLocation uses both GPSand triangulation from known cell-phone transmitters and wifi-hotspots to derive locationdata, but this distinction is hidden to the user of MoLocation.
Classes are provided to poll the current location, and the previously sensed location. Call-backs can also be registered, which will trigger when the location data is updated. Thecallback should be constructed according to the prototype:
void <LocationCallback> (CLLocation * newLoc, CLLocation * oldLoc,void * userData)
{\\ processing code};
The first two parameters provide the two most recent locations recorded by the device. Ascan be anticipated, the parameter userData is used to pass information out of the callback.
6

3.2.5 MoTouch
MoTouch is the class dedicated to dealing with input from the multi-touch display of thedevice. Touch data cannot be polled in the current version of MoMu, and is dealt withexclusively through callbacks. Callbacks should take the following form:
void <TouchCallback> (NSSet * touchSet, UIView * view,const std::vector<UITouch*> & touchVec, void * userData)
{\\ processing code};
The first parameter offers an un-ordered set of touch data, as derived from the underlyingUIResponder UITouch classes provided by the device. The second parameter gives the indexof the current UI page that the user is interacting with. The third parameter offers atime-ordered set of touch data, which makes tracking of individual touch tracks over timemuch simpler. Again the final parameter, userData, is used to pass information out of thecallback.
3.2.6 MoNet
MoNet is the class dedicated to dealing with network messages, specifically in the OpenSound Control (OSC) (Wright and Freed (1997)) standard. MoMu supports both incomingand outgoing OSC traffic. Sending messages is handled by the sendMessage method, whichtakes as arguments the standard information needed to send an OSC message - port, IPaddress, pattern address (this is the identifier which OSC uses to specify what the messageis supposed to do), message content etc. Incoming messages are responded to via callbacks.A separate callback is required for each specific pattern address, and therefore messageswith unknown pattern addresses are ignored. The pattern address which the callback ismeant to deal with is specified when registering the callback with Callbacks are constructedaccording to the prototype:
void <pattern_x_Callback> (void * message, void * userData){\\ processing code};
Again userData is used to pass information out of the callback. Various utility methods areprovided to set listening port, poll the devices IP address and other useful functions.
3.2.7 MoFFT
MoFFT is a utility class which provides FFT methods based on code adapted from the CARL(Moore (1980)) computer music software distribution, along with methods to generate anumber of common window types. Note that no inverse FFT is provided, and so the use ofthis class would generally be for audio analysis rather than spectral processing.
7

3.2.8 MoFilter
MoFilter is an umbrella class that contains a number of sub-classes designed to makeimplementation of simple digital filters easy. Sub-classes are provided for commonly usedfilter types such as biquads, single pole, single zero etc filters. MoFilter and its sub-classesare not static, and hence may be instantiated many times to provide as many filters asneeded. Once instantiated, a filter can be controlled via a number of methods that allowdirect setting of filter coefficients or alternatively specification of pole and zero locations. Thefilters are incremented using a tick method, which takes the input sample as an argument.Processing of signals with MoFilter is therefore not necessarily tied to the audio samplerate (although using it within the MoAudio callback will result in audio-rate filters), andMoFilter can be used for other applications such as within a sensor callback to providesmoothing.
3.2.9 MoFun
MoFun is a static utility class used to provide access to a number of small and commonly usedutility functions, in this case for generating random integers (rand2i) and random floats(rand2f).
3.2.10 MoGfx
MoGfx is different to many of the other elements of MoMu, as it does not provide a completesolution to the problem it is addressing. Drawing graphics whilst using MoMu still requiresthe use of the OpenGL ES implementation available on the device. However, MoGfx imple-ments a number of useful functions missing form the OpenGL ES implementation, makingdevelopment of graphics easier and quicker. These functions include perspective and cameraview changes, orthographic projection and texture handling.
3.2.11 MoThread
MoThread is a utility class that simplifies multi-threading of the application. It providesfacilities for instantiating threads, executing them and setting their priority. Multi-threadingis important for good application performance, as many recent iOS devices have multipleprocessor cores.
8

3.2.12 STK
MoMu also includes a full port of STK for iOS. STK (Synthesis Tool Kit) was introduced byCook and Scavone (1999), and is a large library of C++ classes for audio signal processingand synthesis. A full overview of STK is beyond the scope of this work, as the facilities itprovides are numerous. Included as classes are many high level synthesis, processing andcontrol blocks. Examples include chorus, delay, FM synthesis, physical models, granularsynthesisers and filters. The use is very similar to the use of MoFilter. A particular classis instantiated, and methods are called to set its parameters. Processing then proceeds bycalling the tick method of the class, with an input sample given as an argument. STKdoes not make any distinction between control-rate signals and audio-rate signals as somecomputer music systems do, instead relying on the person implementing the program todecide at what rate a particular object should be ticked.
3.3 Code example
Presenting a full MoMu application here would be impractical due to the large amount ofperipheral code, much of it relating to the UI. Instead, as an example of the usage of MoMu,we present here a simplified piece of code that shows how a simple audio processing graphcan be created in MoMu, interfaced with a sensor, and run via the main audio callback.As an example, we should how to create a program implementing simple two-operator FMcontrolled by the accelerometer.
Firstly, we create a structure containing instances of all the audio generation or processingclasses we would like to use in the program - in this case two sine-wave oscillators. Thisallows the structure to be passed in and out of the various callbacks via the userDataparameter. We then initialise the frequency of the two oscillators.
struct graph{SineWave oscOne;SineWave oscTwo;};
graph.oscOne.setFrequency(200);graph.oscTwo.setFrequency(400);
We then initialise MoAudio, and register a callback:
MoAudio::init(44100, 128, 2) \\MoAudio::start(audioCallback, &graph)
Next, we change the update speed of MoAccel, and register a callback with it:
MoAccel::SetUpdateInterval(0.05);MoAccel::AddCallback(accelCallback,&graph)
9

Finally, we define the callback functions that respond to the accelerometer updates andgenerate new output audio samples.
void audioCallback(Float32 * buffer, Uint32 numFrames, void * graph){SineWave *oscOne = (SineWave*) graph.oscOne;SineWave *oscTwo = (SineWave*) graph.oscTwo;for(int i=0; i<numFrames; i++)
{graph.oscOne.addPhaseOffsett(graph.oscTwo->tick());buffer[i] = graph.oscOne->tick();}
}
void accelCallback(double x, double y, double z, void * graph){SineWave *oscOne = (SineWave*) graph.oscOne;SineWave *oscTwo = (SineWave*) graph.oscTwo;graph.oscOne.setFrequency(x*200);graph.OscTwo.setFrequency(y*300);}
The end result (once wrapped in the appropriate peripheral code), is a simple two-operatorFM (technically PM) instrument where the frequencies of the two operators are modified bythe acceleration in x and y directions.
4 Applications of MoMu to Mobile Instrument Design
MoMu has been used in a number of prominent projects, both academic and commercial. Inthis section, we describe the most notable applications.
4.1 MoPhO
The idea of a Mobile Phone Orchestra (MoPhO), was first presented by Wang et al. (2008).Each of the authors of this paper went on to form their own mobile phone orchestras - Stan-ford MoPhO, Helsinki MoPhO and MiPhO (Michigan Phone Orchestra). These orchestrasgenerally consist of 3-10 performers, each with their own mobile device. The sound may comefrom the device itself, from an attached individual amplifier, or generated centrally based oncontrol messages from the mobile devices and presented over a loudspeaker system.
Initially, both Stanford and Helsinki MoPhOs used Nokia N95 phones as their instruments.Later incarnations of the Stanford MoPhO have switched over to instruments written withMoMu and running on the Apple iPhone. This incarnation of the orchestra is described byOh et al. (2010).
Oh et al. (2010) describes four different instruments implemented in MoMu for MoPhO. Theyare:
10

Figure 7: Screenshots of Instruments: (from left to right) Colors, interV, Wind Chimes, SoundBounce.
such as gentle tilts or larger arm movements, allowing theaudience to visually map sounds to movements. Also, theinstrument is capable of receiving and displaying instruc-tions sent by a central server during the performance. Us-ing this instrument, MoPhO performed intraV, a piece thattakes advantage of the two main features of the instru-ment — motion control and network message transmission.Based on the instructions received, performers move aroundthe stage and walk in between the audience, while mov-ing their hands and arms to create a continuously changingsoundscape.
Similar to this idea, Wind Chimes by Nicholas J. Bryanleverages mobile phones as directional controllers within a8-channel surround sound audio system (Fig. 7). To doso, the physical metaphor of wind chimes was used to con-nect “physical” chimes (8-channel system) to a wind force(performer/mobile phone). For performance, one or moreplayers stand in the center of the playback system, orientthemselves in a specific direction, and physically blow intothe phone microphone to trigger a gradual wash of windchimes sounds moving across the performance space. Whilethe metaphor is fairly simple in concept, the familiarity anddirect interaction proved beneficial and allowed audiencemembers to immediately associate the performers actionsto the auditory result, just as in a traditional musical en-semble.
Finally, the piece SoundBounce by Luke Dahl is basedon the metaphor of a bouncing ball [3]. Virtual balls andtheir physics are simulated, with the height of the balls con-troling the sound synthesis. Performers are able to bouncesounds, drop them, take aim at other performers, and throwsounds to them, causing the sound to move spatially fromone performer to the other. The instrument is designedto be gesturally interactive, requiring minimal interactionwith the GUI. To that aim, all instrument interactions andstate changes have audible results which contribute to thesound-field of the piece. The piece ends with a game inwhich performers try to throw sounds and knock out otherplayers’ sounds. As players’ sounds are knocked, their soundoutput becomes progressively more distorted until they areejected from the game and silenced. The winner is the lastplayer still making sound.
4. ANALYSISSince the instantiation of MoPhO in 2007, transforming mo-bile phones into “meta-instruments” has become an achiev-
able reality. A switch to the iPhone platform, with itspowerful capabilities and well-documented SDK, has facil-itated the process of repurposing the phone into a musi-cal instrument. The 2008 paper on the birth of MoPhOnoted that “there is no user interface that would allownon-programmers to easily set up their own compositionyet.” While this still remains problematic, the problem hasbeen partly mitigated through the newly written MoMuToolkit [1]. Developers can now write primarily in C/C++,avoiding Cocoa and the iPhone SDK if they desire. Addi-tionally, Georg Essl has authored an environment that offersabstractions for interaction and interface design on mobiledevices [4]. In this manner, many of the technical barriersto creating a mobile phone instrument are being tackled bynumerous research groups.
Nonetheless, there are many areas for future develop-ment, especially with regards to instrument re-use and per-formance concepts in light of the burgeoning interest of mo-bile music making. With the ease of software developmentcomes proliferation of instruments, and consequently these“soft instruments” have become more or less disposableitems: often times, an instrument gets written for a specificpiece and gets abandoned thereafter. A public repositoryon existing instruments and documentation may encourageinstrument sharing, re-use and further development.
As for exploring mobile music performance paradigms,future work should focus on the social and geographicalelements of performance. These types of musical experi-ences may manifest partly on-device, and partly in back-end “cloud computing” servers, and seeks to connect usersthrough music-making (iPhone’s Ocarina is an early exper-iment [17]). Future directions for the ensemble include ex-perimenting with pieces that involve participation from theaudience as well as performers from geographically diverselocations and potentially asynchronous models for collab-orative performance. An architecture to facilitate socialmusical interaction between performers who may be dis-tributed in space should be developed to better understandthe phenomenon of mobile music making. Mobile phones’ubiquity, mobility, and accessibility have begun to breakdown the temporal and spatial limitations of traditionalmusical performances, and we anticipate blurring of once-distinctive roles of a composer, performer, and audience, asone can now more easily partake in the integrated musicmaking experience.
Figure 2: Screenshots of the Stanford MoPhO instruments, adopted from Oh et al. (2010)
• Colors is a type of virtual keyboard, allowing the production of five simultaneous noteswith continuously variable pitch and volume. The instrument can also use presetparameter movements to make changes between sections of a piece. The aim of theinstrument is to allow playing without looking at the device, allowing more attentionand communication with the other performers.
• interV is a simple instrument that controls the volume of two separate notes basedon accelerometer data from two axes. The app can receive messages from a centralconductor, instructing on what direction the performance should take.The idea is thatthe performer employs large gestures, which can easily be linked to the sound producedby the audience.
• WindChimes uses orientation data from the performers, and control derived fromthe audio input, to control synthesised sound in an 8-channel loudspeaker setup.The performers position themselves near the centre of the speaker setup, orientsthemselves in a certain direction, and blows into the phone. This blowing gesturetriggers a wash of wind-chime sounds moving across the space in the same orientationas the player.
• SoundBounce again uses the individual devices to control a spatialised sound environ-ment. In this case, each player can throw physically modelled balls within a virtual3D environment. The balls are linked with sounds, which move spatially based on theposition of the ball. The performers throw balls/sounds to each other, bounce themaround, collide them etc.
Figure 2 shows screenshots of these instruments consecutively from right to left.
Oh et al. (2010) conclude that MoMu is of great benefit to the concept of MoPhO, as it allowsrapid-development of new instruments designed for specific pieces or performances. It alsoallows a generally technically competent person with only a knowledge of C/C++ to startdeveloping instruments without knowing the details of the the iOS SDK, Carbon and otherdevice specific knowledge.
11

Figure 3: Screenshot of Magic Piano running on an iPhone, courtesy of Smule.
4.2 Magic Piano
Smule’s Magic Piano is a hybrid mobile musical instrument and musical game. The basicpremise of the game is similar to other popular music games, such as Harmonix’s GuitarHero and Rock Band [cite]. The user is tasked with playing back a solo-piano interpretationof a popular piece of music, by triggering notes represented as circles as they scroll down thescreen. Figure 3 shows a screenshot of this configuration. Magic Piano differs from earlierentries in this genre of game in a variety of ways. The primary difference is that MagicPiano allows, and to an extent encourages, deviation from mimicking the exact timing of thepiece. New notes arrive to play only after the previous ones have been triggered, allowingthe player to use rhythm expressively. Chords do not have to be voiced as a block chordby the user, but can also be arpeggiated. The application can automatically quantise theplaying to the correct pitch, or alternatively allow any notes to be played.The end result issomething between a music game and guided instrument playing.
Other modes are provided that allow the user to simply play the piano sound (and a numberof other instruments) with several different on-screen keyboards (a spiral keyboard, acircular keyboard and a standard linear keyboard). The instrument is somewhat limited inexpressivity, as it lacks the main mechanism used for articulation in piano playing - thatbeing the velocity with which the keys are struck.
4.3 Magic Fiddle
Smule’s Magic Fiddle for iPad is the latest commercial application to use MoMu. The designprocess is documented by Wang et al. (2011). It is a development of Magic Piano and occupiesa similar part-game, part-instrument niche. The difference is that whilst Magic Piano’s
12

instrument is a simple touch-implementation of a keyboard instrument, Magic Fiddle insteadattempt to recreate something of the experience of playing a bowed-string instrument.
The playing interface of Magic Fiddle consists of four elements. There are three ’strings’,represented by lines with a patterned circular area at their base. These elements can be seenin the screenshot show in Figure 4. The circular are is used for ’bowing’ the strings. However,a bowing motion is not required, just a touch within the circular area. When the bowing isactivated by the user, the three strings can then be played by touching them somewherealong their length. Strings that are not touched do not sound. They behave like a real stringin that the pitch of each is determined by a base tuning, with an offset determined by howclose to the bowing area the string is touched (closer being a higher pitch). Like most realbowed-string instruments, the Magic Fiddle is not fretted and hence allows continuouslyvariable pitch. One note may be play for each string, giving three-voice polyphony.
The game/guided-playing section of Magic Fiddle operates similarly to that of Magic piano.Instead of small circles, lines scroll across the screen towards the strings. The lines havea colour, which corresponds to the colour of one of the strings and indicates which shouldbe played. The length of the line represents how long the note should be held, whereas theposition of the line shows the pitch.
Compared to Magic Piano, Magic Fiddle appears initially harder to play. However, theinterface allows much more expressivity due to the continuously variable pitch and limitednumber of notes. This allows the player to apply techniques such as bends, portamento andnatural vibrato.
5 Conclusions
The design of mobile instruments is an exciting and challenging field. In this work, wehave discussed the problems inherent in mobile instrument design and examined a softwaretoolkit, MoMu, that attempts to alleviate some of these problems. We have described thestructure of MoMu, and briefly shown how it can be used. Finally, we discussed some projectsin which MoMu has been used to ease and speed development. We conclude that MoMu isa interesting tool for the mobile instrument designer, and one that lowers the peripheralknowledge necessary for a potential design to start producing instruments.
6 References
R. Bencina. oscpack–a simple C++ OSC packet manipulation library, 2006.
N. Bryan, J. Herrera, J. Oh, and G. Wang. Momu: A mobile music toolkit. In Proceedings ofthe 10th International Conference on New Interfaces for Musical Expression (NIME), 2010.
P. Cook and G. Scavone. The Synthesis Toolkit (STK). In Proceedings of the InternationalComputer Music Conference, pages 164–166, 1999.
G. Essl, G. Wang, and M. Rohs. Developments and challenges turning mobile phones intogeneric music performance platforms. In 5Th International Mobile Music Workshop 2008,13-15 May 2008, Vienna, Austria, 2008.
13

Figure 4: Screenshot of Magic Fiddle running on an iPad, courtesy of Smule
14

G. Geiger. Pda: Real time signal processing and sound generation on handheld devices. InProceedings of the 2003 International Computer Music Conference: 29th September-4thOctober 2003, Singapore, page 283. International Computer Music Association, 2003.
G. Geiger. Using the touch screen as a controller for portable computer music instruments.In Proceedings of the 2006 conference on New Interfaces for Musical Expression (NIME06),pages 61–64. IRCAM Centre Pompidou, 2006.
O. Gillet. Bhaji’s loops. http://www.chocopoolp.com, 2004.
J. Kotlinski. Lsdj. http://www.littlesounddj.com/lsd/, 2000.
C. Mealey. minimusic. http://www.minimusic.com/, 1999.
F. R. Moore. Computer Audio Research Laboratory (CARL) software distribution. (http://crca.ucsd.edu/cmusic/cmusic.html), 1980.
J. Oh, J. Herrera, N. Bryan, L. Dahl, and G. Wang. Evolving the mobile phone orchestra.In Proceedings of the 10th International Conference on New Instruments for MusicalExpression, 2010.
G. Scavone. Rtaudio: A cross-platform c++ class for realtime audio input/output. In Pro-ceedings of the 2002 International Computer Music Conference: 16-21 September 2002,Göteborg, Sweden, page 196. International Computer Music Association, 2002.
G. Scavone, P. Cook, X. Amatraian, P. Arumi, D. Garcia, P. Cook, G. Scavone, and U. Reiter.Rtmidi, rtaudio, and a synthesis toolkit (STK) update. Computer Music Journal, 13(2),2005.
A. Tanaka. Mobile music making. In Proceedings of the 2004 conference on New interfacesfor musical expression, pages 154–156. National University of Singapore, 2004.
G. Wang. The ChucK audio programming language." A strongly-timed and on-the-fly envi-ron/mentality". PhD thesis, Princeton University, 2008.
G. Wang. Designing smule’s ocarina: The iphone’s magic flute. In Proceedings of 9thConference on New Interfaces for Musical Expression (NIME),(Pittsburgh, PA, USA), pages303–307, 2009.
G. Wang, G. Essl, and H. Penttinen. Do mobile phones dream of electric orchestras. InProceedings of the International Computer Music Conference (ICMC-08), 2008.
G. Wang, G. Essl, J. Smith, S. Salazar, P. Cook, R. Hamilton, R. Fiebrink, J. Berger, D. Zhu,M. Ljungstrom, et al. Smule= sonic media: An intersection of the mobile, musical, andsocial. In Proceedings of the International Computer Music Conference (ICMC 2009), pages16–21, 2009.
G. Wang, J. Oh, and T. Lieber. Designing for the ipad: Magic fiddle. In Proceedings of the11th International Conference on New Interfaces for Musical Expression (NIME-11), 2011.
B. Whitman. Hedgehog sequencer. http://www.crudites.org/soundventures/software/hedgehog/, 1999.
O. Witchow. Nanoloop 1.0. http://www.nanoloop.de/, 1998.
15

M. Wright and A. Freed. Open sound control: A new protocol for communicating with soundsynthesizers. In Proceedings of the 1997 International Computer Music Conference, pages101–104. International Computer Music Association San Francisco, 1997.
16

Collaborative and networked music approaches on mobileplatforms
Archontis PolitisAalto University School of Electrical EngineeringDepartment of Signal Processing and Acoustics
Abstract
The current study presents an overview of collaborative music practices on mobile musicplatforms. General trends are mentioned towards composition, performance and improvi-sation and some example platforms are analysed. Issues related to complexity, response ofthe system, mapping of control data and latency are isolated and discussed. Furthermore,the social aspects of the collaborative music networks are presented and some specificways that this aspects can be utilised in the networked music platform are discussed.
1 Introduction
In the last fifty years, music performing and listening has transformed increasingly from apublic or group activity to a personal one, both in terms of creation and listening. However,music is essentially a collaborative art in most aspects, creation of content, performance,or sharing of musical experiences from the side of the listener. This collaborative core isreinventing itself through the new media that present technology supports, such as theweb and mobile networked devices. The mobile phone as a collaborative networked musicplatform shows a great potential, due to its mobility, sufficient computing capabilities,constant connectivity and recently its various input and output modes.
Recently, there have been various approaches at incorporating the mobile phone as thetool for distributing the main musical practices to a network of users/musicians. Mobilenetworked music refers to any kind of musical activity that involves mobile devices andparticipation of more than one users through some kind of electronic network, commonlyLANs or the internet. Even though the connection between users does not explicitly indicatesome collaborative creative process, it does however reveal some kind of participation os eachconnected member, either by participating actively in the musical process or passively (forexample by listening to music produced by other members of the network). Networked musichas a history of a few decades now, with works appearing even before the explosion of thepersonal computers, utilising networks of radio stations or telephone landlines (Kim-Boyle(2009)).
Mobile networked music can be seen as a subset of the more general network music practiceand is still a field of research and experimentation in its infancy. Being focused on the
1

use of mobile devices, it does not cover the whole field of collaborative music based on PCs,which have a well developed suite of both music creation and connectivity tools. For examplemusic improvisation between instrumental ensembles at different locations by real-timeaudio streaming through the network and video feedback from each ensemble to the other issomething that does not make much sense in the case of mobile devices. However, it is themobility itself which is of interest in this case as well as the integration of many interactivemodalities that are converging on a mobile phone at present. These two characteristics opennew possibilities in musical collaboration and expression which are currently being activelyexplored.
By mentioning mobile devices, we mean any kind of mobile device that can transmit musicalcontrol data or audio to other devices directly or through a server, and receive audio or thecontrol data that generate it on the device itself. In previous years various scenarios likethat have been studied with use of separate accelerometers, PDAs, small display screensetc. linked together as one device. The target was to create a musical device or instrumentthat could convey information about the user’s musical action, plus additional data relatedto the interaction of the group as a whole. Nowadays, all these technologies can be found atmost normal mid-priced mobile phones on the market, along with a computing speed thatexceeds the one of PCs in the beginning of the previous decade. Hence, when we refer tomobile devices we assume use of mobile phones. Another reason in favour of mobile phonesis their widespread use and their inherent capabilities in communication, social networkingand distribution of services. Furthermore, current mobile phones provide well-documentedprogramming APIs for application development that provide easy access to the devices’various input sensors, audio handling, audiovisual output and connectivity features, in aconsistent manner.
2 Categorisation of collaborative musical practices on mobile devices
The list of potential applications is endless. First of all there is a wealth of implementationsthat has been explored up to some extent in the case of computers and can be adapted orenhanced by use of mobile phones. A non exhaustive list includes:
• Collaborative composition
By collaborative composition we mean any kind of organisation of sonic material bymultiple users, either in traditional note-based format or, more commonly in the field,by some kind of sequencing in time midi events, sound objects (such as samples andloops) or control data for audio generators and effects.
• Collaborative performance and improvisation
This includes any collaborative performance activity of connected users, either ofpre-arranged material or an improvised one (jamming).
• Collaborative remixing and music listening
Collaborative mobile music listening refers to applications where a network of usersshare their music playlists which are processed in some ways that reflect the groupinteraction, for example based on the geographical distance between the members. Theapplication can support active mixing by the users in a DJ-like fashion, or remixing ofsongs that provide separate tracks.
2

• Collaborative sonic installations and interactive sonic art
Even though implementations of this category are frequently not driven by musicalthinking they nevertheless share common design issues, such as how can a sonic workcan respond to input send by many users simultaneously. They will not be consideredthough in the present study.
Generally, existing applications in the field are combining more than one (or all) of the afore-mentioned musical practices and are still experimental, meaning that they are consideredas test platforms to observe how the interactions between the participants are taking place,and what form does the final musical output take. The field is very new and examples thatinvolve only one mode of musical expression are hard to find. Furthermore, in this studymany examples are taken from systems that were realised on desktop computers or othernon-mobile devices, but with relevant issues to the mobile music systems.
2.1 Mobile Phone Orchestras
There are furthermore applications that are unique to the mobile devices and they exploitfully what is available by the device, omitting external dependencies to some central computerserver, loudspeakers and other additional hardware. One fine example are the various mobilephone orchestras that have appeared the last years. The list includes the Stanford MobilePhone Orchestra (MoPho)1, the Helsinki MoPho2, the Michigan Mobile Phone Ensemble3
and the KAIST Mobile Phone Orchestra4. The name orchestra is probably a humorous takeon the weight and seriousness that is associated commonly with a traditional symphonicorchestra, but it also signifies the fact that an ensemble of mobile phones can be a completeautonomous performance unit capable of producing a wide range of sounds by itself, likean orchestra. The mobile phone in a MoPho is equipped with sound generators and its ownmapping to the movements or input actions of its player, and the sound is produced throughits speakers (or small portable speakers are attached for additional amplification).
In essence a mobile phone is a small portable computer capable of graphics computing anddigital signal processing in real-time. Hence, it is natural that many applications stem fromprevious attempts with personal computers. For example, mobile phone orchestras resemblethe laptop orchestras that preceded them by a few years. However, there are significantdifferences between mobiles and personal computers. First, mobile phones are much morelimited in computing power and more careful design should be applied on how to use theavailable resources. Second, its design is restricted and non-extendable, at least at present,while a computer can be extended with multiple controllers, sensors, displays etc. On theother hand, this restriction can be seen as a positive thing too, since it shifts the weight fromthe user learning how to operate a complex system, to the application engineer, designingan interface that is accessible and intuitive. In this way the mobile phone comes closer to atraditional instrument than a workstation with a peripherals - it is portable, responsive andcan be learned intuitively. In this sense a mobile phone orchestra would look at the eyes ofan observer closer to a instrumental ensemble than a laptop orchestra.
1http://mopho.stanford.edu2http://www.acoustics.hut.fi/projects/helsinkimopho3http://mopho.eecs.umich.edu4http://kampo.kaist.ac.kr
3

2.2 Other types of categorisation
Work in the field can be categorised in various other ways. For example, depending on theapplication of course, it can be synchronous, where the change coming from one memberpropagates instantly to the rest of the network. During a performance that would meanreal-time transmission of audio or control parameters through the network. Or changescould be asynchronous, or even on demand, for example in case of a compositional applicationwhere one user could navigate the graph of edits and apply selectively changes by othermembers.
Another distinction can be made between small ensembles with a limit in the number ofconnected players, or large networks of participants without limits on the connections. Thisrelates also on the notion of music practice space - the application can assume that theplayers share the same physical space, or that they populate a virtual space without closecontact.
Furthermore, another useful notion on the various implementations of collaborative musicsystems is the one of voluntary and involuntary actions. Voluntary actions are the onesthat the user performs consciously with the aim to transform some characteristic of thecollaborative audio stream. Involuntary actions on the other hand can be indirectly relatedto the music - they can express either unconscious actions, such as holding pressure on thedevice, or other actions that are not inherently musical but express the group dynamics,such as the movement of the performer closer or further away from the rest of the group(Tanaka (2004b), Tahiroglu (2009)).
2.3 Performance and the audience
A distinctive power of the mobile phone is its potential in blurring the boundaries betweenperformers and audience. Everybody is equipped with one and its connectivity featurespermit connection to ad-hoc networks, either via bluetooth, wifi or more indirectly byimitating some telephonic service. As it has been put forward by Rowe (1992), “let’s developcomputer musicians that do not just play back music for people, but become increasinglyadept at making new and engaging music with people, at all levels of technical proficiency”.
An early example on the use of networked mobile phones and the participation of theaudience was orchestrated by Goran Levin in 2001, titled “DialTones”5. By a manipulationof the electronic service of purchasing a ticket for a performance, the audience memberbecomes a musical node in a distributed orchestra of mobile phones comprised entirely fromthe audience. More specifically, the audience selects a ringtone from the event’s websitethat uploads the ringtone to the phone, register its number and assigns a seat in the event’sspace. During the performance a team of "conductors" on stage ring as many as 60 phonessimultaneously, thus creating complex clusters of ringtones coming from their predefinedpositions. The audience though has no active involvement in the performance other than thepersonal selection of each ringtone.
5http://www.flong.com/projects/telesymphony
4

A similar idea was presented on the installation of Ligna and Jens Rohm titled “Dial thesignals”6. 144 mobiles constituted instruments arranged in the space, and participants couldcall their publicised numbers. The resulting piece naturally had a more prominent chanceelement than “DialTones” and was broadcasted over radio.
Another example of collaborative music generation by exploitation of normal communicationor messaging actions of a mobile phone, is “Call in the Dark”7 (2006) by Koray Tahiroglu,where the audio was generated by transforming SMS texts that participants were sending toa central number into sonic structures. The participants could listen to the result throughlive streaming and try to alter it with additional messages.
3 Some example architectures
In this chapter we’re presenting different approaches that research takes on how to imple-ment collaborative musical platforms. Naturally the various proposed architectures varya lot in what they are trying to achieve and how. Some of the mentioned implementationshave been realised with use of mobile phones in mind, others for networked computers butwith an approach that could be easily adapted for mobile phones.
3.1 Collaborative improvisation and performance
With a large number of participants connected to a musical network a distinction betweenvoluntary and involuntary actions that can affect the musical result can be made. In Tanaka(2004b) the structure of a generic platform for mobile music making is described, that aimsto utilise both voluntary and involuntary actions. While at the time of the specific study theinvoluntary actions were captured by means of an additional data-acquisition board attachedto the mobile, its sensors are nowadays incorporated by default in all newer mobile phones.In general, their proposed system consists of a) mobile devices that can stream the controland involuntary data to the terminal, b) the terminal in which maps the data to the soundmanipulation and generation module, renders separate audio channels for each user andfinally streams the audio back to the connected users. That study focuses more on creatingthe conditions of a collaborative platform than on the mapping of the actions to the sound orthe synthesis part. The proposed implementation uses sample-based generation and samplemanipulation, such as re-ordering of small snippets of music, time-stretching etc. However,a distinction is made between low-level and high-level re-sequencing though, the former isthe direct manipulation of the samples by the users while the latter is a slower evolvingmanipulation that can be mapped to the overall social activity that drives the song. Theconnected users are regulated in groups by means of a trust-and-permission model similarto the popular social networks.
The approach described above is considered suited for both creation of new material aswell as re-mixing and re-structuring of existing songs and tracks, resulting in a “malleable”mobile music. More specifically it is presented in the case of a shared listening experience ofsongs that give away their individual tracks (such as Creative Commons licensed tracks),
6http://ligna.blogspot.com/2009/07/dial-signals-radio-concert-for-144.html7http://mlab.uiah.fi/noisecity/calltext
5

and thus can be re-mixed and manipulated at will by the group. Tanaka (2004a) describesan alternative version of the previous platform, where only the involuntary actions shapethe musical output. In this study a collaborative listening process and its social dynamicsaffect an adaptive music track that is streamed to the connected users. For example, therelative geographic locations of the group members determine the mixing parameters onthe audio channels that are streamed from the server, motion of the mobile phone maps totime-stretching parameters etc.
Another similar model for interactive improvisation and performance is the one presentedby Tahiroglu (2009), under the name Control Augmented Adaptive System for AudienceParticipation (CAASAP), targeted at medium scale groups of participants that share thesame physical space. The proposed system is also tracking both voluntary and involuntarydata from the members, however it is more clear on the how the mapping of these data tothe synthesis module is implemented. An interesting feature of this platform is spatial-isation control as an additional dimension for collaborative synthesis, which means thatthe final audio output will be rendered on a multichannel reproduction system. The audiosynthesis is implemented by RjDj8 patches, which is a popular wrapper of the puredatahttp://puredata.info/ graphical music programming language for Apple’s last generation ofmobile devices (iPhone, iPod Touch and iPad). Additional graphical cues are presented to theusers visualising overall characteristics of the audio stream.
Figure 1. Modular structure of interaction in CAASAP performances.
give more possibilities to increase the amount of partici-pants in collaborative music performances. However, de-signing such a system to include audience participation re-quires bringing together different technical platforms andmanaging the complexity of their integration. In literature,the collaborative, improvisatory and technological aspectsof mobile music performances are introduced as alternativeapproaches for this integration in mobile music systems.
Golan Levin’s mobile music piece Dialtones (A Telesym-phony) (2001) 1 is a large-scale collaborative performancethat brings forth a different approach to the performativerole of the audience. Low-level interaction achieved in termsof decisions made by the audience; however, using mobilephones as means of musical instruments, by hacking the di-altones of the audience’s mobile phones and performing apre-composed piece by ringing and dialing, is a remarkableevent for the use of mobile devices in musical contribution.
A mobile phone, being a significant communication toolfor the majority of people, gives the opportunity to interfaceits everyday-life practice for a collaborative musical experi-ence. Call in the Dark Noise (2006) is a performance thatprovided the audience with a responsive environment forparticipating in an act of musical improvisation [1]. In thisperformance, the interactive performance system allowedthe audience to use their mobiles phones as a musical in-strument by sending SMS messages. The interactive sys-tem altered SMS messages into sound structures and createdrespond text messages. Using an everyday communicationmedium as a musical instrument can make the audience feelcomfortable about participation and improvisation by send-ing SMS messages can create an exciting framework for col-laborative music making. Today, the technology of mobiledevices can support more possibilities than only receivingand responding to SMS messages during a live performance.
As the technological aspects are developed further, newcapabilities and tools in mobile phone technologies have be-gun to provide alternative feedback mechanisms. Tappingon a touch screen, tilting the mobile device, multi-touch in-terfaces change the way we interact with a mobile phone.Moreover, they create a new gestural dictionary within the
1 http://www.flong.com/
context of interactive gestures 2 . Nokia N-series phones,Apple iPhone and iPod touch mobile devices are the lead-ing new alternatives that support these types of gestures.Interfacing new mobile functions as expressive musical in-strument is an interesting prospect. Mobile devices providealternative possibilities for experimenting with new musicmaking processes. MoPhO is the Mobile Phone Orches-tra of CCRMA using mobile phones as musical instrumentsin a larger scale performance [5]. They are using not onlynew feedback mechanisms that come with the new seriesof mobile phones, but they are also using the advantage ofenriched computational possibilities. However, the compu-tational possibilities for audio synthesis in mobile phonesare still limited compared to other portable devices.
MoPhO compositions are performed through perform-ers’ actions on mobile phones guided by the conductor ofthe performance. These compositions can be interpreted asfreely composed pieces. Conducted improvisation in mu-sic or the performance of pre-composed pieces might limitthe type of free communication that could be achieved ina free or structured improvisation performance. The over-all control structure in CAASAP does not scale down par-ticipants’ collective activities as the performers of a pre-composed piece, instead, it supports them developing theirmusical ideas and activities in a real-time performance.
Malleable Mobile Music Engine in a broader scope showssimilarities with CAASAP as it serves as a platform for col-laborative music making through mobile wireless networks[6]. Malleable Music encourages participatory activity byfacilitating a system that detects involuntary gestures and theremote geographic location of the participants. In contrast,CAASAP is a facilitator for audience participation wherethe improvised music content is generated through the vol-untary actions of the participants.
3 OVERVIEW OF CAASAP
CAASAP is based on independently developed modules;their interaction forms the characteristics of the interactivesystem and its performance. The system consists of inter-face, registration, adaptive control, and audio & visual syn-
2 http://intertactivegestures.com
Proceedings of the SMC 2009 - 6th Sound and Music Computing Conference, 23-25 July 2009, Porto - Portugal
Page 184
(a)
Figure 2. Block diagram of the system modules.
thesis modules. In addition to receiving and collecting con-trol parameters, these modules also analyze control-data andperform audiovisual synthesis allowing these actions to beinterfaced within a mobile device.
The modular structure of the system requires sequencedaction of particular modules. Figure 2 shows the intercon-nected system modules. Registration module represents theinitial act that alters participation into action. This moduleis in charge of creating a local network and maintaining therequirements for real-time connections of the participants.It includes assigning the server IP for participants to accessand join the local network. When all the participants areconnected, then the registration module uploads the inter-face module to the participants’ mobile devices. The currentversion of the registration and interface modules are enabledby mrmr technology 3 . Mrmr is an ongoing research projectto develop a standardized set of protocols and syntax con-ventions to control live installations and multimedia perfor-mances. This technology, based on the Open Sound Control(OSC) and other open standards, makes it possible to usemobile devices as controllers in audio-visual performances.
Interface module is based on the design of a collectivemobile interface that enables interactive gestures and sendsparameter changes to the audio & visual synthesis module.This module modifies main control parameters, includinginstrument’s ID number, volume level, direction of the au-dio stream, reverb level, noise level and text messages. In-terface module also sends the state changes of participants’interactive gestures to the adaptive control module for fur-ther analysis of the control-data.
The adaptive control module will analyze the control-data and it will generate overall control parameters for theaudio synthesis module. As a result of the different modesof the participants’ musical activities, this module will gen-erate alternative improvisation models during the collectiveimprovisation performance. Section 5 introduces the anal-ysis and generative strategies that will be implemented inadaptive control module in detail.
Audio & visual synthesis module receives control param-eters and maps them onto control values of the digital instru-ments. The changes of the direction of the audio stream willbe also used as visualized representation of the participants’location in the performance space. Three-axis (x,y,z) ac-
3 http://poly.share.dj/projects/#mrmr
celerometer’s control data will be visualized as three circlesfor each participant [7]. The rotation speed of each circlewill represent the participant’s speed of the action on theparticular axis.
4 INTERFACES IN CAASAP
In the course of the development of CAASAP, several avail-able technologies have been studied and practiced. Figure3 illustrates the UI every participant operates on. The inter-face is made by using mrmr protocol and tools. The fourpush-buttons on the top enable/disable up to four shared in-struments (see section ”Audio Synthesis” for more discus-sion). At this instant, the first instrument is selected andthe values for reverb, noise and volume parameters are as-signed. The state changes of the interface are sent throughOSC protocol. The current version of mrmr technology sup-ports one-way OSC communication, which does not enablethe system to send feedback based on state changes to theinterface module. On the other hand, this interface modulesupports text message affordance, which opens up anothercommunication channel for participants and possible sonifi-cation strategies for the audio synthesis module.
In the process of developing the interface module, RjDjapplication 4 has also been experimented with. RjDj is atechnology that uses sensory input to generate and processembedded scenes for iPhone and other mobile devices. RjDjtechnology enables Pure Data 5 for processing live data takenin mobile devices. The overall system architecture of theCAASAP has been developed by using the Pure Data en-vironment; therefore, RjDj gives more possibilities to inte-grate control-data with other CAASAP modules. Accelerom-eter and touch screen sensor data of the mobile device isavailable and can be accessed with RjDj application. More-over, it takes in the sensory input from microphone device,which makes it possible to process the audio as a sensorydata in mobile devices. In order to improve CAASAP per-formance, some part of the analyzes can be embedded inmobile devices through RjDj application and resulted eventdata can be transfered for further use in adaptive and audio& visual modules. At the moment RjDj application alsoonly supports one-way OSC data stream; however when
4 http://rjdj.me/5 http://www.puredata.info/
Proceedings of the SMC 2009 - 6th Sound and Music Computing Conference, 23-25 July 2009, Porto - Portugal
Page 185
(b)
Figure 1: (a) Schematic of actions in collaborative performance and (b) corresponding pro-cessing modules (adopted from Tahiroglu (2009)).
The three systems mentioned above share a similar architecture as the one presented inFigure 1, which can be summarised in the following modules:
• Registration module
This is the module that registers a member to the network and grants access to it.8http://rjdj.me/
6

• Interface module
It encompasses the GUI and all sensors and protocols used for gathering of the actiondata.
• Control-data
These can be divided in two streams. The first are the ones that are mapped directlyto parameters of synthesis engine, hence the user can experience a direct connectionbetween action and musical output. The second stream are indirect control data,including the involuntary ones, that are going through some analysis stage and moregeneric features of interaction are extracted and then mapped to to overall controlparameters. These are control data for example that express group dynamics, andtheir result can be mostly felt by the member rather than experienced directly.
• Control module
This is the brain of the interaction in the system. It is the module that containsthe mapping instructions and it is probably the most crucial and challenging from adesign aspect part of the system. The control module takes the control data from theplayers and performs some kind of mapping between them and the synthesis, henceit is the part that sets the limits on the the structure of musical output, the responseof the system, the number of participants and generally the capacity of the systemfor interactivity and feedback. Normally this part is implemented in some externalterminal (a separate computer).
• Synthesis module
The synthesis module performs the audio or audiovisual generation according to thereceived control data and of course it is responsible for the style of musical output.Many platforms assume a high degree of modularity in the synthesis engine so thatmany different kinds of electronic instruments and effects can be realised, accordingto the application. That gives a more general scope and flexibility in the design. Anexternal workstation usually implements the synthesis, due to the heavy processingthat can exceed the capabilities of a mobile device. Then the audio can be reproducedin a sound system or streamed, usually in some compressed form, back to the mobilephones.
Some visual feedback is commonly generated too, on the mobile devices’ screens, withthe aim to give some additional feedback to the performers. That helps them torealise their place in the total sound output by visualising certain parameters of theperformance, either local or global.
We have mentioned already the Mobile Phone Orchestra model of collaborative performance.In a MoPho all the input and output is handled solely on the mobile phones and the roleof each unit is predetermined in the group. In this case, a human conductor is the onethat distributes and regulates the musical tasks or the players interact directly with oneanother in a traditional musical improvisation fashion. The first implementation of a MoPhoWang et al. (2008) defines itself as “a new repertoire-based ensemble using mobile phones asthe primary musical instrument”. The repertoire corresponds to publicly premiered pieceswhich cover a wide range of electronic music practices, such as scored compositions, sonicsculptures, directed or free improvisations. A strong requirement is mobility, hence audio
7

Figure 2. The Mobile Phone Orchestra performing Drone In/Drone Out by Ge Wang.
has been pioneer by Greg Schiemer [17] in his PocketGame-lan instrument. At the same time there has been an effortto build up ways to allow interactive performance on com-modity mobile phones. CaMus is a system that uses thecamera of mobile phones for tracking visual references toallow performance [16]. CaMus2 extended this to allowmultiple mobile phones to communicate with each otherand with a PC via an ad hoc Bluetooth network. In bothcases an external PC was still used to generate the sound.
The MobileSTK port of Perry Cook’s and Gary Scav-one’s Synthesis Toolkit (STK) [4] to Symbian OS [7] isthe first full parametric synthesis environment availableon mobile phones. It was used in combination with ac-celerometer and magnetometer data in ShaMus [8] to al-low purely on-the-phone performance without any laptop.
Specifically the availability of accelerometers in pro-grammable mobile phones like Nokia’s N95 or Apple’siPhone has been an enabling technology to more fullyconsider mobile phones as meta-instruments for gesturedriven music performance. The main idea for the mo-bile phone as a meta-instrument is to provide a generic-as-possible platform on which the composer can craft hisor her artistic vision. At the same time the abilities of-fered by the phone have to be in a sense stabilized to offera persistent repertoire for an ensemble.
There is also earlier body of work using mobile devicesas part of artistic performances. In these, mobile phonesdid not yet play the role a traditional instrument within aperformance ensemble.
Golan Levin’s DialTones performance is one of the ear-liest concert concepts which used mobile devices as partof the performance [14].
The concept of the performance is that the audience
itself serves as part of the sound source display and thelocalization of people in the concert hall is part of the per-formance. A precomposed piece is played by calling upvarious numbers of members of the audience. Visual pro-jections display the spatial patterns that make currentlysounding telephones.
The main conceptional use of mobile phones in thisconcert was passive yet spatial in nature, blurring the per-former and audience boundary.
The art group Ligna and Jens Rohm created an installa-tion performance called “Whlt die Signale” (German for“Dial the signals”). The performance used 144 mobilephones that were arranged in an installation space. Peoplecould call the publicised phone numbers and the result-ing piece would be broadcast over radio. Unlike Levin’spiece the compositional concept is aleatoric, meaning thatthe randomness of the calling participants is an intendedpart of the concept [2].
A performance installation that used mobile technol-ogy indirectly, and predates both Levin’s and Ligna’s workis Wagenaar’s “Kadoum” [2]. Here heart-rate sensors wereattached to 24 Australians. The signals were sent via mo-bile phones to other international locations where electric-motor excited water bucket installation would display theactivity of the Australians. Here mobile technology wasprimarily used for remote wireless networking and themobile devices themselves were not an inherent part ofthe concept of the piece but rather served as a means ofwireless communication.
Wagenaar’s piece serves as an example of what we willcall “locative music”. This is music where distributed lo-cation plays a conceptual role in a piece. Some authorsthink of mobile music making as referring to the mobility
(a) (b)
Figure 2: (a) Stanford Mobile Phone orchestra in action, (b) Helsinki Mobile Phone Orches-tra ((a) adopted from Wang et al. (2008)).
is played through the mobiles’ or wearable speakers. In contrast to laptop orchestras, anew performance can be initialised on-the-go. The synthesis is preformed completely onthe device itself, hence either existing libraries or software should be used for the synthesismodules. Recently, high-level audio programming languages are starting to appear, either asports of existing PC-based software (e.g. libpd9) or written from scratch for use of mobilephones in mind (e.g. MoMu10, urMus11). However, compared to PCs the options are verylimited and quite experimental at the moment. In addition, many of them separate theoperation of an audio unit on the mobile and its programming, which has to be performed ona PC (e.g. RjDj). That poses some limitations to the design of new sounds and instrumentsin a MoPho context, as well as new compositions. More importantly, these design proceduresare not available to a non-technical performer. Certain approaches aim to overcome theselimitations by making accessible high-level design of synthesis modules completely on themobile (e.g. urMus).
3.2 Collaborative Composition
Networked collaborative composition was one of the first music practices to be studied, firstbecause of its feasibility since it can be implemented in some non-real-time form, and secondbecause it is challenging a traditional music notion. In contrast to performance, compositiontraditionally has been a solitary practice, either in the case of a composer creating a scorefor an ensemble or in the case of an electronic music producer, painstakingly overlappingand shaping his audio loops in a real or virtual studio environment. The general notionassumes that a personal supervision and control on the organisation of the sound results ina coherent music product expressing a clear creative view. While this can be true, nothingprevents the possibility of a compositional process of exchange, where successive membersadapt or refine, each according to his own criteria, an initial idea. Then the composition
9http://puredata.info/community/projects/software/libpd10http://momu.stanford.edu/toolkit/11http://urmus.eecs.umich.edu/
8

itself can be seen as a social practice, expressing the interaction between the members, thedynamics of the group and possibly a convergence towards some common consensus. Thisis already taking place up to some extent in a music band where compositional tasks areequally distributed between members. In this case each member brings to the sum its owninfluences and experience, however the result may be something new and different than justthe sum of the parts.
Collaborative compositional approaches can be distinguished in two main categories. Thefirst one is organised around the idea of a score, which can be notational, graphical, or anykind of set of instructions for generation of music. In these systems real-time propagation ofthe changes to the connected nodes is not crucial. Here a user can edit a current or previousversion of the scorefile and send the changes to the server. Usually some synthesis enginewill be implemented on the client side for sonification of the result. An interesting pointhere is the version control similar to software development, meaning that the server hasthe task of storing the tree of changes and permitting regression to any previous versionof the scorefile. Such an architecture is presented in the FMOL system (Jorda and Wust(2001)), originally implemented for a PC network. Here the user can pick any of the existingcomposition from a database, listen to it and edit any of the 8 maximum tracks, overdubthem or add new. The rework is considered a new composition, however the server stores therelation of the new to the previous one in a tree structure, as a child node to the compositionthe user picked. The child node points to a new scorefile which implements only the changesrelative to the parent scorefile. The deeper a node is in the tree the more revisions have beenperformed. Hence the tree structure itself is implementing the version control.
The second compositional category is the one somewhere between composition and perfor-mance. It is closer to the practice of people generating a piece by picking up a theme, playingtogether, listen, reshape and repeat, thus creating a feedback loop that is repeated till thepiece takes a shape liked by all members. In this case, the boundaries between compositionand performance are blurred as is in the music practice itself, and the procedure is not muchdifferent from the interactive performance platforms that we described already. The onedifference is that here the focus is on a pattern with a definite duration (the composition)that the members can be altering in real-time by editing the pattern itself. This approach isdemonstrated in Daisyphone (Bryan-Kinns and Healey (2006)), a circular step-sequencerwith an editable pattern simultaneously by all users (Figure 3). Two modes are investigatedin that study, a persistent one, where changes are permanent until they are overwrittenby some member, or decaying, meaning that each contribution is gradually decaying intime. In the second case the sequencer pattern avoids being overpopulated by successivecontributions while retaining “memory” of older edits by their effect on the more recent ones.
The mobile phones pose limitations as to how a composition-based approach should beimplemented in the limited display of the device. Simple models though, such as collaborativestep sequencers, drum machines or simple graphic scores should be possible to implement.
In Renaud (2010), a model on how to organise, characterise and distribute control parametersin large-scale collaborative performance is attempted. These cues can be transmitted from aprecomposed work, generated by a human or electronic composer in real-time or generatedby some kind of response to various input data. The authors classify the control parametersin three categories: temporal, behavioural and notational. Temporal cues are related totiming, e.g. duration of an action that the performer has to realise or an indication that the
9

!"# !$%&$'&'# %(# ")**(+%# ,(%-# !"#$! %&$' %"( # .!%-!$# %-&/(0*("!%!($1# 2$'# "(/!23# 2$'# '!"/)+"!4&# &5/-2$6&"
7+&4!()"# "%)'!&"# 891# :;# -24&# !'&$%!<!&'# "&4&+23# '&"!6$# !"")&".!%-# =2!">*-($&# 2$'# !%"# ")**(+%# <(+# 6+()*# /+&2%!4!%>?# @$# %-!"*2*&+#.&#&5*3(+&#%-&#$2%)+&# (<# *&+"!"%&$/&# !$# /($%+!,)%!($"?# @$*&+4!()"# 4&+"!($"# (<# =2!">*-($&# 233# /($%+!,)%!($"# .&+&*&+"!"%&$%?# @%# A)!/B3># ,&/20&# /3&2+# %-+()6-# "%)'!&"# %-2%*2+%!/!*2$%"# '!'# $(%# /3&2+# )*# 2<%&+# %-&0"&34&"# 2$'# %-&# 0)"!/23"*2/&# A)!/B3># ,&/20&# "2%)+2%&'# .!%-# $(%&"# .-!/-# /+&2%&'# 2/2/(*-($()"# $(!"&?# C-&# 2,!3!%># %(# 0(4&# %(# $&.1# /3&2$1"&""!($"#.2"#($&#(<# %-&# <!+"%#'&"!6$#'&4&3(*0&$%"#2$'# +&")3%&'!$# %-&# /!+/)32+# "&""!($# "&3&/%(+# !33)"%+2%&'# !$# %-&# %(*# 3&<%# (<<!6)+&#D?#E(.&4&+1# <)+%-&+# "%)'!&"# "-(.&'# %-2%# %-!"# "%!33# .2"$(%# ")<<!/!&$%# %(# *+(0(%&# <3(.!$6# 2$'# &$626!$6# 0)"!/23!$%&+2/%!($# F# *2+%!/!*2$%"# "!0*3># 6(%# ,(66&'# '(.$# !$# 2# "&2# (</($%+!,)%&'# $(%&"?# @$# (+'&+# %(# !$4&"%!62%&# %-&# &<<&/%# (<*&+"!"%&$/&# (<# 0)"!/23# /($%+!,)%!($1# 2# $&.# 4&+"!($# (<=2!">*-($&# !$# .-!/-# $(%&"# '!"2**&2+# .2"#'&4&3(*&'# G+&<&++&'%(#2"#%-&#!"#$%#4&+"!($H?#I$3>#%-&#$(%&"# 2+&# %+2$"!&$%1# %-&+&<(+&%-&# 6+2*-!/23# 2$$(%2%!($# /+&2%&'# .-&$# %-&# $(%&"# 2+&/($%+!,)%&'# +&02!$# *+(4!'!$6# "(0&# 4!")23# /)&"# %(# %-&/($%+!,)%!($"# G2# <(+0# (<# -!"%(+># (<# /($%+!,!%!($H?# C-&# +2%&# (<'&/2># (<# %-&# $(%&"# !"# /+!%!/23# %(# %-&# '&"!6$# F# %((# A)!/B# 2$'/(-&+&$%# "-2+!$6# (<# 0)"!/# .!33# $(%# (//)+# 6!4&$# %-&# "&0!J">$/-+($()"# $2%)+&# (<# %-&# !$<+2"%+)/%)+&K# %((# "3(.# 2$'# %-&0)"!/23# "*2/&# .!33# /($%!$)&# %(# ,&/20&# (4&+/+(.'&'?# L(+# %-&"%)'!&"#-&+&1# '&/2># !"# /+&2%&'# ,># -234!$6# %-&# 4(3)0&# (<# $(%&"&4&+># %!0&# %-&# 2+0# *2""&"# (4&+# %-&0?# C-!"# %>*!/233># 6!4&"# :*32>"# (<# 2# 3()'# $(%&# ,&<(+&# !%# '!"2**&2+"# .-!/-# 2**&2+"# <+(0!$!%!23# "%)'!&"# %(# ,&# ")<<!/!&$%# <(+# /(J(+'!$2%!($?
&'()*"+,-+.$'/%0123"+'34"*5$#"
67! 89:.;C-!0"#(<#%-!"#"%)'>#2+&#%.(<(3'M#DH# C(# !$4&"%!62%&# %-&# &<<&/%'&/2># (<# /($%+!,)%!($"# -2"# ($# +&0(%&# 6+()*# /+&2%!4!%># !$0)"!/K#9H#C(#<)+%-&+#&5*3(+&# %-&# $2%)+&# (<# +&0(%&# 6+()*# 0)"!/02B!$6# !$#6&$&+23?
67,! &2*<$4C&$# *("%# 6+2')2%&# "%)'&$%"# "%)'>!$6# N'42$/&'# O&%-('"# !$P(0*)%&+#Q/!&$/%# %-)%-(+"R#!$"%!%)%!($#.&+&#"&%#2#*!&/&# (</()+"&.(+B#!$#.-!/-#%-&>#.&+"B&'#%(M
! ! S"&#,(%-# %-&#*&+"!"%&$%#2$'#'&/2>#4&+"!($"# (<#=2!">*-($&%(#+&0(%&3>#/+&2%�)"!/#%(6&%-&+#(4&+#%-+&&#.&&B"?
! ! 7&+<(+0#%-&!+#*!&/&#(<#0)"!/#<(+#%-&#+&"%#(<#%-+()*?
! ! N$23>T&# 2$'# +&*(+%# ($# %-&# !$%&+2/%!($# %-2%# %((B# *32/&# !$=2!">*-($&# !$# ,(%-# 4&+"!($"?
C-&# "%)'&$%"# 6+()*&'# %-&0"&34&"# !$%(# :# 6+()*"?# C-&># -2'# 2.!'&# +2$6&# (<# 0)"!/23# 2,!3!%># <+(0# $(4!/&# %(# *+(<!/!&$%0)"!/!2$"# *32>!$6# !$# ,2$'"?# U($&# -2'# &4&+# )"&'# 2# %((3# 3!B&=2!">*-($&# ,&<(+&?
72+%!/!*2$%"# .&+&# 2"B&'# %(# +&*(+%# ($# .-&%-&+1# 2$'# -(.1# %-&>&5*&+!&$/&'#<3(.#2"#2#6+()*#8V;?#W"(#2"B&'# %-&# *2+%!/!*2$%"%(# !'&$%!<>#*(!$%"#(<#$'')(*+*('#,&%.&&$# &2/-# (%-&+# ($# 2# %-+&&*(!$%# "/23&M#=#>32?@"!("<"34# F%-&># .&+&# 2.2+&# (<# %-&/($%+!,)%!($"# (<# 2$(%-&+K# A'**2*'3( # F# %-&># 0!++(+&'1# (++&<3&/%&'1# (%-&+"R# /($%+!,)%!($"K# 9*$3/52*<$4'23 # F# %-&>%+2$"<(+0&'# (%-&+"R# /($%+!,)%!($"# G!$'!/2%!$6# 2# -!6-# 3&4&3# (<0)%)23# &$626&0&$%H?# C-&"&# +&*(+%"# 2$'# &$")!$6# '!"/)""!($"2+&# )"&'# !$# %-&# +&"%# (<# %-!"# *2*&+# %(# -&3*# 02B&# "&$"&# (<# %-&(,"&+4&'# ,&-24!(+?# L3(.#.2"# /2%&6(+!T&'# !$# %&+0"# (<M# P-2$/&(<# /(0*3&%!$6# %-&# 2/%!4!%>K# N,!3!%># %(# /($/&$%+2%&# ($# .-2%%-&>R+&# '(!$6# 2"# 2# 6+()*# ')&# %(# /3&2+# 6(23"# 2$'# 2'&A)2%&<&&',2/BK# =&&*1# &<<(+%3&""# !$4(34&0&$%# .!%-# 2# +&')/%!($# !$/($/&+$# <(+# &5%&+$23# <2/%(+"K# Q&$"&# (<# /($%+(3# (4&+# 2/%!($"KC+2$"<(+02%!($#(<# %!0&?
N''!%!($233>1# 3(6"#(<#233# 2/%!($"# !$#=2!">*-($&#.&+&# "%(+&'# <(+32%&+# +&J*32># 2$'#2$23>"!"?
B7! C=99DEF8+G&+:8DC-!"# "&/%!($# ()%3!$&"# %-&# *2%%&+$"# (<# )"&# 2$'# ,&-24!(+# %-2%%((B#*32/&# !$# %-&#"%)'>#.!%-# %-&# *&+"!"%&$%# 2$'# '&/2># 4&+"!($"(<# =2!">*-($&?# @$!%!23# 2$23>"!"# (<# 3(6"# 2+&# *+&"&$%&'# -&+&# F'&%2!3&'# 2$23>"!"# !"# /)++&$%3># ,&!$6# )$'&+%2B&$?# N$#24&+26&# (<X# "&""!($"#.!%-# %-&# *&+"!"%&$%# 4&+"!($# 2$'# :# "&""!($"# .!%-# %-&'&/2># 4&+"!($# .&+&# +&/(+'&'# <(+# &2/-# 6+()*?# Y2/-# "&""!($32"%&'#($#24&+26&#DZ#0!$)%&"#<(+#%-&# *&+"!"%&$%# 4&+"!($# 2$'# D90!$)%&"# <(+# %-&#'&/2>#4&+"!($?
72+%!/!*2$%"# +&*(+%&'# ,&!$6# <2!+3># +&325&'# 2,()%# '&3&%!$6# (%-&+*2+%!/!*2$%"# $(%&"# 2$'# 02B!$6# 0('!<!/2%!($"# %(# %-&!+/($%+!,)%!($"?# C-!"# !"# !$# /($%+2"%# %(# *+&4!()"# "%)'!&"# 2$'($6(!$6# *),3!/# )"&# .-&+&# +&3)/%2$/&# %(# &'!%# (%-&+"R/($%+!,)%!($"# !"# &4!'&$%?# W&# ")66&"%# %-2%# %-!"# !"# ')&# %(# %-&$2%)+&# (<# %-&# &5&+/!"&# "&%# G[>()#0)"%# /+&2%&# 2# *!&/&# (<# 0)"!/%(6&%-&+# <(+# *&+<(+02$/&# 32%&+RH# 2$'# %-&# "(/!23# "!%)2%!($# G%-&>233# B$&.# &2/-# (%-&+# A)!%&# .&33# 2$'# -2'# *(""!,3># .(+B&'%(6&%-&+# ,&<(+&H?
B7,! C$44"*3/+25+:/"+?'41+C"*/'/4"34+H"*/'23N"# .!%-# ($6(!$6# 2$23>"!"# (<# %-&# )"&# (<# =2!">*-($&1# !$# ,(%-4&+"!($"# %-&# *2+%!/!*2$%"# %&$'&'# %(# "*&$'# %-&# <!+"%# *2+%"# (<%-&!+# "&""!($"# &5*3(+!$6# =2!">*-($&# ($# %-&!+# (.$?# C>*!/233>!$# %-&# "-2+&'# &$4!+($0&$%# %-!"# 0&2$%# .(+B!$6# !$# 2# *2+%!/)32+A)2'+2$%# (<# %-&# 3((*# (<#0)"!/?# I$/&# *2+%!/!*2$%"# .&+&# 2,3&# %()$'&+"%2$'# =2!">*-($&R"# !$%&+<2/&# %-&># %-&$# 0(4&'# ($# %(.(+B!$6# !$#(%-&+#2+&2"# %(#'&4&3(*# 3($6&+# %)$&"#(+#/($%+!,)%&# %((%-&+# *2+%!/!*2$%"R#.(+B?
@$%&+&"%!$63>1# 2$# !$<(+023# +(3&# 2""!6$0&$%# '&4&3(*&'# .-&$)"!$6# %-&# *&+"!"%&$%# 4&+"!($#.!%-# *2+%!/!*2$%"# %&$'!$6# %(# "%!/B%(# ($&# !$"%+)0&$%?# O(+&(4&+1# 2# [3&2'&+R# %&$'&'# %(# &0&+6&')+!$6# %-&# "&""!($"?# C-!"# *&+"($# %>*!/233># /($"%+)/%&'# %-&02!$# 0&3('># .-!/-# .2"# %-&$# ")**3&0&$%&'# ,># (%-&+"# !$# %-&6+()*?# =2!">*-($&# -2"# $(# &5*3!/!%# 0&/-2$!"0"# (+# 6)!'2$/&
!"#$%%&'()*+#,+-.%+/001+2(-%"(3-'#(34+5#(,%"%($%+#(+6%7+2(-%",3$%*+,#"+89*'$34+:;<"%**'#(+=628:01>?+!3"'*?+@"3($%
AAB
Figure 3: Graphical user interface of Daisyphone’s collaborative sequencer, with visible textmessages that the users can post during the editing (adopted from Bryan-Kinnsand Healey (2006)).
performer can switch to improvisation for a specific interval. Behavioural cues contain aperformance scenario, e.g. triggering of a waveform or following some musical constraint.Notational cues are the ones responsible for giving visual feedback to the performers thatcontains useful information of the performance evolution. Furthermore, two types of statesfor each cue type are identified. These are a passive and an active state. In a passive statethe cue i sent as a suggestion - it is the decision of the performer to follow it or not. Activecueing on the other hand is triggering events on the connected node, such as lowering itsvolume or activating a remote oscillator.
4 Mapping
As it was mentioned already, in the case of performance and interaction, the way thevarious input data from the users are mapped to the sound is crucial to the scope of theimplementation. More specifically the mapping relates to the following points:
1. Interactivity and responsiveness
It is possible that a direct mapping of each users’ action to a specific synthesis pa-rameter will result to a rapidly changing and incoherent musical result, unable totransmit to the players the state of the group and the link of each player to the other.This gets especially problematic in large scale implementations with many performers,or open ones where the audience can connect and join at any time. Some regulatorymechanism can be applied in this case based on overall group dynamics, after someanalysis of the input control data. Such a mapping system can be dominant, so thatno user action has a direct result in some sound parameter, or adaptive, falling onthe background when more action from the users is expected. Careful design againis needed to ensure that the system remains responsive to some extent, so that theperformer can discern his actions to the music.
10

2. Scale of the system
A well-defined detailed mapping usually assumes a fixed or small number of partici-pants. The more large-scale or open the system is the more flexible the mapping shouldbe kept too, in order to facilitate the various number of connections.
3. Character of musical output
The musical output is the result of the specific mapping choices and the synthesisoptions. Elements such as fast or slow variations, tempo and spectrum define thecharacter of the music. In a collaborative performance it is hard to predict the outputbefore hand, hence careful design between the synthesis parameters and the userinput is needed to affect these elements in an expressive manner.
In Malloch et al. (2007), the mapping layer is divided in four parts, as is presented in Figure4. Here it is argued that the first two and last two layers are technical and should be part ofa good controller’s and a good synthesis module’s design. Since specifying gestural semanticsand synthesis semantics are excluded from the design of a collaborative instrument, it is theconnection between the two semantic layers that are of main interest. It is also stated inthis and previous studies that direct mapping of one gestural to one sound parameter is lessinteresting both for the performer and in terms of musical output. Instead, one-to-many andmany-to-one mappings are proposed between gestural parameters and sound parameters.
Co
ntr
ol P
ara
me
ters
Ge
stu
ral S
em
an
tics
So
un
d S
em
an
tics
Syn
the
sis
Pa
ram
ete
rs
First MappingLayer (Technical)
Second MappingLayer (Semantic)
Third Mapping Layer (Technical)
Figure 1. A diagram of the 3-layer framework used forDigital Orchestra development, adapted from [4].
musician will likely interface with them, and what soundsthe instrument will make, there is still the decision ofwhich sensors should control which aspects of the sound.This task, known as mapping , is an integral part of theprocess of creating a new musical instrument [6].
3.1. The Semantic Layer
An important result of previous discussions on mappinghas been the acknowledgement of the need for a multi-layered topology. Specifically, Hunt and Wanderley [4]suggested the need for 3 layers of mapping, in which thefirst and last layers are device-specific mappings betweentechnical control parameters and gestures (in the case ofthe first) or aesthetically meaningful “sound parameters”,such as brightness or position (in the case of the third).This leaves the middle layer for mapping between param-eter names that carry proper gesture and sound semantics.We shall refer to this layer as the “semantic layer”, as de-scribed in Figure 1.
The tools presented here adhere to this idea. However,since the first and last mapping layers are device-specific,the mapping between technical and semantic parameters(layers 1 and 3) are considered to be part of the controllerand synthesizer interfaces. Using an appropriate OSC ad-dressing namespace, controllers present all available pa-rameters (gestural and technical) to the mapping tool. Thetool is used to create and modify the semantic layer, withthe option of using technical parameters if needed.
As a simple example, the T-Stick interface [8] presentsthe controller’s accelerometer data for mapping, but alsooffers an event-based “jabbing” gesture which is extractedfrom the accelerometers. The former is an example oflayer 1 data which can be mapped directly to a synthe-sizer parameter. The latter is gestural parameter presentedby layer 2, which can be mapped, for example, to a soundenvelope trigger. The mapping between layer 1 and layer2 for the “jabbing” gesture, (what we call gesture extrac-tion ), occurs in the T-Stick’s interface patch.
We have also used this system in another project 2 formapping gesture control to sound spatialization parame-ters, which in turn has influenced system development [9].In this case a technical mapping layer exposes abstract
2 Compositional Applications of Auditory Scene Synthesis in Con-cert Spaces via Gestural Control is a project supported by theNSERC/Canada Council for the Arts New Media Initiative.
spatialization parameters (such as sound source trajecto-ries) to the semantic layer, rather than synthesis parame-ters.
3.2. Connection Processing
Gestural data and sound parameters will necessarily carrydifferent units of measurement. On the gestural side, wehave tried, whenever possible, to use units related to phys-ical measurements: distance in meters, angles in degrees.In sound synthesis, units tend to be more arbitrary, butsome standard ones such as Hertz and MIDI note numberare obvious. In any case, data ranges will differ signif-icantly between controller outputs and synthesis inputs.The mapping tool attempts to handle this by providingseveral features for scaling and clipping data streams.
One interesting data processing tool that we are explor-ing is a filter system for performing integration and differ-entiation. We have often found during sessions that a par-ticular gesture might be more interesting if we could mapits energy or its rate of change instead of the value directly[3]. Currently the data processing is limited to first-orderFIR and IIR filtering operations, and anything more com-plex must be added as needed to the “gesture” mappinglayer and included in the mappable namespace.
3.3. Divergent and Convergent Mapping
It has been found in previous research that for expert inter-action, complex mappings are more satisfying than simplemappings. In other words, connecting a single sensor orgestural parameter to a single sound parameter will resultin a less interesting feel for the performer [6, 11].
Of course, since our goal is to use abstracted gesture-level parameters in mapping as much as possible, simplemappings in the semantic layer are in fact already com-plex and multi-dimensional [5]. Still, we found it wouldbe useful to be able to create one-to-many mappings, andso the mapping tool we present here supports this. Eachconnection may have different scaling or clipping applied.
We also considered the use of allowing the tool to cre-ate many-to-one mappings. The implication is that theremust be some combining function which is able to arbi-trate between the various inputs. Should they be summed,or perhaps multiplied, or should some sort of comparisonbe made between each of the inputs?
A combining function implies some relationship be-tween gestural parameters; in some cases, the combina-tion of gestural data may itself imply the extraction of adistinct gesture, and should be calculated on the first map-ping layer and presented to the mapping tool as a singleparameter. In other cases the combination may imply acomplex relationship between synthesis parameters thatcould be better coded as part of the abstracted synthesislayer. In yet other cases the picture is ambiguous, but theprospect of needing to create on-the-fly many-to-one map-pings during a working session seemed to be unlikely. Wedid not implement any methods for selecting combining
66
Figure 4: Categorisation of mapping layers (adopted by Malloch et al. (2007)).
Approaches based on analysis of both voluntary and involuntary data have been mentionedalready (Tanaka (2004b)). In Tahiroglu (2009) specifically, each user is given a set ofinstruments that he can switch during the performance, and some direct controls for eachone of them. On the other hand, group parameters are generated from an adaptive controlmodule, based on swarm logic. Common parameters shared between the performers aretreated as members of a swarm and the adaptive module applies swarm rules to the synthesissuch as a) if the parameters converge, move them apart, b) if the parameters are too muchapart move them closer, c) if the parameters are too dissimilar attempt to match their rate ofchange. If the individual parameters are outside of the system thresholds, then the adaptivemodule becomes dominant (negative feedback). If the performers’ actions are aligned thenthe adaptive module does not interfere (positive feedback).
A similar approach is followed in an interactive sound installation called TGarden (Ryan andSalter (2003)). In TGarden, the mapping layer between performers gestures and musicalparameters is done via a layer of simulated physics, which represents individual parameters
11

as phantom masses coupled between the participants and inducing ballistic behaviour in theoverall response. Their aim is to hide a direct relationship to some musical characteristic,like pitch and tempo, and instead allow the participant to understand bounces, recoils andlags in the sound as his/her own. Their models are based some on kinetics and some onenergy. Energies, densities and angular momentum of the whole group is mapped to thelarge-scale behaviour of the system.
In Burtner (2006) it is stated that simple solutions such as smoothing, or interpolate betweenindividual data to bound the input are not adequate because they work against the richnessof a multi-performer system. Instead the authors propose a perturbation approach toemphasise dependencies between performers, pull individual tendencies towards tendenciesof the whole group and mitigate influence from one node to the others.
5 Interface and complexity
A mobile phone at present permits a wide range of input data from its user. A commonsetup has a video camera, a microphone and a keyboard. More and more devices incorporateaccelerometers and/or gyroscopes and touch or multi-touch input on their displays. Combinedtogether, all these input devices give a wide range of user data that can be mapped to somecontrol parameter. However it is important that the interface presented to the participant isintuitive and simple to use. As it is noted in Gurevich (2006), especially in the case of openconnection systems, public installations and designs that aim to involve the audience shouldprovide an interface that a new member can enjoy and learn in a short period of time. Onthe other hand, very constrained designs they do not allow much space for experimentation.Some parameters that determine how much constrained an interface should have is theexpected engagement time that the participants will have with the system, its location andthe nature of the system. For example much more complex use of the sensors and complexmappings can be permitted in the case of a mobile phone orchestra, where the performerscan achieve higher degrees of virtuosity by practice, compared to novices participating in apublic interactive installation.
In Laney et al. (2010), the aspect of multi-user controller design is considered. It is arguedthat the two main issues for engaging social interaction are distribution of the controls andcomplexity versus simplicity. They make a distinction between shared and local controls.Shared controls between users result in a shared sonic impression and are negotiatedbetween the participants. Local controls on the other hand are reached more easily andthey result in an individual sonic impression. The focus of that study is on multi-touchcollaborative instruments but their arguments are equally valid for mobile devices.
Multi-touch interaction, if the mobile phone supports it, is well-suited to musical control . Itcan support both discrete and continuous input and it adheres to contact and movement ofthe fingers, which resemble playing of traditional musical instruments. Furthermore, manyof normal GUI interactions for normal use of the device (dragging, zooming, rotating) can beeasily adapted for musical control.
An interesting interface implementation for collaborative use is explored in Rohs and Essl(2007) using the camera of the mobile phones. In the proposed implementation, calledCAMUS2, the camera tracks its relative motion with respect to a marker grid, using basic
12

computer vision techniques, and hence it becomes a 3-dimensional controller in a virtualinteraction space. Multiple devices can share the same interaction space by tracking thesame marker surface. Their position and orientation control sound elements and audioeffects, while semantic information of the mapping is visualised on the camera displays.
The keyboard has also been traditionally used in mobile improvisation for triggering actionsor as a musical keyboard, even though in this sense multi-touch input is probably bettersuited. The keyboard can be also used for textual communication between the members,in addition to musical and visual cues, allowing verbal instructions and queries betweenthem about the performance, as has been implemented in Tahiroglu (2009), Bryan-Kinnsand Healey (2006).
Visualisation is an important cue that helps the evolution of the performance by informingthe participants of their place in the group, their influence, their relation to other participants,the overall group dynamics etc. This is realised in various different ways, depending on thetype of application and the semantics of the specific mapping.
Finally, there have been a number of platforms that take as additional input the location ofthe performers, either in the same space or globally, by using the capabilities of the mobilephones for GPS information. In the case of Tanaka (2004a) it is an additional cue of groupdynamics for overall control of sound parameters, for collective improvisation or sharedmusic listening. In Tanaka and Gemeinb (2006), the concept of geographical data as amusical interface is studied, and its place in a more general location aware category of mediaart termed “locative” media.
6 Latency
Latency has been the most significant technical challenge of networked music in general,especially in the context of real-time performance with audio streaming between musiciansnot sharing the same physical space. Leaving that extreme cases aside, in the context ofthe collaborative practices and approaches that has been mentioned in this overview, it isstated in Jorda and Wust (2001) that the needed synchronicity from a musical performancepoint of view do not differ from the requirements of multi-user online-gaming. Consideringthe layers of complex mapping that govern multi-user interaction in most of the systemsthat were mentioned here, some latency is probably deemed acceptable. The limits in thesecases could be higher than the latency of the sound response for a single-performer using acontroller, however they should be small enough to allow the user to distinguish the effect oflocal controls in contrast to the effect of group parameters. In the case of LAN networks thetransmission speeds are fast enough to keep the latencies below the limits. When the groupis connected through the internet though, the successive lags that may occur are impossibleto predict. In these cases Schroeder et al. (2007) argue that the platform should consider thelatency as a crucial characteristic of the network as a medium and a musical feature in itself.In Gurevich (2006) and Jorda and Wust (2001), the effect of the latency is compared to theeffect of reverberation in a highly reverberant space, such as a cathedral. Slowly-varyingsynthesis algorithms with more spectral than rhythmical changes are proposed in this case.
13

7 Social Networks, Trusts and Permissions
Social networks have always been a fundamental element in music practices as a socialactivity. First, there are the networks of performers, groups of people that perform togetherfor some time, groups that share performers between them, networks of performers of thesame instrument etc. All musician’s create affiliations with other musician’s based on theirinstrument of choice, musical preferences, virtuosity and experience, and locality. On theother hand, there are the networks of music listeners, which are usually based along musicalpreferences and music genres, and which are active enough to generate whole subcultures,connecting strongly people all around the globe.
Mobile phones, inherently networked devices with the aim of communication, become alsotools of musical social interaction, where listeners can connect to the communication channelsof their favourite music circles, share their music playlists or make public whatever they arelistening at the moment. In the context of mobile collaborative music, musical networks canbe used as a model for organisation of access on large-scale decentralised platforms, where alarge number of people can connect simultaneously without apparent links between.
In Tanaka (2004b) the groups of connected users are orgnised in circles of friends in a mannersimilar to popular social networks such as facebook or myspace. The aim is to distributepermissions for a musical practice in the network in a natural manner, with the idea of musicactivity among friends. When a user connects to the network, he/she can discover if thereare other members around him with some level of musical acquaintance. A “friend” meansfull access permissions, a “friend of a friend” is lower in trust and so on. Circles can expandand propagate trust based on locality or musical compatibility. Four level of acquaintanceare specified with corresponding permissions:
1. Level 1: play music together
2. Level 2: listen to friends playing, with access to each players individual stream andwith the ability to visualise his/her input control
3. Level 3: listen to the overall performance, with no access to individual tracks
4. Level 4: no access
In Jorda and Wust (2001) additional social tools are proposed to enhance the social organ-isation of their collaboratve composition approach. More specifically, a rating system wasimplemented - users could vote on the quality of each composition. This information showsboth general acceptance of a piece and information on the user’s preferences. User profilingis also suggested as means to enable the system to propose compositions or sessions to theuser based on his preferences. Profiling is implemented firstly by input from the user in apreferences section, such as musical genre, instrument, training level etc. Furthermore, theuser’s interaction with the system is monitored through the composition he choses and hisvotes. Organisation of the users in virtual communities can be done by the system. Secondly,profiling is performed based on content retrieval on the users’ compositions themselves,such as harmonicity, density of notes, rhythm and others. These musical descriptors forma feature space which can be compared with other users’ ones. Using user profiling thesystem itself can propose virtual communities to the user for joining, or compositions forparticipation.
14

8 Discussion and conclusions
It is becoming evident that collaborative networked music is looking more and more inthe direction of mobile devices, since they can replace computers to a sufficient degree andthey offer some important advantages in terms of mobility, compactivity, connectivity andinteraction, allowing more truly interactive and dynamic designs. The field is still novel andthere are various approaches to various problems. The related research borrows ideas froma vast range of fields such as music theory and practice, computer science, signal processing,human-machine interaction design, social media, new media art and others, in order toorganise rationally the various proposed frameworks for musical collaboration.
The implementations that were presented herein are mostly experimental, meaning thatthey are designed as a proposition as much as an experiment to observe how it is runningand what outcomes can be deduced from it. By observing the interaction between performers,performer and the mobile device, performers and the music, it should be possible to extractuseful information about the semantics that should govern a collaborative mobile musicdesign and what can be expected of it.
The same experimental approach is naturally extended to the music itself. The systems underdiscussion are primarily focused on how to provide the conditions for a collaborative musicperformance and not how to produce certain musical qualities. In this sense musicologicalevaluation is still absent, which is something that is coming after a certain degree ofmatureness and a consensus on the semantics of the various systems. The music is stillmostly treated as something to observe and see how it is evolving.
Generally, there are a number of important trade-offs that govern a specific design. Theseinclude pre-composed versus improvised, complexity versus simplicity, long engagement ofthe performers and the system versus short engagement, complex mapping versus directmapping, large-scale versus small-scale. In the case of performance and improvisationspecifically, it is a well accepted fact that the more time the performers have to learn theirtools and their co-performers the finer the results can be. But it is an important designchoice if the system allows a degree of virtuosity to develop, which would subsequently havean impact to the short-term enjoyment of the system and the simplicity of use.
To conclude, mobile phones offer an exciting fast-evolving platform for collaborative music.They are portable and can be controlled with various modes of interaction like real instru-ments. Both performance and compositional approaches have been demonstrated to workand more importantly to engage the participants. There are various designs at the momentwith respect to the application and the desired type of interaction, however it is expected thatmany of these approaches will converge towards a more general framework as the respectivesystems are tested and are maturing with time.
15

9 References
N. Bryan-Kinns and P. Healey. Decay in Collaborative Music Making. In 2006 InternationalConference on New Interfaces for Musical Expression (NIME06), pages 114–117, Paris,France, 2006.
M. Burtner. Perturbation Techniques for Multi-Performer or Multi-Agent Interactive MusicalInterfaces. In 2006 International Conference on New Interfaces for Musical Expression(NIME06), pages 129–133, Paris, France, 2006.
M. Gurevich. JamSpace : Designing A Collaborative Networked Music. In 2006 InternationalConference on New Interfaces for Musical Expression (NIME06), pages 118–123, Paris,France, 2006.
S. Jorda and O. Wust. A System for Collaborative Music Composition over the Web. In 1stInternational Workshop on Web Based Collaboration, in 12th International Conferenceon Database and Expert Systems Applications (DEXA2001), pages 537–542, Munich,Germany, 2001.
D. Kim-Boyle. Network Musics: Play, Engagement and the Democratization of Performance.Contemporary Music Review, 28(4-5):363–375, 2009.
R. Laney, C. Dobbyn, A. Xamb, M. Schirosa, D. Miell, K. Littleton, and S. Dalton. Issues andTechniques for Collaborative Music Making on Multi-Touch Surfaces. In 7th Sound andMusic Computing Conference (SMC’10), Barcelona, Spain, 2010.
J. Malloch, S. Sinclair, and M. M. Wanderley. From Controller to Sound: Tools for Collabora-tive Development of Digital Musical Instruments. In 2007 International Computer MusicConference (ICMC07), pages 65–72, Copenhagen, Denmark, 2007.
A. Renaud. Dynamic Cues for Network Music Interactions. In 7th Sound and MusicComputing Conference (SMC’10), Barcelona, Spain, 2010.
M. Rohs and G. Essl. CaMus 2: Collaborative Music Performance with Mobile CameraPhones. In ACM SIGCHI International Conference on Advances in Computer Entertain-ment Technology (ACE07), pages 190–195, Salzburg, Austria, 2007.
R. Rowe. Interactive Music Systems – Machine Listening and Composing. The MIT Press,1992.
J. Ryan and C. Salter. TGarden : Wearable Instruments and Augmented Physicality. In2003 International Conference on New Interfaces for Musical Expression (NIME03), pages87–90, Montreal, Canada, 2003.
F. Schroeder, A. B. Renaud, P. Rebelo, and F. Gualdas. Addressing the Network: PerformativeStrategies for Playing Apart. In 2007 International Computer Music Conference (ICMC07),pages 133–140, Copenhagen, Denmark, 2007.
K. Tahiroglu. Towards an Experimental Platform for Collective Mobile Music Performance.In 6th Sound and Music Computing Conference (SMC’09)), pages 23–25, Porto, Portugal,2009.
16

A. Tanaka. Malleable Mobile Music. In 6th International Conference on Ubiquitous Comput-ing (Ubicomp 2004), Nottingham, UK, 2004a.
A. Tanaka. Mobile Music Making. In 2004 International Conference on New Interfaces forMusical Expression (NIME04), pages 154–156, Hamamatsu, Japan, 2004b.
A. Tanaka and P. Gemeinb. A Framework for Spatial Interaction in Locative Media. In2006 International Conference on New Interfaces for Musical Expression (NIME06), pages26–30, Paris, France, 2006.
G. Wang, G. Essl, and H. Penttinen. Do Mobile Phones Dream of Electric Orchestras? In2008 International Computer Music Conference (ICMC08), Belfast, UK, 2008.
17

1
Aud
io-d
rive
n m
obile
mus
ic a
pplic
atio
ns: a
des
ign
pers
pect
ive
Rob
erto
Pug
liese
Sc
hool
of S
cien
ce, D
epar
tmen
t of M
edia
Tec
hnol
ogy
A
bstr
act
The
appe
al o
f mob
ile p
hone
s as i
nter
face
s for
mus
ic-m
akin
g is
stro
ngly
due
to th
e av
aila
bilit
y of
man
y se
nsor
-tech
nolo
gies
insi
de a
gra
spab
le a
nd li
ght d
evic
e. T
he
focu
s of
this
pap
er b
uild
s up
on th
e op
portu
nitie
s pr
ovid
ed b
y th
e m
icro
phon
e an
d a
parti
cula
r cl
ass
of
audi
o-dr
iven
so
und
synt
hesi
s:
timbr
e re
map
ping
. A
n ov
ervi
ew o
f au
dio-
driv
en s
ound
syn
thes
is te
chni
ques
impl
emen
ted
on d
eskt
op is
fir
st p
rese
nted
, with
par
ticul
ar fo
cus o
n tim
bre
rem
appi
ng te
chni
ques
. Fol
low
ing
a pr
evio
us
fram
ewor
k fo
r th
e ev
alua
tion
of
digi
tal
mus
ical
in
stru
men
ts,
the
inte
ract
ion
desi
gn g
oals
and
pos
sibl
e is
sues
are
con
text
ualiz
ed t
o th
e ca
se o
f a
mob
ile p
hone
pla
tform
. Whe
n ap
plie
d to
aud
io-d
riven
mob
ile m
usic
app
licat
ion,
th
ese
crite
ria i
ndic
ate
the
case
of
voic
e-dr
iven
sou
nd s
ynth
esis
as
a st
rong
ca
ndid
ate
for
the
crea
tion
of e
njoy
able
, sa
tisfy
ing
and
soci
al m
obile
mus
ic
inst
rum
ents
. For
that
, a d
esig
n fo
r a v
oice
-driv
en m
usic
al a
pplic
atio
n is
pro
pose
d.
1 IN
TR
OD
UC
TIO
N
Mod
ern
mob
ile p
hone
s em
bed
a gr
owin
g nu
mbe
r of
sen
sor
tech
nolo
gies
sui
tabl
e fo
r ef
fect
ive
cont
rolli
ng o
f m
usic
al a
pplic
atio
ns.
Than
ks t
o th
e in
crea
sing
com
puta
tiona
l po
wer
of
the
devi
ces,
pre-
exis
ting
map
ping
stra
tegi
es a
nd a
udio
syn
thes
is c
ontro
ls
desi
gned
on
non-
mob
ile p
latfo
rms a
re n
owad
ays “
at-h
and”
for m
obile
mus
ic a
pplic
atio
n de
velo
pers
. Am
ong
the
avai
labl
e se
nsor
y in
put (
for
an o
verv
iew
, see
for
inst
ance
Ess
l an
d R
ohs
2009
), th
e m
icro
phon
e is
the
old
est
to h
ave
appe
ared
but
onl
y re
cent
ly
expl
ored
in th
e co
ntex
t of m
usic
mak
ing.
The
app
eal o
f mob
ile p
hone
s as
mus
ic-m
aker
de
vice
s ar
e st
rong
ly l
inke
d to
int
egra
tion
of m
any
sens
or-te
chno
logi
es i
n a
gras
pabl
e an
d lig
ht d
evic
e. T
he d
egre
e of
int
erac
tivity
eac
h av
aila
ble
sens
or c
an p
rovi
de t
o th
e de
sign
er in
the
case
of m
usic
per
form
ance
has
bee
n an
alyz
ed (E
ssl,
& R
ohs,
2009
). Th
e au
thor
s do
not
pos
ition
the
mic
roph
one
in t
he d
esig
n sp
ace
othe
rwis
e oc
cupi
ed b
y ac
cele
rom
eter
s, ca
mer
a an
d so
forth
, bec
ause
of i
ts v
ersa
tility
that
doe
s no
t poi
nt to
any
sp
ecifi
c m
otor
ic a
ffor
danc
e. O
n th
e ot
her
hand
, a m
icro
phon
e-ba
sed
inte
ract
ion
mod
el
(MiM
us)
is p
rovi
ded
unde
rlyin
g th
e po
ssib
ility
to
deriv
e se
man
tic a
nd g
estu
ral
info
rmat
ion
from
aud
io in
put (
Essl
, & R
ohs,
2009
, 204
). M
isra
and
col
leag
ues
(200
8)
prop
osed
the
use
of th
e m
icro
phon
e of
a m
obile
pho
ne a
s a
high
-fid
elity
sen
sor t
hat c
an
prov
ide
addi
tiona
l sou
rce
of in
put t
o th
e de
velo
ping
fiel
d of
mob
ile p
hone
per
form
ance
. Fo
r th
at,
they
add
ed s
uppo
rt fo
r fu
ll-du
plex
aud
io i
nput
in
the
Mob
ileST
K a
nd
desc
ribed
som
e in
stru
men
t de
sign
bas
ed o
n th
e m
icro
phon
e-as
-sen
sor
conc
ept.
Not

2
surp
risin
gly,
the
pro
toty
pe b
ased
on
the
blow
ing
into
mic
roph
one
gest
ure
is n
ow a
co
mm
erci
al m
usic
al in
stru
men
t app
licat
ion
for t
he iP
hone
(Wan
g, 2
009)
. Th
is p
aper
is a
n ov
ervi
ew o
f th
e st
ate
of th
e ar
t of
curr
ent m
obile
mus
ic a
pplic
atio
ns
taki
ng a
dvan
tage
of a
udio
inpu
t. In
Sec
tion
2, a
con
cept
ual m
odel
of a
udio
-inpu
t aud
io-
outp
ut t
rans
form
atio
n w
ill b
e pr
ovid
ed.
A s
elec
tion
of e
xist
ing
appl
icat
ions
and
sy
nthe
sis
tech
niqu
es f
rom
ins
ide
and
outs
ide
the
wor
ld o
f m
obile
app
licat
ion
will
be
desc
ribed
, fo
cusi
ng o
n au
dio-
driv
en s
ound
syn
thes
is t
echn
ique
s. In
Sec
tion
3, t
he
prob
lem
of
ev
alua
ting
digi
tal
mus
ical
in
stru
men
ts
is
addr
esse
d.
Gui
delin
es
and
prin
cipl
es f
or n
on-m
obile
dig
ital m
usic
al in
stru
men
ts a
re c
onte
xtua
lized
to th
e ca
se o
f in
tera
ctio
n w
ith t
he m
obile
pho
ne d
evic
e Em
erge
nt t
hem
es a
nd t
heir
rela
tions
hip
are
disc
usse
d. I
n Se
ctio
n 4
the
audi
o-dr
iven
syn
thes
is te
chni
ques
will
be
pres
ente
d ag
ains
t th
ose
crite
ria,
play
abili
ty a
nd e
njoy
men
t, in
clud
ing
fact
ors
such
as
lear
ning
cur
ve,
degr
ees o
f con
trol,
resp
onsi
vene
ss a
nd e
xten
sibi
lity
of th
e m
usic
per
form
ed.
Fina
lly,
a pr
opos
ed d
esig
ned
for
a m
obile
mus
ic a
pplic
atio
n ba
sed
on v
oice
-driv
en
synt
hesi
s is
pre
sent
ed.
The
diff
eren
t co
mpo
nent
s of
the
app
licat
ion
are
dire
ctly
in
form
ed b
y th
e sp
ecifi
city
of
the
mod
ality
of
the
inte
ract
ion,
the
synt
hesi
s te
chni
que
empl
oyed
and
the
desi
gn p
rinci
ples
and
gui
delin
es d
raw
n.
2 A
UD
IO IN
PUT
– A
UD
IO O
UT
PUT
CO
NC
EPT
UA
L M
OD
EL
This
sec
tion
prov
ides
a h
igh-
leve
l m
odel
to
repr
esen
t th
e tra
nsfo
rmat
ion
from
aud
io-
inpu
t to
audi
o-ou
tput
. Whi
le th
e m
odel
is b
y no
mea
ns g
ener
al e
noug
h to
des
crib
e ev
ery
poss
ible
pre
sent
and
fut
ure
audi
o pr
oces
sing
tec
hniq
ue,
neve
rthel
ess
it ill
ustra
tes
the
two
poss
ible
stra
tegi
es a
ddre
ssed
in th
is p
aper
, tha
t are
sou
nd a
s co
ntro
ller a
nd s
ound
as
sour
ce. A
s it w
ill b
e cl
ear i
n la
ter s
ectio
ns, t
his e
xem
plifi
catio
n of
the
situ
atio
n w
ill h
elp
us id
entif
y a
sim
ple
taxo
nom
y fo
r diff
eren
t aud
io p
roce
ssin
g te
chni
ques
.
2.1
Def
inin
g th
e at
trib
utes
of t
rans
form
atio
n in
put-o
utpu
t
The
appr
oach
of u
sing
aud
io in
put t
o ge
nera
te a
udio
out
put i
s ve
ry g
ener
al, e
mbr
acin
g al
l cas
es o
f sou
nd p
roce
ssin
g. F
or th
is, i
n th
is s
ectio
n w
e lim
it th
e di
scus
sion
to a
udio
-dr
iven
app
licat
ion
that
is th
e ca
se o
f au
dio
outp
ut th
e cr
eatio
n of
whi
ch is
aff
ecte
d in
su
btle
or s
ubst
antia
l way
s by
the
audi
o in
put b
een
used
. Fi
gure
1 d
epic
ts a
blo
ck d
iagr
am t
hat
abst
ract
s tw
o m
ain
situ
atio
ns o
f au
dio
inpu
t –
audi
o ou
tput
tran
sfor
mat
ion.
Th
e fir
st c
hain
(top
of f
igur
e) is
the
case
of a
n au
dio
effe
ct. I
ts p
aram
eter
s ca
n be
sta
tic,
or c
ontro
lled
by m
eans
of a
GU
I, m
aybe
mim
icki
ng th
e an
alog
ue c
ount
erpa
rt if
any,
or
in m
ore
soph
istic
ated
cas
es, b
y ex
tract
ing
from
the
audi
o so
me
perc
eptu
al p
aram
eter
s (lo
udne
ss,
pitc
h, t
imbr
e-re
late
d),
furth
er m
appe
d to
the
pro
cess
ing
para
met
ers
of t
he
effe
ct.
This
is
the
case
for
ins
tanc
e of
a c
ompr
esso
r, or
a v
ocod
er o
r so
me
cust
om
solu
tions
. We
can
refe
r to
this
cas
e w
ith th
e na
me
of a
udio
-con
trolle
d au
gmen
tatio
n of
th
e au
dio
inpu
t, w
here
the
term
aug
men
tatio
n is
her
e us
ed to
indi
cate
a tr
ansf
orm
atio
n th
at p
rese
rves
to d
iffer
ent e
xten
ts th
e or
igin
al c
hara
cter
istic
s of t
he a
udio
inpu
t. Th
e se
cond
cha
in (
botto
m p
art)
repr
esen
ts a
udio
-driv
en s
ynth
esis
: by
ext
ract
ing
the
perc
eptu
al c
hara
cter
istic
s of
the
audi
o-in
put,
one
obta
ins
cont
rol p
aram
eter
s th
at d
rive
the
synt
hesi
s of
new
sou
nds.
The
cons
eque
nce
is t
hat
the
audi
o ou
tput
can
diff
er
sign
ifica
ntly
fro
m t
he o
rigin
al d
rivin
g so
und,
or
rese
mbl
ing
and
follo
win
g ce
rtain
as
pect
s of
it. T
he “
Synt
h” p
art,
inde
ed, c
ould
gre
atly
var
y fr
om v
ery
sim
ple
synt
hesi
s to
ph
ysic
al m
odel
ing.
In th
e fo
llow
ing
sect
ion
we
will
focu
s on
a pa
rticu
lar s
et o
f syn
thes
is

3
refe
rred
as T
imbr
e m
odel
and
Tim
bre
Rem
appi
ng.
Fig.
1. A
udio
Inp
ut –
aud
io o
utpu
t tra
nsfo
rmat
ion
mod
el. S
enso
r in
put i
s re
pres
ente
d bu
t not
dis
cuss
ed in
this
pap
er.
2.2
A p
anor
ama
of a
udio
-dri
ven
synt
hesi
s tec
hniq
ues
The
topi
c of
dig
ital a
udio
pro
cess
ing
and
digi
tal e
ffec
ts h
as a
lway
s be
en th
ere
sinc
e th
e di
gita
l m
ediu
m i
tsel
f. N
owad
ays,
real
-tim
e au
dio
proc
essi
ng o
ffer
s bo
th e
mul
atio
n of
or
igin
ally
ana
logu
e au
dio
effe
cts,
idio
sync
ratic
tec
hniq
ues
such
as
spec
tral
mod
elin
g an
d re
alis
tic p
hysi
cal
mod
elin
g of
rea
l in
stru
men
ts.
In t
he l
ast
deca
de a
udio
-driv
en
feat
ure
anal
ysis
-bas
ed s
ynth
esis
eng
ines
hav
e co
me
to t
he f
orth
. In
thes
e ap
proa
ches
ch
arac
teris
tics
of t
he i
nput
sou
nd,
feat
ures
, ar
e us
ed t
o “c
onst
ruct
” th
e so
und
of t
he
outp
ut.
2.2.
1 Ti
mbr
e m
odel
Jeha
n (2
001)
dev
elop
ed a
tim
bre
mod
el t
hat
can
be u
sed
as a
cre
ativ
e to
ol b
y pr
ofes
sion
al m
usic
ians
pla
ying
an
arbi
trary
con
trolle
r in
stru
men
t. H
is h
yper
-vio
lin, f
or
inst
ance
, use
s a
stan
dard
vio
lin a
s th
e so
und
inpu
t for
the
synt
hesi
s en
gine
; per
cept
ual
feat
ures
suc
h as
pitc
h, lo
udne
ss a
nd b
right
ness
are
ext
ract
ed f
rom
the
audi
o st
ream
of
the
cont
rolle
r in
stru
men
t an
d dr
ive
the
mod
el.
The
audi
o ou
tput
stre
am c
onta
ins
iden
tical
mus
ical
con
tent
(pe
rcep
tual
cha
ract
eris
tics
of lo
udne
ss, b
right
ness
and
pitc
h)
but w
ith a
diff
eren
t tim
bre.
The
mod
el is
ulti
mat
ely
a tim
bre
mod
el (i
bid.
p. 3
2), w
here
an
inpu
t vec
tor d
escr
ibin
g pi
tch,
loud
ness
, and
brig
htne
ss, a
nd o
utpu
t vec
tor c
onta
inin
g fr
eque
ncy
and
ampl
itude
val
ues a
re u
sed
to tr
ain
a fe
ed-f
orw
ard
inpu
t-out
put n
etw
ork
to
pred
ict f
requ
enci
es a
nd a
mpl
itude
s. In
real
-tim
e, a
new
stre
am o
f aud
io in
put d
ata
feed
s th
e tim
bre
pred
ictio
n an
d au
dio-
driv
en s
ynth
esis
and
the
perc
eptu
al c
ontro
l fea
ture
s ar
e ex
tract
ed. A
non
linea
r pre
dict
or fu
nctio
n ou
tput
s th
e m
ost s
uite
d ve
ctor
of s
pect
ral d
ata
for t
hat i
nput
in re
al ti
me.
Th
is a
ppro
ach
to a
udio
-driv
en s
ynth
esis
off
ers
man
y in
tere
stin
g pr
os fo
r the
des
ign
of a
m
usic
app
licat
ion:
•
It ha
s be
en c
once
ptua
lized
to
augm
ent
any
kind
of
acou
stic
ins
trum
ent,
even
vo
ice,
by
keep
ing
the
inst
rum
ent i
tsel
f as
a co
ntro
ller o
f wel
l-kno
wn
phys
ical
ity
for
the
mus
icia
n. T
his
is p
artic
ular
ly r
elev
ant
for
the
case
of
a m
obile
pho
ne,
whi
ch d
oes n
ot o
ffer
any
phy
sica
l mus
ical
aff
orda
nces
bes
ide
the
mic
roph
one.

4
• It
offe
rs p
ossi
bilit
y fo
r cr
oss-
synt
hesi
s of
all
kind
: tra
inin
g w
ith a
cer
tain
in
stru
men
t an
d dr
ivin
g w
ith a
noth
er o
ne,
for
exam
ple,
a s
inge
r co
ntro
ls t
he
mod
el o
f a S
tradi
variu
s vio
lin o
r vic
e ve
rsa.
•
It of
fers
pos
sibi
lity
for m
orph
ing
acro
ss d
iffer
ent t
imbr
e m
odel
s. •
It is
sca
labl
e-do
wn
to i
ncre
ase
perf
orm
ance
(he
re l
aten
cy)
on l
ess
pow
erfu
l sy
stem
s by
redu
cing
the
num
ber o
f add
itive
com
pone
nts o
f the
out
put.
Con
s:
Po
tent
ially
com
puta
tiona
lly e
xpen
sive
2.2.
2 Ti
mbr
e re
map
ping
Stow
ell (
2010
) inv
estig
ated
del
ayed
dec
isio
n-m
akin
g in
real
-tim
e cl
assi
ficat
ion
of a
udio
in
put,
as a
stra
tegy
to o
verc
ome
the
late
ncy
of c
lass
ifica
tion
in m
achi
ne le
arni
ng sy
stem
. In
the
case
of a
udio
out
put c
onsi
stin
g of
pre
-rec
orde
d sa
mpl
es to
be
trigg
ered
acc
ordi
ng
to th
e au
dio
inpu
t, St
owel
l sho
ws
that
trig
gerin
g a
degr
aded
ver
sion
of
a dr
um s
ound
w
hile
the
syst
em c
orre
ctly
cla
ssifi
es th
e so
und
inpu
t and
then
trig
gers
the
appr
opria
te
soun
d, is
per
cept
ually
acc
epta
ble
(Sto
wel
l, 20
10, p
. 91)
. A d
elay
of 2
3 m
s is
sug
gest
ed
as a
goo
d tra
de-o
ff b
etw
een
clas
sific
atio
n ac
cura
cy a
nd r
eal-t
imen
ess
in t
he c
ase
of
drum
soun
ds.
As
an a
ltern
ativ
e to
the
even
t-bas
ed p
arad
igm
con
side
red
abov
e, ti
mbr
e re
map
ping
is
anot
her
appr
oach
to
synt
hesi
s w
here
tim
bral
inp
ut i
s m
appe
d to
the
syn
thes
izer
pa
ram
eter
s by
a r
eal-t
ime
map
ping
bet
wee
n tw
o tim
bre
spac
es (
Stow
ell,
2010
, cha
pter
5)
. Ti
mbr
al r
emap
ping
has
bee
n ap
plie
d to
the
cas
e of
Con
cate
nativ
e Sy
nthe
sis
(Sch
war
z, 2
007)
. Th
e id
ea b
ehin
d co
ncat
enat
ive
synt
hesi
s or
aud
io-m
osai
cing
is
to
crea
te n
ew a
udio
fro
m s
egm
ents
of
usua
lly 1
00m
s ex
tract
ed b
y au
dio
reco
rdin
gs. T
he
segm
ents
are
aut
omat
ical
ly o
btai
ned
and
anno
tate
d in
ter
ms
of s
ound
fea
ture
s an
d st
ored
in a
dat
abas
e. In
real
-tim
e, th
e au
dio
is o
btai
ned
by e
xplo
ring
the
n-di
men
sion
al
spac
e po
pula
ted
by t
he s
egm
ents
acc
ordi
ng t
o so
me
crite
ria t
hat
dete
rmin
es t
he
traje
ctor
y in
that
spa
ce. T
he e
xplo
ratio
n ca
n be
driv
en b
y au
dio-
inpu
t whi
ch is
ana
lyze
d so
to e
xtra
ct th
e fe
atur
es to
be
rem
appe
d in
to th
e au
dio
pres
ent i
n th
e da
taba
se. I
n su
ch a
w
ay,
hybr
id s
ynth
esis
tec
hniq
ues
are
poss
ible
by
driv
ing
the
syst
em w
ith s
ome
char
acte
ristic
s of
an
inst
rum
ent u
sed
to s
earc
h si
mila
r con
tent
in th
e da
taba
se o
f sou
nd,
som
etim
es re
ferr
ed to
as “
corp
us”.
V
oice
-driv
en s
ynth
esis
has
bee
n ex
tend
ed t
o au
dio-
mos
aici
ng b
y Ja
ner
(200
8).
The
syst
em p
rovi
des
the
user
with
voc
al c
ontro
l cap
abili
ties
over
con
cate
nativ
e sy
nthe
sis
by
rem
appi
ng t
imbr
e pr
esen
t in
the
voi
ce w
ith t
imbr
e pr
esen
t in
the
cor
pus.
Sim
ilar
to
Stow
ell’s
app
roac
h, e
mph
asis
is
give
n he
re t
o th
e lo
opin
g of
the
rem
appe
d sy
llabl
es
extra
cted
fro
m t
he v
oice
and
lay
erin
g of
the
m t
o cr
eate
com
plex
stru
ctur
es.
The
impl
emen
tatio
n w
orks
with
1 lo
op d
elay
.
2.3
Sele
ctio
n of
the
soun
d m
ater
ial
As
alre
ady
men
tione
d, f
rom
the
audi
o si
gnal
, one
cou
ld e
xtra
ct q
ualit
y of
the
gest
ure
prod
ucin
g th
at s
ound
, suc
h as
exc
itatio
n ge
stur
e, i
nsta
ntan
eous
or
cont
inuo
us (
Cad
oz
and
Wan
derle
y, 2
000)
. Thi
s is
the
tre
nd i
n th
e co
ntex
t of
mus
ical
ins
trum
ent
desi
gn
base
d on
the
conc
ept o
f en
actio
n an
d th
e hy
poth
esis
of
wea
k se
nsor
imot
or in
tegr
atio
n (E
ssl a
nd O
’Mod
hrai
n, 2
006,
p. 2
88),
i.e. i
t is
assu
med
the
real
wor
ld s
uppo
rts s
ome
amou
nt o
f fle
xibi
lity
in th
e co
uplin
g of
act
ion
and
sens
ory
resp
onse
. For
inst
ance
the
auth
ors
prop
osed
the
cas
e of
det
ectin
g co
llisi
on s
ound
s to
driv
e gr
anul
ar s
ynth
esis
(O
’Mod
hrai
n an
d Es
sl,
2004
) or
scr
atch
ing
to s
ense
mot
ion
dire
ctio
n an
d pr
oduc
e

5
fric
tiona
l sou
nds (
Essl
and
O’M
odhr
ain,
200
5).
The
enac
tive
appr
oach
for t
he d
esig
n of
inte
rfac
es ta
ckle
s an
issu
e em
ergi
ng in
the
field
of
New
Int
erfa
ces
for
Mus
ical
Exp
ress
ion
(NIM
E) d
esig
n: th
e la
ck o
f ph
ysic
ality
and
fe
lt co
uplin
g be
twee
n th
e so
urce
pro
duci
ng g
estu
re a
nd t
he s
ound
pro
duce
d. T
he
ques
tion
whe
ther
mob
ile p
hone
s ca
n ev
er b
ecom
e m
usic
al i
nstru
men
t or
jus
t to
y-lik
e m
usic
al a
pplic
atio
n re
mai
ns q
uite
ope
n. N
ever
thel
ess,
thes
e en
activ
e in
terf
aces
sho
w
how
car
eful
aug
men
tatio
n of
the
sou
nd a
nd a
dded
phy
sica
lity
by m
eans
of
hapt
ic
feed
back
or
phys
ical
-bas
ed b
ehav
ior
(fric
tion
betw
een
mat
eria
ls,
shak
ing
gest
ure
to
prod
uce
colli
sion
sou
nds,
resp
ectiv
ely)
circ
umve
nt i
ssue
s ty
pica
l of
fre
e-ai
r ge
stur
al
cont
rolle
r. Th
e us
e of
car
eful
ly c
rafte
d ha
ptic
s fe
edba
ck w
ould
be
kind
ly w
elco
me
but
tech
nolo
gy o
f pre
sent
mob
ile p
hone
s of
fer i
t onl
y pa
rtial
ly d
ue to
the
sens
or te
chno
logy
em
bedd
ed.
Mor
eove
r, th
ese
enac
tive
inte
rfac
e de
sign
s re
quire
add
ed p
hysi
calit
y th
at
wou
ld b
e pr
obab
ly u
npra
ctic
al in
the
case
of
the
mob
ile p
hone
. For
thes
e re
ason
s, th
e pr
esen
t ove
rvie
w w
ill n
ot c
onsi
der t
his a
ppro
ach
any
furth
er.
Envi
ronm
enta
l so
unds
as
audi
o in
put
has
been
use
d as
one
pot
entia
l ca
se o
f th
e iO
S pl
atfo
rm R
jDj1 . T
his
appl
icat
ion
is a
ful
ly f
unct
iona
l por
t of
Pure
Dat
a2 whi
ch c
an r
un
patc
hes
deve
lope
d on
the
orig
inal
ver
sion
of
the
prog
ram
with
the
add
ed b
onus
of
offe
ring
supp
ort
for
touc
h in
put,
acce
lero
met
ers
and
othe
r av
aila
ble
sens
ors.
Whi
le
som
e pa
tche
s ar
e in
spire
d by
the
idea
of r
e-co
ntex
tual
izin
g th
e ex
perie
nce
of a
pla
ce b
y pr
oces
sing
th
e so
und
of
the
envi
ronm
ent,
othe
rs
prop
ose
mor
e in
stru
men
t-lik
e in
tera
ctio
n. F
or t
he p
urpo
se o
f th
is s
urve
y, R
jDj
repr
esen
ts o
nly
a sa
ndbo
x fo
r fa
st
prot
otyp
ing
of m
usic
app
licat
ion
idea
s ra
ther
than
a p
artic
ular
syn
thes
is te
chni
que
that
in
form
s th
e in
stru
men
t des
ign
and
the
inte
ract
ion
with
it. I
t is
wor
th o
bser
ving
that
the
emph
asis
in a
pla
tform
suc
h as
RjD
j is
to b
uilt
a co
mm
unity
aro
und
it, b
oth
user
s an
d de
velo
pers
, an
d of
fer
the
poss
ibili
ty t
o sh
are
and
sell
patc
hes
thus
cre
atin
g a
mic
ro-
mar
ket w
ithin
the
maj
or m
arke
t of t
he m
obile
pho
ne a
pp st
ore.
Whi
le th
ese
obse
rvat
ions
ar
e re
leva
nt f
rom
a m
arke
ting
or p
rodu
ct p
lace
men
t po
int
of v
iew
, w
e be
lieve
the
m
negl
igib
le fo
r dra
win
g de
sign
prin
cipl
es o
f the
dig
ital m
usic
inst
rum
ent i
tsel
f.
3 IN
TE
RA
CT
ING
WIT
H T
HE
DE
SIG
N: A
MA
TT
ER
OF
EN
JOY
ME
NT
AN
D
PLA
YA
BIL
ITY
Bef
ore
desc
ribin
g po
ssib
le
impl
emen
tatio
n on
m
obile
pl
atfo
rm
of
the
soun
d sy
nthe
sis
desc
ribed
bef
ore,
it
is w
orth
und
erst
andi
ng w
hich
are
the
des
ign
prin
cipl
es
insp
iring
the
con
cept
and
rea
lizat
ion
of a
dig
ital
mus
ical
ins
trum
ent
in g
ener
al.
Prin
cipl
es a
nd g
uide
lines
info
rm th
e de
sign
and
sug
gest
als
o cr
iteria
for
its
eval
uatio
n.
Eval
uatin
g th
e de
sign
of
a di
gita
l m
usic
al i
nstru
men
t (D
MI)
is
by n
o m
eans
an
easy
ta
sk. A
sur
vey
of re
cent
rese
arch
pap
ers
pres
ente
d at
the
conf
eren
ce o
n N
IME
show
s a
cons
iste
ntly
low
pro
porti
on o
f pa
pers
con
tain
ing
form
al e
valu
atio
ns (
Stow
ell,
2009
). Th
e di
ffic
ulty
of
the
eval
uatio
n m
ainl
y ar
ises
due
to
the
com
plex
nat
ure
of t
he
expe
rienc
e of
mus
ic m
akin
g w
hich
can
be
hard
ly sy
stem
atiz
ed a
s a se
t of t
asks
in w
hich
th
e ac
tiviti
es in
volv
ed c
an b
e m
easu
red
quan
titat
ivel
y. N
ever
thel
ess,
seve
ral a
utho
rs a
re
dire
ctin
g th
eir s
ight
s to
war
ds th
e m
etho
ds o
f hum
an-c
ompu
ter i
nter
actio
n (H
CI)
. In
the
last
yea
rs H
CI
addr
esse
d th
e la
ck o
f pa
radi
gm a
ble
to f
it th
e do
mai
n of
non
- ta
sk-
orie
nted
com
putin
g an
d a
third
par
adig
m o
f H
CI
is b
elie
ved
to b
e em
erge
d by
som
e
1 RjD
j By
Rea
lity
Jock
ey L
td. h
ttp://
rjdj.m
e 2 P
ureD
ata,
– R
eal-t
ime
grap
hica
l dat
aflo
w p
rogr
amm
ing
envi
ronm
ent f
or a
udio
, vid
eo,
and
grap
hica
l pro
cess
ing.
http
://pu
reda
ta.in
fo/

6
(Har
rison
et a
l., 2
007)
. Thi
s th
ird w
ave
focu
ses
on e
mbo
died
inte
ract
ion,
mea
ning
and
m
eani
ng c
onst
ruct
ion,
in s
peci
fic c
onte
xts
and
situ
atio
ns (H
arris
on e
t al.,
200
7, p
. 7).
In
the
next
sec
tion
we
will
see
how
thes
e tre
nds
are
influ
enci
ng th
e m
etho
ds o
f eva
luat
ion
in th
e ca
se o
f DM
Is.
3.1
Eva
luat
ing
DM
Is
O’M
odhr
ain
prop
oses
a f
ram
ewor
k fo
r th
e ev
alua
tion
of d
igita
l m
usic
ins
trum
ents
(O
’Mod
hrai
n, 2
011)
. Dep
endi
ng o
n th
e pe
rspe
ctiv
e on
the
desi
gn, d
iffer
ent s
take
hold
ers
diff
eren
tly e
valu
ate
and
shap
e th
e fin
al d
esig
n. I
n Ta
ble
1, t
he c
ateg
orie
s au
dien
ce,
mus
ic-m
aker
(pe
rfor
mer
/com
pose
r) a
nd d
esig
ner
need
to a
sses
s tw
o di
men
sion
s of
the
expe
rienc
e of
pla
ying
the
inst
rum
ent,
enjo
ymen
t and
pla
yabi
lity,
with
diff
eren
t met
hods
du
e to
the
fac
t th
eir
goal
s as
act
ors
of t
he o
vera
ll lif
e-cy
cle
of t
he i
nstru
men
t ar
e di
ffer
ent.
The
tabl
e is
ver
y in
form
ativ
e to
sum
mar
ize
the
goal
s th
e st
akeh
olde
rs s
houl
d ha
ve i
n m
ind
whe
n ev
alua
ting
the
desi
gn.
Whe
ther
the
ana
lysi
s is
qua
ntita
tive
or
qual
itita
tive
the
core
issu
e is
whi
ch d
imen
sion
s are
the
one
to b
e ev
alua
ted.
Tabl
e 1:
Ada
ptat
ion
of O
’Mod
hrai
n (2
011)
Met
hods
Use
d by
Diff
eren
t Sta
keho
lder
s for
Ev
alua
ting
DM
I D
esig
ns:
Poss
ible
eva
luat
ion
Goa
ls.
The
last
tw
o co
lum
ns o
f th
e or
igin
al ta
ble
are
omitt
ed b
ecau
se c
onsi
dere
d no
t rel
evan
t in
the
scop
e of
this
pap
er.
Stak
ehol
der
E
njoy
men
t Pl
ayab
ility
A
udie
nce
cr
itiqu
e, re
flect
ion,
qu
estio
nnai
res,
obse
rvat
iona
l stu
dies
expe
rimen
ts c
once
rnin
g m
enta
l mod
els
Perf
orm
er/ C
ompo
ser
refle
ctiv
e pr
actic
e,
deve
lopm
ent o
f rep
erto
ire,
long
-term
eng
agem
ent
(long
itudi
nal s
tudy
?)
quan
titat
ive
met
hods
for
eval
uatio
n of
use
r int
erfa
ce,
map
ping
, etc
.
Des
igne
r ob
serv
atio
n, q
uest
ionn
aire
, In
form
al fe
edba
ck
quan
titat
ive
met
hods
for
user
inte
rfac
e ev
alua
tion
3.1.
1 Pl
ayab
ility
For
wha
t co
ncer
ns p
laya
bilit
y, a
ppro
ache
s on
the
lin
e of
usa
bilit
y te
st a
re w
ell
acce
pted
(W
ande
rlay,
Orio
, 200
2). T
hese
aut
hors
sug
gest
tha
t re
leva
nt f
eatu
res
to b
e te
sted
mig
ht i
nclu
de l
earn
abili
ty,
expl
orab
ility
, fe
atur
e co
ntro
llabi
lity,
and
tim
ing
cont
rolla
bilit
y. T
his
appr
oach
is w
ell s
uite
d fo
r com
parin
g di
ffer
ent d
esig
n al
tern
ativ
es
and
asse
ssin
g th
e re
liabi
lity
of t
he c
oupl
ing
betw
een
user
int
erac
tion
and
mus
ical
ou
tcom
e. N
ever
thel
ess,
sche
mat
izin
g th
e in
tera
ctio
n un
der
disc
ussi
on i
nto
segm
ente
d m
icro
-task
s se
ems
still
insu
ffic
ient
. The
inst
rum
ents
sho
uld
prov
ide
the
play
er w
ith th
e ne
cess
ary
amou
nt o
f co
ntro
l st
ill s
uppo
rt di
ffer
ent
mus
ical
app
roac
hes
and
styl
es
allo
win
g th
e pe
rfor
mer
to re
aliz
e th
e m
usic
al g
oal.
For t
hat,
Jord
a (2
004)
intro
duce
s th
e co
ncep
t of d
iver
sity
that
is th
e ab
ility
of t
he in
stru
men
t to
supp
ort b
oth
mac
ro d
iver
sity
(“
Mac
D”)
, or
styl
istic
div
ersi
ty, a
s w
ell
as M
id d
iver
sity
(“M
idD
”), o
r “p
erfo
rman
ce
dive
rsity
,” th
at e
xpre
sses
the
degr
ee to
whi
ch tw
o pe
rfor
man
ces
on th
e sa
me
inst
rum
ent
can
diff
er a
nd th
e M
icro
div
ersi
ty (“
Mic
D”)
, the
leve
l of t
he n
uanc
es.
3.1.
2 En
joym
ent a
nd fl
ow
The
need
for e
valu
atin
g ex
perie
nce
com
es d
irect
ly fr
om H
CI a
pplie
d to
all
new
form

7
of m
ulti-
mod
al in
tera
ctio
n. W
ithin
this
goa
l, th
e id
ea o
f enj
oym
ent c
omes
to th
e fo
re fo
r th
e na
ture
of m
usic
exp
erie
nce
and
mus
ic-m
akin
g w
ith a
n in
stru
men
t, w
hen
the
goal
s of
the
inte
ract
ion
are
eith
er n
ot c
lear
ly s
tate
d, o
r the
y co
ncur
in a
non
-obv
ious
way
to th
e ov
eral
l exp
erie
nce.
The
cur
rent
tren
ds in
HC
I try
to d
efin
e w
hat e
lem
ents
nee
d to
be
cons
ider
ed in
mod
elin
g us
er e
xper
ienc
e. In
the
case
of v
ideo
gam
e, S
wee
tser
and
Wye
th
(200
5) h
ave
deve
lope
d a
mod
el o
f “ga
me
flow
” fo
r eva
luat
ing
enjo
ymen
t of g
ame
play
. Th
e ga
me
flow
is
mod
eled
as
the
com
bina
tion
of e
ight
ele
men
ts –
con
cent
ratio
n,
chal
leng
e, s
kills
, con
trol,
clea
r go
als,
feed
back
, im
mer
sion
, and
soc
ial i
nter
actio
n. F
or
each
of
thes
e fa
ctor
s a
set
of c
riter
ia f
or a
chie
ving
enj
oym
ent
in g
ames
is
prop
osed
. U
sual
ly th
ese
stud
ies
requ
ire lo
ngitu
dina
l stu
dy, w
here
the
perio
d of
obs
erva
tion
of th
e ex
perie
nce
can
span
from
man
y se
ssio
ns to
wee
ks o
r mon
ths.
3.2
Des
ign
prin
cipl
es sp
ecifi
c to
the
mob
ile in
terf
ace
The
desi
gner
of
a m
usic
app
licat
ion
for
mob
ile p
hone
fac
es c
onst
rain
ts a
nd
affo
rdan
ces
com
ing
from
the
inte
rfac
e it
has
to d
eal w
ith. F
or in
stan
ce, m
obile
pho
nes
are
gras
pabl
e an
d lig
ht, a
nd h
ave
very
adv
ance
d gr
aphi
cs a
nd m
ultit
ouch
cap
abili
ties.
On
the
othe
r ha
nd t
hey
are
not
mus
ical
ins
trum
ents
per
-se
thus
the
cou
plin
g so
und-
prod
ucin
g ge
stur
e an
d so
und
outp
ut n
eeds
to b
e cr
eate
d by
usi
ng th
e av
aila
ble
sens
or
tech
nolo
gies
, for
ins
tanc
e us
e of
hap
tics
to e
nfor
ce s
enso
rimot
or i
nteg
ratio
n, s
ensi
ble
map
ping
and
so
forth
. Mor
eove
r if
the
desi
gn r
elie
s on
inte
ract
ion
thro
ugh
touc
h of
a
grap
hica
l us
er i
nter
face
(G
UI)
, the
ges
tura
l co
ntro
ller
capa
bilit
ies
cann
ot b
e ex
plor
ed
fully
. Ey
es-f
ree
inte
ract
ion
is u
sual
ly d
esire
d in
the
cas
e of
a m
usic
al i
nstru
men
t be
caus
e it
free
s th
e pe
rfor
mer
s fr
om f
ocus
ing
on th
e in
terf
ace
and
conc
entra
te o
n th
e m
usic
al g
oals
and
pla
y to
geth
er w
ith o
ther
s. A
n in
stru
men
t tha
t can
be
play
ed w
ithou
t de
eply
rel
ying
on
visu
al c
ues
stro
ngly
nee
ds t
o su
ppor
t th
e de
velo
pmen
t of
mus
cle
mem
ory
thro
ugh
train
ing.
Th
ose
aspe
cts
affe
ct
dire
ctly
di
men
sion
s su
ch
as
cont
rolla
bilit
y, le
arna
bilit
y an
d lo
ngev
ity o
f the
inst
rum
ent.
3.3
Issu
es a
nd o
ppor
tuni
ties s
peci
fic to
the
mob
ility
The
porta
bilit
y of
the
devi
ce a
nd it
s pol
yval
ence
, as a
pho
ne, a
s a c
ompu
ter,
as a
tool
, as
a m
usic
al in
stru
men
t, ha
ve a
n ef
fect
on
the
prac
tices
ass
ocia
ted
with
it. M
aybe
it is
to
o m
uch
to a
sk f
rom
a m
ultip
urpo
se p
latfo
rm t
o be
use
d as
a s
ophi
stic
ated
and
de
man
ding
inst
rum
ent a
nyw
ay. I
t see
ms
mor
e lik
ely
and
mor
e pr
esen
t on
the
mar
ket a
ga
min
g at
titud
e to
war
ds m
obile
mus
ic a
pplic
atio
n th
at p
rivile
ges
fun
and
casu
al p
layi
ng
over
virt
uosi
ty.
The
num
erou
s m
obile
pho
ne o
rche
stra
and
ens
embl
es o
ff-s
prin
ging
fr
om d
iffer
ent a
cade
mic
inst
itutio
ns a
nd e
lsew
here
are
the
cons
eque
nce
of th
e ea
se o
f sh
arin
g th
e m
usic
al e
xper
ienc
e ra
pidl
y an
d in
form
ally
. M
oreo
ver,
the
ubiq
uito
us
conn
ectiv
ity o
f th
e de
vice
brin
gs f
orth
new
eff
ectiv
e an
d ef
ficie
nt w
ays
of e
valu
atin
g cu
stom
er s
atis
fact
ion.
Man
y qu
antit
ativ
e in
dica
tors
can
be
extra
cted
from
the
use
of th
e ap
plic
atio
n, l
ogge
d an
d se
nt t
o a
cent
raliz
ed s
yste
m a
ble
to a
ggre
gate
the
res
ults
, co
mpa
re a
nd i
nfor
m t
he d
esig
n de
cisi
on f
or f
utur
e re
leas
es o
r m
inor
fix
es o
f th
e ap
plic
atio
n. T
he O
carin
a by
Sm
ule3 ,
for
inst
ance
, al
low
s re
cord
ing
and
shar
ing
the
mel
odie
s cr
eate
d by
the
use
r. In
tur
ns,
info
rmat
ion
abou
t th
e us
age
of t
he m
obile
in
stru
men
t ar
e av
aila
ble
to t
he d
evel
oper
s: o
n th
e in
divi
dual
lev
el t
hey
can
obta
in
play
ing
habi
ts, s
kills
, var
iety
of t
he re
perto
ire s
o fa
r pla
yed
and,
on
a m
acro
leve
l, th
ey
can
try t
o as
sess
how
the
int
ende
d de
sign
ed p
ract
ice
of t
he i
nstru
men
t m
atch
es t
he
3 Sm
ule:
Exp
erie
nce
Soci
al M
usic
, http
://w
ww
.smul
e.co
m/

8
curr
ent a
vera
ge u
ser.
Thes
e in
dica
tors
can
be
furth
er u
sed
to in
fer e
vent
ual f
law
s of
the
desi
gn.
Als
o di
rect
fee
dbac
k an
d co
mm
ents
of
the
user
s ar
e ve
ry v
alua
ble
and
inex
pens
ive
indi
catio
ns to
impr
ove
the
desi
gn it
erat
ivel
y.
4 A
UD
IO-D
RIV
EN
SY
NT
HE
SIS
MU
SIC
APP
LIC
AT
ION
ON
MO
BIL
E
PHO
NE
: A P
RO
POSE
D D
ESI
GN
In S
ectio
n 3,
an
over
view
of e
valu
atio
n m
etho
ds a
nd d
esig
n pr
inci
ples
of D
MIs
was
pr
ovid
ed,
toge
ther
with
the
im
plic
atio
ns o
f de
sign
ing
for
a m
obile
dev
ice.
With
thi
s fr
amew
ork
in m
ind,
we
are
now
read
y to
pos
ition
aud
io-d
riven
synt
hesi
s in
this
con
text
, an
d in
par
ticul
ar v
oice
-driv
en s
ynth
esis
. The
latte
r app
ears
pro
mis
ing
for t
he c
onte
xt o
f m
obile
mus
ic a
pplic
atio
ns b
ecau
se s
uita
ble
to a
ddre
ss s
peci
fic is
sues
of a
mob
ile m
usic
ex
perie
nce.
4.1
Voi
ce-d
rive
n tim
bre
rem
appi
ng
The
timbr
e-re
map
ping
tec
hniq
ues
desc
ribed
in
Sect
ion
2 ar
e al
l w
ell
equi
pped
to
prov
ide
the
play
er w
ith v
arie
ty a
nd e
xten
dibi
lity.
We
disc
uss
here
the
cas
e of
voi
ce-
driv
en s
ynth
esis
in w
hich
voi
ce in
put i
s an
alyz
ed r
eal-t
ime
to e
xtra
ct s
ome
perc
eptu
al
para
met
ers
rela
ted
to
loud
ness
, pi
tch
and
timbr
e.
In
the
case
of
co
rpus
-bas
ed
conc
aten
ativ
e sy
nthe
sis
thes
e pa
ram
eter
s ar
e re
map
ped
to a
nalo
gous
fea
ture
s of
the
so
unds
pre
sent
in th
e co
rpus
. The
them
es e
mer
ging
from
Sec
tion
3 ar
e lis
ted
belo
w a
nd
addr
esse
d fo
r thi
s sy
nthe
sis
in o
rder
to p
rovi
de th
e re
ader
with
a d
iscu
rsiv
e m
otiv
atio
n fo
r re
com
men
ding
vo
ice-
driv
en
synt
hesi
s ba
sed
appl
icat
ion
for
mob
ile
mus
ic
appl
icat
ions
.
4.1.
1 Pl
ayab
ility
Whe
n dr
iven
by
hum
an v
oice
, th
e us
e of
the
mic
roph
one
does
not
sub
stan
tially
ch
ange
the
natu
re o
f the
mob
ile p
hone
, int
rodu
cing
issu
es re
late
d to
lack
of p
hysi
calit
y of
the
ins
trum
ent
or f
indi
ng j
ustif
icat
ion
to t
he m
appi
ng o
f ge
stur
es t
o so
unds
. M
icro
phon
e is
a w
ell-a
ccep
ted
“med
iato
r” w
hich
is li
kely
to d
isap
pear
whe
n on
e ta
lks
and
sing
s int
o it.
4.1.
2 Le
arna
bilit
y
Voi
ce c
an c
reat
e an
inc
redi
ble
varie
ty o
f so
unds
, w
hich
can
be
exte
nded
with
ex
erci
se. R
athe
r tha
n le
arni
ng a
new
inte
rfac
e to
mak
e so
und,
the
play
er c
an e
xplo
re a
nd
impr
ove
her
own
cont
rol
of t
he s
ound
sou
rce
for
the
synt
hesi
s, th
e vo
ice,
fur
ther
m
odifi
ed b
y th
e tim
bre
rem
appi
ng. W
hile
the
inst
rum
ent d
efin
itely
sat
isfy
the
gene
ral
prin
cipl
e “i
nsta
nt m
usic
, sub
tlety
late
r” (C
ook,
200
1), o
n th
e ot
her h
and
the
play
er c
an
expl
ore
at fi
rst a
lim
ited
subs
pace
of t
imbr
e sp
ace
and
disc
over
by
prac
ticin
g ne
w v
ocal
te
chni
ques
rem
ote
corn
ers
of th
e ou
tput
spa
ce. C
ontro
l and
div
ersi
ty c
oexi
st p
rovi
ding
fir
st im
med
iacy
, the
n ex
perim
enta
tion
and,
at l
ater
sta
ges,
man
agem
ent o
f nu
ance
s. In
th
is w
ay,
the
exte
ndib
ility
of
the
soun
d ou
tput
whi
le k
eepi
ng t
he s
ame
inte
ract
ion
para
digm
aff
ords
a m
ore
inst
rum
ent-l
ike
lear
ning
cur
ve. M
oreo
ver,
it is
like
ly th
at s
kill
lear
nt f
or a
cer
tain
cor
pus
can
be t
rans
ferr
ed t
o a
diff
eren
t se
t of
sou
nd s
ince
the
in
tera
ctio
n is
em
bodi
ed r
athe
r th
an s
ymbo
lic, i
.e. n
ot r
elyi
ng o
n ic
ons
on s
cree
n to
be
touc
hed
or m
oved
in a
GU
I fas
hion
. As
a co
nseq
uenc
e m
ajor
issu
es o
f acc
essi
bilit
y ar
e al
so o
verc
ome.

9
4.1.
3 So
cial
-inte
ract
ion
and
prac
tices
Dis
cuss
ing
the
soci
al d
imen
sion
of
a m
usic
exp
erie
nce
is o
utsi
de th
e sc
ope
of th
is
pape
r. N
ever
thel
ess,
if on
e lo
oks
at th
e pe
rfor
mer
per
spec
tive,
the
poss
ibili
ty o
f sha
ring
the
mus
ic-m
akin
g ac
tivity
with
fel
low
s is
hig
hly
desi
rabl
e. M
oreo
ver,
a m
usic
al
inst
rum
ent a
nd p
ract
ices
bou
nd to
it a
re m
ore
likel
y to
co-
evol
ve in
tim
e if
thei
r use
is
diff
used
in
ense
mbl
es o
r co
llect
ive
situ
atio
ns,
rath
er t
han
isol
ated
ins
tanc
es.
On
one
hand
, be
at-b
oxin
g is
now
aday
s a
disc
iplin
e st
udie
d in
aca
dem
ic e
nviro
nmen
t an
d ex
tend
ed
tech
niqu
es
spec
ific
for
voic
e ha
ve
a lo
ng
tradi
tion
in
the
hist
ory
of
cont
empo
rary
mus
ic. O
n th
e ot
her
hand
, suc
cess
ful
mus
ic g
ames
on
cons
ole
such
as
Gui
tar H
ero
or S
ing
Star
dem
onst
rate
s th
at th
e pa
rty-g
ame
form
at is
wel
l acc
epte
d an
d es
tabl
ishe
d fo
r hom
e en
terta
inm
ent.
Thou
gh n
ot m
uch
mor
e th
an a
spe
cula
tion,
it is
not
to
o m
uch
of a
lea
p of
fai
th t
o be
lieve
tha
t vo
ice-
cont
rolle
d m
obile
mus
ic a
pplic
atio
n w
ill n
ot o
ffer
a h
igh
thre
shol
d of
acc
epta
nce
from
the
user
.
4.2
A p
ropo
sed
desi
gn
Just
at
the
leve
l of
con
cept
pro
toty
ping
, a
mob
ile m
usic
app
licat
ion
and
its m
ain
func
tiona
litie
s ar
e pr
opos
ed.
The
appl
icat
ion
coul
d be
im
plem
ente
d an
d ev
alua
ted
to
asse
ss th
e qu
alita
tive
disc
ussi
on o
f Sec
tion
4.1.
4.2.
1 D
escr
iptio
n
The
appl
icat
ion
is a
sou
nd-m
akin
g m
achi
ne t
he u
ser
can
play
with
her
voi
ce.
Diff
eren
t sou
nd c
orpu
ses
can
be c
hose
n an
d th
e pl
ayer
can
cre
ate
a va
riety
of
mus
ical
im
prov
isat
ion.
“V
oice
is th
e in
stru
men
t, Te
chno
logy
ass
ists
” is
the
mot
to h
ere.
4.2.
2 M
ain
Inte
rfac
e
The
user
can
sele
ct d
iffer
ent o
ptio
ns, l
iste
d be
low
. Afte
r sel
ectin
g th
e op
tion,
the
user
do
es n
ot n
eed
to lo
ok a
t the
scr
een
(with
the
exce
ptio
n of
som
e sp
ecifi
c fe
edba
ck in
the
train
ing
mod
e, se
e be
low
) and
the
scre
en c
an b
e di
sabl
ed fo
r ene
rgy
savi
ng.
4.2.
3 Pl
ay m
ode
In p
lay
mod
e th
e ap
plic
atio
n al
low
the
user
to s
elec
t diff
eren
t syn
ths
or s
ound
cor
pus
(in t
he l
atte
r ca
se t
he u
ser
can
impo
rt so
und
or s
ongs
fro
m t
he d
evic
e).
Diff
eren
t av
aila
ble
timbr
e re
map
ping
cou
ld p
rovi
de i
ncre
asin
gly
soph
istic
ated
ins
trum
ents
by
incr
easi
ng th
e de
nsity
of
the
soun
d se
gmen
ts p
rese
nt in
the
corp
us o
r th
e ra
nge
of th
e ou
tput
par
amet
er sp
ace
for t
he sy
nths
.
4.2.
4 Tr
aini
ng m
ode
and
stat
istic
s
In tr
aini
ng m
ode
the
left
spea
ker p
lay
back
the
sam
ple
and
the
right
the
resu
lt of
the
timbr
e m
appi
ng r
eal-t
ime.
The
app
licat
ion
is a
ble
to a
sses
s ho
w p
reci
se w
as t
he
repe
titio
n of
the
sam
ple
(imita
tion)
by
com
parin
g th
e di
ffer
ence
bet
wee
n th
e au
dio
perc
eptu
al fe
atur
e of
the
user
voi
ce w
ith th
e de
sire
d in
put t
o pr
oduc
e th
at o
utpu
t. A
lso
timin
g ac
cura
cy c
ould
be
calc
ulat
ed. O
ther
indi
cato
rs s
uch
as d
iver
sity
of t
he re
perto
ire
perf
orm
ed,
anal
ytic
s of
the
pre
ferr
ed o
r m
ost
play
ed s
ound
s ca
n be
eva
luat
ed.
The
play
er c
an a
cces
s th
ose
indi
cato
rs a
nd u
nder
stan
d w
hy th
at in
dica
tor
was
not
pos
itive
. Th
e ap
plic
atio
n sh
ould
pro
vide
reg
ular
ly s
ugge
stio
ns h
ow to
impr
ove
her
perf
orm
ance

10
or p
ropo
se n
ew v
oice
arti
cula
tion
othe
rwis
e un
expl
ored
. Th
is f
eedb
ack
shou
ld b
e pr
ovid
ed n
ot i
n te
rms
of p
erce
ptua
l fe
atur
es,
whi
ch a
re n
ot u
nder
stan
dabl
e by
a
com
mon
use
r, bu
t pl
ayin
g so
und
exam
ples
and
sho
win
g im
ages
of
how
to
use
the
mou
th p
rope
rly, i
n an
alog
y of
lang
uage
teac
hing
.
4.2.
5 C
olle
ctiv
e m
ode
This
mod
e of
fers
the
poss
ibili
ty o
f sha
ring
one
or m
ore
corp
uses
am
ong
play
ers f
or a
co
llect
ive
perf
orm
ance
. Pla
yers
can
pla
y di
ffer
ent r
egio
ns o
f th
e sa
me
corp
us th
ey a
re
fam
iliar
with
. Ind
icat
ors
abou
t co
ordi
natio
n, i
nitia
tive
of t
he i
ndiv
idua
l an
d re
latio
nal
desc
ripto
rs c
ould
be
defin
ed a
nd c
alcu
late
d to
pro
vide
feed
back
to th
e pe
rfor
mer
s.
4.2.
6 D
ownl
oads
The
user
can
dow
nloa
d ne
w c
orpu
ses
toge
ther
with
ann
otat
ion
of t
he p
erce
ptua
l fe
atur
es. M
oreo
ver,
she
can
uplo
ad a
cor
pus
crea
ted
by th
e us
er: i
f th
e m
obile
is f
ast
enou
gh, t
he a
pplic
atio
n ca
n ca
lcul
ate
the
perc
eptu
al fe
atur
es w
ith a
bat
ch p
roce
ssin
g on
th
e ph
one,
oth
erw
ise
the
user
can
use
a c
lient
app
licat
ion
on th
e de
skto
p th
at p
rodu
ces
a ta
ble
cont
aini
ng t
he a
nnot
atio
n of
the
cor
pus
segm
ents
to
be u
ploa
ded
to t
he m
obile
ph
one.
5 C
ON
CL
USI
ON
S
In t
his
pape
r, th
e fe
asib
ility
of
audi
o-dr
iven
syn
thes
is t
echn
ique
s fo
r fu
ture
mob
ile
mus
ic a
pplic
atio
ns w
as d
iscu
ssed
. Fi
rst,
a pa
rtial
sur
vey
of a
udio
-driv
en s
ynth
esis
te
chni
ques
was
pro
vide
d. R
athe
r th
an a
ugm
entin
g or
pro
cess
ing
the
orig
inal
aud
io
inpu
t, th
ese
tech
niqu
es e
mpl
oy a
mea
ning
ful t
rans
form
atio
n of
the
inpu
t by
extra
ctin
g pe
rcep
tual
fea
ture
s th
at, a
fter
bein
g re
map
ped
to a
diff
eren
t sp
ace,
in
turn
s co
ntro
l a
synt
hesi
s en
gine
. The
pro
blem
of e
valu
atin
g di
gita
l mus
ic in
stru
men
t is
then
pre
sent
ed
by
desc
ribin
g a
prev
ious
ev
alua
tion
fram
ewor
k.
Play
abili
ty
and
enjo
ymen
t ar
e ad
dres
sed
as t
he m
ain
desi
gn c
riter
ia t
o be
eva
luat
ed t
oget
her
with
diff
eren
t st
rate
gy
prop
osed
by
othe
r au
thor
s to
eva
luat
e th
ose.
Fur
ther
gui
delin
es o
r th
emes
spe
cific
to
mob
ile a
pplic
atio
n de
sign
are
pro
pose
d, s
uch
lack
of
phys
ical
ity, i
ssue
s of
rel
ayin
g on
no
n so
und-
prod
ucin
g in
tera
ctio
n m
odal
ity. A
lso
oppo
rtuni
ties
rela
ted
to p
orta
bilit
y an
d ev
alua
tion
of p
layi
ng p
ract
ices
, by
mea
ns o
f au
tom
atic
col
lect
ion
of a
naly
tics,
are
disc
usse
d. A
mon
g th
e vo
ice-
driv
en t
echn
ique
s, vo
ice-
base
d au
dio-
driv
en s
ynth
esis
in
conj
unct
ion
with
cor
pus-
base
d co
ncat
enat
ive
synt
hesi
s is
sug
gest
ed a
s pr
omis
ing
in th
e co
ntex
t of
mob
ile m
usic
app
licat
ion
and
its p
oten
tial
in t
he e
mer
ging
the
mes
of
the
mob
ile c
onte
xt q
ualit
ativ
ely
dem
onst
rate
d. F
inal
ly a
con
cept
for
a m
obile
mus
ic
appl
icat
ion
is b
riefly
des
crib
ed i
n its
fun
ctio
nalit
ies
for
futu
re w
ork
and
in-d
epth
ev
alua
tion.
RE
FER
EN
CE
S
Cad
oz, C
. Wan
derle
y, M
. 200
0. G
estu
re –
Mus
ic. I
n M
. Wan
derle
y an
d M
. Bat
tier (
eds)
C
D-r
om T
rend
s in
Ges
tura
l Con
trol o
f Mus
ic. P
ublic
atio
n Ir
cam
.
Coo
k, P
. 200
1. “
Prin
cipl
es fo
r Des
igni
ng C
ompu
ter M
usic
Con
trolle
rs.”
In P
roce
edin
gs
of th
e In
tern
atio
nal C
onfe
renc
e on
New
Int
erfa
ces
for
Mus
ical
Exp
ress
ion
(NIM
E).
New
Yor
k: A
ssoc
iatio
n fo
r Com
putin
g M
achi
nery
, pp.
1–4
.
Essl
, G. &
O’M
odhr
ain,
S.,
2005
. Scr
ubbe
r: an
inte
rfac
e fo
r fric
tion-
indu
ced
soun
ds. I
n

11
Proc
eedi
ngs
of t
he 2
005
conf
eren
ce o
n N
ew i
nter
face
s fo
r m
usic
al e
xpre
ssio
n (N
IME
’05)
. Nat
iona
l Uni
vers
ity o
f Sin
gapo
re, p
p. 7
0–75
.
Ess
l, G
. & O
’Mod
hrai
n, S
., 20
06. A
n en
activ
e ap
proa
ch to
the
desi
gn o
f new
tang
ible
m
usic
al in
stru
men
ts. O
rgan
ised
Sou
nd, 1
1(03
), p.
285.
Essl
, G. &
Roh
s, M
., 20
09. I
nter
activ
ity f
or M
obile
Mus
ic-M
akin
g. O
rgan
ised
Sou
nd,
14(0
2), p
.197
-207
.
Har
rison
, S.,
Tata
r, D
. & S
enge
rs, P
., 20
07. T
he th
ree
para
digm
s of
HC
I. In
Alt.
Chi
. Se
ssio
n at
the
SIG
CH
I C
onfe
renc
e on
Hum
an F
acto
rs i
n C
ompu
ting
Syst
ems
San
Jose
, Cal
iforn
ia, U
SA. p
. 1-1
8.
Jane
r, J.
& B
oer,
M. d
e, 2
008.
Ext
endi
ng v
oice
-driv
en s
ynth
esis
to a
udio
mos
aici
ng. I
n 5t
h So
und
and
Mus
ic C
ompu
ting
Con
fere
nce,
Ber
lin.
Jeha
n, T
., 20
01.
Perc
eptu
al S
ynth
esis
Eng
ine :
An
Aud
io-D
riven
Tim
bre
Gen
erat
or
Perc
eptu
al S
ynth
esis
Eng
ine :
An
Aud
io-D
riven
Tim
bre
Gen
erat
or. P
hD T
hesi
s.
Jord
a, S
. 20
04.
“Dig
ital
Inst
rum
ents
and
Pla
yers
: Pa
rt II
: D
iver
sity
, Fr
eedo
m a
nd
Con
trol.”
In
Proc
eedi
ngs
of t
he I
nter
natio
nal
Com
pute
r M
usic
Con
fere
nce.
San
Fr
anci
sco,
Cal
iforn
ia: I
nter
natio
nal C
ompu
ter M
usic
Ass
ocia
tion,
pp.
706
–710
.
Mis
ra,
A.,
Essl
, G
. &
Roh
s, M
., 20
08.
Mic
roph
one
as s
enso
r in
mob
ile p
hone
pe
rfor
man
ce. P
roce
edin
gs o
f the
8th
Inte
rnat
iona
l Con
fere
nce
on N
ew In
terf
aces
for
Mus
ical
Exp
ress
ion
NIM
E 20
08.
O’M
odhr
ain,
M
.S.,
2011
. A
fr
amew
ork
for
the
eval
uatio
n of
di
gita
l m
usic
al
inst
rum
ents
. Com
pute
r Mus
ic Jo
urna
l, 35
(1),
p.28
-42.
O’M
odhr
ain,
M.S
., Es
sl, G
., 20
04. P
ebbl
eBox
and
Cru
mbl
eBag
: Ta
ctile
Int
erfa
ces
for
Gra
nula
r Syn
thes
is. I
nter
face
s, p.
74-
79.
Schw
arz,
D.,
2007
. C
orpu
s-B
ased
Con
cate
nativ
e Sy
nthe
sis.
IEEE
Sig
nal
Proc
essi
ng
Mag
azin
e, 2
4(2)
, p. 9
2-10
4.
Stow
ell,
D.
et
al.,
2009
. Ev
alua
tion
of
live
hum
an–c
ompu
ter
mus
ic-m
akin
g:
Qua
ntita
tive
and
qual
itativ
e ap
proa
ches
. Int
erna
tiona
l Jo
urna
l of
Hum
an-C
ompu
ter
Stud
ies,
67(1
1), p
. 960
-975
.
Stow
ell,
D.,
2010
. M
akin
g m
usic
thr
ough
rea
l-tim
e vo
ice
timbr
e an
alys
is:
mac
hine
le
arni
ng a
nd ti
mbr
al c
ontro
l, Ph
D T
hesi
s.
Swee
tser
, P.
, an
d P.
Wye
th.
2005
. “G
ameF
low
: a
Mod
el
for
Eval
uatin
g Pl
ayer
En
joym
ent i
n G
ames
.” C
ompu
ters
in E
nter
tain
men
t 3(3
): 1–
24.
Wan
derle
y, M
. M
., an
d N
. O
rio.
2002
. “E
valu
atio
n of
Inp
ut D
evic
es f
or M
usic
al
Expr
essi
on: B
orro
win
g To
ols f
rom
HC
I.” C
ompu
ter M
usic
Jour
nal 2
6(3)
: 62–
76.
Wan
g, G
., 20
09. D
esig
ning
Sm
ule’
s iPh
one
Oca
rina.
In P
roce
edin
gs o
f the
Inte
rnat
iona
l C
onfe
renc
e on
New
Inte
rfac
es fo
r Mus
ical
Exp
ress
ion.
Pitt
sbur
gh.

1
Mo
bil
e g
am
e au
dio
eff
ects
: M
idd
lew
are
an
d a
rtif
icia
l
rev
erb
era
tio
n
Mii
kk
a V
alto
nen
A
alto
Univ
ersi
ty, S
cho
ol
of
Ele
ctri
cal
En
gin
eeri
ng
, D
epar
tmen
t o
f S
ign
al
Pro
cess
ing
and
Aco
ust
ics
A
bst
ract
Au
dio
in
ga
mes
is
easi
ly o
verl
oo
ked
wh
ile
gra
ph
ics
get
all
th
e a
tten
tion
.
Tw
o d
iffe
ren
t m
idd
lew
are
pro
gra
ms,
Fm
od
an
d W
wis
e, a
re i
ntr
od
uced
to
hel
p g
am
e d
eve
lop
ers
to c
rea
te m
ore
ela
bo
rate
au
dio
eff
ects
. S
ou
nd
See
d,
wh
ich
is
an
ad
d-o
n f
or
Ww
ise
to c
rea
te p
roce
du
ral
au
dio
, is
als
o i
ntr
od
uce
d
bri
efly
. M
ob
ile
dev
ices
req
uir
e ef
fici
ent
imp
lem
enta
tio
ns
of
effe
ct
alg
ori
thm
s.
Sca
tter
ing
D
ela
y N
etw
ork
(S
DN
) a
nd
O
pen
AIR
p
roje
ct
are
pre
sen
ted
an
d t
hei
r a
pp
lica
bil
ity
to m
ob
ile
ga
mes
is
con
sid
ered
. S
DN
is
a
reve
rber
ato
r th
at
is u
sed
to
cre
ate
aco
ust
ic s
pa
ces
an
d O
pen
AIR
is
a p
roje
ct
to s
ha
re i
mp
uls
e re
spo
nse
s o
f va
rio
us
spa
ces
an
d a
nec
ho
ic r
eco
rdin
gs.
It
als
o in
tro
du
ces
a P
ure
Da
ta-e
xter
na
l to
co
nvo
lve
imp
uls
e re
spo
nse
s a
nd
reco
rdin
gs.
1 I
NT
RO
DU
CT
ION
Au
dio
eff
ects
in
gam
es a
re u
sual
ly u
nd
erra
ted
. M
ost
gam
e d
evel
op
ers
con
cen
trat
e o
n
vis
ual
eff
ects
an
d a
ud
io i
s le
ft t
o m
inim
al a
tten
tion
. M
ost
ly a
ud
io i
n g
ames
is
lim
ited
to
rep
etit
ive
bac
kgro
un
d m
usi
c an
d a
ll t
he
effe
cts
are
sam
ple
s re
cord
ed i
n a
dv
ance
wit
h n
o
real
-tim
e ca
lcu
lati
on
s. Y
et t
he
amo
un
t o
f d
iffe
ren
t m
oo
ds
that
au
dio
alo
ne,
wit
ho
ut
any
vis
ual
eff
ects
, ca
n p
rod
uce
is
asto
nis
hin
g.
Wh
at i
s m
ore
am
azin
g i
s th
at a
ll t
his
co
uld
be
do
ne
wit
h m
uch
les
s co
mp
uta
tio
nal
req
uir
emen
ts t
han
vis
ual
eff
ects
th
at w
ou
ld c
reat
e th
e sa
me
atm
osp
her
e. I
s th
e re
aso
n f
or
po
or
gam
e au
dio
in
th
e d
evel
op
ers’
in
adeq
uat
e k
no
wle
dg
e ab
ou
t au
dio
sig
nal
pro
cess
ing,
or
is t
he
gam
e in
du
stry
ju
st o
ver
loo
kin
g o
ne
of
ou
r se
nse
s? W
hat
dif
fere
nt
met
ho
ds
ther
e ar
e to
hel
p g
ame
dev
elo
per
s w
ith
au
dio
si
gn
al p
roce
ssin
g a
nd
ach
iev
ing h
igh
-qu
alit
y s
ou
nd
eff
ects
? M
ob
ile
dev
ices
are
no
wad
ays
also
cap
able
of
run
nin
g v
ery e
lab
ora
te g
ames
. M
any
mo
bil
e p
ho
nes
al
read
y
hav
e d
ual
-co
re
pro
cess
ors
in
th
em.
Th
e li
mit
ed
scre
en
size
re
du
ces
the
effi
cien
cy o
f p
ure
ly v
isu
al e
ffec
ts,
in w
hic
h c
ase
aud
io s
ho
uld
be
con
sid
ered
m
ore
car
efu
lly t
han
in
tr
adit
ion
al P
C o
r co
nso
le gam
es.
Th
ere
are,
ho
wev
er,
som
e fu
nd
amen
tal
dif
fere
nce
s in
m
ob
ile
aud
io co
mpar
ed to
d
esk
top
o
r co
nso
le u
se.
Th
e p
ort
able
nat
ure
of
mo
bil
e d
evic
es m
akes
th
e li
sten
ing e
nv
iro
nm
ent
mo
re c
hal
len
gin
g,
and
p
hysi
cal
lim
itat
ion
s re
stri
ct
the
freq
uen
cy
resp
on
se
and
st
ereo
-lis
ten
ing
of

2
lou
dsp
eak
ers
suit
able
fo
r m
ob
ile
dev
ices
(R
um
sey,
20
08
).
On
e so
luti
on
fo
r th
e fr
equ
ency
re
spo
nse
-p
rob
lem
is
to
as
sum
e th
at
use
r w
ill
be
list
enin
g
aud
io
wit
h
hea
dp
ho
nes
. T
his
can
no
t al
way
s b
e ap
pli
ed,
bu
t w
ith
sin
gle
-pla
yer
gam
es i
t is
a g
oo
d
app
roac
h.
Als
o t
he
com
pu
tati
on
al l
imit
atio
n c
alls
fo
r ef
fici
ent
solu
tio
ns
for
aud
io s
ign
al
pro
cess
ing.
Is th
ere
a co
mp
uta
tio
nal
ly ef
fici
ent
way
s to
ac
hie
ve
hig
h q
ual
ity
aud
io
effe
cts
so t
hat
it
wo
n’t
dem
and
all
th
e p
roce
ssin
g p
ow
er a
mo
bil
e d
evic
e ca
n a
ffo
rd?
Th
is
pap
er
con
sid
ers
dif
fere
nt
way
s to
im
ple
men
t au
dio
ef
fect
s fo
r g
ames
an
d
effi
cien
t al
go
rith
ms
to g
ener
ate
them
to
be
use
d i
n l
imit
ed h
ard
war
e se
tup
s, e
.g.
mo
bil
e p
ho
nes
. It
is
co
nst
ruct
ed
as
foll
ow
s:
in
sect
ion
2
, F
MO
D
and
W
wis
e m
idd
lew
are
soft
war
e ar
e in
tro
du
ced
. T
hey
co
mb
ine
gam
e en
gin
es
and
au
dio
si
gn
al
pro
cess
ing
so
ftw
are
pro
vid
ing g
rap
hic
al t
oo
ls t
o d
esig
n d
iffe
ren
t so
un
d s
chem
es u
sin
g v
ario
us
aud
io e
ffec
ts.
In s
ecti
on
3,
com
pu
tati
on
ally
eff
icie
nt
rev
erb
erat
ion
alg
ori
thm
s fo
r so
un
d
pro
cess
ing t
hat
can
be
imp
lem
ente
d i
n m
ob
ile
gam
e au
dio
are
pre
sen
ted
. F
inal
sec
tio
n i
s co
ncl
usi
on
s an
d s
ug
ges
tio
ns
for
futu
re w
ork
. 2
MID
DL
EW
AR
E
Mid
dle
war
e is
a p
rogra
m t
hat
op
erat
es b
etw
een
tw
o o
ther
so
ftw
are
com
po
nen
ts b
y
tran
sfer
rin
g d
ata
bet
wee
n t
he
soft
war
e. U
sual
ly i
t is
use
d w
hen
th
e d
iffe
ren
t co
mp
on
ents
ar
e w
ork
ing o
n d
iffe
ren
t o
per
atin
g s
yst
ems.
In
gam
e in
du
stry
mid
dle
war
e su
ch a
s F
mo
d
and
Au
dio
kin
etic
Ww
ise
can
be
inte
gra
ted
to
mo
der
n g
ame
engin
es,
allo
win
g m
ore
ad
van
ced
au
dio
si
gn
al
pro
cess
ing
and
so
un
d
des
ign
o
f g
ames
w
ith
ou
t v
ery
dee
p
kn
ow
led
ge
abo
ut
aud
io e
ffec
ts.
FM
OD
an
d W
wis
e m
idd
lew
are
are
intr
od
uce
d i
n t
he
foll
ow
ing s
ecti
on
s.
2.1
Fm
od
(h
ttp
://w
ww
.fm
od
.org
)
Fm
od
is
m
idd
lew
are
soft
war
e th
at h
as b
een
u
sed
w
idel
y in
v
ario
us
com
mer
cial
gam
es.
It i
s d
ivid
ed i
nto
tw
o m
ain
pro
gra
ms,
Fm
od
Ex
Pro
gra
mm
er’s
AP
I an
d F
mo
d
Des
ign
er,
wh
ich
all
hav
e in
div
idu
al f
un
ctio
nal
itie
s. R
ou
gh
ly,
the
Ex
is
wh
ere
all
the
pro
cess
ing
of
sou
nd
s is
d
on
e an
d
Des
ign
er
is
the
gra
ph
ical
to
ol
to im
ple
men
t th
e fu
nct
ion
alit
ies
that
th
e E
x p
rov
ides
to c
reat
e au
dio
eff
ects
fo
r gam
es.
Fm
od
is
also
av
aila
ble
fo
r iO
S a
nd
An
dro
id.
Th
e F
mo
d E
x i
s a
C/C
++
-bas
ed A
PI
for
low
-lev
el a
nd
dat
a-d
riv
e th
at i
s u
sed
in
co
mb
inat
ion
wit
h t
he
Des
ign
er.
All
th
e ca
lcu
lati
on
s ar
e d
on
e in
flo
atin
g p
oin
t an
d w
ith
32
-bit
in
terp
ola
tio
n.
It w
ork
s as
a s
ou
nd
en
gin
e p
rov
idin
g s
tan
dar
d D
SP
eff
ects
e.g
. ec
ho
, ch
oru
s an
d r
ever
b.
It a
lso
su
pp
ort
s fe
atu
res
such
as
osc
illa
tors
, v
ario
us
filt
ers,
p
aram
etri
c E
Q a
nd
pit
ch s
hif
ter,
wh
ich
can
be
use
d i
n c
reat
ing
syn
thet
ic s
ou
nd
s an
d
pro
cess
ing e
xis
tin
g o
nes
. A
ll t
hes
e ef
fect
s an
d f
un
ctio
ns
are
usa
ble
fro
m t
he
des
ign
er
too
l. C
ross
pla
tfo
rm m
idi
pla
yb
ack
an
d l
ow
-lat
ency
rec
ord
ing a
nd
pro
cess
ing i
s al
so
sup
po
rted
. In
ad
dit
ion
, n
ativ
ely n
on
-su
pp
ort
ed f
ile
form
ats,
en
cod
ers
or
ou
tpu
t m
od
es
can
be
add
ed a
s a
plu
g-i
n.
Fm
od
Des
ign
er i
s th
e d
esig
n t
oo
l fo
r au
dio
eff
ects
. T
he
new
est,
20
10
ver
sio
n i
s in
tegra
tio
n o
f U
nre
al E
ngin
e 3
, b
ut
ther
e is
als
o i
nte
gra
tio
ns
for
oth
er g
ame
engin
es,
such
as
Cry
En
gin
e an
d U
nit
y.
Th
e D
esig
ner
su
pp
ort
s a
gra
ph
ical
in
terf
ace
for
effe
ct

3
des
ign
. It
has
co
ntr
ols
fo
r v
olu
me,
pit
ch,
rev
erb
, fa
de
etc.
All
of
the
DS
P e
ffec
ts f
rom
th
e E
x A
PI
can
be
use
d.
Th
ere
is a
lso
a m
ult
i-tr
ack
ed
ito
r th
at c
an b
e u
sed
to
cre
ate
dif
fere
nt
sou
nd
sch
emes
. T
hey
can
in
clu
de
var
iou
s ef
fect
s to
cre
ate
a re
alis
tic
amb
ien
t so
un
d f
or
traf
fic,
gu
nfi
gh
t o
r w
hat
ever
sit
uat
ion
in
a g
ame
cou
ld o
ccu
r. T
hes
e ef
fect
s ca
n b
e m
ade
to r
esp
on
d t
o w
hat
hap
pen
s in
th
e g
ame.
Lik
ewis
e, t
he
effe
cts
can
fu
rth
er
inv
ok
e n
ew e
ffec
ts o
r m
usi
c tr
ack
s, w
hic
h a
re c
on
tro
lled
via
tre
e-st
ruct
ure
d d
esig
n,
mak
ing t
he
sou
nd
sch
eme
mo
re i
nte
ract
ive
rath
er t
han
ju
st p
re-a
ssig
ned
so
un
ds
for
even
ts.
An
act
ual
so
un
d d
esig
n f
or
An
dro
id u
sin
g t
he
FM
OD
can
be
per
form
ed a
s P
eter
D
resc
her
(h
ttp
://b
road
cast
.ore
illy
.co
m/2
01
1/0
6/f
mo
d-f
or-
and
roid
.htm
l)
has
ex
pla
ined
. H
e m
ade
an i
nte
ract
ive
sou
nd
trac
k t
o a
pin
bal
l-gam
e u
sin
g F
mo
d.
Fir
st,
the
aud
io t
o b
e p
layed
h
as
to
be
crea
ted
, fo
r ex
amp
le
wit
h
a sy
nth
esiz
er.
In
the
exam
ple
, th
e b
ack
gro
un
d m
usi
c is
co
nst
ruct
ed o
f b
ass,
dru
ms
and
pad
tra
cks,
wh
ich
can
be
pla
yed
in
div
idu
ally
or
in a
rbit
rary
co
mb
inat
ion
s. D
resc
her
has
als
o t
un
ed t
he
sou
nd
eff
ects
in
to
the
sam
e k
ey a
s th
e b
ack
gro
un
d m
usi
c, c
reat
ing a
mu
sica
l, r
ingin
g s
ou
nd
. A
fter
th
e so
un
ds
hav
e b
een
cre
ated
, th
e F
mo
d D
esig
ner
is
use
d t
o d
eter
min
e h
ow
th
e ef
fect
s an
d
mu
sic
is p
layed
du
rin
g t
he
gam
e p
lay.
In h
ere,
e.g
. th
e b
um
per
ev
ent
pro
du
ces
ran
do
mly
o
ne
of
six
dif
fere
nt
sam
ple
s, c
reat
ing v
aria
tio
n t
o t
he
sou
nd
eff
ect.
Th
e m
usi
c p
layb
ack
is
gen
erat
ed s
o t
hat
dif
fere
nt
trac
ks
var
y b
ut
the
bea
t st
ays
on
b
etw
een
tra
cks,
in
ord
er t
o s
ust
ain
co
nti
nu
ou
s p
layb
ack
. D
resc
her
has
do
ne
this
by
inse
rtin
g t
he
dru
ms
and
bas
s li
ne
them
es i
nto
sam
e ti
mel
ine
in t
he
Fm
od
Des
ign
er.
Var
iati
on
to
th
e d
rum
tr
ack
is
o
bta
ined
b
y al
go
rith
mic
ally
st
arti
ng
and
st
op
pin
g
dif
fere
nt
dru
m lo
op
s fr
om
th
e gam
e co
de,
ei
ther
b
y p
layin
g th
em se
par
atel
y o
r in
co
mb
inat
ion
. T
his
ap
pro
ach
red
uce
s th
e d
isk
usa
ge
bu
t in
crea
ses
com
pu
tin
g t
ime
sin
ce
the
pla
yb
ack
is
ca
lcu
late
d
on
-th
e-fl
y
rath
er
than
p
layed
fr
om
p
re-s
amp
led
tr
ack
s.
Dre
sch
er a
lso
fin
ds
the
Fm
od
ab
ilit
y t
o l
iste
n t
o t
he
con
stru
cted
so
un
d s
chem
es i
n r
eal
tim
e u
sin
g t
he
aud
itio
n-w
ind
ow
ver
y u
sefu
l, b
ecau
se t
his
way
it
can
be
ensu
red
th
at t
he
sou
nd
s ar
e p
layed
as
they
are
des
ign
ed t
o b
e p
layed
. C
om
pre
ssio
n a
nd
lo
adin
g o
f th
e au
dio
fil
es i
s d
efin
ed i
n t
he
sou
nd
ban
k.
Sin
ce F
mo
d l
ibra
ries
are
wri
tten
in
C a
nd
An
dro
id i
s Ja
va-
bas
ed,
the
Jav
a N
ativ
e In
terf
ace
(JN
I) i
s u
sed
to
acc
ess
the
AP
Is o
f F
mo
d.
Wit
h t
he
JNI
it i
s p
oss
ible
to
cal
l Ja
va
cod
e ru
nn
ing i
n a
Jav
a V
irtu
al M
ach
ine
wit
h a
pp
lica
tio
ns
wri
tten
in
so
me
oth
er
lan
gu
age.
Fm
od
is
avai
lab
le u
nd
er v
ario
us
lice
nse
typ
es f
or
dif
fere
nt
use
. T
he
No
n-C
om
mer
cial
li
cen
se
is
mea
nt
for
no
n-p
rofi
tab
le
use
s an
d
it’s
fr
ee
of
any
lice
nse
ch
arges
. T
he
Co
mm
erci
al l
icen
se i
s fo
r fu
ll-s
cale
pro
fita
ble
use
s o
f F
mo
d a
nd
it
cost
s $
90
00
US
D f
or
the
firs
t p
latf
orm
an
d $
30
00
fo
r su
bse
qu
ent
pla
tfo
rms.
Th
ird
lic
ense
typ
e fa
lls
bet
wee
n
thes
e tw
o
extr
emes
. T
he
Cas
ual
L
icen
se
is
targ
eted
fo
r sm
alle
r re
leas
es,
mai
nly
el
ectr
on
ical
ly d
ow
nlo
adab
le,
and
th
eref
ore
it
is t
he
lice
nse
typ
e to
be
use
d i
n a
mo
bil
e gam
e d
evel
op
men
t. T
he
casu
al l
icen
se c
ost
s $
50
0 p
er y
ear
per
pla
tfo
rm.
2.2
Ww
ise
(htt
p:/
/ww
w.a
ud
iok
inet
ic.c
om
)
An
oth
er w
idel
y u
sed
mid
dle
war
e is
Ww
ise
mad
e b
y A
ud
iok
inet
ic.
It c
on
sist
s o
f a
cro
ss-p
latf
orm
so
un
d e
ngin
e fo
r au
dio
pro
cess
ing a
nd
an
au
tho
rin
g a
pp
lica
tio
n.
Th
e

4
sou
nd
en
gin
e su
pp
ort
s v
ario
us
DS
P e
ffec
ts i
ncl
ud
ing r
ever
b,
par
amet
ric
equ
aliz
er a
nd
to
ne
gen
erat
ors
. O
pti
miz
atio
n
has
b
een
p
erfo
rmed
so
th
at
dif
fere
nt
effe
cts
can
b
e p
roce
ssed
in
rea
l-ti
me.
It
also
has
a s
imu
lato
r to
tes
t ef
fect
s an
d s
ou
nd
sch
emes
in
th
e gam
e. T
he
sou
nd
en
gin
e is
co
mp
atib
le w
ith
v
ario
us
pla
tfo
rms
incl
ud
ing W
ind
ow
s,
Pla
yst
atio
n3
an
d i
OS
.
Th
e au
tho
rin
g a
pp
lica
tio
n i
s th
e gra
ph
ical
in
terf
ace
for
man
ipu
lati
ng s
ou
nd
eff
ects
. It
ca
n p
rod
uce
sp
atia
l so
un
d f
or
3D
-au
dio
pro
cess
ed i
n r
eal
tim
e o
r p
red
efin
ed s
ou
nd
o
utp
ut
for
surr
ou
nd
so
un
d
spea
ker
sy
stem
. F
or
op
tim
izin
g
CP
U
tim
e an
d
mem
ory
u
sag
e, s
ou
nd
pla
yb
ack
can
be
pri
ori
tize
d i
n t
hre
e d
iffe
ren
t w
ays.
On
e w
ay i
s to
lim
it t
he
sou
nd
pla
yb
ack
to
a n
um
ber
of
sou
nd
s to
be
pla
yed
sim
ult
aneo
usl
y.
An
oth
er i
s b
y
ran
kin
g t
he
imp
ort
ance
of
a so
un
d s
o t
hat
th
e le
ast
imp
ort
ant
on
es c
an b
e le
ft o
ut
if
nee
ded
. T
hir
d w
ay i
s b
ased
on
a t
hre
sho
ld o
f v
olu
me
so t
hat
in
aud
ible
so
un
ds
wil
l n
ot
be
pla
yed
.
Sev
eral
ad
d-o
ns
can
be
inst
alle
d t
o W
wis
e in
ord
er t
o e
nh
ance
its
usa
ge.
Mo
tio
n-a
dd
-o
n
gen
erat
es
mo
tio
n
fro
m
sou
nd
to
b
e u
sed
in
sh
ock
-co
ntr
oll
ers.
S
ou
nd
See
d
is
a co
llec
tio
n
of
cro
ss-p
latf
orm
so
un
d
gen
erat
ors
fo
r p
roce
du
ral
aud
io
that
ar
e v
ery
mem
ory
-eff
icie
nt.
It
has
tw
o d
iffe
ren
t m
od
ule
s, S
ou
nd
See
d A
ir a
nd
So
un
dS
eed
Im
pac
t.
Th
e A
ir
is
spec
iali
zed
in
d
iffe
ren
t w
ind
-eff
ects
an
d
the
Imp
act
pro
du
ces
syn
thet
ic
var
iati
on
s o
f a
sou
nd
fro
m a
sin
gle
au
dio
fil
e. I
t w
ork
s b
y d
ivid
ing t
he
sou
rce
file
in
to
two
se
ctio
ns,
th
e re
sid
ual
so
un
d an
d p
aram
etri
c m
od
el d
ata.
T
he
resi
du
al so
un
d is
b
asic
ally
th
e so
urc
e fi
le w
ith
ou
t an
y re
son
ant
con
ten
t. T
he
par
amet
ric
dat
a in
clu
des
in
form
atio
n a
bo
ut
the
freq
uen
cy,
ban
dw
idth
an
d m
agn
itu
de
char
acte
rist
ics
of
the
sou
nd
. T
his
is
do
ne
by m
od
al a
nal
ysi
s in
off
-lin
e. T
hes
e tw
o f
iles
are
th
en u
sed
in
th
e ru
nti
me
So
un
dS
eed
Im
pac
t W
wis
e p
lug-i
n.
It
crea
tes
var
iati
on
s o
f th
e o
rigin
al
sou
nd
b
y
mo
dif
yin
g t
he
pro
per
ties
of
the
par
amet
ric
dat
a. T
he
sou
nd
s ar
e cr
eate
d o
n-t
he-
fly a
nd
p
layed
im
med
iate
ly i
n t
he
gam
e, s
o t
her
e is
no
nee
d t
o k
eep
lar
ge
sam
ple
co
llec
tio
n t
o
hav
e v
aria
tio
n i
n s
ou
nd
eff
ects
. T
ime
is a
lso
sav
ed b
ecau
se t
her
e is
no
nee
d t
o r
eco
rd
man
y s
amp
les
of
sam
e ev
ent
in o
rder
to
ach
iev
e v
aria
tio
n.
So
un
dS
eed
Air
is
com
ple
tely
par
amet
er-b
ased
syn
thes
is a
pp
lica
tio
n t
o c
reat
e so
un
ds
sim
ilar
of
a w
ind
blo
win
g t
o d
efle
cto
rs.
To
in
corp
ora
te t
he
add
-on
, it
is
sele
cted
as
a so
urc
e in
Ww
ise
sou
nd
pro
ject
. T
he
pro
per
ties
of
the
gen
erat
ed e
ffec
t ar
e d
ivid
ed i
nto
tw
o c
ateg
ori
es.
On
e d
efin
es t
he
pro
per
ties
an
d p
osi
tio
n o
f w
ind
def
lect
or
and
th
e o
ther
d
efin
es p
rop
erti
es o
f th
e w
ind
its
elf.
Th
e d
efle
cto
r p
rop
erti
es i
ncl
ud
e it
s m
ain
res
on
ance
fr
equ
ency
an
d Q
fac
tor
that
des
crib
es t
he
shap
e o
f th
e o
bje
ct.
A l
ow
Q f
acto
r sh
ou
ld b
e u
sed
fo
r ir
regu
lar
shap
es a
nd
hig
h f
acto
r fo
r ro
un
d a
nd
reg
ula
r fo
rms.
Th
e w
ind
set
tin
gs
con
sist
o
f w
ind
sp
eed
, d
irec
tio
n,
var
iab
ilit
y,
gu
stin
ess
and
glo
bal
p
aram
eter
s fo
r fr
equ
ency
, Q
fac
tor
and
vo
lum
e fo
r al
l w
ind
def
lect
ors
. A
ll p
aram
eter
s h
ave
also
a
ran
do
miz
er v
alu
e th
at d
efin
es a
ran
do
m o
ffse
t fo
r th
e se
lect
ed p
aram
eter
.
Lic
ensi
ng
of
Ww
ise
is s
imil
ar t
o t
he
FM
OD
, th
e n
on
-co
mm
erci
al l
icen
se i
s fr
ee,
smal
l b
ud
ged
li
cen
se
is
app
lica
ble
fo
r el
ectr
on
ical
ly
do
wn
load
able
m
ater
ials
, an
d
Co
mm
erci
al l
icen
se i
s fo
r fu
ll-s
cale
gam
es.
Th
e ad
d-o
ns
are
no
t in
clu
ded
to
th
e li
cen
ses
and
th
ey n
eed
to
be
bo
ug
ht
sep
arat
ely.
Th
e iO
S l
icen
se i
s $
50
0,
so i
t is
th
e sa
me
pri
ce a
s th
e F
mo
d.
Bo
th F
mo
d a
nd
Ww
ise
are
go
od
ch
oic
es f
or
aud
io p
roce
ssin
g i
n m
ob
ile
gam
es.
Th
ey
hav
e al
l th
e b
asic
so
un
d e
ffec
ts,
con
tro
ls a
nd
mu
lti-
trac
kin
g t
o c
reat
e a
nu
mb
er o
f d
iffe
ren
t so
un
d s
chem
es.
Wit
h p
lug-i
ns,
fu
nct
ion
alit
ies
of
bo
th p
rogra
ms
can
be
tail
ore
d

5
to o
ne’
s n
eed
s. O
pti
miz
atio
n o
f ef
fect
s is
po
ssib
le s
o t
he
com
pu
tati
on
al r
equ
irem
ents
ca
n b
e m
ade
suff
icie
nt
for
mo
bil
e d
evic
es.
Th
e m
ain
ch
oic
e b
etw
een
th
ese
pro
gra
ms
is
up
to
th
e p
latf
orm
fo
r w
hic
h t
he
gam
e is
dev
elo
ped
. F
rom
eco
no
mic
al p
oin
t o
f v
iew
b
oth
pro
gra
ms
cost
th
e sa
me,
so
it
do
esn
’t m
ake
a d
iffe
ren
ce.
Th
e W
wis
e is
a b
it m
ore
cu
sto
miz
able
wit
h t
he
larg
er v
arie
ty o
f p
lug-i
ns,
bu
t th
is a
lso
rai
ses
the
cost
of
the
soft
war
e, a
nd
it’
s o
nly
av
aila
ble
fo
r iO
S.
3 R
EV
ER
BE
RA
TIO
N A
LG
OR
ITH
MS
Th
is s
ecti
on
pre
sen
ts t
wo
dif
fere
nt
algo
rith
ms
for
crea
tin
g a
rtif
icia
l re
ver
ber
atio
n.
Fir
st i
s th
e S
catt
erin
g D
elay
Net
wo
rk,
wh
ich
pro
po
ses
a n
ew m
eth
od
, b
ased
on
Dig
ital
W
aveg
uid
e N
etw
ork
s an
d S
catt
erin
g D
elay
N
etw
ork
s. T
he
seco
nd
is
th
e O
pen
AIR
p
roje
ct
that
u
ses
imp
uls
e re
spo
nse
s,
anec
ho
ic
reco
rdin
gs
and
co
nv
olu
tio
n
to
crea
te
rev
erb
erat
ion
. S
om
e d
igit
al
sign
al
pro
cess
ing
bas
ics
use
d
by
thes
e m
eth
od
s an
d
a co
nsi
der
atio
n a
bo
ut
the
met
ho
ds’
su
itab
ilit
y to
mo
bil
e so
luti
on
s is
als
o m
ade.
3.1
Sca
tter
ing
del
ay
net
wo
rk
Th
e S
catt
erin
g D
elay
Net
wo
rk p
rop
ose
d b
y D
e S
ena
et a
l. (
De
Sen
a et
al.
, 2
01
1)
is
an e
ffic
ien
t w
ay t
o c
reat
e a
rev
erb
erat
or
that
can
mo
del
an
aco
ust
ic s
pac
e. I
t is
bas
ed o
n
Fee
db
ack
D
elay
N
etw
ork
s (F
DN
) an
d
Dig
ital
W
aveg
uid
e N
etw
ork
s (D
WN
).
A
Fee
db
ack
Del
ay N
etw
ork
was
fir
st i
ntr
od
uce
d b
y S
tau
tner
& P
uck
ette
in
19
82
(S
tau
tner
&
Pu
cket
te,
19
82
). I
t is
a m
eth
od
fo
r d
esig
nin
g d
igit
al r
ever
ber
ato
rs b
y t
akin
g i
nto
ac
cou
nt
the
earl
y p
art
of
rev
erb
erat
ion
an
d t
he
ov
eral
l lo
ng t
erm
res
po
nse
. T
he
lon
g
term
res
po
nse
is
app
rox
imat
ed w
ith
a r
ecu
rsiv
e d
elay
net
wo
rk.
It i
s b
ased
on
a d
esig
n o
f p
aral
lel
com
b f
ilte
rs.
Dig
ital
Wav
egu
ide
Net
wo
rks
(Kar
jala
inen
et
al.,
20
05
) ar
e ar
ran
gem
ents
of
dig
ital
w
aveg
uid
es,
wh
ich
are
bi-
dir
ecti
on
al d
elay
lin
es m
od
elin
g w
ave
pro
pag
atio
n i
n o
ne
dim
ensi
on
. T
he
wav
egu
ides
are
als
o c
on
nec
ted
to
get
her
by s
catt
erin
g j
un
ctio
ns.
If
the
wav
egu
ides
ar
e ar
ran
ged
in
a
regu
lar
gri
d,
resu
ltin
g
stru
ctu
re
is
call
ed
Dig
ital
W
aveg
uid
e M
esh
(D
WM
). D
WM
mak
es u
se o
f th
e tr
avel
ing w
ave
solu
tio
ns
of
the
wav
e eq
uat
ion
in
ela
stic
med
ia.
FD
N r
ever
ber
ato
rs a
re t
hen
sp
ecia
l ca
ses
of
DW
M
mo
del
s an
d
mu
ltid
imen
sio
nal
D
WM
ca
n
be
con
sid
ered
as
a
net
wo
rk
of
FD
N
rev
erb
erat
ors
co
nn
ecte
d t
oget
her
.
Sca
tter
ing
Del
ay
Net
wo
rk
con
sist
s o
f d
iffe
ren
t sc
atte
rin
g
no
des
th
at
rep
rese
nt
refl
ecti
ve
surf
aces
in
th
e m
od
eled
sp
ace.
Lik
ewis
e, s
ou
nd
so
urc
es a
nd
th
e re
ceiv
er h
ave
also
in
div
idu
al n
od
es.
Th
is w
ay i
t is
po
ssib
le t
o c
reat
e th
e ac
tual
ro
om
im
pu
lse
resp
on
se
for
a so
urc
e an
d r
ecei
ver
syst
em.
To
cre
ate
an a
cou
stic
sp
ace,
th
e su
rfac
e n
od
es a
re
con
nec
ted
to
eac
h o
ther
wit
h b
idir
ecti
on
al d
elay
lin
es w
ith
ab
sorp
tio
n t
o m
od
el t
he
actu
al
sou
nd
ab
sorp
tio
n
of
a su
rfac
e.
Lik
ewis
e,
the
sou
rce
and
re
ceiv
er
no
des
ar
e co
nn
ecte
d
to
the
surf
ace
no
des
v
ia
un
idir
ecti
on
al
del
ay
lin
es
that
h
ave
atte
nu
atio
n
acco
rdin
g t
o t
he
dis
tan
ce o
f th
e co
nn
ecte
d n
od
es.
Th
is n
od
e d
esig
n o
f th
e re
ver
ber
ato
r giv
es r
ise
to t
he
nam
e sc
atte
rin
g d
elay
net
wo
rk.

6
Th
e sc
atte
rin
g f
or
the
rev
erb
erat
ion
eff
ect
is o
bta
ined
by
usi
ng a
un
itar
y m
atri
x.
Th
e sc
atte
rin
g
mat
rix
em
plo
yed
b
y
De
Sen
a et
al
. is
th
e D
igit
al
Wav
egu
ide
Net
wo
rk
scat
teri
ng m
atri
x a
nd
it
is s
ho
wn
in
Eq
. 1
�=2 �−
1� �� ×
�� −
�
1 w
her
e N
is
the
nu
mb
er o
f w
alls
in
th
e m
od
eled
sp
ace
and
I i
s an
id
enti
ty m
atri
x.
Th
e m
atri
x i
s u
nit
ary t
o e
nsu
re e
ner
gy p
rese
rvat
ion
.
Sca
tter
ing
no
de
inte
rco
nn
ecti
on
s co
nsi
st o
f a
bid
irec
tio
nal
del
ay e
lem
ent
that
mo
del
s th
e p
rop
agat
ion
del
ay.
Ab
sorp
tio
n f
ilte
rs a
re a
lso
em
plo
yed
to
mo
del
th
e ab
sorp
tio
n o
f th
e w
alls
at
issu
e. T
he
abso
rpti
on
fil
ters
can
be
sele
cted
as
min
imu
m-p
has
e II
R f
ilte
rs t
o
kee
p c
om
pu
tati
on
al c
ost
s at
min
imu
m.
Wit
h t
hes
e co
nn
ecti
on
s th
e ro
om
rev
erb
erat
ion
is
mo
del
ed b
ecau
se i
t si
mu
late
s th
e en
erg
y ex
chan
ge
bet
wee
n w
alls
. D
elay
lin
e le
ngth
is
det
erm
ined
by t
he
no
de
po
siti
on
s an
d i
t ca
n b
e ea
sily
cal
cula
ted
fo
r st
raig
htf
orw
ard
sp
aces
. W
ith
th
e n
od
e p
osi
tio
ns
it i
s p
oss
ible
to c
alcu
late
acc
ura
te e
arly
ref
lect
ion
s fr
om
th
e so
urc
e to
th
e m
icro
ph
on
e.
Co
nn
ecti
on
s b
etw
een
SD
N n
od
es a
nd
so
urc
e n
od
es a
re e
stab
lish
ed b
y u
nid
irec
tio
nal
d
elay
lin
e w
ith
att
enu
atio
n a
nd
dir
ecti
vit
y o
f th
e so
urc
e. T
he
atte
nu
atio
n i
s o
bta
ined
by
1/r
law
of
spre
adin
g o
f th
e so
un
d.
A r
ou
gh
ap
pro
xim
atio
n o
f th
e d
irec
tiv
ity i
s o
bta
ined
b
y w
eigh
tin
g t
he
ou
tpu
t si
gn
als
wit
h s
ou
rce
dir
ecti
vit
y a
nd
th
e an
gle
bet
wee
n s
ou
rce
refe
ren
ce a
xis
an
d t
he
lin
e co
nn
ecti
ng s
ou
rce
and
SD
N n
od
e. A
n e
xam
ple
of
sou
rce
and
S
DN
no
de
con
nec
tio
n i
s il
lust
rate
d i
n F
ig.
1.
Fig
ure
1:
A s
ou
rce-S
DN
-no
de
con
nect
ion
dep
icti
ng
th
e d
irec
tivi
ty f
ilte
r ( Γ
s(Θ
sk),
del
ay
an
d a
tten
ua
tio
n.
(De
Sen
a e
t a
l.,
20
11
)
Mic
rop
ho
ne
to
SD
N
no
de
–co
nn
ecti
on
is
li
kew
ise
ob
tain
ed
wit
h
un
idir
ecti
on
al
atte
nu
atin
g d
elay
lin
e. T
he
mic
rop
ho
ne
dir
ecti
vit
y p
atte
rn i
s m
od
eled
wit
h a
pla
in g
ain
el
emen
t.
Fig
ure
2 s
ho
ws
a si
mp
lifi
ed b
lock
dia
gra
m o
f th
e S
DN
rev
erb
erat
or,
wh
ere γ s
an
d
γ M a
re v
ecto
rs f
or
the
sou
rce
and
mic
rop
ho
ne
dir
ecti
vit
y,
Ds(
z) a
nd
DM
(z)
are
sou
rce
and
mic
rop
ho
ne
del
ay m
atri
ces,
Gs
and
GM
are
so
urc
e an
d m
icro
ph
on
e at
ten
uat
ion
m
atri
ces,
�� is m
atri
x r
epre
sen
tin
g t
he
scat
teri
ng o
per
atio
n,
Df(
z) i
s th
e d
elay
mat
rix
fo
r n
od
e to
no
de
del
ays,
H(z
) is
th
e w
all
abso
rpti
on
mat
rix
an
d P
is
a p
erm
uta
tio
n m
atri
x.

7
Fig
ure
2:
A S
DN
rev
erb
era
tor
blo
ck d
iag
ram
(D
e S
ena
et
al.
, 2
01
1)
Insp
ecti
ng t
he
blo
ck d
iag
ram
, tr
ansf
er f
un
ctio
n i
s ex
pre
ssed
as
� �
=���� �
�+
� ��� �
� � ��� −
�� �� �
�� �� ! " �
2 W
ith
Eq
. 2
it
is p
oss
ible
to
cre
ate
imp
uls
e re
spo
nse
s o
f a
roo
m t
hat
can
be
use
d i
n t
he
Op
enA
IR-p
roje
ct d
escr
ibed
in
sec
tio
n 3
.2.
Wh
ile
the
SD
N m
eth
od
is
sim
ilar
to
th
e p
rev
iou
s D
WN
wo
rk o
f K
arja
lain
en e
t al
. (K
arja
lain
en e
t al
., 2
00
5)
ther
e ar
e al
so s
om
e d
iffe
ren
ces.
Th
e m
icro
ph
on
e in
th
e S
DN
is
a p
assi
ve
elem
ent,
wh
ile
in t
he
DW
N i
t is
a s
catt
erin
g n
od
e. D
WN
rev
erb
erat
or
is a
lso
m
ore
co
mp
lex
in
co
mp
uta
tio
n
and
ac
cura
cy
bec
ause
th
ere
are
mo
re
wav
egu
ides
co
nn
ecte
d t
o t
he
mic
rop
ho
ne
no
de.
Th
e ab
sorp
tiv
e lo
sses
are
mo
del
ed i
n t
he
SD
N b
y
min
imu
m-p
has
e II
R f
ilte
rs,
wh
ich
all
ow
dir
ect
use
of
abso
rpti
on
co
effi
cien
ts f
or
the
wal
ls.
In t
he
DW
N,
abso
rpti
on
is
mo
del
ed w
ith
ad
mit
tan
ce c
on
nec
ted
to
th
e w
all
no
des
, an
d t
his
ad
mit
tan
ce i
s ob
tain
ed h
euri
stic
ally
. S
DN
rev
erb
erat
or
can
als
o r
end
er f
irst
o
rder
ref
lect
ion
s d
irec
tly,
wh
ich
is
a p
rob
lem
fo
r D
WN
. T
his
was
av
oid
ed b
y u
sin
g t
he
imag
e-so
urc
e m
eth
od
in
th
e D
WN
met
ho
d.
Th
e S
DN
met
ho
d i
s sc
alab
le t
o d
iffe
ren
t au
dio
rep
rod
uct
ion
fo
rmat
s, e
.g.
coin
cid
ent
mic
rop
ho
ne
form
ats,
set
up
s co
nsi
stin
g o
f se
par
ated
mic
rop
ho
nes
or
bin
aura
l re
cord
ings.
T
hes
e se
tup
s ar
e es
tab
lish
ed b
y a
dju
stin
g t
he
gai
ns
and
SD
N r
ever
ber
ato
rs o
r u
sin
g
HR
TF
fil
ters
. In
tera
ctiv
ity i
s ac
hie
ved
by u
pd
atin
g t
he
mo
del
acc
ord
ing t
o t
he
chan
ges
in
so
urc
e an
d m
icro
ph
on
e p
osi
tio
ns
and
ro
tati
on
s. B
ein
g c
om
pu
tati
on
ally
lig
hte
r th
an
the
DW
N m
eth
od
an
d g
iven
th
e p
roce
ssin
g p
ow
er o
f a
mo
der
n m
ob
ile
pho
ne,
th
e S
DN
m
eth
od
co
uld
be
suit
able
fo
r m
ob
ile
gam
es.
3.2
Op
enA
IR
An
eff
icie
nt
way
to
cre
ate
rev
erb
erat
ion
to
so
un
d f
iles
is
to c
on
vo
lve
them
wit
h a
n
imp
uls
e re
spo
nse
rep
rese
nti
ng a
n a
cou
stic
sp
ace.
If
the
sou
rce
file
is
larg
e, i
t is
no
t co
nv
enie
nt
to c
alcu
late
th
e w
ho
le c
on
vo
luti
on
at
on
ce b
ecau
se i
t ca
nn
ot
be
do
ne
in r
eal
tim
e. T
he
ov
erla
p-a
dd
met
ho
d o
f co
nv
olu
tio
n (
Op
pen
hei
m &
Sch
afer
, 1
99
9,
p.
58
5-
58
6)
can
b
e u
sed
to
get
ar
ou
nd
th
is
pro
ble
m.
It
is
a m
eth
od
to
d
ivid
e th
e la
rge
con
vo
luti
on
in
to s
mal
ler
pie
ces
wh
ich
are
th
en s
um
med
to
get
her
. T
he
bas
ic i
dea
is
to
frag
men
t th
e in
pu
t si
gn
al i
nto
sh
ort
er s
egm
ents
wh
ich
are
th
en i
nd
ivid
ual
ly c
on
vo
lved
w
ith
th
e im
pu
lse
resp
on
se.
Th
ese
sep
arat
ely c
alcu
late
d b
lock
are
th
en s
um
med
to
get
her
to
pro
du
ce t
he
com
ple
te c
on
vo
luti
on
. T
he
con
vo
luti
on
of
two
sig
nal
s o
f le
ngth
M a
nd
N

8
resu
lts
in a
sig
nal
len
gth
of
M +
N –
1 (
Mit
ra,
20
06
, p
. 8
1),
wh
ich
giv
es r
ise
to t
he
nam
e o
ver
lap
-ad
d.
Mat
hem
atic
al
rep
rese
nta
tio
n
of
ov
erla
p-a
dd
co
nv
olu
tio
n
met
ho
d
is
pre
sen
ted
nex
t.
Let
’s s
tart
wit
h t
he
bas
ic c
on
vo
luti
on
su
m t
hat
is
exp
ress
ed i
n E
q.
3 (
Mit
ra,
20
06
, p
. 7
9).
# $ =
%& $' ⊛
ℎ& $' =
*%& $
−�' ℎ& �
'
3 , -.�
,
wh
ere
x[n
] is
th
e in
pu
t si
gn
al,
h[n
] is
th
e im
pu
lse
resp
on
se a
nd
⊛ is
th
e co
nv
olu
tio
n
sum
op
erat
or.
Th
e in
pu
t si
gn
al i
s th
en d
ivid
ed i
nto
sh
ort
er s
egm
ents
as
sho
wed
in
Eq
. 4
.
% -&
$' =/%& $
+�0' 0
2 ,0≤$≤
0−1
56ℎ789
:;7,
4
wh
ere
L i
s an
arb
itra
ry s
egm
ent
len
gth
. N
ow
, x
[n]
is e
xp
ress
ed a
s
%
& $'=*
% -& $−�
0', -.=
,
5
an
d i
nea
r ti
me-
inv
aria
nt
pro
per
ty o
f co
nv
olu
tio
n g
ives
us
#& $' =
?*# -& $
−�0'
, -.=@ ,
6
wh
ere
# -& $' =
% -⊛ℎ& $
' .
7 L
et’s
co
nsi
der
th
e ca
se w
her
e h
[n]
is t
he
len
gth
of
P,
and
wh
ile
the
seq
uen
ces
xk[n
]
hav
e L
no
nze
ro p
oin
ts,
each
ter
m o
f y
k[n
] is
of
len
gth
L + P –
1. N
ow
th
e li
nea
r
con
vo
luti
on
is
ob
tain
ed u
sin
g N
-po
int
DF
T,
wh
ere
N ≥
L + P –
1. Th
e n
on
zero
po
ints
of
the
filt
ered
sec
tio
n o
ver
lap
s b
y P –
1, bec
ause
th
e b
egin
nin
g o
f ea
ch i
np
ut
sect
ion
is
L p
oin
ts aw
ay fr
om
ea
ch o
ther
an
d th
e le
ngth
o
f ea
ch se
ctio
n is
L +
P – 1.
Th
is
met
ho
d i
s ca
lled
th
e o
ver
lap
-ad
d-m
eth
od
bec
ause
th
e se
gm
ents
ov
erla
p e
ach
oth
ers,
an
d
they
are
th
en s
um
med
to
get
her
to
ob
tain
th
e o
utp
ut.
Op
enA
IR (
Op
en A
cou
stic
Im
pu
lse
Res
po
nse
, w
ww
.op
enai
rlib
.net
), i
ntr
od
uce
d b
y
Sh
elle
y e
t al
. (S
hel
ley e
t al
., 2
01
1)
is a
pro
ject
to
co
llec
t an
ech
oic
rec
ord
ings
and
ro
om
im
pu
lse
resp
on
ses
of
dif
fere
nt
spac
es.
In
the
web
site
th
ere
is
also
av
aila
ble
fo
r d
ow
nlo
ad a
Pu
reD
ata-
exte
rnal
to
im
ple
men
t co
nv
olu
tio
n b
etw
een
an
an
ech
oic
rec
ord
ing
and
ro
om
im
pu
lse
resp
on
se.
Th
e ad
van
tag
e o
f th
e sy
stem
is
that
th
e co
nv
olu
tio
n c
an b
e d
on
e in
rea
l ti
me,
bu
t it
req
uir
es i
mp
uls
e re
spo
nse
of
a ro
om
th
at i
s ei
ther
rec
ord
ed f
rom
a
real
sp
ace
or
crea
ted
art
ific
iall
y.
Th
e ar
tifi
cial
ly c
reat
ed i
mp
uls
e re
spo
nse
is
mo
re
app
eali
ng a
pp
roac
h f
or
gam
es b
ecau
se m
ost
sp
aces
in
gam
es a
re n
ot
exac
t re
pli
cas
of
a sp
aces
fo
un
d i
n r
eal
life
. T
he
imp
uls
e re
spo
nse
can
be
crea
ted
e.g
. w
ith
ray
tra
cin
g o
r im
age-
sou
rce
met
ho
d (
Sh
elle
y e
t al
., 2
01
1),
or
wit
h t
he
SD
N t
ran
sfer
fu
nct
ion
in
Eq
. 2
.

9
A
rev
erb
erat
ion
sy
stem
th
at
rep
rese
nts
an
ac
ou
stic
sp
ace
is
per
form
ed
wit
h
a co
nv
olu
tio
n o
f an
ech
oic
rec
ord
ings
and
vir
tual
ly m
ade
or
mea
sure
d i
mp
uls
e re
spo
nse
s o
f th
e sp
ace
in
dif
fere
nt
loca
tio
ns.
A
su
itab
le
imp
uls
e re
spo
nse
is
ch
ose
n
fro
m
a d
atab
ase
of
pre
-est
abli
shed
im
pu
lse
resp
on
ses.
P
rob
lem
s ar
ise
wh
en t
her
e is
a t
ran
siti
on
bet
wee
n t
wo
im
pu
lse
resp
on
ses.
To
av
oid
th
is,
a fa
de
in a
nd
fad
e o
ut
of
the
imp
uls
e re
spo
nse
s is
d
on
e in
th
e P
D
exte
rnal
. T
he
spac
e is
d
ivid
ed
into
se
ver
al
imp
uls
e re
spo
nse
s ac
cord
ing
to
th
e lo
cati
on
of
the
rece
iver
. W
ith
a l
arg
e n
um
ber
of
imp
uls
e re
spo
nse
s th
e au
dib
le d
iffe
ren
ce b
etw
een
tw
o i
mp
uls
e re
spo
nse
s is
gre
atly
red
uce
d,
bu
t th
is r
equ
ires
lar
ge
dat
abas
e o
f d
iffe
ren
t im
pu
lse
resp
on
ses.
Op
enA
IR i
s a
pro
mis
ing p
roje
ct,
bu
t th
ere
are
yet
no
t v
ery m
any a
nec
ho
ic r
eco
rdin
gs
in t
he
web
site
. Im
pu
lse
resp
on
ses
hav
e b
ette
r si
tuat
ion
, th
ere
are
a fe
w c
hu
rch
es,
a w
areh
ou
se a
nd
a l
arg
e h
alls
, st
airw
ay a
nd
a c
lass
roo
m.
If i
t is
po
ssib
le t
o p
rov
ide
ow
n
anec
ho
ic r
eco
rdin
gs,
th
e im
pu
lse
resp
on
ses
sho
uld
be
suff
icie
nt
for
a b
asic
set
up
fo
r gam
es.
Or
if b
oth
im
pu
lse
resp
on
ses
and
an
ech
oic
rec
ord
ings
are
avai
lab
le,
the
PD
ex
tern
al c
an b
e u
sed
to
co
nv
olv
e th
em,
even
in
rea
l-ti
me.
4 C
ON
CL
US
ION
S
In
this
p
aper
, tw
o
mid
dle
war
e p
rog
ram
s,
Fm
od
an
d
Ww
ise,
w
hic
h
hel
p
gam
e d
esig
ner
s in
au
dio
p
roce
ssin
g,
wer
e in
tro
du
ced
. T
hey
ar
e v
ery
go
od
to
ols
fo
r a
dev
elo
per
, p
rov
idin
g m
any o
f th
e d
iffe
ren
t au
dio
eff
ects
an
d p
roce
ssin
g t
oo
ls t
hat
are
w
idel
y u
sed
, in
clu
din
g r
ever
b,
cho
rus
and
to
ne
gen
erat
ors
. T
hey
als
o o
ffer
a g
rap
hic
al
too
l to
des
ign
so
un
d s
chem
es f
or
a ce
rtai
n s
itu
atio
n i
n a
gam
e. A
pro
ced
ura
l au
dio
plu
g-
in,
So
un
dS
eed
, is
als
o a
vai
lab
le t
o W
wis
e, w
hic
h a
llo
ws
crea
tin
g a
ir a
nd
im
pu
lse
effe
cts
that
are
cal
cula
ted
on
-th
e-fl
y p
rov
idin
g m
ore
var
yin
g s
ou
nd
eff
ects
an
d l
ess
dis
k s
pac
e u
sag
e. T
he
algo
rith
ms,
ho
wev
er,
has
to
be
effi
cien
t in
ord
er t
o b
e ab
le t
o u
se t
hem
on
m
ob
ile
dev
ices
. B
ecau
se
of
the
rela
tiv
ely
low
li
cen
se
pri
cin
g
for
elec
tro
nic
ally
d
ow
nlo
adab
le s
oft
war
e, t
hey
are
su
itab
le c
ho
ices
fo
r d
esig
nin
g m
ob
ile
gam
es.
Tw
o d
iffe
ren
t ap
pro
ach
es f
or
crea
tin
g e
ffec
ts w
ere
also
pre
sen
ted
. T
he
Sca
tter
ing
D
elay
N
etw
ork
p
rov
ides
re
ver
ber
atio
n
for
vir
tual
sp
aces
, co
nti
nu
ing
the
pre
vio
us
rese
arch
of
Fee
db
ack
Del
ay N
etw
ork
s an
d D
igit
al W
aveg
uid
e N
etw
ork
s. W
ith
th
e S
DN
it
is
po
ssib
le t
o c
reat
e im
pu
lse
resp
on
ses
that
can
be
use
d e
.g.
in t
he
Op
enA
IR p
roje
ct.
Th
e O
pen
AIR
-pro
ject
o
ffer
s an
ech
oic
re
cord
ings,
ro
om
im
pu
lse
resp
on
ses
and
a
Pu
reD
ata-
exte
rnal
to
co
nv
olv
e th
em
toget
her
to
o
bta
in
roo
m
rev
erb
erat
ion
, d
ow
nlo
adab
le f
rom
th
e w
ebsi
te.
Wit
h s
uff
icie
nt
imp
uls
e re
spo
nse
s an
d r
eco
rdin
gs,
it
is
a go
od
ap
pro
ach
fo
r cr
eati
ng r
oo
m a
cou
stic
s. F
utu
re r
esea
rch
to
pic
s fo
r m
ob
ile
aud
io
cou
ld b
e m
ore
co
mp
uta
tio
nal
ly e
ffic
ien
t au
dio
eff
ects
, fo
r w
hil
e th
e p
roce
ssin
g p
ow
er o
f h
and
-hel
d
dev
ices
is
co
nst
antl
y in
crea
sin
g,
it
is
lik
ely
that
th
ere
are
stil
l n
o
extr
a re
sou
rces
to
be
was
ted
.
RE
FE
RE
NC
ES
Kar
jala
inen
, M
., H
uan
g,
P.,
Sm
ith
, J.
O.
20
05
. D
igit
al W
aveg
uid
e N
etw
ork
s fo
r R
oo
m
Res
po
nse
Mo
del
ing a
nd
Syn
thes
is.
AE
S 1
18
th C
on
ven
tio
n.
Bar
celo
na,
Sp
ain
.

10
Mit
ra,
S.K
. 2
00
6.
Dig
ital
Sig
nal
Pro
cess
ing,
a co
mp
ute
r b
ased
ap
pro
ach
, 3
rd e
dit
ion
.
San
ta B
arb
ara,
Cal
ifo
rnia
. M
cGra
w-H
ill.
Op
pen
hei
m,
A.V
& S
chaf
er,
R.
W.
19
99
. D
iscr
ete-
Tim
e S
ign
al P
roce
ssin
g,
2n
d e
dit
ion
.
Up
per
Sad
dle
Riv
er,
NJ.
Pre
nti
ce H
all.
Ru
mse
y,
F.
20
08
. L
et t
he
Gam
es b
e M
ob
ile.
Jo
urn
al
of
Au
dio
En
gin
eeri
ng
So
ciet
y, V
ol.
56
, N
o.
10
.
De
Sen
a, E
., H
acih
abib
oglu
, H
., C
vet
ko
vic
, Z
. 2
01
1.
Sca
tter
ing D
elay
Net
wo
rk:
an
Inte
ract
ive
Rev
erb
erat
or
for
Co
mp
ute
r G
ames
. A
ES
4
1st
In
tern
ati
on
al
Co
nfe
ren
ce.
Lo
nd
on
, U
K.
Sh
elle
y,
S.,
F
ote
ino
u,
A,
Mu
rph
y,
D.T
. 2
01
1.
Op
enA
IR:
An
O
utl
ine
Au
rali
zati
on
Res
ou
rce
wit
h
Ap
pli
cati
on
s fo
r G
ame
Au
dio
D
evel
op
men
t.
AE
S
41
st
Inte
rna
tio
na
l
Co
nfe
ren
ce.
Lo
nd
on
, U
K.
Sta
utn
er,
J &
P
uck
ette
, M
. 1
98
2.
Des
ign
ing
mu
ltic
han
nel
re
ver
ber
ato
rs.
Co
mp
ute
r
Mu
sic
Jou
rna
l. V
ol.
6,
No
. 1
, p
p.
52
-65
.
htt
p:/
/ww
w.f
mo
d.o
rg/
htt
p:/
/ww
w.a
ud
iok
inet
ic.c
om
/
htt
p:/
/bro
adca
st.o
reil
ly.c
om
/20
11
/06
/fm
od
-fo
r-an
dro
id.h
tm

Mobile application of audio-based activity recognition
Rafael Cauduro Dias de PaivaAalto University School of Electrical EngineeringDepartment of Signal Processing and Acoustics
Abstract
This work presents a review on activity recognition for mobile devices. Activity recognition,as well as context aware systems, provide good opportunities for improving iterationsbetween humans and mobile devices. In this type of system, it is possible to triggeractions by the mobile device, such as emergency calls, automatic ringtone silencing andautomatic messages, as well as manage the user’s activity in a natural way. Activityrecognition systems involve several challenges. The first one is how to integrate this type ofsystem in a software architecture that includes sensors, and an application layer interface.Secondly, the selection of sensors and features is fundamental for obtaining accurateand economical activity inference, as well as the methods for simplifying these features.Next, it is important to determine the type of machine learning algorithm that is the mostsuitable for this recognition purpose. Finally, aspects related to the power consumptionand how to handle distributed sensors influence the usability and performance of the finalsystem. The objective of this work is to review the aspects related to building an activityrecognition system. It looks at aspects related to system/hardware implementation, aswell as feature selection, simplification and how to apply machine learning algorithmsfor activity recognition.
Keywords — Mobile programming, auditory scene analysis, pattern recognition
1 Introduction
Mobile devices comprise an important part of the life of people. However, their capabilitiesare still not fully explored. A possible way to extend the mobile devices capabilities is tointroduce activity dependent applications and features. With this type of system, activitydetection would be involved and it could be possible to trigger actions and manage resourceswithout requiring the user attention.
Many interesting applications can be derived from activity based systems. A leisure guide,based on estimated user activity and observed user profile, has been presented by Bellottiet al. (2008). In this system, the mobile device predicts the most likely next user activity,and suggests new places that could fit the interests of the user. Physical activities canalso be supported by this type of system. Consolvo et al. (2008) describe a system thatrecognizes physical activities, and uses this information for helping the user to achieve itsgoals. Support for elderly people is also possible as shown by Istrate et al. (2008) and medical
1

care systems can also benefit from activity detection. Choudhury et al. (2008) present areal-time activity detection system used to adjust insulin dosage for Type I diabetes patients.Additionally, context recognition can be used for making interaction with mobile phonesmore natural (Järvi et al., 2002).
Many challenges are involved in the application of systems involving activity detection.First of all, care should be taken in the architecture of this type of system. Henricksen andIndulska (2005) describe the problems involved in building context aware systems froma software engineering perspective. In addition to the software structure, it is importantto have in mind that this type of system will be working on a mobile device. This posessome restrictions on how the system should work, since this type of device is powered bybatteries. Most of the activity recognition applications are supposed to work constantly,hence the power consumed by this application needs to be considered (Stäger et al., 2007).Some aspects that influence the power consumed by this type of application are the numberof sensors, the sampling rate, the frame size and the set of features chosen for recognition.
Next, the characteristics of the recognition part itself need to be considered. The setof features that are relevant for activity recognition need to be chosen. These featuresmay include cepstral coefficients (Deller et al., 2000), zero-crossing rate, spectral flatness,spectral bandwidth, and others, which are defined latter in this paper. Additionally, theuse of accelerometers is also important for recognition of activities, since movement is wellcorrelated with the type of activity (Ganti et al., 2010; Kern et al., 2007). The proper selectionof the features is important for achieving high recognition rate with low computational cost.These features can also be simplified by using a technique that decorrelates the features. Oneexample of this type of technique is the Principal Component Analysis (PCA), with which itis possible to obtain a compressed feature vector (Himberg et al., 2001). Finally, the featurevector is used for classifying the activity. This is done using a machine learning techniquesuch as Support Vector Machine (SVM) (Perttunen et al., 2008), k-Nearest Neighbors (kNN)(Duda et al., 2001), Gaussian Mixture Model (GMM) (Ince et al., 2007), Minimum-distanceclassifier (MDC), Hidden-Markov Models (HMM) (Rabiner, 1989; Kern et al., 2007) andConcept Matrix (CM) (Räsänen et al., 2011; Räsänen and Laine, 2012).
This paper is organized as follows. Sec. 2 presents an analysis of typical architecture ofcontext recognition systems. The features used for activity recognition are reviewed in Sec. 3.Some machine learning techniques are reviewed and compared for activity recognition inSec. 5. Sec. 4 shows how the feature vector can be reduced using PCA and ICA. Systems withdistributed sensors and their challenges are discussed in Sec. 6. Sec. 7 analyzes the powerrequirements by activity recognition and discusses how it can be optimized with recognitionaccuracy. Sec. 8 concludes the paper and discusses future challenges.
2 Context-Aware system structure
A general structure for recognizing context is shown in Figure 1. Most of the works analyzedin this paper follow this simplified structure. In this type of system, the raw data of oneor more sensors is first processed by a feature extraction block. In this block the relevantfeatures for recognition of the type of activity are obtained. Since there may be severalrelevant features, and some of the features may be correlated, a grouping block may bepresent. In this block, decorrelation between features and reduction of the dimension of the
2

feature vector may be performed. Next, activity inference is performed, where the featurevector is classified into a given activity class. Once the activity of the user is obtained,the system may either trigger automatic events, manage the user activities, suggest newactivities, etc..
Sensor 1x1
x11
x12
x1K
Sensor 2x2
x21
x22
x2L
Sensor NxN
xN1
xN2
xNM
FeatureExtraction
FeatureExtraction
FeatureExtraction
Grouping
y1
y2
y3
yR
Activity Inference
ActivityDatabase
Ringtone control
Emergency call
Authomatic message
Activity/event trigger
mapping
OtherStore in database
Application layer
Activity management
Figure 1: Framework for systems with context recognition.
Although the system in Figure 1 may be complete when only activity detection is analyzed, itmisses details that are needed when complete applications are designed. Figure 2 presents abroader overview on the general blocks and system structure that are needed in this case. InFigure 2 (a) an example of the Context Modeling Language (CML) is shown (Henricksen andIndulska, 2005). The CML is used for modeling context aware systems, in which the designerof the system can explore and specify the requirements of a context-aware application. TheCML captures the relationships between users, devices and communication channels and theactivities of the users in a temporal manner (Henricksen and Indulska, 2005). Additionally,it includes several facts types, as illustrated by the Key in the bottom of Figure 2 (a). The facttypes include profiled information given by the user, static information on a given equipment,or information obtained by the sensors.
In addition to the CML, a layered software structure for context aware systems is shown inFigure 2 (b). In this layered structure, the context gathering layer is responsible for mappingthe sensor inputs into appropriate context facts. These facts may include the position ofthe user, its activity or relevant data from the environment. The context reception layeris responsible for translating the inputs form the context gathering layer into fact-basedrepresentation for the context management layer. Additionally, the context reception layerroutes the queries from the management layer to the components of the gathering layer.The context management layer keeps the context models and their instantiations. Thequery layer provides an interface from higher layers to the context management layer. Theadaptation layer manages common definition repositories that are shared by groups ofapplications. The application layer provides an interface for several applications that maybe running using the same context aware infrastructure (Henricksen and Indulska, 2005).
3

Applicationlayer
Adaptationlayer
Querry layer
Context managementlayer
Context receptionlayerContext gatheringlayer
(a) (b)
Figure 2: Framework for systems with context recognition. (a) Context modeling languageexample and (b) layered architecture (adopted from (Henricksen and Indulska,2005)).
Aggregator
Composer
PCS PCS PCS
Application/User input
Complexitycontrol
Platformperformance
EAK
Figure 3: Architecture for context recognition with system adaptation including PrimitiveContext Server (PCS) and Empirical Ambient Knowledge (EAK) blocks (adaptedfrom (Dargie, 2009)).
Another architecture is presented by Dargie (2009) in Figure 3, which focuses more onthe context recognition itself. In this architecture, the Primitive Context Server (PCS) isresponsible for extracting data from the sensors, and can be reconfigured for allowing lowpower or decreased latency modes. The aggregator is responsible for extracting the featuresfrom th PCS and combining the information from multiple sensors. The Empirical AmbientKnowledge (EAK) determines the mapping between the features and the activity classes. Thecomposer is responsible for determining the activity given the features from the aggregatorand the model from the EAK (Dargie, 2009).
In addition to the activity classification, the architecture in Figure 3 also allows for adjustingthe recognition accuracy (Dargie, 2009). This is adjusted by the Complexity Control block,
4

which sets the sampling frequency and other relevant parameters of the PCS. The Platformperformance block monitors the resource usage, and which are the proportion of the resourcesdedicated to the context recognition system. With these blocks, it is possible to decrease theaccuracy of the activity detector when another application with higher priority is demandingresources. Additionally, the user may also define higher priority for recognition accuracy orprocessing time, which will define the complexity of the recognition system.
3 Features for activity recognition
A large set of features can be selected for determining activities in context recognition. Mostof these are related to audio signals, but also some important ones are related to othersensors such as the accelerometer. The selection of the features for activity selection isa fundamental step for obtaining high accuracy without compromising the computationalcomplexity of the final system.
Some of the simplest features are extracted from audio in the time domain. One of these isthe zero crossing rate (Deller et al., 2000; Stäger et al., 2007; Istrate et al., 2008)
ZC = 1N2 −N1
N2∑n=N1+1
|sgn(x(n))−sgn(x(n−1))| (1)
where N1 and N2 are the beginning and end of the analyzed frame, and
sgn(x)=
1, x > 00, x = 0−1, x < 0
. (2)
The zero-crossing rate is particularly interesting for distinguishing between tonal or quasi-periodic sounds, such as voiced speech utterances, and noise-like sounds.
Additionally, the energy of the signal can be obtained in a frame by frame basis, and thefluctuation of amplitude can be obtained (Stäger et al., 2007). The energy itself is usuallynot a good feature for activity classification, due to inherent problems in this type of system.This type of problem is related to the fact that for the energy measurement to be accurate,the mobile device would need to be calibrated. Furthermore, the energy measurement alsovaries in accordance to the position the user keeps the device (Perttunen et al., 2008). Hence,energy derived features are often more robust to this problem. This includes the energyfluctuation or energy normalization using some long-time averaging.
Other features are obtained with a frequency domain representation of sound. These includethe spectral centroid
SC =∑N/2−1
k=0 ‖X (k)‖kfs∑N/2−1k=0 ‖X (k)‖ (3)
where X (k) is the audio signal x(n) in frequency domain, fs is the sampling frequency andN is the size of the FFT. The spectral centroid is related to the perception of brightness ofa sound (Istrate et al., 2008; Stäger et al., 2007). The next feature is the bandwidth of thesignal. Together with the spectral centroid, it is related to the timbre of a sound source.Other spectral features include the spectral roll-off, which is the frequency that concentrates85% of the power at lower frequencies (Istrate et al., 2008).
5

Speech recognition often uses cepstral features. The real-cepstrum is obtained by takingthe inverse fast Fourier transform from the logarithm of the signal in frequency domain, asshown in Figure 4 (a) (Deller et al., 2000). When this operation is done, the first ceptrumcoefficients are related to the spectral envelope of the signal. An improvement on the cepstralcoefficients is obtained with a perceptual frequency scale, the Mel scale. This scale is anapproximation of the frequency resolution of human hearing and gives more emphasis for lowfrequencies. The Mel-frequency cepstral coefficients are obtained as in Figure 4 (b), where aMel-scale filterbank is used as an intermediate step, and the inverse Fourier transform as afinal step (Deller et al., 2000). One advantage of most implementations of MFCC is that theMel-frequency filterbank has a fixed number of coefficients, which yields a constant numberof MFCCs independently of the segment size being analyzed (Perttunen et al., 2009).
FFT FFT-1logabs(.) FFT FFT-1logabs(.) Mel-scaleFilterbank
(a) (b)
Figure 4: Cepstrum calculation. (a) Real cepstrum on linear frequency scale and (b) Mel-frequency cepstral coeficients (MFCC).
Accelerometers can also give important information for activity detection, and many featurescan be obtained from accelerometer data. These features include the relative change in bodyorientation
θ = arctan
√
m2ax +m2
ay
maz
, (4)
where max, may and maz are the average acceleration in the x, y and z axis respectively(Ganti et al., 2010). The next feature if related to the energy of acceleration, which is givenby
Eac =a2
x +a2y +a2
z
2(5)
where ax, ay and az is the acceleration in the x, y and z axis respectively (Ganti et al., 2010).Additionally, the skewness Sac and entropy Hac of the acceleration are calculated as
Sac = E
[(ai −µ
)3
σ3
](6)
Hac = −t2∑
i=t1
p(ai) log2p(ai) (7)
where ai is the 3 dimensional acceleration, µ is the mean value of ai, E[.] is the expectedvalue operation and p(.) is the probability mass function of the acceleration.
Dargie (2009) presents results comparing the recognition accuracy with different set offeatures. In this classification system, MFCCs where used together with other featureswith a Hidden Markov Model (HMM) classifier. Table 1 shows a summary on these results,where some conclusions can be drawn. Including more features is not always improvingthe recognition accuracy. This can be observed by comparing the results of 12 MFCCs with14 MFCCs, where 12 MFCCs has provided better recognition accuracy than 14 MFCCs.
6

In this case, it can be inferred that the last MFCCs are probably noisy or not relevant forthe classification task. Additionally, including the log-energy has increased the recognitionaccuracy for this system. However, this system was tested with signals recorded in acontrolled condition. In a real situation, where the microphones can be placed in differentplaces, and calibration is usually not possible, the accuracy due to signal energy might bereally different.
Table 1: Effect of audio features on accuracy (adapted from (Dargie, 2009)).
Audio features Recognition Accuracy (%)14 MFCC 79.8512 MFCC 81.5510 MFCC 79.688 MFCC 69.78
12 MFCC + log-Energy 83.4612 MFCC + ZCR 79.43
12 MFCC + spectral centroid 78.05
Figure 5 shows the feature analysis for a multi sensor system (Lester et al., 2005). Thissystem includes accelerometers, barometers, Humidity/temperature sensors, light sensors,compass and audio input. The final classification is done with HMMs. In this system, 650features are calculated, and the feature selection is performed using the AdaBoost algorithm(Lester et al., 2005; Viola and Jones, 2001). For each activity, the feature ordering was chosenindividually with this algorithm, where 80% of the data was using for trainning and 20%was used for obtaining the test error shown in Figure 5. In Figure 5 it is possible to observethat there is not much improvement in the recognition error for some classes when usingmore than 50 features.
Figure 5: Effect on the number of features on testing error (adopted from (Lester et al.,2005)).
7

4 Feature grouping
Data pre-processing is an important step in any machine classification task. In Figure 1 thisstep is represented by the grouping block. During this pre-processing, it is possible to identifyhighly correlated input features, which may indicate that the input data is redundant, orperform operations in the data that improve separability of classes during the recognitionstages. These techniques include the Principal Component Analysis (PCA) (Jolliffe, 2002),Independent Component Analysis (ICA) (Himberg et al., 2001) and Linear DiscriminantAnalysis (LDA) (Kern et al., 2007).
The Principal Component Analysis (PCA) is a technique often used for dimensionalityreduction (Jolliffe, 2002). The principal components are calculated by first determining thecorrelation matrix of the feature vector. In a second step, the eigendecomposition of thecorrelation matrix is performed. Each eigenvector points to a principal direction in whichthe data varies, and each direction has a variance given by its corresponding eigenvalue.This means that the eigenvectors with large corresponding eigenvalues represent mostof the information in the feature vector. Additionally, the eigenvector matrix serves as abasis for mapping the feature vector into its principal directions, and the mapped directionsare decorrelated and the first principal components usually represent most of the usefulinformation in the data.
Figure 6 (a) shows one example where PCA is useful. In this example all the data points aregrouped in a tilted ellipsis, where the data varies more in one direction than in other, whichare represented by additional arrows. When PCA is performed, the data in Figure 6 (a) ismapped into the space in Figure 6 (b). It can be observed that the data in Figure 6 (b) has alarger variance in horizontal axis, while the vertical axis has low energy. It means that thedata could be roughly represented only by the horizontal axis.
(a) (b)
Figure 6: Example of PCA use, with (a) data points on the original data space and (b) datapoints mapped into the principal directions (adapted from (Jolliffe, 2002)).
Figure 7 shows example results obtained when using PCA (Himberg et al., 2001). In this sys-tem, a feature vector was collected with data from 3 accelerometers, audio and illumination,temperature, humidity and skin conductivity sensors. In this experiment, 7 principal com-ponents out of 27 explain 96% of the data variance, indicating a good compression capacity.Figure 7 shows the mapped data into the first two principal components for one experiment.
8

Walkingin the corridornormal light
Doors(modest sound)
In the elevator(stable)
In the elevator (unstable)Waiting for the elevatorMoving by the desk
Phone onthe desk
Walking in the dark
Outdoors: bright
PC1
PC
2
Figure 7: Class separation with 2 principal components (adapted from Himberg et al.(2001)).
In this figure, the arrows point to groups of data representing one type of activity. It ispossible to observe that with these principal components good class separation is possible formost of the cases.
Differently from PCA, the Linear discriminant analysis (LDA) looks at the direction inwhich the class separation is maximized. For that purpose, it maximizes the inter-classvariance, while it minimizes the intra-class variance. This transformation is related to theFisher linear discriminant (Duda et al., 2001). Since PCA is performed independently fromclasses, the LDA has one advantage over PCA, since it focuses specifically on helping classdiscrimination.
Figure 8 presents results of recognition accuracy for PCA and LDA. In this experiment,performed by Kern et al. (2007), 12 3D acceleration sensors are used as in Figure 12 (a).Additionally, audio data was analyzed to extract 10 cepstral coefficients, the spectral centerof gravity, power spectrum width, zero crossing rate, total power, among others. The finalclassification was obtained using a two-state HMM. In Figure 8 (a) the results are presentedfor the full feature vector, whose best result is lower than 80%. Figure 8 (b) shows the resultswhen 15 PCA components are used. In this case, the best result has a recognition accuracyof nearly 90%. Test cases with 10 and 20 principal components resulted in 8.5% and 5.4%reduction in recognition accuracy when compared to the case with 15 principal components.The results with LDA are shown in Figure 8 (c), with a peak performance of 94.4%. LDA hasshown significant improvement over the results with the full feature vector, and more than5% improvement than when compared with PCA.
The Independent Component Analysis (ICA) also looks at a transformation in the featurevector space. With ICA the variables mapped in the transformed space are statisticallyindependent. The experiment performed by Himberg et al. (2001) has shown no significantconclusions on usage of ICA. Eronen et al. (2009) have used PCA, ICA and LDA for environ-ment detection. In this experiment, MFCC and MFCC derivatives where used as featurevector, and both PCA and ICA provided marginal recognition accuracy gains.
9

Classification SegmentSampling Rate (kHz) 511
2244.1
15
1015R
ecog
nitio
n R
ate
(%)
60
70
80
90
Classification SegmentSampling Rate (kHz) 511
2244.1
15
1015R
ecog
nitio
n R
ate
(%)
60
70
80
90
(a) (b)
Classification SegmentSampling Rate (kHz) 511
2244.1
15
1015R
ecog
nitio
n R
ate
(%)
60
70
80
90
(c)
Figure 8: Recognition accuracy with (a) Full feature set; (b) 15 principal components; and(c) LDA transformed coefficients (adopted from Kern et al. (2007)).
5 Recognition techniques
As a final stage for activity recognition, a machine learning technique has to be used. Thisstage is represented as the activity inference block in Figure 1, which takes the pre-processedfeature vector as an input. Many techniques can be used at this stage, and this sectionreviews some of them.
Among the techniques for recognizing activities there are static ones and dynamic ones. Inthe static techniques, the class inference is done based only on the features collected forone frame. In some systems it is also possible to combine the inference for many frames, inorder to obtain an estimation that is more robust (Stäger et al., 2007). Examples of staticclassification include the Minimum-distance classifier (MDC) (Räsänen et al., 2011), thek-Nearest Neighbors (kNN) and the Support Vector Machines (SVM) (Duda et al., 2001).In the dynamic techniques, the evolution of the features is analyzed, hence many featureframes are collected for classification. Examples of dynamic techniques include the HiddenMarkov Models (HMM) (Rabiner, 1989; Deller et al., 2000) and the Concept Matrix (Räsänenand Laine, 2012).
The MDC classifier is trained by taking the average of the feature vector for each class.Hence, each class is represented by one average feature vector (Räsänen et al., 2011). Forthat reason, the region in which a class is classified depends only on the center of the class,and not on how it spreads around its center. Figure 9 (b) shows how the two classes in
10

Figure 9 (a) are separated. It is possible to notice that the classification surface follows asimple line for 2 classes, and it is not able to draw complex separation curves, as wouldbe needed to separate squares and circles in Figure 9 (a). Although this technique hassome accuracy limitations, it is very efficient computationally, since the computation forclassification only requires one distance calculation per class for each feature vector (Räsänenet al., 2011).
(a) (b) (c)
margin
(d)
Figure 9: Conceptual comparison of classifiers. (a) Training examples with 2 classes(squares and circles); (b) Class separation with MCD; (c) Class separation withkNN; (d) Class separation with SVM (adapted from (Duda et al., 2001)).
The k-Nearest Neighbors (kNN) is an example-driven technique. In this technique, allthe data points in the training database are analyzed during classification (Duda et al.,2001). This is done by taking the distance from the feature vector to all the examples in thedatabase. After that, the algorithm takes the k examples from the database with smallerdistance to the feature vector, and counts how many of those k examples belongs to eachclass. The algorithm than infers that the input feature belongs to the class with the largernumber of neighbors. This algorithm has the advantage that it is able to draw very complexseparation curves, and the region where each training example has an influence is controlledby the parameter k. Figure 9 (c) shows one possible separation surface for the classes inFigure 9 (a), where it is possible to notice a complex separation curve in comparison to theMDC in Figure 9 (b).
The Support Vector Machine (SVM), is a popular technique for robust pattern recognition.Originally, it attempts to find an optimum separation hyperplane, which maximizes theseparation margin between classes (Duda et al., 2001). This margin is illustrated in Fig-ure 9 (d), where a line separates the 2 classes, and three training points are on the maximummargin line. Since SVM finds a hyperplane that maximizes the class separation, it is also
11

able to provide a robust solution for a pattern classification problem. The support vectorsare the training points laying on the maximum margin surface. In order to obtain complexseparating surfaces with SVM, the feature vector is often augmented with a high orderkernel function. With this approach, the feature vector is mapped to a higher order featurevector through a nonlinear function, e.g. a radial basis function or a polynomial function.
Hidden Markov model (HMM) is one of the most popular technique for speech recognitionand synthesis (Rabiner, 1989). In a Markov model, a process is modeled by its states, and theprobabilities for remaining in a given state, or changing state. Figure 10 shows one exampleof three states and its probabilities. In the HMM, the Markov states are in reality hidden,and the link between each state and the feature vector is through the probability of thatstate to generate the feature vector. In discrete HMM, the feature vector is quantized usinga vector quantizer (VQ), where each feature vector is represented by a codebook. TrainingHMMs is often done using the Baum-Welch Expectation Maximization-algorithm, whereeach class has a HMM model. For classification the probability for feature vector sequencebeing generated by each HMM is computed, and the inferred class corresponds to the modelwith higher probability (Rabiner, 1989).
a b
c
pabpba
pbcpcbpac pca
paa pbb
pcc
Figure 10: Three state Markov model (adapted from (Rabiner, 1989)).
The Concept Matrix (CM) is another dynamic recognition technique (Räsänen and Laine,2012). The CM is trained by taking the transition probabilities between feature vectors withdifferent delays. As with the HMM, a model is obtained for each class. During classification,the class probability is determined based on the transition probability of the observedsequence of input feature vectors. The final classification is based on the class that has thehigher probability of having generated that sequence of feature vectors.
A comparison on the different machine learning techniques is shown in Fig 11. In this system13 MFCCs and their first and second order derivatives were obtained from audio data. Theacceleration direction and magnitude were obtained from a 3-axis acceleration sensor. Thefeature vector was discretized using vector quantization for the CM and HMM algorithms(Räsänen et al., 2011). Additionally, a weight on the acceleration and audio features wasapplied, and is shown as the horizontal axis of Figure 11.
Some conclusions can be derived from Fig 11. Firstly, the CM method has outperformedall of the methods. Although it is a simpler method, it has shown superior performance incomparison to HMM, except when only acceleration is used. The kNN has shown similarperformance to CM, and the best performance when only acceleration or audio is used.
12

Figure 11: Recognition accuracy with several machine learning techniques, as a function ofweighting between acceleration and audio data (α= 0 and α= 1 stands for pureacceleration and pure audio, respectively, adopted from (Räsänen and Laine,2012)).
Additionally, the MDC has shown the worst results, with recognition accuracy decrease of10% in comparison with CM. Moreover, the balance between the acceleration and audiodata can be observed in Fig 11. For most of the recognition methods, there is a significantimprovement when noth audio and acceleration data is used. Finally, when sensor data isconsidered alone, audio data has provided better performance when acceleration data, exceptwhen using MDC.
6 Hardware implementation with distributed sensors
This section focuses on hardware implementation of systems with distributed sensors.Distributed sensors may be needed in order to avoid different sensing conditions. As anexample, an mobile phone may be placed in a pocket, in a handbag, in a jacket or hold inhand. This yields different sensing conditions that may be hard to overcome in a genericsystem.
Distributed sensors may be placed at any part of the body or the environment. In Figure 12examples of systems with distributed sensors are shown. In Figure 12 (a) accelerometers aredistributed over the body for accurate recognition of activity (Kern et al., 2007). A platformfor sensing user activities is placed at the user belt in Figure 12 (b) (Choudhury et al.,2008). In this system this platform communicates to a mobile phone using Bluetooth. InFigure 12 (c) several wireless microphones are distributed in an apartment for detectingdistress events for elderly people (Istrate et al., 2008). Although this system is not mobile byitself, mobile context recognition systems often make use of sensors at static positions, suchas in indoor localization using WiFi access points Duvallet and Tews (2008).
In all of the cases shown in Figure 12, different system structure can be used. Figure 13 showssome possible architectures for distributed sensors. Figure 13 (a) shows the architecturewith least computational complexity on the sensor nodes. In this architecture, the outputof the sensors is sent over a wireless channel to a mobile device performing the centralprocessing. This device is responsible for feature extraction from raw data, as well as foractivity inference, and performing the activity dependent tasks shown in Figure 1.
13

accelerometer
accelerometer
sensingplatform
sensor
sensor
sensor
sensorsensor
sensor
sensor
(a) (b) (c)
Figure 12: Examples of distributed sensor systems: (a) distributed accelerometers in thebody joints (adapted from (Kern et al., 2007)); (b) mobile sensing platform in thebelt of the user (adapted from (Choudhury et al., 2008)); (c) distributed sensorsin a house (adapted from (Istrate et al., 2008))
An alternative architecture is shown in Figure 13 (b). In this distributed sensor architecture,the sensor nodes are responsible not only for capturing data, but also for feature extraction.Hence, the sensors do not transmit the raw sensor data, but the pre-processed data, whichis often much smaller than the raw microphone data. Although this leads to increasedcomputational requirements for the sensor node, it reduces significantly the amount of datathat has to be transmitted over a wireless channel. This means that the computationalpower of the node has to be increased, while the wireless transmission requirements arereduced.
A study on a mobile sensing platform is presented by Choudhury et al. (2008). In their studythey have evaluated two different hardware configurations. In both hardware configurations,a sensing platform was equipped with an electret microphone, a visible light phototransistor,a 3-axis accelerometer, a barometer, a humidity/temperature sensor, an infrared light sensorand a compass. In the first configuration, the sensing platform was wirelessly accessed by anexternal device (e.g. mobile phone) which makes the activity detection, as in Figure 13 (a).In that case the sensing platform had limited processing capability with no local storage andwas powered by a 200 mAh battery. This experiment has shown that when the device wasconnected to a mobile phone by Bluetooth, the battery would last only for 4 hours, whereaswhen no wireless communication was used the battery would last 12 hours. Additionally,Choudhury et al. (2008) have reported that streaming all the sensors data on real time wasnot very reliable due to packet errors and connection drops. Hence, this experiment clearlyshows that some savings are desirable in the wireless communication capacity.
An improvement of the system described above can be obtained by using pre-processingin the sensor nodes as in Figure 13 (b). The second system implemented by Choudhuryet al. (2008) uses this type of architecture, however, since all the sensors are placed int hesame package, the activity inference module was also placed with the sensor module. In theexperiments made by Choudhury et al. (2008), it is reported that battery life has increasedsignificantly. This resulted in a system which is more realistic for real implementation.
14

Sensor 1x1
Sensor 2x2
Sensor NxN
x11
x12
x1K
FeatureExtraction
Activity Inference
ActivityDatabase
Wireless communication
Distributed sensors
x1
x2
xN
Central processing
(a)
Sensor 1x1
x11
x12
x1K
Sensor 2x2
x21
x22
x2L
Sensor NxN
xN1
xN2
xNM
FeatureExtraction
FeatureExtraction
FeatureExtraction
Activity Inference
ActivityDatabase
Distributed sensors/processing
Wireless communication
Central processing
(b)
Figure 13: Hardware implementation with distributed sensors. (a) Raw data is transmittedover wireless networks. (b) Sensors are responsible for pre-processing.
7 Power consumption
Although most of the work in activity recognition focuses on the training/testing proceduresand recognition accuracy, it is important to keep in mind that these systems should beapplied in real mobile devices using battery. For that purpose, the power consumed by thesystem need to be analyzed, and optimized for increasing the battery life.
15

Stäger et al. (2007) have presented a systematic study of the power consumed by an activityrecognition system, and how its parameters can be optimized for lower power consumption.For that purpose, a system was built with a 3-axis MT9 accelerometer from Xsens, an electretcondenser microphone from Sony (ECM-C115) and a microcontroller MSP430F1611 fromTexas instruments.
The empirical model for power consumption is given by
Ptotal = Pmictw
TP+PSigAcq
tw
Tp+PµC
tcalc
Tp+PµCidle
Tp − tw − tcalc
Tp(8)
where Pmic is the microphone power, tw is the analysis window, TP is the period betweenmeasurements, PSigAcq is the signal acquisition power by the microcontroller, PµC is themicrocontroller power during feature calculation and classification, tcalc is the time taken forcalculating the features and classification, and PµCidle is the microcontroller power while inidle mode (Stäger et al., 2007). The power of each element depends on the hardware chosen.In the case of the study presented in this section, the power is given as shown in Table 2.
Table 2: Power consumed by each element (adapted from (Stäger et al., 2007)).
Phases Sensor/Microcontroller mode Power (mW)Sensors Microphone 0.8
Accelerometer 1.34Signal Acquisition Sampling Microphone 14.8×10−6 fs +1.8
Accelerometer (10Hz) 1.8Features Microcontroller On 5.6
Idle phase Microcontroller low power mode 0.08
Figure 14 shows an analysis of the power consumed by the systems described above. Fig-ure 14 (a) shows how much time each feature calculation takes from the microntroller. Thefeatures shown in Figure 14 (a) are the Bandwidth (BW), frequency centroid (FC), fluctuationof amplitude (FLUC), fluctuation of amplitude spectra (FLUC-S), band energy ratio (BER),spectral roll-off frequency (SRF), and the zero-crossing rate (ZCR). From these, it is possibleto notice that all the time domain features, FLUC and ZCR, are in general less complex thanthe frequency domain features. Additionally, this figure ignores the fact that some featuresreuse the common calculation steps from other features (Stäger et al., 2007).
Figure 14 (b) shows the total power consumption (Stäger et al., 2007). The curves haveeither a fixed block size in samples N = 256, or a fixed block size in seconds tw ≈ 50ms. It ispossible to observe in Figure 14 (b) that for a fixed tw the power for signal acquisition only isnearly constant. On the other hand, when N is fixed, the power decreases with the samplingfrequency. This indicates that the power consumed by power acquisition is mainly comingfrom the time the microphone and microcontroller needs to be on, hence it is proportional totw. Additionally, the power increases significantly when feature calculation is performed.When the sampling frequency is 5 kHz, the consumed power increases almost 4.5 timeswhen the features are calculated.
16

(a) (b)
(c)
Figure 14: Tradeoff between consumed power and recognition accuracy with different sam-pling frequencies; (a) Execution times for feature calculation; (b) total powerconsumed for microphone reading and feature calculation; (c) recognition timeswith microphone only, microphone average for 3 frames, microphone and 1 axisaccelerometer, and microphone and 2 axis accelerometer (adopted from (Stägeret al., 2007)).
Figure 14 (c) shows how recognition rate and consumed power can be balanced for a particularsystem (Stäger et al., 2007). In this figure each curve represents a measurement situation,and the points in the curves are obtained by changing the sampling frequency, the numberof features used and the frame size. In the first curve, only the microphone is used forrecognition, whereas in the second one 3 frames are obtained and the recognized activityis a result of averaging. When comparing these cases, the averaged results are able todeliver better recognition accuracy with lower power. The third curve shows the results whenincluding one axis accelerometer. It can be observed that by including the accelerometerthe minimum power is increased by approximately 2.5 mW. However, the inclusion of oneaccelerometer has increased the recognition rate by nearly 5% when the power is 5 mW. Inthe last case 2 accelerometers are used. It can be observed that this situation only increasesthe consumed power. Hence, when comparing it with the case using 1 accelerometer, and nosignificant benefit in the recognition rate was observed.
One simple example can be given for the battery of the Nokia E5 mobile phone. Thisphone uses a 3.7 V battery, with capacity of 1200 mAh, or equivalently 4.4 Wh. For that
17

battery, assuming 100% efficiency of the internal converters, and ignoring operationalsystem overhead, a system consuming 5 mW would take 36 days and 16 hours to consumethe capacity of the battery. Equivalently, typical mobile phones take 1 week or less to becharged. In this case, if an application consuming 5 mW is constantly running in parallelwith the other applications, the mobile phone would have its energy capacity decreased byone day and three hours. If this same application has its power consumption reduced to2 mW, the battery life would be decreased only 12 h.
As a result from Figure 14, it is possible to draw some guidelines for designing context recog-nition systems. The first one is that adding extra sensors increases the consumption powersignificantly, and not always the recognition gain is significant. The power consumptioncaused by feature calculation is also significant. Hence, it is advisable to select featuresbased on their computational cost, and to take advantage of features that have commoncalculation steps.
Finally, some simplifications in the activity recognition systems may be derived, due to thisanalysis. For power saving systems, it would be advisable to have a pre-processing step,in which only the low complexity features are calculated. After this pre-processing stage,the system could decide whether the frame it is analyzing has interesting information, anddiscard it otherwise. Additionally, this type of low-power processing could be used to decidewhen the accelerometer should be turned on. This type of issue can also be mitigated throughthe architecture of the system, as shown in Sec. 2 (Dargie, 2009).
8 Conclusions
This work has presented a review on aspects related to implementing mobile activity detec-tion systems. This type of system has the potential to improve significantly the user/mobiledevice iteration, which could be handled in a more natural way to the user. Building suchsystem involves several technical challenges.
This work has shown that the architecture of context aware systems must be analyzed. Inthe simplest architecture, the information of the sensors is pre-processed to extract features,which are used for activity detection and trigger actions from the system. Most of theliterature focuses on this simple architecture, where no adaptation is available for adjustingthe activity detection blocks for the system requirements. In one enhanced architecture,it was shown that it is possible to build an activity recognition system that adjusts thesystem complexity for optimizing inference latency and power consumption of the devices.Additionally, context modeling language is useful for describing the behavior of such systemintegrating sensors and behavior observable by the final user.
However, further modifications on the system structure could be developed for power con-sumption optimization. As an example, an efficient segmentation algorithm would beinteresting in order to run the classification algorithm only over significant sounds. In manyactivities there are specific short segment sounds that usually keeps a signature of theenvironment/activity. If such segments can be extracted in an efficient way, the system couldhave its efficiency increased.
Next this work has shown relevant features for context recognition. Several features areavailable for that purpose, which include features from multiple types of sensors, such as the
18

accelerometer, and audio related features, such as zero-crossing rate and MFCC. The chosenfeature set has an important influence on the recognition accuracy of the final system, andit was shown that not always increasing the number of features improves the recognitionaccuracy.
Different machine learning techniques were reviewed. In this review static methods anddynamic methods were analyzed. The results presented have shown that not always thedynamic methods will perform better than the static ones. This may be due to the fact thattraining of dynamic methods is more complex, and that the relevant sounds for activityrecognition may have small time variation. Additionally, it was shown that use of theacceleration data is important for activity recognition, particularly when combined withaudio data.
Different feature grouping methods were reviewed. The reviewed methods for groupingfeatures are the Principal Components Analysis (PCA), the Independent Component Analysis(ICA) and Linear Discriminant Analysis (LDA). It was shown that PCA and LDA have someadvantages. On one hand, PCA decorrelates variables, and leads to a representation of themost relevant part of the information in the feature vectors. On the other hand, LDA providesa transform over the feature vector that improves class separation. In the examples shown,both methods provided recognition accuracy improvements, while LDA have presented thebest results.
Power consumption issues were also analyzed. This was approached in an architectural man-ner, by analyzing systems with distributed sensors transmitting data over wireless networks.In this case, it was shown that have sensor nodes with pre-processing is generally better thantransmitting the raw data from the sensors. Since the pre-processed data is a compressedversion of the raw data, the wireless transmission requirements are reduced, and hence thesystem is able to run on batteries for longer time before recharging. Additionally, the powerconsumption was analyzed as a function of recognition parameters and number of sensors.This has shown that including more sensors may only increase the power requirementswithout significant benefit on recognition accuracy, and that it is possible to balance betweenpower and accuracy depending on the system capability and user expectations.
There are some other challenges for activity recognition systems uncovered in this work.Since many people may be using activity recognition systems, it may be possible to senseactivities in a cooperative manner (Järvi et al., 2002). In this case, cooperation may be usedto improve the recognition accuracy by using sensors distributed among different mobiledevices.
Additionally, more information is needed on how the users perceive the recognition errors andwhen they are significant or not (Bellotti et al., 2008). It was shown by Eronen et al. (2009)that current recognition systems perform just as well as real listeners, however they have notconsidered in their listening conditions how people really detect their activity/environment.People use all the available cues, such as image, light level, temperature, wind speed, etc., toinfer in which environment they are, and maybe the visual cues are much more significantthan auditory ones. Moreover, the recognition accuracy must be good enough in order todeliver a good user experience with the activity detection system.
Finally, the full potential of activity recognition systems has not been explored yet in itsapplications. This type of system has been used mostly for simple tasks such as keeping
19

user database of physical activities, annotating recordings, or triggering emergency calls.However, this type of technique can still improve the user interface. As en example, the usermay not want to receive a call from his boss while he is on an amusement park, or the usermay want a simplified interface while jogging.
9 References
V. Bellotti, B. Begole, E. H. Chi, N. Ducheneaut, J. Fang, E. Isaacs, T. King, M. W. Newman,K. Partridge, B. Price, P. Rasmussen, M. Roberts, D. J. Schiano, and A. Walendowski.Activity-based serendipitous recommendations with the magitti mobile leisure guide. InProc. of the CHI’08, 26th annual SIGCHI conference on Human factors in computingsystems, pages 1157 – 1166, Florence, Italy, April 2008.
T. Choudhury, S. Consolvo, B. Harrison, J. Hightower, A. LaMarca, L. LeGrand, A. Rahimi,A. Rea, G. Bordello, B. Hemingway, P. Klasnja, K. Koscher, J. Landay, J. Lester, D. Wyatt,and D. Haehnel. The mobile sensing platform: An embedded activity recognition system.IEEE Pervasive Computing, 7(2):32 –41, April 2008. doi: 10.1109/MPRV.2008.39.
S. Consolvo, D. W. McDonald, T. Toscos, M. Y. Chen, J. Froehlich, B. Harrison, P. Klasnja,A. LaMarca, L. LeGrand, R. Libby, I. Smith, and J. A. Landay. Activity sensing in the wild:A field trial of ubifit garden. In Proc. of the CHI’08, 26th annual SIGCHI conference onHuman factors in computing systems, pages 1797 – 1806, Florence, Italy, April 2008.
W. Dargie. Adaptive audio-based context recognition. IEEE Transactions on Systems,Man and Cybernetics, Part A: Systems and Humans, 39(4):715 – 725, July 2009. doi:10.1109/TSMCA.2009.2015676.
J. Deller, J. Hansen, and J. Proakis. Discrete-Time Processing of Speech Signals. Wiley-IEEEPress, 2000.
R. O. Duda, P. E. Hart, and D. G. Stork. Pattern classification. Wiley, 2001.
F. Duvallet and A. D. Tews. Wifi position estimation in industrial environments usinggaussian processes. In Proc. of the IROS’ 08, IEEE/RSJ International Conference onIntelligent Robots and Systems, pages 2216 – 2221, Nice, France, September 2008. doi:10.1109/IROS.2008.4650910.
A. J. Eronen, V. T. Peltonen, J. T. Tuomi, A. P. Klapuri, S. Fagerlund, T. S. G. Lorho, andJ. Huopaniemi. Audio-based context recognition. IEEE Transactions on Audio, Speech,and Language Processing, 14(1):321 – 329, January 2009. doi: 10.1109/TSA.2005.854103.
R. K. Ganti, S. Srinivasan, and A. Gacic. Multisensor fusion in smartphones for lifestylemonitoring. In Proc. of the BSN’2010, International Conference on Body Sensor Networks,pages 36 – 43, Singapore, Singapore, June 2010. doi: 10.1109/BSN.2010.10.
K. Henricksen and J. Indulska. Developing context-aware pervasive computing applications:Models and approach. Pervasive and Mobile Computing, 3(1):37–64, February 2005. doi:10.1016/j.pmcj.2005.07.003.
20

J. Himberg, J. Mäntyjärvi, and P. Korpipää. Using pca and ica for exploratory data analysisin situation awareness. In Proc. of the MFI’2001, International Conference on MultisensorFusion and Integration for Intelligent Systems, pages 127 – 131, Baden-Baden, Germany,August 2001.
N. F. Ince, C.-H. Min, and A. H. Tewfik. A feature combination approach for the detection ofearly morning bathroom activities with wireless sensors. In Proc. of the SIGMOBILE’2007,1st International Workshop on Systems and Networking Support for Healthcare andAssisted Living Environments, pages 61 – 63, Florence, Italy, April 2007.
D. Istrate, M. Binet, and S. Cheng. Real time sound analysis for medical remote monitoring.In Proc. of the EMBS’2008, 30th Annual Conference of the IEEE Engineering in Medicineand Biology Society, pages 4640 – 4643, Vancouver, Canada, August 2008. doi: 10.1109/IEMBS.2008.4650247.
J. M. Järvi, P. Huuskonen, and J. Himberg. Collaborative context determination to supportmobile terminal applications. IEEE Wireless Communications, 9(5):39 – 45, October 2002.doi: 10.1109/MWC.2002.1043852.
I. T. Jolliffe. Principal Component Analysis. Springer Series in Statistics, 2nd edition, 2002.
N. Kern, B. Schiele, and A. Schmidt. Recognizing context for annotating a live life recording.Personal and Ubiquitous Computing - Memory and Sharing of Experiences, 11(7):251 –263, April 2007. doi: 10.1007/s00779-006-0086-3.
J. Lester, T. Choudhury, N. Kern, G. Borriello, and B. Hannaford. A hybrid discrimina-tive/generative approach for modeling human activities. In Proc. of the IJCAI’05, Nine-teenth International Joint Conference on Artificial Intelligence, pages 766–772, Edinburgh,Scotland, UK, July 2005.
M. Perttunen, M. Van Kleek, O. Lassila, and J. Riekki. Auditory context recognition usingSVMs. In Proc. of the UBICOMM’08, 2nd International Conference on Mobile UbiquitousComputing, Systems, Services and Technologies, pages 102 – 108, Valencia, Spain, October2008.
M. Perttunen, M. Van Kleek, O. Lassila, and J. Riekki. An implementation of auditory contextrecognition for mobile devices. In Proc. of the MDM’09, 10th International Conferenceon Mobile Data Management: Systems, Services and Middleware, pages 424 –429, Tapei,Taiwan, May 2009.
L. R. Rabiner. A tutorial on hidden markov models and selected applications in speechrecognition. Proc. of the IEEE, 77(2):257 – 286, February 1989. doi: 10.1109/5.18626.
O. Räsänen and U. K. Laine. A method for noise-robust context-aware pattern discovery andrecognition from categorical sequences. Pattern Recognition, 45(1):606 – 616, 2012. ISSN0031-3203. doi: 10.1016/j.patcog.2011.05.005. URL http://www.sciencedirect.com/science/article/pii/S0031320311002044.
O. Räsänen, J. Leppänen, U. Laine, and J. Saarinen. Comparison of classifiers in audio andacceleration based context classification in mobile phones. In Prof. of the 19th EuropeanSignal Processing Conference, EUSIPCO’2011, pages 946–950, Barcelona, Spain, 2011.
21

M. Stäger, P. Lukowicz, and G. Tröster. Power and accuracy trade-offs in sound-based contextrecognition systems. Pervasive and Mobile Computing, 3(3):300–327, June 2007. doi:10.1016/j.pmcj.2007.01.002.
P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features.In Proc. of the CVPR’01, IEEE Conference on Computer Vision and Pattern Recognition,volume I, pages 511–518, 10.1109/CVPR.2001.990517, 2001.
22
Recommended

















