Embed Size (px)
Citation preview

Khalid Belhajjame
Joint work with Daniela Grigori, Mariem Harmassi et Manel Ben Yahia
LAMSADE, Université Paris Dauphine
Keyword-Based Search of Workflow Fragments and their Composition
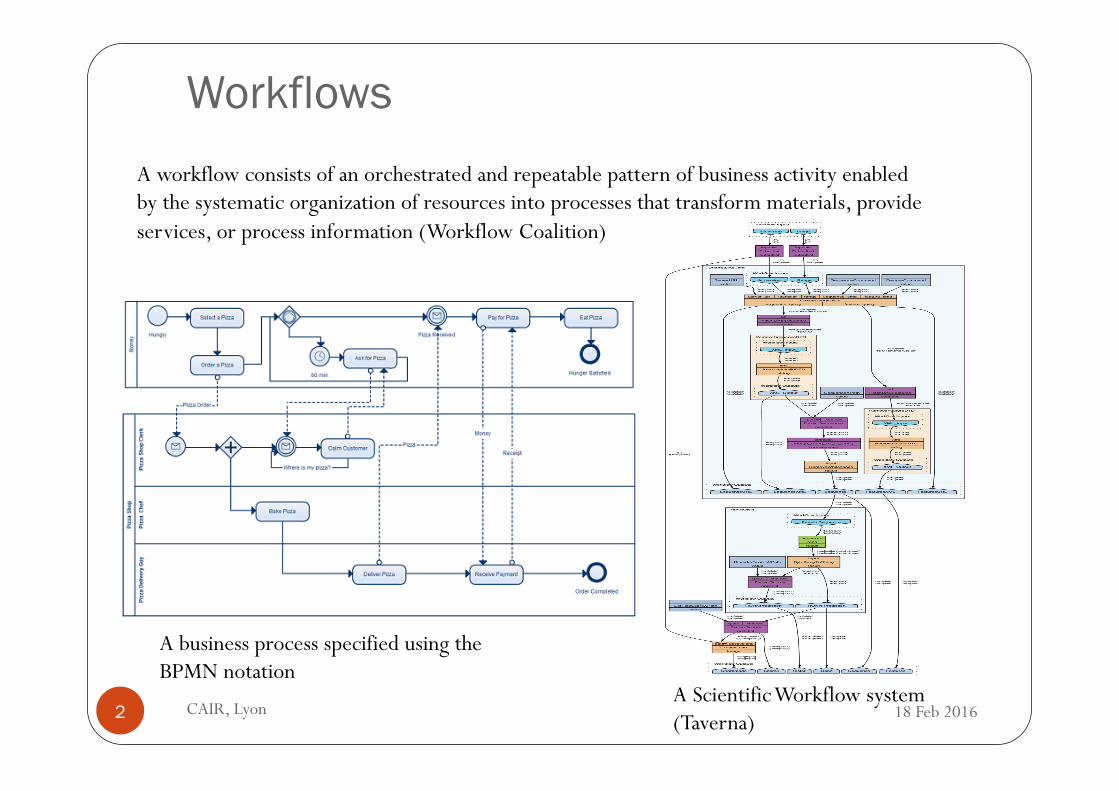
Workflows
A business process specified using the BPMN notation
A Scientific Workflow system (Taverna)
A workflow consists of an orchestrated and repeatable pattern of business activity enabled by the systematic organization of resources into processes that transform materials, provide services, or process information (Workflow Coalition)
CAIR, Lyon 2 18 Feb 2016

Workflows are difficult to design � The design of scientific workflows, just like business process,
can be a difficult task � Deep knowledge of the domain � Awareness of the resources, e.g., programs and web
services, that can enact the steps of the workflow � Publish and share workflows, and promote their reuse.
� myExperiment, CrowldLab, Galaxy, and other various business process repository
� Reuse is still an aim. � There are no capabilities that support the user in identifying the
workflows, or fragments thereof, that are relevant for the task at hand.
CAIR, Lyon 4 18 Feb 2016

Assisting designers of workflows through reuse
CAIR, Lyon 5
� There has been a good body of work in the literature on workflow discover. � The typical approach requires the user to specify a query in the
form of a workflow that is compared against a collection of workflows.
� In our work, we focus on a problem that is different and that received little attention.
� We position ourselves in a context where a designer is specifying his/her workflow and needs assistance to design parts of her workflow (which we term fragments).
18 Feb 2016
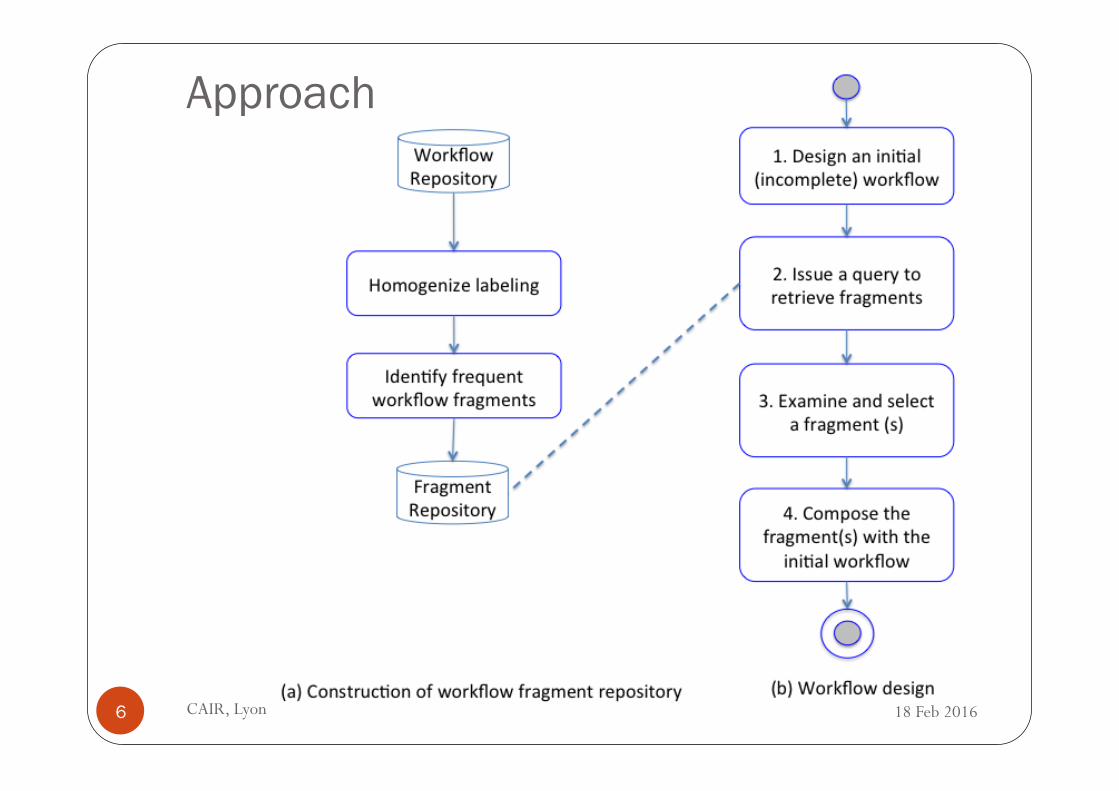
Approach
CAIR, Lyon 6 18 Feb 2016

Mining Frequent Workflow Fragments
18 Feb 2016 CAIR, Lyon 7
Given a repository of workflows, we would like to mine frequent workflow fragments, i.e., fragments that are used across multiple workflows. This raises two questions: � How to deal with the heterogeneity of the labels used by
different users to model the activities of their workflows within the repository?
� Which graph representation is best suited for formatting workflows for mining frequent fragments?

Homogenizing Activity Labels
18 Feb 2016 CAIR, Lyon 8
� Activities implementing the same functionality should have the same names.
� Workflow authored by different people are likely to use different labels for naming activities that perform the same task.
� To homogenize activity labels we use state of the art techniques, which rely on a common dictionary for: � Identifying the activities that perform the same task, and � Selecting the same label for naming them.

Detecting Recurrent Fragments � We use graph mining algorithms to identify the fragments in
the repository that are recurrent. � We use the SUBDUE algorithm.
� Which graph representation to use to represent (workflow) fragments? � We examined a number of workflow representation
CAIR, Lyon 12 18 Feb 2016
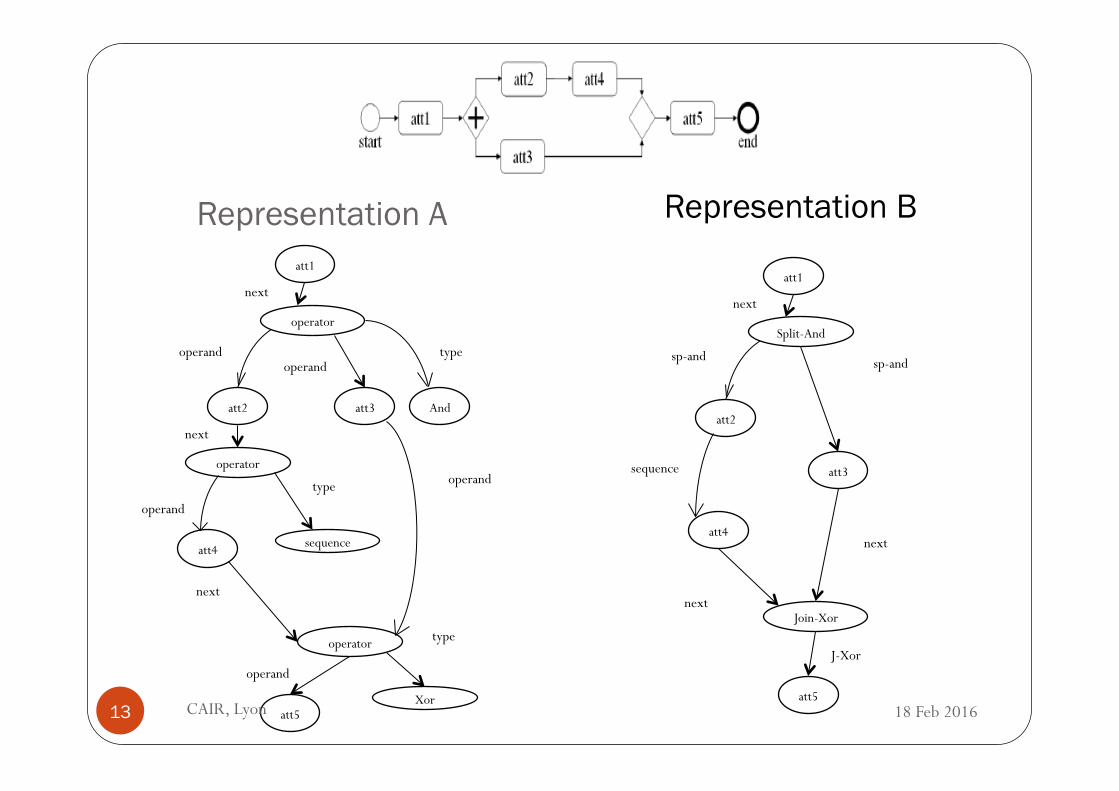
Representation A att1
att2 att3
att4
att5
next
operator
And
operator
sequence
next
operand
operator
Xor
type
type
operand
next
operand
type operand operand
Representation B
att1
att2
att3
att4
att5
next
Split-And
next
Join-Xor
J-Xor
sequence
next
sp-and sp-and
CAIR, Lyon 13 18 Feb 2016
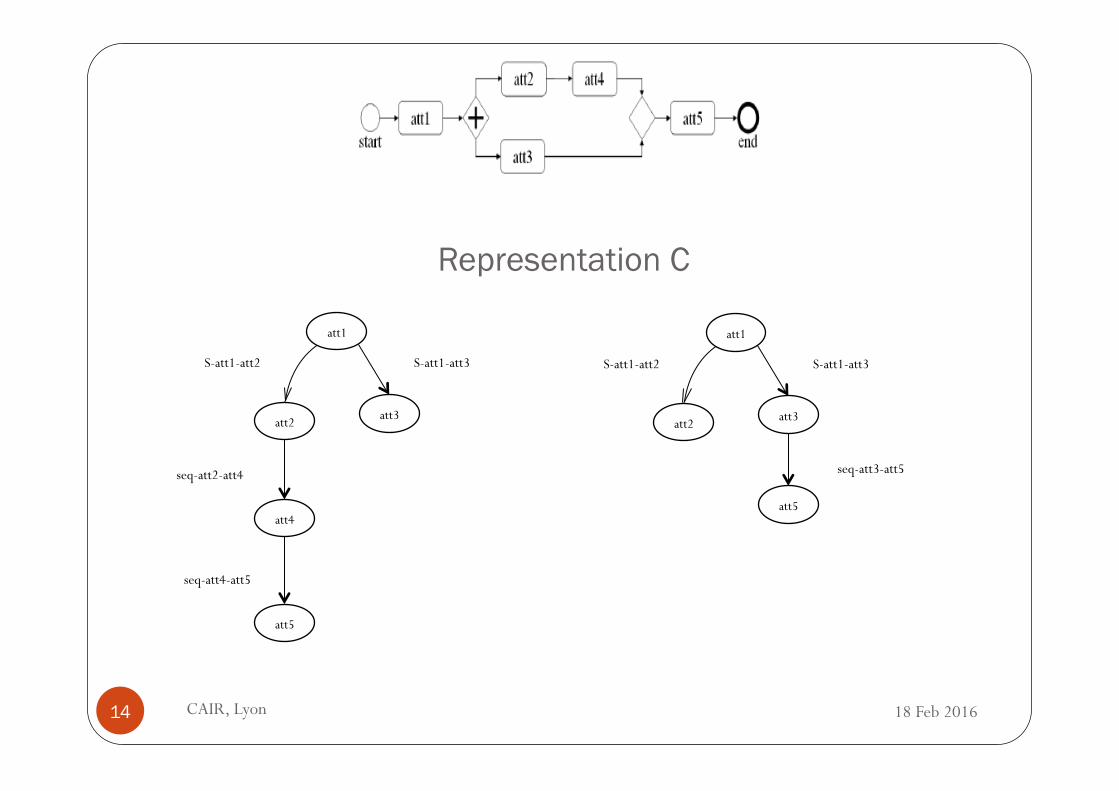
Representation C
att2 att3
att4
att5
att1
S-att1-att2 S-att1-att3
seq-att2-att4
seq-att4-att5
att2 att3
att5
att1
S-att1-att2 S-att1-att3
seq-att3-att5
CAIR, Lyon 14 18 Feb 2016
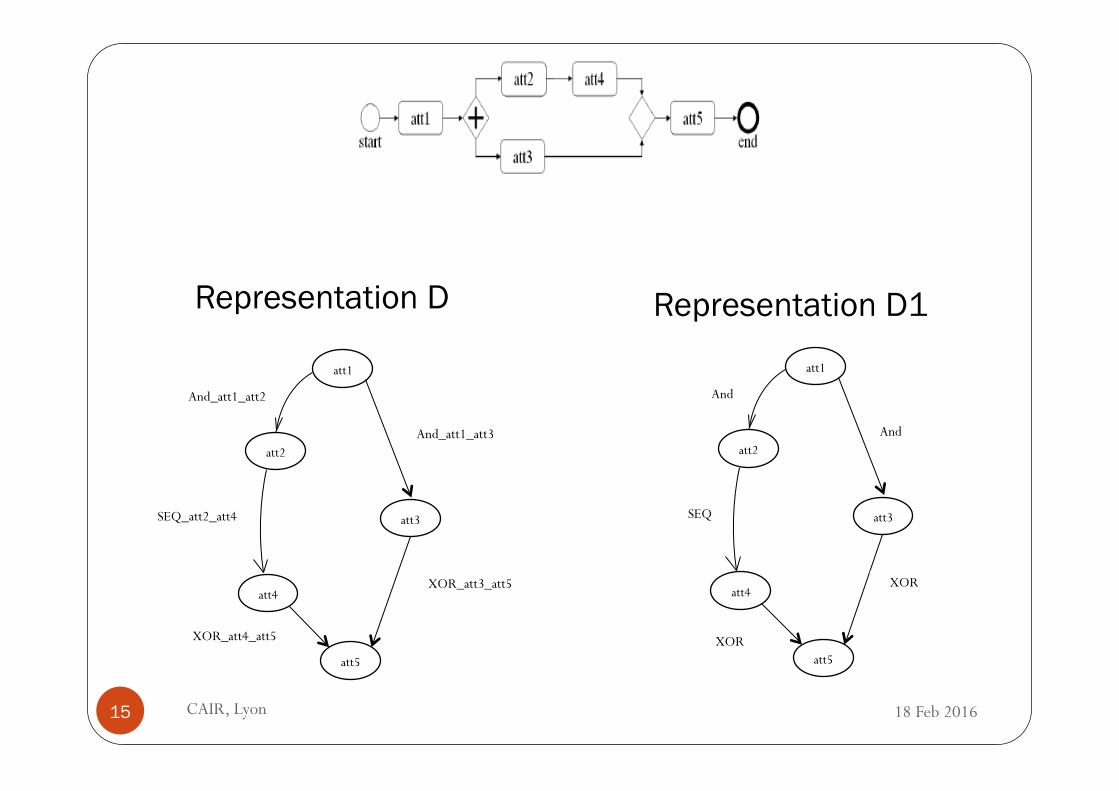
att1
att2
att3
att4
att5
And_att1_att3
And_att1_att2
XOR_att3_att5
SEQ_att2_att4
XOR_att4_att5
Representation D Representation D1
att1
att2
att3
att4
att5
And
And
XOR
SEQ
XOR
CAIR, Lyon 15 18 Feb 2016

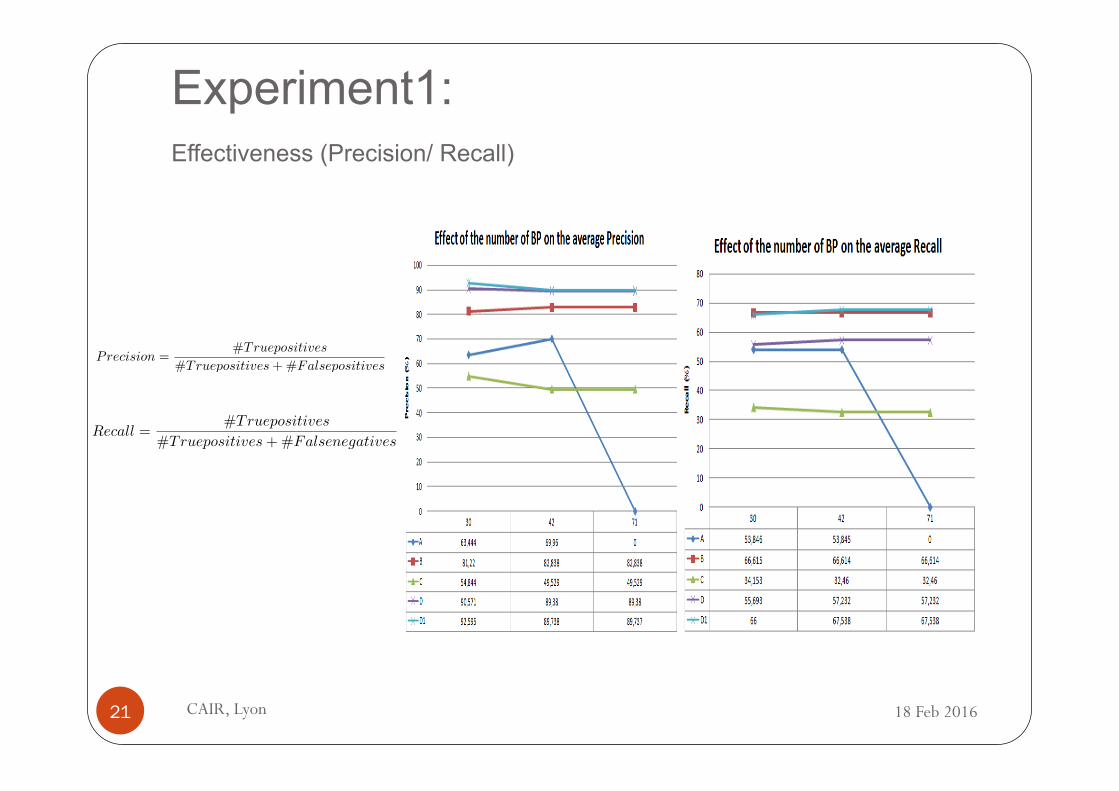
Experiment
l Objective: To assess the suitability of the graph representations for mining workflow graphs l Effectiveness : Precision/ Recall l Size of the graphs l Execution time
CAIR, Lyon 16 18 Feb 2016

Dataset
� We created three datasets of workflow specifications, containing respectively 30, 42, and 71 workflows.
� 9 out of these workflows are similar to each other and, as such contain recurrent structures, that should be detected by the mining algorithm.
� Despite the small size of the collection, these datasets allowed to distinguish to a certain extent between the different representations.
CAIR, Lyon 17 18 Feb 2016
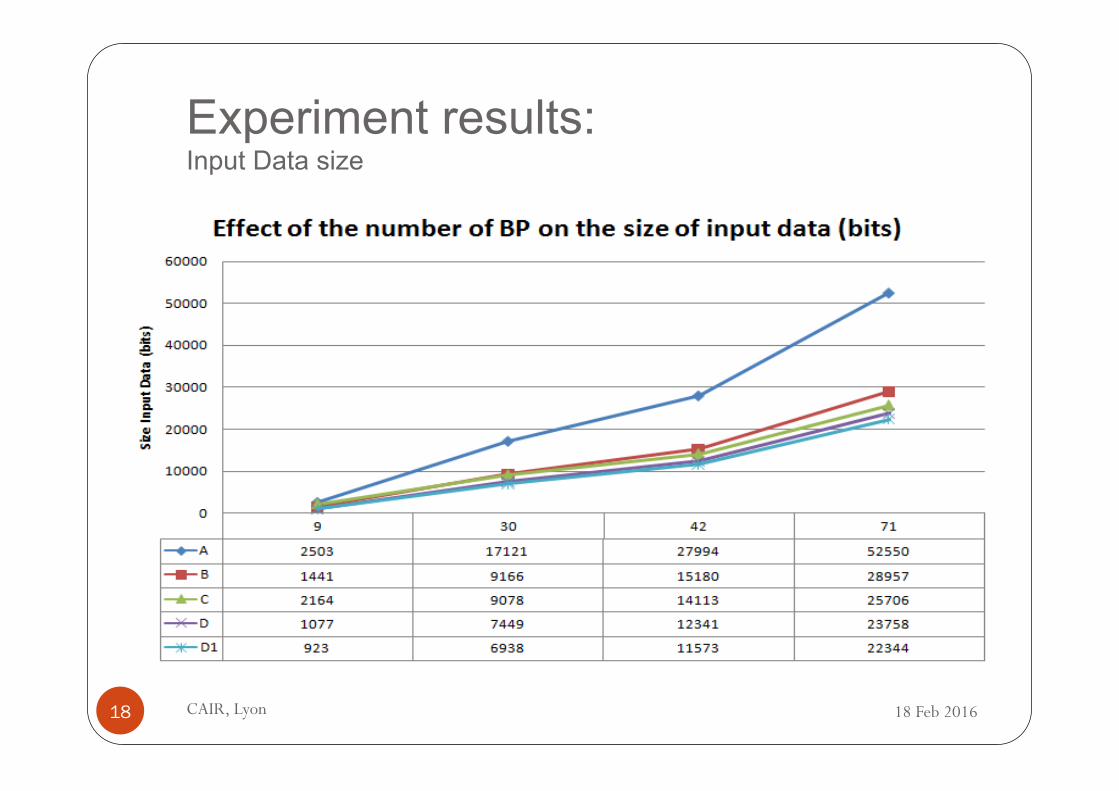
Experiment results: Input Data size
CAIR, Lyon 18 18 Feb 2016
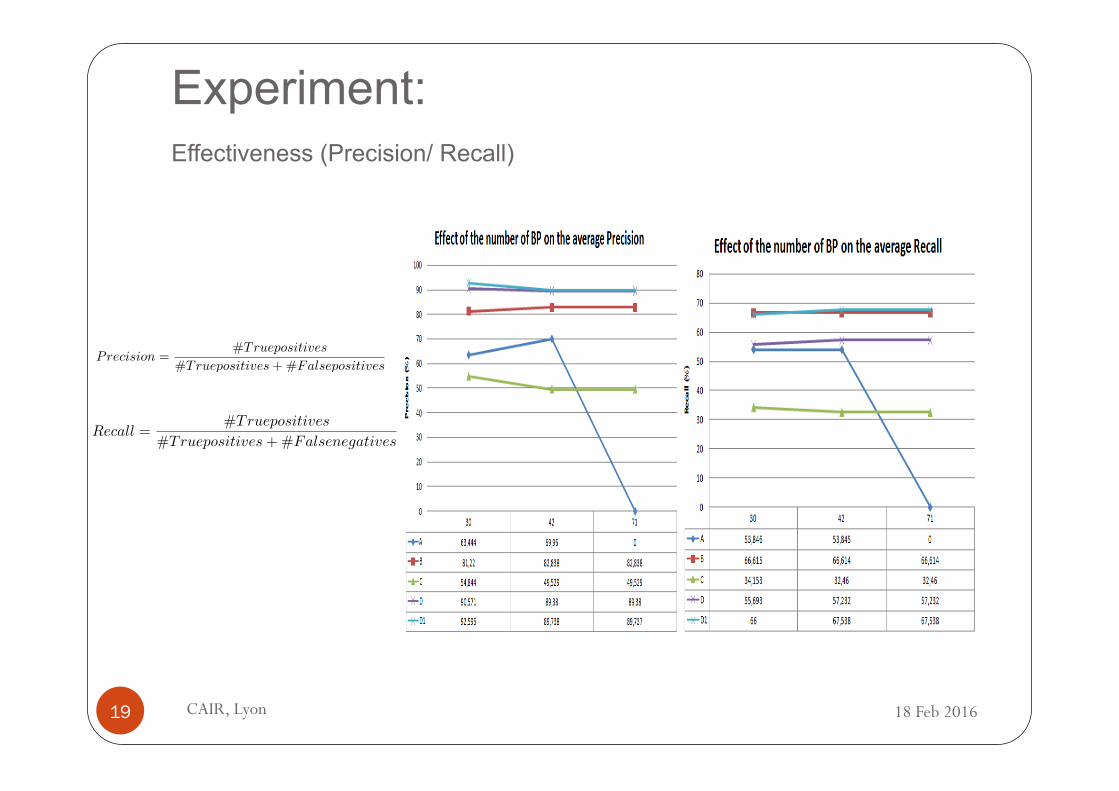
Experiment:
Effectiveness (Precision/ Recall)
CAIR, Lyon 19
Precision =#Truepositives
#Truepositives+#Falsepositives
Recall =#Truepositives
#Truepositives+#Falsenegatives
18 Feb 2016
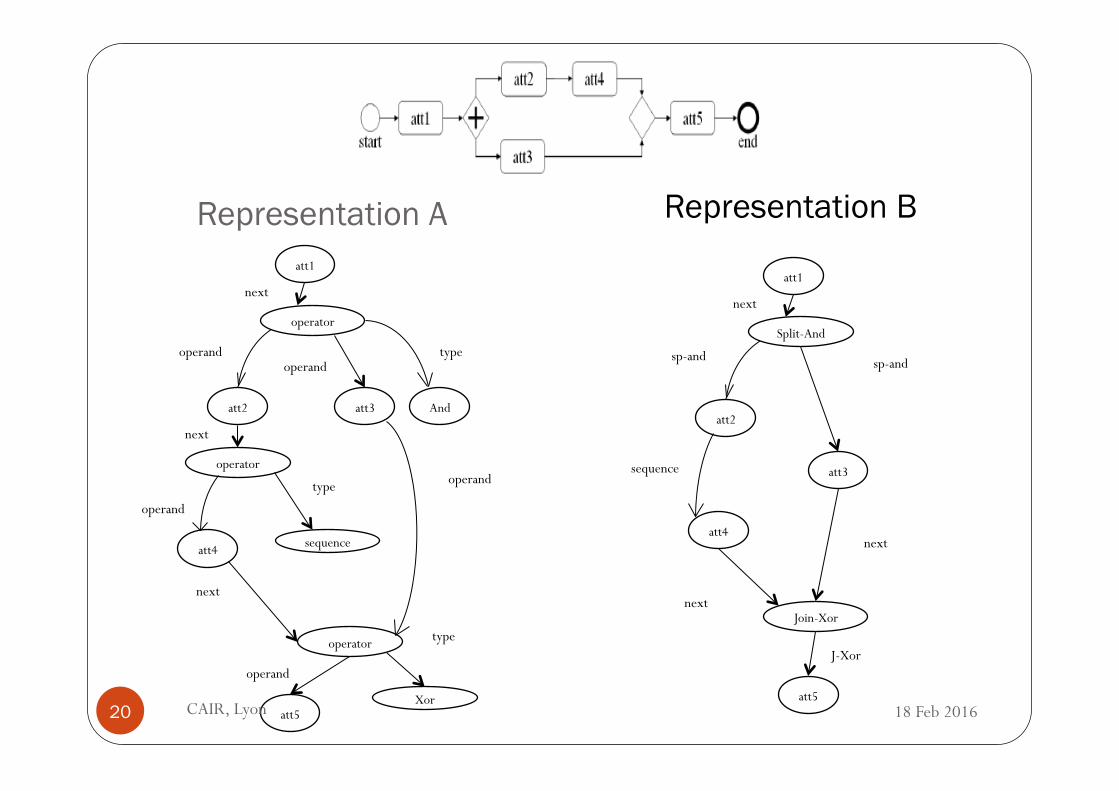
Representation A att1
att2 att3
att4
att5
next
operator
And
operator
sequence
next
operand
operator
Xor
type
type
operand
next
operand
type operand operand
Representation B
att1
att2
att3
att4
att5
next
Split-And
next
Join-Xor
J-Xor
sequence
next
sp-and sp-and
CAIR, Lyon 20 18 Feb 2016
Experiment1:
Effectiveness (Precision/ Recall)
CAIR, Lyon 21
Precision =#Truepositives
#Truepositives+#Falsepositives
Recall =#Truepositives
#Truepositives+#Falsenegatives
18 Feb 2016

Approach
CAIR, Lyon 24 18 Feb 2016

Keyword-Based Search for frequent workflow fragments
18 Feb 2016 CAIR, Lyon 25
Given an initial workflow, the user issues a query to characterize the desired missing workflow fragment. The query is composed of two elements: 1. A set of keywords {kw1,…,kwn} characterizing the
functionality that the fragment should implement 2. The set of activities in the initial workflow that are to be
connected to the fragment in question. Acommon = {a1,…,am}, We call these activities common or joint activities, interchangeably.

Retrieving Relevant Fragments
18 Feb 2016 CAIR, Lyon 26
� The first step in processing the user query consists in identifying the fragments in the repository that are relevant given the specified keywords.
� In doing so, we adopt the widely used technique of TF/IDF (term frequency / inverse document frequency) measure.
� Note however that workflow fragments are indexed by the labels of the activities obtained by homogenization, which we refer to by IDX
� Whereas, the user uses keywords of his own choosing

Retrieving relevant Fragments
18 Feb 2016 CAIR, Lyon 27
� For each keyword kwi provided by the user, we retrieve its synonyms, syn(kwi), from an existing thesaurus, e.g., Wordnet
� The index IDX is trawled to identify if there is a term in syn(kwi) U kwi, which is can be used to represent the keyword in the vector used for retrieving fragments.
� Once the fragments are retrieved, their constitent activities are matched against the common activities in the initial workflow that the user identified

Ranking Fragments
18 Feb 2016 CAIR, Lyon 28
The score used for ranking candidate fragments given a user query uq is defined as follows:
� Relevance: denotes the score obtained using TF-IDF � Frequency: A workflow fragment that is frequently used
across multiple workflow is likely to implement best practices that are useful for the designer compared with a fragment that apperas in, say one workflow
ated matching score. Specifically, we define the compatibility of a workflowfragment given the activities uq.A
common
specified in the user query uq asfollows:
Compatibility(wffrg
, uq.Acommon
) =
Pa
j
2A
common
matchingScore(aj
, wffrg
)
|Acommon
|
where matchingScore(aj
, wffrg
) is the matching score between aj
and thebest matching activity in wf
frg
, and |Acommon
| the number of activitiesin A
common
. Compatibility(wffrg
, Acommon
) takes a value between 0 and 1.The larger is the number of activities A
common
that have a matching activityin wf
frg
and the higher are the matching scores, the higher is the compati-bility between the candidate workflow fragment and the initial workflow.
Based on the above factors, we define the score used for ranking candidatefragments given a user query uq as:Score(wf
frg
, uq) =w
r
.Relvance(wf
frg
, uq) + w
f
.
Frequency(wf
frg
)
MaxFrequency
+ w
c
.Compatibility(wf
frg
, uq.A
common
)
where wr
, wf
and wc
are positive real numbers representing weights such thatw
r
+ wf
+ wc
= 1. MaxFrequency is positive number denoting the frequencyof the fragment that appears the maximum of times in the workflow repositoryharvested. Notice that the score takes a value between 0 and 1. Once the can-didate fragments are scored, they are ranked in the descendant order of theirassociated scores. The top-k fragments, e.g., 5, are then presented to the designerwho selects to the one to be composed with the initial workflow.
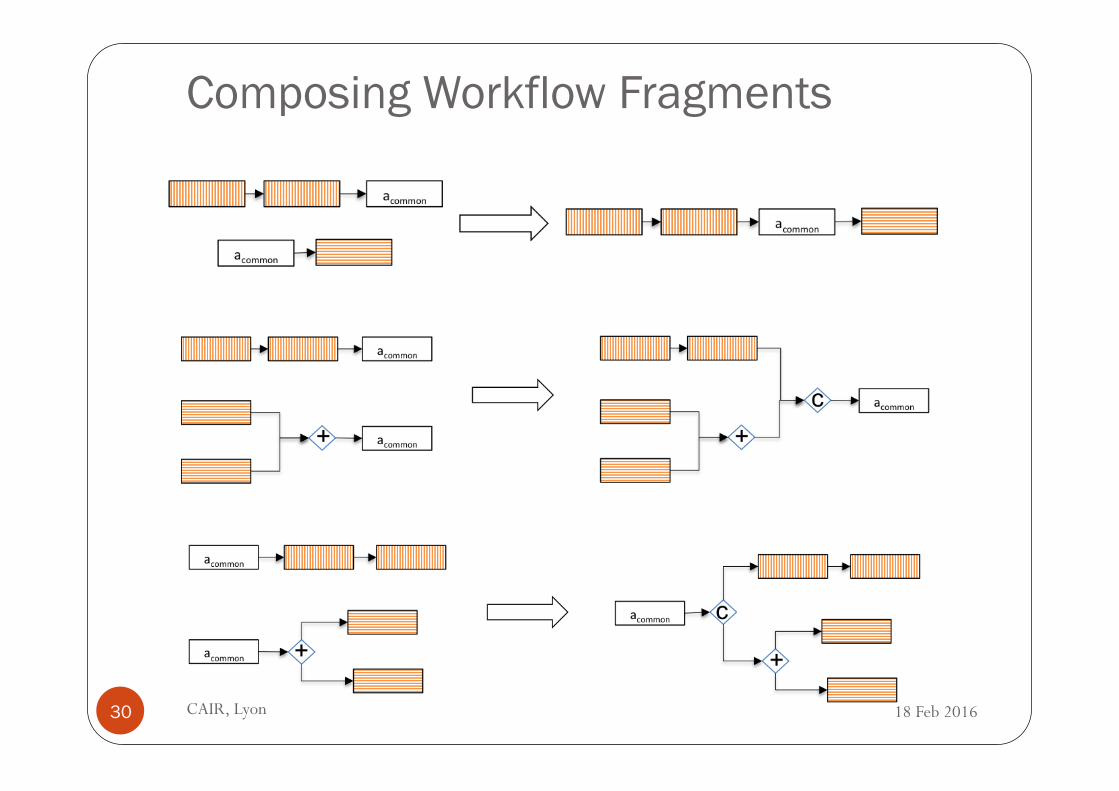
5 Composing Workflow Fragments
Once the user has examined the fragments that are retrieved given the setof keywords s/he specified, s/he can choose a fragment to be composed withthe initial workflow she was designing. We present in this section a methodthat can assist the designer in the composition task. Specifically, we considerthat the user has designed an initial workflow wf
initial
and selected a fragmentwf
frg
to be composed with wfinitial
. We turn our attention first to the casewhere wf
initial
and wffrg
has one activity in common acommon
. We denote byin(a
common
, wf) the set of activities that precedes acommon
in the workflow wf ,and by out(a
common
, wf) the set of activities that succeed acommon
in the work-flow wf .
Figure 7 sketches the algorithm used for composing wfinitial
and wffrg
. Ifthere is no succeeding activity for a
common
in wffrg
and there is no precedingactivity for a
common
in wffrg
then wfinitial
is composed in sequence with wffrg
based on acommon
(lines 1 and 2). Inversely, if there is no preceding activity foracommon
in wffrg
and there is no succeeding activity for acommon
in wffrg
then

Ranking Fragment: Compatibility
18 Feb 2016 CAIR, Lyon 29
To estimate the compatibility, we consider the number of activities in Acommon that have a matching activity in the workflow fragment and their associated matching score. ated matching score. Specifically, we define the compatibility of a workflowfragment given the activities uq.A
common
specified in the user query uq asfollows:
Compatibility(wffrg
, uq.Acommon
) =
Pa
j
2A
common
matchingScore(aj
, wffrg
)
|Acommon
|
where matchingScore(aj
, wffrg
) is the matching score between aj
and thebest matching activity in wf
frg
, and |Acommon
| the number of activitiesin A
common
. Compatibility(wffrg
, Acommon
) takes a value between 0 and 1.The larger is the number of activities A
common
that have a matching activityin wf
frg
and the higher are the matching scores, the higher is the compati-bility between the candidate workflow fragment and the initial workflow.
Based on the above factors, we define the score used for ranking candidatefragments given a user query uq as:Score(wf
frg
, uq) =w
r
.Relvance(wf
frg
, uq) + w
f
.
Frequency(wf
frg
)
MaxFrequency
+ w
c
.Compatibility(wf
frg
, uq.A
common
)
where wr
, wf
and wc
are positive real numbers representing weights such thatw
r
+ wf
+ wc
= 1. MaxFrequency is positive number denoting the frequencyof the fragment that appears the maximum of times in the workflow repositoryharvested. Notice that the score takes a value between 0 and 1. Once the can-didate fragments are scored, they are ranked in the descendant order of theirassociated scores. The top-k fragments, e.g., 5, are then presented to the designerwho selects to the one to be composed with the initial workflow.
5 Composing Workflow Fragments
Once the user has examined the fragments that are retrieved given the setof keywords s/he specified, s/he can choose a fragment to be composed withthe initial workflow she was designing. We present in this section a methodthat can assist the designer in the composition task. Specifically, we considerthat the user has designed an initial workflow wf
initial
and selected a fragmentwf
frg
to be composed with wfinitial
. We turn our attention first to the casewhere wf
initial
and wffrg
has one activity in common acommon
. We denote byin(a
common
, wf) the set of activities that precedes acommon
in the workflow wf ,and by out(a
common
, wf) the set of activities that succeed acommon
in the work-flow wf .
Figure 7 sketches the algorithm used for composing wfinitial
and wffrg
. Ifthere is no succeeding activity for a
common
in wffrg
and there is no precedingactivity for a
common
in wffrg
then wfinitial
is composed in sequence with wffrg
based on acommon
(lines 1 and 2). Inversely, if there is no preceding activity foracommon
in wffrg
and there is no succeeding activity for acommon
in wffrg
then
Composing Workflow Fragments
18 Feb 2016 CAIR, Lyon 30
Algorithm ComposeInput: wf
initial
initial workflowwf
frg
: workflow fragmenta
common
: activity in common between wf
initial
and wf
frg
Output:wf
merge
: workflow obtained by composing wf
initial
and wf
frg
based on a
common
Begin1 If (card(out(a
common
, wf
initial
)) = 0) and (card(in(acommon
, wf
frg
)) = 0)2 Then connect in sequence wf
initial
followed by wf
frg
using a
common
3 If (card(in(acommon
, wf
initial
)) = 0)and(card(out(acommon
, wf
frg
)) = 0)4 Then connect in sequence wf
frg
followed by wf
initial
using a
common
5 If (card(in(acommon
, wf
initial
)) � 1)and(card(in(acommon
, wf
frg
)) � 1)6 Then create a configurable join operator and7 connect it to the preceeding activities of wf
initial
and those of wf
frg
8 If (card(out(acommon
, wf
initial
)) � 1)and(card(out(acommon
, wf
frg
)) � 1)9 Then create a configurable branching operator and10 connect it to the succeeding activities of wf
initial
and those of wf
frg
11 wf
merge
is the workflow obtained as a result of the above manipulation.End
Fig. 7: Composition algorithm
wffrg
is composed in sequence with wfinitial
based on acommon
(lines 3 and 4).The above cases are illustrated using Figure 8.
If both wfinitial
and wffrg
have preceding activities (line 5), then we connectthe two workflows using a configurable join operator as illustrated in Figure 8(lines 6 and 7). We call such an operator configurable because it is up to the userto choose if such an operator is of a type and�join, or�join or xor�join. Thepreceding activities of such an operator are the preceding activities of wf
initial
and wffrg
, and its succeeding activity is acommon
.If both wf
initial
and wffrg
have succeeding activities (line 8), then we use aconfigurable split operator to connect the two workflows as illustrated in Figure10 (lines 9 and 10). We call such an operator configurable because it is upto the user to choose if such an operator is of a type and � split, or � splitor xor � split. The preceding activity of such an operator is a
common
and itssucceeding activities are the succeeding activities of wf
initial
and wffrg
.
Fig. 8: Merging the initial workflow and a fragment in sequence based on thecommon activity a
common
.
Fig. 9: Merging the preceding activities of the initial workflow and a fragmentusing a configurable join control operator.
Fig. 10: Merging the succeeding activities of the initial workflow and a fragmentusing a configurable split control operator.
If the initial workflow and the fragment has more than one activity in commonthen we perform the processing we have just described above iteratively usingone activity at a time. Note, however, that one would expect in the generalcase that there is one activity in common between the initial workflow and thefragment selected by the user. Having multiple activities in common between theinitial workflow and the fragment is likely to lead to complex workflows that aredifficult to understand thereby out-weighting the benefits that can be derivedfrom fragment reuse. Once the initial workflow and the fragment selected aremerged, the user examines the obtained workflow, makes changes in terms ofactivities and control flow connectors if necessary. In particular, the user willneed to substitute configurable join and split operators with concrete operators,e.g., and-split or or-split, that meet the semantics of the process s/he has in mind.As mentioned earlier, the user may want to merge another fragment once theinitial workflow and fragment has been merged. The same processing describedabove will be applied to the newly selected fragment.
6 Example from eScience
In this section, we illustrate the use of the method we have proposed in this paperto assist a designer of a workflow from the eScience field. Specifically, we showhow the method described can help the designer specify a workflow that is usedfor analyzing Huntington’s disease (HD) data. Huntington’s disease is the mostcommon inherited neurodegenerative disorder in Europe, affecting 1 out of 10000
Fig. 9: Merging the preceding activities of the initial workflow and a fragmentusing a configurable join control operator.
Fig. 10: Merging the succeeding activities of the initial workflow and a fragmentusing a configurable split control operator.
If the initial workflow and the fragment has more than one activity in commonthen we perform the processing we have just described above iteratively usingone activity at a time. Note, however, that one would expect in the generalcase that there is one activity in common between the initial workflow and thefragment selected by the user. Having multiple activities in common between theinitial workflow and the fragment is likely to lead to complex workflows that aredifficult to understand thereby out-weighting the benefits that can be derivedfrom fragment reuse. Once the initial workflow and the fragment selected aremerged, the user examines the obtained workflow, makes changes in terms ofactivities and control flow connectors if necessary. In particular, the user willneed to substitute configurable join and split operators with concrete operators,e.g., and-split or or-split, that meet the semantics of the process s/he has in mind.As mentioned earlier, the user may want to merge another fragment once theinitial workflow and fragment has been merged. The same processing describedabove will be applied to the newly selected fragment.
6 Example from eScience
In this section, we illustrate the use of the method we have proposed in this paperto assist a designer of a workflow from the eScience field. Specifically, we showhow the method described can help the designer specify a workflow that is usedfor analyzing Huntington’s disease (HD) data. Huntington’s disease is the mostcommon inherited neurodegenerative disorder in Europe, affecting 1 out of 10000

Example from eScience
18 Feb 2016 CAIR, Lyon 31
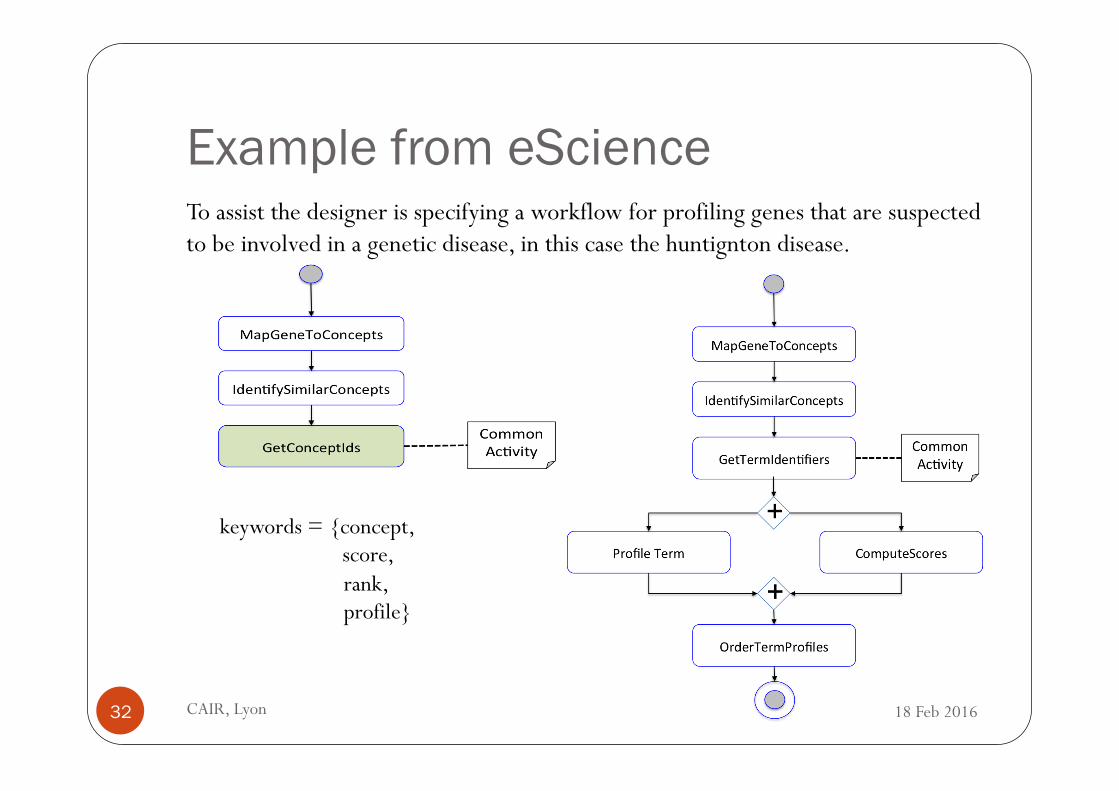
To assist the designer is specifying a workflow for profiling genes that are suspected to be involved in a genetic disease, in this case the huntignton disease.
people. Although the genetic mutation that causes HD was identified 20 yearsago [19], the downstream molecular mechanisms leading to the HD phenotypeare still poorly understood. Relating alterations in gene expression to epigeneticinformation might shed light on the disease aetiology. With this in mind, thescientist wanted to specify a workflow that annotate HD gene expression datawith publicly available epigenetic data [20].
Fig. 11: Initial Huntington Disease profiling workflow.
The initial workflow specified by the designer is illustrated in Figure 11.The workflow contains three activities that are ordered in sequence. The firstactivity MapGeneToConcept is used to extract the concepts that are used indomain ontologies to characterize a given gene that is known or suspected tobe involved in an infection or disease, in this case the Huntigton Disease. Thesecond activity IndentifySimilarConcepts is then used to identify for each ofthose concept the concepts that are similar. The rational behind doing so is thatgenes that are associated with concepts that are similar to concepts that areinvolved in the disease have chances of being also involved in the disease. Thisactivity involves running ontological similarity tests to identify similar concepts.The third activity GetConceptIds is then used to extract the identifiers of thesimilar concepts.
The workflow depicted in Figure 11 does not completely implement the anal-ysis that the designer would like. In particular, the designer would like to profileand rank the similar concepts that have been identified by the third activitybut is unware of the service implementations that can be used to do so. Toassist the designer in this task, we asked him to identify the common activityto which the missing fragment is to be attached to. He identified the activityGetConceptIDs as the common activity. We then asked him to provide a set ofkeywords characterizing the desired fragment. He provided as a result the follow-ing set: {concept, score, rank, profile}. Using the method presented in Section4, we retrieved candidate fragments. Figure 12 illustrates the fragment that wasfirst ranked in the results and was selected by the user. The common activity isnamed GetTermIdentifiers in the fragment, which is different from the label of
keywords = {concept, score,
rank, profile}
the common activity in the initial workflow, GetConceptIds. Still, our methodwas able detect it as a common activity thanks to the string similarity utilized.
Fig. 12: Candidate fragment selected by the workflow designer.
By applying the composition algorithm presented in Section 5 to merge theinitial workflow and the fragment selected by the user, we obtained the workflowdepicted in Figure 13. Indeed, the common activity has no succeeding activityin the initial workflow and has no preceding activity in the workflow fragment(lines 1, 2 in Figure 7). Therefore, the two workflows are connected ins sequenceusing the common activity.
7 Related work
There are three lines of work that are similar to our proposal which we analyze inthis section and compare to our work: workflow similarity and mining, semanticenrichment as a means for improving workflow discovery and intelligent supportfor process modelling.
Workflow similarity and workflow mining The literature of business and scien-tific workflows is rich with proposals that seek to mine existing workflows and/oridentify similarities between workflows. Existing work on workflow mining, fo-cused mainly on deriving a workflow specification (usually as a petri-net) fromlogs of executions of the workflows. There are however some proposals that fo-cused on examining workflow specification using clustering [21] and case-based
Example from eScience
18 Feb 2016 CAIR, Lyon 32
To assist the designer is specifying a workflow for profiling genes that are suspected to be involved in a genetic disease, in this case the huntignton disease.
people. Although the genetic mutation that causes HD was identified 20 yearsago [19], the downstream molecular mechanisms leading to the HD phenotypeare still poorly understood. Relating alterations in gene expression to epigeneticinformation might shed light on the disease aetiology. With this in mind, thescientist wanted to specify a workflow that annotate HD gene expression datawith publicly available epigenetic data [20].
Fig. 11: Initial Huntington Disease profiling workflow.
The initial workflow specified by the designer is illustrated in Figure 11.The workflow contains three activities that are ordered in sequence. The firstactivity MapGeneToConcept is used to extract the concepts that are used indomain ontologies to characterize a given gene that is known or suspected tobe involved in an infection or disease, in this case the Huntigton Disease. Thesecond activity IndentifySimilarConcepts is then used to identify for each ofthose concept the concepts that are similar. The rational behind doing so is thatgenes that are associated with concepts that are similar to concepts that areinvolved in the disease have chances of being also involved in the disease. Thisactivity involves running ontological similarity tests to identify similar concepts.The third activity GetConceptIds is then used to extract the identifiers of thesimilar concepts.
The workflow depicted in Figure 11 does not completely implement the anal-ysis that the designer would like. In particular, the designer would like to profileand rank the similar concepts that have been identified by the third activitybut is unware of the service implementations that can be used to do so. Toassist the designer in this task, we asked him to identify the common activityto which the missing fragment is to be attached to. He identified the activityGetConceptIDs as the common activity. We then asked him to provide a set ofkeywords characterizing the desired fragment. He provided as a result the follow-ing set: {concept, score, rank, profile}. Using the method presented in Section4, we retrieved candidate fragments. Figure 12 illustrates the fragment that wasfirst ranked in the results and was selected by the user. The common activity isnamed GetTermIdentifiers in the fragment, which is different from the label of
keywords = {concept, score,
rank, profile}
Fig. 13: Workflow obtained by merging the initial workflow and selected frag-ment.
reasoning [22], among other techniques. For example, in the case of clustering-based techniques, several similarity measures were employed to estimate thedistance between workflows. For example, Bae et al. [4] proposed a metric thatuses tree structures to take into account flow blocks such as parallel branchingand conditional choice. Wang et al. estimate the similarity between workflowsbased on the representation of workflows as Event Condition Action rules (ECA)[15]. Other authors apply sub-graph isomorphism techniques, e.g. [5] and [6].
The above methods assess the similarity between entire workflows. In ourwork, we are interested in identifying the similarity between fragments of work-flows. In this respect, our work is more related to the proposal by Diamantiniet al. [14] who applied hierarchical graph clustering method in order to extractcommon fragments of workflows. We focus on fragment as opposed to entireworkflows since there are more (realistic) opportunities for reuse at the level ofthe fragment as opposed to the entire workflow. In other words, the chances thatthe user finds a workflow that match her needs are slim. On the other hand, thechances that she finds workflows that contains one of more fragments that maycontribute to her workflow are more substantial.

Conclusions
18 Feb 2016 CAIR, Lyon 33
1. The method we have described for mining workflow fragments have been empirically tested.
2. The method for retrieving and composing workflow fragments has been used in an eScience use case to assist the design of a Huntington Disease workflow
3. The work on mining frequent workflow fragments has been published in the International Keystone conference
4. The extended version with results on the retrieval and composition of workflow fragments has been submitted to a special issue on keyword search of the Springer Journal: Transactions on Computational Collective Intelligence

Khalid Belhajjame
Joint work with Daniela Grigori, Mariem Harmassi et Manel Ben Yahia
LAMSADE, Université Paris Dauphine
Keyword-Based Search of Workflow Fragments and their Composition





























