Embed Size (px)
Citation preview

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
Poker AIの最新動向
October 31, 2017
Jun Ernesto Okumura
AI System Dept.
DeNA Co., Ltd.

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
自己紹介
名前
奥村 エルネスト 純(@pacocat)
経歴(2017/11時点)
宇宙物理学 Ph.D
→ DeNA入社(2014年)
→ データアナリスト@分析部(〜2016年)
- ゲームデータ分析、ゲームパラメータデザイン
→ 機械学習エンジニア@AIシステム部(2017年〜)
- 強化学習・深層学習を使ったゲームAI研究開発
2
強化学習を使った実ビジネスの応用事例を作っていきたい
モチベーション
本日の発表では、現在興味のある「展開型不完全情報ゲーム」や「マルチエージェント問題」に関連してポーカーAIをサーベイをした時の内容をまとめています。

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
今回の話の流れ
■ ポーカーAIの背景
■ 不完全情報ゲームへのアプローチ方法
⁃ ε-ナッシュ均衡
⁃ CFRアルゴリズム(Counterfactual Regret Minimization)
■ 近年の技術動向の紹介
⁃ ゲームの抽象化手法の発展
⁃ NN/RLを使ったモデルの登場
⁃ No limit Pokerでプロに勝つポーカーの出現
• Libratus
• DeepStack

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
今回の話の流れ
■ ポーカーAIの背景
■ 不完全情報ゲームへのアプローチ方法
⁃ ε-ナッシュ均衡
⁃ CFRアルゴリズム(Counterfactual Regret Minimization)
■ 近年の技術動向の紹介
⁃ ゲームの抽象化手法の発展
⁃ NN/RLを使ったモデルの登場
⁃ No limit Pokerでプロに勝つポーカーの出現
• Libratus
• DeepStack

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ CMUのグループによって開発されたポーカーAI
■ 2017年1月11日〜1月30日@”Brains vs AI”, Rivers Casino, Pittsburgh
■ Heads up No-limit Texas Hold’em(HUNL)のルールに完全準拠
■ 4人のプロプレイヤーと累計120,000回バトルを繰り返し$1.7Mの勝利※ポーカーの強さ指標(Exploitability)で 147mbb/h※
プロプレイヤーに勝利したポーカーAI:Libratus
※1ゲームあたりの儲けをbig blind(≒参加費)で規格化した量(ここでは1,766,250/120,000*10 = 147)勝ち負けよりもどれだけチップを搾取(exploit)したかを重視するため、レーティングのような指標は使わない
CMU Artificial Intelligence Is Tough Poker Player - Carnegie Mellon University
https://www.cmu.edu/news/stories/archives/2017/january/AI-tough-poker-player.html
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
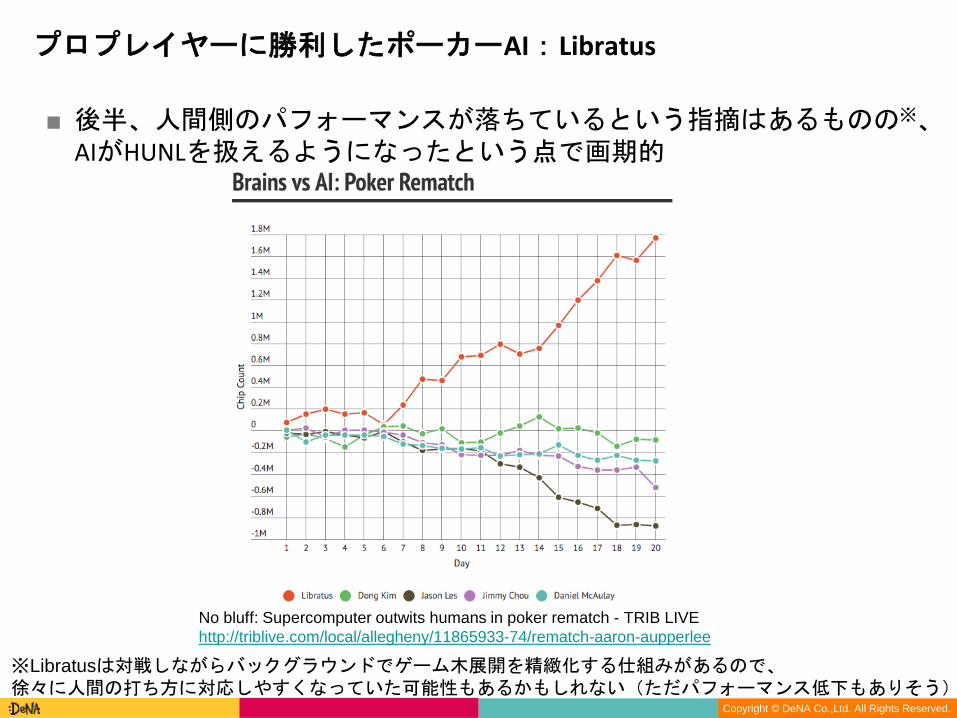
■ 後半、人間側のパフォーマンスが落ちているという指摘はあるものの※、AIがHUNLを扱えるようになったという点で画期的
プロプレイヤーに勝利したポーカーAI:Libratus
※Libratusは対戦しながらバックグラウンドでゲーム木展開を精緻化する仕組みがあるので、徐々に人間の打ち方に対応しやすくなっていた可能性もあるかもしれない(ただパフォーマンス低下もありそう)
No bluff: Supercomputer outwits humans in poker rematch - TRIB LIVE
http://triblive.com/local/allegheny/11865933-74/rematch-aaron-aupperlee
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
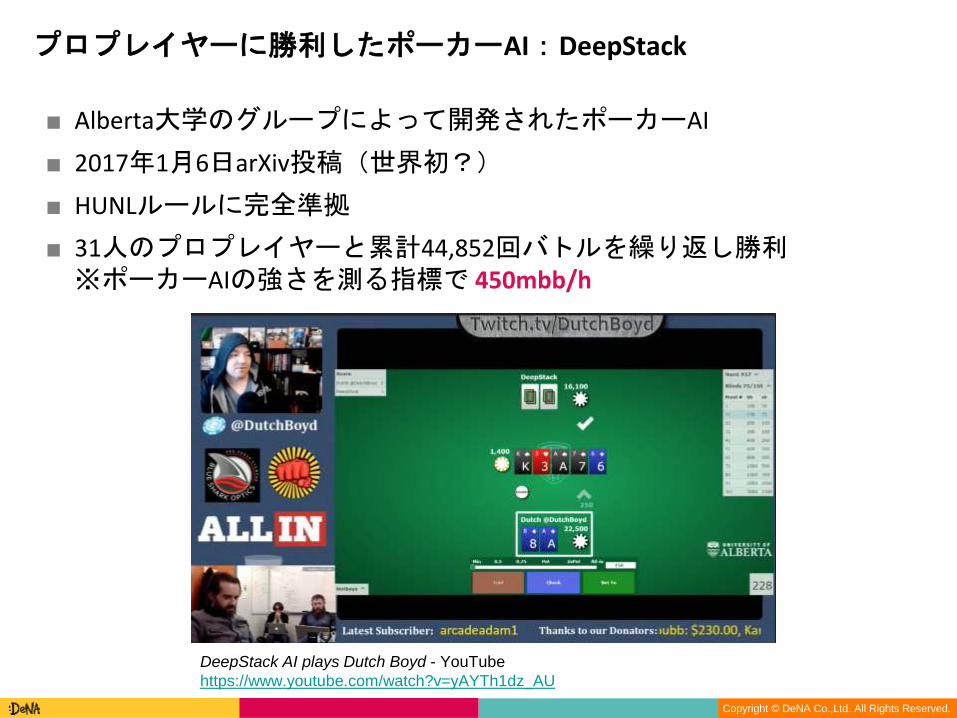
■ Alberta大学のグループによって開発されたポーカーAI
■ 2017年1月6日arXiv投稿(世界初?)
■ HUNLルールに完全準拠
■ 31人のプロプレイヤーと累計44,852回バトルを繰り返し勝利※ポーカーAIの強さを測る指標で 450mbb/h
プロプレイヤーに勝利したポーカーAI:DeepStack
DeepStack AI plays Dutch Boyd - YouTube
https://www.youtube.com/watch?v=yAYTh1dz_AU
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
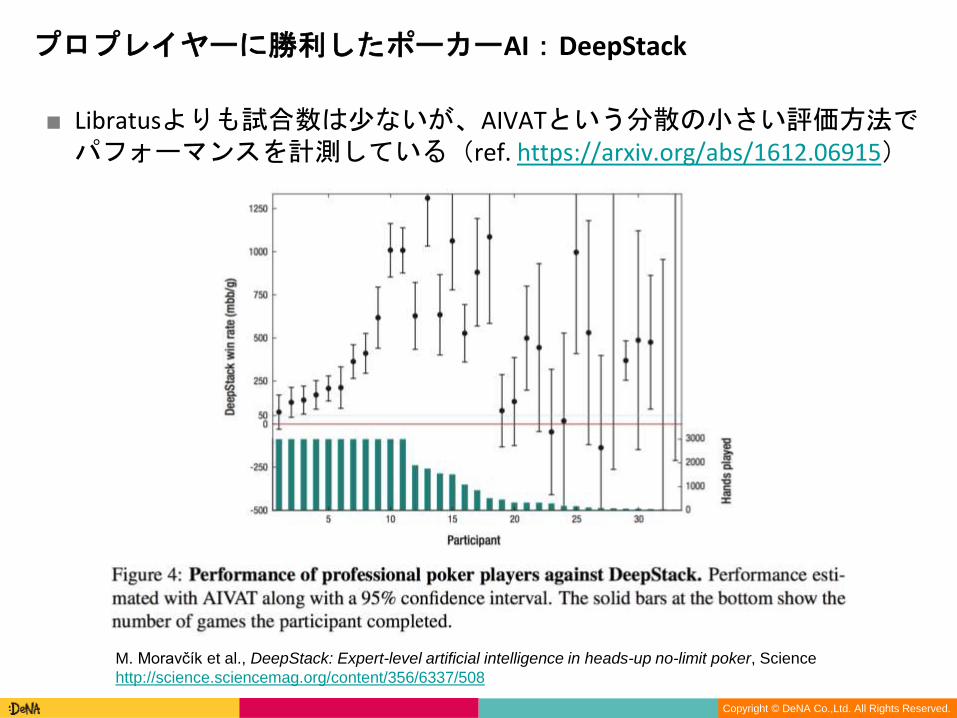
■ Libratusよりも試合数は少ないが、AIVATという分散の小さい評価方法でパフォーマンスを計測している(ref. https://arxiv.org/abs/1612.06915)
プロプレイヤーに勝利したポーカーAI:DeepStack
M. Moravčík et al., DeepStack: Expert-level artificial intelligence in heads-up no-limit poker, Science
http://science.sciencemag.org/content/356/6337/508

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
困難①状態数が多い
⁃ 探索・学習にかかる時間が膨大
⁃ HUNLで局面数は~10160と言われている
• 局面数を大きくしている主要因はbet額の選択肢が多いこと
⁃ (参考)Heads up Limit Hold’em(HUL): ~1016、囲碁: ~10180
困難②不完全情報ゲームである
⁃ 相手の手が分からない状態で意思決定しないといけない
⁃ ゲーム理論での分類:二人零和有限確定不完全情報ゲーム
⁃ (参考)完全情報ゲームの例:チェッカー・オセロ・チェス・将棋・囲碁(みなAIで勝てている)
ポーカーAI(HUNL)の難しさ

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ ゲームの目的は他プレイヤーの持ちチップを搾取(Exploit)すること
■ 2枚のprivate card + 5枚のcommunity cardから選んだ3枚、で役を作る
■ プレイヤーの行動は{raise(bet), call(check), fold}のどれか
⁃ Raise: 賭け金を増やす
• 賭ける額はNo-limit Pokerでは0〜持ち金全部まで、Limit Pokerでは制限
⁃ Call: 相手のRaiseに乗る・ゲームを続ける
⁃ Fold: ゲームを降りる
Texas Hold’emの基本ルール
Learn Texas Hold'em in Less Than 4 Minutes! - YouTube
https://www.youtube.com/watch?v=cnm_V7A-G6c

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
ポーカーの状態数(Heads up Pokerの場合)
最初に配られるprivate cards: 52C2×50C2 = 1,624,350
Bet Sequence: 可能なaction数Fold Raise Call
…
Limit PokerではRaiseが2,3通りに制限されているが、No-limit Pokerではほぼ無制限(状態数を爆発させている主要因)
Bet Sequence: 可能なaction数Fold Raise Call
3枚のCommunity Cards: 48C3 = 17,296
4枚目のCommunity Card: 45C1 = 45
Bet Sequence: 可能なaction数Fold Raise Call
Bet Sequence: 可能なaction数Fold Raise Call
ゲーム進行
全部掛け合わせて、• Limit PokerではO(1016)
• No-limit PokerではO(10160)5枚目のCommunity Card: 44C1 = 44

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ HUNLをまともに相手にすると無理なので、ポーカーAIの実験ではルールを単純化したトイゲームが使われることが多い
⁃ Luduc Poker
• カードを{J, J, Q, Q, K, K}に制限
• Betting roundsを2つに制限(※3,4つのパターンもある)
• Betting amountを2つに制限
• 状態数(144)
⁃ 他にKuhn Poker, Rhode Island Hold 'Em, …
■ これまでは単純化したゲームを解くアルゴリズム開発が行われていたが、近年になってようやく本丸のHUNLに届き始めた現状
⁃ 計算リソースの発達
⁃ 状態数の抽象化/圧縮手法の進捗
⁃ 探索方法の効率化
⁃ NNを使った方策の近似(汎用的な表現力の獲得)、など
AI開発で使われるポーカールール

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 実世界の問題の多くは不完全情報ゲームの枠組みで扱える
⁃ 限られた情報・相手の意図が読めないの中での利得最大化
⁃ 例:交渉、政策決定、営業、スポーツ…
ポーカーAIの開発のなにが嬉しいか?

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
今回の話の流れ
■ ポーカーAIの背景
■ 不完全情報ゲームへのアプローチ方法
⁃ ε-ナッシュ均衡
⁃ CFRアルゴリズム(Counterfactual Regret Minimization)
■ 近年の技術動向の紹介
⁃ ゲームの抽象化手法の発展
⁃ NN/RLを使ったモデルの登場
⁃ No limit Pokerでプロに勝つポーカーの出現
• Libratus
• DeepStack

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
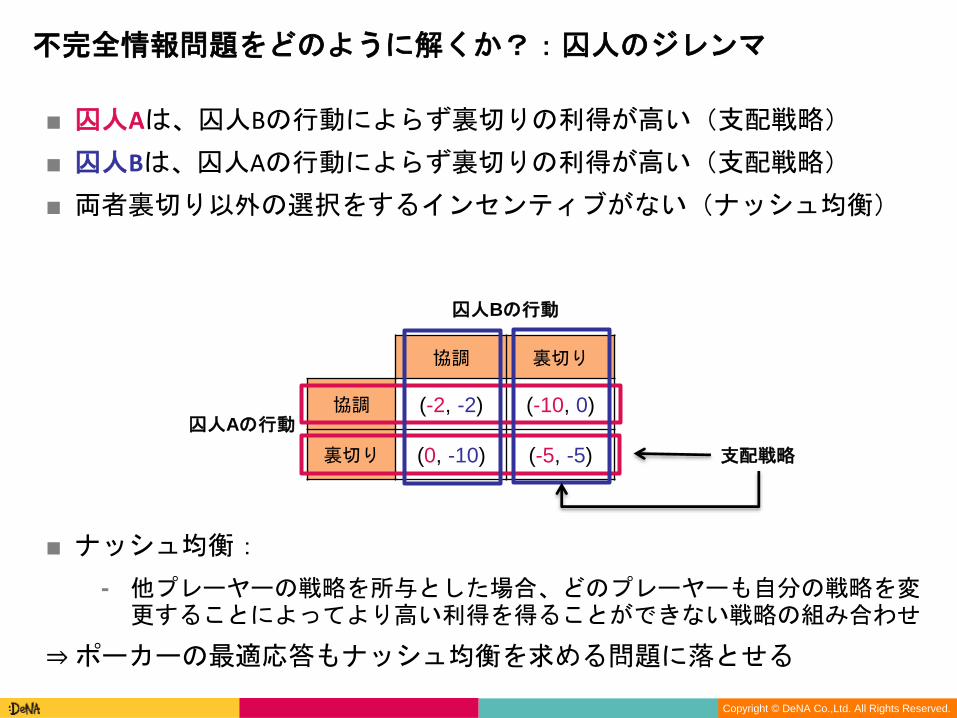
■ 問題設定
⁃ 囚人A, Bがそれぞれ {協調、裏切り} の行動を取る
⁃ 意思決定に際してお互い相談は出来ない(不完全情報)
⁃ 意思決定の結果は以下の行列で表される※(Payoff Matrix/利得行列)
不完全情報問題をどのように解くか?:囚人のジレンマ
協調 裏切り
協調 (-2, -2) (-10, 0)
裏切り (0, -10) (-5, -5)
※懲役n年を-n、利得を(囚人Aの懲役年数、囚人Bの懲役年数)と表記
囚人Aの行動
囚人Bの行動
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 囚人Aは、囚人Bの行動によらず裏切りの利得が高い(支配戦略)
■ 囚人Bは、囚人Aの行動によらず裏切りの利得が高い(支配戦略)
■ 両者裏切り以外の選択をするインセンティブがない(ナッシュ均衡)
■ ナッシュ均衡:
⁃ 他プレーヤーの戦略を所与とした場合、どのプレーヤーも自分の戦略を変更することによってより高い利得を得ることができない戦略の組み合わせ
⇒ポーカーの最適応答もナッシュ均衡を求める問題に落とせる
不完全情報問題をどのように解くか?:囚人のジレンマ
協調 裏切り
協調 (-2, -2) (-10, 0)
裏切り (0, -10) (-5, -5)
囚人Aの行動
囚人Bの行動
支配戦略

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ じゃんけん(二人零和有限確定不完全情報ゲーム)
⁃ {グー, チョキ, パー} = {1/3, 1/3, 1/3}の混合戦略はナッシュ均衡
■ グリコ/チョコレート/パイナップル(二人有限確定不完全情報ゲーム)
⁃ {グー, チョキ, パー} = {1/3, 1/3, 1/3} の混合戦略はナッシュ均衡ではない
⁃ {グー, チョキ, パー} = {2/5, 2/5, 1/5} の混合戦略はナッシュ均衡
様々なナッシュ均衡
グー チョキ パー
グー (0, 0) (1, -1) (-1, 1)
チョキ (-1, 1) (0, 0) (1, -1)
パー (1, -1) (-1, 1) (0, 0)
グー チョキ パー
グー (0, 0) (3, 0) (0, 6)
チョキ (0, 3) (0, 0) (6, 0)
パー (6, 0) (0, 6) (0, 0)
Quiz

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ じゃんけん(二人零和有限確定不完全情報ゲーム)
⁃ {グー, チョキ, パー} = {1/3, 1/3, 1/3}の混合戦略はナッシュ均衡
■ グリコ/チョコレート/パイナップル(二人有限確定不完全情報ゲーム)
⁃ {グー, チョキ, パー} = {1/3, 1/3, 1/3} の混合戦略はナッシュ均衡ではない
⁃ {グー, チョキ, パー} = {2/5, 2/5, 1/5} の混合戦略はナッシュ均衡
様々なナッシュ均衡
グー チョキ パー
グー (0, 0) (1, -1) (-1, 1)
チョキ (-1, 1) (0, 0) (1, -1)
パー (1, -1) (-1, 1) (0, 0)
グー チョキ パー
グー (0, 0) (3, 0) (0, 6)
チョキ (0, 3) (0, 0) (6, 0)
パー (6, 0) (0, 6) (0, 0)

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ ナッシュ均衡
⁃ 2人のプレイヤー1,2を考え、各々の戦略をσ1, σ2、戦略集合をΣ1, Σ2で表す
⁃ 相手の戦略が所与の時、利得uが以下を満たす戦略σはナッシュ均衡となる
• ポーカーにおいても、AIはナッシュ均衡を満たす戦略を探すことになる
• しかし、状態数が増えると現実的な計算では求まらないので、以下のようにナッシュ均衡を緩和した均衡を定義する
■ ε-ナッシュ均衡
もう少しちゃんと定義
Fix Fix

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 基本的な考え方
⁃ 「この選択をした方が利得が最大化出来た」という後悔(regret)を定量化
⁃ Regretを使って平均戦略を更新し、徐々にナッシュ均衡に近づけていく
■ Regretの定義
⁃ プレイヤーiの現在の戦略に対して様々な戦略を取ってみた時の利得増分
⁃ ゼロ和ゲームにおいてRegretをε以下に抑えることが出来れば、得られた平均戦略は2ε-ナッシュ均衡を満たす
ε-ナッシュ均衡へのアプローチ:Regret Minimization
現在の戦略を続けた時の利得(※ t は各roundを表す)
≈
他プレイヤーの戦略を現在のもの σtに固定した時に、自分が他の戦略 σ* を取った場合の仮想利得
M. Zinkevich et al., Regret Minimization in Games with Incomplete Information,
Advances in Neural Information Processing Systems 20 (NIPS 2007)
https://papers.nips.cc/paper/3306-regret-minimization-in-games-with-incomplete-information.pdf
収束したrigretから得られた戦略σtを平均化して、平均戦略を導出

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ ε-ナッシュ均衡を求める問題がRegretを最小化する問題に変換出来た
■ Regretは平均戦略を更新し続ければいずれ収束するので嬉しい
■ 展開型ゲームにおいてRegretを拡張したのがCounterfactural Regret※
⁃ じゃんけんなど同時手番で決着がつくゲームは標準型 (normal form game)
⁃ ポーカーはプレイヤーが順に行動する展開型ゲーム (extensive form game)
■ 前頁で定義したRegretよりも計算量が少なくて済む
Counterfactual Regret Minimization
※基本的に展開型ゲームは標準型ゲームの形式で表現することが可能だが、ポーカーのような状態数の多いゲームでは前頁のregret minimizationを使うのは現実的ではない

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ Counterfactual Utility(≒ある状態における特定戦略の評価値)
⁃ を行動系列 (history)、 を から終端状態を集めた集合とする
⁃ プレイヤー が把握している情報の集合を (information set)とする
• 自分の手札、Community card、相手のベット額、…のタプル
⁃ は系列 に到達する確率、 は から に到達する確率
⇒状態 の地点から戦略 を取った時の期待利得
※木が深い時はrolloutなどのサンプリングで近似できる
Counterfactual Utilityの定義
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
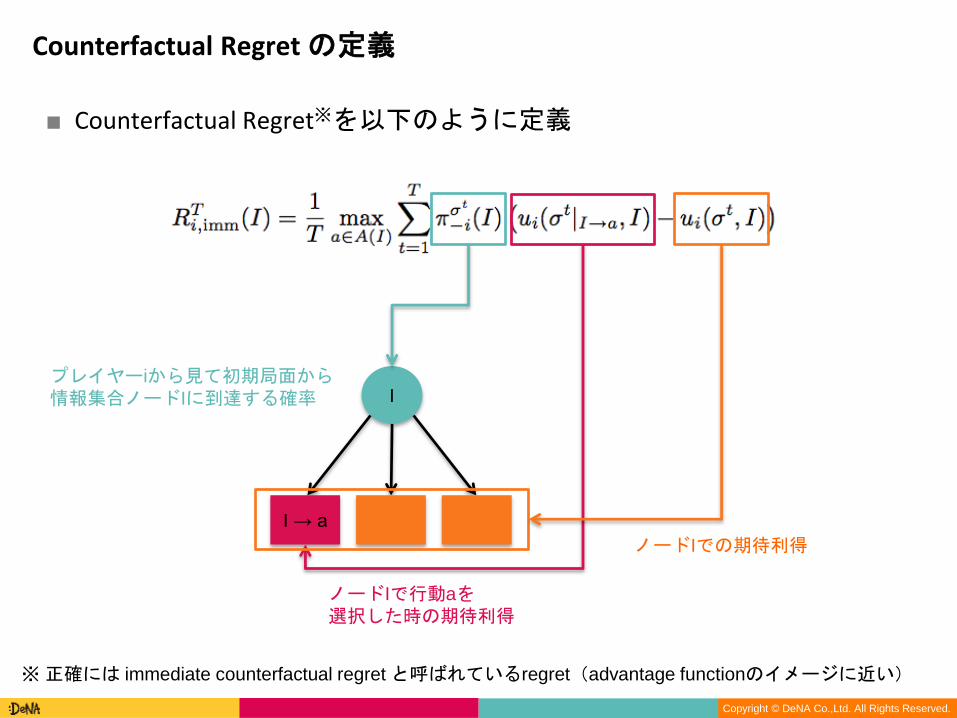
■ Counterfactual Regret※を以下のように定義
Counterfactual Regret の定義
Iプレイヤーiから見て初期局面から情報集合ノードIに到達する確率
I → a
ノードIで行動aを選択した時の期待利得
ノードIでの期待利得
※正確には immediate counterfactual regret と呼ばれているregret(advantage functionのイメージに近い)

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ Counterfactual Regretの意味
⁃ Rが負の時:行動aは平均戦略よりも損をする行動
⁃ Rが正の時:行動aは平均戦略よりも得(より最適応答に近い!)
■ Rが正の時にのみ以下のように戦略を更新(CFRアルゴリズム※)
⁃ この更新でRはT-1/2に比例する上限を置けるので、収束が保証される
Counterfactual Regret Minimization(CFRアルゴリズム)
※ CFRについて詳しくは以下講義資料が参考になるT.W. Neller, and M. Lanctot, An Introduction to Counterfactual Regret Minimization
http://modelai.gettysburg.edu/2013/cfr/cfr.pdf
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
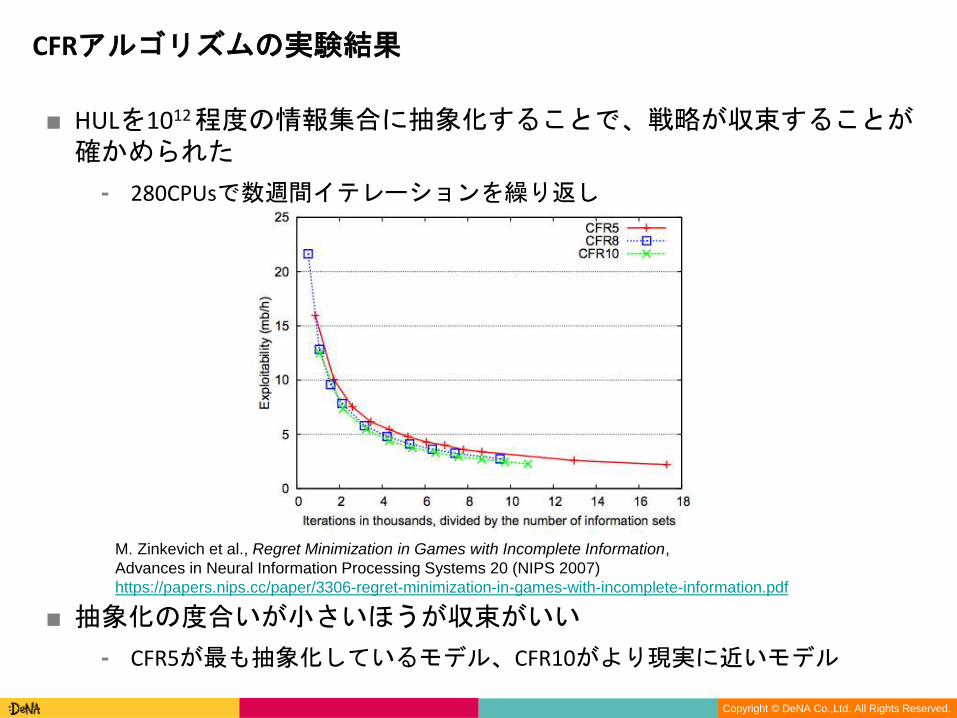
■ HULを1012程度の情報集合に抽象化することで、戦略が収束することが確かめられた
⁃ 280CPUsで数週間イテレーションを繰り返し
■ 抽象化の度合いが小さいほうが収束がいい
⁃ CFR5が最も抽象化しているモデル、CFR10がより現実に近いモデル
CFRアルゴリズムの実験結果
M. Zinkevich et al., Regret Minimization in Games with Incomplete Information,
Advances in Neural Information Processing Systems 20 (NIPS 2007)
https://papers.nips.cc/paper/3306-regret-minimization-in-games-with-incomplete-information.pdf

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ ポーカーのような不完全情報ゲームを解く問題は、ナッシュ均衡を求める問題に帰着される
⁃ 現実的には、ε-ナッシュ均衡に戦略を近づける問題を解くことになる
■ ε-ナッシュ均衡を満たす戦略は、regretの最小化問題に変換できる
⁃ 最小化は、平均戦略の更新によって達成される
⁃ ポーカーのような展開型ゲームではCounterfactual Regretの最小化に対応
■ CFRでは情報集合を1012程度に抽象化したポーカーで収束を確認
⁃ その後、同チームによってCFRはCFR+というアルゴリズムに改良され、1014程度の抽象化ポーカーでも収束させることが出来た
• 重み付け平均の導入、負のregretを無視する、等の改良
ここまでのおさらい
O. Tammelin, Solving Heads-Up Limit Texas Hold’em,
Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence
https://www.ijcai.org/Proceedings/15/Papers/097.pdf
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
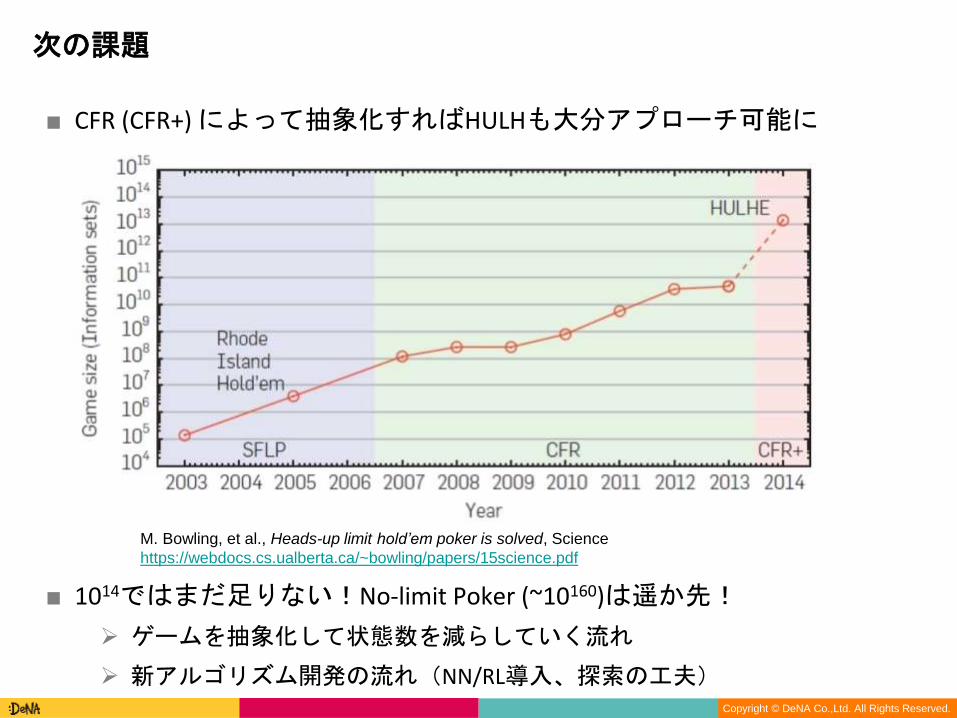
■ CFR (CFR+) によって抽象化すればHULHも大分アプローチ可能に
■ 1014ではまだ足りない!No-limit Poker (~10160)は遥か先!
ゲームを抽象化して状態数を減らしていく流れ
新アルゴリズム開発の流れ(NN/RL導入、探索の工夫)
次の課題
M. Bowling, et al., Heads-up limit hold’em poker is solved, Science
https://webdocs.cs.ualberta.ca/~bowling/papers/15science.pdf

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
今回の話の流れ
■ ポーカーAIの背景
■ 不完全情報ゲームへのアプローチ方法
⁃ ε-ナッシュ均衡
⁃ CFRアルゴリズム(Counterfactual Regret Minimization)
■ 近年の技術動向の紹介
⁃ ゲームの抽象化手法の発展
⁃ NN/RLを使ったモデルの登場
⁃ No limit Pokerでプロに勝つポーカーの出現
• Libratus
• DeepStack

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ ゲームの抽象化は様々な手法が提案されており、大きく2つに分かれる
⁃ Card/Information Abstraction(状態空間の縮減)
⁃ Action Abstraction(行動空間の縮減)
1. Action Abstractionの例
⁃ Suit(絵柄)の抽象化4!=24の縮減※ Card/Informationに関しても同様
⁃ Betting Round Reduction(ドメインベースでactionを刈り込み)
kK kBf kBc kBrF kBrC kBrRf kBrRc kBrRrF kBrRrC
bF bC bRf bRc bRrF bRrC bRrRf bRrRc ※k=check, b=bet, f=fold, c = call, r = raise
⁃ Bet額を数パターンに制限
⁃ Elimination of betting rounds
• 4-roundのゲームを3/2-roundに縮減
• 後半の意思決定は前半に比べ重要度が低いので手抜きをする
ポーカーの抽象化
D. Billings, et al., Approximating game-theoretic optimal strategies for full-scale poker,
Proceedings of the 18th international joint conference on Artificial intelligence
http://poker.cs.ualberta.ca/publications/IJCAI03.pdf
T. Sandholm. The State of Solving Large Incomplete-Information Games, and Application to Poker,
AI Magazine, special issue on Algorithmic Game Theory
http://www.cs.cmu.edu/~sandholm/solving%20games.aimag11.pdf
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
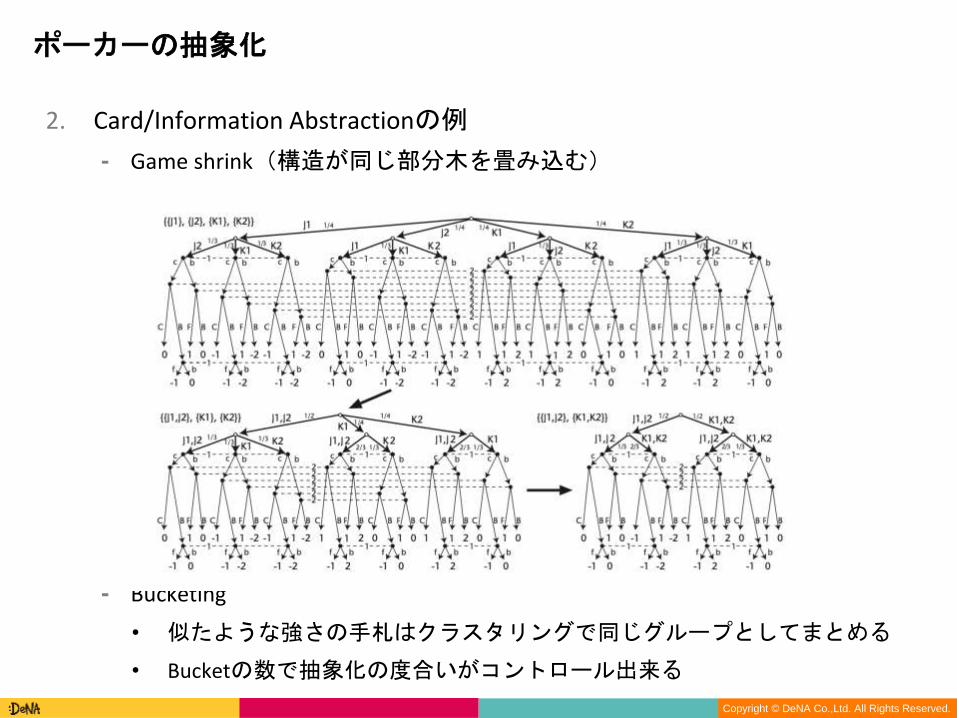
2. Card/Information Abstractionの例
⁃ Game shrink(構造が同じ部分木を畳み込む)
⁃ Bucketing
• 似たような強さの手札はクラスタリングで同じグループとしてまとめる
• Bucketの数で抽象化の度合いがコントロール出来る
ポーカーの抽象化

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ Limit Pokerでは最高O(107)程度まで状態を減らせる
⁃ ただし、抽象化するほど現実の問題から乖離するので注意が必要
⁃ 抽象化をしすぎるとパフォーマンスが下がるという指摘も
抽象化の課題

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ DQNやAlphaGoにも関わっていたDavid Silver (DeepMind)達の研究
■ ”最適応答戦略の強化学習”と”教師あり学習”の組み合わせ
■ 背景にある考え方
「ある戦略を取る相手に対して最適な応答をすれば最適戦略に近づく」
■ 学習の鍵になる2つのNN
⁃ Action value net:
• 対象の戦略に相手に強化学習でよりよい戦略を学ぶネットワーク
• DQNと同じ枠組み、探索はε-greedy
• 対象戦略より利得が高かった戦略の行動系列をgreedyにサンプリング (MRL)
⁃ Average policy net:
• MRLでサンプリングした行動対を用いて教師あり学習で平均戦略に近づける
■ Action value netとAverage policy netを組み合わせて最適戦略を更新
NN/RLを使ったモデルの登場:Neural Fictitious Self-Play (NFSP)
η: anticipatory parameter
J. Heinrich, D. Silver, Deep Reinforcement Learning from Self-Play in Imperfect-Information Games
https://arxiv.org/abs/1603.01121
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
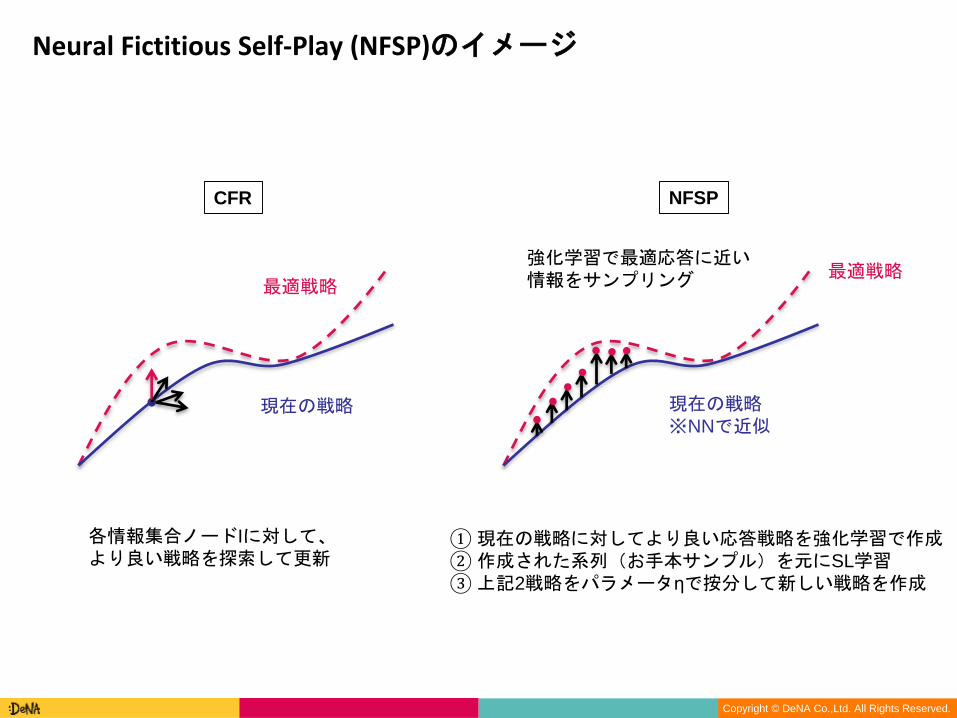
Neural Fictitious Self-Play (NFSP)のイメージ
CFR NFSP
各情報集合ノードIに対して、より良い戦略を探索して更新
現在の戦略
最適戦略
現在の戦略※NNで近似
強化学習で最適応答に近い情報をサンプリング 最適戦略
①現在の戦略に対してより良い応答戦略を強化学習で作成②作成された系列(お手本サンプル)を元にSL学習③上記2戦略をパラメータηで按分して新しい戦略を作成
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
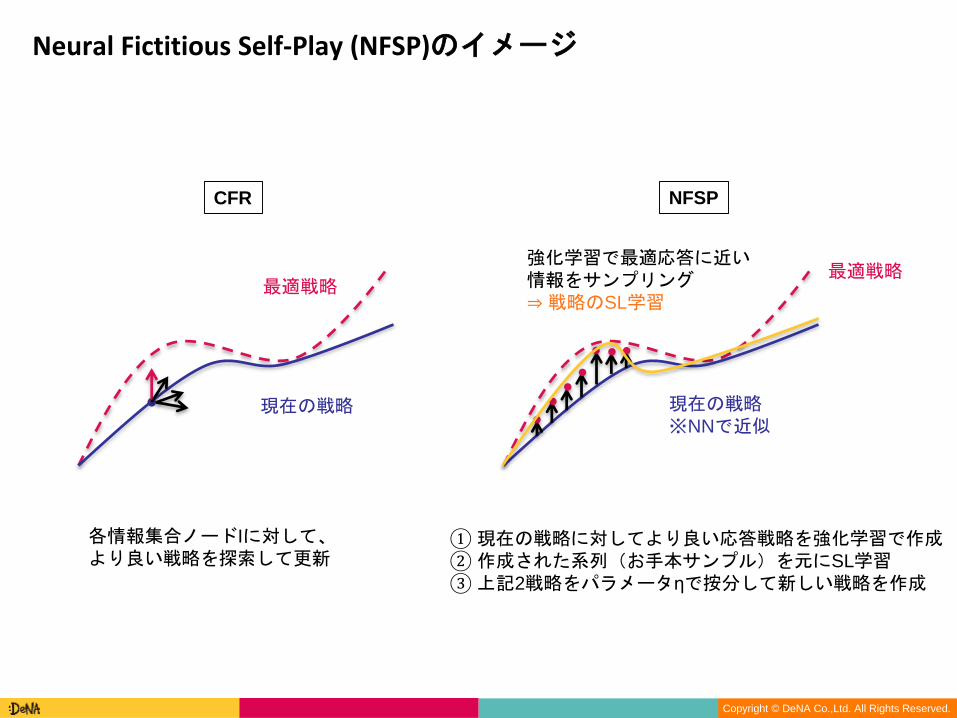
Neural Fictitious Self-Play (NFSP)のイメージ
CFR NFSP
各情報集合ノードIに対して、より良い戦略を探索して更新
①現在の戦略に対してより良い応答戦略を強化学習で作成②作成された系列(お手本サンプル)を元にSL学習③上記2戦略をパラメータηで按分して新しい戦略を作成
現在の戦略
最適戦略
現在の戦略※NNで近似
強化学習で最適応答に近い情報をサンプリング⇒戦略のSL学習
最適戦略

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
Pseudo-code for Neural Fictitious Self-Play (NFSP)
戦略σはavarage-policyとaction valueの混合戦略として定義
行動系列をサンプリングし、それをもとにSL/RLを実行
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
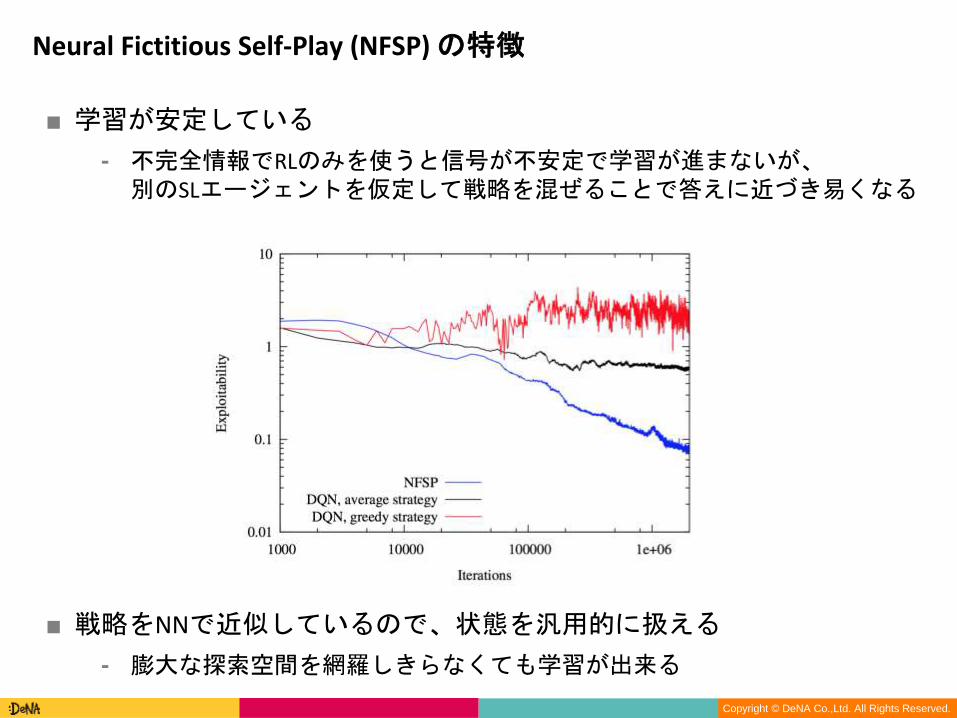
■ 学習が安定している
⁃ 不完全情報でRLのみを使うと信号が不安定で学習が進まないが、別のSLエージェントを仮定して戦略を混ぜることで答えに近づき易くなる
■ 戦略をNNで近似しているので、状態を汎用的に扱える
⁃ 膨大な探索空間を網羅しきらなくても学習が出来る
Neural Fictitious Self-Play (NFSP) の特徴

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 当時の強かった3つのAIモデルに負けている
⁃ しかし、ドメインベースの抽象化をすることなく、簡単なNNモデルで僅差まで迫ったのは興味深い
Neural Fictitious Self-Play (NFSP)の結果

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 不完全情報ゲームに取り組み続けているCMUのチーム
■ 3つのモジュールで構成されている
1. ゲーム抽象化(大まかな戦略)
• 徹底的な抽象化で10160の状態数を1012まで縮減
⁃ Action Abstraction: bettingの抽象化
⁃ Card Abstraction: 3, 4 roundではそれぞれ55M→2.5M, 24billion→1.25Mに縮減
• 抽象化したゲームをMonte Carlo CFRで解く
2. Subgameを解く(より細かい戦略)
• 途中から抽象化を使わずに部分木を探索
• 不完全情報ゲームではゲーム木展開が困難だが、モジュール1で得られた評価値を元に抽象ゲーム木を再展開するイメージ
3. 抽象ゲーム木の自己改良
• 全ての情報集合ノードは一番近い抽象化ノードに吸収されるが、距離が離れている場合は、そのノードを新たに抽象化ノードとして保持
HUNLを扱えるAIの登場①Libratus
N. Brown, et al., Libratus: The Superhuman AI for No-Limit Poker,
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence
https://www.ijcai.org/proceedings/2017/0772.pdf
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
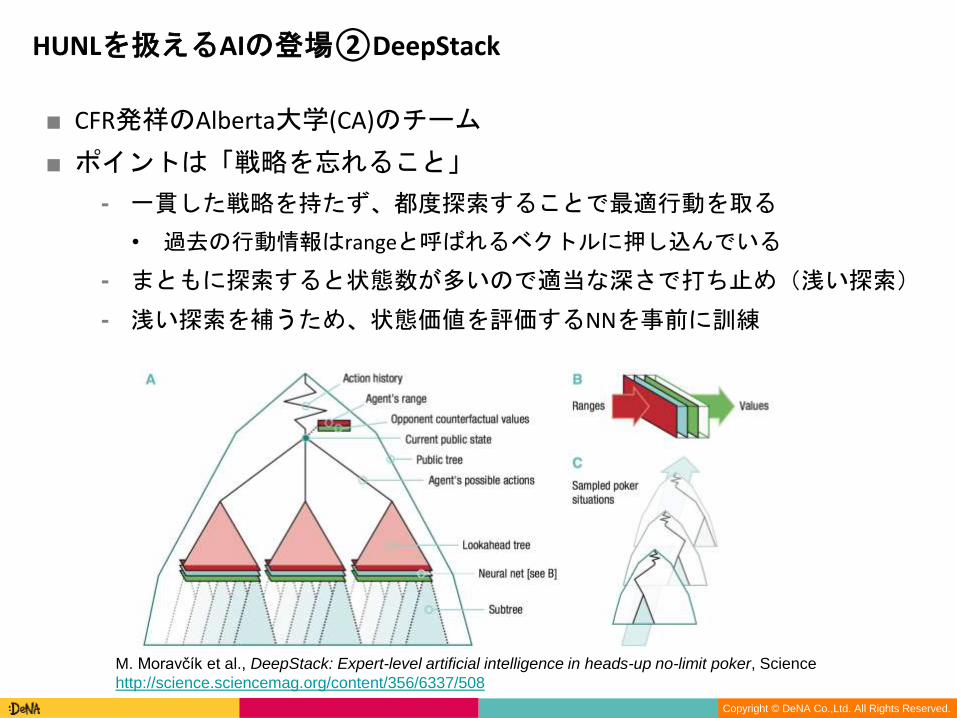
■ CFR発祥のAlberta大学(CA)のチーム
■ ポイントは「戦略を忘れること」
⁃ 一貫した戦略を持たず、都度探索することで最適行動を取る
• 過去の行動情報はrangeと呼ばれるベクトルに押し込んでいる
⁃ まともに探索すると状態数が多いので適当な深さで打ち止め(浅い探索)
⁃ 浅い探索を補うため、状態価値を評価するNNを事前に訓練
HUNLを扱えるAIの登場②DeepStack
M. Moravčík et al., DeepStack: Expert-level artificial intelligence in heads-up no-limit poker, Science
http://science.sciencemag.org/content/356/6337/508

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 入力:card range(52C2の各組み合わせが起こる確率), bet amount, pot
⁃ card rangeはaction毎に更新(e.g. 相手が大きくbetしてきたら強い組み合わせの確率を上げて、弱い組み合わせの確率を下げる)
⁃ range入力時に、カード状態を低次元にエンコードする処理を入れている
DeepStackはどのように局面を評価しているか

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 出力:自分・敵のCounterfactual Value(≒局面評価値)
⁃ 途中、自分と相手の評価を零和にするための処理が入っている
DeepStackはどのように局面を評価しているか

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
1. flop (2round), turn (3round)におけるranges, pot size, public cardsをそれぞれランダムに100万局、1000万局生成
2. 生成された局面を元に、CFR+アルゴリズムでNNを訓練
⁃ 1000 iteration
⁃ 行動はfold, call, pot-size bet, all-inの4種類のみ考える(action abstraction)
■ Reference:
⁃ DeepStackの詳細についてはビデオ講義が分かりやすいです
• Michael Bowling (Alberta Machine Intelligence Institute) Artificial Intelligence Goes All-In: Computers Playing Pokerhttps://vimeo.com/212288252
⁃ github
• https://github.com/lifrordi/DeepStack-Leduc
NNの訓練方法

Copyright (C) DeNA Co.,Ltd. All Rights Reserved.Copyright © DeNA Co.,Ltd. All Rights Reserved.
■ 主にCMU、Albertaの2大学がしのぎを削っている
⁃ David Silver(DeepMind)も一時参戦していた
⁃ CNNを使うアイデアも出てきている(役の特徴を掴みやすい)
■ プロプレイヤーに勝利した2アルゴリズムの技術的特徴は以下
⁃ Libratus: 大雑把な抽象木による探索と、詳細な探索のハイブリッド
⁃ DeepStack: 深さの打ち止めと、粗い探索を補う局面評価NNの導入
最新ポーカーAI像まとめ
N. Yakovenko, et al., Poker-CNN: A Pattern Learning Strategy for Making Draws and Bets in Poker Games
Using Convolutional Networks, Proceedings of the 30th AAAI Conference on Artificial Intelligence, 2016.
http://colinraffel.com/publications/aaai2016poker.pdf














![Application guideline Rough Draft 20171031 - domestic[1]€¦ · Application guideline: applying to the Institute of Biosciences and Technology in Houston (a research institute of](https://img.pdfslide.net/doc/110x75/5fcf206d3320645e23109d05/application-guideline-rough-draft-20171031-domestic1-application-guideline.jpg)











![[20171031 db tech salon] クラウド移行をベトナムで!? by 株式会社インサイトテクノロジー 森 茂紀](https://img.pdfslide.net/doc/110x75/5a6478b97f8b9a4c568b45cb/20171031-db-tech-salon-by-.jpg)


