Embed Size (px)
Citation preview

Submitted byAnkur Kumar AgrawalM.Tech(CS)-II Year13535009
Under the guidance ofDr. Dhaval Patel

Introduction Why Article Extraction and Comments Monitoring ? Challenges in Article Extraction and Comments Monitoring Article Extraction Techniques
Learning Based Techniques
Heuristic Techniques
Visual Based Approach Comments Monitoring
News Article Popularity Prediction
Extracting Discussion Structure Conclusion

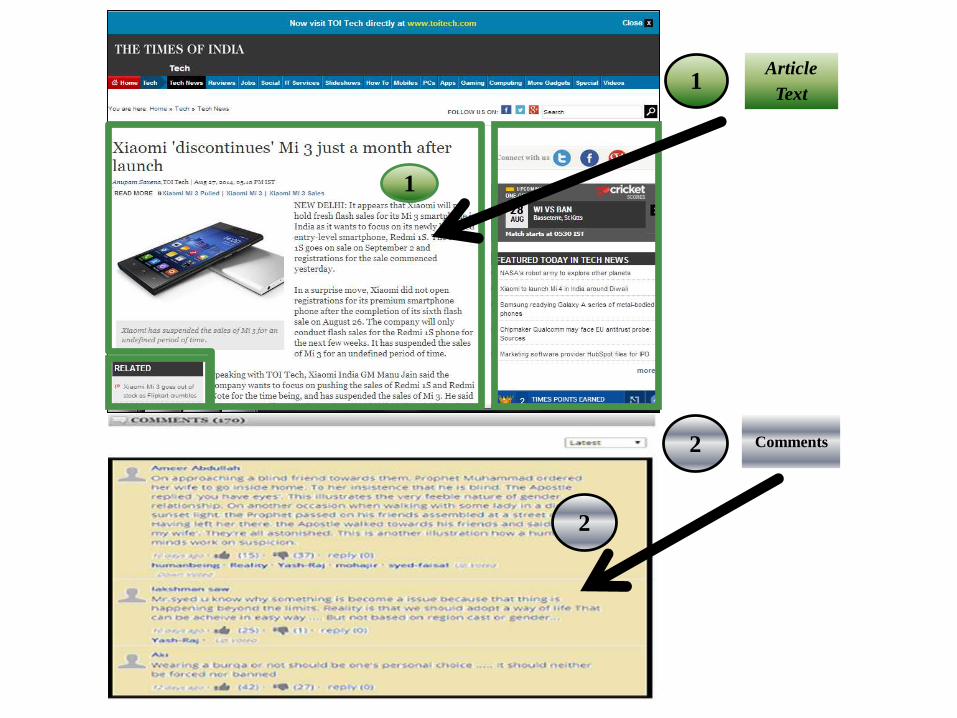
What is Article on news web page? Online news sources publish their news in the form of
articles. Article describes about a particular event happened. The main content on the news web page is Article Content. Other content on web pages like hyperlinks, images, and side
banners etc. is considered as noise content.
What are Comments? Comments are the reactions by the citizens on the article
published by the news media.
1
1
2
Comments2
Article
Text

Article Extraction can be used in Information Retrieval Systems. Search Engines (Indexing on Article content for giving best
search result) like Google , Yahoo. News Aggregator Systems like Google News.
Comments monitoring can be used for News Article Popularity Prediction. Advertisement Agencies News Agencies Debate Identification Sentimental Analysis and Opinion Mining

1
1
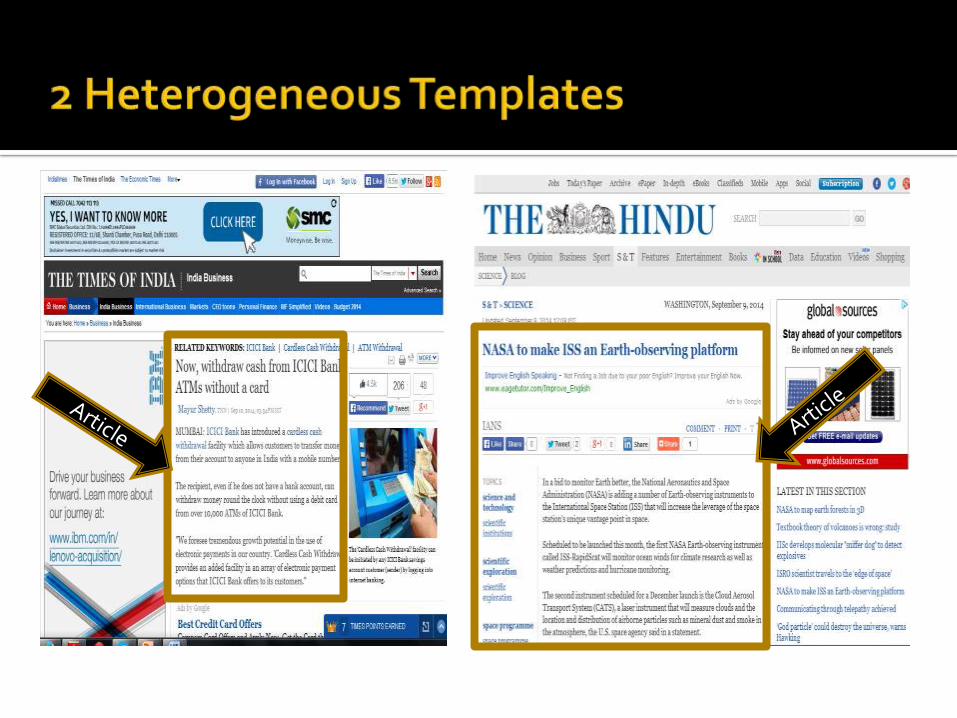
Article
Text
2Noise
Content
Menus
Advertisements
Side Banners
Hyperlinks
2
2
2

Public Comments are not always available for every newssource. Some websites provides their comments data
It is difficult to apply standard NLP techniques in commentssince comments may not be syntactically correct.

Heuristic Based Techniques
Visual Based Techniques
Learning Based Techniques

Parsed
News Web Page
Applying Heuristics on
parsed document Article Text
Content
output

Web page is processed using DOM Tree. DOM Tree represents each tag as Node Object in a tree.
Two important factors in heuristic techniques are Text Countand Link Count.
Text Count: Text count is the number of words in the text ofa node.
Link Count: Number of links a node has in the sub treerooted at any node.
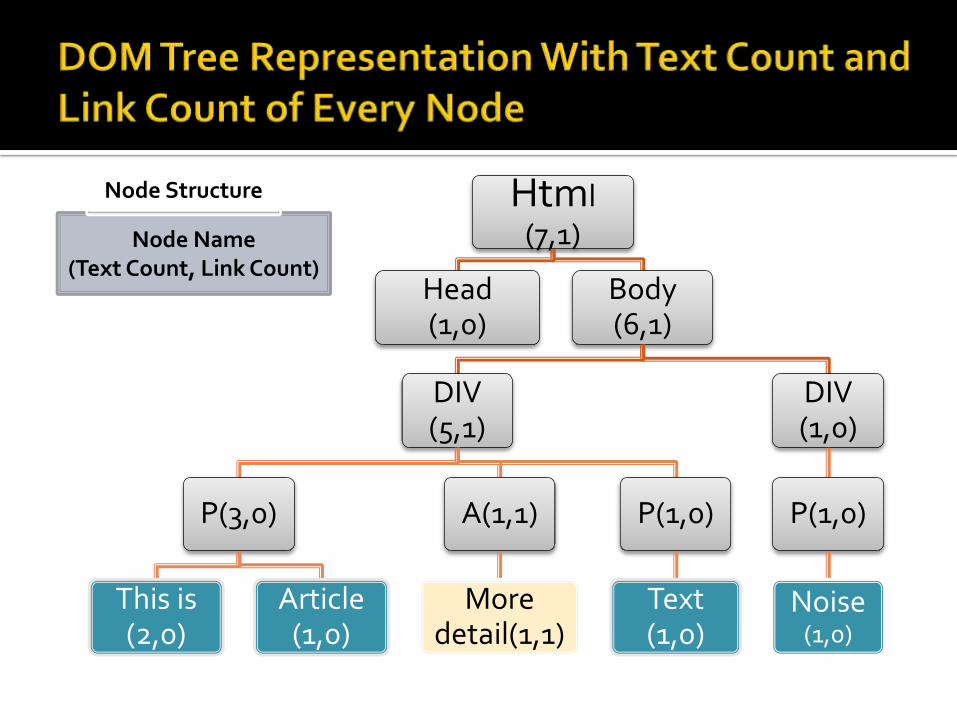
Html (7,1)
Head (1,0)
Body (6,1)
DIV (5,1)
P(3,0)
This is (2,0)
Article (1,0)
A(1,1)
More detail(1,1)
P(1,0)
Text (1,0)
DIV (1,0)
P(1,0)
Noise(1,0)
Node Name (Text Count, Link Count)
Node Structure

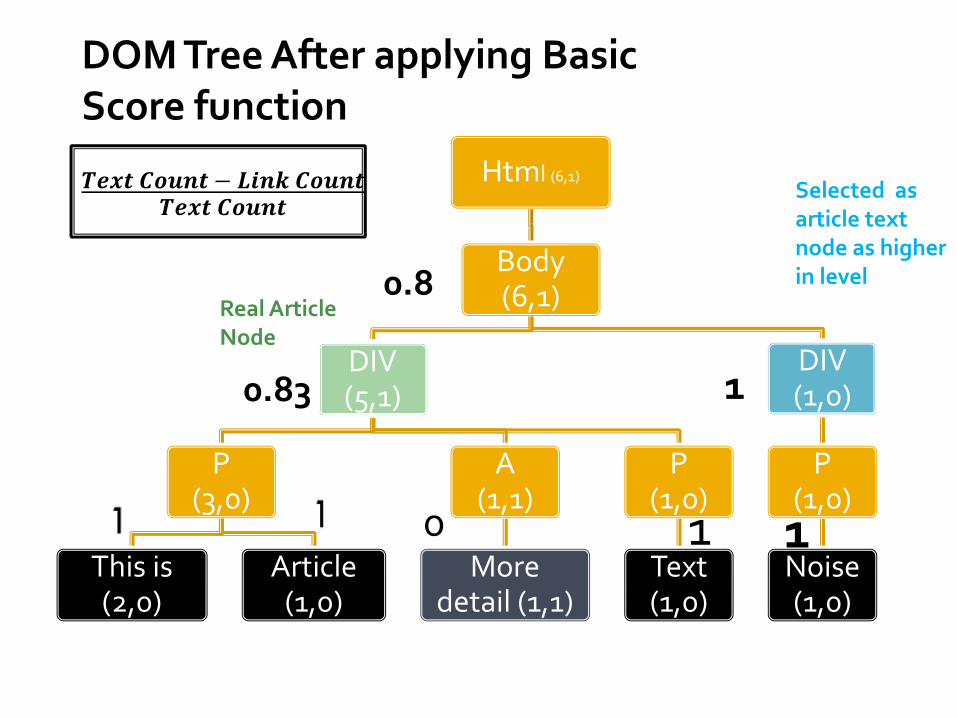
For each node of DOM Tree a Basic Score is calculated using the following formula.
Basic Score Function=𝑻𝒆𝒙𝒕 𝑪𝒐𝒖𝒏𝒕−𝑳𝒊𝒏𝒌 𝑪𝒐𝒖𝒏𝒕
𝑻𝒆𝒙𝒕 𝑪𝒐𝒖𝒏𝒕
A node having Maximum Basic Score is selected as a probable node having Article Text.
If multiple nodes are having same Maximum Score:Select the one which is higher in level
DrawbackFavors some nodes having less text count and no link.
Html (6,1)
Body (6,1)
DIV (5,1)
P (3,0)
This is (2,0)
Article (1,0)
A (1,1)
More detail (1,1)
P (1,0)
Text (1,0)
DIV (1,0)
P (1,0)
Noise (1,0)
DOM Tree After applying Basic Score function
1 1 10
1 0
1 1
10.83
0.8
Selected as article text node as higher in level
Real Article Node
𝑻𝒆𝒙𝒕 𝑪𝒐𝒖𝒏𝒕 − 𝑳𝒊𝒏𝒌 𝑪𝒐𝒖𝒏𝒕𝑻𝒆𝒙𝒕 𝑪𝒐𝒖𝒏𝒕

Here one extra factor is added in basic scoring function. Extra factor describes the fraction of Total text of page in a
node. Now optimal weights are assigned to both the factors. This extra factor removes the drawback of using only basic
scoring function.
Weightratio ×𝑻𝒆𝒙𝒕 𝑪𝒐𝒖𝒏𝒕−𝑳𝒊𝒏𝒌 𝑪𝒐𝒖𝒏𝒕
𝑻𝒆𝒙𝒕 𝑪𝒐𝒖𝒏𝒕+ Weighttext×
𝑻𝒆𝒙𝒕 𝑪𝒐𝒖𝒏𝒕
𝑷𝒂𝒈𝒆𝑻𝒆𝒙𝒕
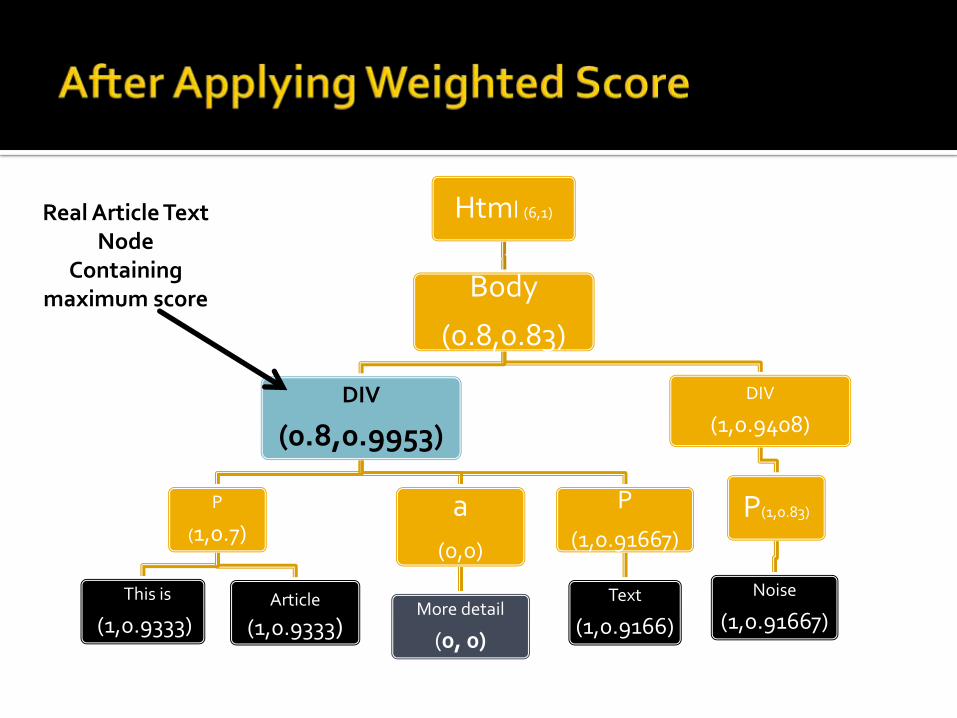
Html (6,1)
Body
(0.8,0.83)
DIV
(0.8,0.9953)
P
(1,0.7)
This is
(1,0.9333)Article
(1,0.9333)
a
(0,0)
More detail
(0, 0)
P
(1,0.91667)
Text
(1,0.9166)
DIV
(1,0.9408)
P(1,0.83)
Noise
(1,0.91667)
Real Article Text Node
Containing maximum score

Experiment was performed on 1620 news Articles from 27 different news sources.
Using a Basic Score: Precision is around 0.85 Recall is 0.02 (Very Poor)
Using Modified Weight Score Function:Precision is around 0.9562 (Improved)Recall is 0.9088 (Great Improvement)
Source: Jyotiak Prasad et. al.,”Coreex: content extraction from online news articles”

Heuristic Based Techniques
Visual Based Techniques
Learning Based Techniques

This approach works in two steps.
STEP 1First Learning is performed from a set of news web pages and a model is build which identifies the location of article content and noise content.
STEP 2A new web page is given as input to the model and Article text is obtained.
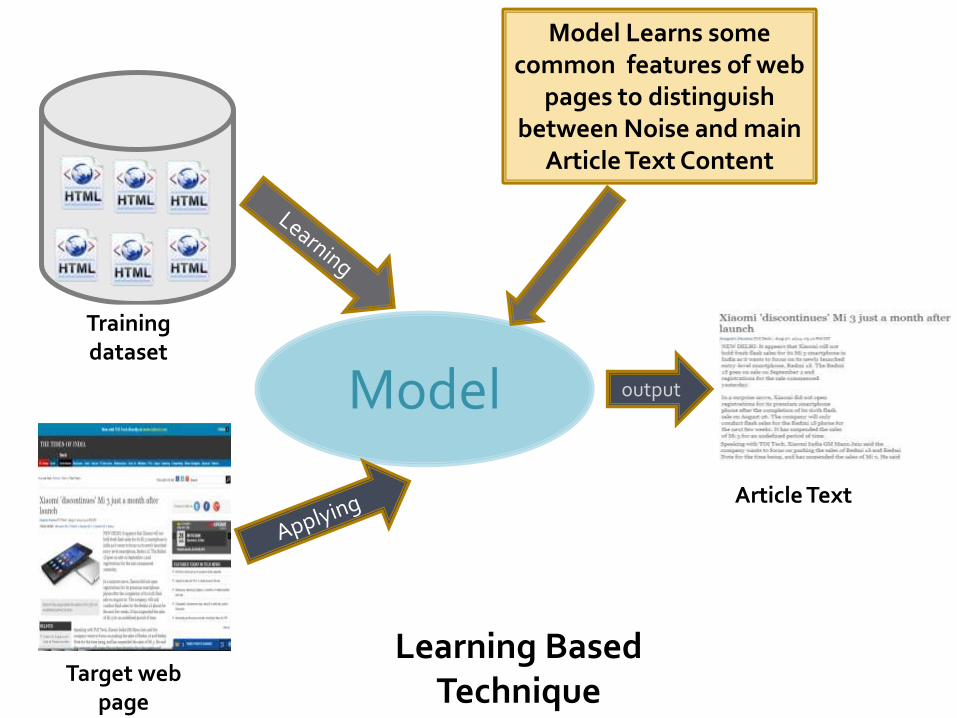
Model output
Target web page
Training dataset
Article Text
Learning Based Technique
Model Learns some common features of web
pages to distinguish between Noise and main
Article Text Content

The technique focus on removing noise content from news web page.
Learning is from web pages of a single news source.
The model builds a Style Tree after learning common layout from all the web pages.
Model(Style Tree) is applied on the target web page of the same news source to classify noise nodes and content nodes.
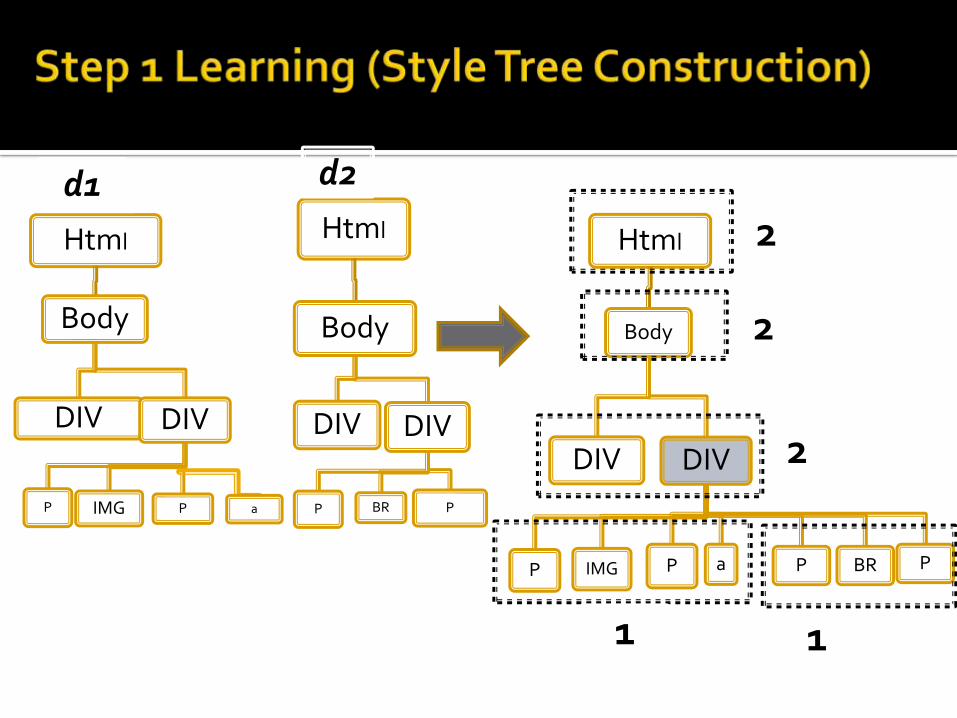
Html
Body
DIV DIV
P IMG P
Html
Body
DIV DIV
P BR Pa
Html
Body
DIV DIV
P IMG P a P BR P
1 1
2
2
2
d2d1

Noise node and content is identified based on the information gain(Entropy) of each node.
So it is assumed that if more presentation style a node have then it may be the Noise Node.
If actual content is more diverted then it may be the probable Content Node.

If E is an Element Node and number of pages that contain Eis m. Then
𝑁𝑜𝑑𝑒𝐼𝑚𝑝 𝐸 =−
𝑖=1
𝑙
𝑝𝑖 𝑙𝑜𝑔 𝑝𝑖 , 𝑖𝑓 𝑚 > 1
1, 𝑖𝑓 𝑚 = 1
Where l denotes number of child style nodes of E and 𝑝𝑖 that web page uses ith style node in l.
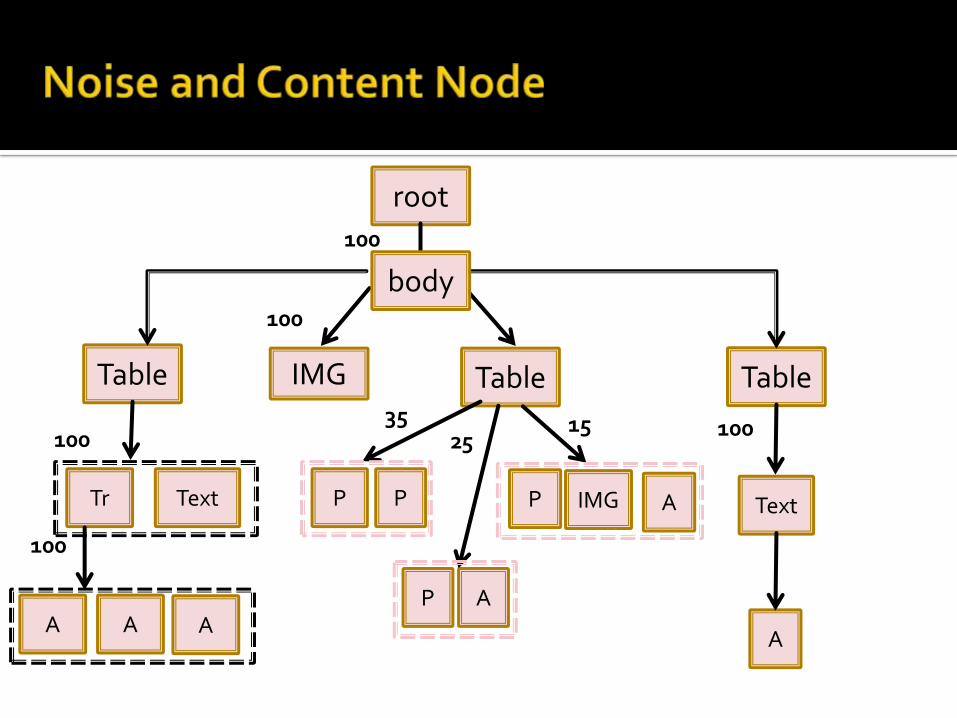
root
TableTable Table
P
AP
PPTextTr TextIMG A
AAAA
100
100
100
100
body
100 2535 15
IMG

Advantage Algorithm is fast once the learning is over.
Disadvantages Style Tree can take large amount of memory. It requires some web pages of a single domain to learn.

Heuristic Based Techniques
Visual Based Techniques
Learning Based Techniques

The techniques learns visual features of web page and identifies the boundary of Article Text content.
A simple visual based technique uses following two steps:
Step 1: Identifying different text segments using beak node identification of CSS.
Step 2: Global optimization method MSS(Maximum Scoring Subsequent) is used to identify article text body .

<Br> and <Hr> tags are always break nodes.
For other element nodes CSS display property is checked.
If CSS display property is “block” then it indicates that element have a line break before or after it.
Now Text segments are formed using nearest line break nodes of every text nodes.
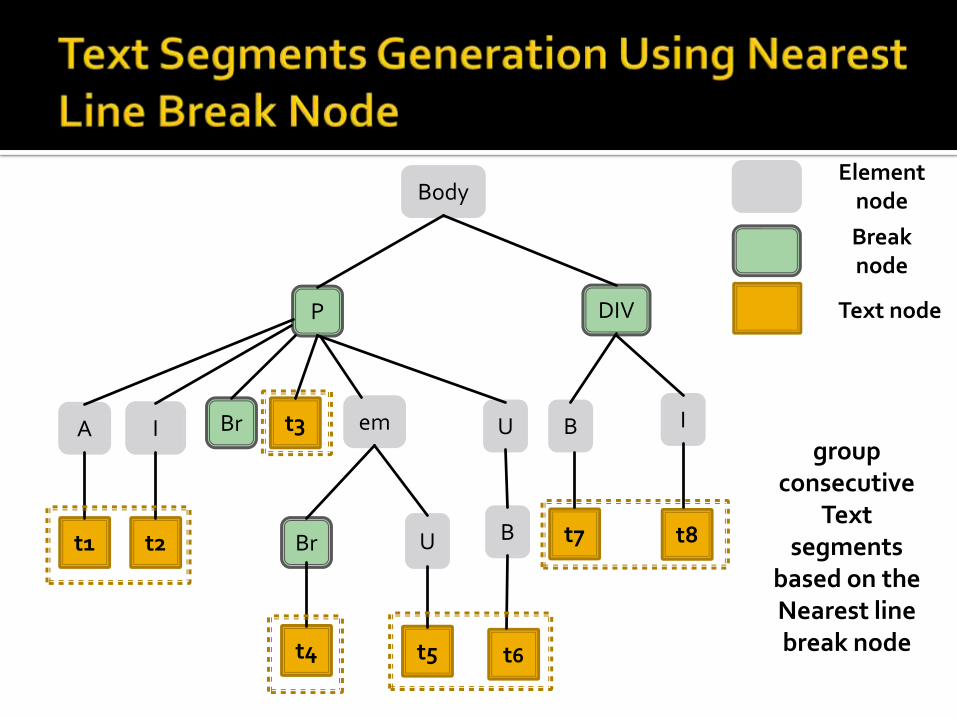
t3
Body
IA Br Uem
U
t5t4 t6
t7 t8
B
B
I
Br
P DIV
t2t1
Element node
Break node
Text node
group consecutive
Text segments
based on the Nearest line break node

Given set of text segments from step 1 we have to group the segments which can be the part of Article Text.
The algorithm gives score to each segments between -1 to 1 in the following way.
{+1 ,Psize>c1,Pcolour>c2,Plink<c3
-1 ,otherwiseF(S) =

Learning based Techniques are fast.
Heuristic Techniques can be applied on any web page.
Heuristic based techniques rely on threshold values which may not be accurate always.
Heuristic techniques are slow.
Learning based techniques require sufficient web pages to learn.

News Comments monitoring can be used to predict the popularity of an article prior to its publication.
Comments also describe the mindset of the citizens about a particular event.
Comments can also be used to identify discussions/debates going on about a news story.

The Technique uses number of comments as a key factor to predict the popularity of an article.
The method also considers the publication hour and category of an article it belongs to.
The method is based on Linear Regression
Y=a + bX Where X=Number of Comments an article received over a
timed
Y= Predicted volume of comments

Comments Repository
Regression Based on
publication hours
Regression Based on category
Regression Based on Per Year
Published Articles
RegressionY=a + bX
Apply output
Predicted volume of comments
Different Regression
models
Article for popularityPrediction
Select bestregression
aghaghgchacbjacjjahcjahcajhcacajajcnjacj
How the Proposed Technique works?

The experiment was performed on the articles data of four years(from February 2006 till June 2010).
Based on Per Year Data: It was concluded that the Articles published during 2008-10 are good for prediction.
Based on publication time of an article: The articles published between 6 to 11 AM suits best for prediction.

When people comments on the comments of other people then a Discussion Structure is created.
So the proposed method is used to identify that discussion structure in Dutch news media.
The technique solves following two questions:1. How to Extract the comments ?2. How to identify the Discussion Thread?
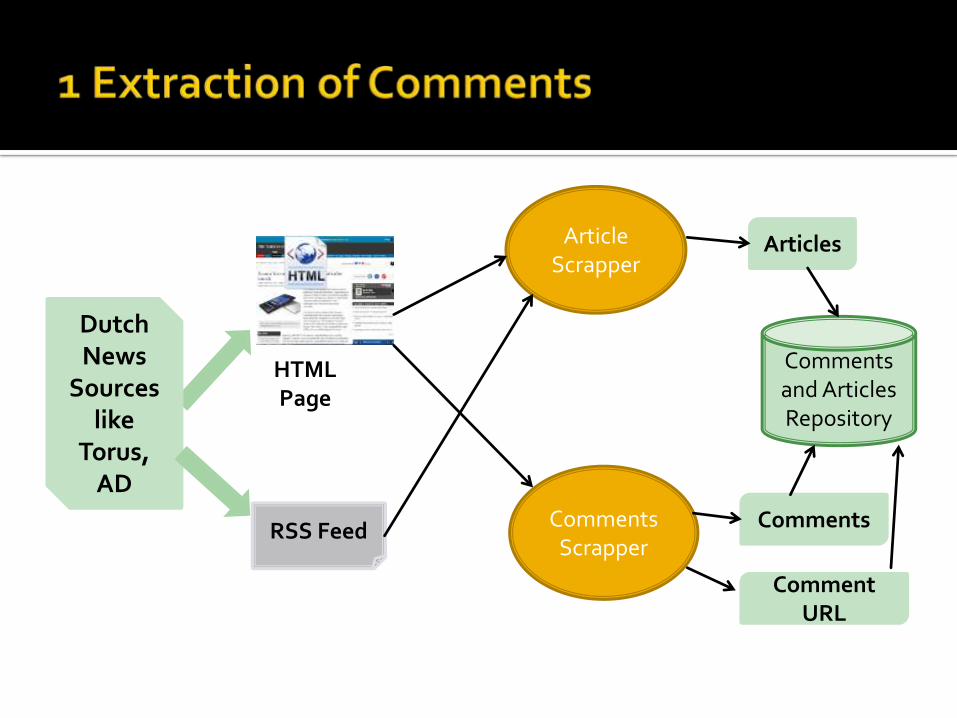
Article Scrapper
Comments Scrapper
Dutch News
Sources like
Torus, AD
RSS Feed
Articles
Comments and Articles Repository
Comment URL
Comments
HTML Page

Technique identifies commenter name in the comment text. “Yes Tom you are right”
Posted by: Bob
It also assumes that @ character can also be used to refer to someone.
“@Bob this is not a good political view.”Posted by: Jimmy
Issue: The issue is that the Author name may be the part of comment text as example is Boy may exist in “good boy”.

Following Machine learning based methods are proposed: Word Boundary Based: Tokenize comments and commenter and
check for commenter name in comments. POS Tagging and Loose Match: Only those words are matched
which are noun and use following method to match.
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑚1,𝑚2) =2.𝑚𝑎𝑡𝑐ℎ(𝑚1,𝑚2)
𝑙𝑒𝑛𝑔𝑡ℎ 𝑚1 + 𝑙𝑒𝑛𝑔𝑡ℎ(𝑚2)Optimal threshold value 0.85 is obtained after experiment.
@ Trigger and Loose Match: The @ character is used to trigger previous comments. Getting all reference of a comment text loose match is used.

We have learned the importance of article text and comments.
Article can be extracted using heuristic technique, learning based technique and visual based techniques.
Comments can be monitored for popularity prediction and identifying discussion structure or debate.





























