
PGI Accelerator Compilers
Dr. Volker WeinbergLeibniz-Rechenzentrum der Bayerischen Akademie der Wissenschaften
GPGPU ProgrammingLRZ, 10.-11. October 2011

Overview
1 The Portland Group (PGI) Compiler Suite
2 GPU Execution Model
3 Setting up, Building and Executing the first Program
4 PGI Accelerator DirectivesAccelerator Compute Region DirectiveAccelerator Loop Mapping DirectiveCombined DirectivesNew Accelerator Data Region DirectiveNew Accelerator Update Directive
5 Runtime Library Routines
6 Conditional Compilation
7 PGI Unified Binaries
8 Profiling and Tuning Accelerator Kernels
9 Introduction to CUDA Fortran
10 References

The Portland Group Inc. (PGI) Product Family
PGI Fortran, C and C++ for Linux, MacOS and Windows workstations,servers and clusters based on multicore 64-bit x64, 32-bit x86 processors& GPUs.
PGCC ANSI C99, K&R C and GNU gcc extensions pgccPGC++ ANSI/ISO C++ pgCC
PGFROTRAN native OpenMP and auto-parallel Fortran 2003 compiler pgf95PGF95 native OpenMP and auto-parallel Fortran 95 compiler pgf95PGF77 native OpenMP and auto-parallel Fortran 77 compiler pgf77PGHPF full HPF language support (Linux only) pghpfPGDBG MPI/OpenMP parallel graphical debugger pgdbgPGPROF MPI/OpenMP parallel graphical profiler pgprof
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

PGI Accelerator Support3 different approaches:
PGI Accelerator Programming Model
Does for GPU programming what OpenMP did for POSIX threads,high-level implicit model for x64+GPU systems,supported both for pgcc (C99) and pgf95 (Fortran 95) compilers,uses directives (C pragmas, Fortran comments) to offloadcompute-intensive code to an accelerator,program remains standard-compliant and portable,PGI 2011 includes the PGI Accelerator Fortran and C99 compilerssupporting x64+NVIDIA systems running under Linux, Mac OS Xand Windows.
CUDA Fortran
Similar to NVIDIA CUDA C,lower-level explicit model,language extension of Fortran, programs not Fortran-standardcompliant
PGI CUDA C++ Compilers for x86initial product release with PGI 11.5 (option: –Mcudax86)Developers can utilize the PGI C++ compiler to compile CUDAC/C++ code and then run it on an x86 target.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

NVIDIA GPU Accelerator Block Diagram
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Program Execution Model
Host
Executes most of the program,allocates memory on the accelerator device,initiates data copies from host memory to accelerator memory,sends the kernel code to the accelerator,queues kernels for the execution on the accelerator,waits for kernel completion,initiates data copy from accelerator back to the host memory,deallocates memory.
Accelerator
Only compute intensive regions should be executed by the GPU,executes kernels, one after the other,concurrently may transfer data between host and accelerator.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Code Generation
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers
Auto-Generated GPU CUDA Code
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> cat c1.001.gpu
#include "cuda_runtime.h"
/* From loop at line 25 */
static __constant__ struct{
int tc2;/* trip count loop:2 */
float* _a;
float* _r;
}a2;
extern "C" __global__ void
main_25_gpu(
)
{
int i1, i1s, ibx, itx;
ibx = blockIdx.x;
itx = threadIdx.x;
/* line:25 par */
for( i1s = ibx*256; i1s < a2.tc2; i1s += gridDim.x*256 ){
i1 = itx + i1s;
/* line:25 vect width(256) */
if( i1 < a2.tc2 ){
/* iltx:19 line:25 */
a2._r[i1] = (2.*a2._a[i1]);
}
}
}
Host x64 asm File
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> grep pgi c1.disasm
Loaded: /home/weinberg/pgi/pgi_tutorial/v1n1a1/c1.exe
#/home/weinberg/pgi/pgi_tutorial/v1n1a1/c1.c@main
0x4014F2: E8 E 1F 0 0 call 0x1F0E <__pgi_cu_init_p>
0x401506: E8 A9 25 0 0 call 0x25A9 <__pgi_cu_module_p>
0x40151F: E8 58 24 0 0 call 0x2458 <__pgi_cu_module_function_p>
0x401543: E8 44 2 0 0 call 0x244 <__pgi_cu_alloc_p>
0x401561: E8 26 2 0 0 call 0x226 <__pgi_cu_alloc_p>
0x4015BD: E8 6A 33 0 0 call 0x336A <__pgi_cu_uploadp_p>
0x4015F7: E8 F8 29 0 0 call 0x29F8 <__pgi_cu_uploadc_p>
0x40160D: E8 9A 27 0 0 call 0x279A <__pgi_cu_paramset_p>
0x401657: E8 7C 2 0 0 call 0x27C <__pgi_cu_launch_p>
0x4016B3: E8 A0 B 0 0 call 0xBA0 <__pgi_cu_downloadp_p>
0x4016CA: E8 B5 1A 0 0 call 0x1AB5 <__pgi_cu_free_p>
0x4016DD: E8 A2 1A 0 0 call 0x1AA2 <__pgi_cu_free_p>
0x4016E2: E8 19 5 0 0 call 0x519 <__pgi_cu_close_p>
Source File: PGI Accelerator Directive
#pragma acc region{
for( i = 0; i < n; ++i ) r[i] = a[i]*2.0f;}

Setting Up
Requirements:
CUDA-enabled NVIDIA graphics card[http://www.nvidia.com/object/cuda learn products.html],
PGI compiler ≥ 9.0
CUDA 3.1, 3.2, 4.0 Toolkit shipped with PGI , driver from NVIDIA.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Using the PGI Compilers on LRZ HPC Systems
At LRZ: 5 Floating Licenses of the PGI Compiler Suite[http://www.lrz-muenchen.de/services/software/programmierung/pgi lic/index.html]
module unload fortran ccompmodule load ccomp/pgi/11.8
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Getting Infos about the Host CPU: pgcpuid
weinberg@fluidyna:~> pgcpuidvendor id : GenuineIntelmodel name : Intel(R) Core(TM) i7 CPU 920 @ 2.67GHzcpu family : 6model : 10stepping : 5processor count : 16clflush size : 8apic physical ID: 5flags : acpi apic cflush cmov cplds cx8 cx16 de dtes ferr fpu fxsrflags : ht lm mca mce mmx monitor msr mtrr nx pae pat pdcm pgeflags : popcnt pse pseg36 selfsnoop speedstep sep sse sse2 sse3flags : ssse3 sse4.1 sse4.2 syscall tm tm2 tsc vme xtprtype : -tp nehalem-64
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Getting Infos about the GPU: pgaccelinfo
lu65fok@tl01:~> pgaccelinfoCUDA Driver Version: 4000NVRM version: NVIDIA UNIX x86_64 Kernel Module 270.27 Fri Feb 18 17:36:20 PST 2011
Device Number: 0Device Name: Tesla X2070Device Revision Number: 2.0Global Memory Size: 5636554752Number of Multiprocessors: 14Number of Cores: 448Concurrent Copy and Execution: YesTotal Constant Memory: 65536Total Shared Memory per Block: 49152Registers per Block: 32768Warp Size: 32Maximum Threads per Block: 1024Maximum Block Dimensions: 1024, 1024, 64Maximum Grid Dimensions: 65535 x 65535 x 65535Maximum Memory Pitch: 2147483647BTexture Alignment: 512BClock Rate: 1147 MHzInitialization time: 4119665 microsecondsCurrent free memory: 5450891264Upload time (4MB): 2170 microseconds ( 760 ms pinned)Download time: 1537 microseconds ( 756 ms pinned)Upload bandwidth: 1932 MB/sec (5518 MB/sec pinned)Download bandwidth: 2728 MB/sec (5548 MB/sec pinned)
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Building Programs
Using C
pgcc -o c1.exe c1.c -ta=nvidia -Minfo=accel -fast
Using Fortran
pgfortran -o f1.exe f1.f90 -ta=nvidia -Minfo=accel -fast
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Compiler Command Line Options
c.f. pgcc -help
-Minfo Generate info messages about optimizations-Minfo=accel Just generate Accelerator information
-ta=nvidia,{analysis | nofma | keepgpu | cc1? | cc20 | cuda* | time | ...} | hostnvidia Select NVIDIA accelerator targetanalysis Analysis only, no code generationnofma Don’t generate fused mul-add instructionskeepgpu/bin/ptx Keep intermediate filescc10/11/12/13 Compile for compute capability 1.?cc20 Compile for compute capability 2.0cuda2.3/3.0/3.1/3.2/4.0 Specify CUDA version of the toolkittime Collect simple timing informationhost Compile for the host, i.e., no accelerator target[no]flushzero En/Disable flush-zo-zero mode for Floating point ops in GPU code
-Mfcon Compile floating point constants as single precision-Msafeptr Specify that all C-pointers are safe-Mcuda[=emu|cc10|cc11|cc13|...] (Fortran only) Enable CUDA Fortran
emu Enable emulation modecc10/11/12/13/20 sets compute capabilitycuda2.3/3.0/3.1/3.2/4.0 Sets the CUDA toolkit versionkeepgpu/bin/ptx Keep intermediate filesptxinfo Print informational messages from PTXAS
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Environment Variables
ACC DEVICEControls the default device type to use when executing acceleratorregions, if the program has been compiled to use more than onedifferent type of device. The value may be the string NVIDIA orHOST.Example: export ACC DEVICE=NVIDIA
ACC DEVICE NUMControls the default device number to use when executingaccelerator regions. The value of this environment variable must bea nonnegative integer between zero and the number of devicesattached to the host. If the value is zero, theimplementation-defined default is used.Example: export ACC DEVICE NUM=1
ACC NOTIFYIf the value is nonzero, a short one-line message is printed to thestandard output whenever an accelerator kernel is executed.Example: export ACC NOTIFY=1
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

PGI Accelerator Directives
C
#pragma acc directive-name [clause [,clause]· · ·]
Fortran Free Form
!$acc directive-name [clause [,clause]· · ·]]!$acc directive-name [clause [,clause]· · ·]] &
continuation to next line
Fortran Fixed Form
!$acc directive-name [clause [,clause]· · ·]]!$acc* continuation to next line
c$acc directive-name [clause [,clause]· · ·]]*$acc directive-name [clause [,clause]· · ·]]
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

PGI Accelerator Directives
Supported PGI Accelerator Directives since PGI 9.0
Accelerator Compute Region DirectiveDefines the region of the program that should be compiled forexecution on the accelerator device.
Accelerator Loop Mapping DirectiveDescribes what type of parallelism to use to execute the loop anddeclare loop-private variables and arrays. Applies to a loop whichmust appear on the following line.
Combined DirectiveIs a shortcut for specifying a loop directive nested immediately insidean accelerator region directive. The meaning is identical to explicitlyspecifying a region construct containing a loop directive. Any clausethat is allowed on a region directive or a loop directive is allowed ona combined directive.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

PGI Accelerator Directives
New Supported PGI Accelerator Directives since PGI 2010
Accelerator Data Region DirectiveThis directive defines data, typically arrays, that should be allocatedin the device memory for the duration of the data region. Further, itdefines whether data should be copied from the host to the devicememory upon region entry, and copied from the device to hostmemory upon region exit.
Accelerator Declarative Data DirectiveDeclarative data directives specify that an array/ arrays are to beallocated in the device memory for the duration of the implicit dataregion of a function, subroutine, or program.
Accelerator Update DirectiveThe update directive is used within an explicit or implicit data regionto do one of the following:
Update all or part of a host memory array with values from the corresponding array indevice memory.Update all or part of a device memory array with values from the corresponding arrayin host memory.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Accelerator Compute Region Directive
C
#pragma acc region [clause [, clause] ...]{...}
Fortran
!$acc region [clause [, clause] ...]...
!$acc end region
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Accelerator Compute Region Directive: Clauses
Clause Description
copy(list) Declares that the variables, arrays or subarrays in the listhave values in the host memory that need to be copiedto the accelerator memory, and are assigned values on theaccelerator that need to be copied back to the host.
copyin(list) Declares that the variables, arrays or subarrays in the listhave values in the host memory that need to be copied tothe accelerator memory.
copyout(list) Declares that the variables, arrays, or subarrays in the listare assigned or contain values in the accelerator memorythat need to be copied back to the host memory at the endof the accelerator region.
if When present, tells the compiler to generate two copies ofthe region - one for the accelerator, one for the host - andto generate code to decide which copy to execute.
local Declares that the variables, arrays or subarrays in the listneed to be allocated in the accelerator memory, but thevalues in the host memory are not needed on the accelerator,and the values computed and assigned on the accelerator arenot needed on the host.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Accelerator Compute Region Directive: New Clauses inPGI 2010
The update clauses allow you to update values of variables, arrays, orsubarrays. The list argument to each update clause is a comma-separatedcollection of variable names, array names, or subarray specifications. Allvariables or arrays that appear in the list argument of an update clause musthave a visible device copy outside the compute or data region.Clause Description
updatein(list) The updatein clause copies the variables, arrays, or subar-rays in the list argument from host memory to the visibledevice copy of the variables, arrays, or subarrays in devicememory, before beginning execution of the compute or dataregion.
updateout(list) The updateout clause copies the visible device copies of thevariables, arrays, or subarrays in the list argument to theassociated host memory locations, after completion of thecompute or data region.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Examples in C for Compute Region Clauses
#pragma acc region{
for( i = 0; i < n; ++i ) r[i] = a[i]*2.0f;}
#pragma acc region if(n>1000){
for( i = 0; i < n; ++i ) r[i] = a[i]*2.0f;}
#pragma acc region copyin(a), copyout(r){
for( i = 0; i < n; ++i ) r[i] = a[i]*2.0f;}
#pragma acc region copyin(a[0:n-1]), copyout(r[0:n-1]){
for( i = 0; i < n; ++i ) r[i] = a[i]*2.0f;}
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Examples in Fortran for Compute Region Clauses
!$acc regiondo i = 1,n
r(i) = a(i) * 2.0enddo
!$acc end region
!$acc region if(n.gt.1000)do i = 1,n
r(i) = a(i) * 2.0enddo
!$acc end region
!$acc region copyin(a), copyout(r)do i = 1,n
r(i) = a(i) * 2.0enddo
!$acc end region
!$acc region copyin(a(1:n)), copyout(r(1:n))do i = 1,n
r(i) = a(i) * 2.0enddo
!$acc end region
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Restrictions on Accelerator Regions
Lots of C and Fortran intrinsics are supported (see Table 7.5-7.7 –7.8 in the PGI user guide), C: #include <accelmath.h>
kernel loops must be rectangular – invariant trip counts,
obstacles with C:
int, float, double , struct supportedunbound pointers – use restrict keyword or -Msafeptr,default is double – use float constants (0.1f) or -Mfcon,
obstacles with Fortran:
integer, real, double precision, complex, derived types supportedFortran pointer attribute not supported
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c1.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <assert.h>
4
5 int main( int argc, char* argv[] )
6 {
7 int n; /* size of the vector */
8 float *restrict a; /* the vector */
9 float *restrict r; /* the results */
10 float *restrict e; /* expected results */
11 int i;
12 if( argc > 1 )
13 n = atoi( argv[1] );
14 else
15 n = 100000;
16 if( n <= 0 ) n = 100000;
17
18 a = (float*)malloc(n*sizeof(float));
19 r = (float*)malloc(n*sizeof(float));
20 e = (float*)malloc(n*sizeof(float));
21 for( i = 0; i < n; ++i ) a[i] = (float)(i+1);
22
23 #pragma acc region
24 {
25 for( i = 0; i < n; ++i ) r[i] = a[i]*2.0f;
26 }
27 /* compute on the host to compare */
28 for( i = 0; i < n; ++i ) e[i] = a[i]*2.0f;
29 /* check the results */
30 for( i = 0; i < n; ++i )
31 assert( r[i] == e[i] );
32 printf( "%d iterations completed\n", n );
33 return 0;
34 }
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c1.c: Building and RunningBuilding c1.exe
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> make c1.exe
pgcc -o c1.exe c1.c -ta=nvidia -Minfo=accel -fast
main:
23, Generating copyin(a[0:n-1])
Generating copyout(r[0:n-1])
25, Loop is parallelizable
Accelerator kernel generated
25, #pragma for parallel, vector(256)
Running c1.exe
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> ./c1.exe
100000 iterations completed
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> export ACC_NOTIFY=1
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> ./c1.exe
launch kernel file=c1.c function=main line=25 device=0 grid=391
block=256
100000 iterations completed
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

The same Program without using restricted C Pointers
Using float *a; float *r; instead of float *restrict a; float *restrict r;Compiling with Normal Options:
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> pgcc -o c1-norestrict.exe \
c1-norestrict.c -ta=nvidia -Minfo=accel -fast
main:
23, No parallel kernels found, accelerator region ignored
25, Complex loop carried dependence of ’a’ prevents parallelization
Loop carried dependence of ’r’ prevents parallelization
Loop carried backward dependence of ’r’ prevents vectorization
Compiling with -Msafeptr Option:
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> pgcc -Msafeptr \
-o c1-norestrict.exe c1-norestrict.c -ta=nvidia -Minfo=accel -fast
main:
23, Generating copyin(a[0:n-1])
Generating copyout(r[0:n-1])
25, Loop is parallelizable
Accelerator kernel generated
25, #pragma for parallel, vector(256)
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example Fortran Program f1.f90
1 program main
2 integer :: n ! size of the vector
3 real,dimension(:),allocatable :: a ! the vector
4 real,dimension(:),allocatable :: r ! the results
5 real,dimension(:),allocatable :: e ! expected results
6 integer :: i
7 character(10) :: arg1
8 if( iargc() .gt. 0 )then
9 call getarg( 1, arg1 )
10 read(arg1,’(i10)’) n
11 else
12 n = 100000
13 endif
14 if( n .le. 0 ) n = 100000
15 allocate(a(n))
16 allocate(r(n))
17 allocate(e(n))
18 do i = 1,n
19 a(i) = i*2.0
20 enddo
21 !$acc region
22 do i = 1,n
23 r(i) = a(i) * 2.0
24 enddo
25 !$acc end region
26 do i = 1,n
27 e(i) = a(i) * 2.0
28 enddo
29 ! check the results
30 do i = 1,n
31 if( r(i) .ne. e(i) )then
32 print *, i, r(i), e(i)
33 stop ’error found’
34 endif
35 enddo
36 print *, n, ’iterations completed’
37 end program
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example Fortran Program f1.f90: Building and RunningBuilding f1.exe
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> make f1.exe
pgfortran -o f1.exe f1.f90 -ta=nvidia -Minfo=accel -fast
main:
21, Generating copyin(a(1:n))
Generating copyout(r(1:n))
22, Loop is parallelizable
Accelerator kernel generated
22, !$acc do parallel, vector(256)
Running f1.exe
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> ./f1.exe
100000 iterations completed
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> export ACC_NOTIFY=1
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> ./f1.exe
launch kernel file=f1.f90 function=main line=22 device=0 grid=391
block=256
100000 iterations completed
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c2.c
...29 //acc_init( acc_device_nvidia );3031 gettimeofday( &t1, NULL );32 #pragma acc region33 {34 for( i = 0; i < n; ++i ){35 s = sinf(a[i]);36 c = cosf(a[i]);37 r[i] = s*s + c*c;38 }39 }40 gettimeofday( &t2, NULL );41 cgpu = (t2.tv_sec - t1.tv_sec)*1000000 + (t2.tv_usec - t1.tv_usec);42 for( i = 0; i < n; ++i ){43 s = sinf(a[i]);44 c = cosf(a[i]);45 e[i] = s*s + c*c;46 }47 gettimeofday( &t3, NULL );48 chost = (t3.tv_sec - t2.tv_sec)*1000000 + (t3.tv_usec - t2.tv_usec);49 /* check the results */50 for( i = 0; i < n; ++i )51 assert( fabsf(r[i] - e[i]) < 0.000001f );52 printf( "%13d iterations completed\n", n );53 printf( "%13ld microseconds on GPU\n", cgpu );54 printf( "%13ld microseconds on host\n", chost );
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c2.cWithout acc init(acc device nvidia)
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> ./c2.exe
launch kernel file=c2.c function=main line=34 device=0
grid=391 block=256
100000 iterations completed
74869 microseconds on GPU
2450 microseconds on host
With acc init(acc device nvidia)
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> ./c2.exe
launch kernel file=c2.c function=main line=34 device=0
grid=391 block=256
100000 iterations completed
1614 microseconds on GPU
2459 microseconds on host
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n1a1> ./c2.exe 10000000
launch kernel file=c2.c function=main line=34 device=0
grid=39063 block=256
10000000 iterations completed
43604 microseconds on GPU
600596 microseconds on hostVolker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c4.c: Gauss-Seidel Iteration
Four-Point Difference Equation
26 typedef float *restrict *restrict MAT;
29 void test( MAT a, MAT b, float w0, float w1, float w2, int n, int m )30 {31 int i, j;32 #pragma acc region33 {34 for( i = 1; i < n-1; ++i )35 for( j = 1; j < m-1; ++j )36 a[i][j] = w0 * a[i][j] +37 w1*(a[i-1][j] + a[i+1][j] + a[i][j-1] + a[i][j+1]);38 }39 }
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n2a1> make c4.exepgcc -o c4.exe c4.c -ta=nvidia -Minfo=accel -fasttest:
32, No parallel kernels found, accelerator region ignored34, Loop carried dependence of ’a’ prevents parallelization
Loop carried backward dependence of ’a’ prevents vectorization35, Loop carried dependence of ’a’ prevents parallelization
Loop carried backward dependence of ’a’ prevents vectorization
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c5.c: Jacobi Iteration
Source Code
26 typedef float *restrict *restrict MAT;29 test( MAT a, MAT b, float w0, float w1, float w2, int n, int m )30 {31 int i, j;32 #pragma acc region33 {34 for( i = 1; i < n-1; ++i )35 for( j = 1; j < m-1; ++j )36 b[i][j] = w0 * a[i][j] +37 w1*(a[i-1][j] + a[i+1][j] + a[i][j-1] + a[i][j+1]);38 for( i = 1; i < n-1; ++i )39 for( j = 1; j < m-1; ++j )40 a[i][j] = b[i][j];41 }42 }
Compiler Message
32, Generating copyout(b[1:n-2][1:m-2])Generating copyin(a[0:n-1][0:m-1])Generating copyout(a[1:n-2][1:m-2])
...
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c5.c
#pragma acc region→
32, Generating copyout(b[1:n-2][1:m-2])
Generating copyin(a[0:n-1][0:m-1])
Generating copyout(a[1:n-2][1:m-2])
#pragma acc region local(b[1:n-2][1:m-1])→
32, Generating local(b[1:n-2][1:m-1])
Generating copyin(a[0:n-1][0:m-1])
Generating copyout(a[1:n-2][1:m-2])
#pragma acc region local(b[1:n-2][1:m-1]) copy(a[0:n-1][0:m-1])→
32, Generating local(b[1:n-2][1:m-1])
Generating copy(a[:n-1][:m-1])
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c9.c: Reductions
Source Code
33 #pragma acc region34 {35 sum = 0.0;36 for( i = 0; i < n; ++i ){37 sum += a[i] * b[i];38 }39 }
Compiler Message since PGI 2010
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n2a1> make c9.exepgcc -o c9.exe c9.c -ta=nvidia -Minfo=accel -fasttest0:
33, Generating copyin(b[0:n-1])Generating copyin(a[0:n-1])
36, Loop is parallelizableAccelerator kernel generated36, #pragma acc for parallel, vector(256)37, Sum reduction generated for sum
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c13.c: Index Arrays test0
Source Code
27 void test0( float *restrict a, float *restrict b, int *restrict ndx, int n )28 {29 int i;
33 #pragma acc region34 {35 for( i = 1; i < n; ++i ){36 a[ndx[i]] = b[i];37 }38 }39 }
Compiler Message
test0:33, Accelerator restriction: size of the GPU copy of an array depends on values
computed in this loopAccelerator region ignored
35, Accelerator restriction: size of the GPU copy of ’a’ is unknownAccelerator restriction: one or more arrays have unknown size
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c13.c: Index Arrays test1
Source Code
42 void test1( float *restrict a, float *restrict b, int *restrict ndx, int n )43 {44 int i;
48 #pragma acc region copy(a[0:n-1])49 {50 for( i = 1; i < n; ++i ){51 a[ndx[i]] = b[i];52 }53 }54 }
Compiler Message
test1:48, No parallel kernels found, accelerator region ignored50, Parallelization would require privatization of array ’a[:n-1]’
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c13.c: Index Arrays test2
Source Code
57 test2( float *restrict a, float *restrict b, int *restrict rndx, int n )58 {59 int i;
62 #pragma acc region63 {64 for( i = 1; i < n; ++i ){65 a[i] = b[rndx[i]];66 }67 }68 }
Compiler Message
test2:62, Accelerator restriction: size of the GPU copy of an array depends on values
computed in this loopAccelerator region ignored
64, Accelerator restriction: size of the GPU copy of ’b’ is unknownAccelerator restriction: one or more arrays have unknown size
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c13.c: Index Arrays test3
Source Code
71 void test3( float *restrict a, float *restrict b, int *restrict rndx, int n )72 {73 int i;
76 #pragma acc region copyin(b[0:n-1])77 {78 for( i = 1; i < n; ++i ){79 a[i] = b[rndx[i]];80 }81 }82 }
Compiler Message
test3:76, Generating copyin(rndx[1:n-1])
Generating copyin(b[:n-1])Generating copyout(a[1:n-1])
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Execution ModelNVIDIA CUDA:kernel ≪ dimGrid, dimBlock ≫(...)dim3 dimBlock(bx,by,bz) → variable threadId.x, threadId.y, threadId.z
1-D, 2-D or 3-D thread blockdim3 dimGrid(gx,gy) → variable blockIdx.x, blockIdx.y
1-D or 2-D grid of thread blocksTesla:max. number of threads per block 512max. number of active warps per multiprocessor 32max. number of active threads per multiprocessor 1024
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Thread Hierarchy
2 Levels of Parallelism:
Threads within a Thread Block Thread Blocks within a Grid
-1-D, 2-D or 3-D blocks -1-D or 2-D blocks-identified by threadIdx -identified by blockIdx-run on the same multiprocessor -run on different multiprocessors-explicit synchronisation supportedand required
-no synchronisation supported
-(synchronous) parallel execution -are required to execute indepen-dently, in any order, in parallel or inseries
-memory coherence if threads are sep-arated by an explicit barrier
-no memory coherence
-inner synchronous (SIMD or vector)loop level
-outer doall (fully parallel) loop level
-SIMD vectorization within a multi-processor
-MIMD parallelization across multi-processors
-PGI vector loops -PGI parallel loops
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers
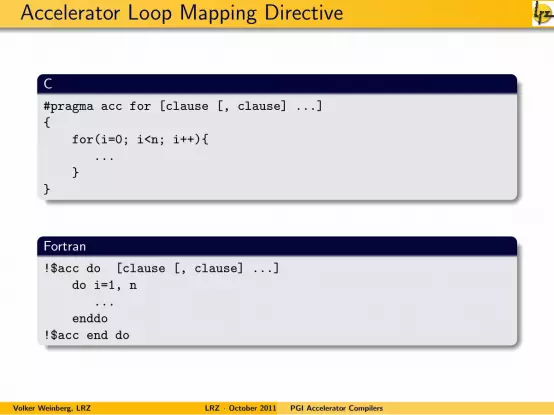
Accelerator Loop Mapping Directive
C
#pragma acc for [clause [, clause] ...]
{
for(i=0; i<n; i++){
...
}
}
Fortran
!$acc do [clause [, clause] ...]
do i=1, n
...
enddo
!$acc end do
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Accelerator Loop Mapping Directive: ClausesClause Description
host[(width)] Tells the compiler to execute the loop sequentially on thehost processor. Stripmining if width is specified.
kernel Tells the compiler that the body of this loop is to be thebody of the computational kernel. Any loops containedwithin the kernel loop are executed sequentially on the ac-celerator.
parallel[(width)] Tells the compiler to execute this loop in parallel mode onthe accelerator. There may be a target-specific limit on thenumber of iterations in a parallel loop or on the number ofparallel loops allowed in a given kernel.
private(list) Declares that the variables, arrays, or subarrays in the listargument need to be allocated in the accelerator memorywith one copy for each iteration of the loop.
seq[(width)] Tells the compiler to execute this loop sequentially on theaccelerator. There is no maximum number of iterations fora seq schedule.Stripmining of the loop if width is specified.
vector[(width)] Tells the compiler to execute this loop in vector mode onthe accelerator. There may be a target-specific limit onthe number of iterations in a vector loop, the aggregatenumber of iterations in all vector loops, or the number ofvector loops allowed in a kernel.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Accelerator Loop Mapping Directive: New Clauses
Clause Description
cache(list) Provides a hint to the compiler to try to move the variables,arrays, or subarrays in the list to the highest level of thememory hierarchy.
independent Tells the compiler that the iterations of this loop are datain-dependent of each other, thus allowing the compiler to gen-erate code to examine the iterations in parallel, withoutsynchronization.
unroll[(width)] Tells the compiler to unroll width iterations for sequentialexecution on the accelerator. The width argument must bea compile time positive constant integer.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example C Program c5.c: Jacobi Iteration26 typedef float *restrict *restrict MAT;
27
28 void
29 test( MAT a, MAT b, float w0, float w1, float w2, int n, int m )
30 {
31 int i, j;
32 #pragma acc region
33 {
34 for( i = 1; i < n-1; ++i )
35 for( j = 1; j < m-1; ++j )
36 b[i][j] = w0 * a[i][j] +
37 w1*(a[i-1][j] + a[i+1][j] + a[i][j-1] + a[i][j+1]);
38 for( i = 1; i < n-1; ++i )
39 for( j = 1; j < m-1; ++j )
40 a[i][j] = b[i][j];
41 }
42 }
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n2a1> make c5.exe
pgcc -o c5.exe c5.c -ta=nvidia -Minfo=accel -fast
test:
32, Generating copyout(b[1:n-2][1:m-2])
Generating copyin(a[0:n-1][0:m-1])
Generating copyout(a[1:n-2][1:m-2])
34, Loop is parallelizable
35, Loop is parallelizable
Accelerator kernel generated
34, #pragma for parallel, vector(16)
35, #pragma for parallel, vector(16)
Cached references to size [18x18] block of ’a’
38, Loop is parallelizable
39, Loop is parallelizable
Accelerator kernel generated
38, #pragma for parallel, vector(16)
39, #pragma for parallel, vector(16)
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n2a1> ./c5.exe
launch kernel file=c5.c function=test line=35 device=0 grid=7x7 block=16x16
launch kernel file=c5.c function=test line=39 device=0 grid=7x7 block=16x16
no errors foundVolker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Examples in C for Compute Region Clausesbased on c5.c (n=1000)
34 #pragma acc for
35 for( i = 0; i < n-1; ++i )
36 for( j = 0; j < n-1; ++j ) b[i][j] = w0 * a[i][j] +...;
-> 35, #pragma for parallel, vector(16)
36, #pragma for parallel, vector(16)
-> launch kernel file=c5.c function=test line=36 device=0 grid=7x7
block=16x16
34 #pragma acc for parallel
35 for( i = 1; i < n-1; ++i ){
36 #pragma acc for parallel, vector(256)
37 for( j = 1; j < m-1; ++j ) b[i][j] = w0 * a[i][j] +...;
-> 35, #pragma for parallel
37, #pragma for parallel, vector(256)
-> launch kernel file=c5.c function=test line=37 device=0 grid=98
block=256
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Examples in C for Compute Region Clauses
34 #pragma acc for vector
35 for( i = 1; i < n-1; ++i ){
36 #pragma acc for parallel
37 for( j = 1; j < m-1; ++j ) b[i][j] = w0 * a[i][j] +...;
-> 35, #pragma for vector(16)
37, #pragma for parallel, vector(16)
-> launch kernel file=c5.c function=test line=37 device=0 grid=7
block=16x16
34 #pragma acc for vector(256)
35 for( i = 1; i < n-1; ++i ){
36 #pragma acc for parallel
37 for( j = 1; j < m-1; ++j ) b[i][j] = w0 * a[i][j] +...;
-> 35, #pragma for vector(256)
Non-stride-1 accesses for array ’a’
Non-stride-1 accesses for array ’b’
37, #pragma for parallel
-> launch kernel file=c5.c function=test line=37 device=0 grid=98
block=256
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Combined Directives
Shortcut for specifying a loop directive nested immediately inside anaccelerator region directive.
C
#pragma acc region for [clause [, clause] ...]
for(i=0; i<n; i++){
...
}
Fortran
!$acc region do [clause [, clause] ...]
do i=1, n
...
enddo
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

New Accelerator Data Region Directive
C
#pragma acc data region [clause [, clause] ...]
{
...
}
Fortran
!$acc data region [clause [, clause] ...]
...
!$acc end data region
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Accelerator Data Region Directive: Clauses
copy(list)
copyin(list)
copyout(list)
local(list)
updatein(list)
updateout(list)
mirror(list)
deviceptr(list) (only for C since PGI 2011)
New Clauses for Data Regions:mirror:Declares that the arrays in the list need to mirror the allocation state of thehost array within the region. Valid only in Fortran on Accelerator data regiondirective.deviceptr:Declares that the pointers in the list are device pointers, so that the compilerdoes not need to move data between the host and device for accesses usingthese base pointers.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Example for Accelerator Data Region
based on c5.c
#pragma acc data region local(b[0:n-1][0:m-1]) copy(a[0:n-1][0:m-1]){
for(int k=0;k<=2000;k++){int i, j;
#pragma acc region{
for( i = 1; i < n-1; ++i )for( j = 1; j < m-1; ++j )
b[i][j] = w0 * a[i][j] +w1*(a[i-1][j] + a[i+1][j] + a[i][j-1] + a[i][j+1]);
for( i = 1; i < n-1; ++i )for( j = 1; j < m-1; ++j )
a[i][j] = b[i][j];}
}}
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Accelerator Update Directive
C
#pragma acc update updateclause [,updateclause] ...
Fortran
!$acc update updateclause [,updateclause] ...
Clauses:
device(list): Copies the variables, arrays, or subarrays in the list argumentfrom host memory to the visible device copy of the variables, arrays, orsubarrays in device memory. Copy occurs before beginning execution ofthe compute or data region.
host(list): Copies the visible device copies of the variables, arrays, orsubarrays in the list argument to the associated host memory locations.The copy occurs after completion of the compute or data region.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Runtime Library Routines I
acc allocs Returns the number of arrays allocated in data or compute regions.acc bytesalloc Returns the total bytes allocated by data or compute regions.acc bytesin Returns the total bytes copied in to the accelerator by data or compute
regions.acc bytesout Returns the total bytes copied out from the accelerator by data or compute
regions.acc copyins Returns the number of arrays copied in to the accelerator by data or
compute regions.acc copyouts Returns the number of arrays copied out from the accelerator by data or
compute regions.acc disable time Tells the runtime to start profiling accelerator regions and kernels, if it is
not already doing so.acc enable time Tells the runtime to start profiling accelerator regions and kernels, if it is
not already doing so.acc exec time Returns the number of microseconds spent on the accelerator executing
kernels.acc free Frees memory allocated on the attached accelerator. [C only]acc frees Returns the number of arrays freed or deallocated in data or compute
regions.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Runtime Library Routines II
acc get device Returns the type of accelerator device used to run the next acceleratorregion, if one is selected.
acc get device num Returns the number of the device being used to execute an acceleratorregion.
acc get free memory Returns the total available free memory on the attached accelerator device.acc get memory Returns the total memory on the attached accelerator device.acc get num devices Returns the number of accelerator devices of the given type attached to
the host.acc init Connects to and initializes the accelerator device and allocates control
structures in the accelerator library.acc kernels Returns the number of accelerator kernels launched since the start of the
program.acc malloc Allocates memory on the attached accelerator. [C only]acc on device Tells the program whether it is executing on a particular device.acc regions Returns the number of accelerator regions entered since the start of the
program.acc set device Tells the runtime which type of device to use when executing an accelerator
compute region.acc set device num Tells the runtime which device of the given type to use among those that
are attached.acc shutdown Tells the runtime to shutdown the connection to the given accelerator
device, and free up any runtime resources.acc total time Returns the number of microseconds spent in accelerator compute regions
and in moving data for accelerator data regions.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Conditional Compilation
ACCEL macro is defined to have a value yyyymm where yyyy is the year andmm is the month designation of the version of the Accelerator directivessupported by the implementation. This macro must be defined by a compileronly when Accelerator directives are enabled. The version described here is200906.
#ifdef _ACCEL
# include "accel.h"
#endif
....
#ifdef _ACCEL
acc_init(acc_device_nvidia);
#endif
→ portable method for factoring GPU initialization out of accelerator regions,to ensure the timings for the regions do not include initialization overhead.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

PGI Unified Binary
PGI Unified Binary for Multiple Accelerator Types
Build PGI Unified binary:
pgcc -ta=nvidia,host ...
Run PGI unified binary:./a.out runs on GPU if present, otherwise on hostexport ACC DEVICE=nvidia; ./a.out runs on GPUexport ACC DEVICE=host; ./a.out runs on hostacc set device(add device nvidia) before 1st region runs on GPUacc set device(add device host) before 1st region runs on host
PGI Unified Binary for Multiple Processor Types
pgcc -tp=nehalem-64,barcelona-64,...
PGI Unified Binary for Multiple Processor Types & MultipleAccelerator Types
pgcc -ta=nvidia,host -tp=nehalem-64,barcelona-64,...
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Profiling Accelerator Kernels: Example C Program c18.cCommand line option: -ta=nvidia,time29 void test( MAT a, MAT b, float w0, float w1, float w2, int n, int m, int iters )
30 {
31 int i, j, iter;
32 #pragma acc region
33 {
34 for( iter = 0; iter < iters; ++iter ){
35 for( i = 1; i < n-1; ++i )
36 for( j = 1; j < m-1; ++j )
37 b[i][j] = w0 * a[i][j] +
38 w1*(a[i-1][j] + a[i+1][j] + a[i][j-1] + a[i][j+1]);
39 for( i = 1; i < n-1; ++i )
40 for( j = 1; j < m-1; ++j )
41 a[i][j] = b[i][j];
42 }
43 }
44 }
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n2a1> pgcc -o c18.exe c18.c -ta=nvidia,time -Minfo=accel -fast
test:
32, Generating copyin(a[0:n-1][0:m-1])
Generating copyout(a[1:n-2][1:m-2])
Generating copyout(b[1:n-2][1:m-2])
34, Loop carried dependence due to exposed use of ’a[1:n-2][0:m-3]’ prevents parallelization
Loop carried dependence due to exposed use of ’a[0:n-1][1:m-2]’ prevents parallelization
Loop carried dependence due to exposed use of ’a[1:n-2][2:m-1]’ prevents parallelization
Parallelization would require privatization of array ’b[i2+1][1:m-2]’
Sequential loop scheduled on host
35, Loop is parallelizable
36, Loop is parallelizable
Accelerator kernel generated
35, #pragma for parallel, vector(16)
36, #pragma for parallel, vector(16)
Cached references to size [18x18] block of ’a’
39, Loop is parallelizable
40, Loop is parallelizable
Accelerator kernel generated
39, #pragma for parallel, vector(16)
40, #pragma for parallel, vector(16)
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Profiling Accelerator Kernels: Example C Program c18.c
weinberg@fluidyna:~/pgi/pgi_tutorial/v1n2a1> ./c18.exelaunch kernel file=c18.c function=test line=36 device=0 grid=7x7 block=16x16launch kernel file=c18.c function=test line=40 device=0 grid=7x7 block=16x16launch kernel file=c18.c function=test line=36 device=0 grid=7x7 block=16x16launch kernel file=c18.c function=test line=40 device=0 grid=7x7 block=16x16launch kernel file=c18.c function=test line=36 device=0 grid=7x7 block=16x16launch kernel file=c18.c function=test line=40 device=0 grid=7x7 block=16x16launch kernel file=c18.c function=test line=36 device=0 grid=7x7 block=16x16launch kernel file=c18.c function=test line=40 device=0 grid=7x7 block=16x16no errors found
Accelerator Kernel Timing datac18.c
test32: region entered 1 time
time(us): total=76482 init=71352 region=5130kernels=310 data=4820
w/o init: total=5130 max=5130 min=5130 avg=513036: kernel launched 4 times
grid: [7x7] block: [16x16]time(us): total=175 max=68 min=35 avg=43
40: kernel launched 4 timesgrid: [7x7] block: [16x16]time(us): total=135 max=36 min=31 avg=33
Dump of region-level and kernel-level performance (timing of initialization,upload/download data movements, kernel execution)
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Performance Goals and Tuning Performance
Data movement between Host and Accelerator
Minimize data amount / number and frequency of data moves,maximize bandwidth,optimize data allocation in device memory,use copyin(), copyout(), local to limit data transfers,add full dimension specification to minimize data transfers,
Parallelism/Performance on the Accelerator
increase MIMD parallelism to fill the multiprocessors and hide devicememory latency,increase SIMD parallelism to fill the cores of a multiprocessor,tune loop schedule,maximize stride-1 array references,pad arrays so that the leading dimensions are a multiple of 16,store array blocks in data cache (CUDA shared memory).
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

CUDA Fortran I
CUDA Fortran is supported by the PGI Fortran compilers when the filenameuses the .cuf extension. CUDA Fortran extensions can be enabled in anyFortran source file by adding the -Mcuda command line option.
Emulation Mode: compile and link with -Mcuda=emulate
Execution Configuration
call ≪ dimGrid, dimBlock [, bytes[, streamid ]] ≫ kernel(...)
dimBlock=dim3(bx,by,bz) → variable threadid%x, threadid%y, threadid%z1-D, 2-D or 3-D thread block
dimGrid=dim3(gx,gy) → variable blockidx%x, blockidx%y1-D or 2-D grid of thread blocks
bytes specifies the number of bytes of shared memoryto be allocated for each thread block to use forassumed-size shared memory arrays
streamid specifies the stream to which this call is en-queued
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

CUDA Fortran II
Subroutine/ Function Qualifiers
Attributes(host) Host Subprogram, compiled for execution on thehost processor.Attributes(global) Kernel Subroutines, compiled as a kernel forexecution on the device, to be called from a host routine using akernel call with chevron syntax.Attributes(device) Device Subprograms, compiled for execution onthe device, must be called from a subprogram with the global ordevice attribute.
Variable Attributes
Attributes(device) Device Variables, allocated in the device globalmemory.Attributes(constant) Device Constant Variables, allocated in thedevice constant memory space.Attributes(shared) (Device) Shared Variables, allocated in theshared memory space of a thread block, may only be declared in adevice subprogram, has lifetime of the thread block.Attributes(pinned) Pinned Variables, allocated in host page-lockedmemory.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

CUDA Fortran III
Data Transfer between Host and Device Memory:data transfers using assignment statements, implicit data transfer inexpressions, data transfer using runtime routines (cudaMemcpy,...) .
Runtime API:The system module cudafor defines the interfaces to the Runtime APIroutines.
Device Management,Thread Management,Memory Management,Stream Management,Event Management,Error Handling.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

CUDA Fortran Example I (saxpy)
Kernel Subroutine
attributes(global) subroutine ksaxpy( n, a, x, y )
real, dimension(*) :: x,y
real, value :: a
integer, value :: n, i
i = (blockidx%x-1) * blockdim%x + threadidx%x
if( i <= n ) y(i) = a * x(i) + y(i)
end subroutine
Host Subroutine
subroutine solve( n, a, x, y )
real, device, dimension(*) :: x, y
real :: a integer :: n
call ksaxpy<<<n/64, 64>>>( n, a, x, y )
end subroutine
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

CUDA Fortran Example II (matmul): Kernel Code! start the module containing the matmul kernel
module mmul_mod
use cudafor
contains
! mmul_kernel computes A*B into C where A is NxM, B is MxL, C is then NxL
attributes(global) subroutine mmul_kernel( A, B, C, N, M, L )
real,device :: A(N,M), B(M,L), C(N,L)
integer, value :: N, M, L
integer :: i, j, kb, k, tx, ty
! submatrices stored in shared memory
real, shared :: Asub(16,16), Bsub(16,16)
! the value of C(i,j) being computed
real :: Cij
! Get the thread indices
tx = threadidx%x
ty = threadidx%y
! This thread computes C(i,j) = sum(A(i,:) * B(:,j))
i = (blockidx%x-1) * 16 + tx
j = (blockidx%y-1) * 16 + ty
Cij = 0.0
! Do the k loop in chunks of 16, the block size
do kb = 1, M, 16
! Fill the submatrices, Each of the 16x16 threads in the thread block loads one element of Asub and Bsub
Asub(tx,ty) = A(i,kb+ty-1)
Bsub(tx,ty) = B(kb+tx-1,j)
! Wait until all elements are filled
call syncthreads()
! Multiply the two submatrices, Each of the 16x16 threads accumulates the dot product for its element of C(i,j)
do k = 1,16
Cij = Cij + Asub(tx,k) * Bsub(k,ty)
enddo
! Synchronize to make sure all threads are done reading the submatrices before overwriting them in the next iteration
! of the kb loop
call syncthreads()
enddo
! Each of the 16x16 threads stores its element to the global C array
C(i,j) = Cij
end subroutine mmul_kernel
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

CUDA Fortran Example II (matmul): Host Code
! The host routine to drive the matrix multiplication
subroutine mmul( A, B, C )
real, dimension(:,:) :: A, B, C
! allocatable device arrays
real, device, allocatable, dimension(:,:) :: Adev,Bdev,Cdev
! dim3 variables to define the grid and block shapes
type(dim3) :: dimGrid, dimBlock
! Get the array sizes
N = size( A, 1 )
M = size( A, 2 )
L = size( B, 2 )
! Allocate the device arrays
allocate( Adev(N,M), Bdev(M,L), Cdev(N,L) )
! Copy A and B to the device
Adev = A(1:N,1:M)
Bdev(:,:) = B(1:M,1:L)
! Create the grid and block dimensions
dimGrid = dim3( N/16, M/16, 1 )
dimBlock = dim3( 16, 16, 1 )
real :: AA(N,M), BB(M,L), CC(N,L)
call mmul_kernel<<<dimGrid,dimBlock>>>( Adev, Bdev, Cdev, N, M, L )
! Copy the results back and free up memory
C(1:N,1:L) = Cdev
deallocate( Adev, Bdev, Cdev )
end subroutine mmul
end module mmul_mod
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

References I
PGI Fortran & C Accelerator Programming Model, v1.3[http://www.pgroup.com/lit/whitepapers/pgi accel prog model 1.3.pdf]
PGI Compiler User’s Guide, Parallel Fortran, C and C++ for Scientistsand Engineers, Release 2011 [http://www.pgroup.com/doc/pgiug.pdf]Chapter 7: Using an Accelerator
PGI Compiler Reference Manual, Parallel Fortran, C and C++ forScientists and Engineers, Release 2011[http://www.pgroup.com/doc/pgiref.pdf]Chapter 4: PGI Accelerator Compilers Reference
CUDA Fortran Programming Guide and Reference, Release 2011[http://www.pgroup.com/doc/pgicudafortug.pdf]
Talk by Coug Miles: PGI Accelerator Compilers ProgrammingTutorial, Tubingen September 2009
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

References II
Tutorial 1: The PGI Accelerator Programming Model on NVIDIAGPUs Part 1, June 2009
[http://www.pgroup.com/lit/articles/insider/v1n1a1.htm ][http://www.pgroup.com/lit/samples/pgi accelerator examples.tar]
Tutorial 2: The PGI Accelerator Programming Model on NVIDIAGPUs Part 2 Performance Tuning, August 2009[http://www.pgroup.com/lit/articles/insider/v1n2a1.htm][http://www.pgroup.com/lit/samples/pginsider v1n2a1 examples.tar]
Tutorial 4: The PGI Accelerator Programming Model on NVIDIAGPUs Part 4: New and Upcoming Features, August 2009[http://www.pgroup.com/lit/articles/insider/v2n1a1.htm]
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers

Mount Hood
Mount Hood, called Wy’east by the Multnomah tribe, is a stratovolcano in the Cascade VolcanicArc of northern Oregon. It was formed by a subduction zone and rests in the Pacific Northwestregion of the United States. It is located about 50 miles (80 km) east-southeast of Portland, onthe border between Clackamas and Hood River counties.
Mount Hood’s snow-covered peak rises 11,249 feet (3,429 m) and is home to twelve glaciers.(Older surveys said 11,239 feet (3,426 m), which is still often cited as its height). It is the highestmountain in Oregon and the fourth-highest in the Cascade Range. Mount Hood is considered theOregon volcano most likely to erupt, though based on its history, an explosive eruption is unlikely.Still, the odds of an eruption in the next 30 years are estimated at between 3 and 7 percent, so theUSGS characterizes it as ”potentially active”, but the mountain is informally considered dormant.
Volker Weinberg, LRZ LRZ · October 2011 PGI Accelerator Compilers
Recommended

















