Embed Size (px)
Citation preview

Presentation on Big Data
Presented by:-
Takrim Ul Islam Laskar(120103006)
Anurag Prasad(120103024)

CONTENTS
• 1> What is Big Data?
• 2> Why Big Data?
• 3> Who are Generating Big Data?
• 4> Characteristics of Big Data.
• 5> What Technology Do We Have For Big Data ?

Introduction
• What is big data?
Big data is an all-encompassing term for any collection of data sets so large and complex that it becomes difficult to process using on-hand data management tools or traditional data processing applications.
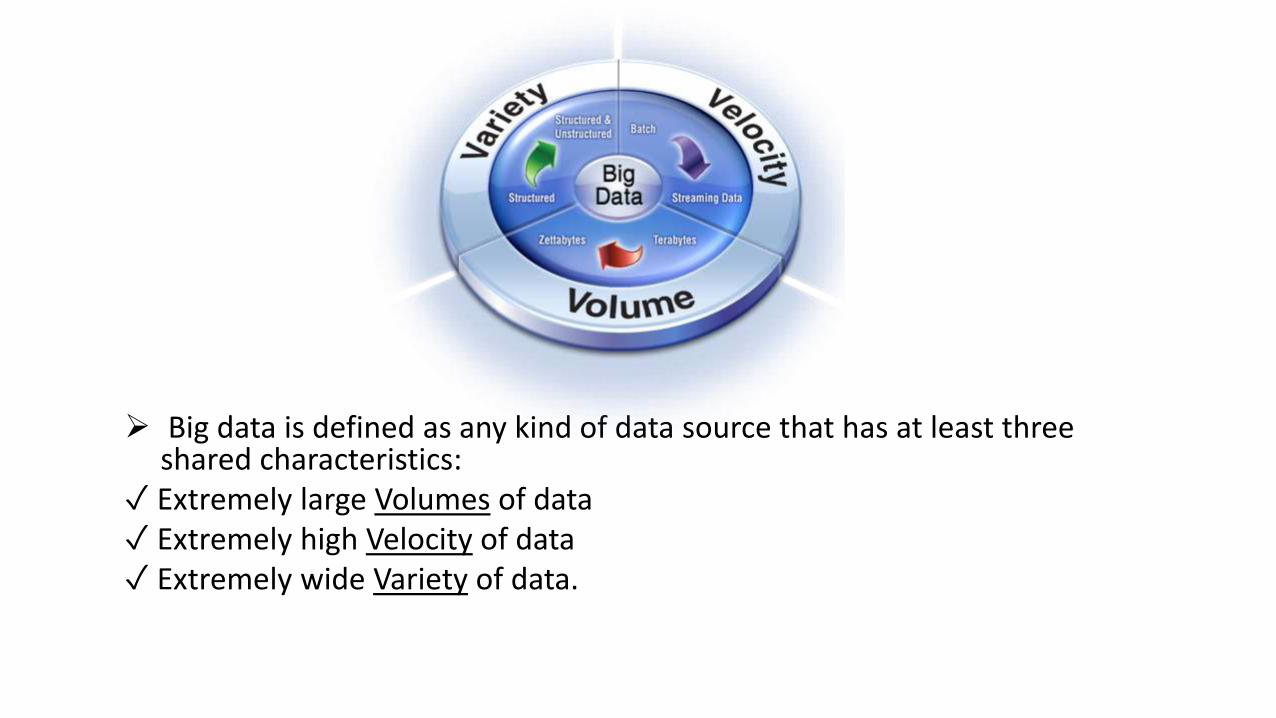
Big data is defined as any kind of data source that has at least three shared characteristics:
✓ Extremely large Volumes of data✓ Extremely high Velocity of data✓ Extremely wide Variety of data.

Why Big Data?

When we are dealing with so much information in so many
different forms, it is impossible to think about data management
in traditional ways. That is when the opportunity and challenges
of BIG DATA arises.

Who’s Generating Big Data?

Social media and networks(all of us are generating data)
Scientific instruments(collecting all sorts of data)
Mobile devices (tracking all objects all the time)
Sensor technology and networks(measuring all kinds of data)
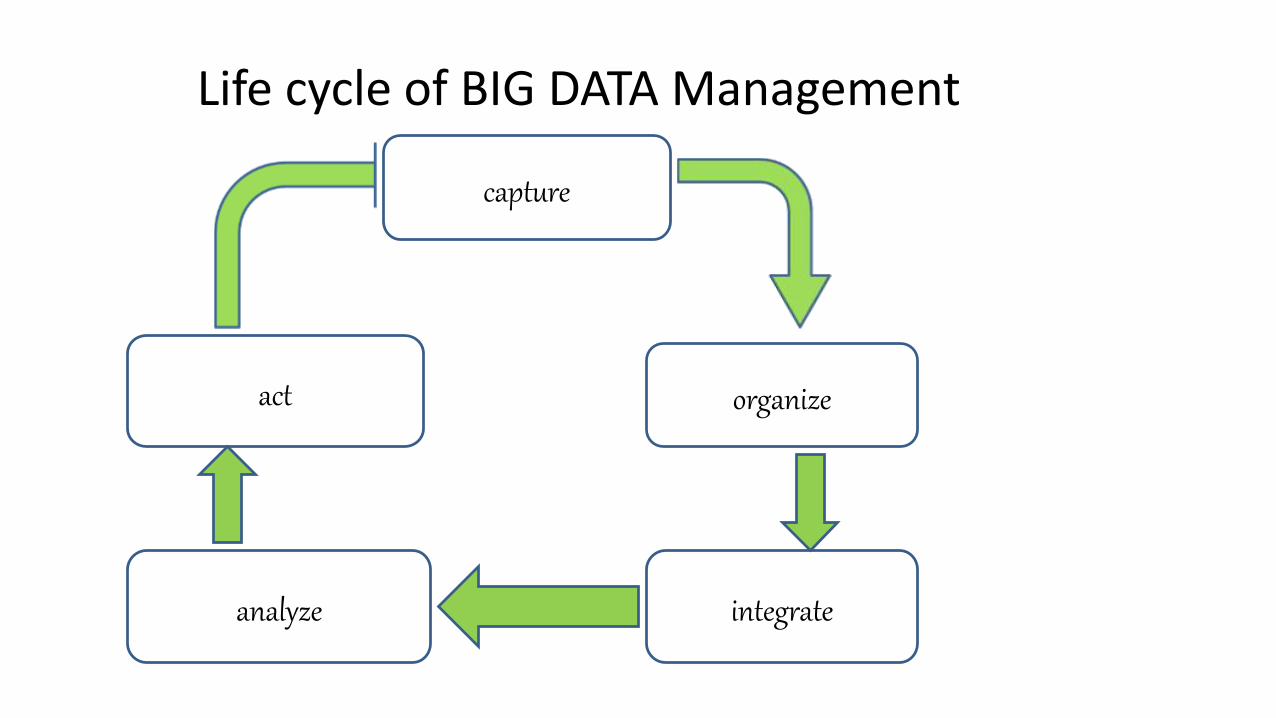
Life cycle of BIG DATA Management
capture
organize
integrate
act
analyze

Characteristics of Big Data

1. Scale (Volume)
• Data Volume– 44x increase from 2009 to 2020– From 0.8 zettabytes to 35zb
• Data volume is increasing exponentially

From the beginning of recorded time until 2003,We created 5 billion gigabytes ( Exabyte ) of data.
In 2011, the same amount was created every two days.
In 2013, the same amount of data is created every 10 minutes.

2. Varity
• Various formats, types, and structures• Text, numerical, images, audio, video,
sequences, time series, social media data, multi-dim arrays, etc…
• Static data vs. streaming data • A single application can be
generating/collecting many types of data

3. Velocity
• Data is begin generated fast and need to be processed fast
• Online Data Analytics
• Late decisions missing opportunities

What Technology Do We Have For Big Data ?

HDFS ( Hadoop Distributed File System)
The Hadoop Distributed File System (HDFS) is the primary storage system used
by Hadoop applications.
Hadoop is an open-source software framework for storage and large-scale
processing of data-sets on clusters of commodity hardware.

Map/Reduce Program
MapReduce was designed by Google. It is a framework for writing/executing
distributed, fault tolerant algorithms functions map which divides a large problem
into smaller problems and then performs the same function on all smaller
problems and reduce which then combines the results.

Sqoop (SQL-to-HADOOP)
Sqoop is a command-line interface application for transferring data between
relational databases and Hadoop.
Hive & Pig
Hive was created by Facebook and is SQL-like, while Pig was created by Yahoo and
is more procedural; both target MapReduce jobs. However due to the complexity of
MapReduce, HiveQL was created to combine the best features of SQL with MapReduce.

TOPIC FOR NEXT SEMINAR
1. Technology Used In Big Data
2. Big Data Architecture
3. Big Data Management

Refferences :
1. Youtube Lecture video on chennal ‘ Training on Big Data and Hadoop ’ By User ‘Edureka’.
2. ‘White Book Of Big Data’ By ‘Fujistu’ .
3. ‘Big Data For Dummies’ by ‘A Wiley Brand’ .
4. Research paper by ‘Kalapriya Kannan’ in ‘IBM Research Labs’.

THANK YOU.We appreciate your patience.





























