Embed Size (px)
Citation preview

CRDT Data StructuresAnd their real world uses
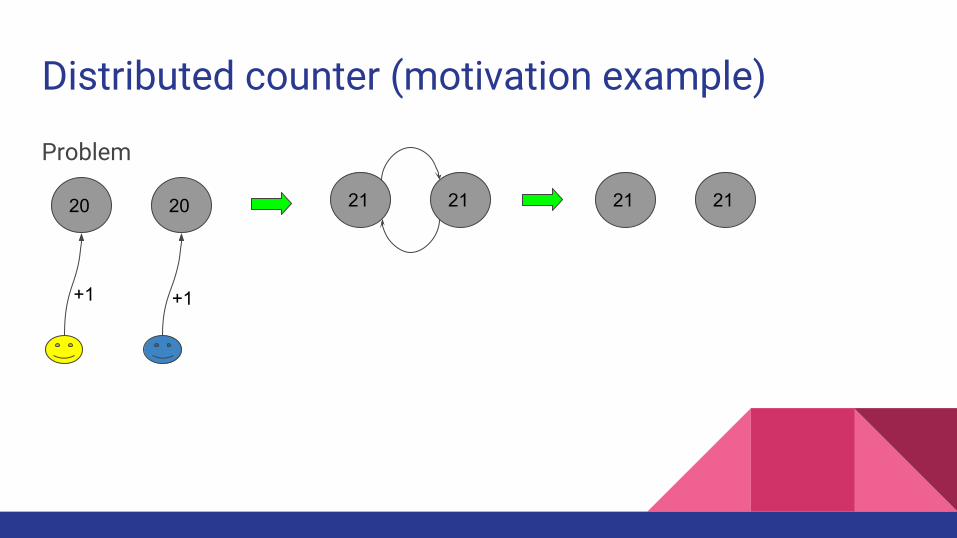
Distributed counter (motivation example)
Problem
20 20
+1 +1
21 21 21 21

The problem
Several active servers
Semi-online systems (navigators, sales support software)
Distributed systems (replication in general)

Consistency
Strong consistency
“All accesses are seen by all parallel processes (or nodes, processors, etc.) in the same order (sequentially)”
● Needs synchronisation● Due to CAP theorem, availability is sacrificed ● It cannot be synchronous

Consistency
Eventual consistency
“ …. eventually all accesses to that item will return the last updated value … “
Strong eventual consistency
“... any two nodes that have received the same (unordered) set of updates will be in the same state … “

CRDT
Conflict-free Replicated Data Type
CvRDT (Convergent) aka 'state-based objects'
CmRDT (Commutative) aka 'ops-based objects'
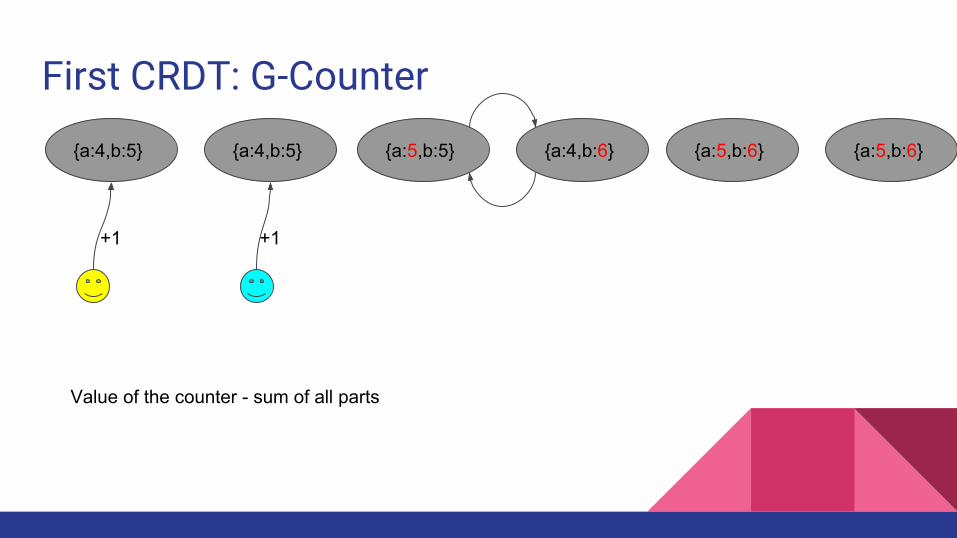
First CRDT: G-Counter
{a:4,b:5} {a:4,b:5}
+1 +1
{a:5,b:5} {a:4,b:6} {a:5,b:6} {a:5,b:6}
Value of the counter - sum of all parts
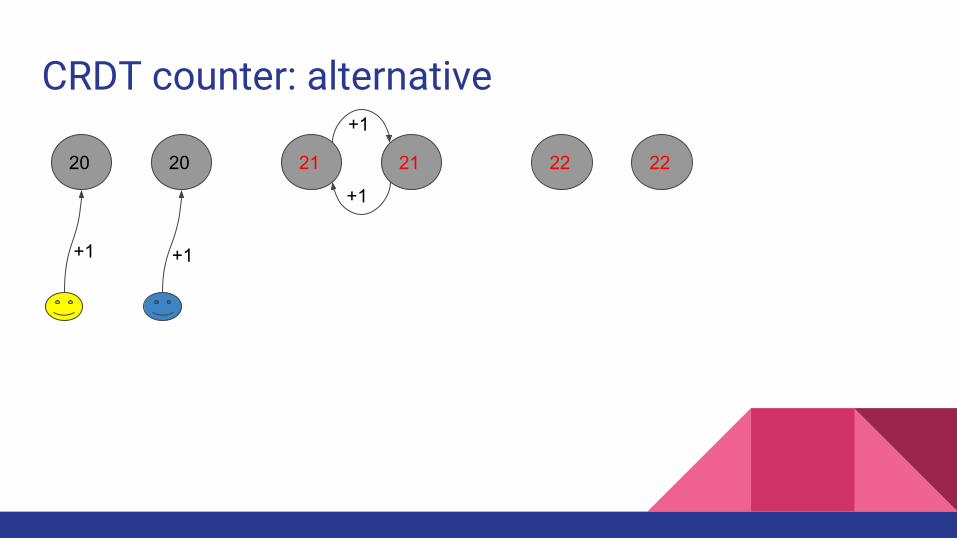
CRDT counter: alternative
20 20
+1 +1
21 21
+1
+1
22 22

G-Counter extension: PN-CounterWhat if decrement operation is also required?
Use two g-counters: one for increments, another for decrements

State based vs ops based
State based:
Merge should be: associative, commutative and idempotent
Ops based:
Replication channels should have exactly-once semantic and support causal ordering
Concurrent operations should commute

Example: Cassandra
Cassandra’s atomic counters are implemented as g-counters (almost)
Cassandra’s general replication is implemented as another CRDT (LWW-Register)

MV-RegisterVector clock
Very similar to g-counter - {a:100, b: 98, c: 101}
Each operation on server increments corresponding value
Merge takes maximum of correlated elements
One event is AFTER another if vector clock of one is less than vector clock
of another:
{a: 10, b: 11, c: 12} < {a:10, b:12, c:12}

MV-Register
Value is stored and replicated with vector clock
On merge if one vector clock is bigger than another then keep value with bigger vector clock
Otherwise keep both and let client choose which one to keep

Example: Riak
It uses MV-Register for general replication if multi-value mode is enabled
It uses LWW-Register otherwise
PN-counter is used to implement distributed counters
Other CRDTs are also used (Sets, flags)

G-Set
Grow-only set
Merge operation is set union, which is idempotent, commutative and associative
Only add operation is supported

OR-Set
Idea is to use two sets for added and removed items, but...
Store them with some unique id. Such id should be assigned during adding of element
(a, id1)(a, id2)(b, id3)(c, id4)
‘Added’ Set
(b, id3)
‘Removed’ Set
(a, id2)
Element is eligible to remove only if it is in ‘added’ set with same id

Real life example: TomTom (navigators)
Challenges:
Account data (like favorites) can be modified from different devices concurrently
Device can be offline during adding new information
Huge number of accounts

Real life example: TomTom (navigators)
CRDT to rescue!
They use combination of CRDT: MV-Register + modified OR-Set (OUR-Set)
*Original image from TomTom’s presentation

Real life example: Swarm.js
Swarm is a reactive data sync library and middleware
Data to synchronize should be CRDT

Real life example: Spark’s accumulator
Docblock of Accumulable class
A data type that can be accumulated, ie has an commutative and associative "add" operation
You must define how to add data, and how to merge two of these together
It seems like CRDT!

Q/A





























