Embed Size (px)
Citation preview

Apache ApexReal Time Insights for Advertising Tech
Tushar GosaviNovember 25, 2015

Agenda
• The Customer - What they do
• The Use Case
• While (! Realtime)– Evaluation of Application– Challenges

• Leading digital automation software company for publishers
• Leading innovator in real-time bidding (RTB) auctions
• Helps publishers monetize their digital assets
• Enables publishers to make smarter inventory decisions and improve revenue
More about the customer

• Reporting of critical metrics from auctions and client logs
• Revenue, impression, and click information
• Aggregate counters and reporting on top N metrics
• Low latency querying using pub-sub model
Understanding the usecase

Scale• 6 geographically distributed data centers
• Combination of co-located & AWS based DCs
• > 5 PB under data management
• 22 TB/day of data generated from auction & client logs
• Heterogeneous data log formats
• North of 15 billion impressions per day
• Average data inflow of 200K events/sec
5Proprietary and Confidential

• Ad server log events consumed as Avro-encoded, Snappy compressed files from
S3. New files uploaded every 10-20 minutes.
• Data may arrive in S3 out of order (time stamps).
• Event size about 2KB uncompressed, only subset of fields retrieved for
aggregation.
• Aggregates kept in memory (checkpointed) with expiration policy and query
processing against in-memory data.
• Front-end integration through pub-sub protocol for real-time dashboard
components.
Initial Requirements
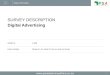
Solution (Phase 1)
7Proprietary and Confidential
AdServer
REST proxy
REST proxy
Real-time architecture- Powered By Apex
Kafka Cluster
S3Reader S3Reader
Filter Filter
Dimensions Aggregator
Dimensions Aggregator
Dimensions Store
Query Query Result
Kafka Cluster
Auction Logs
Middleware
Auction Logs
Filtered Events Filtered Events
Aggregates
Query from MW
Query Query Results
S3 S3 Client logsAuction Logs

Learning & Challenges• Unstable S3 client libraries
– Unpredictable hangs and Corrupted data– On Hang, Master kills the container and restart reading of file from different container– Corrupt files caused containers to kill – application configurable retry mechanism and skip
bad files
• Out of Order data– Tuples with timestamp in future and past
• Memory Requirement for Store– Cardinality Estimation for incoming data

Solution (Phase 2)
9Proprietary and Confidential
REST proxy
Real-time architecture- Powered By Apex
Client logs
KafkaInput
(Auction logs)
ETL
Filter Filter
Dimensions Aggregator
Dimensions Aggregator
Dimensions Store
Query Query Result
Kafka Cluster
Auction LogsKafka Cluste
r
Middleware
AdServerREST proxy
Kafka Cluste
r
Auction Logs
Client logs
Kafka Messages
Decompress & Flatten
Filtered Events Filtered Events
Aggregates
Query from MW
Query Query Results
S3
S3Reader
KafkaInput
(Auction logs)Auction Logs

Learning & Challenges• Complex Logical DAG
• Kafka Operator– Dynamic Partitioning disabled– Memory configuration– Offset snapshotting to ensure exactly once semantics – Limit Kafka read rate
• Harder Debugging (More number of components)– GBs of container logs– Difficult to locate the sequence of failure (Feature being added)
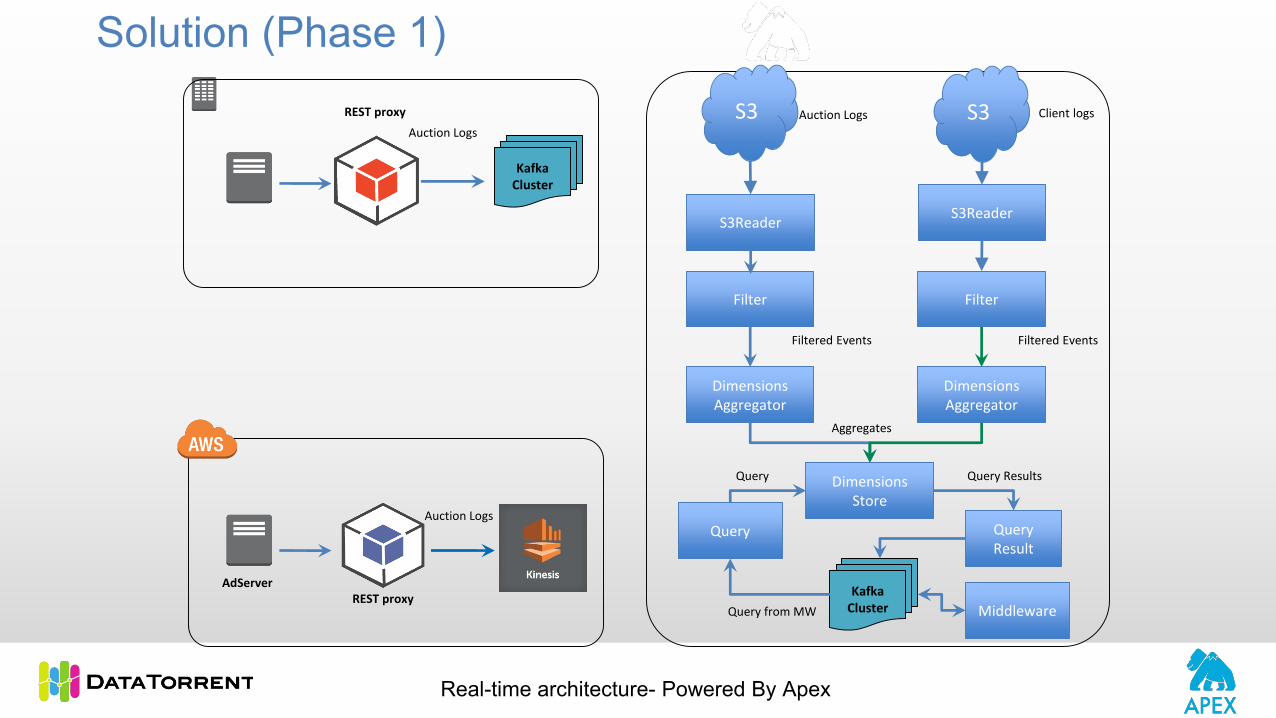
Solution
11Proprietary and Confidential
User Browser
AdServer
REST proxy
REST proxy
Real-time architecture- Powered By Apex
Kafka Cluster
Client logs
KafkaInput
(Auction logs)
Kafka Input
(Client logs)
CDN(Caching of
logs)
ETL ETL
Filter Filter
Dimensions Aggregator
Dimensions Aggregator
Dimensions Store
Query Query Result
Kafka Cluster
Auction Logs
Client logs
Middleware
Auction Logs
Client logs
Kafka Messages Kafka Messages
Decompress & Flatten
Decompress & Flatten
Filtered Events Filtered Events
Aggregates
Query from MW
Query Query Results
Kafka Cluster

Application Configuration• 64 Kafka Input operators reading from 6 geographically distributed DCs
• Under 40 seconds end-to-end latency, from ad-serving to visualization
• 32 instances of in-memory distributed store
• 64 aggregators
• 1.2 TB memory footprint @ peak load
• Work underway on a fault tolerant application using HDHT
12Proprietary and Confidential
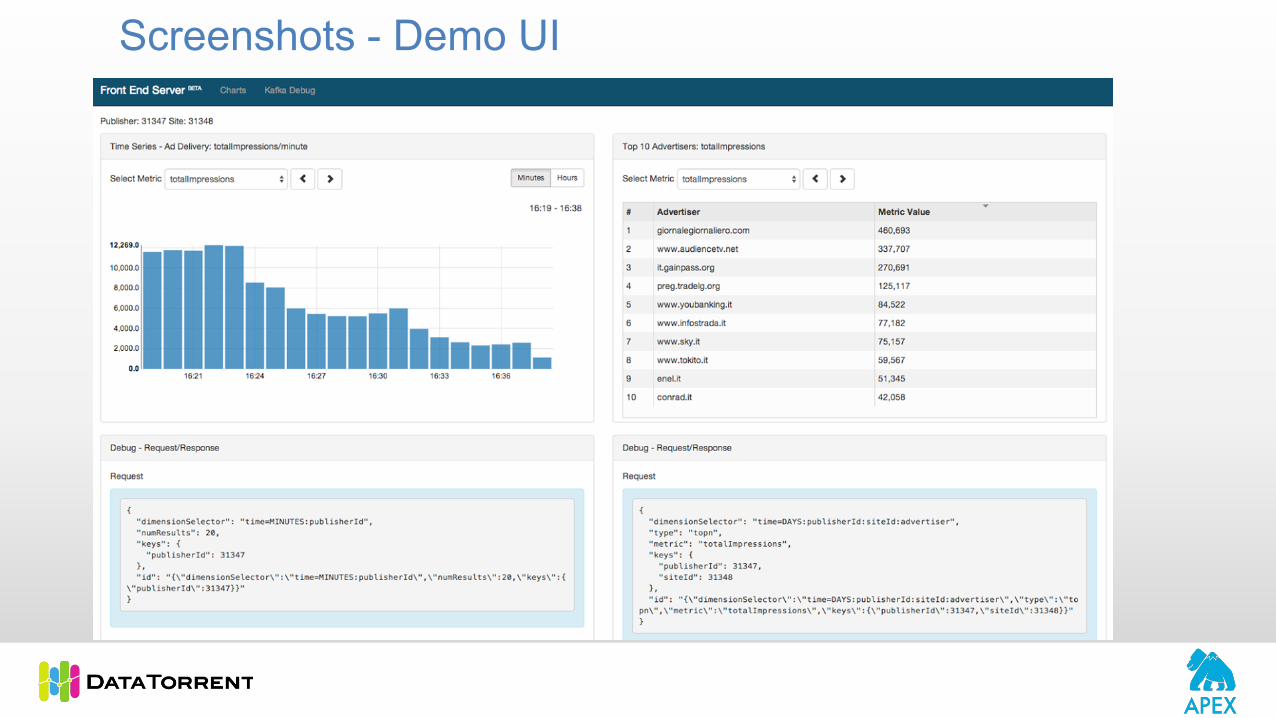
Screenshots - Demo UI
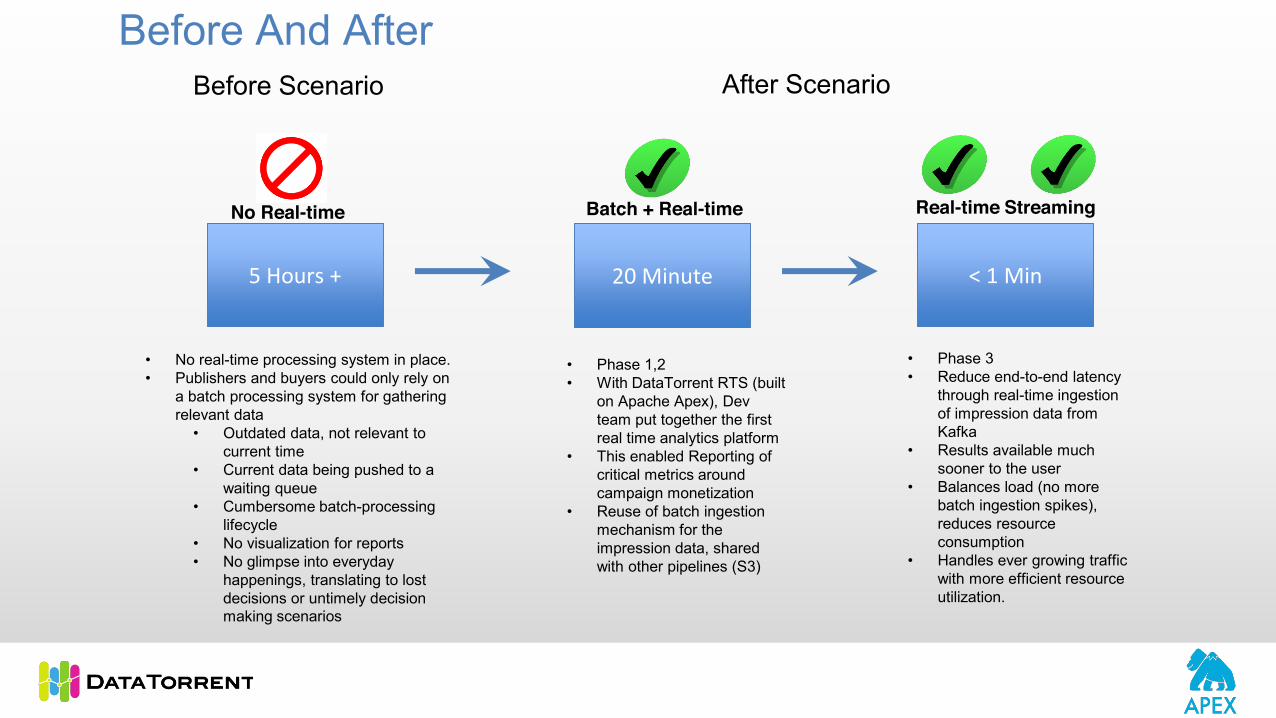
Before And After
14Proprietary and Confidential
5 Hours + 20 Minute
• No real-time processing system in place. • Publishers and buyers could only rely on
a batch processing system for gathering relevant data
• Outdated data, not relevant to current time
• Current data being pushed to a waiting queue
• Cumbersome batch-processing lifecycle
• No visualization for reports• No glimpse into everyday
happenings, translating to lost decisions or untimely decision making scenarios
Before Scenario After Scenario
• Phase 1,2• With DataTorrent RTS (built
on Apache Apex), Dev team put together the first real time analytics platform
• This enabled Reporting of critical metrics around campaign monetization
• Reuse of batch ingestion mechanism for the impression data, shared with other pipelines (S3)
< 1 Min
No Real-time Batch + Real-time
• Phase 3• Reduce end-to-end latency
through real-time ingestion of impression data from Kafka
• Results available much sooner to the user
• Balances load (no more batch ingestion spikes), reduces resource consumption
• Handles ever growing traffic with more efficient resource utilization.
Real-time Streaming

Operators used
S3 reader (File Input Operator)- Recursively reading the contents of a S3 bucket based on a partitioning pattern
- Inclusion & exclusion support- Fault tolerance (replay and idempotence)- Throughput of over 12K reads/second for event size of 1.2 KB each
Kafka Input Operator- Ability to consume from multiple Kafka clusters - Offset management support- Fault tolerant reads- Support for idempotence & exactly once semantics- Controlled reads for managing backpressure
15Proprietary and Confidential

Cont’d…
Dimension Store- Distributed in-memory store- Support for re-aggregation of events- Partitioning of aggregates- Low latency query support with a pub/sub model using Kafka
HDHT- HDFS backed embedded key-value store- Fault tolerant, random read & write- Durability in-case of cold restarts
16Proprietary and Confidential

Key learnings
• DAG – sizing, locality & partitioning (Benchmark)
• Benchmark each Operator
• Memory sizing for the Operators
• Manage Backpressure
• Think fault tolerance & recovery before starting implementation
17Proprietary and Confidential

© 2016 DataTorrent
Resources • Apache Apex - http://apex.apache.org/• Subscribe - http://apex.apache.org/community.html• Download - https://www.datatorrent.com/download/• Twitterᵒ @ApacheApex; Follow - https://twitter.com/apacheapexᵒ @DataTorrent; Follow – https://twitter.com/datatorrent
• Meetups - http://www.meetup.com/topics/apache-apex• Webinars - https://www.datatorrent.com/webinars/• Videos - https://www.youtube.com/user/DataTorrent• Slides - http://www.slideshare.net/DataTorrent/presentations• Startup Accelerator Program - Full featured enterprise productᵒ https://www.datatorrent.com/product/startup-accelerator/

© 2016 DataTorrent
We Are Hiring • [email protected]• Developers/Architects• QA Automation Developers• Information Developers• Build and Release• Community Leaders

Questions?
19Proprietary and Confidential