Embed Size (px)
Citation preview

ANOMALY DETECTION: BEST PRACTICES
Carol Hargreaves 21 March 2016

WHAT IS ANOMALY DETECTION?
▪ Anomaly Detection (or outlier detection) is the identification of items, events or observations which do not conform to an expected pattern or other items in a dataset.
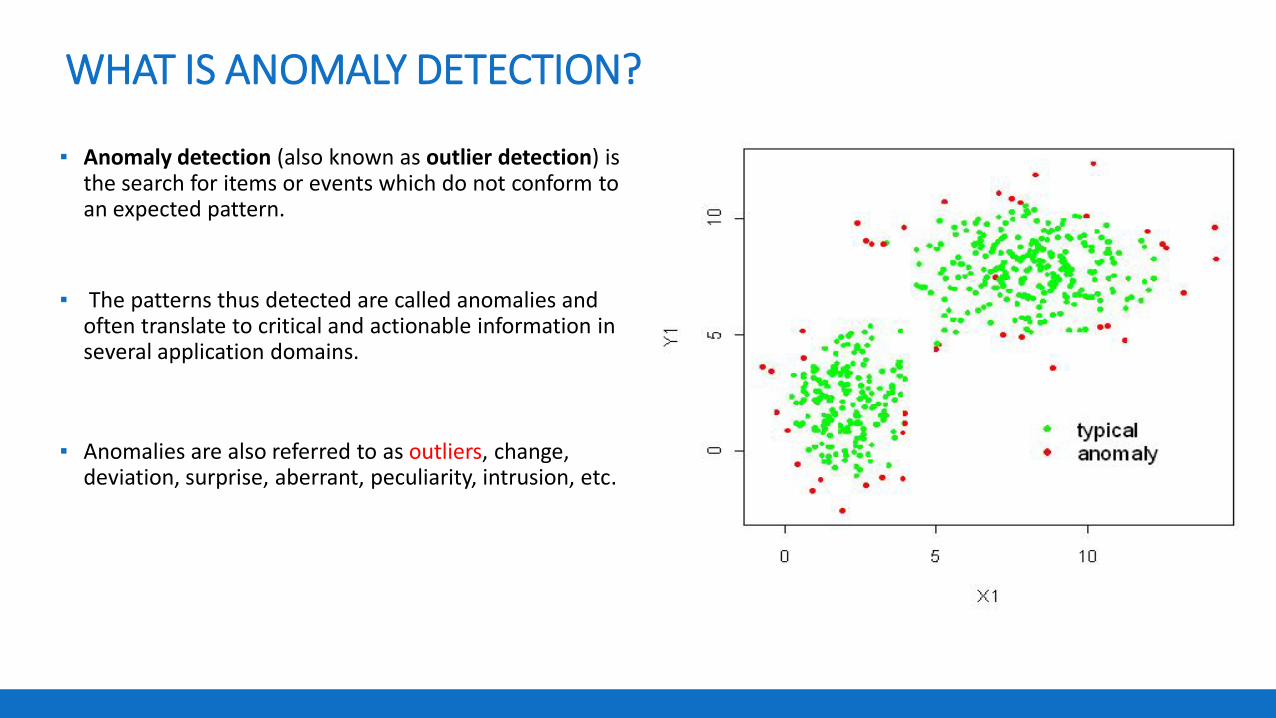
WHAT IS ANOMALY DETECTION?
▪ Anomaly detection (also known as outlier detection) is the search for items or events which do not conform to an expected pattern.
▪ The patterns thus detected are called anomalies and often translate to critical and actionable information in several application domains.
▪ Anomalies are also referred to as outliers, change, deviation, surprise, aberrant, peculiarity, intrusion, etc.
WHAT IS ANOMALY DETECTION?
▪ Anomaly detection is applicable in a variety of domains, such as intrusion detection, fraud detection, fault detection, system health monitoring, event detection in sensor networks, and detecting Eco-system disturbances.
▪ It is often used in preprocessing to remove anomalous data from the dataset.
▪ In supervised learning, removing the anomalous data from the dataset often results in a statistically significant increase in accuracy.
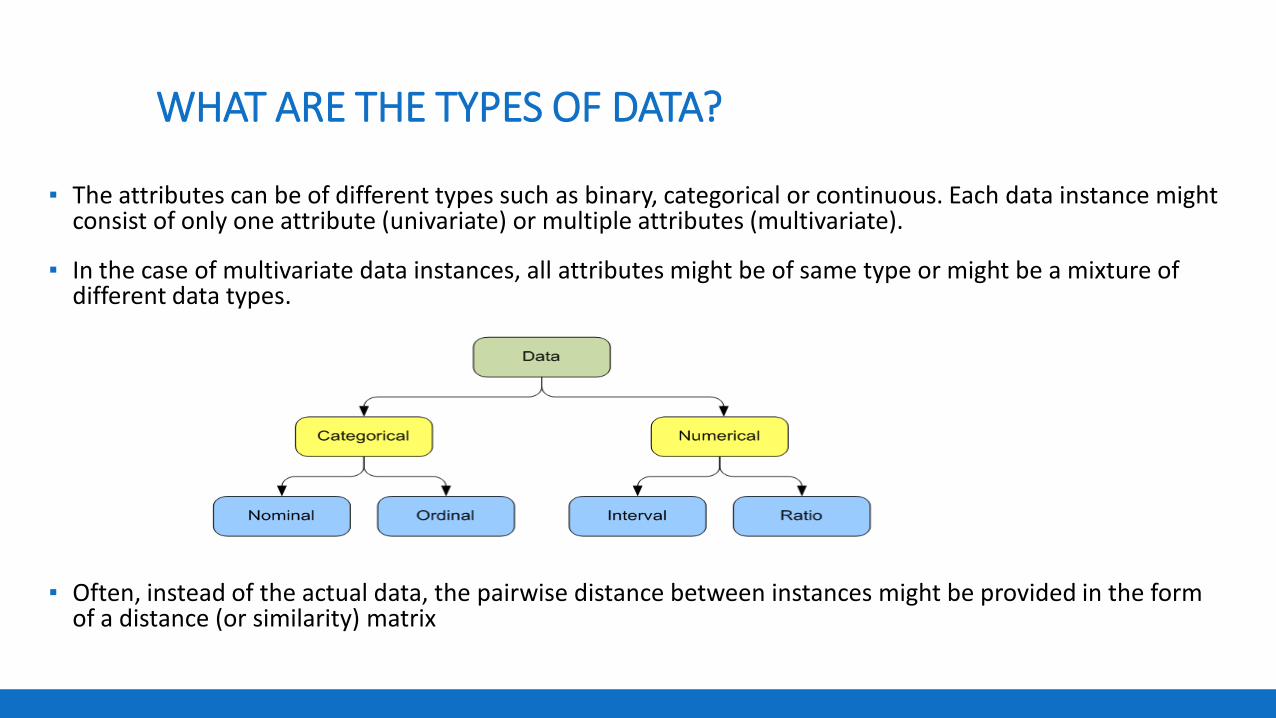
WHAT ARE THE TYPES OF DATA?
▪ The attributes can be of different types such as binary, categorical or continuous. Each data instance might consist of only one attribute (univariate) or multiple attributes (multivariate).
▪ In the case of multivariate data instances, all attributes might be of same type or might be a mixture of different data types.
▪ Often, instead of the actual data, the pairwise distance between instances might be provided in the form of a distance (or similarity) matrix

WHAT ARE THE TYPES OF ANOMALIES?
▪ Anomalies can be classified into following three categories:
Point Anomalies. If an individual data instance can be considered as anomalous with respect to the rest of data, then the instance is termed as a point anomaly. This is the simplest type of anomaly and is the focus of majority of research on anomaly detection.
As a real life example, consider credit card fraud detection. Let the data set correspond to an individual’s credit card transactions. For the sake of simplicity, let us assume that the data is defined using only one feature: amount spent. A transaction for which the amount spent is very high compared to the normal range of expenditure for that person will be a point anomaly.

WHAT ARE THE TYPES OF ANOMALIES?
▪ Contextual Anomalies.
Contextual attributes. The contextual attributes are used to determine the context (or neighborhood) for that instance. For example, in spatial data sets, the longitude and latitude of a location are the contextual attributes. In time series data, time is a contextual attribute which determines the position of an instance on the entire sequence.
Behavioural attributes. The behavioural attributes define the non-contextual characteristics of an instance. For example, in a spatial data set describing the average rainfall of the entire world, the amount of rainfall at any location is a behavioural attribute.

WHAT ARE THE TYPES OF ANOMALIES?
▪ In particular, in the context of abuse and network intrusion detection, the interesting objects are often not rare objects, but unexpected bursts in activity.
▪ These ‘unexpected bursts of activity patterns’ do not adhere to the common statistical definition of an outlier as a rare object, and many outlier detection methods (in particular unsupervised methods) will fail on such data, unless it has been aggregated appropriately.
▪ Instead, a cluster analysis algorithm may be able to detect the micro clusters formed by these patterns.

WHAT ARE THE TYPES OF ANOMALIES?
▪ Collective Anomalies. If a collection of related data instances is anomalous with respect to the entire data set, it is termed as a collective anomaly. The individual data instances in a collective anomaly may not be anomalies by themselves, but their occurrence together as a collection is anomalous.

WHAT ARE THE TYPES OF ANOMALY DETECTION TECHNIQUES?
Three broad categories of anomaly detection techniques exist.
1. Unsupervised anomaly detection techniques detect anomalies in an unlabeled
test data set under the assumption that the majority of the instances in the data
set are normal by looking for instances that seem to fit least to the remainder of
the data set.
2. Supervised anomaly detection techniques require a data set that has been labeled as
"normal" and "abnormal" and involves training a classifier (the key difference to many
other statistical classification problems is the inherent unbalanced nature of outlier
detection).
3. Semi-supervised anomaly detection techniques construct a model representing normal
behavior from a given normal training data set, and then testing the likelihood of a test
instance to be generated by the learnt model.

WHAT ARE THE POPULAR ANOMALY DETECTION METHODS?
▪ Several anomaly detection techniques have been proposed in literature. Some of the popular techniques are:
▪ Distance based techniques (k-nearest neighbor, local outlier factor)
▪ One class support vector machines.
▪ Replicator neural networks.
▪ Cluster analysis based outlier detection.
▪ Pointing at records that deviate from learned association rules.
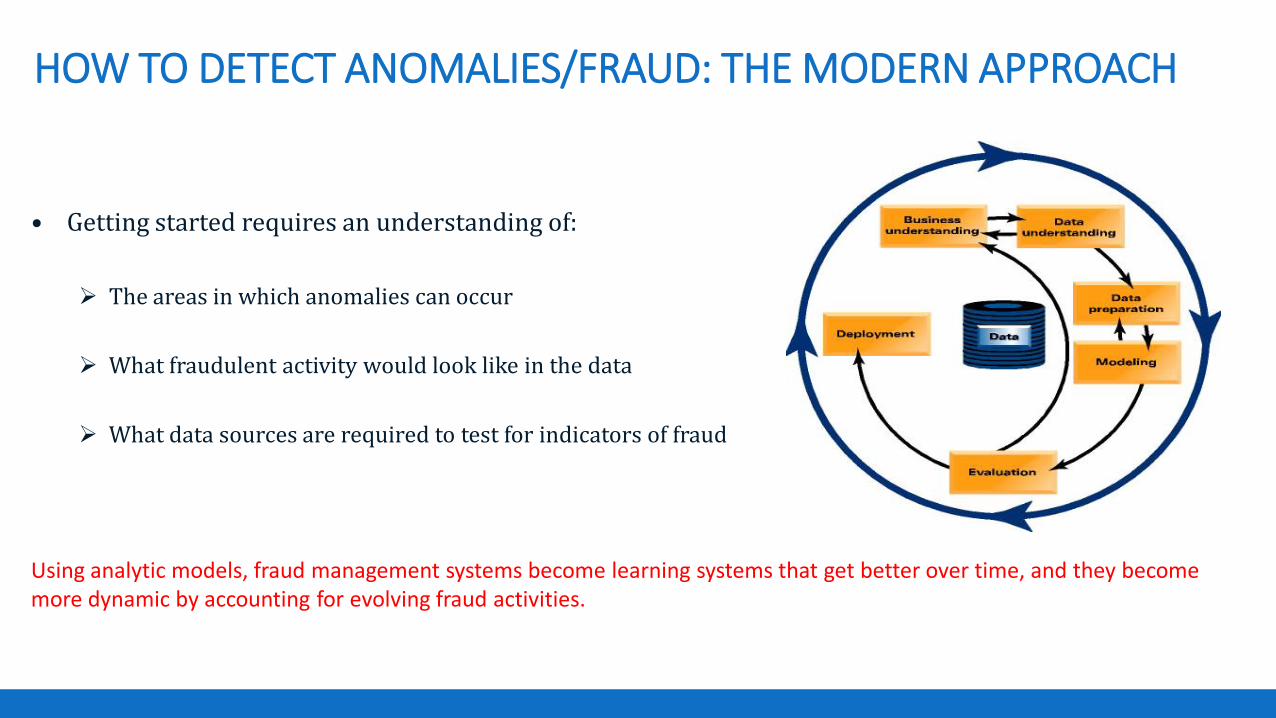
HOW TO DETECT ANOMALIES/FRAUD: THE MODERN APPROACH
• Getting started requires an understanding of:
The areas in which anomalies can occur
What fraudulent activity would look like in the data
What data sources are required to test for indicators of fraud
Using analytic models, fraud management systems become learning systems that get better over time, and they become more dynamic by accounting for evolving fraud activities.
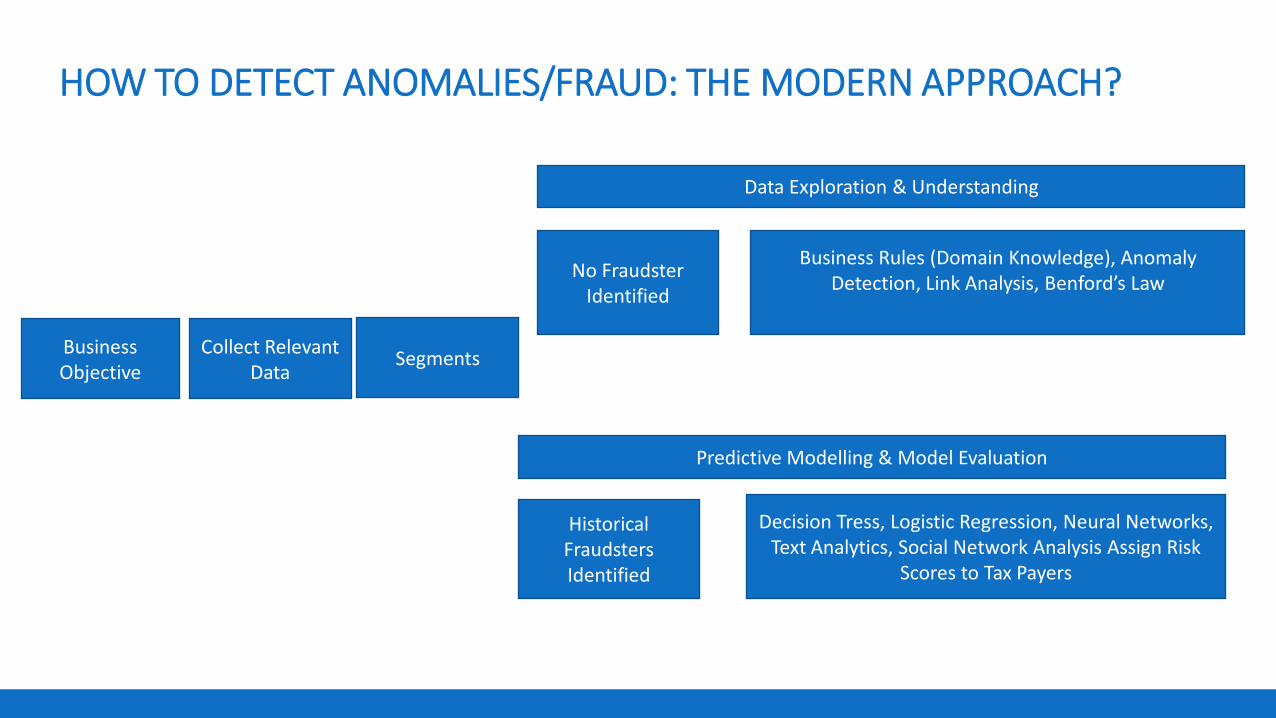
HOW TO DETECT ANOMALIES/FRAUD: THE MODERN APPROACH?
Business Objective
Collect Relevant Data
No Fraudster Identified
Historical Fraudsters Identified
Business Rules (Domain Knowledge), Anomaly
Detection, Link Analysis, Benford’s Law
,,
Decision Tress, Logistic Regression, Neural Networks, Text Analytics, Social Network Analysis Assign Risk
Scores to Tax Payers
Segments
Data Exploration & Understanding
Predictive Modelling & Model Evaluation
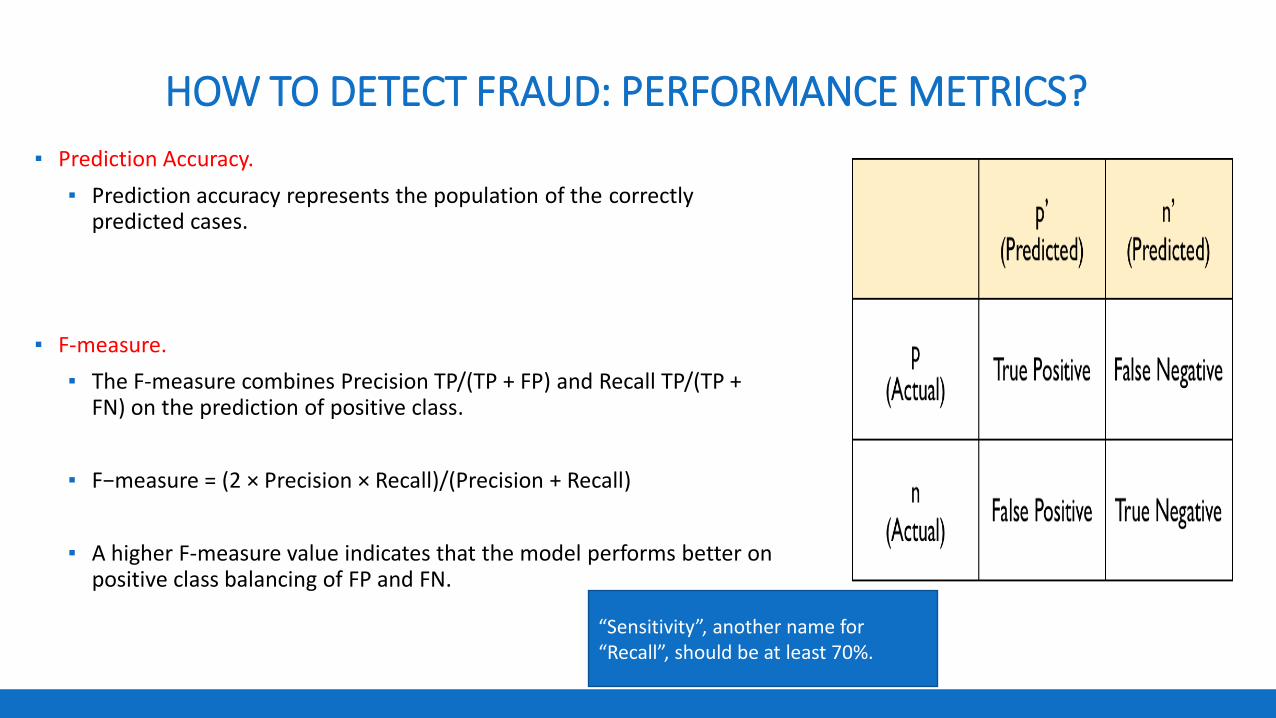
HOW TO DETECT FRAUD: PERFORMANCE METRICS?
▪ Prediction Accuracy.
▪ Prediction accuracy represents the population of the correctly predicted cases.
▪ F-measure.
▪ The F-measure combines Precision TP/(TP + FP) and Recall TP/(TP + FN) on the prediction of positive class.
▪ F−measure = (2 × Precision × Recall)/(Precision + Recall)
▪ A higher F-measure value indicates that the model performs better on positive class balancing of FP and FN.
“Sensitivity”, another name for “Recall”, should be at least 70%.

WHAT ARE THE BEST PRACTICES IN ANOMALY DETECTION?
▪ Build a central data mart that imports data from other databases
▪ Other best practices include tracking results to refine future fraud research by identifying key patterns that have proven successful in highlighting fraud activity
▪ Providing information to management and stakeholders across other departments to help develop a sense of teamwork and informed decision making
▪ Building public awareness campaign to highlight the state's fraud-fighting activities and to encourage compliance

WHAT ARE THE BEST PRACTICES IN ANOMALY DETECTION?
• The following techniques are effective in detecting fraud.
Calculation of statistical parameters (e.g., averages,
standard deviations, high/low values) – to identify
outliers that could indicate fraud.
Classification – to find patterns amongst data elements.
Stratification of numbers – to identify unusual (i.e., excessively high or low) entries.
Digital analysis using Benford’s Law – to identify unexpected occurrences of digits in naturally occurring data sets.

WHAT ARE THE BEST PRACTICES IN ANOMALY DETECTION?
▪ The network view of the case base is also becoming increasingly important in detecting fraud and error, with group risk and risk propagation through a network of connected entities becoming increasingly easier to detect using techniques such as social network analysis.
▪ Unstructured data including text, voice, image and spatial data – has just begun to be used for fraud detection on a large scale, and its importance and usefulness will undoubtedly grow in the future.
▪ Since tax authorities have the unusual position of having population data, not just sample data, there are few limits to how data mining techniques can be used to improve their performance.
▪ Some have even deployed these techniques in real time in their live transactional systems, including the Irish Tax and Customs authority

WHAT ARE THE BEST PRACTICES IN ANOMALY DETECTION?
▪ By its weblike nature, organized crime has always lent itself to detection and prosecution through its social network.
▪ Organised crime typically conceals itself behind the façade of small businesses, or the anomity of cyber walls.
▪ Other industries such as financial markets have long dealt with complex crime structure, including operations that have offshore or international elements.
▪ The healthcare sector lags in efforts to deal with this problem, including in employing fraud and misuse solutions.

WHAT ARE THE BEST PRACTICES IN ANOMALY DETECTION?
▪ Social Network analysis provides another whole aspect and adjunct to the pursuit of fraud, putting intelligence gathering in a relationship context that highlights associated risk.
▪ Graphing analysis displays degree of association and confidence for each relationship linkage shown.

WHAT IS THE VALUE OF ANOMALY DETECTION?
▪ In the US Department of Health & Human Services (HHS), received approximately $7 for every $1 invested in pursuing Medicare Fraud/Anomaly Detection.
▪ Likewise US States invested roughly $200 million in Medicaid integrity programs (Anomaly Detection Programs) with recoveries approaching $1.5 billion.

If you have any questions, please contact me: Tel: +61 478 066 323 Email: [email protected] Linkedin: http://linkedin.com/carolhargreaves Twitter: http://twitter.com/DataAnalytic Blog: carolhargreaves.com

![Comparison of Unsupervised Anomaly Detection Techniques · a RapidMiner [10] Extension Anomaly Detection was developed that contains several unsupervised anomaly detection techniques](https://img.pdfslide.net/doc/110x75/5b014b8c7f8b9a952f8e25e8/comparison-of-unsupervised-anomaly-detection-rapidminer-10-extension-anomaly-detection.jpg)







![Anomaly Detection: Principles, Benchmarking, Explanation ...web.engr.oregonstate.edu/~tgd/...anomaly-detection... · Towards a Theory of Anomaly Detection [Siddiqui, et al.; UAI 2016]](https://img.pdfslide.net/doc/110x75/5fd8992320a65f059c333c6d/anomaly-detection-principles-benchmarking-explanation-webengr-tgdanomaly-detection.jpg)



















