Embed Size (px)
Citation preview

Dimensionamento de Redes Ópticas Multi-débito com Agregação deTráfego Intermédio
Bruno Délcio Mendes Caseiro(Licenciado)
Dissertação para obter o grau de Mestre em
Engenharia Electrotécnica e de Computadores
JúriPresidente: Professor José Manuel Bioucas DiasOrientador: Professor João José de Oliveira PiresCo-Orientador: Doutor João Pedro, Nokia Siemens NetworksVogal: Professor Paulo Miguel Nepomuceno Pereira Monteiro
Maio 2012


Anyone who has never made a mistake has never tried anything new.Albert Einstein


Agradecimentos
Gostaria de agradecer primeiramente aos meus orientadores Professor João Pires, Doutor João
Pedro da Nokia Siemens Networks e engenheiro João Santos da Nokia Siemens Networks por esta-
rem sempre disponíveis e dispostos a ajudar-me em todos os desafios que foram surgindo ao longo
desta dissertação. De seguida, quero deixar um agradecimento a minha família por todos estes anos
de Universidade onde tiverem de fazer muitos sacrifícios para manter-me a estudar. A minha filha
Larissa Caseiro e a minha namorada Iara Rocha por estarem do meu lado e preencherem a minha
vida com muita alegria.
Por fim, mas não menos importante, um agradecimento aos meus amigos e colegas, em especial ao
Pedro Sousa, pela força e pelos conselhos que me foram passando durante este longo ciclo que se
encerra.
iii


Abstract
This dissertation address the capacity and optimization problem in Long-Haul Optical Networks
applying a novel algorithm for grooming different traffic requests from service layers. This work is
important mainly because the Internet and others interactive services such High Definition Television
(HDTV) and Television over Internet Protocol (IPTV) are increasing dramatically and the capacity
deployed will soon reach the limit. To avoid network strangulation and enormous investments in new
infra-structures and equipments, we developed a tool based on mathematical approach called Integer
Linear Programming (ILP) and an heuristic approach in order to maximize resources utilization and
operators revenue at same time as providing the best service for clients. The ILP shows that when we
deploy in the network muxponders together with cascade technique, just few wavelengths operating
at 111 Gbit/s line rate (with Forward Error Correction (FEC)) are needed to carry many clients with
different rates, 2.5, 10 and 40 Gbit/s. This improvement in efficiency can be boosted if we allow any
node in the trail from source to sink to do grooming with cascade even if this intermediate node does
not have any traffic to send to sink, working as hub node.
The results discussed in this dissertation are very useful in the meaning of network planning
and optimization for the future Optical Transport Networks. This will help operators to delay new
investments and get more revenue from the old network with some minor improvements.
Keywords
Planning, Grooming, Transponders, Muxponders, Optical Transport Network, Integer Linear Pro-
gramming.
v


Resumo
O rápido crescimento da Internet e de alguns serviços interactivos tais como IPTV fazem crer
que brevemente atingir-se-á o estrangulamento das redes, havendo por isso uma necessidade ime-
diata de se efectuar uma optimização eficaz de forma a termos um aumento gradual da capacidade.
Das duas opções que se colocam aos operadores, aborda-se nesta dissertação a optimização das
redes ópticas com multi-débito com agregação de tráfego multi-débito recorrendo-se a muxponders
em cascata nos nós fonte, destino e também em todos os nós intermédios que façam parte do ca-
minho escolhido para transportar o tráfego desde que a operação se justifique em termos de custos
e utilização dos recursos da rede. Para este objectivo desenvolveram-se dois algoritmos, o primeiro
foi elaborado recorrendo-se a Programação Linear Inteira e o segundo é um modelo heurístico que
nos permite uma aproximação a solução óptima para o problema em estudo. Os modelos criados
permitem-nos concluir que é possível optimizar-se os recursos da rede colocando em cada compri-
mento de onda disponível uma maior quantidade de tráfego com granularidades diferentes, passando
cada serviço por um processo de multiplexagem interno sempre que seja necessário ajustar o seu
ritmo de entrada com os demais serviços. Nas redes de telecomunicações a parte mais penosa
em termos orçamentais de se alterar é a infraestrutura que suporta a cablagem. Os modelos aqui
apresentados permitem-nos planear e optimizar as redes com o mínimo custo para os operadores
tirando proveito do estado da rede quer de infraestrutura quer de equipamentos.
Palavras Chave
Dimensionamento, Agregação, Tráfego, Muxponders, Transponders, Redes-ópticas.
vii


Conteúdo
1 Introdução 1
1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Conceitos e Trabalho Relacionado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2.1 Evolução do Processo para Agregação de Tráfego . . . . . . . . . . . . . . . . . 7
1.3 Contribuições Originais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3.1 Contribuição Científica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3.2 Contribuição não Científica - Software . . . . . . . . . . . . . . . . . . . . . . . . 11
1.4 Organização do Documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 Redes de Transporte Ópticas 13
2.1 Redes de Longo Alcance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2 Arquitectura Multicamadas dos Protocolos . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Planeamento em redes WDM de Longo e Ultra-Longo Alcance . . . . . . . . . . . . . . 16
2.4 Introdução ao Dimensionamento de Redes de Transporte Ópticas . . . . . . . . . . . . 18
2.4.1 Multiplexagem por Divisão do Comprimento de Onda - WDM . . . . . . . . . . . 18
2.4.2 Encaminhamento e Atribuição de Comprimento de Onda . . . . . . . . . . . . . 19
2.4.3 Aspectos da Transmissão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.4.4 Recolha de informação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.5 Agregação de Tráfego nas Redes de Transporte . . . . . . . . . . . . . . . . . . . . . . 21
2.6 Aspectos Físicos da Agregação de Tráfego . . . . . . . . . . . . . . . . . . . . . . . . . 22
3 Proposta de Algoritmos para Agregação de Tráfego 25
3.1 Grafo de nós alcançáveis sem regeneração - Reachability Graph . . . . . . . . . . . . . 26
3.2 Algoritmo ILP para Agregação na Fonte com Muxponders em Cascata . . . . . . . . . . 28
3.2.1 Validação do Modelo para Agregação na Fonte . . . . . . . . . . . . . . . . . . . 32
3.3 ILP para Agregação Intermédia com Muxponders em Cascata . . . . . . . . . . . . . . 35
3.3.1 Validação do Modelo Global . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.3.2 Comparação e conclusões sobre os modelos de programação linear . . . . . . . 39
3.4 Modelo Heurístico para Agregação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4.1 Validação da Heurística . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.4.2 Conclusões sobre a validade do modelo heurístico . . . . . . . . . . . . . . . . . 50
ix

4 Simulação e Resultados 51
4.1 Ambiente de Simulação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2.1 Primeira cenário - Comparação entre ILP intermédio versus heurístico . . . . . . 52
4.2.1.A Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2.2 Segundo cenário - Aplicação do modelo heurístico na rede NSFNET . . . . . . . 52
4.2.3 Segundo cenário - Aplicação do Modelo Heurístico na rede NSFNET com alte-
ração dos parâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.2.3.A Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5 Conclusões e Trabalho Futuro 57
Bibliografia 59
Apêndice A Manipulação da Aplicação A-1
Apêndice B Resultados da simulação B-1
Apêndice C Matriz dos testes heurísticos C-1
Apêndice D Resultados da validação do modelo global D-1
x

Lista de Figuras
1.1 Optical Add-Drop Multiplexer (OADM) com grau três, [1]. . . . . . . . . . . . . . . . . . . 4
1.2 Bypass óptico, [1]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 A figura, extraída de [1], mostra o comportamento para o número de regeneradores
que são necessários instalar em função do alcance máximo para o sinal óptico . . . . . 5
1.4 Light-trail versus Light-path, retirada de [2]. . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.5 Ocupação dos circuitos nas redes de transporte ópticas apresentados em [3]. . . . . . 6
1.6 Arquitectura de nó com Reconfigurable Optical Add-Drop Multiplexer (ROADM), [4] e [5] 9
1.7 Aplicação desenvolvida para auxiliar o utilizador a obter e interpretar os resultados dos
modelos apresentados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1 Enquadramento do GFP na pilha de protocolos. . . . . . . . . . . . . . . . . . . . . . . 15
2.2 IP sobre ATM sobre SDH sobre WDM, [6] . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 IP over SDH over DWDM, [6] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 IP sobre DWDM, [6] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.5 Hierarquia da rede, modelo consensual. . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.6 Evolução da estrutura das redes, [7] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.7 Encaminhamento eficiente de tráfego IP, [7]. . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.8 Esquema de ligação WDM ponto-a-ponto . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.9 Mapeamento e multiplexagem do SDH, [8] . . . . . . . . . . . . . . . . . . . . . . . . . 22
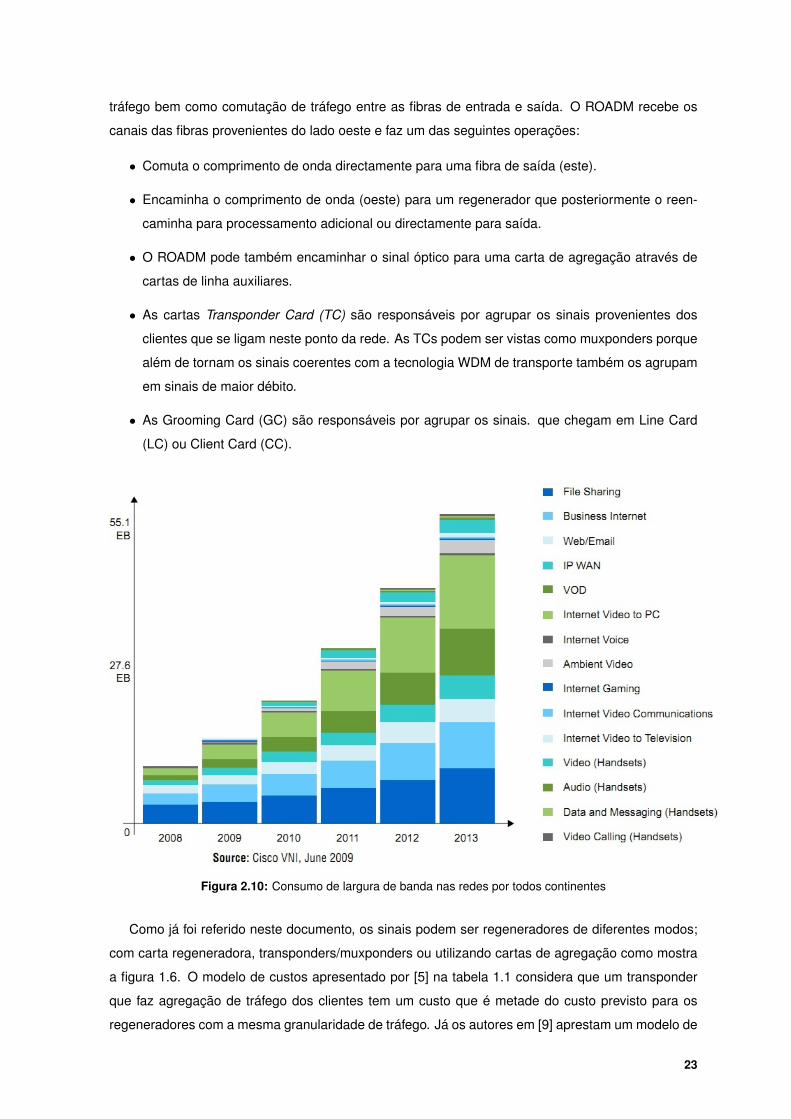
2.10 Consumo de largura de banda nas redes por todos continentes . . . . . . . . . . . . . . 23
3.1 Rede obtida para 2.5 e 10 Gbit/s. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2 Rede obtida para 40 Gbit/s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3 Rede obtida para 100 Gbit/s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4 Caminhos disjuntos para 10 Gbit/s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.5 Agregação na fonte com cascata de muxponders . . . . . . . . . . . . . . . . . . . . . . 29
3.6 Matriz de pedidos para validação do ILP com agregação na fonte . . . . . . . . . . . . . 33
3.7 Rede de seis nós para validação do modelo ILP . . . . . . . . . . . . . . . . . . . . . . 33
3.8 Relação entre o número de comprimentos de onda e o custo total da rede . . . . . . . . 34
3.9 Agregação na fonte e intermédia com cascata . . . . . . . . . . . . . . . . . . . . . . . 36
3.10 Relação entre o número comprimentos de onda e o custo total da rede . . . . . . . . . 40
3.11 Matriz de pedidos com predominância nos 2.5 Gbit/s . . . . . . . . . . . . . . . . . . . . 45
xi

3.12 Rede de 6 nós para validação do modelo heurístico . . . . . . . . . . . . . . . . . . . . 45
3.13 Matrizes após multiplexagem inversa para 40G . . . . . . . . . . . . . . . . . . . . . . . 46
3.14 Matrizes após multiplexagem directa para 2.5G . . . . . . . . . . . . . . . . . . . . . . . 47
3.15 Matrizes de 2.5G (superior) e 10G(inferior) antes da cascata . . . . . . . . . . . . . . . . 47
3.16 Matrizes de 2.5G (superior) e 10G(inferior) depois da cascata . . . . . . . . . . . . . . . 48
3.17 Resultados obtidos para agregação intermédia a 2.5 Gbit/s . . . . . . . . . . . . . . . . 48
3.18 Light-trails criados durante a execução do exemplo ilustrativo de agregação intermédia
entre o par 6− > 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.19 Matrizes após agregação intermédia para 2.5G . . . . . . . . . . . . . . . . . . . . . . . 49
4.1 ILP versus Heurístico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2 Rede NSFNET com 14 nós. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.3 Resultados obtidos para duas matrizes criadas aleatoriamente alterando o débito pre-
dominante. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.4 Segundo teste com parâmetros dos muxponder de 40 Gbit/s modificados . . . . . . . . 54
4.5 Custos totais para os exemplos testados . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
A.1 Janela Principal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-2
A.2 Caixa de dialogo para selecionar a rede de teste . . . . . . . . . . . . . . . . . . . . . . A-2
A.3 Rede carregada com sucesso na aplicação . . . . . . . . . . . . . . . . . . . . . . . . . A-3
A.4 Ilhas transparentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-3
A.5 Exemplo de output das ilhas transparentes . . . . . . . . . . . . . . . . . . . . . . . . . A-4
A.6 Parâmetros para modelo heurístico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-4
C.1 Matrizes 2.5, 10, 40 Gbps geradas de forma aleatória . . . . . . . . . . . . . . . . . . . . C-2
xii

Lista de Tabelas
1.1 Table de preços extraída de [4],[5] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1 Débitos de linha normalizados para SDH/SONET . . . . . . . . . . . . . . . . . . . . . . 14
2.2 Débitos de linha normalizados para OTN’s . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Considerações de planeamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.4 Eficiência do SDH convencional versus SDH de nova geração [8] . . . . . . . . . . . . . 22
2.5 Modelo de custos usado em [9] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.6 Modelo de custos utilizado nesta dissertação derivado de [5] e [9]. . . . . . . . . . . . . 24
3.1 Distâncias máximas sem 3R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.2 ILP sem operação de agregação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.3 ILP com agregação na fonte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.4 ILP com agregação intermédia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.5 Modelo de custos utilizado nesta dissertação derivado de [5] e [9]. . . . . . . . . . . . . 44
xiii


Acrónimos
FEC Forward Error Correction
ASON Automatically switched optical network
SDH Syncronous Digital Hierarchy
WDM Wavelength Division Multiplexing
WDM Wavelength Division Multiplexing
DWDM Dense Wavelength Division Multiplexing
OXC Optical Cross Conect
ASE Amplified Spontaneous Emission
TDM Time Division Multiplexing
IP Internet Protocol
DXC Digital Cross Connect
OTN Optical Transport Network
ILP Integer Linear Programming
ADM Add Drop Multiplexer
OEO Optical-Electrical-Optical
WRS Wavelength-Routing Switch
ROADM Reconfigurable Optical Add-Drop Multiplexer
OADM Optical Add-Drop Multiplexer
SONET Synchronous Optical Network
3R Re-transmission, Re-timing, Re-Shapping,
LC Line Card
CC Client Card
xv

TC Transponder Card
GC Grooming Card
RPP Regenerator Placement Problem
SPM Self-phase Modulation
PMD Polarization Mode Disperson
CAPEX Capital expenditure
CWDM Coarse Wavelength Division Multiplexing (WDM)
XTalk Cross-Talk
POTS Plain Old Telephone Service
FOADM Fixed Optical Add-Drop Multiplexer (OADM)
IPTV Television over Internet Protocol
OLA Optical Line Amplifier
EDFA Erbium Doped Fiber Amplifier
HDTV High Definition Television
GSM Global System for Mobile Communications
GFP Generic Frame Procedure
ATM Asyncronous Transfer Mode
FWM Four Wave Mixing
SPM Self Phase Modulation
VCAT Virtual Concatenation
xvi

Lista de Símbolos
Q: Q-Factor, valor que está relacionado com a relação sinal ruído e probabilidade de erro.
BER : Bit Error Ratio.
ASE Amplified Spontaneous Emission.
K : Número de caminhos que devem ser calculados entre cada par de nós.
xvii


1Introdução
Contents1.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Conceitos e Trabalho Relacionado . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Contribuições Originais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4 Organização do Documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1

1.1 Motivação
O rápido e incessante crescimento da Internet motivado pelos serviços agora disponibilizados
aos utilizadores que vão desde uma simples página informativa passando por operações bancárias
até as redes socais, têm forçado os servidores de Internet a aumentarem a capacidade de trans-
porte de dados nas suas redes. Porém, hoje em dia, nenhum operador pode ficar indiferente às leis
do mercado, a globalização e os factores económicos que devem estar presentes em cada decisão
estratégica e que tem levado as empresas no sector das telecomunicações a desenvolverem metodo-
logias de planeamento cada vez mais eficientes. A redução de custos pode passar pela reutilização
dos equipamentos já existentes na rede, tornando-a mais eficiente ou, instalar novos equipamentos
com uma relação custo-beneficio que comprove ser mais vantajosa em termos globais para a em-
presa. Nas redes, existe uma componente que podemos designar como a componente estática ou
seja, ligações físicas entre os diferentes elementos de rede dispostos pelo conjunto de nós (ligação
por fibra óptica). Os operadores de redes de transporte ópticas sempre que possível tentam não
efectuar alterações a infraestrutura já existente por se tratar dum processo bastante dispendioso.
Por esta razão, o correcto aproveitamento dos canais por cada banda deve ser constantemente per-
seguido evitando-se assim modificações para acréscimo de fibras na rede. A tecnologia existente
(Dense Wavelength Division Multiplexing (DWDM)) combinada com lasers de elevada eficiência es-
pectral e filtros cada vez mais selectivos permite que dezenas de canais com débitos de linha até
1111 Gbit/s sejam agrupados na mesma banda com um espaçamento de apenas 25 GHz entre cada
canal empurrando a capacidade dessas redes para os Terabit/s por ligação física.
Apesar dos novos avanços permitirem dezenas de canais a operarem ao débito máximo de li-
nha, é ainda necessário ter em consideração a variedade de sinais provenientes da camada supe-
rior (camada de serviço) e se os mesmos estão optimizados para serem transportados numa rede
Syncronous Digital Hierarchy (SDH) ou Optical Transport Network (OTN). Uma vez que a grande
parte dos dados que ocupam as redes de transporte são provenientes de routers Ethernet com ca-
pacidades significativamente inferiores a capacidade de linha, torna-se essencial proceder a uma
agregação de vários routers de modo a criar-se um sinal com um débito mais elevado reduzindo o
número de canais ópticos ocupados. Este trabalho centra-se no caso em que os sinais agrupados
têm granularidades de 2.5, 10 e 40 Gbit/s, como se verifica nas redes de transporte de longo alcance,
tendo em consideração que os mesmos podem ser combinados em qualquer ponto/nó estratégico
da rede. Esta combinação será objecto de estudo de modo a inferir-se sobre o impacto causado em
termos de custos relativamente ao tipo de tráfego que tem de ser encaminhado tendo em atenção
as limitações de distância impostas pela camada física. Uma vez que o custo do investimento na
rede pode ser previamente estimado em relação ao custo de operação de rede, é natural que este
seja um critério várias vezes escolhido para decisões de investimento e por isso deve representar
tão bem quanto possível a realidade dos operadores.
Todos os factores descritos acima quando combinados forçam as redes a serem escaláveis e
1Para simplicidade este valor poderá ser referenciado como 100 Gbit/s.
2

flexíveis para que possam satisfazer o grande fluxo de tráfego proveniente dos mais variados sec-
tores. Ter uma rede desenhada com equipamento que permite acompanhar a evolução da Internet
maximizando ao mesmo tempo as receitas é fundamental para a sobrevivência no sector das te-
lecomunicações e é por esta razão que se estuda a optimização com recursos a muxponders e
agregação intermédia de tráfego não homogéneo.
1.2 Conceitos e Trabalho Relacionado
O problema da agregação de tráfego ou Grooming2 está identificado desde as redes SDH [10],[11]
conhecidas pela sua topologia em anel. Porém, ao transpor-se este conceito para redes com topo-
logia que se aproxima a uma malha ou seja, conjunto de anéis interligados, devemos ter em consi-
deração que redes SDH em funcionamento dito normal os sinais percorrem todos o mesmo sentido
(rede direccional) e, em caso de falha ou corte o mesmo caminho mas no sentido oposto suporta a
ligação. Nestas redes (SDH) poucos são os nós com grau3 três (ver figura 1.1), havendo por isso
dois conceitos de agregação; Intra-anel e Inter-Anel. Agregação intra anel consiste em criar um trail
não fechado permitindo que outros nós dentro do trail possam usar os recursos disponíveis para
transmitir dados. No caso do Inter-Anel, a agregação processa-se na Digital Cross Connect (DXC)
de alta ordem onde todo o tráfego que deve ser enviado para um outro anel é agrupado. Nas redes
em malha facilmente encontram-se nós com grau superior a três o que permite que o tráfego flua de
forma não controlada ou pré-defina, deixando a cargo de cada nó na rede a decisão de encaminha-
mento. Para redes/nós onde a opção de encaminhamento para o canal em serviço não está restricta
a apenas uma saída, é possível aplicar o protocolo Automatically switched optical network (ASON)
[12] deixando a rede/nó decidir de forma independente qual o caminho a usar para transportar o seu
tráfego dentro das alternativas e das restrições de distância que por sua vez são dependentes do
débito a transportar. De forma a reduzir-se a complexidade do problema introduziu-se o conceito de
Reachability Graph que permite saber para um determinado nó da rede quais os nós que estão ao
seu alcance sem que o sinal óptico seja regenerado antes de atingir o seu destino. Em seguida são
descritos os conceitos principais da área científica onde este trabalho se insere.
Redes de Longo Alcance : São redes onde a distância física entre dois pontos encontra-se
normalmente contida entre os 1000 e 3500 quilómetros, valores estes que dependem do débito a
transmitir mas a tendência aponta para distâncias cada vez maiores. Estas redes são normalmente
esparsas e a distância é maioritariamente balizada pelos limites tecnológicos dos emissores e recep-
tores [1] bem como pelo ruído introduzido pelos amplificadores de linha conhecido como Amplified
Spontaneous Emission (ASE) [13]. Em [1], é apresentado um estudo sobre o impacto nos custos
da rede com o aumento do alcance máximo que cada nó pode atingir permitindo que alguns sinais
sejam comutados no domínio óptico sem haver necessidade de regeneração apenas a introdução
de Optical Cross Conect (OXC) (figura 1.2) que apresenta, em média, um custo inferior a um rege-
nerador. O estudo mostra ainda que nós com capacidade de alcance entre 2500 e 3500 reduzem2Termo anglo-saxónico adoptado na literatura3número de ligações físicas que incidem no nó
3

Figura 1.1: OADM com grau três, [1].
o número de equipamentos activos (regeneradores) a 90 % o que torna o custo da rede muito mais
reduzido quando comparado com ligações com 1000 Km. Alguns resultados obtidos por [1] estão
ilustrados na figura 1.3 onde é possível verificar para quatro redes distintas o mesmo comportamento.
Figura 1.2: Bypass óptico, [1].
Embora se esteja a caminhar para redes que trabalhem totalmente no domínio óptico, ainda con-
tinuará a ser necessário regenerar o sinal para que este atinja o seu destino em condições aceitáveis
para ser recuperado e interpretado. Mais informações sobre tipos de arquitectura de regeneração
que podem ser usados estão em [1] tendo em consideração o custo e a flexibilização em termos de
reconfiguração. Dos três tipos que podem ser encontrados no estudo, o método mais simples porém
menos flexível e que é tido em consideração ao longo desde trabalho é, ligando dois transponders
costas com costas (back-to-back ) quando não há necessidade de agrupar os sinais. Caso seja ne-
cessário agrupar os sinas, os transponders e muxponder são ligados através de um backplane que
permite uma maior flexibilidade de configuração das ligações alcançando-se, para o mesmo custo,
maior capacidade de configuração da rede e eficiência.
4
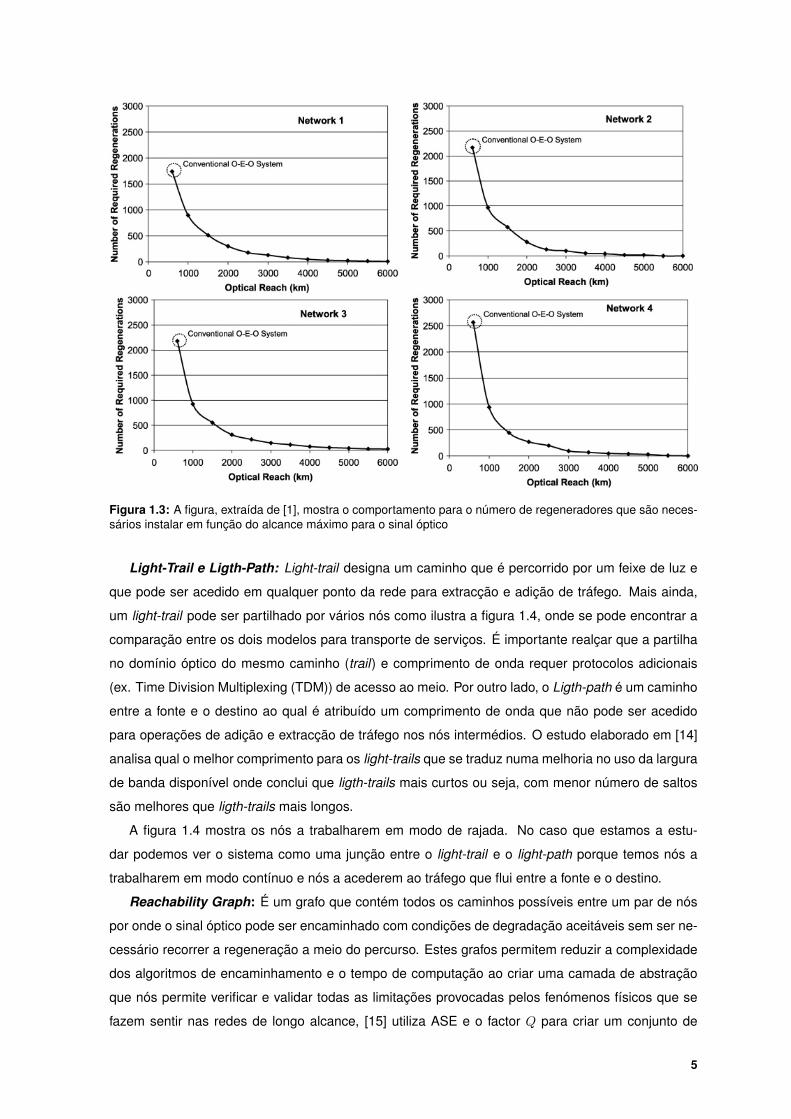
Figura 1.3: A figura, extraída de [1], mostra o comportamento para o número de regeneradores que são neces-sários instalar em função do alcance máximo para o sinal óptico
Light-Trail e Ligth-Path: Light-trail designa um caminho que é percorrido por um feixe de luz e
que pode ser acedido em qualquer ponto da rede para extracção e adição de tráfego. Mais ainda,
um light-trail pode ser partilhado por vários nós como ilustra a figura 1.4, onde se pode encontrar a
comparação entre os dois modelos para transporte de serviços. É importante realçar que a partilha
no domínio óptico do mesmo caminho (trail) e comprimento de onda requer protocolos adicionais
(ex. Time Division Multiplexing (TDM)) de acesso ao meio. Por outro lado, o Ligth-path é um caminho
entre a fonte e o destino ao qual é atribuído um comprimento de onda que não pode ser acedido
para operações de adição e extracção de tráfego nos nós intermédios. O estudo elaborado em [14]
analisa qual o melhor comprimento para os light-trails que se traduz numa melhoria no uso da largura
de banda disponível onde conclui que ligth-trails mais curtos ou seja, com menor número de saltos
são melhores que ligth-trails mais longos.
A figura 1.4 mostra os nós a trabalharem em modo de rajada. No caso que estamos a estu-
dar podemos ver o sistema como uma junção entre o light-trail e o light-path porque temos nós a
trabalharem em modo contínuo e nós a acederem ao tráfego que flui entre a fonte e o destino.
Reachability Graph: É um grafo que contém todos os caminhos possíveis entre um par de nós
por onde o sinal óptico pode ser encaminhado com condições de degradação aceitáveis sem ser ne-
cessário recorrer a regeneração a meio do percurso. Estes grafos permitem reduzir a complexidade
dos algoritmos de encaminhamento e o tempo de computação ao criar uma camada de abstração
que nós permite verificar e validar todas as limitações provocadas pelos fenómenos físicos que se
fazem sentir nas redes de longo alcance, [15] utiliza ASE e o factor Q para criar um conjunto de
5
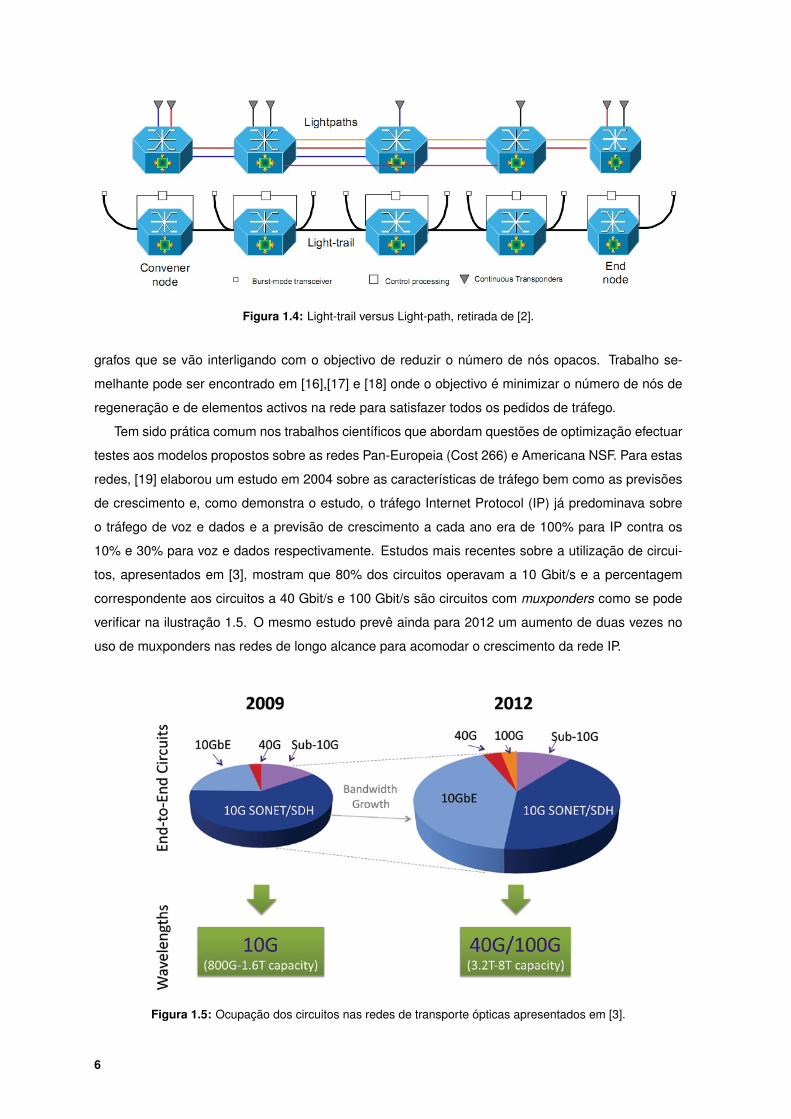
Figura 1.4: Light-trail versus Light-path, retirada de [2].
grafos que se vão interligando com o objectivo de reduzir o número de nós opacos. Trabalho se-
melhante pode ser encontrado em [16],[17] e [18] onde o objectivo é minimizar o número de nós de
regeneração e de elementos activos na rede para satisfazer todos os pedidos de tráfego.
Tem sido prática comum nos trabalhos científicos que abordam questões de optimização efectuar
testes aos modelos propostos sobre as redes Pan-Europeia (Cost 266) e Americana NSF. Para estas
redes, [19] elaborou um estudo em 2004 sobre as características de tráfego bem como as previsões
de crescimento e, como demonstra o estudo, o tráfego Internet Protocol (IP) já predominava sobre
o tráfego de voz e dados e a previsão de crescimento a cada ano era de 100% para IP contra os
10% e 30% para voz e dados respectivamente. Estudos mais recentes sobre a utilização de circui-
tos, apresentados em [3], mostram que 80% dos circuitos operavam a 10 Gbit/s e a percentagem
correspondente aos circuitos a 40 Gbit/s e 100 Gbit/s são circuitos com muxponders como se pode
verificar na ilustração 1.5. O mesmo estudo prevê ainda para 2012 um aumento de duas vezes no
uso de muxponders nas redes de longo alcance para acomodar o crescimento da rede IP.
Figura 1.5: Ocupação dos circuitos nas redes de transporte ópticas apresentados em [3].
6

1.2.1 Evolução do Processo para Agregação de Tráfego
Na sua maioria, os estudos científicos sobre agregação de tráfego nas redes ópticas, modelados
sobre programação linear inteira, lidam apenas com a problemática na fonte e também separam ou
simplesmente não incluem a conversão de comprimentos de onda nos nós opacos onde é efectuada
a regeneração do sinal. Além disso, poucos são os que focam o custo efectivo dos equipamentos
nas suas abordagens quer em Programação Linear Inteira (Integer Linear Programming (ILP)) como
heurísticas. O artigo [20] foi das primeiras publicações a estudar a agregação de tráfego tendo em
vista a redução de custos com a utilização de equipamentos activos na rede. A abordagem adoptada
simplificava o problema centrando o custo nos transmissores/receptores (transceivers), definindo à
priori um conjunto de light-paths baseado no caminho mais curto entre dois nós. O modelo deixa cla-
ramente de fora a atribuição de comprimentos de onda e a liberdade de utilização de outros possíveis
caminhos. A heurística apresentada utiliza uma das abordagens de [21] onde primeiro se satisfaz
cada pedido e posteriormente tenta-se utilizar a capacidade máxima disponível em cada light-path,
eliminando sucessivamente àqueles que apresentam uma baixa eficiência espectral migrando o seu
tráfego para outros.
O objectivo de [22] é apresentar um modelo matemático flexível em termos de objectivos podendo-
se inferir sofre o número máximo de light-paths ou, por exemplo, a quantidade total de DXC. En-
quanto [20] não considera restrições ao nível de atribuição e continuidade de comprimentos de onda
nem a possibilidade de agrupar no mesmo ligth-path pedidos de diferentes fontes, [22] já considera
todas estas hipóteses no seu modelo elaborado um ano mais tarde, em 2002. Em ambos os es-
tudos é considerado que os pedidos de tráfego são todos da mesma granularidade não havendo
qualquer diferenciação. Por sua vez, [23] torna o problema mais próximo da realidade permitindo
que os pedidos de tráfego possam ser uma fracção da capacidade do canal com objectivo de mi-
nimizar o número de Add Drop Multiplexer (ADM) maximizando a quantidade de pedidos que são
transportados em cada light-path que se estabelece. Ao contrário de [20] e [22], [23] menciona que
os sinais deverão ser agrupados no domínio eléctrico usando TDM, técnica esta que ainda perma-
nece dominante para este tipo de operações devido a complexidade do processo no domínio óptico.
[23] no seu modelo de programação linear não tem em consideração o custo em ter light-paths com
diferentes débitos permitindo que pedidos de débito mais baixo sejam encaminhados directamente
aumentando a probabilidade de bloqueio para pedidos de alto débito que se traduz numa maior ine-
ficiência no uso da largura de banda disponível em cada canal. [23] não descreve no seu estudo o
impacto em termos de custo ao fazer-se a agregação de vários pedidos de tráfego com granularida-
des distintas. O trabalho em [24, 25] é bastante semelhante a [23] tendo o primeiro como objectivo
a redução do atraso de propagação que é proporcional ao número de saltos que cada light-path
deve dar até atingir o seu destino e o segundo a redução dos custos com transponders. [25] resolve
primeiro o problema de encaminhamento e só depois a atribuição dos comprimentos de onda o que
pode levar ao bloqueio de alguns pedidos como demonstra [26]. Para questões de agregação de
tráfego com preocupações no consumo de energia o artigo [27] serve como referência.
Os autores em [28] pela primeira vez apresentam um modelo ILP para resolver a questão de
7

agregação usando light-trails mas, a complexidade da formulação (NP-hard) [21] torna o problema
intratável para a maioria das redes. Adicionalmente, o conceito light-trail introduz em cada nó em
que o sinal atravessa uma penalidade na potência devido a necessidade de dividir o sinal a entrada
e recombina-lo novamente na saída o que limita a sua utilização para redes que operam a débitos
acima dos 10 Gbit/s porque, embora se possa amplificar o sinal várias vezes, existe um limite im-
posto pelo ruído que se acumula de secção em secção e que não é possível eliminar sem se recorrer
ao domínio eléctrico para regenerar o sinal. O artigo [28] utiliza estrategicamente alguns nós como
concentradores (hub) para maximizar a carga em determinadas ligações e minimizar o número de
comprimentos de onda a custa de menor balanceamento da carga na rede. A abordagem utilizada
nesta dissertação é semelhante embora permita que todos os nós se comportem como concentrado-
res não apenas um conjunto pré-seleccionado. O estudo apresentado em [29] analisa com algoritmos
não matemáticos a probabilidade de bloqueio entre ligth-path versus ligth-trails no que diz respeito a
agregação de tráfego. Os trabalhos de [30, 31] apresentam modelos que combinam light-paths com
light-trails explorando agregação de tráfego só ao nível óptico com resultados bastante promissores
na redução de operações Optical-Electrical-Optical (OEO) mas, partindo de um conjunto vasto de
suposições que na prática podem ser de difícil implementação.
O conceito light-trail tem conquistado espaço na comunidade científica pelo facto de permitir a
redução significativa de conversões OEO porém, em todos os modelos consultados não foi possível
perceber a partir de que ponto se torna mais viável usar ligth-trails em detrimento de ligth-paths uma
vez que os custo de se ter todos os equipamentos, desde os simples monitores da rede que permitem
verificar os time-slots livres, os encaminhadores ópticos ou Wavelength-Routing Switch (WRS) até
aos transmissores não é estudado.
Em relação ao problema da agregação de tráfego e colocação de regeneradores tendo em con-
sideração as limitações físicas, expressas no Reachability Graph, encontra-se na heurística de [4]
um estudo aprofundado com um modelo de custos pré-definido para os elementos de rede, ficando
apenas de fora a utilização de muxponders em cascata, a possibilidade das ligações poderem ser
efectuadas por qualquer caminho que cumpra com as restrições e o estudo para débitos de 100
Gbit/s. O modelo em [4] compara a utilização de duas cartas de linha com cartas de agregação
para regenerar o sinal interligando-as através do backplane do Reconfigurable Optical Add-Drop
Multiplexer (ROADM) (figura 1.6), em conjunto com cartas de regeneração através de um algoritmo
heurístico. Os mesmos autores, apresentam uma nova versão [5] mas desta vez modelando o pro-
blema sobre programação linear inteira. A tabela 1.1 mostra os valores que foram usados nos dois
artigos mencionados. O modelo de custos bem como os algoritmos apresentados nestes artigos
([4],[5]) foram de elevada importância na realização desta dissertação tendo servido como ponto de
partida e de referência ao longo do processo de desenvolvimento dos algoritmos.
Os autores de [9] abordam um problema semelhante ao que é abordado nesta dissertação, apre-
sentando um modelo matemático extenso e complexo com utilização de transponders e muxponders
e ainda protecção de tráfego. O problema da atribuição de comprimento de onda é resolvido de
forma separada além dos nós capazes de agregação serem pré-definidos numa camada superior
8
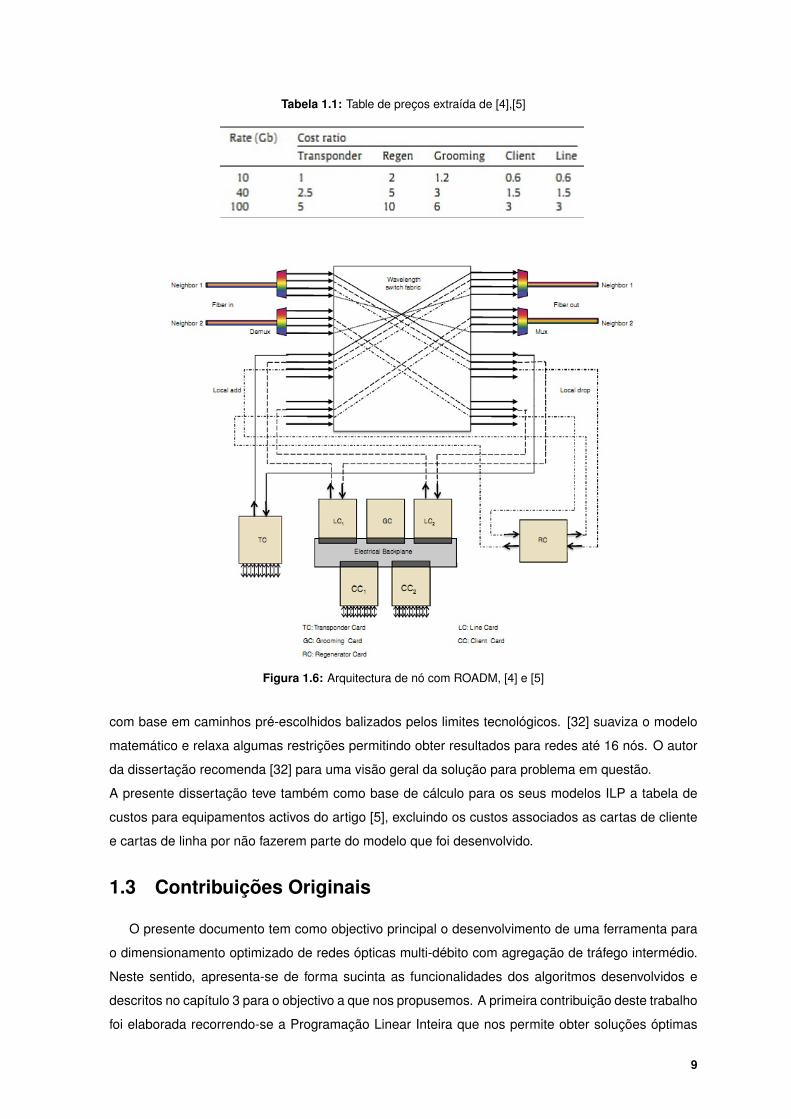
Tabela 1.1: Table de preços extraída de [4],[5]
Figura 1.6: Arquitectura de nó com ROADM, [4] e [5]
com base em caminhos pré-escolhidos balizados pelos limites tecnológicos. [32] suaviza o modelo
matemático e relaxa algumas restrições permitindo obter resultados para redes até 16 nós. O autor
da dissertação recomenda [32] para uma visão geral da solução para problema em questão.
A presente dissertação teve também como base de cálculo para os seus modelos ILP a tabela de
custos para equipamentos activos do artigo [5], excluindo os custos associados as cartas de cliente
e cartas de linha por não fazerem parte do modelo que foi desenvolvido.
1.3 Contribuições Originais
O presente documento tem como objectivo principal o desenvolvimento de uma ferramenta para
o dimensionamento optimizado de redes ópticas multi-débito com agregação de tráfego intermédio.
Neste sentido, apresenta-se de forma sucinta as funcionalidades dos algoritmos desenvolvidos e
descritos no capítulo 3 para o objectivo a que nos propusemos. A primeira contribuição deste trabalho
foi elaborada recorrendo-se a Programação Linear Inteira que nos permite obter soluções óptimas
9

para os problemas em estudo enquanto a segunda é uma heurística criada a partir dos resultados
observados após aplicação do modelo matemático e que nos permite atingir uma aproximação ao
valor ideal sendo, em contrapartida, menos complexa em termos computacionais. Para a segunda
solução foram aplicados conhecimentos de programação (C#) que ajudaram a criar uma ferramenta
simples e intuitiva permitindo qualquer utilizador testar as soluções que aqui se apresentam bem
como dos trabalhos científicos que foram usados como base, colmatando-se assim alguma lacuna
existente nesse sentido.
1.3.1 Contribuição Científica
O trabalho realizado no âmbito da presente dissertação vem clarificar alguns resultas publicados
na literatura e introduz novos modelos matemáticos para optimização de redes de transporte hete-
rogéneas. O dimensionamento das redes de transporte com agregação de tráfego é abordado quer
com modelos já estudados na literatura e melhorados de modo a atender as exigências futuras de
requisitos de banda que vai de certo forçar a adopção prematura de OTN. As grandes contribuições
científicas, que serão detalhadas no capítulo 3, são as seguintes:
1. Desenvolvimento de um algoritmo ILP que permite efectuar a agregação de tráfego na fonte
usando Muxponders que agregam tráfego do seguinte modo : 4 × 2.5 Gbit/s para 10 Gbit/s, 4
× 10 Gbit/s para 40 Gbit/s e por último, 2 × 40 Gbit/s para 100 Gbit/s.
• 1o Melhoramento: Permitir que vários muxponders possam ser agrupados em cascata.
• 2o Melhoramento: Permitir que na entrada de um muxponder esteja um sinal proveniente
de outro muxponder de débito inferior ou um sinal proveniente de um transponder.
• 3o Melhoramento: Possibilidade de ter-se sinais de 2.5 Gbit/s agrupados com sinais de
40 Gbit/s para serem transportados num canal a 100 Gbit/s utilizando os andares de mux-
ponders.
Para os melhoramentos propostos no primeiro algoritmo o autor desconhece qualquer estudo
publicado sobre o assunto sendo esta uma nova abordagem que visa responder aos problemas
de custos de instalação e operação que os operadores enfrentam.
2. Desenvolvimento (ou melhoramento do anterior) de um modelo ILP que permite efectuar todas
as operações descritas no primeiro algoritmo com as seguintes novas funcionalidades:
• 1o : O tráfego pode ser agrupado em qualquer nó da rede sem perder as propriedades do
primeiro algoritmo. Agregação Intermédia com muxponders em escada.
• 2o : O nó em que é feita a agregação não tem de necessariamente produzir tráfego po-
dendo servir apenas como um ponto de aglomeração de todos ou alguns sinais que por ele
passam. Até onde o autor conhece através da investigação efectuada, os modelos apre-
sentados só permitem agregação de tráfego quando o nó agregador em causa também
tem pedidos para serem satisfeitos.
10

3. Desenvolvimento de um algoritmo heurístico que permite resolver o problema de dimensiona-
mento para redes de maior escala. O algoritmo efectua agregação do tráfego comparando para
K caminhos qual o caminho que oferece melhor poupança em termos de custos totais da rede.
Para dar alguma clareza em relação aos modelos publicados no que diz respeito ao transporte
de 100 Gbit/s, o modelo permite verificar se é possível transportar um sinal de alto débito na
rede e, caso não seja possível não se efectua agregação de 40 Gbit/s para 100 Gbit/s mas
sim uma multiplexagem inversa que consiste em dividir o sinal de 40 Gbit/s em quatro sinais
distintos de 10 Gbit/s.
1.3.2 Contribuição não Científica - Software
Dado o número de variáveis e pré-processamento necessários para se implementar e testar os
modelos desenvolvidos, criou-se uma ferramenta em software que permite a qualquer utilizador vali-
dar os modelos apresentados nesta dissertação, visualizar grafos e ainda efectuar outras pequenas
operações através de uma interface de utilizador gráfica desenvolvida em C#, ver figura 1.7. Mais
detalhe sobre a utilização desta ferramenta pode ser encontrado no anexo A
Figura 1.7: Aplicação desenvolvida para auxiliar o utilizador a obter e interpretar os resultados dos modelosapresentados.
1.4 Organização do Documento
O presente documento organiza-se da seguinte forma:
O capitulo dois apresenta a caracterização das redes ópticas salientando os aspectos fundamen-
tais da multiplexagem por comprimento de onda, vulgo WDM, prossegue com uma descrição breve
sobre as questões fulcrais a ter com consideração aquando do planeamento de uma rede de teleco-
municações em geral e em particular as redes de transporte de longo alcance. Descreve a divisão
11

das redes em dois tipos de topologia e apresenta as diferentes formas como estas podem ser usadas
para transportar os distintos protocolos da camada de rede. Ainda neste capítulo é abordada a ques-
tão do encaminhamento dos pedidos bem como a gestão dos comprimentos de onda. Apresenta-se
e descreve-se os elementos quer passivos e activos relevantes nas redes WDM e por fim estuda-se
as limitações impostas pelo meio físico.
Reserva-se para o capítulo 3 a apresentação do algoritmo para agregação na fonte com objectivo
de resolver o problema mais simples do dimensionamento para posteriormente acrescentar-se gra-
dualmente os modelos seguintes que vão tentar resolver o problema abrangendo um número maior
de possibilidades. No capítulo 4 descreve-se o ambiente de simulação e a bateria de testes utilizada
para se comparar os modelos apresentados. O capítulo 5 traz as conclusões gerais discutidas no
capítulo 4 e infere sobre o cumprimento dos objectivos e a sua utilidade. Algumas directrizes para
futuras pesquisas na área de planeamento de redes ópticas heterogéneas são aqui mencionadas.
12

2Redes de Transporte Ópticas
Contents2.1 Redes de Longo Alcance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2 Arquitectura Multicamadas dos Protocolos . . . . . . . . . . . . . . . . . . . . . . 142.3 Planeamento em redes WDM de Longo e Ultra-Longo Alcance . . . . . . . . . . . 162.4 Introdução ao Dimensionamento de Redes de Transporte Ópticas . . . . . . . . 182.5 Agregação de Tráfego nas Redes de Transporte . . . . . . . . . . . . . . . . . . . 212.6 Aspectos Físicos da Agregação de Tráfego . . . . . . . . . . . . . . . . . . . . . . 22
13

2.1 Redes de Longo Alcance
As redes de longo alcance são uma grande vantagem para as as comunicações pois permitem
que uma grande quantidade de tráfego flua entre países e continentes com uma atraso muito inferior
as comunicações via satélite e com uma capacidade em termos de largura de banda centenas de
vezes maior a um custo claramente compensatório. As redes de longo e ultra longo alcance vêm dar
um novo ânimo aos serviços, principalmente a Internet, onde o atraso associado a distância deixa
de ser uma preocupação.
Os valores típicos que se encontram nas redes de transporte de longo alcance são de 2.5 Gbit/s
e 10 Gbit/s no entanto, alguns operadores já começam a introduzir 40 Gbit/s para conseguirem
acomodar o acréscimo que tem se verificado em termos de largura de banda. A tabela 2.1 apresenta
os débitos disponíveis na tecnologia SDH que vai desde 155.52 Mbit/s eléctrico ou óptico, até aos 40
Gbit/s óptico. Como na tecnologia SDH apenas estão normalizados dois comprimentos de onda, 1310
nm e 1550 nm, rapidamente se percebe que é necessário utilizar muitos canais físicos para suportar
todo o tráfego e este valor deve ser multiplicado por dois caso se pretenda uma protecção do tipo
1 : 1 reduzindo-se drasticamente a capacidade total da rede. A tecnologia WDM em combinação com
Generic Frame Procedure (GFP) (figura 2.1) vem tornar o encapsulamento dos dados mais directo
e eficiente permitindo adaptar os débitos da camada de serviços a rede de transporte e ajustar a
capacidade da ligação. Os débitos normalizados para OTN, com Forward Error Correction (FEC),
estão descritos na tabela 2.2.
Tabela 2.1: Débitos de linha normalizados para SDH/SONET
Optical Carrier (OC-x) Synchronous Transport Mode (STM-x) Line rate (Mbit/s)OC-3 STM-1 155.52OC-12 STM-4 622.08OC-48 STM-16 2488.32 (2.5G)OC-192 STM-64 9953.28 (10G)OC-768 STM-256 39813.12 (40G)
Tabela 2.2: Débitos de linha normalizados para OTN’s
Optical Transport Unit (OTUk) Line rate (Gbit/s) Market Rate (Gbit/s)OTU1 2.666 2.5OTU2 10.709 10OTU3 43.018 40OTU4 111.809 100
2.2 Arquitectura Multicamadas dos Protocolos
Observando o modelo de rede de referência da figura 2.5 podemos verificar que as redes de
transporte ou backbones são redes em malha formadas por interligação de anéis de fibra. A rede
14

Figura 2.1: Enquadramento do GFP na pilha de protocolos.
encontra-se partida em quatro camadas, longas-distâncias, rede metropolitana core, rede de metro-
politana de acesso e clientes. A rede metro de acesso serve como ponto de convergência dos sinais
dos mais variados clientes como por exemplo, uma micro empresa ou uma estação de base de co-
municações móveis, Global System for Mobile Communications (GSM). Os equipamentos instalados
nestas redes são, na sua maioria, routers de baixa capacidade e equipamentos SDH com capacidade
de inserção e extracção de tributários E1 (2048 Kbit/s) e cartas do tipo Fast Ehternet (100 Mbit/s).
Os routers IP de baixa capacidade por sua vez interligam-se aos equipamentos SDH levando-nos
ao modelo de protocolos 2.2 que, nos dias de hoje, começa a fazer pouco sentido tendo em conta
o avanço na tecnologia WDM, a ineficiência espectral e complexidade que se verifica quando se
transporta IP sobre SDH.
Figura 2.2: IP sobre ATM sobre SDH sobre WDM, [6]
No modelo da figura 2.2, em cada camada o tráfego tem de ser ajustado antes de ser transportado
levando a um acumular de ineficiências e além disso cada protocolo actua de forma independente,
por exemplo, no caso de uma falha os elementos da hierarquia tentam recuperar da falha cada um
com o seu protocolo distinto. Uma vez que o IP tem sido dominante, a tecnologia Asyncronous
Transfer Mode (ATM) vai sendo abandonada e aos poucos a arquitectura evolui no sentido de IP ->
SDH -> DWDM como mostra a figura 2.3.
Figura 2.3: IP over SDH over DWDM, [6]
O objectivo final na redução e simplificação de camadas é atingir-se IP sobre DWDM. Muitos
15

Figura 2.4: IP sobre DWDM, [6]
routers de elevada capacidade de comutação já possuem interfaces ópticas que permitem uma li-
gação com a rede OTN através de transponders. Para se eliminar definitivamente a camada SDH
da pilha, é necessário incorporar-se nos routers interfaces já normalizadas para DWDM tornando o
mapeamento IP -> DWDM directo e consequente redução dos custos. As figuras 2.4 e 2.6 mostram
a evolução lógica nesse sentido. Repara-se que, o objectivo é interligar directamente os elementos
da rede de acesso à rede core. As redes metro normalmente apresentam uma separação entre nós
adjacentes de poucas dezenas de quilómetros, número facilmente atingível pelos routers mais mo-
dernos com interfaces ópticas incorporadas permitindo alcances até aproximadamente 80 Km a um
débito de 2.5 Gbit/s como se pode confirmar em [33].
Para que seja possível alcançar a tão desejada arquitectura simplificada é necessário por parte
do planeamento uma convergência no sentido de se optimizar as redes e reduzir-se os custos não
generalizando o conceito IP em todas as camadas da rede e também não subestimando as suas
capacidades. O trabalho desenvolvido em [7] de onde foi retirada a figura 2.7 mostra quando se deve
optar por transportar IP sobre uma rede IP e IP sobre uma rede WDM.
2.3 Planeamento em redes WDM de Longo e Ultra-Longo Al-cance
Motivadas pelo crescimento dos dados provenientes dos routers IP, as redes de transporte sen-
tem necessidade de fazer revisões ou mesmo alterar profundamente os seus paradigmas. Sistemas
de fibra ótpica instalados antes de 1995 normalmente apresentam fibras com parâmetros de disper-
são elevados e problemas com as não linearidades. Para sistemas ópticos após essa data parâme-
tros limitadores de alcance como Polarization Mode Disperson (PMD) foram melhorados para níveis
de 2ps/√Km para 0.1ps/
√km permitindo ter redes de muito longo alcance a operar nos 10 Gbit/s e
40 Gbit/s com esquemas de detecção directa.
Para alguns operadores de redes de transporte pode ser preferível débitos binários inferiores e
16

Figura 2.5: Hierarquia da rede, modelo consensual.
ter mais comprimentos de onda por cada ligação do que ter canais a 40 Gbit/s mas poucos compri-
mentos de onda por fibra devido as não linearidades como Self Phase Modulation (SPM) e PMD que
se fazem sentir com maior impacto a débitos mais elevados.
Por outro lado, os sistemas WDM oferecem transparência o que permite que diferentes canais
dentro da mesma fibra possam operar a diferentes débitos e além disso o sistema oferece uma
grande flexibilidade ao permitir que se extraia só parte do sinal em cada nó da rede usando OADM
ao invés de terminar todos os sinais/canais da fibra.
Sistemas WDM com capacidade acima das dez dezenas de comprimentos de onda já estão
comercialmente disponíveis e com os avanços nas técnicas de modulação e detecção já é possível
instalar sistemas de longo alcance, 2500 km, com canais a operar até aos 100 Gbit/s [34].
Na seguintes secções desta dissertação aborda-se a questão fulcral da heterogeneidade das
Fredes e o modo eficiente como os novos equipamentos de grande capacidade que começam a
ser disponibilizados podem ser instalados e operados de modo a acomodar todo o tipo de tráfego
que é gerado pelos serviços de uma forma economicamente viável sem sacrificar-se a qualidade do
serviço. O objectivo final é explorar ao máximo as capacidades existentes tendo em consideração
todas as limitações já descritas e o custo efectivo de instalação (Capital expenditure (CAPEX)) e
operação (OPEX) das redes.
17

Figura 2.6: Evolução da estrutura das redes, [7]
2.4 Introdução ao Dimensionamento de Redes de Transporte Óp-ticas
As redes de telecomunicações têm vindo a evoluir desde os tempos da Plain Old Telephone Ser-
vice (POTS) até aos dias de hoje onde a fibra óptica é termo dominante. O dimensionamento das
redes de telecomunicações exige um levantamento exaustivo da evolução do tráfego e da sua pre-
visão futura em médio longo prazo. Projectar de raiz ou estender uma rede deve sempre ser um
processo faseado, primeiro devido aos custos associados ao investimento em infraestruturas e equi-
pamentos, depois pelo facto das necessidades variarem de acordo com a região. Várias decisões
têm de ser tomadas, escolha da tecnologia, capacidades a instalar, topologia da rede, anel, malha,
estrela ou ponto-a-ponto, serviços e ainda a estratificação. Recai sobre esta dissertação a preocupa-
ção com as redes de transporte de longo alcance, redes essas que foram na sua maioria SDH com
topologia com topologia em anel. Na verdade, as redes em malhas nascem da sucessiva interliga-
ção de redes em anel que, a um certo ponto permitem que nós de grau dois (Este-Oeste) evoluam
para nós de três ou mais graus. Esta evolução natural das redes vem introduzir mais dois elemen-
tos, Fixed OADM (FOADM) e ROADM, o primeiro é um OADM fixo ou seja, as configurações uma
vez feitas são permanentes e a sua alteração implica por vezes o corte de serviços acima dos 50
ms. O segundo elemento permite reconfigurar o OADM remotamente sem afectação dos serviços.
Estes dois novos elementos devem ser tidos em conta no processo de dimensionamento de modo a
balancear-se entre a flexibilidade e o custo dos nós que compõem a rede óptica.
2.4.1 Multiplexagem por Divisão do Comprimento de Onda - WDM
As redes de longo alcance podem ser vistas como redes que interligam cidades com distâncias
que podem rapidamente ultrapassar as centenas de quilómetros indo até aos poucos milhares de qui-
lómetros. Redes deste tipo são responsáveis por transportar grandes volumes de tráfego interligando
países e requerem equipamentos e técnicas de transmissão cada vez mais avançadas a medida que
18

Figura 2.7: Encaminhamento eficiente de tráfego IP, [7].
o quantidade de tráfego aumenta. Ao contrário das redes de acesso e das redes metropolitanas por
fibra óptica que comportam distâncias de poucas centenas de quilómetros onde a potência lançada
e a atenuação são os factores mais importantes na análise, as redes de longo alcance trazem as
mesmas limitações acrescidas de efeitos não lineares (Four Wave Mixing (FWM), SPM, etc.) que se
começam a sentir para grandes distâncias de transmissão limitando assim o ritmo de transmissão.
Para uma exploração eficiente dos recursos que a fibra óptica oferece na sua extensa mas não
ilimitada largura de banda, utiliza-se a multiplexagem por divisão do comprimento de onda. Com este
processo é possível ter-se na mesma fibra serviços com características distintas ao nível do débito
e do tipo de tráfego. A utilização de amplificadores EDFA com ganho uniforme dentro da banda C,
por exemplo, permite-nos olhar para esta gama de comprimentos de onda da mesma forma durante
a transmissão. Existem duas formas de utilizar a técnica WDM, a primeira designa-se como Coarse
WDM (CWDM) onde o espaçadamente entre cada canal é de 20 nm que vão desde a banda O (Ori-
ginal) até a banda L (Long) permitindo até 18 canais centrados em 1250nm+ i× 20nm. Esta técnica
permite uma redução efectiva dos custos com a utilização de filtros menos selectivos e lasers com
maior largura espectral mas em contrapartida ter-se-a que reduzir os débitos a transmitir e as dis-
tância ponto-a-ponto. A segunda técnica, DWDM, faz uso de filtros ópticos de elevada selectividade
e equipamentos que reduzem as interferências entre canais Cross-Talk (XTalk) permitindo espaça-
mento entre canais de 100, 50, 25 e até 12.5 GHz. A frequência de referência está situada nos 193.10
THz (1552.52 nm). Hoje em dia, os sistemas DWDM usam até 160 canais com espaçamento de 25
GHz. Os equipamentos DWDM dada a sua elevada performance e requisitos de estabilidade são
mais caros em relação aos CWDM e a sua utilização está quase restrita a interligação de Backbones
e redes de Longo/Ultra-longo alcance.
2.4.2 Encaminhamento e Atribuição de Comprimento de Onda
Nas redes WDM dado o elevado número de comprimentos de onda disponíveis para transportar
todos os serviços é necessário ser feita uma gestão desses recursos de modo eficiente tendo em
19

consideração os custos. Várias técnicas para encaminhamento têm sido usadas como por exemplo,
caminho mais curto, ou caminho com menos nós. Em relação a atribuição de comprimentos de onda
também estão disponíveis vários algoritmos [35],[36] que têm em consideração as características
físicas de cada canal e o débito que transportam. Nesta dissertação utiliza-se o algoritmo First-Fit
que consiste em atribuir o primeiro comprimento de onda disponível.
2.4.3 Aspectos da Transmissão
A transmissão de sinais em redes de longo alcance utilizando a tecnologia WDM tem a configu-
ração que se ilustra em 2.8 onde os nós podem ser caracterizados da seguinte fora:
• Regeneradores - Re-transmission, Re-timing, Re-Shapping, (3R);
• Amplificadores - Optical Line Amplifier (OLA);
• FOADM;
• ROADM.
Figura 2.8: Esquema de ligação WDM ponto-a-ponto
A regeneração do sinal é feita no domínio eléctrico com recurso a duas cartas de linha (trans-
ponders ou muxponders) ligadas costas-com-costas. Os nós amplificadores normalmente recorrem
a Erbium Doped Fiber Amplifier (EDFA) e, à entrada e saída de cada amplificador encontra-se um
módulo usado para a compensação de dispersão.
2.4.4 Recolha de informação
A recolha de informação sobre os diferentes aspectos afectos a transmissão deve ser feita logo
no inicio do planeamento da rede. As principais questões, dadas na tabela 2.3, envolvem débitos
binários, taxas de erro de bits, largura de banda, efeitos não lineares, relação sinal-ruído e distâncias
de transmissão. Estas questões de quão longe, quão bom e quão rápido definem as restrições do
sistema.
20

Tabela 2.3: Considerações de planeamento
Factores Considerações / EscolhasDistância de transmissão Complexidade aumenta com a distânciaTipos de fibras ópticas Multimodal ou UnimodalDispersão Regeneração ou Compensação de dispersãoNão Linearidades Comprimentos de onda e potências de emissãoComprimento de onda de serviço Janelas de transmissão (Banda-C, Banda-E)Fonte de luz LED ou LASERSensibilidade do receptor Débito e distância de transmissãoFoto-detector PIN, APDModulação Externa, chirp e débito a transmitirBit Error Ratio (BER) 10−9, 10−12, possibilidade de usar FECRelação Sinal-Ruído Limites por secção e da cadeia completaComprimento de secção Número de conectores e perdas de inserçãoRequisitos de funcionamento Temperatura, voltagens de trabalho, espaço
2.5 Agregação de Tráfego nas Redes de Transporte
Tendo sido notório o rápido crescimento em termos de largura de banda que os utilizares con-
somem nas suas casas onde grande fatia desde consumo está ligada as aplicações interactivas
como mostra o estudo da figura 2.10. O tráfego correspondente aos dados tem vindo a aumen-
tar de uma forma insaciável e as redes têm convergido cada vez mais para redes IP. As redes
que se encarregam de transportar o tráfego IP são, na sua maioria, redes SDH/Synchronous Optical
Network (SONET). Uma vez que as redes metro têm requisitos diferentes das redes de longo alcance
[13], a escolha do tipo de tecnologia deve ser cautelosamente estudada para que não exista sobre
dimensionamento ou sub-dimensionamento e para isso os operadores desenvolvem ou compram
ferramentas para os ajudar nesse processo.
A Ethernet foi desenvolvida com o objectivo de interligar diferentes máquinas no âmbito das redes
locais de computadores. No entanto, com a evolução e o baixo custo da tecnologia, a Ethernet foi-se
expandindo e actualmente encontra-se largamente usada quer nas redes do cliente como nas redes
metropolitanas de acesso e core. Hoje, já é possível adquirir-se um computador pessoal com uma
interface Ethernet com capacidade para gerar informação a um ritmo até 1 Gbit/s que corresponde
ao um décimo do tipo de tráfego dominante nas redes de transporte ou seja, 10 Gbit/s. O SDH
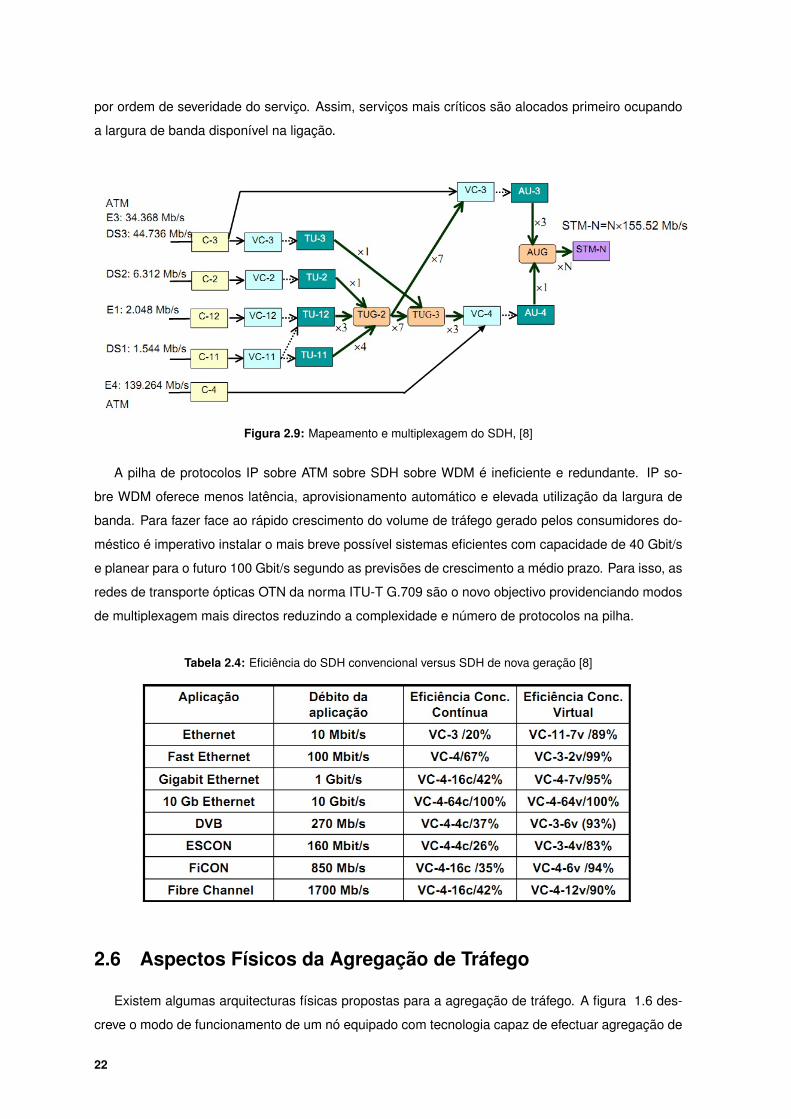
convencional devido a sua estrutura de multiplexagem (figura 2.9) apresenta algumas ineficiências
no transporte de tramas Ethernet e por isso foi desenvolvido o SDH de nova geração que permite
concatenação virtual (Virtual Concatenation (VCAT)) dos contentores que transportam a informação
aumentando para quase 100 % a eficiência como se pode ver na tabela 2.4. Com VCAT parte do pro-
blema fica resolvido mas a questão do desperdício de largura de banda com a protecção de serviços
não cruciais (best-effort) mantém-se. Para estes serviços a protecção de tráfego não é de elevada
importância e transportá-los sobre a tecnologia SDH com protecção de caminho seria sem duvida
um desperdício de capacidade e custos não lhes conferindo nenhuma vantagem adicional. Com
OTN e WDM podemos ter na mesma fibra vários canais a transportar diferentes serviços e em caso
de falha podemos comutar os sinais para outros portos que correspondem a caminhos redundantes
21
por ordem de severidade do serviço. Assim, serviços mais críticos são alocados primeiro ocupando
a largura de banda disponível na ligação.
Figura 2.9: Mapeamento e multiplexagem do SDH, [8]
A pilha de protocolos IP sobre ATM sobre SDH sobre WDM é ineficiente e redundante. IP so-
bre WDM oferece menos latência, aprovisionamento automático e elevada utilização da largura de
banda. Para fazer face ao rápido crescimento do volume de tráfego gerado pelos consumidores do-
méstico é imperativo instalar o mais breve possível sistemas eficientes com capacidade de 40 Gbit/s
e planear para o futuro 100 Gbit/s segundo as previsões de crescimento a médio prazo. Para isso, as
redes de transporte ópticas OTN da norma ITU-T G.709 são o novo objectivo providenciando modos
de multiplexagem mais directos reduzindo a complexidade e número de protocolos na pilha.
Tabela 2.4: Eficiência do SDH convencional versus SDH de nova geração [8]
2.6 Aspectos Físicos da Agregação de Tráfego
Existem algumas arquitecturas físicas propostas para a agregação de tráfego. A figura 1.6 des-
creve o modo de funcionamento de um nó equipado com tecnologia capaz de efectuar agregação de
22
tráfego bem como comutação de tráfego entre as fibras de entrada e saída. O ROADM recebe os
canais das fibras provenientes do lado oeste e faz um das seguintes operações:
• Comuta o comprimento de onda directamente para uma fibra de saída (este).
• Encaminha o comprimento de onda (oeste) para um regenerador que posteriormente o reen-
caminha para processamento adicional ou directamente para saída.
• O ROADM pode também encaminhar o sinal óptico para uma carta de agregação através de
cartas de linha auxiliares.
• As cartas Transponder Card (TC) são responsáveis por agrupar os sinais provenientes dos
clientes que se ligam neste ponto da rede. As TCs podem ser vistas como muxponders porque
além de tornam os sinais coerentes com a tecnologia WDM de transporte também os agrupam
em sinais de maior débito.
• As Grooming Card (GC) são responsáveis por agrupar os sinais. que chegam em Line Card
(LC) ou Client Card (CC).
Figura 2.10: Consumo de largura de banda nas redes por todos continentes
Como já foi referido neste documento, os sinais podem ser regeneradores de diferentes modos;
com carta regeneradora, transponders/muxponders ou utilizando cartas de agregação como mostra
a figura 1.6. O modelo de custos apresentado por [5] na tabela 1.1 considera que um transponder
que faz agregação de tráfego dos clientes tem um custo que é metade do custo previsto para os
regeneradores com a mesma granularidade de tráfego. Já os autores em [9] aprestam um modelo de
23
custo onde o valor dos transponder é diferenciado dos muxponders como se pode observar na tabela
2.5. Das duas relações de custos consultadas (tabelas 1.1 e 2.5) o autor desta dissertação decidiu
combinar e derivar uma terceira relação que será usada na presente dissertação e encontra-se na
tabela 2.6. Para além disso, e uma vez que não há uma correspondência unívoca, na ferramenta
desenvolvida é possível variar os custos ajustando-se os valores a cada realidade.
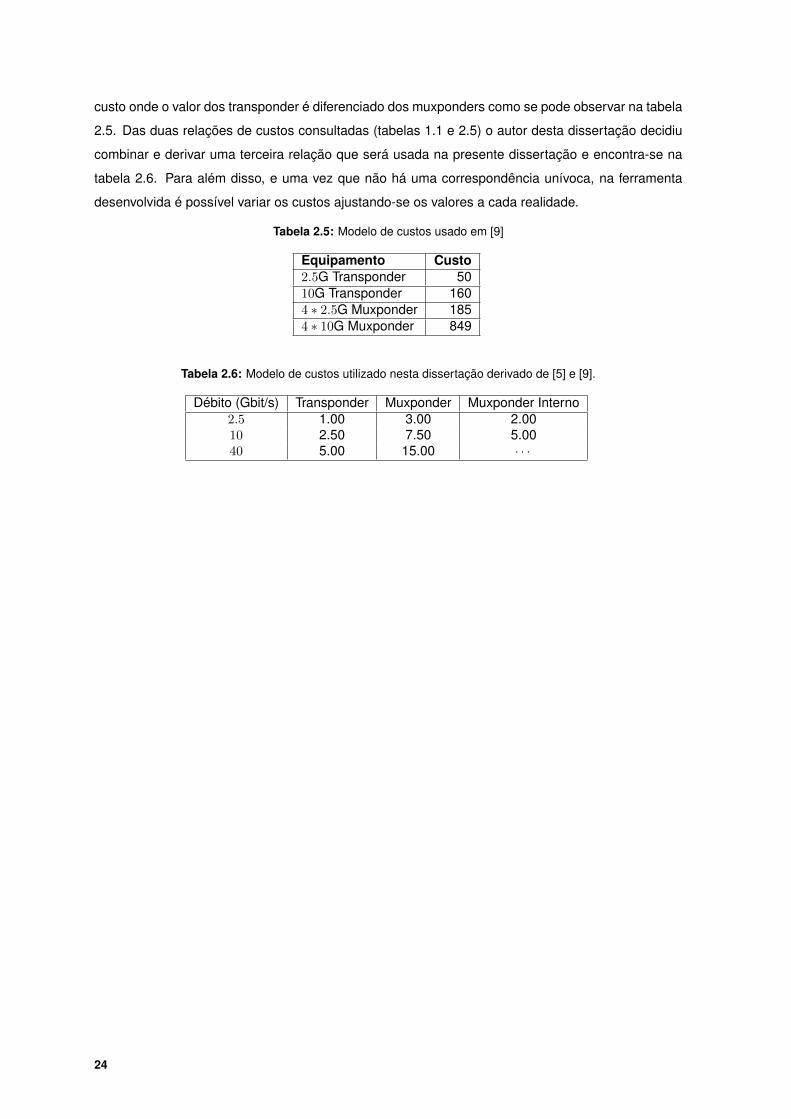
Tabela 2.5: Modelo de custos usado em [9]
Equipamento Custo2.5G Transponder 5010G Transponder 1604 ∗ 2.5G Muxponder 1854 ∗ 10G Muxponder 849
Tabela 2.6: Modelo de custos utilizado nesta dissertação derivado de [5] e [9].
Débito (Gbit/s) Transponder Muxponder Muxponder Interno2.5 1.00 3.00 2.0010 2.50 7.50 5.0040 5.00 15.00 · · ·
24

3Proposta de Algoritmos para
Agregação de Tráfego
Contents3.1 Grafo de nós alcançáveis sem regeneração - Reachability Graph . . . . . . . . . 263.2 Algoritmo ILP para Agregação na Fonte com Muxponders em Cascata . . . . . . 283.3 ILP para Agregação Intermédia com Muxponders em Cascata . . . . . . . . . . . 353.4 Modelo Heurístico para Agregação . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
25

Nesta secção aborda-se o problema da agregação de tráfego, encaminhamento e atribuição de
comprimento de onda (Grooming, Routing, and Wavelength Assignment - GRWA) em conjunto com
o problema de alocação de regeneradores, Regenerator Placement Problem (RPP) que também é
abordado em [1] através de um modelo heurístico. A colocação eficiente de regeneradores e car-
tas capazes de efectuar agregação de tráfego no domínio eléctrico nos nós ROADM é necessária
para que todos os pedidos de tráfego possam ser satisfeitos ao mínimo custo possível com os re-
cursos já instalados. O algoritmo que se apresenta tem como objectivo responder ao problema da
saturação das redes, fornecendo a possibilidade de se efectuar agregação de tráfego com o mínimo
impacto nos custos. O modelo matemático baseia-se em Programação Linear Inteira (Integer Linear
Programming - ILP) e será validado para alguns casos relevantes e posteriormente uma heurística
será desenvolvida com base nos resultados de alguns testes simples mas esclarecedores que serão
efectuados.
3.1 Grafo de nós alcançáveis sem regeneração - ReachabilityGraph
É agora evidente que não se pode simplesmente empregar os mesmos sistemas em todos os nós
da redes devido as características únicas de cada ligação, distância, tipo de fibra, volume de tráfego
gerado, tipo de tráfego dominante e dimensões físicas do local que vai acomodar toda a tecnologia
de transporte. Embora que por vezes haja canais suficientes na fibra estes não são ilimitados e,
como já se demonstrou, o crescimento do volume de tráfego rapidamente levará ao estrangulamento
no uso dos comprimentos de onda disponíveis nas redes se nenhuma acção for rapidamente to-
mada. A técnica de agregação que temos vindo a referenciar ao longo desta dissertação vai permitir
acompanhar a evolução. No entanto, deve ter-se presente que nem todas as ligações poderão su-
portar agregações além dos 10 Gbit/s e por este motivo nestas ligações será sempre necessário a
instalação de novas fibras para aumentar a capacidade da rede. Para se conhecer as limitações do
alcance no domínio óptico, vamos recorrer ao conceito de Reachability Graph.
• Definição: seja G(N,E), o grafo da topologia física onde N representa o conjunto dos nós
e E o conjunto das ligações físicas entre nós. Cada nó é inequivocamente identificado, e.g.,
nó i é presentado como Ni. A ligação entre dois nós Ni e Nj é identificada como l(i,j). C(r)(i,j)
é o conjunto de todas as ligações ao nível físico que podem ser usadas para estabelecer um
caminho de luz entre o nó Ni e Nj ao débito r sem o sinal necessitar de regeneração durante
o seu percurso. Assim, Cri,j é definido como um sub-grafo de G(N,E). TI(r)i , é um sub-grafo
de G, definido do seguinte modo:
TIri =⋃j⊂N
(Cri,j). (3.1)
Em síntese, caminhos de luz que se iniciam em Ni, a um ritmo r, e que não necessitam de
3R são caminhos de TIri . Caminhos de luz que contenham loops não são permitidos. Um
segundo grafo é então definido, i.e G′(r)(N,A′(r)), é usado para representar a conectividade
26

entre os nós baseada nas suas próprias ilhas transparentes.
A′(r) =⋃i⊂N
l′(r)(i,j),∀j ∈ TI
(r)i . (3.2)
Se l′(r)(i,j) ∈ ∀A′(r) é possível estabelecer um caminho de luz desde o nó i até o nó j ao débito r
sem 3R.
Utilizando a rede exemplo de seis nós, podemos verificar os diferentes grafos que se obtêm para
as ilhas transparentes por débito. Para 2.5 e 10 Gbit/s verifica-se que a rede não sofre alterações 3.1.
Porém, se for necessário transportar informação a um ritmo de 40 Gbit/s temos de nos limitar a rede
3.2 e para 100 Gbit/s 3.3. Note-se, que não é possível estabelecer um único caminho físico para os
nós 4 e 6 à 40 e 100 Gbit/s respectivamente, deixando estes de fazer parte da rede. Em relação a
rede de partida, podemos verificar que é possível estabelecer dois caminhos disjuntos à 10 Gbit/s
entre alguns pares de nós, por exemplo (1,3) onde a soma dos caminhos nunca excede os 3500 km
3.4 podendo o sinal viajar sempre no domínio óptico sem regeneração. Embora haja possibilidade
de se calcular até três caminhos disjuntos entre todos os nós da rede, neste trabalho não é explorada
a questão da protecção dos caminhos.
Figura 3.1: Rede obtida para 2.5 e 10 Gbit/s.
Figura 3.2: Rede obtida para 40 Gbit/s
27

Figura 3.3: Rede obtida para 100 Gbit/s
Figura 3.4: Caminhos disjuntos para 10 Gbit/s
3.2 Algoritmo ILP para Agregação na Fonte com Muxpondersem Cascata
A agregação na fonte utilizando cascata de muxponders consiste em agrupar sucessivamente no
nó fonte s os pedidos de tráfego (iguais ou não) que tenham d como destinatário comum. Uma vez
que os recursos são limitados, é assumido que o número inicial de comprimentos de onda disponíveis
para cada par (s, d) é de 1. Neste cenário, a figura 3.5 pretende mostrar como deve ser feita a
agregação de todos os pedidos a fim de se maximizar a utilização dos recursos de modo a cumprir
restrições impostas e minimizar o custo da rede.
É claramente visível que para uma rede linear com apenas um comprimento de onda o custo
cresce consideravelmente se tivermos pedidos de todas as granularidades uma vez que é necessário
introduzir vários muxponders em cascata.
Os resultados obtidos com o modelo ILP para a rede linear usada como exemplo (3.5) estão
expostos no anexo B e podem ser reproduzidos com a aplicação que foi desenvolvida neste trabalho.
28

Figura 3.5: Agregação na fonte com cascata de muxponders
O algoritmo baseado em programação linear inteira elaborado nesta dissertação para o processo
de agregação na fonte e que se encontra detalhado nesta secção é, de um modo geral, uma sim-
plificação do modelo usado em [5] com alguns melhoramentos no que diz respeito a utilização de
muxponders em cascata. Umas das simplificações que se efectuou foi a remoção dos conceitos de
carta de linha e carta de cliente. O lado cliente pode sempre ser visto com sendo a entrada dum
transponder ou muxponder uma vez que se assume que é possível ter clientes com débitos simila-
res aos débitos de linha e por isso podem ser directamente agrupados. A função de regeneração é
efectuada com a ligação dos transponders/muxponders costas-com-costas.
Parâmetros.
• G(N,E) : Grafo da topologia física onde N corresponde ao conjunto de nós e E o conjunto de
ligações entre cada par de nós i, j. (i, j) ∈ N .
• T (r)i : Contém todos os nós j ⊂ N alcançáveis a partir de i sem ser necessário efectuar rege-
neração do sinal óptico.
• Λrsd : Matriz de pedidos de tráfego entre o par (s, d) para cada débito r:
• r : Identificador ritmo binário. r ⊂ [0, 1, 2, 3] => [2.5, 10, 40, 100] Gbit/s.
• Υ(i,j),rKth : Matriz booleana que contém o identificar dos k-caminhos disjuntos possíveis de per-
correr entre i, j ao débito r sem regenerar o sinal.
29

• CrTX, CrMX
: Custo do transponder e muxponder, respectivamente, para o débito de entrada r e
saída r + 1.
• CrIMX: Custo residual a contabilizar pela utilização de muxponders em cascata.
• δij,rm,n,k : Constante que assume o valor 1 se a ligação física entre (m,n) pertence ao k caminho
entre os nos (i, j) da topologia lógica para o débito r. 0 caso contrário.
• P i,jr : Indica o número de caminhos disjuntos possíveis de percorrer na camada física entre os
nós i, j.
Variáveis e constantes.
• λsd,r : Variável inteira positiva. Número de pedidos ao ritmo r entre (s, d) que deverão ser
agregados antes de serem enviados para linha.
• λsd,rij,w : Variável binária cujo valor se torna 1 se for criado um light-path com transponder na
topologia lógica entre o par i, j.
• Msd,rij,w : Variável binária cujo valor se torna 1 se for criado um light-path usando muxponder na
topologia lógica entre o par i, j.
• IMsd,ri : Variável inteira e positiva. Conta o número de muxponders dispostos em cascata para
satisfazer o pedido entre o par (s, d) ∈ N . Esta variável será referenciada como ”Muxponder
Interno” uma vez que a sua saída vai ligar a outro muxponder e nunca directamente à linha.
• γ(r) : Variável binária que se altera em função do débito. Assume o valor 2 se r = 40 Gbit/s e 1
caso contrário.
• P ij,rk,w : Variável binária. 1 se ao k caminho entre os nós (i, j) for atribuído o comprimento de
onda w pré-escolhido na definição do light-path da camada lógica.
• V ij,rw : Variável inteira que contabiliza o número de light-paths criados na camada lógica com o
comprimento de onda w.
Formulação do Problema.
(i) Função Objectivo: Dada uma matriz de tráfego e o grafo da rede, o objectivo é encontrar a
configuração que em termos de equipamentos minimiza o custo total da rede. O menor custo
consistirá na melhor combinação entre o número de light-paths que devem ser criados na ca-
mada lógica e o volume de tráfego agregado por cada light-path tendo em consideração os
custos inerentes a agregação.
min∑s
∑d
∑i
∑j
∑r
(λsd,rij,w · C
rTX
+Msd,rij,w · C
rMX
)+∑s
∑d
∑r
∑i
(IMsd,r
i · CrIMX
) (3.3)
30

(ii) Restrições para encaminhamento de tráfego: As equações (3.4), (3.5) garantem que todos
os pedidos de tráfego entre o par (s, d) são satisfeitos por intermédio de uma light-path directo
ou seja, utilizando um transponder directamente virado para a linha ou indirectamente através de
um muxponder. No caso de encaminhamento indirecto é necessário que o pedido seja agregado
e para isso temos as equações (3.8), (3.9) que vão certificar-se que o pedido é posto na linha
com o número de andares em cascata necessários. Uma vez atribuído um comprimento de
onda e um nó de saída a cada pedido, cabe as equações (3.5) e (3.6) garantirem a correcta
conservação do fluxo em cada nó utilizando, se necessário, a conversão de comprimentos de
onda.
∑j
∑w
λsd,rsj,w + λsd,r = Λrsd ∀sd,r : j ∈ Ts(r) (3.4)
∑i
∑w
λsd,rij,w =∑k
∑w
λsd,rjk,w ∀sd,r,j : j ∈ Ti(r) (3.5)
∑i
∑w
Msd,rij,w =
∑k
∑w
Msd,rjk,w ∀sd,r,j : j ∈ Ti(r) (3.6)
∑i
∑w
λsd,rid,w + λsd,r = Λrsd ∀sd,r : d ∈ Ti(r) (3.7)
(iii) Equações para agregação de tráfego: As equações de agregação recebem todos os pedidos
de tráfego, independentemente do débito, que não foram enviados directamente para linha. No
caso de agregação homogénea é usada a equação (3.8) e se os pedidos a serem agrupados
não forem da mesma natureza é necessário que sejam primeiramente alinhados e para este fim
recorre-se a equação (3.9).
λsd,r
4≤∑j
∑w
Msd,rsj,w +
θ∑i=0
IMsd,ri ∀sd,r=0 : j ∈ Ts(r) (3.8)
γ
[λsd,r+1
4+
∑θi=0 IM
sd,ri
4
]≤∑j
∑w
Msd,r+1sj,w +
∑IMsd,r+1
i ∀sd,r : j ∈ Ts(r) (3.9)
(iv) Mapeamento entre a camada lógica e a camada física:
Uma vez que o modelo proposto e todas as equações até aqui descritas baseiam-me numa
topologia lógica obtida do reachability graph, é necessário fazer o mapeamento e a certificação
de todos os light-paths gerados (3.10) podem ser encaminhados na camada física sem que haja
colisões de comprimentos de onda (3.13).
31

V ij,rw =∑s
∑d
(λsd,rij,w +Msd,r−1
ij,w
)∀ij,w,r : j ∈ Ti(r) (3.10)
P i,jr ≥ V ij,rw ∀i,j,r,w (3.11)
V ij,rw =∑k
P ij,rk,w ∀i,j,w,r (3.12)
∑i
∑j
∑k
∑r
P ij,rk,w · δij,rmn,k ≤ 1 ∀m,n,w (3.13)
(v) Restrições adicionais:
As restrições que se seguem servem para garantir que, em primeiro lugar, um sinal de 100
Gbit/s não pode ser agregado por atingir a capacidade máxima permitida e também pelo facto
da matriz de tráfego apenas ter pedidos até 40 Gbit/s. Em segundo lugar, os muxponder internos
só podem gerar sinais internos até 40 Gbit/s (3.15) . Por último, de (3.16) temos a limitação na
capacidade máxima de agregação, gerando sinais de linha até os 100 Gbit/s.
λsd,r = 0 ∀sd,r>2 (3.14)
IMsd,r = 0 ∀sd,r>1 (3.15)
Msd,rij,w = 0 ∀sd,r>2 (3.16)
3.2.1 Validação do Modelo para Agregação na Fonte
Na presente secção serão efectuados alguns testes simples para uma rede de seis nós (figura
3.7), de modo a garantir-se a validade do modelo e ter-se um melhor entendimento do seu comporta-
mento. Pressupõe-se que a matriz de tráfego é esparsa e que as ligações são bidireccionais. Para a
construção do reachability graph utilizaram-se os valores de distância retirados de [37] e atribuiu-se
para 2.5 Gbit/s uma distância máxima de 3500 Km sem regeneração uma vez que [37] não apresenta
valores para este débito. O número de comprimentos de onda WMAX disponíveis em qualquer nó da
rede foi limitado a 1. Os resultados obtidos têm como objectivo espelhar todas as situações possíveis
de agregação e encaminhamento de tráfego para o pior caso possível em que apenas se pretende
32

satisfazer os pedidos com as limitações impostas. Uma vez mais, os valores aqui usados podem ser
alterados na aplicação.
Tabela 3.1: Distâncias máximas sem 3R
Gbit/s Km2.5 350010 250040 1500
100 800
2.5G =
0 6 0 0 1 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 10 1 0 0 0 10 0 0 0 0 0
10G =
0 0 0 0 1 00 0 0 0 0 00 3 0 0 0 00 1 0 0 0 00 0 0 0 0 00 0 0 0 0 0
40G =
0 0 0 0 0 00 0 0 0 0 00 0 0 0 1 00 0 0 0 0 00 0 0 0 0 10 0 0 0 0 0
Figura 3.6: Matriz de pedidos para validação do ILP com agregação na fonte
Figura 3.7: Rede de seis nós para validação do modelo ILP
A ilustração 3.7 foi escolhida de modo a que fosse possível espelhar na mesma rede quase todos
os casos possíveis no que diz respeito as possibilidades de encaminhamento dos comprimentos
de onda bem como a formação do reachability graph. Como se verifica, a distância mínima foi
imposta a 800 km de modo a que o modelo de programação linear possa convergir desde que o
cumprimento das restantes restrições se verifiquem. Para o mesmo grafo foi tido em consideração
que não deve haver nós isolados para os débitos de 2.5, 10 que são os valores predominantes nas
redes de transporte uma vez que 40 e 100 Gbit/s são muitas vezes consequência dos processos de
agregação de tráfego.
33
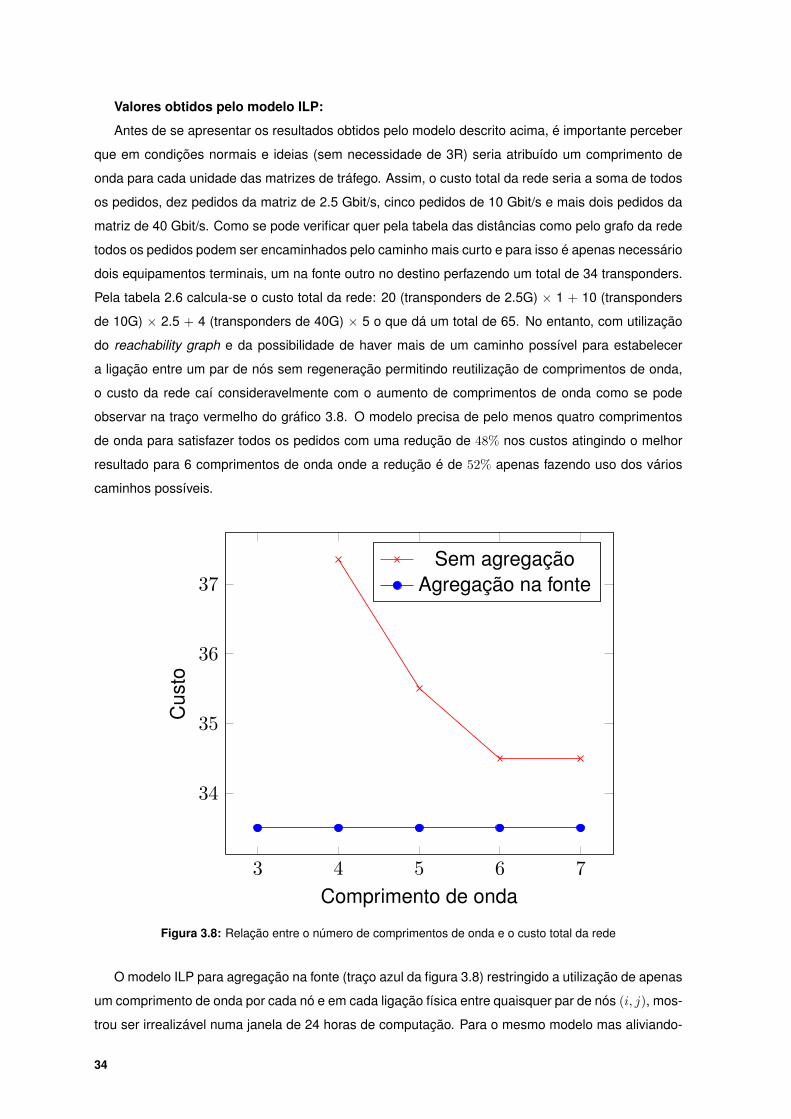
Valores obtidos pelo modelo ILP:
Antes de se apresentar os resultados obtidos pelo modelo descrito acima, é importante perceber
que em condições normais e ideias (sem necessidade de 3R) seria atribuído um comprimento de
onda para cada unidade das matrizes de tráfego. Assim, o custo total da rede seria a soma de todos
os pedidos, dez pedidos da matriz de 2.5 Gbit/s, cinco pedidos de 10 Gbit/s e mais dois pedidos da
matriz de 40 Gbit/s. Como se pode verificar quer pela tabela das distâncias como pelo grafo da rede
todos os pedidos podem ser encaminhados pelo caminho mais curto e para isso é apenas necessário
dois equipamentos terminais, um na fonte outro no destino perfazendo um total de 34 transponders.
Pela tabela 2.6 calcula-se o custo total da rede: 20 (transponders de 2.5G) × 1 + 10 (transponders
de 10G) × 2.5 + 4 (transponders de 40G) × 5 o que dá um total de 65. No entanto, com utilização
do reachability graph e da possibilidade de haver mais de um caminho possível para estabelecer
a ligação entre um par de nós sem regeneração permitindo reutilização de comprimentos de onda,
o custo da rede caí consideravelmente com o aumento de comprimentos de onda como se pode
observar na traço vermelho do gráfico 3.8. O modelo precisa de pelo menos quatro comprimentos
de onda para satisfazer todos os pedidos com uma redução de 48% nos custos atingindo o melhor
resultado para 6 comprimentos de onda onde a redução é de 52% apenas fazendo uso dos vários
caminhos possíveis.
3 4 5 6 7
34
35
36
37
Comprimento de onda
Cus
to
Sem agregaçãoAgregação na fonte
Figura 3.8: Relação entre o número de comprimentos de onda e o custo total da rede
O modelo ILP para agregação na fonte (traço azul da figura 3.8) restringido a utilização de apenas
um comprimento de onda por cada nó e em cada ligação física entre quaisquer par de nós (i, j), mos-
trou ser irrealizável numa janela de 24 horas de computação. Para o mesmo modelo mas aliviando-
34

se WMAX para dois comprimentos de onda não foi possível obter-se em tempo útil (24h) resultados.
Porém, com três comprimentos de onda os resultados provam que é possível minimizarem-se os
custos uma vez que em condições de não optimização o número mínimo de comprimentos de onda
necessários seria igual a soma de todas as matrizes de tráfego (=17). Isto prova que a utilização de
agregação pode atingir dois objectivos em simultâneo:
1. Redução de custos;
2. Maximizar a utilização dos recursos.
3.3 ILP para Agregação Intermédia com Muxponders em Cas-cata
A evolução natural do algoritmo anterior consiste na possibilidade de nós intermédios poderem
servir como nós agregadores de tráfego ou seja, embora um dado nó i que pertence ao conjunto
dos nós regeneradores do caminho que liga o par s, d não tenha qualquer tráfego para enviar para o
nó d, este pode servir como ponto de agregação do tráfego que flui com destino d. Esta abordagem
difere das abordagens encontradas na literatura onde os nós em que é feita a agregação têm obri-
gatoriamente de acrescentar tráfego em direcção ao destinatário limitando o número de pontos de
agregação na rede. O exemplo que se segue ilustra exactamente este caso, onde o nó 3 (três) funci-
ona apenas como ponto de agregação tendo a sua matriz de tráfego nula para 10 Gbit/s. Repare-se
que, o nó 3 pode gerar até 3 pedidos de 10 Gbit/s sem que o custo se altere fazendo uso do mux-
ponder que teve obrigatoriamente de ser criado para aglomerar o pedido de 5− > 4 com tráfego
proveniente da ligação 2− > 3. O algoritmo ILP desenvolvido permite que o nó agregador tenha a
matriz nula ou não. O exemplo de agregação de se representa na figura 3.9 é composto por diversas
matrizes de pedidos de 10 Gbit/s onde os recursos estão limitados a um comprimento de onda por
ligação física. Como se pode observar para que todos os pedidos sejam satisfeitos são utilizados
muxponders com taxas de utilização de 50 % no nó 2 e 25% no nó 3. Embora todos os pedidos
originais sejam de 10G o tráfego de chegada no nó 4 é de 100 Gbit/s o que vai obrigar o nó 4 a fazer
o processo de desmultiplexagem para aceder a todos os tributários. O que se pretende com este
exemplo é mostrar a capacidade e versatilidade do algoritmo desenvolvido que permite satisfazer os
pedidos de tráfego com apenas um comprimento de onda. Se aumentar-mos o número de compri-
mentos de onda disponíveis por ligação observaremos uma redução significativa nos custos devido
a utilização de transponders em detrimento dos muxponders que foram forçadamente criados.
35

Figura 3.9: Agregação na fonte e intermédia com cascata
Em comparação com o modelo de [5], o novo modelo aqui descrito permite que os nós inter-
médios que compõem um light-path possam servir como pontos de agregação de tráfego. Nestes
pontos intermédios o tráfego agregado não necessita de ser da mesma granularidade pois existe
ainda a possibilidade de se colocar muxponders em cascata para alinhar os canais a serem transmi-
tidos.
Parâmetros.
• G(N,E) : Grafo da topologia física onde N corresponde ao conjunto de nós e E o conjunto de
ligações entre cada par de nós i, j. (i, j) ∈ N .
• Λrsd : Matriz de pedidos de tráfego entre o par (s, d) para cada débito r:
• r : Identificador de ritmo binário. r ⊂ [0, 1, 2, 3] => [2.5, 10, 40, 100]Gbit/s.
• T (r)i : Caminhos possíveis entre i e j ⊂ N que não precisam de regeneração.
• Υ(i,j),r : Matriz que contém o identificar dos k-caminhos disjuntos possíveis de percorrer entre
i, j ao débito r sem regenerar o sinal.
• CrTX, CrMX
: Custo do transponder e muxponder, respectivamente, para o débito de entrada r e
saída r + 1.
• CrIMX: Custo residual a contabilizar pela utilização de muxponders em cascata.
• δij,rm,n,k : Constante que assume o valor 1 se a ligação física entre (m,n) pertence ao k caminho
entre os nos (i, j) da topologia lógica para o débito r. 0 caso contrário.
36

• P i,jr : Indica o número de caminhos disjuntos possíveis de percorrer na camada física entre os
nós i, j.
Variáveis e constantes.
• λsd,r : Variável inteira positiva. Número de pedidos a r entre (s, d) que deverão ser agregados
antes de serem satisfeitos.
• λsd,rij,w : Variável binária cujo valor se torna 1 se for criado um light-path com transponder na
topologia lógica entre o par i, j.
• Msd,rij,w : Variável binária cujo valor se torna 1 se for criado um light-path usando muxponder na
topologia lógica entre o par i, j.
• IMsd,ri : Variável inteira e positiva. Conta o número de muxponders dispostos em cascata para
satisfazer o pedido entre o par (s, d) ∈ N . Esta variável será referenciada como ”Muxponder
Interno” uma vez que a sua saída vai ligar a outro muxponder e nunca directamente à linha.
• γ(r) : Variável binária que se altera em função do débito. Assume o valor 2 se r = 40 Gbit/s e 1
caso contrário.
• V ij,rw : Variável inteira que contabiliza o número de light-paths criados na camada lógica com o
comprimento de onda w.
• P ij,rk,w : Variável binária. 1 se ao k caminho entre os nós (i, j) for atribuído o comprimento de
onda w pré-escolhido na definição do light-path da camada lógica.
• IGsd,rj : Variável inteira e positiva que contabiliza o número de light-paths (com transponder)
gerados em s e com destino d mas que foram alvos de agregação no nó intermédio j.
• IGGsd,rj : Variável inteira e positiva que contabiliza o número de light-paths (com muxponder)
gerados em s e com destino d mas que foram alvos de agregação no nó intermédio j.
Formulação do Problema.
(i) Função Objectivo: Dada uma matriz de tráfego e o grafo da rede, o objectivo é encontrar
a configuração que em termos de equipamentos, minimiza o custo total da rede. O menor
custo consistirá na melhor combinação entre o número de light-paths que devem ser criados na
camada lógica e o volume de tráfego agregado por cada light-path tendo em consideração os
custo inerentes a agregação.
min∑s
∑d
∑i
∑j
∑r
(λsd,rij,w · C
rTX
+Msd,rij,w · C
rMX
)+∑s
∑d
∑r
∑i
IMsd,ri · CrIMX
+∑s
∑d
∑j
(IGsd,rj · CrTX
+ IGGsd,rj · CrTX
) (3.17)
37

(ii) Restrições para encaminhamento de tráfego: Neste caso o sinal pode ser encaminhado da
entrada para à saída através de transponder/muxponder ligados costas com costas ou, pode
ser simplesmente retirado de circulação e posto para agregação utilizando a variável IG para
transponder ou IGG no caso de muxponder.
∑j
∑w
λsd,rsj,w + λsd,r = Λrsd ∀sd,r : j ∈ Ts(r) (3.18)
∑i
∑w
λsd,rij,w =∑k
∑w
λsd,rjk,w + IGsd,rj ∀sd,r,j : j ∈ Ti(r) (3.19)
∑i
∑w
Msd,rij,w =
∑k
∑w
Msd,rjk,w + IGGsd,rj ∀sd,r,j : j ∈ Ti(r) (3.20)
∑i
∑w
λsd,rid,w + λsd,r +∑j
IGsd,rj = Λrsd ∀sd,r : d ∈ Ti(r) (3.21)
(iii) Equações para agregação de tráfego: As equações (3.22) e (3.23) agrupam todos os sinais
que foram “largados” (drop) provenientes de diferentes nós com os sinais gerados localmente e
encaminha todos para o mesmo destino.
[∑i IG
id,rs + λsd,r
]4
≤∑j
∑w
Msd,rsj,w +
θ∑i=0
IMsd,ri ∀sd,r=0 : j ∈ Ts(r) (3.22)
γ
[λsd,r+1
4+
∑i IG
id,r+1s
4+
∑θi=0 IM
sd,ri
4+
∑i IGG
id,rs
4
]≤∑j
∑w
Msd,r+1sj,w +
∑IMsd,r+1
i ∀sd,r (3.23)
(iv) Mapeamento entre a camada lógica e a camada física:
Não sofre qualquer alteração em relação ao modelo de agregação na fonte.
V ij,rw =∑s
∑d
(λsd,rij,w +Msd,r−1
ij,w
)∀ij,w,r (3.24)
P i,jr ≥ V ij,rw ∀i,j,r,w (3.25)
V ij,rw =∑k
P ij,rk,w ∀i,j,w,r (3.26)
38

∑i
∑j
∑k
∑r
P ij,rk,w · δij,rmn,k ≤ 1 ∀m,n,w (3.27)
(v) Restrições adicionais:
As restrições que se seguem servem para garantir que, em primeiro lugar, um sinal de 100
Gbit/s não pode agregado por atingir a capacidade máxima permitida e também pelo facto da
matriz de tráfego apenas ter pedidos até 40 Gbit/s. Em segundo lugar, os muxponder internos
só podem gerar sinais (3.29) internos até 40 Gbit/s. Por último, da equação (3.30), temos a
limitação na capacidade máxima de agregação gerando sinais de linha até os 100 Gbit/s.
λsd,r = 0 ∀sd,r>2 (3.28)
IMsd,r = 0 ∀sd,r>1 (3.29)
Msd,rij,w = 0 ∀sd,r>2 (3.30)
3.3.1 Validação do Modelo Global
Os resultados que se seguem foram obtidos correndo ao algoritmo com as alterações que permi-
tem agregação intermédia de sinais com outros sinais que já estejam a transitar na rede, quer estes
estejam em modo não agrupado ou em modo agrupado. O modo não agrupado como o próprio nome
indica, trata-se de um sinal que saiu do nó origem a partir de um transponder. O modo agrupado sig-
nifica que o sinal antes de ser transmitido foi aglomerado com outros sinais do mesmo débito binário
ou com sinais de débitos superior através de uma cascata de Muxponders.
Para a rede que tem sido usada como teste (figura 3.7), foi aplicado o algoritmo e o resultado
obtido foi o seguinte: Tempo de computação, 1907 segundos (aproximadamente 32 minutos) e função
objectivo (ou custo total) = 75.5.
Numa primeira análise aos resultados que estão expostos no anexo D podemos verificar que para
os débitos mais altos estão reservados os caminhos mais curtos que é o comportamento esperado
uma vez que o custo pode aumentar quando se usam percursos mais longos devido a probabili-
dade de ser necessário regeneração ser proporcional. As variáveis que foram accionadas nesta
experiência visam demonstrar claramente que o modelo é capaz que efectuar todas as combinações
possíveis para o qual foi projectado.
3.3.2 Comparação e conclusões sobre os modelos de programação linear
Os resultados obtidos com os testes efectuados a rede de seis nós permitem perceber que existe
uma vantagem não desprezível quando se adicionam os nós intermédios como nós passíveis de
39
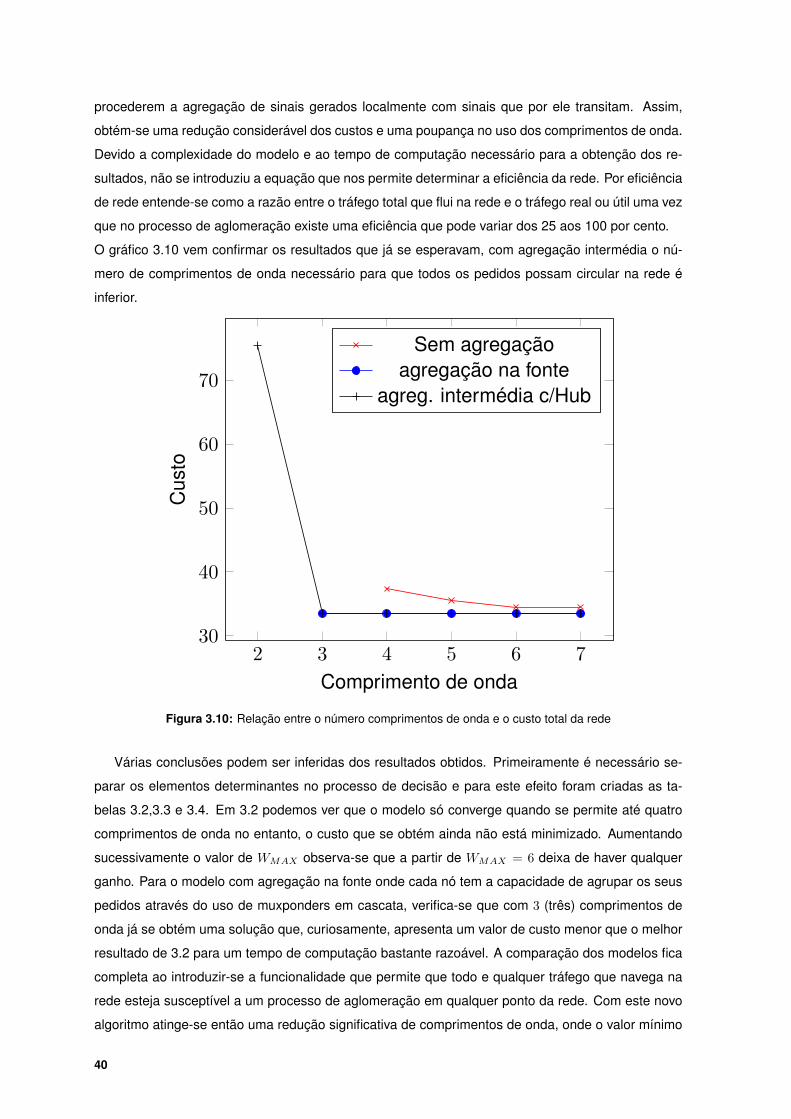
procederem a agregação de sinais gerados localmente com sinais que por ele transitam. Assim,
obtém-se uma redução considerável dos custos e uma poupança no uso dos comprimentos de onda.
Devido a complexidade do modelo e ao tempo de computação necessário para a obtenção dos re-
sultados, não se introduziu a equação que nos permite determinar a eficiência da rede. Por eficiência
de rede entende-se como a razão entre o tráfego total que flui na rede e o tráfego real ou útil uma vez
que no processo de aglomeração existe uma eficiência que pode variar dos 25 aos 100 por cento.
O gráfico 3.10 vem confirmar os resultados que já se esperavam, com agregação intermédia o nú-
mero de comprimentos de onda necessário para que todos os pedidos possam circular na rede é
inferior.
2 3 4 5 6 730
40
50
60
70
Comprimento de onda
Cus
to
Sem agregaçãoagregação na fonte
agreg. intermédia c/Hub
Figura 3.10: Relação entre o número comprimentos de onda e o custo total da rede
Várias conclusões podem ser inferidas dos resultados obtidos. Primeiramente é necessário se-
parar os elementos determinantes no processo de decisão e para este efeito foram criadas as ta-
belas 3.2,3.3 e 3.4. Em 3.2 podemos ver que o modelo só converge quando se permite até quatro
comprimentos de onda no entanto, o custo que se obtém ainda não está minimizado. Aumentando
sucessivamente o valor de WMAX observa-se que a partir de WMAX = 6 deixa de haver qualquer
ganho. Para o modelo com agregação na fonte onde cada nó tem a capacidade de agrupar os seus
pedidos através do uso de muxponders em cascata, verifica-se que com 3 (três) comprimentos de
onda já se obtém uma solução que, curiosamente, apresenta um valor de custo menor que o melhor
resultado de 3.2 para um tempo de computação bastante razoável. A comparação dos modelos fica
completa ao introduzir-se a funcionalidade que permite que todo e qualquer tráfego que navega na
rede esteja susceptível a um processo de aglomeração em qualquer ponto da rede. Com este novo
algoritmo atinge-se então uma redução significativa de comprimentos de onda, onde o valor mínimo
40

cinge-se a 2 (dois). Neste caso, não se verifica uma redução dos custos muito menos do tempo de
computação. Porém, devemos ter em conta que nestas condições estamos a condicionar a utilização
de muxponders na rede em detrimento dos transponders o que tem um impacto directo no custo da
rede e na sua eficiência. O último modelo ILP apresentado tem a vantagem de conseguir acomodar
um maior acréscimo na matriz de tráfego fazendo uso dos “portos” vagos e por sua vez aumentado
a eficiência sem necessidade de mais recursos.
Tabela 3.2: ILP sem operação de agregação
WMAX Custo Tempo (seg)1 ∞ ∞2 ∞ ∞3 ∞ ∞4 37.5 85 35.5 106 34.5 147 34.5 18
Tabela 3.3: ILP com agregação na fonte
WMAX Custo Tempo (seg)1 ∞ ∞2 ∞ ∞3 33.5 194 33.5 41
Tabela 3.4: ILP com agregação intermédia
WMAX Custo Tempo (seg)1 ∞ ∞2 75.5 19073 33.5 194 33.5 41
3.4 Modelo Heurístico para Agregação
Uma vez que o modelo ILP é bastante complexo devido ao número de variáveis e equações que
levam a um tempo de computação intratável, foi desenvolvido um algoritmo heurístico com base nos
resultados observados do ILP e também dos conceitos gerais de agregação com multi-débito. Este
algoritmo começa por verificar para todos os requisitos de débito r se existe pelo menos um caminho
possível para que o serviço seja estabelecido. Caso não se verifique este caminho em toda a rede o
pedido é retirado da matriz original, dividido em quatro pedidos e adicionado a matriz de débito ime-
diatamente inferior na hierarquia. O processo repete-se até que todos os nós sejam processados.
O segundo passo do algoritmo é a agregação na fonte. Para todos os pares na matriz de tráfego
previamente alterada pelo processo de multiplexagem inversa, é efectuada a agregação de pedidos
sempre que se verifique uma redução de custos. A decisão é tomada com base na tabela de custos
41

previamente definida e sempre que se verifique que a soma de custos de transponder entre dois
pares é superior, é posto um muxponder para este conjunto de pedidos. Posteriormente, se a soma
dos custos referentes aos muxponder de débito r entre o par de nós for superior a agregação dos
mesmos para débito r + 1 procede-se a cascata de muxponder e o processo repete-se até a cadeia
atingir o seu limite máximo, 40 Gbit/s. Todas as decisões de custo são com base no caminho mais
curto e no número de regeneradores que são necessários instalar no percurso entre a fonte e o des-
tino.
Após estar concluída a fase de agregação na fonte com cascata de muxponders, passa-se ao
processo de agregação intermédia. De realçar que neste caso não se efectua a agregação intermé-
dia com cascata ou seja, não é possível injectar um sinal de 2.5 Gbit/s num light-trail de 10 Gbit/s
com recurso aos muxponders internos. Sendo assim, o processo é descrito da seguinte forma:
Para cada light-trail que foi previamente criado usando o caminho mais curto e cuja capacidade má-
xima não foi totalmente preenchida, percorre-se todos os nós intermédios que estejam conotados
como regeneradores e verifica-se se:
1. O nó fonte s tem alguma informação para enviar para o nó intermédio i e, caso se verifique este
ocupada a vaga existente. De seguida, verifica-se se o nó i tem tráfego para ser expedido para
o nó d.
2. Caso o trail tenha mais de um nó regenerador, após a fase 1, se existir alguma vaga em pelo
menos uma das secções do conjunto que perfaz o light-trail, é verificado para todos os pares
de regeneradores se há tráfego para ser entregue. O processo termina quando todos os nós
forem percorridos.
O pseudo-código que se apresenta de seguida está divido em quatro partes:
Multiplexagem inversa: Os pedidos que não podem ser satisfeitos devido a não existência de
pelo menos um caminho na camada física cujas ligações individuais que o compõem nunca excedem
o limite máximo imposto para o débito em causa são partidos em 4 pedidos iguais de débito inferior.
Por exemplo, se não for possível estabelecer um caminho com débito binário de 40 Gbit/s este é
partido em quatro pedidos de 10 Gbit/s. Se por acaso também não for possível transportar a este
débito é então feita mais uma partição e o resultado final são 16× 2.5 Gbit/s.
42

Input: Set of traffic demands matricesOutput: Set of traffic demands, muxponders, transponder and stuffing matriceswhile r ≥ 2.5 Gbps do
foreach Traffic matrix []r doforeach element at [i, j]r do
if (([i, j]r ≥ 0) and ( not ∃ one phisycal path at r connecting (i, j))) then[i, j]r = 0;[i, j]r−1 = [i, j]r × 4;
endend
endend
Algorithm 1: Pré-processamento: Multiplexagem inversa
Multiplexagem/agregação na fonte: Vários tributários com o mesmo débito binário são agrupa-
dos (em blocos até 4) num único sinal de débito quatro vezes superior, no caso de 2.5 e 10 Gbit/s, e
duas vezes e meia no caso de 40 Gbit/s. Durante o procedimento de agregação na fonte é tido em
conta que todos os sinais irão percorrer o caminho mais curto que interliga a fonte e o destinatário.
O algoritmo decide com base nos custos quantos tributários devem ser transladados para a matriz
dos muxponders e quantos devem ser enviados directamente para a linha através da matriz de trans-
ponders e, por último, é criada uma matriz que retém informação acerca da quantidade de “portos”
vagos nos muxponders que já foram criados para que posteriormente possam ser usados pelos nós
intermédios para injectar sinal.
Input: Set of tasks and processorsOutput: Mapping of tasks to processorsforeach Traffic matrix []r do
foreach element at [i, j]r dooldcost← COST ();muxponder[i,j]r ← d demand[i,j]r
4 e ;transponder← demands not counted for mux operation ;stuffing[i,j]r ← slacks left;newcost← COST ();if newcost ≤ oldcost then
continue;else undo [i, j] operations;
endend
endAlgorithm 2: Multiplexagem directa sem cascata
Agregação em cascata na fonte: O terceiro passo do algoritmo é uma extensão da agregação
na fonte ou seja, após ter-se efectuado a agregação não se procede ao envio dos sinais para linha
como seria expectável mas sim repete-se o procedimento considerando-se agora que todos os ele-
mentos da matriz de muxponders podem ser vistos como simples tributários e são transpostos para
matriz de pedidos correspondente ao seu débito de saída que neste caso é o débito imediatamente
acima na hierarquia. Uma vez mais, só é posto em cascata a quantidade de muxponders que mostre
43

ser mais económica. Por exemplo, é provável que 4 (quatro) muxponders com entradas de 2.5 Gbit/s
sejam novamente agrupados e as suas saídas ligadas a 1 (um) muxponder de entrada 10 Gbit/s. Por
outro lado, um muxponder de saída 40 Gbit/s não deve ser ligado a um muxponder com saída de
100 Gbit/s a menos que seja agrupado com um tributário de 40 Gbit/s ou com outro muxponder do
mesmo nível. A lógica de agregação mantém a mesma dependência nos custos.
Input: Set of tasks and processorsOutput: Mapping of tasks to processorsforeach r do
oldcost← COST ();demandr+1[i, j]← muxponderr[i, j];muxponder[i, j]r+1 ← d demand[i,j]r+1
4 e ;transponder[i, j]← demands not counted for mux operation ;stuffing[i,j]r+1 ← slacks left;newcost← COST ();if newcost ≤ oldcost then
continue;else undo [i, j] operations;
endend
Algorithm 3: Multiplexagem directa com cascata
Agregação intermédia sem cascata: Esta última operação consiste basicamente em aproveitar
todas as “folgas” deixadas pelos processos anteriores e postas na “stuffing matrix”. Observando a
tabela de custos 3.5, verifica-se de imediato que o processo de agregação torna-se viável desde que
existam pelo menos 3 (três) tributários para serem transmitidos (excluindo de 40G) fazendo com que
a ocupação dos comprimentos de onda fique nos 75%. O algoritmo faz uma busca em todos os Kth
caminhos possíveis qual aquele que oferece melhor relação em termos de aproveitamento dos recur-
sos e custo associado a operação de regeneração para se atingir maior eficiência na ocupação dos
comprimentos de onda. É de realçar que neste ponto reside um enorme trade-off devido a extrema
dificuldade em estabelecer um equilíbrio entre os custos tornando esta operação muito depende do
modo como os valores são definidos logo à priori. Uma vez que o processo de agregação intermé-
dia exige que haja regeneração é de esperar que percursos com apenas um nó regenerador j com
tráfego a transmitir não sejam preteridos devido ao custo na colocação de OADM em j para inserção
de apenas um sinal até ao mesmo destinatário. Alguns destes comportamentos serão analisados
posteriormente nesta dissertação.
Tabela 3.5: Modelo de custos utilizado nesta dissertação derivado de [5] e [9].
Débito Gbits Transponder Muxponder Muxponder Interno2.5 1.00 3.00 2.0010 2.50 7.50 5.0040 5.00 15.00 · · ·
44

Input: Set of tasks and processorsOutput: Mapping of tasks to processorsforeach r do
oldcost← COST ();demandr+1[i, j]← muxponderr[i, j];muxponder[i, j]r+1 ← d demand[i,j]r+1
4 e ;transponder[i, j]← demands not counted for mux operation ;stuffing[i,j]r+1 ← slacks left;newcost← COST ();if newcost ≤ oldcost then
continue;else undo [i, j] operations;
endend
Algorithm 4: Agregação intermédia
3.4.1 Validação da Heurística
Os resultados que se apresentam demonstram o funcionamento do modelo heurístico de modo a
clarificar cada passo do algoritmo e validar as suas operações. Por questões de simplicidade os re-
sultados foram filtrados destacando-se apenas os casos mais relevantes. Também para este modelo
iremos usar a rede típica de seis nós para teste e um conjunto de matrizes geradas aleatoriamente.
2.5G =
0 26 29 28 19 1215 0 2 18 1 21 13 0 14 18 184 13 24 0 17 1724 21 6 18 0 119 3 3 27 0 0
10G =
0 13 15 14 10 68 0 1 9 0 10 6 0 7 9 92 6 12 0 8 912 11 13 9 0 64 1 1 14 0 0
40G =
0 7 8 7 5 34 0 0 5 0 00 3 0 3 5 51 3 6 0 4 46 5 1 4 0 32 0 0 7 0 0
Figura 3.11: Matriz de pedidos com predominância nos 2.5 Gbit/s
Figura 3.12: Rede de 6 nós para validação do modelo heurístico
Descrição passo a passo:
1. Multiplexagem inversa: Por exemplo, a entrada [1, 4] da matriz de tráfego de 40 Gbit/s tem
7 unidades o que corresponde a um total de 280 Gbit/s que devem fluir no sentido 1− > 4.
45

A tabela 3.1 impõe um limite de 1500 km para transporte de sinais de 40 Gbit/s, isso implica
que cada unidade terá de ser “partida” em quatro sinais de 10 Gbit/s por não existir um único
caminho físico possível que respeite a restrição imposta pela distância. Após feita a partição,
o algoritmo elimina por completo a entrada [1, 4] na matriz de 40G e coloca 28 sinais de 10G
na matriz de pedidos de 10G passando esta a ter 14 + (7 ∗ 4)(= 42) unidades 3.13. O mesmo
processo é aplicado a todas as entradas do tipo [i, 4] ou [j, 4] para 40G e depois salta para a
matriz de 10G para a mesma verificação de tangibilidade em cada par (i, j).
2.5G =
0 26 29 28 19 1215 0 2 18 1 21 13 0 14 18 184 13 24 0 17 1724 21 6 18 0 119 3 3 27 0 0
10G =
0 13 15 42 10 68 0 1 29 0 10 6 0 19 9 92 6 12 0 8 912 11 13 25 0 64 1 1 42 0 0
40G =
0 7 8 0 5 34 0 0 0 0 00 3 0 0 5 51 3 6 0 4 46 5 1 0 0 32 0 0 0 0 0
Figura 3.13: Matrizes após multiplexagem inversa para 40G
2. Multiplexagem directa: Processo simples de agregação onde são gerados muxponders com
ocupação de 75% quando são apenas agrupadas três unidades ou de 100% no caso quatro
unidades. Com este processo são criadas três novas matrizes: matriz com a quantidade de
muxponders; matriz com a quantidade de pedidos que vão para linha com transponders; e
por último, matriz com as folgas deixadas pelos muxponders. A decisão para a transferência
das unidades é baseada na comparação dos custos, vejamos: Se a entrada [1, 3] da matriz de
pedidos tem 29 unidades, fazendo 29/4 obtém-se 7.25 o que nos leva a um arredondamento por
defeito para 7 muxponders e 1 transponder. Já no caso da entrada [5, 6] temos 11/4(= 2.75),
como a parte decimal é superior a 0.5 é feito um arredondamento por excesso e acrescenta-se
uma unidade na matriz das folgas que corresponde a uma preenchimento de 75% do sinal de
linha.
3. Multiplexagem em cascata: Consiste em tirar as unidades (uma de cada vez) da entrada [i, j]
da matriz de muxponders com débito r e adicionar essa unidade ao valor da posição [i, j] da
matriz de pedidos com débito imediatamente superior (r + 1) até se encontrar um número que
corresponda ao mínimo custo. Note-se que, se forem retiradas todas unidades da matriz de
muxponders r e, a matriz folga correspondente na posição [i, j] não for zero, então a posição
deve ser colocada imediatamente a zero porque passa a ser inacessível.
4. Agregação intermédia: Trata-se de um processo de optimização que é despoletado em todos
os light-trails criados através das matrizes de muxponders e que não apresentem 100% de
utilização. Como até agora todas as operações foram efectuadas tendo em consideração o
caminho mais curto, é agora necessário varrer todos os caminhos possíveis e verificar se há
possibilidade de aproveitar a folga existente no trail para adicionar tráfego que é gerado num
ponto intermédio que por sua vez é nó de regeneração para a combinação (trail, Kth caminho).
Todos os nós intermédios i têm acesso ao trail e podem inserir tráfego para ser enviado ou
46

para d que é o ponto final, ou para um segundo nó também ponto de regeneração j que por
sua vez está a montante de i. A explicação clarifica-se com um excerto do resultado obtido
após aplicação do modelo e com a apresentação das matrizes modificadas.
Mx =
0 6 7 7 5 34 0 0 4 0 00 3 0 3 4 41 3 6 0 4 46 5 1 4 0 32 1 1 7 0 0
Tx =
0 2 1 0 0 00 0 2 2 1 21 1 0 2 2 20 1 0 0 1 10 1 2 2 0 01 0 0 0 0 0
Folga =
0 0 0 0 1 01 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 10 1 1 1 0 0
Figura 3.14: Matrizes após multiplexagem directa para 2.5G
Após a multiplexagem directa podemos verificar que foram criadas duas novas matrizes que cor-
respondem aos sinais que serão postos directamente na linha por intermédio de transponders, matriz
Tx da figura 3.14. Uma vez criadas as matrizes auxiliares e visto que já não se pode alterar a matriz
dos transponders de 2.5 Gbit/s, é feito o processo de agregação na fonte com cascata onde a matriz
de muxponders com entrada de 2.5 Gbit/s será combinada com a matriz de transponder de 10 Gbit/s
e calcula-se o custo associado a este processo para validar a operação. Para os casos em que o
processo é validado verificam-se novamente alterações nas matrizes de tráfego, figuras 3.15 e 3.16.
Mx2.5G =
0 6 7 7 5 34 0 0 4 0 00 3 0 3 4 41 3 6 0 4 46 5 1 4 0 32 1 1 7 0 0
Folga2.5G =
0 0 0 0 1 01 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 10 1 1 1 0 0
Pedidos10G =
0 13 15 42 10 68 0 1 29 0 10 6 0 19 9 96 18 36 0 24 2512 11 3 25 0 64 1 1 42 0 0
Mx10G =
0 3 4 10 2 12 0 0 7 0 00 1 0 5 2 21 4 9 0 6 63 3 1 6 0 11 0 0 10 0 0
Tx10G =
0 1 0 2 2 20 0 1 1 0 10 2 0 0 1 12 2 0 0 0 10 0 0 1 0 20 1 1 2 0 0
Figura 3.15: Matrizes de 2.5G (superior) e 10G(inferior) antes da cascata
Vejamos um caso para agregação intermédia para um light-trail de 2.5 Gbit/s no algoritmo heu-
rístico. O par escolhido é o 6− > 2:
Para o primeiro caminho mais curto o algoritmo verifica que os nós que o compõem são 6− >
4− > 2 dos quais o nó 4 é um nó de regeneração. A matriz de muxponders após agregação na
fonte em cascata indica que existe uma folga no trail 6->2. Sendo o nó 4 um ponto de regeneração o
algoritmo verifica se este tem algum tráfego para receber do nó 6 ou para enviar para o nó 2. Neste
caso entre 6->4 não existe tráfego para ser encaminhado mas, entre 4− > 2 existe tráfego para ser
enviado do nó 4 para o nó 2 como podemos verificar na matriz de transponders de 2.5 Gbit/s. O nó
4 vai enviar o tráfego através da folga existente no trail criado entre 6− > 2 economizando assim
um comprimento de onda na rede. Todo o processo repete-se para o número de caminhos que
47

Mx2.5G =
0 6 6 7 5 34 0 0 4 0 00 3 0 2 4 41 3 6 0 4 46 4 0 4 0 32 1 1 7 0 0
Folga2.5G =
0 0 0 0 1 01 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 10 1 1 1 0 0
Pedidos10G =
0 13 16 42 10 68 0 1 29 0 10 6 0 20 9 96 18 36 0 24 2512 12 4 25 0 64 1 1 42 0 0
Mx10G =
0 3 4 10 2 12 0 0 7 0 00 1 0 5 2 21 4 9 0 6 63 3 1 6 0 11 0 0 10 0 0
Tx10G =
0 1 0 2 2 20 0 1 1 0 10 2 0 0 1 12 2 0 0 0 10 0 0 1 0 20 1 1 2 0 0
Figura 3.16: Matrizes de 2.5G (superior) e 10G(inferior) depois da cascata
foi introduzido como parâmetro da aplicação de modo a comprar qual dos caminhos (normalmente
compara-se até 3) oferece melhor custo final. Para o exemplo em causa, o modelo optou pelo
caminho número dois como podemos ver pela figura 3.17 e 3.18.
Figura 3.17: Resultados obtidos para agregação intermédia a 2.5 Gbit/s
A figura 3.17 visa demosntrar como o algoritmo heurístico executa os seus procedimentos a
procura do caminho que oferece melhor custo total na rede. Para o caso em estudo o caminho
escolhido foi segundo por ter o mesmo número de saltos de regeneração mas em contrapartida
transporta mais tráfego no seu light-trail reduzindo assim o número de comprimentos de onda na
rede e consequentemente equipamentos activos. Se durante a pesquisa o algoritmo encontrasse
um solução de empate em termos de custos então o caminho escolhido seria sempre o caminho
mais curto porém, esta decisão pode ser alterada internamente no código fonte do algoritmo.
48
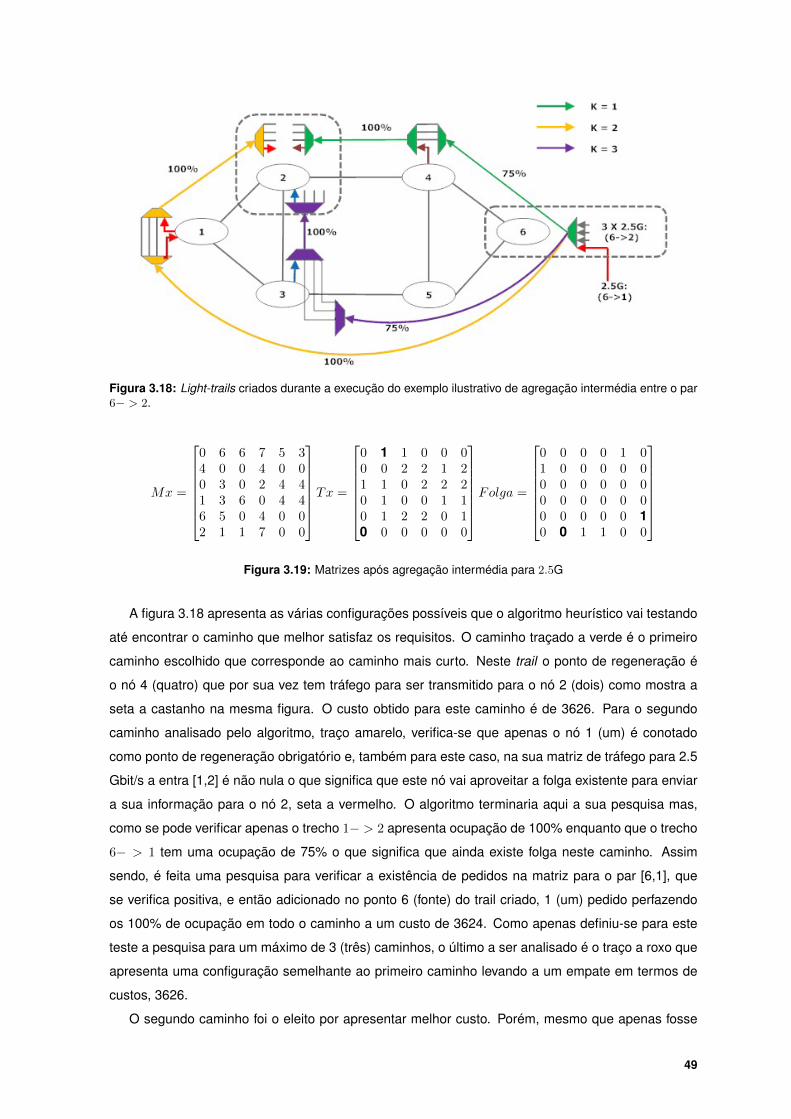
Figura 3.18: Light-trails criados durante a execução do exemplo ilustrativo de agregação intermédia entre o par6− > 2.
Mx =
0 6 6 7 5 34 0 0 4 0 00 3 0 2 4 41 3 6 0 4 46 5 0 4 0 02 1 1 7 0 0
Tx =
0 1 1 0 0 00 0 2 2 1 21 1 0 2 2 20 1 0 0 1 10 1 2 2 0 10 0 0 0 0 0
Folga =
0 0 0 0 1 01 0 0 0 0 00 0 0 0 0 00 0 0 0 0 00 0 0 0 0 10 0 1 1 0 0
Figura 3.19: Matrizes após agregação intermédia para 2.5G
A figura 3.18 apresenta as várias configurações possíveis que o algoritmo heurístico vai testando
até encontrar o caminho que melhor satisfaz os requisitos. O caminho traçado a verde é o primeiro
caminho escolhido que corresponde ao caminho mais curto. Neste trail o ponto de regeneração é
o nó 4 (quatro) que por sua vez tem tráfego para ser transmitido para o nó 2 (dois) como mostra a
seta a castanho na mesma figura. O custo obtido para este caminho é de 3626. Para o segundo
caminho analisado pelo algoritmo, traço amarelo, verifica-se que apenas o nó 1 (um) é conotado
como ponto de regeneração obrigatório e, também para este caso, na sua matriz de tráfego para 2.5
Gbit/s a entra [1,2] é não nula o que significa que este nó vai aproveitar a folga existente para enviar
a sua informação para o nó 2, seta a vermelho. O algoritmo terminaria aqui a sua pesquisa mas,
como se pode verificar apenas o trecho 1− > 2 apresenta ocupação de 100% enquanto que o trecho
6− > 1 tem uma ocupação de 75% o que significa que ainda existe folga neste caminho. Assim
sendo, é feita uma pesquisa para verificar a existência de pedidos na matriz para o par [6,1], que
se verifica positiva, e então adicionado no ponto 6 (fonte) do trail criado, 1 (um) pedido perfazendo
os 100% de ocupação em todo o caminho a um custo de 3624. Como apenas definiu-se para este
teste a pesquisa para um máximo de 3 (três) caminhos, o último a ser analisado é o traço a roxo que
apresenta uma configuração semelhante ao primeiro caminho levando a um empate em termos de
custos, 3626.
O segundo caminho foi o eleito por apresentar melhor custo. Porém, mesmo que apenas fosse
49

efectuada agregação intermédia para o caminho mais curto (verde), o custo já seria inferior por haver
inserção de tráfego o que levaria a redução de custos com transponder e ao mesmo tempo é salvo
um comprimento de onda que pode vir a ser útil futuramente quando a rede estiver congestionada.
Também para este algoritmo o reachability graph foi importante permitindo ignorar os nós que não
são pontos de regeneração da pesquisa como é o caso do nó 5 do último caminho (roxo) que se
torna transparente por estar dentro do alcance óptico para o débito de 2.5 Gbit/s.
3.4.2 Conclusões sobre a validade do modelo heurístico
O modelo apresentado, de um modo geral, vai de encontro as expectativas e os requisitos impos-
tos para um algoritmo de agregação que tem em conta uma diversidade de factores. Porém, algumas
consideração tiveram de ser abandonadas tais como:
1. Limitação do número de comprimentos de onda disponíveis. Assim sendo, o parâmetro a ter
em conta será sempre a quantidade de recursos necessários para satisfazer todas as necessi-
dades de tráfego;
2. Neste modelo não é possível um nó intermédio funcionar como nó agregador de tráfego. A
representação deste tipo de casos num modelo heurístico tornaria o próprio modelo intratável;
3. Não foi mapeado no modelo a possibilidade de ter-se muxponders em cascata nos nós inter-
médios dum light-trail de modo a fazer agregação de serviços heterogéneos.
A complexidade do modelo ILP e o número de variáveis a avaliar nesta dissertação não per-
mitiu que o modelo heurístico fosse uma consequência directa do ILP mas sim uma aplicação dos
conceitos de gerais sobre agregação em redes ópticas multi-débito.
50

4Simulação e Resultados
Contents4.1 Ambiente de Simulação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.2 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
51
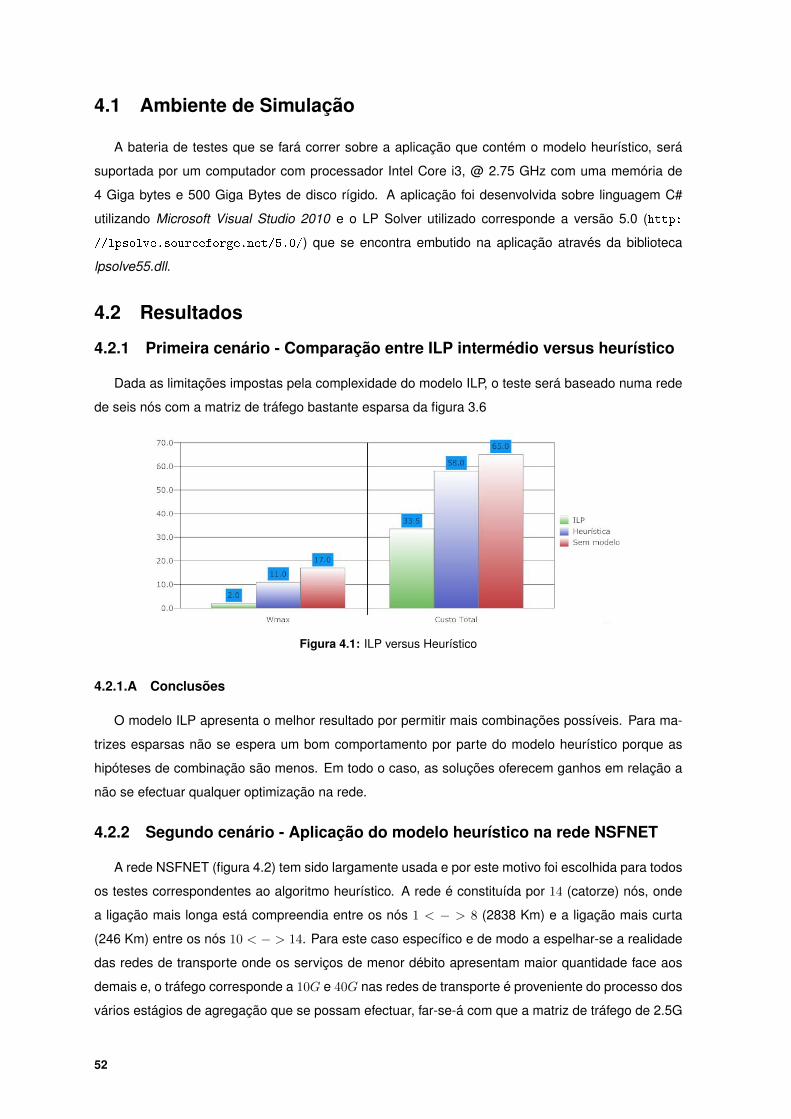
4.1 Ambiente de Simulação
A bateria de testes que se fará correr sobre a aplicação que contém o modelo heurístico, será
suportada por um computador com processador Intel Core i3, @ 2.75 GHz com uma memória de
4 Giga bytes e 500 Giga Bytes de disco rígido. A aplicação foi desenvolvida sobre linguagem C#
utilizando Microsoft Visual Studio 2010 e o LP Solver utilizado corresponde a versão 5.0 (http:
//lpsolve.sourceforge.net/5.0/) que se encontra embutido na aplicação através da biblioteca
lpsolve55.dll.
4.2 Resultados
4.2.1 Primeira cenário - Comparação entre ILP intermédio versus heurístico
Dada as limitações impostas pela complexidade do modelo ILP, o teste será baseado numa rede
de seis nós com a matriz de tráfego bastante esparsa da figura 3.6
Figura 4.1: ILP versus Heurístico
4.2.1.A Conclusões
O modelo ILP apresenta o melhor resultado por permitir mais combinações possíveis. Para ma-
trizes esparsas não se espera um bom comportamento por parte do modelo heurístico porque as
hipóteses de combinação são menos. Em todo o caso, as soluções oferecem ganhos em relação a
não se efectuar qualquer optimização na rede.
4.2.2 Segundo cenário - Aplicação do modelo heurístico na rede NSFNET
A rede NSFNET (figura 4.2) tem sido largamente usada e por este motivo foi escolhida para todos
os testes correspondentes ao algoritmo heurístico. A rede é constituída por 14 (catorze) nós, onde
a ligação mais longa está compreendia entre os nós 1 < − > 8 (2838 Km) e a ligação mais curta
(246 Km) entre os nós 10 < − > 14. Para este caso específico e de modo a espelhar-se a realidade
das redes de transporte onde os serviços de menor débito apresentam maior quantidade face aos
demais e, o tráfego corresponde a 10G e 40G nas redes de transporte é proveniente do processo dos
vários estágios de agregação que se possam efectuar, far-se-á com que a matriz de tráfego de 2.5G
52
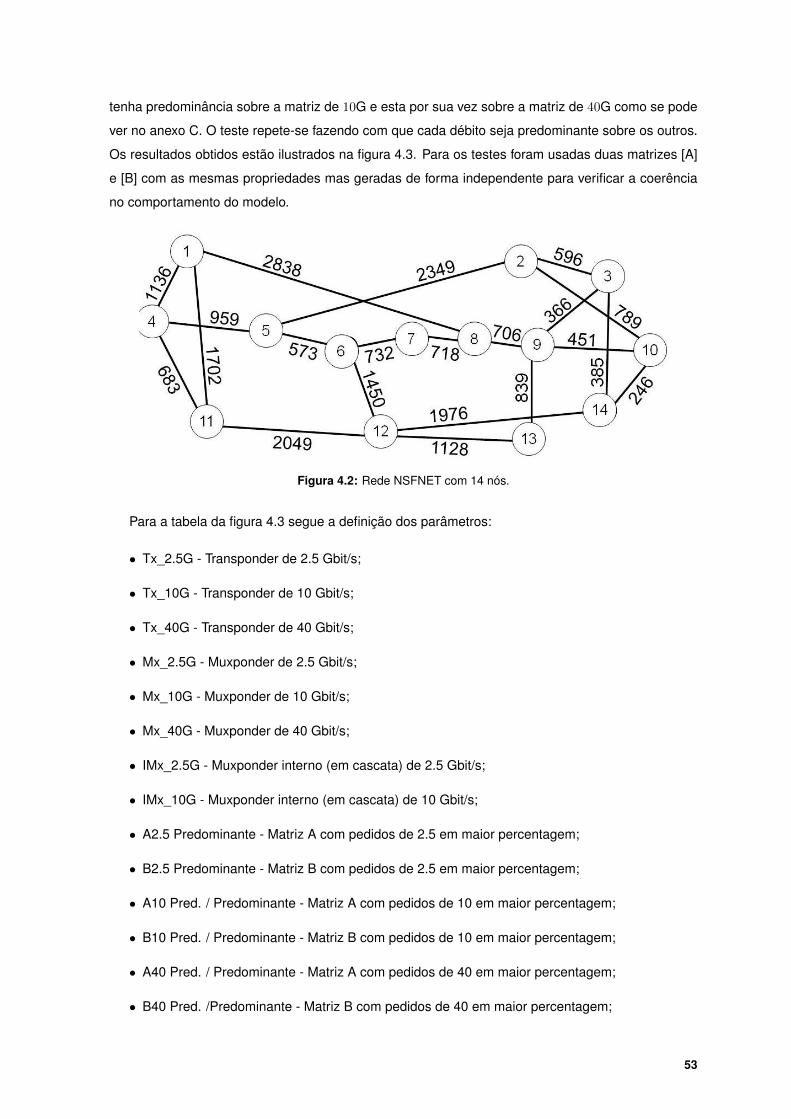
tenha predominância sobre a matriz de 10G e esta por sua vez sobre a matriz de 40G como se pode
ver no anexo C. O teste repete-se fazendo com que cada débito seja predominante sobre os outros.
Os resultados obtidos estão ilustrados na figura 4.3. Para os testes foram usadas duas matrizes [A]
e [B] com as mesmas propriedades mas geradas de forma independente para verificar a coerência
no comportamento do modelo.
Figura 4.2: Rede NSFNET com 14 nós.
Para a tabela da figura 4.3 segue a definição dos parâmetros:
• Tx_2.5G - Transponder de 2.5 Gbit/s;
• Tx_10G - Transponder de 10 Gbit/s;
• Tx_40G - Transponder de 40 Gbit/s;
• Mx_2.5G - Muxponder de 2.5 Gbit/s;
• Mx_10G - Muxponder de 10 Gbit/s;
• Mx_40G - Muxponder de 40 Gbit/s;
• IMx_2.5G - Muxponder interno (em cascata) de 2.5 Gbit/s;
• IMx_10G - Muxponder interno (em cascata) de 10 Gbit/s;
• A2.5 Predominante - Matriz A com pedidos de 2.5 em maior percentagem;
• B2.5 Predominante - Matriz B com pedidos de 2.5 em maior percentagem;
• A10 Pred. / Predominante - Matriz A com pedidos de 10 em maior percentagem;
• B10 Pred. / Predominante - Matriz B com pedidos de 10 em maior percentagem;
• A40 Pred. / Predominante - Matriz A com pedidos de 40 em maior percentagem;
• B40 Pred. /Predominante - Matriz B com pedidos de 40 em maior percentagem;
53
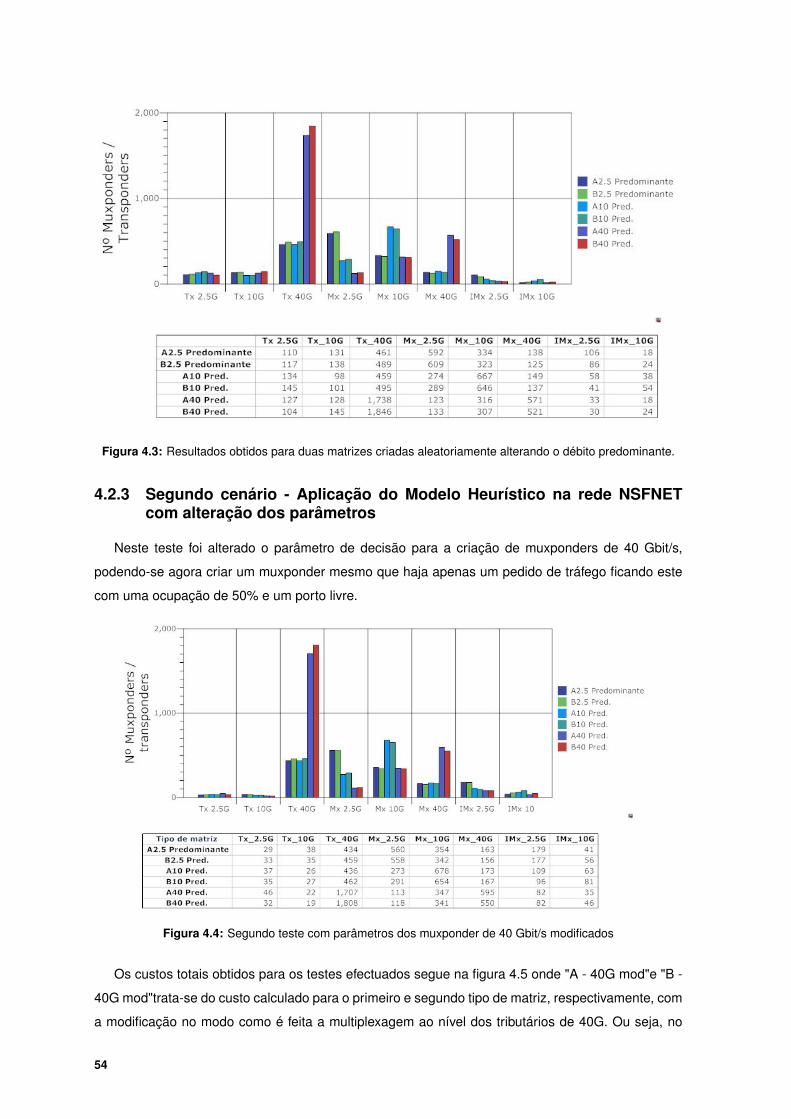
Figura 4.3: Resultados obtidos para duas matrizes criadas aleatoriamente alterando o débito predominante.
4.2.3 Segundo cenário - Aplicação do Modelo Heurístico na rede NSFNETcom alteração dos parâmetros
Neste teste foi alterado o parâmetro de decisão para a criação de muxponders de 40 Gbit/s,
podendo-se agora criar um muxponder mesmo que haja apenas um pedido de tráfego ficando este
com uma ocupação de 50% e um porto livre.
Figura 4.4: Segundo teste com parâmetros dos muxponder de 40 Gbit/s modificados
Os custos totais obtidos para os testes efectuados segue na figura 4.5 onde "A - 40G mod"e "B -
40G mod"trata-se do custo calculado para o primeiro e segundo tipo de matriz, respectivamente, com
a modificação no modo como é feita a multiplexagem ao nível dos tributários de 40G. Ou seja, no
54

Figura 4.5: Custos totais para os exemplos testados
primeiro caso se apenas houver um pedido de 40G não é criado um muxponder e no segundo caso
pode ser criado o muxponder tendo uma taxa de ocupação de 50% permitindo assim que outros nós
intermédios possam usar o light-trail para enviar informação.
4.2.3.A Conclusões
As ilustrações mostram que embora as matrizes usadas sejam distintas, o comportamento do
modelo heurístico é constante não havendo desvios consideráveis no modo como o processo de-
corre.
O modelo tende a usar menos transponder de baixo débito, colocando os sinais agrupados para um
nível superior de modo a utilizar a capacidade máxima dos comprimentos de onda. Porém, isto condi-
ciona de certo modo o número de nós que poderão usar os trails para inserção de tráfego. A inserção
de tráfego em nós intermédios é facilmente entendida quando se recorre a aplicação desenvolvida
que nos permite ver passo a passo como o algoritmo vai tomando as decisões de encaminhamento
e agregação de tráfego.
Em relação aos custos totais da redes, verifica-se uma proporcionalidade directa, já esperada, pelo
facto dos custos crescerem com o débito. Porém, para matriz com 2.5G e 10G predominante os
valores assemelham-se devido ao facto dos pedidos de 10G serem por vezes agrupados para 40G.
Todos os valores aqui apresentados estão fortemente dependentes da tabela de custos que foi pré-
estabelecida.
55

56

5Conclusões e Trabalho Futuro
57

Os resultados obtidos permitem verificar que os transponders de 40 Gbit/s são largamente usados
permitindo uma maior eficiência na utilização dos comprimentos de onda mas, por outro lado, faz
com que os custos aumentem consideravelmente. Mesmo que a matriz predominante não seja a
de 40 Gbit/s o modelo heurístico tem tendência em agrupar sucessivamente os pedidos de tráfego
até atingir o débito máximo possível para cada ligação. Valores sobre a quantidade de caminhos
escolhidos para transportar o tráfego que não o caminho mais curto podem ser encontrados no
anexo B onde se pode verificar que por vezes o caminho mais longo pode ser o mais apelativo por
agrupar mais sinais de nós intermédios.
Para trabalho futuro, sugere-se a adição no algoritmo heurístico da possibilidade de se poder
fazer agregação intermédia em cascata bem como de tráfego multi-débito. Esta modificação vai de
certeza permitir obter melhores resultados no que diz respeito a utilização de comprimentos de onda
e do custo total da rede. Deve ainda ser feito um estudo mais exaustivo ao comportamento do modelo
em relação a todos os graus de liberdade usando a aplicação desenvolvida que permite alterações a
vários parâmetros sendo apenas necessários compilar e inferir sobre os resultados.
Em relação aos modelos ILP, apesar de ser bastante completo e ir de encontro com os objectivos
propostos, sugere-se equações que permitam efectuar a multiplexagem inversa nos nós terminais e
talvez um melhoramento de modo a tornar o problema menos complexo.
O modelo ILP sugere ainda que será possível acompanhar a evolução das redes de transporte
com a introdução de muxponders em cascata de modo eficiente permitindo uma redução significativa
na ocupação dos comprimentos de onda e possibilitando a interligação directa das redes IP a rede
de transporte evitando custos acrescidos com operações de adaptação dos débitos de entrada aos
canais DWDM.
58

Bibliografia
[1] J. M. Simmons, “On determining the optimal optical reach for a long-haul network,” Lightwave
Technology, Journal of, vol. 23, no. 3, pp. 1039–1048, 2005.
[2] A. Gumaste, “On control plane for service provisioning in light-trail wdm optical ring networks,”
Communications, 2007. ICC ’07. IEEE International Conference on, pp. 2442 – 2449, 2007.
[3] I. Corporation. How to maximize network bandwith efficiency (and avoid a "muxponder tax").
White Paper. [Online]. Available: http://www.infinera.com/pdfs/whitepapers/Network_Efficiency_
Muxponder_Tax.pdf
[4] A. N. Patel, C. Gao, J. P. Jue, X. Wang, Q. Zhang, P. Palacharla, and T. Naito, “Traffic grooming
and regenerator placement in impairment-aware optical wdm networks,” Optical Network Design
and Modeling (ONDM), 2010 14th Conference on, pp. 1–6, 1-3 Feb. 2010.
[5] ——, “Cost efficient traffic grooming and regenerator placement in impairment-aware optical
wdm networks,” Optical Switching and Networking, vol. 9, pp. 225–239, 2012. [Online].
Available: journalhomepage:www.elsevier.com/locate/osn
[6] J. Networks, “Otn interfaces for ip over dwdm, ip- optical integration for mana ging wavelengths
in routers,” White Paper, 2010. [Online]. Available: http://www.techrepublic.com/whitepapers/
otn-interfaces-for-ip-over-dwdm-ip-optical-integration-for-managing-wavelengths-in-routers/
1729509
[7] Huawei. Technical white paper for multi-layer network planning. Huawei. [Online]. Available:
http://www.huawei.com/za/static/hw-076758.pdf
[8] J. Pires, Redes de Transporte SDH, redes de telecomunicações ed., Instituto Supeior Técnico,
2010/2011.
[9] M. Scheffel, R. G. Prinz, C. G. Gruber, A. Autenrieth, and D. A. Schupke, “Ngl01-6: Optimal
routing and grooming for multilayer networks with transponders and muxponders,” Global Tele-
communications Conference, 2006. GLOBECOM ’06. IEEE, pp. 1–6, Nov. 27 2006-Dec. 1 2006.
[10] A. Chiu and E. Modiano, “Traffic grooming algorithms for reducing electronic multiplexing costs
in wdm ring networks,” Lightwave Technology, Journal of, vol. 18, pp. 2 – 12, 2000.
59

[11] J. Wang, V. Rao Vemuri, W. Cho, and B. Mukherjee, “Improved approaches for cost-effective
traffic grooming in wdm ring networks: nonuniform traffic and bidirectional ring,” Communications,
2000. ICC 2000. 2000 IEEE International Conference on, vol. 3, pp. 1295 – 1299, 2000.
[12] P. Azevedo, Parte IV GMPLS/ASON e proximos standards, Nokia Siemens Networks, March
2007, slides.
[13] K. S. Rajiv Ramaswami, Optical Networks: A Practical Perspective, Third Edition. The Morgan
Kaufmann Series in Networking, 2005.
[14] A. K. Somani and D. Lastine, “Determining optimal light-trail length,” Local and Metropolitan Area
Networks (LANMAN), 2010 17th IEEE Workshop on, pp. 1–5, 5-7 May 2010.
[15] G. Shen, W. V. Sorin, and R. S. Tucker, “Cross-layer design of ase-noise-limited island-based
translucent optical networks,” Lightwave Technology, Journal of, vol. 27, no. 11, pp. 1434–1442,
2009.
[16] B. Garcia-Manrubia, P. Pavon-Marino, R. Aparicio-Pardo, M. Klinkowski, and D. Careglio, “Offline
impairment-aware rwa and regenerator placement in translucent optical networks,” Lightwave
Technology, Journal of, vol. 29, no. 3, pp. 265–277, 2011.
[17] M. S. Savasini, P. Monti, M. Tacca, A. Fumagalli, and H. Waldman, “Regenerator placement with
guranteed connectivity in optical networks,” Optical Network Design and Modeling, LNCS 4534,
pp. 438–447, 2007.
[18] G. Rizzelli, G. Maier, and A. Pattavina, “Translucent optical network design: A novel two-step
method,” Optical Communication (ECOC), 2010 36th European Conference and Exhibition on,
pp. 1–3, 19-23 Sept. 2010.
[19] A. Betker, C. Gerlac, R. Hulsermann, M. Jager, M. Barry, S. Bodmer, and J. Spath, “Reference
transport network scenarios,” MultiTeraNet project, 2004.
[20] V. R. Konda and T. Y. Chow, “Algorithm for traffic grooming in optical networks to minimize the
number of transceivers,” High Performance Switching and Routing, 2001 IEEE Workshop on, pp.
218–221, 2001.
[21] A. K. Somani, Survivability and Traffic Grooming in WDM Optical Networks, C. U. Press, Ed.
Cambridge University Press, 2006.
[22] R. Dutta and G. N. Rouskas, “Traffic grooming in wdm networks: past and future,” Network, IEEE,
vol. 16, no. 6, pp. 46–56, 2002.
[23] K. Zhu and B. Mukherjee, “Traffic grooming in an optical wdm mesh network,” Selected Areas in
Communications, IEEE Journal on, vol. 20, no. 1, pp. 122–133, 2002.
60

[24] P. Prathombutr, J. Stach, and E. K. Park, “An algorithm for traffic grooming in wdm optical
mesh networks with multiple objectives,” Computer Communications and Networks, 2003. IC-
CCN 2003. Proceedings. The 12th International Conference on, pp. 405–411, 20-22 Oct. 2003.
[25] J. Q. Hu and B. Leida, “Traffic grooming, routing, and wavelength assignment in optical wdm
mesh networks,” INFOCOM 2004. Twenty-third AnnualJoint Conference of the IEEE Computer
and Communications Societies, vol. 1, 7-11 March 2004.
[26] C. Xin, C. Qiao, and S. Dixit, “Traffic grooming in mesh wdm optical networks - performance
analysis,” Selected Areas in Communications, IEEE Journal on, vol. 22, no. 9, pp. 1658–1669,
2004.
[27] S. Huang, D. Seshadri, and R. Dutta, “Traffic grooming: A changing role in green optical
networks,” Global Telecommunications Conference, 2009. GLOBECOM 2009. IEEE, pp. 1–6,
Nov. 30 2009-Dec. 4 2009.
[28] S. Balasubramanian, A. K. Somani, and A. E. Kamal, “Sparsely hubbed light-trail grooming
networks,” Computer Communications and Networks, 2005. ICCCN 2005. Proceedings. 14th
International Conference on, pp. 249–254, 2005.
[29] Y. Ye, H. Woesner, and I. Chlamtac, “Traffic grooming techniques in optical networks,” Broadband
Communications, Networks and Systems, 2006. BROADNETS 2006. 3rd International Confe-
rence on, pp. 1–9, 1-5 Oct. 2006.
[30] J. L. Marzo, F. Solano, J. C. de Oliveira, L. F. Caro, and R. Fabregat, “Optimal traffic grooming in
wdm using lighttours,” Transparent Optical Networks, 2006 International Conference on, vol. 3,
pp. 13–17, 2006.
[31] A. S. Ayad, K. M. F. Elsayed, and S. H. Ahmed, “Enhanced optimal and heuristic solutions of the
routing problem in light trail networks,” High Performance Switching and Routing, 2007. HPSR
’07. Workshop on, pp. 1–6, May 30 2007-June 1 2007.
[32] L. C. Resendo, L. C. Calmon, and M. R. N. Ribeiro, “Simple ilp approaches to grooming, rou-
ting, and wavelength assignment in wdm mesh networks,” Microwave and Optoelectronics, 2005
SBMO/IEEE MTT-S International Conference on, pp. 616–619, 2005.
[33] Cisco sfp optics for packet-over-sonet/sdh and atm applications. [Online].
Available: http://www.cisco.com/en/US/prod/collateral/modules/ps5455/ps6579/product_data_
sheet0900aecd80285547.html
[34] N. S. Networks. (2012, 02) Dwdm with hit 7300. [On-
line]. Available: http://www.nokiasiemensnetworks.com/portfolio/products/transport-networks/
optical-transport/dwdm-with-hit-7300
61

[35] X. Zhang and C. Qiao, “Wavelength assignment for dynamic traffic in multi-fiber wdm networks,”
Computer Communications and Networks, 1998. Proceedings. 7th International Conference on,
pp. 479–485, 12-15 Oct 1998.
[36] G. Shen, S. K. Bose, T. H. Cheng, C. Lu, and T. Y. Chai, “Efficient wavelength assignment
algorithms for light paths in wdm optical networks with/without wavelength conversion,” Photonic
Network Communications, pp. 349–359, 2000.
[37] K. Christodoulopoulos, K. Manousakis, and E. Varvarigos, “Reach adapting algorithms for mixed
line rate wdm transport networks,” Lightwave Technology, Journal of, vol. 29, no. 21, pp. 3350–
3363, 2011.
62

AManipulação da Aplicação
A-1
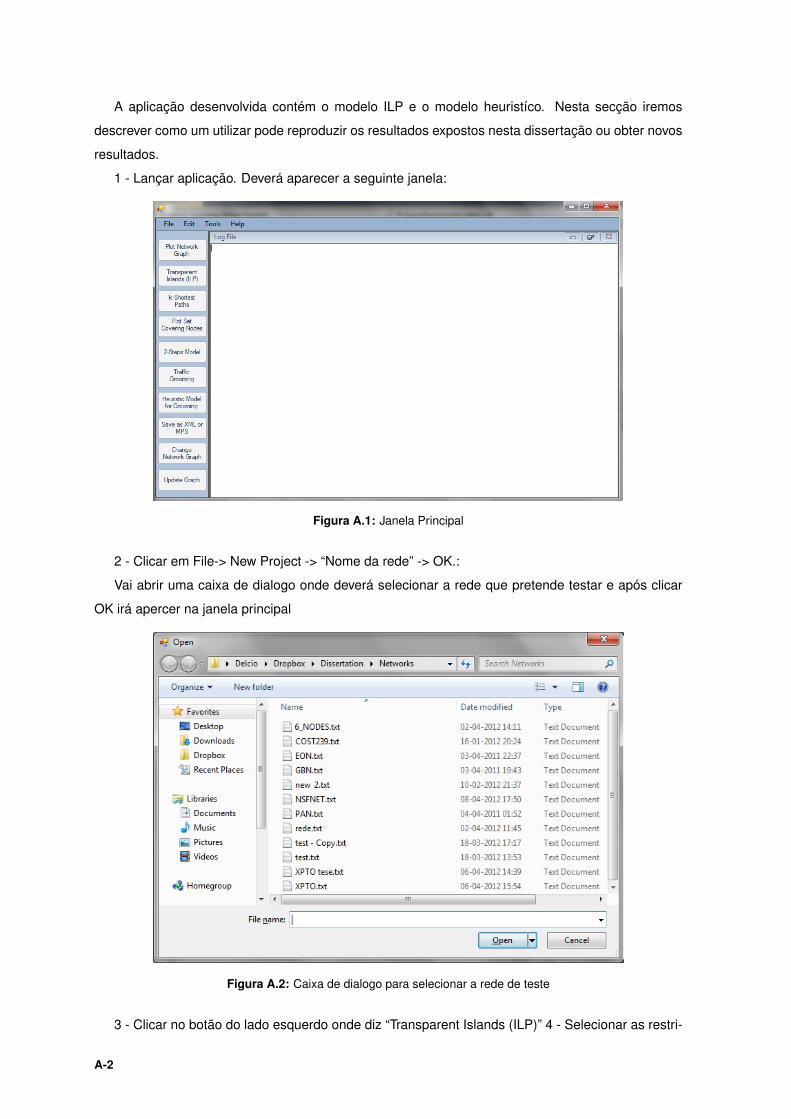
A aplicação desenvolvida contém o modelo ILP e o modelo heuristíco. Nesta secção iremos
descrever como um utilizar pode reproduzir os resultados expostos nesta dissertação ou obter novos
resultados.
1 - Lançar aplicação. Deverá aparecer a seguinte janela:
Figura A.1: Janela Principal
2 - Clicar em File-> New Project -> “Nome da rede” -> OK.:
Vai abrir uma caixa de dialogo onde deverá selecionar a rede que pretende testar e após clicar
OK irá apercer na janela principal
Figura A.2: Caixa de dialogo para selecionar a rede de teste
3 - Clicar no botão do lado esquerdo onde diz “Transparent Islands (ILP)” 4 - Selecionar as restri-
A-2

Figura A.3: Rede carregada com sucesso na aplicação
ções de distância para cada ritmo binário e o número de caminhos distintos que o algoritmo deve ter
em conta.
Figura A.4: Ilhas transparentes
5 - Deverá obter um resultado que se assemelha ao seguinte:
6 - O ultimo passo consiste na escolha do algoritmo para a gregação: ILP ou Heurístico. Neste
caso clicou-se no modelo Heurístico. Novamente aparece uma janela onde se pode modificar vários
parâmetros tais como modelo de custos, caminhos a percorrer, etc.
7 - O algortimo vai correr e no final apresentará o resultado obtido.
A-3
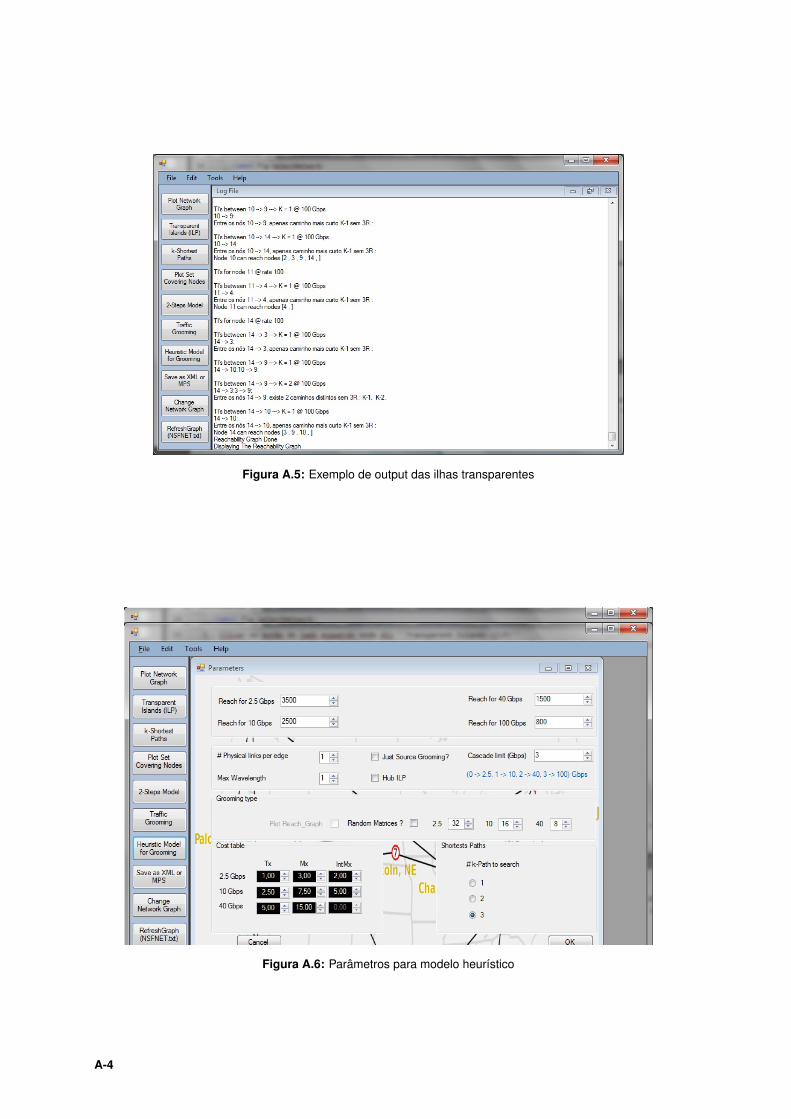
Figura A.5: Exemplo de output das ilhas transparentes
Figura A.6: Parâmetros para modelo heurístico
A-4

BResultados da simulação
B-1

Matriz A com 2.5 predominante:
O custo total é = 31704
Printing all results:
countTx25 = 110
countTx10 = 131
countTx40 = 461
countMX25 = 592
countMX10 = 334
countMx40 = 138
countIntMx25to10 = 106
countIntMx10to40 = 18
numtrail25 = 110
numtrail10 = 723
numtrail40 = 795
numtrail100 = 138
k1-25 = 15
k1-10 = 0
k1-40 = 0
k1-100 = 0
k2-25 = 5
k2-10 = 0
k2-40 = 0
k2-100 = 0
k3-25 = 26
k3-10 = 0
k3-40 = 0
k3-100 = 0
num-of-total-paths = 1766
cost25 = 4310
cost10 = 8660
cost40 = 18610
total groomed for 2.5 = 9
total groomed for 10 = 0
total groomed for 40 = 0
total-cost = 31580
Matriz A com 10 predominante:
O custo total é = 37176
Printing all results:
B-2

countTx25 = 134
countTx10 = 98
countTx40 = 459
countMX25 = 274
countMX10 = 667
countMx40 = 149
countIntMx25to10 = 58
countIntMx10to40 = 38
num-trail-25 = 134
num-trail-10 = 372
num-trail-40 = 1126
num-trail100 = 149
k1-25 = 11
k1-10 = 0
k1-40 = 0
k1-100 = 0
k2-25 = 8
k2-10 = 2
k2-40 = 0
k2-100 = 0
k3-25 = 16
k3-10 = 5
k3-40 = 0
k3-100 = 0
num-of-total-paths = 1781
cost25 = 2270
cost10 = 15770
cost40 = 19040
total groomed for 2.5 = 12
total groomed for 10 = 9
total groomed for 40 = 0
total-cost = 37085
Matriz A com 40 predominante:
Printing all results:
countTx25 = 127
countTx10 = 128
countTx40 = 1738
countMX25 = 123
countMX10 = 316
B-3

countMx40 = 571
countIntMx25to10 = 33
countIntMx10to40 = 18
num-trail-25 = 127
num-trail-10 = 251
num-trail-40 = 2054
num-trail100 = 571
k1-25 = 14
k1-10 = 0
k1-40 = 0
k1-100 = 0
k2-25 = 1
k2-10 = 2
k2-40 = 0
k2-100 = 0
k3-25 = 14
k3-10 = 8
k3-40 = 0
k3-100 = 0
num-of-total-paths = 3003
cost25 = 1198
cost10 = 8115
cost40 = 73030
total groomed for 2.5 = 3
total groomed for 10 = 14
total groomed for 40 = 0
total-cost = 82343
B-4

CMatriz dos testes heurísticos
C-1

2.5G
0 18 23 0 27 5 29 12 7 15 20 29 30 109 0 0 1 4 24 27 20 8 22 31 3 19 2115 15 0 4 22 16 14 1 32 32 14 1 19 221 22 21 0 11 7 16 25 15 21 4 21 4 3023 21 23 29 0 24 30 8 17 14 30 3 25 414 28 10 9 18 0 0 18 22 6 30 20 10 2419 26 5 26 10 15 0 17 19 24 12 8 3 233 10 18 7 24 17 19 0 3 2 30 5 12 1920 19 8 17 24 2 19 0 0 11 15 12 20 2020 8 17 23 16 2 6 27 29 0 7 3 31 62 24 20 17 28 0 14 24 27 31 0 11 6 215 17 23 25 28 6 20 4 29 11 18 0 11 143 5 24 24 11 4 18 17 0 27 12 27 0 1912 5 28 25 9 6 16 27 29 22 4 4 11 0
10G
0 9 11 0 14 2 15 6 3 7 10 14 15 54 0 0 0 2 12 14 10 4 11 16 1 9 108 7 0 2 11 8 7 0 16 16 7 0 9 111 11 10 0 6 3 8 13 8 11 2 10 2 1512 11 12 15 0 12 15 4 9 7 15 1 13 27 14 5 5 9 0 0 9 11 3 15 10 5 1210 13 2 13 5 8 0 9 10 12 6 4 1 121 5 9 3 12 9 9 0 1 1 15 2 6 910 10 4 8 12 1 9 0 0 5 7 6 10 1010 4 9 12 8 1 3 14 15 0 3 1 16 31 12 10 8 14 0 7 12 14 16 0 5 3 113 8 12 13 14 3 10 2 15 5 9 0 6 71 2 12 12 6 2 9 9 0 14 6 13 0 96 3 14 13 5 3 8 14 14 11 2 2 6 0
40G
0 5 6 0 7 1 8 3 2 4 5 7 8 22 0 0 0 1 6 7 5 2 6 8 0 5 54 4 0 1 6 4 4 0 8 8 4 0 5 05 6 5 0 3 2 4 7 4 5 1 5 1 86 5 6 8 0 6 8 2 4 3 8 0 7 13 7 2 2 4 0 0 5 6 1 8 5 2 65 7 1 7 2 4 0 4 5 6 3 2 0 60 2 5 2 6 4 5 0 0 0 8 1 3 55 5 2 4 6 0 5 0 0 3 4 3 5 55 2 4 6 4 0 1 7 8 0 2 1 8 10 6 5 4 7 0 3 6 7 8 0 3 1 51 4 6 6 7 1 5 1 8 3 5 0 3 30 1 6 6 3 1 5 4 0 7 3 7 0 53 1 7 7 2 1 4 7 7 6 1 1 3 0
Figura C.1: Matrizes 2.5, 10, 40 Gbps geradas de forma aleatória
C-2

DResultados da validação do modelo
global
D-1
IGGsd_15_r_1_j3 V alue : 1IGGsd_32_r_1_j1 V alue : 1IGsd_56_r_0_j4 V alue : 1IMs1d2_r0_i1 V alue : 1IMs1d2_r0_i2 V alue : 1IMs1d2_r1_i11 V alue : 1IMs1d5_r0_i1 V alue : 1λs1d5_r0 V alue : 1λs1d2_r0 V alue : 6λs1d5_r1 V alue : 1λs3d2_r1 V alue : 3λs3d5_r2 V alue : 1λs4d6_r0 V alue : 1λs4d2_r1_i4_j2_w0 V alue : 1λs5d2_r0_i3_j2_w0 V alue : 1λs5d2_r0_i5_j3_w0 V alue : 1λs5d6_r0_i5_j4_w0 V alue : 1λs5d6_r2_i5_j6_w0 V alue : 1Ms1d2_r2_i1_j2_w0 V alue : 1Ms1d5_r1_i1_j3_w0 V alue : 1Ms3d2_r1_i3_j1_w0 V alue : 1Ms3d5_r2_i3_j5_w0 V alue : 1Ms4d6_r0_i4_j6_w0 V alue : 1Pij1, 2_w0_k1_r3 V alue : 1Pij1, 3_w0_k1_r2 V alue : 1Pij3, 1_w0_k1_r2 V alue : 1Pij3, 2_w0_k2_r0 V alue : 1Pij3, 5_w0_k1_r3 V alue : 1Pij4, 2_w0_k1_r1 V alue : 1Pij4, 6_w0_k1_r1 V alue : 1Pij5, 3_w0_k1_r0 V alue : 1Pij5, 4_w0_k1_r0 V alue : 1Pij5, 6_w0_k1_r2 V alue : 1
D-2





























