Embed Size (px)
Citation preview

1
GENÉTICA CUANTITATIVA II MODELOS LINEALES
1. Introducción En la Mejora Genética Animal, la utilización de modelos, en general
lineales, es de uso común en un número elevado de cuestiones centrales de esta materia. La estimación de efectos que afectan a los caracteres, tales como el sexo o la estación del año en el crecimiento, o el orden del parto en el tamaño de camada, necesitan el planteamiento y la resolución de modelos lineales. Igualmente, la evaluación genética de los animales, es decir la estimación del valor genético respecto a los caracteres de interés en un programa de selección. En la estimación de los parámetros genéticos que determinan la herencia de los caracteres es, en general, también necesario el uso de modelos lineales.
En principio, la calidad de cualquier análisis estadístico depende de la
calidad del modelo propuesto para describir los datos. El modelo debe representar el modo en que se han obtenido los datos y los aspectos de la biología de los caracteres que se analizan. En un sentido amplio se considera que el modelo verdadero, que es el que describe perfectamente los datos no es conocido y es necesario limitarse a formular un modelo ideal que se piensa que está tan próximo al verdadero como es posible y que debiera ser el utilizado en los análisis. No obstante, en la práctica, por diversas razones, como carencias de información o por falta de disponibilidad de los métodos estadísticos necesarios, el modelo ideal no puede utilizarse. Es el que podemos llamar modelo operacional, que es más sencillo que el ideal, el que realmente se utiliza para analizar los datos. Si el modelo operacional exige excesivas simplificaciones e hipótesis añadidas respecto al ideal, pudiera llegar la situación de cuestionarse el valor del análisis de los datos. En cualquier caso se debe de estar perfectamente consciente de las hipótesis que se han tenido que hacer y de la adecuación del modelo operacional a utilizar.
2. Factores y variables Los datos a analizar se recogen en un vector de observaciones que se
considera como un vector aleatorio conceptualmente muestreado de una población infinita de vectores de la misma longitud. Se considera que su distribución es multivariante y, en caso de que se conozca la distribución, el método de análisis puede aprovecharla. En general la mayoría de los métodos estadísticos que consideraremos suponen que la distribución es multinormal, y muchos de los caracteres de producción de los animales son caracteres continuos para los que la hipótesis de normalidad es aceptable a efectos aplicativos. Tal es el caso de los pesos, de la velocidad de crecimiento, del índice de conversión y muchos otros.

2
Sin embargo existe otro grupo de caracteres de interés cuya naturaleza o medida es discontinua, tales como la fertilidad, la tasa de ovulación, la prolificidad, la clase de una canal o la evaluación de la conformación de un animal. Para estos caracteres no se aplica de modo estricto la teoría aplicable a los caracteres continuos y existen métodos específicos para ellos como es el caso de los modelos umbral. Sin embargo, en muchos casos el análisis de estos caracteres con los métodos de los caracteres continuos ha dado resultados prácticamente idénticos al análisis con métodos específicos de caracteres discretos, aunque siempre se debería intentar el análisis con los métodos mas adecuados.
En un modelo, los elementos que se consideran para explicar los datos
observados se llaman factores que a su vez pueden ser de naturaleza discreta o continua. Así, por ejemplo, la tasa de ovulación de una coneja puede depender del orden de parto, del peso del animal y de la coneja como tal. Los factores de naturaleza discreta suelen tener clases o niveles como sería el caso del orden del parto, para los que el análisis proporcionará estimaciones de sus efectos. Los factores de naturaleza continua se llaman covariables y el análisis estimará el coeficiente de regresión correspondiente. En nuestro ejemplo, se obtendría un coeficiente que nos indicaría como se espera que varíe la tasa de ovulación al variar una unidad el peso de la coneja. Tanto si los factores son de interés directo para quien hace el análisis como si no lo son, deben incluirse en el análisis, pues si son importantes en la explicación de los datos, su omisión podría afectar la interpretación de los resultados del análisis.
3. Factores fijos y aleatorios En un análisis tradicional, no bayesiano, de los datos es necesario
distinguir entre factores fijos y aleatorios. Factores fijos son aquéllos en que las clases o niveles de los mismos
comprenden todos los niveles de interés que podrían ser observados y en general el número de clases es pequeño. Tal es el caso del sexo o del orden de parto y, probablemente, si se hiciese una nueva repetición de obtención de datos no sería conceptualmente imposible repetir la misma distribución de niveles de estos factores. Así, en un experimento de crecimiento podría repetirse en los mismos alojamientos o con los mismos tipos de raciones, pero sería imposible volver a utilizar los mismos animales. En este caso los factores tipo de alojamiento y tipo de ración se considerarían fijos, mientras que el animal sería un factor aleatorio. Los niveles de los factores aleatorios se consideran como muestras aleatorias de una población infinita de niveles.
Otro modo de considerar si un factor debe considerarse como fijo o
aleatorio es función de la forma en que los resultados vayan a utilizarse, Así, en una experiencia de nutrición, si las conclusiones respecto al tipo de raciones va a limitarse a las raciones concretas consideradas en el experimento y no a otras dietas posibles el factor tienen naturaleza de factor fijo. Por contra, los efectos de

3
los animales, observados en el experimento, serían extrapolables, en su conjunto, a otra muestra aleatoria de animales y el factor animal se consideraría aleatorio.
Las contestaciones a las preguntas que siguen son clarificadoras en la decisión de si un factor debe considerarse fijo o aleatorio.
a-. ¿Cuántos niveles del factor se consideran en el modelo?. Si son pocos,
el factor probablemente sea fijo, si muchos aleatorio. b-. ¿Es en la población el número de niveles suficientemente grande para
considerarlo infinito? En caso afirmativo, probablemente el factor sea aleatorio. c-. ¿Podrían volver a utilizarse los mismos niveles del factor si se repitiese
el experimento? Si así fuera, el factor pudiera ser fijo. d-. ¿Van a extrapolarse las inferencias a niveles no incluidos en el
experimento? Si sí, el factor debiera ser aleatorio. e-. ¿Se determinaron aleatoriamente los niveles del factor? En caso
negativo, el factor debe tratarse como fijo. 4. El modelo.
Los modelos lineales, que serán los que trataremos en este curso, son los que consideran factores que afectan aditivamente a las observaciones, pese a que algún factor considerado sea la potencia, raíz o logaritmo de una variable. Un modelo lineal exige la consideración de tres elementos: a-. La ecuación
b-. Las esperanzas y matrices de varianzas-covarianzas de los efectos aleatorios.
c-. La especificación de las hipótesis, restricciones y limitaciones. La ecuación del modelo especifica los factores que pueden afectar al
carácter que vamos a analizar. Si, por ejemplo, vamos a estudiar en conejos el número de nacidos vivos por camada, podemos pensar que el orden de parto y el período de tiempo (año-estación) en que se ha producido el parto son factores fijos importantes. Por otra parte, es evidente que el animal que produce el parto y del que se pueden tener varias observaciones también afecta al carácter. Este factor animal, puede descomponerse en una componente genética aditiva y en un resto de su efecto no aditivo y ambos factores se consideran aleatorios. Lo anterior puede escribirse en la siguiente ecuación:
ijkkkjiijk epato ++++=y
en la que, yijk , representa el número de nacidos vivos del parto i-mo, producido en el
año estación j-mo por la hembra número k, oi , es el efecto del orden de parto i-mo, tj , es el efecto del período de tiempo (año-estación), j-mo ,

4
ak (pk ), representa el efecto genético aditivo (permanente no aditivo) del animal número k, y, eijk , es el residual del modelo o parte de la observación no explicada por los factores considerados. Para ilustrar conceptos que trataremos a continuación supongamos que
tenemos un conjunto de observaciones de nacidos vivos por camada de un conjunto de hembras, según se muestra en la siguiente tabla:
Hembra Orden
de parto Fecha de
parto Periodo de parto
Nacidos vivos
2 1 01-98 1 8 2 2 03-98 1 9 2 3 05-98 2 10 3 1 01-98 1 9 3 2 03-98 1 9 3 3 05-98 2 11 4 1 06-98 2 7 4 2 08-98 3 8 6 1 06-98 2 7 6 2 08-98 3 9 6 3 10-98 4 9 7 1 11-98 4 9
, en la que suponemos que cada tres meses es un período de tiempo o año-estación. El período número uno corresponde a enero-febrero-marzo del año 1998. El período dos a abril-mayo-junio del mismo año y así sucesivamente. Si tuviésemos partos de febrero de 1999, corresponderían al período 5.
Las hembras anteriores, de las que conocemos su tamaño de camada,
pueden estar emparentadas y en la tabla que sigue indicamos la genealogía y por tanto las relaciones de parentesco:
Individuo 1 2 3 4 5 6 7
Padre 0 0 0 1 1 1 5 Madre 0 0 0 2 2 3 6
Los individuos 1, 2 y 3 no están emparentados, ni son consanguíneos e
indicamos con 0 el que desconocemos sus padres. Volviendo a la ecuación del modelo, ésta puede escribirse en forma
matricial del siguiente modo: y = Xb + Zu + e en la que,

5
y, representa el vector de observaciones. En nuestro ejemplo,
[ ]99978711991098´=y
b, es el vector representando los efectos de los distintos niveles de los efectos fijos. En nuestro ejemplo,
[ ]4321321´ ttttooo=b
u, es el vector representando los efectos de los distintos niveles de los
efectos aleatorios. En nuestro ejemplo,
[ ]76543217654321´ pppppppaaaaaaa=u
e, es el vector de los residuales. Tiene tantas componentes como
observaciones. En nuestro ejemplo, tendría 12 componentes.
X, es la matriz que muestra para cada observación los efectos fijos que le corresponden. Se le llama matriz de diseño de los efectos fijos. Tiene tantas filas como observaciones y tantas columnas como componentes tiene b, es decir, como el total de niveles de los factores fijos, covariables incluidas (hay una columna por cada covariable). En nuestro ejemplo,
=
100000110001000100010001000101000100010001001010000010100001001001010000010100001001
X
Z, es la matriz de diseño referida a los efectos aleatorios. En nuestro
ejemplo,

6
=
100000010000000100000010000001000000100000010000001000000001000000100000010000001000000010000001000000100000010000001000000100000001000000100000010000001000000100000010
Z
Los modelos que únicamente tienen como factor aleatorio el residual se
llaman modelos de efectos fijos. Aquéllos que únicamente tienen un factor fijo con un solo nivel (la media) y efectos aleatorios se llaman modelos de efectos aleatorios. En el caso de que se consideren varios niveles de efectos fijos y algún efecto aleatorio, además del residual el modelo se considera como modelo mixto, tal como ocurre en nuestro ejemplo.
L a especificación de las esperanzas de los términos aleatorios sería,
=
00
Xb
eu
y
E
y la matriz de varianzas-covarianzas de los factores aleatorios,
=
R00G
eu
V
en donde G y R son matrices cuadradas regulares, simétricas y definidas
positivas. La matriz G se puede particionar del siguiente modo,
=
p
A
G00G
G
siendo,
2AσAGA =
en la que A es la matriz con los coeficientes de parentesco, entre los
individuos, multiplicados por dos

7
2pσΙ=pG
y la matriz de varianzas-covarianzas de las observaciones, función de las anteriores sería,
[ ] RZGZ´Vy +==V
En nuestro ejemplo, en el que suponemos que σ 2
A =1, σ 2p =1.5 y σ 2
e =10
=
125.1625.0625.0375.025.025.05.0625.0125.025.05.005.0625.025.015.005.05.0375.025.05.0105.05.025.05.00010025.005.05.00105.05.05.05.0001
AG
podemos advertir que el último término de la diagonal principal de GA es 1.125 dado que el individuo número 7 es consanguíneo y tiene un coeficiente de consanguinidad F7=0.125 . Por tanto,
[ ] 125.1)1( 2
77 =+= AFaV σ
[ ]5.15.15.15.15.15.15.1diagG p =
[ ]101010101010101010101010diagR = y
=
625.12625.0625.0625.0375.0375.025.025.025.025.025.025.0625.05.125.25.225.025.05.05.05.0000625.05.25.125.225.025.05.05.05.0000625.05.25.25.1225.025.05.05.05.0000375.025.025.025.05.125.20005.05.05.0375.025.025.025.05.25.120005.05.05.025.05.05.05.0005.125.25.200025.05.05.05.0005.25.125.200025.05.05.05.0005.25.25.1200025.00005.05.00005.125.25.225.00005.05.00005.25.125.225.00005.05.00005.25.25.12
V
Una vez establecido el modelo operacional resulta necesaria una
reconsideración crítica sobre las simplificaciones que hemos hecho respecto al

8
modelo ideal, las hipótesis que hemos tenido que hacer y las limitaciones a las que nos hemos constreñido. Por ejemplo, en nuestro caso, hemos supuesto que el tamaño de camada anterior no influye sobre el siguiente, que no hay efectos maternales o que la determinación genética del tamaño de camada es la misma para todos los partos.
Un concepto interesante, que en muchas ocasiones puede facilitar el
cálculo, es el concepto de modelo equivalente. Esto significa que las observaciones pueden explicarse exactamente igual a través de modelos distintos, que se dice que son equivalentes cuando las esperanzas y la matriz de varianzas-covarianzas de las observaciones son las mismas en ambos modelos. En el ejemplo que venimos considerando, el valor aditivo y permanente del animal lo podemos incluir en un solo factor aleatorio ap.
En este caso el modelo se escribiría así,
ijkkjiijk eapto +++=y
, para el que los elementos de su ecuación matricial serían los mismos que para el anterior, salvo,
[ ]77665544332211 papapapapapapa +++++++=u´
=
100000001000000100000010000000010000001000000010000001000000100000001000000100000010
Z
y

9
=
625.2625.0625.0375.025.025.05.0625.05.225.025.05.005.0625.025.05.25.005.05.0375.025.05.05.205.05.025.05.0005.2005.05.05.05.005.205.05.05.05.0005.2
G
de tal modo que [ ]yE y [ ]yV V= son los mismos que para el primer modelo. Otro modo de escribir el modelo del ejemplo, con otro modelo equivalente, podría ser incluyendo los efectos p en el residual. En este caso, la G sería igual que la GA definida anteriormente, Z sería como en el modelo segundo y R ya no sería diagonal, sino.
=
5.110000000000005.115.15.10000000005.15.115.10000000005.15.15.110000000000005.115.100000000005.15.110000000000005.115.15.10000000005.15.115.10000000005.15.15.110000000000005.115.15.10000000005.15.115.10000000005.15.15.11
R
En temas posteriores de este curso, cuando estudiemos el modelo
animal reducido, ejemplificaremos las ventajas de cálculo que pueden lograrse con un modelo equivalente

10
GENÉTICA CUANTITATIVA II ESTIMACION
1. Propiedades de un estimador De acuerdo con el concepto de modelo equivalente, cualquier modelo
mixto,
eZuXby ++=
tiene un modelo equivalente de efectos fijos,
rXby +=
tal que,
eZur +=
y, correspondientemente,
[ ] Xby =E
y,
[ ] [ ] [ ] VRZGZ´eZury =+=+== VVV El modelo así presentado, como modelo de efectos fijos, es un modo de
expresar que nuestro interés se centra en la estimación de b y en la realización de tests de hipótesis acerca de los elementos de b. En lo que sigue expondremos la teoría general aplicable a cualquier modelo de efectos fijos.
En general la cuestión de la estimación se puede formular como la
estimación de funciones de b, como K´b, utilizando una función lineal del vector de observaciones, como L´y, en el que tenemos que calcular L de forma que el estimador cumpla una serie de condiciones. Así, apoyándonos en el ejemplo del primer capítulo, si nuestro interés radicase en estimar el número de nacidos vivos de una hembra de segundo parto, que pare en el cuarto período,
[ ]1000010´=K
y si quisiésemos estimar las diferencias entre la prolificidad de primero y segundo parto,
[ ]0000011 −=K´ y si ambas cosas,

11
−
=00000111000010
´K
Los criterios que se consideran para calcular L son, 1. La esperanza de L´y debe de ser K´b. Es decir, el estimador debe ser
insesgado. 2. Las varianzas de los errores de estimación, L´y - K´b, es decir los
elementos de la diagonal de la matriz de varianzas- covarianzas de dichos errores de estimación, L´VL, deben ser mínimos. Es la condición de mejor estimador.
La primera condición se expresa como,
[ ] [ ] L´XbyL´L´y == EE
que se cumple si, ´KL´X = es decir, que las filas de K´, deben ser vectores pertenecientes al espacio vectorial definido por las filas de la matriz X.
2. Deducción
La consideración de los dos criterios se combinan en la minimización de las varianzas de los errores de estimación mediante una función F que tenga en cuenta la condición de insesgamiento a través de un vector θ de multiplicadores de LaGrange,
θ)(2 K´L´XL´VLF −+= Derivando, respecto a las incógnitas L y θ e igualando a cero, tenemos,
0XVLLF
=+=∂∂
θ22
y
0KX´LF
=−=∂∂
)(2θ
que origina el siguiente sistema de ecuaciones,
=
K0L
X´XV
θ0

12
Del primer grupo de ecuaciones, despejamos L,
θXVL 1−−=
y como,
θXX´VX´LK 1−−==
entonces
KXX´V 1 −−−= )(θ
y
KX)X(X´VVL ´1 −−−= 1
y por tanto
bK´yX´VX)K´(X´VL´y 11 ˆ== −−−
siendo
yX´VX)(X´Vb 11 −−−=ˆ (1) y
( ) [ ] −−−−−−−− ==−= )(ˆˆ XX´VX)X(X´VVVX´VX)(X´Vbbb 11111VV Si volvemos al ejemplo del primer capítulo podemos ver que la matriz X no
es de rango completo en sus columnas, pues es fácil de observar que la suma de las tres primeras columnas dan una columna de 1´s (es decir, las observaciones corresponden a uno u otro orden de parto), y las cuatro últimas columnas al sumarlas también dan otra columna de 1´s (las observaciones se hacen en uno u otro período de tiempo). El hecho que acabamos de señalar ocurre siempre que hay más de un efecto fijo y su consecuencia es que la matriz XX´V 1− es una matriz singular (su determinante es cero) y no tiene inversa. Esto significa que las ecuaciones que nos van a dar la solución de L o b , forman un sistema que si es compatible, lo cual suele ocurrir prácticamente siempre, es indeterminado, lo que quiere decir que hay infinitas soluciones para L y b . En estas situaciones, para una matriz singular existen un número infinito de matrices, llamadas inversas generalizadas, que multiplicando al término independiente del sistema de ecuaciones dan las soluciones posibles, si el sistema es compatible. En las fórmulas anteriores −− X)(X´V 1 es el símbolo de la inversa generalizada de la matriz
XX´V 1− . En nuestro caso existen formas sencillas de calcular alguna de las inversas generalizadas, haciendo cero ciertas filas y las mismas columnas e
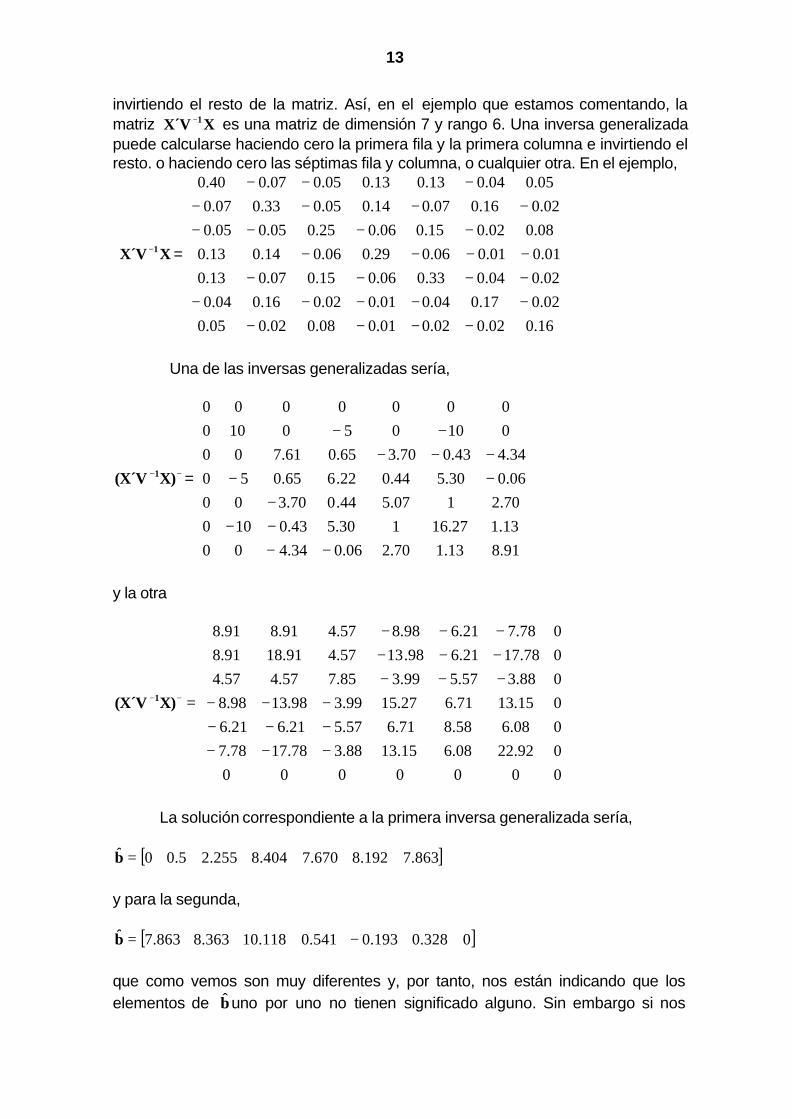
13
invirtiendo el resto de la matriz. Así, en el ejemplo que estamos comentando, la matriz XX´V 1− es una matriz de dimensión 7 y rango 6. Una inversa generalizada puede calcularse haciendo cero la primera fila y la primera columna e invirtiendo el resto. o haciendo cero las séptimas fila y columna, o cualquier otra. En el ejemplo,
XX´V 1− =
−−−−−−−−−−−−−−−−−
−−−−−−−−
−−−
16.002.002.001.008.002.005.002.017.004.001.002.016.004.002.004.033.006.015.007.013.001.001.006.029.006.014.013.0
08.002.015.006.025.005.005.002.016.007.014.005.033.007.0
05.004.013.013.005.007.040.0
Una de las inversas generalizadas sería,
−− X)(X´V 1 =
−−−−−
−−−−−
−−
91.813.170.206.034.40013.127.16130.543.010070.2107.544.070.30006.030.544.022.665.05034.443.070.365.061.700
0100501000000000
y la otra
−− X)(X´V 1 =
−−−−−−−−−
−−−−−−−−−
0000000092.2208.615.1388.378.1778.7008.658.871.657.521.621.6015.1371.627.1599.398.1398.8088.357.599.385.757.457.4078.1721.698.1357.491.1891.8078.721.698.857.491.891.8
La solución correspondiente a la primera inversa generalizada sería,
[ ]863.7192.8670.7404.8255.25.00ˆ =b y para la segunda,
[ ]0328.0193.0541.0118.10363.8863.7ˆ −=b que como vemos son muy diferentes y, por tanto, nos están indicando que los elementos de buno por uno no tienen significado alguno. Sin embargo si nos

14
volviéramos a plantear la estimación de la prolificidad de una hembra de segundo parto, que pare en el cuarto período, en ambas soluciones la contestación sería, la misma:
363.80363.8863.75.0ˆˆ72 =+=+=+ bb
o si nos preguntásemos por la diferencia de prolificidad entre primer y segundo parto, la solución también es la misma en ambos casos,
5.0363.8863.75.00ˆˆ
21 −=−=−=− bb Estas funciones cuya estima es independiente de la inversa generalizada utilizada en la solución se llaman funciones estimables y a continuación trataremos el problema de la estimabilidad. Antes de hacerlo indicaremos que el procedimiento de estimación es un procedimiento BLUE (Best (mejor por minimizar las varianzas), Unbiased (insesgado), Linear (lineal), Estimator (estimador)). También es GLS (Generalized (generalizados), Least (mímimos), Squares (cuadrados)) o de Mínimos Cuadrados Generalizados, ya que los Mínimos Cuadrados Ordinarios (OLS) son un caso particular en el que la matriz V se sustituye por la matriz I. 3. Estimabilidad La condición que se exige para que la combinación lineal K´b sea estimable es que, independientemente de la solución de b , la combinación K´ bsea la misma, como ha sido el caso en los ejemplos mostrados anteriormente. Para satisfacer la anterior condición es suficiente que se cumpla que, TXK´= es decir que las filas de K´ pertenezcan al espacio vectorial definido por las filas de X, es decir la misma condición que era necesaria para obtener un estimador insesgado. En el ejemplo que venimos mostrando,
−
=00000111000010
´K
y la matriz T correspondiente sería,
−
−−=
000000000011010001000111
T
Para demostrar lo anterior basta recordar dos propiedades,

15
AAAA −= ,siendo A- una inversa generalizada de A y que, ´´ QXPXXQX´VXPX´V 11 =⇒= −− pues si G es una inversa generalizada de X´V-1X, XXXGX´VX´XGX´X´VXX´VXXGX´VX´V 11111 =⇒=⇒= −−−−− y por tanto, si S es otra inversa generalizada de X´V-1X, ´´ XSXXGXXXSX´VXXGX´V 11 =⇒= −− y yX´VX)VTX(XbTXbK´ 11 −−−== ´ˆˆ no depende de la inversa generalizada. En general, suelen ser estimables diferencias entre niveles de un mismo factor fijo, como corresponde a la segunda fila de K´ en nuestro ejemplo, o a las sumas de efectos de niveles de los distintos factores (uno por factor), como es el caso de la primera fila de K´. También son estimables lo que se llaman Medias Mínimo Cuadráticas (LSM), que para cada nivel de un factor se calculan como la suma del efecto de ese nivel mas los promedios de los efectos de cada factor. Así, para orden de parto, las Medias Mínimo Cuadráticas serían, Parto1 8.032 Parto2 8.532 Parto3 10.287 y para periodo Periodo1 9.322 Periodo2 8.589 Periodo3 9.110 Periodo4 8.782 La media para el Parto1 se obtendría,
40328.0193.0541.0
863.7032.84
863.7192.8671.7404.80
++−+==
++++
, la media para el Periodo3,

16
3118.10363.8863.7
328.0110.93
255.25.00192.8
+++==
+++
En experimentos con un número elevado de niveles por cada efecto fijo y datos muy desequilibrados, pueden plantearse problemas de estimabilidad cuando hay falta de conexión entre combinaciones de niveles de factores. Podría haber ocurrido en nuestro ejemplo si todos los datos de primer parto se hubiesen producido en el primer periodo, y los datos de segundo y tercer parto en los tres últimos. En esta situación no sería estimable la diferencia de efectos entre primer parto y otro cualquiera, o la suma de efectos de primer parto y un período diferente al primero.
4. Test de hipótesis
Antes de tratar el test para probar la significación de una función estimable
es conveniente que de forma más general veamos como el modelo explica parte de la variación total incluida en los datos.
Dado que los datos están relacionados entre sí y su varianza no es uno, a
efectos de establecer una situación tipo de comparación, podría transformarse el vector de datos y cuya matriz de varianzas-covarianzas es V en otro vector z cuya matriz de varianza-covarianzas fuese I. Esto puede hacerse teniendo en cuenta que siendo V una matriz simétrica definida positiva, admite la factorización de Choleski,
′= TTV
siendo T una matriz triangular inferior, llamada factor de Choleski. En el ejemplo que venimos mostrando,
=
54.312.014.017.008.010.005.006.007.005.006.007.0041.357.069.006.007.010.012.014.00000046.369.006.007.010.012.014.000000053.306.007.010.012.014.0000000046.370.000010.012.014.00000053.300010.012.014.000000042.358.071.0000000000046.371.00000000000054.300000000000042.358.071.0000000000046.371.00000000000054.3
T
La matriz T tiene inversa y si hacemos la transformación,

17
yTz 1−=
[ ] ITVTz 11 =′= −−V
En el ejemplo,
−−−−−−−−−−
−−−−−−−
−−−−−−−
−−−
−−−
=−
28.01.01.01.01.01.000000029.05.05.0001.01.01.0000029.06.0001.01.01.00000028.0001.01.01.000000029.06.00001.01.01.0000028.00001.01.01.00000029.05.05.000000000029.06.0000000000028.00000000000029.05.05.000000000029.06.0000000000028.
1T
y
[ ]02.266.196.169.173.176.134.208.255.210.214.226.2=′z Por tanto una forma tipificada de mostrar la Suma de cuadrados total de los
datos (SCT), sería:
yVyTyTyzz 11 −− ′=′′=′ La suma de cuadrados imputable al modelo completo (SCR), teniendo en
cuenta que el vector y , predicción de los datos por el modelo, es:
bXy ˆˆ =
sería,
yVXX)VXX(VyyVXbyVXX)VXX(VXbbXVXbyVy 111111111 −−−−−−−−−−− ′′′=′′=′′′′=′′=′ ˆˆˆˆˆˆ , que desde un punto de vista de cálculo la expresión, yVXb 1−′′= ˆSCR , es cómoda pues no es otra cosa que la suma de los productos de las soluciones de b por los términos independientes de las ecuaciones de mínimos cuadrados generalizados utilizadas para obtener b .
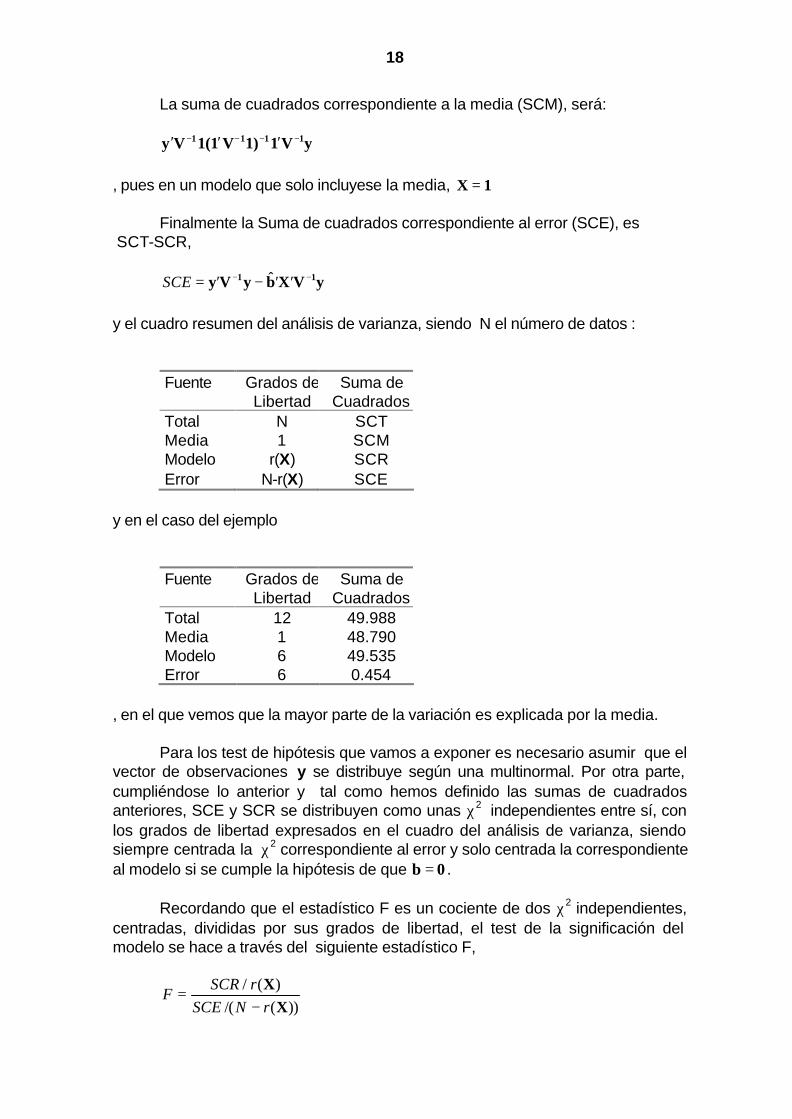
18
La suma de cuadrados correspondiente a la media (SCM), será: yV11)V11(Vy 1111 −−−− ′′′ , pues en un modelo que solo incluyese la media, 1X = Finalmente la Suma de cuadrados correspondiente al error (SCE), es SCT-SCR, yVXbyVy 11 −− ′′−′= ˆSCE y el cuadro resumen del análisis de varianza, siendo N el número de datos :
Fuente Grados de Libertad
Suma de Cuadrados
Total N SCT Media 1 SCM Modelo r(X) SCR Error N-r(X) SCE
y en el caso del ejemplo
Fuente Grados de Libertad
Suma de Cuadrados
Total 12 49.988 Media 1 48.790 Modelo 6 49.535 Error 6 0.454
, en el que vemos que la mayor parte de la variación es explicada por la media.
Para los test de hipótesis que vamos a exponer es necesario asumir que el vector de observaciones y se distribuye según una multinormal. Por otra parte, cumpliéndose lo anterior y tal como hemos definido las sumas de cuadrados anteriores, SCE y SCR se distribuyen como unas χ2 independientes entre sí, con los grados de libertad expresados en el cuadro del análisis de varianza, siendo siempre centrada la χ2 correspondiente al error y solo centrada la correspondiente al modelo si se cumple la hipótesis de que 0b = . Recordando que el estadístico F es un cociente de dos χ2 independientes, centradas, divididas por sus grados de libertad, el test de la significación del modelo se hace a través del siguiente estadístico F,
))(/(
)(/X
XrNSCE
rSCRF
−=

19
En el ejemplo F=109.153, que es mayor que el F(6,6;0.05)=4.28 Un F significativo, superior al valor de las tablas para el α (error de primera especie) estipulado, indica que b no es un vector nulo y que el modelo explica significativamente algo de la variación total. En general el modelo debe ser siempre significativo dado que b incluye la media de los datos. Por tanto, resulta de mayor interés probar la significación de funciones estimables de b que no incluyan la media. La forma de hacerlo la vamos a describir a continuación. El test consta de cuatro partes,
1. La hipótesis nula de la función estimable 2. La hipótesis alternativa 3. El estadístico en el que se basa el test, y 4. Un nivel de error de primera especie (α), que determina la región de
rechazo de la hipótesis nula. La hipótesis nula se escribe como, cbK =′ o como, 0cbK =−′ donde,
bK′ es una función estimable y las filas de K′ son independientes entre sí. Si llamamos, )ˆˆ( cbK(K)X)VX(K()cbK 11 −′′′′−′= −−−s el estadístico F del test es,
))(/(
)(/X
KrNSCE
rsF
−′
=
En el ejemplo, si queremos ver si la prolificidad esperable de una coneja de segundo parto en el cuarto periodo es igual a cinco,
[ ]1000010=′K y la hipótesis nula a probar,
5=′bK

20
luego F=7.908 que es mayor que F(1,6;0.05)=5.99, luego se rechaza la hipótesis nula. En el caso que quisiésemos probar si la diferencia de la prolificidad entre los dos primeros partos es distinta,
[ ]0000011 −=′K
0=′bK y F=0.331<5.99, luego se acepta la hipótesis nula de no diferencia entre los dos primeros partos.

21
GENÉTICA CUANTITATIVA II
PREDICCIÓN
1. El mejor predictor (BP) El término de predicción lo vamos a utilizar para la estimación del valor realizado de una variable aleatoria que ha sido muestreada de una población con una estructura conocida de varianzas-covarianzas, lo que permite incrementar la precisión, frente a la situación en la que ignorásemos, o no hiciésemos uso de dicha estructura. La predicción de los valores genéticos de los animales es el punto básico de los programas de selección y en base a ellas se toman las decisiones de selección. En lo que sigue, utilizaremos para la descripción de los datos un modelo mixto, con factores fijos y aleatorios, tal como hemos descrito en el capítulo uno, que recordamos se escribía, eZuXby ++= , en el que el significado de sus términos e hipótesis sobre sus componentes son los que comentamos anteriormente.
Únicamente añadiremos aquí la nomenclatura necesaria para considerar el hecho de que hayan varios factores aleatorios y consecuentemente, Z, u y V(u), tendrán una estructura acorde a ello. Suponiendo que hay s factores aleatorios,
[ ]s2´1 u...uuu ′′′=′
[ ]s21 Z...ZZZ =
y
=
=
sss2s1
2s2221
1s1211
2
1
G...GG..................
G...GG
G...GG
u...
u
u
u
s
VV )(
, suponiendo que se conocen todas las Gij .
De forma general, el problema de la predicción se plantea como la predicción de una función de efectos fijos y aleatorios,

22
uMbK ′+′
en la que bK ′ es una función estimable. En el caso en que nuestro interés sea la predicción estricta de los efectos aleatorios, es decir de u, entonces 0K =′ y
IM =′
El mejor predictor, para cualquier tipo de modelo, requiere conocer la distribución de las variables aleatorias y todos los momentos de estas distribuciones. Entonces el mejor predictor, que es el que es insesgado y tiene el menor error cuadrático medio de todos los predictores es la esperanza condicional del predictor dados los datos,
)|( yuMbK ′+′E
El cálculo de este predictor depende de la distribución de y, pudiendo ser
lineal o no en función de dicha distribución. En el caso de que la distribución sea normal y conozcamos las medias (momentos de primer orden) y la matriz de varianzas -covarianzas (momentos centrados de segundo orden) el mejor predictor es lineal.
2. El mejor predictor lineal (BPL) En muchos casos el cálculo del mejor predictor no es posible y resulta
necesario restringirse a predictores que sean funciones lineales de y. En este caso no es necesario conocer la distribución de y, basta con conocer las medias, es decir Xb y la matriz de varianzas-covarianzas V(y)=V . Entonces el mejor predictor lineal es,
))( Xb(yVCbKVb,y,|uMbK 1 −′+′=′+′ −E
siendo )cov( yu,MC ′=′ que es la fórmula bien conocida de la regresión lineal múltiple, o en relación con la genética cuantitativa es la fórmula de un índice de selección. Si tal como hemos comentado en el apartado anterior la distribución de y es multinormal entonces el mejor predictor lineal es también el mejor predictor. El mejor predictor lineal es el de menor error cuadrático medio entre los lineales. En el ejemplo que hemos puesto en el primer capítulo si asumimos que además de V conocemos b,
[ ]9.787.75.83.25.00=′b

23
y queremos predecir los efectos aditivos de los animales, es decir K´=0 y
[ ][ ]0diagM 1111111=′ En este caso, ZGMC ′′=′ , será:
=′
125.1625.625.625.375.375.25.25.25.25.25.25.625.11125.25.5.5.5.000625.25.25.25.5.5.0005.5.5.375.25.25.25.110005.5.5.25.5.5.5.0011100025.0005.5.0001115.5.5.5.5.5.000000
C
[ ]1.12.15.7.5.7.105.005.)( −−−−−=′− Xby
y
[ ]032.011.018.081.066.043.041.ˆˆ −−−−−==′ auM
3. El mejor predictor lineal insesgado (BLUP) Lo usual es que no se conozca Xb, primer momento de y, y en este caso si se asume que se conoce V, el mejor predictor lineal debe condicionarse a ser insesgado. En este caso el mejor predictor lineal insesgado es, )bX(yVCbK 1 ˆˆ −′+′ − siendo, yVX)XVX(b 11 −−− ′′=ˆ y C´ tiene el mismo significado que en el apartado anterior. Es decir la fórmula para el mejor predictor lineal insesgado es análoga a la del mejor predictor lineal sustituyendo b por b , siendo este último una solución de los efectos fijos del modelo equivalente para y de efectos fijos, tal como vimos en el capítulo anterior. Si la distribución de y no es multinormal, pueden existir predictores no lineales de
uMbK ′+′ con errores cuadráticos medios menores que el BLUP.
3.1. Deducción
Llamaremos a uMbK ′+′ , cantidad a predecir, predictando, y a la función lineal de los datos L´y , predictor. A la diferencia entre el predictando y el

24
predictor se le llama error de predicción (EP). La condición de insesgamiento del predictor la estableceremos exigiendo que sean las mismas las esperanzas del predictor y del predictando. Es decir,
bKuMbKXbLyL ′=′+′=′=′ )()( EE
, condición que si se ha de cumplir para todos los b posibles, exige que: KXL ′=′ La condición de mejor exige la minimización del error de predicción, por lo que a continuación vamos a calcular dicho error, para luego hallar su mínimo sometido a la condición de insesgamiento.
)()()( EPZGMLLZGMVLLGMMyLuMyLuMbK VVV =′−′′−′+′=′−′=′−′+′
En definitiva hay que minimizar los elementos de la diagonal de la matriz, θ)KXLEPF ′−′+= (2)(V , siendo θ el vector de multiplicadores de LaGrange considerado para introducir la condición de insesgamiento. Derivando respecto a L y θ e igualando a 0 tenemos,
0KLX
F
0XZGMVLF
=−′=∂∂
=+−=∂∂
)(2
222
θ
θL
Del primer grupo de ecuaciones podemos despejar L , )θX(ZGMVL 1 −= − , que sustituida en el segundo grupo, tenemos: 0KX(ZGMVX 1 =−−′ − )θ
)( KZGMVX(X)VX
KZGMVXXVX11
11
−′′=
−′=′−−−
−−
θ
θ
Sustituyendo la solución de θ en la ecuación en que hemos despejado L, tenemos, 111111 VXX)VXX(VZGMVXX)VX(KVZGML −−−−−−−− ′′′′−′′′+′′=′

25
, y si recordamos que, yVX)XVX(b 11 −−− ′′=ˆ , entonces, )bX(yVZGMbKyL 1 ˆˆ −′′+′=′ − , que es el BLUP de K´b+M´u, y si K´=0 y M´=I )bX(yVZGu 1 ˆˆ −′= − , resultando claro que el predictor de K´b+M´u es uMbK ˆˆ ′+′ Si ejemplificamos lo anterior con los datos que venimos utilizando desde el primer capítulo, utilizando una cualquiera de las soluciones de los efectos fijos, como,
[ ]863.7192.8670.7404.8255.25.00ˆ =b , entonces,
[ ]14.112.131.67.69.67.07.110.60.07.10.40.)ˆ( −−−−−=− bXy , y
[ ]035.0010.0016.0085.0079.0031.0048.0ˆ −−−−−=′a
3.2. Varianza de los predictores En el capítulo anterior vimos que, PXVXb 1 =′= −− )()ˆ(V Ahora vamos a calcular )ˆ(uV y para ello tendremos en cuenta que,
WyVZG)yVXXP(IVZGy)VXXP(yVZG)bX(yVZGu 111111 −−−−−− ′=′−′=′−′=−′= ˆˆ Si recordamos del capítulo anterior el resultado de las inversas generalizadas, tal que, XXVXXP 1 =′ − , resulta evidente, que 0)XVXXP(IWX 1 =′−= −

26
, y por tanto, ZGVXXPVZGZGVZGZGVWWVVZGu 11111 −−−−− ′′−′=′′=)ˆ(V La covarianza entre by u es, 0ZGVWXPZGVWVVXPu,b 111 =′′=′′= −−−)ˆˆ(Cov , y por tanto la varianza del predictor es, )MuMPKKuMbK ˆ()ˆˆ( VV ′+′=′+′ 3.3. Varianza del error de predicción Teniendo en cuenta que )ˆ(ˆ( bb)b VV =− dado que b es un efecto fijo y que,
)ˆ()ˆ()ˆ( uu,uuu, VCovCov == , )ˆ()ˆ()()ˆ()ˆ()()ˆ()ˆ( uGuuuu,u,uuuuu VVVCovCovVVV −=−=−−+=− , y ZGVXPuy,VXPu,buub,b 11 −− ′−=′−=−=−− )()ˆ()ˆˆ( CovCovCov , por lo que,
XPKVZGMZGMVXPKMu(GMPKKuu(Mbb(K 11 −− ′′−′′−−′+′=−′+−′ ))ˆ())ˆ)ˆ( VV En el ejemplo,
−−−−−−−
−−−−−−−
−−−−−−−−−−−−
=
006.007.002.015.008.004.004.007.067.035.050.062.070.008.002.035.025.030.048.051.003.015.050.030.060.064.059.005.
008.062.048.064.098.097.001.004.070.051.059.097.102.005.004.008.003.005.001.005.007.
)ˆ(aV
, y

27
=−
119.1618.627.390.242.254.504.618.933.285.300.438.070.492.627.285.975.470.048.449.503.390.300.470.940.064.441.495.242.438.048.064.902.097.001.254.070.449.441.097.898.005.504.492.503.495.001.005.993.
)ˆ( aaV
3.4. Las ecuaciones del modelo mixto El cálculo del predictor BLUP que acabamos de mostrar exige calcular la inversa de V, que en los modelos animales que mostraremos más adelante es una matriz cuya dimensión es del orden de la dimensión de y. Aunque en algunos casos la inversión queda facilitada por características de su estructura, en general la naturaleza desequilibrada de los datos y el elevado número de ellos, hace imposible o prohibitivamente costosa la inversión de V. La solución a este problema la encontró Henderson en 1949, al descubrir un sistema de ecuaciones que, al resolverlo, nos da las soluciones BLUP de u y las de mínimos cuadrados generalizados de b, que ya hemos comentado en el anterior capítulo y en este mismo. El sistema de ecuaciones es el siguiente,
′′
=
+′′′′
−
−
−−−
−−
yRZyRX
ub
GZRZZRZZRXXRX
1
1
111
11
ˆ
ˆ
, ecuaciones, que son conocidas como las ecuaciones del modelo mixto y que se resuelven, como veremos más adelante, de forma iterativa sin necesidad de invertir la matriz de coeficientes. Requieren, sin embargo, invertir la matriz R que es de la misma dimensión que V y la matriz G cuya dimensión coincide con la de los elementos de u y que, por tanto, puede ser muy elevada en algunos casos. No obstante en la mayoría de las situaciones no hay problemas serios en la inversión de estas matrices, pues R suele ser diagonal o bloque diagonal y para la matriz G en la que suele estar implicada la matriz de parentesco A existen soluciones sencillas que expondremos más adelante.
3.4.1. Demostración de la equivalencia Si volvemos al sistema de ecuaciones generado de derivar F en el apartado 3.1. de este capítulo tenemos,
=
′ K
ZGML0XXV
θ

28
Recordando que RZZGV +′= podemos reescribir el sistema anterior, como:
=
′
′ K
ZGM
LZG
L
00XZXR
θ
o
=
−′
′ K
0
GMLZG
L
00XZXR
θ
llamando GMLZGS −′= y añadiendo una nueva identidad al sistema, tenemos:
=
−′′
− MK
0
S
L
G0Z00X
ZXR
1
θ
Despejando L en el primer grupo de ecuaciones y sustituyendo en los otros tenemos,
[ ]
−−
= −−
SZRXRL 11 θ
y
=
−−
+′′′′
−−−
−−
MK
SGZRZXRZZRXXRX
111
11 θ
Llamando C a una inversa generalizada de la matriz de coeficientes del anterior sistema, que particionamos del siguiente modo,
=
zzzx
xzxx
CCCC
C
, una solución del sistema anterior la podemos expresar como,
=
−−
MK
CCCC
S zzzx
xzxxθ
, y, por tanto, el predictor de uMbK ′+′ será,

29
[ ] [ ]
′′=
′′
′′=′
−
−
ub
MKyRZyRX
CCCC
MKyL1
1
zzzx
xzxx
ˆ
ˆ
Es decir b y u que son una solución BLUP, son a la vez una solución de las ecuaciones del modelo mixto.
En los casos en que R es diagonal, es decir 2eσIR = y 2
eσI
R 1 =− , las
ecuaciones del modelo mixto pueden multiplicarse por 2eσ en ambos miembros y
escribirse del siguiente modo,
′′
=
+′′
′′− yZ
yX
ub
GZZXZZXXX
1 ˆ
ˆ2eσ
Vamos a mostrar las matrices anteriores en el ejemplo, con el objeto de comprender su significado. Así, en
=′
2000101020002000402020004022102030002020401022005
XX
, vemos que la parte formada por las tres primeras columnas es diagonal con elementos 5(número de datos de orden de parto 1), 4(datos de orden de parto 2) y 3(datos de tercer parto). Similarmente las cuatro últimas filas, con las cuatro últimas columnas forman otra matriz diagonal con el número de datos correspondientes a cada uno de los cuatro periodos de parto (4 4 2 2). Si analizamos la segunda fila vemos que hay 4 datos de segundo parto y estos se han producido: 2 en el primer periodo, 0 en el segundo, 2 en el tercero y 0 en el cuarto periodo. Es decir X´X nos indica para los distintos niveles de los efectos fijos, el número de datos existentes y como se distribuyen entre ellos. En el caso de,

30
=′
11000001100000010100001010000101110010111000002200000220010011001001100101110010111011011101101110
ZX
, cada fila de la matriz, que corresponde a un nivel de los distintos efectos fijos nos dice la distribución de datos de este nivel en relación con los niveles de los efectos aleatorios. Así, la quinta fila se refiere a los cuatro datos del segundo período que pertenecen a los animales 2, 3 ,4 y 6, uno de cada animal. Las siete primeras columnas se refieren a los siete niveles de los efectos aditivos y las siete últimas a los correspondientes efectos permanentes. Por ello, las siete primeras columnas son iguales a las siete últimas. Finalmente,
=′
1000000100000003000000300000000000000000000002000000200000003000000300000003000000300000000000000010000001000000030000003000000000000000000000020000002000000030000003000000030000003000000000000000
ZZ
, tiene 14 filas y 14 columnas (siete para los efectos aditivos de los animales y siete para los efectos permanentes), indicándonos el número de datos existentes en las distintas combinaciones de los niveles de los efectos aleatorios. En nuestro caso, dado que los dos efectos aleatorios se refieren a los mismos animales, la matriz completa se puede particionar en cuatro matrices 7 por 7 iguales entre sí y diagonales con el número de datos de cada animal en la diagonal (0 3 3 2 0 3 1).
A esta matriz hay que sumarle 2
1
2
1
21e
P
Ae σσσ
=
−
−
−
G0
0A
G , siendo

31
−−−−−−−−
−−−
−−−−−
=−
20101000001025501001010525001010000200101001000150500101002010010101051025
2
21
A
e
σσ
A
, y
[ ]67.667.667.667.667.667.667.62 diagG 1P =−
eσ Por lo que se refiere a los términos independientes de las ecuaciones del modelo mixto,
[ ]18173535303540)´( =′yX , cuyos términos representan la suma de los valores de los datos para cada nivel de los efectos fijos. Así el tercer componente, 30, es la suma de los nacidos vivos en partos de orden tres (10+11+9) o el séptimo, 18, es la suma de los nacidos vivos en el periodo cuatro(9+9). Análogamente en
[ ]9250152927092501529270)´( =′yZ , sus componentes representan los nacidos procedentes de los animales a los que se refieren los correspondientes efectos aleatorios. Así, el primer componente es 0, indicando que el primer animal no tiene datos. El componente treceavo es 25, número de nacidos vivos obtenidos en los tres partos del animal 6. Por las mismas razones que hemos explicado en Z´Z, aquí las siete primeras componentes son idénticas a las siete últimas. Una solución del sistema anterior es,
[ ]863.7192.8670.7404.8255.25.00ˆ =b [ ]035.0010.0016.0085.0079.0031.0048.0ˆ −−−−−=′a [ ]144.0150.00137.0158.0014.00ˆ −−−=′p
Respecto a las soluciones, vale la pena resaltar que:
• b′ˆ y a′ˆ coinciden con las soluciones dadas anteriormente y que lo mismo ocurriría con p′ˆ si hubiésemos mostrado la solución en el apartado 3.1.
• la suma de las estimas de los valores aditivos de los tres primeros animales, únicos de los que se desconocen sus padres y por tanto se supone que proceden de la población base, es cero.

32
• los efectos permanentes de los animales 1 y 5 que no tienen datos se estiman como cero, cosa que no ocurre con sus efectos aditivos, que se predicen utilizando la información de parientes a través de la matriz A-1.
3.4.2. Varianza de los predictores y de los errores de predicción Recordemos que,
′′
=
′′
+′′′′
=
−
−
−
−−
−−−
−−
yRZyRX
CCCC
yRZyRX
GZRZXRZZRXXRX
ub
1
1
zzzx
xzxx1
1
111
11
ˆ
ˆ
, y supongamos, para hacer más sencillas las demostraciones que siguen, que la matriz de coeficientes es de rango completo. En este caso su inversa generalizada es una verdadera inversa y, por tanto, su producto es una matriz identidad, y
−−
=
′′′′
−
−−
−−
−−
1zz
1xz
11
11
zzzx
xzxx
GCI0GCI
ZRZXRZZRXXRX
CCCC
Con todo lo anterior en cuenta,
[ ] [ ]
[ ] [ ] [ ]
[ ] xxzx
xx1xzzx
1xz
zx
xx11xzxxzx
1xz
zx
xx11
1
1
xzxx1
1
xzxx
CCC
GCICGC
CC
ZRXRZX
CCCGCCC
ZRXR
RZZGRZRX
CCyRZRX
CCbbb
=
−+
=
′′
+=
+′
′′
=
′′
=−=
−−
−−−−−
−
−
−
−
)()()ˆ()ˆ( VVV
Análogamente,
[ ] [ ] [ ]
[ ] [ ]
[ ] zzzz
xz1zzzz
zz1
zzz
x11zxzz
11zz
z
x111
1
zx1
1
zx
CGCC
GCI02C
CGCGCC
ZRXRZX
CCCG)G(IGCI
CC
ZRXRRZZGRZRX
CCyRZRX
CCu
−=
−+−
+=
′′
+−−=
+′
′′
=
′′
=
−
−−−−−
−−−
−
−
−
z
zzz
z
zzzzzVV
)(
)()()ˆ(
Como sabemos que la )ˆ(ˆ( u)uu, VCov = , entonces,
zzzz CCGGuuuu =+−=−=− )ˆ()()ˆ( VVV Asimismo, como 0u,b =)ˆˆ(Cov , entonces,

33
[ ] xz1
1
xzxx CZGRZRX
CCu,buu,b =
′′
−=−=−−
−
)ˆ()ˆˆ( CovCov
Luego la varianza de los predictores es,
−
=
zz
xx
CG00C
ub
Vˆ
ˆ
, y la varianza de los errores de predicción,
=
− zzzx
xzxx
CCCC
Vuu
bˆ
ˆ
, que son fórmulas equivalentes a las dadas en los apartados 3.2. y 3.3.
Así en nuestro ejemplo,
xxC =
−−−−−
−−−−−
−−
91.813.170.206.034.40013.127.16130.543.010070.2107.544.070.30006.030.544.022.665.05034.443.070.365.061.700
0100501000000000
, que es exactamente igual a la primera de las Inversas generalizadas de XVX 1−′ dada en el capítulo segundo, y la matriz formada por las siete primeras filas y columnas de Czz es
119.1618.627.390.242.254.504.618.933.285.300.438.070.492.627.285.975.470.048.449.503.390.300.470.940.064.441.495.242.438.048.064.902.097.001.254.070.449.441.097.898.005.504.492.503.495.001.005.993.
, que como vemos es igual a la )ˆ( aa −V dada en el apartado 3.3.

34
3.4.3. Algoritmos de resolución Una posibilidad para resolver las ecuaciones del modelo mixto podría ser hallar la inversa de la matriz de coeficientes y multiplicar los términos independientes por esta inversa. Si representamos abreviadamente el sistema de ecuaciones del modelo mixto, como vCx = , la solución al sistema sería, vCx 1−= Esta solución tiene la ventaja que C-1 representa la matriz de varianzas covarianzas de los errores de predicción, tal como hemos visto en el apartado anterior. No obstante la dimensión del sistema hace impracticable la inversión y la solución del sistema se hace por métodos iterativos. En este caso si uno está interesado en el cálculo de las varianzas de los errores de predicción, estos tienen que calcularse por métodos aproximados. Los métodos iterativos más utilizados son los que iteran sobre el sistema de ecuaciones previamente construido y los que iteran directamente sobre los datos, que se organizan en archivos ordenados de tal manera y en ocasiones de varios modos, con el fin de ir construyendo las ecuaciones, ecuación a ecuación e iteración tras iteración, conforme se van leyendo y releyendo los archivos. En estas notas únicamente explicaremos el método de Gauss-Seidel y el de Jacobi que son dos métodos iterativos del primer tipo. Explicaremos ambos a través de un sistema de tres ecuaciones y tres incógnitas. Sea este sistema,
3333232131
2323222121
1313212111
vxcxcxcvxcxcxcvxcxcxc
=++=++=++
, cuya matriz de coeficientes es simétrica definida positiva. El método de Jacobi, como hemos dicho va aproximando iterativamente la solución del sistema. Si llamamos [ ]rrr xxx 321 a la solución aproximada en la iteración r, la solución de la iteración r+1 se calcula del siguiente modo, 113132121
11 )( cxcxcvx rrr ÷−−=+
2232312121
2 )( cxcxcvx rrr ÷−−=+
3323213131
3 )( cxcxcvx rrr ÷−−=+ La solución inicial propuesta para iniciar el proceso es arbitraria y el proceso se da por terminado cuando se ha satisfecho la condición de convergencia establecida. Una condición de convergencia frecuentemente utilizada es que la suma de cuadrados de las diferencias entre la última solución y

35
la anterior dividida por la suma de cuadrados de la última sea menor que un número muy pequeño, como por ejemplo 10-9. Otras posibles, como que el máximo del valor absoluto de las diferencias entre la solución actual y la previa o la suma de cuadrados de las diferencias sean menores que una cantidad dada tienen el inconveniente de ser dependientes de la escala de medida del carácter. Como hemos visto en el método de Jacobi en la iteración r+1 únicamente se utilizan las soluciones de la iteración completa anterior, sin embargo en el método de Gauss-Seidel cuando en la iteración r+1 se calcula 1+r
ix , se utilizan las soluciones de la iteración r+1 de las incógnitas anteriores a la i, y las soluciones de la iteración r de las incógnitas posteriores. El procedimiento sería, 113132121
11 )( cxcxcvx rrr ÷−−=+
223231
12121
2 )( cxcxcvx rrr ÷−−= ++
331
2321
13131
3 )( cxcxcvx rrr ÷−−= +++ El método de Gauss-Seidel tiene asegurada su convergencia si la matriz es definida positiva o semidefinida positiva y, como en el método de Jacobi, la solución de partida puede ser arbitraria y similar la condición de convergencia. Aunque la solución inicial puede ser arbitraria, la convergencia puede acelerarse con soluciones iniciales más aproximadas a la final y con otros métodos, como el uso de factores de relajación, que no comentamos.
3.5. Pruebas de hipótesis Las pruebas de hipótesis relativas a los efectos fijos son las planteadas en el capítulo anterior si bien las fórmulas que vamos a dar, equivalentes a las ya dadas, tienen expresiones que se basan en la estructura de las ecuaciones del modelo mixto. Así, si queremos probar la hipótesis, 0cbK =−′ , calcularemos s como, )ˆˆ( cbK(K)CK()cbK 1
xx −′′′−′= −s , y SCE, como, yRZuyRXbyRy 111 −−− ′′−′′−′= ˆˆSCE , que es fácil demostrar su equivalencia con la SCE calculada en el capítulo anterior, como, yVXbyVy 11 −− ′′−′= ˆSCE
El estadístico F del test será,

36
))(/(
)(/X
KrNSCE
rsF
−′
=
Si repitiésemos con estas fórmulas los test de prolificidad hechos en el capítulo 2 tendríamos exactamente los mismos resultados.

37
GENÉTICA CUANTITATIVA II EL MODELO ANIMAL
1. El modelo y las ecuaciones del modelo mixto En los programas de selección de los animales, basados en los efectos aditivos de los genes, el punto central de la evaluación es la predicción del valor aditivo de cada animal para los caracteres objeto de selección. Un modo de obtener estas predicciones es plantear modelos que expliquen los datos en los que se incluye el valor aditivo de los animales que producen los datos, con independencia de la consideración de cuantos efectos fijos se deban incluir y de otros efectos aleatorios. La consideración de modelos animales en los programas de selección actuales se ha ido extendiendo progresivamente en las distintas especies animales, con particular intensidad en la década de los noventa, en la que la disponibilidad pública de programas y de capacidad de cálculo suficiente ha hecho posible su uso casi generalizado. En el caso de que se consideren varios caracteres a la vez el modelo es multicarácter y las exigencia de cálculo son mucho mayores. En principio, salvo que se usen técnicas especiales las necesidades de cálculo en una situación n-carácter son n3 las de una unicarácter. En este capítulo nos vamos a centrar en la predicción del valor aditivo de los animales de los que se dispone de datos y de sus parientes, considerando únicamente un carácter. Por otra parte, por el momento, el único factor aleatorio que tendremos en cuenta, además del residual, será el valor aditivo de los animales. En este modelo o en ampliaciones de este modelo se basan los programas de mejora genética de vacuno lechero y de carne, de ovinos, de cerdos, de aves, de conejos y de otras especies en numerosos países y compañías de mejora. En la forma básica que hemos indicado, el modelo se escribiría, así,
eZaXby ++=
, en el que el significado de los términos, en general, ya se han explicado, y ahora únicamente precisaremos algunas particularidades. El vector de observaciones y se refiere a un único carácter cuya varianza aditiva es 2
Aσ y la varianza fenotípica 2Pσ es 22
eA σσ + . Es decir en e, residual del modelo, se consideran los efectos ambientales y los genéticos no aditivos. El vector a representa los valores aditivos de los animales que producen los datos y de sus parientes. En este modelo se asume que, 2)( AV σAGa == , siendo A la matriz con los coeficientes de parentesco multiplicados por dos, entre los animales a los que se refieren los elementos de a. También se asume que,

38
2)( eV σIRe == , y que la 0ea, =)(Cov
Llamando 2
2
2
2 1h
h
A
e −==
σσ
α , podemos escribir las ecuaciones del modelo
animal de la siguiente manera,
′′
=
+′′
′′− yZ
yX
ub
AZZXZZXXX
1 ˆ
ˆ
α
La construcción de este sistema de ecuaciones únicamente presenta el problema del cálculo de 1−A , que puede implicar a un muy elevado número de animales y por tanto podría presentar las mismas dificultades que el cálculo de
1−V . Esto podría ser un problema que limitase la utilización del BLUP en cualquiera de sus procedimientos de resolución. No obstante en 1975 Henderson demostró que el cálculo de 1−A podía hacerse directamente a partir de una genealogía completa de los individuos de los que se tienen datos y de sus antecesores hasta la población base. Esto se hace de manera sencilla y poco costosa según unas reglas, que explicaremos en el siguiente apartado, que no necesitan el cálculo previo de A, que si se tuviese que calcular sería muy costoso en tiempo de cálculo y memoria de almacenamiento. De hecho cuando en la población hay individuos consanguíneos el cálculo de 1−A exige el cálculo previo de la diagonal de A que es 1+F, y es la parte realmente exigente en cálculo. El vector F representa los coeficientes de consanguinidad de los individuos a los que se refiere a. Advirtamos que por este procedimiento se pueden predecir los valores aditivos de individuos de los que no se tienen datos, como ya se vio en el ejemplo del capítulo anterior. Así se pueden evaluar, por ejemplo, toros para el carácter producción de leche por los datos de todos sus parientes, especialmente de sus hijas que es lo que constituye la prueba de descendencia del toro. También puede hacerse una valoración, aunque poco precisa, de animales no nacidos de apareamientos que pueden o no programarse para, por ejemplo, obtener machos candidatos a una prueba de descendencia. Por otra parte como se calcula a para todos los individuos desde la fundación de la población hasta el momento actual, la curva que representa las medias de los valores aditivos predichos de los individuos nacidos en un momento t, frente a t, puede interpretarse como la expresión de la tendencia genética de la población y por tanto como un indicador de la respuesta que se está obteniendo en el programa de selección. Esta forma de calcular la tendencia genética de una población puede ser errónea si el modelo no es correcto y si la 2h no es la correcta. Actualmente, las compañías que utilizan el BLUP como método para evaluar sus animales utilizan esta forma

39
de calcular la respuesta al programa de selección con fines propagandísticos comerciales, generalmente de modo poco crítico e intentando deslumbrar a los posibles compradores de sus animales. Advirtamos, que la tendencia genética calculada a partir de las soluciones BLUP es muy sensible a la 2h considerada como verdadera para el carácter y, aunque el modelo fuera correcto, se sobreestimaría la respuesta obtenida en el programa de selección si se utilizase una 2h superior a la verdadera. 2. Consideración del parentesco, matrices A y 1−A Recordemos que la matriz de parentesco A está compuesta por elementos ija cuyo significado es el doble del coeficiente de parentesco entre los
individuos i y j, definido el coeficiente de parentesco en términos de identidad de genes por descendencia. Es como lo hizo Malécot, si bien Wright lo hizo como la correlación entre los valores aditivos de los individuos, en cuyo caso dicho coeficiente es,
5.0)( jjii
ij
aaa
, por lo que a A se le suele llamar la matriz del numerador del parentesco, pues tiene los numeradores de los coeficientes de parentesco de Wright, que son los pertinentes para el cálculo de las covarianzas entre los valores aditivos de los distintos animales. Aunque, como ya se ha dicho, el cálculo de A es costoso en tiempo de cálculo y de memoria de ordenador, sin embargo las fórmulas de cálculo son sencillas. Una de las fórmulas más importantes es la que relaciona el coeficiente de parentesco entre dos individuos y los de los padres de uno de los individuos con el otro, )(5.0 idisij aaa +=
, para ji ≠ , s y d padres de j y no siendo j un ascendiente de i. La fórmula anterior, junto con la que relaciona el parentesco de un individuo consigo mismo, sdjjj aFa 5.011 +=+=
, permiten calcular A recurrentemente cuando los individuos están ordenados de tal manera que siempre los padres precedan a sus descendientes. Aunque nuestro interés está en A-1 es conveniente analizar la estructura de A para entender de forma más sencilla como abordar el cálculo de A-1. Para ello vamos a estudiar la factorización de A. 2.1. Factorización de A

40
Dada la naturaleza de A, que cuando no hay individuos que sean gemelos monocigóticos o de un mismo clon es simétrica definida positiva, o si los hay es simétrica semidefinida positiva, es posible hacer la descomposición de Cholesky, tal que, LLA ′= , siendo L el factor de Cholesky que es una matriz triangular inferior. También podría expresarse como, TTDA ′= , siendo T una matriz triangular inferior con 1´s en la diagonal y D una matriz diagonal. Las relaciones entre ambas son, 5.05.0
iiiiiiii ddtl == y 5.0jjijij dtl =
A continuación vamos a ver el significado de los términos anteriores. Para ello vamos a relacionar el valor aditivo de un animal con los de sus padres, en el caso de que éstos se conozcan. En el caso de que alguno de ellos o los dos se desconozcan, asumiremos que pertenecen a la población base de la que se originaron los individuos que estamos considerando y que los individuos de la población base no están emparentados entre sí, y no son consanguíneos. Así, si de un individuo j conocemos sus padres s y d podemos escribir, jdsj aaa φ++= 5.05.0
, siendo jφ la diferencia del valor aditivo del individuo j, respecto a la media de
sus padres. Es una variable independiente entre individuos e independiente de los valores de los padres. Calculando varianzas en la fórmula anterior tenemos que,
22
222
))(25.05.0(
)2)1()1((25.0)1(
Ads
sddsAAj
FF
aFFF
σσ
σσσ
φ
φ
+−=
+++++=+
, ya que sdj aF 5.0=
En el caso de que se conozca un solo padre,
)25.075.0(
)1(25.0
5.0
22
222
dA
AdA
jdj
F
F
aa
−=
++=
+=
σσ
σσσ
φ
φ
φ
, ya que en este caso 0=jF , pues se asume que sus padres no están
emparentados.

41
Cuando no se conoce ninguno de los padres,
22A
jja
σσ
φ
φ =
=
, y como en el caso anterior, 0=jF . Las fórmulas escalares anteriores de relación
entre valores aditivos de los individuos con los de sus padres conocidos los podemos expresar vectorialmente así, φ+= Paa 5.0 , en donde P es una matriz cuadrada que indica los padres de los individuos. A cada individuo le corresponde una fila, que únicamente tiene ceros si ningún padre es conocido, tiene un uno en la columna del padre conocido cuando solo se conoce uno, o tiene dos unos en las posiciones de los padres si ambos se conocen. Para el ejemplo que venimos comentando desde el primer capítulo,
=
0110000000010100000110000011000000000000000000000
P
, y es patente que con la ordenación de individuos que hemos comentado anteriormente P es triangular inferior, con 0´s en la diagonal. Ahora vamos a manipular la ecuación vectorial anterior para expresar a en
función de φ , recordando que los componentes de son independientes y que por tanto, 2)( AV σφ D= , siendo, )(25.05.0 dsjj FFd +−= , si ambos padres son conocidos,
djj Fd 25.075.0 −= , si solo se conoce un padre y
1=jjd , si no se conoce ningún padre.
Haciendo lo que queríamos hacer,

42
2112
1
)5.0()5.0(.)(
)5.0(
)5.0(
AAV σσ
φ
φ
−−
−
′−−==
−=
−=
PIDPIAa
PIa
aPI
, es decir, 11 )5.0()5.0( −− ′−−=′= PIDPITTDA Es interesante conocer el significado de las distintas potencias de P, ya que, kk PPPIPIT 5.0....5.05.0)5.0( 221 +++=−= − , siendo k el número máximo de generaciones que hay entre una pareja de antecesor-descendiente. Para visualizarlo vamos a recurrir al ejemplo que venimos utilizando. Ya se ha indicado que P representaba los padres de los individuos. Análogamente las filas de P2 representan los abuelos del individuo al que se refiere la fila. Si un individuo tiene un doble abuelo en la columna correspondiente aparecerá un 2. Las filas de P3 representan los bisabuelos y así sucesivamente. En el ejemplo,
=
0000112000000000000000000000000000000000000000000
2P
, que nos muestra que en la genealogía que consideramos el único individuo que tiene abuelos conocidos es el 7 y que estos son el 1 por partida doble ya que es el padre de sus dos padres y los individuos 2 y 3. La matriz P3 es nula, pues en nuestro caso de ningún individuo se conocen los bisabuelos y, correspondientemente, son nulas las potencias superiores de P. En el ejemplo k=2, pues la máxima distancia entre un ascendiente y un descendiente es entre un abuelo y un nieto. De la fórmula de T, en función de las potencias de P, se deduce que el significado de ti j es la contribución esperable de genes del individuo j al individuo i. Por otra parte esta fórmula nos muestra que los términos de T pueden calcularse recurrentemente del siguiente modo,

43
)(5.0
1
dmsmjm
jj
ttt
t
+=
=
En el ejemplo,
=
15.5.025.25.5.01005.05.001005.5.000105.5.000010000000100000001
T
El cálculo de los elementos de D lo demoraremos al apartado siguiente. 2.2. Cálculo de 1−A Si recordamos que, 11 )5.0()5.0( −− ′−−= PIDPIA , entonces,
PDPPDDPDPIDPIA 11 −−−−−− ′+−′−=−′−= 25.05.05.0)5.0()5.0( 1111
que muestra que 1−A puede calcularse con facilidad si se conoce D, a través de la lista de los animales incluidos en a, ordenados tal como hemos dicho anteriormente e incluyendo los animales necesarios de la población base. Así, la contribución del animal j a 1−A sería, a través de D-1, 1−
jjd a aj j (los términos de 1−A los expresamos con supraíndices)
, a través de 15.0 −′DP y PD 15.0 − , -0.5 1−
jjd a ajs, ajd, asj,y adj
, y a través de PDP 125.0 −′ 0.25 1−
jjd a ass, asd, ads, y add
Esto en caso de que se conozcan s y d, padres de j. Si se desconoce alguno desaparecen los términos correspondientes a ese padre y si se desconocen los dos, el único término que se conserva es la aportación a aj j que

44
como hemos visto era 1−jjd . En cualquier caso, contrariamente a lo que ocurre con
A, que conforme pasan las generaciones la mayoría de los individuos son parientes y, por tanto, las filas de A se van ocupando por elementos no nulos, en el caso de A-1 los únicos elementos no nulos fuera de la diagonal son aquéllos que relacionan padres con hijos y parejas que han tenido descendencia. Ahora vamos a tratar el cálculo de dj j que, como hemos visto anteriormente, depende de la consanguinidad de sus padres y del número de padres conocidos.
2.2.1. Ignorando la consanguinidad En poblaciones muy grandes, en las que se intenta, además, evitar el apareamiento entre parientes, los individuos son en su mayor parte no consanguíneos y los que lo son tienen coeficientes de consanguinidad bajos. En estos casos, el cálculo de la matriz A-1 se simplifica mucho si se asume que todos los individuos son no consanguíneos. En este caso los valores de d j j y 1−
jjd serían,
dj j=0.5 ( 1−
jjd =2),si ambos padres son conocidos
dj j=0.75 (341 =−
jjd ), si sólo un padre es conocido, y
dj j=1−
jjd =1, si no se conoce ningún padre.
En nuestro ejemplo ningún padre es consanguíneo, únicamente lo es el individuo 7, que no tiene descendencia, por lo que podemos aplicar los resultados anteriores para calcular A-1. Así los individuos 1, 2 y 3 cuyos padres son desconocidos, aportarán respectivamente a a11, a22 y a33 un 1. El individuo 4 hijo de 1 y de 2 aportará un 2 al elemento a44, un -1 a los elementos a41, a42, a14 y a24, y un
0.5 a a11,a12,a21 y a22 Las contribuciones del individuo 5 son, 2 al elemento a55, un -1 a los elementos a51, a52, a15 y a25, y un
0.5 a a11,a12,a21 y a22 Las del individuo 6, 2 al elemento a66, un -1 a los elementos a61, a63, a16 y a36, y un
0.5 a a11,a13,a31 y a33

45
Finalmente el individuo 7 contribuirá con un,
2 al elemento a77, un -1 a los elementos a75, a76, a57 y a67, y un
0.5 a a55,a56,a65 y a66 Los elementos resultantes no nulos serían:
a11=1+0.5+0.5+0.5=2.5 a21=0.5+0.5=1 a22=1+0.5+0.5=2 . . . a75=-1 a76=-1 a77=2 Escribiendo la matriz A-1 completa tenemos,
−−−−−−−−
−−−
−−−−−
=−
211000015.25.0010115.05.20011
000201101005.105.0001102101115.015.2
1A
2.2.2. Considerando la consanguinidad Como ya hemos comentado anteriormente, en 2.1., el cálculo de jjd exige
el cálculo del coeficiente de consanguinidad de los padres conocidos de j, que desde un punto de vista de necesidades de cálculo es la parte más exigente para el cómputo de A-1. En 1976 Quaas propuso un algoritmo para dicho cálculo, que tenía su fundamento en la consideración de que el cálculo sucesivo de las columnas de la matriz L y la acumulación de sus cuadrados por filas permitía el cálculo de los elementos de la diagonal de A y, por tanto, de los coeficientes de consanguinidad de los individuos. Recordemos que,
LLA ′=
y por tanto,

46
222
21
233
232
231333
222
221222
211111
.....1
.1
1
1
iiiiiii lllFa
lllFa
llFa
lFa
+++=+=
++=+=
+=+=
=+=
El algoritmo exige la consideración de dos vectores de trabajo de longitud igual al número de animales en a. En uno de los vectores se acumulan las sumas de cuadrados, por filas, de los elementos de las columnas de L que sucesivamente se van calculando. En el otro se tienen los elementos de la columna de L que se está calculando de acuerdo a las fórmulas mostradas en 2.1., que relacionaban los términos de L con los de T y D. Es decir, )(5.0)(5.0 5.05.05.0
disiiidiiisiiijiji lldtdtdtl +=+==
, y
∑ ∑= =
−−=−−==s
m
d
mdmsmddssjjjj llaadl
1 1
5.0225.05.0 )25.025.01()25.025.01(
El procedimiento que acabamos de describir requiere, cuando se consideran n animales, el cálculo de n(n+1)/2 elementos de L, lo que nos da una idea de las exigencias de cálculo implícitas, pero tiene el inconveniente de adaptarse mal a la situación de incorporación de nuevos animales. La razón es que los cálculos tendrían que repetirse totalmente, calculando de nuevo todos los elementos de cada columna y sus sumas de cuadrados por filas. En 1992 Meuwisen y Luo propusieron otro algoritmo para calcular jjd que se adapta mejor
a la incorporación de nuevos animales al archivo de datos. La idea es calcular los elementos de L, fila por fila, apoyándonos en la relación de L, con T y D y en el hecho de que cuando abordamos el cálculo de la fila j de L los elementos de D necesarios están relacionados con filas anteriores de L y, por tanto, están previamente calculados. Para comprender este algoritmo recordemos la forma recursiva de calcular T,
)(5.0
1
dmsmjm
jj
ttt
t
+=
=
, y nuevamente la relación de L con T y D, 5.0
iijiji dtl =
5.0jjjj dl =
Con estas fórmulas en mente, resulta claro que los únicos elementos no nulos de la fila j de L, son los que corresponden a los ascendientes del individuo j

47
y el de la diagonal principal. El algoritmo consiste en crear tres vectores de trabajo que podemos llamar j, t y d que se van construyendo recurrentemente al considerar, primero el individuo j, el jjt y el jjd , luego los padres de j,
componentes para el cálculo de los elementos de éstos en la fila j de T y los correspondientes elementos de la diagonal de D. Luego los abuelos y antecesores sucesivos, hasta llegar a la generación base. Veámoslo con la genealogía del ejemplo de la prolificidad, en el que vamos a calcular 77a . Por los cálculos previos sabemos que,
1332211 === ddd ; 5.0665544 === ddd ; 1665544332211 ====== aaaaaa ; 0654321 ====== FFFFFF y
5.025.025.05.0 5677 =−−= FFd Así, empezamos el algoritmo para la fila 7 de L, con el individuo 7, con lo que j, t y d, serán: j t d 7 1 0.5=d77 , a continuación añadimos los padres de 7 a j, 0.5 a t y los d´s correspondientes a d. j t d 7 1 0.5=d77 6 0.5 0.5=d66 5 0.5 0.5=d55 , ahora añadimos a j los padres de 6 y 5 , a t 0.25 y a d los correspondientes d´s. j t d 7 1 0.5=d77 6 0.5 0.5=d66 5 0.5 0.5=d55 1 0.25 1=d11 3 0.25 1=d33 1 0.25 1=d11 2 0.25 1=d22 El algoritmo continuaría añadiendo los padres de los últimos cuatro componentes de j, poniendo en t, 0.125 y en d los d´s. Sin embargo, esta fase del algoritmo se interrumpe aquí, pues los últimos cuatro componentes de j, (1 3 1 y 2), son animales de la población base de los que desconocemos sus padres. La

48
siguiente fase, consiste en sumar los elementos de t, que corresponden a elementos idénticos de j, j t d 7 1=t77 0.5=d77 6 0.5=t76 0.5=d66 5 0.5=t75 0.5=d55 3 0.25=t73 1=d33 2 0.25=t72 1=d22 1 0.5=t71 1=d11 La última parte consiste en calcular,
125.115.0125.0125.05.05.05.05.05.01)1( 222222777 =×+×+×+×+×+×=+= Fa
apoyándonos en la fórmula,
∑∑==
==j
iiiji
j
ijijj dtla
1
2
1
2
La eficiencia de este algoritmo depende del número de generaciones existente en cada genealogía, disminuyendo conforme aumenta dicho número. Para aumentar la eficacia, el coeficiente de consanguinidad obtenido para un individuo es el mismo que para sus hermanos de padre y madre, por lo que éstos no necesitan ser reprocesados. En situaciones de 3 o 4 generaciones el algoritmo es muy rápido y la memoria que necesita es baja, comparada con otros algoritmos propuestos, como el que en 1990 propuso Tier. En 1995, Quaas, propuso una modificación del algoritmo de Meuwissen y Luo, basada en las igualdades,
∑ ∑===k k
kkdkskdksksdj dttllaF2 , en el que índice k de sumación es
únicamente para los antecesores comunes de los padres de j. Este algoritmo procede para las filas s y d, como el de Meuwissen y Luo para la fila j, pero conservando en los respectivos vectores de trabajo que identifican los individuos ascendientes, solamente aquéllos comunes a ambos padres.

49
GENÉTICA CUANTITATIVA II EL PROBLEMA DE LA POBLACION BASE
1. El modelo animal con grupos genéticos En los modelos mixtos una hipótesis básica es que la esperanza de los efectos aleatorios es cero, incluso para los valores aditivos. Cuando una población es sometida a selección, evidentemente la hipótesis anterior no se cumple para todos los animales, pues, si hay respuesta, los individuos de las generaciones sucesivas tendrán una esperanza de su valor aditivo que irá variando en función de la respuesta esperable. Si el programa de selección tiende a aumentar el valor genético del carácter, los individuos resultantes de varios ciclos de selección tenderán a tener esperanzas positivas y lo contrario si el programa tendiese a reducir el carácter objeto de selección, tal como sería el caso en cerdos en que se intenta disminuir la grasa dorsal y el índice de conversión de los alimentos en carne magra. En principio, la aparente violación de esta hipótesis no es un problema si en el vector de datos están presentes todos aquéllos que han servido para tomar las decisiones de selección y además se dispone de la genealogía completa de los animales, con la excepción de los que forman parte de lo que hemos llamado población base. La condición esencial de un animal para que forme parte de la población base es que sea una muestra al azar de una población homogénea en la que los valores aditivos de los animales se distribuyen con media cero y varianza σ A
2 . Para un animal j de esta población que no tuviese descendientes la predicción de su valor aditivo sería, $ ( )a h yj j j= −2 µ
En el caso de que este animal j no pertenezca a la población base sino a
una generación avanzada de selección y se conoce la genealogía completa y los datos sobre los que se han tomado las decisiones de selección, el método BLUP tiene en consideración la información anterior y como ya hemos visto en los dos capítulos anteriores considera que a j se muestrea de una población cuya
media es la media de los valores aditivos de los padres y varianza la del correspondiente muestreo mendeliano. A través de este mecanismo, implícito en la matriz de parentesco de los animales, el método BLUP no necesita que la esperanza de los valores aditivos sea cero para los animales que no son de la población base. Si el animal j fuese realmente un animal cuyos padres nos son desconocidos y una muestra al azar de otra población que la que hemos tomado como base, si no tomamos en consideración la diferencia genética entre ambas poblaciones se haría una predicción incorrecta del valor genético de este animal y de sus descendientes. En lugar de la fórmula anterior, si llamamos g a la diferencia entre la media genética de la población de la que procede el individuo j y la de la población base general, la fórmula sería,
)y(hgga jj
2j µ−+=+

50
, es decir la regresión del valor fenotípico, corregido por los efectos fijos, para calcular el valor genético no se haría respecto a cero sino respecto a g. En experimentos de comparación de diferentes razas o líneas de animales, estamos en la situación clara en que si dentro de raza o línea las genealogías son completas, los animales del origen pertenecerán a poblaciones base diferentes. El procedimiento para tratar esta situación es inmediato, basta con introducir un nuevo factor fijo que llamaremos raza, línea, o grupo genético con tantos niveles como razas o líneas estemos comparando. El modelo lo escribiríamos como,
eZagXbXy 21 +++=
, donde g es el factor fijo en el que se contemplan los distintos efectos de los grupos genéticos. En este caso la matriz de parentesco A es bloque diagonal, refiriéndose cada bloque a los animales de un mismo grupo genético. La construcción de las ecuaciones del modelo mixto y su resolución no tienen ningún problema, correspondiendo completamente con lo explicado en los dos capítulos anteriores. Normalmente en esta situación, el interés radica, fundamentalmente, en la comparación de los grupos genéticos entre si, planteándose pruebas o contrastes de diferencias entre las razas o líneas del experimento. En el capítulo tercero de estas notas se ha explicado como realizar estos contrastes. Una situación distinta se suele plantear en el curso de los programas de selección de algunas especies, cuando la población que se selecciona no está cerrada reproductivamente, es decir hay inmigraciones de animales de otras poblaciones y países o hay fallos en la genealogía. En este caso, de animales de la población, resultantes del proceso de selección seguido, se desconoce uno o ambos padres, que no pueden ser considerados como muestras aleatorias de la población base general. La inmigración puede producirse, de una forma más o menos regular, en cualquier programa de mejora de cualquier especie. La situación de genealogías incompletas es común en las poblaciones de vacuno lechero y en programas similares, en las que la población que se selecciona es la suma de los rebaños de numerosos ganaderos. En estos casos un ganadero puede decidir inseminar a alguna de sus hembras con semen de un macho extranjero del cual es imposible rastrear su genealogía y los datos correspondientes, una determinada ganadería puede incorporarse a un programa de selección con animales con control genealógico incompleto o en las ventas de animales entre ganaderías puede haberse perdido la genealogía. La diferencia frente a la primera de las situaciones expuestas radica en que los animales que pertenecen a un grupo genético se van a reproducir entre si, y van a originar descendencia en cuya composición genética van a participar los diferentes grupos genéticos en proporciones determinadas. A su vez tendrán descendientes con diferentes proporciones de los genes de los diferentes grupos y así sucesivamente. Esto plantea la cuestión de considerar en el modelo, para cada individuo, su composición genética respecto a los grupos genéticos, a través de

51
una matriz de incidencia Q, que relaciona grupos genéticos con individuos. Así, las ecuaciones del modelo serían, y Xb ZQg Za e= + + + , siendo a el vector de valores aditivos de los animales referidos a las medias genéticas, Qg, definidas por la proporción de cada grupo genético que componen los animales. Esto significa que el valor genético que interesa predecir y sobre el que habrá que tomar las decisiones de selección es, Qg a+
El cálculo de Q en sí misma, y los cálculos en que ésta participa pueden ser complicados. En 1988 Westell, Quass y Van Vleck mostraron que el problema anterior se simplificaba enormemente con la consideración de lo que llamaron padres fantasmas y la asignación de éstos a grupos genéticos definidos. La idea consiste en asignar un padre o madre fantasma a aquellos individuos cuyo padre o madre se desconozca. Se asume que un padre fantasma únicamente tiene un descendiente y que los padres fantasmas son independientes entre sí. La asignación de los padres fantasmas a grupos genéticos pretende identificar poblaciones de las que los padres fantasmas constituyen muestras al azar. Así, en vacuno lechero, cuando no hay inmigración de genes foráneos en una población y las carencias de genealogía se deben a fallos de registro, se ha tomado como criterio el año presumido de nacimiento del padre fantasma y si éste es padre o madre de un macho o de una hembra. Esto en atención a que el nivel genético de las poblaciones de las que proceden los padres de los toros, los padres de las vacas, las madres de los toros o las madres de las vacas son distintos entre sí, en función de las distintas intensidades de selección y precisiones de evaluación correspondientes a cada vía. La media de estas poblaciones va evolucionando con el tiempo y el presunto año de nacimiento de un padre fantasma dependerá del año de nacimiento del hijo y del intervalo generacional de la vía correspondiente. Vamos a ejemplificarlo, con la siguiente genealogía en la que P j significa padre fantasma j ,
Individuo Padre Madre Año na-
cimiento Sexo
1 P1 P2 1980 1 2 P3 P4 1982 2 3 P5 P6 1983 2 4 1 2 - - 5 1 2 - - 6 1 3 - - 7 5 6 - - 8 5 6 - -
si el intervalo generacional de las diferentes vías de transmisión de los genes fuese,
• 10 años para la vía padre-hijo

52
• 9 años para la vía padre-hija • 3 años para la vía madre-hijo, y • 5 años para la vía madre-hija
, los presuntos años de nacimiento de los padres fantasma y los correspondientes grupos genéticos, bajo el supuesto de que cada dos años consecutivos de una misma vía se consideren un mismo grupo, serían, Individuo Año na-
cimiento Grupo
genético P1 1970 G1 P2 1977 G2 P3 1973 G3 P4 1977 G4 P5 1974 G3 P6 1978 G4
En el caso de que se produzca inmigración de individuos, la definición de grupos genéticos debería tener en cuenta el lugar de origen del individuo inmigrante, su sexo y su año de nacimiento. Vamos a explicar ahora como la consideración de los padres fantasma ayuda al cálculo de Q, en caso de que ello fuese necesario, pues como veremos más adelante, el cálculo de las ecuaciones del modelo mixto no requerirá dicho cálculo. Empezaremos definiendo una matriz Qf que relaciona los padres fantasmas con los grupos genéticos. Será una matriz de tantas filas como padres fantasma y tantas columnas como grupos. En la fila correspondiente a un padre todo serán ceros, salvo un 1 en la posición correspondiente al grupo que pertenece el padre fantasma. En el ejemplo anterior,
=
100001001000010000100001
fQ
[ ]4321 gggg=′g
Si llamamos, aa =i , al vector de valores aditivos de los animales
identificados (no fantasmas) y fa al correspondiente de los padres fantasma, podemos definir,

53
=
iaa
a ft
En concordancia con los anteriores vectores podemos definir las matrices
de parentesco, iii AAA == , IAA == fff y
=
AAAI
Aif
fit ,
)d()d( jjiijji∗=≠== diagDdiagDD , no coincidiendo D y iiD porque en la última
todos los individuos identificados tienen ambos padres en la genealogía, debido a la inclusión de los padres fantasma. )1(fff diagIDD === , [ ])d()1( jjt
∗= diagdiagdiagD ,
iii TTT == , ITT == fff , y
=
TT0I
Tif
t
Si recordamos el significado de la matriz T visto en el capítulo cuatro, es evidente que ifT es la matriz que expresa la participación de los padres fantasma en el genotipo de los individuos identificados, y como fQ relaciona a padres fantasma con grupos, la matriz Q que relaciona individuos identificados con grupos genéticos será,
fif QTQ =
En el ejemplo,
=
125.125.125.125.25.25.125.125.125.125.25.25.25.25.0025.25.0025.25.25.25.0025.25.25.25.5.5.0000005.5.0000005.5.
ifT
y

54
=
25.025.025.025.025.025.025.025.025.025.025.025.025.025.025.025.025.025.025.025.05.05.0005.05.000
005.05.0
Q
Para cálculos posteriores será útil la siguiente relación,
[ ] ifjj
ifif )d()1(
T0I
diag00diag
TTA =
= ∗
2. Ecuaciones del modelo En el apartado anterior hemos escrito la ecuación del modelo, y Xb ZQg Za e= + + + y se ha explicado el significado de sus componentes. De la anterior expresión se derivan directamente las ecuaciones del modelo mixto,
′′′
′
=
α+′′′′′′′′′
′′′
− yZyZQ
yX
agb
AZZZQZXZZZQZQZQXZQ
ZXZQXXX
ˆˆ
ˆ
1
Es conveniente modificar el sistema anterior atendiendo a que nuestro interés radica más en predecir aQg + que a . Esto puede conseguirse, manteniendo la simetría del sistema utilizando la matriz,
=
IQ00I0
00I
P
, su inversa,
−=−
IQ00I0
00I
P 1
, y realizando las siguientes operaciones,

55
′′′
′′=
α+′′′′′′′′′
′′′′ −−
−
−
yZyZQ
yXP
agb
PPAZZZQZXZZZQZQZQXZQ
ZXZQXXXP )(
ˆˆ
ˆ
)( 11
1
1
cuyo resultado es
′
′
=
+
α+′α−′α′−α′
′′
−−
−−
yZ0yX
agQgb
AZZQAXZAQQAQ0ZX0XX
ˆˆˆ
ˆ
11
11
En 1988 Westell, Quass y Van Vleck mostraron, a través de la consideración de los padres fantasmas, que el cálculo de α′ − QAQ 1 y α′− −1AQ se puede hacer de una forma sencilla, sin necesidad de calcular previamente Q y
1−A , siguiendo unas reglas análogas a las de Henderson para el cálculo de 1−A . Seguidamente mostramos estas reglas y las aplicamos al ejemplo. Recordemos que α′ − QAQ 1 es la parte de las ecuaciones del modelo mixto que relaciona grupos genéticos con grupos genéticos y α′− −1AQ , relaciona grupos genéticos con individuos identificados. Las aportaciones a los coeficientes de estas partes de las ecuaciones proceden de los animales que tienen al menos un padre fantasma. Así, si tenemos un individuo j, hijo de s y de una madre fantasma que
pertenece al grupo genético Gd, si s no es consanguíneo, 34
d 1jj =− y las
aportaciones serían -0.66α a los elementos (j,Gd) y (Gd, j), y 0.33α a los elementos (s,Gd), (Gd,s) y (Gd, Gd) Si los dos padres del individuo j son fantasmas de los grupos Gs y Gd, entonces, 1d 1
jj =− y las aportaciones serían,
-0.5 α a los elementos (j,Gd), (j, Gs), (Gd, j) y (Gs, j), y 0.25α a los elementos (Gd, Gd), (Gs, Gs), (Gd, Gs) y (Gs, Gd) Individuo Padre-
Grupo Madre-Grupo
1 G1 G2 2 G3 G4 3 G3 G4 4 1 2 5 1 2 6 1 3 7 5 6 8 5 6

56
Es decir el calculo de 1jjd− sigue las reglas de Henderson en función de los
padres realmente conocidos del individuo j, y se siguen aplicando dichas reglas sustituyendo los padres fantasmas (realmente no conocidos), por los grupos genéticos a los que pertenecen. Así en el ejemplo, para 4=α , La contribución del animal 1, sería: -2 a (1,G1 ), (1,G2), (G1,1) y (G2,1) y 1 a (G1,G1),(G2,G2),(G1,G2)y (G2,G1), la contribución del animal 2, sería: -2 a (2,G3 ), (2,G4), (G3,2) y (G4,2) y 1 a (G3,G3),(G4,G4),(G3,G4)y (G4,G3), y la contribución del animal 3, sería: -2 a (3,G3 ), (3,G4), (G3,3) y (G4,3) y 1 a (G3,G3),(G4,G4),(G3,G4)y (G4,G3) Por lo que la matriz de coeficientes del modelo mixto sería la misma que la indicada en el ejemplo del capítulo anterior, antes de aplicar la simplificación del modelo animal reducido, ampliada con las filas y columnas correspondientes a los grupos genéticos.
4 0 2 2 0 0 0 0 1 1 1 1 0 0 0 0 0 4 2 2 0 0 0 0 0 0 0 0 1 1 1 1 2 2 4 0 0 0 0 0 1 0 0 1 1 0 1 0 2 2 0 4 0 0 0 0 0 1 1 0 0 1 0 1 0 0 0 0 1 1 0 0 -2 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 -2 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 0 -2 -2 0 0 0 0 0 0 0 0 0 0 0 2 2 0 -2 -2 0 0 0 0 0 1 0 1 0 -2 -2 0 0 11 4 2 -4 -4 -4 0 0 1 0 0 1 0 0 -2 -2 4 9 0 -4 -4 0 0 0 1 0 0 1 0 0 -2 -2 2 0 7 0 0 -4 0 0 1 0 1 0 0 0 0 0 -4 -4 0 9 0 0 0 0 0 1 1 0 0 0 0 0 -4 -4 0 0 13 4 -4 -4 0 1 0 1 0 0 0 0 -4 0 -4 0 4 13 -4 -4 0 1 1 0 0 0 0 0 0 0 0 0 -4 -4 9 0 0 1 0 1 0 0 0 0 0 0 0 0 -4 -4 0 9
Como los grupos genéticos son efectos fijos, las ecuaciones que les corresponden mantienen relaciones de dependencia lineal con otros grupos de ecuaciones de otros efectos fijos y, en la forma modificada que hemos presentado, lo anterior se traduce en que las ecuaciones son homogéneas, es decir, sus términos independientes son cero, lo que crea un sistema compatible indeterminado que exige para su solución alguna restricción a las soluciones y la comprensión de qué funciones estimables representan las soluciones de los grupos. En los animales con ambos padres desconocidos puede darse una confusión completa entre el grupo del padre y el de la madre lo que genera un problema para obtener las soluciones. La experiencia personal de Schaeffer le sugirió la solución de añadir α a las diagonales de las ecuaciones de los grupos genéticos en las ecuaciones modificadas finales que hemos presentado. Este

57
procedimiento elimina automáticamente la confusión, aunque probablemente para los grupos que están confundidos se obtenga la misma solución y en un modelo animal se fuerza a las soluciones de los grupos genéticos que sumen cero. APÉNDICE Seguidamente vamos a demostrar las reglas aplicadas anteriormente para el cálculo de las partes de las ecuaciones del modelo mixto que se refieren directamente a la relación de grupos genéticos con grupos genéticos, α′ − QAQ 1 ,y a la que relaciona individuos con grupos genéticos, α′− −1AQ . Para ello recordemos que,
fiffif QAQTQ == , por lo que,
α′−=α′− −− 1fif
1 AAQAQ
y α′=α′ −−
fif1
fif1 QAAAQQAQ
En las anteriores expresiones, vamos a intentar expresar los productos matriciales en los que intervienen las matrices de parentesco como productos exclusivos de inversas o partes de inversas de matrices de parentesco, pues como vimos hace dos capítulos su cálculo es sencillo. Para ello nos apoyaremos en la siguiente expresión.
=
I00I
AAAA
AAAA
iiif
fiff
iiif
fiff
De ella se deduce,
0AAAA =+ ifii
ffif ; 1ffif
if1
ii )( −− −= AAAA ; 1ffifif
1 )( −− −= AAAA
, y
IAAAA =+ iffi
ffff ; IAAAAAA =−+ − )( ff
if1
iififf
ff ; IAAAAA =− − ))( ffif
1iififf ;
if1
iififf1ff )( AAAAA −− −= ; 1ff
ffif1
iifi )( −− −= AAAAA ; 1ffif
1fi )( −− −= AIAAA
La siguiente consideración que hay que hacer es que en la inversa de una matriz de parentesco, vimos que los únicos elementos no nulos son los que corresponden a individuos con individuos, individuos con sus padres y éstos entre

58
ellos y entre si mismos. Dado que los padres fantasmas únicamente tienen un hijo, la consideración anterior determina que ffA y ifA tienen una estructura de bloques, determinando cada bloque el individuo que tiene al menos un padre fantasma. Así, si un individuo j tiene dos padres fantasmas, los bloques correspondientes a ffA y ifA son respectivamente,
=
5.15.05.05.1ff
jA ;
−
−=−
75.025.025.075.0
)( 1ffjA ; [ ]11if
j −−=A ; luego,
[ ]5.05.0)( 1ff
jifj −−=−AA , que al multiplicar al bloque de fQ correspondiente a los
dos padres fantasmas explica las reglas dadas para este caso en la relación individuos, grupos genéticos. Por lo que respecta a la relación grupos con grupos,
=− −
25.025.025.025.0
)( 1ffjAI , que justifica las reglas dadas.
Si el individuo sólo tiene un padre fantasma y el otro padre es el individuo s, entonces,
5.1ffj =A ; 66.0)( 1ff
j =−A ;
−=
5.01if
s,jA ; luego,
−=−
33.066.0
)( 1ffj
ifj AA , que justifica la contribución al elemento que relaciona un
individuo con su padre fantasma y al padre conocido con su consorte fantasma. En este caso,
[ ]33.0)( 1ffj =− −AI , en concordancia con la regla dada.

59
GENÉTICA CUANTITATIVA II OTROS MODELOS ANIMALES
Hasta el momento hemos presentado la teoría general del BLUP, y hemos estudiado las condiciones de aplicación y las peculiaridades de cálculo de modelos animales. Sin embargo, el análisis de muchos caracteres de interés exige la consideración de más efectos aleatorios. Por ejemplo, cuando un animal tiene varios registros de un mismo carácter, resulta necesario considerar en el modelo, además del efecto aditivo, el resto de efectos permanentes que afectan a todos los registros del carácter del animal. Este modelo es el que se llama modelo animal de repetibilidad y en principio sería adecuado para caracteres relacionados con la lactación, en animales de producción de leche, o con caracteres de tamaño de camada, en especies como el porcino o el conejo. Lo normal es que de una vaca, oveja o cabra lechera tengamos datos de varias lactaciones y de una cerda o coneja datos de varios partos. En otro tipo de caracteres, especialmente los relacionados con animales jóvenes de especies prolíficas, es frecuente que las crías compartan factores ambientales comunes, que para algunos de sus caracteres pueden ser muy influyentes y que, por tanto, tenemos que considerar en el modelo. Un ejemplo es el peso de los conejos al destete que es muy dependiente de la camada concreta en que los gazapos han nacido. Es decir, en el análisis de este carácter habría que considerar un factor aleatorio ambiental añadido que sería la camada de origen y que sería compartido por todas las crías de la misma camada. En cualquier carácter, cuando la estructura de los datos sea tal que para factores como el año-rebaño-estación el número de datos por nivel sea muy pequeño, puede ser aconsejable el tratar como efecto aleatorio, en lugar de fijo, a este factor. Por otra parte, es bien conocida la influencia de los efectos maternales sobre algunos caracteres, como es el caso del tamaño de camada en especies prolíficas. Las hijas de hembras que tienden a tener camadas numerosas tienen un efecto negativo de sus madres que empieza a operar durante su gestación y continúa, incluso, durante la lactación. Este efecto materno, que es ambiental en lo que se refiere al animal que produce el dato, es genético y ambiental por parte de la madre. Este hecho introduce complejidades en el modelo que, en principio, obligan a considerar por separado los efectos maternales de componente genética de los de naturaleza ambiental. Por otra parte hay que hacer notar que la disponibilidad de estimas precisas de los componentes de varianza que afectan a estos factores aleatorios es infrecuente. En definitiva, el objetivo de este capítulo es presentar modelos con más de un factor aleatorio, que son una extensión del modelo animal simple y que representan situaciones comunes en el análisis de caracteres de interés en producción animal y por tanto suelen ser objetivos de selección en programas de mejora genética.

60
1. Repetibilidad Como hemos dicho en la introducción, este modelo es adecuado cuando de un carácter se dispone de varias medidas en un mismo animal. Este modelo es el que se utiliza para la evaluación genética y selección de las líneas maternales V, H y LP en la Unidad de Mejora Genética Animal del Departamento de Ciencia Animal de la E. T. S. I. Agrónomos de Valencia. Si lo ejemplificamos para la línea V, que se selecciona por tamaño de camada al destete, el modelo en forma escalar sería, ijkkkjiijk epaEFAEy ++++=
, en el que yi jk es un dato de tamaño de camada de la hembra k, considerándose los efectos fijos, año-estación (AE) en que se produce el parto y estado fisiológico (EF) de la coneja en el momento de quedar preñada - se tiene en cuenta si la hembra es nulípara o no, y en este caso si estaba o no amamantando gazapos de la camada anterior -. Los efectos aleatorios que se consideran son, ak, valor aditivo de la hembra k para tamaño de camada al destete, pk, efecto permanente, no aditivo, de la hembra k, sobre el tamaño de camada al destete de sus diversos partos, y ek, o residual del modelo. En este modelo se asume que los efectos de los genes no cambian con el orden del registro, es decir, que son los mismos para el primer parto, segundo, tercero o siguientes y que los efectos permanentes no genéticos afectan también por igual a todos los registros del mismo animal, mientras que los otros efectos de tipo ambiental son específicos de cada dato e independientes entre sí. Así, si llamamos 2
Aσ , 2pσ y 2
eσ a las varianzas de los tres efectos aleatorios del modelo y 2Pσ a la varianza fenotípica del carácter, la matriz de varianzas-covarianzas de dos
datos de una hembra k y otros dos de una hembra l sería, si ambas hembras no estuviesen emparentadas,
σ+σ+σσ+σσ+σσ+σ+σ
σ+σ+σσ+σσ+σσ+σ+σ
=
2e
2p
2All
2p
2All
2p
2All
2e
2p
2All
2e
2p
2Akk
2p
2Akk
2p
2Akk
2e
2p
2Akk
l..
l..
k..
k..
aa00aa00
00aa00aa
yyyy
V
En este modelo la relación de la heredabilidad, h2, y de la repetibilidad, r ,
con las varianzas de los factores aleatorios es,
2P
2A2h
σσ
= y 2P
2p
2Arσ
σ+σ=
En general, la forma matricial del modelo de repetibilidad sería,

61
epZaZXby +++= 21
, en el que Z1 y Z2 serán iguales si en p se consideran los mismos animales que en a. Ello es posible, si bien las componentes de p que corresponden a animales sin datos serían cero. Estos animales se incluyen en a para tener la genealogía completa. La matriz de varianzas-covarianzas de los efectos aleatorios será,
σσ
σ=
2e
2p
2A
VI00
0I000A
epa
, y la de los datos, 2
e2p22
2A11)(V σ+σ′+σ′= IZZZAZy
Las correspondientes ecuaciones del modelo mixto son,
′′′
=
α+′′′′α+′′′′′
−
yZyZyX
pab
IZZZZXZZZAZZXZZXZXXX
2
1
222122
211
1111
21
ˆˆ
ˆ
en las que,
22
A
2p
2A
2P
2A
2e
1 hr1 −
=σ
σ−σ−σ=
σσ
=α y 22
A2p
2A
2e
2p
2e
2 hrr1
−−
=σ−σ+σ
σ=
σσ
=α
Este modelo es ampliamente utilizado, si bien resulta dudoso si realmente las hipótesis que se han asumido en el modelo y que hemos enunciado anteriormente son realistas. Es probable que la correlación entre datos del mismo individuo sea mayor entre datos adyacentes que entre datos alejados y, por otra parte, es razonable asumir que los genes implicados en la variación de una medición no sean exactamente los mismos, en número y efecto que los que afectan a otra medición. Por ejemplo, en prolificidad en conejos, para el primer parto pueden ser importantes genes de precocidad, mientras que para el segundo parto pueden serlo genes que afecten a la recuperación de una hembra que tiene que seguir creciendo, pues no ha llegado todavía a su peso adulto y, a la vez, tiene que recuperarse del esfuerzo del parto anterior y amamantar a las crías de dicho parto. La solución teórica a esta cuestión sería el considerar las distintas medidas como caracteres diferentes y plantear un modelo multicarácter como explicaremos en el tema siguiente. No obstante, algunos estudios de riesgo han aconsejado seguir utilizando el modelo simple de repetibilidad cuando no se tienen estimas fiables de los parámetros necesarios para implementar el análisis multicarácter, esencialmente las correlaciones genéticas, que según la naturaleza del carácter y la estructura de datos disponible son difíciles de estimar.
2. Efectos ambientales comunes

62
Ya hemos dicho en la introducción del tema que hay caracteres en que la parte no aditiva del modelo no se reduce exclusivamente a un efecto aleatorio peculiar de cada medición y, por tanto, independiente entre los diferentes datos. Por contra hay conjunto de datos que comparten efectos ambientales comunes como sería el caso de animales nacidos en la misma camada o en el mismo año-rebaño-estación , cuando este factor se considera aleatorio. El modelo se escribiría, ecZaZXby +++= 21 , en el que c representa el vector de efectos ambientales comunes. La matriz de varianzas-covarianzas de los efectos aleatorios es,
σσ
σ=
2e
2c
2A
VI00
0I000A
eca
, y las ecuaciones del modelo mixto,
′′′
=
α+′′′′α+′′′′′
−
yZyZyX
cab
IZZZZXZZZAZZXZZXZXXX
2
1
222122
211
1111
21
ˆˆ
ˆ
, siendo
2A
2e
1 σσ
=α y 2c
2e
2 σσ
=α
Es evidente que todos los hijos de una misma madre comparten algún efecto común imputable a ella y que, para algunos caracteres, puede ser importante. Este hecho, a primera vista, estaría contemplado por el modelo que acabamos de presentar pero la consideración de que el efecto maternal (capacidad de una madre para atender a sus crías, cantidad de leche que les ofrece, etc…) tiene una componente genética por parte de la madre genera la necesidad de un tipo de modelos especial, que trataremos en el apartado siguiente. 3. Efectos maternales En los caracteres influidos por los efectos maternos ya hemos comentado que su expresión depende, entre otros factores, de los genes del individuo, la mitad de los cuales provienen de la madre, y del efecto ambiental que proporciona la madre y que favorece o dificulta, según los casos, dicha expresión.

63
Un tipo de caracteres en que el efecto materno puede ser especialmente importante es el del peso al destete, incluso en especies como el vacuno, que suelen tener partos de una sola cría. En este caso el peso al destete depende de los genes del ternero que determinan su capacidad de aprovechar la leche materna y del suministro de leche por parte de la madre que dependerá de los genes de la madre y del ambiente más o menos favorable que la madre haya tenido para producir leche y atender a su cría.
En este caso es conveniente introducir la terminología específica y, en este sentido, los efectos debidos a los genes del individuo se llaman efectos genéticos directos y los debidos a los genes de la madre responsables del efecto materno, se llaman efectos genéticos maternos. Estos efectos genéticos pueden estar correlacionados entre si, de tal manera que la estructura de varianzas covarianzas entre ellos se recoge en la matriz,
2e
2221
12112AmAdm
Adm2Ad
dm gggg
σ
=
σσσσ
=G
, donde,
2Adσ es la varianza de los efectos directos aditivos, 2
Amσ es la varianza de los efectos aditivos maternos y Admσ es la covarianza entre los anteriores. Se denominará 2
pmσ a la varianza de los efectos maternales que no son
genéticos aditivos. De acuerdo con la terminología anterior, el modelo de efectos maternales puede escribirse como sigue: epZaZaZXby ++++= m3m2d1 , siendo la matriz de varianzas covarianzas entre los efectos aleatorios la siguiente,
2e1
3
2221
1211
m
m
d
gggg
V σ
α=
−
I0000I0000AA00AA
epaa
, siendo 2pm
2e
3 σσ
=α
La expresión anterior de la matriz de varianzas covarianzas entre efectos aleatorios, en lo que concierne a los efectos aditivos directos y maternales supone que los vectores ad y am se refieren a los mismos animales, igualmente

64
ordenados en ambos. Si pm se refiere solo a los individuos que han sido realmente madres Z2 es igual a Z3 pero ampliada con columnas de ceros que corresponden a los animales incluidos en am pero que no han sido madres. El que ad y am se refieran a los mismos animales nos permite considerar una única matriz de parentesco A y la utilización de la operación algebraica llamada producto directo (⊗ ) para el cálculo de las varianzas-covarianzas entre sus elementos. Así,
AGAAAA
Gaa
⊗=σ
==
dm
2e
2221
1211
m
d
gggg
V
, que como vemos afecta a dos matrices, y el resultado es una nueva matriz que tiene una estructura de bloques definida por la matriz izquierda, siendo cada bloque el resultado de multiplicar escalarmente el elemento correspondiente de la matriz izquierda por la matriz derecha. La matriz resultante tiene un número de filas igual al producto de las filas de las dos matrices que intervienen en el producto directo y como número de columnas el producto de los respectivos números de columnas. En nuestro caso Gdm es una matriz 2,2 y A n,n , si es n el número de animales considerados en ad y am, por lo que la matriz producto directo de ambas será 2n,2n. Es conveniente tener presente algunas propiedades del producto directo, que serán útiles cuando tratemos modelos multivariantes. Entre ellas están,
111)( −−− ⊗=⊗ BABA
BDACDCBABABA
⊗=⊗×⊗′⊗′=′⊗
)()()(
La última propiedad requiere que las dimensiones de A y C, así como las de B y D sean las adecuadas para que puedan multiplicarse. En nuestro caso, por ejemplo, la primera de las propiedades es útil para formar las ecuaciones del modelo mixto, pues
2e
122121
11211111
dm1 1
gggg
σ×
=⊗=
−−
−−−−−
AAAA
AGG
, y las correspondientes ecuaciones del modelo mixto serán,
′′′′
=
α+′′′′′+′+′′′+′+′′′′′′
−−
−−
yZyZyZyX
paab
IZZZZZZXZZZAZZAZZXZZZAZZAZZXZZXZXZXXX
3
2
1
m
m
d
33323133
32122
22121
122
31112
21111
111
321
ˆˆˆ
ˆ
gggg

65
GENÉTICA CUANTITATIVA II MODELOS ANIMALES MULTICARÁCTER
1. Definición y necesidad de análisis multivariantes. Precisión y sesgo por selección
En muchos programas de mejora genética los objetivos son múltiples y las decisiones de selección exigen la evaluación genética de los animales para varios caracteres, que adecuadamente ponderadas permiten obtener un índice sobre el que se racionalizan las decisiones de selección. Si los caracteres están correlacionados, genética y ambientalmente, es conveniente plantear un modelo conjunto que explique cada uno de los caracteres y que a su vez tenga en cuenta sus relaciones. De este modo aprovechamos la información que unos caracteres tienen sobre otros y, además, como en los casos unicarácter, la información de los individuos emparentados entre sí. La varianza del error de predicción disminuye, y consecuentemente la precisión aumenta, en función de la información disponible. Probablemente, en los casos de machos en que se dispone de información de un elevado número de hijos, el incremento de precisión aportado por el modelo multivariante no sea importante. Sin embargo, si que puede serlo para el caso de animales con pocos datos, fundamentalmente los suyos y que incluso para algunos caracteres pueden faltarle. En esta última situación la predicción del valor genético en estos caracteres, tendrá su apoyo esencial en la información procedente de los caracteres correlacionados. El incremento en precisión del análisis multicarácter frente a los unicarácter depende de las diferencias absolutas entre las correlaciones genéticas y residuales entre los caracteres. A mayor diferencia entre las correlaciones mayor incremento en la precisión. Si las heredabilidades de dos caracteres son semejantes y también lo son la correlación genética y la residual las predicciones multicarácter son prácticamente análogas a las unicarácter. Por otra parte, los caracteres con heredabilidades más bajas se ven claramente favorecidos en un análisis multicarácter con caracteres de mayor heredabilidad y significativamente correlacionados con ellos. Otra ventaja del análisis multicarácter proviene de la mejora de la precisión, por una mejor conexión entre los datos debida a la covarianza residual entre los caracteres. Un aspecto distinto que puede hacer necesario el análisis multicarácter es el relacionado con el análisis de caracteres, que no han sido criterios de selección pero que pertenecen a una población que ha sido sometida a selección por otros caracteres. La cuestión radica en el sesgo en que se puede incurrir cuando se analizan aquéllos de forma unicarácter. Para evitar el sesgo es necesario analizar conjuntamente los caracteres de interés con todos aquéllos que han intervenido en las decisiones de selección. Un ejemplo lo tenemos en las líneas paternales que se seleccionan en conejo por velocidad de crecimiento post-destete y en las que queremos analizar el peso al final del cebo. Para hacer un análisis no sesgado de este carácter es necesario analizarlo en un análisis bicarácter con la velocidad de crecimiento post-destete.

66
Junto con las ventajas señaladas del análisis multicarácter existen algunos inconvenientes. El primero es el costo, pues el análisis conjunto de c caracteres es muy superior al de c análisis unicarácter, pues en el primer caso, si no se recurre a estrategias especiales, la necesidad de memoria puede crecer con el cuadrado de c y el de cómputo con el cubo. Por otra parte, un análisis multicarácter puede exigir el uso de memoria externa, que es claramente menos eficiente que el uso de memoria interna. A veces la complejidad de un análisis multicarácter tiende a que se acepten proposiciones de simplificación de los modelos que pueden llegar a comprometer la ventaja del multicarácter frente a los unicarácter. Finalmente la eficacia de un análisis multicarácter depende de la precisión con que se conozcan los parámetros de relación entre los caracteres. Algunos de ellos, como las correlaciones genéticas, en algunos casos tienen dificultades intrínsecas para ser estimadas con precisión y, por otra parte, conforme el número de caracteres a analizar aumenta, el número de parámetros necesarios se incrementa de forma no lineal. Así, si son tres los caracteres a analizar, en un análisis separado de ellos con un modelo animal estricto únicamente se necesitaría conocer las tres heredabilidades, mientras que uno tricarácter requiere doce. Además de las tres heredabilidades, se necesitarían tres correlaciones genéticas, tres correlaciones ambientales y tres varianzas fenotípicas. La teoría para abordar el análisis multicarácter es la general que se dio en el capítulo dedicado a la PREDICCIÓN y que se ha particularizado en los capítulos siguientes. Vamos a ejemplificar, para un caso bicarácter, cómo plantear los modelos unicarácter y el modelo bicarácter correspondiente. En este aspecto el punto esencial es la definición de la matriz de varianzas covarianzas de los factores aleatorios implicados en ambos modelos unicarácter. Para evitar expresiones largas, vamos a considerar todos los factores aleatorios reunidos en un único vector por carácter que llamaremos u1 o u2. Los modelos unicarácter serían,
222222
111111
euZbXyeuZbXy++=
++=
en donde el subíndice 1 0 2 se refiere al primero o al segundo carácter. El modelo bicarácter sería,
eZuXbyee
uu
Z00Z
bb
X00X
yy
++==
+
+
=
2
1
2
1
2
1
2
1
2
1
2
1
en el que los datos se ordenan por animal dentro de carácter y, consecuentemente, la matriz de varianzas-covarianzas de los efectos aleatorios sería,

67
=
2221
1211
2221
1211
2
1
2
1
V
RR00RR0000GG00GG
eeuu
, y su inversa,
=
−
2221
1211
2221
12111
2
1
2
1
V
RR00RR0000GG00GG
eeuu
En apartados posteriores explicaremos como se aborda el cálculo de la
inversa anterior. Ahora utilizaremos dicha expresión para escribir las ecuaciones del modelo mixto,
′+′′+′′+′′+′
=
+′+′′′+′+′′′
′′′′′′′′
222
21212
212
1111
1
222
2121
2
212
1111
1
2
1
2
1
222
222
211
2122
2221
212
122
121
111
1112
1211
111
222
2121
2222
2121
2
212
1111
1212
1111
1
yRZyRZyRZyRZyRXyRXyRXyRX
uubb
GZRZGZRZXRZXRZGZRZGZRZXRZXRZ
ZRXZRXXRXXRXZRXZRXXRXXRX
De la expresión anterior queda patente el incremento en la complejidad de cálculos en las situaciones multicarácter frente a las unicarácter, conforme aumentan el número de caracteres a considerar y el número de factores fijos y aleatorios por carácter . Hay situaciones que permiten estrategias de cálculo especiales, que simplifican mucho las necesidades de cálculo. La situación más clara es la del análisis multicarácter que tiene el mismo modelo para los distintos caracteres, permitiendo las mismas matrices de diseño para cualquiera de ellos y que, además, únicamente considera un factor aleatorio. En este capítulo vamos a tratar primeramente este caso, cuando todos los caracteres se han medido en todos los individuos y cuando en algunos individuos faltan registros de algunos datos. En el resto abordaremos otros casos que admiten, también, simplificaciones en su resolución. 2. Transformación canónica en el caso de un solo factor aleatorio. En el caso en que los c caracteres implicados en el análisis multicarácter se midan en todos los individuos, las matrices de diseño sean las mismas, independientemente del carácter y sólo se considere un factor aleatorio es posible transformar los c caracteres en otros c caracteres distintos, combinación lineal de los anteriores, llamados caracteres canónicos, que se caracterizan por

68
tener como matriz de varianzas-covarianzas del efecto aleatorio, una matriz diagonal, y como matriz de varianzas-covarianzas del residual, la matriz identidad, además de mantener la independencia entre los efectos del factor aleatorio considerado y el residual. Esto permite hacer c análisis unicarácter que desde el punto de vista de cálculo es mucho menos exigente que un análisis c-carácter. Según lo que explicamos en la introducción, la memoria necesitada se dividiría por c y el tiempo por c2. En esta situación, asumiendo que el efecto aleatorio considerado es el que corresponde a los efectos aditivos del animal sobre los distintos caracteres,
0j21 XXXX === ; 0XIX ⊗= ; 0j21 ZZZZ === ; 0ZIZ ⊗=
au = ; AGa ⊗= 0)(V ; y IRe ⊗= 0)(V
, siendo G0 la matriz de varianzas-covarianzas genéticas (de efectos aditivos) entre los caracteres y R0 la correspondiente para los efectos residuales. Si, por ejemplo, estuviésemos considerando la ganancia diaria post-destete en conejos (g/d) y el peso a los 70 días (g), las anteriores matrices podrían tener los siguientes valores,
=
1400023623625.6
0G y
=
5600071771775.18
0R
La matriz A tiene el significado habitual de matriz de numeradores de coeficientes de parentesco entre los animales. El hecho de que las matrices de diseño sean las mismas nos permite escribir la ecuación del modelo de la siguiente manera, y Xb Za e I X b I Z a e= + + = ⊗ + ⊗ +( ) ( )0 0 ,que directamente conduce a un sistema de ecuaciones tal como se ha expresado en el apartado anterior, pero con la salvedad de que las matrices de diseño son las mismas y además, G Aij ijg= −
01 y R Iij ijr= 0 , pues
G G A= ⊗0 ; G G A− − −= ⊗10
1 1 ; R R I= ⊗0 ; y R R I− −= ⊗10
1 El sistema de ecuaciones anterior puede simplificarse transformando los c datos de cada individuo en otros c diferentes, combinación lineal de los anteriores, a través de una matriz de transformación, Q, tal que los nuevos caracteres que se llaman canónicos tengan una matriz diagonal de varianzas covarianzas genéticas, y una matriz identidad de varianzas covarianzas de residuales.

69
Si llamamos yij al dato i del animal j e yqij al correspondiente dato
canónico del mismo individuo, la transformación de unos en otros, a través de la matriz Q de c filas y c columnas, la podemos expresar así,
yy
y
yy
y
q j
q j
qcj
j
j
cj
1
2
1
2
.
...
=
Q
Para el conjunto de todos los datos, ordenados por animal dentro de carácter, la transformación anterior se expresaría así, llamando yq al vector de
todos los datos canónicos, y Q I yq = ⊗( )
, por lo que la ecuación del modelo será, y Q I y Q I I X b Q I I Z a Q I e Q X b Q Z a
Q I e I X Q I b I Z Q I a Q I e I X b I Z a eq
q q q
= ⊗ = ⊗ ⊗ + ⊗ ⊗ + ⊗ = ⊗ + ⊗ +
⊗ = ⊗ ⊗ + ⊗ ⊗ + ⊗ = ⊗ + ⊗ +
( ) ( )( ) ( )( ) ( ) ( ) ( )
( ) ( )( ) ( )( ) ( ) ( ) ( )0 0 0 0
0 0 0 0
En la última expresión de la ecuación del modelo se pone de manifiesto la transformación de los vectores de efectos fijos (b), aditivos (a) y residuales (e) en los correspondientes canónicos bq, aq y eq a través de la misma matriz de transformación Q. De acuerdo con lo anterior podemos definir la nueva matriz de varianzas-covarianzas genética G0q y residual R0q entre los caracteres canónicos, que tendrían las siguientes expresiones, G QG Q0 0q = ′ y QQRR ′= 0q0
El objeto de la transformación canónica es hallar Q de tal modo que, G0q =D, matriz diagonal y R0q=I Para ello, primero, hay que hallar el factor (matriz) de Cholesky de la matriz R0 , que llamaremos L. Es decir, R LL0 = ′ , seguidamente se calculan los vectores y valores propios de la matriz ,
L G L− − ′1
01( )
, que permite la siguiente factorización,

70
L G L UDU− − ′ = ′1
01( )
siendo U la matriz ortonormal de vectores propios y D la matriz diagonal con los correspondientes valores propios. Finalmente la matriz Q se calcula como,
1−′= LUQ Podemos comprobar que, DIDIUUUDUULGLUQQGG ==′′=′′=′= −− )( 1
01
oq0
IUUULLLLUQQRR =′=′′′=′= −− )( 110q0
, que es lo que se pretendía con la transformación canónica. En el ejemplo anterior,
=
0619.1695841.16503301.4
L
=′
5600071771775.18
LL
−
=−
0059.02262.002309.01L
−
−=′−−
1781.00041.00041.03333.0
)( 10
1 LGL
−
=9997.00264.00264.09997.0
U
=′=′
1001
UUUU
=
1780.0003334.0
D
−
−=
−
−=
0059.02200.00002.02368.0
0059.02262.002309.0
9997.00264.00264.09997.0
Q
=
−
−
−
−=
1780.0003334.0
0059.00002.02200.02368.0
1400023623625.6
0059.02200.00002.02368.0
q0G
=
−
−
−
−=
1001
0059.00002.02200.02368.0
5600071771775.18
0059.02200.00002.02368.0
q0R
A continuación vamos a ver como se haría la transformación canónica en el siguiente conjunto de datos. Individuo Padre Madre Periodo Sexo Crecimiento
diario (gr/d) Peso a los 70 días (gr)
1 0 0 1 1 42 2300 2 0 0 1 2 40 2100 3 0 0 1 2 45 2550 4 1 2 1 1 43 2250

71
5 1 2 2 1 38 2100 6 1 3 2 2 36 1950 7 5 6 2 1 39 2200 8 5 6 2 2 37 1800
Para el individuo 1 sus caracteres canónicos son,
−
−=
230042
0059.02200.00002.02368.0
36.459.9
, y para el séptimo
−
−=
220039
0059.02200.00002.02368.0
43.489.8
Así, el vector de datos original,
[ ]′=′ 180022001950210022502550210023003739363843454042y , se transforma en el de datos canónicos,
[ ]5.24.46.31.48.32.56.34.45.89.82.87.88.93.102.96.9q =′y
En el ejemplo la matriz de transformación de y en yq IQ ⊗ es un matriz (16,16), dado que q es (2,2) e I (8,8). Las filas 1 y 9 de esta matriz serían,
−
−000000000591.00000000220.0000000000016.00000000237.0
, y las filas 7 y 15
−
−000591.00000000220.0000000000016.00000000237.0000000
La matriz de diseño global para los efectos aleatorios 0ZIZ ⊗= es una matriz (16,16) pues aquí I es (2,2) y Z0 (8,8). Como en este ejemplo Z0 es una matriz unidad, Z también lo es. La matriz de diseño global para los efectos fijos 0XIX ⊗= es una matriz (16,8) pues I es (2,2) y X0 es (8,4) y sería,

72
=
10100000011000001010000001100000010100001001000010010000010100000000101000000110000010100000011000000101000010010000100100000101
X
Aunque si se hace la transformación canónica las matrices R-1 y G-1 no son necesarias, con objeto de familiarizarnos con el producto directo, vamos a dar los valores numéricos de alguna de sus componentes en el ejemplo que se está presentando. Primero veamos que,
G01 0 4402 0 0074
0 0074 0 0002− =
−−
. .. .
y Ro− =
−−
1 01045 0 00130 0013 0 00003. .. .
así que, por ejemplo,
G12 0 0074= − .
−−−−
−−−−−−−−
−−−
−−−−−
−=−
20110000021100001131010111130011
00002011001005.105.000011021001115.015.2
0074.01A
y R I22 0 00003= . , siendo aquí la matriz identidad de orden 8 como corresponde al número de pares de datos del ejemplo.

73
Para resolver el modelo en su forma canónica se plantean por separado los análisis unicarácter de cada carácter canónico, en el que el correspondiente cociente entre la varianza residual y la varianza aditiva sería, por ejemplo para el carácter canónico j,
α ijjd
=1
que en el ejemplo sería, α1
103334
3= =.
y α2
10178
562= =.
.
Las ecuaciones del modelo mixto para el primer carácter canónico serán,
=
−−−−
−−−−−−−−
−−−
−−−−−
48.889.822.867.883.926.1015.959.911.3699.3627.3483.38
aaaaaaaab
bb
b
70330000101007330000011033103030310103331000330110
000070330101003005.505.11001000330731001003335.135.80101101001104022010110010422111100002240000011112204
18q
17q
16q
15q
14q
13q
12q
11q
14q
13q
12q
11q
Un sistema de ecuaciones similar se construye para el segundo carácter
canónico, obteniéndose las siguientes soluciones a ambos,
$$$$
$$$$$$$$
.....
...
.
..
bbbbaaaaaaaa
q
q
q
q
q
q
q
q
q
q
q
q
11
12
13
14
11
12
13
14
15
16
17
18
0115
9 879 580 070 09
0150 070 06
0 020 010 01
=
−
−−
−−
−
y
$$
$$
$$$$$$$$
.....
...
.
..
bbbbaaaaaaaa
q
q
q
q
q
q
q
q
q
q
q
q
21
22
23
24
21
22
23
24
25
26
27
28
00 61
4544 02007010
017014008
005002009
=
−
−−
−−
−

74
Si no se hubiese hecho la transformación canónica y se hubiese resuelto el sistema de ecuaciones bicarácter, las soluciones, expresándolas, del mismo modo, que las canónicas serian,
$$$$
$$$$$$$$
.....
...
.
..
bbbbaaaaaaaa
11
12
13
14
11
12
13
14
15
16
17
18
05 05
43 234193
0 290 40
0 690 320 25
0 110 050 04
=
−
−−
−−
−
y
$$$$
$$$$$$$$
.
....
..
.
bbbbaaaaaaaa
21
22
23
24
21
22
23
24
25
26
27
28
0290
2377224122 653199
54 6535 0223 56
12 236 0216 81
=
−
−−
−−
−
La cuestión inmediata es la forma de obtener las soluciones no canónicas a partir de las soluciones canónicas. Para ello hay que deshacer la transformación. Recordemos por ejemplo que, $ ( )$a Q I aq = ⊗
, luego, $ ( ) $ ( )$a Q I a Q I a= ⊗ = ⊗− −1 1
q q
En el ejemplo,
Q− =
1 4 3286 01142161 0684 1733695
. .. .
Así, si queremos encontrar la solución del efecto del primer período sobre la ganancia diaria, sería, 4.3286x0+0.1142x0=0 ; para el efecto del sexo 2 sobre el peso a los 70 días, 161.0684x9.58+173.3695x4.02=2241 ; para el efecto aditivo del animal 7 sobre la velocidad de crecimiento, 4.3286x0.01+0.1142x0.02=0.05

75
, y para el efecto aditivo del mismo animal sobre el peso,
161.0684x0.01+173.3695x0.02=6.02 Tal como hemos establecido al principio, las condiciones para aplicar la
transformación canónica son bastante restrictivas, y algunos investigadores como Ducrocq y Besbes en 1993 o Ducrocq y Chapuis en 1997 han estudiado formas para generalizar en lo posible el uso de la transformación canónica en la solución de los modelos mixtos multicarácter. En el apartado que sigue explicaremos la forma de utilizarla cuando se cumplen todos los requisitos, salvo que en algunos animales falta alguno de los datos. Esta situación puede ser normal, cuando alguno de los caracteres solo se registra en un sexo o en programas de selección por niveles independientes, en los que un carácter se mide o no en función de que el animal haya superado o no el umbral de selección de los caracteres anteriores.
3. Tratamiento de los datos faltantes
En lo que sigue nos apoyamos en el trabajo de Ducrocq y Besbes de 1993. Continuamos en la situación de que los diferentes caracteres tienen las mismas matrices de diseño y únicamente consideramos como efecto aleatorio, el efecto aditivo del animal sobre cada carácter. El problema radica, como hemos comentado al final del apartado anterior, en que en algunos animales hay algún dato que falta. La idea es que si llamamos βy al conjunto de datos que faltan para que los
animales que tienen algún dato los completasen todos, hacer con los datos existentes una estimación de βy y continuar como en el apartado anterior. El
algoritmo EM permite abordar la idea que acabamos de expresar de un modo riguroso. Vamos, antes de continuar, a ampliar la nomenclatura que hemos utilizado hasta ahora. Así, llamaremos
ay al vector de datos aumentado, que contiene los verdaderamente observados, y o yα , y los que serán estimados βy .
Como veremos más adelante, la estimación de βy se hace dentro de cada
iteración por lo que a los datos faltantes estimados en la iteración k les llamaremos, )k(
βy .
Por otra parte vamos a llamar,
αjy , al vector con los datos realmente registrados del animal j, y
)k(
jβy , a los datos faltantes del individuo j, estimados en la iteración k.
Análogamente llamaremos,

76
)k(
jˆ αa y )k(jˆ βa a las predicciones de los valores aditivos del animal j para los
caracteres medidos y faltantes respectivamente en la iteración k, )k(
jˆ αe y )k(jˆ βe tienen el mismo significado, pero referido a los residuales, y
)k(b a la solución de los efectos fijos en la iteración k. Finalmente, recordando que la matriz de diseño de los efectos fijos, tal como la definimos en el apartado anterior, 0XIX ⊗= , llamaremos, ′xj a la fila de X0 correspondiente al individuo j,
βjX ( αjX ), a la matriz con las filas de X , correspondientes a los caracteres
faltantes(observados) del animal j, de tal modo que, [ ]X I 0 xj jα = ⊗ ′ y [ ]X 0 I xj jβ = ⊗ ′
βα0R ( αα0R ), a la parte de 0R que tiene las covarianzas entre residuales de
los caracteres faltantes (observados) con los observados. El primer paso del algoritmo EM es el E, cálculo de los valores estimados para los datos faltantes. Para el individuo j y la iteración k, )k(
j)k(
j)k(
j)k(
j ˆˆˆββββ ++= eabXy
, en donde únicamente desconocemos el vector de residuales, éste se calcula como una regresión sobre los residuales de los caracteres observados, )ˆˆ(ˆ )k(
j)k(
jj1
00)k(
j ααα−
ααβαβ −−= abXyRRe
El segundo paso del algoritmo es el M (maximización) que consiste en realizar una nueva iteración, la k+1, con el vector )k(
ay (por ejemplo un ciclo de
Gauss-Seidel) haciendo la transformación canónica pues en )k(ay no falta ningún
dato. En este paso, por tanto, obtenemos, )1k(ˆ +a y )1k(ˆ +b que nos permiten ir de nuevo al paso E del algoritmo, en caso de que no se hayan satisfecho las condiciones de convergencia. Detallando lo que acabamos de explicar, el proceso para una iteración k es el siguiente,
1. Para cada animal j con datos faltantes calcular )k(jβy en función de αjy ,
)k(a y )k(b , con lo que tenemos )k(ay , que por ser completo lo
transformamos a los caracteres canónicos, )k(qay .

77
2. Realizar un ciclo de Gauss-Seidel para los caracteres canónicos y obtener )1k(
qˆ +a y )1k(q
ˆ +b
3. Haciendo la transformación inversa a la canónica obtener )1k(ˆ +a y )1k(ˆ +b 4. Volver a 1. Si no se ha alcanzado la convergencia.
En la práctica el procedimiento iterativo puede discurrir hasta la convergencia en la escala canónica, realizándose, únicamente, la transformación inversa al final para conocer las soluciones en la escala original. A efectos de presentación del álgebra implicada en esta cuestión consideraremos que el vector ampliado de los caracteres del animal j en la iteración k es,
yy
j
jkα
β( )
, es decir los datos observados preceden a los faltantes. Si reordenamos las filas y columnas de Q y de R0 del mismo modo que en el vector anterior y consideramos las correspondientes particiones,
[ ]Q Q Q= α β QQQ
− =
1
α
β y RR RR R0
0 0
0 0=
αα αβ
βα ββ
, el vector ampliado de caracteres canónicos del animal j en la iteración k, sería,
( ){ })k(j
)k(jj
100
)k(j
)k(j
)k(jj
)k(qj ˆˆˆˆˆˆ ααα
−ααβαβββααββαα −−+++=+= abXyRRabXQyQyQyQy
, y teniendo en cuenta que,
==
β
α−
β
α)K(
qj
)k(qj)k(
qj1
)k(j
)k(j
ˆˆ
ˆˆˆ
aQaQ
aQaa
XXXj
j
j=
α
β , $ ( )$( ) ( )b Q I bk
qk= ⊗−1
[ ]( )( )( ) ( ) ( )X Q I 0 I x Q I Q x Q I 1x Q Xj j j j jββ β β( )− −⊗ = ⊗ ′ ⊗ = ⊗ ′ = ⊗ ′ =1 1 y
[ ]( )( )( ) ( ) ( )X Q I I 0 x Q I Q x Q I 1x Q Xj j j j jαα α α( )− −⊗ = ⊗ ′ ⊗ = ⊗ ′ = ⊗ ′ =1 1
, podemos escribir el vector canónico del animal j , como,
( ) ( )( )( )
$ $ $
$ $
( ) ( ) ( )
( ) ( )
y Q Q R R y Q Q Q R R Q X b a
Q y Q X b a
qjk
j j qk
qjk
j j qk
qjk
+ − −= + + − + =
+ +
10 0
10 0
1
1 2
α β βα αα α ββ
β βα ααα
α
En la expresión anterior las matrices Q1 y Q2 dependen de los datos concretos que falten, y habrá tantas parejas de ellas como situaciones de datos faltantes existan. En el ejemplo que venimos considerando, dado su carácter

78
bicarácter, únicamente podrían existir dos parejas: la correspondiente a los casos en que el dato faltante fuese el crecimiento diario o aquéllos en que se desconoce el peso a los 70 días.
Veamos como se procedería si en el animal 4 faltase la velocidad de crecimiento diario y dispusiésemos del peso a los 70 días. Supongamos que estamos en la iteración 40 y por comodidad aceptamos que $ ( )a 40 y $ ( )b 40 coinciden con las soluciones finales que se han dado en el apartado anterior cuando no había datos faltantes. Esto supone que $ ( )aq
40 y $ ( )bq40 coincidirán
también con las soluciones canónicas dadas. En este caso,
[ ]y4 2250α =
[ ]′ =x4 1 0 1 0
X4
1 0 1 0 0 0 0 00 0 0 0 1 0 1 0
=
[ ]X4 1 0 1 0 0 0 0 0α =
[ ]X4 0 0 0 0 1 0 1 0β =
Qα =−
0 00590 0002..
Qβ =−
0 22000 2368
..
[ ]Qα = 1733695 1610684. . [ ]Qβ = 01142 4 3286. .
[ ]R0 717βα = [ ] [ ]R 01 156000 0000018αα
− −= = .
Q1
0 00310 0029
=
.
. Q2
0 4633 0 49860 4986 0 5367
=−
−
. .. .
$..
( )a440 35 02
0 32=
−−
$
.
.( )aq440 0 14
0 07=
−−
$ . ( ( ) ( . )) .( )e440 717 0000018 2250 0 2377 3502 11734β = − + − − = −x
$ ( . ) ( . ) ( . ) .( )y441 0 4323 032 11734 4173β = + + − + − =
Ahora los caracteres canónicos estimados para el individuo 4 serían,
−
−=
0059.02200.00002.02368.0
Q
$. .. .
. ..
( )yq441 0 2368 0 0002
0 2200 0 005941 732250
9 534 12
=−
−
=
Con estos datos estimados se habría completado el paso E del algoritmo EM y se pasaría al paso M que consistiría en hacer la iteración 41 del Gauss-Seidel calculando $ ( )aq
41 y $ ( )bq41 . Si al comparar dos iteraciones consecutivas se cumple
el criterio de convergencia se finaliza el proceso y si no se vuelve a estimar el crecimiento diario del individuo 4 y se pasa a la siguiente iteración. Como se ha explicado en la teoría no es necesario, en este proceso pasar de la escala normal a la canónica y de esta a la normal en cada iteración, pues se

79
puede operar en la escala canónica exclusivamente hasta la convergencia. En nuestro caso,
=
−−
+
++
−
−+
=
53.912.4
07.014.0
87.9054.40
5367.04986.04986.04633.0
22500029.00031.0
ˆ )41(4qy
mismo resultado, pero obtenido directamente desde las soluciones canónicas de la última iteración.
4. Matrices de diseño idénticas y patrón secuencial de ausencia de datos.
Hay casos en que sobre los animales se controla un máximo de n caracteres, pero es frecuente que no todos los caracteres estén registrados para todos los animales. Por ejemplo, si se sigue un procedimiento de selección por niveles independientes, un determinado carácter solo se controla en los animales que han superado los umbrales fijados en los caracteres anteriores. Imaginemos que una determinada población se selecciona por este procedimiento por peso al destete, ganancia diaria en un primer período e índice de conversión en un segundo período. En este caso todos los animales tendrán datos de peso al destete, pero no tendrán datos de ganancia y conversión aquellos animales que no hayan superado el umbral de selección fijado para el peso al destete. Tendrán peso al destete y ganancia diaria todos los animales que hayan superado el umbral anterior, y a todos los que superen el umbral de selección de la ganancia diaria se les medirá el índice de conversión. Aquí el patrón de ausencia de datos es secuencial en el sentido de que si a un animal le falta el dato imo, le faltarán también los siguientes. Sería también el caso del estudio de caracteres de lactación o de partos, considerando como caracteres distintos los datos de cada lactación o parto. Así, si por ejemplo, de una cerda tenemos datos hasta su parto imo y se elimina a continuación, a partir de ese momento ya careceremos de registros. Esta situación admite la solución de datos faltantes explicada en el tema anterior o una solución multicarácter basada en una transformación triangular de los datos que hace que la matriz de varianza-covarianza de residuales sea la unidad. Esta transformación, como veremos, tiene algunas ventajas de cálculo en la parte de las ecuaciones del modelo mixto, relativa a los efectos fijos. Vamos a ejemplificarlo para un caso de tres caracteres, en el que hay animales con solo el primer carácter controlado, otros con el primero y el segundo y finalmente otros con los tres. Hemos indicado que las matrices de diseño deben de ser iguales y en sentido estricto no puede ser, debiendo de interpretarse esta condición en el sentido de que serían idénticas para todos los caracteres si todos los animales tuviesen todos los datos. Así, por ejemplo, X1 únicamente se diferencia de X2 en que tiene las filas adicionales de los animales que tienen controlado el carácter primero pero no el segundo. Similarmente ocurre con X2 respecto a X3.

80
Si llamamos, como habitualmente,
==
333231
232221
131211
rrrrrr
rrr
030 RR
, a la matriz de varianza-covarianza de los residuales de los tres caracteres intra-individuo, y definimos similarmente,
=
2221
1211
rrrr
02R y 11r=01R
, podemos hacer la transformación triangular que nos independiza los residuales, apoyándonos en los factores de Cholesky de las anteriores. Así, si llamamos iL al factor de Cholesky de i0R , es decir, 3303 LLR ′= , 222 LLR 0 ′= y 111 LLR 0 ′= , siendo,
=
333231
2221
11
lll0ll
00l
3L ,
=
2221
11
ll0l
2L y 11l=1L
, y recordando que los términos de las matrices inversas se representan por superíndices, la transformación propuesta es, para el individuo j,
3j33
2j32
1j31
3jt
2j22
1j21
2jt
1j11
1jt
ylylyly
ylyly
yly
++=
+=
=
, siendo yj i el dato del carácter imo del individuo j e yjti el dato del carácter transformado imo del individuo j. Si un individuo tiene solo dos datos, únicamente genera dos caracteres transformados y si uno, solo el primero. Igualmente se transforman los vectores de efectos fijos (aleatorios aditivos), b1 (a1), b2(a2) y b3(a3) en bt1(at1), bt2(at2) y bt3(at3). Así, el modelo para los caracteres transformados quedaría,
+
+
=
3t
2t
2t
3t
2t
1t
3
2
1
3t
2t
1t
3
2
1
3t
2t
1t
ee
e
aa
a
Z000Z0
00Z
bb
b
X000X0
00X
yy
y
, en el que

81
ALGLAGaa
a
G ⊗′=⊗=
= −− )(var 1
301
3t0
3t
2t
1t
t
y
Iee
e
R =
=
3t
2t
1t
t var
En correspondencia con lo anterior el sistema de ecuaciones sería:
′′′′′′
=
+′′+′′
+′′′′
′′′′
−−−
−−−
−−−
3t3
2t2
1t1
3t3
2t2
1t1
3t
2t
1t
3t
2t
1t
133t033
132t0
131t033
123t0
122t022
121t022
113t0
112t0
111t01111
3333
2222
1111
ggggggggg
yZyZyZyXyXyX
aaabbb
AZZAAXZ00AAZZA0XZ0AAAZZ00XZZX00XX00
0ZX00XX000ZX00XX
Vemos que la matriz de coeficientes tiene bloques nulos y, en el caso que se desease efectuar la absorción de los efectos fijos, esta operación estaría facilitada.
El paso de las soluciones transformadas a la de los caracteres originales se hace mediante la transformación inversa.
5. Caracteres medidos en parientes diferentes.
En la mejora genética animal se encuentran, a veces, situaciones en las que de unos animales se tienen datos de un carácter o conjunto de caracteres y de otros animales se dispone de datos de otro carácter o caracteres distintos de los anteriores. Es el caso, por ejemplo, de cuando se estudia la interacción genotipo medio ambiente en un carácter, que para estudiarla se consideran como caracteres distintos las mediciones realizadas en los diferentes ambientes. Así, si estuviésemos estudiando la interacción genotipo medio de la ganancia diaria de peso corporal de una raza de conejos criada en Valencia y en Alejandría,

82
consideraríamos como dos caracteres distintos la ganancia en Valencia y la ganancia en Alejandría y es evidente, que los conejos que han crecido en Valencia no lo han hecho en Alejandría y por tanto no se tienen los dos datos en un mismo animal. Lo mismo ocurriría si se estuviera controlando la producción lechera de vacas en un área templada y en un área de clima tropical. Desde el punto de vista del modelo, el punto importante en esta estructura de datos es que la matriz R0 es diagonal o bloque diagonal entre los dos conjuntos de datos, medidos en cada tipo de individuos. Así en el caso de dos caracteres, uno medido en unos individuos y el otro en otros diferentes, pero emparentados, tendríamos:
=
22
110 r0
0rR ,
=
=−
22
1122
111
0
r1
0
0r1
r00r
R
=
2221
12110 gg
ggG , AGG ⊗= 0 , 11
01 −−− ⊗= AGG ,
=−
2221
12111
0 gggg
G
y las ecuaciones del modelo mixto serían,
′′′′
=
+′′+′′
′′′′
−−
−−
2222
1111
2222
1111
2
1
2
1
12222
2212122
22
11211111
1111
1122
2222
2211
1111
11
rrrr
grgrggrr
rrrr
yZyZyXyX
aabb
AZZAXZ0AAZZ0XZ
ZX0XX00ZX0XX
, que como vemos tiene una estructura semejante al caso anterior y, por tanto, puede presentar ventajas de cálculo en el caso de que el número de efectos fijos sea muy elevado.

83
GENÉTICA CUANTITATIVA II APROVECHAMIENTO DE LA VARTIACIÓN GENÉTICA NO
ADITIVA 1. La depresión consanguínea Los ganaderos conocen desde siempre que la consanguinidad es perjudicial y que deprime el rendimiento de muchos caracteres y deteriora la salud y el vigor. Caracteres letales y anormalidades de desarrollo aparecen más frecuentemente con el aumento de la consanguinidad, debido al aumento de homocigotos, tal como se explicó anteriormnte. A nivel de un locus con dos alelos, A1 y A2, cuyos genotipos A1A1 , A1A2 y A2A2 determinan un carácter con valores a , d y -a, la media del carácter en la población, si la consanguinidad es cero será, dpp2)pp(a 21210 +−=µ , y si la consanguinidad es F, la media será, )F1(dpp2)pp(a 2121F −+−=µ , y la diferencia de ambas, dFpp2 210F −=µ−µ Si son varios los loci que afectan al carácter, están en equilibrio respecto a las frecuencias genotípicas y no hay epistasia, la diferencia total entre la media de la población no consanguínea y la consanguínea será la suma de las diferencias originadas por cada locus y su importancia dependerá del valor y el signo de d para cada locus. En el caso de que d sea cero, el gen en cuestión es aditivo y entonces no contribuye a la depresión consanguínea. Si para la mayoría de ellos tiende a ser positivo, entonces, el efecto de la consanguinidad deprimiendo el carácter podrá ser importante. De la fórmula anterior queda también patente que los genes con frecuencias intermedias serán los que más contribuyan a la depresión consanguínea. La constatación experimental y práctica de que la consanguinidad deprime a la mayoría de los caracteres indica que el valor de d tiende a ser favorable. Fisher lo explica mediante la teoría de la evolución de la dominancia, que indica que la selección natural de genes modificadores pueden convertir en dominante el gen cuyo homocigoto es favorable. Si las circunstancia cambian, de tal manera que resulta favorable el homocigoto recesivo, se inicia un proceso de selección de los alelos de los genes modificadores que poco a poco convierten este gen en dominante y el otro en recesivo. Wright da otra explicación, no excluyente de la anterior, para explicar los valores favorables de d y su explicación es de base

84
fisiológica. Piensa que si los genes afectan al carácter a través de la producción de encimas, la tasa de producción del heterocigoto, aunque sea intermedia entre la de los dos homocigotos, puede ser suficiente para asegurar una función normal. Así, en humanos, en el locus de la glucosa transferasa, la carencia del alelo normal origina galactosemia, mientras que clínicamente el heterocigoto y el homocigoto normal son indistinguibles pese a que electroforéticamente si que lo son. Ejemplos como el anterior son frecuentes. Los efectos de la consanguinidad a través de la epistasia son más complejos. Se ha demostrado que los efectos de tipo aditivo por aditivo no contribuyen a la depresión consanguínea, pero si lo hacen las interacciones con componentes de dominancia, determinando una relación curvilínea de la media con la consanguinidad, en lugar de lineal, como hemos visto que es el caso cuando sólo está presente la dominancia. Los resultados experimentales han encontrado con frecuencia que la relación lineal entre la media y la consanguinidad explica bien su relación, sugiriendo la escasa importancia que debe tener la epistasia tal como se define estadísticamente en el contexto de la genética cuantitativa. Existen diferencias entre caracteres en cuanto a su sensibilidad a la consanguinidad. Caracteres como el contenido en grasa de la leche, espesor del tocino dorsal en cerdos o tamaño del huevo en gallinas muestran un cambio ligero o positivo con la consanguinidad. La velocidad de crecimiento diario de los animales en cebo es más sensible, disminuye relativamente más conforme aumenta la consanguinidad. Los caracteres más sensibles son los más relacionados con la aptitud reproductiva, como el tamaño de la camada en cerdos, el número de huevos puestos y su incubabilidad en gallinas. Estos caracteres suelen tener heredabilidades medias o bajas, mientras que los menos sensibles a la consanguinidad las suelen tener altas, indicando su naturaleza esencialmente aditiva. En líneas objeto de selección el incremento de consanguinidad, causado por el tamaño finito de la población y la propia selección, puede deprimir el carácter objeto de selección en tal grado que contrarreste lo que se gana por selección. Se ha estimado que un incremento de alrededor de un 2% por generación en F contrarrestaría la respuesta esperable en la selección por producción de huevos en gallinas. No obstante este hecho no es muy preocupante si luego las líneas seleccionadas se utilizan en cruzamiento pues, entonces, el efecto de la consanguinidad desaparece en los individuos cruzados y pueden manifestarse los avances de la selección. Existen ejemplos en que la consanguinidad parece afectar a la capacidad homeostática de los individuos, pues se ha observado en los individuos consanguíneos una mayor sensibilidad frente al ambiente, de tal manera que tanto en experiencias con animales de laboratorio como de animales de interés productivo se ha observado una mayor varianza intra-línea que la correspondiente intra-cruce.

85
2. Heterosis La heterosis es el fenómeno en el que la descendencia de cruces entre líneas consanguíneas tiende a ser mejor que la media de las dos líneas. Así, la heterosis es el reverso de la depresión consanguínea y usualmente aparece en los caracteres que muestran depresión consanguínea. Se admite que la causa de la heterosis, como igualmente se acepta en la depresión consanguínea, es la dominancia y es la consecuencia del aumento de heterocigotos en las poblaciones cruzadas, frente al promedio de las líneas tal como se vio anteriormente. Al estudiar los apareamientos genéticamente negativos interpoblacionales se ve que la ventaja del cruzamiento depende del valor de d y de la diferencia en las frecuencias génicas de las líneas. Por ello, en los cruces se intenta utilizar líneas genéticamente alejadas para las que se espera una mayor diferencia de frecuencias génicas. No obstante, experimentalmente no se ha comprobado lo anterior como totalmente cierto, pues en el caso que se crucen líneas muy alejadas que se han adaptado a ambientes muy diferentes, la manifestación de la heterosis puede fallar. En este caso entraría en juego la epistasia, que en general hemos desestimado. La adaptación a condiciones locales muy diferentes, supone que muchas características se coadaptan armoniosamente y, consecuentemente, se seleccionan conjuntamente grupos de genes en función de su acción sobre la aptitud reproductiva, resultando coadapdtados. Así, cuando se cruzan dos poblaciones adaptadas a condiciones muy diferentes, los individuos cruzados pueden no estar adaptados a ninguna. La heterosis suele expresarse como porcentaje de la diferencia de las medias de los individuos cruzados de la de las líneas respecto a estas últimas. Si llamamos ABµ y BAµ las medias de los dos cruces entre la línea A y B (en el primer caso las hembras son de la línea B y en el segundo de la línea A), y AAµ , BBµ las medias de las líneas A y B, la expresión para la heterosis es,
100)()(
HeterosisBBAA
BBAABAAB ×µ+µ
µ+µ−µ+µ=
La heterosis anterior es lo que llamamos heterosis individual si bien es importante, en algunos caracteres, lo que podríamos llamar heterosis maternal, que sería debida a la heterocigosidad de las madres y que causaría la heterosis en el efecto materno que afecta al carácter en cuestión. Así, por ejemplo, las cerdas cruzadas pueden ser mejores madres que las cerdas de línea pura y ello puede traducirse en mejores supervivencias y crecimientos de los lechones durante la lactación. Por tanto, esta heterosis materna, importante en especies prolíficas como el cerdo o el conejo, no aparece en los cruzamientos simples, ya que en esta situación no son cruzadas las hembras y sólo lo son los descendientes del cruce, en los que sí podremos beneficiarnos de la heterosis individual en caracteres de crecimiento y aprovechamiento del pienso. Para una explotación completa de la heterosis son necesarios cruces de tres vías, para que así, las propias hembras sean cruzadas y la heterosis maternal pueda expresarse, esencialmente en aquellos caracteres con efectos maternos importantes.

86
En mamíferos, las diferencias observadas en los cruces recíprocos son fundamentalmente debidas al hecho de que en muchos caracteres el ambiente suministrado por la madre es un factor importante en su determinación. Es conveniente considerar que la manifestación de la heterosis no es independiente del ambiente. A este respecto es interesante el trabajo de Orozco que ha puesto de manifiesto en Tribolium que la heterosis se muestra de un modo más patente en ambientes adversos. Esta observación le ha llevado a formular su teoría sobre la heterosis como una interacción de genes de vigor y resistencia que serían sobredominantes con genes aditivos responsables de la manifestación del carácter, interacción que se manifestaría de forma positiva en los ambientes desfavorables. Una cuestión importante para entender el interés del cruzamiento en la producción animal es el hecho de que los pequeños % de heterosis de los caracteres individuales se acumulan, originando importantes % de heterosis en la eficiencia global de la producción, lo que permite explicar el hecho frecuente de que los cruzados, carácter por carácter, no suelen ser mejores que la mejor de las líneas parentales, pero muy a menudo si lo son en producción total. 3. Aptitud combinatoria general y específica Aquí analizaremos los resultados del cruzamiento de un conjunto de líneas, derivado de una misma población base en todas las combinaciones posibles, que es lo que se llama cruce dialélico. A estos efectos, son importantes los conceptos de aptitud combinatoria general y específica, pues en función de su importancia se determina la estrategia para buscar los mejores cruzamientos. En lo que sigue, para facilitar la exposición, asumiremos que el valor de un cruzamiento y el de su recíproco es el mismo. Llamamos aptitud combinatoria general de una línea A, ACGA, al rendimiento por encima de la media general de todos los cruzamientos de los descendientes de los cruces en que ha intervenido esta línea. De igual modo llamaremos aptitud combinatoria específica de las líneas A y B, ACEAB, a la diferencia del rendimiento de los individuos de este cruce respecto a la suma de la media general y las aptitudes combinatorias generales de las líneas A y B. Así, si definimos como GAB el rendimiento de los individuos cruzados de ambas líneas, o valor genotípico de este cruzamiento, podemos escribir, ABBAAB ACEACGACGG +++µ= , siendo µ la media general. Lógicamente, la aptitud combinatoria general es debida a la acción aditiva de los genes y a los tipos de epistasia aditivaxaditiva y semejantes, en los que no hay interacciones de dominancia. Por contra la determinación de la aptitud combinatoria específica se deberá a la dominancia de los genes y a los tipos de

87
epìstasia con componentes dominantes como la adtivaxdominante o la dominantexdominante. Para describir la estructura de la varianza entre cruzamientos de un experimento dialélico, asumiremos que las líneas tienen una consanguinidad F y que proceden sin selección de una misma población base. Teniendo en cuenta que el coeficiente de parentesco rXY dentro de línea es el de consanguinidad de la generación siguiente, generalizando la fórmula de la covarianza entre parientes que vimos anteriormente, podemos escribir, ......FFFFF 2
D42
AD32
A22
D22
A2G 22 +σ+σ+σ+σ+σ=σ
, ya que dentro de cruzamiento 2F
rXY = y 2XY Fu = .
De la fórmula anterior se sigue que la varianza de la aptitud combinatoria general será, ......FFF 2
A32
A22
A2ACG 32 +σ+σ+σ=σ
, y la varianza de la aptitud combinatoria específica, ......FFF 2
D42
AD32
D22
ACE 2 +σ+σ+σ=σ
Comparando ambas expresiones se ve que la importancia de la aptitud combinatoria específica, como fuente de variación entre cruzamientos, se incrementa fuertemente conforme progresa la consanguinidad y conforme más complejos son los efectos genéticos causantes de la variación. Las combinaciones génicas complejas pueden considerarse estables, en tanto que reaparecen en los cruzamientos repetidos de las mismas líneas. La gran ventaja del cruzamiento es el resultado, relativamente constante, que puede repetirse a voluntad o aproximadamente así. Aún en las condiciones más favorables, el aprovechamiento de la aptitud combinatoria específica sería difícil y, para entenderlo, vamos a hacer las siguientes consideraciones:
• Aunque se disponga de pocas líneas consanguíneas, el número de cruzamientos a evaluar es grande, lo cual exige muchos recursos experimentales, que normalmente no están disponibles. Así, si se dispusiese de 10 líneas el número de cruces simples, sin considerar los recíprocos, serían 45 lo que supone una tarea imposible de evaluar.
• Las poblaciones de animales, como ya se ha comentado, soportan mal niveles de consanguinidad medios o incluso bajos, pues su aptitud reproductiva se deteriora y, por tanto, resulta muy costoso y a veces imposible mantener estas líneas consanguíneas. Esto, por una parte determina que la consanguinidad no sea muy alta, lo que reduce la importancia de la aptitud combinatoria específica, pues su varianza será baja y, por otra parte, obliga en muchos casos a utilizar en la práctica

88
cruzamientos triples o de mayor orden para trabajar con hembras no consanguíneas. La consecuencia es que el número de combinaciones de cruzamientos posibles se incrementa y la tarea de encontrar el mejor se hace imposible.
Las consideraciones anteriores nos hacen comprender, que desde un punto de vista práctico va a ser mucho más importante la explotación de la aptitud combinatoria general que la de la específica, máxime si se tiene en cuenta que la correlación entre el rendimiento de una línea y la de sus descendientes cruzados es generalmente alta para caracteres con alta aptitud combinatoria general. Como veremos en el tema siguiente, la decisión de qué líneas van a entrar en un cruzamiento va a depender de la producción propia de la línea.
4. La selección para la mejora del cruzamiento. Los métodos de selección que hemos estudiado en temas anteriores aprovecha la variación aditiva estadística, advirtiendo que en ellos se aprovecha la aditividad genética y lo que en genética mendeliana llamamos dominancia. La epistasia y la sobredominancia, realmente, no son verdaderamente aprovechados por los métodos anteriores. En las primeras preguntas de este tema se han puesto de relieve la depresión consanguínea y la heterosis que en esencia son expresión de acciones génicas dominantes y sobredominantes. También hemos visto, en la pregunta anterior, que a través de cruces de líneas consanguíneas se podría reproducir en forma creciente, al aumentar el coeficiente de consanguinidad de las líneas, la variabilidad genética existente en un conjunto de cruzamientos. Cuando F=1, cada cruzamiento reproduciría uno de los genotipos posibles de la población original de F=0. Así, si fuera posible disponer de un número muy elevado de líneas altamente consanguíneas sería posible aprovechar integralmente la epistasia, pero ya hemos razonado que esto no es posible. La alternativa para disponer establemente de un genotipo, del que podamos tener una estimación precisa de su valor genotípico, es la reproducción vegetativa (clonación) a gran escala. Cuando ésta esté disponible en animales entonces se podrá aprovechar la variación de tipo epistático. La situación es muy distinta para la variación dominante y sobredominante. Para la primera ya se ha comentado que es aprovechada por los métodos de selección que se basan en la variación aditiva. Para la sobredominancia, hace años que los mejoradores del maíz propusieron la selección recurrente y recíproca recurrente, como métodos de aprovecharla, conjuntamente con la variación aditiva y dominante. El objetivo de los dos métodos es incrementar la frecuencia de alelos distintos de los genes que muestran sobredominancia en las líneas que se cruzan.

89
4.1. Selección recurrente
Fue propuesta en 1945 por Hull para mejorar la aptitud combinatoria específica del maíz. En esta especie se propuso que plantas de una línea, inicialmente poco consanguínea, polinizasen a las plantas de otra línea altamente consanguínea, que era la línea tester. Sin embargo, dada la depresión consanguínea de los caracteres reproductivos en los animales, la adaptación de este método a ellos obligó a que los machos fuesen los que perteneciesen a la línea consanguínea y las hembras a la línea no consanguínea. En este método de selección las hembras se seleccionan por el rendimiento de su descendencia cruzada con los machos de la línea tester. Estas hembras seleccionadas se aparean finalmente con machos de su propia línea para originar la siguiente generación de su línea. Con la descendencia femenina de la nueva generación se repite el ciclo de nuevo y así sucesivamente de generación en generación. La consecuencia de esta forma de proceder es que, por una parte se va incrementando la frecuencia de los alelos aditivamente favorables y por otra, para los genes altamente heteróticos (sobredominantes), se incrementa en la línea poco consanguínea la frecuencia de los alelos diferentes a los que están fijados o casi fijados en la línea tester. Así, si en un locus sobredominante la línea tester es A1A1, en la línea no consanguínea se irá incrementando poco a poco la frecuencia del alelo A2 y de esta manera se incrementará en el cruce la frecuencia de heterocigotos sobredominantes A1A2. Cuando se fije el alelo A2, y los correspondientes alelos complementarios de la tester en los demás loci sobredominantes, en la línea de las hembras, la selección recurrente dejará de ser efectiva. Este método de selección ha tenido poca importancia en la mejora genética animal, probablemente debido a que en la mayoría de las especies no se disponen de líneas consanguíneas que hagan la función de tester. Distinta es la situación de la selección recíproca recurrente que en cerdos, y especialmente en aves, ha tenido su importancia.
4.2. Selección recíproca recurrente La selección recíproca recurrente fue propuesta en 1949 por Comstock y sus colaboradores, estableciendo la selección dentro de dos poblaciones en virtud del rendimiento de los descendientes de su cruce. En este método se aprovecha la variación aditiva y la superdominante, que de ser relevantes se aprovecharían al máximo con este método de selección. De forma gráfica (UUU=macho, TTT= hembra) sería,

90
Generación Población 1 Cruces prueba Población 2 0 UUU TTT UUU TTT 1 UUU TTT UUU TTT 2 UUU TTT UUU TTT Los individuos parentales de ambas poblaciones se cruzan para producir la descendencia que va a servir para valorarlos. En base a esta prueba de la descendencia se seleccionan los machos y hembras de cada línea que, apareándose entre sí, originan la siguiente generación de cada población con la que se repite de nuevo el ciclo. Este método como el de la selección recurrente tiene el inconveniente de la prueba de descendencia, que alarga el intervalo generacional. La selección recíproca recurrente fuerza a las frecuencias génicas en loci superdominantes a frecuencias extremas opuestas en ambas poblaciones. En estos genes, al principio de la selección, el cambio de las frecuencias será lento, especialmente si eran similares, y consecuentemente el progreso por esta vía será lento, siendo más importante el debido a los genes de acción aditiva. Conforme diverjan las frecuencias de los alelos de los genes sobredominantes en ambas líneas se incrementará la velocidad de su cambio y por tanto su contribución a la mejora de los cruzados. Probablemente, conforme esto suceda, puede que se vaya agotando la variación aditiva y, si es así, disminuirá la mejora por la contribución de la aditividad. La importancia de ambas contribuciones en el curso de la selección recíproca recurrente dependerá de la importancia de la variación de cada tipo y de las frecuencias iniciales de los genes implicados en cada una de ellas.
4.3. Crítica a estos métodos de selección.
En lo que se refiere a los componente sobredominantes, el límite a la selección es el mismo para la selección recurrente que para la recíproca recurrente, aunque al inicio la selección recurrente será superior, ya que el uso de

91
testers consanguíneos hace que las frecuencias de los alelos de los loci sobredominantes estén más altamente diferenciadas que entre las dos poblaciones, ambas segregantes, de la selección recíproca recurrente. Para las partes aditivas de la variación, ambos esquemas de selección son inferiores a la selección intralínea, como se ha visto para los caracteres de heredabilidad alta. Incluso para caracteres de heredabilidad baja, que muestran heterosis, la selección intralínea es superior en los estados iniciales del proceso de selección. Después de que la mayoría de los genes que muestran efectos aditivos lleguen a la fijación y solamente los loci heteróticos muestren variación, la selección continuada por la aptitud combinatoria mejorará el cruce, mientras que las líneas parentales se deteriorarán, debido al aumento de la homocigosidad en los loci heteróticos. En este estado, los valores del carácter objeto de selección en las líneas y en los cruzamientos estarán negativamente correlacionados.
Ha sido objeto de larga discusión la cuestión de la superioridad de la
selección recíproca recurrente y la conveniencia de su utilización para mejorar el cruzamiento de dos líneas. Los resultados experimentales no son del todo clarificadores debido a que el planteamiento de las experiencias, a veces, no ha sido suficientemente crítico. En Drosophila se ha comparado la selección intralínea con la selección recurrente, recíproca recurrente y con el cruce de líneas consanguíneas. La selección individual y familiar intralínea fueron las mejores para caracteres como el tamaño de huevo que tiene una elevada heredabilidad. La selección intralínea también tuvo la mayor respuesta a corto plazo en la producción de huevos, que es un carácter, en Drosophila, de baja heredabilidad. Posteriormente, sin embargo, los otros métodos superaron a la selección intralínea. Los valores superiores se consiguieron en un cruzamiento de líneas consanguíneas. Las líneas que se mejoraban por su aptitud combinatoria mostraron una mejora continuada a lo largo de 40 generaciones, sin que apareciese ningún plateau al final de la experiencia, por lo que la selección continuada por el comportamiento al cruce podría haber superado al cruce de las líneas consanguíneas. También se confirmó la eficacia de la selección recurrente en los primeros estadios de la selección. En otra experiencias con ratones y también con Drosophila los resultados muestran a la selección intralínea siempre superior, si bien estas experiencias fueron de duración más limitada que la anterior y realizadas sobre poblaciones no seleccionadas previamente, en las que era esperable una variación aditiva relativamente alta. Cuando decíamos que estas experiencias no se han planteado de modo suficientemente crítico, queríamos decir, por ejemplo, que la selección recíproca recurrente se había comparado con la selección intralínea individual, y no con el método de selección intralínea óptimo. Si se hubiese hecho así, posiblemente siempre hubiese quedado por encima la selección intralínea, dado que la sobredominancia, que es el tipo de acción génica en que la selección recíproca recurrente es claramente superior parece ser rara. No son abundantes los ejemplos de genes simples en que el heterocigoto es claramente superior a cualquiera de los dos homocigotos. Uno de ellos es el de la anemia falciforme. El alelo Hb l transporta bien el oxígeno y es dominante frente al alelo Hbs, que en homocigosis determina la anemia falciforme. Este alelo, sin embargo, respecto a la resistencia a la malaria es dominante, de tal manera que el heterocigoto HbsHbl es mejor que cualquiera de

92
los dos homocigotos en ambientes en que la resistencia a la malaria es importante. Otro ejemplo similar es el de la resistencia a la warfarina en roedores. En él un alelo es dominante en relación con la resistencia al veneno, pero recesivo respecto a necesidades extra de vitamina K. El otro alelo se comporta al contrario y por tanto el heterocigoto reúne las ventajas de ambos, sin ninguno de los inconvenientes. Otra situación semejante es la del gen del halotano en los cerdos. Para este gen, los heterocigotos no tienen el inconveniente de la sensibilidad al estrés, ni del músculo pálido, blando y exudativo, manteniendo la ventaja del desarrollo muscular. Los tres ejemplos anteriores lo son de un modelo, propuesto por Wright, en que la superdominancia aparece cuando genes con acción pleiotrópica tienen alelos que son favorables para un carácter y desfavorables para otros, presentando, según el carácter, una dominancia total o parcial en el sentido favorable. El desequilibrio de ligamiento, cuando reúne en un mismo segmento cromosómico, alelos favorables de unos genes con alelos desfavorables de otros genes, genera lo que se llama pseudo-superdominancia. Los individuos más favorecidos serán aquéllos que digamos son heterocigotos para dichos segmentos cromosómicos. En experimentos con plantas, cruzando diversas líneas, es posible obtener evidencias de si la interacción dominante es o no de tipo sobredominante. Las primeras evidencias obtenidas de sobredominancia, finalmente tuvieron que interpretarse como pesudo-superdominancia, al ir perdiendo intensidad, conforme generaciones de apareamientos al azar permitían la desaparición del desequilibrio de ligamiento. Falconer, en ratones, y Abplanalp, en gallinas, han obtenido líneas consanguíneas tan buenas como la población original para el carácter seleccionado, lo que es una evidencia añadida de que la sobredominancia no es importante. En la mejora práctica, sin embargo, pueden permanecer intactos, durante varias generaciones, segmentos cromosómicos amplios, que determinasen una importancia temporal de la pseudo-superdominancia.
Volviendo a la cuestión del interés de la selección recíproca recurrente
frente la selección intralínea, todo lo que acabamos de considerar, junto con el hecho de que la puesta en marcha de la selección recíproca recurrente es complicada por la prueba de descendencia que implica y los largos intervalos generacionales, ha hecho que desde hace años el uso este tipo de selección se ha reducido muchísimo. En el cerdo y en conejos las líneas que se utilizan en los cruzamientos están siendo seleccionadas por métodos de selección intralínea y en aves parece ocurrir lo mismo en la mayor parte de los casos.

93
GENÉTICA CUANTITATIVA II LOS CRUZAMIENTOS EN LA PRODUCCIÓN ANIMAL
1. Interés del cruzamiento en la producción ganadera. En la producción ganadera, especialmente en especies prolíficas, como en el conejo o cerdo, aunque también en ovejas, es frecuente recurrir al cruzamiento de líneas o razas para mejorar la producción de los animales o la adaptación a las condiciones ambientales de producción. Una de las razones por las que se hace el cruzamiento es el aprovechamiento de la heterosis de la que hemos hablado en el tema anterior. En algunos casos la heterosis puede ser negativa y en muy pocos casos supera la media de los cruzados a la mejor de las líneas o razas que intervienen en el cruzamiento. Sin embargo, los cruzamientos se aconsejan con bastante generalidad y la razón de ello se debe a la siguiente consideración, que ya expusimos en el tema anterior. La consideración se refiere al hecho de que si bien carácter por carácter los individuos cruzados no suelen superar al mejor de los padres, de una manera global suelen ser más beneficiosos si se han elegido adecuadamente las líneas que intervienen en el cruzamiento. El criterio sería elegir líneas que sean semejantes en cuanto a su productividad global, que debería ser lo más alta posible, y que fuesen entre si complementarias. Complementarias quiere decir que en los caracteres simples en que una fuese menos sobresaliente la otra línea lo fuese más. Así, si una línea A de conejos produce gazapos que crecen a 34 g/d y desteta 7 gazapos por camada, mientras que en otra B los gazapos crecen a 30 g/d y desteta 8 gazapos por camada, ambas líneas son complementarias para estos dos caracteres. Si los individuos cruzados crecen a 32 g/d, es decir no hay heterosis y destetan a 7.8 g/d, hay una ligera heterosis, vemos que en ningún carácter los cruzados superan a la mejor de las líneas. Si pensamos en un carácter mas global, como el incremento de peso diario de todos los conejos de una camada, veremos que,
• la línea A incrementa en 7x34=238 g/d.camada • la línea B incrementa en 8x30=240 g/d.camada • que ambas líneas son muy semejantes en el carácter más global del
incremento de peso diario de toda la camada, y • los cruzados AB incrementan en 7.8x32=250g/d.camada
, es decir, los cruzados superan a ambas líneas en el carácter global. En el grado en que el rendimiento total de los animales es el producto de numerosos caracteres simples, que en el cruzamiento pueden no presentar heterosis o heterosis intermedias, los cruzados serán globalmente más ventajosos que las líneas que se cruzan, si éstas cumplen los requisitos que hemos establecido anteriormente. Este hecho se ha demostrado experimentalmente y así, en cruces de vacuno simples y dobles, entre las razas Ayrshire, Holstein y Parda Suiza, se ha visto que el mérito total, basado en los valores económicos de los diversos caracteres productivos de los animales cruzados, comparados con el de las

94
razas, puede diferir bastante de los resultados obtenidos en los caracteres individuales. En los cruzamientos relativos a especies animales prolíficas, en las que la producción total depende del adecuado comportamiento reproductivo de las hembras madre y de la capacidad de crecimiento y aprovechamiento del pienso de las crías, se hace un uso más extremado de la complementariedad entre las líneas. En esta situación, las líneas que van a actuar como madres o van a cruzarse para producir hembras cruzadas deben de tener una alta capacidad reproductiva y un crecimiento razonable. Aquéllas que se utilizan como padres de las crías que se sacrifican tras el final del cebo, deben elegirse por su potencialidad en características de crecimiento, siendo más irrelevante su capacidad reproductiva. Los tipos de cruzamiento interesantes en producción animal son diversos y son función de consideraciones reproductivas de las distintas especies y de cuestiones económicas. En función de la especie puede tener interés o no la utilización de madres cruzadas para aprovechar la heterosis en los caracteres reproductivos. Es el caso de cerdos, conejos o aves. Por otra parte, las exigencias de animales de reemplazamiento pueden ser elevadas en algunas especies, como el vacuno, que determinen que ciertos cruzamientos no sean interesantes. Por otra parte, el desarrollo y mantenimiento de las líneas que intervienen en los cruzamientos es costoso y ello puede hacer conveniente la imposición de esquemas de cruzamiento con pocas líneas.
2. Cruzamientos de dos, tres o cuatro vías. Este tipo de cruzamientos suelen ser característicos de especies como cerdos, conejos o aves de prolificidad elevada, en los que las necesidades de reposición no son un % elevado de las crías producidas. El cruzamiento de dos vías o cruzamiento simple es aquél en que hembras (T) de una línea A y machos (U) de una línea B se cruzan para dar los animales que se engordan y luego se sacrifican,
U Bx T A
animales de sacrificio
Este tipo de apareamientos permite explotar la complementariedad entre las líneas A y B y la heterosis a nivel de las crías. En producción animal este tipo de apareamiento tiene un interés parcial en ovino y vacuno. En ovino suele utilizarse en zonas intermedias de recursos alimenticios, a las que es fácil el suministro de ovejas de razas rústicas que se cruzan con machos de razas de mayor potencialidad de crecimiento. En vacuno lechero, las hembras, cuyas crías

95
no van a utilizarse como hembras de reposición, se aparean con machos de razas especializadas en la producción de carne. En cerdos, en el Reino Unido y en el Norte de Europa, a veces se utiliza el retrocruzamiento, que consiste en aparear las hembras del cruce simple con machos de una de las líneas utilizadas en el cruce anterior,
U A x T B
U A o B x T
Animales de sacrificio En principio, los animales del cruce simple inicial pueden producirse, también, con el cruce recíproco. El retrocruzamiento valoriza la utilización de las líneas A y B, cuyo desarrollo es costoso, permite explotar la heterosis a nivel de las madres y parcialmente a nivel de las crías y no exige disponer de una tercera línea. Dado que en el porcino, hasta hace algunos años, la selección de las líneas hacía énfasis, fundamentalmente, en caracteres de crecimiento, como velocidad de crecimiento, índice de conversión y % de magro de la canal, se entiende el sentido del retrocruzamiento en esta situación, máxime si en el país en que se practica, la conformación no es especialmente apreciada.
En el cruce de tres vías o cruzamiento doble, muy común en conejos y frecuente en cerdos, se aprovecha la heterosis en las madres y en las crías y, además, puede hacerse un uso extremo de la complementariedad al elegir la línea de los machos finalizadores con características excelentes de crecimiento, de conformación o de contenido en magro, por ejemplo. Tal como se aplica en la producción, el cruce de tres vías consiste en la utilización de tres líneas poco consanguíneas, A, B y C. Las líneas A y B son líneas que teniendo unas características aceptables de crecimiento, son sobresalientes en cuanto a características reproductivas y a este respecto tienen una buena aptitud al cruzamiento, es decir combinan bien para que sus hijas (AB) sean muy prolíficas. Estas hembras cruzadas AB son explotadas en las granjas, cruzándose con machos de una línea C caracterizada por sus buenas cualidades de crecimiento, aprovechamiento del alimento y características de la canal.
U A x T B
U C x T AB
Animales de sacrificio Frente al esquema de retrocruzamiento, además de las diferencias ya
comentadas, son mayores los costos de desarrollo y mantenimiento de las líneas, debido a que es necesaria una línea más y no se rentabilizan los machos de las

96
líneas A y B como machos terminales. Sin embargo desde el punto de vista del progreso genético puede sacarse ventaja de la fuerte presión de selección en la línea C para los caracteres de crecimiento.
En ovino, el cruce de tres vías puede tener, también, interés en el mismo
sentido que hemos manifestado para el cruce simple en esta especie. El interés radica en plantear el cruce simple de una raza rústica con una raza prolífica en la zona de recursos escasos, donde se cría la raza rústica. Las hembras resultantes de este cruce se trasladan a zonas con mayores recursos alimenticios y se aparean con machos de razas con fuerte potencialidad de crecimiento. Resaltamos, que en los ejemplos de ovino que hemos señalado, el cruzamiento se utiliza como un medio flexible de adecuar el tipo de animal a explotar a los recursos alimenticios que ofrecen los distintos medios de producción.
En el cruce de tres vías que acabamos de describir, a los individuos de las
líneas A y B se les llama abuelos, porque lo son de los animales de sacrificio. Existen organizaciones de mejora, públicas o privadas, que se ocupan de la mejora genética de las líneas que intervienen en el cruzamiento doble. La forma en que los ganaderos utilizan estos animales consiste en comprar a multiplicadores de las anteriores organizaciones, hembras cruzadas AB y machos terminales. La exigencia de mantener completo el número total de hembras productivas obliga a la introducción continua de hembras cruzadas, lo que plantea problemas económicos y sanitarios en las explotaciones. En razón de ello, cuando las explotaciones ganaderas son suficientemente grandes suelen suministrarse directamente los abuelos, produciéndose las hembras cruzadas en su propia explotación. De esta manera se reducen, también, los problemas de adaptación de una explotación a otra.
También es posible, aunque no está tan difundido como el cruce a tres
vías, el cruce a cuatro vías, que es un esquema análogo al anterior, en que el macho del cruce terminal es un macho obtenido del cruzamiento de dos líneas D y E.
U D x T E U A x T B
U DE x T AB
Animales de sacrificio Evidentemente, en este esquema, el utilizar cuatro líneas lo hace gravoso y el utilizar machos cruzados, únicamente permite sacar ventajas de la heterosis en algunos aspectos reproductivos del macho, como la líbido y la producción de espermatozoides. Desde un punto de vista comercial, tiene la ventaja de permitir a las organizaciones de mejora mantener la propiedad estricta de las líneas D y E, pues a los multiplicadores que producen los machos DE, únicamente se les

97
suministra machos de la línea D y hembras de la línea E. Cuando éste no es el problema y únicamente se quiere sacar partido a la mejor líbido de los machos cruzados, una modificación del retrocruzamiento descrito anteriormente resuelve la cuestión. Basta con utilizar como machos finalizadores, machos AB, como las hembras . En este caso los animales de sacrificio son realmente una F2. Cuando los beneficios del cruzamiento se deben fundamentalmente a la acción dominante o superdominante de los genes y la epistasia es despreciable, se puede predecir, para un carácter concreto, el valor del cruzamiento doble en función de los valores medios de los cruzamientos simples. Así, si llamamos, G(AxB)x(CxD) , al valor medio del cruzamiento de cuatro vías indicado y, G(XxY) , al valor medio del cruzamiento simple entre las líneas X e Y, podemos escribir que, G(AxB)x(CxD) =0.25(G(AxC) + G(AxD) + G(BxC) + G(BxD))
2.1. La selección de las líneas que intervienen en los cruzamientos. Una vez establecido el tipo de cruzamiento de interés y determinadas las líneas que van a intervenir, se plantea el problema de cómo mejorar las líneas a efectos de que los resultados del cruzamiento sean cada vez mejores. Vamos a tratar esta cuestión conjuntamente con la referente al enfoque general del aprovechamiento de los cruzamientos, enfoque que ha variado a lo largo del tiempo. Si se examina lo que ha ocurrido en avicultura y aprovechamos la síntesis de Orozco, vemos que al principio los intentos de aprovechar las ventajas del cruzamiento se centraron en la realización de cruzamientos simples entre diferentes razas. Se continuó con la producción de híbridos, resultantes del cruce entre líneas consanguíneas de diferentes razas, al principio, y después de la misma raza (Leghorn blanca para la producción de huevos). No obstante, especialistas de la materia, como Abplanalp, matizaron respecto a esta fase, que pese a que el uso de líneas por los mejoradores comerciales de gallinas estuvo bien establecida y fue muy útil para producir ponedoras, no era ningún secreto que las líneas empleadas no eran muy consanguíneas, ni especialmente elegidas por su aptitud al cruce simple. Siguiendo con las aves, posteriormente se desarrolló el método más simple del cruce entre estirpes (líneas muy poco consanguíneas) e igualmente se osciló de estirpes de distinta raza a estirpes de la misma raza. Hoy día se da esta situación para las ponedoras de huevo blanco, utilizándose estirpes de dos razas en las de huevo pardo y en los broilers. Se pueden dar tres razones por las que los programas que pretendían utilizar líneas consanguíneas, especialmente elegidas por su aptitud al cruce, perdieron terreno. La primera es la complejidad de su realización, la segunda es su elevado costo y la tercera su escasa flexibilidad frente a una eventual pérdida de rendimiento del híbrido resultante o a un cambio en las preferencias del mercado.

98
La tendencia que finalmente se ha impuesto mayoritariamente ha sido la de sustituir la selección de las estirpes, en lugar de por métodos de selección especifica para mejorar la aptitud al cruce, como son la selección recurrente y recíproca recurrente, por métodos de selección intra estirpe, con la esperanza de que la superioridad original de un cruzamiento será mantenida en el curso de las generaciones. Por lo que se refiere a cerdos, existe una experiencia antigua y larga realizada en varias estaciones experimentales de Estados Unidos en la que se comparaban dos métodos para mejorar cerdos cruzados. Un método consistía en la utilización de un índice basado en el rendimiento de los cerdos dentro de las razas y el otro utilizaba otro índice, basado parcialmente en el rendimiento de los propios cerdos cruzados. Se utilizaban las razas Minessota 1, 2 y 3. Las cerdas cruzadas se obtenían apareando verraco nº 3 con cerdas nº 1. Estas cerdas cruzadas eran montadas por verracos nº 2 para obtener los productos finales. Los resultados indicaron que el método intraraza fue mejor que el otro, en todos los caracteres con excepción del tamaño de camada y quizá el peso al destete, en que la selección basada en el segundo método fue mejor. No obstante, en cerdos, las tentativas del uso de líneas consanguíneas han sido muy limitadas, debido en parte a los costes elevados implicados en el proceso de producción de líneas consanguíneas y del ensayo de su aptitud combinatoria. En definitiva, en cerdos y también en conejos, actualmente se utilizan en los cruzamientos líneas poco consanguíneas que al fundarse se procuró que fueron lo más sobresalientes en la especialización que se deseaba que tuviesen, continuando su selección a través de métodos de selección intralínea. Debido a que, como ya se ha comentado, el ensayo extenso de la aptitud combinatoria de las líneas posibles a entrar en un cruzamiento es muy costoso o imposible, es pertinente disponer de un criterio razonable para elegir las líneas. En este sentido Robertson analizó el problema y concluyó que lo más general cuando se cruzan líneas, incluso en el caso del maíz, es que una alta proporción de la variación entre cruzamientos es debida a la aptitud combinatoria general y que por tanto el rendimiento de las propias líneas es una guía buena para predecir la de los cruzados. Respecto al análisis de la conveniencia de seleccionar líneas conjuntamente para caracteres reproductivos y de crecimiento o separadamente en líneas diferentes, se concluyó que la selección separada de los dos componentes del cruzamiento era de máximo valor cuando entre los dos tipos de caracteres existen correlaciones genéticas negativas altas.
3. Cruzamientos en rotación En las especies poco prolíficas el cruzamiento tiene un interés limitado porque la proporción de hembras de una de las líneas tendría que ser una parte importante de las cruzadas, a efectos de atender las necesidades de reemplazamiento. Esto plantea problemas prácticos y de aprovechamiento importantes.

99
En estos casos se plantean, como alternativa, los cruzamientos en rotación en los que, sobre las hembras que se van obteniendo en cada cruzamiento, se utilizan secuencialmente machos de las líneas que intervienen en la rotación. Para comprender mejor lo anterior, imaginemos que es de nuestro interés, en vacuno de carne, un cruce simple de hembras de la raza A que tenemos y mantenemos en nuestra explotación, con machos de la raza B que se compran. En esquema sería, Toros A Vacas A Toros B comprados Terneros A Terneros cruzados Animales de sacrificio Asumiendo que las vacas de raza A tienen una cría anual y que la tasa anual de reposición es el 30% para atender a los fallos reproductivos, de salud, de producción o de muerte, así, incluso con el 100% de tasa de concepción y supervivencia desde el nacimiento a la edad de entrada en reproducción, únicamente podríamos tener el 40% de las hembras de raza A dedicadas al cruzamiento. Por ello se ha buscado la alternativa de los cruzamientos en rotación. Estos cruzamientos, a la ventaja organizativa que suponen, unen el inconveniente de que el aprovechamiento de la heterosis es menor que en el cruzamiento simple. Así mismo, el tamaño de las líneas que intervienen debe de ser similar para no crear problemas de parto. El esquema que sigue muestra un diagrama de un cruzamiento en rotación con tres razas o líneas y la proporción de genes de las distintas razas esperados en las generaciones sucesivas.
U B x T A U C x T (50%A%50%B) U A x T (25%A 25%B 50%C) U B x T (62.5%A 12.5%B 25%C) U C x T (31.2%A 56.3%B 12.5%C) U A x T (15.6%A 28.1% B 56.3%C)
(57.8 %A 14.1%B 28.1%C)
Es fácil deducir que las proporciones de participación de cada raza al resultado del cruzamiento tiende a unos valores, que llamaremos de equilibrio,

100
constantes para las líneas en función del número de generaciones que haga que la línea haya actuado como padre por última vez. Más adelante puntualizaremos esta cuestión.
Bajo las mismas hipótesis que expusimos para predecir el valor del cruzamiento de cuatro vías, en función de los cruzamientos simples, es posible predecir el valor de la descendencia de los cruzamientos en rotación a partir de la media de los cruzamientos simples y de la media de las líneas que intervienen en la rotación. Así, en un cruzamiento en rotación entre las líneas A y B, si llamamos GR(AB) al valor medio de los descendientes del cruzamiento en rotación, podemos escribir,
G GG G G
R AB AB
AB A B
( )
( )= −
− +12
3
, llamando GX al valor medio de los individuos de la línea X. La expresión anterior muestra que el valor del cruzamiento en rotación de dos vías es inferior al del cruzamiento simple en 1/3 de la diferencia entre el cruzamiento simple y la media de las líneas parentales. Esta reducción es debida a la heterocigosidad reducida de la descendencia de los cruzamientos rotativos, relativos a los cruzamientos simples. La ecuación de predicción para un cruzamiento en rotación de las líneas A, B y C sería,
G G G GG G G G G G
R ABC AB AC BC
AB AC BC A B C
( ) ( )( ) ( )
= + + −+ + − + +1
3
13
13
7
En este caso la reducción relativa a los cruzamientos simples es menor que el caso de los cruzamientos en rotación de dos líneas, ya que la heterocigosidad permanece más alta en el cruce que implica a tres líneas. En ratones se han comparado los diversos esquemas de cruzamientos. Los cruzamientos simples fueros superiores a los cruzamientos en rotación y éstos a las líneas. Según la teoría es esperable que, al aumentar el número de líneas, los cruzamientos en rotación se aproximen a la media de los cruzamientos simples, lo cual es cierto, pero conforme el número de líneas aumenta la media de los simples disminuye, pues entran líneas con peor aptitud combinatoria y su rendimiento medio se rebaja y se va aproximando a la media de la población. Como hemos comentado, el cruzamiento en rotación de tres líneas conserva un alto grado de heterocigosidad, concretamente después de alcanzarse el equilibrio, 6/7 de las parejas génicas tienen genes de líneas diferentes y solamente 1/7 de los loci tienen ambos genes de la misma línea. Para entender como se determinan las anteriores proporciones vamos, en el cruzamiento rotativo de tres líneas, a llamar x a la proporción, cuando se alcanza el equilibrio de participación de las líneas, de la línea que más generaciones hace

101
que ha actuado como padre, “y” a la proporción de la siguiente y z a la de la última. Entonces se cumplirá que,
xz
yx
zy
205
2
2
+ =
=
=
.
, cuyas soluciones son, x=1/7, y=2/7, z=4/7 Así, si por ejemplo, es la línea A la última que ha actuado como macho, la proporción de sus genes en los cruzados será 1/7, la de la B, 2/7 y la de la C 4/7. A la generación siguiente dichas proporciones corresponderán a las líneas B, C y A. A la siguiente a las C, A y B. La composición de los cruzados variará cada tres generaciones y los valores medios que hemos dado más arriba se refieren al promedio de tres generaciones consecutivas, una vez alcanzado el equilibrio. Si se desea una población cruzada de composición constante, el tipo anterior de rotación no es útil. Para evitarlo se ha sugerido un esquema de apareamiento entre individuos de generaciones sucesivas, tal como mostramos a continuación, A B C P1 P2 P3 P4 La tabla que sigue muestra la proporción de genes en las generaciones sucesivas de las líneas originales Generació
n A B C
1 1/2 1/2 - 2 1/4 1/4 1/2 3 3/8 3/8 2/8 4 5/16 5/16 6/16 5 11/3
2 11/32 10/32
. . . . ∝ 1/3 1/3 1/3

102
La población que se cruza resulta cerrada después de la segunda generación. Por tanto, si tal población compuesta va a desarrollarse, el tamaño efectivo de la población deberá mantenerse razonablemente alto, para evitar la depresión consanguínea. Este esquema de cruzamiento mezcla genes de las tres líneas, pero no explota convenientemente la heterosis. De hecho es equivalente a una población sintética fundada con igual participación de las tres líneas.
4. Comparación entre cruzamientos. En las preguntas anteriores hemos expuesto distintos tipos de cruzamientos y se han señalado sus principales puntos de interés, sus inconvenientes y sus diferencias. En este apartado se va a adoptar una posición más básica, apoyándonos en el modelo propuesto por Dickerson que permite visualizar los efectos conjuntos de la complementariedad y de la heterosis en los distintos tipos de cruzamientos. La idea consiste en el establecimiento de un modelo que intenta explicar las diferentes medias de los distintos cruzamientos en función de los efectos genéticos directos y maternos asociados a las líneas y razas, así como los efectos de heterosis directa y maternal asociados a la combinación de las parejas de líneas o razas. Para definir el modelo, llamaremos,
-Gc al valor medio de los descendientes de un cruzamiento dado c que, en sentido general, incluye incluso a las líneas, -gi
I al efecto genético directo asociado a la línea i -gi
M al efecto genético materno asociado a la línea i
-hijI a la heterosis individual entre las líneas i y j
-hijM a la heterosis materna entre las líneas i y j
De acuerdo con los anteriores términos, el valor de Gc será, G g g h hc j j
Ik k
Mlm lm
Inp np
M= + + + +∑∑ ∑∑µ λ β γ δ
En la fórmula anterior, cada λ j representa la contribución de la línea j a los
individuos del cruzamiento Gc , por tanto, λ j =∑ 1 ,
-βk , representa la contribución de la línea k a las madres de los individuos
del cruzamiento Gc, por tanto βk =∑ 1 , - γ lm , es la contribución de las líneas l, m a la heterosis de los individuos del
cruzamiento Gc, por tanto ∑ ≤γ lm 1 , pues los individuos de Gc pueden no ser totalmente cruzados, y
-δnp , es la contribución de las líneas n, p a la heterosis de la madres de los
individuos del cruzamiento Gc, por tanto δnp ≤∑ 1
En la tabla que sigue se dan los valores de λ, β, γ y δ para diferentes cruzamientos en que están implicadas las líneas A, B y C.
103
λ´s
β´s
γ´s
δ´s
U T gAI gB
I gCI gA
M gBM gC
M hABI hAC
I hBCI hAB
M hACM hBC
M A A 1 0 0 1 0 0 0 0 0 0 0 0 B B 0 1 0 0 1 0 0 0 0 0 0 0 C C 0 0 1 0 0 1 0 0 0 0 0 0 A B ½ ½ 0 0 1 0 1 0 0 0 0 0 B A ½ ½ 0 1 0 0 1 0 0 0 0 0 A C ½ 0 ½ 0 0 1 0 1 0 0 0 0 C A ½ 0 ½ 1 0 0 0 1 0 0 0 0 B C 0 ½ ½ 0 0 1 0 0 1 0 0 0 C B 0 ½ ½ 0 1 0 0 0 1 0 0 0 A BC ½ ¼ ¼ 0 ½ ½ ½ ½ 0 0 0 1 B AC ¼ ½ ¼ ½ 0 ½ ½ 0 ½ 0 1 0 C AB ¼ ¼ ½ ½ ½ 0 0 ½ ½ 1 0 0 A AB ¾ ¼ 0 ½ ½ 0 ½ 0 0 1 0 0 B AB ¼ ¾ 0 ½ ½ 0 ½ 0 0 1 0 0 A AC ¾ 0 ¼ ½ 0 ½ 0 ½ 0 0 1 0 C AC ¼ 0 ¾ ½ 0 ½ 0 ½ 0 0 1 0 B BC 0 ¾ ¼ 0 ½ ½ 0 0 ½ 0 0 1 C BC 0 ¼ ¾ 0 ½ ½ 0 0 ½ 0 0 1 El modelo anterior puede ampliarse incluyendo efectos de recombinación, efectos ligados al sexo o la heterosis paterna. El modelo tiene la utilidad de poder comparar cruzamientos y poder interpretar en que se diferencian sus valores y poder determinar cada cual en qué grado aprovechan los efectos directos o maternos de las distintas líneas o la heterosis individual o materna de las combinaciones de las líneas. La estimación de los anteriores efectos requiere conocer los valores medios de las distintas líneas y cruzamientos, que se intentan explicar mediante una regresión múltiple en los que las incógnitas son los diferentes efectos y los coeficientes los dados en la tabla anterior, o análogos, según los cruzamientos y líneas de los que se tengan datos.
5. Uso de líneas especializadas Este punto ha sido mencionado en apartados anteriores del presente tema y, aquí, únicamente queremos presentar el análisis de Moav y Smith sobre el beneficio obtenible en una actividad ganadera como función de los caracteres productivos de las crías, en general caracteres de crecimiento, y de la capacidad reproductiva de las hembras. El beneficio B, puede aproximarse de acuerdo con la siguiente expresión, B=A+Cy-N/x

104
, donde A, C y N son constantes, “y” representa la productividad de las crías y x la capacidad reproductiva de las madres. En el caso del cruzamiento, cuando la contribución de los padres y de las madres al beneficio es desigual, como en la fórmula anterior, está justificada la utilización de líneas especializadas como macho o hembra. Tengamos en cuenta que y va a ser determinado por todas las líneas que intervienen en el cruzamiento que origina las crías, en función de su % de participación y de la eventual heterosis que manifieste el carácter productivo. Sin embargo, el valor de x va a estar determinado por la línea o cruzamiento que haga de madre. La expresión anterior del beneficio pone de manifiesto que él es proporcional a la productividad y que la capacidad reproductiva incrementa B en función del valor concreto de x, en el sentido de que un incremento de una unidad de x repercute tanto menos en B cuanto mayor es x. Esto ha tenido su influencia en el enfoque de la selección de las líneas que intervienen en el cruzamiento, sobre las que se ha actuado fundamentalmente sobre la componente “y”, sobre todo en aves y cerdos para los que se consideraba que el nivel de x era ya satisfactorio. Los análisis anteriores son correctos cuando se razona sobre el beneficio producido por animal criado. Sin embargo, cuando la base del razonamiento es el beneficio obtenido por un número fijo de hembras reproductoras, cobra mayor importancia la componente reproductora.





























