Embed Size (px)
DESCRIPTION
Mining a Web 2.0 service for the discovery of semantically similar terms : A case study with Del.icio.us. Kwan Yi School of Library and Information Science College of Communications and Information Studies University of Kentucky. Social bookmarking: Del.icio.us. - PowerPoint PPT Presentation
Citation preview

1
Mining a Web 2.0 service for the discovery of semantically similar terms:
A case study with Del.icio.us
Kwan YiSchool of Library and Information Science
College of Communications and Information StudiesUniversity of Kentucky

Social bookmarking: Del.icio.us
• Del.icio.us is one of most popular social bookmarking systems:–3 million registered users and–100 million unique URLs bookmarked,
as of September 2007

Folksonomy
• We define folksonomy as a collective set of tags (keywords or terms) assigned by participants in a social tagging system.–User-created vocabulary–Uncontrolled vocabulary–Built in a collaborative manner
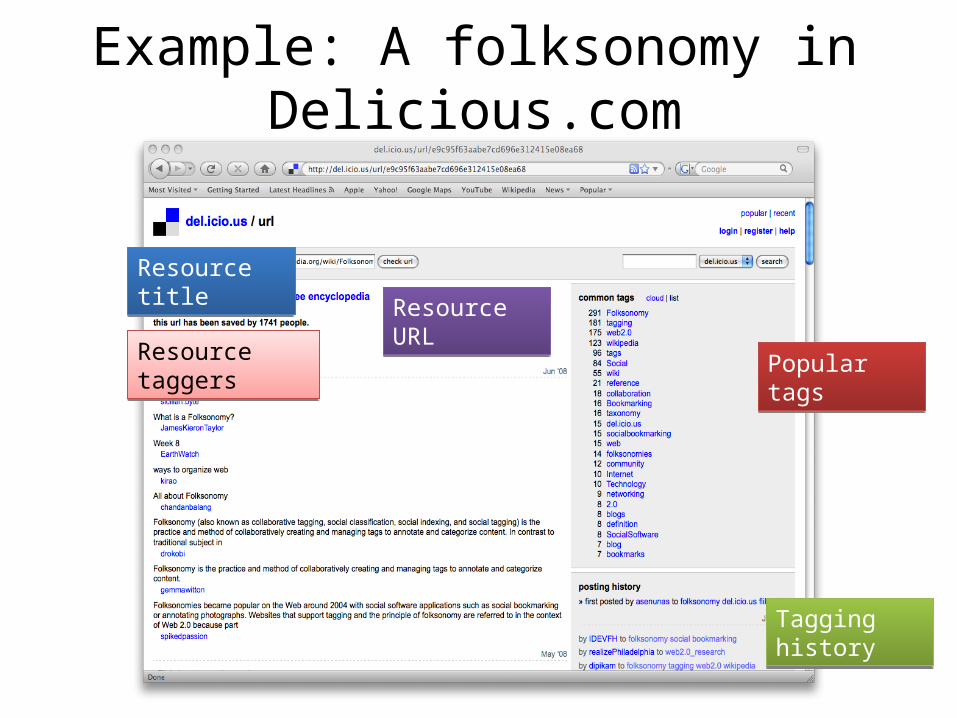
Example: A folksonomy in Delicious.com
Resource titleResource title
Resource taggersResource taggers
Resource URLResource URL
Tagging historyTagging history
Popular tagsPopular tags

Objective of the Study
• To examine an effective way of mining semantically similar terms from folksonomy for the purpose of investigating the feasibility of folksonomy as a potential data source of semantically similar terms

Proposed algorithms for mining similar terms from Folksonomy
• Co-occurrence-based similarity algorithm
• Correlation-based similarity algorithm

Experiment (I)
• To identify similar terms of each of the 121 most popular tags on Del.icio.us posted on the fifteenth of May 2008

Result: How many similar terms for the 121 popular tags?
• Co-occurrence-based algorithm– 2.6 similar terms (Level of similarity = 0.9)– 5.1 similar terms (Level of similarity = 0.7)– 10.1 similar terms (Level of similarity = 0.5)
• Correlation-based algorithm– 0.9 similar terms (Level of similarity = 0.9)– 1.6 similar terms (Level of similarity = 0.7)– 2.6 similar terms (Level of similarity = 0.5)

Experiment (II)
• To identify similar terms of each of the 32 tags (out of the 121) that are not listed on the online version of Merriam-Webster Dictionary

Result: How many similar terms for the 32 not-in-the-dictionary tags?
• Co-occurrence-based algorithm– 3.3 similar terms (Level of similarity = 0.9)– 5.9 similar terms (Level of similarity = 0.7)– 10.1 similar terms (Level of similarity = 0.5)
• Correlation-based algorithm– 1 similar terms (Level of similarity = 0.9)– 1.7 similar terms (Level of similarity = 0.7)– 2.4 similar terms (Level of similarity = 0.5)

Webdesign(similarity level: 0.9)
• Co-occurrence [12]:
resources css web design reference html tutorial tutorials inspiration gallery development webdev
• Correlation [4]:
css design html inspiration

Findings
• The correlation-based is more selective than the co-occurrence-based.• The co-occurrence-based appears to
be most attractive with the similarity level of 0.7.

Conclusion
• As social bookmarking systems are more popularly utilized, the potential of their folksonomies for the mining task will be more increased.

Thanks!


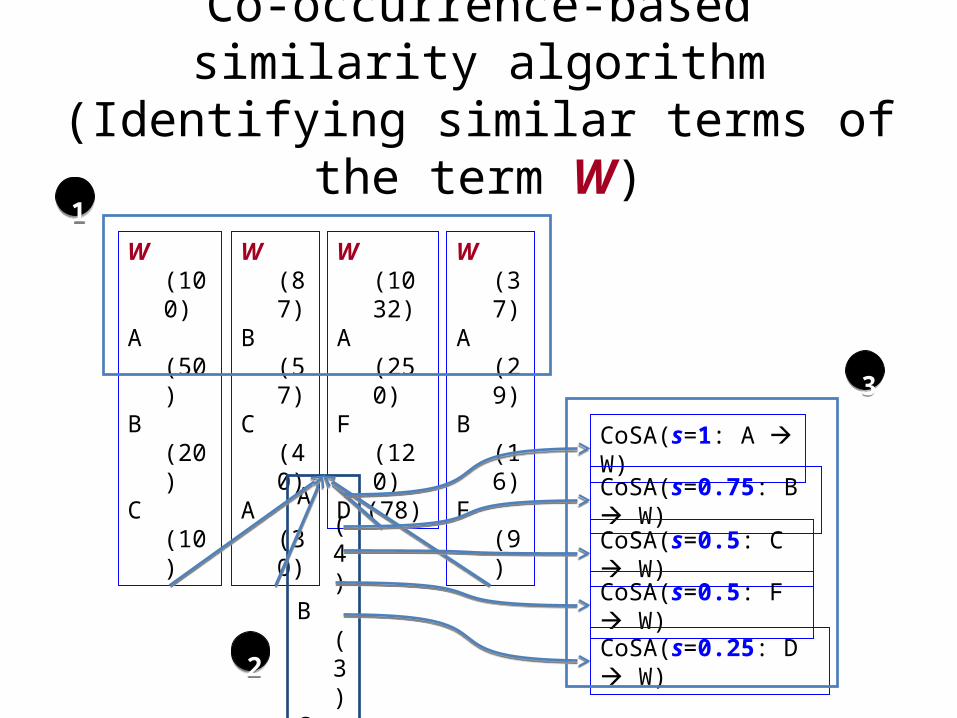
Co-occurrence-based similarity algorithm (Identifying similar terms of the term W)
W (100)A (50)B (20)C (10)
W (87)B (57)C (40)A (30)
W (1032)A (250)F (120)D (78)
W (37)A (29)B (16)F (9)
A (4)B (3)C (2)F (2)D (1)
11
22
CoSA(s=1: A W)
CoSA(s=0.75: B W)
CoSA(s=0.5: C W)
CoSA(s=0.5: F W)
33
CoSA(s=0.25: D W)

Correlation-based similarity algorithm
• Term X is said to be similar to term W on the basis of the correlation-based algorithm: CrSA(s: XW)
• CrSA(s: XW) can be defined only if both CoSA(s: XW) and CoSA(s: WX) are satisfied.

![[M2] Traffic Control Group 2 Chun Han Chen Timothy Kwan Tom Bolds Shang Yi Lin Manager Randal Hong Wed. Nov. 05 Overall Project Objective : Dynamic Control](https://img.pdfslide.net/doc/110x75/56649d365503460f94a0dcb5/m2-traffic-control-group-2-chun-han-chen-timothy-kwan-tom-bolds-shang-yi.jpg)













![Avalokitesvara [Kwan Im]](https://img.pdfslide.net/doc/110x75/577c7b031a28abe05496ed08/avalokitesvara-kwan-im.jpg)













