Embed Size (px)
Citation preview

Lecture 10: Parallel Scheduling
CSE599W: Spring 2018

NOTE
● Office hour CSE 220 2:30pm - 3:30pm
● No class on next Thursday (OSDI)
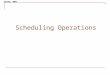
Where are we
Gradient Calculation (Differentiation API)
Computational Graph Optimization and Execution
Runtime Parallel Scheduling
GPU Kernels, Optimizing Device Code
Programming API
Accelerators and Hardwares
User API
System Components
Architecture
High level Packages
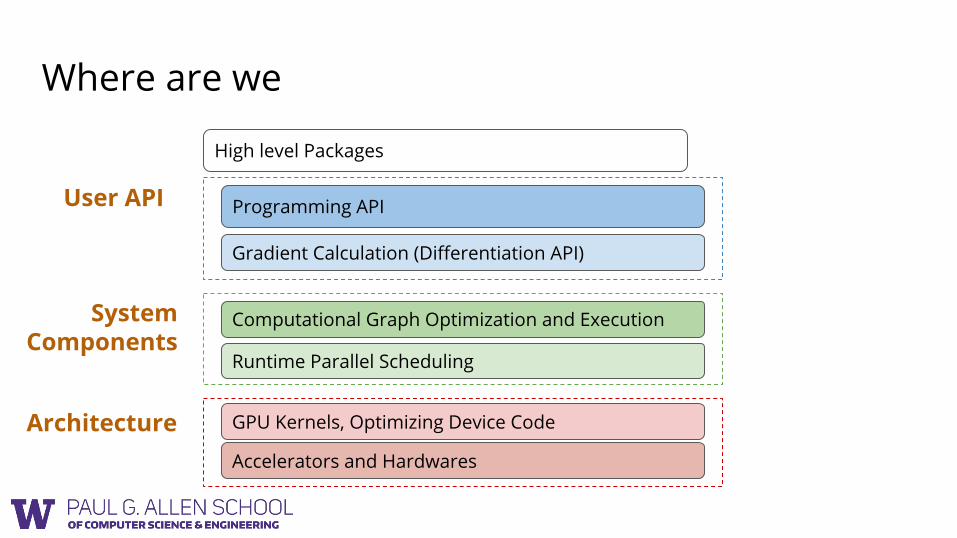
Where are we
Gradient Calculation (Differentiation API)
Computational Graph Optimization and Execution
Runtime Parallel Scheduling
Programming API
GPU Kernels, Optimizing Device Code
Accelerators and Hardwares

Parallelization Problem
● Parallel execution of concurrent kernels● Overlap compute and data transfer
Parallel over multiple streams
Serial execution
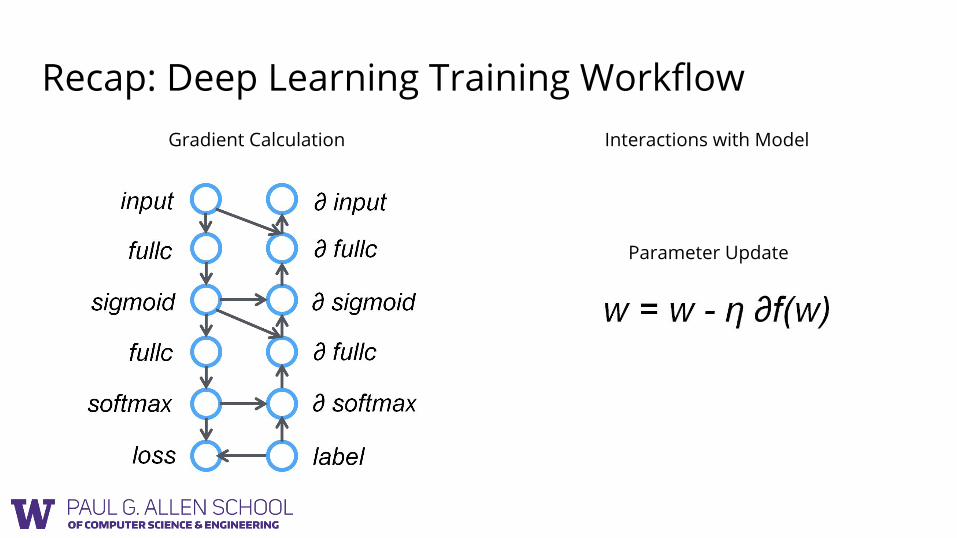
Recap: Deep Learning Training WorkflowGradient Calculation Interactions with Model
Parameter Update

Questions to be answered
● What are common patterns of parallelization
● How can we easily achieve these patterns
● What about dynamic style program
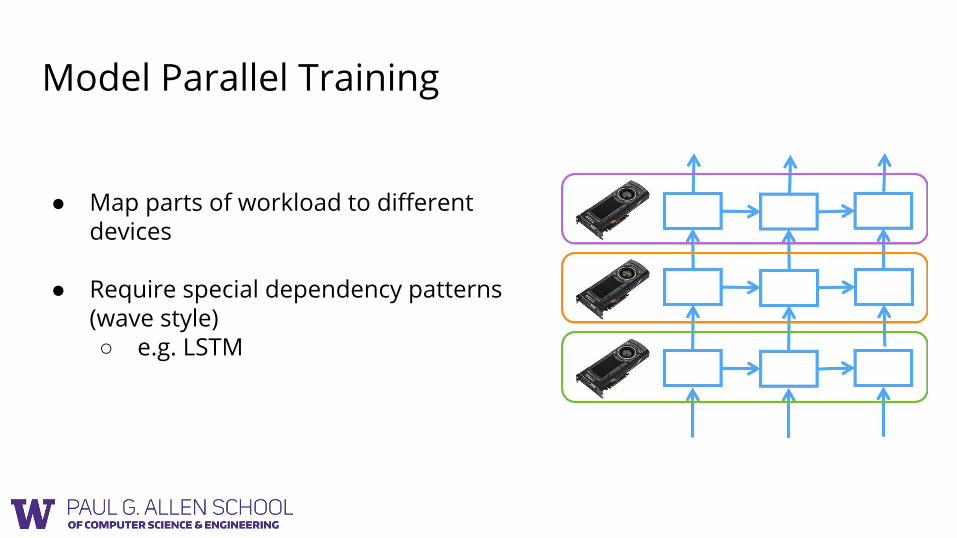
Model Parallel Training
● Map parts of workload to different devices
● Require special dependency patterns (wave style)○ e.g. LSTM
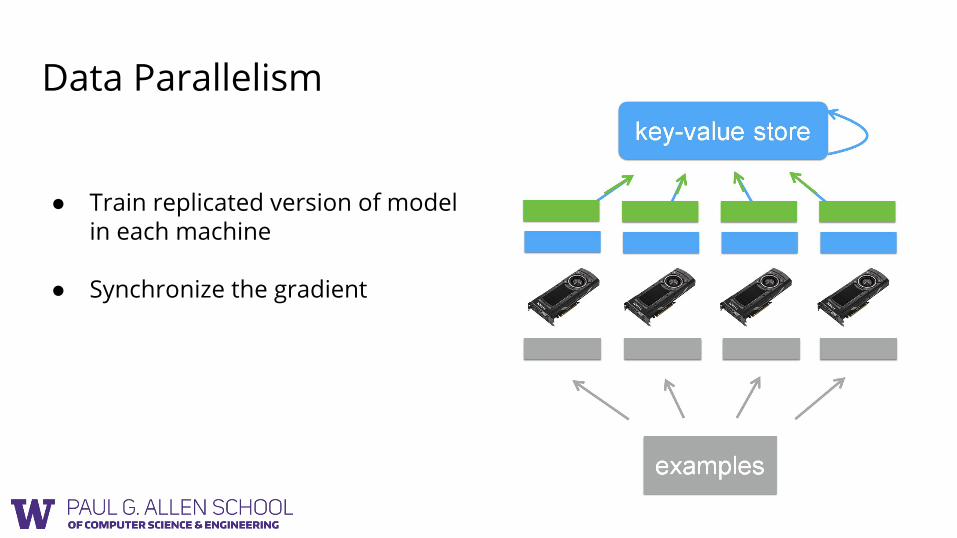
Data Parallelism
● Train replicated version of model in each machine
● Synchronize the gradient
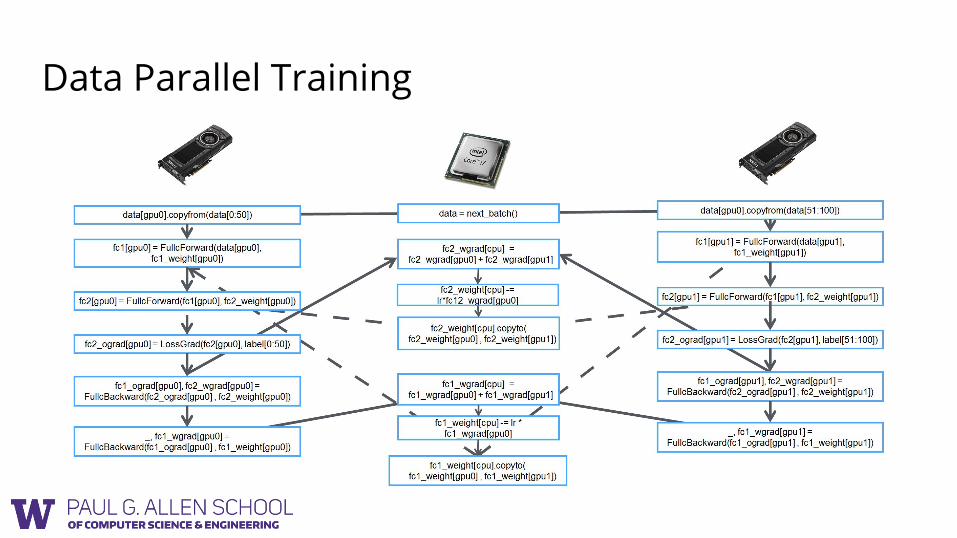
Data Parallel Training
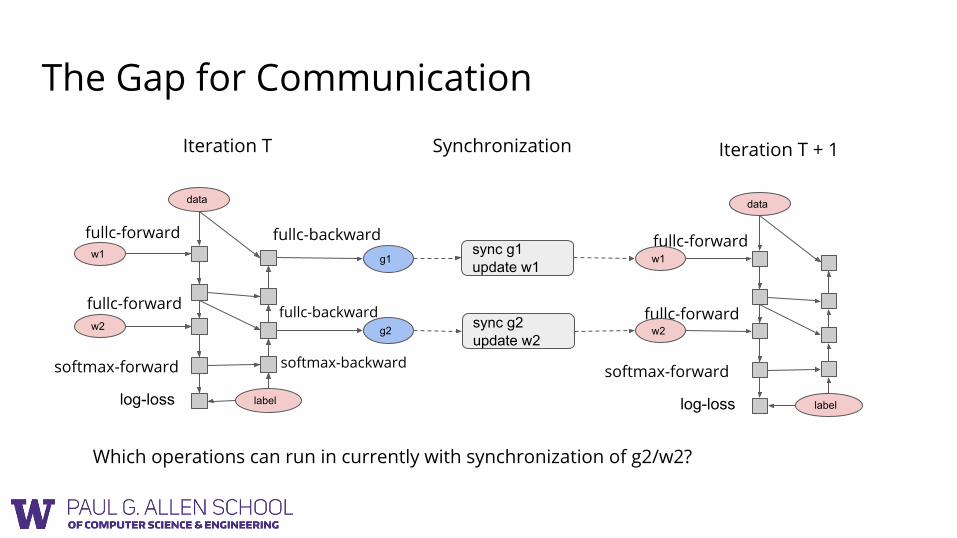
The Gap for Communication
fullc-forward
fullc-forward
fullc-backward
fullc-backward
softmax-forward softmax-backward
log-loss
w1
w2 g2
g1
data
label
sync g1 update w1
Iteration T Iteration T + 1
fullc-forward
fullc-forward
softmax-forward
log-loss
w1
w2
data
label
sync g2update w2
Synchronization
Which operations can run in currently with synchronization of g2/w2?
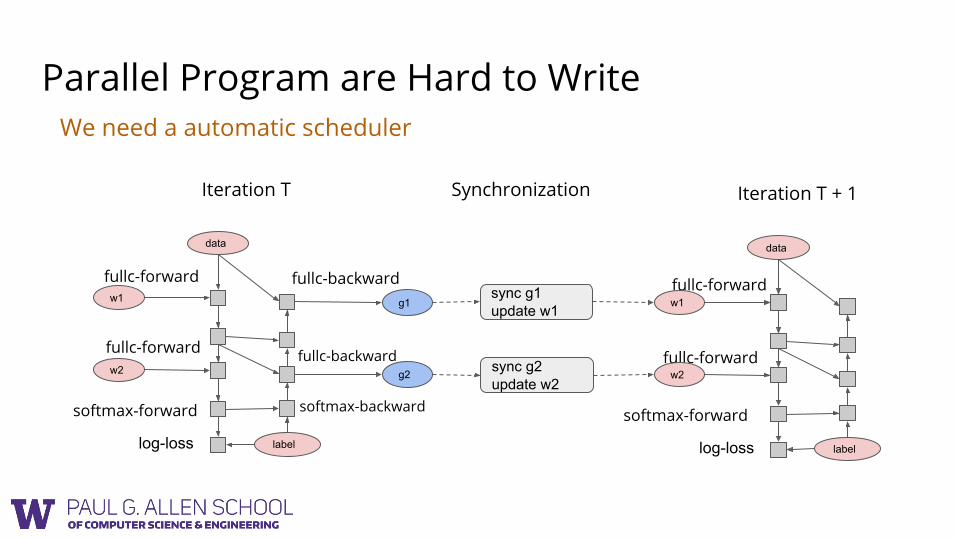
Parallel Program are Hard to Write
fullc-forward
fullc-forward
fullc-backward
fullc-backward
softmax-forward softmax-backward
log-loss
w1
w2 g2
g1
data
label
sync g1 update w1
Iteration T Iteration T + 1
fullc-forward
fullc-forward
softmax-forward
log-loss
w1
w2
data
label
sync g2update w2
Synchronization
We need a automatic scheduler

Goal of Scheduler Interface
A = 2
B = A + 1C = A + 2
D = B * C
● Write Serial Program● Possibly dynamically (not declare graph
beforehand)
● Run in Parallel ● Respect serial execution order
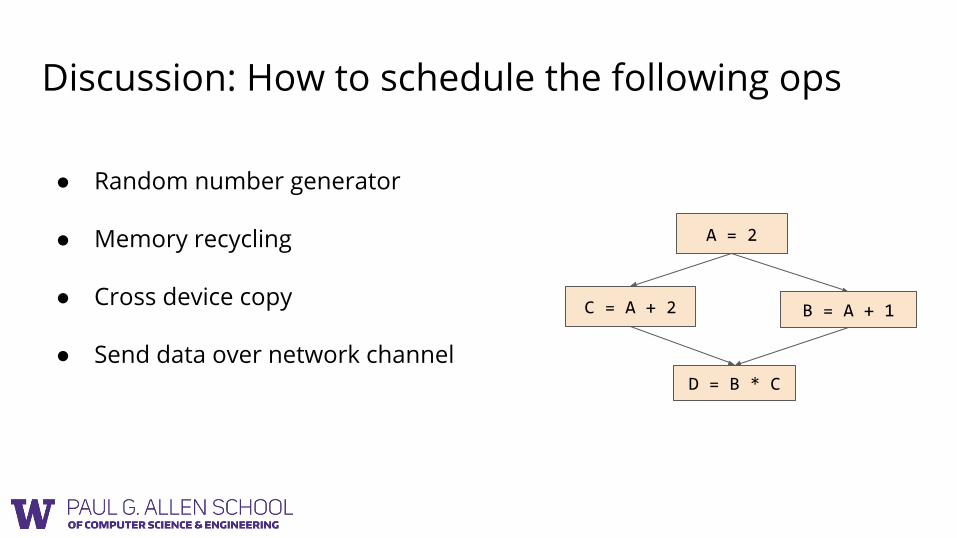
Discussion: How to schedule the following ops
● Random number generator
● Memory recycling
● Cross device copy
● Send data over network channel
A = 2
B = A + 1C = A + 2
D = B * C
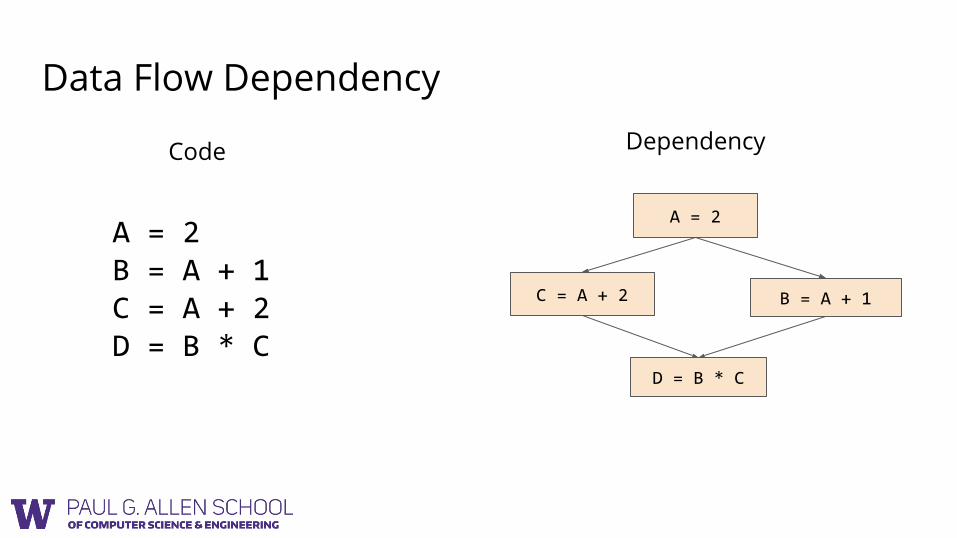
Data Flow Dependency
A = 2
B = A + 1C = A + 2
D = B * C
A = 2B = A + 1C = A + 2D = B * C
Code Dependency
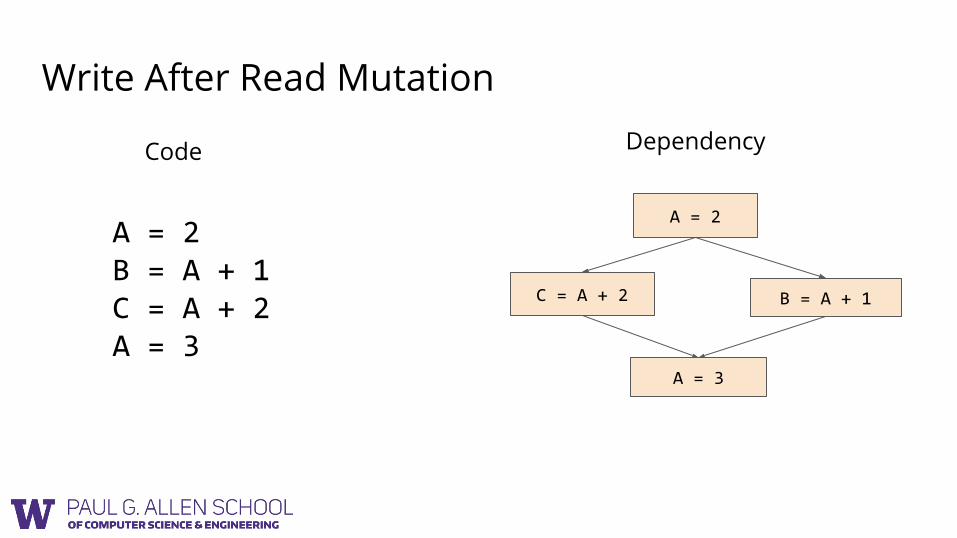
Write After Read Mutation
A = 2B = A + 1C = A + 2A = 3
A = 2
B = A + 1C = A + 2
A = 3
DependencyCode
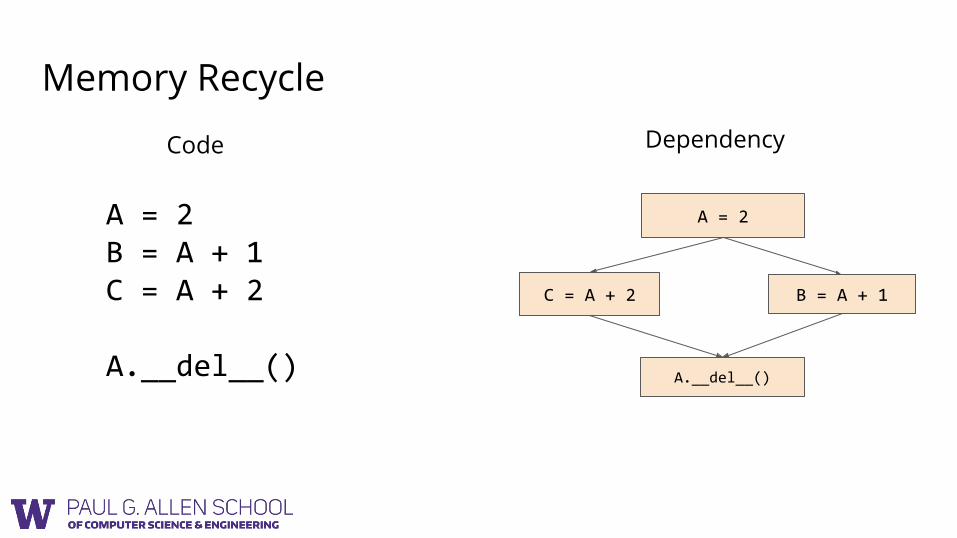
Memory Recycle
A = 2B = A + 1C = A + 2
A.__del__()
A = 2
B = A + 1C = A + 2
A.__del__()
Code Dependency

Random Number Generator
rnd = RandomNGenerator()
B = rnd.uniform(10, -10)
C = rnd.uniform(10, -10)
rnd = RandomNGenerator()
rnd.uniform(10, -10)
rnd.uniform(10, -10)
DependencyCode

Goal of Scheduler Interface
● Schedule any resources○ Data○ Random number generator○ Network communicator
● Schedule any operation

DAG Graph based scheduler
engine.push(lambda op, deps=[])A = 2
C = A + B
● Explicit push operation and its dependencies● Can reuse the computation graph structure● Useful when all results are immutable● Used in typical frameworks (e.g. TensorFlow)
● What are the drawbacks?
Interface:B = 3

Pitfalls when using Scheduling Mutations
Write after Readtf.assign(A, B + 1)tf.assign(T, B + 2)tf.assign(B, 2)
Read after WriteT = tf.assign(B, B + 1)tf.assign(A, B + 2)
A mutation aware scheduler can solve these problems much easier than DAG based scheduler

MXNet Program for Data Parallel Trainingfor dbatch in train_iter:
% iterating on GPUs
for i in range(ngpu):
% pull the parameters
for key in update_keys:
kvstore.pull(key, execs[i].weight_array[key])
% compute the gradient
execs[i].forward(is_train=True)
execs[i].backward()
% push the gradient
for key in update_keys:
kvstore.push(key, execs[i].grad_array[key])
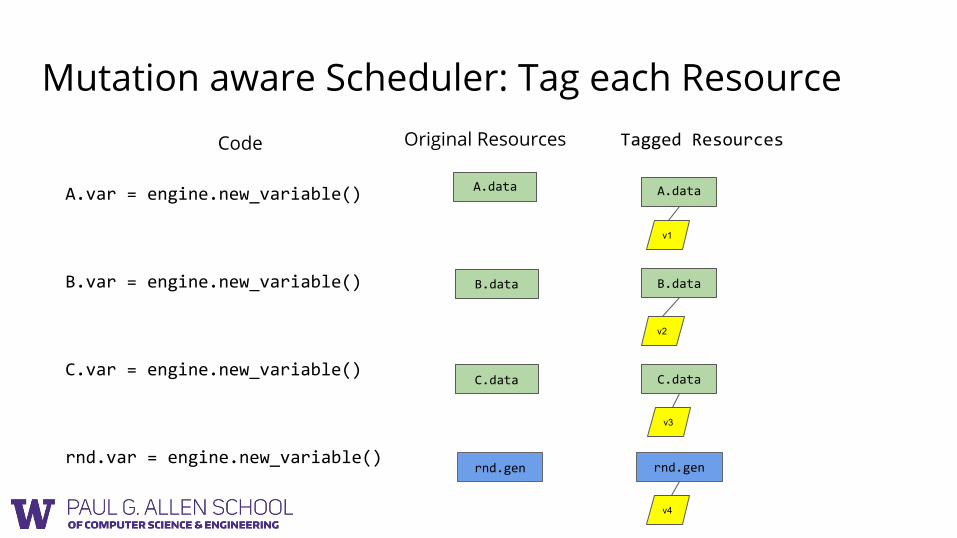
Mutation aware Scheduler: Tag each Resource
A.data
rnd.gen
v1
B.data
C.data
A.data
rnd.gen
B.data
C.data
v2
v3
v4
Original Resources Tagged Resources Code
A.var = engine.new_variable()
B.var = engine.new_variable()
C.var = engine.new_variable()
rnd.var = engine.new_variable()
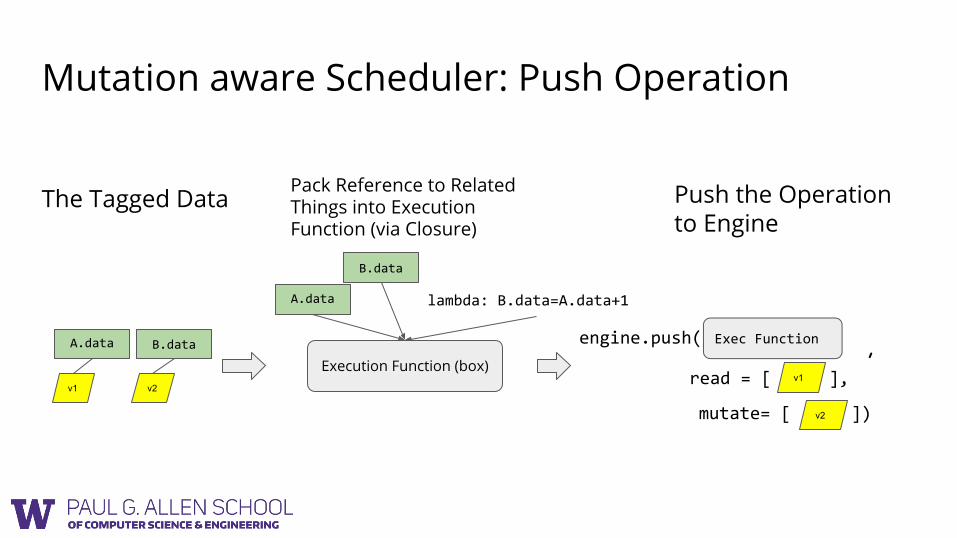
Mutation aware Scheduler: Push Operation
Execution Function (box)
A.data
B.data
v2
v1
lambda: B.data=A.data+1
The Tagged Data Pack Reference to Related Things into Execution Function (via Closure)
engine.push( Exec Function , read = [ ],
mutate= [ ])
Push the Operation to Engine
v1
A.data B.data
v2

Example Scheduling: Data Flow
engine.push(lambda: A.data=2, read=[], mutate= [A.var])
engine.push(lambda: B.data=A.data+1, read=[A.var], mutate= [B.var])
engine.push(lambda: D.data=A.data * B.data, read=[A.var, B.var], mutate=[D.var])
A = 2
B = A + 1
D = A * B

Example Scheduling: Memory Recycle
engine.push(lambda: A.data=2, read=[], mutate= [A.var])
engine.push(lambda: B.data=A.data+1, read=[A.var], mutate= [B.var])
engine.push(lambda: A.data._del__(), read=[], mutate= [A.var])
A = 2
B = A + 1
A.__del__()

Example Scheduling: Random Number Generator
B = rnd.uniform(10, -10)
C = rnd.uniform(10, -10)
engine.push(lambda: B.data = rnd.gen.uniform(10,-10), read=[], mutate= [rnd.var])
engine.push(lambda: C.data = rnd.gen.uniform(10,-10), read=[], mutate= [rnd.var])

Queue based Implementation of scheduler
A
B
B = A + B {2}
C
C = A + 2 {1}
B = A + B {2}
● Like scheduling problem in OS
● Maintain a pending operation queue
● Schedule new operations with event update

Enqueue DemonstrationB = A + 1 (reads A, mutates B)
C = A + 2 (reads A, mutates C)
A = C * 2 (reads C, mutates A)
D = A + 3 (reads A, mutates D)
B’s queue:
C’s queue:
D’s queue:
A’s queue:
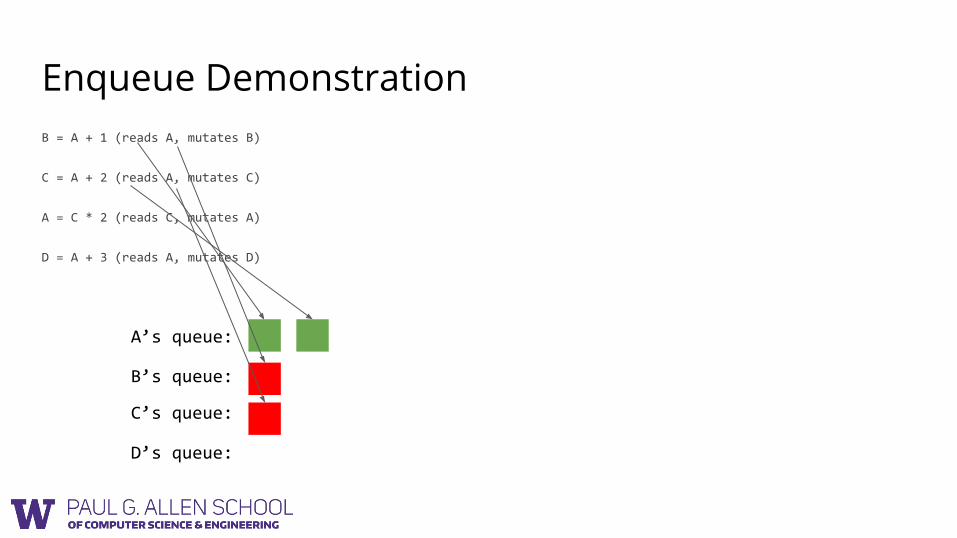
Enqueue DemonstrationB = A + 1 (reads A, mutates B)
C = A + 2 (reads A, mutates C)
A = C * 2 (reads C, mutates A)
D = A + 3 (reads A, mutates D)
A’s queue:
B’s queue:
C’s queue:
D’s queue:
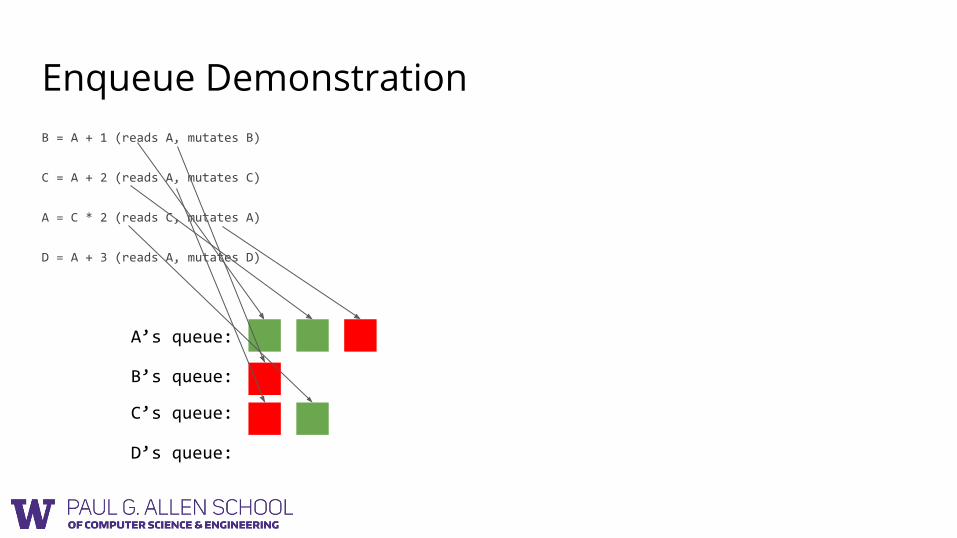
Enqueue DemonstrationB = A + 1 (reads A, mutates B)
C = A + 2 (reads A, mutates C)
A = C * 2 (reads C, mutates A)
D = A + 3 (reads A, mutates D)
A’s queue:
B’s queue:
C’s queue:
D’s queue:
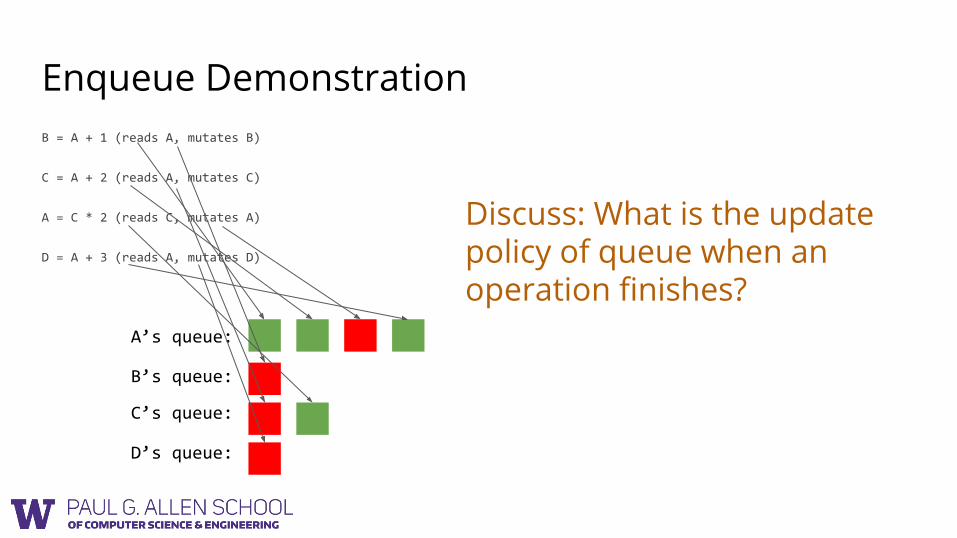
Enqueue DemonstrationB = A + 1 (reads A, mutates B)
C = A + 2 (reads A, mutates C)
A = C * 2 (reads C, mutates A)
D = A + 3 (reads A, mutates D)
A’s queue:
B’s queue:
C’s queue:
D’s queue:
Discuss: What is the update policy of queue when an operation finishes?

Update Policy
A
B
C
Queue
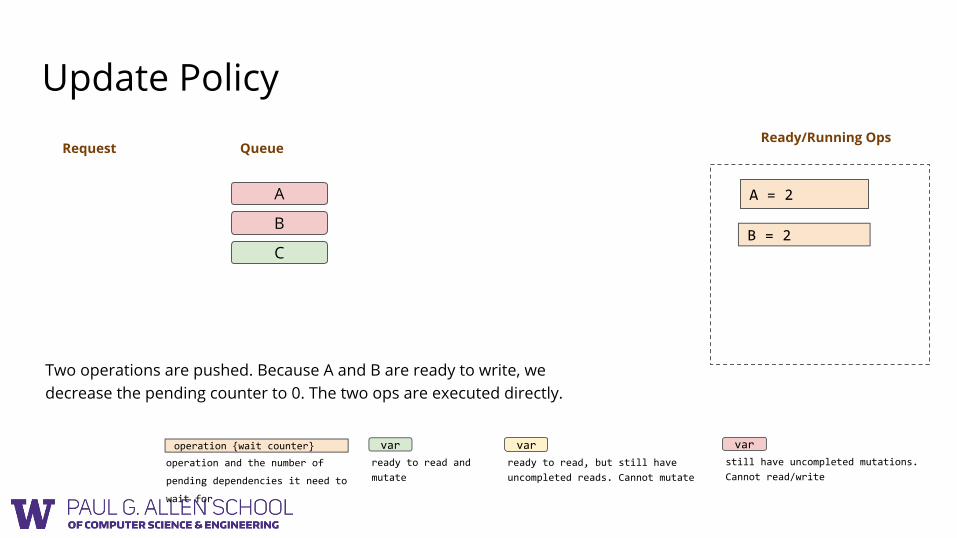
A = 2 {1}
B = 2 {1}
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
Two operations are pushed. Because A and B are ready to write, we decrease the pending counter to 0. The two ops are executed directly.
Ready/Running OpsRequest
Update Policy
A
B
C
Queue
A = 2
B = 2
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
Two operations are pushed. Because A and B are ready to write, we decrease the pending counter to 0. The two ops are executed directly.
Ready/Running OpsRequest
Update Policy
A
B
C
Queue
A = 2
B = 2
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
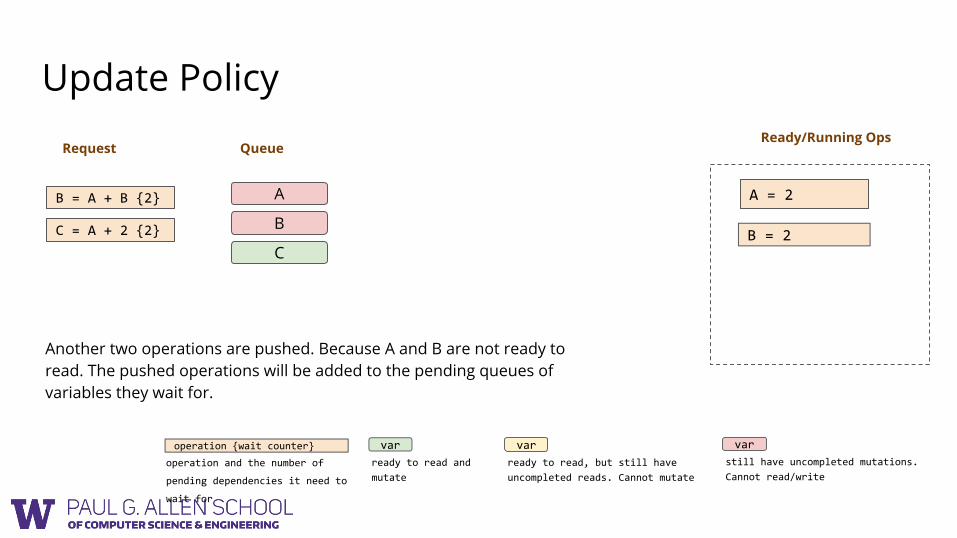
Another two operations are pushed. Because A and B are not ready to read. The pushed operations will be added to the pending queues of variables they wait for.
Ready/Running OpsRequest
B = A + B {2}
C = A + 2 {2}
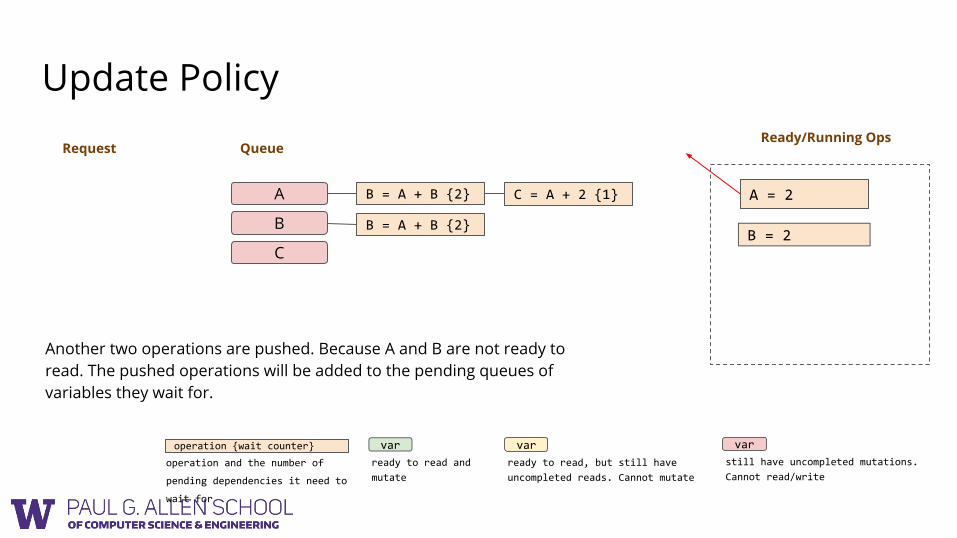
Update Policy
A
B
C
Queue
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
Another two operations are pushed. Because A and B are not ready to read. The pushed operations will be added to the pending queues of variables they wait for.
Ready/Running OpsRequest
B = A + B {2} C = A + 2 {1}
B = A + B {2}
A = 2
B = 2
Update Policy
A
B
C
Queue
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
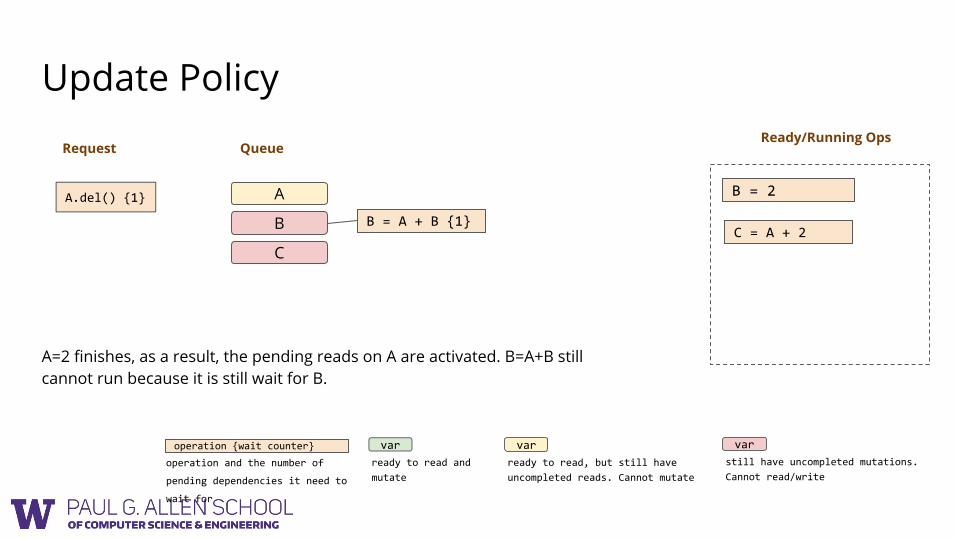
Ready/Running OpsRequest
B = A + B {1}
B = 2
A=2 finishes, as a result, the pending reads on A are activated. B=A+B still cannot run because it is still wait for B.
C = A + 2
A.del() {1}
Update Policy
A
B
C
Queue
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
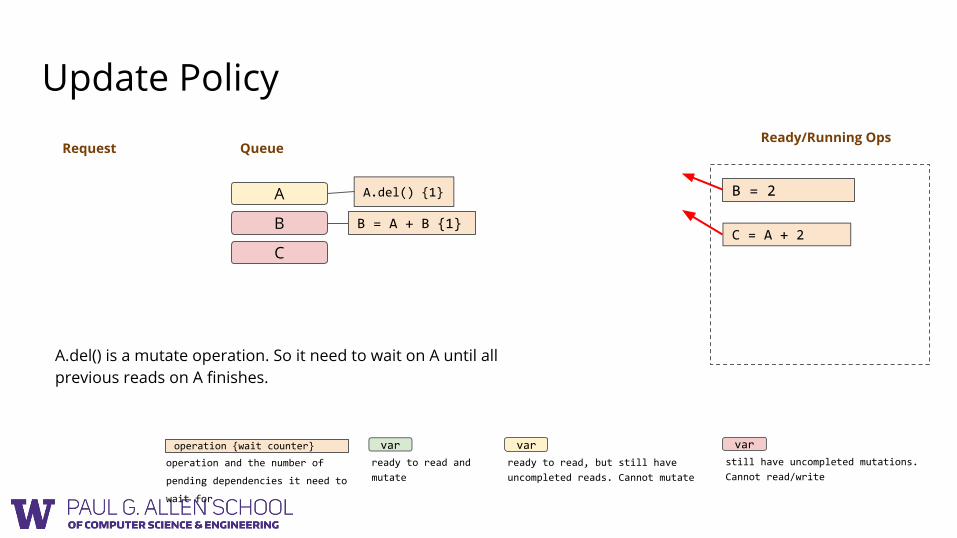
Ready/Running OpsRequest
B = A + B {1}
B = 2
A.del() is a mutate operation. So it need to wait on A until all previous reads on A finishes.
C = A + 2
A.del() {1}
Update Policy
A
B
C
Queue
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
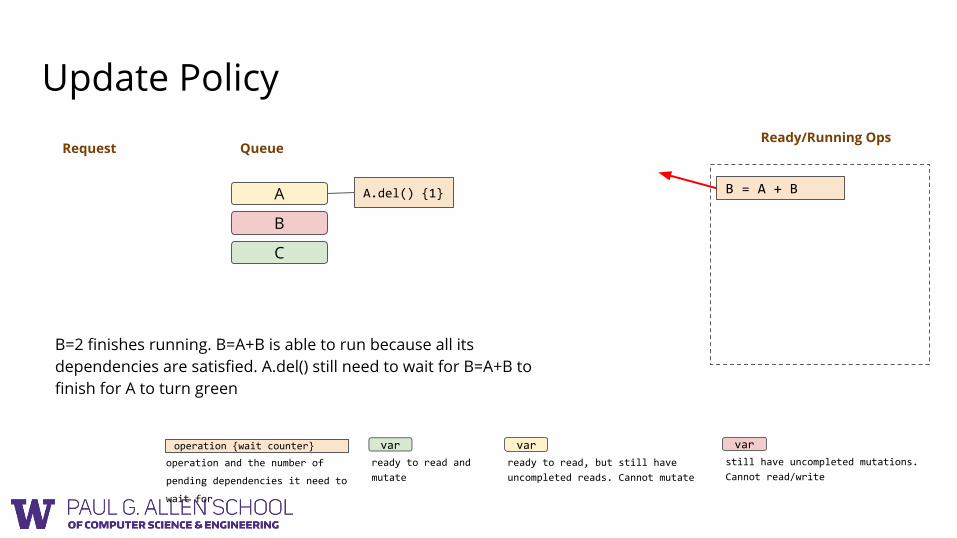
Ready/Running OpsRequest
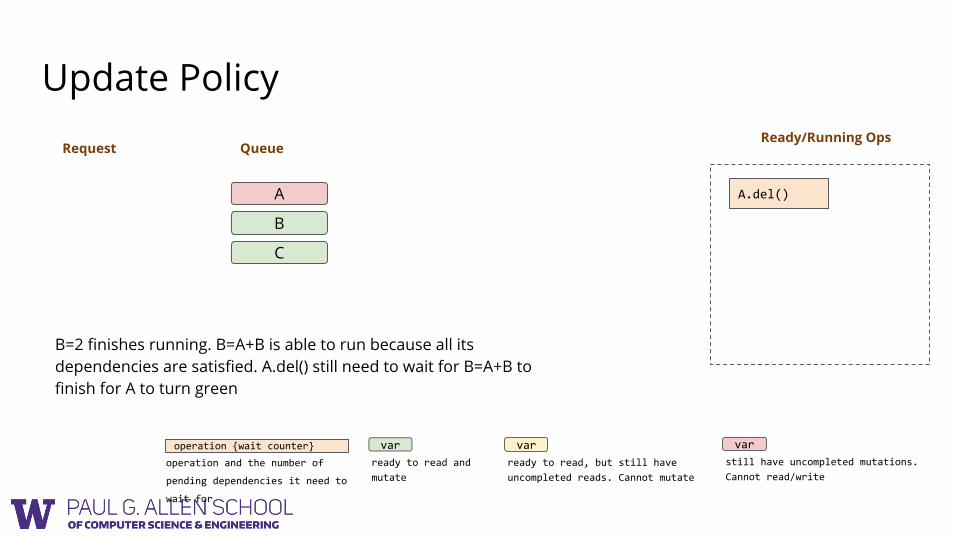
B=2 finishes running. B=A+B is able to run because all its dependencies are satisfied. A.del() still need to wait for B=A+B to finish for A to turn green
A.del() {1} B = A + B
Update Policy
A
B
C
Queue
operation {wait counter}
operation and the number of
pending dependencies it need to
wait for
var
ready to read and
mutate
var
ready to read, but still have
uncompleted reads. Cannot mutate
var
still have uncompleted mutations.
Cannot read/write
Ready/Running OpsRequest
B=2 finishes running. B=A+B is able to run because all its dependencies are satisfied. A.del() still need to wait for B=A+B to finish for A to turn green
A.del()

Take aways
● Automatic scheduling makes parallelization easier
● Mutation aware interface to handle resource contention
● Queue based scheduling algorithm