Embed Size (px)
Citation preview

MONALISA Document Number 0006.3.1.6
The MONALISA Binary Data File Format :
A guide for users.
Paul Coe Sat 05 July 2008
Abstract
This document describes a binary file format and contains user guidance for individualparts of the supporting software. As of 11 Aug 2007, binary I/O support libraries havebeen written for v3.1 of the MONALISA binary file format in C (compatible with the ANSIC99 standard), Java 1.5 and LabVIEW v8.2. These libraries, together with GIACoNDE,(a cross platform, Java based software tool which assists user construction of a hierarchicalstructure for data identification tags), allow user written software to store and retrievedata in binary files; with the user free to write in any of the three supported languages.Hence this format offers great flexibility in the exchange of data, between different piecesof user software.
Contents
1 Introduction 31.1 The scope of the binary I/O format . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Overview of binary file usage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Recommendation for user written software . . . . . . . . . . . . . . . . . . . . . 41.4 Version numbers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 MONALISA format binary file structure 52.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 The data file header . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 Data array label . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.4 Data identification codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.5 User data arrays . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Using binary files 123.1 Minting a new binary file . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2 Opening and closing the binary files . . . . . . . . . . . . . . . . . . . . . . . . . 133.3 Writing data to a binary file . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.4 Reading data from a binary file . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.5 (Un)locking a binary file . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.6 Reading the file header . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1

Oxford MONALISA Document No: Page: 2 of 800006 Rev. No. : 3.1.6
4 Using the C binary file I/O library 184.1 The I/O Library . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.2 Obtaining the C I/O library . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204.3 Writing code to utilise the C library functions . . . . . . . . . . . . . . . . . . . 234.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.5 Addendum for C++ users . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5 Using the Java binary file I/O packages 365.1 Packages Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.2 Binary I/O core package . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.3 The extension package uk ac ox physics.monalisa.BinaryIOx . . . . . . . . . . . 405.4 Getting the Java I/O packages onto your machine . . . . . . . . . . . . . . . . . 455.5 Writing code to use the Java packages . . . . . . . . . . . . . . . . . . . . . . . 45
6 Using the LabVIEW binary file I/O VIs 536.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 536.2 Getting the VIs onto your LabVIEW installation . . . . . . . . . . . . . . . . . 566.3 Writing LabVIEW VIs to utilise the LabVIEW I/O VIs . . . . . . . . . . . . . . 56
7 Data identification schemes and the GIACoNDE software tool 657.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 657.2 Obtaining a copy of GIACoNDE . . . . . . . . . . . . . . . . . . . . . . . . . . . 667.3 The GIACoNDE users guide . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
A Binary Quick Reference 76
B Glossary 77
C Disclaimer which must accompany stdint.h written for windows 78
D File format and documentation revision history 79

Oxford MONALISA Document No: Page: 3 of 800006 Rev. No. : 3.1.6
1 Introduction
This document is a users guide of the binary file I/O protocol (version 3.1) which has beendeveloped for particle physics related research at the Department of Physics, University ofOxford. It has been named “The MONALISA binary format” because it was developed initiallyfor the MONALISA research group during 2005/7. The first users of the format, beyond theMONALISA group, are likely to use binary files for holding experimental data and simulationsas part of their research into uses of interferometers. This is merely an historical accident andshould not be taken to imply that the binary file format presented here is only suitable forinterferometer work.
1.1 The scope of the binary I/O format
The binary file format has been developed for as wide as possible usage, beyond the initial usersin the MONALISA group, with certain caveats given here.
The format allows any numerical data to be exchanged between user software in Lab-VIEW, Java and C, with I/O libraries in each language handling the low level functionality.The I/O libraries have been written to work on any platform with the file format fixed as littleendian and the I/O software providing the necessary byte order conversions. The three lan-guages for the support libraries have been chosen because they were the three most commonlyused platforms for data acquisition, data processing and data analysis in the MONALISA group.
The design aim is a minimal sized, easy to use, flexible data structure to define filecompliance. Most of the details are left to the user to choose and alter, offering versatilitywhile maintaining file legibility through the use of the two strictly defined file components; thefile header and the data array label.
Although the format is flexible, it is not designed for every binary file usage. The mostimportant element not present in this format is any means of rewriting the contents of a file.Data can always be appended to an existing file, but in many applications it is preferable toedit existing contents. When infrequent editing is required, users of this format should createa new binary file, so that copies exist before and after the edit.
There are cases where the generation of a new file after every edit is inefficient, especiallyfor very short files which are created to store a very small quantity of rapidly updated data:An example might be file numbers being logged in a data directory. For such cases, this binaryformat is not recommended. The header overhead is too large, reading the data across differentplatforms is very unlikely to be necessary and the I/O functions are unnecessarily demandingfor this and similarly simple applications.
1.2 Overview of binary file usage
The binary files store data, labelled using a customised data identification scheme. The threeuser operations which involve a data identification scheme are therefore :
• customising a data identification scheme,
• writing data to a binary file using a published data identification scheme,
• reading data from a binary file using a published data identification scheme.
Each binary file labels all data arrays within it, using a single data identification scheme (set ofconstants). The identification scheme is implemented by user software incorporating the schemeconstants, (which are most likely to be generated with the GIACoNDE tool) as illustrated in

Oxford MONALISA Document No: Page: 4 of 800006 Rev. No. : 3.1.6
Figure 1: A user application includes binary I/O libraries and source files containingdata ID constants, to enable interaction with binary data files. Routines in the I/Olibraries handle the reading and writing of user data and are passed the data IDconstants to find and label stored data, respectively.
figure 1. The data identification scheme version number (see section 1.4) and related data arelogged in the file header (see section 2.2).
Reading software checks a file header first, to ensure that the data file is from a source ofinterest and that the user data in the file is of relevance for the reading software.
1.3 Recommendation for user written software
It is hereby strongly recommended that users of these binary files only access the files using thefunctions in the I/O libraries provided. Detailed information on how to use the I/O libraries isgiven below.
1.4 Version numbers
Version numbering is used for many separate and independent “entities”. The fact that inde-pendent entities (or things) can all be given a version number, leads to potential confusion1.
Version numbers are given to the following :
1People are strongly tempted to assume the version numbers for completely unrelated things are insteadrelated.

Oxford MONALISA Document No: Page: 5 of 800006 Rev. No. : 3.1.6
1. User written software
2. The MONALISA binary file format protocol
3. User data identification schemes
4. The user data identification support application GIACoNDE
5. Languages in which people write code such as Java, LabVIEW etc
For some of these, the version numbers are more obviously independent. Java 1.5 is aversion number given by Sun Microsystems to their release of the Java language. Their choiceof version numbers was clearly uninfluenced by user data identification scheme numbers.
The version numbers of all items in the above list should be assumed to be similarlyindependent. This is the safest assumption.
As a concrete example : Version 2.1 of GIACoNDE supports version 3.1 of the MONAL-ISA binary file format and this GIACoNDE version 2.1 can be used to create a data identifica-tion scheme which will be published as scheme version 1.0.
A later version of GIACoNDE might well be version 3.1 but there is no way of knowing,a priori, what version of the MONALISA binary file format this will support, because thenumbering schemes are independent.
One thing that the version numbers for items 2 to 4 do have in common, however in theabove list is the following internal convention, which governs the relationship between versionnumbers given to the same (type of) thing.
Version numbers are represented in all cases using a two number scheme, version.revision;for example v3.7 indicates a Version number 3 (the third generation) and Revision number 7;implying - at least in theory - the existance of v3.0 to v3.6.
Within a set of version numbers applied to the same type of thing, a common Versionnumber (3.x for example) is used to indicate mutual compatibility; with later revisions in agiven generation, merely adding to the previous revision in the sequence. All fundamentalchanges which cause compatibility issues, including the removal of anything2, necessitate achange in generation, indicated to users by a change in Version number.
Hence there is no guarantee or enforced requirement, that any software which can readv4.2 of a data identification scheme, would understand a file constaining data written with v3.7(of the same scheme); whereas v4.1 and v4.0 will be read and understood in full, since theearlier schemes are subsets of the later scheme.
2 MONALISA format binary file structure
The I/O support software interacts with a binary file under the assumption of a predefined filestructure. This structure is explained in detail in this section, but may vary in future protocolversions. Elements of the structure are referred to regularly throughout later sections of thisdocument, when describing key user operations, such as writing data to a file and reading datafrom a file.
2Removing elements of some “thing” which has a version number under this convention, is banned betweenrevisions. If it were instead permitted, version 1.3 of a data identifcation scheme might have a constant whichcould be removed in version 1.4 and then be added again in a different / incompatible form in version 1.5. Thiswould render versions 1.3 and 1.5 mutually incompatible, whereas the version convention adopted here, with itsban on removals between revisions, leads instead to a numbering sequence 1.3, 2.0 and 2.1 for the same threechanges.
Oxford MONALISA Document No: Page: 6 of 800006 Rev. No. : 3.1.6
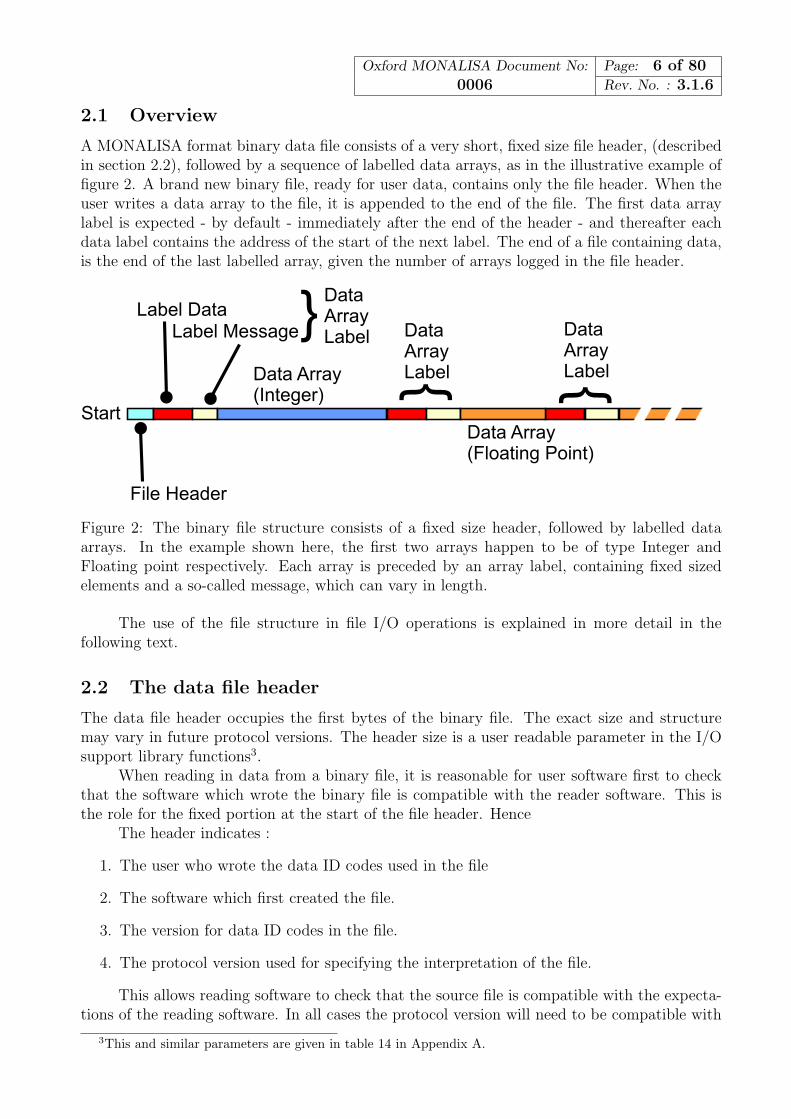
2.1 Overview
A MONALISA format binary data file consists of a very short, fixed size file header, (describedin section 2.2), followed by a sequence of labelled data arrays, as in the illustrative example offigure 2. A brand new binary file, ready for user data, contains only the file header. When theuser writes a data array to the file, it is appended to the end of the file. The first data arraylabel is expected - by default - immediately after the end of the header - and thereafter eachdata label contains the address of the start of the next label. The end of a file containing data,is the end of the last labelled array, given the number of arrays logged in the file header.
Figure 2: The binary file structure consists of a fixed size header, followed by labelled dataarrays. In the example shown here, the first two arrays happen to be of type Integer andFloating point respectively. Each array is preceded by an array label, containing fixed sizedelements and a so-called message, which can vary in length.
The use of the file structure in file I/O operations is explained in more detail in thefollowing text.
2.2 The data file header
The data file header occupies the first bytes of the binary file. The exact size and structuremay vary in future protocol versions. The header size is a user readable parameter in the I/Osupport library functions3.
When reading in data from a binary file, it is reasonable for user software first to checkthat the software which wrote the binary file is compatible with the reader software. This isthe role for the fixed portion at the start of the file header. Hence
The header indicates :
1. The user who wrote the data ID codes used in the file
2. The software which first created the file.
3. The version for data ID codes in the file.
4. The protocol version used for specifying the interpretation of the file.
This allows reading software to check that the source file is compatible with the expecta-tions of the reading software. In all cases the protocol version will need to be compatible with
3This and similar parameters are given in table 14 in Appendix A.

Oxford MONALISA Document No: Page: 7 of 800006 Rev. No. : 3.1.6
that used by the reading software, in almost all applications, the reading software will expectto recognise the scheme under which the data ID codes have been generated in the source fileand in many cases will want the user and software ID to match predetermined values.
After the fixed header elements, come the variable elements which change throughout thelifetime of the file. These elements :
• Allow users to lock or unlock write access to the file - without having to resort to O/Sspecific file permissions.
• Indicate the number of stored data arrays held in the file.
Other file identification roles may be required by the user, but these are not the respon-sibility of the file header, which has been kept as small as possible. Application specific metadata schemes can be easily designed to fulfill any requirements, with the relevant meta data inlabelled data array entries.
The parts of the header, (together with byte locations offset from the start of the file inhexadecimal) are listed below.
User identity (0x00 - 0x01) A 16 bit number identifying the (GIACoNDE) user who definedthe ID codes used for data in this file. This number is unique to each user, is issued witheach copy of the GIACoNDE tool and propagates automatically from GIACoNDE outputfiles into the user’s own software as a constant.
Software identity (0x02 - 0x03) A 16 bit number, which is optionally modified by the filecreating software to indicate to any software which later reads the file, which softwarewrote the data in the file. Although optional, the user is urged to utilise this part of theheader, which can take one of (216 − 1) 32767 positive values.
Data identification scheme version/revision (0x05 - 0x06, 0x07- 0x08) Two 16 bit num-bers, the version and revision number for the GIACoNDE user defined data identificationscheme. File reading software would use this part of the header, to switch to the appro-priate data identification scheme for recognising the data arrays in this file. (GIACoNDEoutput files define the scheme of identification codes for data entries in user binary files).
Binary I/O protocol version/revision (0x09, 0x0A) Two single byte numbers, the versionand revision numbers for the protocol.
File lock (0x0B) A single byte which holds either of the two allowed values which correspondto LOCKED (the default assumption unless proven otherwise) or UNLOCKED. The I/Olibrary routines fail safe by defaulting to LOCKED, to protect files from buggy software.
Number of data arrays stored (0x0C - 0x0F) Incremented every time an array is added tothe data file. Set to zero when the file is empty. The maximum positive value for thisnumber, (232 − 1), does not limit the data array entries per file, since the file size limit of2 GB (limited by the data array label) is guaranteed to be reached first.
2.3 Data array label
Each array of user data is identified and specified by a data array label. The label holds meta-data relating to the array in two parts, the fixed size (binary) label data and the variable sized(ASCII) label message.
The meta-data contains :

Oxford MONALISA Document No: Page: 8 of 800006 Rev. No. : 3.1.6
1. A user-specified data array identification code (see subsection 2.4).
2. A counter indicating the number of arrays labelled with this code since the start of thefile, (including this array, hence the first value is one - not zero), software should use theFIRST INSTANCE LABEL parameter to search for the first instance of particular data.
3. The location in the file, after the end of the data array - where the next label begins orwill begin when added.
4. The type of data stored in the array.
5. The number of array elements.
6. An error detection checksum evaluated at the time of writing the data array to the file.
7. The length of the label message.
8. The ASCII label message.
The byte structure of the meta-data portion of the array label is described in more detailbelow.
2.3.1 Fixed size part of the “Label data”
The byte structure of the array label meta-data follows a fixed pattern. The offsets relative tothe start of the label are shown here (in HEX):
Data identification code (0x00 - 0x08) The first 9 bytes contain the five numbers whichidentify the data array. The same data identification code is used to label data entries ofthe same (highly specific) type (see subsection 2.4).
Instance counter (0x09 - 0x0A) When more than one array has the same data identificationcode, they are distinguished from one another using this (16-bit signed) instance counter,which is set to 1 for the first instance of each data identification code. The largest positivevalue is 216 − 1, (32767).
Location of the next array label (0x0B - 0x0E) The absolute location (offset from the startof the file), at the start of the next data array label. This element limits the permittedfile size, since the next label cannot be further than 231−1 bytes from the start of the file.If this limit is exceeded, by writing more than 2 GB of data to the file, the data beyondthat point is unreadable and error free file handling is not guaranteed for this file. It isup to users to ensure that this limit is not exceeded.
Data type (0x0F) There are several recognised data types, each is either a signed integer typeor a floating point type. Integer types are labelled by the width of the type in bytes (forexample the value 2 represents the data type 16-bit signed integer), floating point typesby the width in bits.
Array length (0x10 - 0x13) This four byte integer specifies the number of elements withinthe data array. The maximum array length is in principle therefore 231−1 elements. Themaximum supported file size is a stronger restriction, preventing any array from reachingthis length.

Oxford MONALISA Document No: Page: 9 of 800006 Rev. No. : 3.1.6
Verification checksum (0x14) This single byte is the result of a fixed calculation on the bytesin this array, performed when the data array is written to the file. When the I/O routinesread the array back into memory, the same algorithm operates on the array in memory,to produce a single byte output. The output byte is compared with this byte in the file.If the two disagree, an error condition is flagged by the I/O routines, indicating that thedata in memory is corrupt4.
Message length (0x15) This byte indicates the length of the label message, values in therange 0 to a protocol specific maximum are permitted. See Appendix A for the maximumallowed value.
2.3.2 Data array label message
The data array label message is used to store a brief ASCII string, describing the array contentsfor users to recognise. The length limit for this string is one of the defined constants in the fileformat protocol.
2.4 Data identification codes
Each user data array is identified in the file using a five element identification code. Four ofthese five elements are defined by the user, in a data identification scheme (usually createdusing the GIACoNDE application - described in section 7). The remaining element is selectedfrom a predetermined list of constants which have been defined as part of the I/O protocol.
Example identification code To give an example from some hypothetical thermometerreadout software: One might have a data array holding coefficients for the characteristicpolynomial which maps resistance as a function of temperature for Pt 100 thermometerdevices. The array of constants would be identified using a data identification code, made upof constants THERMOMETER, PT 100, META DATA, GLOBAL CONSTANTS, CHARACTER-ISTIC POLYNOMIAL COEFFICIENTS.
The five numbers of the data identification codes can be used as a classification system;analoguous to the dewey decimal system used in libraries for cataloguing the books held. Thefives numbers in each data identification code are represented as named constants in user writtensoftware, to make it easier to recognise.
There are restrictions on the choices of constant and representative numerical values givenafter the separate elements of the identification code have been explained.
1. Category : This is the most general element of the data identification code5. The examplefrom an experimental scenario, uses the category THERMOMETER,
2. SubCategory : This is a refinement of the category to a specific area, for example PT 100is a type of thermometer and is therefore used as the example subcategory. Other sub-categories for THERMOMETER might include, THERMISTOR, PT 1000 etc.
4The implication is that the data in the file is corrupt at the bit level. This will not detect problems causedby the data type being misindentified or by the endian handling of the data being incorrect.
5Some thought will be required and experimentation may be needed to match the category choices to theusers application.

Oxford MONALISA Document No: Page: 10 of 800006 Rev. No. : 3.1.6
3. Context : This element sets the context for the data array, explaining how it is being used.There are eight predetermined values, defined in the binary I/O protocol, in alphabeticalorder these are :
ACQUIRED Data recorded in an experiment, from an instrument (e.g. a digitisedvoltage) or from the operating system (e.g. a timestamp).
ANALYSED The results of one or more stages of analysis performed on acquired, sim-ulated or test data.
INPUT PARAMETER A user adjustable control parameter for an analysis or pro-cessing stage in data handling. Examples include seed parameters for a fit, averagingperiod for a smoothing filter etc. The distinction between input parameter and metadata is a fine one, ultimately down to the user choice, but as a guide I would suggestthat input parameters can be changed when analysing the same data with the sameanalysis algorithm (e.g. where to seed the fit), whereas for a given data set analysedwith a given algorithm, meta data does not change.
LABEL DATA The array contains information which is more useful to a human thanto a machine, examples might include a string naming the location of an instrument.An analysis programme might display this string on a GUI or as a column headingin ASCII output, but could not really be expected to process the meaning of thestring.
META DATA Numerical data about the other data arrays which might be used byanalysis or processing algorithms, including indexing information (such as the num-ber of arrays of a particular type stored in the file) and global constants.
PROCESSED The results of a data preparation stage, such as averaging, filtering,cutting etc.
SIMULATED An array of data produced in a simulation which is not a throwawaytest.
TEST DATA “Throwaway” test data used to check software behaviour.
4. Division : This element divides up all the possible data types under the chosen context,category and subcategory. In the example the division is GLOBAL CONSTANTS. Divi-sions are either subdivided or iterated. Subdivided divisions have subdivisions specifiedin the data identification scheme.
5. Subdivision
(a) For an iterated division : the subdivisions for N iterated arrays take on values from 0upwards to N-1 (chosen to match the index in a for loop in C, Java and LabVIEW);for example if there are N thermometers, there might be N arrays of raw thermometerdata. A META DATA array should record the value of N so that the readout softwarecan loop over the correct number of iterations efficiently.
(b) For a subdivided division : the subdivision fully specifies the division in a similarmanner to subcategories fully specifying categories.
There are some restrictions and other considerations you should be aware of regardingdata identification schemes :
Oxford MONALISA Document No: Page: 11 of 800006 Rev. No. : 3.1.6
• Any constant represented by 0, (except at the subdivision level) indicates some form of testdata which is throwaway and can be ignored. Data which is labelled 0.0.TEST DATA.0.0is very clearly marked out for testing purposes.
• Amongst the different elements, no two elements can have the same name.
• A catgegory can have up to 200 subcategories6. Subcategories from different categoriesmust be represented by different values, a requirement imposed by the LabVIEW imple-mentation.
• Divisions can be shared across any categories and subcategories7.
Since there is a lot of effort required to design a data identification scheme to match therequirements of a user application, a software package, called GIACoNDE, has been providedfor converting a user designed data ID scheme into constants available for use in each of thesupported I/O languages, C, Java and LabVIEW. This tool is described in section 7.
2.5 User data arrays
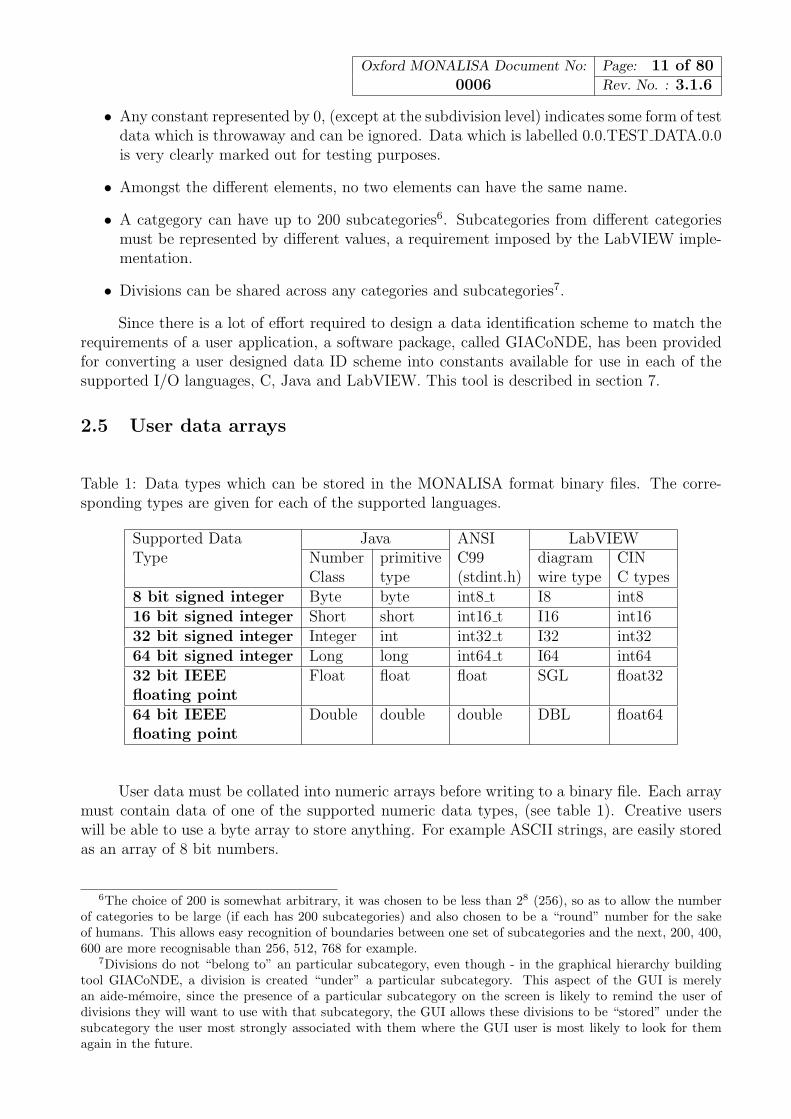
Table 1: Data types which can be stored in the MONALISA format binary files. The corre-sponding types are given for each of the supported languages.
Supported Data Java ANSI LabVIEWType Number primitive C99 diagram CIN
Class type (stdint.h) wire type C types8 bit signed integer Byte byte int8 t I8 int816 bit signed integer Short short int16 t I16 int1632 bit signed integer Integer int int32 t I32 int3264 bit signed integer Long long int64 t I64 int6432 bit IEEE Float float float SGL float32floating point64 bit IEEE Double double double DBL float64floating point
User data must be collated into numeric arrays before writing to a binary file. Each arraymust contain data of one of the supported numeric data types, (see table 1). Creative userswill be able to use a byte array to store anything. For example ASCII strings, are easily storedas an array of 8 bit numbers.
6The choice of 200 is somewhat arbitrary, it was chosen to be less than 28 (256), so as to allow the numberof categories to be large (if each has 200 subcategories) and also chosen to be a “round” number for the sakeof humans. This allows easy recognition of boundaries between one set of subcategories and the next, 200, 400,600 are more recognisable than 256, 512, 768 for example.
7Divisions do not “belong to” an particular subcategory, even though - in the graphical hierarchy buildingtool GIACoNDE, a division is created “under” a particular subcategory. This aspect of the GUI is merelyan aide-memoire, since the presence of a particular subcategory on the screen is likely to remind the user ofdivisions they will want to use with that subcategory, the GUI allows these divisions to be “stored” under thesubcategory the user most strongly associated with them where the GUI user is most likely to look for themagain in the future.

Oxford MONALISA Document No: Page: 12 of 800006 Rev. No. : 3.1.6
3 Using binary files
This section gives an overview of using I/O library software to handle binary files. Languagespecific details for calling the relevant code in each I/O support library are given in latersections.
3.1 Minting a new binary file
The process of making a new file, complete with file header, is referred to here as minting8,by analogy with minting a coin; in the sense that minting a coin, makes it ready for use bystamping it with identification markings. A minted file starts out in the unlocked state readyfor new data to be written to it.
3.1.1 Cross references to language specific advice
The language specific calls for minting a file are described in the following sections:
C See section 4.3.2.
Java See section 5.5.1.
LabVIEW See section 6.3.3.
3.1.2 User input requirements
A new binary file is minted by a single call to the I/O support library code (using a single subVIin LabVIEW). When a new binary file is minted, the user code must specify the following :
• The filepath where the new binary file should appear, including the filename and exten-sion.
• The (GIACoNDE) user identity and data identification scheme version information, whichthe writing software should take directly from the corresponding GIACoNDE output file(which defines the data identification scheme for data in the file).
• The user selected software identification number in the form of a 16 bit integer.
Other elements of the header are automatically generated by the I/O software routines and theresulting file appears, with completed header, at the specified filepath. Existing files are notoverwritten or replaced by minting, instead the I/O library will indicate an error. This is aprecaution to protect important user data from accidentally being overwritten.
3.1.3 Error conditions
If any error occurs during the minting process and is flagged by the I/O software, the user codeshould be prepared to handle the error condition and should not attempt to use the resultingbinary file, which may be incomplete or non-existent.
The error conditions which might be encountered when minting a file, can be separatedinto :
8See for example the Oxford English Dictionary second entry as a verb, part 1c. includes a reference tomanufacturing by stamping or printing.

Oxford MONALISA Document No: Page: 13 of 800006 Rev. No. : 3.1.6
I/O conditions These depend on circumstances and include all potential filepath and fileaccess problems, creating and opening the file, including any attempt to overwrite/replacean existing file.
Protocol related problems These should be easily reproducible as they are symptomatic ofa bug in the I/O library code. These might arise as the software tries to write the headerelements at the start of the file.
The details of each error condition are language specific and covered in later sections in furtherdetail.
3.2 Opening and closing the binary files
The calls to open and close a file are made automatically by the Java library and should nottherefore be made by the user software. The operations described in this section are onlynecessary in C and LabVIEW, where the user creates a sequence of read and write operationsbetween opening and closing the file.
3.2.1 Cross references to language specific advice
The language specific advice for opening and closing files.
C See section 4.3.3.
Java Section 5.5.2 reiterates the point made in the first paragraph of section 3.2, that separatecalls are unnecessary for opening and closing files in the Java implementation.
LabVIEW See sections 6.3.4 to 6.3.6.
3.2.2 Opening in read-write mode
A minted data file must be opened for writing before the user data arrays can be added.Opening the file in the read-write mode is achieved by a single call to the function (subVI) ofthe same name in the C (LabVIEW) version I/O support library.
If an older file, which already holds data, (presumably written by another piece of soft-ware), is being opened for further data writing, the user ought to check whether or not the filehas been locked, before trying to write to it. None of the error flags which might be triggeredwhen the file is opened in read-write mode, relate to the state of the file lock.
An attempt to write arrays to a locked file will result in an error condition being flaggedand no data being added to the file. User calls to write data, must be able to handle thisand other (predictable) error conditions which might arise during writing. See section 3.5 forinformation on checking the file header lock status and section 3.3 for further details on writingarrays to a file.
3.2.3 Opening in read-only mode
As with opening in read-write mode, a single call to the relevant I/O library routine, opens afile in read-only mode. For software operations which only involve reading, it is safer to openthe file in (operating system defined) read-only mode, because data corruption is much lesslikely in read-only mode. There are also fewer error conditions to handle in read-only mode.
As one might expect, data can be read from a file, once opened in either read-only orread-write mode, irrespective of the status of the header file lock.

Oxford MONALISA Document No: Page: 14 of 800006 Rev. No. : 3.1.6
3.2.4 Closing a file
Once a chain of operations, to be performed on an open file, is complete, the operating systemwill expect the file to be closed. Files are closed by a single call to the I/O support libraryfunction named “close file”.
3.2.5 Error conditions
Opening a file will generate errors if the requested file does not exist or cannot be accesseddue to file permissions, or an I/O related failure. Much rarer, although still possible are errorsgenerated when trying to close the file, most likely to be due to a change in the I/O set upmidway through using the file (as might be caused, for example, by a disk failure).
3.3 Writing data to a binary file
Data arrays are added to a binary file by a single use of the I/O library data writing func-tion/method/subVI; one array at a time. In addition to the array, the user must also provideenough information for the I/O software to construct a data label. This information includes adata array identification code, built up from elements in a user data identification scheme (seeSection 2.4).
3.3.1 Cross references to language specific advice
Language specific details on writing data arrays to files can be found in these sections :
C See section 4.3.4.
Java See section 5.5.3.
LabVIEW See section 6.3.7.
3.3.2 Input requirements
A call to the array writing function passes on the array to be written, the data identificationcode and the label message to the I/O software. In LabVIEW and Java the other meta-data(including data type and array length) can all be worked out automatically from the inputarray. In C, the data type and array length information are input parameters which the usersoftware must provide.
3.3.3 Error conditions
Any attempt to write arrays to a locked file will result in an error condition being flagged andno data being added to the file. User calls to write data must be able to handle this and other(predictable) error conditions which might arise during writing.
The error conditions which might arise when writing an array to a file, can be separatedinto :
I/O conditions These depend on circumstances and include all potential file access problems.
File locked The file header lock is set to FILE LOCKED to prevent arrays from being writtento the file.

Oxford MONALISA Document No: Page: 15 of 800006 Rev. No. : 3.1.6
Data type unrecognised If the data type flag is not one which the reading software recog-nises (see Table 1), an error will be flagged. This should only be possible in the Cimplementation, since the user will have no function to call for the unsupported datatype in Java or LabVIEW (a forced conversion will appear on the wiring diagram).
Protocol related problems These should be easily reproducible as they are symptomatic ofa bug in the I/O library code. These are flagged when the size of an element (of eitherthe file header or the data array label), as specified in the protocol constants, does notmatch the element size expected by the code in the called function. This error conditionis designed to pick up bugs which arise when protocol specifications change from oneversion to the next.
The details of each error condition are language specific and covered in later sections in furtherdetail.
3.4 Reading data from a binary file
User software requests user data from a binary file, one array at a time, by a call to the arrayreading function/method/subVI. The requested array is first found within the file and the arraylabel and the array contents are read into memory and made available to the user software.Every individual array to be read, is requested using the data identification code for the arrayand the instance number. The first instance (which is most often the instance of interest)should be specified using the protocol constant FIRST INSTANCE LABEL.
3.4.1 Cross references to language specific advice
Language specific details on reading data arrays from files can be found in these sections :
C See section 4.3.5.
Java See section 5.5.4.
LabVIEW See section 6.3.8.
3.4.2 Input requirements
A call to the array reading function requires the data identification code and the instance toidentify which data array is to be found and read in.
3.4.3 Error conditions
The error conditions which might arise when reading an array from a file, can be separatedinto :
I/O conditions These depend on circumstances and include all potential file access problems.
Data absent The data array the user requested may not be present in the binary file. Thisobvious condition must be handled by user software.
Data type unrecognised If the data type flag is not one which the reading software recog-nises, an error will be flagged.

Oxford MONALISA Document No: Page: 16 of 800006 Rev. No. : 3.1.6
Protocol related problems Various errors might arise due to protocol specific changes, in-cluding changes in the supported data types and incomplete implementations of file struc-ture changes from earlier protocol versions.
The details of each error condition are language specific and covered in later sections in furtherdetail.
3.5 (Un)locking a binary file
The lock element of the file header can be set to either of the protocol constants FILE LOCKEDor FILE UNLOCKED by calling the relevant library function/method, when the file has beenopened in read-write mode.
3.5.1 Cross references to language specific advice
Language specific details on (un)locking files can be found in these sections :
C See section 4.3.7.
Java See section 5.5.5.
LabVIEW See section 6.3.9.
3.5.2 Input requirements
The input parameters transmit the following information :
• A reference to the binary file to be (un)locked.
• The new state of the file lock (which may be implicit in the function/method) call.
Exactly how this information is transmitted depends on the specific language in which thesoftware is written. The reader should refer to the relevant language specific sections givenabove.
3.5.3 Error conditions
Attempting to lock a locked file or unlock an unlocked file should not generate an error condition.The error conditions which could arise when changing the files lock state can be separated into :
I/O conditions These depend on circumstances and include all potential file access problems.Trying to alter a file in read-only mode, will result in an I/O error.
Protocol related problems These should be easily reproducible as they are symptomatic ofa bug in the I/O library code. These are flagged when the size of the lock an element of theheader as specified in the protocol constants, does not match the element size expectedby the (un)locking function in the particular I/O library code being used. This errorcondition is designed to pick up bugs which arise when protocol specifications changefrom one version to the next.
Writing error This error is flagged if the expected final file lock state is not observed afterthe lock has been changed.
The details of each error condition are language specific and covered in later sections in furtherdetail.

Oxford MONALISA Document No: Page: 17 of 800006 Rev. No. : 3.1.6
3.6 Reading the file header
The header of a binary file needs to be read out, to check for file compatibility. User softwarecan access the header contents by a single call to the relevant function/method/subVI in thesupport library. The contents of the file header are described in detail in section 2.2.
3.6.1 Cross references to language specific advice
Language specific details for reading the file header can be found in these sections :
C See section 4.3.8.
Java See section 5.5.6.
LabVIEW See section 6.3.10.
3.6.2 Input requirements
The only input information is the language specific reference to the binary file to be read.
3.6.3 Error conditions
The error conditions which might arise when reading the file header can be separated into :
I/O conditions These depend on circumstances and include all potential file access problems.
Protocol related problems These should be easily reproducible as they are symptomatic ofa bug in the I/O library code. These are flagged when the size of an element of the headersection as specified in the protocol constants, does not match the element size expected bythe handling function in the particular I/O library code being used. This error conditionis designed to pick up bugs which arise when protocol specifications change from oneversion to the next.
The details of each error condition are language specific and covered in later sections in furtherdetail.

Oxford MONALISA Document No: Page: 18 of 800006 Rev. No. : 3.1.6
4 Using the C binary file I/O library
This section covers all aspects of the C implementation of the I/O library. It starts with anoverview of the C library files, followed by information on how to download and unpack thelibrary code, how to build the code into a static library under windows or the equivalent underlinux and finishes off with detailed examples showing how to write user code to call each of thefunctions which were introduced as generic I/O operations in section 3.
4.1 The I/O Library
This library was written for other writers of C code. The natural compatibility between C andC++ should allow writers of code in the latter language also to use these C libraries. Somenotes have been added to the end of this chapter for C++ users.
4.1.1 Files
The I/O library consists of source files and header files. These are organised into directories asshown in Table 2, with the header9 files in the inc subdirectory and the source files in the srcsubdirectory.
Table 2: The files of the C I/O library.`inc `src
` binaryIO c definitions.h `` BinaryIO def.h `` binaryIO.h ` binaryIO.c` binaryIO dynamicHeader.h ` binaryIO dynamicHeader.c` binaryIO readDataLabel.h ` binaryIO readDataLabel.c` binaryIO readHeader.h ` binaryIO readHeader.c` binaryIO writeDataLabel.h ` binaryIO writeDataLabel.c` binaryIO writeHeader.h ` binaryIO writeHeader.c` endian.h ` endian.c
If the user code includes the header binaryIO.h all the other necessary I/O relatedheaders will be included.
4.1.2 Roles for each file
The role of each file and the potential need for users to directly access the file or not areexplained in the following:
binaryIO c definitions (.h only) This header defines all the integer constants used as returnvalues by the library functions.
BinaryIO def (.h only) This header is created automatically by a “protocol defining” pythonscript which sets the constants across all the language implementations. The constantswhich are relevant for user code are :
9In the windows implementation an extra header file stdint.h has been added to the inc directory. This isa vital part of the ANSI 99 C definition and is relied upon by the I/O library to provide fixed width file tpyedefinitions throughout the binary file structure. It is necessary to include it here because it is not provided withthe Visual Studio C compiler.

Oxford MONALISA Document No: Page: 19 of 800006 Rev. No. : 3.1.6
• PROTOCOL VERSION and PROTOCOL REVISION used when the user softwareneeds to check for compatibility between a binary file and the current I/O soft-ware. These constants in this header are the definitive label for the protocol versionimplemented by this C library.
• FIRST INSTANCE LABEL Used when reading in data and the user wishes tofind the first instance (or the one and only instance). For other instances, theuser is recommended to offset from this constant, i.e. the fifth instance being4 + FIRST INSTANCE LABEL.
• FILE UNLOCKED and FILE LOCKED are stored in the header lock to put the file inthe corresponding state. These should be used when interpreting the header lockstatus byte.
• “Definitions for DataTypes” listed from LONG TYPE to SHORT TYPE, should beused to label user data arrays when writing and to identify how to interpret thedata when reading. Even if the user is familiar with the input file when reading, thesoftware should cross check that the data type matches expectations.
• “Definitions for DataContexts” listed from META DATA to SIMULATED (describedin detail in section 2.4). These are used for building data ID codes when writingdata and for identification when reading data.
binaryIO If the user code includes the header binaryIO.h all the other necessary I/O relatedheaders will be included. Almost all the functions which the user needs to call are con-tained in this file. These functions implement the I/O operations described in section 3.The functions in this file call other (internal) functions in the other files as necessary.
binaryIO dynamicHeader This contains functions which interact with those parts of thebinary file header which are variable. The user can lock and unlock the file by direct callsto correspondingly named functions in this file.
binaryIO readDataLabel This contains functions to read the label on a data array. Theuser will not need to make direct calls to these functions.
binaryIO readHeader This contains functions to read all elements of the header at the startof the binary file. The user can read the header contents by making direct calls tofunctions in this file.
binaryIO writeDataLabel This contains functions to write the label of a data array to file.The user will not need to make direct calls to these functions.
binaryIO writeHeader This contains functions to write the header to the start of a newlyminted file. The user will not need to make direct calls to these functions.
endian This contains internal functions which perform endian dependent byte manipulationto ensure that the binary file format is little endian. The header file endian.h contains 3precompiler definitions. Only one of these three options, LITTLE ENDIAN , BIG ENDIANor UNKNOWN ENDIAN should be uncommented; see section 4.1.3 for further details.
4.1.3 Endian settings
The I/O library has been implemented in C with the assumption that any users machine useseither big endian or little endian byte order. Other possibilities exist but these are not supportedby the C implementation of the binary I/O support library.

Oxford MONALISA Document No: Page: 20 of 800006 Rev. No. : 3.1.6
If the user knows the endian state of their machine, the relevant precompiler optionLITTLE ENDIAN or BIG ENDIAN should be uncommented in the header file endian.h, priorto compiling and building the static library.
If the user does not know the endian state of their machine, the safest (but slowest runningcode) option is to, uncomment only UNKNOWN ENDIAN , prior to compiling and building thestatic library.
1. With LITTLE ENDIAN uncommented, all interactions with the binary file are direct, thedata is read from and written to the binary file without any corrections applied to thebyte order.
2. With BIG ENDIAN uncommented, all interactions with the binary file which involve typeslonger than a single byte, are forced to go via byte order reversal functions.
3. With UNKNOWN ENDIAN uncommented, the interactions with the binary file can beexpected to be significantly slower. All interactions with the binary file which involvetypes longer than a single byte, lead to execution of an endian test function which decideswhether or not to invoke byte order reversal functions.
4.2 Obtaining the C I/O library
4.2.1 Downloading the library
The C code implementing the I/O functions described here can be downloaded from the MON-ALISA project web page at : http://www-pnp.physics.ox.ac.uk/∼monalisa/ , followingthe links for the binary I/O software. The C library code is available for linux and for windows(in a .zip file).
4.2.2 C code for linux
The linux version of the C library is downloaded as a .tar.gz file. The following explains howto extract the C code, compile it to create a static library and how to use the resulting librarywith your code.
1. Create a directory for the C library, (presumably among the directories for your C code).This directory is represented below as /DirForBinaryIOdownload.
2. Download the .tar.gz file, saving it in the created directory.
3. Decompress the tar.gz file using the gunzip utility :
myLinuxPrompt% gunzip binaryIO c v3 1.tar.gz
4. Extract the archive contents using the tar utility :
myLinuxPrompt% tar -xf binaryIO c v3 1.tar
This will create subdirectories and a README.txt file which explains how to executethe make file to build the static library.
5. Run the makefile in the /src subdirectory, to build the I/O library.

Oxford MONALISA Document No: Page: 21 of 800006 Rev. No. : 3.1.6
6. When writing the make file for any user code which needs to access the I/O library,include something similar to the example commands10 given in Table 3. The penultimateline passes the include directory to the compiler so it can find the binary I/O libraryheaders. This is assuming the user has included the binaryIO.h header file from thebinary I/O library in their own code. The last line links the static library to the usersobject files.
Table 3: Example commands for a user makefile accessing the static library for the I/O library- which should be built using the makefile provided. The I/O library should be compiled beforecompiling the user code with the user makefile.
incDir = /DirForBinaryIOdownload/inc/
libDir = /DirForBinaryIOdownload/lib/
IOlib = BinaryIOv3 1
. . .
$(CC) -c *.c -I$(incDir)
. . .
$(CC) *.o -o myExecutable -L$(libDir) -l$(IOlib)
4.2.3 C code for windows
The windows version of the C library is downloaded as a .zip file. The following explains howto extract the C code. An extra header file, stdint.h has been included. This was taken from asource on the web referenced from wikipedia11 once it became clear that MS visual studio doesnot include stdint.h in their definition of C.
Compiling using MS Visual Studio An example using MS Visual Studio 2005 shows oneway to compile the source code to create a static library and how to use the resulting librarywith your code in other MS Visual Studio projects. If you use a different C compiler, you willhave to work out the equivalent steps for yourself.
1. Create a directory for the C library, (presumably among the directories for your C code).This directory is represented here as \DirForBinaryIOdownload.
2. Download the .zip file, saving it in the created directory.
3. Decompress the .zip file using whatever utility you have.
10It is up to the user to adapt these examples to their own makefile. The GNU make manualhttp://www.gnu.org/software/make/manual/make.html is a good starting point for more informationon writing makefiles.
11The wikipedia page on stdint.h - at least when checked in June 2007 - referred the reader to the linkhttp://msinttypes.googlecode.com/svn/trunk/stdint.h. This header file has been bundled with thewindows version of the I/O library and is copyright Alexander Chemeris 2006, the full disclaimer is given inAppendix C.

Oxford MONALISA Document No: Page: 22 of 800006 Rev. No. : 3.1.6
4. This will create subdirectories and a README.txt file which explains the directorycontents.
5. Open MS Visual Studio 2005.
6. Create a new project using File:New:Project. . .
7. Select Visual C++:Win32 in the left hand project types panel and Win32 project inthe right hand templates panel.
8. Fill in the name, location and solution name as you see fit. The unambiguous nameMSVS binaryIO v3 1 static library was used when constructing the LabVIEW I/O librariesfrom the C implementation.
9. Pressing OK moves on to the Win32 application wizard, with Overview and Applica-tion Settings on the left hand side. Select Application Settings.
10. Under Application Type in the middle, click the radio button for Static library.
11. Ignore Add common header files for: but under Additional options: deselect the Pre-compiled Header tick box.
12. Press Finish to enter the project.
13. On the left hand side, the Solution Explorer window should be visible. Add the sourcefiles from the \src subdirectory into the source files folder.
14. Similarly add the header files from the \inc subdirectory into the header files folder,except the file stdint.h which should be placed in the resources folder.
15. The previous two steps are mainly symbolic, but help to organise the project in a moreeasily recognised and understood form.
16. Before building the static library, certain changes need to be made to the project settings.In the Solution Explorer window, right click on the second line - which should be in boldfont - and choose properties from bottom of the pop-up window. This will bring up theproperties dialog.
17. The left hand uppermost control configuration should say (Active) Release - if it does notchange it to this setting. If the current (active) setting is Debug, it will not be possibleto select Release as the active setting. Release should be made active by following thesesteps:
(a) Press cancel
(b) Select from the Visual Studio main toolbar menu Build:ConfigurationManager. . .
(c) Change the Active solution configuration to Release
(d) Follow the previous step, to reopen the properties dialog.
18. On the left hand side select Configuration properties:General. On the right hand sideunder General:Output Directory enter the full path to the \lib subdirectory of the binaryI/O library.

Oxford MONALISA Document No: Page: 23 of 800006 Rev. No. : 3.1.6
19. On the left hand side select Configuration properties:C/C++:General. On the right handside under Additional include directories enter the full path to the \inc subdirectory ofthe binary I/O library.
20. On the left hand side select Configuration properties:C/C++:Advanced. On the righthand side second line Compile As select the option Compile as C Code (/TC).
21. Use the build command in this project to create the static library file which will have the.lib extension.
22. When building user code in a user MS Visual Studio project, the static library can belinked by including the \lib subdirectory of the binary I/O library in the AdditionalLibrary Directories option under Linker:General in the Configuration properties. Thisoption does not appear to be available under a static library project (where the user codeand I/O library would have to be built together). But here it is assumed that a userapplication would be an executable project or DLL.
4.3 Writing code to utilise the C library functions
This subsection goes into the details of writing software to handle binary files. Writing binaryfile handling software combines a user data identification scheme (in the form of GIACoNDEoutput header files), with the C version of the I/O support library and the users own C code.
4.3.1 Integer return values
Calls to I/O library functions always return an integer value, (collected by a variable namedflag in the code examples given below), which should be checked by user code as shown inTable 4. The value returned will be one of the constants defined in the header file bina-ryIO c definitions.h. Any value not equal to FILE OPERATION OK represents some form oferror condition, which the user code should be prepared to handle.
Table 4: Code fragment example for checking the integer value returned after a call to an I/Olibrary routine.
int flag;
. . .
// check for errorsif(FILE OPERATION OK!=flag) {
// handle anything needed before exit. . .
return flag;
}

Oxford MONALISA Document No: Page: 24 of 800006 Rev. No. : 3.1.6
4.3.2 Minting a new binary file
A new binary file is minted by calling the function of the same name, declared in the headerbinaryIO.h and implemented in the corresponding source file binaryIO.c. The functiondeclaration is
int mintNewFile(const char *filePath,
const int16 t userID,
const int16 t softwareID,
const int16 t dataID LUT Version,
const int16 t dataID LUT Revision);
The input parameters are :
filePath A string representation of the path where the binary file is to be made.
userID This parameter should be taken from the constant USER ID in the user data identifi-cation GIACoNDE output header file. (Later revisions of GIACoNDE have renamed thisparameter to GROUP ID in the GIACoNDE output.)
softwareID This is for the user software to define, it must be of type int16 t when passed tothis function.
dataID LUT Version This parameter should be taken from the constant ID LUT VERSIONin the user data identification GIACoNDE output header file.
dataID LUT Version This parameter should be taken from constant ID LUT REVISION inthe user data identification GIACoNDE output header file.
The returned int value should be checked to see whether or not it equals the value ofFILE OPERATION OK, (defined in binaryIO c definitions.h). An illustrative example isgiven in Table 5.
Possible return values are defined in the header file binaryIO c definitions.h. Otherthan the default FILE OPERATION OK the possible return values are listed below, togetherwith the corresponding causes :
• FILE LOCKED The file you are trying to mint exists already.
• FILE NOT CREATED The attempt to create a new file, failed.
• ERROR TRYING TO CLOSE The file could not be closed; either immediately after it wascreated (by opening in read-write mode) or once the header was written.
• FILE COULD NOT BE ACCESSED The file could not be reopened after it was created.
• WRITING ERROR Writing one of the header elements to the file, was unsuccessful.
• FILE POSITION ERROR Moving the file pointer within the file generated an error.

Oxford MONALISA Document No: Page: 25 of 800006 Rev. No. : 3.1.6
Table 5: A c code example, illustrating the use of the mintNewFile function.
#include ′′userDataIdentificationScheme.h′′
#include ′′binaryIO.h′′
. . .
int userFunction(char *myDataFile, . . .) {. . .
int flag;
flag = mintNewFile(myDataFile, USER ID, SOFTWARE ID,
ID LUT VERSION, ID LUT REVISION);
// check for errors as in code example in Table 4// continue with rest of user function. . .
return 0;
}
int openFileToReadOnly(const char *filePath, FILE **fileHandle);
int openFileToReadWrite(const char *filePath, FILE **fileHandle);
• ELEMENT SIZE ERROR There is a mismatch between the binary I/O protocol definitions,which specify the sizes of file header elements and the c code. This indicates a seriousbug in the c code which needs to be rectified.
• INSTANCE MISPLACEMENT ERROR The ordering of instances of data arrays which sharea common identification code, does not match the expected progression, in order, throughthe positive integers. The implication is that some data is missing or corrupt. This errorarises midway through writing the data label to the file. Under these circumstances thedata array will not have been written to the file. The best advice is to “rescue” the file,copying individual arrays over to a new file, to restore a valid instance count.
4.3.3 Opening and closing binary files
The functions for opening and closing binary files are all declared in the library header file,binaryIO.h and implemented in the corresponding source file binaryIO.c. The functiondeclarations for opening files are : The two opening modes match those described in the overview(see section 3.2). An existing file, located at the path specified by the input parameter *filePathis opened in the requested mode and a file pointer giving access to the open disk file, is passedback to the calling code, via the file handle **fileHandle, which is passed on to other file handlingI/O functions, described below.
After calling either function, the returned int value should be checked to see whether ornot it equals the value of FILE OPERATION OK, (defined in binaryIO c definitions.h), usingcode similar to that in the example given for file minting above in section 4.3.2. The only other

Oxford MONALISA Document No: Page: 26 of 800006 Rev. No. : 3.1.6
int closeFile(FILE **fileHandle);
possible return value is FILE COULD NOT BE ACCESSED which is returned when the internalcall to fopen returns a FILE pointer equal to NULL.
Once all operations on an open file are complete, the file must be closed. This is handledby the function :
If the file could not close successfully, the value ERROR TRYING TO CLOSE is returned.Therefore after calling either opening or closing function function, the returned int value
should be checked to see whether or not it equals the value of FILE OPERATION OK, (definedin binaryIO c definitions.h), using code similar to that in the example given for file mintingabove in section 4.3.2.
4.3.4 Writing data to a binary file
A data array and label are written to a data file by calling the function writeDataArrayToFiledeclared in the header binaryIO.h and implemented in the corresponding source file bina-ryIO.c. The function declaration is :
int writeDataArrayToFile(FILE **open file handle, void **data handle,
const int8 t *dataType ptr,
const int32 t *number of elements ptr, const int8 t data context,
const int16 t data category, const int16 t data subcategory,
const int16 t data division, const int16 t data subdivision,
const char *label string);
The input parameters are :
∗∗open file handle The file handle - assumed to have been opened by an earlier, successfulcall to the function openFileToReadWrite.
∗∗data handle A handle (pointer to the pointer holding the first address) of the data arraywhich the user is writing to the binary file.
∗dataType ptr The user needs to pass on the address of a local variable, set to a value whichrepresents the data type being written in the array. The representative value should bemade equal to the corresponding constant, defined in the protocol definition header fileBinaryIO def.h.
∗number of elements ptr The address of a variable holding the size of the array to be writtento the file (or portion of interest) should be entered here.
data context The data constant value entered here should be one of the defined context valuesdefined in the protocol definition header BinaryIO def.h.
data category The data constant value entered here should be one of the category values de-fined in the GIACoNDE output header which defines the user data identification scheme.

Oxford MONALISA Document No: Page: 27 of 800006 Rev. No. : 3.1.6
data subcategory The data constant value entered here should be one of the defined sub-category values defined in the GIACoNDE output header which defines the user dataidentification scheme.
data division The data constant value entered here should be one of the defined divisionvalues defined in the GIACoNDE output header which defines the user data identificationscheme.
data subdivision The data constant value entered here should be one of the defined sub-division values defined in the GIACoNDE output header which defines the user dataidentification scheme.
∗label string The message string which is to be written between the fixed part of the arraydata label and the data array (as described in section 2.3).
The returned int value from any call to the I/O functions should be checked to see whetheror not it equals the value of FILE OPERATION OK, (defined in binaryIO c definitions.h) asin the example code in Table 4.
Possible return values are defined in the header file binaryIO c definitions.h. Otherthan the default FILE OPERATION OK the possible return values are listed below, togetherwith the corresponding causes :
• DATA TYPE NOT RECOGNISED The data type represented in the input parameter ofthe same name, does not match a code for any of the supported types.
• FILE POSITION ERROR Moving the file pointer within the file generated an error.
• ELEMENT SIZE ERROR There is a mismatch between the binary I/O protocol definitions,which specify the sizes of file header or data label elements and the c code. This indicatesa serious bug in the c code which needs to be rectified. If this occurs for the first time,when writing an array, it implies that the bug relates to the data array label and doesnot relate to the header, since a header related bug should have triggered an error whenthe file was minted.
• READING ERROR There was a problem reading one of the header elements pertinent towriting a new array to a file.
• WRITING ERROR There was a problem writing to the file, writing updates of headerelements, array label elements or the array elements to the file.
• CANNOT WRITE LOCKED FILE The file header lock is in the locked state. This call towrite a new array is vetoed by the I/O library.
• LOCK STATUS NOT RECOGNISED The file header lock is in an undefined state, implyingsome unknown error condition. To protect the data already in the file, this call to writedata to the file is abandoned.
4.3.5 Reading data from a binary file
A data array and label is located in a file and read out by calling the function readDataAr-rayFromFile declared in the header binaryIO.h and implemented in the corresponding sourcefile binaryIO.c. The function declaration is :

Oxford MONALISA Document No: Page: 28 of 800006 Rev. No. : 3.1.6
Table 6: Example c code, illustrating the use of the function writeArrayToData.
#include ′′binaryIO.h′′ // includes all the other support library headers#include ′′userDefinedDataIDscheme.h′′ // GIACoNDE output. . .
int userFunction(. . .) {. . .
int flag;
int32 t N = (int32 t)100; // size of the array in this caseint8 t dataContext = SIMULATED; // data contains simulated data// constant : SIMULATED defined in BinaryIO def.h
float *userDataArray; // memory allocation and value assignment not shown. . .
int8 t dataType = FLOAT TYPE;
FILE *fp = (FILE*)0; // set up a blank file pointerFILE **fileHandle = (FILE**)(&fp); // the file handle links to the file pointer. . .
// open user data fileflag = openFileToReadWrite(′′myDataFile.dat′′,fileHandle);
// check for errors as in Table 4.// write data to the file using data ID constants from user scheme
flag = writeDataArrayToFile(fileHandle,(void**)&userDataArray,
&dataType, &N, dataContext, USER CATEGORY, USER SUBCATEGORY,
USER DIVISION, USER SUBDIVISION, ′′Hundred floats example array′′);
// check for errors as in Table 4.// close file
flag = closeFile(fileHandle);
// check for errors as in Table 4.// continue with rest of user function. . .
return 0;
}
int readDataArrayFromFile(FILE **open file handle, void **data handle,
const int16 t required instance, int8 t *dataType ptr,
int32 t *number of elements ptr,
const int8 t data context,
const int16 t data category, const int16 t data subcategory,
const int16 t data division, const int16 t data subdivision,
char **label handle);
The input parameters are :
∗∗open file handle The file handle - assumed to have been opened in either read-only or

Oxford MONALISA Document No: Page: 29 of 800006 Rev. No. : 3.1.6
read-write mode.
∗∗data handle A handle (pointer to the pointer holding the first address) which will be con-nected to the data array read from the binary file, if a match array is found. The memoryallocation for this array is done by the I/O library functions, the user does not needto allocate memory for the array being read, but does need to assign a pointer, cast tothe appropriate type, to the address stored in the dereferenced handle (see code examplebelow and subsection 4.3.6).
∗dataType ptr The user can dereference this pointer to get back the data array label flagwhich indicates the array type. The representative value can be compared with theconstants defined in the protocol definition header file BinaryIO def.h. This should bechecked to ensure that the data type, matches that expected by the user code. In practice,user code will be written with a preconceived idea of what the expected data type is, asthe variables in the code will have to be initialised with the type information.
∗number of elements ptr The user can dereference this pointer to get the size of the array.
data context The data constant value entered here should be one of the context values definedin the protocol definition header BinaryIO def.h.
data category The data constant value entered here should be one of the defined categoryvalues defined in the GIACoNDE output header which defines the user data identificationscheme.
data subcategory The data constant value entered here should be one of the defined sub-category values defined in the GIACoNDE output header which defines the user dataidentification scheme.
data division The data constant value entered here should be one of the defined divisionvalues defined in the GIACoNDE output header which defines the user data identificationscheme.
data subdivision The data constant value entered here should be one of the defined sub-division values defined in the GIACoNDE output header which defines the user dataidentification scheme.
∗∗label handle The message string which is in the array data label (as described in section 2.3)can be dereferenced from this handle. The handle points to the char* pointer whichreferences the string.
The returned int value should be checked to see whether or not it equals the value ofFILE OPERATION OK, (defined in binaryIO c definitions.h), as in the example code in Ta-ble 4.

Oxford MONALISA Document No: Page: 30 of 800006 Rev. No. : 3.1.6
Table 7: C code example using readDataArrayFromFile to read an array of floats and a string(array of bytes) from the same binary file.
#include ′′binaryIO.h′′ // includes all the other support library headers#include ′′userDefinedDataIDscheme.h′′ // GIACoNDE outputint userFunction(. . .) {int flag;
int32 t N; // size of the array gets read into this varint8 t dataContext, dataTypeRead;
const int16 t reqInstance = (int16 t)1;
const int8 t expectedDataType1 = FLOAT TYPE; //defined in BinaryIO def.hconst int8 t expectedDataType2 = BYTE TYPE; //defined in BinaryIO def.h// am expecting to receive 1st data as float valuesfloat *userDataArray=(float*)0;
char *userDataString=(char*)0; // second data array is a stringchar *mesg1 = (char*)0; // first data array messagechar *mesg2 = (char*)0; // second data array messageFILE *fp = (FILE*)0; // set up a blank file pointerFILE **fileHandle = (FILE**)(&fp); // the file handle links to the file pointer
. . .
// open a fileflag = openFileToReadOnly(′′myDataFile.dat′′,fileHandle);
// check for errors as in Table 4.dataContext = SIMULATED; // defined in BinaryIO def.hflag = readDataArrayFromFile(fileHandle,(void**)&userDataArray,
reqInstance, &dataTypeRead, &N, dataContext, USER CATEGORY,
USER SUBCATEGORY, USER DIVISION, USER DATA SUBDIVISION,&mesg1);
// check for errors as in Table 4.. . .
printf(′′Data array with label %s found\n′′,mesg1);
. . .
dataContext = LABEL DATA; // defined in BinaryIO def.hflag = readDataArrayFromFile(fileHandle,(void**)&userDataString,
reqInstance, &dataTypeRead, &N, dataContext, USER CATEGORY,
USER SUBCATEGORY, USER DIVISION, USER LABEL SUBDIVISION,&mesg2);
// check for errors as in Table 4.. . .
printf(′′%s %s \n′′,mesg2,userDataString);
// continue with rest of user function. . .
// close fileflag = closeFile(fileHandle);
// check for errors as in Table 4.return 0;
}

Oxford MONALISA Document No: Page: 31 of 800006 Rev. No. : 3.1.6
Possible return values are defined in the header file binaryIO c definitions.h. Otherthan the default FILE OPERATION OK the possible return values are listed below, togetherwith the corresponding causes :
• INVALID INSTANCE REQUEST The instance which the user has requested, is not a validvalue (for example if it is less than 1, it is not a valid instance).
• DATA NOT FOUND The instance and data identification code do not match any array inthe file.
• MEMORY ALLOCATION FAILED A problem was encountered allocating space in memoryeither for the data array or the data array label message string.
• DATA CORRUPT The data checksum calculated on the array after it was read into mem-ory, does not match the original checksum created when the array was written. Theimplication is that that data array has been corrupted.
• DATA TYPE NOT RECOGNISED The data type represented in the array label does notmatch a code for any of the supported types. This can occur if a new data file is readwith old software.
• FILE POSITION ERROR Moving the file pointer within the file generated an error.
• ELEMENT SIZE ERROR There is a mismatch between the binary I/O protocol definitions,which specify the sizes of file header or data label elements and the c code. This indicates aserious bug in the c code which needs to be rectified. If this occurs for the first time, whenreading an array, it implies that the reading software uses an I/O library implementingone protocol version and the data file was written by another version.
• READING ERROR There was a problem reading one of the header elements, data arraylabel or data array.
4.3.6 Correctly accessing array contents
The example code in Table 7 covered the ideas of setting up and using the data identificationcode to find and read out the required array. A more subtle point was glossed over; regardingthe second parameter in the array reading function readDataArrayFromFile; which is a handle; apointer to a pointer to the first element of the array. It is easy to misunderstand the behaviourof the I/O library function and get unexpected problems with code written to call this function.This is a brief guide to avoiding such pitfalls: An example function is given with a fatal flaw,arising from a likely misunderstanding. The flaw is explained and the remedies described.
Imagine, as a hypothetical example, a user function called specificDataReader which callsreadDataArrayFromFile to read an array of int16 t data. If the return value of the function isreserved for an integer flag (to indicate the success or failure of the I/O operation); there areseveral ways to pass the array back out to callers of specificDataReader via parameters in thefunctions parameter list.
One function specification from the amongst the many possible options is int specific-DataReader(FILE **openFileHandle, int16 t *array ptr). An example of such a function is givenin Table 8. One might imagine that constructing the data handle around the address of thearray pointer is a perfectly valid thing to do. If the array were to be accessed solely within

Oxford MONALISA Document No: Page: 32 of 800006 Rev. No. : 3.1.6
the specificDataReader function, this would be fine. The problem arises for callers of the func-tion specificDataReader; who have a reasonable right to expect to access array contents via thearray ptr parameter and instead will find no trace of the array read out from the file.
Table 8: An example hypothetical user function, which might look correct, but is instead wrong.In fact this function will fail to pass the array contents out to callers.
int specificDataReader(FILE **openFileHandle, int16 t *array ptr) {
int flag;
void **dataHandle = (void**)(&array ptr); //flawed idea
flag = readDataArrayFromFile(openFileHandle, dataHandle, . . .other parametersmore parameters here );
//pass flag back out for external error checkreturn flag;
}
The problem is caused by the multiple copies of pointers which become unsynchronisedand the wrong pointer has data assigned to it. The subtleties are best illustrated with thesketch given in Figure 3. The external, calling function passes the array pointer to the functionspecificDataReader which makes an internal copy. A handle, (a pointer to this pointer) is con-structed and passed to readDataArrayFromFile which copies the handle internally. This functionalso dereferences the copied handle to obtain the copied pointer, which is then redirected tospace in memory allocated for the incoming array; read in from the binary file. The externalpointer is left “high and dry”, pointing to the wrong memory location.
Figure 3: The relationships between the important pointers (and handles) in the example of afatally flawed function given in Table 8.
In cases where the array is only one element long, the problem can be solved by creatinganother pointer inside the specificReader function, a pointer which is independent of the array ptr
parameter. The handle can then be made to point to this independent pointer. After the call

Oxford MONALISA Document No: Page: 33 of 800006 Rev. No. : 3.1.6
to readDataArrayFromFile (and the usual associated error checking), the dereferenced contents ofthe internal pointer can be copied into the contents of the (copied) external pointer12 using:array ptr[0] = internal ptr[0]; or something similar.
The only realistic solution for longer arrays is to rewrite the function specification forspecificDataReader to use an array handle; rather than the pointer. This pushes the problemone level higher up in the code; with all the same considerations applying in the next layerof calling function. The successive layers of calling functions must continue to communicatewith one another via array handles, until the layer is reached where the data array elementsare accessed, saved or in some other manner copied; by dereferencing the array handle. Thisis the level in the code where the handle should be initialised, (by setting the handle to theaddress of a pointer in scope), prior to making the nested set of function calls down to thereadDataArrayFromFile function.
4.3.7 (Un)locking a binary file
The binary file header lock status can be switched between locked and unlocked statesusing the correspondingly named functions. These function are declared in header filebinaryIO dynamicHeader.h and implemented in the corresponding source file bina-ryIO dynamicHeader.c. The function declarations are :
int lockFile(FILE **open file handle);
int unlockFile(FILE **open file handle);
The sole input parameter in each case is :
∗∗open file handle The file handle - assumed to have been opened in read-write mode.
Trying to lock an already locked file, or similarly unlock a previously unlocked file doesnot in itself cause an error. The user will not be warned that the action was redundant. Theuser code can check the header contents using the function call described in subsection 4.3.8.
As with all other calls to the I/O C library functions, the returned int value fromeither of the above functions should be checked to see whether or not it equals the valueof FILE OPERATION OK, (defined in binaryIO c definitions.h). Other than the defaultFILE OPERATION OK the possible return values are listed below, together with the corre-sponding causes :
• FILE POSITION ERROR Moving the file pointer within the file generated an error.
• ELEMENT SIZE ERROR There is a mismatch between the binary I/O protocol definitions,which specify the sizes of file header elements and the c code. This indicates a seriousbug in the c code which needs to be rectified.
12This assumes the latter was sensibly initialised to point to a variable in the external function or to anotherwise allocated block of memory with at least the required two bytes, necessary to receive the single int16 tvalue.

Oxford MONALISA Document No: Page: 34 of 800006 Rev. No. : 3.1.6
• WRITING ERROR Writing the new header status to the file generated an error.
• READING ERROR Only generated by lockFile. An error occurred when trying to read thestatus of the header lock element, to confirm that the lock had been applied.
4.3.8 Reading the file header
The internal structure of the binary file header is explained in detail in subsection 2.2. Theheader binaryIO readHeader.h, declares one function to read all of the header contents atonce and eight other functions to read out the eight individual header elements in isolation.
The function declaration for reading out the entire header at once is :
int readDataFileHeader(FILE **open file handle, int16 t *userID ptr,
int16 t *softwareID ptr, int16 t *dataID LUT Version ptr, int16 t *dataID LUT Revision ptr,
int8 t *protocol Version ptr, int8 t *protocol Revision ptr,
int8 t *file lock status ptr, int32 t *number of data entries in file ptr);
The input parameters for this function are the file handle for an opened file and eightpointers, one to access each of the header variables13.
The above function calls each of the following functions in turn to read out each headerelement. User code can call any of these functions to do the same :
int readHeader userID(FILE **open file handle, int16 t *userID ptr);
int readHeader softwareID(FILE **open file handle, int16 t *softwareID ptr);
int readHeader dataID LUT Version(FILE **open file handle, int16 t *dataID LUT Version ptr);
int readHeader dataID LUT Revision(FILE **open file handle, int16 t *dataID LUT Revision ptr);
int readHeader protocol Version(FILE **open file handle, int8 t *protocol Version ptr);
int readHeader protocol Revision(FILE **open file handle, int8 t *protocol Revision ptr);
int readHeader lockStatus(FILE **open file handle, int8 t *file lock status ptr);
int readHeader number of entries(FILE **open file handle, int32 t *number of data entries in file ptr);
The input parameters for each function are the file handle for an opened file and a pointerfor header variable of interest. variables.
User code calling any of the header reading functions, should check the returned integervalue to make sure it is equal to FILE OPERATION OK defined in binaryIO c definitions.h,an example fragment of code to do this is given in Table 4. All other return values indicate
13The parameter named softwareRegLUT ID ptr is an older name for user ID ptr. This will be tidied up ina later revision of the code.

Oxford MONALISA Document No: Page: 35 of 800006 Rev. No. : 3.1.6
an error condition which the user code should be prepared to handle. Possible error valuesreturned from header reading functions are :
• FILE POSITION ERROR Moving the file pointer within the file generated an error.
• ELEMENT SIZE ERROR There is a mismatch between the binary I/O protocol definitions,which specify the sizes of file header elements and the c code. This indicates a seriousbug in the c code which needs to be rectified.
• READING ERROR There was a problem reading one of the header elements.
4.4 Summary
The C library which implements I/O handling of MONALISA format compatable binary files isdescribed in this section. All user interactions with binary files can be performed using functioncalls given above. Each function call returns an integer value. All possible return values aredefined in binaryIO c definitions.h. For each function in this section, those values whichcorrespond to an error condition are listed below the corresponding function. User code shouldhandle integer return values from the I/O functions and check for the possible error conditions.An example of such error checking code is given in Table 4.
4.5 Addendum for C++ users
When using the header files, BinaryIO.h and myUserDefinedIDconstants.h it might bethat the include statement for each header, when writing the C++ file, is insufficient to getcompilation of and linking to the I/O libraries to work; the I/O code and the user definedconstants might need to be labelled as C.
This can be done using code of the form given below14:
Table 9: Example C++ include statement for getting the I/O library C headers into a userC++ code compilation.
extern”C”
{#include ”BinaryIO.h”
#include ”myUserDefinedIDconstants.h”
};
14Courtesy of Greg Moss who provided this example after trying to get the I/O library to compile with someC++ code.

Oxford MONALISA Document No: Page: 36 of 800006 Rev. No. : 3.1.6
5 Using the Java binary file I/O packages
This section covers all aspects of the Java support software for binary file handling. Each ofthe key I/O operations, introduced in section 3, have been implemented in a core Java package.A complementary extensions package offers extra file handling functionality.
The first subsections below give an overview of the two binary file I/O support packages,introducing the key classes and how they interoperate, followed by a guide to downloading thejar files and the accompanying documentation (javadoc generated html files). The rest of thechapter thereafter, contains brief code examples for each key I/O operation.
5.1 Packages Introduction
Binary file handling methods have been grouped into two packages :
• The core package uk ac ox physics.monalisa.BinaryIO
• A supplementary package uk ac ox physics.monalisa.BinaryIOx
All the basic binary file operations are available in the core package, which offers the samefunctionality as the C and LabVIEW I/O implementation libraries, described in other sectionsof this report. The classes in this core package have been designed to be as small and simpleas possible. Some level of user friendliness has been sacrificed to keep the code as simple aspossible, because simpler code should be more robust and more reliable.
User friendly versions of some of the core package functions and more complicated filehandling operations are made available in a supplementary package. Users should find thesupplementary package methods more convenient for repetitive use.
5.2 Binary I/O core package
The core package for binary file handling is uk ac ox physics.monalisa.BinaryIO. Thispackage provides the same core file handling functionality as the C and LabVIEW supportsoftware.
5.2.1 Relations between core package classes
The important classes and interfaces of the core package are summarised in Figure 4. Thepurpose of this package is to connect user data arrays with a binary file on disk.
The implementation class which performs most of the operations is BinaryFile. This classprovides methods for reading arrays from a binary file on disk and appending new data arrays tothe file. Each instance of BinaryFile interacts with a particular file, selected when the constructoris called.
Files are minted by the interface FileMinting (shown on the left in Figure 4), which has adefault implementation class DataFileMint.
All file I/O is regulated by file structure specification constants in the final class Proto-col Defs. The code in this class has been generated by a protocol defining python script15.
The data file header is represented by the interface ReadableFileHeader which has a defaultimplementation class DataFileHeader. These are the classes used when reading the headercontents.
15The same python script generates the equivalent definition files for the I/O libraries in all supported lan-guages, synchronising the different implementations.
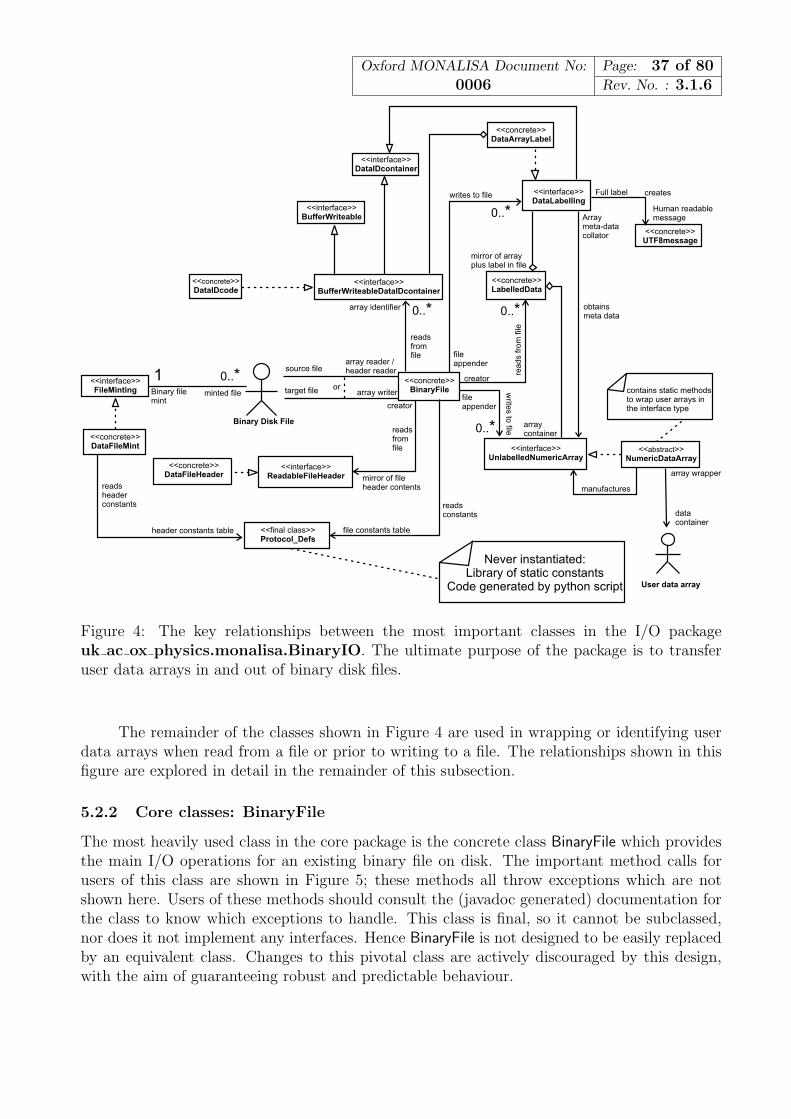
Oxford MONALISA Document No: Page: 37 of 800006 Rev. No. : 3.1.6
Figure 4: The key relationships between the most important classes in the I/O packageuk ac ox physics.monalisa.BinaryIO. The ultimate purpose of the package is to transferuser data arrays in and out of binary disk files.
The remainder of the classes shown in Figure 4 are used in wrapping or identifying userdata arrays when read from a file or prior to writing to a file. The relationships shown in thisfigure are explored in detail in the remainder of this subsection.
5.2.2 Core classes: BinaryFile
The most heavily used class in the core package is the concrete class BinaryFile which providesthe main I/O operations for an existing binary file on disk. The important method calls forusers of this class are shown in Figure 5; these methods all throw exceptions which are notshown here. Users of these methods should consult the (javadoc generated) documentation forthe class to know which exceptions to handle. This class is final, so it cannot be subclassed,nor does it not implement any interfaces. Hence BinaryFile is not designed to be easily replacedby an equivalent class. Changes to this pivotal class are actively discouraged by this design,with the aim of guaranteeing robust and predictable behaviour.

Oxford MONALISA Document No: Page: 38 of 800006 Rev. No. : 3.1.6
Figure 5: Important methods for users of the central classuk ac ox physics.monalisa.BinaryIO.BinaryFile. Those publicmethods which are not needed by users, are not shown.
Each instance of BinaryFile maps one disk file to the java code; the disk file being determinedby the constructor call parameter fullPathInput. This class has three main roles:
1. Reading the header contents of a file,
2. writing arrays to a file and
3. reading arrays from a file.
A minor role is the manipulation of the file header lock status.
5.2.3 Core classes: FileMinting
The core package file minting classes are shown in Figure 6. File minting methods are specifiedby the interface FileMinting.
Figure 6: Important methods for users of the file minting classes inthe core package uk ac ox physics.monalisa.BinaryIO.
Any user software needing to store data, should mint binary files with the same headerconstants - as required by the file format protocol for later file identification. The default

Oxford MONALISA Document No: Page: 39 of 800006 Rev. No. : 3.1.6
implementation class, DataFileMint produces identically minted binary files, using constants setby its constructor. Other methods provided by this class, allow users to find out which headerconstants are used when new files are minted.
5.2.4 Core classes: Array wrapping
Before a user data array is written to a binary file, the data is first wrapped in an instance ofthe interface type UnlabelledNumericArray. This wrapper type provides the interface methodsshown in Figure 7. Array wrapping is provided by a set of overloaded static methods in theabstract class NumericDataArray. Arrays of all numeric types - all java.lang subclasses16 ofjava.lang.Number and all corresponding primitive numerical types - can be wrapped by thisclass. An equivalent method for wrapping strings (ready to be stored in a file as a byte array)is given in the extension package class UTF8string (see section 5.3.6).
Figure 7: User arrays are wrapped using the static methods in the abstractclass NumericDataArrays. The wrapped type is the implemented interface typeUnlabelledNumericArray. Concrete implementation classes of the interface typeare not shown here, nor need the user know about them.
5.2.5 Core classes: Data identification
User data arrays are labelled (prior to writing to a file) and identified (when reading from a file),using data identification codes, (described in section 2.4). The inheritance and implementationrelationships between data identification classes first appear in Figure 4 above. They are shownin more detail in Figure 8.
The default implementation class representing a data identification code is DataIDcodewhich implements the interface BufferWriteableDataIDcontainer; a sub-interface of DataIDcon-
16These are : Byte, Short, Integer, Long, Float and Double.

Oxford MONALISA Document No: Page: 40 of 800006 Rev. No. : 3.1.6
tainer. A DataIDcode can be instantiated directly via its public constructors and used as eitherinterface type. The subtype BufferWriteableDataIDcontainer is used when writing data andDataIDcontainer is used when reading data. In many situations, users may chose to gener-ate data identification codes using the extensions package, data identification generator classDataIDtagGenerator described in section 5.3.2.
Figure 8: Data identification classes and interfaces.
5.3 The extension package uk ac ox physics.monalisa.BinaryIOx
The extension package is a much looser collection of classes than the core package, with mostof its internal method calls relying on the core package. What the extension package classeshave in common is a supporting role for users of binary files. Some of the package classes offermethods for tasks not covered directly by the core classes. Other extension classes providealternative implementations of core package tasks which are more user friendly. These packageroles are covered in the following subsections.
5.3.1 Extension classes : Exception handled data I/O
The core package class BinaryFile provides methods for reading and writing data arrays whichthrow a list of condition specific exceptions. User code directly calling these methods musthandle these exceptions or declare that they are thrown. Most of these exceptions extendjava.io.IOException so users might be tempted to declare throws IOException for their own

Oxford MONALISA Document No: Page: 41 of 800006 Rev. No. : 3.1.6
methods17 which call the either of BinaryFile methods.An alternative has been provided by the exception handling I/O methods in the extension
package classes shown in Figure 9.
Figure 9: Exception handling data array reading and writing classes provided by theextensions package, uk ac ox physics.monalisa.BinaryIOx.
The constructor call for the concrete classes ExceptionHandledDataFileWrite and Exception-HandledDataFileRead respectively writes or reads a single data array into or out of the BinaryFilepassed to the constructor. If an exception is thrown during the process, the user can find out bycalling errorOccurred():boolean and the exception message can be accessed from errorMessage():String. If user software requires the error report to have a prefix string18, the longer constructoris used, where the prefix is placed in a StringBuffer. The string buffer forms the error reportbuffer for the instantiated class, it is not defensively copied, allowing user software to directlymanipulate the buffer for flexible error reporting.
It is assumed that the user will be responsible with their code and will ensure that theerrorOccurred() method is checked whenever array I/O operations are performed19.
17There remain a few exceptions, such as PositionException which are not subclasses of IOException andwould therefore remain, to be declared or handled.
18For example, “While reading the temperature data for thermometer channel 12 :”.19As they say in the numerical recipes books, when the revolution comes, users who fail to comply with such
basic standards will be executed and their code will not.

Oxford MONALISA Document No: Page: 42 of 800006 Rev. No. : 3.1.6
5.3.2 Extension classes : Mass producing data identification codes
User data arrays are identified using data identification codes as described in section 2.4. Manydata identification codes generated by a given piece of software are likely to share the samecategory and subcategory elements by design. The extension package class DataIDtagGeneratorproduces data identification codes which share the same category and subcategory elementvalues.
The user sets the category and subcategory values with the constructor call. Methodsprovided in the class allow users to generate data identification codes (as instances of the corepackage interface type BufferWriteableDataIDcontainer) with specific contexts, divisions andsubdivisions. Each of the eight methods is named after one of the eight corresponding datacontexts, as shown in Figure 10.
Figure 10: User software can generate data ID codes using the extension pack-age convenience class DataIDtagGenerator. The core package data identificationclasses are copied from Figure 8.
5.3.3 Extension classes : Searching for data
Arrays stored in a binary file are identified by hierarchical, five element codes, which occupy partof the array labels. All arrays containing related data are labelled using related identificationcodes. Therefore any search through data identification codes, to find those which match aparticular pattern of element values, allows topically related arrays to be sifted out from abinary file. Classes which search through a binary file are shown in Figure 11.
The methods specified by the interface DataIndexing produce a HashMap containing corepackage DataIDcontainer key values, with corresponding Short value entries. The key is adata identification code which has been found, labelling at least one array in the binary filebeing searched. The Short value is the highest value of the data label instance variable20 forarrays in the file. The indexMatchingInstance() methods sift out particular arrays which match
20Not to be confused with the OO term of the same name.

Oxford MONALISA Document No: Page: 43 of 800006 Rev. No. : 3.1.6
Figure 11: Extension package classes which search through the contents of abinary file.
particular ID code search criteria, the mapFileContents() methods map out all file contents.Users can search through the default file (specified in the constructor call and updated by thesetFileToRead method in the default implementation class), or can specify the file to searchthrough, using the extra parameter version of each method.
Identification code pattern matching is provided by the extensions package classes shownin Figure 12. These are the interface DataIDcontainerMatch and the default implementationclass DefaultDataIDcontainerMatch.
Figure 12: Extension package classes used for data ID code matching.
The interface method matchesIDcode(toCheck : DataIDcontainer):boolean checks an iden-tification code against the match criteria represented by the concrete implementation instance,(accessed via the interface type). All the other interface methods allow a user to ask an instance(of a match pattern), which of the five data identification code elements it matches against. Inthe default implementation class, the match criteria are set by the constructor call.
Increasingly longer constructor options descend hierarchically, from category only (must

Oxford MONALISA Document No: Page: 44 of 800006 Rev. No. : 3.1.6
match), category and subcategory only down to all five elements must match. The constructorwith n numerical parameters instantiates a pattern which matches on n out of the five hierar-chical levels, starting from category, going down to subdivision. A shortcut constructor for thestrictest match pattern, takes the five values to match from a DataIDcontainer input parameter.
5.3.4 Extension classes : Checking file header compatibility
User software which needs to read data from a binary file should ensure that the file is com-patible with the reading software. In particular the data ID codes used in the file, should befrom the same version of the same scheme as the scheme being used by the reading software.If the data in the file is labelled under a different scheme, it probably is not the data you werelooking for and a check of file header compatibility is a very quick way to find out.
The extension package contains several classes for verifying binary file headers. Theseclasses are shown in Figure 13.
Figure 13: The extension package classes which verify binary source file compatibility withfile reading software, by checking the contents of the file header accessed via the core packageinterface ReadableHeader.
The interface FileHeaderCompatibilityChecker specifies the baseline list of criteria for sourcefile compatibilty with reading software. The default means for checking file compatibility, is tocompare the contents of the file header with the corresponding values in a template. Once usersoftware compatibility has been specified in a header template, the same template instance canbe used to verify many files.
The default implementation class DefaultFileHeaderCompatibilityChecker compares the con-tents of a file header (accessed via the interface type ReadableFileHeader from the core package)with a template - an instance of the FileHeaderTemplate class. The comparison methods whichcheck a single header parameter, indicate compatibility if the values in file header and templateare identical. Those methods which check protocol, or ID LUT version and revision numbers,indicate compatibilty if the version part of the (version, revision) pair matches.
If this behaviour needs to be altered, the default implementation class can easily be re-placed by any user written class for header compatibility checking. Users are recommended

Oxford MONALISA Document No: Page: 45 of 800006 Rev. No. : 3.1.6
to implement the interface FileHeaderCompatibilityChecker and to make use of the FileHead-erTemplate class. The default header verification implementation class has been designed to beextended with protected methods giving subclass access to :
• The file being read (accessFile():uk ac ox physics.monalisa.BinaryIO.BinaryFile).
• The file header (accessHeader():uk ac ox physics.monalisa.BinaryIO.ReadableFileHeader).
• The header template (accessTemplate():FileHeaderTemplate).
The default implementation of the optional interface method readNotesBufferCon-tents():String produces a human readable report on the outcome of a header compatibilitycheck across all criteria. The buffer holding this report can be emptied between files by callingthe implementation class method clearNotesBuffer():void.
User software methods can throw the extension package exception, FileIncompatibleExcep-tion to indicate that an input source file does not match the compatibility requirements of thereading software.
5.3.5 Extension classes : Identifying context types
The convenience class DataContextIdentifier provides a public static methodtoString(dataContext:byte):String which names a data context when given the correspondingbyte code. For user software which can read the byte value of a data context and needs thesame information as a context name in String form, this class provides the solution. Contextvalues are one of the five elements in data array identification codes (described above insection 2.4).
5.3.6 Extension classes : Wrapping strings
The convenience class UTF8string provides a static method for wrapping strings. The methodcorresponds to those in the core class NumericDataArray (described above in section 5.2.4)for wrapping numerical data arrays. An exception, java.io.UnsupportedEncodingException isthrown by this method and the behaviour of the method is not guaranteed, if the UTF-8character set is not supported on your machine21.
5.4 Getting the Java I/O packages onto your machine
The Java code implementing the I/O functions described here can be downloaded from theMONALISA project web page at http://www-pnp.physics.ox.ac.uk/∼monalisa/ , fol-lowing the links for the binary I/O software. The jar files, one for the BinaryIO package andone for the BinaryIOx package, are available in a gzipped tar file and in a .zip file. Similar fileshold a copy of the javadoc generated html documentation for the two packages. The same htmldocumentation is also available on-line at the above website.
5.5 Writing code to use the Java packages
This subsection gives code examples using methods in the core Java package and the alternativesfor array reading and writing from the extensions package.
21For further details on UTF-8 see for example http://en.wikipedia.org/wiki/UTF-8

Oxford MONALISA Document No: Page: 46 of 800006 Rev. No. : 3.1.6
5.5.1 Minting a new binary file
New binary files are created in the “minting” process described in section 3.1. The Java corepackage classes for file minting are described above in section 5.2.3 and shown in Figure 6. Anew binary file is minted by calling any class which implements the interface FileMinting. Themethod mintFile(filePath):void creates a file at the location specified by the path (which shouldinclude file name and extension). The path parameter is either an instance of java.lang.Stringor java.io.File.
Two exceptions are thrown by this method:
java.io.IOException is thrown if the target path is unreachable or the user does not have writepermission or a similar I/O problem occurs.
uk ac ox physics.monalisa.BinaryIO.PositionException is thrown if elements of the header are be-ing written to unexpected locations within the file header, almost certainly due to a bugin the I/O software, likely after a recent version change in the binary I/O protocol.
The class DataFileMint is provided as a default class for this interface. Each instance of thisclass mints files with identical file headers. All constructor parameters relate to the contents offile headers which an instance of DataFileMint will mint. The constructor parameters can eitherbe all short or all int. Each corresponds to one of the header elements described in section 2.2.They are :
userID The GIACoNDE user identification. The value is read from the constant USER ID inthe interface file provided by GIACoNDE for the data identification scheme for the dataarrays in this file.
softwareID This element is used to distinguish user software tools from one another, accordingto any scheme the user wishes to employ.
ID LUT version The Version number for the data identification scheme. The value is read fromthe constant ID LUT version in the interface file provided by GIACoNDE for the dataidentification scheme for the data arrays in this file.
ID LUT revision The Revision number for the data identification scheme. The value is readfrom the constant ID LUT revision in the interface file provided by GIACoNDE for thedata identification scheme for the data arrays in this file.

Oxford MONALISA Document No: Page: 47 of 800006 Rev. No. : 3.1.6
An example of some file minting Java code (using a hypothetical example GIACoNDEgenerated user data identification scheme myScheme) is given below :
import java.io.IOException;import uk ac ox physics.monalisa.BinaryIO.∗;. . .// sets up the FileMinting implementing instance// probably in the constructor for this class
FileMinting this.myFileMint =new DataFileMint(myScheme.USER ID, MY SOFTWARE ID,
myScheme.ID LUT version, myScheme.ID LUT revision);. . .// called to access the FileMinting instancepublic FileMinting accessFileMint() {
return this.myFileMint;}. . .// calls the I/O library minting methodpublic void mintDataFile(String myDataFilePath)throws IOException, PositionException {
this.accessFileMint().mintFile(myDataFilePath);}. . .
5.5.2 Opening and closing binary files
There are no direct calls required to make the Java libraries open and close the binary files.This aspect of binary file I/O is handled automatically within the library routines. This maybe slow where many small data arrays are being stored in a given file.
5.5.3 Writing data arrays to binary files
An array is written to a binary data file, by calling the method addDataToFile(theData, ID,message) : void of an instance of BinaryFile, (described above in section 5.2.2). The threeparameters are :
theData : UnlabelledNumericArray The data array to be written, suitably wrapped by the rele-vant method in the class NumericDataArray.
ID : BufferWriteableDataIDcontainer The data identification tag, which has been set up with the5 numbers, Context, Category, Subcategory, Division and Subdivision.
message : java.lang.String The message to be added to the array label, a String identifying thearray contents.
An array of user data is prepared by wrapping in an implementation of the interface Unla-belledNumericArray. This is achieved for an array in each of the supported numerical data typesby calling the static method NumericDataArray.wrapArray(dataArray):UnlabelledNumericArray. A

Oxford MONALISA Document No: Page: 48 of 800006 Rev. No. : 3.1.6
string can be wrapped by calling the equivalent static method wrapString(inputString) in thesupplementary package class uk ac ox physics.monalisa.BinaryIOx.UTF8string.
The data identification tag is built up from user defined constants which appear in aGIACoNDE output file, in a Java interface bearing the name of the user data identificationscheme. An example is given below, in the following hypothetical code example :
import uk ac ox physics.monalisa.BinaryIO.∗;import userPackage.userDataIDscheme; // the GIACoNDE output. . .// the data array is accessed by calling this methodpublic double[] accessDataArray() {
return this.dataArray; // assumed set from outside}. . .// a data array is passed into this method for later accesspublic void setDataArray(double[] aDataArray) {
this.dataArray = aDataArray; // called from outside}. . .// the data array is written to the binary file using this methodpublic void hypotheticalDataWriter(String myFilePath,
BufferWriteableDataIDcontainer dataID)throws FileAccessException, FileWritingException,FileReadingException, PositionException,
FileClosingException, FileLockedException,UTFexception {BinaryFile myDataFile = new BinaryFile(myFilePath);myDataFile.addDataToFile(NumericDataArray.wrapArray(this.accessDataArray()),
exampleDataID(),“Hypothetical data array”);}. . .// a data ID is constructed using constants from the user scheme// together with a context selected from the protocol definitions// alternatively the extension package class DataIDtagGenerator might be usedpublic BufferWriteableDataIDcontainer exampleDataID() {
return new DataIDcode(Protocol Defs.SIMULATED,userDataIDscheme.CATEGORY, userDataIDscheme.SUBCATEGORY,userDataIDscheme.DIVISION, userDataIDscheme.SUBDIVISION);
}. . .

Oxford MONALISA Document No: Page: 49 of 800006 Rev. No. : 3.1.6
The above example requires the calling code to handle a large number of potential exceptionswhich the array writing method throws. As described above in section 5.3.1, an alternative hasbeen provided in the extended I/O library package uk ac ox physics.monalisa.BinaryIOx usingcode similar to this example :
import uk ac ox physics.monalisa.BinaryIO.∗;import uk ac ox physics.monalisa.BinaryIOx.∗;import userPackage.userDataIDscheme; // the GIACoNDE output. . .// the data array is accessed by calling this method// public double[] accessDataArray() as in above example. . .// a data array is passed into this method for later access// public void setDataArray(double[] aDataArray) as above. . .// the data array is written to the binary file// using this alternative methodpublic void alternativeDataWriter(String myFilePath,
BufferWriteableDataIDcontainer dataID) throws UserDefinedException {BinaryFile myDataFile = new BinaryFile(myFilePath);// this constructor call attempts to write the array
ExceptionHandledDataFileIO aWriter = newExceptionHandledDataFileWrite(myDataFile,this.accessDataArray(),exampleDataID(),′′Another user data array′′);
// the user then checks to see if// an error occurred when writing the arrayif(aWriter.errorOccurred()) {
// handle the error in some way// - usually by throwing a user defined Exception
. . .throw new UserDefinedException(aWriter.errorMessage());} // end of if statement
}. . .// a data ID is constructed using constants from the user scheme// together with a context selected from the protocol definitionspublic BufferWriteableDataIDcontainer exampleDataID() {
// written as in above example}. . .

Oxford MONALISA Document No: Page: 50 of 800006 Rev. No. : 3.1.6
5.5.4 Reading data arrays from binary files
An array is found in a binary file and read out using a single call to the method readLa-belledDataFromFile(DataIDcontainer ID, short inst):LabelledData, which returns the contents ofboth the array label and the data array, wrapped in an instance of LabelledData. The inputparameters are :
ID : DataIDcontainer The specification of the data array which the user wishes to find.
inst : short The instance of the data array within the file, which the user wishes to read.
The data values are unpacked from the output LabelledData using the method access-DataArray() if they are a numerical array, or if they are a string, using the method convert-ToString().
If the original data array is of the byte type, this method will attempt to convert thebytes within a byte data array, into a UTF-8 unicode string22. A UTFexception is thrown, ifthe UTF-8 charset is not supported on the machine. The behaviour of this operation is notguaranteed, if the bytes in the source array do not correspond to bytes in the UTF-8 charset.For compatibility with the other supported languages, strings which are intended to be readby all binary I/O software should only contain ASCII characters.
If instead, the original data array is labelled as containing data of some type other thanbyte, a UTFexception will automatically be thrown.
An example of code for reading an array and its label is given below :
import uk ac ox physics.BinaryIO.∗;import userPackage.userDataIDscheme; // the GIACoNDE output. . .// a data ID is constructed using constants from the user scheme// together with a context selected from the protocol definitionspublic DataIDcontainer exampleDataID() {
return new DataIDcode(Protocol Defs.SIMULATED,userDataIDscheme.CATEGORY, userDataIDscheme.SUBCATEGORY,userDataIDscheme.DIVISION, userDataIDscheme.SUBDIVISION);
}. . .// data reading example method, which throws many exceptions// which any calling code will have to handlepublic LabelledData hypotheticalDataReader(BinaryFile sourceFile,
short instance) throwsCorruptDataException, DataInstanceNotFoundException,DataTypeNotRecognisedException, FileAccessException,FileReadingException, PositionException,FileClosingException {return sourceFile.readLabelledDataFromFile(this.exampleDataID(),instance);
}. . .
22Even if the bytes were not originally generated from a string source.

Oxford MONALISA Document No: Page: 51 of 800006 Rev. No. : 3.1.6
The above example requires the calling code to handle a large number of potential exceptionswhich the array reading method throws. As described above in section 5.3.1, an alternativehas been provided in the extended I/O library package uk ac ox physics.monalisa.BinaryIOxusing code similar to this example :
import uk ac ox physics.BinaryIO.∗;import uk ac ox physics.monalisa.BinaryIOx.∗;. . .// a data ID is constructed using constants from the user scheme// together with a context selected from the protocol definitionspublic DataIDcontainer exampleDataID() {// code as in above example. . .}. . .// an alternative means of reading the data arraypublic LabelledData alternativeDataReader(BinaryFile sourceFile,
short instance) throws UserDefinedException {// reads the array into memory with this constructor callExceptionHandledDataFileReader aReader = new
ExceptionHandledDataFileRead(sourceFile, this.exampleDataID(), instance);// the user then checks to see if// an error occurred when reading the arrayif(aReader.errorOccurred()) {
// handle the error in some way// - usually by throwing a user defined Exception
. . .throw new UserDefinedException(aReader.errorMessage());} // end of if statement
// having succeeded in reading the array - access the contentsint firstDataElement =
aReader.accessLabelledData().accessDataArray()[0].intValue();System.out.println(′′The second element in the array is′′+aReader.accessLabelledData().accessDataArray()[1].toString());. . .
5.5.5 (Un)locking a binary file
The lock status of a file is altered by calling the correspondingly named methods in BinaryFile.
public void lockFile() throws FileAccessException, FileReadingException, FileWritingEx-ception, FileClosingException, PositionException
public void unlockFile() throws FileAccessException, FileReadingException,FileWritingException, FileClosingException, PositionException
These methods throw Exceptions relating to potential I/O problems or bugs in the im-plementation of the I/O library.

Oxford MONALISA Document No: Page: 52 of 800006 Rev. No. : 3.1.6
FileAccessException I/O related problem.
FileReadingException I/O related problem.
FileWritingException I/O related problem.
FileClosingException I/O related problem triggered only when trying to close the file.
PositionException Problem triggered by mismatch in locations in the file header. Indicatespossible file incompatibility due to handling a binary file from another I/O protocolversion, or a bug in the I/O handling Java library.
5.5.6 Reading the file header
Most interactions with the file header can be handled by intermediate classes describedabove, such as the extension package interface FileHeaderCompatibilityChecker (described insection 5.3.4) when checking the file header to verify the source of the data contained withinthe file, the author software and the identification scheme under which the file contents havebeen labelled. The malleable parts of the file header are similarly handled by intermediateclasses: the file lock is altered by the core class BinaryFile (see section 5.2.2) and the recordednumber of entries is usually of interest when searching through the array contents of the file; atask performed using methods in the extension package interface DataIndexing (section 5.3.3).
If the classes mentioned in the previous paragraph do not meet requirements and itis really necessary to read a copy of the contents of the file header, the interface Read-ableFileHeader can be summoned for a particular file using the ReadHeader() method ofthe core class BinaryFile. This method throws four types of exception (all from the coreuk ac ox physics.monalisa.BinaryIO package) which user methods should handle or de-clare to be thrown; three of these are subclasses of java.ioIOException and the other is Posi-tionException.
FileAccessException I/O related problem opening or closing the file.
FileReadingException I/O related problem reading from the file.
FileClosingException I/O related problem triggered only when trying to close the file.
PositionException Problem triggered by mismatch in locations in the file header. Indicatespossible file incompatibility due to handling a binary file from another I/O protocolversion, or a bug in the I/O handling Java library.
Once the ReadableFileHeader has been read from the file, its contents can be read using thecorrespondingly named methods. There is a one to one mapping between the header elementsintroduced in section 2.2 and the methods in the interface.
The concrete implementation class DataFileHeader is not designed for user software inter-action and is best avoided.

Oxford MONALISA Document No: Page: 53 of 800006 Rev. No. : 3.1.6
6 Using the LabVIEW binary file I/O VIs
This section covers the LabVIEW VIs written to handle binary files. The code performs thecore I/O tasks described in section 3.
The first subsection provides an overview of the binary I/O project, with the directorylayout of the sub VIs and a recognition chart, allowing VI icons to be more readily identified inVI diagrams. This is followed by advice on downloading and installing the VIs on your machineand the final subsection on writing LabVIEW code to interact with the subVIs.
6.1 Introduction
At present the LabVIEW support library is only available for the windows operating system.There are no plans at the time of writing to offer a LabVIEW implementation which will workon alternative platforms.
6.1.1 VI overview
The LabVIEW implementation of the binary file handling differs from the implementation inthe other supported languages in two important respects.
1. The file handling operations rely on a binary file handling DLL written in another language(C compiled under windows).
2. The constants from a user data identification scheme have to be loaded (once) into asubVI for use, in a “semi-automatic” process, described in section 6.3.11. (The othersupported languages have constants available for immediate use).
The differences in LabVIEW arise from the practical difficulties of manipulating the con-tents of a subVI from software outside LabVIEW. Therefore indirect means are used to prop-agate constant values into LabVIEW.
These external sources of constant values are:
• The “protocol defining” python script (which sets the constants for the I/O file format)and
• The application GIACoNDE (which creates constants files for user defined, data identifi-cation schemes).
The python generated C code, (one header file for a given version of the MONALISA file format)is incorporated into the C implementation of the I/O support libraries which are accessed fromthe DLL called by the LabVIEW VIs. The data identification schemes from GIACoNDE arepublished for LabVIEW users in specialised binary files to be read into LabVIEW using thecustom DLL provided. The scheme constants from the binary file are planted into controls inthe corresponding subVI, see subsection 6.3.11 for details.
6.1.2 Project directory structure
The directory structure for the project is shown in Table 10. The project VIs are grouped intosubdirectories according to function. In a few cases one key VI in a subdirectory is supportedby subVIs which the user does not need to use (or know about). In each of these cases,the supporting subVIs are placed in a subsubdirectory, which is named in the table. Thesubsubdirectory contents have been omitted for brevity.

Oxford MONALISA Document No: Page: 54 of 800006 Rev. No. : 3.1.6
Table 10: The sub-directories and subVIs of the binary file handling project. The templatessubsubdirectory contains files which should be cloned as explained in section 6.3.11.
—DataIDcodes 3 1+———————————— templates 3 1
—DLLs 3 1+———————————— dataIDcodes reading DLL pathfinder binaryIO v3 1.vi+———————————— DLL pathfinder binaryIO v3 1.vi+———————————— LabVIEW binaryIO v3 1 DLL.dll+———————————— LabVIEW dataIDschemeReader DLL.dll
—ErrorHandling 3 1+———————————— ErrorCollator 3 1.vi+———————————— InitialisedErrorMessageValues 3 1.vi
—File Access 3 1+———————————— CloseFile 3 1.vi+———————————— FilePadlock 3 1.vi+———————————— MintNewFile 3 1.vi+———————————— OpenFileToReadOnly 3 1.vi+———————————— OpenFileToReadWrite 3 1.vi
—File Header 3 1+———————————— FileHeaderReader 3 1.vi
—Location Browsing 3 1+———————————— DataLabelBrowser 3 1.vi+———————————— InstanceFinder 3 1.vi
—Protocol Constants 3 1+———————————— BinaryIO v3 1 Protocol Constants.vi+———————————— DataIDcodeContextNumericToString 3 1.vi+———————————— Global Erroneous File Ptr Value 3 1.vi
—Reading Data 3 1+———————————— ReadDataTypes 3 1+———————————— DataReader 3 1.vi+———————————— FindAndReadData 3 1.vi
—Writing Data 3 1+———————————— WriteDataTypes 3 1+———————————— WriteData 3 1.vi
6.1.3 VI identification
The VIs in the project have distinctive icons to allow rapid recognition in the diagram panelof a user VI. The icons for the most important project subVIs are shown in Table 11. Eachicon is accompanied by a short description of the corresponding VI and a quick reference linkto the subsections in which the VI is described.

Oxford MONALISA Document No: Page: 55 of 800006 Rev. No. : 3.1.6
Table 11: Icon recognition chart for the important subVIs of the (MONALISA format) binaryfile handling LabVIEW project. The purpose of each subVI and a reference to the relevantsection is given for each.
Mints a new file. - section 6.3.3.
Opens a file in read write mode. - section 6.3.4.
Opens a file in read only mode. - section 6.3.5.
Closes a file. - section 6.3.6.
Changes the file lock status. - section 6.3.9.
Reads the header of an open file. - section 6.3.10.
Provides protocol constants. - section 6.3.2.
Writes an array to an open file. - section 6.3.7.
Locates an array in an open file and reads it into memory. - section 6.3.8.
6.1.4 Support DLLs
There are two DLLs which accompany the windows based LabVIEW implementation of theI/O code:
LabVIEW binaryIO v3 1 DLL.dll The main I/O DLL which provides binary file handling.
LabVIEW dataIDschemeReader DLL.dll A data scheme constants reading DLL whichloads in a set of constants from a GIACoNDE produced binary file.
The binary file handling in the LabVIEW implementation is supported by a wrapped ver-sion of the C library (discussed in sectionC), compiled under windows as a DLL. All LabVIEW

Oxford MONALISA Document No: Page: 56 of 800006 Rev. No. : 3.1.6
file handling operations (indirectly) call the corresponding function in the C implementation(via intermediate C code) in the main I/O DLL23.
The implementation of a user defined data scheme in LabVIEW takes the form of alook up table subVI, with user selectable ring constant controls, offering all possible values ofdata identification code elements, from category to subdivision, by name. A custom DLL hasbeen written to load the names and associated numerical constants of a data scheme from aGIACoNDE produced binary file.
Each subVI which accesses a DLL function has been written to automatically load in theDLL it requires, using its own VI path and the relative path from itself to the location of theDLL. It is vital that this relative arrangement is preserved by the project file when installed onanother machine. The relative paths ought to be preserved in the default installation process,but if the DLLs are not loading correctly, the first thing to check is that installed and expectedrelative paths for the DLL agree on your machine. The expected paths for DLLs and subVIsare given in subsection 6.1.2.
6.2 Getting the VIs onto your LabVIEW installation
The project is available on the website at http://www-pnp.physics.ox.ac.uk/∼monalisa/, following the links for software, binary file format and download I/O support libraries. It canbe downloaded as a zip file. The zip was created under LabVIEW version 8.2 in Windows XP24
Once the zip file has been downloaded and the contents extracted, any machine runningwindows XP and LabVIEW version 8.2 (or later) should be able to open the project file Lab-VIEW 8 2 binaryIO v 3 1.lvproj. This should give access to the subVIs from a projectpalate.
6.3 Writing LabVIEW VIs to utilise the LabVIEW I/O VIs
Users of the LabVIEW project will need to use the key binary I/O subVIs in their own diagrams.The following subsections explain which subVIs are used for each of the main binary file handlingroles.
6.3.1 Error conditions
Error conditions are indicated using the standard LabVIEW error cluster with LabVIEW stan-dard codes. These error codes have been mapped over from the equivalent error conditionsmentioned in the documentation for the corresponding C functions.
Error clusters are passed along a chain of subVIs, where each error cluster output isconnected to the input of the next subVI in the chain; as per standard LabVIEW programmingpractice. Any subVI which receives an error cluster indicating a pre-existing error condition,will not perform its usual operations. Instead it will yield default output values (if there areany outputs to be produced) and will pass the incoming error cluster to its error cluster outputterminal. The entire chain of subVIs downstream from an error are thereby prevented fromnormal operation.
23The DLL includes an entire copy of the C implementation.24There is no equivalent version available for Linux at the time of writing, due to the heavy reliance of this
implementation on the windows format dynamic libraries (DLLs). It is unclear if this implementation will workdirectly on Windows Vista.

Oxford MONALISA Document No: Page: 57 of 800006 Rev. No. : 3.1.6
6.3.2 Protocol constants
In the C and Java implementations, protocol constants are accessed directly using namedparameters. In LabVIEW the constants appear at output terminals of the protocol constantssubVI, shown with wiring diagram connections in Figure 14. This subVI propagates the relevantprotocol constants into the LabVIEW code from a DLL, which uses C implementation librariesconstants in the protocol definitions header file (see Table 2 in section 4.1.1).
The protocol definitions subVI also translates input signals, in one form, into corre-sponding output signals in a related form, using input / output terminal pairs. The followingconversion services are provided:
• User selections (by name) of Context and Data Type are converted into the correspondinginteger constant (defined by the I/O protocol).
• Integer constant values (as might be read out from a data label in a binary file) areconverted to strings containing the name of the Context or Data Type respectively.
Figure 14: Wiring connections to the File Access subVI Binary v3 1 Protocol Constants.vi
One of these signal conversion control/indicator (input/output) terminal pairings connectsContext Selector control to Selected Context Flag. These are most likely to be used to providethe Context element, when constructing a five element data identification code25.
6.3.3 Minting new binary files
A new binary file is minted (see section 3.1), in LabVIEW, using the VI shown, (with wiringconnections) in Figure 15. The user connects the header parameter input terminals of thissubVI to corresponding output terminals of the user defined Data ID codes subVI. The lattersubVI provides the data identification scheme being used to label data within this file, (seesection 6.3.11). The only other input terminal of the file minting VI takes the full filepath(directory, filename and extension) at which the new binary file should appear (including filename and extension).
In common with the file minting functions in the other language implementations, anexisting file at the given path will not be overwritten or wiped by a call to the file mintingsubVI. This prevents accidental obliteration of valuable data owing to mislabelled filepaths.Any attempt to overwrite an existing file generates an error condition.
Any operating system problems with creating the file, (such as an invalid or inaccessiblefilepath) or any problems with writing the header or closing the file afterwards will also generatean error condition.
25Data identification codes are described in section 2.4.

Oxford MONALISA Document No: Page: 58 of 800006 Rev. No. : 3.1.6
Figure 15: Wiring connections to the File Access subVI Minting 3 1.vi.
6.3.4 Opening a file in read-write mode
An existing binary file can be opened in read-write mode using the correspondingly namedsubVI, shown with wiring connections in Figure 16. The path for the file to be opened is fedinto the main input and the (address for the) file pointer of the opened file is fed out of themain output terminal. Error cluster chain input and output terminals are also provided.
Figure 16: Wiring connections to the File Access subVI OpenFileToReadWrite 3 1.vi
If the error cluster input contains an error from a previous VI, this VI will take no internalaction, the requested file input will be ignored and the earlier error cluster will be passed on.In this case, the file pointer address output will be set to the value of the global variableGlobal Erroneous File Ptr Value.vi, in the Protocol Constants 3 1 folder.
6.3.5 Opening a file in read-only mode
An existing binary file can be opened in read-only mode using the correspondingly namedsubVI, shown with wiring terminal connections in Figure 17. The path for the file to be openedis fed into the main input and the corresponding file pointer for the opened file is the mainoutput. Error cluster chain input and output are also provided.
Figure 17: Wiring connections to the subVI File Access OpenFileToReadOnly 3 1.vi
If the error cluster input contains an error from a previous VI, this VI will take no internalaction, the requested file input will be ignored and the earlier error cluster will be passed on.

Oxford MONALISA Document No: Page: 59 of 800006 Rev. No. : 3.1.6
In this case, the file pointer address output will be set to the value of the global variableGlobal Erroneous File Ptr Value.vi, in the Protocol Constants 3 1 folder.
6.3.6 Closing a file
An opened file can be closed using Close File 3 1.vi, shown in Figure 18.
Figure 18: Wiring connections to the File Access subVI CloseFile 3 1.vi
This VI is designed to close the file no matter what errors have occurred previously. Inmost cases, an error in the previous chain, will result in an invalid file pointer (usually setto NULL) which is typically ignored by most I/O subVIs in the error chain (because they allreceive an error cluster containing an error). This close file subVI is usually the first to reactto the erroneous condition of the file pointer, reporting an independent error at its own outputerror cluster. The independence of this error cluster breaks the error chain and creates a smallbifurcation of the error chain which users should be able to handle with dignity and poise.
6.3.7 Writing data to a file
User data in the form of a numerical array or string is written to a data file using the polymor-phic subVI WriteArray 3 1.vi. The data array input terminal takes a one-dimensional numericalarray (or a LabVIEW string which gets converted into a byte array) as the data array to writeto file. The subVI is polymorphic, adapting itself to the type of wire connected to this terminal.Other input terminals take the data identification code elements, the open file pointer, a stringfor the data label message and the input error cluster. The wiring connections and the basisicon for all the type specific subVI icons in this set are shown in Figure 19.
Figure 19: Wiring connections to the array / string writing subVI WriteData 3 1.vi
6.3.8 Reading data from a file
A single user data array is located in a file and read out, using the subVI Find and Read 3 1.vishown in Figure 20. The input terminals take in the pointer to the opened source file, the

Oxford MONALISA Document No: Page: 60 of 800006 Rev. No. : 3.1.6
elements of the data identification code and the instance for the required array and the usualerror cluster.
The instance should be based on the protocol constant First Instance Label provided bythe protocol constants subVI (see section 6.3.2 for the subVI and section 2.3 for guidance onthe use of the constant).
Figure 20: Wiring connections to the array / string reading subVI FindAndReadData 3 1.vi
The data array in the file is converted to an array of type DBL (double precision), becausethe output type of a terminal must be well defined26 before execution. The only solution is toforce a cast to the type with the highest numerical precision and allow users to cast their arraysback in their own LabVIEW code, if they know - in a given application - what type to expect.
Arrays stored in the file as byte type data are also converted into a LabVIEW string andpassed to the string output terminal. If the original byte data was not intended to be a string,this string will be meaningless characters.
For supported data types other than byte, the default string “Data is not a string”, ispassed to the string output terminal. If the data array type in the file is not recognised by thereading software the string at this output terminal is “Unrecognised data type, data not read”.
Aside from the standard error cluster output, the remaining output is a cluster whichcontains those parts of the array label except for the instance and data identification elements(which would be redundant).
6.3.9 Change the lock status of the file
The FilePadlock 3 1 VI is shown with input and output connections in Figure 21. The booleaninput sets the lock status of the file using TRUE for locked and FALSE for unlocked and theboolean output confirms the current file status as read after the change. The file pointer forthe opened file and the standard error cluster input are the other two input terminals. Thesecond output is the standard error cluster output. The open file must be have been opened inread/write mode for the lock status to be changeable.
The most common use for this VI will be for enforcing a “write once archive” status on afile. For example when data is acquired from an experiment, a timestamped file containing theraw data can be usefully sealed off from further changes by setting the lock to true just beforeclosing the file.
26This is a subtle point which is not immediately obvious. You might expect to make the array outputterminal polymorphic, adapting to the data type stored in the file. This is not possible because the LabVIEWdiagram wants the output terminal type to be defined before use, so that the diagram can be checked out bythe interpreter. The array reader cannot know a priori, what type of array it is going to read - in fact it has tobe capable of reading all 6 supported array types.

Oxford MONALISA Document No: Page: 61 of 800006 Rev. No. : 3.1.6
Figure 21: Wiring connections to the file lock adjustment subVI FilePadlock 3 1.vi
This is not a guarantee against all possible changes, but does protect against accidentaladditions to the file.
6.3.10 Reading the file header
The full contents of a file header are read out from an opened file using the VI shown inFigure 22.
Figure 22: Wiring connections to the header reading subVI FileHeaderReader 3 1.vi
The input terminals take the open file pointer and the standard error cluster. Similarlythe output terminals provide the header and standard error output clusters. The elements ofthe header cluster correspond one to one with the elements in the file header (described insection 2.2).
6.3.11 Implementation of a user data identification scheme in LabVIEW
A data identification scheme starts with a GIACoNDE session and ends (in the LabVIEWimplementation) with a custom subVI providing the constants of the scheme for any LabVIEWdiagram. When a user scheme is generated with the GIACoNDE application (described insection 7), it is published into a set of output files, one per supported language. Each publishedfile carries the scheme constants into the user code. For LabVIEW programs, the schemeconstants are made available in a binary file with extension .lhb (LabVIEW hierarchy binary).
A couple of template subVIs have been provided in the project subdirectory templates 3 1,to save users from having to write their own data scheme subVI from scratch. These templatesubVIs are a selector and a generator. The former includes the latter in its diagram27.
The generator subVI uses a DLL to automatically load the data identification schemeonto the front panel of the higher level selector subVI. This renders the top level selector subVI(once it has been run for the first time) a source of user defined constants for the publisheddata identification scheme.
LabVIEW users are advised to start a LabVIEW project palette28 specifically for dataidentification schemes, to keep the data identification schemes separate from the binary I/Olibrary.
27When the two templates are cloned, the user will have to make sure that the copied generator replaces thetemplate in the copied selector diagram.
28A LabVIEW project palette is a set of soft links to various files and directories, to which the user wouldlike to have access from one control.

Oxford MONALISA Document No: Page: 62 of 800006 Rev. No. : 3.1.6
The data identification palette should include links to:
• The template directory provided in the binary I/O project.
• A directory created by the user for test data identification schemes
• A directory created by the user for published data identification schemes
An example of such project palette is shown in Figure 23. The following advice on loading upa data identification scheme is based around the assumption that the user has created such aproject.
Figure 23: An example project palette for data identification schemes. An example test schemeis shown in the opened folder, as copied from the GIACoNDE output directory.
When writing any LabVIEW code which will create and fill a binary data file, it is usefulto be able to try things out with a test scheme generated by issuing a test publication fromGIACoNDE; rather than publishing an untested scheme and having to republish every timeyou notice something missing.
1. The entire directory contents of a test publication directory from GIACoNDE can becopied into an subdirectory of the LabVIEW working area and linked to from the dataidentification schemes project palette. The copied subdirectory is now the working direc-tory for the test scheme.
2. The generator and selector template subVIs (with .vit extensions) provided in the binaryfile I/O project templates subdirectory (under the DataIDcodes directory) should becopied into the working directory for the test scheme created in the previous step andsaved as subVIs (with a .vi extension).
3. The user is strongly advised to rename these copied subVIs and edit their icons to associatethem with the test scheme and clearly distinguish them from the template files.

Oxford MONALISA Document No: Page: 63 of 800006 Rev. No. : 3.1.6
4. The new subVIs should be included in the project palette. The easiest way to do this is:
(a) Remove the test directory reference from the palette
i. Right click on the subdirectory icon
ii. Select Remove from project
iii. Agree to the pop-up warning you that the reference will be remove from theproject.
(b) Add a new reference on the palette to the same directory
i. Right click on the palette
ii. Select Add folder. . .
iii. Browse for the directory
The subdirectory reference on the palette should now include references to the sub-VIs; when the subdirectory contents are listed by clicking on the folder icon.
5. In the diagram of the selector subVI, the user should ensure that the scheme specific (i.e.newly copied) generator subVI replaces the template generator subVI.
6. The front panel of the generator subVI contains a filepath control. This should be edited topoint to the LabVIEW constants binary file (with .lhb extension) in the working directoryfor the test scheme. Once the new path has been entered into the filepath control, thisdata should be made the default data for that control (by right clicking on the controland selecting Make current data default).
7. The new generator subVI should be saved to preserve the .lhb filepath.
8. The scheme should be loaded into the selector subVI by running the selector subVI withthe initialisation switch (shown in Figure 24) pressed in.
9. The selector subVI initialisation switch should be deactivated.
10. The scheme constants can now be “locked in” to the selector subVI using the menu optionEdit:Make current values default
11. The selector subVI should be saved to preserve the uploaded scheme.
Figure 24: A new user scheme is uploaded by running the selector subVI with the switch shownhere, pressed to the TRUE or active state.
These subVIs can be recycled for each iteration through test schemes while the user iswriting and developing the LabVIEW code which will generate binary data files. The data filesproduced using a test scheme will have scheme version and revision numbers set to zero in theheader and will be seen is incompatible with any reading software which expects the publishedscheme.

Oxford MONALISA Document No: Page: 64 of 800006 Rev. No. : 3.1.6
Therefore, all data other than throwaway test data, must be generated under a publishedscheme for the data file to be recognisable to reading software. For extra protection, thegenerator and The sequence given here for test schemes can be adapted for use with publishedschemes, once the user is satisfied that they are ready to publish. The user may wish to addfurther protection to the subVIs for the published scheme by locking them with the middleoption under File:VI options:Protection.

Oxford MONALISA Document No: Page: 65 of 800006 Rev. No. : 3.1.6
7 Data identification schemes and the GIACoNDE soft-
ware tool
7.1 Introduction
7.1.1 Purpose of GIACoNDE
The GIACoNDE29 tool allows its users to create, save, publish, revise and edit schemes for dataidentification. GIACoNDE enables each user to define their own data identification schemesproviding great flexibility for the binary file format. Published schemes can be shared withother users, so they can read files you create and vice versa.
7.1.2 Hierarchical data identification schemes
Each data identification code identifies an individual data array in a binary data file. A dataidentification scheme is a hierarchy of the scheme name and up to five lower levels. One elementfrom each level is used to form a five element data identification code (described in section 2.4).The data identification scheme hierarchical structure is reflected in the GIACoNDE graphicaluser interface.
1. The highest element in the scheme, is the name of the scheme itself.
2. Each scheme contains a set of categories.
3. Each category has a set of subcategories.
4. At this point the hierarchy is interrupted - a set of eight choices for context are impliedfor all subcategories. These context values are defined in the I/O protocol.
5. Below the level of contexts are the divisions.
6. Each division can have subdivisions.
The subdivisions can be used in one of two ways; fixed or iterative.
A fixed subdivision has a particular, defined use, with an associated subdivision name.
An iterative subdivision remains unnamed and is used as a counting index, which is iteratedby a for loop in the users code. The for loop steps through a set of related data arrays,for example, a set of thermometer channels.
An example of iterative subdivision use is shown in Table 12 where thermometer relateddata across eight thermometer channels has user data arrays for:
• thermometer location
• theromemeter raw data readings
• thermometer correction coefficients
• thermometer readout channel number
29The name GIACoNDE is an acronym : Graphical Interface Allocating Code Numbers for Data Identifi-cation Elements30.

Oxford MONALISA Document No: Page: 66 of 800006 Rev. No. : 3.1.6
Table 12: A hypothetical example of a data identification hierarchy for thermometer relateddata arrays. This example illustrates the use of the subdivision in iterative mode.
Category:Subcategory Context:Division iLABEL DATA:LOCATIONACQUIRED:RAW DATA
THERMOMETERS:PT 100 INPUT PARAMETER:CORRECTION COEFFICIENTS 0 . . . 7PROCESSED:TEMPERATURE VALUESMETA DATA:CHANNEL NUMBER
The arrays which belong to the same physical thermometer (inside a given binary file),are assigned the same subdivision number. The subdivision number which they are assigned isarbitrary and its numerical value is of no consequence. Important numeric information relatingto the channel, such as channel number, is given in a meta data array and is not indicatedindirectly via the identification code. Given eight thermometers, one might expect iterativesubdivisions from 0 to 7 inclusive.
In the hypothetical scheme of Table 12 the location of the nth thermometerchannel (in the for loop) is given by the array (in the file) labelled THERMOME-TERS,PT 100,LABEL DATA,LOCATION,n. The raw voltage readings from the same instru-ment will be in an array labelled THERMOMETERS,PT 100,ACQUIRED,RAW DATA,n and thechannel number (as far as users of the set up are concerned) is recorded in an array labelledTHERMOMETERS,PT 100,META DATA,CHANNEL NUMBER,n. It is the common (yet arbi-trary) value of n for the “iterated” subdivision which allows users of these data arrays toassociate them with each other.
7.2 Obtaining a copy of GIACoNDE
7.2.1 Downloading GIACoNDE from the web
The GIACoNDE package is available for download at the MONALISA project websiteat http://www-pnp.physics.ox.ac.uk/∼monalisa/ . Individual user configuration files,unique to each user are also required, these are requested by e-mail.
A central log file registers unique user ID numbers which are also added to the userconfiguration files. This user ID number become the first element of the header in a usercreated binary file and is used to distinguish binary data files written by different users.
Once a new user requests a copy of GIACoNDE, a unique jar file is made available,together with scripts for running GIACoNDE under linux and windows. These are bundled ina zipped file which the user can install on their machine following instructions given on the mainGIACoNDE website, reproduced below in section 7.2.2. GIACoNDE was written in Java 1.5so should run on any platform supported by Java 1.5 or later Java version.
Under windows or linux, the launch script tries to back-up the latest state of the uniqueuser configuration file31. Once this back-up copy has been made, the script launches Java witha request to start the code in the GIACoNDE.jar file, passing on the user working directoryand the user configuration file as input parameters. Once GIACoNDE has started, if the input
31This is to protect against any corruption or accidental user mistakes which can be rolled back, albeit bymanually renaming back-up files

Oxford MONALISA Document No: Page: 67 of 800006 Rev. No. : 3.1.6
parameters are incorrect, the GIACoNDE GUI will explain the problem and exit. If the inputparameters are viable the GUI will run. The first job performed by a successfully launchedGIACoNDE “session” is to rename the back-up configuration file with a timestamp32
Using the GUI to create a data identification scheme is covered in subsection 7.3.
7.2.2 Unpacking the GIACoNDE application zip
Once a new user has received their user specific zipped file and downloaded the common corezip from the MONALISA website (at http://www-pnp.physics.ox.ac.uk/∼monalisa/ ),the following steps are necessary to complete installation33.
1. Place the user specific zip file in the same directory as the GIACoNDE general zippedfile.
2. Extract both zipped files.
3. Run the file called “deploy” (which will have been in the user specific file). After “deploy”has finished GIACoNDE will have been customised and should be ready to run on linuxand windows.
4. Run GIACoNDE using invoke.bat (windows) or invoke.sh (linux).
The directory structure after step 3 in this list, should look like that given in Table 13.
Table 13: Directory structure which appears once the GIACoNDE software has been deployedon a user machine.—admin files
+——————————— —admin README.txt+——————————— —USERNAME.gpf
—common launch.bat—common launch.sh—invoke.bat—invoke.sh—jar files
+——————————— —GIACoNDE+——————————— —TimeStampedFileMove
—README.txt—user data ID schemes
+——————————— —user data README.txt
7.3 The GIACoNDE users guide
This subsection offers a users guide to the GIACoNDE graphical interface. Users will find themajority of the operations are intuitive, matching equivalent operations in most GUI applica-tions. The life cycle of a GIACoNDE scheme is shown in Figure 25.
32Any files which appear to be configuration files (from the .cfg extension) which are neither the default file,nor named with a timestamped filename will be leftovers from partially successful launches.
33N.B. If you want to change O/S do not copy the files, move them, you should not have parallel workingcopies of your config file - there can be only one!
Oxford MONALISA Document No: Page: 68 of 800006 Rev. No. : 3.1.6
Figure 25: Life cycle flow chart for a data identification scheme within GIACoNDE. The editingoption near the top of the flow, represents both full editing (in full edit mode) and revising (inrevision mode).
One aspect of the usage cycle is highly counter-intuitive. This is the abrupt break inthe flow of scheme development that is made when freezing and publishing a scheme. Usersrestarting a scheme after publication should not take the “obvious” step of reloading the projectfile. Instead users should load the frozen publication record and then save that file as the currentscheme file34. Preferably the file is saved under a different name, in case the user wishes to rollback any changes. This is discussed in more detail in section 7.3.12.
34This might seem strange, but is required because only the frozen publication file contains the up to dateversion information, which must synchronise with the publications register in the user configuration file.

Oxford MONALISA Document No: Page: 69 of 800006 Rev. No. : 3.1.6
7.3.1 Element name requirements
The names of all elements within a scheme must comply with the same rules as variable namesin the supported languages. Names must contain either:
• letters of the roman alphabet
• arabic numerals 0 to 9
• or an underscore.
The first character must be a letter. No other characters will be permitted in the name of anelement.
Upper and lower case letters are permitted, but upper case is recommended for all lettersas the names given will appear in C and Java code as names of constant parameter, which mostprogrammers (users of your constants) will expect to find capitalised. Since there may be timeswhere there is a need (albeit unforseen) for lower case letters, the GIACoNDE software makesno attempt to prevent their use.
No elements within the hierarchy are allowed to clash names. Names clashes are caseinsensitive, meaning “Example” would be considered to clash with “example”. The most likelyoccasions for name clashes are:
• When entering divisions which are already present (but unseen) in the hierarchy
• When choosing category and division names it is sometimes unclear which name belongsat which level.
Any editing operation which produces a name clash will be rejected by the software with awarning dialog box appearing, bearing a message to that effect.
7.3.2 Launching GIACoNDE
The GIACoNDE tool is started under windows by running the batch file, invoke.bat (or theshell script invoke.sh under linux) in the user main GIACoNDE directory (see Table 13).
Once launched the screen should display a window resembling that shown in Figure 26.The launch batch file (or shell script) will have arranged for the user configuration file to becopied to a timestamped copy so that any “damage” done by the user in the current sessioncan be rolled back to the status quo ante.
The starting options for a user session are three fold:
1. If no schemes have been created, the only option is to start a new scheme (see section 7.3.3.
2. If a scheme is in mid-edit, the user can load the scheme file (with a .gtd extension) usingthe open file option on the file menu, (see section 7.3.4).
3. If the user is restarting a scheme, after it has been published, the user needs to browsethe latest frozen publication file using the browse publication file option on the file menu(see section 7.3.4).

Oxford MONALISA Document No: Page: 70 of 800006 Rev. No. : 3.1.6
Figure 26: The GIACoNDE user interface as it appears at start up, with the File menu selected.
7.3.3 Starting a new project
From the file menu, the user selects the New File. . . option. This brings up a dialog box, askingthe user to name the project. Scheme names must comply with the name rules explained insection 7.3.1. An invalid entry into the dialog box will be ignored without any warning thatthe input was incorrect.
If a valid project name has been given, a project interface will appear, with the nameof the new hierarchy as shown in Figure 27. The use of this interface to edit hierarchies isdescribed in section 7.3.5.
7.3.4 Loading a project
If a user scheme already exists on disk, this can be loaded in one of two ways:
1. If the user scheme has never published, (or has been edited or copied from the frozenpublication file since it was last published), there should a file in the subdirectoryuser data ID schemes with the .gtd extension.
2. If the last work on the scheme was to publish it, the latest status of the scheme will havebeen recorded in a frozen publication file with the extension .pub, which will be found inthe subdirectory of user data ID schemes, with the name of the subdirectory reflectingthe name and version of the published scheme. This .pub file can be loaded using theBrowse published File. . . option from the File menu of the main menubar.
7.3.5 Editing an active scheme
After loading (or starting) a project, the GUI will resemble that shown in Figure 27. Theelements of the tree displays are a bit temperamental35 and may need more clicking than youmight hope, to get the GUI to recognise that they have been selected or that the user wishesto open out the subcategories of a category. Reasons for this “sticky” behaviour lie in the(standard java) swing library elements used for the GUI and are not fully understood at thetime of writing.
35At least they are when running under java 1.5

Oxford MONALISA Document No: Page: 71 of 800006 Rev. No. : 3.1.6
Figure 27: The GIACoNDE GUI with an active session, editing a user scheme. The mainfeatures of note are annotated.
The uppermost rectangular panel is the status display, which gives the following informa-tion:
• the scheme name,
• the publication state,
• the editing mode
• the save state
in that order. The save state information here is complementary to the asterisk which willappear and disappear from the end of the GIACoNDE user name in the frame title, to indicatewhether or not the active scheme has been saved since the last changes. This asterisk conventionis the same as in many other editor GUIs on linux and windows.
On the left hand side is the hierarchy tree for categories and subcategories. Elements areselected by a left click on the element to be selected. In the panel, category and sub-category elements can be renamed, reordered, deleted and added as allowed within therestrictions of the current editing mode. Information on each can be accessed from theoperations pop-up. The operations menu is accessed for the selected tree element by aright click on the tree panel. The name of the element is given at the top of the pop upmenu which appears.

Oxford MONALISA Document No: Page: 72 of 800006 Rev. No. : 3.1.6
On the right hand side is a set of eight context tabs - one each for the eight standardcontexts defined in the binary file format. These are active whenever a subcategory isselected on the left hand panel. The active subcategory name appears at the bottomof the right hand panel and remains along with the tree if the left hand panel focusmoves away from the subcategories. Inside each tab is a hierarchy tree for division andsubdivision elements. These elements can be renamed, reordered, deleted and added asallowed within the restrictions of the current editing mode.
Edit mode restrictions affect the operations which are made available/permitted on thehierarchy elements displayed in one of the GUI trees. Viewing information on an element isalways possible. All editing operations are permitted in full edit mode, which is available priorto the publication of a new version of the scheme. No editing operations are possible in a frozenfile which has just been published. Only adding is permitted in the intermediate “revisions”editing state.
7.3.6 Saving a scheme to disk
Schemes which are already using an active .gtd file, can be saved back to the same file nameusing the File menu option Save file. This option is greyed out if there is no current .gtd file,or if there has been no change since the last time the scheme was saved.
Alternatively the user can save a scheme to any (other) .gtd file using the Save As. . .option, also from the File menu.
Saving to a .gtd file creates a back up file36 with the suffix “ backup” between the mainfile name and the .gtd extension, made by moving the previously saved .gtd file (if one existed).If the user wishes to guarantee the ability to go back more than one save iteration, they willhave to organise their own file copying.
7.3.7 Publishing as a test
A scheme being edited (or revised) can be published as a test at any point by selecting thePublish as test option from the Publishing menu on the menubar at the top of the GUIframe.
Publishing as a test produces experimental versions of output files for Java, C and testdocumentation files in html and for LATEX. It produces a fully functional binary file for Lab-VIEW. This is fully functional for the following reasons:
• Unlike the output for the other languages, it is not possible to see by eye, (by reading) ifthe scheme is as one would like it for the LabVIEW.
• In writing the code (especially for a DAQ application), it is not always obvious whatthe complete set of required data identification codes should contain. It is thereforeconvenient to be able to experiment without “wasting” data identification scheme, versionand revision numbers; which is what the test publications allow one to do.
All test publication files appear in the GIACoNDE user working directory under a sub-directory named after the scheme. Below this is a subdirectory called Test Publications andwithin this directory is a timestamped subdirectory name. In that timestamped subdirectoryare the test output files.
36Any existing back up file is deleted by this process.

Oxford MONALISA Document No: Page: 73 of 800006 Rev. No. : 3.1.6
7.3.8 Publishing a scheme
A scheme is published by choosing the Publish option from the Publishing menu of themenubar at the top of the main GIACoNDE frame.
The appropriate version number for the publication is derived from the informationrecorded in the scheme in memory. An attempt is made to register the scheme under thenew publication version number with the user configuration file.
If the attempted publication version clashes with a previously registered version number,the user is trying to publish a version of the scheme which has already been published. Thesoftware rejects the attempt to publish with a warning message. The GIACoNDE user in thiscase is likely to be a group of people and it is most likely that someone else has publishedthe scheme first. Alternative possibilities exist including mistaken identity of the scheme, etc.These are best cleared up by first checking which publication versions have been registered in theuser log file for the scheme in memory. This is done by selecting View version informationfrom the Version menu in the menubar.
If there is no clash, the scheme is registered as published in the configuration file, frozenin the editor and saved to a (frozen) publication file (with the .pub extension) in the samesubdirectory (of the GIACoNDE main working directory) in which the published constant filesappear. The name of this publication subdirectory is built from the scheme name and theversion number under which the publication is issued. The published files are described insubsection 7.3.9.
7.3.9 GIACoNDE output files
The output files from a full publication are:
The published, frozen GIACoNDE scheme in a binary file with .pub extension. Thisfile should be looked after carefully as it is the only complete record of the publishedscheme. All other publication output files can be recreated from this file, (see reprintingin subsection 7.3.11).
The published Java (final) class in a text file37 with .java extension. The constants are allpublic static and final.
The published C header in a text file with .h extension. This sets the constants and theirtypes using #define preprocessor directives.
The LabVIEW binary file with .lhb extension. This file can only be read by the customisedDLL supplied with the LabVIEW binary file handling implementation project.
An html documentation page in a simple text file with the .html extension. This file shouldbe readable in any browser. This file is optional even for full publication.
A LATEX documentation file in a .tex file suitable for compiling with LATEX or pdflatex.This file is optional even for full publication.
Although the documentation files are optional, the user is recommended to produce atleast one, if not both of these files when publishing in full.
For test publications any of the output files are optional.
37The first line in the Java file which sets the package for the class has been left to the user to add.

Oxford MONALISA Document No: Page: 74 of 800006 Rev. No. : 3.1.6
7.3.10 Publication settings
Users can choose which output files should appear for a test or full publication by altering thesettings, selecting the Adjust settings from the Publishing menu.
The settings window which appears has a checkbox for each output file of the test pub-lications. These can be independently turned on or off. Similarly the two documentation filesfor the full publication can be independently turned on or off.
7.3.11 Reprinting a publication
Reprinting is useful whenever some subset of the publication output files are missing. Providingthe .pub file is not lost, the other output files may be reissued.
This may be necessary if the optional, documentation, output files were not producedwhen the publication was issued. The user may later find themselves requiring the documenta-tion they neglected and use reprinting to obtain them. The reprint option is available from thePublishing menu, once the user has loaded in a frozen publication file (with .pub extension)for browsing as described in subsection 7.3.4.
7.3.12 Rolling back accidental changes
Rolling back accidental changes is not undertaken lightly. The user is strongly urged to readthrough the cautions in this section before using GIACoNDE, especially if planning to roll backany changes. All users should be aware of the situations which would require a “roll back” androughly what level of effort might be involved.
GIACoNDE has been designed to minimise the number of accidentally created problems.Nevertheless accidental damage can occur in two forms:
1. Accidental changes to a scheme.
2. Accidentally premature publication.
The former is slightly less serious, since a scheme can be loaded from the back up file ifthe damage was recent. The back up and/or current scheme file should be copied manuallyimmediately one notices a problem which needs to be undone. Once the user has the option ofloading in the state of the scheme before and after the latest save, the user will be best placedto decide
1. Whether or not either of the recently saved files is of use.
2. If both are potentially useful, which one requires least effort.
There is no silver bullet here and the user can easily find themselves facing a lot of workto recover a deleted portion of the hierarchy, particularly if the deleted element is high up inthe chain; for example at category level.
The premature publication makes things wrong for the scheme and for the user configu-ration file. If there is more than one person operating as the same GIACoNDE user, all personsneed to be made aware of the problem as soon as possible, since any roll back will affect theirwork too.
Rolling back an accidental publication requires:
1. Finding a .gtd file prior to the problematic publication. This is usually relatively simple.If this file is lost, there will be no rolling back of the accidental publication.

Oxford MONALISA Document No: Page: 75 of 800006 Rev. No. : 3.1.6
2. Finding a copy of the GIACoNDE user configuration file38 prior to the moment of publica-tion. The back up copies of these files are timestamped to assist in locating an appropriatefile. If an appropriate configuration file cannot be found, there will be no rolling back ofthe accidental publication.
Assuming both prerequisite files have been located, the user must manually copy thebacked up, GIACoNDE user configuration file from the timestamped copy, to the name of theactive file.
THE USER(S) SHOULD BE AWARE THAT ALL REGISTERED PUBLI-CATIONS ISSUED IN THE MEANTIME ARE BEING ABANDONED BY THISPROCESS. IF THE WRONG BACK UP IS CHOSEN, THE PUBLICATION HIS-TORY OF MANY SCHEMES WILL BE DISRUPTED39.
Once the configuration file has been rolled back, the prepublication scheme can be loadedfrom the old .gtd file and editing continued until such time as the user really is ready to publishthe scheme.
38The back up files are stored in the subdirectory admin files from the main GIACoNDE directory.39In principle the situation can be corrected by loading a different timestamped backup configuration file,
but in the end, the user will have to choose what - if anything - must be lost for ever. Hence the importanceof fixing the problem before meantime publications (of other schemes registered for the same GIACoNDE user)render it too late to do anything sensible.

Oxford MONALISA Document No: Page: 76 of 800006 Rev. No. : 3.1.6
A Binary Quick Reference
A brief overview of essential facts relating to the binary format is given in table 14 for readyreference. The full details of the structure are given in section 2.
Table 14: The essentials of the binary format, for quick reference.File specificiations
Endian format Little EndianMaximum supported
file size 2 GBMaximum number of 2.14 billion (231 − 1)
data array entries
File header Header size 15 bytesC int DATA HEADER SIZE in BinaryIO def.hJava int Protocol Defs.DATA HEADER SIZELabVIEW I32 Header Size indicator Protocol Constants v3 1.vi
Data label size before label message 22 bytesC int LABEL SIZE in BinaryIO def.hJava int Protocol Defs.LABEL SIZELabVIEW I32 Data Label Size indicator Protocol Constants v3 1.viData label max permitted message length 126 bytesC int LABEL MESSAGE MAX LENGTH in BinaryIO def.hJava int Protocol Defs.LABEL MESSAGE MAX LENGTHLabVIEW I32 Data Label Size indicator Protocol Constants v3 1.vi
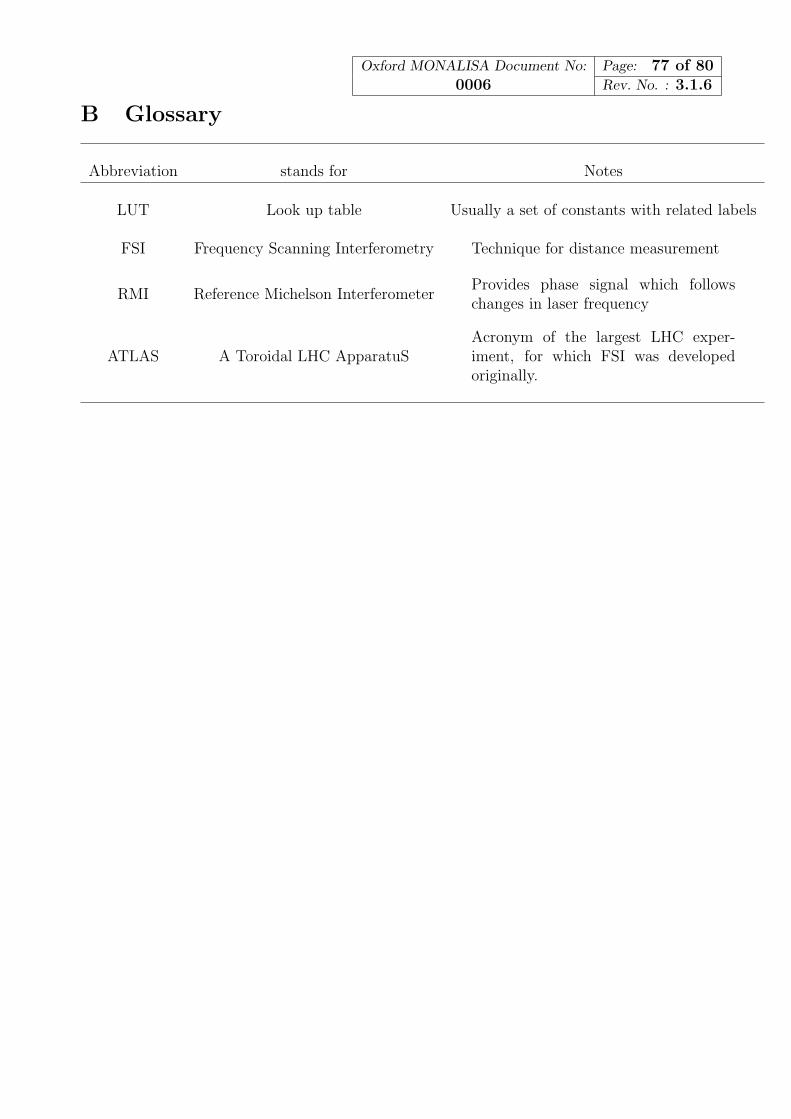
Oxford MONALISA Document No: Page: 77 of 800006 Rev. No. : 3.1.6
B Glossary
Abbreviation stands for Notes
LUT Look up table Usually a set of constants with related labels
FSI Frequency Scanning Interferometry Technique for distance measurement
RMI Reference Michelson InterferometerProvides phase signal which followschanges in laser frequency
ATLAS A Toroidal LHC ApparatuSAcronym of the largest LHC exper-iment, for which FSI was developedoriginally.

Oxford MONALISA Document No: Page: 78 of 800006 Rev. No. : 3.1.6
C Disclaimer which must accompany stdint.h written
for windows
Since Microsoft Visual Studio does not include the header stdint.h in their implementation ofC, (despite it being part of the ANSI C99 standard), I had to use a substitute found on theweb via the wikipedia page on stdint.h as explained in section 4.2.3.
The following text, taken verbatim from the copyright file stdint.h, is included here tocomply with the requirements stated therein, for users of the file.
// ISO C9x compliant stdint.h for Microsoft Visual Studio
// Based on ISO/IEC 9899:TC2 Committee draft (May 6, 2005) WG14/N1124
//
// Copyright (c) 2006 Alexander Chemeris
//
// Redistribution and use in source and binary forms, with or without
// modification, are permitted provided that the following conditions are met:
//
// 1. Redistributions of source code must retain the above copyright notice,
// this list of conditions and the following disclaimer.
//
// 2. Redistributions in binary form must reproduce the above copyright
// notice, this list of conditions and the following disclaimer in the
// documentation and/or other materials provided with the distribution.
//
// 3. The name of the author may be used to endorse or promote products
// derived from this software without specific prior written permission.
//
// THIS SOFTWARE IS PROVIDED BY THE AUTHOR “AS IS” AND ANY EXPRESS OR IMPLIED
// WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF
// MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO
// EVENT SHALL THE AUTHOR BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
// PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS;
// OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY,
// WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR
// OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF
// ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
//
///////////////////////////////////////////////////////////////////////////////

Oxford MONALISA Document No: Page: 79 of 800006 Rev. No. : 3.1.6
D File format and documentation revision history
Revision When Notes
1.0 Tue 25 - Wed 26 Oct 2005 First draft of proposal, abstract & sections 1 to 4
1.0 Fri 10 February 2006 Cosmetic changes to appendices
1.1 Mon 20 February 2006 Amended proposal to add file locking function
1.1 Fri 03 March 2006 Reduced file header first 2 elements from 32 to 16 bitnumbers
1.2 Thu 16 March 2006 Moved data ID code LUT information from data la-bels up into file header, removing redundant softwareversion info in bytes 5 and 6 of header and replacingthese with data ID code LUT version
1.3 Fri 22 September 2006 Renamed SubDivision to Division, renamed Subsub-division to SubDivision.
2.0 Sun 07 October 2006 1 Changed data label so that human readable stringis of variable length up to 254 bytes, first byte allo-cated to indicate length, this should make files morecompact, yet able to contain long strings. 2 Changedfile header, adding two bytes which hold the binaryprotocol which the data file complies with.
2.1 Fri 19 January 2007 1 Added 64 bit integer type to recognised storabledata types. 2 Changed C code, to check for endianstate of machine on which the code runs.
2.1 Sat 20 January 2007 Added indexing functionality to supplied supportsoftware. This gets round issue of maybe mak-ing some (indexing) entries re-writeable which wouldhave broken the write-once model for the data file.

Oxford MONALISA Document No: Page: 80 of 800006 Rev. No. : 3.1.6
3.0 Tue 19 June 2007 1 Altered document tone. With the release of version3.0, the document loses its redundant proposal role,to become a historical sequence of steps by which theI/O software matured into this first stable release. 2Widened the Data ID codes LUT version and DataID code revision entries in the file header from onebyte to two bytes. 3 Widened the Category and Sub-Category entries in the Array Label from one byte totwo bytes - altering the GIACoNDE support softwareto make all SubCategory numbers unique, by offsetingby 200 between each Category. 4 All single byte en-tries across all supporting languages were harmonisedto be signed (I8 in LabVIEW, char in C and byte inJava - with I8 arrays also converted to U8 for inter-pretation as strings in LabVIEW.
3.1 Mon 13 Aug 2007 Altered document for version 3.1 I/O software. Themain changes : DLLs in LabVIEW in place of theseparate I/O CINs, LabVIEW constants are loadedfrom a GIACoNDE binary file, rather than compiledinto a CIN and a major bug was fixed in the Java I/Olibrary.
3.1.1 Tue 11 Sep 2007 Finished first issue of 3.1 software description in com-plete form, with chapters on three support languagesand GIACoNDE usage.
3.1.2 Sun 16 Sep 2007 Made editorial changes after noticing problems withfirst issue of completed document.
3.1.3 Mon 17 Sep 2007 Added issue number to document identity. Changesin this indicate minor edits and prevent users frommistaking one issue for another.
3.1.4 Mon 24 Sep 2007 Corrected references to platinum RTDs, from the er-roneous PTR100 to the correct Pt 100. Amendedhypothetical example data identification scheme ele-ment names from PTR100 to PT 100 accordingly.
3.1.5 Sat 05 May 2008 Added a short section with advice on using C librarieswith C++ code.
3.1.6 Sat 05 July 2008 Altered references to web site URLs after renamingof MONALISA web address from StaFF to monalisa.Other minor typos corrected where found.
END OF DOCUMENT - 05 Jul 2008





























