Embed Size (px)
Citation preview

1
PEMODELAN SEM DENGAN GENERALIZED STRUCTURED COMPONENT ANALYSIS (GSCA)
Dewi Fenty Ekasari1, Sony Sunaryo2
1Institut Teknologi Surabaya 2Institut Teknologi Surabaya
Fakultas MIPA-Jurusan Statistika ITS, Surabaya
E-mail: [email protected]
Abstract
Poverty can be seen from income dimension, as well as its characteristic from social, health, education, access o f clean water and housing dimension. PLS and GSCA are variance-based SEM or often called component-based SEM are powerfull analysis method because they are not based on many assumption. GSCA have a single criteria to minimize residual to determination of model parameter estimation determination. Due to the problem, GSCA gives optimum solution and can not provide mechanism to evaluate overall goodness-fit ot the model. The intention of the research is to apply GSCA on Case study of Poverty in Regency of Jawa Tengah Province. Data that is used is secondary data from National Socio-economic Survey 2009 in Jawa Tengah Province and other related data. The purpose of this research is to develop a program computer for GSCA and implement program on a case study of poverty in Regency/City in Jawa Tengah Province. Data that is used is secondary data from National Socio-economic Survey 2009 in Jawa Tengah Province and other related data. The result show that all the indicator variable is a valid measurement tool and reliable to measure the latent variables. Quality of health affects the quality of economic, quality of economic affects the quality of human, quality of health affects ponerty, quality of economic affects poverty Keywords : Poverty, Structural Equation Modeling (SEM), Generalized Structured Component Analysis (GSCA)
Abstrak
Kemiskinan selain dapat dilihat dari dimensi pendapatan juga dapat dilihat dari dimensi sosial, dimensi kesehatan dan dimensi pendidikan. Partial Least Square (PLS) dan Generalized Structured Component Analysis (GSCA) adalah Structural Equation Modeling (SEM) yang berbasis varian atau sering disebut juga berbasis komponen, merupakan metode analisis yang powerfull oleh karena tidak didasarkan banyak asumsi. GSCA memiliki satu kriteria tunggal secara konsisten untuk meminimumkan residual guna mendapatkan estimasi parameter model sehingga GSCA memberikan solusi yang optimal dan dapat memberikan mekanisme untuk menilai overall goodness-fit dari model. Tujuan dari penelitian ini adalah membuat program GSCA untuk studi kasus kemiskinan

Kabupaten/Kota di Provinsi Jawa Tengah dan mengimplementasikannya pada studi kasus. Data yang digunakan merupakan data sekunder yaitu berasal dari Survei Sosial Ekonomi Nasional 2009 Provinsi Jawa Tengah dan data terkait lainnya. Hasil dari penelitian ini adalah bahwa semua variabel indikator merupakan alat ukur yang valid dan reliabel untuk mengukur variabel latennya. Kualitas kesehatan berpengaruh terhadap kualitas ekonomi, kualitas ekonomi berpengaruh terhadap kualitas SDM, kualitas kesehatan berpengaruh terhadap kemiskinan, kualitas ekonomi berpengaruh terhadap kemiskinan. Kata kunci : Kemiskinan, Structural Equation Modeling (SEM), Generalized Structured Component Analysis (GSCA)
1. Pendahuluan
Hwang dan Takane mengusulkan metode baru untuk SEM dengan nama Generalized Structured Component Analysis (GSCA)[1]. GSCA merupakan bagian dari SEM berbasis komponen yang memiliki criteria global least square optimization, dimana dapat secara konsisten meminimumkan sum squares residual untuk memperoleh estimasi parameter model. GSCA juga dilengkapi dengan ukuran goodness-of fit model secara keseluruhan. GSCA merupakan metode analisis yang powerfull [2]. Hal ini disebabkan karena tidak berdasarkan pada banyak asumsi seperti variabel tidak harus berdistribusi normal multivariat (indikator dengan skala kategori, ordinal , interval sampai ratio dapat digunakan pada model yang sama), jumlah data tidak harus besar (minimal direkomendasikan berkisar dari 30 sampai 100 kasus).
Kemiskinan selalu menjadi topik yang dibahas dalam berbagai forum dan bahkan cenderung diperdebatkan. Fakta menunjukkan bahwa pembangunan telah dilakukan namun belum mampu meredam meningkatnya jumlah penduduk miskin di dunia, khususnya negara-negara berkembang. Selama ini kemiskinan lebih cenderung dikaitkan dengan dimensi ekonomi karena dimensi ini paling mudah diamati, diukur dan diperbandingkan. Padahal kemiskinan berkaitan juga dengan berbagai dimensi lain seperti: dimensi sosial, budaya, sosial politik, lingkungan, kesehatan, pendidikan, agama, dan budi pekerti. Kemiskinan selain dilihat dari dimensi pendapatan, kemiskinan juga perlu dilihat dari dimensi lain yaitu dimensi sosial, dimensi kesehatan dan dimensi pendidikan [3].
Penelitian ini dilakukan di Jawa Tengah karena jumlah penduduk miskin Provinsi Jawa Tengah pada tahun 2010 adalah sebesar 16,60%, berada diatas rata-rata jumlah penduduk miskin Indonesia yaitu 13,3%. Pada wilayah pulau Jawa dan Bali, Provinsi Jawa Tengah merupakan provinsi dengan peringkat kedua untuk jumlah penduduk miskin terbanyak setelah DI Yogyakarta [4]. Walaupun jumlah penduduk miskinnya tinggi akan tetapi proporsi rumah tangga dengan akses kepemilikan terhadap sumber air minum layak di Provinsi Jawa Tengah pada tahun 2010 adalah 58,30% (peringkat ke-2 tertinggi untuk wilayah pulau Jawa dan Bali) cukup baik, berada diatas rata-rata Indonesia (47,71%). Demikian pula dengan proporsi rumah tangga yang memiliki akses terhadap sanitasi layak adalah sebesar 54,06%, diatas rata-rata Indonesia. Sedangkan proporsi rumah tangga kumuhnya adalah sebesar 5,6%, (peringkat ke-2 terendah untuk wilayah pulau Jawa dan Bali).

3
Menelaah kemiskinan secara multidimensional sangat diperlukan untuk perumusan kebijakan pengentasan kemiskinan [5]. Melihat kemiskinan dari berbagai dimensi lain secara simultan, seperti kualitas kesehatan, kualitas ekonomi dan kualitas sumber daya manusia dapat digunakan sebagai kajian dan informasi untuk kebijakan pengentasan kemiskinan.
Dalam penelitian ini ruang lingkup permasalahan dibatasi dengan membuat model SEM-GSCA yang rekursif (satu arah) dan variabel laten dengan indikator refleksif. Tujuan yang ingin dicapai dalam penelitian ini adalah (i) membuat program SEM-Generalized Sturctured Component Analysis (GSCA) untuk studi kasus penentuan struktur model kemiskinan di Provinsi Jawa Tengah dengan software open source, (ii) menerapkan SEM-GSCA terhadap studi kasus penentuan struktur model kemiskinan di Provinsi Jawa Tengah dengan software open source.
2. Metode
Jika 𝐙𝐙 = [𝐳𝐳1, 𝐳𝐳2, … , 𝐳𝐳n ]′ melambangkan matrik variabel indikator yang telah distandarisasi (berukuran nxj). GSCA merupakan SEM berbasis komponen dimana variabel laten didefinisikan sebagai komponen atau komposit tertimbang dari indikatornya dengan persamaan [6]:
𝛄𝛄 = 𝐖𝐖′𝐳𝐳 (1) dimana 𝜸𝜸 adalah vektor variabel laten ukuran tx1 untuk observasi ke-1 sampai ke n dan W adalah matrik component weight dari variabel indikator berukuran jxt.
Secara matematis persamaan pada model pengukuran dapat dituliskan sebagai berikut:
𝐳𝐳 = 𝐂𝐂′𝛄𝛄 + 𝛆𝛆 (2) dimana C adalah matrik loading antara variabel laten dengan indikatornya berukuran txj, 𝜺𝜺𝑖𝑖 adalah vektor residual (jx1). Sedangkan persamaan pada model struktural dinyatakan seperti persamaan dibawah ini:
𝛄𝛄 = 𝐁𝐁′𝛄𝛄 + 𝛏𝛏 (3) dimana B adalah matrik koefisien jalur (txt) yang menghubungkan sesama variabel laten dan 𝝃𝝃𝑖𝑖 adalah vektor residual (tx1) untuk 𝜸𝜸𝑖𝑖 . GSCA mengintegrasikan ketiga persamaan tersebut diatas menjadi persamaan tunggal seperti berikut:
𝐳𝐳𝛄𝛄 = 𝐂𝐂′
𝐁𝐁′ 𝛄𝛄 +
𝛆𝛆𝛏𝛏
𝐈𝐈𝐖𝐖′ = 𝐂𝐂′
𝐁𝐁′𝐖𝐖′𝐳𝐳i +
𝛆𝛆𝛏𝛏 (4)
jika I adalah matriks indentitas, 𝐕𝐕 = [𝐈𝐈,𝐖𝐖], 𝐀𝐀 = [𝐂𝐂,𝐁𝐁], 𝐞𝐞i = 𝛆𝛆𝛏𝛏
𝐕𝐕′𝐳𝐳 = 𝐀𝐀′𝐖𝐖′𝐳𝐳 + 𝐞𝐞 𝐙𝐙𝐕𝐕 = 𝐙𝐙𝐖𝐖𝐀𝐀 + 𝐄𝐄 (5)
persamaan tersebut dikatakan sebagai model GSCA. Parameter GSCA yang tidak diketahui (V, W dan A) diestimasi sehingga nilai sum
squares dari semua residual (E) sekecil mungkin untuk semua observasi. Hal ini sama dengan meminimumkan dengan least square optimization criterion
f = trace((𝐙𝐙𝐕𝐕 − 𝐙𝐙𝐖𝐖𝐀𝐀)′(𝐙𝐙𝐕𝐕 − 𝐙𝐙𝐖𝐖𝐀𝐀)) (6)

dengan memperhatikan V, W dan A. Komponen didalam ψ dan/atau τ dinormalisasi untuk tujuan identifikasi, misalnya 𝛾𝛾1
′ 𝛾𝛾1=1 Metode Alternating Least Squares (ALS) adalah pendekatan umum untuk estimasi
parameter yang melibatkan pengelompokkan parameter ke beberapa subset, dan kemudian mendapatkan kuadrat terkecil untuk salah satu subset parameter dengan asumsi bahwa semua parameter yang tersisa adalah kostan. Algoritma ALS yang digunakan dalam GSCA terdiri dari 2 step yaitu: A di update dengan V dan W fixed kemudian V dan W di update dengan A fixed. Algoritma yang digunakan untuk memperbaharui A yaitu: Step 1 : Inisialisasi V dan W Step 2 : Bentuk matrik ⊗Iτ Step 3 : Bentuk matrik Ω Step 4 : Perbaharui matrik A dengan menggunakan estimasi least squares sebagai berikut: 𝐚𝐚 = (𝛀𝛀′𝛀𝛀)−𝟏𝟏𝛀𝛀′vec(𝚿𝚿) Step 5 : Bentuk matrik A baru dengan memasukkan nilai 𝒂𝒂 yang telah diperbaharui Algoritma yang digunakan untuk memperbaharui V dan W yaitu: Step 6 : Inisialisasi A dengan menggunakan A yang telah diperbaharui. Step 7 : Bentuk matrik S yang berisi parameter bobot yang akan diestimasi. Step 8 : Definisikan tiap kolom pada matrik S (sebanyak k kolom) tersebut berasal dari kolom mana saja pada matrik W (sebanyak q kolom) dan V (sebanyak p kolom). Step 9 : Definisikan 𝜷𝜷′ dan Δ Step 10 : Bentuk matrik ⊗Zβ Step 11 : Bentuk matrik Π Step 12 : Estimasi s1 dengan η1 = (𝚷𝚷′𝚷𝚷)−1𝚷𝚷′vec(𝐙𝐙𝐙𝐙) Step 13 : Perbaharui s1 yang lama dengan s1 yang baru, masukkan kedalam kolom pada matrik W dan/atau V yang sesuai dimana matrik W dan V yang telah diperbaharui ini digunakan untuk perbaharui s2. Step 14 : Ulangi step 12 dan step 13 sebanyak K kali (K kolom). Step 15 : Didapatkan matrik W dan V baru Step 16 : Cek konvergen bila belum konvergen maka ulangi step 1.
Variabel penelitian yang digunakan adalah sebagai berikut: 1. Y1= Persentase pengeluaran perkapita untuk non makanan 2. Y2= Persentase penduduk usia 15 tahun keatas yang bekerja disektor non
pertanian 3. Y3= Persentase penduduk usia 15 tahun keatas yang bekerja disektor formal. 4. Y4= Angka Melek Huruf (15-55 tahun) 5. Y5= Rata-rata lama sekolah 6. Y6= Persentase penduduk yang tamat SD/SLTP/SLTA/SLTA+ 7. Y7= Persentase penduduk miskin 8. Y8= Indeks kedalaman kemiskinan 9. Y9= Indeks keparahan kemiskinan 10. X1= Persentase balita yang proses kelahirannya ditolong oleh nakes. 11. X2= Angka harapan hidup

5
12. X3= Persentase rumah tangga yang menggunakan jamban sendiri/bersama. 13. X4= Persentase rumah tangga yang menggunakan air bersih
Berdasarkan teori yang telah dipaparkan, terdapat hubungan langsung atau tidak langsung antar sesama variabel laten dan juga antara variabel laten dengan indikatornya seperti terlihat dalam diagram jalur pada model konseptual dibawah ini.
Kemiskinan Kualitas SDM
Kualitas Ekonomi
Y8
Y9
Y10
Y5 Y6 Y7
Y1
Y2
Y3
X3X2X1 X4
Kualitas Kesehatan
Gambar 1 Model Konseptual Penelitian
Berdasarkan model diatas, dapat diajukan 5 hipotesa sebagai berikut: H1 : Kualitas kesehatan berpengaruh terhadap kualitas ekonomi H2 : Kualitas ekonomi berpengaruh terhadap kualitas SDM H3 : Kualitas kesehatan berpengaruh terhadap kemiskinan H4 : Kualitas ekonomi berpengaruh terhadap kemiskinan H5 : Kualitas SDM berpengaruh terhadap kemiskinan
Langkah-langkah analisis SEM dengan Generalized Stuctured Component Analysis adalah sebagai berikut: a. Mendapatkan model berbasis konsep dan teori guna merancang model struktural dan model
pengukuran. b. Membuat diagram jalur (diagram path) yang menjelaskan pola hubungan antara variabel
laten dengan indikatornya. c. Konversi diagram jalur ke dalam persamaan. d. Mengestimasi parameter, yang terdiri dari estimasi bobot, estimasi factor loading, estimasi
koefisien jalur dan estimasi bootstrap standar error.

e. Menentukan koefisien parameter (standar error) dan nilai t statistik dengan menggunakan metode bootstrap.
f. Menguji signifikansi parameter pada model pengukuran. g. Menguji signifikansi parameter pada model struktural. h. Menentukan overall goodness fit model. i. Membuat kesimpulan.
Input data yang digunakan dalam penelitian ini adalah matrik X yang merupakan matrik data berukuran n x j dimana n merupakan banyaknya observasi (n=35) dan j merupakan banyaknya indikator yang digunakan (j=13). Selain input data, diperlukan pula inputan lain untuk menjalankan program SEM dengan GSCA yaitu matrik yang menunjukkan hubungan diantara variabel dan inputan ini digunakan sebagai nilai inisialisasi awal, yaitu matrik: V, W, B, Cdan n, dimana: V = merupakan gabungan matrik identitas dari indikator dengan matrik bobot antara seluruh indikator dengan seluruh variabel laten endogen. Bila ada hubungan antara indikator dengan variabel laten endogen, maka diberi nilai sembarang, bila tidak ada hubungan maka diberi nilai nol. Nilai bobot untuk indikator dengan variabel laten endogen harus sama dengan isian pada matrik W. W = matrik bobot yang menyatakan hubungan antara seluruh indikator dengan seluruh variabel laten, dimana bila ada hubungan diberi nilai sembarang dan bila tidak ada hubungan diberi nilai 0. Matrik ini berukuran j x t B = matrik jalur yang menyatakan hubungan antara seluruh variabel laten dengan variebel laten endogen, dimana bila ada hubungan diberi nilai sembarang dan bila tidak ada hubungan diberi nilai 0. C = matrik factor loadings yang menyatakan hubungan antara variabel laten dengan indikator refleksif, dimana bila ada hubungan diberi nilai sembarang dan bila tidak ada hubungan diberi nilai 0. Matrik ini berukuran t x j. n = banyaknya resampling yang dilakukan untuk proses bootstrap. Model struktural yang digunakan pada penelitian ini adalah sebagai berikut: 𝛄𝛄 = 𝐁𝐁′𝛄𝛄 + 𝛏𝛏
1
2
3
1
3
52 4
bb
b b b
0 0 00 0 0
0= +
ξ ξ ξ
12
23
34
4
γγγ
γγ
γγ
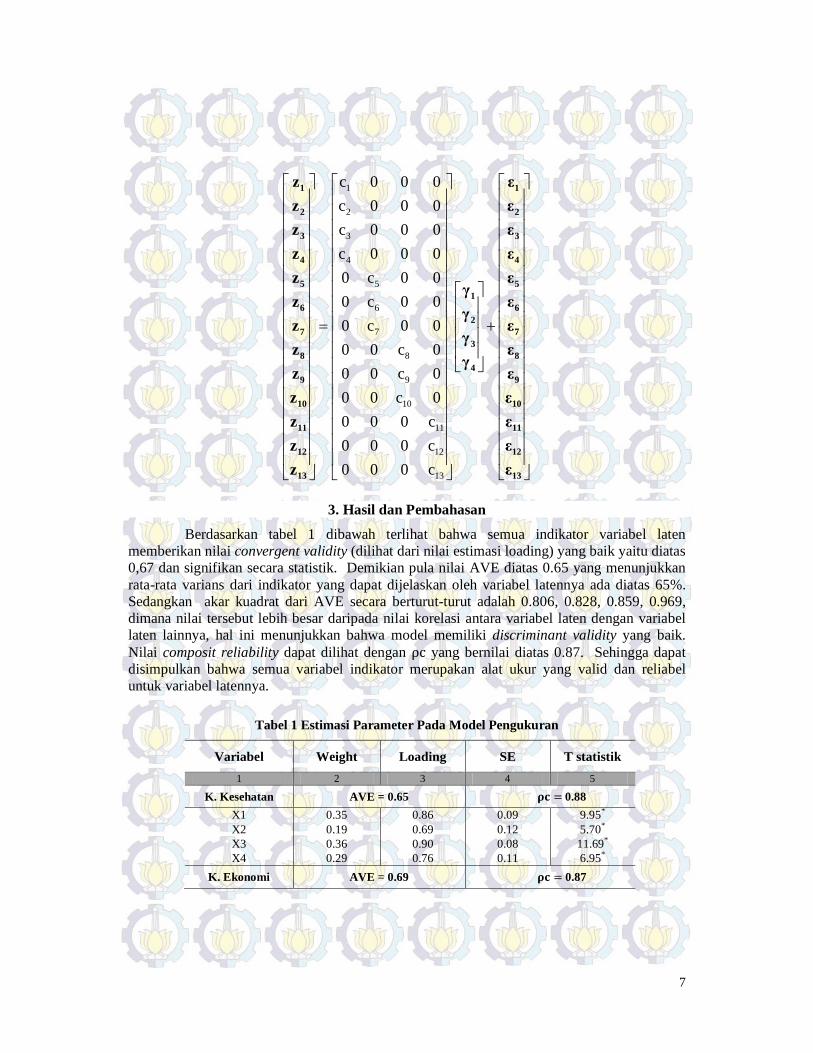
Model pengukuran yang digunakan pada penelitian ini adalah sebagai berikut: 𝐳𝐳 = 𝐂𝐂′𝛄𝛄 + 𝛆𝛆
ic= +i izε 1γ jika i ≤ 4
ic= +i izε 2γ jika 5 ≤ i ≤ 7
ic= +i 3 izε γ jika 8 ≤ i ≤ 10
ic= +i izε 4γ jika 11 ≤ i ≤ 13 dimana i= banyaknya variabel indikator. ekivalen dengan persamaan dalam matrik sebagai berikut:
7
1
2
3
4
5
6
7
8
9
10
11
12
13
c 0 0 0c 0 0 0c 0 0 0c 0 0 00 c 0 00 c 0 00 c 0 00 0 c 00 0 c 00 0 c 00 0 0 c0 0 0 c0 0 0 c
=
1
2
3
4
51
62
73
84
9
10
11
12
13
zzzzz
γz
γz
γz
γzzzzz
+
1
2
3
4
5
6
7
8
9
10
11
12
13
εεεεεεεεεεεεε
3. Hasil dan Pembahasan
Berdasarkan tabel 1 dibawah terlihat bahwa semua indikator variabel laten memberikan nilai convergent validity (dilihat dari nilai estimasi loading) yang baik yaitu diatas 0,67 dan signifikan secara statistik. Demikian pula nilai AVE diatas 0.65 yang menunjukkan rata-rata varians dari indikator yang dapat dijelaskan oleh variabel latennya ada diatas 65%. Sedangkan akar kuadrat dari AVE secara berturut-turut adalah 0.806, 0.828, 0.859, 0.969, dimana nilai tersebut lebih besar daripada nilai korelasi antara variabel laten dengan variabel laten lainnya, hal ini menunjukkan bahwa model memiliki discriminant validity yang baik. Nilai composit reliability dapat dilihat dengan ρc yang bernilai diatas 0.87. Sehingga dapat disimpulkan bahwa semua variabel indikator merupakan alat ukur yang valid dan reliabel untuk variabel latennya.
Tabel 1 Estimasi Parameter Pada Model Pengukuran
Variabel Weight Loading SE T statistik 1 2 3 4 5
K. Kesehatan AVE = 0.65 𝛒𝛒𝛒𝛒 = 0.88 X1 0.35 0.86 0.09 9.95* X2 0.19 0.69 0.12 5.70* X3 0.36 0.90 0.08 11.69* X4 0.29 0.76 0.11 6.95*
K. Ekonomi AVE = 0.69 𝛒𝛒𝛒𝛒 = 0.87
Y1 0.26 0.67 0.13 5.38* Y2 0.28 0.86 0.09 9.41* Y3 0.40 0.93 0.07 13.68*
K. SDM AVE = 0.74 𝛒𝛒𝛒𝛒 = 0.89 Y5 0.25 0.80 0.10 7.80* Y6 0.43 0.92 0.07 13.22* Y7 0.32 0.86 0.09 9.30*
Kemiskinan AVE = 0.94 𝛒𝛒𝛒𝛒 = 0.98 Y8 0.46 0.97 0.05 19.03* Y9 0.09 0.99 0.03 34.69* Y10 0.34 0.95 0.05 17.79*
T statistik* = significant at .05 level (1.96)
Berdasarkan tabel 2 dibawah ini terlihat bahwa tidak semua koefisien jalur signifikan secara statistik, koefisien jalur antara kualitas SDM dan kemiskinan tidak signifikan secara statistik dan nilai koefisien parameternya sangat kecil (0.25) sehingga jalur antara kualitas SDM dengan kemiskinan dihilangkan dari model. Model yang baru (model 2) didapatkan dengan menghilangkan jalur yang tidak signifikan secara statistik, dan kemudian dilakukan proses estimasi dan evaluasi untuk model pengukuran kembali.
Tabel 2 Estimasi Parameter Pada Model Struktural
Koefisien Jalur SE CR K. Kesehatan -> K. Ekonomi 0.55 0.11 4.89* K. Kesehatan -> Kemiskinan -0.45 0.11 -4.03*
K. Ekonomi -> K. SDM 0.84 0.07 11.24* K. Ekonomi -> Kemiskinan -0.60 0.11 -5.29*
K. SDM -> Kemiskinan 0.25 0.16 1.60 T statistik* = significant at .05 level(1.96)
Evaluasi untuk model pengukuran baru (model 2) tidak terdapat banyak perubahan dan untuk evaluasi model struktural terlihat bahwa semua koefisien jalur telah signifikan secara statistik. Evaluasi model struktural untuk model 2 terlihat seperti pada tabel 3 dibawah ini. Koefisien jalur dari kualitas kesehatan ke kualitas ekonomi sebesar 0.56 sehingga dapat disimpulkan bahwa kualitas kesehatan berpengaruh positif terhadap kualitas ekonomi atau semakin tinggi kualitas kesehatan maka kualitas ekonomi juga semakin baik, demikian pula cara menganalisa koefisien jalur untuk kualitas ekonomi dengan kualitas SDM. Koefisien jalur dari kualitas kesehatan ke kemiskinan sebesar -0.39 sehingga dapat disimpulkan bahwa kualitas kesehatan berpengaruh negatif terhadap ekonomi atau semakin tinggi kualitas kesehatan maka kemiskinan rendah. Terlihat pula bahwa semakin tinggi kualitas ekonomi maka kemiskinan rendah.
9
Tabel 3 Estimasi Parameter Pada Model Struktural Model 2
Koefisien Jalur SE CR K.Kesehatan -> K. Ekonomi 0.56 0.11 5.04* K. Kesehatan -> Kemiskinan -0.39 0.11 -3.40*
k. Ekonomi -> K. SDM 0.85 0.07 11.15* K. Ekonomi -> kemiskinan -0.40 0.11 -3.79*
T statistik* = significant at .05 level(1.96)
Tabel 4 Evaluasi Model Fit pada Model 2
Ukuran Model Fit Target Tingkat Kecocokan Hasil Estimasi Tingkat Kecocokan
Model
FIT FIT ≥ 0.50 0.70 Baik (good fit)
AFIT AFIT ≥ 0.50 0.68 Baik (good fit)
Evaluasi model secara keseluruhan untuk model baru (model 2) dapat dilihat dari pengujian model fit nya seperti ditunjukkan oleh tabel 4 diatas, dimana pada penelitian ini digunakan FIT dan AFIT. Terlihat bahwa nilai FIT dan AFIT diatas 0.68 yang menunjukkan bahwa model mampu menjelaskan sekitar 68% variasi dari data. Tingkat kecocokan model yang dihasilkan adalah terdapat 2 ukuran yang mengatakan bahwa model baik sehingga dapat disimpulkan bahwa model yang digunakan baik. Pada model ini terdapat sebanyak 30 parameter yang diestimasi.
Berdasarkan hasil factor score dari masing-masing variabel laten, didapatkan bahwa terdapat 17 Kabupaten yang memiliki kualitas kesehatan dibawah rata-rata yaitu: Kabupaten Cilacap, Banyumas, Purbolinggo, Banjarnegara, Kebumen, Purworejo, Wonosobo, Magelang, Grobogan, Jepara, Demak, Kendal, Batang, Pekalongan, Pemalang, Tegal dan Brebes. Lima Kabupaten yang terendah kualitas kesehatannya yaitu: Brebes, Purbolinggo, Batang, Pemalang dan Banjarnegara.
Hanya terdapat 13 Kabupaten/Kota yang memiliki kualitas ekonomi diatas rata-rata yang terdiri dari 7 Kabupaten (Banyumas, Klaten, Sukoharjo, Kudus, Jepara, Pekalongan dan Tegal) dan 6 Kota (Magelang, Surakarta, Salatiga, Semarang, Pekalongan dan Tegal). Lima Kabupaten yang terendah kualitas ekonominya yaitu: Wonosobo, Temanggung, Grobogan, Wonogiri dan Banjarnegara.
Terdapat 20 Kabupaten/Kota yang memiliki kualitas sumber daya manusia dibawah rata-rata yang terdiri dari 1 Kota yaitu Semarang dan 19 Kabupaten (Cilacap, Purbolinggo, Banjarnegara, Kebumen, Wonosobo, Magelang, Boyolali, Wonogiri, Karanganyar, Sragen, Blora, Pati, Semarang, Temanggung, Kendal, Batang, Pemalang, Tegal dan Brebes). Lima Kabupaten yang terendah kualitas SDM nya adalah Tegal, Batang, Cilacap, Banjarnegara dan Brebes.
Factor score dari variabel laten kemiskinan memperlihatkan bahwa terdapat 17 Kabupeten yang memiliki kemiskinan diatas rata-rata yaitu Cilacap, Banyumas, Purbolinggo,

Banjarnegara, Kebumen, Purworejo, Wonosobo,Klaten, Wonogori, Sragen, Grobogan, Blora, Rembang, Demak, Pekalongan, Pemalang dan Brebes). Lima Kabupeten tertinggi kemiskinannya adalah Brebes, Purbolinggo, Rembang, Kebumen dan Wonosobo.
Kabupaten Sukoharjo dan Kudus, Kota Magelang, Surakarta, Salatiga, Pekalongan dan Tegal memiliki kualitas kesehatan, ekonomi serta SDM yang tinggi dan kemiskinan yang rendah. Kabupaten Cilacap, Purbolinggo, Banjarnegara, Kebumen, Wonosobo, Pemalang dan Brebes memiliki kualitas kesehatan, ekonomi serta SDM yang rendah dan kemiskinan yang tinggi.
Model persamaan struktural yang didapatkan dari model 2 adalah sebagai berikut:
K. KesehatanK.Ekonomi 0.56 0 0 0 1K.Ekonomi
K.SDM 0 0.84 0 0 2K.SDMKemiskinan 0.39 0.40 0 0 3Kemiskinan
ξ ξ − − ξ
= +
sedangkan model persamaan pengukuran yang didapatkan dari model 2 adalah sebagai berikut:
1
2
3
4
1
2
3
4
5
6
7
8
9
X
K. KesehatanK.
0.86 0 0 0X 0.68 0 0 0X 0.90 0 0 0X 0.76 0 0 0Y 0 0.67 0 0Y 0 0.86 0 0Y = 0 0.92 0 0Y 0 0 0.79 0Y 0 0 0.92 0Y 0 0 0.85 0Y 0 0 0 0.97Y 0 0 0 0.99Y 0 0 0 0.94
1
2
3
4
5
6
7
8
9
10
11
12
13
EkonomiK. SDM
Kemiskinan
+
εεεεεεεεεεεεε
4. Kesimpulan
Beberapa kesimpulan yang didapatkan dari hasil penelitian ini antara lain adalah program SEM-GSCA untuk model rekursif dan variabel laten dengan indikator reflektif dapat dibuat dengan software open source yaitu Octave, dengan inputan adalah matriks V, W, C dan B serta n. Output yang dihasilkan adalah estimasi bobot, estimasi koefisien loading, estimasi koefisien jalur, estimasi standard error, factor score dari variabel laten serta overall goodness-fit model.

11
Kualitas kesehatan berpengaruh terhadap kualitas ekonomi, kualitas ekonomi berpengaruh terhadap kualitas SDM, kualitas kesehatan berpengaruh terhadap kemiskinan, kualitas ekonomi berpengaruh terhadap kemiskinan, dan kualitas SDM tidak berpengaruh terhadap kemiskinan.
Semakin tinggi kualitas kesehatan penduduk di suatu Kabupaten/Kota pada Provinsi Jawa Tengah berpengaruh terhadap tinggi nya kualitas ekonomi penduduknya, dan rendahnya kemiskinan pada Kabupaten/Kota tersebut. Semakin tinggi kualitas ekonomi penduduknya, maka semakin tinggi kualitas SDM penduduk pada Kabupaten/Kota tertentu.
Model konseptual yang dihasilkan dalam penelitian ini menunjukkan bahwa secara keseluruhan merupakan model yang baik berdasarkan nilai FIT dan AFIT yang diatas 0.50. Model baru ini didapat dengan menghilangkan koefisien jalur antara kualitas SDM dengan kemiskinan.
Berdasarkan factor score yang didapatkan untuk variabel laten, terlihat bahwa lima Kabupaten yang terendah kualitas kesehatannya yaitu: Brebes, Purbolinggo, Batang, Pemalang dan Banjarnegara. Lima Kabupaten yang terendah kualitas ekonominya yaitu: Wonosobo, Temanggung, Grobogan, Wonogiri dan Banjarnegara. Lima Kabupaten yang terendah kualitas SDM nya adalah Tegal, Batang, Cilacap, Banjarnegara dan Brebes. Lima Kabupeten tertinggi kemiskinannya adalah Brebes, Purbolinggo, Rembang, Kebumen dan Wonosobo. Kabupaten Cilacap, Purbolinggo, Banjarnegara, Kebumen, Wonosobo, Pemalang dan Brebes memiliki kualitas kesehatan, ekonomi serta SDM yang rendah dan kemiskinan yang tinggi. Daftar Pustaka
[1] Hwang, H. & Takane, Y., 2004, ”Generalized Structured Component Analysis”, Psychometrika vol 69, pp.81-99.
[2] Wold, H.,1985, “Partial Least Square”, In S Kotz & N.L.Johnson(Eds). Encyclopedia of Statistical Sciences K, Wiley. New York, vol 8, pp.587-599.
[3] Word Development Report., 2008, “Attacking Poverty”, WDR. [4] Bappenas, 2010, “Laporan Pencapaian Tujuan Pembangunan Millenium Indonesia 2010”,
Kementrian Perencanaan Pembangunan Nasional/Badan Perencanaan Pembangunan Nasional (Bappenas), Jakarta.
[5] Suryawati, C., 2005, “Memahami Kemiskinan Secara Multidimensional”, JMPK, Jakarta.vol 08/03.
[6] Hwang, H., 2009, “Regularized Generalized Structured Component Analysis”, Psychometrika, vol 74, pp.517- 530.





























