Embed Size (px)
Citation preview

ProseminarMethoden II
für das Modul P4Stefan Jahr

Methoden II – Stefan Jahr 2
Organisatorisches
• Teilnahmebedingungen– Bestandene Methoden I – Klausur oder– Stattgegebener Härtefallantrag
• Leistungen für den Teilmodulabschluss– max. zweimaliges Fehlen– Klausur am 11.2.2008, HS 146 UHG– Nachklausur 3.3.2008, HS 146 UHG
• „alter“ Methoden II – Schein– Zusatzleistung in Statistik I erforderlich

Methoden II – Stefan Jahr 3
Kursmaterialien
• Folien + Fragebogen + Datensatz + weitere Infos:www.eurelite.uni-jena.de/Methoden2/Methoden
• Fragebogen + Datensatz:• Studentenbefragung von Michael Behr• Allgemeine Fragen zur Demographie,
Studium, Einstellungen• Panel• n = Studenten aller bisherigen Kurse
Methoden II – Stefan Jahr 4
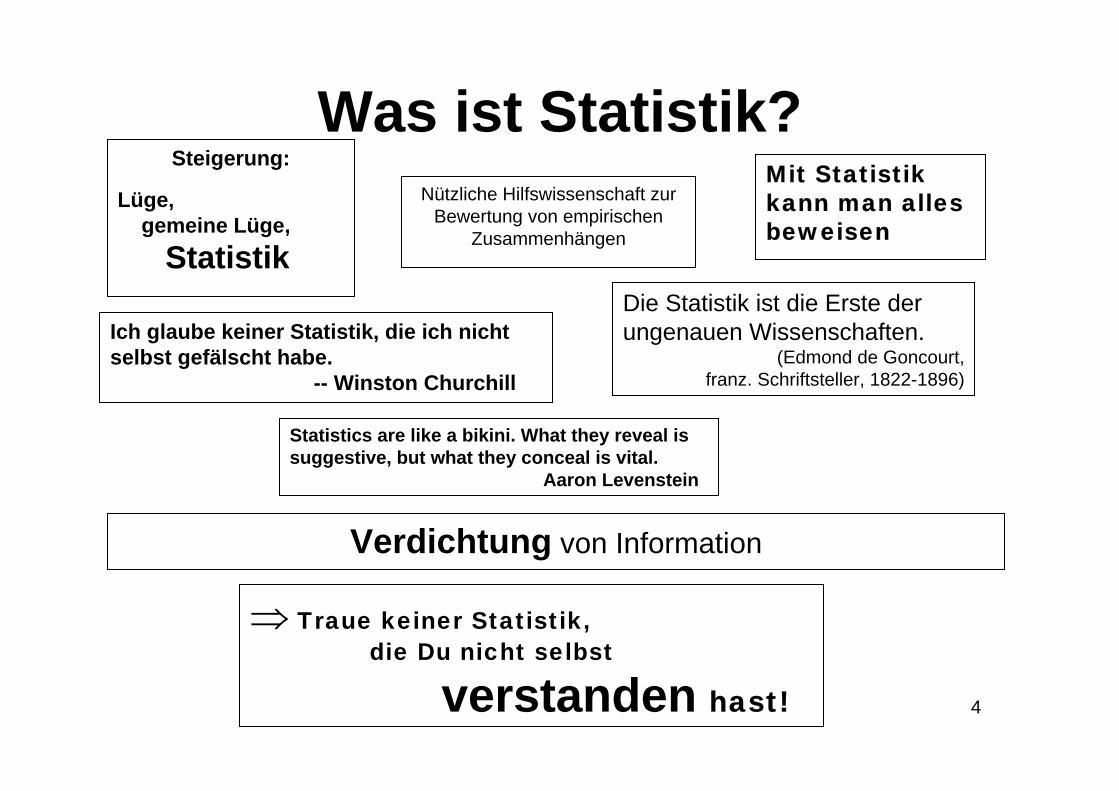
Was ist Statistik?Steigerung:
Lüge,gemeine Lüge,
Statistik
Nützliche Hilfswissenschaft zur Bewertung von empirischen
Zusammenhängen
Mit Statistik kann man alles beweisen
Verdichtung von Information
Ich glaube keiner Statistik, die ich nicht selbst gefälscht habe.
-- Winston Churchill
⇒ Traue keiner Statistik, die Du nicht selbst
verstanden hast!
Die Statistik ist die Erste der ungenauen Wissenschaften.
(Edmond de Goncourt,franz. Schriftsteller, 1822-1896)
Statistics are like a bikini. What they reveal issuggestive, but what they conceal is vital.
Aaron Levenstein

Methoden II – Stefan Jahr 5
Forderung an empirische Daten
1. Quantifizierbare Daten2. Exakte Definitionen3. geeignete Messung/Erhebung

Methoden II – Stefan Jahr 6
Vorteile von Statistik
• Möglichkeit der Präzisierung
• Verallgemeinerbarkeit von Stichprobenergebnissen
• Genauigkeit und Sicherheit der Ergebnisse einschätzbar
• Modellrechnungen möglich

Methoden II – Stefan Jahr 7
Nachteile von Statistik
• Keine Aussagen zur inhaltlichen Bedeutsamkeit der durchgeführten Untersuchung
• Liefert keine Kriterien für die notwendigen Beobachtungsgrößen
• Keine Anhaltspunkte für die Wahl des Erhebungsinstrumentes
• Keine inhaltliche Interpretation
• Kann sich gegen Voraussetzungsverletzungen nicht wehren

Methoden II – Stefan Jahr 8
Ablauf einer statistischen Untersuchung
• Codeplanerstellung
• Dateneingabe
• Formulierung der statistischen Hypothesen
• Untersuchung der benötigten Variablen im Datensatz und gegebenenfalls Datenbereinigung und Datentransformation
• Allgemeine Voraussetzungsprüfung
• Wahl des statistischen Verfahrens
• Spezielle Voraussetzungsprüfung
• Durchführung des statistischen Verfahrens und Interpretation derErgebnisse

Methoden II – Stefan Jahr 9
Kursablauf
SPSS IX: Ausblick auf multiple Regressionsanalyse4.2
SPSS IIX: Lineare Regressionsanalyse II28.1.
SPSS I: Programm- und Versionshistorie, Programmmodule, Struktur, Menü, Fenster, Hilfe, Syntaxgrammatik, Programmoptionen
5.11.
Abschlussklausur: 10-12 Uhr HS 146 ÚHG11.2.
SPSS VIII: Lineare Regressionsanalyse I21.1.
SPSS VII: Zusammenhangsmaße II14.1.
SPSS VI: Zusammenhangsmaße I7.1.
SPSS V: Kreuztabellenanalyse17.12.
SPSS IV: Datentransformation und –manipulationen, Indexbildung10.12.
SPSS III: Mittelwerte und Streuungsmaße, Darstellungsformen: Tabellen und Grafiken in SPSS, Word und Excel, Ergebnissexport
3.12.
SPSS II: Häufigkeiten, Deskriptive Maßzahlen26.11.
Auswertung III: Indifferenz und Assoziation, PRE-InterpretationAuswertung IV: Kreuztabellenanalyse, Zusammenhangsmaße
19.11.
Auswertung II: Prüfung auf NV, Häufigkeiten, Mittelwerte und Streuungsmaße12.11.
Auswertung I: Vom Fragebogen zur Datenmatrix, Codeplan, Datenorganisation, Auswertungsstrategien, Fragebogen zur Erstellung eines Datensatzes für den Kurs
29.10.
Organisatorisches, Vorstellung der Themen, Einführung22.10

Methoden II – Stefan Jahr 10
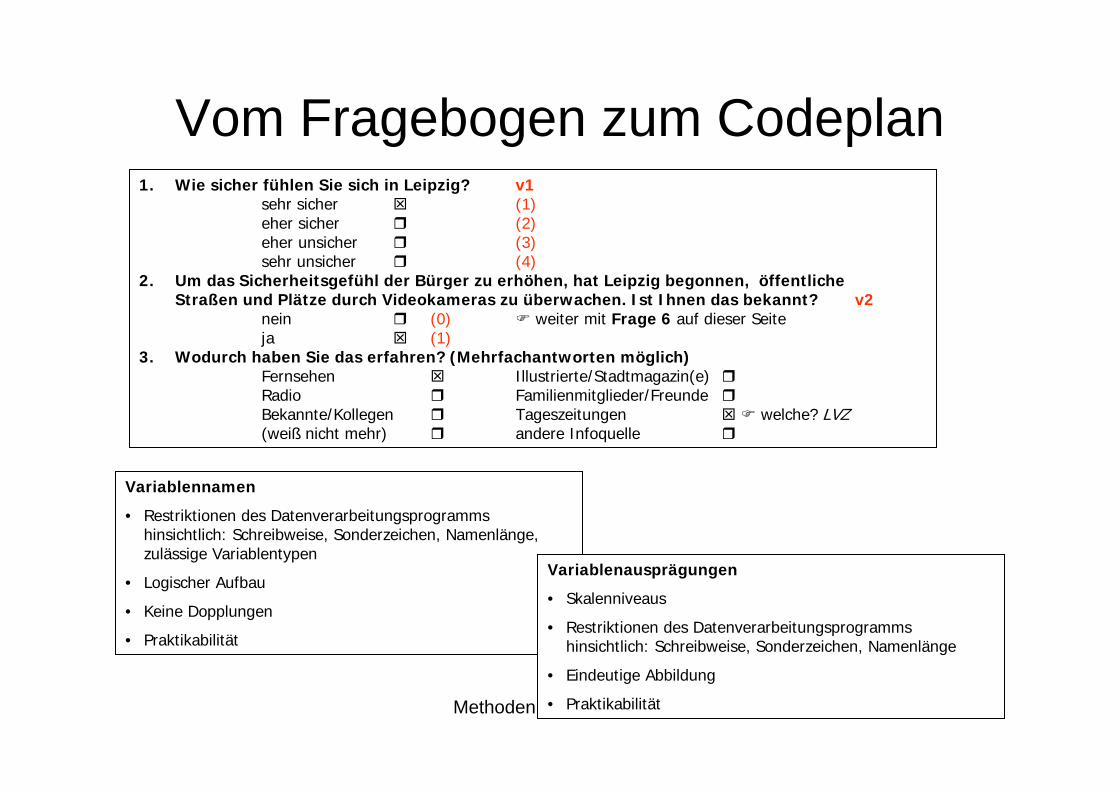
Vom Fragebogen zum Codeplan1. Wie sicher fühlen Sie sich in Leipzig?
sehr sichereher sichereher unsichersehr unsicher
2. Um das Sicherheitsgefühl der Bürger zu erhöhen, hat Leipzig begonnen, öffentlicheStraßen und Plätze durch Videokameras zu überwachen. Ist Ihnen das bekannt?
nein weiter mit Frage 6 auf dieser Seiteja
3. Wodurch haben Sie das erfahren? (Mehrfachantworten möglich)Fernsehen Illustrierte/Stadtmagazin(e)Radio Familienmitglieder/FreundeBekannte/Kollegen Tageszeitungen welche? LVZ(weiß nicht mehr) andere Infoquelle
Methoden II – Stefan Jahr 11
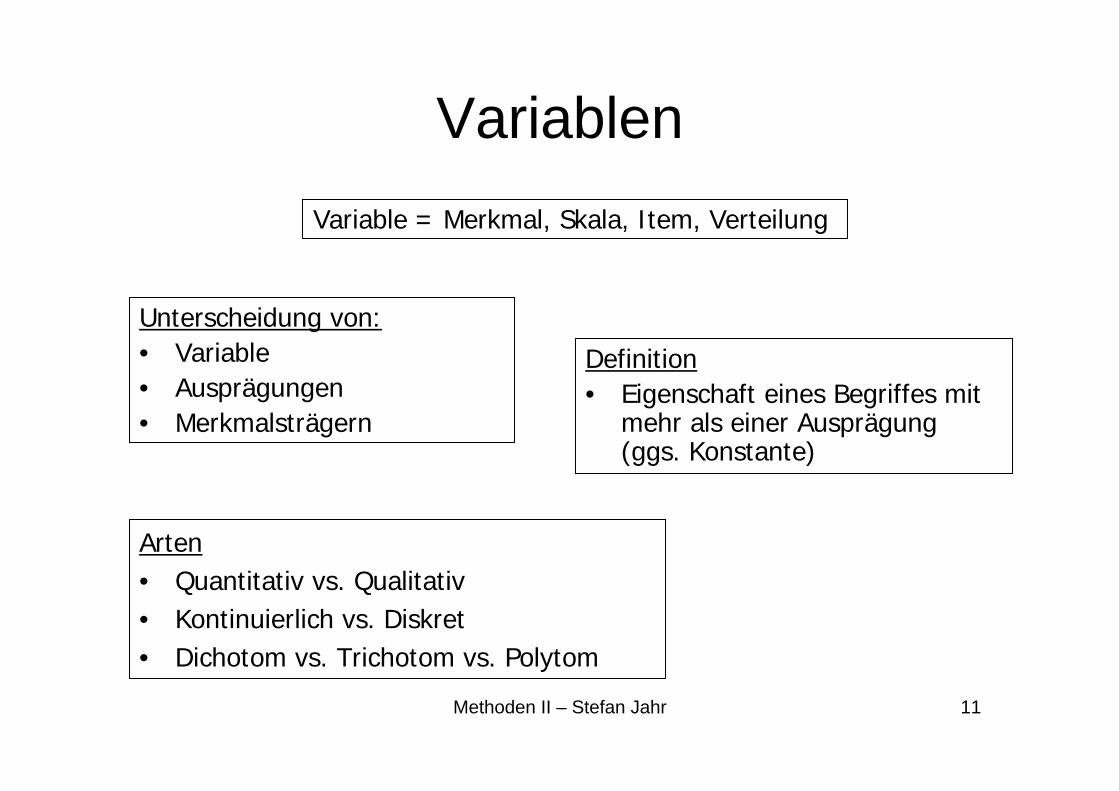
Variablen
Unterscheidung von:• Variable• Ausprägungen• Merkmalsträgern
Definition• Eigenschaft eines Begriffes mit
mehr als einer Ausprägung (ggs. Konstante)
Arten• Quantitativ vs. Qualitativ• Kontinuierlich vs. Diskret• Dichotom vs. Trichotom vs. Polytom
Variable = Merkmal, Skala, Item, Verteilung
Methoden II – Stefan Jahr 12
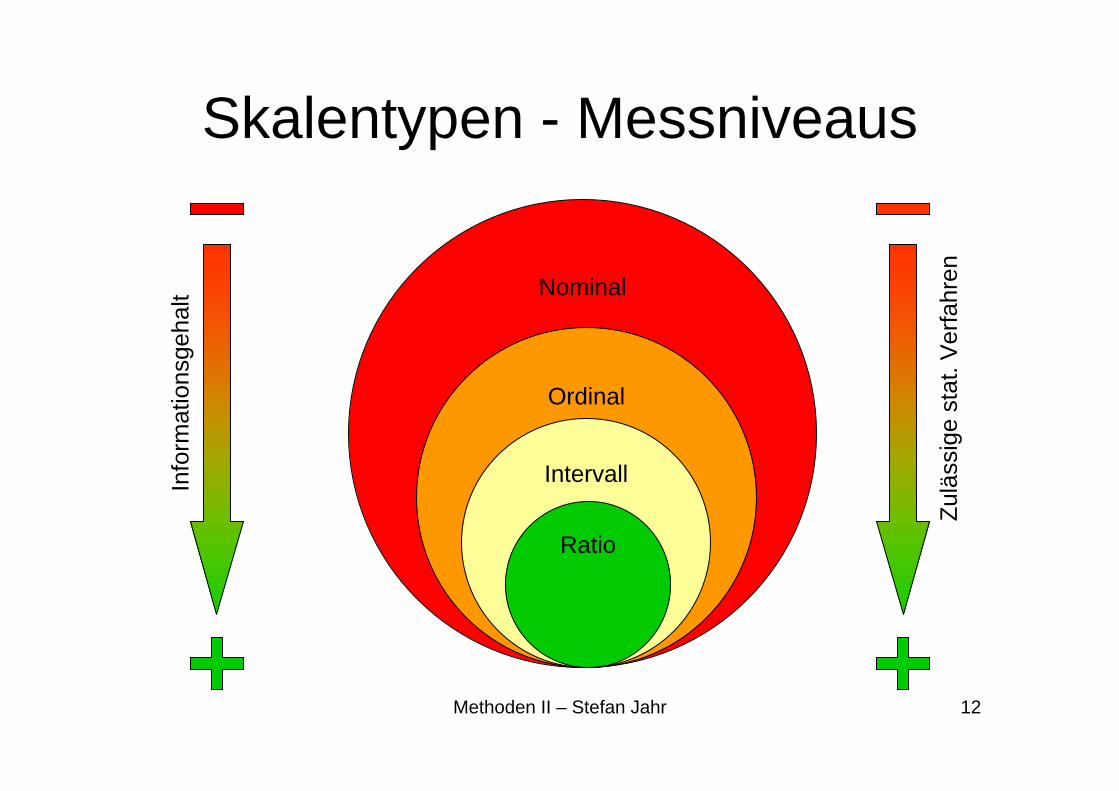
Skalentypen - Messniveaus
Nominal
Ordinal
Intervall
Ratio
Info
rmat
ions
geha
lt
Zulä
ssig
e st
at. V
erfa
hren
Methoden II – Stefan Jahr 13
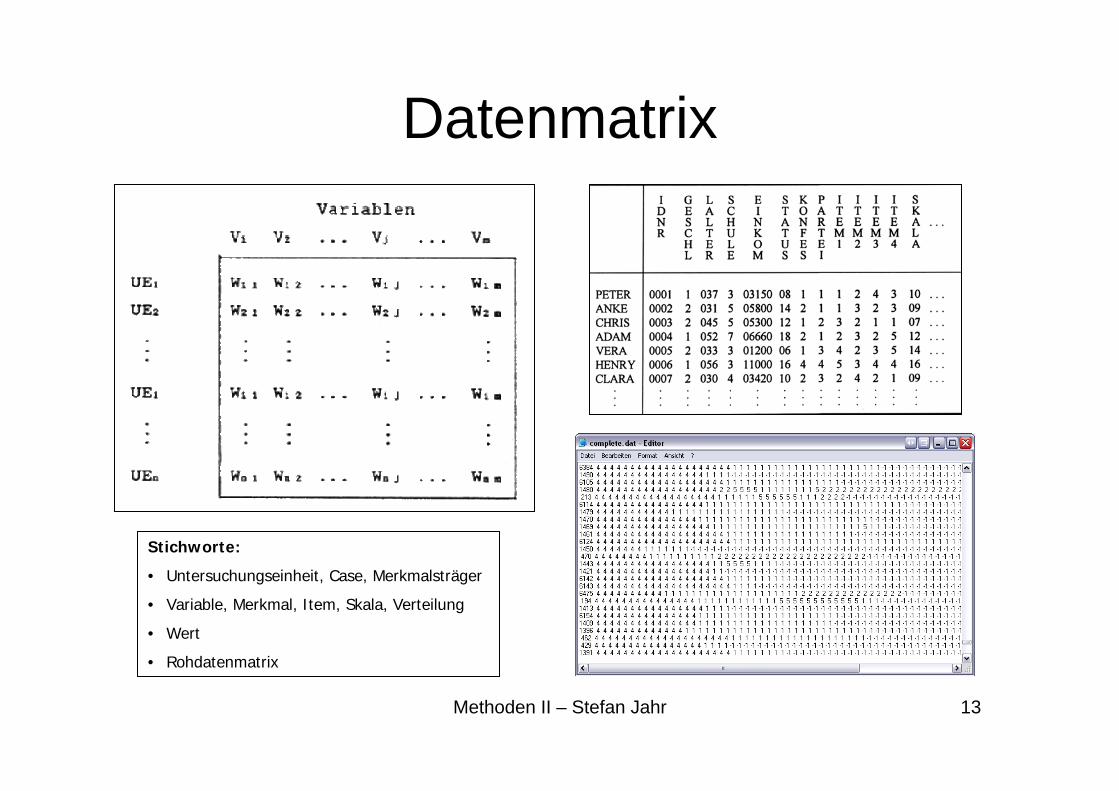
Datenmatrix
Stichworte:
• Untersuchungseinheit, Case, Merkmalsträger
• Variable, Merkmal, Item, Skala, Verteilung
• Wert
• Rohdatenmatrix

Methoden II – Stefan Jahr 14
Datenorganisationsformen (I)
• Standardformat
Methoden II – Stefan Jahr 15
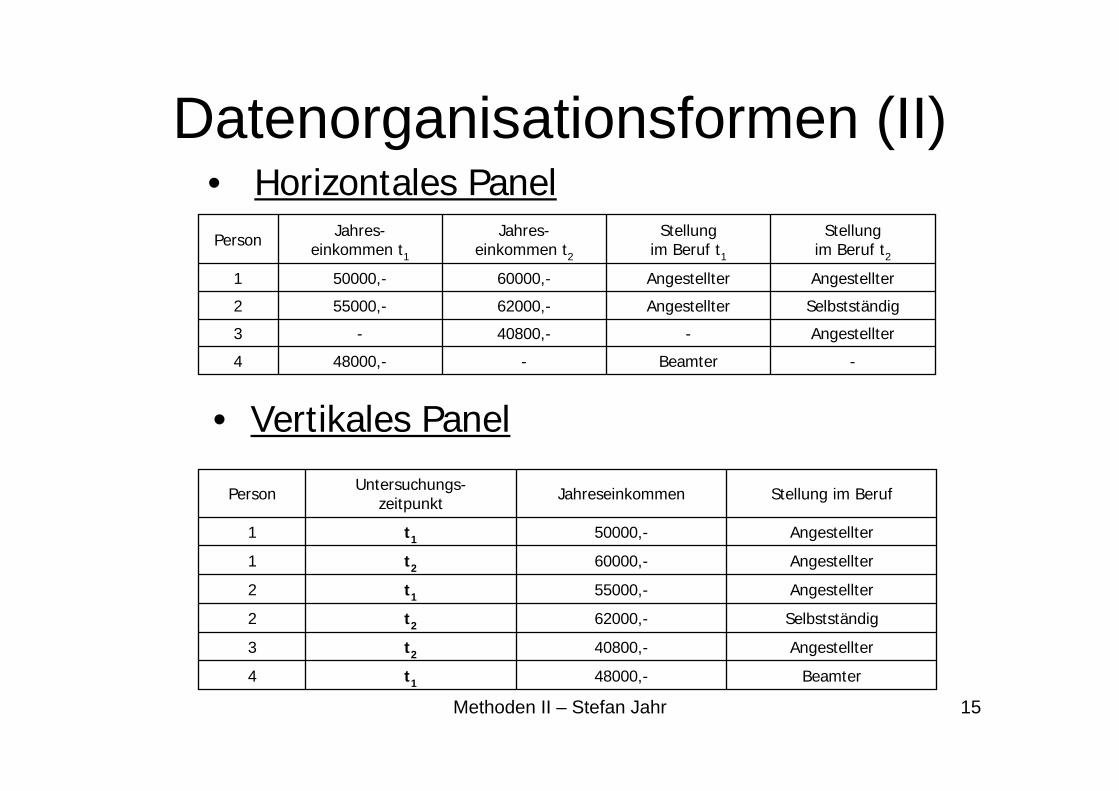
Datenorganisationsformen (II)• Horizontales Panel
-
40800,-
62000,-
60000,-
Jahres-einkommen t2
Beamter
-
Angestellter
Angestellter
Stellungim Beruf t1
-48000,-4
Angestellter-3
Selbstständig55000,-2
Angestellter50000,-1
Stellungim Beruf t2
Jahres-einkommen t1
Person
• Vertikales Panel
t1
t2
t2
t1
t2
t1
Untersuchungs-zeitpunkt
Beamter
Angestellter
Selbstständig
Angestellter
Angestellter
Angestellter
Stellung im Beruf
48000,-4
40800,-3
62000,-2
55000,-2
60000,-1
50000,-1
JahreseinkommenPerson
Methoden II – Stefan Jahr 16
Vom Fragebogen zum Codeplan1. Wie sicher fühlen Sie sich in Leipzig? v1
sehr sicher (1)eher sicher (2)eher unsicher (3)sehr unsicher (4)
2. Um das Sicherheitsgefühl der Bürger zu erhöhen, hat Leipzig begonnen, öffentlicheStraßen und Plätze durch Videokameras zu überwachen. Ist Ihnen das bekannt? v2
nein (0) weiter mit Frage 6 auf dieser Seiteja (1)
3. Wodurch haben Sie das erfahren? (Mehrfachantworten möglich)Fernsehen Illustrierte/Stadtmagazin(e)Radio Familienmitglieder/FreundeBekannte/Kollegen Tageszeitungen welche? LVZ(weiß nicht mehr) andere Infoquelle
Variablennamen
• Restriktionen des Datenverarbeitungsprogramms hinsichtlich: Schreibweise, Sonderzeichen, Namenlänge, zulässige Variablentypen
• Logischer Aufbau
• Keine Dopplungen
• Praktikabilität
Variablenausprägungen
• Skalenniveaus
• Restriktionen des Datenverarbeitungsprogramms hinsichtlich: Schreibweise, Sonderzeichen, Namenlänge
• Eindeutige Abbildung
• Praktikabilität
Methoden II – Stefan Jahr 17
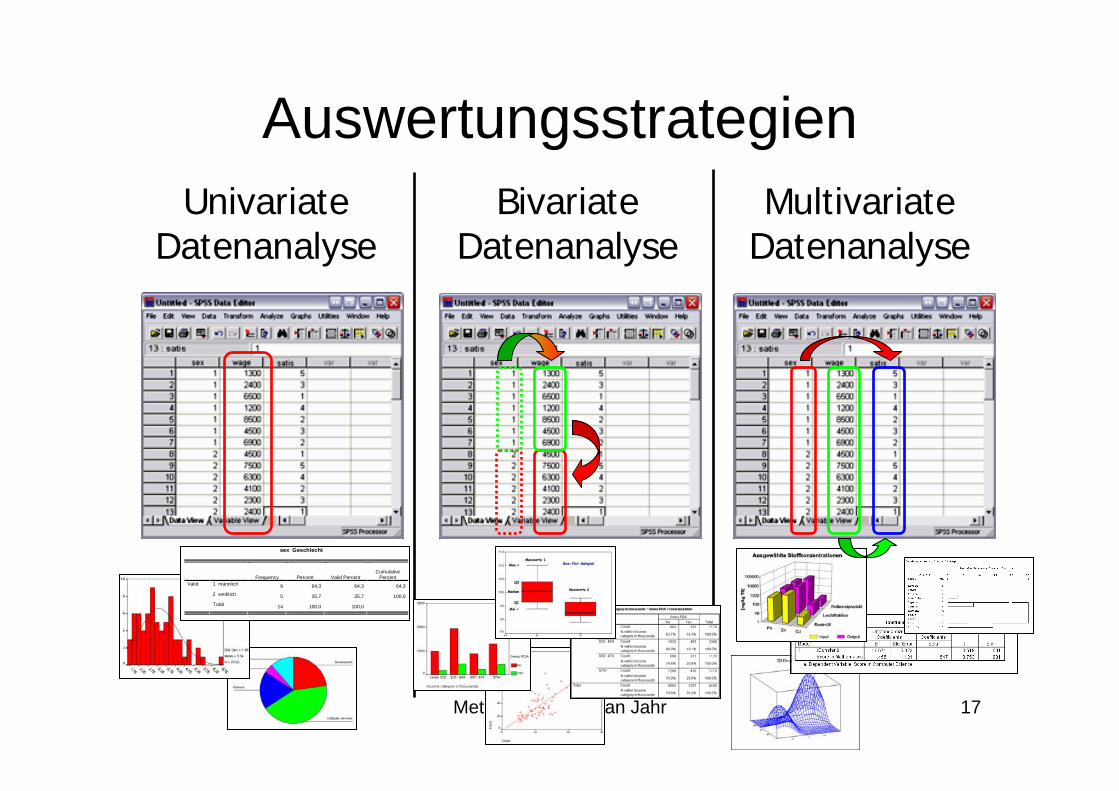
AuswertungsstrategienUnivariate
DatenanalyseBivariate
DatenanalyseMultivariate
Datenanalyse
sex Geschlecht
Frequency Percent Valid Percent Cumulative
Percent 1 männlich 9 64,3 64,3 64,32 weiblich 5 35,7 35,7 100,0
Valid
Total 14 100,0 100,0

Methoden II – Stefan Jahr 18
SPSS – Allgemein
• Superior Performing Statistical Software– Alter Name: Statistical Package for the Social Sciences
• 1965 von Norman Nie und Dale Bent an der Stanford University entwickelt– 1968 Teamerweiterung mit Hadlai Hull– In FORTRAN programmiert– Erstes zusammenhängendes Statistikpaket– 1981 für IBM-kompatible PC weiterentwickelt
(SPSS/PC+)– 1992 für Windows portiert
• Aktuelle Version: 15.0• Modularer Aufbau
Methoden II – Stefan Jahr 19
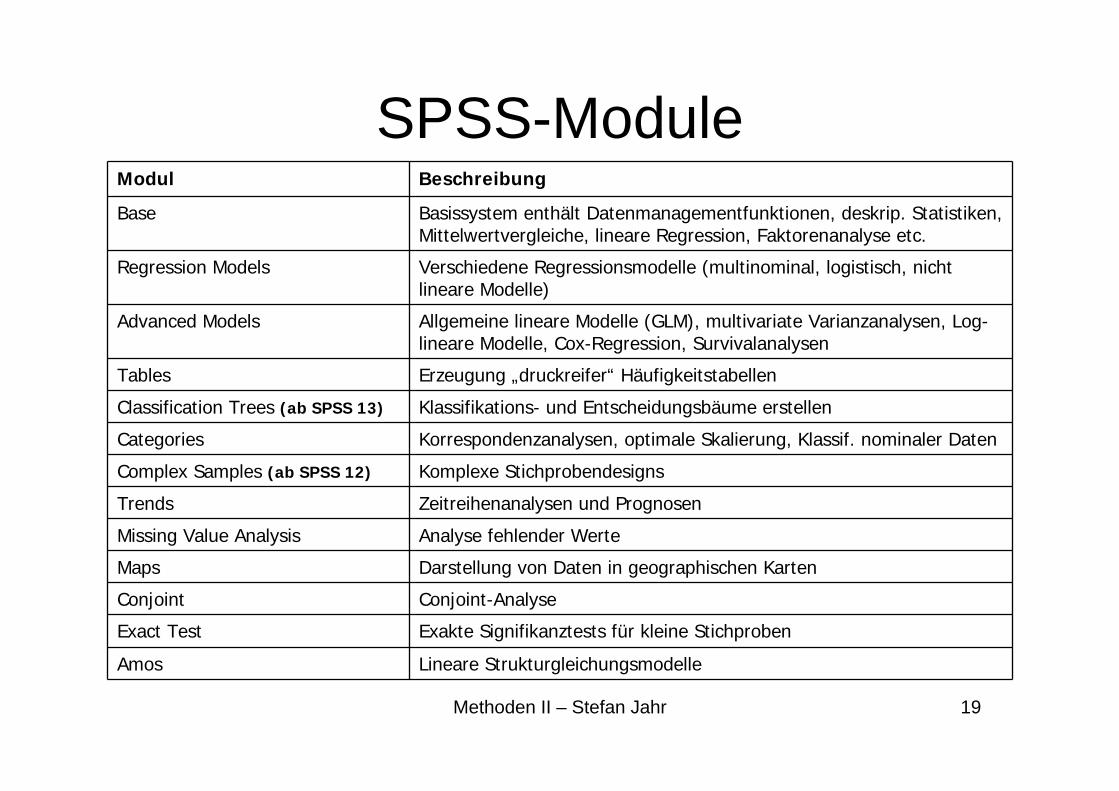
SPSS-Module
Korrespondenzanalysen, optimale Skalierung, Klassif. nominaler DatenCategories
Erzeugung „druckreifer“ HäufigkeitstabellenTables
Lineare StrukturgleichungsmodelleAmos
Analyse fehlender WerteMissing Value Analysis
Komplexe StichprobendesignsComplex Samples (ab SPSS 12)
Klassifikations- und Entscheidungsbäume erstellenClassification Trees (ab SPSS 13)
Verschiedene Regressionsmodelle (multinominal, logistisch, nichtlineare Modelle)
Regression Models
Exakte Signifikanztests für kleine StichprobenExact Test
Conjoint-AnalyseConjoint
Darstellung von Daten in geographischen KartenMaps
Zeitreihenanalysen und PrognosenTrends
Allgemeine lineare Modelle (GLM), multivariate Varianzanalysen, Log-lineare Modelle, Cox-Regression, Survivalanalysen
Advanced Models
Basissystem enthält Datenmanagementfunktionen, deskrip. Statistiken, Mittelwertvergleiche, lineare Regression, Faktorenanalyse etc.
Base
BeschreibungModul

Methoden II – Stefan Jahr 20
SPSS-Vorteile• Umfangreiche Datenmengen bearbeitbar
(32768 Variablen und 2,15 Billionen Fälle bis SPSS9.x; ab SPSS10 2,15 Billionen Variablen und Fälle; Excel kann nur 65.536 Datenzeilen und XX Variablen bearbeiten)
• Moderate Hardwareanforderungen(z.B. geringerer Speicherverbrauch im vgl. zu TDA)
• Gute Symbiose aus menü- und syntaxgeführter Bedienung
• Relativ leicht zu erlernen• Im Vergleich recht gute Darstellung der Ergebnisse• Gute Export- und Importfunktionen
(ODBC-Quellen [Open Database Connectivity])
• Gute Interaktion mit Office-Programmen• Hoher Verbreitungsgrad
(Quasi-Standard)

Methoden II – Stefan Jahr 21
SPSS - Nachteile
• Recht teuer 12.131 € Neuanschaffung2690 € Lizenzverlängerung pro Jahr
– Studentenversion (1500 Fälle und 50 Variablen): bei http://www.statcon.defür 75.00 €
– 30 Tage voll funktionsfähige Demoversion nach Anmeldung: www.spss.com– Statistica: 998,00 € / Stata: 1215,00 € / TDA: kostenlos
• Recht rigide Datenorganisation• Schlechter Debugger der Syntax• Noch teilweise fehlerhafte Prozeduren enthalten• Einige (mittlerweile) wichtige Analyseverfahren
nicht oder nur halbherzig integriert(Korrespondenzanalyse – SIMCA, Verlaufdatenanalyse – TDA/STATA)

Methoden II – Stefan Jahr 22
Gefahren von Statistikpaketen
• Programmstruktur beeinflusst Forschungslogik– Forschungsfragen werden auf die Möglichkeiten des Programms
zugeschnitten
• Unvollständigkeit der Pakete– Man rechnet nicht mit dem optimalen, sondern mit dem vorhanden
Verfahren
• Leichtigkeit der Anwendung– Verfahren werden oft explorativ genutzt, ohne genaue Überlegungen
ihrer Verwendbarkeit anzustellen
Kein Test, der auf Wahrscheinlichkeitstheorie beruht, kann von sich aus nützliche Belege für die Richtigkeit oder Unrichtigkeit einer Hypothese liefern.
Neyman/Pearson 1933

Methoden II – Stefan Jahr 23
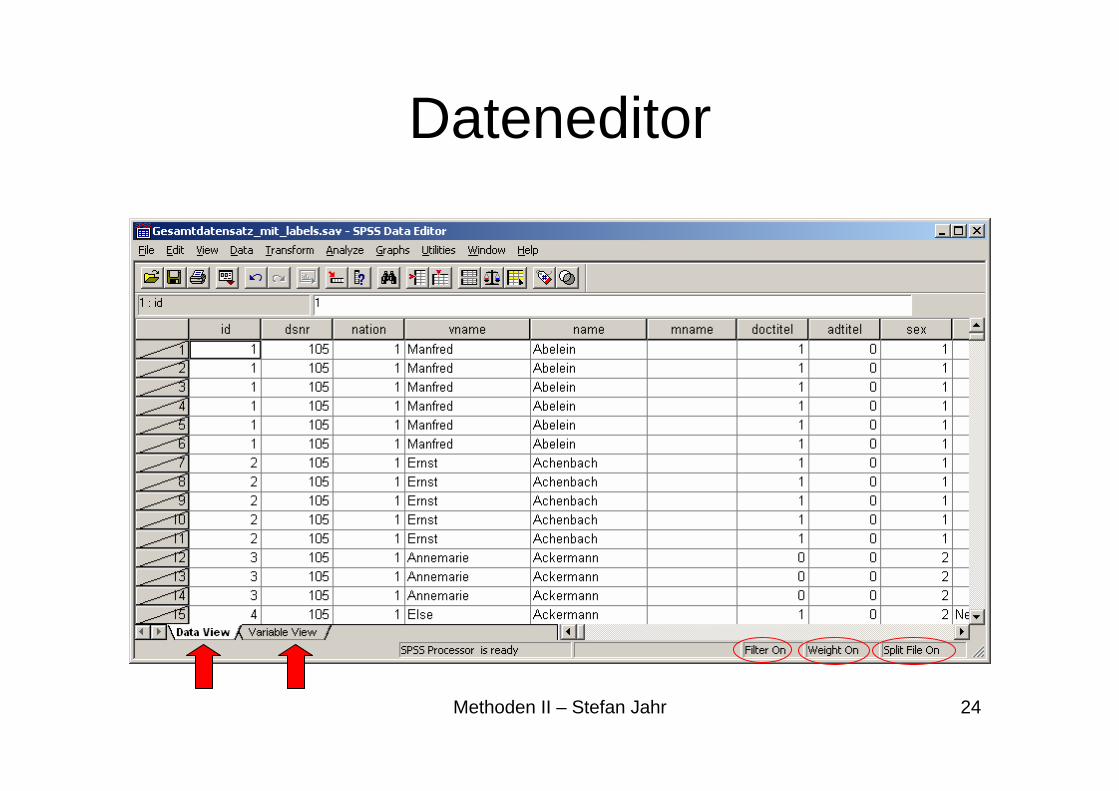
SPSS-Bestandteile• Dateneditor
– Hauptmodul von SPSS– Seit Version 10 mehrere Instanzen möglich– Spezielle Menüpunkte „Daten“ und „Transformieren“– Seit Version 7.XX und 13 neues Format der Datenspeicherung (nicht mit
älteren Versionen kompatibel)• Syntaxeditor
– Normaler Texteditor mit angepassten Menüs– Spezieller Menüpunkt „Ausführen“
• Ausgabeviewer– Über Menüpunkt „Optionen“ Wahl zw. neuem Viewer oder (altem)
Draft-Viewer• Diagrammeditor
– Nachbearbeitung der Diagramme• Pivot-Tabellen-Editor
– Nachbearbeitung von Tabellen
Methoden II – Stefan Jahr 24
Dateneditor

Methoden II – Stefan Jahr 25
Variablennamen
Normen:
• Darf maximal 8 Zeichen lang sein und keine Leerzeichen enthalten(ab SPSS 12: 64 Zeichen)
• Muss mit einem Buchstaben oder Zeichen: @ # $ beginnen, aber:
• # indiziert eine Arbeitsvariable (wird nicht im Editor angezeigt)
• $ indiziert eine Systemvariable (sind von SPSS vorgegeben)
• Alle Zeichen des Alphabets zulässig (keine Unterscheidung zwischen Groß- und Kleinschreibung)
• An zweiter Stelle alle Ziffern von 0 – 9 zulässig
• Dürfen nicht mit Punkt oder Unterstrich enden
• Bestimmte Schlüsselwörter ausgeschlossen (z.B. and, or, eq, lt, with)
• Umlaute und ß machen in älteren SPSS-Versionen Probleme
Methoden II – Stefan Jahr 26
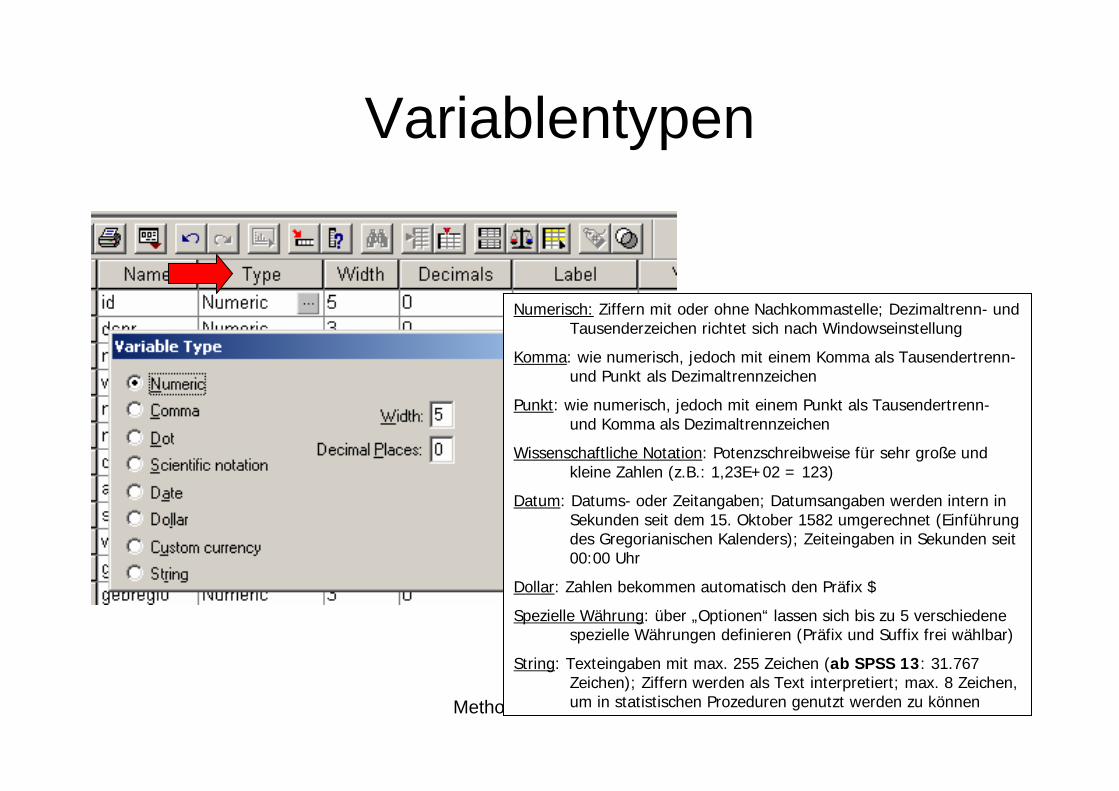
Variablentypen
Numerisch: Ziffern mit oder ohne Nachkommastelle; Dezimaltrenn- und Tausenderzeichen richtet sich nach Windowseinstellung
Komma: wie numerisch, jedoch mit einem Komma als Tausendertrenn-und Punkt als Dezimaltrennzeichen
Punkt: wie numerisch, jedoch mit einem Punkt als Tausendertrenn-und Komma als Dezimaltrennzeichen
Wissenschaftliche Notation: Potenzschreibweise für sehr große und kleine Zahlen (z.B.: 1,23E+02 = 123)
Datum: Datums- oder Zeitangaben; Datumsangaben werden intern in Sekunden seit dem 15. Oktober 1582 umgerechnet (Einführung des Gregorianischen Kalenders); Zeiteingaben in Sekunden seit 00:00 Uhr
Dollar: Zahlen bekommen automatisch den Präfix $
Spezielle Währung: über „Optionen“ lassen sich bis zu 5 verschiedene spezielle Währungen definieren (Präfix und Suffix frei wählbar)
String: Texteingaben mit max. 255 Zeichen (ab SPSS 13: 31.767 Zeichen); Ziffern werden als Text interpretiert; max. 8 Zeichen,um in statistischen Prozeduren genutzt werden zu können
Methoden II – Stefan Jahr 27
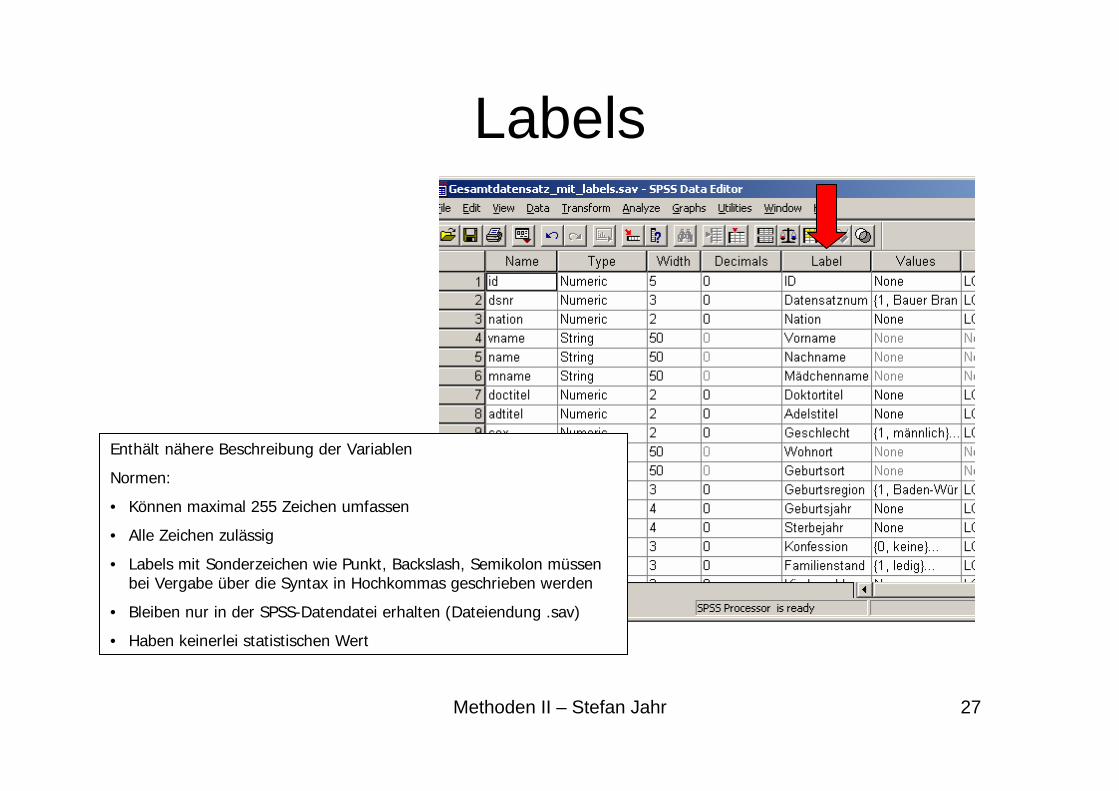
Labels
Enthält nähere Beschreibung der Variablen
Normen:
• Können maximal 255 Zeichen umfassen
• Alle Zeichen zulässig
• Labels mit Sonderzeichen wie Punkt, Backslash, Semikolon müssen bei Vergabe über die Syntax in Hochkommas geschrieben werden
• Bleiben nur in der SPSS-Datendatei erhalten (Dateiendung .sav)
• Haben keinerlei statistischen Wert
Methoden II – Stefan Jahr 28
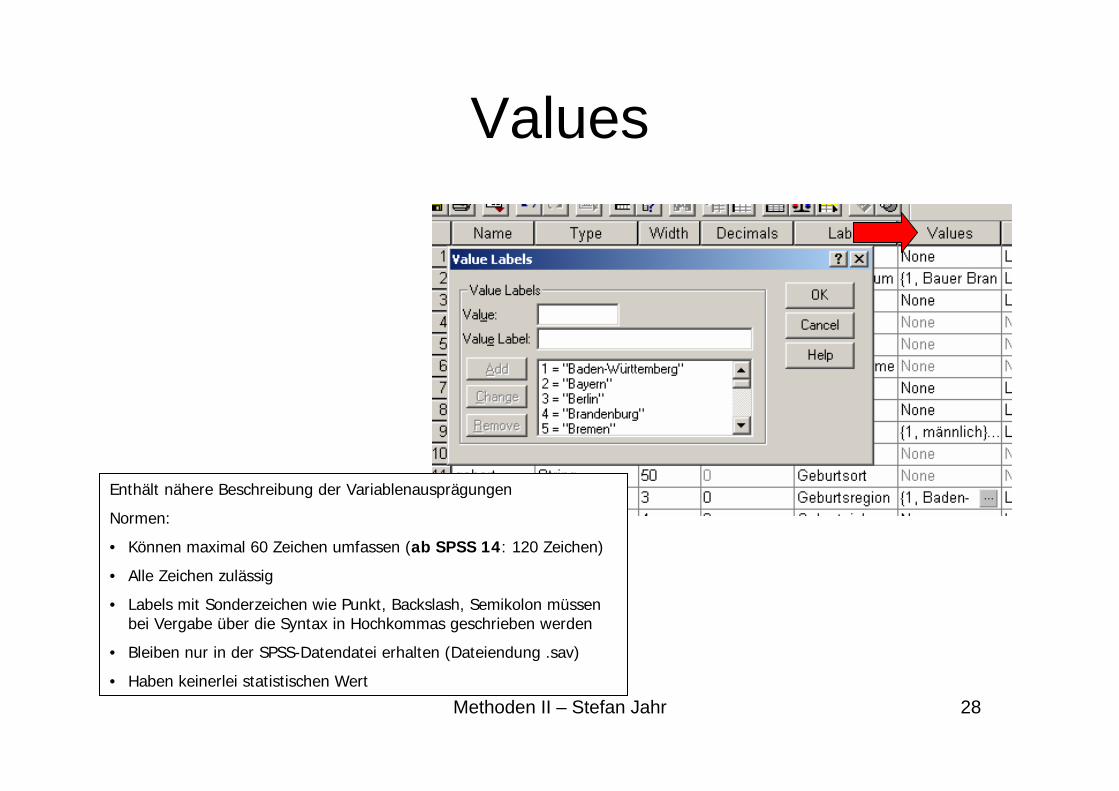
Values
Enthält nähere Beschreibung der Variablenausprägungen
Normen:
• Können maximal 60 Zeichen umfassen (ab SPSS 14: 120 Zeichen)
• Alle Zeichen zulässig
• Labels mit Sonderzeichen wie Punkt, Backslash, Semikolon müssen bei Vergabe über die Syntax in Hochkommas geschrieben werden
• Bleiben nur in der SPSS-Datendatei erhalten (Dateiendung .sav)
• Haben keinerlei statistischen Wert

Methoden II – Stefan Jahr 29
Missing values
Indizieren SPSS welche Werte bei Analysen ausgelassen werden sollen
Zwei Möglichkeiten der Wertebereichsangabe:
1. Drei einzelne (diskrete) Werte
2. Einen zusammenhängenden Wertebereich plus einen Wert außerhalb dieses Wertebereichs
Methoden II – Stefan Jahr 30
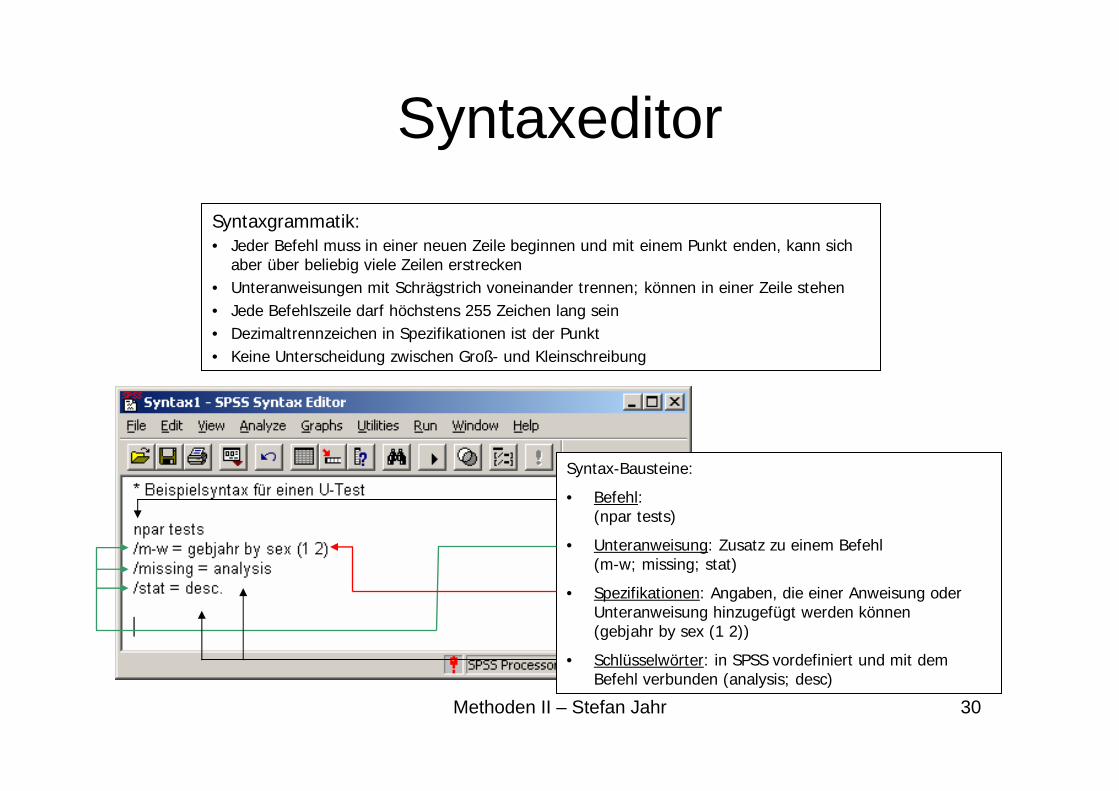
Syntaxeditor
Syntax-Bausteine:
• Befehl:(npar tests)
• Unteranweisung: Zusatz zu einem Befehl (m-w; missing; stat)
• Spezifikationen: Angaben, die einer Anweisung oder Unteranweisung hinzugefügt werden können(gebjahr by sex (1 2))
• Schlüsselwörter: in SPSS vordefiniert und mit dem Befehl verbunden (analysis; desc)
Syntaxgrammatik:• Jeder Befehl muss in einer neuen Zeile beginnen und mit einem Punkt enden, kann sich
aber über beliebig viele Zeilen erstrecken• Unteranweisungen mit Schrägstrich voneinander trennen; können in einer Zeile stehen• Jede Befehlszeile darf höchstens 255 Zeichen lang sein• Dezimaltrennzeichen in Spezifikationen ist der Punkt• Keine Unterscheidung zwischen Groß- und Kleinschreibung

Methoden II – Stefan Jahr 31
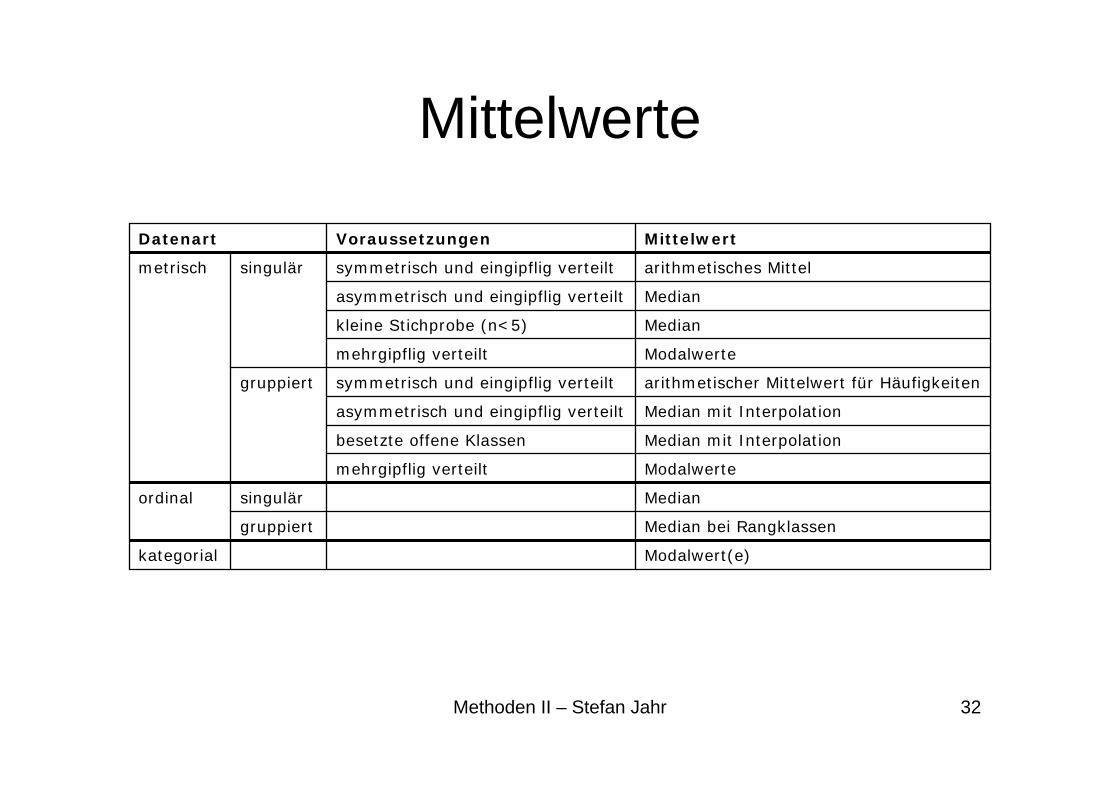
Mittelwerte• Modus
• Median
• Arithmetisches Mittel
1
1 *n
i ii
x f xn =
= ∑
50 11 12 2m m
m
nx x x Ff −⎛ ⎞= = − + −⎜ ⎟⎝ ⎠
%
maxhh x x Modus= = =
Methoden II – Stefan Jahr 32
Mittelwerte
Modalwert(e)kategorial
Median bei Rangklassengruppiert
Mediansingulärordinal
Modalwertemehrgipflig verteilt
Median mit Interpolationbesetzte offene Klassen
Median mit Interpolationasymmetrisch und eingipflig verteilt
arithmetischer Mittelwert für Häufigkeitensymmetrisch und eingipflig verteiltgruppiert
Modalwertemehrgipflig verteilt
Mediankleine Stichprobe (n<5)
Medianasymmetrisch und eingipflig verteilt
arithmetisches Mittelsymmetrisch und eingipflig verteiltsingulärmetrisch
MittelwertVoraussetzungenDatenart
Methoden II – Stefan Jahr 33
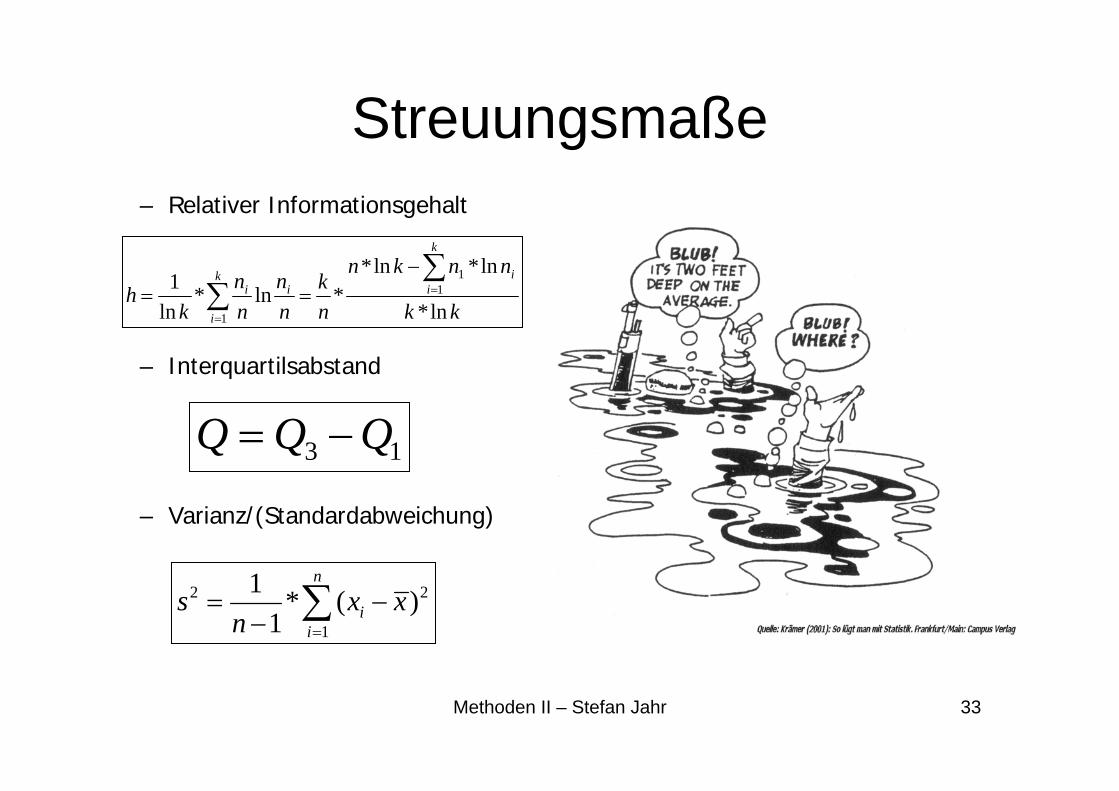
– Relativer Informationsgehalt
– Interquartilsabstand
– Varianz/(Standardabweichung)
13 QQQ −=
Streuungsmaße
2 2
1
1 * ( )1
n
ii
s x xn =
= −− ∑
∑∑
=
=
−==
k
i
k
ii
ii
kk
nnkn
nk
nn
nn
kh
1
11
ln*
ln*ln**ln*
ln1

Methoden II – Stefan Jahr 34
Streuungsmaße
Relativer Informationsgehaltkategorial
Unterschied der Quartilsklassengruppiert
Interquartilsbereichsingulärordinal
Relativer Informationsgehaltmehrgipflig verteilt
Quartilsabstand mit Interpolationbesetzte offene Klassen
Quartilsabstand mit Interpolationasymmetrisch und eingipflig verteilt
Standardabweichungen für Häufigkeitensymmetrisch und eingipflig verteiltgruppiert
Relativer Informationsgehaltmehrgipflig verteilt
Variationsbreitekleine Stichprobe (n<12)
Mittlerer Quartilsabstandasymmetrisch und eingipflig verteilt
Standardabweichungsymmetrisch und eingipflig verteiltsingulärmetrisch
StreuwertVoraussetzungenDatenart
Methoden II – Stefan Jahr 35
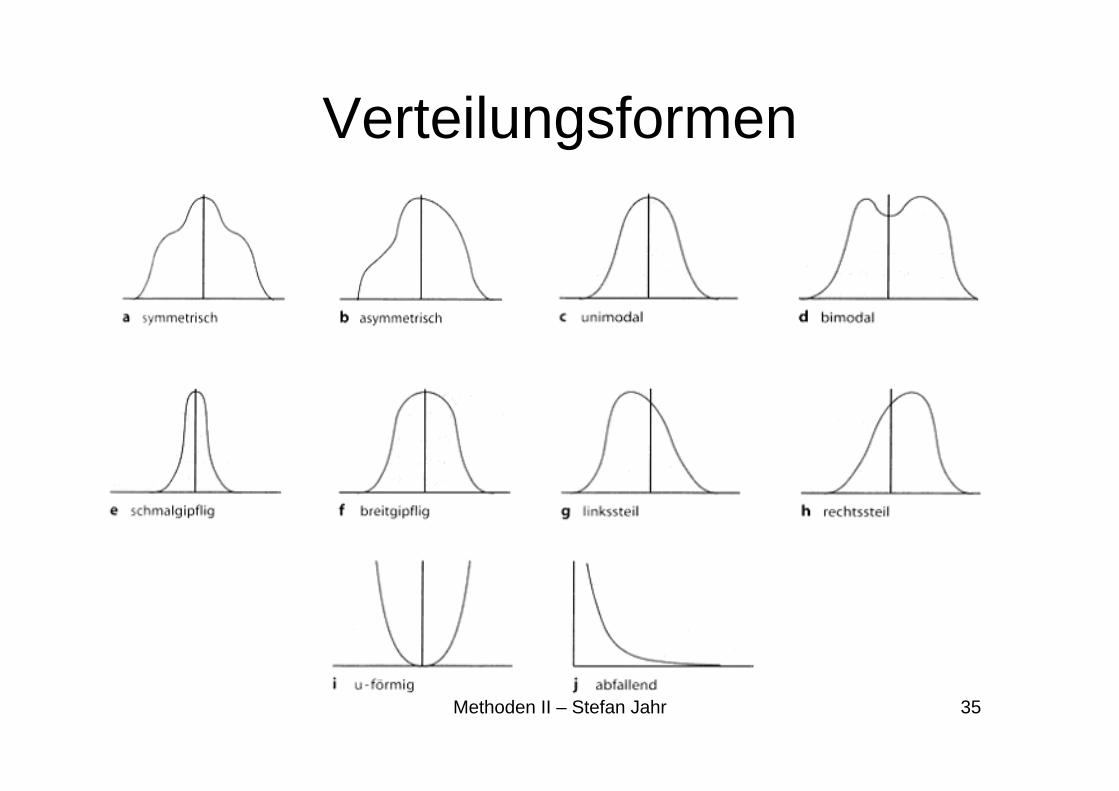
Verteilungsformen
Methoden II – Stefan Jahr 36
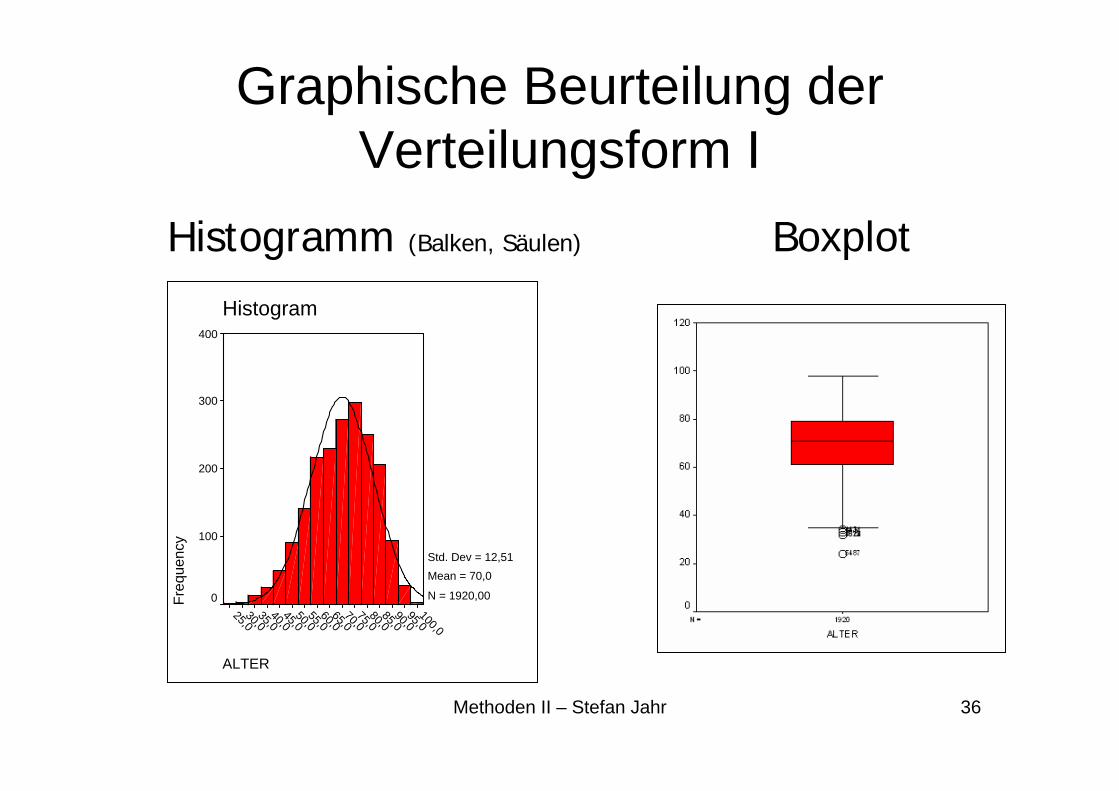
Graphische Beurteilung der Verteilungsform I
Histogramm (Balken, Säulen) Boxplot
ALTER
100,0
95,0
90,0
85,0
80,0
75,0
70,0
65,0
60,0
55,0
50,0
45,0
40,0
35,0
30,0
25,0
Histogram
Freq
uenc
y
400
300
200
100
0
Std. Dev = 12,51 Mean = 70,0
N = 1920,00
Methoden II – Stefan Jahr 37
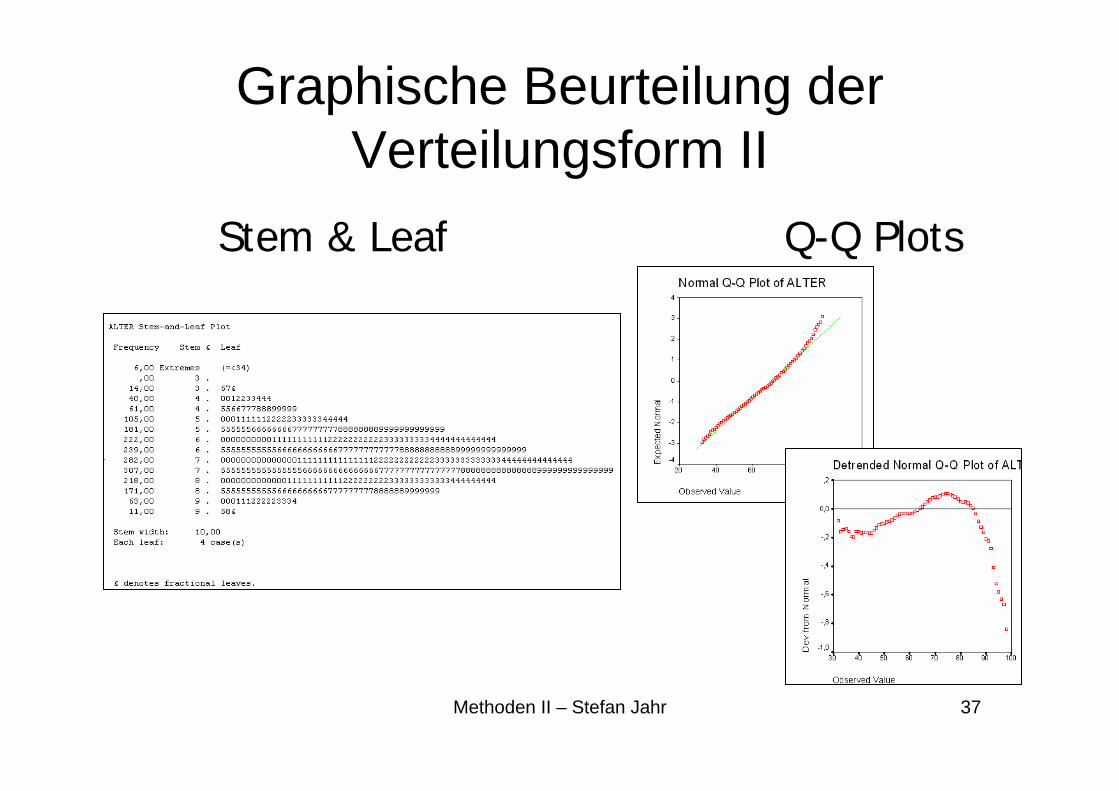
Graphische Beurteilung der Verteilungsform II
Stem & Leaf Q-Q Plots
Methoden II – Stefan Jahr 38
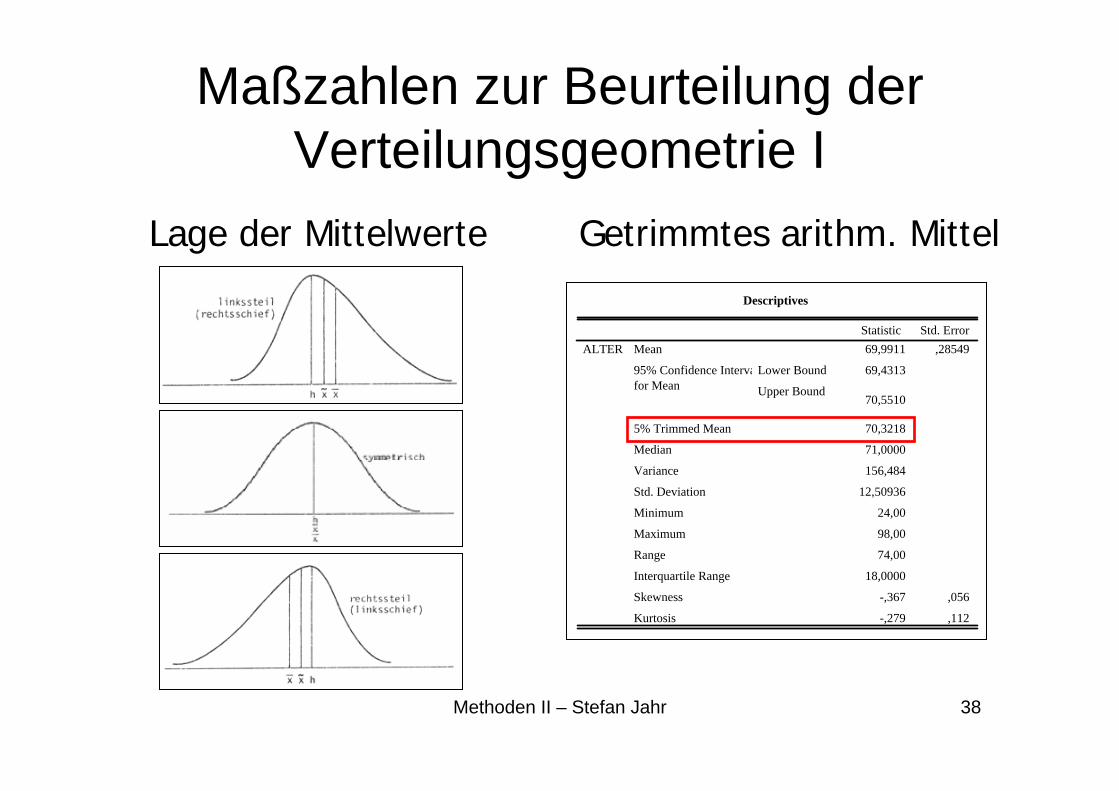
Maßzahlen zur Beurteilung der Verteilungsgeometrie I
Lage der Mittelwerte
Descriptives
69,9911 ,28549
69,4313
70,5510
70,3218
71,0000
156,484
12,50936
24,00
98,00
74,00
18,0000
-,367 ,056
-,279 ,112
Mean
Lower Bound
Upper Bound
95% Confidence Intervafor Mean
5% Trimmed Mean
Median
Variance
Std. Deviation
Minimum
Maximum
Range
Interquartile Range
Skewness
Kurtosis
ALTERStatistic Std. Error
Getrimmtes arithm. Mittel
Methoden II – Stefan Jahr 39
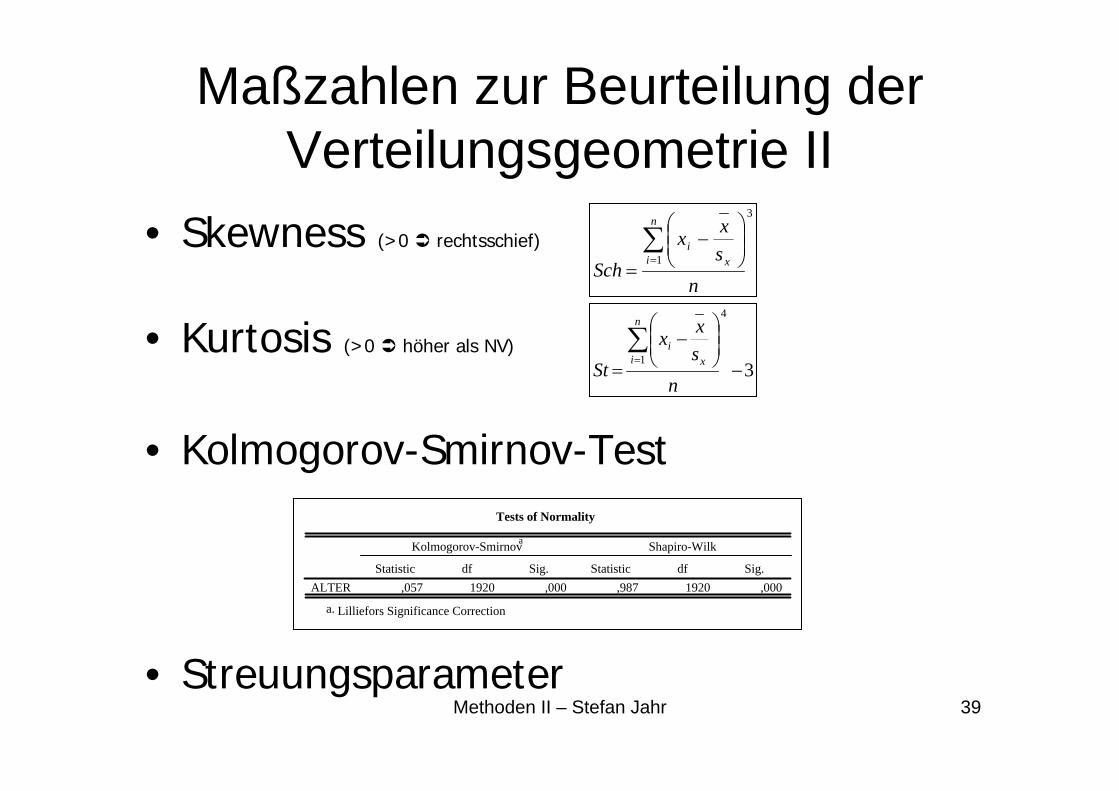
Maßzahlen zur Beurteilung der Verteilungsgeometrie II
• Skewness (>0 rechtsschief)
• Kurtosis (>0 höher als NV)
• Kolmogorov-Smirnov-Test
• Streuungsparameter
3
1
nsxx
Sch
n
i xi∑
=⎟⎟⎠
⎞⎜⎜⎝
⎛−
=
3
4
1−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=∑=
nsxx
St
n
i xi
Tests of Normality
,057 1920 ,000 ,987 1920 ,000ALTERStatistic df Sig. Statistic df Sig.
Kolmogorov-Smirnova Shapiro-Wilk
Lilliefors Significance Correctiona.
Methoden II – Stefan Jahr 40
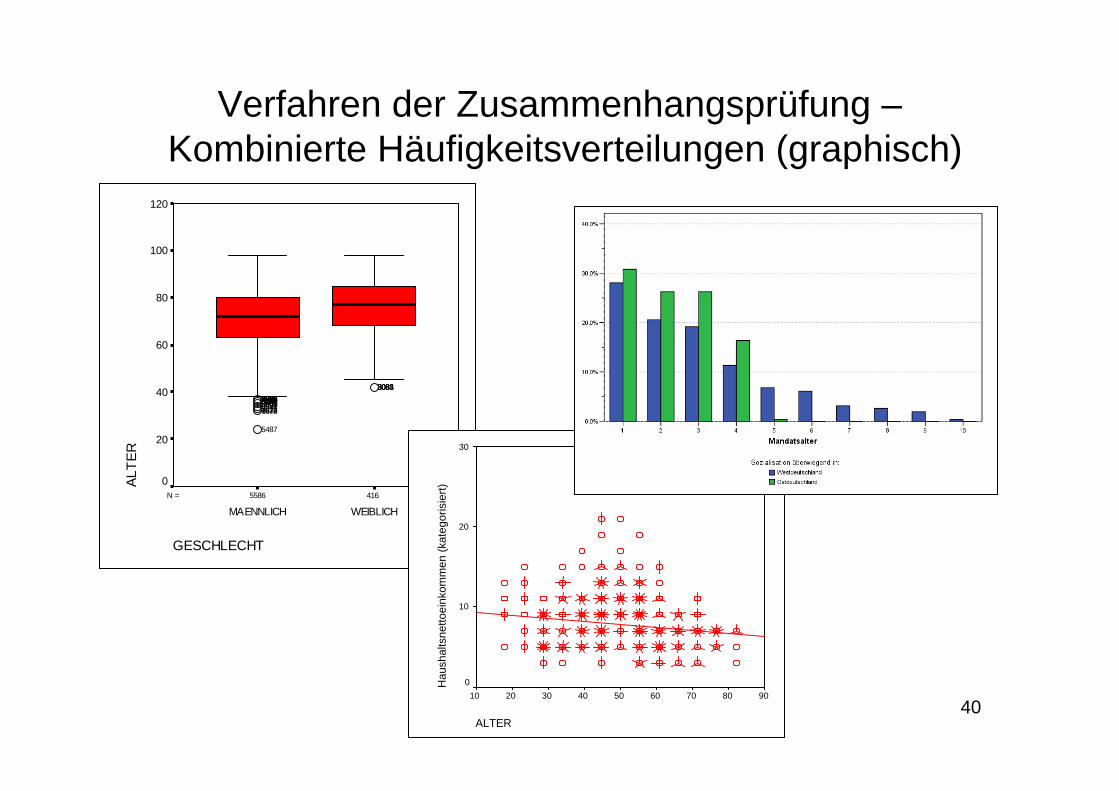
Verfahren der Zusammenhangsprüfung –Kombinierte Häufigkeitsverteilungen (graphisch)
4165586N =
GESCHLECHT
WEIBLICHMAENNLICH
ALTE
R
120
100
80
60
40
20
0
308430823083308538973028339238991716263898253391698862003413698734126199300369603005696130044431443250175016482416721673
5487
ALTER
908070605040302010
Hau
shal
tsne
ttoei
nkom
men
(kat
egor
isie
rt)30
20
10
0
Methoden II – Stefan Jahr 41
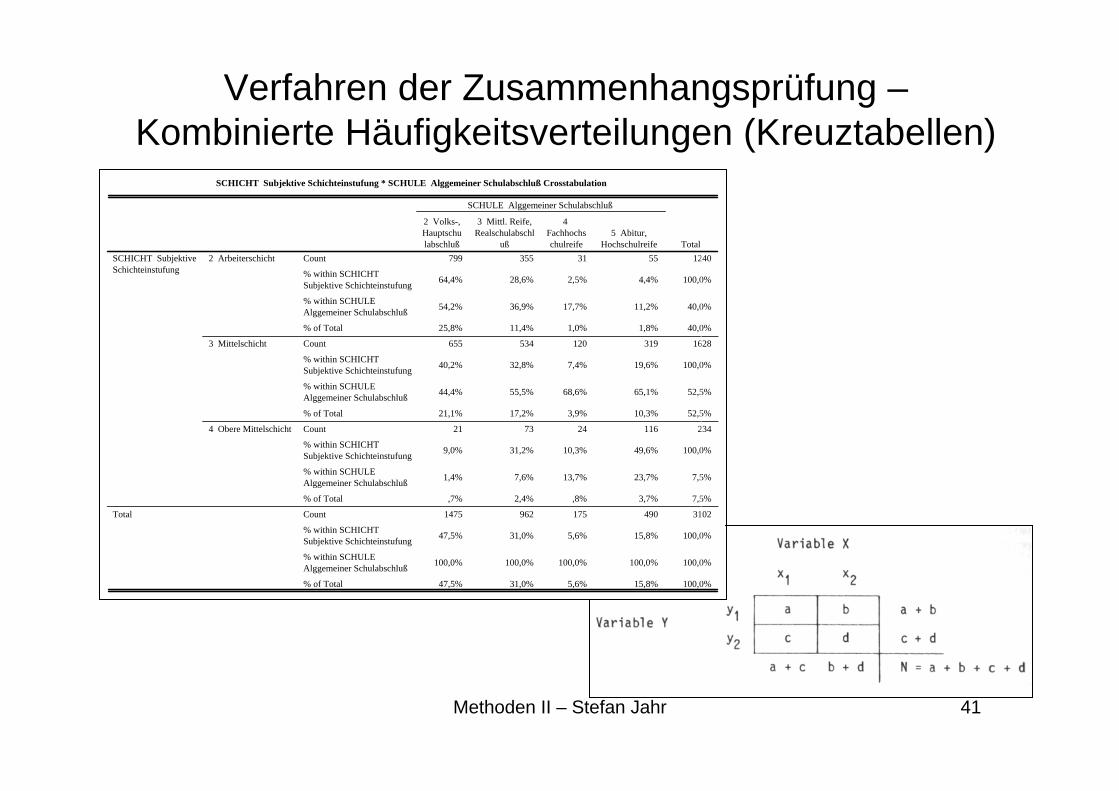
SCHICHT Subjektive Schichteinstufung * SCHULE Alggemeiner Schulabschluß Crosstabulation
799 355 31 55 1240
64,4% 28,6% 2,5% 4,4% 100,0%
54,2% 36,9% 17,7% 11,2% 40,0%
25,8% 11,4% 1,0% 1,8% 40,0%
655 534 120 319 1628
40,2% 32,8% 7,4% 19,6% 100,0%
44,4% 55,5% 68,6% 65,1% 52,5%
21,1% 17,2% 3,9% 10,3% 52,5%
21 73 24 116 234
9,0% 31,2% 10,3% 49,6% 100,0%
1,4% 7,6% 13,7% 23,7% 7,5%
,7% 2,4% ,8% 3,7% 7,5%
1475 962 175 490 3102
47,5% 31,0% 5,6% 15,8% 100,0%
100,0% 100,0% 100,0% 100,0% 100,0%
47,5% 31,0% 5,6% 15,8% 100,0%
Count
% within SCHICHT Subjektive Schichteinstufung
% within SCHULE Alggemeiner Schulabschluß
% of Total
Count
% within SCHICHT Subjektive Schichteinstufung
% within SCHULE Alggemeiner Schulabschluß
% of Total
Count
% within SCHICHT Subjektive Schichteinstufung
% within SCHULE Alggemeiner Schulabschluß
% of Total
Count
% within SCHICHT Subjektive Schichteinstufung
% within SCHULE Alggemeiner Schulabschluß
% of Total
2 Arbeiterschicht
3 Mittelschicht
4 Obere Mittelschicht
SCHICHT SubjektiveSchichteinstufung
Total
2 Volks-,Hauptschulabschluß
3 Mittl. Reife,Realschulabschl
uß
4 Fachhochschulreife
5 Abitur,Hochschulreife
SCHULE Alggemeiner Schulabschluß
Total
Verfahren der Zusammenhangsprüfung –Kombinierte Häufigkeitsverteilungen (Kreuztabellen)

Methoden II – Stefan Jahr 42
Zusammenhangsprüfung
• Begrifflichkeiten– Assoziation, Kontingenz, Korrelation– Kausalität und Korrelation
• Logiken der Zusammenhangsprüfung– Abweichung von der Indifferenz– Paarbildung– Fehlerreduktion bei der Vorhersage der
abhängigen Variable (PRE)
Methoden II – Stefan Jahr 43
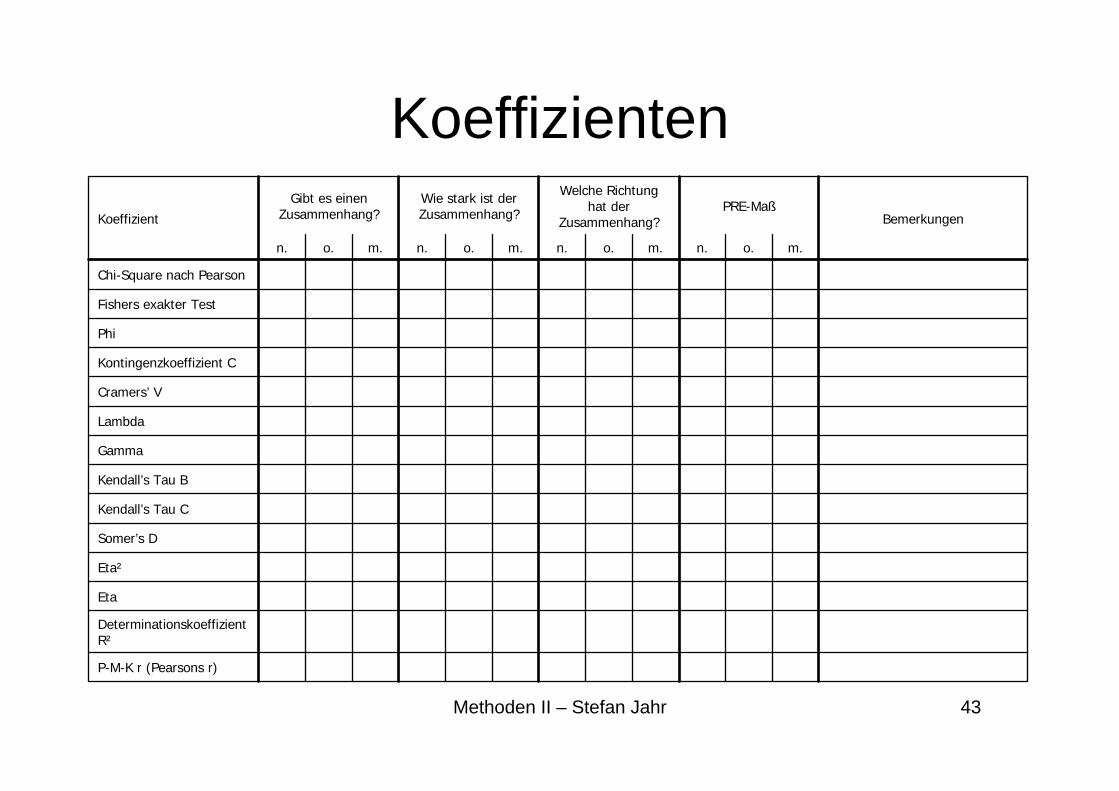
Koeffizienten
P-M-K r (Pearsons r)
Determinationskoeffizient R²
Eta
Eta²
Somer’s D
Kendall’s Tau C
Kendall’s Tau B
Gamma
Lambda
Cramers’ V
Kontingenzkoeffizient C
Phi
Fishers exakter Test
Chi-Square nach Pearson
m.o.n.m.o.n.m.o.n.m.o.n.
BemerkungenPRE-Maß
Welche Richtung hat der
Zusammenhang?
Wie stark ist der Zusammenhang?
Gibt es einen Zusammenhang?Koeffizient

Methoden II – Stefan Jahr 44
Variablen und Werte benennen
Benutzte Befehle/Schlüsselwörter:
VARIABLE LABELS
• Benennt eine Variable
• Kurzform: VAR LAB
VALUE LABELS
• Benennt die Ausprägungen einer Variable
• Kurzform: VAL LAB
MISSING VALUE
• Definiert bestimmte Werte in der Variable als fehlende Werte
• Als „missing value“ definierte Ausprägungen werden von SPSS in Analysen nicht berücksichtigt
• Nicht auf Variablentyp „String“ anwendbar
• Kurzform: MIS VAL
Methoden II – Stefan Jahr 45
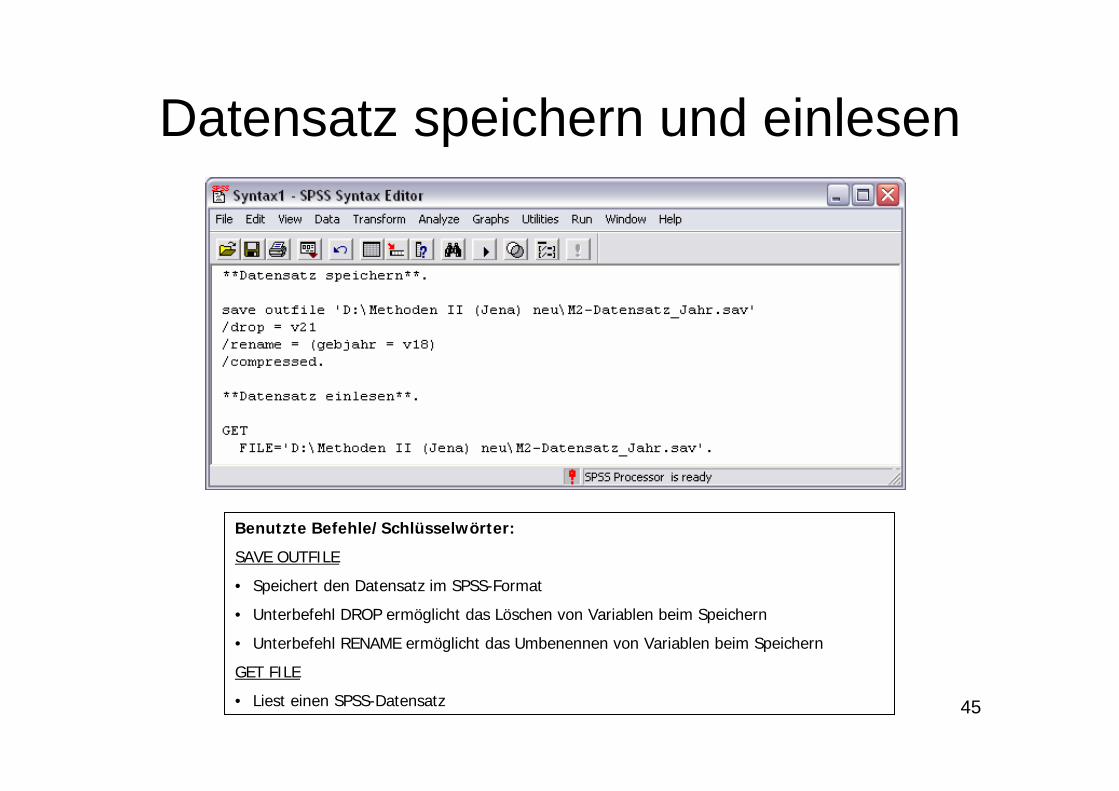
Datensatz speichern und einlesen
Benutzte Befehle/Schlüsselwörter:
SAVE OUTFILE
• Speichert den Datensatz im SPSS-Format
• Unterbefehl DROP ermöglicht das Löschen von Variablen beim Speichern
• Unterbefehl RENAME ermöglicht das Umbenennen von Variablen beim Speichern
GET FILE
• Liest einen SPSS-Datensatz
Methoden II – Stefan Jahr 46
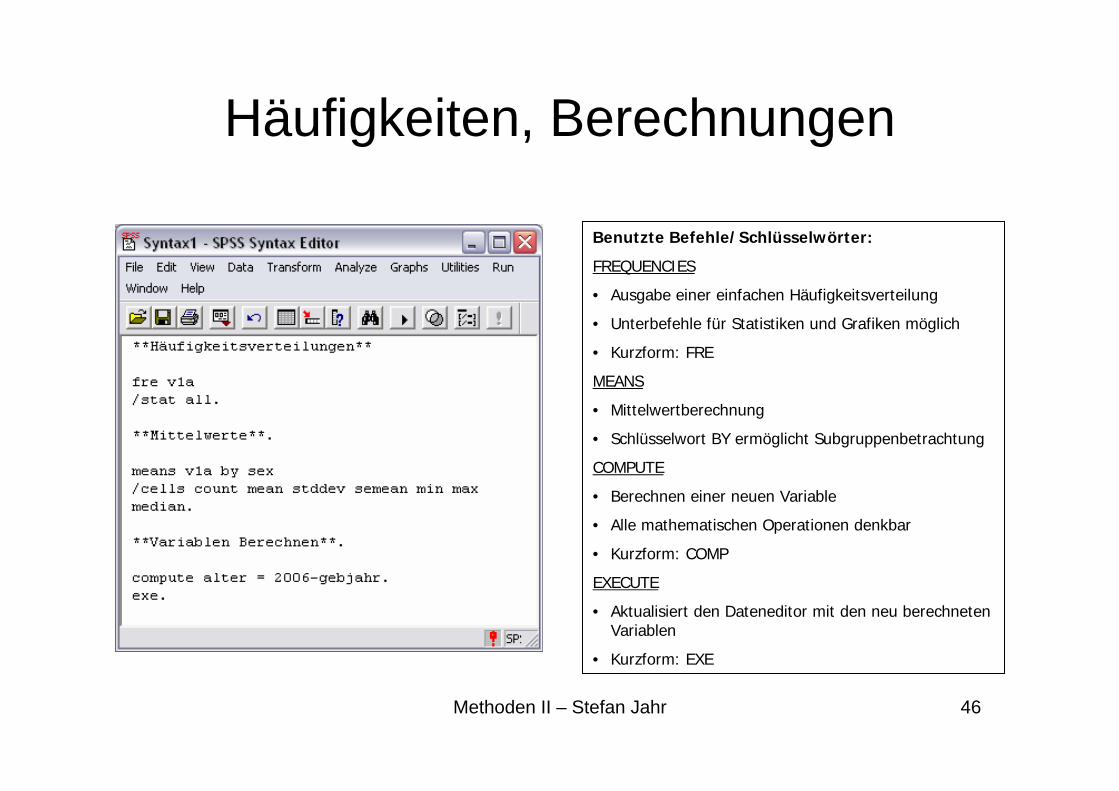
Häufigkeiten, Berechnungen
Benutzte Befehle/Schlüsselwörter:
FREQUENCIES
• Ausgabe einer einfachen Häufigkeitsverteilung
• Unterbefehle für Statistiken und Grafiken möglich
• Kurzform: FRE
MEANS
• Mittelwertberechnung
• Schlüsselwort BY ermöglicht Subgruppenbetrachtung
COMPUTE
• Berechnen einer neuen Variable
• Alle mathematischen Operationen denkbar
• Kurzform: COMP
EXECUTE
• Aktualisiert den Dateneditor mit den neu berechneten Variablen
• Kurzform: EXE

Methoden II – Stefan Jahr 47
Indexbildung mit Compute
Benutzte Befehle/Schlüsselwörter:
COMPUTE
• Schlüsselwort SUM führt eine einfache Addition der in Klammern genannten Variablen aus
• Schlüsselwort MEAN bildet den Durchschnittswert aus den in Klammern genannten Variablen. Diese sollten daher in der gleichen Einheit vorliegen.
Achtung: unterschiedliche Behandlung der fehlenden Werte in den gezeigten Alternativen

Methoden II – Stefan Jahr 48
Prüfung auf NV –Variablen umcodieren
Benutzte Befehle/Schlüsselwörter:
RECODE
• Ersetzt die Werte oder Wertebereiche einer Variable nach vorgegebenem Muster in entweder eine neue Variable (Schlüsselwort: INTO) oder in die selbe Variable (ohne Schlüsselbefehl).
• Kurzform: REC
Benutzte Befehle/Schlüsselwörter:
EXAMINE
• Gibt verschiedene Kennwerte, Grafiken und Tests aus, um Grad der Übereinstimmung mit der NV zu prüfen
• Schlüsselwort BY ermöglicht Subgruppenbetrachtung
• Kurzform: EXA
Methoden II – Stefan Jahr 49
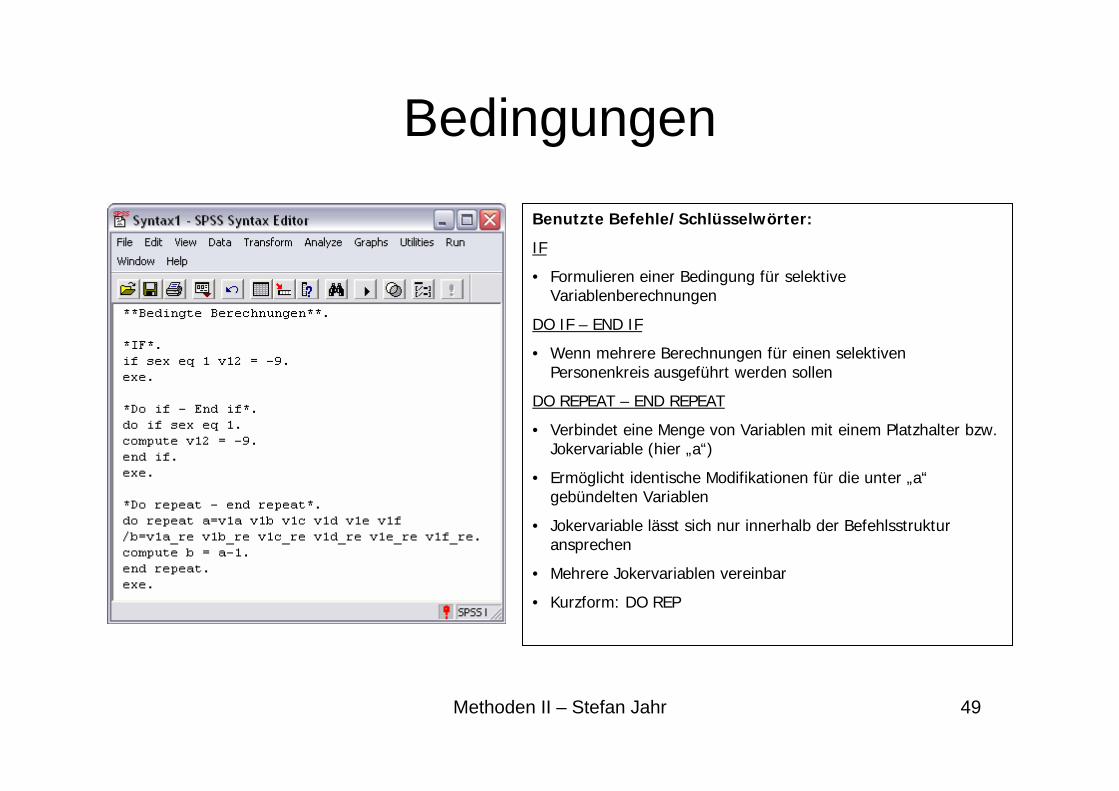
BedingungenBenutzte Befehle/Schlüsselwörter:
IF
• Formulieren einer Bedingung für selektive Variablenberechnungen
DO IF – END IF
• Wenn mehrere Berechnungen für einen selektiven Personenkreis ausgeführt werden sollen
DO REPEAT – END REPEAT
• Verbindet eine Menge von Variablen mit einem Platzhalter bzw. Jokervariable (hier „a“)
• Ermöglicht identische Modifikationen für die unter „a“ gebündelten Variablen
• Jokervariable lässt sich nur innerhalb der Befehlsstruktur ansprechen
• Mehrere Jokervariablen vereinbar
• Kurzform: DO REP
Methoden II – Stefan Jahr 50
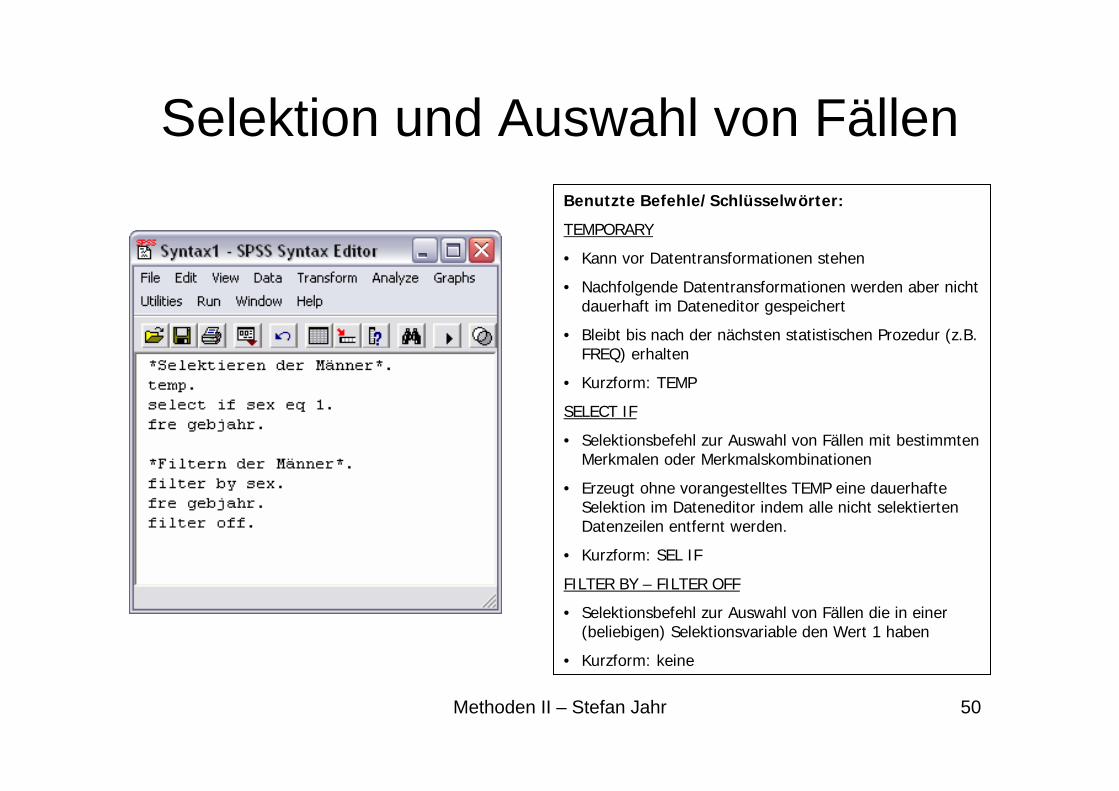
Selektion und Auswahl von FällenBenutzte Befehle/Schlüsselwörter:
TEMPORARY
• Kann vor Datentransformationen stehen
• Nachfolgende Datentransformationen werden aber nicht dauerhaft im Dateneditor gespeichert
• Bleibt bis nach der nächsten statistischen Prozedur (z.B. FREQ) erhalten
• Kurzform: TEMP
SELECT IF
• Selektionsbefehl zur Auswahl von Fällen mit bestimmten Merkmalen oder Merkmalskombinationen
• Erzeugt ohne vorangestelltes TEMP eine dauerhafte Selektion im Dateneditor indem alle nicht selektierten Datenzeilen entfernt werden.
• Kurzform: SEL IF
FILTER BY – FILTER OFF
• Selektionsbefehl zur Auswahl von Fällen die in einer (beliebigen) Selektionsvariable den Wert 1 haben
• Kurzform: keine
Methoden II – Stefan Jahr 51
Datensatz zur Analyse aufteilen -Werte zählen
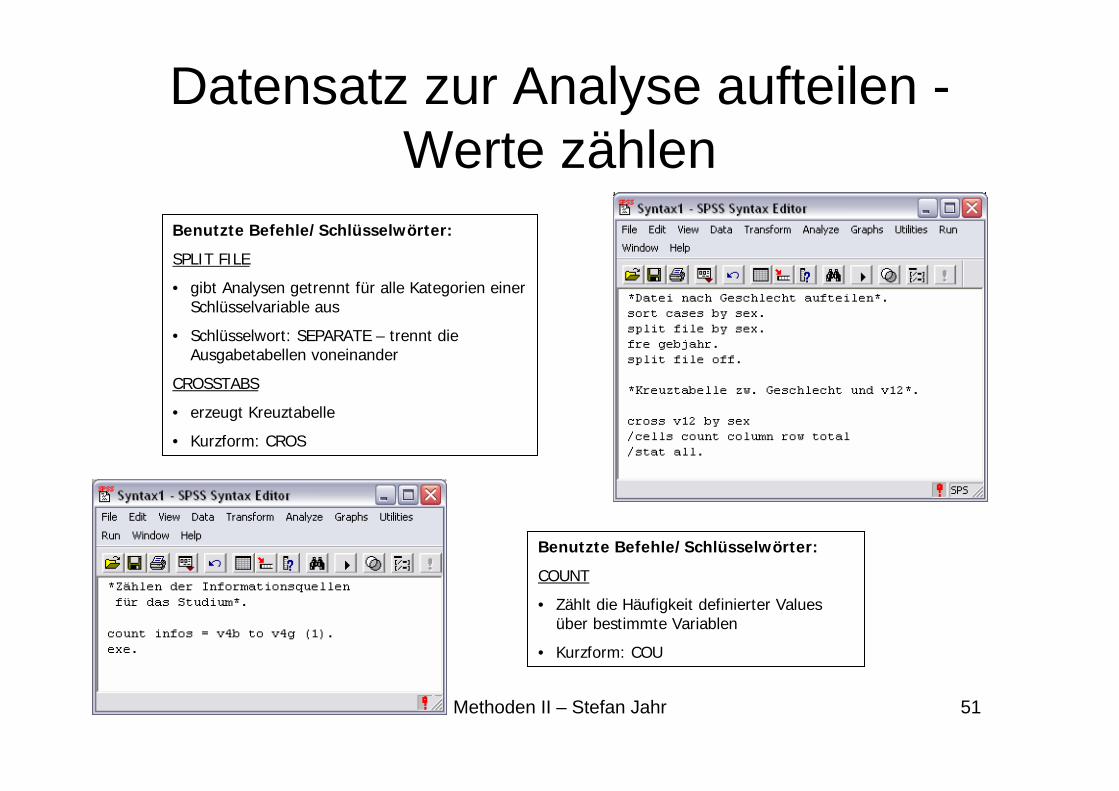
Benutzte Befehle/Schlüsselwörter:
SPLIT FILE
• gibt Analysen getrennt für alle Kategorien einer Schlüsselvariable aus
• Schlüsselwort: SEPARATE – trennt die Ausgabetabellen voneinander
CROSSTABS
• erzeugt Kreuztabelle
• Kurzform: CROS
Benutzte Befehle/Schlüsselwörter:
COUNT
• Zählt die Häufigkeit definierter Valuesüber bestimmte Variablen
• Kurzform: COU

Methoden II – Stefan Jahr 52
Mittelwertunterschiede analysiert mit MEANS
Case Processing Summary
133 97,1% 4 2,9% 137 100,0%income * sex GeschlechtN Percent N Percent N Percent
Included Excluded Total
Cases
Report
income
577,0588 51 427,59646
504,6098 82 235,43219
532,3910 133 323,29592
sex Geschlecht1,00 männlich
2,00 weiblich
Total
Mean N Std. Deviation
ANOVA Table
165043,333 1 165043,333 1,586 ,210
13631630,336 131 104058,247
13796673,669 132
(Combined)Between Groups
Within Groups
Total
income * sex GeschlechtSum of Squares df Mean Square F Sig.
Measures of Association
,109 ,012income * sex GeschlechtEta Eta Squared
Methoden II – Stefan Jahr 53
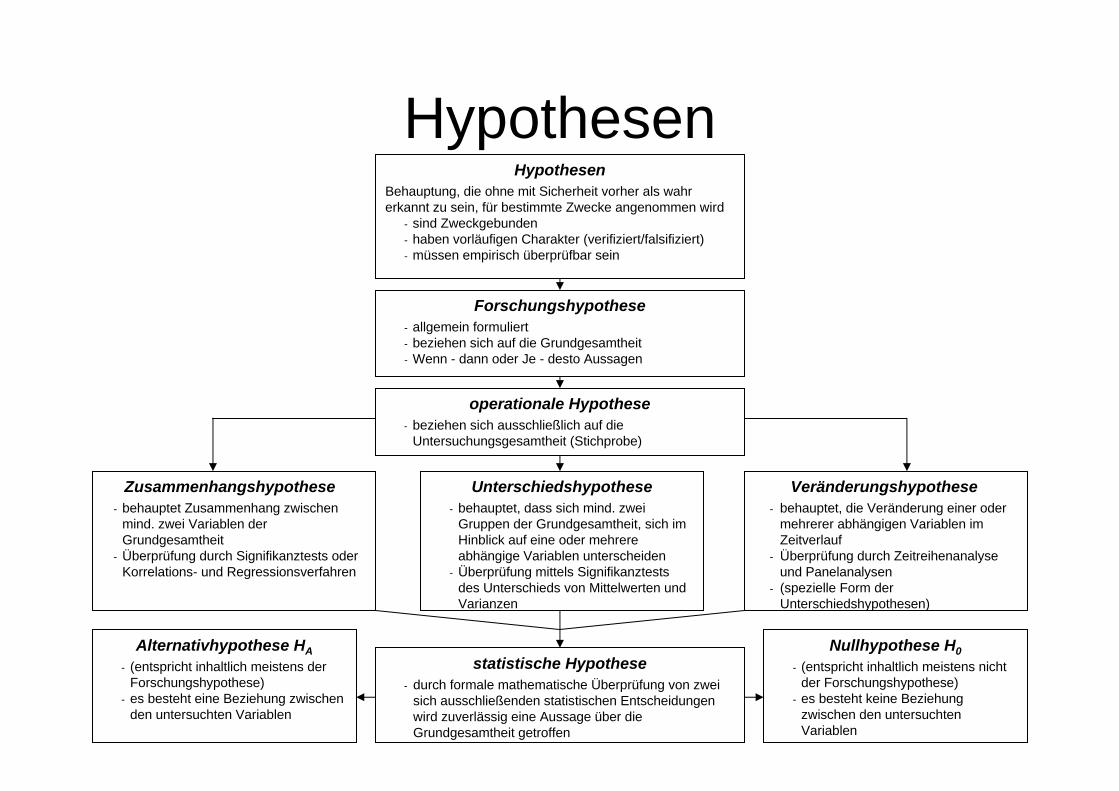
HypothesenHypothesen
Behauptung, die ohne mit Sicherheit vorher als wahr erkannt zu sein, für bestimmte Zwecke angenommen wird
- sind Zweckgebunden- haben vorläufigen Charakter (verifiziert/falsifiziert)- müssen empirisch überprüfbar sein
Forschungshypothese- allgemein formuliert- beziehen sich auf die Grundgesamtheit- Wenn - dann oder Je - desto Aussagen
operationale Hypothese- beziehen sich ausschließlich auf die
Untersuchungsgesamtheit (Stichprobe)
statistische Hypothese- durch formale mathematische Überprüfung von zwei
sich ausschließenden statistischen Entscheidungen wird zuverlässig eine Aussage über die Grundgesamtheit getroffen
Alternativhypothese HA- (entspricht inhaltlich meistens der
Forschungshypothese)- es besteht eine Beziehung zwischen
den untersuchten Variablen
Nullhypothese H0- (entspricht inhaltlich meistens nicht
der Forschungshypothese)- es besteht keine Beziehung
zwischen den untersuchten Variablen
Zusammenhangshypothese- behauptet Zusammenhang zwischen
mind. zwei Variablen der Grundgesamtheit
- Überprüfung durch Signifikanztests oder Korrelations- und Regressionsverfahren
Veränderungshypothese- behauptet, die Veränderung einer oder
mehrerer abhängigen Variablen im Zeitverlauf
- Überprüfung durch Zeitreihenanalyse und Panelanalysen
- (spezielle Form der Unterschiedshypothesen)
Unterschiedshypothese- behauptet, dass sich mind. zwei
Gruppen der Grundgesamtheit, sich im Hinblick auf eine oder mehrere abhängige Variablen unterscheiden
- Überprüfung mittels Signifikanztests des Unterschieds von Mittelwerten und Varianzen
Methoden II – Stefan Jahr 54
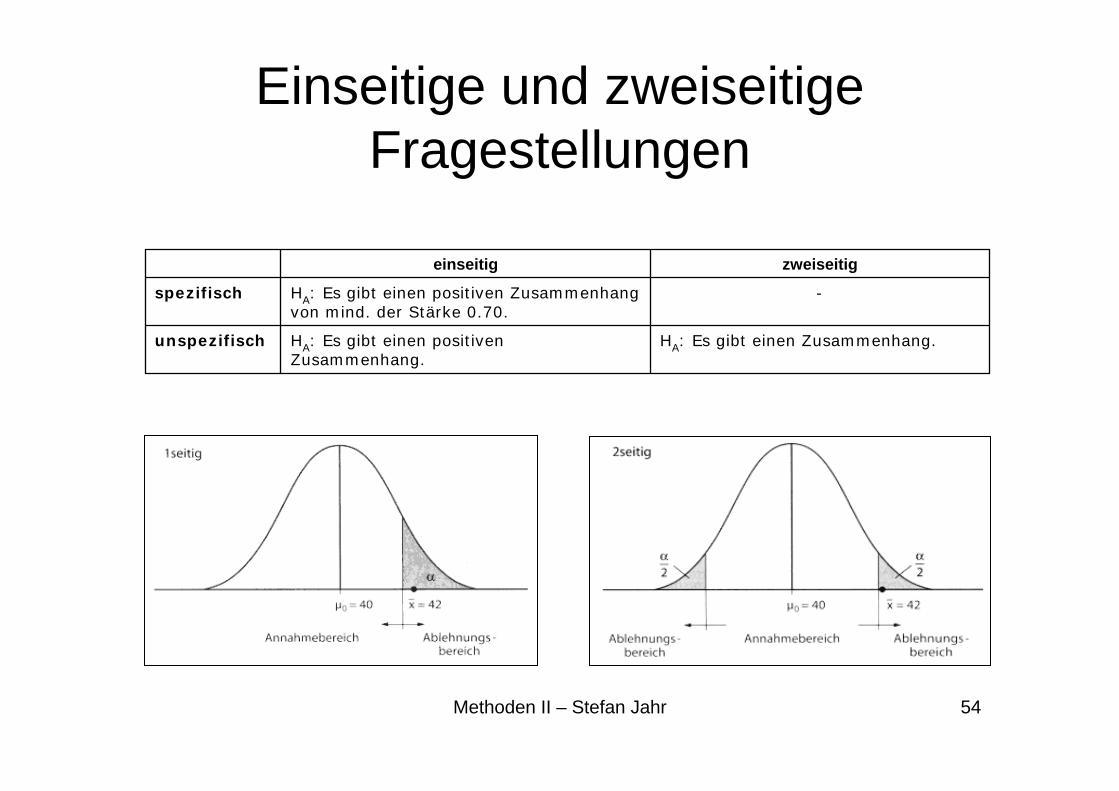
Einseitige und zweiseitige Fragestellungen
HA: Es gibt einen Zusammenhang.HA: Es gibt einen positiven Zusammenhang.
unspezifisch
-HA: Es gibt einen positiven Zusammenhang von mind. der Stärke 0.70.
spezifisch
zweiseitigeinseitig

Methoden II – Stefan Jahr 55
Statistische Hypothesenprüfung•Sprachliche Regelung
–Ist die Irrtumswahrscheinlichkeit <5%, dann bezeichnet man das Ergebnis als signifikant(graphisches Symbol: *).–Ist die Irrtumswahrscheinlichkeit <1%, dann bezeichnet man das Ergebnis als sehr signifikant(graphisches Symbol: **).–Ist die Irrtumswahrscheinlichkeit <0,1%, dann bezeichnet man das Ergebnis als höchst signifikant(graphisches Symbol: ***).–Ist die Irrtumswahrscheinlichkeit ≥ 5%, dann bezeichnet man das Ergebnis als nicht signifikant.
•α- und β-Fehler
Methoden II – Stefan Jahr 56
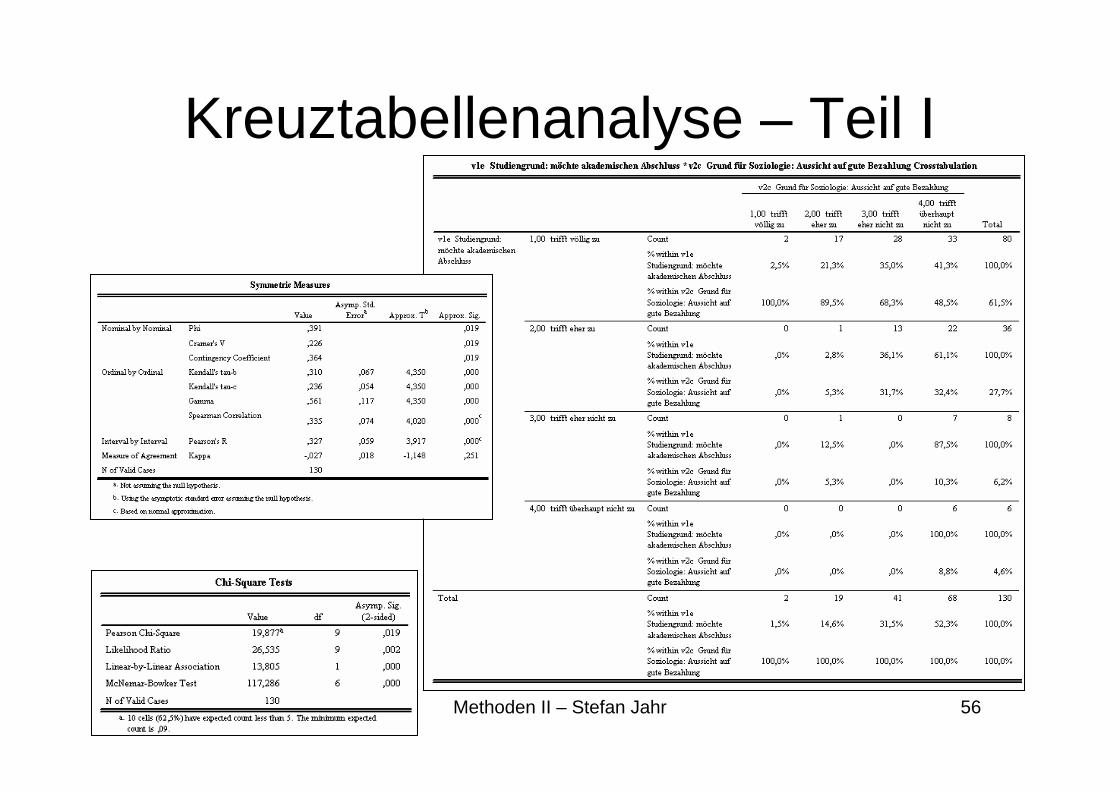
Kreuztabellenanalyse – Teil I

Methoden II – Stefan Jahr 57
Kreuztabellenanalyse – Teil II
Methoden II – Stefan Jahr 58
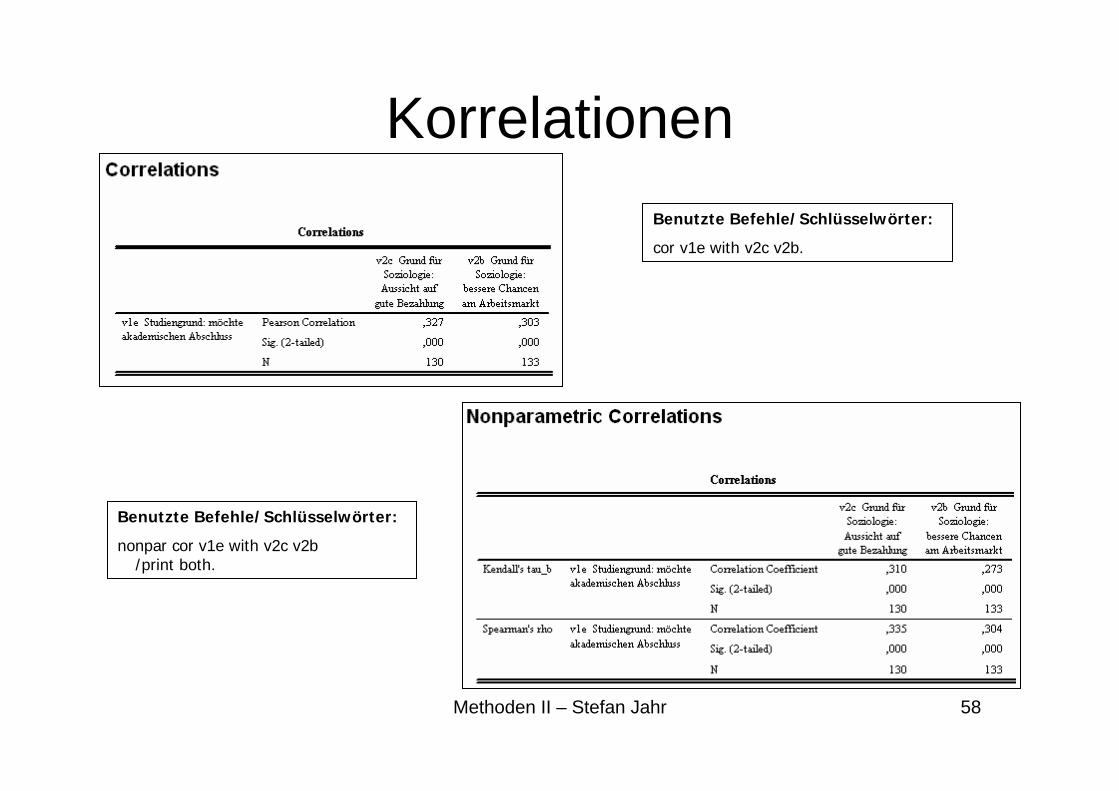
KorrelationenBenutzte Befehle/Schlüsselwörter:
cor v1e with v2c v2b.
Benutzte Befehle/Schlüsselwörter:
nonpar cor v1e with v2c v2b/print both.

Methoden II – Stefan Jahr 59
Regression I

Methoden II – Stefan Jahr 60
Regression II





























