Embed Size (px)
Citation preview

RISC Processors
Chapter 14S. Dandamudi

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 2
Outline
• Introduction• Evolution of CISC
processors• RISC design principles• PowerPC processor
∗ Architecture∗ Addressing modes∗ Instruction set
• Itanium processor∗ Architecture∗ Addressing modes∗ Instruction set∗ Instruction-level parallelism∗ Branch handling∗ Speculative execution

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 3
Introduction
• CISC∗ Complex instruction set
» Pentium is the most popular example
• RISC∗ Simple instructions
» Reduced complexity
∗ Modern processors use this design philosophy» PowerPC, MIPS, SPARC, Intel Itanium
– Borrow some features from CISC
∗ No precise definition» We can identify some common characteristics

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 4
Evolution of CISC Designs
• Motivation to efficiently use expensive resources∗ Processor∗ Memory
• High density code∗ Complex instructions
» Hardware complexity is handled by microprogramming» Microprogramming is also helpful to
– Reduce the impact of memory access latency– Offers flexibility
Low-cost members of the same family
∗ Tailored to high-level language constructs
2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 5
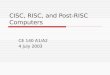
Evolution of CISC Designs (cont’d)
CISC RISC
VAX 11/780
Intel 486 MIPS R4000
# instructions 303 235 94
Addr. modes 22 11 1
Inst. size (bytes) 2-57 1-12 4
GP registers 16 8 32

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 6
Evolution of CISC Designs (cont’d)
Example∗ Autoincrement addressing mode of VAX
» Performs the following actions:(R2) = (R2) + R3; R2 = R2 + 1
∗ RISC equivalentR4 = (R2)
R4 = R4 + R3
(R2) = R4
R2 = R2 + 1

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 7
Why RISC?
• Simple instructions are preferred∗ Complex instructions are mostly ignored by compilers
» Due to semantic gap• Simple data structures
∗ Complex data structures are used relatively infrequently∗ Better to support a few simple data types efficiently
» Synthesize complex ones• Simple addressing modes
∗ Complex addressing modes lead to variable length instructions
» Lead to inefficient instruction decoding and scheduling

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 8
Why RISC? (cont’d)
• Large register set∗ Efficient support for procedure calls and returns
» Patterson and Sequin’s study– Procedure call/return: 12−15% of HLL statements
Constitute 31−33% of machine language instructionsGenerate nearly half (45%) of memory references
∗ Small activation record» Tanenbaum’s study
– Only 1.25% of the calls have more than 6 arguments– More than 93% have less than 6 local scalar variables– Large register set can avoid memory references

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 9
RISC Design Principles
• Simple operations∗ Simple instructions that can execute in one cycle
• Register-to-register operations∗ Only load and store operations access memory∗ Rest of the operations on a register-to-register basis
• Simple addressing modes∗ A few addressing modes (1 or 2)
• Large number of registers∗ Needed to support register-to-register operations∗ Minimize the procedure call and return overhead
2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 10
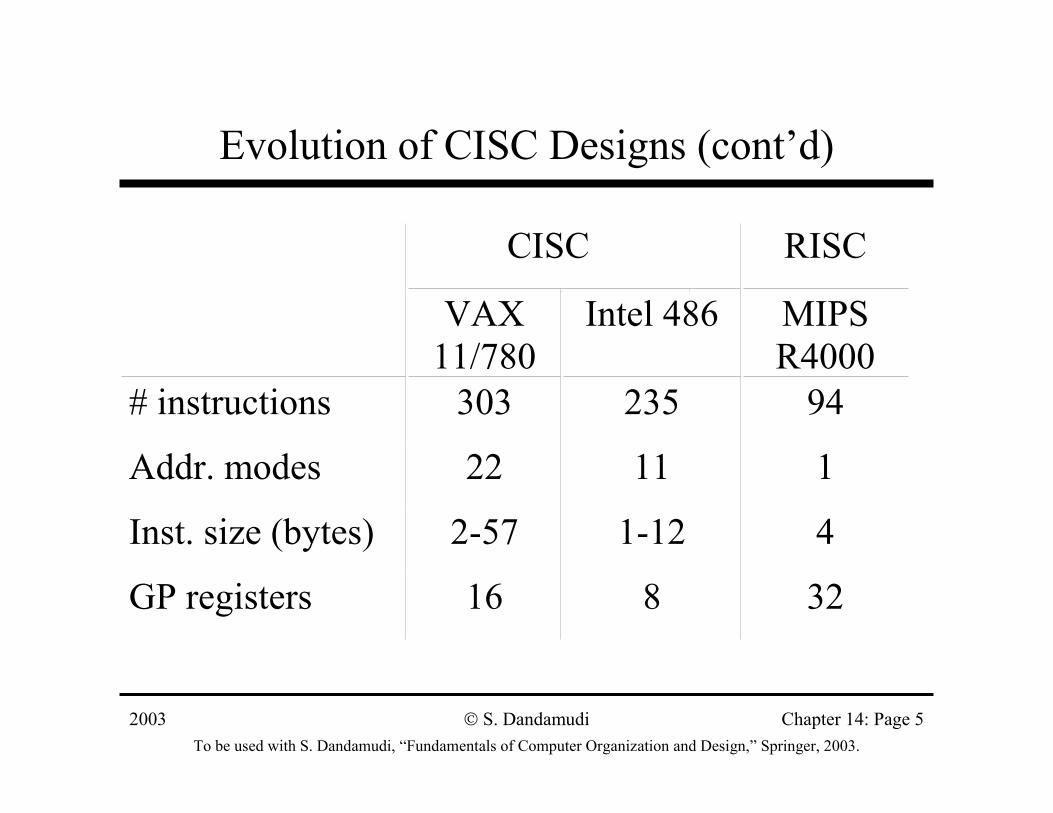
RISC Design Principles (cont’d)
Register windows storing activation records

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 11
RISC Design Principles (cont’d)
• Fixed-length instructions∗ Facilitates efficient instruction execution
• Simple instruction format∗ Fixed boundaries for various fields
» opcode, source operands,…
• Other features∗ Tend to use Harvard architecture∗ Pipelining is visible at the architecture level

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 12
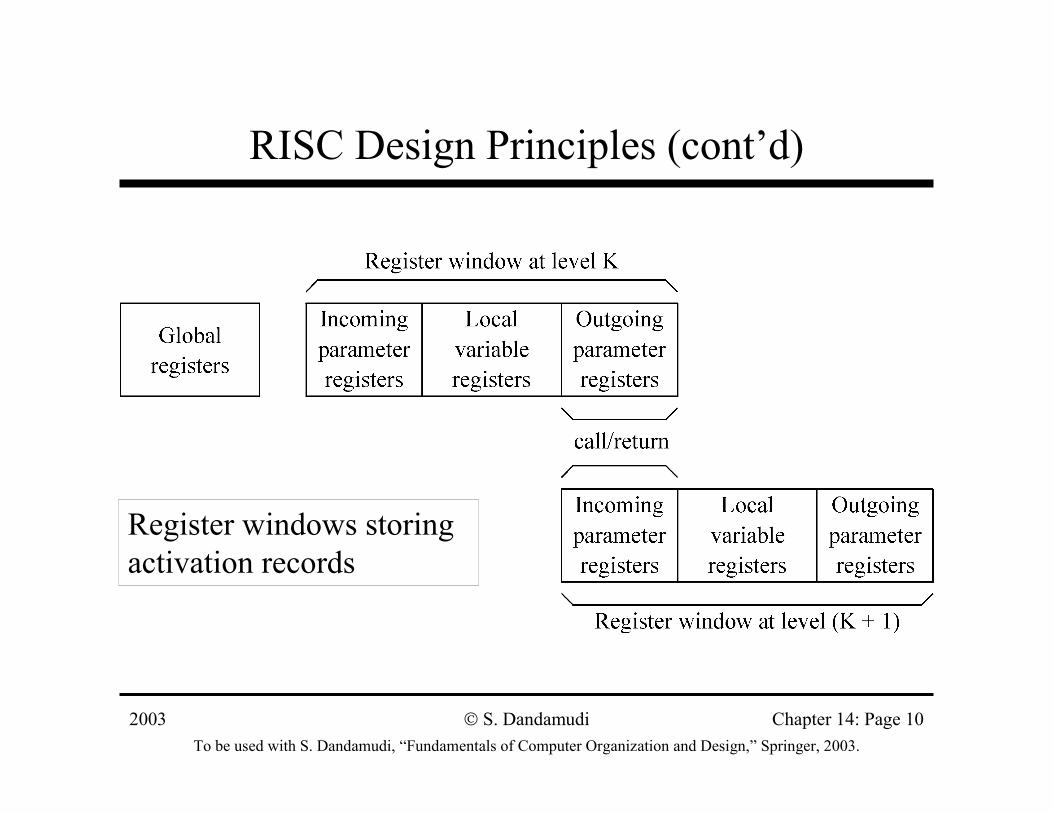
PowerPC
• Registers∗ 32 general-purpose registers (GPR0 – GPR31)∗ 32 floating-point registers (FPR0 – FPR31)∗ Condition register (CR)
» Similar to Pentium’s flags register» Divided into 8 CR fields (4 bits each)
– “less than” (LT), “greater than” (GT), “equal to” (EQ), Overflow (SO)
– CR1 is for floating-point exceptions– Other CR fields can be used for integer or FP exceptions– Branch instructions can test a specific CR field bit
2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 13
PowerPC (cont’d)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 14
PowerPC (cont’d)
∗ XER register serves two distinct purposes» Bits 0, 1, and 2 are used to capture
– Summary overflow (SO), overflow (OV), carry (CA)– OV and CA are similar to Pentium’s overflow and carry– SO, once set, only a special instruction can clear it
» Bits 25 to 31 (7 bits)– Specifies the number of bytes to be transferred between
memory and registers– Two instructions
Load string word indexed (lswx)Store string word indexed (stswx)Can load/store all 32 registers (GPR0-GPR31)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 15
PowerPC (cont’d)
∗ Link register (LR)» Used to store the procedure return address
– Stores the effective address of the instruction following the procedure call instruction
– Procedure calls use the branch instructionsExample: b = branch, bl = procedure call
∗ Count register (CTR)» Maintains loop count value
– Similar to Pentium's ECX register– Branch instructions can test the value
• 32-bit PowerPC implementations use segmentation like the Pentium

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 16
PowerPC (cont’d)
• Addressing modes∗ Load/store instructions support three addressing modes
» Can use GPRs
∗ Register Indirect» Effective address = contents of rA or 0» Specifying 0 generates address 0
∗ Register Indirect with Immediate Index» Effective address = Contents of rA or 0 + imm16
∗ Register Indirect with Index» Effective address = Contents of rA or 0 + contents of rB

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 17
PowerPC (cont’d)
Instruction format

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 18
PowerPC (cont’d)
• Bits 0-5∗ Specify primary opcode∗ Other fields specify suboperations
» Depends on instruction type
• AA bit∗ 1 (use absolute address)∗ 0 (use relative address)
• LK bit∗ 0 (no link --- branch)∗ 1 (link --- turns branch into a procedure call)
2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 19
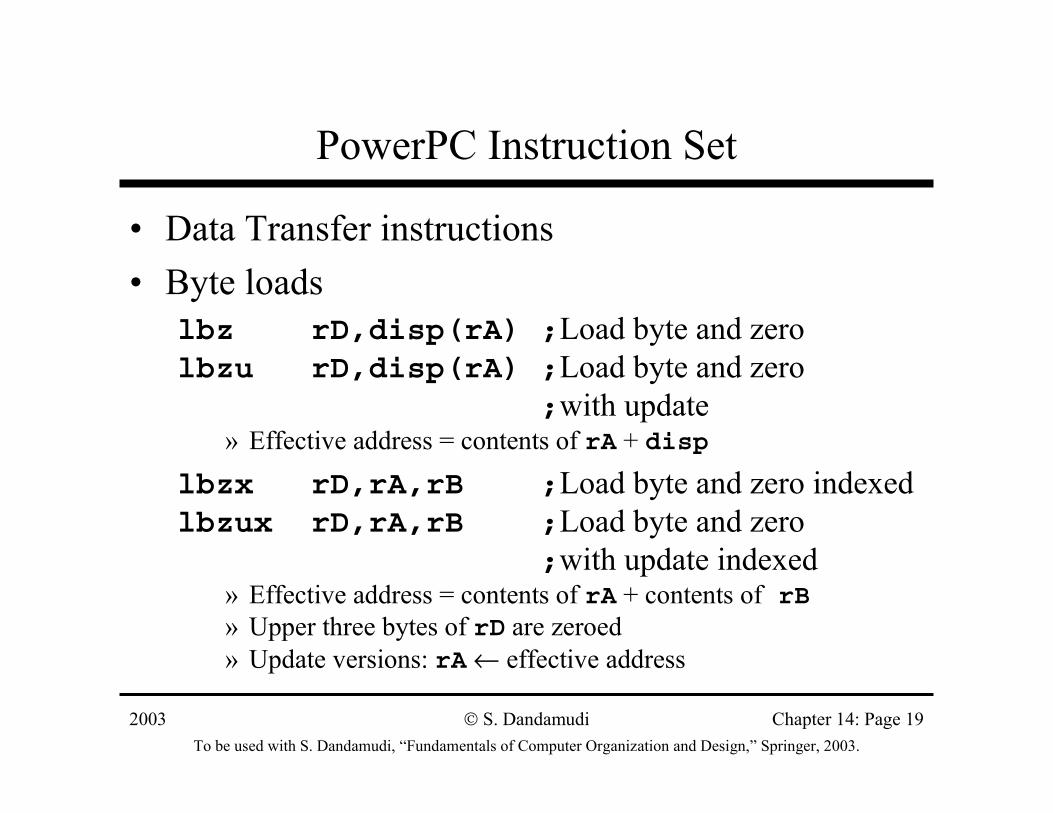
PowerPC Instruction Set
• Data Transfer instructions• Byte loads
lbz rD,disp(rA) ;Load byte and zerolbzu rD,disp(rA) ;Load byte and zero
;with update» Effective address = contents of rA + disp
lbzx rD,rA,rB ;Load byte and zero indexedlbzux rD,rA,rB ;Load byte and zero
;with update indexed» Effective address = contents of rA + contents of rB» Upper three bytes of rD are zeroed» Update versions: rA ← effective address

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 20
PowerPC Instruction Set (cont’d)
• Similar instructions for halfword and word loadslhz, lhzu, lhzx, lhzxu
lwz, lwzu, lwzx, lwzxu
• For halfword loads, sign extension is possiblelha, lhau, lhax, lhaxu
• Multiword loadlmw rD,disp(rA)
» Loads n consecutive words at EA to registers rD, …, r31

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 21
PowerPC Instruction Set (cont’d)
• Similar instructions for storestbz, stbzu, stbzx, stbzxu
sthz, sthzu, sthzx, sthzxu
stwz, stwzu, stwzx, stwzxu
• Multiword storestmw rD,disp(rA)
» Stores n consecutive words at EA to registers rD, …, r31

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 22
PowerPC Instruction Set (cont’d)
Arithmetic Instructions• Add instructions
add rD,rA,rB ; rD ← rA + rB
» Status and overflow bits of CR0 and XER are not altered
add. rD,rA,rB ; alters LT,GT,EQ,SO of CR0addo rD,rA,rB ; alters SO,OV of XERaddo. rD,rA,rB ; alters LT,GT,EQ,SO of CR0
; and SO,OV of XER» These four instructions do not alter the CA bit of XER

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 23
PowerPC Instruction Set (cont’d)∗ To alter CA bit, use
adde rD,rA,rB∗ To alter the other bits, use
adde., addeo, addeo.
∗ Immediate operand version
addi rD,rA,Simm16
∗ We can use addi to implement other instructions
li rD,value as addi rD,0,value
la rD,disp(rA) as addi rD,rA,disp
subi rD,rA,value as addi rD,rA,-value

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 24
PowerPC Instruction Set (cont’d)
• Subtract instructions
subf rD,rA,rB ; rD ← rB − rA
–subf = subtract from
∗ Like add, other forms are availablesubf., subfo, subfo.
∗ Negate instructionneg rD,rA ; rD ← 0 − rA

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 25
PowerPC Instruction Set (cont’d)
• Multiply instructions∗ Two instructions to get upper and lower 32 bits of the
64-bit resultmullw rD,rA,rB ; signed/unsigned multiply
» Stores the lower-order 32 bits of the result» Use the following to get the upper 32 bits
mulhw rD,rA,rB ; signedmulhwu rD,rA,rB ; unsigned
∗ Immediate formmulli rD,rA,Simm16
» Stores only lower 32 bits of the 48-bit result

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 26
PowerPC Instruction Set (cont’d)
∗ Divide instructions» Two divide instructions
– Signed (divw)
divw rD,rA,rB ; rD = rA/rB– Unsigned (divwu)
» Both give only quotient
» For quotient and remainder, use
divw rD,rA,rB ; quotient in rD
mullw rX,rD,rB
subf rC,rX,rA ; remainder in rC

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 27
PowerPC Instruction Set (cont’d)
∗ Logical instructionsand rD,rS,rB and. rD,rS,rB
andi. rD,rS,Uimm16 andis. rD,rS,Uimm16
andc rD,rS,rB andc. rD,rS,rB
» andis = left shift uimm16 by four positions before ANDing» andc = complement rB before ANDing» Dot versions update the LT, GT, EQ, SO bits of CR0» Logical OR also has these six versions» Move register instruction is implemented using OR
mr rA,RS is equivalent to or rA,rS,rS
» NOP is implemented asori 0,0,0

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 28
PowerPC Instruction Set (cont’d)
∗ Other logical operations» NAND
– nand– nand.
» NOR– nor
– nor.
» XOR– xor, xor.
– xori, xoris
» Equivalence (exclusive-NOR)– eqv– eqv.

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 29
PowerPC Instruction Set (cont’d)
∗ Shift and Rotate instructions» Shift left
slw rA,rS,rB ; shift left word» Shift left the word in rS by rB positions and store result in rA
– Shifted out bits get zeroes» Also have the dot version slw.» Shift right
srw srw. (logical)sraw sraw. (arithmetic)
» Rotate left instructionsrlwnm rA,rS,rB,MB,ME
rotlw rA,rS,rB ≡≡≡≡ rlwnm rA,rS,rB,0,31

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 30
PowerPC Instruction Set (cont’d)
∗ Compare instructions» Two versions:
– For signed and unsigned» Two formats
– Register and immediate» Register compare
cmp crfD,rA,rB» Updates LT (rA < rB), GT (rA > rB), EQ, SO bits in the crfD» If crfD is not specified, CR0 is used» Immediate version
cmp crfD,rA,Simm16

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 31
PowerPC Instruction Set (cont’d)
∗ Branch Instructions» Used for both branch (LK = 0) and procedure calls (LK = 1)» Can use absolute (AA = 1) or relative address (AA = 0)
b target (AA=0, LK=0) Branchba target (AA=1, LK=0) Branch Absolutebl target (AA=0, LK=1) Branch then linkbla target (AA=1, LK=1) Branch Absolute then link
» The last two are procedure calls» Three types of conditional branches
– Direct address– Register indirect
CTR or LR

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 32
PowerPC Instruction Set (cont’d)
∗ Conditional branch instructions (direct address)bc BO,BI,target (AA=0, LK=0)
Branch Conditionalbca BO,BI,target (AA=1, LK=0)
Branch Conditional Absolutebcl BO,BI,target (AA=0, LK=1)
Branch Conditional then linkbcla BO,BI,target (AA=1, LK=1)
Branch Conditional Absolute then link» BO = branch options (5 bits) ⇒ specifies branch condition» BI = branch input (5 bits) ⇒ specifies a bit in CR field

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 33
PowerPC Instruction Set (cont’d)
∗ Nine different branch conditions can be specified» Decrement CTR; branch if CTR ≠ 0 AND cond = false» Decrement CTR; branch if CTR = 0 AND cond = false
» Decrement CTR; branch if CTR ≠ 0 AND cond = true» Decrement CTR; branch if CTR = 0 AND cond = true
» Branch if cond = false
» Branch if cond = true
» Decrement CTR; branch if CTR ≠ 0» Decrement CTR; branch if CTR = 0
» Branch always

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 34
PowerPC Instruction Set (cont’d)
∗ LR-based branch instructionsbclr BO,BI (LK=0)
Branch Conditional to Link Registerbclrl BO,BI (LK=1)
Branch Conditional to Link Register then Link» Target address is taken from LR» Used to return from procedure calls
∗ CTR-based branch instructionsbcctr BO,BI (LK=0) bcctrl BO,BI (LK=1) » CTR instead of LR is used to get target

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 35
Itanium
• Intel’s 64-bit processor∗ RISC based∗ Based on EPIC design philosophy
» Explicit Parallel Instruction Computing» Support for ILP
– 3-instruction wide word» Speculative computation
– Hides memory latency» Predication
– Improves branch handling» Large number of registers
– 128 integer and 128 FP– Aids in efficient procedure calls

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 36
Itanium (cont’d)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 37
Itanium (cont’d)
• Registers∗ 128 general purpose register (gr0 – gr127)
» 64-bit wide» NaT (Not-a-Thing) bit
– Used in speculative loading» Divided into static and stacked
– StaticFirst 32 registers (gr0 – gr31)gr0 is read-only (always provides zero)
– StackedAvailable for programsUsed as register stack frame

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 38
Itanium (cont’d)
• Registers∗ Branch registers
» 8 in total (br0 – br7)» 64-bit wide» Specify target address for
– Conditional branches– Procedure calls– Return
∗ User mask register» Alignment, byte ordering, …
∗ Other registers» Predicate register, Application registers, Current frame marker

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 39
Itanium (cont’d)
• Addressing modes∗ Load/store instructions can access memory
» Specify three registers: r1, r2, r3– r32 and r3 are used to compute effective address– r1 receives/supplies data
∗ Register indirect addressing» Effective address = contents of r3
∗ Register indirect with immediate addressing» Effective address = contents of r3 + imm9» r3 = Effective address
∗ Register indirect with index addressing» Effective address = contents of r3 + contents of r2» r3 = Effective address

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 40
Itanium (cont’d)
• Instruction Format[(qp)] mnemonic[.comp] dests = srcs
∗ qp = qualifying predicate» Specifies a predicate register
– 64 1-bit registers– Executed if the specified PR is 1– Otherwise, instruction is treated as NOP
» mnemonic
– Identifies an instruction (e.g., compare)» comp
– Gives more information to completely specify instruction– E.g., Type of comparison is equality

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 41
Itanium (cont’d)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 42
Itanium (cont’d)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 43
Itanium (cont’d)
• Examplesadd r1 = r2,r3
Predicate instruction(p4) add r1 = r2,r3
add r1 = r2,r3,1
Compare instructionscmp.eq p3 = r2,r4
cmp.gt p2,p3 = r3,r4
Branch instructionbr.cloop.sptk loop_back

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 44
Instruction-level Parallelism
• Itanium provides∗ Runtime support for explicit parallelism
– Compiler/assembler can indicate parallelism» Instruction groups
∗ Large number of registers
• Instruction groups∗ Set of instructions that do not have conflicting
dependencies» Can be executed in parallel
∗ Compiler/assembler can indicate this by ;; notation

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 45
Instruction-level Parallelism
• Example: Logical expression with four termsif (r10 || r11 || r12 || r13) {
/* if-block code */
}
can be done using or-tree evaluationor r1 = r10,r11 /* Group 1 */
or r2 = r12,r13 ;;
or r3 = r1,r2 /* Group 2 */Other instructions /* Group 3 */
∗ Processor can execute as many instructions from group as it can
» Depends on the available resources

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 46
Itanium Instruction Bundle
• Each instruction is encoded using 41 bits• Three instructions are bundled together
∗ 128-bit Instruction bundle∗ No conflicting dependencies among the three instructions
» Aids in instruction–level parallelism∗ 5-bit template
» Specifies mapping of instruction slots to execution instruction types– Six instruction types
Integer ALU, non-ALU integer, memory, branch, FP, extended

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 47
Itanium Instructions
• Data transfer instructions» Load and store instructions are more complicated than a typical
RISC processor
∗ Load instructions(qp) ldSZ.ldtype.ldhint r1=[r3]
(qp) ldSZ.ldtype.ldhint r1=[r3],r2
(qp) ldSZ.ldtype.ldhint r1=[r3],imm9» Loads SZ bytes from memory
– SZ can be 1, 2, 4, or 8 to load 1, 2, 4, or 8 bytes– Example:
ld8 r5 = [r6]
Locality of memory access
Special load operations:advanced, speculative

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 48
Itanium Instructions (cont’d)
• ldtype∗ This completer can be used to specify special load
operations» Advanced
ld8.a r5 = [r6]
» Speculativeld8.s r5 = [r6]
• ldhint∗ Locality of memory access
None – Temporal locality, level 1nt 1 – No temporal locality, level 1nt a – No temporal locality, all levels

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 49
Itanium Instructions (cont’d)
• Store instructions∗ Simpler than load instructions
(qp) stSZ.sttype.sthint r1=[r3]
(qp) stSZ.sttype.sthint r1=[r3],imm9
• Move instructions(qp) mov r1 = r3
(qp) mov r1 = imm2
(qp) mov r1 = imm64
» First two are pseudo-instructions– Implemented using other processor instructions

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 50
Itanium Instructions (cont’d)
• Arithmetic instructions∗ Simpler than load instructions
(qp) add r1 = r2,r3
(qp) add r1 = r2,r3,1
(qp) add r1 = imm,r4
∗ Move instruction(qp) mov r1 = r3
implemented as(qp) add r1 = 0,r3
∗ Move instruction(qp) mov r1 = imm22
implemented as(qp) add r1 = imm22,r0
can be imm14or imm22

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 51
Itanium Instructions (cont’d)
• Similar instructions for subtraction• Shift-add
(qp) shladd r1 = r2,count,r3
» Before adding, r2 is left-shifted by count bit positions
• Integer multiply is realized using the xmainstruction and floating-point registers
• No divide instruction∗ Done in software

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 52
Itanium Instructions (cont’d)
• Logical instructions∗ AND∗ OR∗ XOR∗ No NOT operation
» Can use and-complement (andcm)– Complements one of the operands before ANDing
• Format(qp) and r1 = r2,r3
(qp) and r1 = imm8,r3

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 53
Itanium Instructions (cont’d)
• Shift instructions∗ Left-shift∗ Right-shift
• Format(qp) shl r1 = r2,r3
(qp) and r1 = imm8,r3
• Right-shift(qp) shr r1 = r2,r3 (signed version)(qp) shr.u r1 = r2,r3 (Unsigned version)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 54
Itanium Instructions (cont’d)
• Compare instructions∗ Format
(qp) cmp.crel.ctype p1,p2 = r2,r3(qp) cmp.crel.ctype p1,p2 = imm8,r3
∗ crel: Type of comparisonCmp type signed unsigned< lt ult
≤≤≤≤ le ule> gt ugt
≥≥≥≥ ge uge= eq eq

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 55
Itanium Instructions (cont’d)
∗ ctype: Specifies how the two predicate registers are to be updated
» Default: – Comparison result in p1 and its complement in p2
» or type– p1 and p2 are set to 1 only if the comparison result is 1– Otherwise, p1 and p2 are not altered– Useful in OR-type simultaneous execution
» andtype– p1 and p2 are set to 0 only if the comparison result is 0– Otherwise, p1 and p2 are not altered– Useful in AND-type simultaneous execution

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 56
Itanium Instructions (cont’d)
• Branch instructions∗ Used for jump as well as procedure calls∗ Supports both direct and indirect branching
» All direct branched are IP-relative∗ IP relative form(qp) br.btype.bwh.ph.dh target25
(basic form)(qp) br.btype.bwh.ph.dh b1=target25
(call form)br.btype.bwh.ph.dh target25
(counted loop form)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 57
Itanium Instructions (cont’d)
∗ Indirect form(qp) br.btype.bwh.ph.dh b2 (basic form)(qp) br.btype.bwh.ph.dh b1=b2 (call form)∗ btype: Type of branch
» cond or none (for basic form)– Branch taken if qp is 1; otherwise not
» To invoke a procedure– Use the call form with btype = call
– Turns branch into a conditional procedure call– Procedure invoked only if qp is 1; otherwise not– Return address is saved in b1 branch register

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 58
Itanium Instructions (cont’d)
» Uncounted counted loop version– Set btype = cloop
– Loop count is in application register ar65– If ar65 not zero, decrements and takes branch
» RET version– Use btype = ret
– Should use the indirect form and specify the branch register that has the return address
• Example 1: Conditional skip(p3) br skip or(p3) br.cond skip

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 59
Itanium Instructions (cont’d)
• Example 2: Loop iterates 100 timesmov lc = 100
Loop_back:
. . .
br.cloop loop_back
• Example 3: Procedure call to sum(p0) br.call br2 = sum
• Example 4: Return from a procedure(p0) br.ret br2

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 60
Handling Branches
• Three techniques:∗ Branch elimination
» Eliminate branches– Best way to handle branches is not to have branches
Possible to eliminate some types of branches
∗ Branch speedup» Reduce the delay associated with branches
– Reorder instructions– Speculative execution
∗ Branch prediction» Discussed before (see Chapter 8)

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 61
Handling Branches (cont’d)
• Branch elimination in Itanium∗ Can be done using predication
if (R1 == R2)
R3 = R3 + R1;
else
R3 = R3 – R1;
cmp r1,r2je equalsub r3,r1jmp next
equal:add r3,r1
next:
cmp.eq p1,p2 = r1,r2(p1) add r3 = r3,r1(P2) sub r3 = r3,r1

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 62
Handling Branches (cont’d)switch (r6){
case 1:
r2 = r3 + r4;
break;
case 2:r2 = r3 - r4;
break;
case 3:
r2 = r3 + r5;
break;case 4:
r2 = r3 – r5;
break;
}
cmp.eq p1,p0 = r6,1
cmp.eq p2,p0 = r6,2
cmp.eq p3,p0 = r6,3
cmp.eq p4,p0 = r6,4;;
(p1) add r2 = r3,r4
(p2) sub r2 = r3,r4
(p3) add r2 = r3,r5
(p4) sub r2 = r3,r5

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 63
Speculative Execution
• Instructions are executed in expectation that they will be needed∗ Keeps pipeline full∗ Masks memory latency
• Itanium supports two types∗ Handles data dependencies
» Data dependencies are discussed in Chapter 8
∗ Handles control dependencies∗ Both are compiler optimizations
» Reorders instructions
2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 64
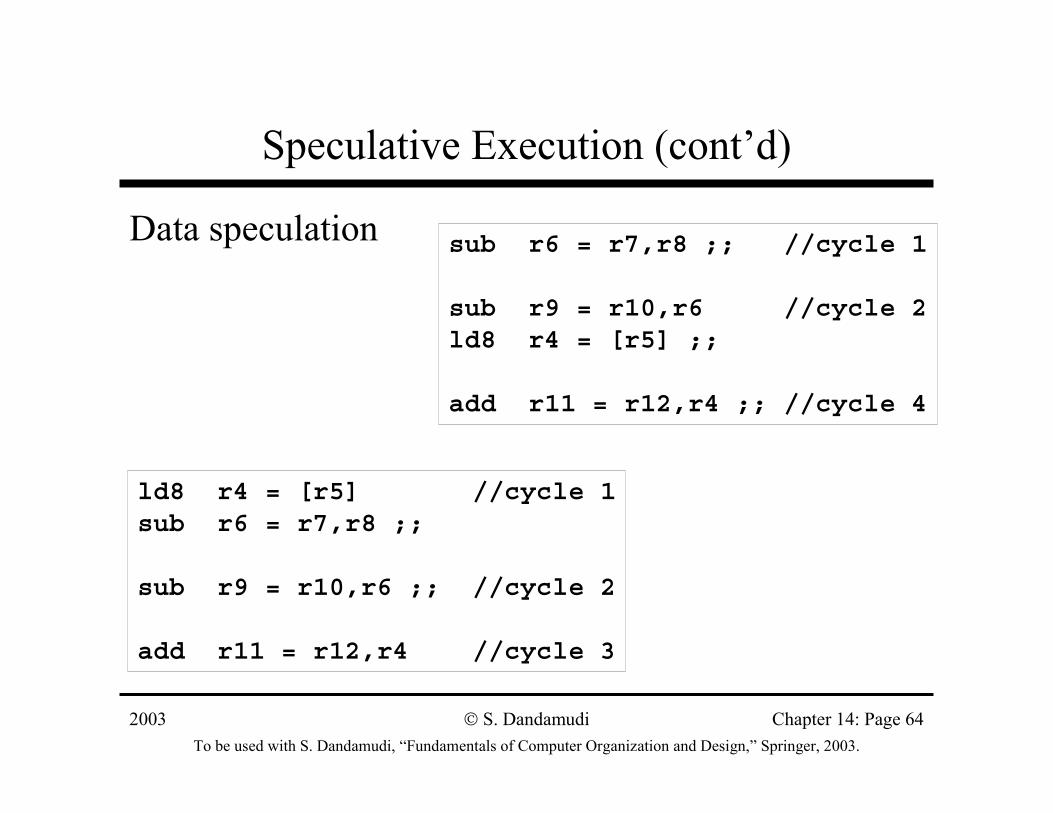
Speculative Execution (cont’d)
Data speculation sub r6 = r7,r8 ;; //cycle 1
sub r9 = r10,r6 //cycle 2ld8 r4 = [r5] ;;
add r11 = r12,r4 ;; //cycle 4
ld8 r4 = [r5] //cycle 1sub r6 = r7,r8 ;;
sub r9 = r10,r6 ;; //cycle 2
add r11 = r12,r4 //cycle 3

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 65
Speculative Execution (cont’d)
• Ambiguous dependency between first st8 and ld8
sub r6 = r7,r8 ;; //cycle 1
st8 [r9] = r6 //cycle 2ld8 r4 = [r5] ;;
add r11 = r12,r4 ;; //cycle 4
st8 [r10] = r11 //cycle 5

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 66
Speculative Execution (cont’d)
• We can move such load instructions using advance load (ld.a) and check load (ld.c)
ld8.a r4 = [r5] //cycle 0 or earlier. . .
sub r6 = r7,r8 ;; //cycle 1
st8 [r9] = r6 //cycle 2ld8.c r4 = [r5]add r11 = r12,r4 ;;
st8 [r10] = r11 //cycle 3
2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 67
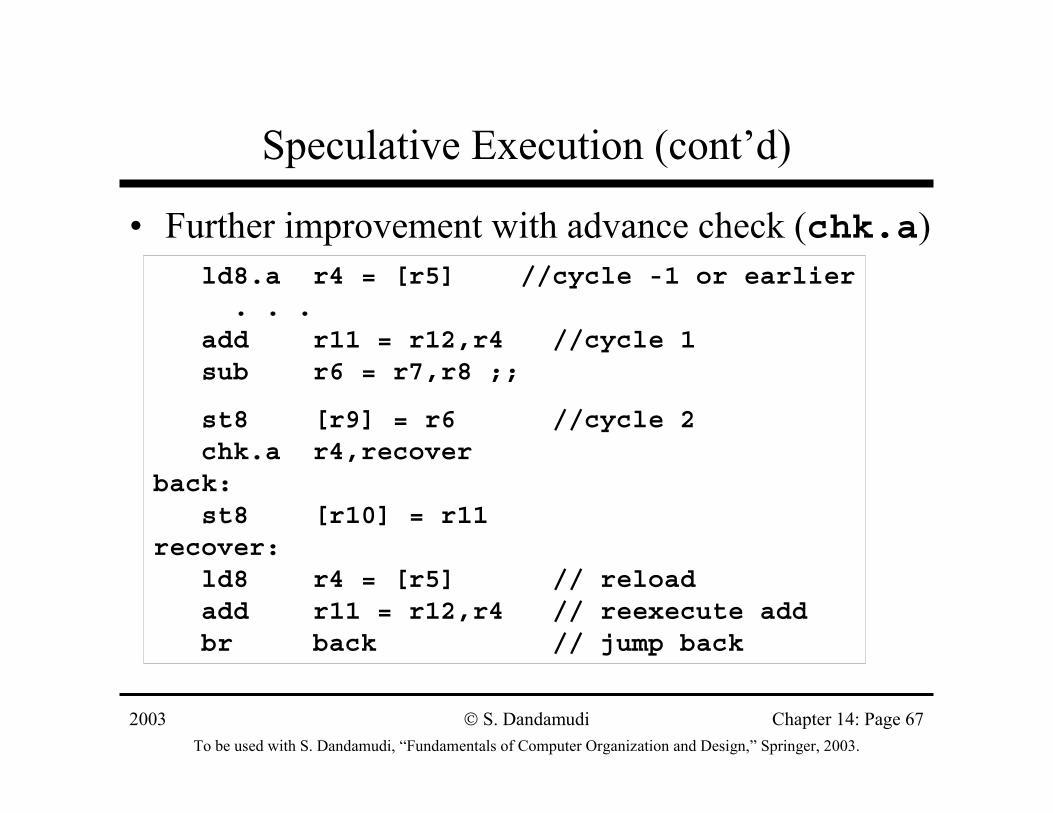
Speculative Execution (cont’d)
• Further improvement with advance check (chk.a)ld8.a r4 = [r5] //cycle -1 or earlier. . .
add r11 = r12,r4 //cycle 1sub r6 = r7,r8 ;;
st8 [r9] = r6 //cycle 2chk.a r4,recover
back:st8 [r10] = r11
recover:ld8 r4 = [r5] // reloadadd r11 = r12,r4 // reexecute addbr back // jump back

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 68
Speculative Execution (cont’d)
• Control speculation∗ To reduce long latency instructions such as loads,
advance them earlier into the code
cmp.eq p1,p0 = r10,10 //cycle 0
(p1) br.cond skip ;; //cycle 0
ld8 r1 = [r2] ;; //cycle 1
add r3 = r1,r4 //cycle 3
skip:
// other instructionsCannot advance because of branch

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 69
Speculative Execution (cont’d)
ld8.s r1 = [r2] ;; cycle –2 or earlier
//other instructions
cmp.eq p1,p0 = r10,10 //cycle 0
(p1) br.cond skip //cycle 0
chk.s r1,recovery //cycle 0
add r3 = r1,r4 //cycle 0
skip:
//other instructions
recovery:
ld8 r1 = [r2]
br skip
Speculative check chk.sallows us to advance ld8

2003To be used with S. Dandamudi, “Fundamentals of Computer Organization and Design,” Springer, 2003.
S. Dandamudi Chapter 14: Page 70
Branch Prediction
• Branch hints∗ bwh completer (branch whether hint)
spnt static branch not takensptk static branch takendpnt dynamic branch not takendptk static branch not taken
• Prefetch hint (ph)∗ Hint about sequential prefetch
» few or many
• Deallocation hint (dh)∗ Specifies whether branch cache should be cleared
» clr indicates deallocationLast slide












![RISC, CISC, and Assemblers - Cornell University · RISC, CISC, and Assemblers ... • Complexity: CISC, RISC Assemblers ... –e.g. Mem[segment + reg + reg*scale + offset] 14 RISC](https://img.pdfslide.net/doc/110x75/5c1068af09d3f254228c84fd/risc-cisc-and-assemblers-cornell-risc-cisc-and-assemblers-complexity.jpg)