Embed Size (px)
Citation preview

優しいベイズ統計への導入法
地方国立大学での実践例とともに
SS-065 ベイズ統計をどう教えていくか-心理統計教育の中への取り入れについて考える-
話題提供:小杉考司(山口大学教育学部)

自己紹介
• 所属;山口大学教育学部小学校コース心理学選修
• 専門;社会心理学
• 担当講義;心理学統計法,心理データ処理法(情報処理演習),社会心理学,グループダイナミックス,心理学実験,心理学研究演習

求めるものが確率変数に
頻度主義 ベイズ主義
母数θ 定数 確率変数
データx,y 確率変数 定数
頻度主義では,たった一つの真値を求めて慎重に議論する
ベイズ主義では,データから考えられる母数の分布を考える
→仮説は真か偽のどちらかである
→確信できる程度を見定める3
(C)岡田先生
実際に用いたスライドの例

信頼区間Confidential Intervals
信頼「区間」というが,分布の情報を持っていない=幅ではないことに注意
出典;山内光哉(著)心理教育のための統計法第二版.サイエンス社
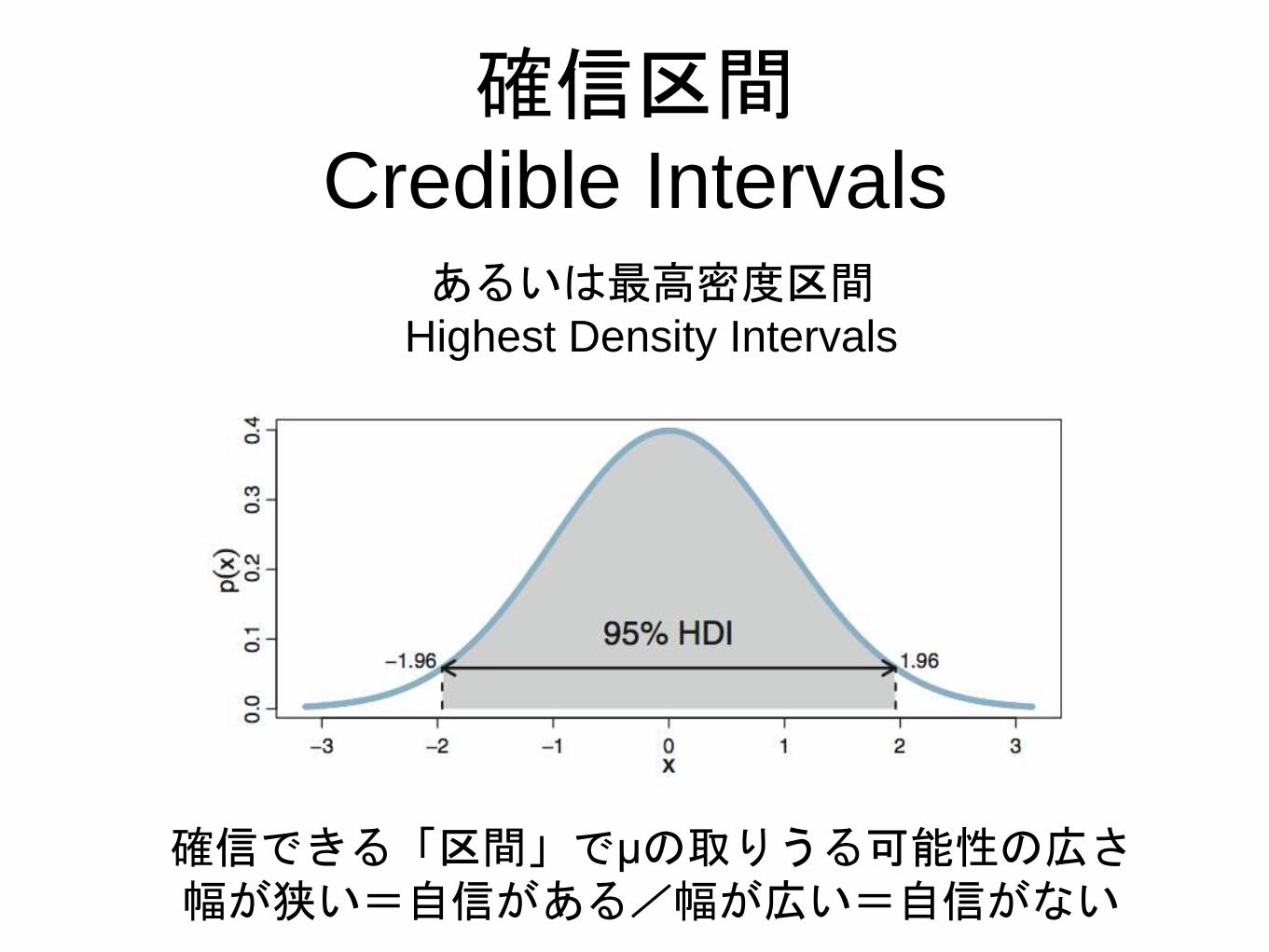
確信区間Credible Intervals
あるいは最高密度区間Highest Density Intervals
確信できる「区間」でμの取りうる可能性の広さ幅が狭い=自信がある/幅が広い=自信がない

ベイジアンになると何がどう変わるのか
• 帰無仮説検定の文脈でいうと,変わるポイントは次の二点だけです。
• 「点」から「幅」へ
• 「ないない」から「あるある」へ
(告知)最終日の午後にこのテーマでTWSします。

「点」から「幅」へ
• これまでは「点」の表現だったので,仮説は「真か偽か」の二択,一点張り
• 母平均を標本平均から推定しても,点推定なのでほぼ確実に外れている。信用区間で表現しても結果は「当たるか外れるか」
• ベイジアンは母数が確率分布=幅をもっているので,仮説は「どれぐらい確からしいか」であり,幅の広さで自信の強さを表現するようになる

「ないない」から「あるある」へ
• 帰無仮説検定は「ないない」づくし
• 帰無仮説は差が「ない」とする
• t検定の場合,muA=muBの一点張り
• それに従って統計量を算出しp値を計算
• 差が「ない」とは「いえない」,が結論

「ないない」から「あるある」へ
• ベイジアンは「あるある」で語る
• 手元のデータから確率変数としての母数を推定する
• 母数はこの辺りに「ある」という
• 群間の差が0である可能性がこれぐらい「ある」。もちろん差がある可能性がこれぐらい「ある」ともいう。
• 一点張りでないので,幅を持って自信の強さを表現

何が変わるか
• 従来型仮説検定の話も,「差があるかないかだけの1bit判断になるのはやめよう」,「効果量をみよう」,「検定力を考えよう」となって来ている→点から幅へ。
• ベイズ統計ではそもそも「効果の大きさをみる」ので幅の話。意味のある幅にしたければたくさんのデータ(エビデンス)にサポートされなければならない。
• 方針の流れとしては同じとも言える

最大のメリット
•初心者にとっての誤用が少なくなる!
•嘘をつかなくて良くなる!
• タイプ1/2エラー,信用区間,効果量と例数設計,下位検定,一実験あたりの危険率など,15回の授業ではサポートしきれない。嘘を教えているような心苦しさ。
• 「モデルに基づく事後分布の生成」さえできれば,切り取り方は自由,読み取り方も素直で,誤用が少ない。

授業の実践例
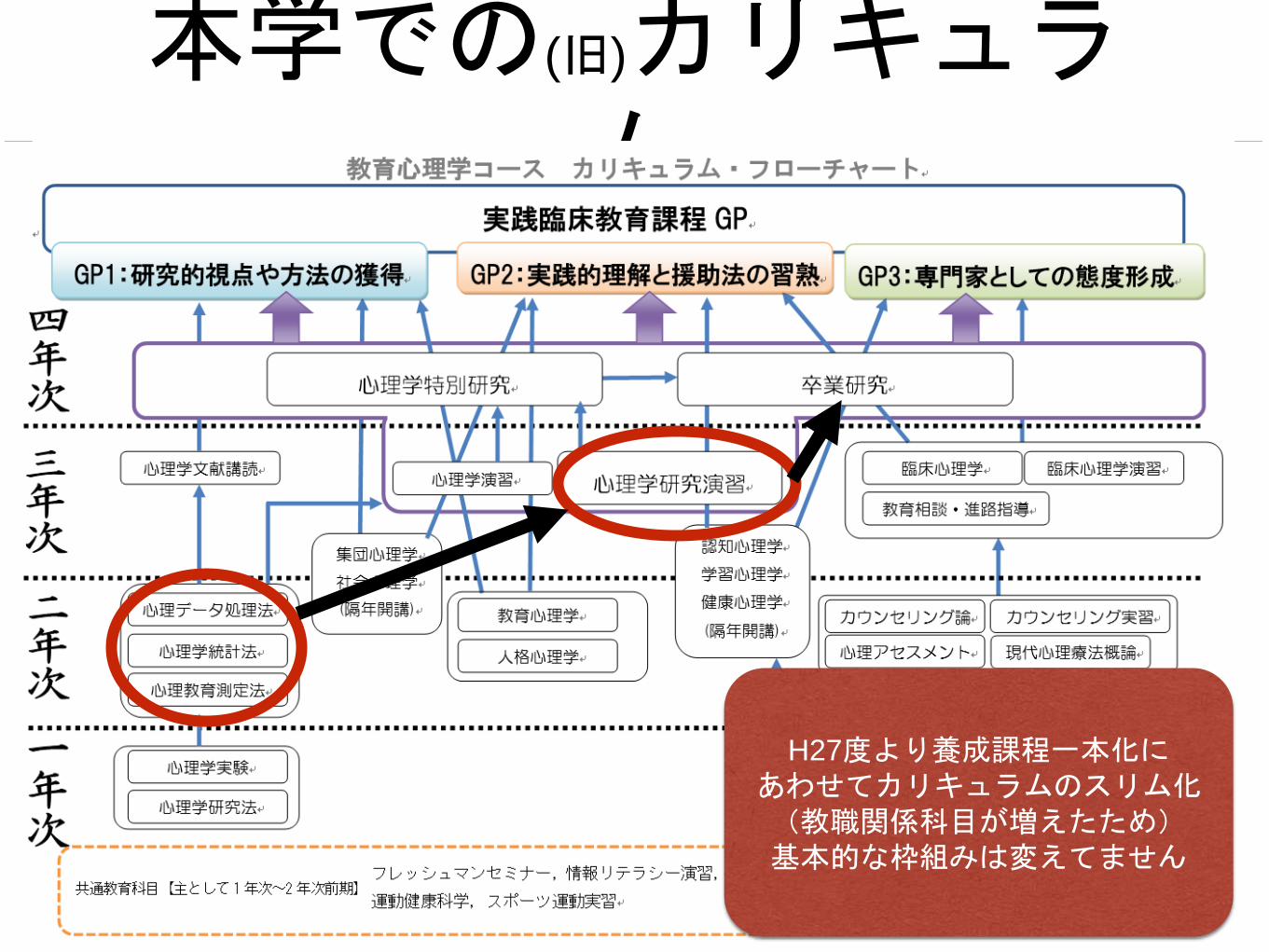
本学での(旧)カリキュラム
H27度より養成課程一本化にあわせてカリキュラムのスリム化(教職関係科目が増えたため)基本的な枠組みは変えてません

対象クラスの特徴
• 受講生10名+上級生数名の少人数クラス
• 上級生(ゼミ生)は自主的にTA役をやってくれる
• 全員がノートパソコン所有。学内無線LANもあり。
• 「研究法」の話があるので,尺度水準や実験計画法,仮説検定の考え方などはすでに一度聞いたことがある状態
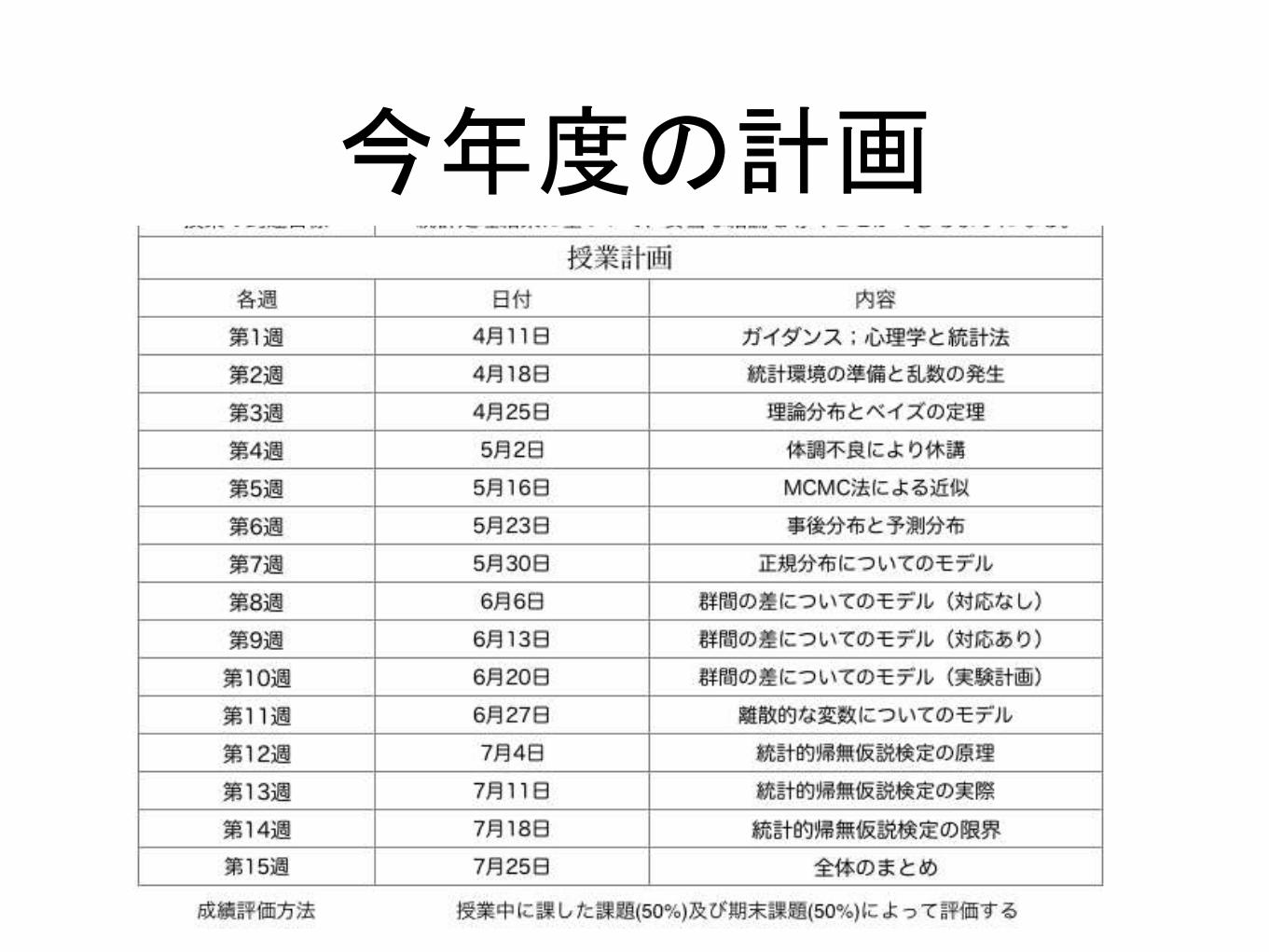
今年度の計画
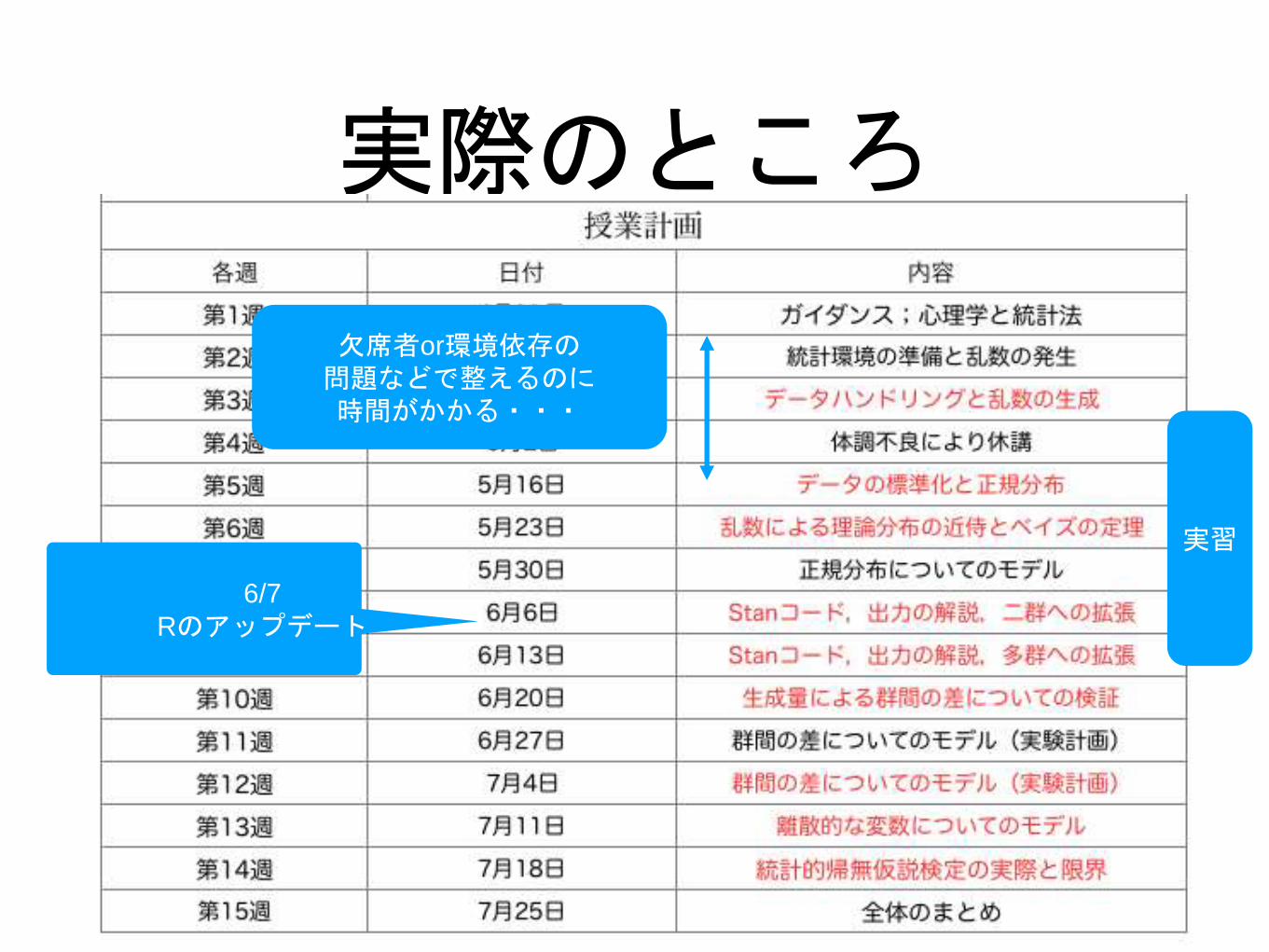
実際のところ
6/7
Rのアップデート
欠席者or環境依存の問題などで整えるのに時間がかかる・・・
実習

実行前の配慮
• (数年前から)統計環境はRに移行済み
• 三年時の演習担当者,基礎系教員にベイズ統計で教える承認を得る→従来型統計も教えてね,との注文も
• 基礎系教員と院生を対象にベイズ統計の概略をレク

教え方の工夫
• 「乱数」の考え方は学生にとって比較的身近(テレビゲームのおかげ?)
• 確率分布の理論的な式はわからなくても,rnormで発生させた乱数のヒストグラムを書くと「こういう形なのね」というのがわかる
• stanを始めとするベイジアンソフトウェアは自分のモデルに沿った乱数発生器である,と説明
• 自分のモデルというのも正規分布しか使っていない

ex)気になるあの人とデートに行こう
• 頻度主義者の場合;「相手が私に全く気がないとすると,そういう人がデートに来てくれる可能性は極めて低いので,あの人は私に気がないとは言えない」
• ベイズ主義者の場合;「相手が私に気があるとする可能性が50%ぐらいだと思っていたが,デートに来てくれるということはこの可能性は80%にあがったかも。私の読みではかなりの確率であの人は私に気がある」
実際に用いたスライドの例
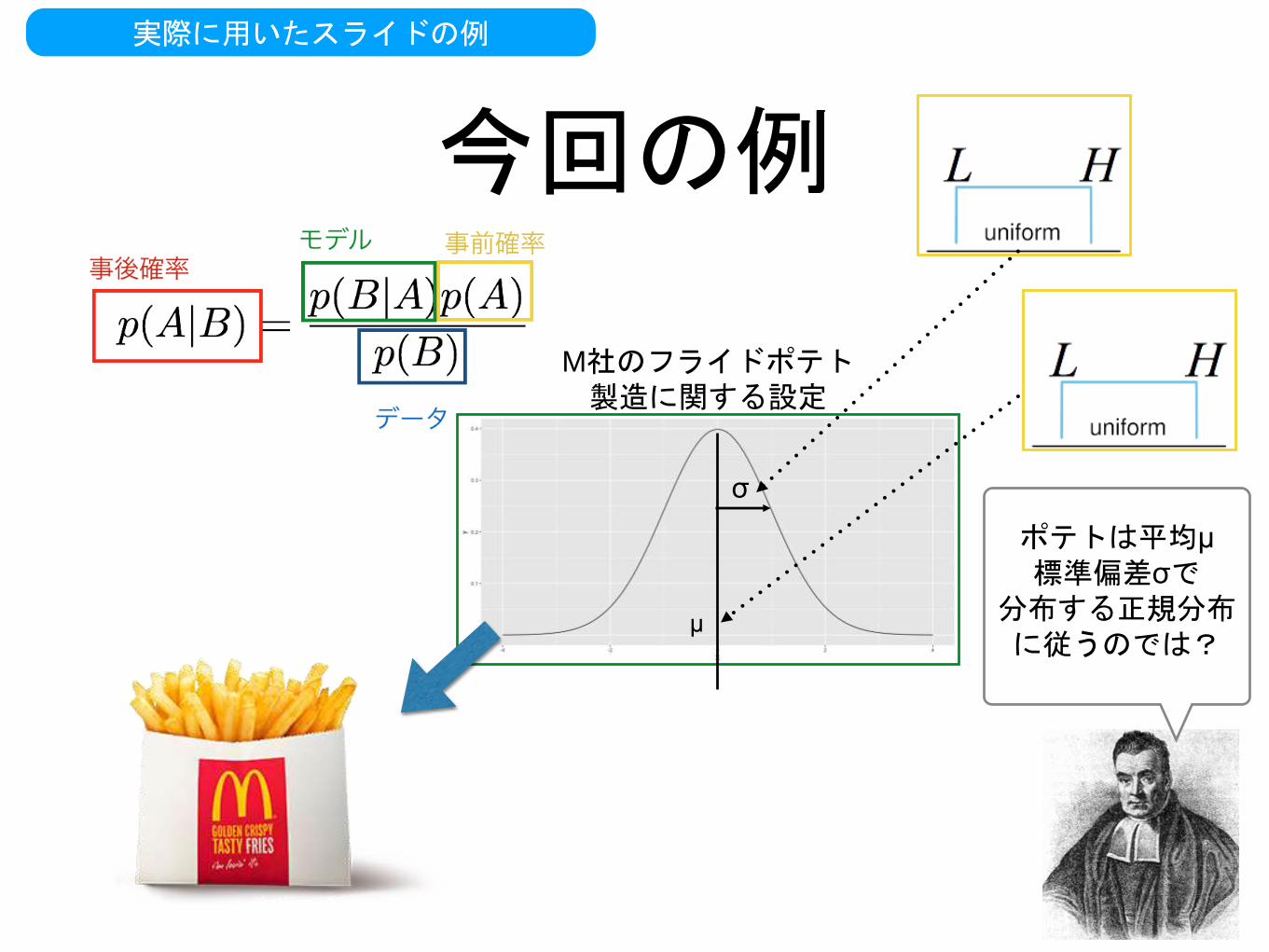
今回の例
M社のフライドポテト製造に関する設定
μ
σ
ポテトは平均μ
標準偏差σで分布する正規分布に従うのでは?
実際に用いたスライドの例

目的
• (M社にしかわからない)ポテト製造ルール,ポテト生成機の設定があって,そこからポテトが作られている
• たぶんそのポテト製造ルール(機械)は正規分布のポテトを生産する
• ルール,設定が知りたい=正規分布のパラメタが知りたい。(※正規分布のパラメタは平均と標準偏差)
• 答えは確率的にしかわからない。だって企業秘密だもん。
実際に用いたスライドの例

ポテト学?
• 我々がやりたいことはポテト学ではなく,心理学である←わかる
• ポテトの長さはあくまでも一例。これを心理テスト,尺度のスコアと考えてみよう。
• 心理学的研究のほとんどは「平均の比較」,しかも正規分布を仮定したもの,なので,このポテト学がそのまま応用できます。
実際に用いたスライドの例

これだけは覚えて帰って
• 事前に一切の仮定を置かないor自分の主張と全く逆のところから論を立てる(背理法)の良さ
• 結果が「でた・でない」だけの判断に陥る愚は避ける
• 従来型の仮説検定法は「厳格な手続き」で「様々な仮定」の上に成り立っているので,一つでも失敗すると間違った結果を報告することになる!
実際に用いたスライドの例

大事なのは選択できること
実際に用いたスライドの例

実際苦労するポイント
• 環境が整わない,足並みが揃わない
• プログラミングに対する苦手意識。「思った通りに動くのではなくて,書いた通りに動く」ことの厳しさ。
• 乱数なので必ずしも答えが揃うわけではない
• 最終レポートもソースコードを添付するように指示
今回全員数字が違っていたのでそれぞれの環境で走らせてはいたようだが,ソースコードのコピペがあるかどうかは見抜けない
可能なら Rstudio-serverを用意して環境の一元管理を。

ちょっと心配なこと
• かなりベイズ寄りになってしまった?
• 帰無仮説検定の考え方(特に背理法であること)は研究上有用な視点であることは強調したつもり
• ただ,従来のやり方だと色々手続きが細かくて面白くなさそうだなあ,という印象を与えている。事実そうだとしても,やりすぎには注意しないと・・・。

優しいベイズ統計への導入法
地方国立大学での実践例とともに
SS-065 ベイズ統計をどう教えていくか-心理統計教育の中への取り入れについて考える-
話題提供:小杉考司(山口大学教育学部)