Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON ROBOTICS, VOL. 23, NO. 6, DECEMBER 2007 1225
Multiobjective Evolution of Neural Controllersand Task Complexity
Genci Capi, Member, IEEE
Abstract—Robots operating in everyday life environments areoften required to switch between different tasks. While learningand evolution have been effectively applied to single task perfor-mance, multiple task performance still lacks methods that havebeen demonstrated to be both reliable and efficient. This paperintroduces a new method for multiple task performance based onmultiobjective evolutionary algorithms, where each task is con-sidered as a separate objective function. In order to verify theeffectiveness, the proposed method is applied to evolve neural con-trollers for the Cyber Rodent (CR) robot that has to switch properlybetween two distinctly different tasks: 1) protecting another mov-ing robot by following it closely and 2) collecting objects scatteredin the environment. Furthermore, the tasks and neural complex-ity are analyzed by including the neural structure as a separateobjective function. The simulation and experimental results us-ing the CR robot show that the multiobjective-based evolutionarymethod can be applied effectively for generating neural networksthat enable the robot to perform multiple tasks simultaneously.
Index Terms—Evolutionary robotics, multiobjective evolution,multiple task performance, neural controller.
I. INTRODUCTION
TRADITIONALLY, research on intelligent agents hasmainly focused on the evolution or learning of individ-
ual perceptual motor and cognitive tasks. Nevertheless, intelli-gent agents operating in everyday life environments are oftenrequired to perform multiple tasks simultaneously or in rapidalternation, which can be a challenge even for humans andprimates.
Several approaches have been proposed to address the prob-lem of multiple task robot performance. The standard method-ology in machine learning has been to break large problems intosmall, independent subproblems, learn the subproblems sepa-rately, and then, recombine the learned pieces [1]. Caruana [2]presented a multiple-task connectionist learning where learningimproves by training one network on several tasks. In [3]–[5], adifferent methodology has been used in which all the tasks arelearned at the same time. Thrun and O’Sullivan [6] presented atask-clustering algorithm that clustered the learning tasks intoclasses of mutually related tasks. In this approach, when the
Manuscript received December 4, 2006; revised May 26, 2007. This paperwas recommended for publication by Associate Editor G. Antonelli and EditorL. Parker upon evaluation of the reviewers’ comments.
The author is with the Graduate School of Science and Engineering, Univer-sity of Toyama, Toyama 930-8555, Japan (e-mail: [email protected]).
This paper has supplementary downloadable material available at http://ieeexplore.ieee.org, provided by the author. This includes movie which isan .mpg file (1.9 MB) illustrating the robot multiple task performance. The“Cyber Rodent” robot protects the moving robot, while also switching to theobject collection task. The protected robot has a red cover with a rectangularshape in order to be detected by the visual and proximity sensors.
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TRO.2007.910773
agent faced a new learning task, it first determined the most re-lated task cluster, then exploited the information from this taskcluster only. However, in all these approaches, the tasks consid-ered were similar to each other. Learning sequences of multipledecision tasks [7] or changing the agent behavior based on theenvironmental conditions [8], [9] have also been undertaken.
In addition to learning, the evolution of neural controllers iswell known for providing a family of naturally inspired algo-rithms that can successfully address a wide range of robot behav-ior learning problems [10]–[12]. In evolutionary robotics [13],different constraints and objectives are typically handled asweighted components of the fitness function [14], [15], thusapplying a single objective evolutionary algorithm (SOEA). Forexample, Floreano and Mondada evolved neural controllers forKhepera robots to perform straight movement while avoidingobstacles [14]. The average rotation speed, absolute differencebetween the right and left wheels, and proximity sensor readingsare all included in a single fitness function. Cliff and Miller coe-volved a pursuer and an evader in a simulated environment [15].While the fitness score of the evader was simply the length oftime it lasted before being hit by the pursuer, the fitness scorefor the pursuer was more complicated. The pursuer received fit-ness points for approaching the evader and bonus for hitting theevader. The bonus was dependent on the timing of the collisions.As the authors noted, they had to try many weight coefficientsbefore they arrived at a successful combination. Therefore, tocombine different objectives into a single fitness function, ana priori decision is needed about the relative importance ofthe objectives, emphasizing a particular type of solution. Thesetechniques often require some problem-specific information,such as the total range each objective covers. In complex prob-lems, such as multiple task performance, such information israrely known in advance, making the selection of single objec-tive weighting parameters extremely difficult.
This article presents a novel approach for multiple taskrobot performance based on multiobjective evolutionary algo-rithms (MOEAs) [16]–[18]. Unlike previous methods, in theexperiments presented here, each task is considered as a sepa-rate objective function. The nondominated sorting genetic al-gorithm (NSGA) [19] is used to generate the Pareto set ofneural networks that tradeoff between the separate task per-formance. MOEAs have been successfully applied to evolveneural networks in which the architectural complexity andperformance are co-optimized [20]–[22]. MOEAs have alsobeen applied to design feedforward neural networks for ob-ject recognition [23] and time series forecasting [24]. In ad-dition, Barlow et al. [25] employed the multiobjective ge-netic programming to evolve controllers for unmanned aerialvehicles.
1552-3098/$25.00 © 2007 IEEE

1226 IEEE TRANSACTIONS ON ROBOTICS, VOL. 23, NO. 6, DECEMBER 2007
In this paper, an MOEA is applied for the first time to evolveneural controllers for multiple task robot performance. Thespecific questions we ask in this study are whether MOEAscan successfully generate neural controllers for multiple taskperformance; the evolved neural controllers optimized byMOEA in a simulated environment perform well in the stepof real hardware implementation; and MOEAs can generateefficient neural controllers and provide information about thecomplexity of the tasks and environment. In order to answerthese questions, in the experiments reported here, we considerthe evolution of neural controllers for the Cyber Rodent (CR)robot that has to perform two different tasks: 1) protecting an-other robot by following it closely while it moves in the envi-ronment and 2) collecting objects scattered in the environment.The tasks are interesting because they conflict with each other,making it difficult to combine them in a single objective func-tion. In order to further verify the effectiveness of the proposedmethod for multiple task robot performance, in addition to pro-tecting another robot and object collection tasks, an environmentexploration task is also undertaken.
In the proposed method, we evolve one single neural con-troller for multiple task performance, considering informationrelevant to each task as the sensory input of the neural con-troller. As the number of tasks increases, additional sensoryinformation related to each task must be considered, resultingin complex neural networks. This makes the evolution processdifficult. In addition, the hardware implementation of evolvedneural controllers may result in poor performance due to the in-creased error in the sensory data. In order to further investigateif the MOEA can also generate efficient neural controllers formultiple task performance, the structure of the neural networkis included as a separate objective function. The robustness ofthe neural controllers evolved in the simulation were also testedin the hardware of the CR robot.
II. MULTIOBJECTIVE EVOLUTIONARY ALGORITHM
A. Multiobjective Optimization Problem
In multiobjective optimization problems, there are many (pos-sibly conflicting) objectives to be optimized, simultaneously.Therefore, there is no longer a single optimal solution but rathera whole set of possible solutions of equivalent quality. Considerwithout loss of generality the following multiobjective maxi-mization problem with m decision variables, x parameters, andn objectives:
y = f(x) = (f1(x1 , . . . , xm ), . . . , fn (x1 , . . . , xm )) (1)
where x = (x1 , . . . , xm ) ∈ X , y = (y1 , . . . , yn ) ∈ Y , andwhere x is called the decision parameter vector, X the param-eter space, y the objective vector, and Y the objective space.A decision vector a ∈ X is said to dominate a decision vectorb ∈ X (also written as a > b) if and only if
∀i ∈ {1, . . . , n} : fi(a) ≥ fi(b) ∧ ∃j ∈ {1, . . . , n} :
fj (a) > fj (b). (2)
The decision vector a is called Pareto-optimal if and onlyif a is nondominated regarding the whole parameter space X .
Fig. 1. Flowchart of NSGA.
Pareto-optimal parameter vectors cannot be improved in any ob-jective without causing degradation in at least one of the otherobjectives. They represent in that sense globally optimal solu-tions. Note that a Pareto-optimal set does not necessarily containall Pareto-optimal solutions in X . The set of objective vectorscorresponding to a set of Pareto-optimal parameter vectors iscalled “Pareto-optimal front.”
In extending the ideas of SOEAs to multiobjective cases, twomajor problems must be addressed: How to accomplish fitnessassignment and selection in order to guide the search towardthe Pareto-optimal set? How to maintain a diverse populationin order to prevent premature convergence and achieve a well-distributed, widespread tradeoff front? Note that the objectivefunction itself no longer qualifies as a fitness function since itis a vector value, and fitness has to be a scalar value. Differentapproaches to relate the fitness function to the objective functioncan be classified with regard to the first issue. The second prob-lem is usually solved by introducing elitism and intermediaterecombination. Elitism is a way to ensure that good individualsdo not get lost (by mutation or set reduction), simply by storingthem in an external set, which, thereafter, only participates inselection. Intermediate recombination, on the other hand, aver-ages the parameter vectors of two parents in order to generateone offspring, which helps to achieve a good distribution of thePareto-optimal set.
B. Nondominated Sorting Genetic Algorithm
NSGA was employed to evolve the neural controller wherethe weight connections are encoded as real numbers. In [26],the authors compared the NSGA with four other MOEAs usingtwo test problems. The NSGA performed better than the others,showing that it can be successfully used to find multiple Pareto-optimal solutions. In NSGA, before selection is performed, thepopulation is ranked on the basis of domination using Paretoranking, as shown in Fig. 1. All nondominated individuals areclassified in one category with a dummy fitness value, which isproportional to the population size [19]. After this, the selection,crossover, and mutation operators are performed.

CAPI: MULTIOBJECTIVE EVOLUTION OF NEURAL CONTROLLERS AND TASK COMPLEXITY 1227
In the ranking procedure, the nondominated individuals in thecurrent population are first identified. Then, these individuals areassumed to constitute the first nondominated front with a largedummy fitness value [19]. The same fitness value is assignedto all of them. In order to maintain diversity in the population,a sharing method is then applied. Afterwards, the individualsof the first front are ignored temporarily, and the rest of thepopulation is processed in the same way to identify individualsfor the second nondominated front. A dummy fitness value thatis kept smaller than the minimum shared dummy fitness of theprevious front is assigned to all individuals belonging to thenew front. This process continues until the whole populationis classified into nondominated fronts. Since the nondominatedfronts are defined, the population is then reproduced accordingto the dummy fitness values.
1) Fitness Sharing: In genetic algorithms, sharing tech-niques aim at encouraging the formation and maintenance ofstable subpopulations or niches [27]. This is achieved by de-grading the fitness values of points belonging to the same nichein some configuration space. Consequently, points that are veryclose to each other, with respect to some space (decision spaceX in this paper), will have their dummy fitness function valuesmore degraded. The fitness value degradation of near individu-als can be executed using (3) and (4), where the parameter dij isthe variable distance between two individuals i and j, and sshared
is the maximum distance allowed between any two individualsto become members of the same niche. In addition, dfi is thedummy fitness value assigned to individual i in the current frontand df ′i is its corresponding shared value. Npop is the numberof individuals in the population. The sharing function (Sh) mea-sures the similarity level between two individuals. The effect ofthis scheme is to encourage searches in unexplored regions. Fordetails about niching techniques, see [28]:
Sh(dij ) =
{(1 − di j
σ shared
)2, if dij < σshared
0, if dij ≥ σshared
(3)
df ′i = df i
Npop∑
j=1
Sh(dij )
−1
. (4)
III. MULTIOBJECTIVE EVOLUTION OF NEURAL CONTROLLERS
A. Tasks and Environment
The CR robot has to learn to perform two different tasks:protecting another moving robot by following it closely andcollecting objects scattered in the environment (Fig. 2). Theentire environment is a rectangle of 4 m × 3.5 m surroundedby walls. There are 15 green colored objects scattered in theenvironment. The individual lifetime of each agent is 700 timesteps, where each time step lasts 0.1 s. During this time, thered color protected robot follows a rectangular trajectory witha constant velocity of 0.1 m/s; at the end, the protected robotreturns to its initial position.
Fig. 2. Environment.
Fig. 3. Relative direction of proximity sensors.
B. Neural Architecture
We implemented a feedforward neural controller with 11, 4,and 2 units in the input, hidden, and output layers, respectively.The inputs of the neural controller are the angle (Aobj), distance(Dobj), and color (Cobj) of the nearest object, the angle (Arob)and color (Crob) of the protected robot, the readings of fiveproximity sensors (PSi), and the distance sensor (DS) in thefront of the CR robot. The five proximity sensors are angledas shown in Fig. 3. The egocentric angle to the protected robotor nearest object varies from 0 to 1, where 0 corresponds to45◦ to the right and 1 is 45◦ to the left. The values of theseneurons become −1 when the protected robot becomes invisibleor there is no object in the visual field. The proximity sensorscan measure up to 0.25 m, while the distance sensor varies from0.1 to 0.8 m. The proximity and distance sensor reading variesfrom 0 to 1, where 0 means no obstacle and 1 means touchingthe obstacle. Random noise, uniformly distributed in the rangeof ±5% of sensor readings, has been added to the angle ofthe nearest object, the angle of the moving robot, the distancesensor, and the five proximity sensors. Because the distance tothe nearest object during the experiments is determined basedon the number of pixels, the random noise in simulations isconsidered in the range of ±10%. Based on the characteristicsof the CR robot visual sensor, in simulations, the visual distanceto the nearest object is limited to 1.2 m. The hidden and outputunits use sigmoid activation function
yi =1
1 + e−xi(5)
where the incoming activation for node i is
xi =∑
jwjiyj (6)
and j ranges over nodes with weights into node i.The output units directly control the right and left wheel
angular velocities where 0 corresponds to no motion and 1corresponds to full-speed forward rotation. The left and right
1228 IEEE TRANSACTIONS ON ROBOTICS, VOL. 23, NO. 6, DECEMBER 2007
wheel angular velocities, ωright and ωleft, are calculated as
ωright = ωmax × yright
ωleft = ωmax × yleft (7)
where ωmax is the maximum angular velocity and yright andyleft are the neuron outputs. The maximum forward velocity isconsidered to be 0.5 m/s.
C. Evolution
For any evolutionary computation technique, a chromosomerepresentation is needed to describe each individual in the popu-lation. The genome of every individual of the population encodesthe weight connections of the neural controller. The genomelength is 52, and the connection weights range from −10 to10. For the protecting task, the target distance dt between theCR robot and the protected robot is considered to be 0.3 m. Inorder to minimize the difference between the target and the realdistance dr , the fitness f1 is considered as
f1 =max st∑i=1
∣∣dit − di
r
∣∣ (8)
where max_st is the maximum number of steps.The fitness of the object collecting task, f2 , is simply the
number of objects collected during its individual lifetime. If anindividual happens to hit the protected robot or the wall, thetrial is terminated and a low fitness is assigned. Therefore, suchindividuals will have a low probability to survive. The followinggenetic parameters are used: Nger = 100, Npop, σshared = 0.4.
IV. RESULTS
A. MOEA Results
In this section, we first discuss the best solutions obtainedfrom the MOEA in terms of multiple task performance. All thesimulations were performed on a Pentium 43.2 GHz computer.
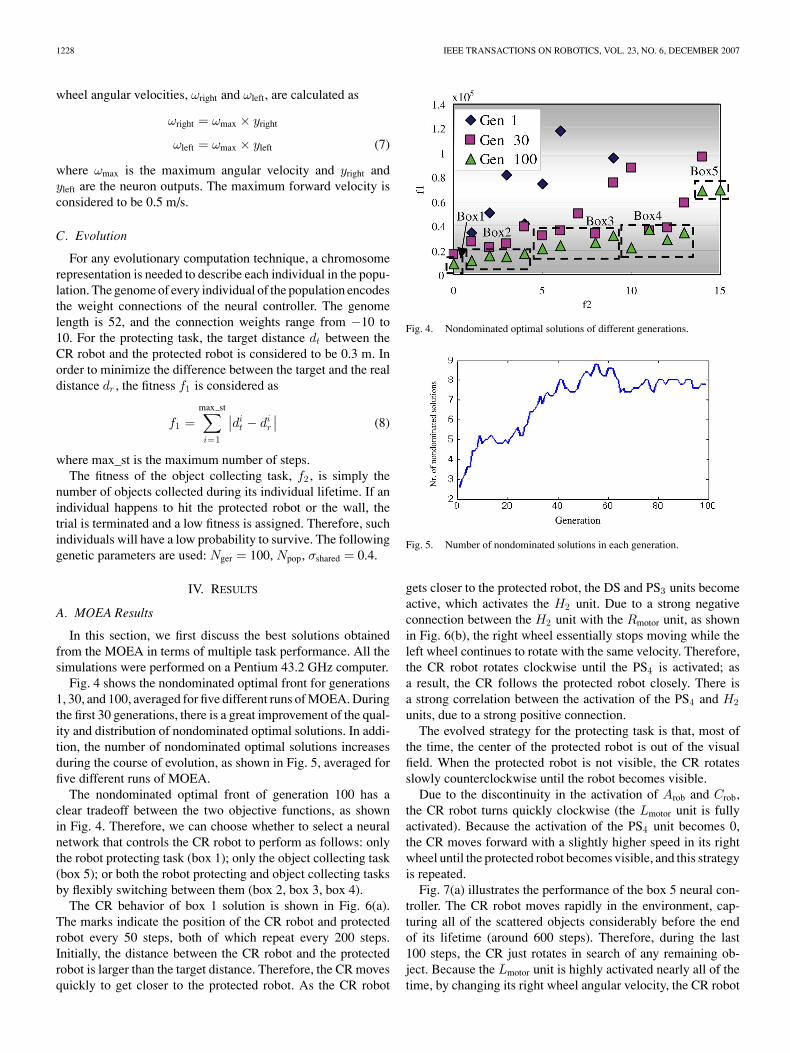
Fig. 4 shows the nondominated optimal front for generations1, 30, and 100, averaged for five different runs of MOEA. Duringthe first 30 generations, there is a great improvement of the qual-ity and distribution of nondominated optimal solutions. In addi-tion, the number of nondominated optimal solutions increasesduring the course of evolution, as shown in Fig. 5, averaged forfive different runs of MOEA.
The nondominated optimal front of generation 100 has aclear tradeoff between the two objective functions, as shownin Fig. 4. Therefore, we can choose whether to select a neuralnetwork that controls the CR robot to perform as follows: onlythe robot protecting task (box 1); only the object collecting task(box 5); or both the robot protecting and object collecting tasksby flexibly switching between them (box 2, box 3, box 4).
The CR behavior of box 1 solution is shown in Fig. 6(a).The marks indicate the position of the CR robot and protectedrobot every 50 steps, both of which repeat every 200 steps.Initially, the distance between the CR robot and the protectedrobot is larger than the target distance. Therefore, the CR movesquickly to get closer to the protected robot. As the CR robot
Fig. 4. Nondominated optimal solutions of different generations.
Fig. 5. Number of nondominated solutions in each generation.
gets closer to the protected robot, the DS and PS3 units becomeactive, which activates the H2 unit. Due to a strong negativeconnection between the H2 unit with the Rmotor unit, as shownin Fig. 6(b), the right wheel essentially stops moving while theleft wheel continues to rotate with the same velocity. Therefore,the CR robot rotates clockwise until the PS4 is activated; asa result, the CR follows the protected robot closely. There isa strong correlation between the activation of the PS4 and H2units, due to a strong positive connection.
The evolved strategy for the protecting task is that, most ofthe time, the center of the protected robot is out of the visualfield. When the protected robot is not visible, the CR rotatesslowly counterclockwise until the robot becomes visible.
Due to the discontinuity in the activation of Arob and Crob,the CR robot turns quickly clockwise (the Lmotor unit is fullyactivated). Because the activation of the PS4 unit becomes 0,the CR moves forward with a slightly higher speed in its rightwheel until the protected robot becomes visible, and this strategyis repeated.
Fig. 7(a) illustrates the performance of the box 5 neural con-troller. The CR robot moves rapidly in the environment, cap-turing all of the scattered objects considerably before the endof its lifetime (around 600 steps). Therefore, during the last100 steps, the CR just rotates in search of any remaining ob-ject. Because the Lmotor unit is highly activated nearly all of thetime, by changing its right wheel angular velocity, the CR robot

CAPI: MULTIOBJECTIVE EVOLUTION OF NEURAL CONTROLLERS AND TASK COMPLEXITY 1229
Fig. 6. Performance of CR robot for protecting task (box 1). (a) CR trajectory. (b) Hinton diagram of connection weights.
Fig. 7. Performance of CR robot for battery capturing task (box 5). (a) CR trajectory. (b) Hinton diagram of connection weights.
rotates clockwise to capture the objects. In addition, Fig. 7(a)shows that the CR robot evolved strategy is to ignore the pro-tected robot when it became visible. During the last 100 timesteps, when there is no uncollected object in the environment,the protected robot became visible five times. However, the ac-tivation of the Arob and Crob units did not have any effect onthe activation of the Lmotor unit, while the activation of Rmotor
was further reduced. Therefore, the CR robot rotates very fast,and the exposure time of the protected robot is very short. TheHinton diagram [Fig. 7(b)] shows that the H3 neuron has themain influence on this strategy.
Even when the nearest object is to the front, the CR robotrotates slowly counterclockwise, due to the strong positive con-nection between the H3 neuron with Rmotor and the negativeconnection with Lmotor units. When the object gets out of thevisual field, the Aobj and Dobj units are deactivated, reducingthe activation of the H3 and Rmotor units. Therefore, the CRrotates very fast, and the nearest object becomes visible again.This strategy is repeated three or four times before the CRreaches the object. When there is no visible object, the leftwheel moves at maximum speed while the right wheel nearlystops moving, resulting in a fast clockwise rotation.
The box 3 neural networks induce the CR robot to simulta-neously perform both tasks with the same priority [Fig. 8(a)].
The CR robot, while following the protected robot, collectedeight of the objects scattered in the environment. The proximityand distance sensors help the CR robot not to hit the protectedrobot, even while it moves very close and perpendicular to themoving direction of the protected robot. The Hinton diagramof the box 3 neural controller [Fig. 8(b)] shows that Dobj hasstrong weight connections with hidden units. This leads us tothe conclusion that the CR robot switches between two tasksbased on the activation of the Dobj unit.
The performance of the evolved neural controllers was alsotested in environments different from those in which they hadbeen evolved (Fig. 9). Fig. 9(a) shows the CR robot perfor-mance controlled by the box 3 neural network. The CR robotis placed initially in a different position near the center of theenvironment. In addition, the objects are placed in different po-sitions. The number of objects collected is increased due tothe new environment. Fig. 9(a) shows that, initially, the CRrobot collects two objects, and then, it starts moving toward theprotected robot. Fig. 9(b) shows the performance of box 4 neu-ral controllers as the protected robot follows a different trajec-tory, and the density of objects in the environment is decreased.These results demonstrate that evolved neural controllers gen-eralize well in new environments. However, in certain specificenvironments, the box 5 neural controllers failed to perform

1230 IEEE TRANSACTIONS ON ROBOTICS, VOL. 23, NO. 6, DECEMBER 2007
Fig. 8. CR multiple tasks performance (box 3). (a) CR trajectory. (b) Hinton diagram of connection weights.
Fig. 9. Performance of evolved neural controllers in different environment settings.
the object collection task. For example, when the number ofobjects was reduced or when they were not well distributed,the CR was unable to explore the environment and find theobjects.
An important advantage of applying MOEAs to evolve neuralcontrollers for multiple task robot performance is the ease withwhich the number of tasks may be increased. In the following,in addition to the protection and object collection tasks, theexploration of the environment, by moving close to the wallsand obstacles, is also undertaken. In order to maintain a constantdistance from the wall while moving along it, the fitness iscalculated as
fwall =max st∑i=1
∣∣dit wall − di
r wall
∣∣ − 3.1dmove (9)
where max_st is the maximum number of steps, dmove is themoving distance of the CR robot, and dt wall and dr wall arethe target and real distance, respectively, to the nearest wall. Inorder to force the evolutionary process to select individuals ableto move in the environment while keeping a specified distancefrom the wall, dmove is added in the fitness function.
Fig. 10(a) shows the CR robot performance controlled by thebest neural controller for the wall following task. The CR robotmoves close to walls and obstacles utilizing the data of proximitysensors (PS3–PS5) and the distance sensor. In addition, the
MOEA generated neural networks that control the CR robot tosimultaneously switch among three tasks [Fig. 10(b)].
B. Comparison to the Weighted Sum Method
As already pointed out, other approaches [14], [15] have com-bined different objectives into a single objective using predeter-mined weight parameters. Although this approach is advanta-geous because it applies traditional SOEA, the method requiressome problem-specific information, such as the total range eachobjective covers. In order to compare the relative performances,we also ran new simulations in which two cost functions of theprotecting and object collecting tasks are merged into a singleobjective. The values of f1 and f2 are normalized between 0and 1, setting the cost function fs as
fs = α
(−min(f1)
f1
)+ (1 − α)
(− f2
max(f2)
)(10)
where α is the weighting constant restricted to [0, 1].The results of five different simulations with different values
of α are given in Table I. Although we utilized the informationabout the fitness functions generated by the MOEA, the resultsshow that it is very difficult and time-consuming to determinethe best weighting constants for a predetermined number ofcollected objects. For example, the CR robot captured five ob-jects while following the protected robot when the weightingcoefficient was selected as α = 0.5. The difference between the

CAPI: MULTIOBJECTIVE EVOLUTION OF NEURAL CONTROLLERS AND TASK COMPLEXITY 1231
Fig. 10. Performance of evolved neural controllers. (a) Environment exploration. (b) Switching between three tasks.
TABLE IRESULTS GENERATED BY SOEA FOR DIFFERENT WEIGHTING COEFFICIENTS
Fig. 11. Comparison of MOEA and SOEA performances.
expected and the actual results generated by SOEA is related tothe discrete nature of f2 . While the MOEA evaluates each func-tion separately, the discrete nature of f2 and the distribution ofobjects in the environment affect the performance of the SOEA.
A comparison between the MOEA and SOEA results showsthat, in some cases, for the same number of collected objects,neural controllers generated by SOEA performed slightly betterthan the protecting task (Fig. 11). However, the behavior of theCR robot was not robust. Due to the error introduced by thesensory input units, the CR robot frequently hit the protectedrobot.
C. Hardware Experiments
We implemented the evolved optimal neural controllers onthe real hardware of the CR robot, which is a two-wheel drivenmobile robot, as shown in Fig. 12. Its body is 22 cm in length and1.75 kg in weight. The CR has a variety of sensory inputs, in-cluding a wide-range CMOS camera, an IR range sensor, sevenIR proximity sensors, a three-axis acceleration sensor, and atwo-axis gyro sensor. Its motion system consists of two wheels
Fig. 12. CR robot.
that allow a CR to move at a maximum speed of 1.3 m/s and amagnetic jaw that latches the battery packs. It also has a speaker,two microphones, a three-color LED for audiovisual commu-nication, and an IR communication port. It is further equippedwith USB and wireless communication ports for connectionwith a host computer. The CR has a Hitachi SH-4 CPU with32 MB memory, which allows fully onboard real-time learn-ing and control. The FPGA graphic processor is used for videocapture and image processing at 30 Hz.
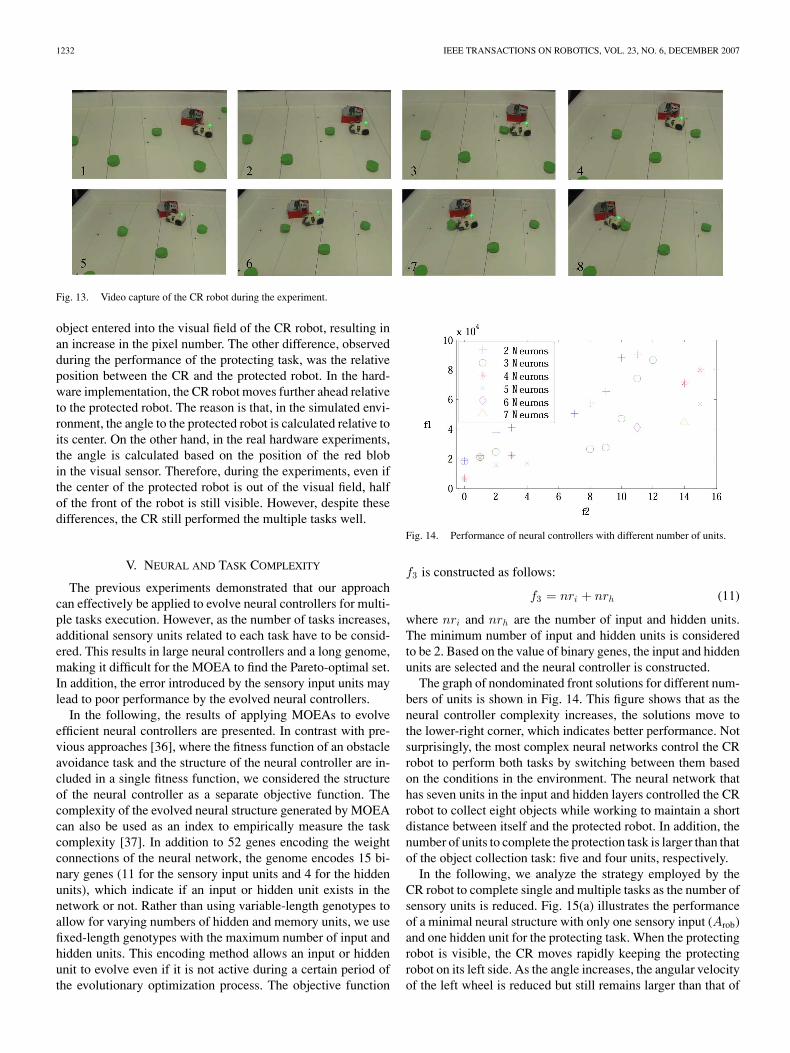
The quality of transference from simulation to real hardwarehas been evaluated over a period of many years [29]–[31]. In or-der to improve the performance, different approaches have beenproposed, such as adding appropriate noise to sensory read-ings [32], [33], switching between simulation and hardwareevolution [34], and combining learning and evolution [35]. Inour simulated environment, random noise was added to the sen-sory data. In addition, during the hardware implementation, thenoise in the calculated angle and the distance was reduced bycareful calibration of the camera [11]. A video capture of the CRrobot controlled by the box 3 neural network is shown in Fig. 13.The protected robot has a red cover with a rectangular shape inorder to be detected by the visual and proximity sensors. Fig. 13shows that the CR robot protected the moving robot, while alsoswitching to the object collection task.
However, there are two main differences between the sim-ulated and real robot performance. First, the distance to thenearest object utilized by the CR robot to switch from the pro-tecting to the object collecting task was longer in the real en-vironment. This is because, in some situations, more than one
1232 IEEE TRANSACTIONS ON ROBOTICS, VOL. 23, NO. 6, DECEMBER 2007
Fig. 13. Video capture of the CR robot during the experiment.
object entered into the visual field of the CR robot, resulting inan increase in the pixel number. The other difference, observedduring the performance of the protecting task, was the relativeposition between the CR and the protected robot. In the hard-ware implementation, the CR robot moves further ahead relativeto the protected robot. The reason is that, in the simulated envi-ronment, the angle to the protected robot is calculated relative toits center. On the other hand, in the real hardware experiments,the angle is calculated based on the position of the red blobin the visual sensor. Therefore, during the experiments, even ifthe center of the protected robot is out of the visual field, halfof the front of the robot is still visible. However, despite thesedifferences, the CR still performed the multiple tasks well.
V. NEURAL AND TASK COMPLEXITY
The previous experiments demonstrated that our approachcan effectively be applied to evolve neural controllers for multi-ple tasks execution. However, as the number of tasks increases,additional sensory units related to each task have to be consid-ered. This results in large neural controllers and a long genome,making it difficult for the MOEA to find the Pareto-optimal set.In addition, the error introduced by the sensory input units maylead to poor performance by the evolved neural controllers.
In the following, the results of applying MOEAs to evolveefficient neural controllers are presented. In contrast with pre-vious approaches [36], where the fitness function of an obstacleavoidance task and the structure of the neural controller are in-cluded in a single fitness function, we considered the structureof the neural controller as a separate objective function. Thecomplexity of the evolved neural structure generated by MOEAcan also be used as an index to empirically measure the taskcomplexity [37]. In addition to 52 genes encoding the weightconnections of the neural network, the genome encodes 15 bi-nary genes (11 for the sensory input units and 4 for the hiddenunits), which indicate if an input or hidden unit exists in thenetwork or not. Rather than using variable-length genotypes toallow for varying numbers of hidden and memory units, we usefixed-length genotypes with the maximum number of input andhidden units. This encoding method allows an input or hiddenunit to evolve even if it is not active during a certain period ofthe evolutionary optimization process. The objective function
Fig. 14. Performance of neural controllers with different number of units.
f3 is constructed as follows:
f3 = nri + nrh (11)
where nri and nrh are the number of input and hidden units.The minimum number of input and hidden units is consideredto be 2. Based on the value of binary genes, the input and hiddenunits are selected and the neural controller is constructed.
The graph of nondominated front solutions for different num-bers of units is shown in Fig. 14. This figure shows that as theneural controller complexity increases, the solutions move tothe lower-right corner, which indicates better performance. Notsurprisingly, the most complex neural networks control the CRrobot to perform both tasks by switching between them basedon the conditions in the environment. The neural network thathas seven units in the input and hidden layers controlled the CRrobot to collect eight objects while working to maintain a shortdistance between itself and the protected robot. In addition, thenumber of units to complete the protection task is larger than thatof the object collection task: five and four units, respectively.
In the following, we analyze the strategy employed by theCR robot to complete single and multiple tasks as the number ofsensory units is reduced. Fig. 15(a) illustrates the performanceof a minimal neural structure with only one sensory input (Arob)and one hidden unit for the protecting task. When the protectingrobot is visible, the CR moves rapidly keeping the protectingrobot on its left side. As the angle increases, the angular velocityof the left wheel is reduced but still remains larger than that of

CAPI: MULTIOBJECTIVE EVOLUTION OF NEURAL CONTROLLERS AND TASK COMPLEXITY 1233
Fig. 15. Performance of neural controller with one sensory input and onehidden unit for protecting task. (a) CR trajectory. (b) Hinton diagram of weightconnections.
Fig. 16. Performance of neural controller with three sensory inputs and twohidden units. (a) CR trajectory. (b) Hinton diagram.
the right wheel. Therefore, the protected robot escapes from thevisual field.
When the protected robot is not visible, H1 is fully activated.Due to the positive connection between the H1 unit with theLmotor unit and the negative connection with the Rmotor unit, asshown in Fig. 15(b), the CR rotates clockwise until the protectedrobot again comes into the visual field. However, the value of f1is nearly three times larger than that of the best neural controllerwith two sensory input and three hidden units (Fig. 14).
Fig. 16(a) shows a successful robot controller with only threesensory inputs (Dobj, Arob, and PS4) along with two hiddenunits that switch between the two tasks and arrange to collect
six objects while also following the protected robot. When thePS4 unit is active, due to the strong positive connections withthe H1 and H2 units [Fig. 16(b)], the CR robot ignores thevisible objects and just follows the protected robot. However,when the protected robot changes direction, the activation of thePS4 unit becomes 0 and the CR switches to the object collectingtask. Therefore, the CR utilized the activation of the PS4 unit toswitch between the two tasks.
VI. CONCLUSION
This paper has experimentally investigated the effectivenessof applying MOEAs to address the multiple task robot perfor-mance problem. In particular, it was demonstrated that, in asingle run of the MOEA, robust neural controllers are generatedwith distinctly different characteristics, ranging from perform-ing each of the assigned tasks to simultaneously performingdifferent tasks, by flexibly switching between them. Therefore,the user can select the most appropriate neural controller basedon the task priority or the environmental conditions. Finally, weapplied the MOEA to generate efficient neural controllers with aminimum number of sensory and hidden units for multiple taskperformance. The robustness of evolved neural controllers wasalso tested on the real hardware of the CR robot, using visual,proximity, and distance sensors.
For future work, we will address two possible extensions.First, we will work to develop a new MOEA. The secondpossible extension is to develop a robot that can learn toswitch between optimal neural controllers in more dynamicenvironments.
ACKNOWLEDGMENT
The author would like to thank the reviewers and editors fortheir helpful suggestions.
REFERENCES
[1] A. Waibel, H. Sawai, and K. Shikano, “Modularity and scaling in largephonemic neural networks,” IEEE Trans. Acoust., Speech Signal Process.,vol. 37, no. 12, pp. 1888–1898, Dec. 1989.
[2] R. Caruana, “Multitask learning,” in Machine Learning, vol. 28. Nor-well, MA: Kluwer, 1997, pp. 41–75.
[3] L. Y. Pratt, J. Mostow, and C. A. Kamm, “Direct transfer of learnedinformation among neural networks,” in Proc. 9th Nat. Conf. Artif. Intell.(AAAI 1991), pp. 584–589.
[4] L. Y. Pratt, “Non-literal transfer among neural network learners,” inArtificial Neural Networks for Speech and Vision, R. J. Mammone, Ed.London, U.K.: Chapman & Hall, 1994, pp. 143–169.
[5] N. E. Sharkey and A. J. C. Sharkey, “Adaptive generalization and thetransfer of knowledge,” AI Rev., vol. 7, pp. 313–328, 1993.
[6] S. Thrun and J. O’Sullivan, “Clustering learning tasks and the selectivecross-task transfer of knowledge,” in Learning to Learn, S. Thrun and L.Y. Pratt, Eds. Norwell, MA: Kluwer, 1998.
[7] S. P. Singh, “Transfer of learning by composing solutions of elementalsequential tasks,” Mach. Learn., vol. 8, no. 3, pp. 323–339, 1992.
[8] G. Capi and K. Doya, “Application of evolutionary computation for effi-cient reinforcement learning,” Appl. Artif. Intell., vol. 20, no. 1, pp. 1–20,2006.
[9] Y. Takahashi, K. Edazawa, K. Noma, and M. Asada, “Simultaneous learn-ing to acquire competitive behaviors in multi-agent system based on mod-ular learning system,” in Proc. 2005 IEEE/RSJ Int. Conf. Intell. RobotsSyst., pp. 153–159.

1234 IEEE TRANSACTIONS ON ROBOTICS, VOL. 23, NO. 6, DECEMBER 2007
[10] S. Nolfi, “Evolving robots able to self-localize in the environment: Theimportance of viewing cognition as the result of processes occurring atdifferent time scales,” Connect. Sci., vol. 14, no. 3, pp. 231–244, 2002.
[11] G. Capi and K. Doya, “Evolution of neural architecture fitting environ-mental dynamics,” Adapt. Behav., vol. 13, no. 1, pp. 53–66, 2005.
[12] G. Capi, E. Uchibe, and K. Doya, “Selection of neural architecture and theenvironment complexity,” in Dynamical Systems Approach for Embod-iment and Sociality, K. Murase and T. Asakura, Eds. Thousand Oaks,CA: Sage, 2003, pp. 311–317.
[13] S. Nolfi and D. Floreano, Evolutionary Robotics: The Biology, Intelli-gence, and Technology of Self-Organizing Machines. Cambridge, MA:MIT Press/Bradford Books, 2000.
[14] D. Floreano and F. Mondada, “Evolution of homing navigation in a realmobile robot,” IEEE Trans. Syst., Man, Cybern. B, Cybern., vol. 26, no. 3,pp. 396–407, Jun. 1996.
[15] D. Cliff and G. F. Miller, “Co-evolution of pursuit and evasion. II: Simu-lation methods and results,” in From Animals to Animats 4, Cambridge,MA: MIT Press, 1996, pp. 506–514.
[16] C. A. Coello, D. A. Van Veldhuizen, and G. B. Lamont, EvolutionaryAlgorithms for Solving Multi-Objective Problems. New York: Kluwer,2002.
[17] K. Deb, Multi-Objective Optimization Using Evolutionary Algorithms.Chichester, U.K.: Wiley, 2001.
[18] C. M. Fonseca and P. J. Fleming, “An overview of evolutionary algorithmsin multiobjective optimization,” Evol. Comput., vol. 3, pp. 1–16, 1995.
[19] N. Srivinas and K. Deb, “Multiobjective optimization using non-dominated sorting in genetic algorithms,” Evol. Comput., vol. 2, no. 3,pp. 279–285, 1995.
[20] H. A. Abbass, “A memetic Pareto evolutionary approach to artificial neuralnetworks,” in Proc. Aust. Joint Conf. Artif. Intell. (Lecture Notes inArtificial Intelligence 2256). New York: Springer-Verlag, 2001, pp. 1–12.
[21] H. A. Abbass, “An evolutionary artificial neural networks approach forbreast cancer diagnosis,” in Artificial Intelligence in Medicine. vol.25, no. 3. Amsterdam, The Netherlands: Elsevier, 2002, pp. 265–281.
[22] H. A. Abbass, “Speeding up back-propagation using multiobjective evo-lutionary algorithms,” in Neural Computation. vol. 15, no. 11. Cam-bridge, MA: MIT Press, 2003, pp. 2705–2726.
[23] S. Roth, A. Gepperth, and C. Igel, “Multi-objective neural network opti-mization for visual object detection,” in Multi-objective Machine Learn-ing, Y. Jin, Ed. New York: Springer-Verlag, 2006, pp. 629–655.
[24] J. E. Fieldsend and S. Singh, “Pareto evolutionary neural networks. Neuralnetworks,” IEEE Trans. Neural Netw., vol. 16, no. 2, pp. 338–354, Mar.2005.
[25] G. J. Barlow, C. K. Oh, and E. Grant, “Incremental evolution of au-tonomous controllers for unmanned aerial vehicles using multi-objectivegenetic programming,” in Proc. IEEE Int. Conf. Cybern. Intell. Syst. (CIS),2004, pp. 689–694.
[26] A. H. F. Dias and J. A. de Vasconcelos, “Multiobjective genetic algorithmsapplied to solve optimization problems,” IEEE Trans. Magn., vol. 38,no. 2, pp. 1133–1136, Mar. 2002.
[27] E. Zitzler, K. Deb, and L. Thiele, “Comparison of multiobjective evo-lutionary algorithms: Empirical results,” in Evolutionary Computation.vol. 8, no. 2. Cambridge, MA: MIT Press, 2000, pp. 173–195.
[28] B. Sareni, L. Krahenbuhl, and A. Nicolas, “Niching genetic algorithms foroptimization in electromagnetics—I. Fundamentals,” IEEE Trans. Magn.,vol. 34, no. 5, pp. 2984–2987, Sep. 1998.
[29] R. A. Brooks, “Artificial life and real robots,” in Towards a Practiceof Autonomous Systems: European Conference on Artificial Life. Cam-bridge, MA: MIT Press, 1991, pp. 3–10.
[30] J. Walker, S Garrett, and M. Wilson, “Evolving controllers for real robots:A survey of the literature,” Adapt. Behav., vol. 11, no. 3, pp. 179–203,2003.
[31] P. E. Hotz and G. Gomez, “The transfer problem from simulation to thereal world in artificial evolution,” in Proc. 9th Int. Conf. Simul. SynthesisLiving Syst. (Alife IX), 2004, pp. 17–20.
[32] P. Husbands, T. Smith, N. Jakobi, and M. O’Shea, “Better living throughchemistry: Evolving gasnets for robot control,” Connect. Sci., vol. 10,no. 3/4, pp. 185–210, 1998.
[33] O. Miglino, H. H. Lund, and S. Nolfi, “Evolving mobile robots in simulatedand real environments,” Artif. Life, vol. 2, no. 4, pp. 417–434, 1995.
[34] A. L. Nelson, E. Grant, J. M. Galeotti, and S. Rhody, “Maze explorationbehaviors using an integrated evolutionary robotics environment,” Robot.Auton. Syst., vol. 46, pp. 159–173, 2004.
[35] S. Nolfi, J. L. Elman, and D. Parisi, “Learning and evolution in neuralnetworks,” Adapt. Behav., vol. 3, no. 1, pp. 5–28, 1994.
[36] R. Odagiri, Y. Wei, T. Asai, O. Yamakawa, and K. Murase, “Measuringthe complexity of the real environment with evolutionary robot: Evolutionof a real mobile robot Khepera to have minimal structure,” in Proc. IEEEInt. Conf. Evol. Comput. (ICEC 1998), pp. 348–353.
[37] J. Teo and H. A. Abbass, “Automatic generation of controllers for embod-ied legged organisms: A Pareto evolutionary multi-objective approach,”Evol. Comput., vol. 12, no. 3, pp. 355–394, 2004.
Genci Capi (M’01) received the B.E. degree in me-chanical engineering from the Polytechnic Universityof Tirana, Tirana, Albania, in 1993, and the Ph.D.degree in information systems engineering from Ya-magata University, Yamagata, Japan, in 2002.
From 2002 to 2004, he was a Researcher in the De-partment of Computational Neurobiology, AdvancedTelecommunications Research Institute International(ATR), Kyoto, Japan. In 2004, he joined the Depart-ment of System Management, Fukuoka Institute ofTechnology, as an Assistant Professor, and in 2006,
he was promoted to Associate Professor. He is currently an Associate Professorin the Department of Electrical and Electronic Systems Engineering, Universityof Toyama, Toyama, Japan. His current research interests include intelligentrobots, multirobot systems, humanoid robots, learning, and evolution.





























