Embed Size (px)
Citation preview

Psychological Review1978, Vol. 85, No. 3, 207-238
Context Theory of Classification Learning
Douglas L. MedinRockefeller University
Marguerite M. SchafferBarnard College
Most theories dealing with ill-defined concepts assume that performance is basedon category level information or a mixture of category level and specific iteminformation. A context theory of classification is described in which judgmentsare assumed to derive exclusively from stored exemplar information. The mainidea is that a probe item acts as a retrieval cue to access information associatedwith stimuli similar to the probe. The predictions of the context theory are con-trasted with those of a class of theories (including prototype theory) that as-sume that the information entering into judgments can be derived from anadditive combination of information from component cue dimensions. Acrossfour experiments using both geometric forms and schematic faces as stimuli, thecontext theory consistently gave a better account of the data. The relation ofthe context theory to other theories and phenomena associated with ill-definedconcepts is discussed in detail.
One of the major components of cognitivebehavior concerns abstracting rules and form-ing concepts. Our entire system of naming ob-jects and events, talking about them, and inter-acting with them presupposes the ability togroup experiences into appropriate classes.Young children learn to tell the difference be-tween dogs and cats, between clocks and fans,and between stars and street lights. Since fewconcepts are formally taught, the evolution ofconcepts from experience with exemplars mustbe a fundamental learning phenomenon. Thefocus of the present article is to explore howsuch conceptual achievements emerge fromindividual instances.
Structure of Concepts
An early step in analyzing task demandsinvolved in conceptual behavior is to ask how
This research was supported by United States PublicHealth Grant MH16100 and by Grant MH 23878 fromthe National Institute of Mental Health.
We wish to acknowledge the support of Edith Skaar,who assisted in all phases of this research, and thepatience of Mark Altom, Lee Brooks, Donald Robbins,and Edward E. Smith, who read earlier drafts of thisarticle and provided helpful suggestions.
Requests for reprints should be sent to Douglas L.Medin, Box 298, Rockefeller University, New York,New York 10021.
individual instances or exemplars are relatedto the superordinate concept. Although thereis general agreement that natural categoriesare structured so that exemplars within acategory are more similar to one another thanto exemplars from alternative categories, thereis disagreement concerning the rigidity of thisstructure. One extreme view is that all naturalconcepts are characterized by simple sets ofdenning features that are singly necessary andjointly sufficient to determine category mem-bership (Katz & Postal, 1964). Each exemplarof the concept must possess these definingfeatures, and therefore, each exemplar isequally representative of the concept. Con-cepts containing singly necessary and jointlysufficient denning features are said to be well-defined concepts.
A contrasting point of view is that mostnatural concepts are not well-defined butrather are based on relationships that are onlygenerally true. Individual exemplars may varyin the number of characteristic features theypossess, and consequently, some exemplarsmay be more representative or more typical ofa concept than others. For example, cows maybe better exemplars of the concept mammalthan are whales. Instances are neither arbi-trarily associated with categories nor strictlylinked by defining features, but rather in-
Copyright 1978 by the American Psychological Association, Inc. 0033-295X/78/8503-0207$00.75
207

208 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
stances reflect more nearly a "family resem-blance" structure (Rosch & Mervis, 1975).
These ideas concerning the structure ofcategories influence the way instances are setup in laboratory studies of artificial concepts.Most early work with concepts used well-defined concepts and focused on such issues asthe relative difficulty of acquiring differentrules, strategies for formulating and testingalternative hypotheses, and the transfer ofbehavior to new stimulus sets (e.g., Bourne,1970; Levine, 1975; Trabasso & Bower, 1968).While this approach has accumulated con-siderable information about processes under-lying hypothesis selection and rule learningwhere rules are well-defined, little informationexists to show how these models might beapplied to a variety of other situations whererules and concepts are not so precisely defined.Therefore, substantial reason exists to examinemore closely the case in which the conceptsand classifications acquired in everyday ex-perience do not conform to well-defined rules.
On the basis of an extensive series of experi-ments, Rosch and her associates (Rosch, 1973,1975a, 1975b, 1975c; Rosch & Mervis, 1975;Rosch et al., 1976) have argued that mostnatural categories do not have well-definedrules or fixed boundaries separating alternativecategories. Rather, members vary in the degreeto which they are judged to be good examples(typical) of the category, and many naturalconcepts cannot be defined by a single set ofcritical features. In addition, subjects appearto use nonnecessary features in making cate-gory judgments. Smith, Shoben, and Rips(1974) found that the items judged to betypical of a category possess features that arecharacteristic of the class but not necessary forcategory definition. For example, robin is atypical member of the category bird and hasthe characteristic feature that it flies, but notall birds fly (e.g., penguins). In a reaction timetask, Smith et al. observed that subjects re-quired less time to verify the category member-ship of the more typical items in a category.Characteristic features and not just definingfeatures appear to be involved in these categoryjudgments.
If many natural categories have a looselydefined structure, how do people acquire anduse this structure? Posner and Keele (1968)
proposed that based on experience with ex-emplars, people form an impression of thecentral tendency of a category and that cate-gorical judgments come to be based on thiscentral tendency, or prototype. While there isnot universal agreement that prototype forma-tion underlies conceptual learning in thisdomain, the increasing evidence that naturalcategories and concepts are not well-definedhas amplified the interest in developing theoriesof conceptual behavior appropriate to ruleswith exceptions.
The present article takes the perspective ofaiming to see if recent theoretical develop-ments arising in the domain of discriminationlearning might be profitably applied to classi-fication learning. In the case of well-definedrules for stimulus classification, there are somestriking parallels between paradigm and theoryin discrimination learning and concept identi-fication. For example, the simple affirmativeconcept "red in one pile, green in the otherpile" corresponds to a simultaneous discrimi-nation learning task, where red is correct andgreen is incorrect. Likewise, hypothesis-testingtheories for concept identification tasks (e.g.,Trabasso & Bower, 1968) are closely mirroredby theories of selective attention in discrimina-tion learning (Medin, 1976; Sutherland &Mackintosh, 1971).
Is there any basis for expecting useful inter-action between the domains of discriminationlearning and concept learning for ill-definedrules? We shall argue that there is. Not alldiscrimination learning problems map ontosimple affirmative rules. For example, in asuccessive brightness discrimination problem,the solution might be "If the choice stimuliare white, go right; if black, go left." Thevarious stimulus components, that is, black,white, left, and right, each are associated withreward half the time, and the problem couldnot be solved on the basis of associations tothese independent stimulus components. In-deed, Spence's (1936) theory of discriminationlearning assumed independence of compo-nents, and it was unable to predict that suc-cessive discrimination problems could be mas-tered. Other discrimination learning theorieshave been proposed that can account for rela-tionships between simultaneous and successivediscrimination learning, and the present article

THEORY OF CLASSIFICATION LEARNING 209
attempts to demonstrate the applicability ofone such theory (Medin, 1975) to learning andclassification involving ill-defined categories.Before discussing this theory, however, weconsider two phenomena that have been ad-duced in support of prototype theory and thatdirectly motivated our theoretical efforts.
Some Evidence Related to Classification InvolvingIll-defined Concepts
In a typical study assessing the learning ofill-defined concepts, subjects learn to sort aset of instances into two or more categoriesand then are given transfer tests with newstimuli, including a pattern representing thecentral tendency, or prototype. An alternativeto the procedure of presenting two or morecontrasting categories is simply to presentsubjects with instances of a single concept andthen to give a new-old recognition test for newand old instances. Stimuli range from sche-matic faces, geometric forms, and dot patternsto letter sequences and biographical descrip-tions. A major theoretical view is that as afunction of experience with exemplars of acategory, subjects abstract out the centraltendency of the category. This summaryrepresentation, or prototype, is assumed toprovide the basis for classification performance.The closer an exemplar is to its category proto-type and the farther it is from the prototypesassociated with alternative categories, thegreater the likelihood that it will be appropri-ately classified.
Two main results arising from this literatureseem to provide cogent evidence for prototypeformation:
1. Subjects classify prototypic patterns theyhave never seen before virtually as fast andaccurately as they classify old training pat-terns. In addition, these two types of patternsare classified better than other new exemplars(e.g., Homa & Chambliss, 1975; Homa &Vosburgh, 1976; Peterson, Meagher, Chait, &Gillie, 1973; Posner & Keele, 1968, 1970;Strange, Keeney, Kessel, & Jenkins, 1970).Transfer performance is well-predicted by dis-tance of a pattern from the prototype and notby the frequency with which individual fea-tures of patterns appeared during training(e.g., Franks & Bransford, 1971; Lasky, 1974;Posnansky & Neumann, 1976).
It is generally proposed that two factorsdetermine classification performance in thesesituations (e.g., Posner & Keele, 1968, 1970).One is specific item information, which leadsto old training patterns being classified betterthan new patterns; the other is abstraction,which gives rise to performance being a func-tion of the distance of a pattern from thecentral tendency, or prototype.
2. The second major finding concerns dif-ferential retention of old and new patterns.When delays on the order of several days areinserted between learning and transfer tests,significantly greater forgetting is observed forthe old training stimuli than for the prototypeand other new patterns (Goldman & Homa,1977; Homa et al., 1973; Homa & Vosburgh,1976; Posner & Keele, 1970; Strange et al.,1970). These results are consistent with theidea that judgments are based on a mixtureof specific item and category level informationand that the specific item information is for-gotten more rapidly than the abstract, cate-gory level information. According to this view,as retention interval increases, judgments areincreasingly likely to be based on the proto-type and less likely to be based on specificexemplar information.
Previous theoretical explanations of theabove two phenomena have relied on positingboth specific item and category level informa-tion. Yet, we noted that at least one dis-crimination learning theory (Medin, 1975)might account for these results and interac-tions simply in terms of the similarity or con-fusability of the learned exemplars. Therefore,it is of interest to see how well this theory canaccount for classification without assumingthat category level information influences per-formance. In the remainder of this article, wepresent a context theory of classification basedon Medin's (1975) context theory of discrimi-nation learning, describe four new experimentsthat contrast the predictions of the contextmodel with predictions derived from a largeclass of classification models, and finally discussmore generally the relationship between thecontext theory and classification behavior.
Context Theory for Classification
The general idea of the context model isthat classification judgments are based on the

210 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
retrieval of stored exemplar information. Spe-cifically, we assume that a probe stimulusfunctions as a retrieval cue to access informa-tion stored with stimuli similar to the probe.This mechanism is, in a sense, a device forreasoning by analogy inasmuch as classifica-tion of new stimuli is based on stored informa-tion concerning old exemplars, but one shouldalso note its similarity to contemporary mem-ory models. For example, Ratcliff (Note 1)has recently proposed a model for recognitionmemory that relies on a resonance metaphor,whereby the set of stored items to be searchedis evoked on the basis of similarity of the in-formation provided by the probe to the infor-mation in the memory items.
Although we shall propose that classifica-tions derive from exemplar information, we donot assume that the storage and retrievabilityof this exemplar information is necessarilyveridical. If subjects are using strategies andhypotheses during learning, the exemplar in-formation may be incomplete and the salienceof information from alternative dimensionsmay differ considerably. A person focusing onthe hypothesis that red cards belong in Cate-gory A and green cards in Category B mightstore and be able to retrieve little informationconcerning, say, the form of the stimuli.The context model attempts to represent theeffect of strategies and hypotheses in termsof the ease of storage and retrieval of informa-tion associated with the component stimulusdimensions.
Notation
In discussing the context theory and alterna-tive theories, it is useful to work with an ab-stract notation. Consider a situation wherethe stimuli to be classified comprise binaryvalues on each of four dimensions (e.g., color[red or blue], form [triangle or circle], size[large or small], and number [one or two]).By assigning the number 1 to one value on adimension and the number 0 to the other, eachstimulus can be described in terms of a simplebinary code. For example, if the dimensionsare ordered as color, form, size, and number,the notation 1001 might refer to a single smallred circle, while 0110 would refer to a stimuluscomprised of two large blue triangles. This
binary code is also useful for noting similarityrelationships. Thus, the two stimuli 1111 and1101 differ only in size, while 0101 and 1101differ only in color.
Before proceeding to the particular assump-tions of the context model, it might provehelpful to consider a specific example. Supposetwo A patterns, AI and A2 (Ai =1110 andA2 = 1010), and two B patterns, BI and B2
(Bi = 0001 and B2 = 1100), have been pre-sented a few times during a classificationlearning task and that now a new stimulus1101 is presented. Suppose further that theperson in the experiment has selectively at-tended to the first two dimensions, so that lessinformation has been stored or is retrievableconcerning the third and fourth dimensions.The subject's representation of exemplar in-formation may be something like this:
lll?~A(Ai) 10?0-A(A2)OO?I-B(B!) no?-B(B2),
where the question marks indicate that infor-mation that would differentiate value 1 andvalue 0 on that dimension either has not beenstored or cannot be accessed. When the probe1101 is presented, the most likely event is thatthe representation associated with the B2 ex-emplar (110?) will be retrieved, and the probewill be classified as a B. The next most likelyevent is that exemplar AI will be retrieved,since the probe differs from the representationof AI only on the third dimension. In thiscase, the probe would be classified as an A.The greater the similarity of a stored ex-emplar to a probe, the more likely it is thatthe probe will retrieve the information associ-ated with that, exemplar. In the followingparagraphs, we provide a general rationale forour ideas concerning similarity and then de-velop the specific assumptions of the contextmodel.
Interactive Similarity
Imagine that a blue circle is presented insome experimental context and that someevent (e.g., the classification assignment) oc-curs. It is not assumed that individual stimuluscomponents get directly and independentlyassociated with the event. Rather, we proposethat information concerning the cue, the con-

THEORY OF CLASSIFICATION LEARNING 211
text, and the event are stored together inmemory and that both cue and context mustbe activated simultaneously in order to re-trieve information about the event. A changein either the cue or the context can impairthe accessibility of information associated withboth.
This idea is depicted in Figure 1. R(cue),R(context), and R (event) refer to the mem-ory representation of the cue, context, andevent, respectively. It is further assumed thata particular stimulus component serves a cuefunction and acts as context for other cues. Inour example, blue is part of the context inwhich circle appears. As a result, transfer orgeneralization along the form dimension willnot be independent of color value. This non-independence represents an important con-straint on the accessibility of stored informa-tion and provides the basis for the experimen-tal contrasts to be considered later.
This formulation is closely related to theassumptions of the Estes hierarchical associa-tion model (Estes, 1972, 1973, 1976). The cue-context node corresponds to what Estes callsa "control element," and we use it to denotethe assumptions (a) that neither cue nor con-text is directly associated with an event oroutcome and (b) that inputs from both cueand context are needed to activate the nodeand provide access to the representation of anevent. The latter assumption implies that theeffect of cue changes and context changes com-bine in an interactive manner.
Specific Assumptions
1. Category judgments are based on theretrieval of specific item information; no cate-gorical information is assumed to enter intothe judgments independently of specific iteminformation. While it is assumed that categori-cal information does not influence judgments,this is not the same as assuming that categorylevel information does not exist. In the case ofnatural categories, information on the level ofcategories is often explicitly presented. Ourproposal simply is that judgments in classifica-tion tasks are based on retrieval of exemplarinformation rather than on category levelinformation.
CUE-CONTEXT NODE
R(CUE)' R(CONTEXT) K(EVENT)
Figure 1. Illustration of factors proposed to determinethe accessibility of information associated with a cuepresented in a particular context. (R refers to thememory representation of the cue, context, or event.)
2. The probability of classifying exemplar iinto category j is an increasing function of thesimilarity of exemplar i to stored category jexemplars and a decreasing function of thesimilarity of exemplar i to stored exemplarsassociated with alternative categories. Specifi-cally, it is assumed that the evidence favoringa category j response to probe i is equal to thesum of the similarities of probe i to the storedj exemplars divided by the sum of the simi-larities of probe i to all stored exemplars. Forpurposes of the present article, we assume thatthe probability of a j response is equal to theevidence favoring a j classification. The mecha-nism by which these similarities operate isdetailed in the next assumption.
3. Probe or test stimuli act as retrieval cuesto access information associated with stimulisimilar to the probe. Which stimuli will beretrieved depends on the overall similarity ofthe stored exemplars to the probe stimulus.Instead of proposing that subjects computethe similarity of a probe to all of the trainingpatterns, we assume that the retrieval rulesact to determine which patterns are likely tobe accessed. In fact, later on we shall considerthe possibility that judgments are based solelyon the first pattern retrieved.
4. The similarity of two cues along a dimen-sion can be represented by a similarity param-eter whose value can range between 0 and 1,with 1 representing maximum similarity. Forexample, the similarity of a yellow circle anda blue triangle along the color dimension wouldbe represented by a parameter c for colorsimilarity, while form similarity would berepresented by a parameter /. The parameterc for color would be larger if the two colorswere yellow and orange than if the two colorswere yellow and blue, since presumably yellowis more similar to orange than to blue.
5. The various cue dimensions comprisingstimuli in some context are combined in an

212 DOUGLAS L, MEDIN AND MARGUERITE M. SCHAFFER
interactive, specifically multiplicative, mannerto determine the overall similarity of twostimuli. This means that the overall similarityof a yellow circle and a blue triangle would beequal to cf. If the form differences were verysalient (i.e., /=0), then variations in colorsimilarity would not alter performance, sincec/=S 0 regardless of the value of c.
Although the rationale for the multiplicativerule grows out of attempts to represent theeffects of similarity and context in other situa-tions (e.g., Estes, 1973; Medin, 1975), it fitswell with certain intuitions concerning naturalconcepts. For example, although mannequinsmay resemble human beings along a varietyof dimensions, we are not tempted to judgethat they are, in fact, human beings. In amultiplicative combination rule, the effects ofvarious dimensions of similarity can be effec-tively overcome by a single dimension of dif-ference (e.g., animacy). If judgments werebased solely on a summing of evidence, itwould be more awkward to represent the dif-ference between mannequins and human beings.In short, the interactive rule has the potentialto represent the effects of necessary featureswithout the theory committing itself to theidea that category membership is defined interms of singly necessary and jointly sufficientfeatures.
The multiplicative rule implies that a pat-tern will be classified more efficiently if it ishighly similar to one pattern (differing in onlyone dimension) and has low similarity to asecond (differing in three dimensions) than ifit has medium similarity (differing in twodimensions to two patterns in its category. Ifall dimensions were equally salient, then inthe first case, the net similarity would be 5 + s3
(where s is the similarity parameter for a differ-ence along a given dimension); and in thesecond, the net similarity would be 2si. Sinces is defined to be between 0 and 1, the firstterm is larger than the second, except for theuninteresting cases where s is 0 or where s is 1.
6. Selective attention can be represented bychanges in the salience or similarity parameterfor dimensions. That is, the similarity param-eter of two cues along a dimension is lesswhen that dimension is attended than when itis not attended.
This assumption is designed to capture theconsequences of active hypothesis testing. Forexample, if subjects were trying out the pos-sibility that all red stimuli belong to CategoryA and all green stimuli to Category B, theymight code much less information about otherattributes such as size or form than otherwise.As a result, the effective similarity of two sizeor two form cues might be greater than usual,and the effective similarity of red and greenwould be expected to be less than otherwise.For tests that can be solved by attending to asingle dimension, subjects may have onlyminimal information to distinguish the indi-vidual exemplars (see Bourne & O'Banion,1969; Calfee, 1969).
7. The last general assumption is that reten-tion loss can be represented by changes(increases) in the similarity parameters. Weassume that retention loss corresponds to aloss of distinctiveness, which we represent asincreased similarity, regardless of whether itarises from forgetting of hypotheses or strate-gies involving selective attention or from de-creased availability of the exemplar informa-tion independent of strategies.
No special assumptions are made to dis-tinguish old and new patterns, and later on wewill indicate how differential forgetting ishandled in terms of changes in the similarityparameters. We propose that the ease of learn-ing to classify a training pattern into CategoryA and the likelihood of classifying a new pat-tern into Category A increases with the simi-larity of the pattern to the stored exemplars inCategory A and decreases with the similarityof an item to the exemplars in Category B.One shortcoming of the context model as sofar developed is that specific assumptions con-cerning learning and storage of exemplar infor-mation have not been spelled out. Predictionsconcerning errors during learning will be basedon the qualitative evidence derived from thesimilarity of an exemplar to other exemplarsof its category versus its similarity to exem-plars of alternative categories.
Application to an Example
In developing the predictions of the contexttheory as well as those alternative classifica-tion theories, it is useful to work with a con-

THEORY OF CLASSIFICATION LEARNING 213
crete example. Consider a situation where sixstimuli are to be presented, three assigned toCategory A and three to Category B. Supposefurther that the stimuli comprise binary valueson the dimensions of color, form, size, andposition. Figure 2 represents this situation interms of our abstract notation. If 1 representsred and 0 blue, then red figures are moreoften associated with Category A than Cate-gory B. One can also see that Stimulus 1differs from Stimulus 2 only on position butdiffers from Stimulus 3 in color, form, andsize. The categories are not well-defined be-cause there is no set of singly necessary andjointly sufficient features to define categorymembership. In fact, no simple feature is evennecessary for category membership. Note thatfor any dimension, two of the three Category Amembers have value 1 and two of the threeCategory B members have value 0. We willnow use this notation and write predictionequations based on our assumptions concern-ing similarity and retrieval.
The similarity parameters for the dimen-sions of color, form, size, and position arerepresented as parameters c, f, s, and p whentwo comparison stimuli differ in their value onthe dimension in question, and the similarityparameter is set at 1 when the two values areidentical. Using this notation for StimulusPattern 1, we can represent the evidencefavoring a Category A assignment (£A) interms of the likelihood that the probe will re-trieve a pattern associated with Category A as
^.^(l- l - l -
-s-pK. (1)
Multiplying out the terms in parenthesis, wecan write the more simple form
£A,Icfs
cfsp + cf+ sp' (2)
The numerator of Equation 2 arises fromthe fact that Stimulus 1 is identical to itself;differs only in position (p) from Stimulus 2;and differs in color, form, and size (cfs) fromStimulus 3. The second three terms of thedenominator represent the overall similarityof Stimulus 1 to Stimulus 4, Stimulus 5, andStimulus 6, respectively.
CATEGORY A
STIMULUS
1
2
3
PATTERNC F S
1 1 1
1 1 1
0 0 0
STIMULUS
7
CATEGORY B
STIMULUSP
1 1
0 S
I 6
TRANSFER
PATTERN
0 1 0 1
PATTERNC F S P
0 0 0 0
0 0 1 1
1 1 0 0
Figure 2. Abstract notation for representing stimuliwith binary values along four dimensions. (C, F, S,and P stand for color, form, size, and position,respectively.)
In a directly analogous manner, one canshow that for Stimulus 4 in Figure 2,
sp + cfcfs' (3)
Comparing Equations 2 and 3, one may notethat if c = / = s = p = x (x 7* 0 or 1), £A,i islarger than £B,4. The denominators of the twoequations are identical; and subtracting thenumerator of Equation 3 from that of Equa-tion 2, we get x — 1y? + x3, which is positivebecause x lies between 0 and 1. Based on thegeneral proposal that ease of learning andaccuracy of classification increase as the evi-dence favoring the category increases, Pattern1 should be easier to learn and classify thanPattern 4.
On a qualitative level, one may note thatthe reason that Stimulus 1 should be easier tolearn and classify than Stimulus 4 is thatStimulus 1 is highly similar to one otherpattern (Stimulus 2), and this pattern is as-sociated with the same category; while Stimu-lus 4 is highly similar to one other pattern(Stimulus 3), but this pattern is associatedwith the opposite category. Therefore, whenStimulus 4 is presented, the representation andcategory assignment associated with Stimulus3 might well be activated and producemisclassifications.
Because of its multiplicative combinationrule for deriving overall similarity, the con-text model implies that performance will beprimarily affected by stored exemplars thatare highly similar to the item in question. Thisrelationship is assumed to hold for transfer as

214 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
well as original learning. Usually classificationmodels make qualitative predictions based onthe evidence favoring one category versusalternative categories. We shall follow thispractice in comparing the context model withalternative models, but at the same time, weshall attempt to make quantitative predictionsby using a simple rule relating the weights toclassification probabilities. As a first attemptat quantitative predictions, we will let theprobability that an item will be classified as anA on transfer tests be equal to the weightfavoring Category A. That is,
PA,, = EA,,-. (4)
For example, for New Stimulus 7 in Figure 2,we would have
A,7cs + csp + /
(5)
where/, s, c, and p are the respective similarityparameters for the dimensions of form, size,color, and position. If all four parameters wereequal to the value .30, then according toEquation 5, New Pattern 7 should be classifiedas an A 61% of the time.
In brief, the context model assumes thatclassification is based on the retrieval of storedexemplar information, that this retrieval pro-cess is directly a function of the similarity ofthe probe item to the stored exemplars, andthat similarity derives from an interactivecombination of component cue dimensions.We consider now how these ideas might ac-count for excellent performance on prototypestimuli and differential retention.
Performance on Prototypic Stimuli andDifferential Retention
Performance on prototype patterns fre-quently equals or exceeds performance on oldtraining patterns. This result can be predictedby the context model because the prototypicpattern almost always is the pattern havingthe greatest number of highly similar categoryexemplars or training patterns. Not only thatbut also because of the ways in which cate-gories have usually been constructed (Reed,1972), the prototype is unlikely to be highlysimilar to any exemplars from alternative
categories. In fact, as Reed (1972) has noted,almost all models generally predict excellentclassification of prototypic patterns, and spe-cial measures must be taken in setting up anexperiment to distinguish alternative models.
Whether performance on new prototypepatterns is better or worse than performanceon old training patterns will depend on thecomponent similarity parameters according tothe context theory. If similarity is low, fewbetween-category confusions will occur, andtraining pattern performance will be excellent;if similarity is higher, more between-categoryconfusions will occur, and this will hinderperformance on training patterns more thanprototype patterns because prototype patternsare unlikely to be highly similar to (confusablewith) alternative category exemplars.
These interactions associated with the degreeof similarity also provide the basis for ac-counting for differential retention. Suppose,for example, that the similarity parametersassociated with the stimuli in Figure 2 wereequal and constant at .10 on an immediatetest and (consistent with Assumption 6) thatthe similarity parameters increased to .40 ona delayed test. Predicted performance on OldPattern 5 (0011) would drop from 91% correctto 63% correct; while performance on the newpattern (1000) would only drop from 91%correct (Category B responses) to 69% correcton the delayed test.
In general, performance on old patterns willsuffer more over a retention interval than per-formance on new patterns because of the de-creasing likelihood that a training patternprobe will successfully access its own storedrepresentation and the associated category as-signment information. By a careful selectionof training and transfer stimuli, one might beable to produce increases in classification per-formance over a retention interval for certainpatterns. As of yet, we are unable tg commitourselves on the issue of whether changes insimilarity parameters derive mainly fromchanges in the availability of component ex-emplar information or whether changes reflectthe forgetting of a strategy involving selectiveattention.
It seems that in principle, the context theorycan account both for excellent classification ofprototypic stimuli and for differential reten-

THEORY OF CLASSIFICATION LEARNING 215
tion of old and new stimuli without positing a(changing) mixture of two types of informa-tion. Rather, both results follow from our as-sumptions concerning retrieval of stored ex-emplars by similarity. In addition to thisapparent parsimony, the context model sug-gests some new theoretical contrasts thatdifferentiate the context theory from a largeclass of classification models including proto-type models. Before discussing these newcontrasts, we characterize this class of models,which we shall call independent cue models.
Independent Cue Models
Independent cue models assume that theinformation entering into category judgments(i.e., overall similarity, distance, or validity)can be derived from an additive combinationof the information (similarity, distance, orvalidity) from the component cue dimensions(Franks & Bransford, 1971; Hayes-Roth &Hayes-Roth, 1977; Reed, 1972). Prototype,average distance, and versions of cue validityand frequency models fall under this domain.First, a general form of an independent cuemodel will be presented and then the relation-ship between this general form and particularmodels will be examined. While the derivationis not completely general, it will hold forbinary-valued dimensions.
Consider again Figure 2. A value 1 on anydimension is more closely or more often as-sociated with Category A than Category B, anda value 0 is more likely to be associated withCategory B. In other words, a value 1 pro-vides information that a stimulus will probablyfall into Category A, while a value 0 providesinformation that a stimulus will probably fallinto Category B. For all of the models to beconsidered, the probability of classifying apattern into Category A is assumed to be anincreasing function of the weight of evidencefavoring Category A and a decreasing functionof the weight of evidence favoring Category B.Owing to perceptual salience, selective atten-tion, or particular learning strategy, the com-ponent dimensions of a stimulus may not beequally weighted. With these considerationsand Figure 2 in mind, one can write an equa-tion for evidence for Category A (£A) as
where We, Wf, W,, and Wp are the weightsassociated with the color, form, size, andposition dimensions, and where //A and Ij-&for a given dimension j (j = c, /, s, or p) are,respectively, the information favoring Cate-gory A and the information favoring CategoryB.
The first term, (!CA — I^)WC, consists of adifference in information value (/CA — lea)and an associated weighting factor (Wc). Whena pattern is presented to be classified at somepoint, the value associated with the color di-mension (red [1] or blue [0] in our example)will be sampled. If red (denoted 1) is sampled,then (7<,A — /CB) would be positive, since redis more closely associated with Category Athan Category B. If blue (denoted as value 0)were sampled, then (/CA — /CB) would benegative, since blue is more closely associatedwith Category B than Category A. This in-formation from the color dimension would thenbe weighted by the parameter Wc and addedto the weighted information from the form,size, and position dimensions to arrive at theoverall evidence favoring Category A. In theexample shown in Figure 2, for each dimension,the associated values are equally informative(i.e., probability of Category A given value 1is equal to the probability of Category B givenvalue 0), which means that IJA. — Ijs for value1 is equal to 7jB — IJA. for value 0. Because ofthis symmetry, Equation 1 can be rewritten as
£A = WJ.k + Wflfk + WJsk + Wvlpk, (7)
where Wc, W/, Ws, and Wv are denned asbefore, and where /,-,* for a given dimension3 (J = c>f> s> or P) and value k (k = 0 or 1) isequal to +1 if k is 1 and equal to —1 if k is 0.Since for each dimension, the values 1 and 0are equally informative and since the weightsfor the various dimensions are arbitrary pa-rameters, Equation 7 represents the generalcase where for each dimension, the value issampled to see in which category it is moreclosely associated. This information is thenweighted according to the importance of thedimension. Equation 7 can be used to derivethe evidence for Category A for the three Atraining stimuli in Figure 2 (£A,I> ^A,S and
(7/A -P, (6) Wc + Wf + W, + WP (8)

216 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
andEA,2 =Wc+Wf+Ws- WP, (9)
EA,3 = -WC-W,-WS+ Wf. (10)
For Stimulus 1, the values on each of thedimensions are more often associated withCategory A, and therefore, each of the termsin Equation 8 are positive. For Stimulus 2,the values associated with color, form, andsize are also more consistent with Category A ;but the value 0 for position was more oftenassociated with Category B, and therefore,Wp in Equation 9 is negative. To the extentthat category judgments are based on theposition dimension, Stimulus 2 would tend tobe inappropriately classified.
From this example, we can see that Stimulus1 should be easier to learn and classify thanStimulus 2 or 3 because unlike the latter twostimuli, all of its values are associated withpositive weights; however, the relative diffi-culty of learning and classifying Stimulus 2and Stimulus 3 will depend on the weightsassociated with the four dimensions.1 If alldimensions are weighted equally, then Stimu-lus 2 should be easier to learn and classifythan Stimulus 3; and in this case, EA.S wouldactually be less than zero, which implies thatthe total information favors the item beingsorted into Category B. If a New Stimulus 7having notation 0101 were introduced, then,
= - We WP, (11)
and no clear prediction concerning its classi-fication would be made unless the weights hadbeen determined. If all dimensions wereweighted equally, EA,7 would be zero, and onewould predict that the stimulus would be aslikely to be classed as an A or as a B.
In evaluating independent cue models, wewill also take into consideration the possibilitythat category judgments of training stimuliare based on specific item information. Thiswill be represented by a parameter M,, and itwill be assumed that this parameter is addedto the other evidence as detailed in Equation 7.In other words, a fifth term, +Mi, will beadded to Equation 7 for predictions concern-ing transfer tests involving old training stimuli.
For patterns in Category B, one can eitherwrite analogous equations for EB and assumeitems are classified into Category B if EB is
greater than EA, or one simply can note thatwhen EA is less than zero, a pattern is moreclosely associated with Category B. In thenext paragraphs, particular independent cuemodels will be described briefly and related toEquation 7.
Prototype Theory
Reed (1972) has provided the most formaland general treatment of prototype theory.The prototype of a category represents itscentral tendency, and the main idea is thatexperience with exemplars of a category leadsto the development of the prototype, whichthen provides the basis for classificationjudgments.
For prothetic (intensity) dimensions, thecentral tendency is defined as some functionof the mean value along each dimension. Formetathetic continua, such as color, the proto-type is more appropriately defined as somefunction of the modal values along each dimen-sion, since subjects presented with red andblue stimuli do not act as if they have beenpresented with purple stimuli (Hirschfeld,Bart, & Hirschfeld, 1975). For binary-valueddimensions, this function will be assumed tobe such that if a value is closer to either themode or the mean associated with a category,the value will be taken as evidence favoringthat category. In our example, the modal pro-totype for Category A is 1111 and for CategoryB is 0000. The decision rule for responding tonew stimuli is to compare the distance fromthe stimulus to the prototype for Category Aand to the prototype for Category B and assignthe stimulus to the category whose prototypeis closest to the stimulus. These distances arederived by summing the distances along eachcomponent dimension. In a generalized formof the model, one allows the distances fromthe various dimensions to be weighted differ-
1 Strictly speaking, Equation 7 and our derivationhave only been shown to hold for transfer. However,if training stimuli are randomly presented and the de-velopment of whichever form of information a modeluses is orderly, then the predictions should also holdfor learning. One cannot, of course, prove this rigor-ously, since none of the classification models has beenelaborated to account for the details of acquisition.

THEORY OF CLASSIFICATION LEARNING 217
entially (Reed, 1972) in order to account forselective attention to distinctive features.
To relate prototype theory to Equations 6and 7, one need only note that distance fromthe prototype corresponds to information. Ifa value of some new stimulus on dimension xis closer to the value of Prototype A thanPrototype B on that dimension, then thisrepresents evidence that the new stimulusbelongs to Category A. Reed (1972) used aparticular algorithm to fix the weights of thecomponent dimensions, and Equation 7 pro-vides the more general case where the weightsare free parameters.
Other Independent Cue Models
Average distance, cue validity, and frequencymodels can also be mapped onto Equations 6and 7. Average distance models assume thatpeople compute the distance of a probe stimu-lus from all of the stored patterns and assignthe probe to the category having the smallestaverage distance from the probe. Cue validitymodels propose that people learn the degree towhich values on individual dimensions can beused to predict category membership and thatcategory judgments are produced by summingthe validity information from the componentdimensions (see Reed, 1972, for a more com-plete presentation of average distance and cuevalidity models).
Simple frequency models propose that peoplestore the frequency with which the individualattributes of dimensions are associated witheach category. In the frequency model assessedby Franks and Bransford (1971), categoryjudgments of probe stimuli are assumed to bederived from summing the frequency withwhich each of the attributes of the probe havebeen associated with each of the categoriesand selecting the category with the higherfrequency sum (for further assessment offrequency models, see Hayes-Roth & Hayes-Roth, 1977).Each of the above models assumesthat classification is based on an additivesummation of component information, andEquations 6 and 7 represent the general casewhere these component dimensions may bedifferentially weighted.
Context Model Versus IndependentCue Models
The context model differs from independentcue models in that it assumes an interactive,specifically multiplicative, combination rulefor component dimensions. This means thathigh similarity to particular patterns shoulddetermine classification performance more thanoverall average similarity of a given patternto other patterns. For independent cue models,average similarity (or its converse, distance) isthe only determinant of performance. Previousresearch does not bear at all directly on thisdifference between the theories, since mostearlier work has concerned itself with theeffects of varying the distance of exemplarsfrom the category prototype. The contextmodel predicts that with distance of an ex-emplar from the prototype held constant,performance will vary with the number ofstored exemplars similar to the exemplar inquestion (category density). Independent cuemodels are insensitive to such density effects.The experiments in the next section of thisarticle are aimed specifically at this differencebetween the theories.
Experiment 1
Design and Theoretical Predictions
The design of the first experiment is shownin Figure 3. For each dimension, two of thethree values in Category A are 1 and two ofthe three values in Category B are 0. Thus,each dimension carries some information, butnone provides a perfectly valid cue. Certaincombinations of cues, such as size 1 and color 1,do provide valid cues. The structure mightcorrespond to an ill-defined concept, where forevery dimension, there exists an exception tothe rule in each category.
All models will predict that Stimulus 6 andStimulus 10 (the modal prototypes) should beeasiest to learn, while Stimulus 15 should bedifficult. Because Stimulus 10 has a high simi-larity pattern in its own category, while Stimu-lus 6 has a highly similar pattern associatedwith the contrasting category, the contextmodel predicts that Stimulus 10 should beeasier to learn than Stimulus 6, assuming that
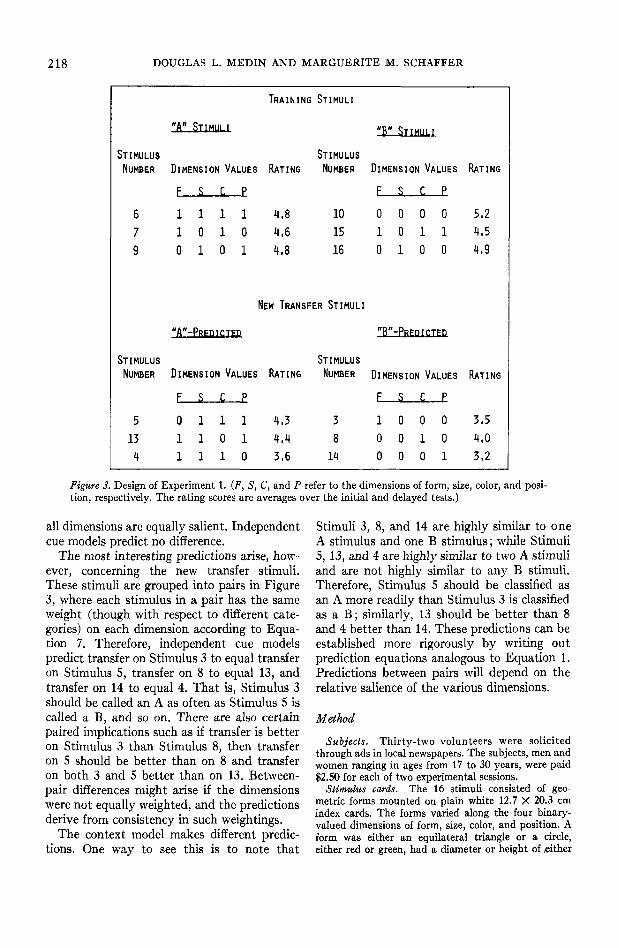
218 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
STIMULUSNUMBER
679
STIMULUSNUMBER
5131
-," STIMULI
DIMENSION VALUES
E S C P
110
"A
1 1 10 1 01 0 1
"-PREDICTED
DIMENSION VALUES
E S C P
011
1 1 11 0 11 1 0
TRAINING STIMULI
STIMULUSRATING NUMBER
1,8 101.6 151.8 16
NEW TRANSFER STIMULI
STIMULUSRATING NUMBER
1.3 31,1 83,6 11
"B" STIMMI
DIMENSION
F S
010
If
001
V/
c010
U.UES
P
010
RATING
5,21.51,9
B"-PREDICTED
DIMENSION
E S
100
000
VALUES
£_ P
010
0
01
RATING
3.51.03,2
Figure 3. Design of Experiment 1. (F, S, C, and P refer to the dimensions of form, size, color, and posi-tion, respectively. The rating scores are averages over the initial and delayed tests.)
all dimensions are equally salient. Independentcue models predict no difference.
The most interesting predictions arise, how-ever, concerning the new transfer stimuli.These stimuli are grouped into pairs in Figure3, where each stimulus in a pair has the sameweight (though with respect to different cate-gories) on each dimension according to Equa-tion 7. Therefore, independent cue modelspredict transfer on Stimulus 3 to equal transferon Stimulus 5, transfer on 8 to equal 13, andtransfer on 14 to equal 4. That is, Stimulus 3should be called an A as often as Stimulus 5 iscalled a B, and so on. There are also certainpaired implications such as if transfer is betteron Stimulus 3 than Stimulus 8, then transferon 5 should be better than on 8 and transferon both 3 and 5 better than on 13. Between-pair differences might arise if the dimensionswere not equally weighted, and the predictionsderive from consistency in such weightings.
The context model makes different predic-tions. One way to see this is to note that
Stimuli 3, 8, and 14 are highly similar to oneA stimulus and one B stimulus; while Stimuli5, 13, and 4 are highly similar to two A stimuliand are not highly similar to any B stimuli.Therefore, Stimulus 5 should be classified asan A more readily than Stimulus 3 is classifiedas a B; similarly, 13 should be better than 8and 4 better than 14. These predictions can beestablished more rigorously by writing outprediction equations analogous to Equation 1.Predictions between pairs will depend on therelative salience of the various dimensions.
Method
Subjects. Thirty-two volunteers were solicitedthrough ads in local newspapers. The subjects, men andwomen ranging in ages from 17 to 30 years, were paid$2.50 for each of two experimental sessions.
Stimulus cards. The 16 stimuli consisted of geo-metric forms mounted on plain white 12.7 X 20.3 cmindex cards. The forms varied along the four binary-valued dimensions of form, size, color, and position. Aform was either an equilateral triangle or a circle,either red or green, had a diameter or height of .either

THEORY OF CLASSIFICATION LEARNING 219
1.25 cm or 2.5 cm, and was centered either on theleft or right side of the card. For a given subject, sixtraining and six additional transfer stimuli were used,and across subjects all 16 cards were used.
The basic design has already been presented inFigure 3. All subjects were presented with cards inaccordance with that general design, but the particularassignment of individual stimulus cards to the abstractnotation varied from subject to subject. For example,1111 might refer to triangle, large, red, and left for onesubject; triangle, small, green, and left for anothersubject; circle, small, green, and right for another sub-ject; and so on. Overall, each card was assigned to agiven stimulus notation exactly twice, once whenStimuli 6, 7, and 9 were associated with Category Aand once when they were associated with Category B.In other words, the assignment of stimulus cards toconditions and category labels was exactly counter-balanced.
Procedure. The basic procedure in the first sessioninvolved initial learning followed by a 5-minute dis-tractor task, which was then followed by transfer tests.In the second session, which was given 1 week later, a5-minute distractor task was followed by a secondtransfer test, and then a final classification test wasgiven with the training stimuli visible.
Training. Initial training consisted of up to 20 runsthrough the list of 6 training stimuli. Subjects weregiven the following instructions:
This is an experiment concerned with how we storeinformation in memory. I'm going to present youwith some cards belonging to two sets, A and B. Atfirst you will just have to guess which set each cardbelongs to. But after you make a choice, I'll tell youwhether you are right or wrong, so that eventuallyyou should be able to learn which set each cardbelongs to. Although this task is very difficult, thereare no tricks involved, and a given card will alwaysbe in the same category.
For training, subjects were shown the cards one at atime and asked to classify them as either A or B. Eachcard was displayed until the subject responded, im-mediate feedback concerning correctness or incorrect-ness was given, and the card continued to be displayedfor about 1 sec after feedback was given. Each of thesix cards was presented once on each run through thelist. The cards were presented in a random order, andthere was no obvious break between runs. Trainingcontinued until a subject made no errors on two con-secutive runs through the list or until the list had beenpresented 20 times.
Interpolated activity. After the training period, thesubjects were asked either to rate the meaningfulnessor the pronounceability of consonant-vowel-consonants(CVCs) on a 7-point scale. This activity lasted 5-10minutes.
Initial transfer test. Subjects were given the follow-ing transfer instructions:
Now I would like you to give a judgment as to whichset each card belongs to, but in addition, I'd like youto indicate how confident you are of your judgment.So after you say "A" or "B," say "one" if you feel
like you were guessing, "three" if you're sure you'recorrect, and "two" for somewhere between guessingand sure. Some of the cards you see may be new. Ifyou see one that's new, say "new," and then giveyour judgment as to which set it belongs to anyway,plus a confidence rating. This time I won't tell youwhether you are right or wrong.
Subjects were then shown the 12 cards, one at a timein a random order. Each card was displayed until thesubject's judgment and confidence rating was com-pleted. No feedback was given concerning either thejudgment or whether the pattern was old or new.
One week later, subjects returned to the laboratoryfor additional tests. First, subjects rated either themeaningfulness or pronounceability of CVCs for 5-10minutes. Subjects who had originally rated meaning-fulness were now asked to rate pronounceability andvice versa. Then, subjects were given a transfer testinvolving the same 12 stimulus cards and the identicalinstructions they had experienced a week earlier. Theonly difference was that a new random order was usedfor the stimulus presentation. Again no feedback wasgiven.
Final classification. Immediately following the trans-fer task, the experimenter laid out the three A trainingcards and the three B training cards in two groups infront of the subjects. They were told that these werethe training cards and then were shown the six newcards, one at a time, and asked with which group theythought the card went. In addition, subjects were askedto give a confidence rating on their judgment. No feed-back was given on judgments, since feedback wouldhave been inappropriate because there were no rightor wrong answers.
Results
Learning. All but 5 of the 32 subjects metthe learning criterion. Mean errors on StimulusNumbers 6, 7, 9, 10, 15, and 16 were 3.6, 4.7,4.4, 3,1, 4.9, and 3.8, respectively. As expectedby all theories, the modal prototypes—Stimu-lus 10 and Stimulus 6—were easiest to learn;while Stimulus 15, which according to indepen-dent cue theories could only be mastered bythe use of specific item information, proved tobe the most difficult to master.
Transfer. The recognition data reveal amodest ability to discriminate training andnew transfer stimuli. On the first transfer test,the hit rate was .98 and the false alarm rate(saying "old" to a new stimulus) was .69; onthe second test given a week later, the hit ratewas .96 and the false alarm rate was .75. Ananalysis of variance on the new stimuli indi-cated that the effect of time did not reachstatistical significance nor were there signifi-cant differences in recognition between newtransfer stimuli.

220 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
The transfer category responses and con-fidence ratings were transformed into a 6-pointrating score as follows: 1 = high confidenceerror, 2 = medium confidence error, 3 = gues-sing error, 4 = guessing correct, 5 = mediumconfidence correct, and 6 = high confidencecorrect. For new stimuli, where correctnessand incorrectness are inappropriate, the scaleis arbitrarily defined with respect to whatwould be predicted from an independent cuemodel with each dimension equally weighted.This definition simply provides a consistentstandard and does not favor one set of theoriesover the other.
The transfer rating data are shown in Figure3, a mean rating of 3.5 representing chance ornondifferential classification. The scores in thefigure are an average of the ratings on theinitial and delayed transfer tests. The greatestinterest lies in performance on the new transferstimuli. On all three tests, Stimulus 5 was ratedhigher than Stimulus 3, 13 was rated higherthan 8, and 4 was rated higher than 14. Thesedifferences are predicted by the context modeland are contrary to the predictions of thegeneral independent cue model. There are alsolarge between-pair differences in rating scores,suggesting that all dimensions were not equallysalient.
An analysis of variance on rating scoresconducted for the new transfer stimuli showedthat both the effect of sets (4, 5, and 13 vs. 3,8, and 14), /?(!, 30) = 4.36, MSe = 6.21,p < .05, and the effect of pairs (3 and 5 vs.8 and 13 vs. 4 and 14), F(2, 60) = 5.76, MSe
= 3.57, p < .01, were significant. Neither theeffects of tests nor the interactions involvingtests were reliable, although both the TestsX Sets, ^(1,30) = 3.29, MSe = lAO,p< .10,and the Tests X Pairs, F(2, 60) = 2.58, MSe
= 2.58, p < .10, interactions approached sig-nificance. On the final classification test, boththe effect of sets, F(l, 30) = 6.79, MSe = 2.86,p < .01, and the effect of pairs, F(2, 60) = 3.18,MSe = 4.16, p < .05, were significant.
Ratings for the training stimuli were quitehigh on the initial test and showed a sharpdrop (from an average of 5.3 to an average of4.4) over the 1-week retention interval. Thenew transfer stimuli did not show this sharpdrop between Test 1 and Test 2, changingfrom an average of 3.9 to an average of 3.8.
An analysis of variance was conducted usingold versus new stimuli and tests as factors toassess differential retention. The effects of oldversus new stimuli, F(l, 30) = 32.5, MSK
= 31.0, p < .01, tests, jF(l, 30) = 23.03, MSe
= 16.0, p < .01, and the interaction of thesetwo factors, F(l, 30) = 24.3, MS6 = 10.0,p < .01, were significant. The interaction sug-gests that old patterns were forgotten morerapidly than new patterns, a result that hasbeen obtained frequently in this area. Onemust be careful in inferring differential reten-tion based on a statistically significant inter-action, particularly since ratings on several ofthe transfer stimuli are near chance. If weconsider only transfer stimuli showing clearabove-chance ratings (5, 8, and 13) versus theold stimuli and subtract 3.5 from each scoreand divide by the base value (first transfertest) to get a measure of percentage retained,old patterns show a mean of 41% retention,while the three new stimuli under considera-tion show a mean of 64% retention. In addi-tion, if we disregard the rating scores andconsider only percentage correct classifica-tions, Stimulus Numbers 5, 8, and 13 againshow a better retention than training stimuliover the 1-week interval (62% vs. 39% re-tained). Therefore, there is at least modestevidence for differential retention of old andnew stimuli.2
2 Two surprising results were that Stimulus IS, whichshould have been difficult to classify, was rated higherthan Stimulus 16 on the initial test, and that Stimulus4 and Stimulus 14 received such low ratings. Wesuspect that this result was produced by a specializedstrategy involving the position dimension. Specifically,it appears that subjects normally pay little attentionto position, but if two stimuli differing only in positionfall into distinct categories, subjects may use thestrategy of assigning all stimuli differing only in posi-tion to distinct categories. In the design of Experiment1, there are two stimulus pairs differing only in position(Stimuli 7 and 15 and Stimuli 9 and 16), and they bothwere assigned to different categories. If such a strategycarried over into transfer, then performance on Stimulus4 and Stimulus 14 would suffer, because Stimulus 14differs from Stimulus 10 only in position, while 4differs from 6 only in position; this strategy would leadto 14 being classified as an A and 4 being classified asa B. Although the use of this strategy undermines anyattempts to fit the transfer data quantitatively, thequalitative differences between Stimuli 3 and 5 andbetween 8 and 13 would not be affected, since none ofthese four stimuli differs from any training stimulus

THEORY OF CLASSIFICATION LEARNING 221
Discussion
The transfer results of Experiment 1 were inaccord with predictions derived from the con-text model but inconsistent with independentcue models. This finding held for an immediatetransfer test, a similar transfer test given 1week later, and on a final classification taskwhere the training cards were displayed andsubjects were asked to sort the new cards intocategories based on the visible training stimuli.
Aside from questions about generality, twoserious reservations might be posed concerningExperiment 1. The most salient objection isthat according to the structural constraintsimposed in some experiments with artificialcategories (e.g., Reed, 1972; Reed & Friedman,1973), the A and B stimuli did not compriseproper categories because Stimulus 15 (1011)belongs in the category where the value 1appears most often (Category A). More form-ally, one would argue that the categories werenot separable by a linear discriminant functionin the sense that no additive combination ofdimension weights and values could be used tocorrectly classify the training stimuli (see Reed,1972; Sebestyen, 1962). Although the trainingstimuli could be unambiguously sorted by anindependent cue model if we used the param-eter Mi for specific item information, this ob-jection must be taken seriously because inde-pendent cue models may operate only whenlinear separability holds. On the other hand,there is no evidence to indicate that naturalcategories conform to linear separability.
A second objection is that Experiment 1 isbiased in the sense that support for indepen-dent cue models would have amounted toembracing the null hypothesis, which generallyspeaking, is not an attractive strategy. Onewould prefer a situation where the contexttheory and independent cue models make dif-ferent predictions, neither of which amount topredicting the absence of differences.
Experiment 2 is directed toward answer-ing both objections. The categories employedconform to linear separability, and the theo-ries make distinctly different qualitativepredictions.
only in position. Because of the potential use of thisstrategy, position was not used as a stimulus dimensionin subsequent experiments.
Experiment 2
Design and Theoretical Predictions
The structure of Experiment 2 is shown inFigure 4. As in Experiment 1, the value 1 islikely to be associated with Category A andthe value 0 with Category B for each of thedimensions. Unlike the other experiments,however, a linear discriminant function maybe used to separate the two categories. Oneeasy way to see this is to note that if the formdimensions were given zero weight, then atleast two of the other three dimension valuesfor each stimulus are appropriate for the cate-gory. The categories are not well defined, sinceno specific feature values are even necessaryfor category membership.
The main prediction of interest concernsStimuli 4 and 7. Since the modal prototype is1111, Stimulus 4 must be at least as close as 7is to the prototype, no matter how the dimen-sions are weighted. More generally, all inde-pendent cue models will predict that Stimulus4 will be easier to learn than 7 because for theonly dimension where the two stimuli differ,4 will have a positive weight and 7 a negativeweight (unless Wf = 0). Unlike Experiment 1,an overall bias favoring one category responseover the other will not change this prediction.3
In contrast, the context model predicts thatStimulus 7 should be easier to learn thanStimulus 4 because the effect of number ofhighly similar patterns is the most importantfactor in performance. Stimulus 7 is highlysimilar (i.e., differs in only one dimension) totwo other Category A patterns (Stimuli 4 and15) but is not highly similar to any Category Bpatterns. Stimulus 4, on the other hand, ishighly similar to one Category A pattern(Stimulus 7) and to two Category B patterns(Stimuli 2 and 12) and hence should be moredifficult to learn. This prediction is not com-pletely parameter free, but it holds over alarge range of parameter values, and param-
3 The symmetry assumption embodied in Equation7 does not hold for the dimensions in the design ofExperiment 2. For example, for color, the probabilityof Category A given a value 1 is .80, while the proba-bility of Category B given a value 0 is .75. The asym-metries are extremely small, however, and the qualita-tive conclusions drawn will not hinge on the symmetryassumption.
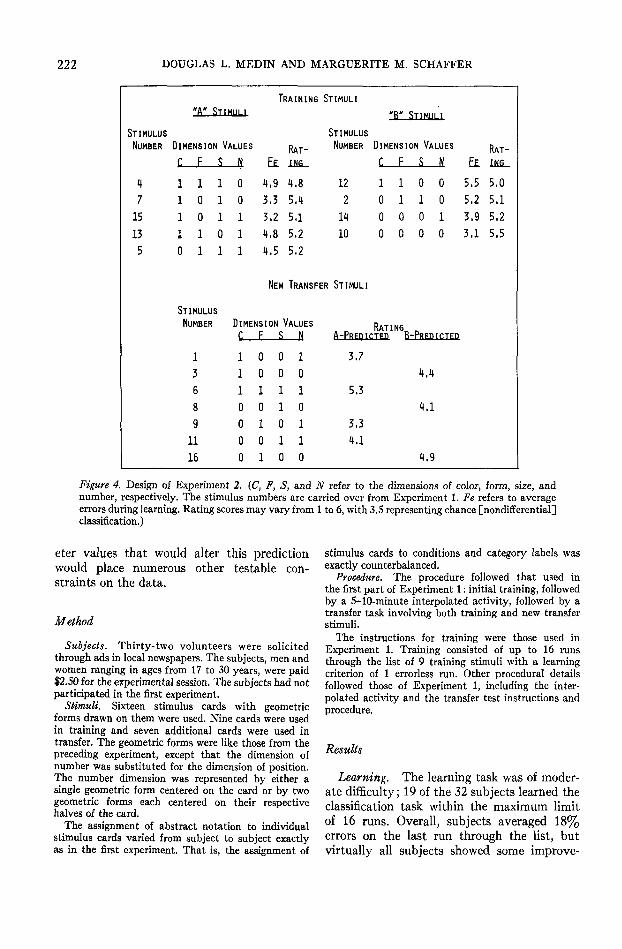
222 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
"A" STIMULI
STIMULUSNUMBER DIMENSION VALUES
C F S N
4
7
15
13
5
1 1 1
1 0 1
1 0 1
1 1 0
O i l
STIMULUSNUMBER
1
3
6
8
9
11
16
0
0
1
1
1
4
3
3
4
4
TRAINING STIMULI
"R" STTMIII i
Et
,9
,3
,2
,8
.5
NEW
STIMULUSRAT_ NUMBER DIMENSION VALUES
ING C F S N FE
4 , 8 1 2 1 1 0 0 5 , 5
5 . 4 2 0 1 1 0 5 , 2
5 , 1 1 4 0 0 0 1 3 , 9
5 , 2 1 0 0 0 0 0 3 , 1
5,2
TRANSFER STIMULI
RAT-
5,0
5,1
5,2
5.5
DIMENSION VALUES RATINGC F S N A-PREDICTED E-PREDICTED
1
1
1
0
0
0
0
0
0
1
0
1
0
1
0
0
1
1
0
1
0
1 3.70 4,41 5,30 4,1
1 3,3
1 4.1
0 4,9
Figure 4. Design of Experiment 2. (C, P, S, and N refer to the dimensions of color, form, size, andnumber, respectively. The stimulus numbers are carried over from Experiment 1. Fe refers to averageerrors during learning. Rating scores may vary from 1 to 6, with 3.5 representing chance [nohdifferential]classification.)
eter values that would alter this predictionwould place numerous other testable con-straints on the data.
Method
Subjects. Thirty-two volunteers were solicitedthrough ads in local newspapers. The subjects, men andwomen ranging in ages from 17 to 30 years, were paid$2.50 for the experimental session. The subjects had notparticipated in the first experiment.
Stimuli, Sixteen stimulus cards with geometricforms drawn on them were used. Nine cards were usedin training and seven additional cards were used intransfer. The geometric forms were like those from thepreceding experiment, except that the dimension ofnumber was substituted for the dimension of position.The number dimension was represented by either asingle geometric form centered on the card or by twogeometric forms each centered on their respectivehalves of the card.
The assignment of abstract notation to individualstimulus cards varied from subject to subject exactlyas in the first experiment. That is, the assignment of
stimulus cards to conditions and category labels wasexactly counterbalanced.
Procedure. The procedure followed that used inthe first part of Experiment 1: initial training, followedby a S-10-minute interpolated activity, followed by atransfer task involving both training and new transferstimuli.
The instructions for training were those used inExperiment 1. Training consisted of up to 16 runsthrough the list of 9 training stimuli with a learningcriterion of 1 errorless run. Other procedural detailsfollowed those of Experiment 1, including the inter-polated activity and the transfer test instructions andprocedure.
Results
Learning. The learning task was of moder-ate difficulty; 19 of the 32 subjects learned theclassification task within the maximum limitof 16 runs. Overall, subjects averaged 18%errors on the last run through the list, butvirtually all subjects showed some improve-

THEORY OF CLASSIFICATION LEARNING 223
ment with practice. Mean errors for eachstimulus are shown in Figure 4. Contrary tothe independent cue models and consistentwith the context model, Stimulus 4 proved tobe more difficult than Stimulus 7.
An analysis of variance on errors showedthat the effect of stimuli, F(S, 240) = 4.29,MSe = 6.27, p < .01, was statistically signifi-cant. A Duncan's multiple-range test using the.05 significance level indicated that Stimuli 2,4, 12, and 13 were associated with more errorsthan 7, 10, and 15; Stimulus 5 had more errorsthan 10; and Stimulus 12 had more errors than14. A planned direct t test of Stimulus 4 versusStimulus 7 was, of course, also significant(/ai = 3.71, p < .01, two-tailed).
Transfer. The overall hit rate for oldstimuli was .99, while the false alarm rate fornew stimuli was .87. Stimulus 6, the modalprototype for Category A, was never correctlyrejected as new. Although no other new stimu-lus had a zero correct rejection rate, an overallanalysis of correct rejections indicated that theeffect of stimuli was not reliable, F(6, 186)= 1.51, MSe = .10, p > .10.
The transfer rating data appear in Figure 4.Stimulus 7 received a higher mean rating thanStimulus 4, but the effect fell short of statisticalsignificance (t=. 1). Old stimuli generally re-ceived higher ratings than new stimuli, andthe transfer rating data were in reasonableaccord with both theories.
Because so many subjects failed to meet thelearning criterion, the data for learners andnonlearners were considered separately. Nosystematic differences were noted. Both learn-ers and nonlearners made more errors onStimulus 4 than Stimulus 7, and there was asimilar overall pattern of performance in thetwo groups. Learners averaged 88% correct onthe transfer test, nonlearners averaged 78%correct, and the rank-order correlation of theclassification probabilities for the two groupswas high and positive (+.62).
Detailed fits of theories and data. Althoughthe focus has been on qualitative comparisonsof the models, it is also of interest to see howwell they fit the data overall. For the contextmodel prediction, equations analogous to Equa-tions 1 and 4 were written for each stimuluspattern in terms of the similarity parametersassociated with the four dimensions. To esti-
mate the similarity parameters, programs werewritten to minimize the average absolute devia-tion of predicted and observed classificationprobabilities. No distinction was made be-tween old training patterns and new patternsin applying the model.
For the error data predictions, equationsanalogous to Equation 1 were again used, andprograms were written to search the parameterspace to maximize the correlation betweenranked evidence values (£A or E-B) and theranked error data. To make appropriate com-parisons with the independent cue model, thecorrelation between ranked evidence valuesand ranked classification data was also calcu-lated. The ranked evidence values were derivedfrom the parameter values used to generatepredictions of classification probabilities.
A similar procedure was used for the classof independent cue models. Equation 7 wasspecialized for each pattern, and the parameterspace was searched to find values that wouldmaximize the correlation between the rankedevidence values (£A and EB) and rankederrors and separately between the rankedevidence values and the ranked transfer classi-fication probabilities. For the error data, pa-rameters corresponding to the weight of eachdimension were used; and for the transfer data,a fifth parameter for the weight of specificitem information was also estimated. Since thedimension weighting parameters involve rela-tive weightings, there really are only threeindependent dimension weight parameters.
The correlation between predicted and ob-served ranked errors was + .99 for the contextmodel and +.81 for the independent cuemodel. The parameters associated with thesecorrelations were c = .14, / = .18, s = .16, andn = .14 for the context model and Wc = .40,Wf = .10, Ws = .50, and Wn = .20 for theindependent cue model. Table Al in the Ap-pendix shows predicted and observed errorranks.
Observed classification probabilities and pre-dictions based on the context model are shownin Table 1. With the exception of Stimulus 15,most of the predictions are quite close: Therank-order correlation between predicted andobserved classification probabilities was +.81.Note that data from both old and new stimuliare all well predicted, even though no special

224 DOUGLAS L. MEDIN AND MARGUERITE M. S CHAFFER
Table 1Predicted and Observed ClassificationProbabilities for the Transfer Task ofExperiment 2
Classification probability
Stimulus number Observed Predicted
4A7A
ISA13A5A
12B2B
14B10B
Training stimuli
.78
.88
.81
.88
.81
.84
.84
.88
.97
.79
.94
.97
.86
.86
.76
.76
.93
.97
New transfer stimuli1A .59 .646A .94 .939A .50 .57
11A .62 .643B .69 .618B .66 .61
16B .84 .87
Note. The letters A and B define the category withrespect to which classification proportions are scored.Each observed proportion is based on 32 observa-tions.
assumptions are made to distinguish new andold stimuli. For the independent cue model,the rank-order correlation was +.79, indi-cating that the overall fit was approximatelyas good as that of the context model. Theparameters associated with the classificationdata were c = .16, / = .16, s = .18, and n = .14for the context model and Wc = .38, Wf = .10,W, = .40, Wn = .20, and Mt = .35 for theindependent cue model. Table A2 in the Appen-dix summarizes these rank-order predictions.
Discussion
The results on errors, but not on classifica-tion, favor the context model. A stimulusclose to the modal prototype proved to bemore difficult to learn and classify than onefarther away. In addition, quantitative pre-dictions of the context model were in goodagreement with the data, and overall ranked-order correlations between predicted and ob-served error and classification data were higher
for the context model than for the independentcue model. Apparently, difficulties for the in-dependent cue model are not confined tosituations where the classes are not linearlyseparable.
So far, we know little about the generalityof these results to other stimulus domains. Thenext experiment uses the same design as em-ployed in Experiment 2, but now the stimuliare Brunswik faces rather than geometricforms. These face stimuli were selected becausethe clearest quantitative evidence favoringprototype models, a subset of independent cuetheories, was derived from studies using thesestimuli (Reed, 1972).
Experiment 3
The structure of Experiment 3 mirrors thatof Experiment 2 as shown in Figure 4. Thetwo categories are linearly separable, and thequalitative focus again is on the learning andclassification of Stimulus 4 versus Stimulus 7,since distance from the category central tend-ency and the number of highly similar trainingpatterns are placed in conflict. In addition tolearning and classification data, Experiment 2included an additional training phase whereresponse latency was the dependent variableof interest. We will assume for both theoriesthat the greater the evidence favoring a re-sponse to a training stimulus, the faster willbe the response. The major difference betweenExperiments 2 and 3 is that Experiment 3employs Brunswik faces rather than geometricforms as stimuli.
Method
Subjects. Thirty-two volunteers were solicitedthrough ads in local newspapers. The subjects, men andwomen ranging in ages from 17 to 30 years, were paid$2.50 for the experimental session, which lasted ap-proximately 50 minutes. No subject had participatedin either of the first two experiments.
Stimuli. The stimuli were Brunswick faces dis-played on an approximately 27 X 34 cm visual displayscreen (Digital Equipment Corp. VR-17 cathode-raytube screen) linked to a PDP-11 computer. The faceoutlines were 13.5 X 11.5 cm and centered on thescreen. The faces differed in nose length, mouth height,eye separation, and eye height, which were the fourdimensions that had been varied previously by Reed(1972). The nose was either a 1.5-cm or a 3.0-cm verticalline centered within the face outline. The mouth was a

THEORY OF CLASSIFICATION LEARNING 225
4.0-cm horizontal line, which was either 1.5 cm or 3.0 cmfrom the chin line. The eyes were 1 cm X 2.5 cm andwere separated either by 1.5 cm or 3.5 cm (measuringfrom inner edges). Finally, the eyes were either 2.5 cmor 5 cm from the top of the face outline (measured tothe top edge of the eye). The two possible values oneach of the four dimensions were combined to produce16 distinct stimuli.
Categories were constructed in accordance with thedesign shown in Figure 4. Moving from left to right,the dimensions of eye height, eye separation, noselength, and mouth height were substituted for thedimensions of color, form, size, and number.
Procedure. The experiment had three main phases;initial training, transfer test, and speeded classification.Initial training consisted of up to 32 runs through thelist of 9 training stimuli with a learning criterion of 1errorless run. The basic trial sequence was as follows:A face appeared on the screen and remained on untilthe subject pressed either the button marked "A" orthe button marked "B," which occupied the lower leftand lower right corners, respectively, of a 4 X 4 buttonresponse box; the face remained on the screen for 2 sec,while feedback ("Correct"; "No, that is A"; or "No,that is B") was displayed below the face; a 1-secinterstimulus interval ensued. The initial training in-structions paralleled those of the first two experiments.
Transfer tests immediately followed initial trainingand mirrored the procedures used in the earlier experi-ments. The only difference was that two randomlyscrambled runs through the 16 possible faces weregiven, staying on the screen until the confidence judg-ment was completed. The interstimulus interval wasas before, but no feedback concerning either recognitionor classification was given.
After these transfer tests, subjects were given anadditional 16 runs through the nine training stimuli.Presentation and feedback were exactly as in initialtraining. The only difference was that subjects weretold we were now recording response latencies andthat we wanted them to respond as fast as they couldwithout making errors.
Results
Learning. Apparently, faces were harder todiscriminate than geometric stimuli, since only14 of the 32 subjects met the learning criterionwithin the maximum of 32 runs. Mean errorsfor each stimulus are shown on the left side ofTable 2. Stimulus 7 again proved to be easierto learn than Stimulus 4, contrary to the quali-tative predictions of the independent cuemodel. This difference is not large, however,and though the overall effect of stimuli issignificant, ^(8, 240) = 31.5, MSe = 17.2, £ <.001, the difference between errors on Stimulus7 and Stimulus 4 was not significant. On theother hand, if we consider only the data of
Table 2Mean Errors and Mean Rating Scores forExperiment 3
Learning Transfer
Stimulusnumber
47
15135
122
1410
Meanerrors
5.54.22.8
11.98.2
15.212.96.64.4
Stimulusnumber
4A7A
ISA13A5A
12B2B
14B10B
1A3B6A8B9A
11A16B
Meanrating
5.25.25.14.74.14.34.15.15.24.03.75.24.72.52.74.8
Note. The mean rating score is with respect to thecategory label (A or B) associated with each stimu-lus in the table. Rating scores may vary from 1 to 6,with 3.5 representing chance (nondifferential) classi-fication.
the 14 subjects who mastered the task, thedifference is reliable (tu = 2.84, p < .02, two-tailed).
Transfer. Recognition scores were low: Theprobability of saying "old" given an old facewas .82, while the probability of saying "old"given a new face was .79. Neither the old-newdifference nor individual stimulus differenceswere significant.
The transfer rating data appear on the rightside of Table 2. The mean rating scores forStimulus 4 and Stimulus 7 were nearly identi-cal. Generally, old stimuli received higherratings than new stimuli; but New Stimulus 6,the modal prototype for Category A, had ashigh a rating as any of the training stimuli.Detailed fits of the models to these data willbe considered shortly.
Speeded classification. Since fewer than halfthe subjects met the learning criterion duringinitial training, the speeded classification datawere associated with a relatively high propor-tion of errors (17% overall). The mean errorand mean correct latency data are shown inTable 3. As can readily be seen, the correlation
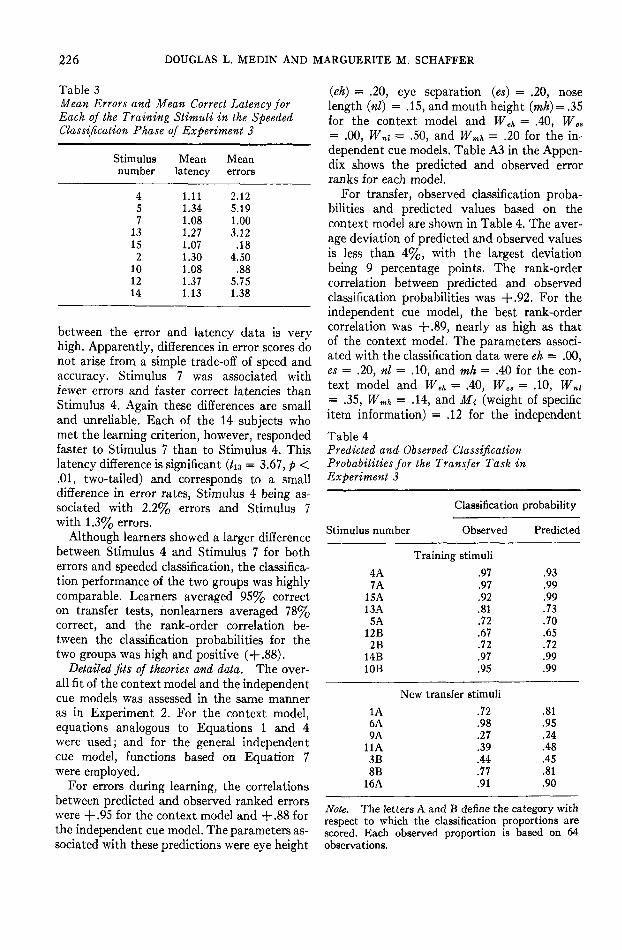
226 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
Table 3Mean Errors and Mean Correct Latency forEach of the Training Stimuli in the SpeededClassification Phase of Experiment 3
Stimulus Mean Meannumber latency errors
4S7
13152
101214
1.111.341.081.271.071.301.081.371.13
2.12S.191.003.12.18
4.50.88
5.751.38
between the error and latency data is veryhigh. Apparently, differences in error scores donot arise from a simple trade-off of speed andaccuracy. Stimulus 7 was associated withfewer errors and faster correct latencies thanStimulus 4. Again these differences are smalland unreliable. Each of the 14 subjects whomet the learning criterion, however, respondedfaster to Stimulus 7 than to Stimulus 4. Thislatency difference is significant (/u = 3.67, p <.01, two-tailed) and corresponds to a smalldifference in error rates, Stimulus 4 being as-sociated with 2.2% errors and Stimulus 7with 1.3% errors.
Although learners showed a larger differencebetween Stimulus 4 and Stimulus 7 for botherrors and speeded classification, the classifica-tion performance of the two groups was highlycomparable. Learners averaged 95% correcton transfer tests, nonlearners averaged 78%correct, and the rank-order correlation be-tween the classification probabilities for thetwo groups was high and positive (+.88).
Detailed fits of theories and data. The over-all fit of the context model and the independentcue models was assessed in the same manneras in Experiment 2. For the context model,equations analogous to Equations 1 and 4were used; and for the general independentcue model, functions based on Equation 7were employed.
For errors during learning, the correlationsbetween predicted and observed ranked errorswere +.95 for the context model and +.88 forthe independent cue model. The parameters as-sociated with these predictions were eye height
(eh) = .20, eye separation (es) = .20, noselength (nl) = .15, and mouth height (mti) = .35for the context model and Weh = .40, We,= .00, Wni = .50, and Wmh = .20 for the in-dependent cue models. Table A3 in the Appen-dix shows the predicted and observed errorranks for each model.
For transfer, observed classification proba-bilities and predicted values based on thecontext model are shown in Table 4. The aver-age deviation of predicted and observed valuesis less than 4%, with the largest deviationbeing 9 percentage points. The rank-ordercorrelation between predicted and observedclassification probabilities was +.92. For theindependent cue model, the best rank-ordercorrelation was +.89, nearly as high as thatof the context model. The parameters associ-ated with the classification data were eh = .00,es = .20, nl = .10, and mh = .40 for the con-text model and Weh = .40, Wea = .10, Wni= .35, Wmh = .14, and Mi (weight of specificitem information) = .12 for the independent
Table 4Predicted and Observed ClassificationProbabilities for the Transfer Task inExperiment 3
Classification probability
Stimulus number Observed Predicted
4A7A
ISA13A5A
12B2B
14B10B
Training stimuli
.97
.97
.92
.81
.72
.67
.72
.97
.95
.93
.99
.99
.73
.70
.65
.72
.99
.99
New transfer stimuli1A .72 .816A .98 .959A .27 .24
11A .39 .483B .44 .458B .77 .81
16A .91 .90
Note. The letters A and B define the category withrespect to which the classification proportions arescored. Each observed proportion is based on 64observations.

THEORY OF CLASSIFICATION LEARNING 227
cue model. Table A4 in the Appendix sum-marizes these rank-order predictions.
For speeded classification, best-fitting pa-rameters for the context model produced rank-order correlations of +.98 with the error dataand +.95 with the latency data. Respectivecorrelations for the independent cue modelwere +.92 and +91. For both models, thesame parameters produced best fits to boththe error data and the latency data, the valuesbeing eh = .00, es = .22, nl = .10, and mh= .40 for the context model and Weh = .40,Wea = .00, Wni = .50, and Wmh = .20 for theindependent cue model. Table AS in the Ap-pendix shows the predicted and observedrankings for these two models.
Discussion
The results again favored the context modelover the independent cue model. Learnersmade more errors on and classified moreslowly a stimulus close to the prototype(Stimulus 4) than one farther away (Stimulus7). Quantitative predictions of both modelswere in good accord with the data, but in eachcase, the correlation between predicted andobserved ranks was higher for the contextmodel than for the independent cue model.Apparently, the advantage of the contextmodel over the independent cue model is notlimited to studies using geometric stimuli ormetathetic stimulus dimensions.
Experiment 4
The retrieval process implied by the contextmodel is straightforward. Although Equation 1seems to require the subject to do considerablecomputation to develop the various similarityestimates, actually this need not be so. Onecould assume that judgments are based on thefirst pattern retrieved, with the similarityparameters determining the likelihood thatparticular stimuli will be the first retrieved.An obvious advantage of assuming that per-formance is based on the initial pattern orpatterns retrieved is that one would like togeneralize the context model to classificationtasks where a large number of exemplars maybe involved, and the plausibility of an exhaus-tive retrieval plan would become quite strained.
If classification judgments are based on thefirst pattern retrieved, on what are confidenceratings based? A strong possibility is thatconfidence ratings are based on how quickly oreasily the first pattern is retrieved. This wouldimply that confidence ratings for new transferstimuli should increase with the number ofhighly similar patterns, regardless of whetherthe same classification response is associatedwith the various patterns. Our data give somesupport to this idea. For example, judgmentsof Stimulus 16 in Experiment 2 received a highconfidence rating 16 times, and in each case,the category assignment was a B; judgmentson Stimulus 9 received a high confidence rating17 times, but the stimulus was assigned toCategory A only 6 of those 17 times. Un-fortunately, the number of patterns highlysimilar to a new transfer stimulus scarcelyvaried within experiments. Stimulus 6 inExperiment 2 had more similar patterns (fourvs. three) than the other transfer stimuliand was most likely to receive a high con-fidence rating and least likely to receive a lowconfidence rating. When a stimulus was judgedto be new, confidence ratings were low—only16% of the time were subjects highly con-fident, and half of the time they reported thatthey were guessing.4
New-old recognition may also be based onhow quickly or easily the probe retrieves in-formation and, therefore, may be based on thenumber of highly similar training patterns.In Experiment 2, a transfer stimulus (Number6) had more highly similar training patternsthan the other stimuli. A direct test indicatesthat this stimulus was more likely to bejudged as old than the other stimuli (t$\ = 4.38,p < .01). Unfortunately, the first three experi-ments provide little variation in the numberof similar training patterns. Experiment 4 was
4 Although confidence judgments depend on thenumber of highly similar exemplar patterns and hencesimilarity parameters, similarity cannot be the soledeterminant of confidence judgments. The contextmodel represents forgetting in terms of increases insimilarity, and it is extremely unlikely that forgettingis accompanied by corresponding increases in confidencerating. Presumably, additional factors such as changesin context determine the general accessibility of storedexemplars, and this general accessibility decreases overtime.

228 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
"A" STIMUL
TRAINING STIMULI
J- "R" STTMIII T
STIMULUS STIMULUSNUMBER DIMENSION VALUES RAT_ NUMBER DIMENSION VALUES
C F S N FE 'ING C F S N FE
21
5
7
13
15
O i l
1 1 1
0 1 1
1 0 1
1 1 0
1 0 1
STIMULUSNUMBER
69
101211
0 5 , 1 1 , 5 1 1 0 0 1 5 . 0
0 3 . 8 1 . 7 3 1 0 0 0 5 . 6
1 1 , 1 5 . 0 8 0 0 1 0 5 , 8
0 1,3 5,1 11 0 0 1 1 1.9
1 1 ,9 1 ,8 16 0 1 0 0 1 ,8
1 1,3 5,1
NEW TRANSFER STIMULI
DIMENSION VALUES RATINGC F S N A-PREDICTED rH>REDiciEn
1 1 1 1 1 . 6
0 1 0 1 3 , 8
0 0 0 0 1 . 1
1 1 0 0 3 . 6
0 0 0 1 3 . 9
RAT-
INS
1,8
1.3
1.3
1,5
1,1
Figure 5. Design of Experiment 4. (C, F, S, and N refer to the dimensions of color, form, size, andnumber, respectively. The stimulus numbers are carried over from the first two experiments. Fe refersto average errors during learning. Rating scores may vary from 1 to 6, with 3.5 representing chance[nondifferential] classification.)
designed to see whether recognition varieswith the number of similar training patterns,as would be expected if recognition were basedon the ease with which stored informationcould be accessed. The experiment also pro-vides still another test of the two main classi-fication models.
The design of Experiment 4 is shown inFigure 5. As before, the value 1 tends to beassociated with Category A and the value 0with Category B. The two categories areseparable by a linear discriminant function, ascan readily be seen by assuming that the num-ber dimension receives no weight at all, for inthat case, two of the three values of eachtraining stimulus match the modal value fortheir category. The main focus of Experiment 4concerns new-old recognition, specifically onthe predictions of the context model that themore stored exemplars similar to the probe,the less likely the probe will be called new.
This should hold for both old and new probestimuli. For example, Stimulus 16 is highlysimilar to only one other training pattern (2),while Stimulus 2 is highly similar to fourtraining stimuli (4, 5, 8, and 16); therefore,Stimulus 16 should be more likely to be callednew than Stimulus 2. Likewise, New Stimulus14 is highly similar to two B training stimuli(1 and 11), while Stimulus 12 is highly similarto two A and two B training patterns, so sub-jects should call Stimulus 14 new more oftenthan Stimulus 12.
No general predictions concerning recogni-tion for independent cue models are available.For new patterns, one might speculate thatthe farther a probe is from a prototype pattern,the more likely it would be called new. In thiscase, Stimulus 6 and Stimulus 10, the modalprototypes, should rarely be called new; if thefour dimensions are equally weighted, Stimulus

THEORY OF CLASSIFICATION LEARNING 229
12 should be called new more often thanStimulus 14.
Although the focus of Experiment 4 was onrecognition, one should note that the twotheories will differ also in their predictionsconcerning classification. According to the in-dependent cue models, each member of thefollowing stimulus pairs should produce equi-valent performance: 2 and 1, 5 and 3, 13 and8, 15 and 16, and 6 and 10. The contextmodel generally predicts that the first memberof each of these pairs will be classified moreaccurately, partly on the basis of high-simi-larity exemplars and partly on the basis ofthe extra Category A pattern that provides anadditional opportunity for an A pattern to beretrieved by a probe.
Method
Subjects. Thirty-two volunteers were solicitedthrough ads in local newspapers. The subjects, men andwomen ranging in ages from 17 to 30 years, were paid$2,50 for the experimental session. The subjects hadnot participated in any of the first three experiments.
Stimuli. Sixteen stimulus cards with geometricforms drawn on them were used. Eleven cards wereused in training, and five additional cards were usedduring transfer tests. The same stimulus dimensionswere used as in Experiment 2, but new values for thecolor and form dimensions were employed. The formswere either equilateral triangles or hexagons, and theywere colored either yellow or purple. The values for thesize and number dimensions were as before.
The assignment of abstract notation to individualstimulus cards varied from subject to subject exactlyas in the preceding experiments. The assignment ofstimulus cards to stimulus conditions and categorylabels was exactly counterbalanced.
Procedure. Original training was followed by aS-10-minute interpolated activity, then a transfer testinvolving both training and new transfer stimuli. Train-ing instructions and the interpolated activity were asin the first two experiments. Training consisted of upto 16 runs through the list of 11 training stimuli with alearning criterion of 1 errorless run. Other proceduraldetails followed those of Experiment 2 including theinterpolated activity and the transfer test instructions.The only difference was that the 16 stimulus cardswere presented twice during transfer in 2 randomizedruns.
Results
Learning. Half of the subjects met thelearning criterion within the 16-run limit, andonly two subjects failed to show improvementwith practice. Mean errors for each stimulus
are shown in Figure 5. There was not muchvariation in errors, and an analysis of varianceon errors did not reach statistical significance(F < 1).
Transfer. For recognition, overall, the prob-ability of saying "old" given an old patternwas .95, and the probability of saying "old"given a new pattern was .72. On both old andnew patterns, the probability of saying "old"increased with the number of training pat-terns highly similar to the probe. For purposesof analysis, patterns were classified as havinglarge, medium, or small numbers of highlysimilar training patterns, with large, medium,and small corresponding to four, three, andtwo highly similar patterns for a new stimulusand corresponding to four, three or two, andone highly similar patterns for an old probestimulus, respectively. The probabilities of newresponses were .03, .05, and .10, respectively,for large, medium, and small numbers ofsimilar patterns for old stimuli and .24, .28,and .38 for corresponding new patterns. Theseresults are consistent with the predictions ofthe context model. An analysis of varianceindicated that both the effects of old versusnew probes, F(l, 31) = 29,8, MS, = 5.08,p < .01, and the effects of number of highlysimilar training patterns, F(2, 62) = 4.65, MSe
= 2.22, p < .05, were significant.The rating scores from classification tests
are shown in Figure 5. Generally speaking,old stimuli received higher ratings than newstimuli, and of the new stimuli, Modal Proto-types 6 and 10 received higher ratings thanother new stimuli. An analysis of varianceindicated that the effect of stimuli was signifi-cant, F(15, 450) = 3.08, MSe = 6.29, p < .01.The relation of the classification results to thetheories will be brought out when the detailedfits of theory and data are considered.
In view of the large number of nonlearners,the data for learners and nonlearners wereconsidered separately. The recognition datarevealed that learners were more accurate indetecting new patterns (probability of saying"new" given new was .35 for learners and .22for nonlearners) and were slightly more likelyto call an old pattern new (.07 vs. .04); also,the effects of the number of highly similarpatterns were more clear for learners than non-learners. On the classification tests, learners

230 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
Table 5Predicted and Observed ClassificationProbabilities for the Transfer Task ofExperiment 4
Classification probability
Stimulus number Observed Predicted
Training stimuli
2A4ASA7A13AISAIB3B8B11B16B
.80
.78
.86
.83
.72
.80
.70
.64
.73
.78
.69
.74
.90
.80
.72
.78
.74
.70
.73
.73
.72
.69
New transfer stimuli
6A .89 .889A .56 .56
10B .78 .8312A .62 .6214B .64 .59
Note. The letters A and B define the category withrespect to which the classification proportions arescored. Each observed proportion is based on 64observations.
averaged 84% correct, nonlearners averaged68% correct, and the correlation between theclassification performance in the two groupswas modest and positive (+.41). No systematicdifferences between the two groups were noted,and the low correlation apparently derivesfrom the low overall performance of non-learners.
Detailed fit of theories and data. Since theeffect of stimuli on errors during learning wasnot significant, no attempt was made to fit theacquisition data. Fits to the classification datawere attempted by using equations analogousto Equations 1 and 4 for the context modeland Equation 7 for the independent cue model.
Observed classification probabilities and pre-dicted values based on the context model areshown in Table 5. Overall, the average devia-tion of predicted from observed values is lessthan 5%, with the largest deviations being theoverprediction of performance on Stimulus 4and the underprediction of performance on
Stimulus 7. The rank-order correlation of pre-dicted and observed classification probabilitieswas +.72. For the independent cue model, thebest rank-order correlation was +.41, con-siderably lower than that for the contextmodel. The problem for the independent cuemodel is that A training stimuli were betterclassified than B training stimuli, a differencenot predicted by the model. The parametersassociated with the classification data werec = .18,/,= .20, i = .28, and n = .33 for thecontext model and Wc = .22, Wt = .27, W.= .30, Wn = .30, and Af,- = .54 for the inde-pendent cue model. Table A6 in the Appendixsummarizes these rank-order predictions.
Discussion
As predicted by the context model, theprobability of calling a probe stimulus old in-creased with the number of training stimulihighly similar to the probe. In addition, theclassification data were predicted considerablybetter by the context model than by the inde-pendent cue model.
General Discussion
Major Results
In each experiment, the data were moreconsistent with the context model than withthe general independent cue model. Qualitativepredictions favored the context model regard-less of whether or not the two classes werelinearly separable and regardless of whetherthe stimuli were geometric forms or face out-lines. Moreover, quantitative predictions ofthe context model were in each case moreaccurate than corresponding predictions of theindependent cue model, though generally thesedifferences were small. At the very least, thecontext model must be taken seriously as acontending classification theory. The resultsalso raise questions concerning the adequacyof the assumption that component stimulusdimensions are treated independently, a basicunderlying assumption of prototype models inparticular and independent cue theories ingeneral.
The context model differs from all inde-pendent cue models in its assumption that

THEORY OF CLASSIFICATION LEARNING 231
component dimensions are not independentand differs from all but average distancemodels in its proposal that classification judg-ments derive from exemplar, rather than cate-gory level, information. The model assumesthat classification judgments are based on theretrieval of specific item information, theretrieval of information about old stimuli whena new stimulus is presented being a functionof similarity. The model contains parametersfor the similarity of the values along eachdimension but adds no special process to dif-ferentiate old and new items. Nonetheless, thecontext model predicts differences between oldand new stimuli, and by representing forgettingin terms of increases in the similarity param-eters, it yields predictions consistent with thedifferential retention of old and new stimulusclassification. Specific details of the variousexperiments were consistent with the contextmodel, and an initial attempt at a quantitativefit to the data produced fairly accurate predic-tions. Finally, the new-old recognition dataand the confidence rating data are consistentwith the idea that recognition and confidenceare related to how easily or quickly the probestimulus retrieves specific stored information.
Relation of the Context Model toOther Theories
Although transfer performance is not wellpredicted by the frequency of individual fea-tures (Franks & Bransford, 1971), a numberof researchers have proposed that subjectsmay encode relational frequencies (Hayes-Roth & Hayes-Roth, 1977; Neumann, 1974,1977; Reitman & Bower, 1973). That is, inaddition to encoding the frequency with whichFeatures A, B, and C occur, subjects may en-code the frequency with which A and B; Band C; A and C; and A, B, and C occurtogether. Judgments are assumed to be basedon combinations of simple frequency (A, B,and C) and relational frequency (AB, AC, BC,and ABC). In most experiments, as distanceof an exemplar from the prototype increases,relational frequency decreases; therefore, rela-tional frequency models can account for mostresults concerning transfer to new patterns.Relational frequency theory and prototypetheory predict transfer about equally well whengeometric stimuli are used (Neumann, 1974;
Posnansky & Neumann, 1976), while rela-tional frequency models actually are betterpredictors of transfer performance than proto-type theory when letter strings and biographi-cal descriptions are used (Hayes-Roth &Hayes-Roth, 1977; Posnansky & Neumann,1976). Whether these differences in accuracyof prediction depend on the nature of thestimuli presented or on details of experimentaldesign that have covaried with the alternativestimuli is uncertain.
Relational frequency models differ from thecontext model in that they assume that cate-gory judgments are based on category levelrather than exemplar information, but like thecontext model, they do not assume that cate-gory judgments are based on an independentsummation of component information. In fact,most of the qualitative predictions of the con-text model examined in the present experi-ments are shared by relational frequencymodels. Several difficulties arise in attemptingto extend these models to the present datawith greater explicitness. For Neumann's at-tribute frequency model, the net frequencyscores of old and new stimuli in our experi-ments frequently overlapped considerably,while ratings of new stimuli generally fellbelow those of old stimuli. Therefore, one wouldhave to posit that a mixture of specific iteminformation and category level (frequency) in-formation controlled performance. A moreserious problem concerns how to treat differ-ential salience of dimensions. If color is moresalient than form, one might imagine that acolor frequency counter is more likely to beincremented than a simple form frequencycounter, but how should one treat the statusof the counter corresponding to color plusform? Another concern is that the encodingprocesses seem quite complex. When a patternhaving values along four dimensions is pre-sented, four one-dimensional counters, six two-dimensional counters, four three-dimensionalcounters, and one four-dimensional counter allget incremented and associated with the cate-gory. Probably none of these difficulties is in-surmountable, but at present, the contextmodel appears to be easier to work with, ifnot more parsimonious.
Hayes-Roth and Hayes-Roth (1977) haveproposed a model called the most diagnostic

232 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
property set model, where classification is basedon the features or combinations of featuresthat are most diagnostic (i.e., have the highestvalidity). The fact that combinations of fea-tures may be used distinguishes this modelfrom independent cue theories. As developedby Hayes-Roth and Hayes-Roth (1977), theproperty set model makes no differential pre-dictions among stimuli that have at least oneperfectly valid cue. In our experiments, thetraining stimuli always contain at least oneperfectly valid combination of features, andtransfer stimuli almost always contain at leastone combination of features valid for each ofthe two categories. As a result, the Hayes-Rothand Hayes-Roth model makes almost no spe-cific predictions for our experiments, exceptthat performance on old patterns should bebetter than performance on new patterns. Ifone assumed that with diagnosticity held con-stant, classification performance varied withthe number and frequency of the associatedproperty sets, then the main qualitative re-sults of our experiments would be predicted.
In the experiments designed to test theproperty set model, Hayes-Roth and Hayes-Roth (1977) varied the frequency with whichthe different exemplars were presented intraining. Differential frequency of exemplarpresentation might naturally be representedin the context model by assuming that differentnumbers of representations are developed. Forexample, if stimulus i appears twice as often asstimulus,/, we might treat the task as involvingtwo stimulus i exemplars and one stimulus _;'exemplar. With this interpretation, the contextmodel would reproduce the main qualitativeresults of the Hayes-Roths' experiment.
Finally, one other very simple classificationmodel, the proximity model, deserves con-sideration. One version of the proximity modelsimply assumes that new patterns are classifiedaccording to the training stimulus that mostclosely resembles the new stimulus. If thattraining stimulus was associated with Class A,then the new pattern is classified as an A. Ifthe training stimulus was a B, then the newpattern would be called a B (for more exten-sive treatment of proximity models, see Reed,1972;Sebestyen, 1962).
The proximity model is similar to the con-text model in that it assumes that classification
is based on specific item information. In fact,the proximity model might be thought of as aspecial case of the context model where per-formance is based on the first pattern re-trieved, and the first pattern retrieved is al-ways the most similar training pattern. Theproximity model would need further elabora-tion to account for the differential retention ofold and new stimulus patterns observed inExperiment 1. Modification with this end inmind would further increase the similarity be-tween the context model and the proximitymodel.
Relation of the Context Model to OtherClassification Results
Many of the results on prototype abstrac-tion and classification with ill-defined rulesderive from studies employing dot patterns.Although it is somewhat risky to discuss theapplication of the context model to theseresults so long as we are unable to specify thecomponent dimensions, the context modelseems qualitatively consistent with some of themain findings.
First of all, transfer to new stimulus patternsappears to increase with the number of exem-plars comprising a category (e.g., Homa &Chambliss, 1975). This result could be derivedfrom the context model by proposing that thegreater the number of training patterns, themore likely it is that a new pattern will behighly similar to at least one training patternfrom the correct category. If this were true,the average dissimilarity (or distortion level)of the training pattern would enter as a de-terminer of transfer in the following manner:For training patterns that were low distortions(quite similar to one another), increasing thenumber of exemplars per category would notfacilitate transfer as much as when the trainingpatterns were more varied. In other words, iftraining patterns were low distortions, no oneof them might be similar enough to a newprobe to be activated by it, so that one mightexpect an interaction between category sizeand level of distortion of category members.Exactly this interaction was obtained by Homaand Vosburgh (1976).
According to prototype theories, learningand transfer behavior depend on the distance

THEORY OF CLASSIFICATION LEARNING 233
of alternative prototypes from each other andon the average distance of exemplar stimulifrom the prototypes. Performance should beunaffected by how these distances arise.Barresi, Robbins, and Shain (1975) held over-all average distance of dot patterns from theprototypes constant and varied whether eachindividual dot in a given dot pattern wasabout the same distance from the correspond-ing dot in the prototype from which it wasderived (low-variance condition) or whethersome individual dots were close and others farfrom the corresponding dot locations in theprototype. Since overall average distance isconstant, prototype theory predicts no effectof variance. The results showed, however, thathigh-variance classes were learned faster andhad better generalization than low-varianceclasses.
The context model predicts that a new itemhighly similar to one member but dissimilarfrom another member of a category would beassigned to that category with greater easethan a new item moderately similar to bothcategory members. Likewise, in distinguishingtwo items in different categories on the basisof the values along two dimensions, one similarvalue and one distinct value should combineto be more discriminable than two valuesintermediate in distinctiveness. Thus, if one iswilling to assume that physical and psycho-logical distances were roughly equivalent inthe Barresi et al. experiment, the contextmodel correctly predicts that high-variancecategories will be more discriminable than low-variance categories.
Generality
While we have indicated informally how thecontext model might apply to other classifica-tion studies, the generality of the context modelto different stimulus populations and experi-mental procedures is an open question. Onereason for optimism concerning generality isthat basically the same ideas give an excellentaccount of a wide range of discriminationlearning and transfer phenomena across avariety of subject populations (Medin, 1975).
Stimulus dimensions. Immediate extensionsto other stimulus populations face some non-trivial obstacles. The problems center around
developing appropriate descriptions of thefeatures or dimensions in terms of which stimu-lus information is stored in memory. In theabsence of such analyses, the experimenters'and subjects' representations of the stimulimay not coincide, relational cues (e.g., ratioof nose length to mouth width) may operate,and interactions caused by factors such asasymmetrical similarity (e.g., Atkinson &Estes, 1963; Bush & Hosteller, 1951; Tversky,1977) may go undetected. Yet, many of thecomparisons that one is most interested inmaking involve natural concepts whose com-ponent features are unknown and undoubtedlycomplex.
Certain tests of the context model are evenpossible in working with complex stimuli, suchas human faces, whose constituent dimensionscannot be specified. Such tests would employa confusion matrix (which could be indepen-dently derived) for the exemplars to be usedin the classification task. The work of Shepardand Chang (1963) suggests that classificationperformance can be predicted from an identi-fication confusion matrix so long as selectiveattention is minimized. The context modelwould predict that with between-categoryconfusability held constant, classification per-formance on an exemplar would be better thegreater within-category confusability. Thebasis for this prediction is that if an exemplaris highly confusable with other exemplars inits category, then when the exemplar is pre-sented as a probe, it will lead to a correctcategorization if either the information as-sociated with the stored representation of thatexemplar is retrieved or if information associ-ated with the representations of the other con-fusable exemplars is accessed. If an exemplaris not confusable with (similar to) any of itsfellow category exemplars, the latter source ofcorrect classifications will not be available.
Test situations. There is reason to thinkthat the context model will account for classi-fication performances in settings where ana-lytical strategies are either absent or irrelevantto the concept in question. Brooks (Note 2)trained subjects on a paired-associate task,where the stimuli were complex symbols andthe responses were either animal or city names.Then, subjects were told that the concept "oldworld" versus "new world" (animals or cities)

234 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
was relevant, and they were asked to classifynew complex symbols as old or new world onthe basis of what they had previously learned.The results suggested that subjects classifiednew patterns by analogy with similar learnedinstances rather than by applying analyticalstrategies. Incidental concept learning provedto be more effective than explicit concepttraining in situations where the stimuli werecomplex and presumably difficult to analyzeor where the conceptual tasks were disguisedduring learning.
Although it was developed without the bene-fit of any knowledge of Brooks's research, theretrieval assumptions of the context modelclosely embody Brooks's propositions concern-ing analogical thinking. Therefore, the con-text model is likely to be at least qualitativelysuccessful in addressing incidental conceptlearning.
The idea that judgments may be based onretrieval of examples has also been applied tosituations distinctly different from conceptlearning situations. Tversky and Kahneman(1973) proposed that people often evaluate thefrequency or likelihood of events by the easewith which relevant instances come to mind.This strategy can be very efficient, but it canlead to systematic biases. For example, peoplecan accurately estimate how many words theycan recall from a category within some timelimit, but they make gross errors on questionssuch as whether the letter k is more likely tobe the first than the third letter of Englishwords. Most subjects guessed that k is morelikely to appear in the first position, perhapsbecause people can generate words beginningwith k more easily than words which have kas the third letter.
There is also some evidence that retrieval ofinstances may play a role in semantic memorytasks. Holyoak and Glass (1975) reportedevidence consistent with the idea that sen-tences such as "All birds are canaries" oftenare disconfirmed by retrieval of counter-examples (e.g., robins). They speculate thattrue judgment of such sentences as "All birdslay eggs" may be confirmed by induction afterthe retrieval of several positive instances (e.g.,robins lay eggs, ducks lay eggs, and ostricheslay eggs).
A related implication of the context model
is that classification judgments depend oncontextual factors. For example, a ratherstrange looking four-legged animal may bemuch more likely to be classified as a dogwhen seen walking down the street on a leashthan when seen running through the woods.Our assumption is similar to the principle ofencoding specificity (Tulving & Thompson,1971, 1973; Watkins, Ho, & Tulving, 1976) inthat the presence of specific context plays arole in whether the specific stimulus informa-tion is accessed.
Further Considerations and Conclusions
If one were going to design a system to learnabout the structural relations between stimulusclasses and events (i.e., a natural conceptlearning device), what kind of system shouldone build? First of all, it would seem that onewould be judicious in one's use of analyticalprocesses, particularly if those processes ac-curately reflected concept identification modelsthat focused on valid cues. One would notwant a system that only learned exceptionlessrules. Hence, in some sense, learning by analogyshould be allowed for.
An analogical process would also serve thefunction of protecting the concept learningsystem from ignoring or throwing away infor-mation that might later prove critical whenother concepts or categories were acquired.For example, in learning to tell the differencebetween dogs and cats, size is a good cue,whereas domesticity is not. But ignoringdomesticity and learning only about size couldprove costly later when one might want todistinguish dogs and wolves or dogs andcoyotes.
At the present time, it is hard to make aperfectly general statement concerning howone ought to balance analytical and analogicalprocesses. On the one hand, Reber (1967,1969,1976) has shown that active rule search caninterfere with acquiring a grammar if thatgrammar involves very complex rules; on theother hand, a system that did not abstract therules within its grasp might prove to be need-lessly inefficient.
Finally, in designing a concept learningsystem, one might want to be guided by thesimplicity of the proposed underlying proces-

THEORY OF CLASSIFICATION LEARNING 235
ses. The context model, embodying instancelearning and retrieval on the basis of similarity,appears to accomplish efficient mastery ofill-defined concepts with a minimum of proces-sing machinery.
Reference Notes
1. Ratcliff, R. A model of recognition memory. Paperpresented at the meeting of Mathematical Psy-chology, New York University, 1976.
2. Brooks, L. Non-analytic concept formation andmemory for instances. Paper presented at the SocialScience Research Council Conference on HumanCategorization, Berkeley, Calif., 1976.
References
Atkinson, R. C., & Estes, W. K. Stimulus samplingtheory. In R. D. Luce, R. R. Bush, & E. Galanter(Eds.), Handbook of mathematical psychology (Vol. 2).New York: Wiley, 1963.
Barresi, J., Robbins, D., & Shain, K. Role of distinctivefeatures in the abstraction of related concepts.Journal of Experimental Psychology: Human Learningand Memory, 1975, 1, 360-368.
Bourne, L. E., Jr. Knowing and using concepts. Psycho-logical Review, 1970, 77, 546-556.
Bourne, L. E., Jr., & O'Banion, K. Memory for indi-vidual events in concept identification. PsychonomicScience, 1969, 16, 101-103.
Bush, R. R., & Mosteller, F. A model for stimulusgeneralization and discrimination. Psychological Re-view, 1951, 58, 413-423.
Calfee, R. C. Recall and recognition memory in conceptidentification. Journal of Experimental Psychology,1969, 81, 436-440.
Estes, W. K. An associative basis for coding andorganization in memory. In A. W. Melton & E.Martin (Eds.), Coding processes in human memory.Washington, D.C.: Winston, 1972.
Estes, W. K. Memory and conditioning. In F. J.McGuigan & D. B. Lumsden (Eds.), Contemporaryapproaches to conditioning and learning. New York:Wiley, 1973.
Estes, W. K. Structural aspects of associative modelsfor memory. In C. N. Cofer (Ed.), The structure ofhuman memory. New York: W. H. Freeman, 1976.
Franks, J. J., & Bransford, J. D. Abstraction of visualpatterns. Journal of Experimental Psychology, 1971,90, 65-74.
Goldman, B., & Homa, D. Integrative and metricproperties of abstracted information as a function ofcategory discriminability, instance variability, andexperience. Journal of Experimental Psychology:Human Learning and Memory, 1977, 3, 375-385.
Hayes-Roth, B., & Hayes-Roth, F. Concept learningand the recognition and classification of exemplars.Journal of Verbal Learning and Verbal Behavior, 1977,16, 321-338.
Hirschfeld, S. L., Bart, W. M., & Hirschfeld, S. F.
Visual abstraction in children and adults. Journal ofGenetic Psychology, 1975, 126, 69-81.
Holyoak, K. J., & Glass, A. L. The role of contradic-tions and counterexamples in the rejection of falsesentences. Journal of Verbal Learning and VerbalBehavior, 1975,14, 215-239.
Homa, D., & Chambliss, D. The relative contributionsof common and distinctive information on the ab-straction from ill-defined categories. Journal of Ex-perimental Psychology: Human Learning and Memory,1975, /, 351-359.
Homa, D., Cross, J., Cornell, D., Goldman, D., &Schwartz, S. Prototype abstraction and classificationof new instances as a function of number of instancesdefining the prototype. Journal of ExperimentalPsychology, 1973, 101, 116-122.
Homa, D., & Vosburgh, R. Category breadth and theabstraction of prototypical information. Journal ofExperimental Psychology: Human Learning and Mem-ory, 1976, 2, 322-330.
Katz, J. J., & Postal, P. M. An integrated theory oflinguistic descriptions. Cambridge, Mass.: MIT Press,1964.
Lasky, R. E. The ability of six-year-olds, eight-year-olds, and adults to abstract visual patterns. Child De-velopment, 1974, 45, 626-632.
Levine, M. A cognitive theory of learning: Research onhypothesis testing. Hillsdale, N.J.: Erlbaum, 1975.
Medin, D. L. A theory of context in discriminationlearning. In G. H. Bower (Ed.), The psychology oflearning and motivation (Vol. 9). New York: AcademicPress, 1975.
Medin, D. L. Theories of discrimination learning andlearning set. In W. K. Estes (Ed.), Handbook oflearning and cognitive processes. Hillsdale, N.J.:Erlbaum, 1976.
Neumann, P. G. An attribute frequency model for theabstraction of prototypes. Memory 6* Cognition, 1974,2, 241-248.
Neumann, P. G. Visual prototype information withdiscontinuous representation of dimensions of vari-ability. Memory & Cognition, 1977, 5, 187-197.
Peterson, M. J., Meagher, R. B., Jr., Chait, H., &Gillie, S. The abstraction and generalization of dotpatterns. Cognitive Psychology, 1973, 4, 378-398.
Posnansky, C. J., & Neumann, P. G. The abstractionof visual prototypes by children. Journal of Experi-mental Child Psychology, 1976, 21, 367-379.
Posner, M. L, & Keele, S. W. On the genesis of abstractideas. Journal of Experimental Psychology, 1968, 77,353-363.
Posner, M. L, & Keele, S. W. Retention of abstractideas. Journal of Experimental Psychology, 1970, 83,304-308.
Reber, A. S. Implicit learning of artificial grammars.Journal of Verbal Learning and Verbal Behavior, 1967,6, 855-863.
Reber, A. S. Transfer of syntactic structure in syn-thetic languages. Journal of Experimental Psychology,1969, 81, 115-119.
Reber, A. S. Implicit learning of synthetic languages:The role of instructional set. Journal of Experi-mental Psychology: Human Learning and Memory,1976, 2, 88-94.

236 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
Reed, S. K. Pattern recognition and categorization.Cognitive Psychology, 1972, 3, 382-407.
Reed, S. K., & Friedman, M. P. Perceptual vs. con-ceptual categorization. Memory &• Cognition, 1973,1, 157-163.
Reitman, J. S., & Bower, G. H. Storage and laterrecognition of exemplars of concepts. Cognitive Psy-chology, 1973, 4, 194-206.
Rosch, E. On the internal structure of perceptual andsemantic categories. In T. E, Moore (Ed.), Cogni-tive development and the acquisition of language. NewYork: Academic Press, 1973.
Rosch, E. Cognitive reference points. Cognitive Psy-chology, 1975, 7, 532-547. (a)
Rosch, E. Cognitive representation of semantic cate-gories. Journal of Experimental Psychology: General,1975, 104, 192-233. (b)
Rosch, E. The nature of mental codes for color cate-gories. Journal of Experimental Psychology: HumanPerception and Performance, 1975, 1, 303-322. (c)
Rosch, E., & Mervis, C. B. Family resemblances:Studies in the internal structure of categories. Cogni-tive Psychology, 1975, 7, 573-605.
Rosch, E., Mervis, C. B., Gray, W. D., Johnson, D. M.,& Boyes-Braem, P. Basic objects in natural cate-gories. Cognitive Psychology, 1976, S, 382-439.
Sebestyen, G. S. Decision-making processes in patternrecognition. New York: Macmillan, 1962.
Shepard, R. N., & Chang, J. J. Stimulus generalizationin the learning of classifications. Journal of Experi-mental Psychology, 1963, 65, 94-102.
Smith, E. E., Shoben, E. J., & Rips, L. J. Structureand process in semantic memory: A featural modelfor semantic decisions. Psychological Review, 1974,81, 214-241.
Spence, K. W. The nature of discrimination learningin animals. Psychological Review, 1936, 43, 427-449.
Strange, W., Keeney, T., Kessel, F. S., & Jenkins, J. J.Abstraction over time of prototypes from distractionsof random dot patterns: A replication. Journal ofExperimental Psychology, 1970, 83, 508-510.
Sutherland, N. S., & Mackintosh, N. J. Mechanisms ofanimal discrimination learning. New York: AcademicPress, 1971.
Trabasso, T., & Bower, G. H. Attention in learning:Theory and research. New York: Wiley, 1968.
Tulving, E., & Thomson, D. S. Retrieval processes inrecognition memory: Effects of associative context.Journal of Experimental Psychology, 1971, 87, 116-124.
Tulving, E., & Thomson, D. M. Encoding specificityand retrieval processes in episodic memory. Psycho-logical Review, 1973, 80, 352-373.
Tversky, A. Features of similarity. Psychological Re-view, 1977, 84, 327-352.
Tversky, A., & Kahneman, D. Availability: A heuristicfor judging frequency and probability. CognitivePsychology, 1973, 5, 207-232.
Watkins, M. J., Ho, E., & Tulving, E. Context effectsin recognition memory for faces. Journal of VerbalLearning and Verbal Behavior, 1976, 15, 505-517.
THEORY OF CLASSIFICATION LEARNING
Appendix
237
Table AlPredicted and Observed Rank Error Data fromExperiment 2 for the Context Model and theIndependent Cue Model
Predicted rank
Stimulusnumber
47
IS135
122
1410
Observedrank
732659841
Contextmodel
731.55.55.59841.5
Independentcue model
3.55267893.51
Table A3Predicted and Observed Rank Error Data fromExperiment 3 for the Context Model and theIndependent Cue Model
Predicted rank
Stimulusnumber
457
13152
101214
Observedrank
462718395
Contextmodel
563719284
Independentcue model
47.5461.591.57.54
Note. The rankings are arranged from least errorsto most errors.
Note. The rankings are ordered from least to mosterrors.
Table A2Predicted and Observed Ranked ClassificationData from Experiment 2 for the Context Modeland the Independent Cue Model
Predicted rank
Stimulusnumber
47
15135
122
1410
1A3B6A8B9A
11A16B
Observedrank
1149.549.57741
15122
1316147
Contextmodel
93.51.57.57.5
111051.5
12153.5
1316146
Independentcue model
4.58269
10114.51
15123
1316147
Table A4Predicted and Observed Ranked ClassificationData from Experiment 3 for the Context Modeland the Independent Cue Model
Predicted rank
Stimulusnumber
47
15135
122
14101A3B6ASB9A
11A16B
Observedrank
3368
11131135
111419
1615
7
Contextmodel
62.52.5
101213112.52.58.5
1558.5
16147
Independentcue model
4.58379
13114.51
14122
1016156
Note. The rankings are arranged from highest class-ification scores to lowest.
Note. The rankings are ordered from highest tolowest classification scores.
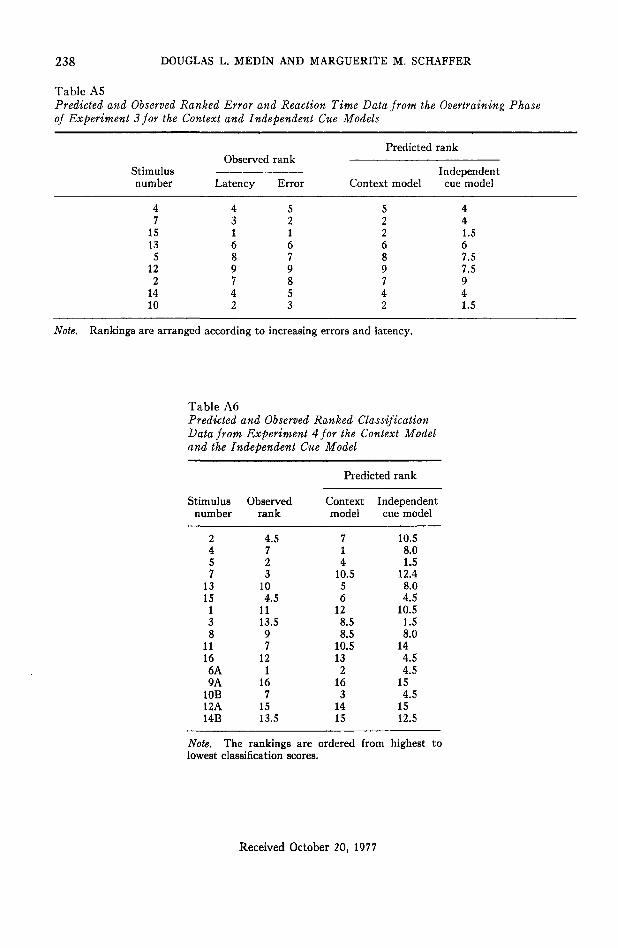
238 DOUGLAS L. MEDIN AND MARGUERITE M. SCHAFFER
Table ASPredicted and Observed Ranked Error and Reaction Time Data from the Overtraining Phaseof Experiment 3 for the Context and Independent Cue Models
Predicted rankV_/UOCi VCl.
Stimuli!"number Latency
4 47 3
IS 113 65 8
12 92 7
14 410 2
i lauii
Error
521679853
Context model
522689742
Independentcue model
441.567.57.5941.5
Note. Rankings are arranged according to increasing errors and latency.
Table A6Predicted and Observed Ranked ClassificationData from Experiment 4 for the Context Modeland the Independent Cue Model
Predicted rank
Stimulus Observed Context Independentnumber rank model cue model
24571315138
11166A9A10B12A14B
4.5723104.51113.5971211671513.5
71410.556128.58.510.51321631415
10.58.01.512.48.04.510.51.58.0144.54.5154.51512.5
Note. The rankings are ordered from highest tolowest classification scores.
Received October 20, 1977




























![[WI 2014]Context Recommendation Using Multi-label Classification](https://img.pdfslide.net/doc/110x75/555a3e68d8b42ae1398b4cef/wi-2014context-recommendation-using-multi-label-classification.jpg)
