Embed Size (px)
Citation preview

R
Issue 61Third Quarter 2007
Xcell journalXcell journalS O L U T I O N S F O R A P R O G R A M M A B L E W O R L DS O L U T I O N S F O R A P R O G R A M M A B L E W O R L D
INSIDE
PCI Express and FPGAs
Reducing CPU Load forEthernet Applications
A High-Speed SerialConnectivity Solution with Aurora IP
Xilinx FPGAs Adapt to Ever-Changing BroadcastVideo Landscape
Making the Most of MOST Control Messaging
INSIDE
PCI Express and FPGAs
Reducing CPU Load forEthernet Applications
A High-Speed SerialConnectivity Solution with Aurora IP
Xilinx FPGAs Adapt to Ever-Changing BroadcastVideo Landscape
Making the Most of MOST Control Messaging
www.xilinx.com/xcell/
Inside Look:ConnectivityIlluminated
Inside Look:ConnectivityIlluminated
P R O G R A M M A B L E S Y S T E M S S O L U T I O N S

Avnet Electronics Marketing designs, manufactures, sells and
supports a wide variety of hardware evaluation, development
and reference design kits for developers looking to get a
quick start on a new project.
With a focus on embedded processing, communications
and networking applications, this growing set of modular
hardware kits allows users to evaluate, experiment,
benchmark, prototype, test and even deploy complete
designs for field trial.
By providing a stable hardware platform that enhances
system development, design kits from Avnet Electronics
Marketing help original equipment manufacturers (OEMs)
bring differentiated products to market quickly and in the
most cost-efficient way possible.
For a complete listing of available boards, visit
www.em.avnet.com/drc
Support Across The Board.™
Design Kits Fuel Feature-Rich Applications
Build your own system bymixing and matching:
Processors
FPGAs
Memory
Networking
Audio
Video
Mass storage
Bus interface
High-speed serial interface
Available add-ons:
Software
Firmware
Drivers
Third-party development tools
•
•
•
•
•
•
•
•
•
•
•
•
•
Enabling success from the center of technology™
1 800 332 8638
em.avnet.com
© Avnet, Inc. 2007. All rights reserved. AVNET is a registered trademark of Avnet, Inc.


InnovationLeadership above all…
Xilinx brings your biggest ideas to reality:
Virtex™-5 FPGAs — Highest Performance. With multiple platformsoptimized for logic, serial connectivity, DSP, and embedded process-ing, Virtex-5 FPGAs lead the industry in performance and density.
Spartan™-3 Generation FPGAs — Lowest Cost. A unique balanceof features and price for high-volume applications. Multipleplatforms allow you to choose the lowest cost device to fit yourspecific needs.
CoolRunner™-II CPLDs — Lowest Power. Unbeatable for low-powerand handheld applications, CoolRunner-II CPLDs deliver more forthe money than any other competitive device.
ISE™ Software — Ease-of-Design. With SmartCompile™ technology,users can achieve up to 6X faster runtimes, while preserving timing and implementation. Highest performance in the fastesttime — the #1 choice of designers worldwide.
Visit our website today, and find out why Xilinx products areworld renowned for leadership . . . above all.
www.xilinx.com
At the Heart of Innovation
©2007 Xilinx, Inc. All rights reserved. XILINX, the Xilinx logo, and other designated brands included herein are trademarks of Xilinx, Inc. All other trademarks are the property of their respective owners.
Get started quickly with easy-to-use kits
Order online at www.xilinx.com/getstarted

WL E T T E R F R O M T H E P U B L I S H E R
Xilinx, Inc.2100 Logic DriveSan Jose, CA 95124-3400Phone: 408-559-7778FAX: 408-879-4780www.xilinx.com/xcell/
© 2007 Xilinx, Inc. All rights reserved. XILINX, the Xilinx Logo, and other designated brands includedherein are trademarks of Xilinx, Inc. All other trade-marks are the property of their respective owners.
The articles, information, and other materials includedin this issue are provided solely for the convenience ofour readers. Xilinx makes no warranties, express,implied, statutory, or otherwise, and accepts no liabilitywith respect to any such articles, information, or othermaterials or their use, and any use thereof is solely atthe risk of the user. Any person or entity using suchinformation in any way releases and waives any claim itmight have against Xilinx for any loss, damage, orexpense caused thereby. Forrest Couch
Publisher
PUBLISHER Forrest [email protected]
EDITOR Charmaine Cooper Hussain
ART DIRECTOR Scott Blair
DESIGN/PRODUCTION Teie, Gelwicks & Associates1-800-493-5551
ADVERTISING SALES Dan Teie1-800-493-5551
TECHNICAL COORDINATOR Alex Goldhammer
INTERNATIONAL Dickson Seow, Asia [email protected]
Andrea Barnard, Europe/Middle East/[email protected]
Yumi Homura, [email protected]
SUBSCRIPTIONS All Inquirieswww.xcellpublications.com
REPRINT ORDERS 1-800-493-5551
Xcell journal
www.xilinx.com/xcell/
Can You Hear Me Now?We’ve all experienced it with our mobile phones: poor voice quality, dropped calls, not enough “bars”to connect. Although inconvenient, the problem usually goes away by moving around or waiting afew minutes before trying your call again.
But if you’re a system designer, connectivity problems launch a multi-dimensional conversation that’squite a bit more complicated to solve. Let’s start with your target market. Is your product a solutionfor the aerospace/defense, automotive, broadcast, consumer, server/storage, industrial/scientific/medical, wired, or wireless market? What are the design challenges in that market, such as signalintegrity, power management, area, and performance? In addition to these decisions, you must selectthe proper protocol for the unique components of your system hierarchy, such as the ubiquitous PCIExpress at one end and Gigabit Ethernet at the other.
Connectivity, in its myriad of forms, is an increasingly important factor in successful system design.Whether designing chip-to-chip, board-to-board, or box-to-box, Xilinx has a connectivity solutionthat helps you differentiate your product within your target market, bring it to market as early aspossible and at the lowest cost. With our connectivity hard blocks, you get the benefits of an ASSP aswell as the flexibility of an FPGA.
This issue of Xcell Journal focuses on connectivity and brings light to some of the key issues, as wellas presenting implementation examples. Additionally, Xilinx offers a variety of resources to help withyour connectivity design challenges. Here are a few connectivity resources that may help.
Connectivity Central(www.xilinx.com/products/design_resources/conn_central/)Xilinx provides end-to-end connectivity solutions supporting serial and parallel protocols. Design forsuccess with Virtex™ and Spartan™ series FPGAs, IP cores, tools, and development kits.
Virtex-5 LXT FPGA Development Kit for PCI Express(www.xilinx.com/xlnx/xebiz/designResources/ip_product_details.jsp?key=HW-V5-ML555-G)The Virtex-5 LXT FPGA Development kit for PCI Express supports PCIe/PCI-X/PCI. This complete development kit passed PCI-SIG compliance for PCI Express v1.1 and enables you torapidly create and evaluate designs using PCI Express, PCI-X, and PCI interfaces.
Spartan-3 PCI Express Starter Kit(www.xilinx.com/onlinestore/spartan_boards.htm)This complete development board solution gives you instant access to the capabilities of theSpartan-3 family and the Xilinx® PCI Express core.
IP Evaluation(www.xilinx.com/ipcenter/ipevaluation/index.htm)Take advantage of Xilinx evaluation IP to “try before you buy.” Visit the Xilinx IP EvaluationLounge and download the evaluation libraries using the links under the “Related Products” tab onthe right side of the page. The IP on this site is covered by the Xilinx LogiCORE™ EvaluationLicense Agreement.
On-Site Help(www.xilinx.com/xlnx/xebiz/designResources/ip_product_details.jsp?key=xgs_ss_titanium)For help with your connectivity designs, Titanium Technical Service provides a dedicated applicationengineer, either on-site or at Xilinx, who can help with system architecture optimization, toolcoaching, and back-end optimization.
O N T H E C O V E R
2626C O N N E C T I V I T Y
3131C O N N E C T I V I T Y
2020C O N N E C T I V I T Y
Reducing CPU Load for Ethernet ApplicationsA TOE makes 10 Gigabit Ethernet possible.
5353I N T E L L E C T U A L P R O P E R T Y
Making the Most of MOST Control MessagingThis case study presents the design of Xilinx LogiCORE MOST NIC control message processing.
A High-Speed Serial Connectivity Solution with Aurora IPAurora is a highly scalable protocol for applications requiring point-to-point connectivity.
Xilinx FPGAs Adapt to Ever-Changing Broadcast Video LandscapeNew digital broadcast standards and applications are addressed by advanced silicon, software, and free reference designs available with Xilinx FPGAs.
PCI Express and FPGAs Why FPGAs are the best platform for building PCI Express endpoint devices.1414

T H I R D Q U A R T E R 2 0 0 7, I S S U E 6 1 Xcell journalXcell journal
VIEWPOINTS
Letter from the Publisher. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Selecting the Right Interconnect . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
FEATURES
Connectivity
Scaling Chip-to-Chip Interconnect Made Simple. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
PCI Express and FPGAs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Virtex-5 FPGA Techniques for High-Performance Data Converters. . . . . . . . . . . . . . . . . . . . . . . 18
Reducing CPU Load for Ethernet Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Automated MGT Serial Link Tuning Ensures Design Margins . . . . . . . . . . . . . . . . . . . . . . . . . . 23
A High-Speed Serial Connectivity Solution with Aurora IP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
Xilinx FPGAs Adapt to Ever-Changing Broadcast Video Landscape . . . . . . . . . . . . . . . . . . . . . . 31
Serial RapidIO Connectivity Enhances DSP Co-Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
The NXP/PLDA Programmable PCI Express Solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
Memory Interface
Create Memory Interface Designs Faster with Xilinx Solutions . . . . . . . . . . . . . . . . . . . . . . . . 47
Intellectual Property
Driving Home Multimedia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Making the Most of MOST Control Messaging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Leveraging HyperTransport on Xilinx FPGAs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
GENERAL
FPGA-Based Simulation for Rapid Prototyping. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
RESOURCES
Featured Connectivity Application Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
Connectivity Boards and Kits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
The Connectivity Curriculum Path . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
XPECTATIONS
Developing Technical Leaders through Knowledge Communities . . . . . . . . . . . . . . . . . . . . . . . 66

by Jag BolariaSr. AnalystThe Linley [email protected]
Interconnects haveevolved from par-allel to serial andincreased in com-
plexity to enable communications withgreater efficiency and less congestion or hotpoints. In addition to connecting end-points, modern interconnects define com-prehensive protocols for moving dataefficiently across a network of endpoints.
Thus, the networks and endpoints thatmust be interconnected often drive therequirements for an interconnect. Theserequirements include data rate, latency,lossy or lossless links, scalability, andredundancy. These requirements then drivethe selection of the appropriate intercon-nects for a specific network.
The existing ecosystem for an intercon-nect technology is another important fac-tor in selection. A good ecosystem can helpreduce development cost and time to mar-ket. In this article, I’ll look at some of theleading interconnects and position thosefor specific applications or market seg-ments. The Linley Group’s report on High-Speed Interconnects, available atwww.linleygroup.com, provides more detailson various interconnects and the leadingproducts for each.
PCIe and EthernetOur research shows that the leading inter-connects are driven by large-volume plat-forms. The economies of scale from largervolume platforms ensure low-cost buildingblocks and broad availability. Additionally,large deployments lead to field-proventechnologies that can be applied in otherplatforms with minimal risk.
Two of the largest platforms are PCsand networking equipment. The PC plat-form drives PCI Express (PCIe) andEthernet, while networking equipmentdrives only Ethernet. But because theseinterconnects were developed for specificapplications, they are not a natural fit inmany other markets. The semiconductorindustry and system vendors are evolvingthese interconnects to meet requirementsfor new applications.
For example, PCIe scalability hasevolved to support greater data rates andmore lanes. With IOV (I/O virtualiza-tion), PCIe is evolving to support virtual-ization, which enables its deployment instorage systems and blade servers.
With IEEE802.3ar and BCN (back-ward congestion notification), Ethernetenhancements include better flow control,congestion management, and attempts toaddress its inherently lossy nature. Theseenhancements will strengthen Ethernetapplicability for storage systems, data cen-ters, and backplanes.
Although Ethernet and PCIe are nowsuitable for more applications, they still fallshort in meeting the technical and businessrequirements for all systems. Blade servers,for example, use a combination of Ethernetand Fibre Channel (FC). Although OEMsmay want to consolidate these fabrics, endusers have a large investment in FC andwant support for that now and in the future.
PCIe and Ethernet also fall short in meet-ing the scalability, latency, and losslessrequirements of high-performance comput-ing (HPC) applications. HPC uses a special-ized interconnect such as InfiniBand, whichprovides better latency and scalability. In thiscase, OEMs will need flexible interconnectsolutions to enable common platforms andthus service different user requirements.
8 Xcell Journal Third Quarter 2007
Selecting the Right Interconnect Because interconnect characteristics vary, define your requirements clearly before selecting the appropriate interconnect.
V I E W P O I N T

Everyone ElseEndpoints and specific system requirementsoften drive the development of specializedinterconnects. RapidIO is one such exam-ple. Steered by system and chip vendors,RapidIO has evolved to address the uniquerequirements of the wireless infrastructure.It enables distributed computing on linecards and networking/wireless infrastruc-ture systems better than most competinginterconnects. RapidIO is also integratedon DSPs from Texas Instruments andPowerPC CPUs from Freescale.
Because base stations use farms of DSPs,it is an easy decision to use RapidIO as aninterconnect in these applications. Overtime, we expect RapidIO to expand toother platforms that perform digital signalprocessing on multiple data streams.
Examples of other specialized intercon-nects include XFI, SFI, XAUI, SPAUI,Interlaken, SPI-S, and KR. These intercon-nects were developed to address the veryspecific low-level requirements of eachapplication. Although addressing all inter-connects is beyond the scope of this article,let’s look at a few to highlight the problemseach solves and its impact in systems.
XFI and SFI are used to connect opti-cal modules at 10 Gbps. At these datarates, the major challenge is signal condi-tioning, including electronic dispersioncompensation for the fiber and equaliza-tion for the board traces and connectors.These requirements drive specialized com-ponents designed specifically for the char-acteristics of the channel through whichthe signal travels.
Because data at these rates may be chan-nelized – that is, include multiple streamson a single physical link – it becomesimportant to add traffic management.Specifications such as Interlaken, SPI-S,and SPAUI address high data rates as wellas traffic management. Because no singlestandard exists, we believe system designers
need to design in solutions that provideflexibility in meeting current and futurerequirements.
The combination of 10 Gbps rates onthe network and multiport line cards drivesthe need for greater bandwidth and there-fore greater data rates over the backplane.The IEEE 802.3ap addresses this with its10GBase-KR specification, which defines10-Gbps serial links. In addition to equal-ization and pre-emphasis, it may be neces-sary to include forward error correction foracceptable performance over a couple ofconnectors and up to 40-inch traces com-mon in backplanes. Additionally, these sys-tems may need compatibility to older linecards, driving the need for backplane oper-ation at 1 Gbps or 3.125 Gbps. Again, aflexible solution is critical to meet the sys-tem requirements.
ConclusionThere are many different applications forinterconnects and many interconnectchoices for system designers. We expectPCIe and Ethernet to be the dominantinterconnects. These will be used in servers,networking, storage systems, wireless net-works, and many other systems. There is,however, no one interconnect (or two) thatcan meet the requirements of all systems.Therefore, the industry has developed andwill continue to support specialized inter-connects for different applications.
Both dominant and specialized inter-connects will continue to evolve to supportgreater data rates, reduced latency, and bet-ter scalability. Additionally, systems willneed to support legacy cards.
We recommend that system designersselect the best interconnect and design inflexibility to cover different interconnectsand the evolving changes in each. FPGAsplay a critical role in offering systemdesigners this flexibility and supporting thebroad interconnect landscape.
Third Quarter 2007 Xcell Journal 9
Both dominant and specialized interconnectswill continue to evolve to support greater datarates, reduced latency, and better scalability.
V I E W P O I N T
Xilinx Events
North America
July 23-27Nuclear and Space Radiation Effects Conference 2007Honolulu, HI
August 7-9NI Week 2007Austin, TX
September 18-20Intel Developer ForumSan Francisco, CA
October 29-31Military Communications Conference 2007Orlando, FL
November 5-9Software Defined Radio Forum 2007Denver, CO
Europe, Middle East, and Africa
August 27-29International Conference on Field Programmable Logic and ApplicationsAmsterdam, Netherlands
September 6-11IBCAmsterdam, Netherlands
Asia Pacific
August 7-10Agilent Digital Measurement ForumTaiwan
Xilinx participates in numeroustrade shows and events through-
out the year. This is a perfectopportunity to meet our siliconand software experts, ask ques-
tions, see demonstrations of newproducts and technologies, andhear other customers’ success stories with Xilinx products.
For more information and themost up-to-date schedule, visit
www.xilinx.com/events.

www.agilent.com/find/logic-offer
© Agilent Technologies, Inc. 2006 Windows is a U.S. registered trademark of Microsoft Corporation
Logic analyzers up to 50% offLogic analyzers up to 50% offA special limited-time offer from Agilent.
Now you can see inside your FPGA designs in a way that will save weeks of development time.
The FPGA dynamic probe, when combined with an AgilentWindows®-based logic analyzer, allows you to access differentgroups of signals inside your FPGA for debug—without requiringdesign changes. You’ll increase visibility into internal FPGA activityby gaining access up to 128 internal signals with each debug pin.
Our 16800 Series logic analyzers offer you unprecedented price-performance in a portable family, with up to 204 channels, 32 M memory depth and a pattern generator available.
And now for a limited time, you can receive up to 50% off ournewest 16901A modular logic analyzer mainframe when youpurchase eligible measurement modules. Offer valid February 1,2007 through August 15, 2007. Reference promotion 5.564.
• Increased visibility with FPGA dynamic probe • Customized protocol analysis with
Agilent's exclusive packet viewer software• Low-cost embedded PCI Express
packet analysis• Pricing starts at $9,450
Agilent portable and modularlogic analyzers

by Farhad Shafai Vice President, R&D Sarance Technologies [email protected]
Kelvin SpencerSenior Design EngineerSarance Technologies [email protected]
As the world gets connected, the demandfor bandwidth continues to increase. Theinterconnect technology for communica-tion systems must not only connect devicestoday, but also provide a roadmap for thefuture. Traditional solutions, such as XAUIor SPI-4.2, cannot scale beyond 10 Gbps.SPI-4.2 uses a low-speed parallel bus,which requires a large number of pins totransfer 10 Gbps of data. XAUI does nothave any provisions for channelizing thepacket stream, making it unsuitable forapplications that differentiate betweenpackets. Several attempts have been madeto build on XAUI and SPI-4.2; all deriva-tives, however, suffer from the inherentlimitations of the solutions on which theyare based, and are therefore not optimal.
Interlaken is a new chip-to-chip, chan-nelized packet interface protocol developedby Cisco Systems and Cortina Systems. It isbased on SERDES technology and provides
a framework for an efficient and robustchip-to-chip packet interface that easilyscales from 10 Gbps to 50 Gbps andbeyond. Several applications for Interlakenare shown in Figure 1. Simply put, you canuse Interlaken as the connectivity solutionfor all devices in a typical network commu-nication line card. The devices includefront-end aggregation ICs or FPGAs, net-work processors, and traffic managers.Additionally, you can use translationFPGAs to bridge between legacy and mod-ern devices that have Interlaken interfaces.
Sarance Technologies has developed a suiteof Interlaken IP cores (IIPC) targeted atXilinx® Virtex™-5 FPGAs. The IIPC familyof cores is a highly optimized implementationof Interlaken that takes advantage of theadvanced features of the Virtex-5 device. TheIIPC abstracts all of the details of Interlakenand provides a very simple and straightforwardinterface. All members of the IIPC family usethe same user-side protocol and programminginterface, greatly simplifying performance scal-ing: using a 10-Gbps IIPC core is no differentthan using a 50-Gbps IIPC.
Third Quarter 2007 Xcell Journal 11
Scaling Chip-to-Chip Interconnect Made SimpleSarance’s high-performance Interlaken IP cores connect devices at up to 50 Gbps.
I
I I
I I I
PortAggregation
IC
PortAggregation
IC
NPUFPGA
TranslationFPGA
NPUIC
TMIC/FPGA
TMFPGA
InterlakenInterlaken
Interlaken SPI4.2 SPI4.2
Figure 1 – Typical applications
C O N N E C T I V I T Y

Interlaken BasicsInterlaken is a narrow, high-speed channel-ized chip-to-chip interface. For simplicity’ssake, we will not discuss the finer details ofthe protocol. At a high level, the basic con-cepts of the protocol include:
• Support for 256 logic channels
• Data scrambling and 64B/67B dataencoding to ensure proper DC balance
• Segmentation of data into bursts delin-eated by control words
• CRC24 protection for each data burst
• CRC32 protection for each lane
• Protocol independence from the num-ber of SERDES lanes and SERDES rate
• Support for in-band and out-of-bandflow-control mechanisms
• Lane diagnostics and lane decommissioning
A typical chip-to-chip implementationis shown in Figure 2. The packet data isstriped across any number of high-speedserial lanes by the transmitting device andthen reassembled by the receiving device.
and can transmit 10 Gbps of real payload.Scaling the interface up to 20G simplyrequires doubling the number of MGTs toeight; the bandwidth scales accordingly.
Sarance’s IIPC FamilyThe IIPC is a highly optimized imple-mentation of Interlaken and, remainingtrue to the intent of Interlaken, is archi-tected to offer the same flexibility andscalability offered by the protocol. IIPCcan stripe and reassemble data across anynumber of SERDES lanes running at anySERDES rate and has support for as manyas 256 channels. It is fully compliant withrevision 1.1 of the Interlaken specificationdocument and is hardware-proven to beinteroperable with several ASIC imple-mentations of Interlaken.
Table 1 lists the device utilization andimplementation details for three differentIIPC cores targeted to Virtex-5 LXT FPGAs.
Figure 3 shows the block diagram of theIIPC. At the time of this writing, IIPC iscapable of supporting as much as 50 Gbpsof raw bandwidth. The IIPC is divided intotwo major functional partitions:
• Lane logic that is replicated for eachSERDES lane
• Striping and reassembly logic and theuser-side interface
Lane-logic circuitry is the dominantportion of the overall utilization of the
The protocol is independent from thenumber of SERDES lanes and theSERDES rate, which makes the perform-ance proportional to the number ofSERDES lanes. As an example, consider a10-Gbps system. Using four multi-gigabittransceivers (MGTs) running at 3.125Gbps, we can build an interface with a totalraw bandwidth of 12.5 Gbps that hasenough headroom for protocol overhead
Device A Device B
IncomingPacketStream
Stripe DataAcross n Lines
InterlakenTransmitter
InterlakenReceiver
Lane 0
Lane 1
Lane 0
Lane 1
Lane n-1
Lane n
Lane n-1
Lane n
Reassemble DataFrom n Lanes
OutgoingPacketStream
CRC32, Scrambler/Desrambler, Gearbox
clkout
dataout[255|127|63:0]
mtyout[4|3|2:0]
chanout[7:0]
{enaout, sopout,eopout, errout}
clkin
rdyout
datain[255|127|63:0]
mtyin[4|3|2:0]
chainin[7:0]
{enain, sopin,eopin, errin}
configuration andstatus bus
Str
ipin
g, R
eass
emb
ly, C
RC
24
Pro
toco
l Man
agem
ent,
Use
r-S
ide
Inte
rfac
e
Lane 0
Lane n
Interlaken Core
Figure 2 – A typical chip-to-chip implementation (only the unidirectional link is shown)
Bandwidth MGT Lanes MGT Rate Logic LUTs Block RAMs
12.5 Gbps 4 3.125 Gbps 9,000 5
25 Gbps 8 3.125 Gbps 18,000 5
50 Gbps 16 3.125 Gbps 32,500 5
Table 1 – Configuration and Virtex-5 LXT resource utilization
Figure 3 – Block diagram (SERDES is on the left; the user-side interface is on the right)
12 Xcell Journal Third Quarter 2007
C O N N E C T I V I T Y

Third Quarter 2007 Xcell Journal 13
C O N N E C T I V I T Y
IIPC, since it is replicated for each lane.Each lane has a gear box, CRC32, and adescrambler/scrambler module. All of thesefunctions have traditionally been veryexpensive in FPGA technology. Our imple-mentation of these functions, however,takes full advantage of the Virtex-5 device’ssix-input LUTs in a way that makes the cir-cuits very compact and efficient.
The striping and reassembly logic per-forms the required MUXing to transfer databetween the user-side interface and the lanecircuitry and handles link-level functions.Although the striping and reassembly logic isrelatively smaller in terms of area, it has toprocess the total bandwidth of the interfaceand therefore is the most timing-critical part.
Specifically, the CRC24 function has topotentially process 50 Gbps of data. Again,we have made the most of the FPGA’s hard-ware features to come up with a very efficientand high-performance implementation ofthe CRC24 function.
User-Side InterfaceTo help ease the integration of the IIPC withother logic in the FPGA, we have imple-mented a very simple and straightforwarduser-side interface. The bus protocol fortransferring packet data to and from theIIPC is similar to the familiar SPI-like busprotocols that are commonly used in theindustry. The configuration interface com-prises a set of configuration input signals andanother set of status output signals that canbe easily connected to any processor inter-face. The status signals monitor the status ofthe link and identify possible configurationor transmission errors.
One key feature of our user-side inter-face is that it can be set to be identical forthe entire IIPC family. This feature allowsyou to implement the same user-side logicin all of your designs, independent of theconfiguration or bandwidth of theInterlaken interface. You can build a 10Gdesign today knowing that your configura-
tion software and FPGA architecture donot change when the design is scaled to20G, 40G, and beyond. Even if you decideto change the SERDES rate or number oflanes, the user-side interface is still notaffected. IIPC provides you with a solutionfor today – and for the future – in a single,highly optimized package.
Ease of UseUsing the IIPC is as simple as powering upthe FPGA, setting the configuration regis-ters, resetting the core, and waiting for thecore to signal that it is ready. The IIPC willautomatically communicate with the otherdevice and, when link integrity is estab-lished, will set a status signal. All you have
to do is monitor the status signal and startsending packets when it is asserted.
The IIPC handles all of the details ofInterlaken, including automatic word andlane alignment and automatic scram-bler/descrambler synchronization. In addi-tion, the IIPC performs full protocolchecking and error handling. It recoversfrom all error conditions (any number ofbit errors are properly detected and appro-priately handled) and will never violate theuser-side protocol.
ConclusionInterlaken is the future of chip-to-chip pack-et interfaces. It combines the benefits of thelatest SERDES technology and a simple yetrobust protocol layer to define a flexible andscalable interconnect technology. SaranceTechnologies’s IIPC is an optimized imple-mentation of the Interlaken revision 1.1specification targeted for the Virtex-5 FPGA.
Our core is hardware-proven to interop-erate with several ASIC implementations ofInterlaken and can support up to 50 Gbps ofraw bandwidth. Our roadmap has us increas-ing the bandwidth to 120 Gbps in the verynear future. For the latest updates and infor-mation about our interactive demonstrationplatform, e-mail [email protected].
Our roadmap has us increasing the bandwidth to 120 Gbps in the very near future.

by Alex GoldhammerTechnical Marketing Manager, Platform SolutionsXilinx, [email protected]
PCI Express is a high-speed serial I/Ointerconnect scheme that employs a clockdata recovery (CDR) technique. The PCIExpress Gen1 specification defines a linerate of 2.5 Gbps per lane, allowing you tobuild applications that have a throughputof 2 Gbps (after 8B/10B encoding) for asingle-lane (x1) link to 64 Gbps for 32lanes. This allows a significant reduction inpin count while maintaining or improvingthroughput. It also reduces the size of thePCB, the number of traces and layers, andsimplifies layout and design. Fewer pinsalso translate to reduced noise and electro-magnetic interference (EMI). CDR elimi-nates the clock-to-data skew problemprevalent in wide parallel buses, makinginterconnect implementations easier.
The PCI Express interconnect architec-ture is primarily specified for PC-based(desktop/laptop) systems. But just likePCI, PCI Express is also quickly movinginto other system types, such as embeddedsystems. It defines three types of devices:root complex, switch, and endpoint (Figure1). The CPU, system memory, and graph-ics controller connect to a root complex,which is roughly equivalent to a PCI host.Because of PCI Express’ point-to-pointnature, switch devices are necessary toexpand the number of system functions.PCI Express switch devices connect a rootcomplex device on the upstream side toendpoints on the downstream side.
Endpoint functionality is similar to aPCI/PCI-X device. Some of the most com-mon endpoint devices are Ethernet con-trollers or storage HBAs (host-busadapters). Because FPGAs are most fre-quently used for data processing and bridg-ing functions, the largest target function forFPGAs is endpoints. FPGA implementa-tions are ideally suited for video, medicalimaging, industrial, test and measurement,data acquisition, and storage applications.
The PCI Express specification main-tained by the PCI-SIG mandates that everyPCI Express device use three distinct proto-
14 Xcell Journal Third Quarter 2007
PCI Express and FPGAsWhy FPGAs are the best platform for building PCI Express endpoint devices. Why FPGAs are the best platform for building PCI Express endpoint devices.
C O N N E C T I V I T Y
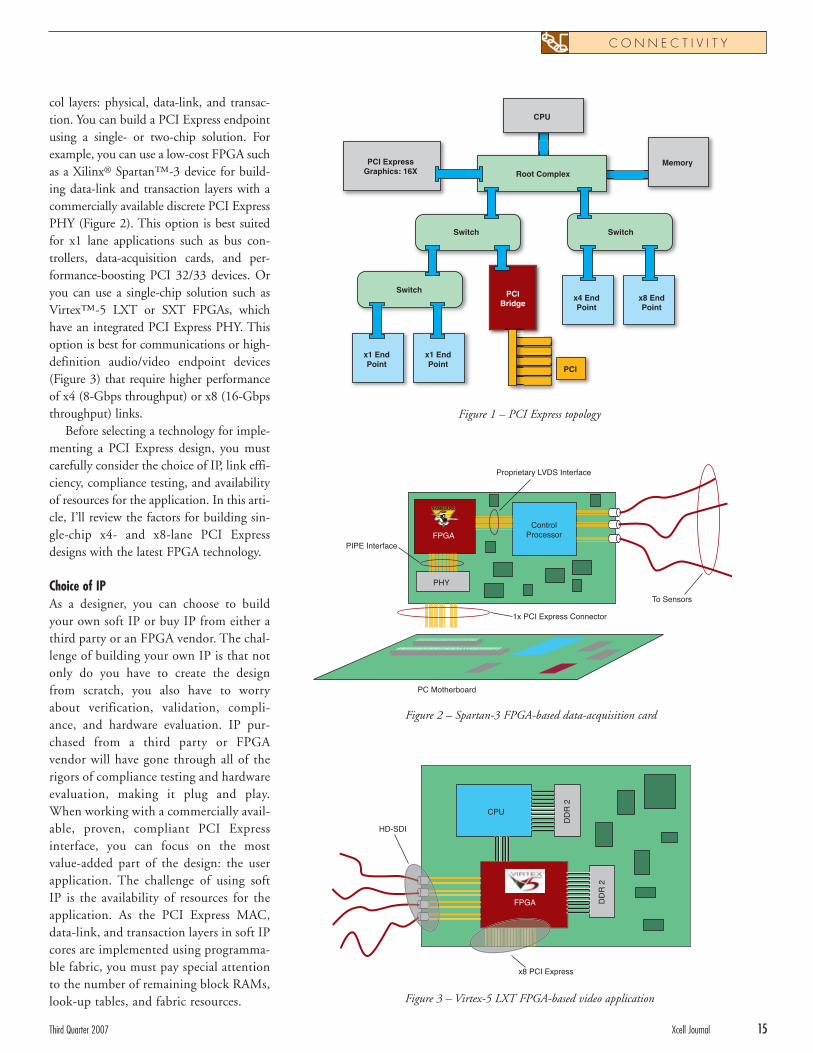
col layers: physical, data-link, and transac-tion. You can build a PCI Express endpointusing a single- or two-chip solution. Forexample, you can use a low-cost FPGA suchas a Xilinx® Spartan™-3 device for build-ing data-link and transaction layers with acommercially available discrete PCI ExpressPHY (Figure 2). This option is best suitedfor x1 lane applications such as bus con-trollers, data-acquisition cards, and per-formance-boosting PCI 32/33 devices. Oryou can use a single-chip solution such asVirtex™-5 LXT or SXT FPGAs, whichhave an integrated PCI Express PHY. Thisoption is best for communications or high-definition audio/video endpoint devices(Figure 3) that require higher performanceof x4 (8-Gbps throughput) or x8 (16-Gbpsthroughput) links.
Before selecting a technology for imple-menting a PCI Express design, you mustcarefully consider the choice of IP, link effi-ciency, compliance testing, and availabilityof resources for the application. In this arti-cle, I’ll review the factors for building sin-gle-chip x4- and x8-lane PCI Expressdesigns with the latest FPGA technology.
Choice of IPAs a designer, you can choose to buildyour own soft IP or buy IP from either athird party or an FPGA vendor. The chal-lenge of building your own IP is that notonly do you have to create the designfrom scratch, you also have to worryabout verification, validation, compli-ance, and hardware evaluation. IP pur-chased from a third party or FPGAvendor will have gone through all of therigors of compliance testing and hardwareevaluation, making it plug and play.When working with a commercially avail-able, proven, compliant PCI Expressinterface, you can focus on the mostvalue-added part of the design: the userapplication. The challenge of using softIP is the availability of resources for theapplication. As the PCI Express MAC,data-link, and transaction layers in soft IPcores are implemented using programma-ble fabric, you must pay special attentionto the number of remaining block RAMs,look-up tables, and fabric resources.
Third Quarter 2007 Xcell Journal 15
PCI ExpressGraphics: 16X
CPU
Root Complex
Switch
Switch
Switch
Memory
PCIBridge
x1 EndPoint
x1 EndPoint
x4 EndPoint
x8 EndPoint
PCI
Proprietary LVDS Interface
PIPE Interface
1x PCI Express Connector
To Sensors
PC Motherboard
FPGAControl
Processor
PHY
CPU
DD
R 2
DD
R 2
HD-SDI
x8 PCI Express
FPGA
Figure 1 – PCI Express topology
Figure 2 – Spartan-3 FPGA-based data-acquisition card
Figure 3 – Virtex-5 LXT FPGA-based video application
C O N N E C T I V I T Y
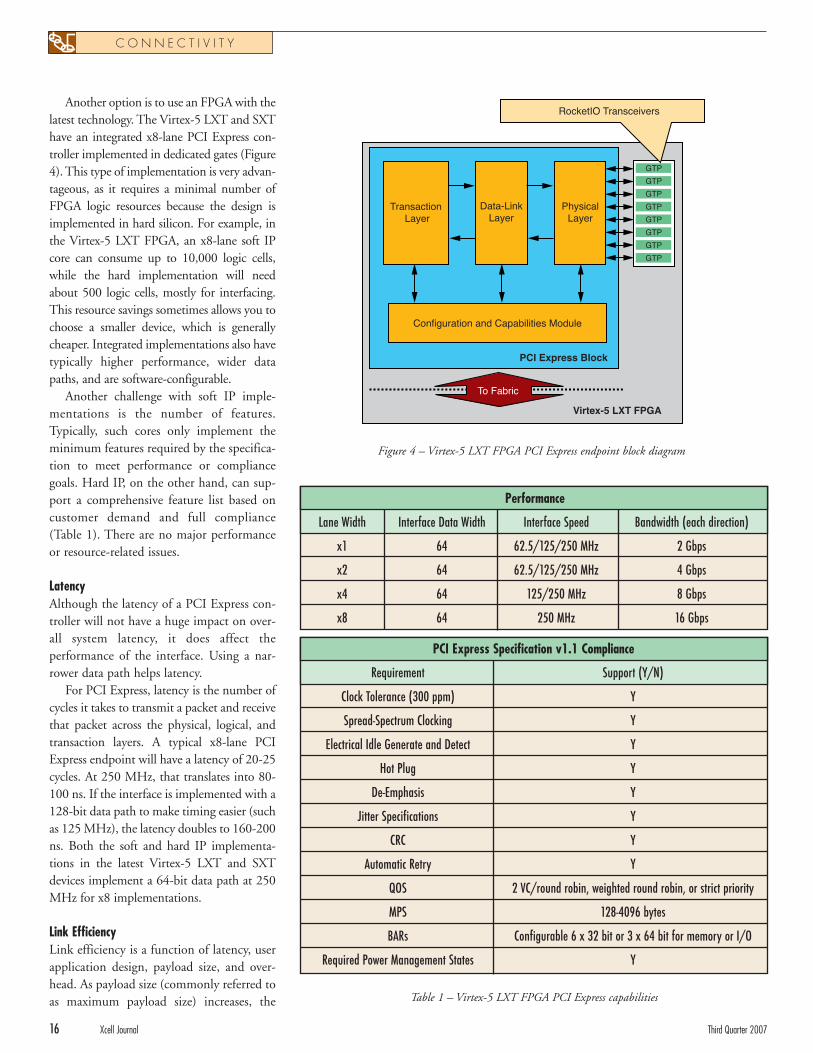
Another option is to use an FPGA with thelatest technology. The Virtex-5 LXT and SXThave an integrated x8-lane PCI Express con-troller implemented in dedicated gates (Figure4). This type of implementation is very advan-tageous, as it requires a minimal number ofFPGA logic resources because the design isimplemented in hard silicon. For example, inthe Virtex-5 LXT FPGA, an x8-lane soft IPcore can consume up to 10,000 logic cells,while the hard implementation will needabout 500 logic cells, mostly for interfacing.This resource savings sometimes allows you tochoose a smaller device, which is generallycheaper. Integrated implementations also havetypically higher performance, wider datapaths, and are software-configurable.
Another challenge with soft IP imple-mentations is the number of features.Typically, such cores only implement theminimum features required by the specifica-tion to meet performance or compliancegoals. Hard IP, on the other hand, can sup-port a comprehensive feature list based oncustomer demand and full compliance(Table 1). There are no major performanceor resource-related issues.
LatencyAlthough the latency of a PCI Express con-troller will not have a huge impact on over-all system latency, it does affect theperformance of the interface. Using a nar-rower data path helps latency.
For PCI Express, latency is the number ofcycles it takes to transmit a packet and receivethat packet across the physical, logical, andtransaction layers. A typical x8-lane PCIExpress endpoint will have a latency of 20-25cycles. At 250 MHz, that translates into 80-100 ns. If the interface is implemented with a128-bit data path to make timing easier (suchas 125 MHz), the latency doubles to 160-200ns. Both the soft and hard IP implementa-tions in the latest Virtex-5 LXT and SXTdevices implement a 64-bit data path at 250MHz for x8 implementations.
Link EfficiencyLink efficiency is a function of latency, userapplication design, payload size, and over-head. As payload size (commonly referred toas maximum payload size) increases, the
Configuration and Capabilities Module
Transaction Layer
Data-LinkLayer
PhysicalLayer
RocketIO Transceivers
To Fabric
Virtex-5 LXT FPGA
PCI Express Block
GTP
GTP
GTP
GTP
GTP
GTP
GTP
GTP
Performance
Lane Width Interface Data Width Interface Speed Bandwidth (each direction)
x1 64 62.5/125/250 MHz 2 Gbps
x2 64 62.5/125/250 MHz 4 Gbps
x4 64 125/250 MHz 8 Gbps
x8 64 250 MHz 16 Gbps
PCI Express Specification v1.1 Compliance
Requirement Support (Y/N)
Clock Tolerance (300 ppm) Y
Spread-Spectrum Clocking Y
Electrical Idle Generate and Detect Y
Hot Plug Y
De-Emphasis Y
Jitter Specifications Y
CRC Y
Automatic Retry Y
QOS 2 VC/round robin, weighted round robin, or strict priority
MPS 128-4096 bytes
BARs Configurable 6 x 32 bit or 3 x 64 bit for memory or I/O
Required Power Management States Y
Figure 4 – Virtex-5 LXT FPGA PCI Express endpoint block diagram
Table 1 – Virtex-5 LXT FPGA PCI Express capabilities
16 Xcell Journal Third Quarter 2007
C O N N E C T I V I T Y

Third Quarter 2007 Xcell Journal 17
effective link efficiency also increases. This iscaused by the fact that the packet overhead isfixed; if the payload is large, the efficiencygoes up. Normally, a payload of 256 bytescan get you a theoretical efficiency of 93%(256 payload bytes + 12 header bytes + 8framing bytes). Although PCI Express allowspacket sizes up to 4 KB, most systems willnot see improved performance with payloadsizes larger than 256 or 512 bytes. A x4 or x8PCI Express implementation in the Virtex-5LXT FPGA will have a link efficiency of 88-89% because of link protocol overhead(ACK/NAK, re-transmitted packets) andflow control protocol (credit reporting).
Using FPGAs for implementation givesyou better control over link efficiencybecause it allows you to choose the receivebuffer size that corresponds to the endpointimplementation. If both link partners do notimplement the data path in a similar way, theinternal latencies on both will be different.For example, if link partner #1 uses the 64-bit, 250-MHz implementation with a laten-cy of 80 ns and link partner #2 uses the128-bit, 125-MHz implementation with alatency of 160 ns, the combined latency forthe link will be 240 ns. Now, if link partner#1’s receive buffer was designed for a latencyof 160 ns – expecting that the link partnerwould also be a 64-bit, 250-MHz imple-mentation – then the link efficiency would
go down. With an ASIC implementation, itwould be impossible to change the size of thereceive buffer, and the loss of efficiencywould be real and permanent.
User application design will also havean impact on link efficiency. The userapplication must be designed so that itdrains the receive buffer of the PCIExpress interface regularly and keeps thetransmit buffer full all the time. If the userapplication does not use packets receivedright away (or does not respond to trans-mit requests immediately), the overall linkefficiency will be affected regardless of theperformance of the interface.
When designing with some processors,you will need to implement a DMA con-troller if the processors cannot performbursts longer than 1 DWORD. This trans-lates into poor link utilization and efficiency.Most embedded CPUs can transmit bursts
longer than 1 DWORD, so the link efficien-cy for such designs can be effectively man-aged with a good FIFO design.
PCI Express ComplianceCompliance is important detail that is fre-quently missed and often undervalued. Ifyou are building PCI Express applicationsthat must work with other devices andapplications, ensuring that your design iscompliant is a must.
The compliance is not just for the IP butfor the entire solution, including the IP, userapplication, silicon device, and hardwareboard (Figure 5). If the entire solution hasbeen validated at a PCI-SIG PCI Expresscompliance workshop (also known as a“plug fest”), it is pretty much guaranteedthat the PCI Express portion of your designwill always work.
ConclusionReplacing PCI, PCI Express has becomethe de facto system interconnect standardand has jumped from the PC into other sys-tem markets including embedded systemdesign. FPGAs are ideally suited to buildPCI Express endpoint devices, as they allowyou to create compliant PCI Expressdevices with the added customization thatembedded users desire.
New 65-nm FPGAs like the Virtex-5LXT and SXT families are fully compliant tothe PCI Express specification v1.1 and offeran abundance of logic and device resourcesto the user application. The Spartan-3 fami-ly of FPGAs with external PHY offer a low-cost solution. These factors, combined withthe inherent programmable logic advantagesof flexibility, reprogrammability, and riskreduction, make FPGAs the best platformsfor PCI Express.
Figure 5 – Virtex-5 LXT FPGA PCI Express compliance workshop results
• Buy the Development Kit for PCI Express:• Virtex-5 FPGA edition• Spartan-3 FPGA edition
• Download the Protocol Pack for PCI Express • Watch our live demo from the Embedded Systems Conference • Register for a PCIe class
TAKE THE NEXT STEP (Digital Edition: www.xcellpublications.com/subscribe/)
C O N N E C T I V I T Y

by Luc LangloisGlobal Technical Marketing Manager, DSPAvnet [email protected]
The incessant demand for higher band-widths and resolutions in communication,video, and instrumentation systems haspropelled the development of high-per-formance mixed-signal data converters inrecent years. This poses a challenge to sys-tem designers seeking to preserve theexceptional signal-to-noise specifications ofthese devices in the signal processing chain.Xilinx® Virtex™-5 FPGAs provide exten-sive resources for high-performance mixed-signal systems, supported by efficientdevelopment tools spanning all phases ofdesign, from system-level exploration tofinal implementation.
Key Specifications of Data Converters A typical mixed-signal processing chainstarts at the analog-to-digital converter(ADC). Modern high-performance ADCsprovide sampling rates extending into thehundreds of megasamples per second(MSPS) for 12- and 14-bit devices. Forexample, the Texas Instruments ADS5463
ADC provides 12 bits at 500 MSPS, with64.5 dB full-scale (dBFS) of signal-to-noise ratio (SNR) to 500 MHz.
Fast sampling rates offer several bene-fits, including the ability to digitize wide-band signals, reduced complexity ofanti-alias filters, and lower noise powerspectral density. The result is improvedSNR in the system. Your challenge is toimplement the high-speed interfacebetween the data converter and FPGAwhile preserving the SNR throughout thesignal processing chain in the FPGA.
Before the digital ADC data is cap-tured in the FPGA, you must take carefulprecautions to minimize jitter on thedata converter sampling clock. Jitterdegrades SNR depending on the signalbandwidth of interest. For example, pre-serving 74 dB of SNR - or approximate-ly 12 effective number of bits (ENOB) -for signal bandwidths extending to 100MHz requires a maximum 300 fs (femto-seconds) of clock jitter. Modern ADCsprovide clever interfaces that simplifydistribution of clean low-jitter clocks onthe board. Let’s examine how key featuresof Virtex-5 FPGAs are used to imple-ment these interfaces.
High-Performance ADC Interface High-performance ADC sampling ratesoften exceed the minimum rate necessaryto avoid aliasing, or Nyquist rate, definedas twice the highest frequency componentin the analog input signal. The highly over-sampled digital signal entering the FPGAneed not maintain a fast sampling ratethroughout the signal processing chain; itcan be decimated with negligible distortionin the digital domain by a high-quality dec-imation filter. This offers the benefits of aslower system clock in subsequent process-ing stages for easier timing closure andlower power consumption.
Xilinx Virtex-5 and Spartan™-3A DSPFPGAs provide the ideal resources toimplement high-performance decimationfilters for fast ADCs using a techniqueknown as polyphase decomposition. Apolyphase decimation filter performs asampling rate change by allocating the DSPworkload among a set of D sub-filters,where D = decimation rate. Each subfilteris only required to sustain a throughput offs/D, a fraction of the fast incoming sam-pling rate fs from the ADC.
As the decimation filter is often thefirst stage of digital processing, it calls for
18 Xcell Journal Third Quarter 2007
Virtex-5 FPGA Techniques for High-Performance Data ConvertersYou can harness the DSP resources of Virtex-5 devices to interface to the analog world.
C O N N E C T I V I T Y

the highest performance resources closestto the FPGA pins. A Virtex-5 FPGA’sinput/output block contains an IDDR(input double-data-rate register) drivendirectly from the FPGA input buffer.Several differential signal standards aresupported, including LVDS, which cansustain in excess of 1-Gbps data rateswhile providing excellent board-levelnoise immunity.
The IDDR is used to de-multiplex thefast incoming digital signal from the ADCinto two single-data-rate data streams, eachat one-half the ADC sampling rate. This isthe ideal format to feed a 2x polyphase dec-imation filter. Using the Virtex-5 DSP48E,each subfilter can sustain 550 MSPS for amaximum 1.1-GSPS ADC sampling rate.Similarly, the Spartan-3A DSP can sustain500 MSPS ADC sampling rates.
With the benefits of faster ADC sam-pling rates come the challenges of smallerdata-valid windows to latch the data intothe FPGA. Furthermore, the wider theADC data-word precision, the moredaunting the layout task and the higherpotential for skew across individual signalsof the data bus, resulting in corrupteddata. Virtex-5 FPGAs provide a robustsolution called IODELAY, a programma-ble delay element contained in every I/Oblock. IODELAY can individually time-shift each signal of the data bus to accu-rately position the data-valid window atthe optimal transition of the half-rate data-ready signal (DRY).
Figure 1 illustrates the unique features inVirtex-5 devices that serve to implement ahigh-performance ADC interface. To mini-mize sampling jitter, the ADC forwards thesource-synchronous DRY signal along withthe data, while the clean, low-jitter sam-pling clock routes directly to the ADCwithout passing through the FPGA.
High-Performance DAC InterfaceFor equal data-word precision, digital-to-analog converters (DACs) typically offerhigher sampling rates than ADCs, resultingin significant design challenges at the DACextremity of the signal chain. Several fea-tures of the Virtex-5 architecture can helpsurmount the task. For example, consider
to situate the polyphase interpolator multi-plexer as close as possible to the LVDS out-put buffers driving the DAC5682Z.Virtex-5 FPGAs provide a dedicatedresource within the I/O block that is ideal-ly suited to this purpose: the ODDR (out-put double-data-rate) registers. The ODDRroutes directly to fast LVDS differentialoutput buffers able to sustain output ratesof 1 GSPS (and beyond) while maintainingsignal integrity on the PCB.
ConclusionIn this article, I’ve presented DSP andinterface techniques for mixed-signal sys-tems using Xilinx Virtex-5 FPGAs. You canoptimize system performance by preservingthe outstanding SNR specifications ofmodern high-performance data convertersusing key features of Virtex-5 devices.
The techniques described in this articlewill be featured in Speedway 2007 DSPsessions, in collaboration with majorAvnet data converter suppliers TexasInstruments, Analog Devices, andNational Semiconductor. For details, visithttp://em.avnet.com/xilinxspeedway.
the Virtex-5 interface to a TexasInstruments (TI) DAC5682Z 16-bit dual-DAC with 1-GSPS sampling rate andLVDS inputs.
In a practical system, the 1-GSPS sam-pling rate need only be deployed at thefinal output stage to the DAC, while inter-mediate stages in the FPGA signal process-ing chain can work at a slower samplingrate commensurate with the signal band-width. This allows a slower system clock inthe intermediate processing stages, with thebenefits of easier timing closure and lowerpower consumption.
As is the case for the ADC, polyphase fil-ters are efficient DSP structures to realizesampling rate changes at the DAC end of thesignal chain. To attain a 1-GSPS output sam-pling rate to the TI DAC5682Z, a 2xpolyphase interpolation filter uses two sub-filters, each with a throughput of 500 MSPS.These rates are within the performance spec-ifications of the Virtex-5 DSP48E slice.
A multiplexer is required to combine theoutputs of the sub-filters to attain the fastoutput rate from the polyphase. For a 1-GSPS output sampling rate, it is advisable
Third Quarter 2007 Xcell Journal 19
2X Polyphase DecimatorI/O Block
IDD
R
DRY
Low-Jitter
Sampling Clock
DATA
IODELAY
Sub-Phase 0
Sub-Phase 1ADC
XtremeDSP
XtremeDSP
2X Polyphase Interpolator
OD
DR IODELAY
Sub-Phase 0
Sub-Phase 1
DAC
Virtex-5 FPGA
I/O Block
XtremeDSP
XtremeDSP
Low-Jitter
Sampling Clock
Figure 1 - High-performance ADC interface
Figure 2 - DAC: polyphase interpolation + ODDR + LVDS
C O N N E C T I V I T Y

by Andreas [email protected]
Ethernet is playing an increasingly impor-tant role today, as it is used anywhere toconnect everything. Not surprisingly,bandwidth requirements are increasing inthe backbone as well as in end systems.
The implication of this increasing band-width is an increased traffic processing loadin end systems. Today, most end systemsuse one or more CPUs with an OS and anetwork stack to implement network inter-face functions. For many applications, theincreasing traffic load leads to performanceissues in the network stack implementa-tion. As these performance issues are seenalready at 1 Gigabit Ethernet (GbE),implementing 10 GbE using a softwarestack is not a viable solution.
To solve these problems, IPBlaze hasdeveloped a unique and highly configurableTCP/IP offload engine (TOE). The TOEprocesses the TCP/IP stack at wire speed in
hardware instead of using a host CPU andthus reduces its processing burden.
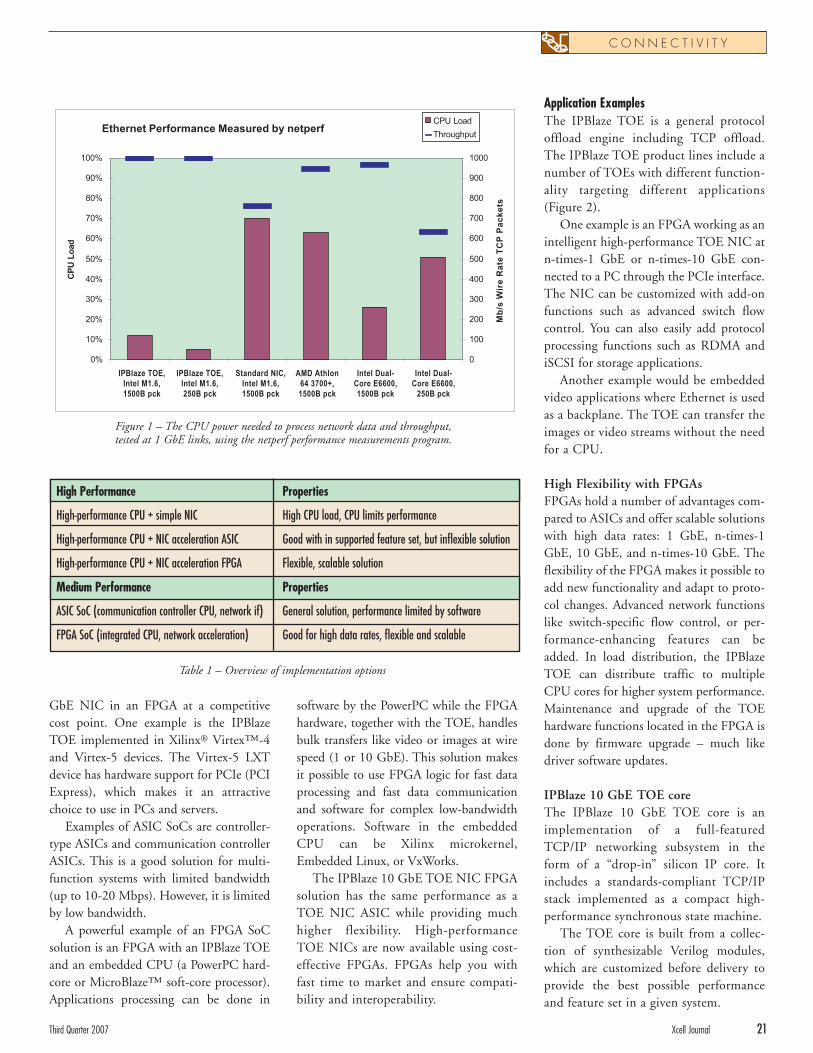
IPBlaze has implemented the TOE forvarious end systems. Our measurementresults show that using an IPBlaze TOEreduces latencies and CPU utilization con-siderably. In this article, I’ll give anoverview of the implementation optionsavailable today for Ethernet applicationsand show where the IPBlaze TOE can giveyou the upper edge in terms of perform-ance. Figure 1 shows performance exam-ples with and without the IPBlaze TOE.
Ethernet ConfigurationsTable 1 shows the five different implemen-tation options available today.
A CPU plus a simple network interfacecard (NIC) is a very general solution usedin most PCs and servers today. A newCPU generation always provides higherperformance and thus also increases net-work performance. However, the increasein network processing performance is sig-nificantly lower than the increase in CPUpower. The same problem exists with
embedded CPUs – the performance issuesarise at 10 to 100 times lower data rates.
A high-performance CPU and simpleNIC is a flexible solution with a well-known API (socket), and it is easy toimplement applications in commonPC/server environments. One of thedownsides is the difficulty in scaling effi-ciently to 10 GbE because the load distri-bution between CPU cores and processintercommunication creates a bottleneck.Power dissipation (heat) is also a limitingfactor in many systems.
Some NIC acceleration ASICs on themarket perform protocol offload for specif-ic applications such as storage. A high-per-formance CPU and NIC accelerationASIC is a good solution if the ASIC sup-ports all of the features needed (iSCSI,TCP offload). The functionality and band-width is fixed, however, which makes itvery hard to add functionality or adapt toprotocol changes without a huge perform-ance impact.
FPGAs are so powerful today that it ispossible to implement an accelerated 10
20 Xcell Journal Third Quarter 2007
Reducing CPU Load for Ethernet ApplicationsA TOE makes 10 Gigabit Ethernet possible.
C O N N E C T I V I T Y
GbE NIC in an FPGA at a competitivecost point. One example is the IPBlazeTOE implemented in Xilinx® Virtex™-4and Virtex-5 devices. The Virtex-5 LXTdevice has hardware support for PCIe (PCIExpress), which makes it an attractivechoice to use in PCs and servers.
Examples of ASIC SoCs are controller-type ASICs and communication controllerASICs. This is a good solution for multi-function systems with limited bandwidth(up to 10-20 Mbps). However, it is limitedby low bandwidth.
A powerful example of an FPGA SoCsolution is an FPGA with an IPBlaze TOEand an embedded CPU (a PowerPC hard-core or MicroBlaze™ soft-core processor).Applications processing can be done in
Application ExamplesThe IPBlaze TOE is a general protocoloffload engine including TCP offload.The IPBlaze TOE product lines include anumber of TOEs with different function-ality targeting different applications(Figure 2).
One example is an FPGA working as anintelligent high-performance TOE NIC atn-times-1 GbE or n-times-10 GbE con-nected to a PC through the PCIe interface.The NIC can be customized with add-onfunctions such as advanced switch flowcontrol. You can also easily add protocolprocessing functions such as RDMA andiSCSI for storage applications.
Another example would be embeddedvideo applications where Ethernet is usedas a backplane. The TOE can transfer theimages or video streams without the needfor a CPU.
High Flexibility with FPGAsFPGAs hold a number of advantages com-pared to ASICs and offer scalable solutionswith high data rates: 1 GbE, n-times-1GbE, 10 GbE, and n-times-10 GbE. Theflexibility of the FPGA makes it possible toadd new functionality and adapt to proto-col changes. Advanced network functionslike switch-specific flow control, or per-formance-enhancing features can beadded. In load distribution, the IPBlazeTOE can distribute traffic to multipleCPU cores for higher system performance.Maintenance and upgrade of the TOEhardware functions located in the FPGA isdone by firmware upgrade – much likedriver software updates.
IPBlaze 10 GbE TOE coreThe IPBlaze 10 GbE TOE core is animplementation of a full-featuredTCP/IP networking subsystem in theform of a “drop-in” silicon IP core. Itincludes a standards-compliant TCP/IPstack implemented as a compact high-performance synchronous state machine.
The TOE core is built from a collec-tion of synthesizable Verilog modules,which are customized before delivery toprovide the best possible performanceand feature set in a given system.
software by the PowerPC while the FPGAhardware, together with the TOE, handlesbulk transfers like video or images at wirespeed (1 or 10 GbE). This solution makesit possible to use FPGA logic for fast dataprocessing and fast data communicationand software for complex low-bandwidthoperations. Software in the embeddedCPU can be Xilinx microkernel,Embedded Linux, or VxWorks.
The IPBlaze 10 GbE TOE NIC FPGAsolution has the same performance as aTOE NIC ASIC while providing muchhigher flexibility. High-performanceTOE NICs are now available using cost-effective FPGAs. FPGAs help you withfast time to market and ensure compati-bility and interoperability.
Third Quarter 2007 Xcell Journal 21
High Performance Properties
High-performance CPU + simple NIC High CPU load, CPU limits performance
High-performance CPU + NIC acceleration ASIC Good with in supported feature set, but inflexible solution
High-performance CPU + NIC acceleration FPGA Flexible, scalable solution
Medium Performance Properties
ASIC SoC (communication controller CPU, network if) General solution, performance limited by software
FPGA SoC (integrated CPU, network acceleration) Good for high data rates, flexible and scalable
Ethernet Performance Measured by netperf
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
IPBlaze TOE,
Intel M1.6,
1500B pck
Intel Dual-
Core E6600,
250B pck
Intel Dual-
Core E6600,
1500B pck
AMD Athlon
64 3700+,
1500B pck
Standard NIC,
Intel M1.6,
1500B pck
IPBlaze TOE,
Intel M1.6,
250B pck
CP
U L
oad
0
100
200
300
400
500
600
700
800
900
1000
Mb
/s W
ire
Ra
te T
CP
Pa
ck
ets
CPU Load
Throughput
Table 1 – Overview of implementation options
Figure 1 – The CPU power needed to process network data and throughput, tested at 1 GbE links, using the netperf performance measurements program.
C O N N E C T I V I T Y

The TOE core can be instantiatedalong with your own IP and configuredto operate without the need for hostCPU support.
The IPBlaze TOE core can support asmany as 1,000 concurrent TCP connec-tions in on-chip memory. When a highernumber of connections are required, aconnection cache will allow you to access
the most recently used connection stateson-chip. The state information for non-cached TCP connections is stored in hostmemory or in dedicated external memory.
For applications where the TOE doesnot terminate connections but monitorsall connections on a backbone, an externaldedicated high-speed memory is used tosupport a very high number (1 million andabove) of concurrent TCP connections.
The IPBlaze TOE core uses three well-defined interfaces:
• Xilinx 1 GbE and 10 GbE MAC net-work interfaces for either 1 GbE or 10GbE support
• A high-speed RAM option for dedicat-ed external memory for TCP connec-tion state information
• Xilinx PCIe type or memory hostprocessor interface
The host interface is essential for systembehavior and performance and represents asignificant part of the system complexity.
The host CPU has register access toTOE registers while the TOE has access tomain memory. The main memory containsthe send and receive data buffers, queuestructures, and TCP connection stateinformation if connection caching is
enabled. An event system is used for fastmessage signaling between the host andthe TOE. The event system includes anumber of optimizations for highthroughput and low latency.
OS-Compliant Socket API Applications software interfaces to theTOE through a fully standards-compliantsocket API, with significantly higher per-formance than a standard software socketimplementation. The socket API is imple-mented at the CPU kernel level. The CPUload is reduced by 5-10 times and latency isimproved by 4-5 times.
Hardware-based acceleration should beable to scale well. The evolution of per-formance in future Xilinx FPGA genera-tions provides a good upgrade path.Furthermore, continuous improvements inthe IPBlaze TOE technology also provideincreased performance.
The flexibility in an FPGA solutionallows easy upgrade of the FPGA code tosupport new protocol features.
The IPBlaze TOE core is designed totarget a variety of FPGA families depend-ing on the performance and functionalityrequirements. The IPBlaze TOE core hasbeen implemented in Virtex-II, Virtex-4,and Virtex-5 devices.
Here are some example numbers froma 10 GbE TOE implemented in Virtex-5devices:
• Core clock: 125 MHz
• TOE latency: 560 ns
• Throughput: 10G line rate (10G bidirectional)
• Packet processing rate: 12 millionpackets per second
Xilinx and IPBlaze provide TCP offloadsolutions that can be implemented as is orcustomized for functionality, size, speed, ortarget application. IPBlaze also offers acomprehensive set of high-performanceTOE solutions for different market seg-ments. Current TOE solutions include:
• IPBlaze General TOE for NIC applications.
• IPBlaze Security TOE for high-per-formance (2-times-10 GbE) bump-in-the-wire network monitoring. Thesecurity TOE supports more than 1 million concurrent TCP connections.
• IPBlaze Embedded TOE for SoCapplications that require high-speednetwork communication (1 GbE and10 GbE).
ConclusionWith standards-compliant TOE cores,IPBlaze has created a technology platformfor the 10 GbE TOE market, working withindustry leaders in high-performance com-puting solutions. Programmable solutionsenable system architects to add functionali-ty as needed. Integrating multiple IP coresinto a single FPGA can reduce board costsand time to market.
To learn more about protocol offloadsolutions, visit www.ipblaze.com.
22 Xcell Journal Third Quarter 2007
Virtex-5 FPGA
High-Performance CPU
CPU + Accelerated NIC
FPGA SOC
Virtex-4 or Virtex-5 FPGAs
Network Interface Network Interface
n*1 GbE/10 GbE PHY
Applications in SW
Applications in HW
e.g., Video CPUPCIe
IPBlaze TOE
n*1 GbE/10 GbE MAC
n*1 GbE/10 GbE PHY
IPBlaze TOE
n*1 GbE/10 GbE MAC
Figure 2 – Block diagram for a high-speed TOE solution for a PC/server and embedded system
C O N N E C T I V I T Y

by Brad FriedenApplications Development EngineerAgilent [email protected]
When implementing high-speed serial linksin FPGAs, you must consider and addressthe effects of transmission line signalintegrity. Used together, transmitter pre-emphasis and receiver equalization extendthe rate at which high-speed serial data canbe transferred by opening up the eye dia-gram, despite physical channel limitations.
An internal bit error ratio tester(IBERT) measurement core from Xilinxcan view serial signals at an internal receiv-er point. Used in conjunction with theAgilent Serial Link Optimizer, you canhave both a graphical view of the BERacross the unit interval and automaticallyadjust pre-emphasis and equalization set-tings to optimize the channel.
In this article, I’ll show you how tooptimize a Virtex-4 MGT high-speedserial link through this process and dis-cuss the results.
Challenges of Signal DegradationAt 3.125- and 6-Gbps rates and risetimes of 130 ps or shorter, it is no won-der that most applications end up withsignificant signal integrity effects fromthe physical channel that distort the sig-nal at the receiver input. Distortion cancome from multiple reflections causedby impedance discontinuities, but amore fundamental effect – especially inFR4 dielectric PC boards – slows downthe edge speeds. Frequency-dependentskin effect causes a “slow tail” to thepulse. To compensate for this, you canapply a time-domain technique calledpre-emphasis to the transmit pulse, withsignificant improvement at the receiver.
Additionally, because the channel is band-width-limited, you can apply a frequency-domain technique called equalization at thereceiver to compensate for channel frequencyroll off. A peaked frequency response yields amore flat response when combined with thechannel roll off. The effects of equalization atthe receiver input are quite drastic, but this isonly visible inside the chip at the actualreceiver input (post-equalization).
Measuring Link PerformanceIt is important to be able to verify the per-formance of a link and to optimize itthrough the combined adjustment oftransmitter pre-emphasis and receiverequalization. Unfortunately, taking a meas-urement on the pins of the FPGA wherethe receiver is located yields a very distort-ed signal, since you are observing the signalwith pre-emphasis applied but withoutcorresponding equalization.
Third Quarter 2007 Xcell Journal 23
Automated MGT Serial Link Tuning Ensures Design MarginsYou can now streamline the serial link tuning process using Agilent’s Serial Link Optimizer tool with Xilinx IBERT measurement cores.
C O N N E C T I V I T Y

Figure 1 is an example of such a meas-urement made with an Agilent digital com-munications analyzer on a 6-Gbps channelimplemented with ASIC technology.Notice that the eye diagram actuallyappears completely closed, even thoughgood signals are present at the receiverinput inside the chip.
IBERT Measurement CoreFortunately, you can observe what isgoing on at the FPGA’s receiver input byusing an IBERT measurement core that ispart of the Xilinx® ChipScope™ ProSerial I/O toolkit. The normal FPGAdesign is temporarily replaced with onethat creates stimulus at the transmitterand measures BER at the receiver. Thesestimulus/response core pairs are placed inthe design using a core generationprocess. Now it is possible to observeBER at the receiver inside the chip. Usingthat basic measurement capability, youcan apply a variety of pre-emphasis andequalization combinations to optimizethe channel response.
Basic BERT MeasurementsTo understand link performance, you musthave the ability to measure bit error rate.To do this, a new tool called the AgilentSerial Link Optimizer takes control ofIBERT core stimulus and response in theserial link to create such a measurement. Ameasurement system as shown in Figure 2allows for this kind of test. Here, twoVirtex™-4 FPGAs comprise the link: oneimplements the transmitter, the other thereceiver. Both FPGAs are under JTAG con-trol from the Serial Link Optimizer soft-ware, and measurements are taken at thereceiver input point inside the FPGA tomeasure BER.
Some of the selectable measurementattributes include:
• Loopback mode (internal, external, or none)
• Test pattern type
• Dwell time at each point across the unit interval
• Manual injection of errors
with the topology of the ML405 boards,dictate the physical channel.
Steps to set up this measurement include(assuming that the IBERT cores are alreadycreated and loaded into the FPGAs):
1. Start tool and configure USB JTAGfor TX and verify connection
2. Configure parallel JTAG for RX andverify connection
3. Select MGT 113A transmitter onUSB cable
I obtained a measurement on a seriallink that comprises a Xilinx Virtex-4XC4VFX20 multi-gigabit transceiver(MGT) 113A transmitter on one XilinxML405 board, with a connection througha SATA cable over to an MGT 113Areceiver in a second Virtex-4 XC4VFX20FPGA on a second ML405 board. I madea USB JTAG connection to the firstFPGA and IBERT core associated withthe transmitter, and a parallel JTAG con-nection to the second IBERT core associ-ated with the receiver. These cores, along
Transmitter Receiver with Equalizer
Agilent DCA at PinsEmbedded BERT
Backplane
PC Board
FPGA
IBERT
PC Board
FPGA
IBERTInsert Core with
FPGA Design Software
JTAG
Software Application on Windows PC
Xilinx Cable
Parallel orUSB
Figure 2 – Serial Link Optimizer block diagram
Figure 1 – DCA measurement on FPGA serial I/O pins versus on-chip measurement at the receiver input
24 Xcell Journal Third Quarter 2007
C O N N E C T I V I T Y

Third Quarter 2007 Xcell Journal 25
4. Select MGT 113A receiver on parallel cable
5. Select loopback (external)
6. Select test pattern type (PRBS7)
7. Setup TX and RX line rates (referenceclock 150 MHz, line rate 6 Gbps)
8. Select BERT tab and press “Run”
I made a measurement on the link withzero errors after 1E+12 bits (~ 3-min meas-urement). This measurement of BER onthe channel occurred at the receiver inputinternal to the chip and required no exter-nal measurement hardware. It forms thebasis for additional capability in the SerialLink Optimizer tool.
A Graphical View of BERThe next step toward understanding linkperformance is to have the ability to graphBER as a function ofthe unit interval. To dothis, the Agilent SerialLink Optimizer takescontrol of IBERT corestimulus and responsein the serial link to cre-ate such a graph.
The same measure-ment system is used aswith the basic BERtest, but now measure-ments are taken at 32discrete steps across theunit interval to showwhere error-free per-formance is achieved.The resulting graph isshown in the upper BER plot in Figure 3.The Virtex-4 MGT macro has the abilityto adjust the sampling position acrossthese 32 discrete points; the Serial LinkOptimizer uses the IBERT core in con-junction with sampling position controlto make the measurements. The link per-formance with default MGT pre-empha-sis and equalization settings has zeroerrors for 0.06 (6%) of the unit interval.This is quite narrow, indicating very littlemargin. The system could benefit fromproper link tuning.
Automated Link TuningLet’s extend this measurement process yetagain by automatically trying combinationsof pre-emphasis and equalization settingsuntil the error-free zone in the unit intervalis maximized, resulting in the best link per-formance for speed and margin. The SerialLink Optimizer does just that. Link config-uration options include an internal loop-back test inside the I/O ring of a singleFPGA; transmit and receive from oneFPGA; and a transmit/receive pair testbetween two different FPGAs. It is also pos-sible to inject signals from an externalBERT instrument and monitor signals atthe receiver inside the FPGA.
In our example, let’s use the same serialchannel between two Virtex-4 FPGAs withthe MGT 113A/B TX/RX pair. On theSerial Link Optimizer interface, select the“Tuning” tab and Run button as shown inFigure 3. The error-free zone with default
FPGA settings was 0.06 unit interval. Afterattempting 141 combinations of pre-emphasis and equalization, the error-freezone increased to 0.281 (28%) unit inter-val, also shown in Figure 3. This means sig-nificantly better margins in the link designat the 6-Gbps speed.
Exporting Link Design ConstraintsThese new pre-emphasis and equalizationsettings must now be incorporated into a realdesign that ultimately uses the serial link. Upuntil this point, I placed a temporary test
design into each FPGA to determine the opti-mal combination of pre-emphasis and equal-ization. Now that I have determined theoptimal combination, the Serial LinkOptimizer outputs the corresponding pre-emphasis and equalization settings for theMGTs. The MGT parameters are representedin VHDL, Verilog, and UCF formats and areoutput when clicking the “Export Setting”button. You can cut and paste these parame-ters back into the source design, thus incor-porating the optimal link settings when thefinal design is programmed into the FPGAs.
For example, the Verilog settings for thefirst transceiver are:
// Verilog
//— Rocket IO MGT Preemphasis and Equalization —
defparam MGTx.RXAFEEQ = 9’b111;
defparam MGTx.RXSELDACFIX = 5’b1111;
defparam MGTx.RXSELDACTRAN = 5’b1111;
Required ComponentsTo take advantage of these measurements,you will need:
1. A PC with Windows XP installed (SP2or higher)
2. Xilinx programming cable(s), paralleland/or USB
3. Xilinx ChipScope Pro Serial I/OToolkit (for IBERT core)
4. Agilent E5910A Serial Link Optimizersoftware
ConclusionThrough automated adjustments of pre-emphasis and equalization, while simultane-ously monitoring BER at the receiver inputinside the FPGA, it is now possible to auto-matically optimize an MGT-based serial link.
At 3.125-Gbps rates, such an optimiza-tion is helpful to get good margins. But at6-Gbps rates, optimization becomes crucialto achieve link performance that ensuresreliable data transfer. This process can savesignificant time in reaching your desireddesign margins and can likely achieve betterresults than what is possible through tradi-tional manual tuning.
For more information, visit www.agilent.com/find/serial_io or www.agilent.com/find/xilinxfpga.
Figure 3 – BER plot before and after automatic adjustment of pre-emphasis and equalization to tune the serial link
C O N N E C T I V I T Y

by Mrinal J. Sarmah Hardware Design Engineer Xilinx, Inc. [email protected]
Hemanth PuttashamaiahHardware Design EngineerXilinx, [email protected]
With advances in communication technol-ogy, you can achieve gigahertz data-transferrates in serial links without having to maketrade-offs in data integrity. The prolifera-tion of serial connectivity can be attributedto its advantages over parallel communica-tion, including:
• Improved system scalability
• More flexible, thinner cabling
• Increased throughput on the line withminimal additional resources
• More deterministic fault isolation
• Predictable and reliable signalingschemes
• Topologies that promise to scale to the needs of the end user
• Exceptional bandwidth per pin withvery high skew immunity
• Reduced system costs because of smallerform factors, fewer PCB traces andlayers, and lower pin/wire count
Although it offers real benefits, serialI/O has some negative attributes. Serialinterfaces require high-bandwidth manage-ment inside the chip, special initializationand monitoring, bonding of lanes in anaggregated channel of multiple lanes, elas-tic buffers for data alignment, and de-skew-ing. Also, flow control is complex and youmust maintain the correct balance betweenhigh-level features and total chip area.
Multi-Gigabit TransceiversFollowing the industry-wide migrationfrom parallel to serial interfaces, Xilinxintroduced multi-gigabit transceivers(MGTs) to meet bandwidth requirementsas high as 6.5 Gbps.
The common functional blocks in thesetransceivers are an 8B/10B encoder/decoder,transmit buffer, SERDES, receive buffer,loss-of-sync finite state machine (FSM),comma detection, and channel bondinglogic. These transceivers have built-in clockdata recovery (CDR) circuits that can per-form at gigahertz rates. Built-in phase-locked loops (PLL) generate the fabric andtransceiver clocks.
Transceivers have several advantages:
• With their self-synchronous timingmodels, they reduce the number oftraces on the boards and eliminateclock-to-data skew
• Multiple MGTs can achieve higherbandwidths
• MGTs with point-to-point connec-tions make switched fabric architec-tures possible
• The elastic buffers available in MGTsprovide high skew tolerance for channel-bonded lanes
MGTs are designed for configurablesupport of multiple protocols; hencetheir control is fairly complex. Whendesigning or integrating designs with ahigh-speed connectivity solution usingMGTs, you will have to consider MGTinitialization, alignment, channel bond-ing, idle sequence generation, link man-agement, data delineation, clock skew,clock compensation, error detection, anddata striping and destriping. Configuringtransceivers for a particular application ischallenging, as you are expected to tunemore than 200 attributes.
The Aurora SolutionThe Xilinx® Aurora protocol and its asso-ciated designs address these challenges bymanaging the MGT’s control interface.
Aurora is free, small, scalable, and cus-tomizable. With low overhead, Aurora is aprotocol-agnostic, lightweight, link-layerprotocol that can be implemented in anysilicon device/technology.
With Aurora, you can connect one ormore MGTs to form a communicationchannel. The Aurora protocol defines thestructure of data packets and procedures for
26 Xcell Journal Third Quarter 2007
A High-Speed Serial ConnectivitySolution with Aurora IPAurora is a highly scalable protocol for applicationsrequiring point-to-point connectivity.
C O N N E C T I V I T Y

flow control, data striping, error handling,and initialization to validate MGT links.
Aurora shrink-wraps MGTs by providinga transparent interface to them, allowing theupper layers of proprietary or industry-stan-dard protocols such as Ethernet and TCP/IPto ride on top of it and provide easily access.
This easy-to-use pre-defined protocolneeds very little time to integrate withexisting user designs. Being lightweight,Aurora does not have an addressing schemeand cannot support switching. It does notdefine correction within data payloads.
Aurora is defined for physical and data-link layers in the Open SystemsInterconnection (OSI) model and can easi-ly integrate into existing networks.
A Typical Connectivity ScenarioFigure 1 is an overview of a typical Auroraapplication. The Aurora interface trans-fers data to and from user applicationfunctions through the user interface. The
a 2- or 4-byte interface should bebased on the throughput require-ments and latency involved. A 4-byte design has more latencythan a 2-byte design, but offersbetter throughput and consumesless resources than an equivalent2-byte design.
Aurora channels can functionas uni-directional (simplex) orbi-directional (full-duplex). Full-duplex module initializationdata comes from the channelpartner through a reverse path,whereas in simplex the initializa-tion happens through four side-band signals. Aurora is availablein simplex TX only, RX only, orboth. “Both” operation is likefull duplex, except that the
transmit and receive sections communicateindependently. You can use Aurora simplexin token-ring fashion. Figure 2 shows thering structure of Aurora-S (simplex).
Data Flow in AuroraData is transferred between Aurora channelpartners as frames. Data flow primarily com-prises the transfer of protocol data units(PDUs) between the user application andthe Aurora interface, as well as the transfer ofchannel PDUs between channel partners.
Soon after power-up, when the corecomes out of all reset states, the trans-mitter sends initialization sequences. Ifthe link is fine and the link partner rec-ognizes these patterns, it sends acknowl-edgement patterns. After receivingsufficient acknowledgement patterns, thetransmitter transits to a link-up state,indicating that the individual transceiverconnection between channel partners isestablished. Once the link is up, theAurora protocol engine moves to a chan-nel verification stage for a single-lanechannel, or a channel-bonding stage(preceeding a verification stage) for amulti-lane channel. When channel verifi-cation is complete, Aurora sends a chan-nel-up signal, which is followed by actualdata transmission. The link initializationprocess is shown in Figure 3.
user interface is not part of the Auroraprotocol specification.
The Aurora protocol engine convertsgeneric arbitrary-length data from theXilinx LocalLink user interface to Auroraprotocol-defined frames and transfers itacross channel partners comprising one ormore high-speed serial links. The numberof links between channel partners is config-urable and device-dependent.
Most Xilinx IPs are developed based onthe legacy LocalLink interface. Any userinterface designed for other LocalLink-based IPs can be directly plugged intoAurora. For more information on theLocalLink interface, visit www.xilinx.com/products/design_resources/conn_central/locallink_member/sp006.pdf.
You can think of Aurora as a bridgebetween the LocalLink interface and theMGT.
Aurora’s LocalLink interface is customiz-able for 2- or 4-byte data. Your selection of
Third Quarter 2007 Xcell Journal 27
UserApplication
Local Link
Interface
Local Link
Interface
UserApplication
UserInterface
UserInterface
Lane 1
Lane NChannel
MGT
MGT
MGT
MGT
AURORA
AURORA
User Frames andFlow Control Messages
User Frames andFlow Control Messages
Interconnect(Ex. Backplane)
Aurora Frames
High-Speed Serial TransceiversMGT = Multi-Gigabit Transceiver
Aurora Channel Partners Aurora Full-Duplex Channel
Each Aurora Lane Uses One MGT
status status status
FPGA FPGA
RX TX RX TX
Figure 1 – Connectivity scenario using Aurora
Figure 2 – Simplex token ring structure
C O N N E C T I V I T Y

Frame TypesAs stated previously, data is sent over Aurorachannels as frames. There are five frametypes, listed in the order of their priority:
• Clock compensation (CC)
• Initialization sequences
• Native flow control (NFC)
• User flow control (UFC)
• Channel PDUs
• Idles
Aurora allows channel partners to useseparate reference clocks by inserting CCsequences at regular intervals. It canaccommodate differential clock rates up to200 parts per million (ppm) between thetransmitter and the receiver.
An Aurora frame sends data in a quanti-ty of two bytes called a symbol. In case thenumber of bytes in the PDU is odd, itappends one extra byte called a pad. On thereceive side, the pad is removed by thereceive logic and data is presented to theLocalLink interface.
The transmit LocalLink frame is encap-sulated in the Aurora frame, as shown inFigure 4. Aurora encapsulates frames withstart-channel PDU (SCP) and end-channelPDU (ECP) symbols. On the receive side,the reverse process occurs. The transceiversare responsible for encoding/decoding theframe into 8B/10B characters, serialization,and de-serialization.
Flow ControlAurora supports an optional flow controlmechanism to prevent data loss caused bydifferent source and sink rates betweenchannel partners (Figure 5).
Native Flow ControlNFC is meant for data-link layer-rate con-trol. NFC operation is governed by twoNFC FSMs: RX and TX.
The RX NFC FSM monitors the state ofthe RX FIFO. When there is a risk of over-flow, it generates NFC PDUs, requesting thatthe channel partner pause transmission ofuser PDUs for a specific time duration. TheTX NFC state machine responds by waitingduring the requested time, allowing the RX
FIFO to come out of its overflow state.While sending NFC requests, the TX
NFC FSM should eliminate any round-trip delay. Ideally, NFC requests are sentbefore receive FIFO overflows to accountfor this delay. You can program the NFCpause value from 0 to 256; the maximumpause value is infinite. An NFC pause valueis non-cumulative and new NFC requestvalues override the old.
There are two NFC request types: imme-diate mode and completion mode. In imme-diate mode, an NFC request is processedwhile low-priority requests are halted. Incompletion mode, the current frame is
transmitted; only after competition of thetransfer is the NFC request processed.
User Flow ControlUFC is used to implement user-definedflow control at any layer. The number ofUFC messages can be 2 to 16 bytes in aframe. UFC messages are generated andinterpreted by the user application.
ApplicationsAurora is a simple, scalable open protocolfor serial I/O. It can be implemented inFPGAs or ASICs. Aurora can be appliedwhere an inexpensive, high-performance
28 Xcell Journal Third Quarter 2007
Start
Align SERDES
Polarity Corrected
Align Polarity
Align SERDES
Operation
Lane Verification
PartnerHandshake
ChannelBonding
Multi-Lane
Padding
Link-Layer Encapsulation
8B/10B Encoding
N Octets
N Octets One Octet
One Octet Two OctetsTwo Octets N Octets
N SymbolsTwo Symbols Two SymbolsOne Symbol
User PDU
User PDU PAD
User PDU PADSCP ECP
User PDU PADSCP ECP
Figure 3 – Data flow in Aurora
Figure 4 – Frame encapsulation in transmit Aurora
C O N N E C T I V I T Y
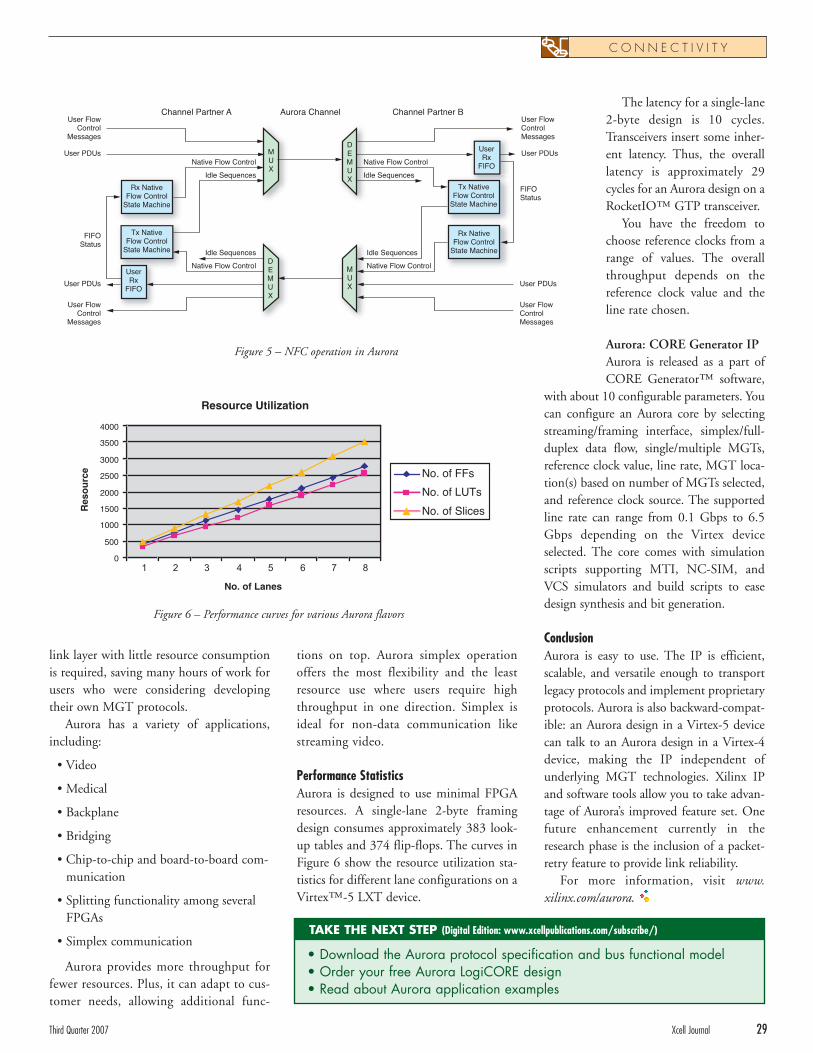
Third Quarter 2007 Xcell Journal 29
link layer with little resource consumptionis required, saving many hours of work forusers who were considering developingtheir own MGT protocols.
Aurora has a variety of applications,including:
• Video
• Medical
• Backplane
• Bridging
• Chip-to-chip and board-to-board com-munication
• Splitting functionality among severalFPGAs
• Simplex communication
Aurora provides more throughput forfewer resources. Plus, it can adapt to cus-tomer needs, allowing additional func-
tions on top. Aurora simplex operationoffers the most flexibility and the leastresource use where users require highthroughput in one direction. Simplex isideal for non-data communication likestreaming video.
Performance StatisticsAurora is designed to use minimal FPGAresources. A single-lane 2-byte framingdesign consumes approximately 383 look-up tables and 374 flip-flops. The curves inFigure 6 show the resource utilization sta-tistics for different lane configurations on aVirtex™-5 LXT device.
The latency for a single-lane2-byte design is 10 cycles.Transceivers insert some inher-ent latency. Thus, the overalllatency is approximately 29cycles for an Aurora design on aRocketIO™ GTP transceiver.
You have the freedom tochoose reference clocks from arange of values. The overallthroughput depends on thereference clock value and theline rate chosen.
Aurora: CORE Generator IP Aurora is released as a part ofCORE Generator™ software,
with about 10 configurable parameters. Youcan configure an Aurora core by selectingstreaming/framing interface, simplex/full-duplex data flow, single/multiple MGTs,reference clock value, line rate, MGT loca-tion(s) based on number of MGTs selected,and reference clock source. The supportedline rate can range from 0.1 Gbps to 6.5Gbps depending on the Virtex deviceselected. The core comes with simulationscripts supporting MTI, NC-SIM, andVCS simulators and build scripts to easedesign synthesis and bit generation.
ConclusionAurora is easy to use. The IP is efficient,scalable, and versatile enough to transportlegacy protocols and implement proprietaryprotocols. Aurora is also backward-compat-ible: an Aurora design in a Virtex-5 devicecan talk to an Aurora design in a Virtex-4device, making the IP independent ofunderlying MGT technologies. Xilinx IPand software tools allow you to take advan-tage of Aurora’s improved feature set. Onefuture enhancement currently in theresearch phase is the inclusion of a packet-retry feature to provide link reliability.
For more information, visit www.xilinx.com/aurora.
User FlowControl
Messages
User FlowControl
Messages
User PDUs
User FlowControlMessages
User PDUs
FIFOStatus
FIFOStatus
User PDUs
User FlowControlMessages
User PDUs
Native Flow Control
Idle Sequences
Native Flow Control
Idle Sequences
Idle Sequences
Native Flow Control
Idle Sequences
Native Flow Control
Rx NativeFlow Control
State Machine
Rx NativeFlow Control
State Machine
Tx NativeFlow Control
State Machine
Tx NativeFlow Control
State Machine
UserRx
FIFO
UserRx
FIFO
MUX
MUX
DEMUX
DEMUX
Channel Partner A Channel Partner BAurora Channel
Resource Utilization
0
500
1000
1500
2000
2500
3000
3500
4000
1 2 3 4 5 6 7 8
No. of Lanes
Res
ou
rce No. of FFs
No. of LUTs
No. of Slices
• Download the Aurora protocol specification and bus functional model• Order your free Aurora LogiCORE design• Read about Aurora application examples
TAKE THE NEXT STEP (Digital Edition: www.xcellpublications.com/subscribe/)
Figure 5 – NFC operation in Aurora
Figure 6 – Performance curves for various Aurora flavors
C O N N E C T I V I T Y

Here are 6 of the new, faster, bigger, Virtex-5 FPGAs on a 12 Million ASIC Gate Boardthat offers unmatched performance to ASIC Prototypers, IP Designers, and FPGADevelopers. The V5 65nm process, with 6 input LUT and advanced interconnect,enables 30% faster clock speeds in your application. The Dini DN9000k10PCI capturesthis performance on an easy to use board with these handy features:
•33/66 MHz PCI bus or stand-alone operation•6 - DDR2 SODIMM Sockets•7 - Global Clock Networks•3 - 400pin FCI-MEG Connectors for daughter cards• Easy configuration via CompactFlash, USB or PCI
All necessary operating software, including referencedesigns and Synplicity Certify™ models to simplifypartitioning, is supplied with the board. If yourneed is speed — visit The Dini Group web site www.dinigroup.com for complete details on the fastest FPGA board ever.
30% faster than lastyear’s model…
1010 Pearl Street, Suite 6La Jolla, CA 92037 (858) 454-3419 [email protected]

by Tim HemkenMarketing DirectorXilinx, [email protected]
The serial digital interface (SDI) protocolfor transporting uncompressed standarddefinition video evolved when broadcaststudios wanted to convert from analogaudio and video to digital audio and videowithout replacing the enormous coaxialtransmission cable infrastructure. Today,the ever-increasing screen resolutions andassociated data rates have spawned newserial data communication formats withthe same goal of coax reuse.
The first such standard for SDI, authoredby the Society of Motion Picture andTelevision Engineers (SMPTE), is known asSMPTE 259M, commercialized in 1989. Atits introduction, the primary chips used forthe interface were provided by application-
specific standard product (ASSP) chip mak-ers. The data rate for SDI is nominally 270Mbps, adequate for standard definition tele-vision (SDTV) resolutions.
In 2002, Xilinx announced the immedi-ate availability of Virtex™-II Pro FPGAs.The feature set of this device includedmulti-gigabit transceivers (MGTs) capableof operating at bit rates as fast as 3.125Gbps. About the same time, the broadcaststudios were starting their adoption of thenew high-definition television (HDTV)standards with greater screen resolutionsand higher data-rate requirements.SMPTE authored a standard known asSMPTE 292M, supporting the serial trans-mission of uncompressed HDTV videocontent at a nominal rate of 1.5 Gbps,known as HD-SDI.
Xilinx® Senior Staff ApplicationsEngineer John Snow realized that the two
data rates could be supported by a singleVirtex™-II Pro MGT and saw an oppor-tunity to integrate multiple ASSP chipsinto a single Xilinx FPGA. The integrationwould vastly reduce the cost of these inter-faces, especially in video switcher and mas-ter controller designs where there aremultiple video streams.
Snow authored the first applicationnotes for these two interface standardsusing FPGAs. These application notesincluded free reference designs written inVerilog and VHDL source code. The codeand documentation allowed broadcast sys-tem engineers to easily implement fully fea-tured SDI and HD-SDI receivers andtransmitters and other associated func-tions, such as video test pattern generators,in Virtex-II Pro FPGAs. Over the next year,Virtex-II Pro FPGAs began to appear inbroadcast equipment throughout theworld, consolidating multiple ASSP chips.
HDTV’s acceptance among the massescontinues to grow. This amazing technolo-gy brings viewers closer to reality and, as aresult, the amount of HD content isincreasing. Today, HD-capable receivers areachieving mass-market price points andconsumers are buying HDTVs at accelerat-ing rates. The multi-rate SDI and HD-SDIreference designs are increasingly impor-tant for distributing digital audio and videocontent inside the broadcast studio.
Today, the SMPTE organization is notstanding still. They consistently publishnew standards to handle video formats that
Third Quarter 2007 Xcell Journal 31
Xilinx FPGAs Adapt to Ever-ChangingBroadcast Video LandscapeNew digital broadcast standards and applications are addressed by advanced silicon, software, and free reference designs available with Xilinx FPGAs.
C O N N E C T I V I T Y
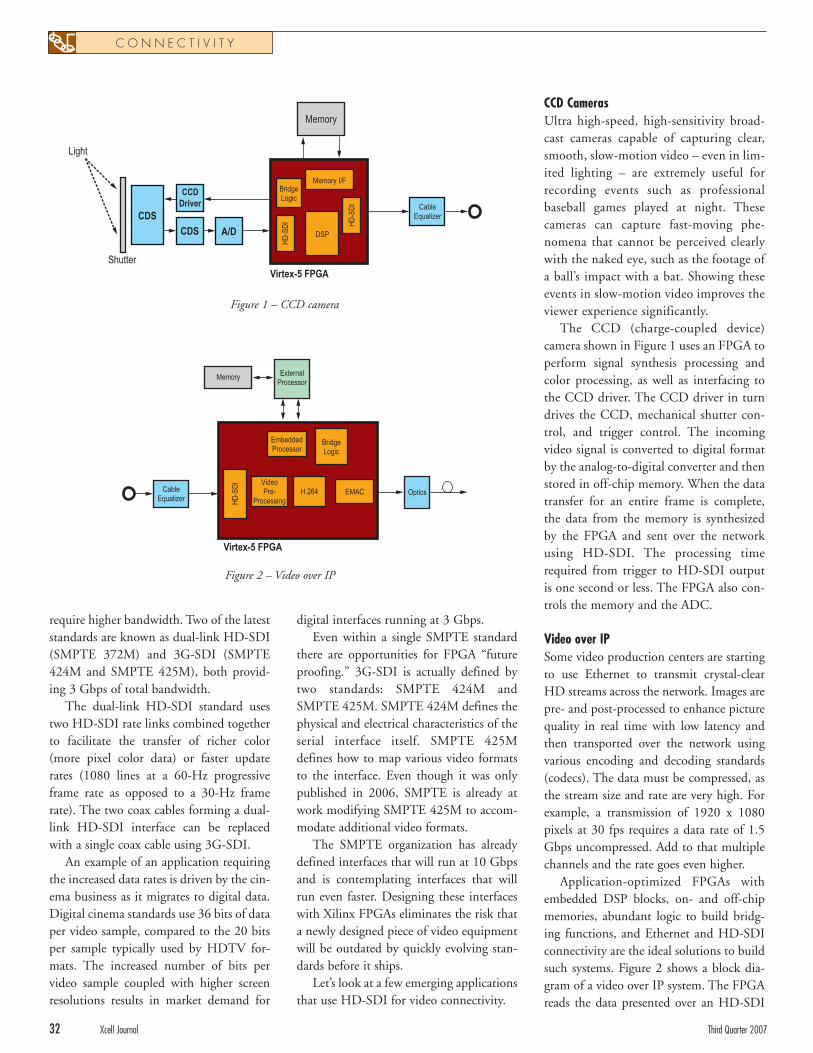
require higher bandwidth. Two of the lateststandards are known as dual-link HD-SDI(SMPTE 372M) and 3G-SDI (SMPTE424M and SMPTE 425M), both provid-ing 3 Gbps of total bandwidth.
The dual-link HD-SDI standard usestwo HD-SDI rate links combined togetherto facilitate the transfer of richer color(more pixel color data) or faster updaterates (1080 lines at a 60-Hz progressiveframe rate as opposed to a 30-Hz framerate). The two coax cables forming a dual-link HD-SDI interface can be replacedwith a single coax cable using 3G-SDI.
An example of an application requiringthe increased data rates is driven by the cin-ema business as it migrates to digital data.Digital cinema standards use 36 bits of dataper video sample, compared to the 20 bitsper sample typically used by HDTV for-mats. The increased number of bits pervideo sample coupled with higher screenresolutions results in market demand for
CCD Cameras Ultra high-speed, high-sensitivity broad-cast cameras capable of capturing clear,smooth, slow-motion video – even in lim-ited lighting – are extremely useful forrecording events such as professionalbaseball games played at night. Thesecameras can capture fast-moving phe-nomena that cannot be perceived clearlywith the naked eye, such as the footage ofa ball’s impact with a bat. Showing theseevents in slow-motion video improves theviewer experience significantly.
The CCD (charge-coupled device)camera shown in Figure 1 uses an FPGA toperform signal synthesis processing andcolor processing, as well as interfacing tothe CCD driver. The CCD driver in turndrives the CCD, mechanical shutter con-trol, and trigger control. The incomingvideo signal is converted to digital formatby the analog-to-digital converter and thenstored in off-chip memory. When the datatransfer for an entire frame is complete,the data from the memory is synthesizedby the FPGA and sent over the networkusing HD-SDI. The processing timerequired from trigger to HD-SDI outputis one second or less. The FPGA also con-trols the memory and the ADC.
Video over IP Some video production centers are startingto use Ethernet to transmit crystal-clearHD streams across the network. Images arepre- and post-processed to enhance picturequality in real time with low latency andthen transported over the network usingvarious encoding and decoding standards(codecs). The data must be compressed, asthe stream size and rate are very high. Forexample, a transmission of 1920 x 1080pixels at 30 fps requires a data rate of 1.5Gbps uncompressed. Add to that multiplechannels and the rate goes even higher.
Application-optimized FPGAs withembedded DSP blocks, on- and off-chipmemories, abundant logic to build bridg-ing functions, and Ethernet and HD-SDIconnectivity are the ideal solutions to buildsuch systems. Figure 2 shows a block dia-gram of a video over IP system. The FPGAreads the data presented over an HD-SDI
digital interfaces running at 3 Gbps.Even within a single SMPTE standard
there are opportunities for FPGA “futureproofing.” 3G-SDI is actually defined bytwo standards: SMPTE 424M andSMPTE 425M. SMPTE 424M defines thephysical and electrical characteristics of theserial interface itself. SMPTE 425Mdefines how to map various video formatsto the interface. Even though it was onlypublished in 2006, SMPTE is already atwork modifying SMPTE 425M to accom-modate additional video formats.
The SMPTE organization has alreadydefined interfaces that will run at 10 Gbpsand is contemplating interfaces that willrun even faster. Designing these interfaceswith Xilinx FPGAs eliminates the risk thata newly designed piece of video equipmentwill be outdated by quickly evolving stan-dards before it ships.
Let’s look at a few emerging applicationsthat use HD-SDI for video connectivity.
Memory I/F
HD
-SD
I
HD
-SD
I
BridgeLogic
DSP
CableEqualizer
A/DCDS
Shutter
Light
CCD
Driver
CDS
Virtex-5 FPGA
Memory
CableEqualizer
EmbeddedProcessor
BridgeLogic
EMACH.264VideoPre-
ProcessingHD
-SD
I
ExternalProcessor
Memory
Virtex-5 FPGA
Optics
Figure 1 – CCD camera
Figure 2 – Video over IP
32 Xcell Journal Third Quarter 2007
C O N N E C T I V I T Y
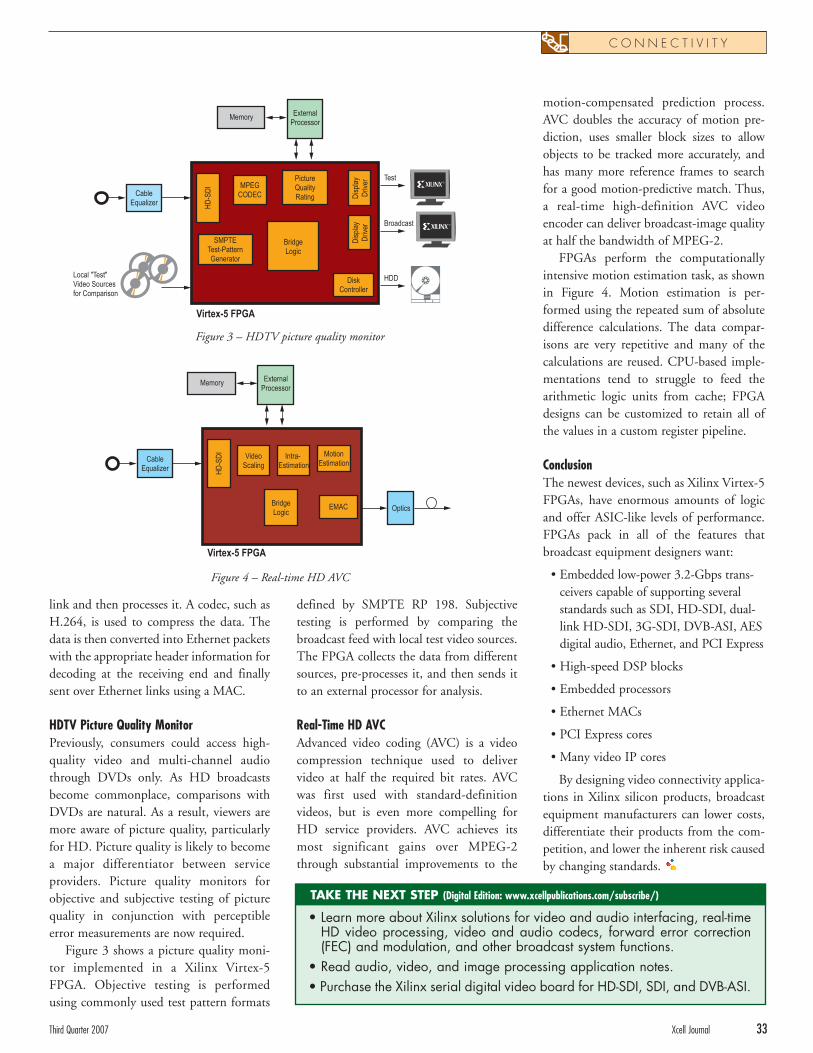
Third Quarter 2007 Xcell Journal 33
link and then processes it. A codec, such asH.264, is used to compress the data. Thedata is then converted into Ethernet packetswith the appropriate header information fordecoding at the receiving end and finallysent over Ethernet links using a MAC.
HDTV Picture Quality MonitorPreviously, consumers could access high-quality video and multi-channel audiothrough DVDs only. As HD broadcastsbecome commonplace, comparisons withDVDs are natural. As a result, viewers aremore aware of picture quality, particularlyfor HD. Picture quality is likely to becomea major differentiator between serviceproviders. Picture quality monitors forobjective and subjective testing of picturequality in conjunction with perceptibleerror measurements are now required.
Figure 3 shows a picture quality moni-tor implemented in a Xilinx Virtex-5FPGA. Objective testing is performedusing commonly used test pattern formats
defined by SMPTE RP 198. Subjectivetesting is performed by comparing thebroadcast feed with local test video sources.The FPGA collects the data from differentsources, pre-processes it, and then sends itto an external processor for analysis.
Real-Time HD AVCAdvanced video coding (AVC) is a videocompression technique used to delivervideo at half the required bit rates. AVCwas first used with standard-definitionvideos, but is even more compelling forHD service providers. AVC achieves itsmost significant gains over MPEG-2through substantial improvements to the
motion-compensated prediction process.AVC doubles the accuracy of motion pre-diction, uses smaller block sizes to allowobjects to be tracked more accurately, andhas many more reference frames to searchfor a good motion-predictive match. Thus,a real-time high-definition AVC videoencoder can deliver broadcast-image qualityat half the bandwidth of MPEG-2.
FPGAs perform the computationallyintensive motion estimation task, as shownin Figure 4. Motion estimation is per-formed using the repeated sum of absolutedifference calculations. The data compar-isons are very repetitive and many of thecalculations are reused. CPU-based imple-mentations tend to struggle to feed thearithmetic logic units from cache; FPGAdesigns can be customized to retain all ofthe values in a custom register pipeline.
ConclusionThe newest devices, such as Xilinx Virtex-5FPGAs, have enormous amounts of logicand offer ASIC-like levels of performance.FPGAs pack in all of the features thatbroadcast equipment designers want:
• Embedded low-power 3.2-Gbps trans-ceivers capable of supporting severalstandards such as SDI, HD-SDI, dual-link HD-SDI, 3G-SDI, DVB-ASI, AESdigital audio, Ethernet, and PCI Express
• High-speed DSP blocks
• Embedded processors
• Ethernet MACs
• PCI Express cores
• Many video IP cores
By designing video connectivity applica-tions in Xilinx silicon products, broadcastequipment manufacturers can lower costs,differentiate their products from the com-petition, and lower the inherent risk causedby changing standards.
CableEqualizer
MPEGCODEC
DiskController
SMPTETest-PatternGenerator
PictureQualityRating
BridgeLogic
HD
-SD
I
Dis
play
Driv
erD
ispl
ayD
river
ExternalProcessor
Memory
Virtex-5 FPGA
Broadcast
Test
HDDLocal "Test"Video Sourcesfor Comparison
R
R
CableEqualizer
VideoScaling
Intra- Estimation
MotionEstimation
BridgeLogic
EMAC
HD
-SD
I
ExternalProcessor
Memory
Virtex-5 FPGA
Optics
• Learn more about Xilinx solutions for video and audio interfacing, real-timeHD video processing, video and audio codecs, forward error correction(FEC) and modulation, and other broadcast system functions.
• Read audio, video, and image processing application notes. • Purchase the Xilinx serial digital video board for HD-SDI, SDI, and DVB-ASI.
TAKE THE NEXT STEP (Digital Edition: www.xcellpublications.com/subscribe/)
Figure 3 – HDTV picture quality monitor
Figure 4 – Real-time HD AVC
C O N N E C T I V I T Y

HAPS™ – High-performance ASIC Prototyping System™
a high performance, high capacity FPGA platform for ASIC prototyping and emulation composed of multi-FPGA boards and standard or custom-made daughter boards
HapsTrak™
a set of rules for pinout and mechanical characteristics, which guarantees compatibility with previous and futuregeneration HAPS motherboards and daughter boards
Synplicity, Inc. 600 West California Avenue, Sunnyvale, CA 94086Phone: (U.S.) +1 408 215-6000
www.synplicity.com, [email protected]
Copyright © 2007 Synplicity, Inc. All rights reserved. Specifications subject to change without notice.Synplicity, the Synplicity logo, and "Simply Better Results" are registered trademarks of Synplicity, Inc.HAPS, "High-performance ASIC Prototyping System", and HapsTrak are trademarks of Synplicity, Inc.
Virtex-II, Virtex-II Pro, Virtex-4, and Virtex-5 are registered trademarks of Xilinx Inc.
Hap
sTrak
2003co
mpat i b
le
Hap
sTrak
2004co
mpat i b
le
Hap
sTrak2005c
o
mpat i b
le
Hap
sTrak
2007co
mpat i b
le
HAPS-10
HAPS-30
HAPS-20
HAPS-50

FREE on-line tutorialswith Demos On Demand
A series of compelling, highly technical product
demonstrations, presented by Xilinx experts, is now
available on-line. These comprehensive videos provide
excellent, step-by-step tutorials and quick refreshers
on a wide array of key topics. The videos are segmented
into short chapters to respect your time and make for
easy viewing.
Ready for viewing, anytime you are
Offering live demonstrations of powerful tools, the
videos enable you to achieve complex design require-
ments and save time. A complete on-line archive is
easily accessible at your fingertips. Also, a free DVD
containing all the video demos is available at
www.xilinx.com/dod. Order yours today!
©2007 Xilinx, Inc. All rights reserved. XILINX, the Xilinx logo, and other designated brands included herein are trademarks of Xilinx, Inc. All other trademarks are the property of their respective owners.

by Navneet RaoTechnical Marketing Manager, Platform SolutionsXilinx, [email protected]
Today, the demand for high-speed commu-nication and super-fast computing is spiral-ing. Wired and wireless communicationstandards are being deployed everywhereand the data-processing infrastructure isscaling everyday. The pervasive means ofwired communication is Ethernet throughLAN, WAN, and MAN networks. Thepervasive means of wireless communicationis through cell phones, enabled by infra-structures using DSP. What was primarily ameans of voice connectivity – the phone –now caters to the ever-increasing demandsfor voice, video, and data.
System designers must create architec-tures that will alleviate the exorbitantdemands of triple-play scenarios whilemeeting such requirements as:
• High performance
• Low latency
• Lower system costs (NRE included)
• Scalable, extensible architectures
• Integrating off-the-shelf (OTS) components
• Distributed processing
• Support for multiple standards and protocols
What emerges from these challengesare two primary themes: connectivity
between compute platforms/boxes inwired or wireless infrastructures and theindividual computing resources in theseplatforms/boxes.
Connectivity Between Compute PlatformsStandards-based connectivity is commontoday. Parallel connectivity standards(PCI, PCI-X, EMIF) may be able tomeet current demands, but will come upshort when scalability and extensibilityare involved. With the advent of packet-based processing, clearly the trend istoward high-speed serial connectivity(Figure 1).
The desktop and networking industrieshave adopted standards like PCI Express(PCIe) and Gigabit Ethernet/XAUI.Data-processing systems in wireless infra-
36 Xcell Journal Third Quarter 2007
Serial RapidIO Connectivity Enhances DSP Co-Processing Serial RapidIO Connectivity Enhances DSP Co-Processing The Virtex-5 LXT FPGA-based SRIO IP solution significantly enhances connectivity by providing a true bi-directional data flow.The Virtex-5 LXT FPGA-based SRIO IP solution significantly enhances connectivity by providing a true bi-directional data flow.
C O N N E C T I V I T Y

structures, however, have slightly differentinterconnect requirements:
• Low pin counts
• Backplane chip-chip connectivity
• Bandwidth and speed scalability
• DMA and message passing
• Support for complex scalable topologies
• Multicast
• High reliability
• Time-of-day synchronization
• Quality of service (QoS)
The Serial RapidIO (SRIO) protocolstandard can easily meet and exceed mostof these requirements. As such, SRIO hasbecome the dominant interconnect fordata-plane connectivity in wireless infra-structure equipment.
SRIO networks are built around twobasic blocks – endpoints and switches(Figure 2). Endpoints source and sinkpackets, while switches pass packetsbetween ports without interpreting them.
SRIO is specified in a three-layer archi-tectural hierarchy (Figure 3):
• The physical layer specificationdescribes device-level interface specificssuch as packet transport mechanisms,flow control, electrical characteristics,and low-level error management.
• The transport layer specification pro-vides the necessary route information fora packet to move from endpoint to end-point. Switches operate at the transportlayer by using device-based routing.
• The logical layer specification definesthe overall protocol and packet for-mats. All packets are 256 payloadbytes or less. The transactions useload/store/DMA operations targetedto a 34-/50-/66-bit address space.The transactions include:
• NREAD – read operation (datareturned is the response)
• NWRITE – write operation, no response
Third Quarter 2007 Xcell Journal 37
Sy
ste
m P
erf
orm
an
ce
TimePCI 32/33
PCI-X 133, EMIF
RapidIO, POS PHY L4...
SRIO, PCIe
> 1 GHz
< 1 GHz
< 133 MHz
< 33 MHz
Parellel I/O
Shared Clock
Shared Bus Device Device
Device Device Device Device
Device Device Device Device
Device DeviceBridge Device
Parellel I/OSource-
SynchronousPoint-to-Point
Switched
Device
Switch Fabric
Device
Device Device
Serial I/OCDR
Point-to-PointSwitched
Device
Switch Fabric
Device
Device Device
DRAM
Port3
Port3
Port2
Port2
Port0
Port0
Port1
ROM
CPU
Endpoint
SwitchEndpoint
Endpoint
Endpoint
EndpointSwitch
Endpoint
SRIO networks are built around two
basic blocks:
- Endpoints
- Switches
Endpoints source and sink packets
Switches pass packets between
ports without interpreting them
All devices support maintenance
transactions for access to
configuration registers
Upper-Layer
Protocols
Session
Layer
Layered
OSI
Architecture
Layered
SRIO
ArchitectureNetwork
Layer
Transport
Layer
Data-
Link
Layer
Physical
Layer
Transport
Layer
Physical
Layer
Logical
Layer
Upper-Layer
Protocols
Figure 1 – Trend toward serial connectivity
Figure 2 – SRIO network building blocks
Figure 3 – Layered SRIO architecture
C O N N E C T I V I T Y

• NWRITE_R – robust write, withresponse from the target endpoint
• SWRITE – streaming write
• ATOMIC – atomic read-modify-write
• MAINTENANCE – system discov-ery, exploration, initialization, config-uration, and maintenance operations
SRIO – An Advantage ScenarioA four-lane SRIO link running at 3.125Gbps can deliver 10 Gbps throughput withfull data integrity. Because SRIO is similarto microprocessor buses – memory anddevice addressing instead of the softwaremanagement of LAN protocols – packetprocessing is implemented in hardware.This means significantly lower I/O process-ing overhead, lower latency, and increasedsystem bandwidth. But unlike most businterfaces, SRIO has low pin count inter-faces and scalable bandwidth based on3.125-Gbps links.
Computing Resources in PlatformsToday’s applications demand greater pro-cessing resources. Hardware-based imple-mentations are gaining traction.Compression/decompression algorithms,firewall applications like anti-virus andintrusion detection, and security applica-tions requiring encryption engines like AES,Triple DES, and Skipjack have been target-ed for hardware implementations after beinginitially implemented in software. Thisdemands a massive parallel ecosystem ofshared bandwidth and processing power.Shared or distributed processing harnessingthrough systems using CPUs, NPUs,FPGAs, or ASICs is required.
Considering all of these application-spe-cific requirements for building a future-proof system, the requirements forcomputing resources include:
• Multiple hosts – distributed processing
• Direct peer-to-peer communications
• Multiple heterogeneous OSs
• Complex topologies:
• Discovery mechanisms
• Redundant paths (failover)
• Ability to support high reliability:
• Lossless protocol
• Automatic retraining and device synchronization
• System-level error management
• Ablity to support communicationsdata plane:
• Multicast
• Traffic-managed (lossy) operation
• Link, class, and stream-based flow control
• Protocol interworking
• Higher transaction concurrency
• Modular and extendable
• Broad ecosystem support
The SRIO protocol was designed tosupport all of the disparate requirementsdriven by compute devices in wirelessinfrastructures.
The SRIO specification (Figure 4)defines a packet-based layered architectureto support multiple domains or market seg-ments for system architects to design next-generation computing platforms. Featureslike architectural independence, ability todeploy scalable systems with carrier-gradereliability, advanced traffic management,and provisioning for high performance and
throughput can easily be accomplished byadopting SRIO as the computing intercon-nect. Furthermore, a broad ecosystem ofvendors makes the selection of OTS partsand components easy.
SRIO is a packet-based protocol thatsupports:
• Data movement using packet-basedoperations (read, write, message)
• I/O non-coherent functions and cachecoherence functions
• Efficient interworking and protocolencapsulation through support for datastreaming and segmentation andreassembly functions
• A traffic-management framework byenabling millions of streams, support for256 traffic classes, and lossy operations
• Flow control to support multiple trans-action request flows, provision for QoS
• Priorities support to alleviate problemslike bandwidth allocation, transactionordering, and deadlock avoidance
• Topology support for standard (treesand meshes) and arbitrary hardware(daisy-chain) topologies through systemdiscovery, configuration, and bring-up,including support for multiple hosts
• Error management and classification(recoverable, notification, and fatal)
38 Xcell Journal Third Quarter 2007
Logical
Specifications I/O System Message
Passing
Global Shared
Memory
Flow
Control
Data
Streaming
Transport
Specifications Common
Transport
Physical
Specifications 1x/4x Serial Higher Speed
PHYs
Ancillary
Specifications Interoperability Error
Management
System
Bring Up
Multicast
Figure 4 – SRIO specification
C O N N E C T I V I T Y

Third Quarter 2007 Xcell Journal 39
Xilinx IP Solutions for SRIOXilinx endpoint IP solutions for SRIO aredesigned to RapidIO specification v1.3.The complete Xilinx endpoint IP solutionfor SRIO comprises the following compo-nents (Figure 5):
• The Xilinx endpoint IP for SRIO is asoft LogiCORE™ solution. It sup-ports fully compliant maximum-pay-load operations for both sourcing andreceiving user data through target andinitiator interfaces on the logical (I/O)and transport layers.
• The buffer layer reference design isprovided as source code to performautomatic packet re-prioritization and queuing.
• The SRIO physical layer IP imple-ments link training and initialization,discovery and management, and errorand retry recovery mechanisms.Additionally, the high-speed trans-ceivers are instantiated in the physicallayer IP to support one- and four-laneSRIO bus links at line rates of 1.25Gbps, 2.5 Gbps, and 3.125 Gbps.
• The register manager reference designenables the SRIO host device to con-figure and maintain endpoint deviceconfiguration, link status, control, andtime-out mechanisms. In addition,ports are provided on the register man-ager for the user design to probe thestatus of the endpoint device.
The complete Xilinx endpoint IPLogiCORE solution for SRIO has beenexhaustively tested, hardware validated,and is undergoing interoperability test-ing with leading SRIO device vendors.The LogiCORE IP is delivered throughthe Xilinx CORE Generator™ softwareGUI tool that enables user customiza-tion for baud rates, endpoint configura-tion, and support for extended featureslike flow control, re-transmit suppres-sion, doorbell, and messaging. Thisenables you to create a flexible, scalable,and customized SRIO endpoint IP opti-mized for your application.
Virtex-5 FPGA Computing ResourcesThe Xilinx endpoint IP for SRIO ensuresthat high-speed connectivity is establishedbetween the link partner using the SRIOprotocol. The IP consumes <20% of theavailable logic resources in the smallestVirtex™-5 device, thereby ensuring thatthe user design has access to the mostlogic/memory/I/Os for targeting a systemapplication. Let’s review the resources inVirtex-5 devices.
Logic BlocksThe Virtex-5 logic architecture, with six-input look-up tables (LUTs) based onthe 65-nm process, offers the highestFPGA capacity. Along with improvedcarry logic, this provides a 30% perform-ance benefit over previous devices. Powerconsumption is significantly lowered
because fewer LUTs are required, and thedevice has a highly optimized symmetricrouting architecture.
MemoryVirtex-5 memory solutions include LUTRAMs, block RAMs, and memory con-trollers for interfacing to large memories.The block RAM structure includes pre-engineered FIFO logic – embedded errorchecking and correction (ECC) logic thatcan be used for external memories. In addi-tion, Xilinx provides comprehensive designresources to instantiate memory controllerblocks in a system design through theMemory Interface Generator (MIG) tool.This enables you to leverage hardware-ver-ified solutions and focus your efforts onother crucial sections of your designs.
Parallel and Serial I/OsSelectIO™ technology is capable of virtual-ly any parallel source-synchronous interfacethe customer needs in the design. Using theSelectIO interface, you can easily createindustry-standard interfaces for more than40 different electrical standards or propri-etary interfaces. The SelectIO interfaceoffers maximum rates at 700 Mbps single-ended and 1.25 Gbps differential.
All Virtex-5 LXT FPGAs have a GTPtransceiver capable of running at speedsfrom 100 Mbps to 3.2 Gbps. The GTPtransceiver is also one of the industry’s low-est power MGTs, with less than 100 mWper transceiver. The design flow process forhigh-speed serial design is alleviated by theintroduction of proven design techniquesand methodologies to simplify the design.
In addition, new design tools(RocketIO™ transceiver wizard andIBERT) and new silicon capabilities (TXand RX equalization and built-in pseu-do-random bit sequence (PRBS) genera-tor and checker) allow you to exploit thefeatures and benefits of migrating archi-tectures from parallel I/O standards tomore than 30 serial standards andemerging serial technologies.
DSP BlocksEach DSP48E slice can provide 550-MHzperformance, enabling you to create appli-
Logical (I/O)
and
Transport
Layer
User
Logic
Register Manager
RapidIO
FabricBu
ffe
r
Physical
Layer
Figure 5 – Xilinx endpoint IP architecture for SRIO
C O N N E C T I V I T Y

cations that require single-precision floating-point capability like multimedia, video andimaging applications, and digital communi-cations. This provides expanded functional-ity compared to previous devices as well asproviding a power advantage by reducingdynamic power consumption by more than40%. The number of DSP48E slices has alsobeen increased in Virtex-5 FPGAs, whichoptimizes the ratio of these blocks relative tothe available logic resources and memory.
Integrated I/O BlocksAll Virtex-5 LXT FPGA devices have oneendpoint block for implementing a PCIefunction. This hard IP endpoint blockenables easy scalability from x1 to x2 and x4or x8 painlessly with easy reconfigurability.The block has also passed stringent PCI-SIGcompliance and interoperability tests for x1,x4, and x8 links, considerably easing theuser adoption for PCIe.
All Virtex-5 LXT FPGA devices also havefour tri-mode Ethernet media access con-trollers (TEMACs) capable of 10-/100-/1,000-Mbps speeds. The block providesdedicated Ethernet functionality, whichtogether with Virtex-5 LXT RocketIOtransceivers and SelectIO technologyenables you to connect to a wide variety ofnetwork devices.
Using the two integrated I/O blocks forPCIe and Ethernet, you can create a rangeof customized packet processing and net-work products that provide a significantreduction in utilization and power con-sumption. Using these varied resourcesavailable in Xilinx FPGAs, you can easilycreate and deploy intelligent solutions.
Let’s look at some system design exam-ples using SRIO and DSP technologies.
SRIO Embedded System Application Consider an embedded system builtaround x86 architecture-based CPUs.The CPU architecture has been highlyoptimized and can easily cater to applica-tions requiring “number crunching.” Youcan easily implement algorithms in hard-ware and software that use CPU resourcesto perform functions like e-mail, databasemanagement, and word processing thatdo not require extensive multiplication.
Performance is measured in millions orbillions of instructions/operations persecond and efficiency is measured interms of time/cycles required to completea specific operation.
High-performance applications requir-ing a wide range of fixed- and floating-point operations take longer to process thedata. Examples include signal filtering, fastFourier transforms, vector multiplicationand searching, image/video analysis andformat conversion, and simple number-crunching algorithms. High-end signalprocessing architectures implemented inDSPs can easily perform these tasks andoptimize such operations. The perform-ance of these DSPs is measured in multi-ply-accumulates per second.
You can easily design embedded systemsthat use CPUs and DSPs to take advantageof both processing techniques. Figure 6shows an example system using FPGAs,CPUs, and DSP architectures.
In high-end DSPs, the primary datainterconnect is SRIO. In x86 CPUs, theprimary data interconnect is PCIe. Asshown in Figure 6, FPGAs can easily bedeployed for scaling the DSP applicationor for bridging across disparate data inter-connect standards, like PCIe and SRIO.
In the system depicted in Figure 6, thePCIe system is hosted by the root complex
chip set. The SRIO system is hosted by aDSP. The 32-/64-bit PCIe address space(base address) can be intelligently mappedto the 34-/66-bit SRIO address space (baseaddress). The PCIe application communi-cates with the root complex through mem-ory or I/O reads and writes. Thesetransactions can be easily mapped to SRIOspace through NReads/NWrites/SWrites.
Designing such bridge functions is easyin Xilinx FPGAs because the back-endinterfaces for these Xilinx endpoint func-tional blocks, PCIe, and SRIO are similar.The “packet-queue” block can then per-form the crossover from PCIe to SRIO orvice-versa to establish packet flow acrosseither protocol domain.
SRIO DSP System ApplicationIn applications where DSP processing is theprimary architectural requirement, the sys-tem architecture can be designed as depict-ed in Figure 7.
Virtex-5 FPGA-based DSP processingcan act as an intelligent co-processing solu-tion with other DSP devices in the system.The complete DSP system solution can bescaled easily if SRIO is used as the datainterconnect. Such solutions can be future-proofed, provide extensibility, and can besupported across multiple form factors. InDSP-intensive applications, fast number
40 Xcell Journal Third Quarter 2007
SRIO IP
PCIe IP
Chipset
(PCIe Root
Complex)
GbE
Links
Packet Queue
DSP
(SRIO Host)3.125G SRIO x4 3.125G SRIO x4
3.125G SRIO x4
x8 PCIe
DDR2
SRIO
Switch
DSP Application
SRIO
PCIe
GbE
CPU CPU
MemoryGbE
Controller
DDR2
10GE
Memory
GbE
Controller
10GE
Figure 6 – CPU-based scalable, high-performance embedded system
C O N N E C T I V I T Y
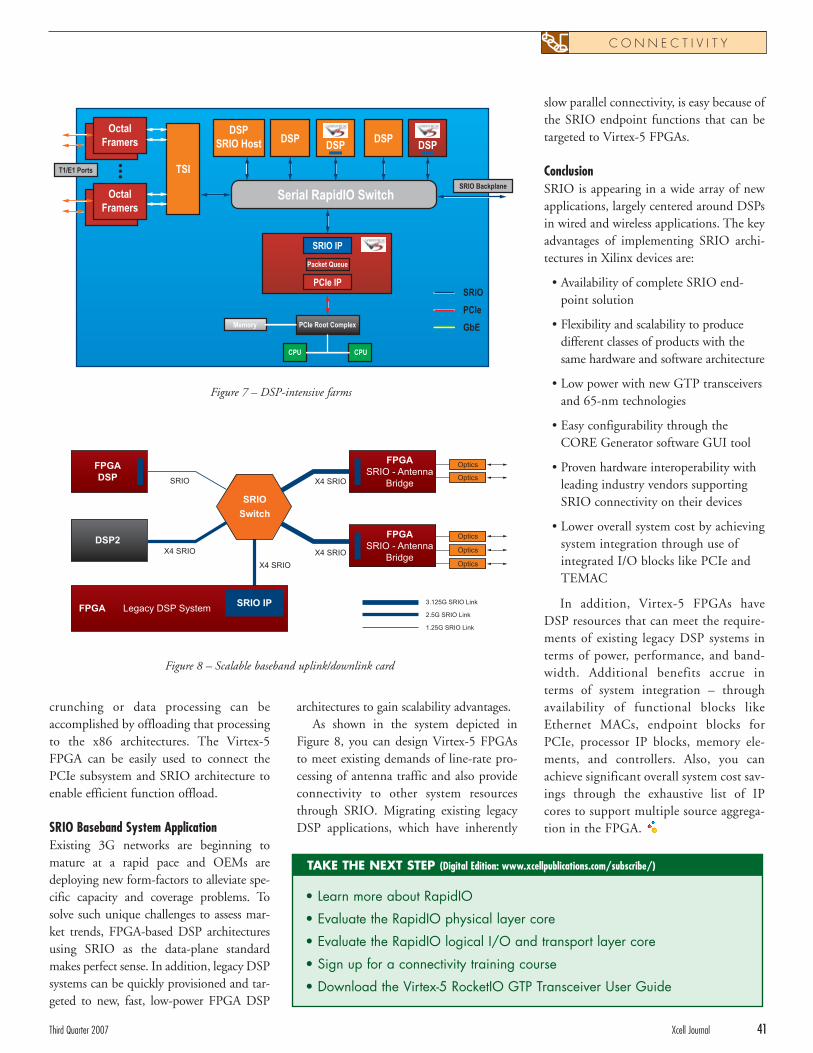
Third Quarter 2007 Xcell Journal 41
crunching or data processing can beaccomplished by offloading that processingto the x86 architectures. The Virtex-5FPGA can be easily used to connect thePCIe subsystem and SRIO architecture toenable efficient function offload.
SRIO Baseband System ApplicationExisting 3G networks are beginning tomature at a rapid pace and OEMs aredeploying new form-factors to alleviate spe-cific capacity and coverage problems. Tosolve such unique challenges to assess mar-ket trends, FPGA-based DSP architecturesusing SRIO as the data-plane standardmakes perfect sense. In addition, legacy DSPsystems can be quickly provisioned and tar-geted to new, fast, low-power FPGA DSP
architectures to gain scalability advantages.As shown in the system depicted in
Figure 8, you can design Virtex-5 FPGAsto meet existing demands of line-rate pro-cessing of antenna traffic and also provideconnectivity to other system resourcesthrough SRIO. Migrating existing legacyDSP applications, which have inherently
slow parallel connectivity, is easy because ofthe SRIO endpoint functions that can betargeted to Virtex-5 FPGAs.
ConclusionSRIO is appearing in a wide array of newapplications, largely centered around DSPsin wired and wireless applications. The keyadvantages of implementing SRIO archi-tectures in Xilinx devices are:
• Availability of complete SRIO end-point solution
• Flexibility and scalability to producedifferent classes of products with thesame hardware and software architecture
• Low power with new GTP transceiversand 65-nm technologies
• Easy configurability through theCORE Generator software GUI tool
• Proven hardware interoperability withleading industry vendors supportingSRIO connectivity on their devices
• Lower overall system cost by achievingsystem integration through use ofintegrated I/O blocks like PCIe andTEMAC
In addition, Virtex-5 FPGAs haveDSP resources that can meet the require-ments of existing legacy DSP systems interms of power, performance, and band-width. Additional benefits accrue interms of system integration – throughavailability of functional blocks likeEthernet MACs, endpoint blocks forPCIe, processor IP blocks, memory ele-ments, and controllers. Also, you canachieve significant overall system cost sav-ings through the exhaustive list of IPcores to support multiple source aggrega-tion in the FPGA.
Octal
Framers
TSI
DSP
SRIO HostDSP
Serial RapidIO Switch
SRIO IP
PCIe IP
SRIO
PCIe
GbE
Packet Queue
DSP
T1/E1 Ports
DSP
Octal
Framers
SRIO Backplane
DSP
PCIe Root ComplexMemory
CPU CPU
FPGA
DSP
FPGA Legacy DSP System
X4 SRIO
SRIO
X4 SRIO
3.125G SRIO Link
2.5G SRIO Link
1.25G SRIO Link
X4 SRIO
X4 SRIO
SRIO IP
SRIO
Switch
FPGA
SRIO - Antenna
Bridge
DSP2
Optics
Optics
FPGA
SRIO - Antenna
Bridge
Optics
Optics
Optics
• Learn more about RapidIO
• Evaluate the RapidIO physical layer core
• Evaluate the RapidIO logical I/O and transport layer core
• Sign up for a connectivity training course
• Download the Virtex-5 RocketIO GTP Transceiver User Guide
TAKE THE NEXT STEP (Digital Edition: www.xcellpublications.com/subscribe/)
Figure 7 – DSP-intensive farms
Figure 8 – Scalable baseband uplink/downlink card
C O N N E C T I V I T Y

by Ho Wai Wong-Lam Marketing Manager NXP Semiconductors [email protected]
Martin GallezotMarketing and Sales [email protected]
Developers today are increasingly squeezedbetween providing ever-greater throughputfor data-hungry applications and shrinkingproduct lifecycles. Take frame grabberproducts, for example, which are image-processing computer boards that capture,process, and store image data for a widerange of scientific, medical, and industrialapplications. Advances in image sensingcontinue to put a greater demand on theinterconnect bandwidth as the number ofpixels, frame rates, and number of camerasserved by a single frame grabber increases.Some applications already require through-put exceeding 1 Gbps.
To meet the demands of today’s devel-opment environment, companies areadopting PCI Express, the next-generationI/O interconnect technology of choice, andincreasingly relying on FPGA-based inter-operable, proven solutions that reduce theintegration risk and decrease a product’stime to market.
PCI Express is designed to replace PCIand PCI-X interconnect technologies, pro-viding a scalable bandwidth from x1 at250 Mbps to x32 at 8 Gbps. The v2.0specification further increases bandwidthby doubling the one-lane data rate from2.5 Gbps in the v1.1 specification to 5Gbps. Besides increased throughput, PCIExpress offers a smaller connector thanPCI/PCI-X, which lowers costs and eases
PCB routing. And to ease the transitionfrom PCI/PCI-X, PCI Express is back-ward-compatible with PCI with regards tosoftware performance.
Interoperable solutions such as the NXPPHY/PLDA IP controller offer the advan-tages of PCI Express coupled with the secu-rity of a PCI-SIG-proven solution,allowing you to concentrate on applica-tion-specific functionality.
42 Xcell Journal Third Quarter 2007
The NXP/PLDA Programmable PCI Express SolutionBased on the Spartan-3 FPGA, NXP and PLDA’s PHY/controller solution delivers affordability and ease of integration.
C O N N E C T I V I T Y

NXP’s PX1012A NXP Semiconductors (previously PhilipsSemiconductors) offers the PX1012A sin-gle-lane 2.5-Gbps PCI Express PHY device,which serves as a companion chip toFPGAs or digital ASICs. The PX1012A isideal for use with PLDA’s XpressLite PCIExpress IP core.
The PX1012A is optimized for use withlow-cost FPGAs. It is available in a verysmall package, delivers superior transmit andreceive performance, and is compliant toPCI Express specifications v1.0a and v1.1.The PX1012A is designed to serve PCIExpress applications in all kinds of form fac-tors, from space-constrained and low-powerExpressCard modules to desktop add-oncards to PXIe test equipment rack add-onmodules. The NXP PCI Express PHYPX1012A has the following key features:
• Compliant to PCI Express base specifi-cation v1.0a and v1.1; the NXP PHYpassed the first official U.S. PCI-SIGv1.1 electrical compliance tests inDecember 2006.
• The Xilinx® Spartan™-3 FPGA com-municates with the PX1012A PHYusing the source-synchronous 250-MHzPXPIPE standard, based on SSTL_2I/O. The use of source-synchronousclocking eases PCB layout by making thedata transactions between the FPGA andPHY devices more robust than the origi-nal PIPE standard, which uses only oneclock for both transmit and receive data.
• A small 9 x 9-mm BGA package withtwo signal rings (so that only one inner-ring signal needs to escape between theballs). In fact, the NXP PHY can be laidout with just two PCB signal layers,which have been proven in actual hard-ware designs. Example referenceschematics are available on request.
• Low power dissipation in normal L0mode (typically <300 mW includingI/O). For further reduction in powerdissipation, the removal of termina-tion resistors on the PHY/FPGA inter-face and optimized PCB layout canfurther reduce PX1012A power dissi-pation to <150 mW.
The XpressLite controller is an RTL-levelIP core fully compliant with the PCI Expressprotocol. As required, the configuration space(located within the transaction layer) imple-ments all configuration registers and associat-ed functions. The configuration space alsogenerates all messages (PME#, INT, error,power slot limit), MSI requests, and comple-tion packets from configuration requests thatflow in the direction of the root complex.
The XpressLite is fully configurablethrough a graphical wizard, making it sim-ple to customize such parameters as maxi-mum payload size, configuration spaceregisters, buffer sizes, and number of DMAchannels. The wizard generates a wrapperthat instantiates the core top level and con-nects ports and assigns parameters accord-ing to specified options. Unused corefeatures are not synthesized.
The XpressLite is PCIe specification1.1-compliant. It has a small footprint andminimal memory utilization. Typicalimplementation requires about 8,000 LUTsand seven block RAMs in a Spartan-3device. These figures include the EZ multi-DMA application layer configured withtwo DMA channels. PCI Express featuressupported by the XpressLite controller aresummarized in Table 1.
• Both commercial temperature grade(0 to 70°C) and industrial grade (-40to 85°C) are available; this is a uniqueindustrial temperature grade devicefor PCI Express PHY, making NXPPHY suitable for various industrialapplications.
PLDA’s XpressLite IP Core PLDA’s XpressLite PCI Express IP core is acomplete PCIe digital controller optimizedfor Spartan-3 FPGAs. It includes all threelayers of the PCIe specification (physical,data link, and transaction layer), plus anadditional application layer called the EZDMA interface.
PLDA’s EZ DMA interface is suitablefor designers who have little or no experi-ence with the PCI Express protocol or forexperienced designers looking for arobust yet simple PCI Express interface.The EZ DMA interface provides design-ers with a target path, which includes asimple address/data bus, and a masterpath, which comprises multiple DMAengines that handle the transfer of data tothe host system memory. The EZ DMAinterface can also be used together withthe built-in PCI Express controller inVirtex™-5 LXT devices.
Core Type Legacy or Native Endpoint
Maximum Payload Up to 2 KB
Backend Data Path 64 bit
Virtual Channels One
BARs, Expansion ROM User-defined, set by the XpressLite wizard
PCI ID User-defined, set by the XpressLite wizard
Legacy Power Management Minimal or full, set by the XpressLite wizard
Message Signaled Interrupt (MSI) • Message count: 1 to 32, set by the the XpressLite wizard
• 64-bit address: Yes
• Per-vector masking: No
EZ Multi-DMA Interface • DMA channels: up to eight, set by the XpressLite wizard
• Number of outstanding requests: one to eight simultaneousrequests, set by the XpressLite wizard
• Maximum DMA transfer size: up to 4 GB
Third Quarter 2007 Xcell Journal 43
Table 1 – PCI Express features supported by the XpressLite controller
C O N N E C T I V I T Y

PLDA’s core package also includes acomplete test bench with an RTL-level PCIExpress bus functional model (BFM),transactor, monitor, and checker.
Fully Compliant and Interoperable SolutionThe NXP/PLDA joint solution successfullycompleted PCI Express compliance testsadministered at the PCI-SIG ComplianceWorkshop #48 in December 2005 andlater workshops in 2006 (see transmittereye pattern results in Figure 1).
NXP, PLDA, and mutual customers haverun extensive and successful system tests in amultitude of PC systems, including:
• ASUS A8NE (x16, two x1 slots andone x4 slot)
• ASUS P5GP motherboard (Intel 915Gchipset)
• ASUS P5LD2 DELUXE (Intel i945chipset)
• Dell Dimension 4700 x1 and x16 slots(Intel 915G chipset)
• Dell Dimension 8400 (Intel 925Gchipset)
• DELL Precision 370
• Dell Precision 470 x8 and x16 slots(Intel Turnwater E7525 chipset)
• HP XW4200
• HP XW4300
• MSI (Intel i915 chipset)
• Serverworks GC-SL
• Shuttle ATI Express 200 chipset
• Supermicro X6DA8G (x16 and x4 slots)
In addition to the standard PCI-SIGcompliance tests, NXP and PLDA alsoused a variety of system tests developedinternally and from third-party test equip-ment vendors:
• PCI scan diagnostic utility
• Transmitter electrical compliance testsv1.0a and v1.1
• PCI-SIG PCI-ECV v1.2
• Agilent protocol test card (PTC) test
• Agilent receiver bit error rate (BER) test
• NXP receiver performance test
• PLDA throughput measurement test
High ThroughputTheoretical maximum throughput is afunction of payload size and PCI Expressprotocol overhead. Actual throughputresults depend on factors such as softwaredriver efficiency, PCI Express IP core effi-ciency, the user’s application design, trans-mitter jitter, and receiver BER performance.Throughput might be further compro-mised by link-layer protocol overhead suchas ACK/NAK packets (acknowledge/non-acknowledge), re-transmitted packets, andflow control protocol (credit reporting).
Theoretical Maximum ThroughputThe line speed of one-lane PCI Express is2.5 Gbps. However, 8B/10B encodingoverhead reduces the maximum PXPIPEdata throughput (2.5 Gbps divided by 10bits per byte = 250 Mbps). Given the over-head performance cost, throughput typical-ly increases with payload size – up to apoint. For example, for a payload of 128bytes, the theoretical efficiency is 86% (128B(ytes) payload + 12B header + 8B fram-ing) and the maximum theoreticalthroughput is 216 Mbps. Although thePCI Express specification specifies a poten-tial maximum payload size of as much as 4KB, most existing applications only imple-ment a maximum payload size of 128B or256B. Throughput measurements for theNXP/PLDA solution are listed in Table 2.
Receiver PerformanceNXP and PLDA have performed exten-sive proprietary system tests in many PCsystems to ensure that there are no recov-erable receiver errors for extended periodsof time (many hours). Test results yield aBER of 1x10-12.
PCI Express specifications v1.0a andv1.1 require 0.6 UI (unit interval) ofreceiver jitter tolerance, but the specifica-tions do not precisely indicate how thejitter components are composed. NXPperformed receiver BER tests using anAgilent BER tester.
• Agilent J-BERT N4903A
• TJ = total jitter; RJ = random jitter; PJ = periodic jitter; DDJ = data-dependent jitter; UI = unit interval; ISI = inter-symbol interference; BER
• 0.60UI TJ = 0.25UI RJ + 0.25UI PJ(at 15 MHz) + 0.1UI DDJ
Throughput ThroughputPCIe PHY IP Core Computer Platform Payload DMA Read DMA Write
(Card–>PC) (PC–>Card)
PX1012A PLDA ASUS A8NE 128 bytes 200 Mbps 175 MbpsSupermicro
X6DA8G
44 Xcell Journal Third Quarter 2007
Figure 1 – PLDA XpressLite SP3 board transmitter eye pattern with v1.1 PCI Express
template (top: non-transition eye; bottom: transition eye)
Table 2 – Throughput measurement results
C O N N E C T I V I T Y

Third Quarter 2007 Xcell Journal 45
• 0.1 UI DDJ = ISI module, which stimulates 9 inches of PCB trace,equivalent to about 0.1-UI jitter andsignificant amplitude degradation.
NXP obtained excellent receiver per-formance results with the Agilent biterror tester.
• PX1012A achieved < 1x10-12 BER witha 800-mVdiff. p-p input signal, which isthe minimum transmit output levelallowed by the PCI Express specification.The 800-mVdiff. p-p signal goes from thepattern generator to the BERT ISI mod-ule before feeding into the PHY receiver.
• Without the ISI module, the PX1012Acan achieve < 1x10-12 BER with a 400-mVdiff. p-p input signal.
PLDA XpressLite SP3 Design KitThe PLDA XpressLite SP3 Design Kit (seeFigure 2) is based on a Spartan-3 FPGA(XC3S2000 device) and integrates theNXP PX1012A. The design kit includes aProtocore (board-only) license of thePLDA XpressLite IP core.
The Protocore license is a full-featuredRTL-level license that is valid for an unlim-ited duration when used with the designkit. It also includes a software developmentkit, with a library of C source code func-
tions and a driver. With the Protocorelicense, you can freely simulate and synthe-size your own design connected to theXpressLite IP core and re-program theFPGA device accordingly.
The complete design has gone throughextensive validation testing, is hardware-proven, and readily available for customerprototyping.
The XpressLite SP3 design kit providesa low-cost solution to prototype yourdesign with PCI Express. It can also beused as part of your final product if youwant to save the effort of designing yourown PCIe board. A 400-hole matrix (2.54-mm step) for prototyping and probing pur-poses is also provided.
ConclusionA prototyping board like PLDA’s XpressLiteSP3 Design Kit, which combines the powerof the Xilinx Spartan-3 FPGA with aproven PCI Express NXP PHY/PLDA IPcontroller solution, responds to today’sdevelopment challenges to produce applica-tions that support ever greater datathroughput in an ever-shrinking productlifecycle. For more information, visitwww.s tandardi c s .nxp . com/produc t s /pcie/phys/ and www.plda.com/products/board_pcie_sp3.php.
Figure 2 – The PLDA XpressLite SP3 is based on a Xilinx Spartan-3 FPGA and includes NXP’s PCIe PX1012A PHY and PLDA’s XpressLite IP controller.
NXP also provides a joint solution with the Xilinx PCI Express PIPE core for Spartan-3FPGAs. You can buy this solution from Xilinx, which includes an x1 PCI Express add-incard and an evaluation version of the PIPE core.
GetPublished
Would you like to be published
in XcellPublications?
It's easier than you think!
Submit an article draft for our Web-based
or printed Xcell Publications and we will
assign an editor and a graphic artist
to work with you to make your work
look as good as possible.
For more information on this
exciting and highly rewarding program,
please contact:
Forrest Couch
Publisher, Xcell Publications
C O N N E C T I V I T Y

SystemBIST™ enables FPGA Configuration that is less filling for your PCB area, less filling for your BOM budget and less filling for your prototypeschedule. All the things you want less of and more of the things you do want for your PCB – like embedded JTAG tests and CPLD reconfiguration.
Typical FPGA configuration devices blindly “throw bits” at your FPGAs at power-up. SystemBIST is different – so different it has three US patentsgranted and more pending. SystemBIST’s associated software tools enable you to develop a complex power-up FPGA strategy and validate it.Using an interactive GUI, you determine what SystemBIST does in the event of a failure, what to program into the FPGA when that daughterboardis missing, or which FPGA bitstreams should be locked from further updates. You can easily add PCB 1149.1/JTAG tests to lower your down-stream production costs and enable in-the-field self-test. Some capabilities:
� User defined FPGA configuration/CPLD re-configuration
� Run Anytime-Anywhere embedded JTAG tests
� Add new FPGA designs to your products in the field
� “Failsafe” configuration – in the field FPGA updates without risk
� Small memory footprint offers lowest cost per bit FPGA configuration
� Smaller PCB real-estate, lower parts cost compared to other methods
� Industry proven software tools enable you to get-it-right before you embed
� FLASH memory locking and fast re-programming
� New: At-speed DDR and RocketIO™ MGT tests for V4/V2
If your design team is using PROMS, CPLD & FLASH or CPU and in-house software to configure FPGAs please visit our website at http://www.intellitech.com/xcell.asp to learn more.
Copyright © 2006 Intellitech Corp. All rights reserved. SystemBIST™ is a trademark of Intellitech Corporation. RocketIO™ is a registered trademark of Xilinx Corporation.

by Adrian CosoroabaMarketing ManagerXilinx, [email protected]
Xilinx® FPGAs provide I/O blocks andlogic resources that make interface designeasier. Nonetheless, designers must stillconfigure, verify, implement, and properlyconnect these I/O blocks – along with extralogic – to the rest of the system in thesource RTL code, carefully simulated andverified in hardware.
In this article, I’ll review the perform-ance requirements, design challenges, andXilinx solutions for memory interfacedesign, from low-cost implementationswith Spartan™-3 Generation FPGAs tothe highest bandwidth interfaces usingVirtex™-5 FPGAs.
Performance Requirements and Xilinx SolutionsIn the late 1990s, memory interfacesevolved from single-data-rate SDRAMs todouble-data-rate (DDR) SDRAMs, withtoday’s DDR2 SDRAMs running at 667Mbps per pin or higher.
Applications can generally be classifiedin two categories:
• Low-cost applications, where the costof the device is most important
• High-performance applications, wheregetting the highest bandwidth is para-mount
DDR SDRAMs and low-end DDR2SDRAMs running below 400 Mbps perpin are adequate to meet the memorybandwidth requirements of most low-costsystems. For these applications, Xilinxoffers Spartan-3 Generation FPGAs:Spartan-3, 3E, 3A, and 3AN devices.
For applications that push the limits ofmemory interface bandwidths, like 667-Mbps-per-pin DDR2 SDRAMs, Xilinxoffers Virtex-5 FPGAs.
Bandwidth is a factor related to boththe data rate per pin and the width of thedata bus. Both Spartan-3 Generation andVirtex-5 FPGAs offer distinct options,spanning a range from smaller low-costsystems with data bus widths of less than72 bits to those as wide as 576 bits for thelarger Virtex-5 packages (Figure 1).
Wider buses at these speeds make chip-to-chip interfaces all the more challenging,requiring larger packages and better power-to-signal and ground-to-signal ratios.Virtex-5 FPGAs have been built withadvanced SparseChevron packaging thatprovides superior signal-to-power andground-pin ratios. Every I/O pin is sur-rounded by sufficient power and groundpins and planes to ensure proper shieldingfor minimum crosstalk noise caused bysimultaneously switching outputs (SSO).
Memory Interfaces with Spartan-3 FPGAsFor low-cost applications where 400-Mbpsbit rates per pin are sufficient, Spartan-3Generation FPGAs coupled with Xilinxsoftware tools provide an easy-to-imple-ment, economical solution.
Third Quarter 2007 Xcell Journal 47
Create Memory Interface DesignsFaster with Xilinx SolutionsCreate Memory Interface DesignsFaster with Xilinx SolutionsXilinx simplifies memory interface design with hardware-verified reference designs, easy-to-use software tools, and complete development kits.Xilinx simplifies memory interface design with hardware-verified reference designs, easy-to-use software tools, and complete development kits.
72 144
Data Bus Width (I/Os)
288 432 576
200
0
400
600
Data Rate/Pin (Mbps)
Virtex-5 FPGAs
667
Spartan-3Generation
FPGAs
333
Figure 1 – Xilinx FPGAs and memory interface bandwidth
M E M O R Y I N T E R F A C E

Three fundamental building blockscomprise a memory interface and con-troller for an FPGA-based design: the readand write data interface, the memory con-troller state machine, and the user interfacethat bridges the memory interface design tothe rest of the FPGA design. Implementedin the fabric, these blocks are clocked bythe output of the digital control manager(DCM) that, in the Spartan-3 Generationimplementation, also drives the look-uptable (LUT) delay calibration monitor (ablock of logic that ensures proper timingfor read data capture).
In the Spartan-3 Generation implemen-tation, read data capture is implementedusing the LUTs in the configurable logicblocks (CLBs). During a read transaction,
the DDR2 SDRAM device sends the readdata strobe (DQS) and associated data tothe FPGA edge-aligned with the read data(DQ). Capturing the DQ is a challengingtask in source-synchronous interfacesbecause data changes at every edge of thenon free-running DQS strobe. The readdata capture implementation uses a tap-delay mechanism based on LUTs.
Write data commands and timings aregenerated and controlled through the writedata interface. The write data interface usesinput/output block (IOB) flip-flops andthe DCM’s 90-, 180-, and 270-degree out-
This trend is readily apparent whencomparing the data valid windows of DDRSDRAMs running at 400 Mbps andDDR2 memory technology, which runs at667 Mbps. The DDR device with a 2.5-nsdata period has a data valid window of 0.7ns, while the DDR2 device with a 1.5-nsperiod has a mere 0.14 ns.
Virtex-5 FPGAs address this challengewith dedicated delay and clocking resourcesin the I/O blocks – called ChipSync™technology. The ChipSync block built intoevery I/O contains a string of delay ele-ments (also known as tap delays), calledIODELAY, with a resolution of 75 ps.
The architecture of the implementationis based on several building blocks. The userinterface that bridges the memory con-troller and physical layer interface to therest of the FPGA design uses a FIFO archi-tecture. The FIFOs hold the command,address, write data, and read data. The maincontroller block controls the read, write,and refresh operations. Two other logicblocks execute the clock-to-data centeringfor read operations: the initialization con-troller and the calibration logic (Figure 2).
The physical layer interface foraddress, control, and data is implementedin the IOBs. The DQ capture uses thememory strobe to capture correspondingDQ and register it with a delayed versionof the strobe. This data is then synchro-nized to the system clock domain in a sec-ond stage of flip-flops. The inputserializer/deserializer feature in the I/Oblock is used for read capture – the firstpair of flip-flops transfer the data fromthe delayed strobe to the system clockdomain. The technique involves the useof 75-ps tap delay (IODELAY) elementsthat are varied during a calibration rou-tine implemented by the calibrationlogic. This routine is performed duringsystem initialization to set the optimalphase between strobe, data, and the sys-tem clock to maximize timing margins.
There are other aspects of the design,such as the overall controller state machinelogic generation and user interface. Tomake the complete design easier for theFPGA designer, Xilinx developed theMemory Interface Generator.
puts to transmit the DQS strobe properlyaligned to the command and data bits.
The implementation of a DDR2SDRAM memory interface has been fullyverified in hardware. The design wasimplemented in the Spartan-3A starter kitboard using a 16-bit-wide DDR2 SDRAMmemory device and the XC3S700A-FG484 device. The reference design usesonly a small portion of the Spartan-3AFPGA’s available resources: 13% of IOBs,9% of logic slices, 16% of global buffer(BUFG) multiplexers (MUXs), and one ofthe eight DCMs.
You can easily customize Spartan-3Generation memory interface designs to fityour application using the MemoryInterface Generator (MIG) software tool.
Memory Interfaces with Virtex-5 FPGAsWith higher data rates, interface timingrequirements become more challenging.The trend toward higher data rates presentsa serious problem to designers in that thedata valid window – that period within thedata period during which DQ can be reli-ably obtained – is shrinking faster than thedata period itself. This is because the vari-ous uncertainties associated with systemand device performance parameters, whichimpinge on the size of the data valid win-dow, do not scale down at the same rate asthe data period.
Address & Control IOBs
Data IOBs
2nd Stage Capture
User Interface
Conflict Logic
Command / Address FIFO Main Controller
Init Controller
Calibration Logic
WE
WERead FIFO
WriteFIFO
DDR2SDRAM
Figure 2 – Virtex-5 FPGA memory interface architecture
48 Xcell Journal Third Quarter 2007
M E M O R Y I N T E R F A C E

Third Quarter 2007 Xcell Journal 49
M E M O R Y I N T E R F A C E
Design and Integration with MIGIntegrating all of the building blocks,including the memory controller statemachine, is essential for the completenessof your designs. Controller state machinesvary with the memory architecture and sys-tem parameters. State machine code can
also be complicated and a function ofmany variables, such as architecture, databus width, depth, access algorithms, anddata-to-strobe ratios.
The complete design can be generatedwith the MIG, a software tool freely avail-able from Xilinx as part of the ISE™ soft-ware CORE Generator™ suite of referencedesigns and IP. The MIG design flow isvery similar to the traditional FPGA designflow. The benefit of the MIG for designersis that there is no need to generate RTLcode from scratch for the physical layerinterface or the memory controller.
You can use the MIG’s GUI to set sys-tem and memory parameters (Figure 3).For example, after selecting the FPGAdevice, package, and speed grade, you canselect the memory architecture and pickthe actual memory device or dual in-line
memory module (DIMM). The same GUIprovides a selection of bus widths and clockfrequencies. Other options provide controlof the clocking method, CAS latency, burstlength, and pin assignments.
The MIG tool can generate in a matter ofminutes the RTL and UCF files, which are
the HDL code andconstraints files,respectively. Thesefiles are generatedusing a library ofhardware-verified ref-erence designs, withmodifications basedon user inputs.
You have com-plete flexibility tofurther modify theRTL code. Unlikeother solutions that
offer “black-box” implementations, the codeis not encrypted, providing complete flexi-bility to change and further customize adesign. The output files are categorized inmodules that apply to different buildingblocks of the design: user interface, physicallayer, or controller state machine. You maywish to customize the state machine thatcontrols the bank access algorithm, for
example. After the optional code change,you can perform additional simulations toverify the functionality of the overall design.
The MIG also generates a synthesizabletest bench with memory checker capability.The test bench is a design example used inthe functional simulation and the hardwareverification of the Xilinx base design.
The final stage of the design is to importthe MIG files in the ISE project, mergethem with rest of your FPGA design files,conduct synthesis and place and route, runadditional timing simulations if needed,and finally perform verification in hard-ware. MIG software also generates a batchfile with the appropriate synthesis, map,and place and route options to help youoptimally generate the final bit file.
Development Boards and Kits Hardware verification of reference designsis an important final step to ensure a robustand reliable solution. Xilinx has verified thememory interface designs for both Spartan-3 Generation and Virtex-5 FPGAs. Table 1shows the memory interfaces supported foreach of the development boards.
The development boards range from low-cost Spartan-3 Generation FPGA implemen-tations to the high-performance solutionsoffered by the Virtex-5 FPGA family.
ConclusionYou can complete your memory interfacedesigns faster with a wide spectrum of XilinxFPGA devices, dedicated software tools likethe MIG, and development boards that fityour application needs, from low cost tohigh bandwidth.
For more information and details onthese memory interface solutions, visitwww.xilinx.com/memory.
Xilinx FPGA Spartan-3E Spartan-3A Spartan-3AN Virtex-5
Development Board/Kit Starter Kit Development Kit Starter Kit ML-561
Memory Interfaces Supported DDR DDR2 DDR2 DDR DDR2QDR-II
RLDRAM II
Selects theMemory
Architecture
Selects the FPGA
Banks
• Download the Memory Interface Generator to generate your referencedesigns for Virtex-5, Virtex-4, and Spartan-3 devices, including HDL codeand pin placements
• See a demo on Memory Interface Solutions with Xilinx FPGAs
• View an on-demand webcast on Low-Cost to High-Performance MemoryInterface Design Made Easy with Xilinx FPGAs
• Contact Xilinx
TAKE THE NEXT STEP
Table 1 – Development boards and kits for memory interfaces
Figure 3 – MIG GUI

by Carl RohrerSenior Design EngineerXilinx, [email protected]
Per square foot, you probably have moremultimedia in your car than you do in yourhouse. There are the two LCD screens forthe kids in the backseat, controlled by aDVD player or a video game console. Anaudio system is powered by the latest MP3player. There’s the navigation system andeven broadcast television in some luxuryvehicles. Plus, you’ve probably got morespeakers in your car than in a high-end sur-round sound system. It’s no wonder thereare so many distracted drivers on the road.What you need is a single, simple controlinterface; what manufacturers need is asophisticated network.
MOST (Media Oriented SystemsTransport) is a network standard on the riseamong automakers and automotive suppli-ers. It provides one single interface formanaging all of your multimedia devices.Its strength resides in the ability to handlemultiple streams of data intended for dif-ferent targets without losing congruity.On-time data: this is something even yourhome network cannot guarantee.
In this article, I’ll explore the MOSTnetwork and demonstrate the flexibility ofthe Xilinx® MOST solution.
Under the HoodThe MOST network runs on optical fiber,typically in a ring topology. The clock andserialized data are bi-phase encoded,requiring just one single piece of fiber tobe routed. MOST offers up to 25 Mbps of
aggregate bandwidth, far surpassing classi-cal automobile networks. In other words,you could play 15 distinct audio streams atthe same time.
Each multimedia device is representedby a node in the ring. A typical MOST net-work will have between three and 10nodes. There is one timing master thatdrives the system clock and generatesframes, or 64-byte sequences, of data. Theremaining nodes all act as slaves. One nodeacts as the user control interface, or MMI(man machine interface). Often, this is alsothe timing master. Figure 1 illustrates abasic MOST ring.
The main payload comprises 60 byteswithin the 64-byte frame. This payload ismade up of synchronous and asynchronousfields. The synchronous field is used forstreaming contiguous data; audio andvideo fall under this category. The asyn-chronous field is used for sporadic datatransfers in applications such as Internetaccess, navigation data transfer, and phonebook synchronization. Also, this channelcould be used for firmware upgrades of thecontrol units.
A node may send or receive data duringits assigned time slots. A time slot – onesynchronous byte within the payload – isdynamically allocated between a requestingnode and the timing master. Typically, onenode will transmit data onto a time slot,while any number of other nodes will col-lect the data from that time slot.
The boundary between synchronousand asynchronous is dynamically con-trolled by the timing master. In any givenframe, the synchronous field may be from4 to 60 bytes, leaving the remainder of the60 bytes to the asynchronous field.
The remaining four bytes of the frameare used for header, trailer, and controlinformation. The header contains a pream-ble for frame alignment. The trailer, amongother things, does a parity check. The con-trol field is used for network-related mes-saging. These messages may be low level,like the allocation and de-allocation of timeslots. Conversely, they can be high-levelapplication messages sent from the opera-tor, such as play next track, volume control,or repeat play.
50 Xcell Journal Third Quarter 2007
Driving Home MultimediaInfotainment hits the road with affordable in-car networking.
I N T E L L E C T U A L P R O P E R T Y

Getting More Out of MOSTInstead of having an external MOST con-troller chip connected to a microcontrolleror DSP, you can integrate all of your com-ponents into one single FPGA. Fewer exter-nal components and reduced PCB spacetranslates into cost savings for developers.
Xilinx offers a fully parameterizableMOST Network Interface Controller (NIC)IP core. You can customize the core to be atiming master or reduce logic with a slave-only configuration. The core is controlled bya full suite of registers accessible through anon-chip peripheral (OPB) interface. TheOPB interface works seamlessly with theXilinx MicroBlaze™ 32-bit RISC processorcore included in Xilinx Platform Studio.
A full set of low-level driver files arealready available in C source code. Thedrivers provide a series of functions foraccessing the register space, handling inter-rupts, and streaming data to the core.Mocean Laboratories AB provides MOSTnetwork services for the IP core for a com-plete network stack, leaving you only towrite your desired application.
Unique to the Xilinx MOST NIC is astreaming port interface that allows data tobe preprocessed in real time. It is ideal forbolting on data filters or encryption/decryp-tion modules. This LocalLink interface, aXilinx standard, will significantly reducetraffic on the processor and processor bus byoffloading dedicated procedures. It’s versa-tile too. You can read or write data in eitherthe receive or transmit directions. Best of all,if you don’t use it, the Xilinx implementa-tion tools will remove the unnecessary logic,allowing you to conserve resources and fityour design into a smaller device.
Synchronous data can be transmittedand received on either the streaming portor the OPB interface. Regardless of themethod you choose and how many timeslots you have assigned, the core formatsdata into 32-bit words for these user inter-faces. Through register definitions, the coreaccumulates received time slot data that isdeposited through one of 16 logical chan-nels. The reverse is true in the transmitdirection. The use of these logical channelsallows for 16 distinct streams of data ineach direction.
network services on top of MicroBlaze forevent scheduling.
You can turn the MP3 player into a high-end audio feed by adding a noise filter bolt-on to eliminate the artifacts of audiocompression. The payload data can run fromthe codec through the noise filter directlyinto the streaming port, completely avoidingthe OPB bus. Once again, you can use theMicroBlaze embedded processor for inter-rupt handling and event scheduling. Figure 2depicts the block diagram of such a design.
The Xilinx MOST NIC core is flexi-ble. Consider the MOST ring in Figure 1again, which illustrates how you mightdesign each node with the Xilinx MOSTNIC. You could configure the core as atiming master to operate as the MMI. Asthe timing master, the core will send andreceive control messages that regulatering operation. This node will also sendapplication messages, also through thecontrol field, on behalf of the user. Youcan also use the driver files and Mocean’s
Third Quarter 2007 Xcell Journal 51
User
Interface
Amplifier
Node
Slave C
MP3 Player
Node
Slave B
MMI Node
Sequence of Events
for playing an audio file
(AM = Application Message)
User presses 'play' on the MMI
1. A > B: AM "Allocate time slots
for MP3 audio"
2. B > A: Allocation control
message request of four
time slots. (Master allocates
time slots 0,5,7, and 8.)
3. B > A: AM "Time slots 0,5,7,
and 8 have been allocated"
4. A > B: AM "Begin
transmission of MP3 audio on
allocated time slots"
5. A > C: AM "Connect to
time slots 0,5,7, and 8."
Stereo audio can be heard from
both speakers.
Master A
MOST Network
MP3
Player
Right
Channel
Speaker
Left
Channel
Speaker
One Frame = 64 BytesH
eader
Contr
ol
Fie
ld
Tra
iler
Synchronous Field Asynchronous Field
Dynamic Boundary
The control field of 16
consecutive frames makes on
control message.
Spartan-3E FPGA
MP3 Audio
Stream
MicroBlaze
Processor
On-Chip Peripheral Bus (OPB)
LMB Bus
OPB
Interface
MOST NIC
Data and
Instruction
SpaceRX
Buffer
TX
Fiber
Optic TX
Data Flow Control Flow
Fiber
Optic RX
Filter Streaming
Port
Be
CC
Figure 1 – An example MOST automotive ring
Figure 2 – Theoretical MP3 node
I N T E L L E C T U A L P R O P E R T Y

For the amplifier, imagine a minimaldesign that simply receives data and for-wards it to the speakers. Instead of usingan embedded processor, as in the MP3node, you can implement a smaller userdesign capable of full network negotia-tion and data collection. Such a compactdesign may be placed in a smaller devicefor further cost savings.
ConclusionIf you drive a high-end European automobile, you may already have aMOST network. It has gained acceptanceas one of the de facto standards for auto-motive networking among European-based OEMs. Those of us driving moreaffordable cars will not have too long towait, however. With the advent of com-petition, this once private standard is
becoming more affordable for cost-conscious automakers.
As demand grows for larger amounts ofdata – from audio to video, telematics, andnavigation-based applications – the MOSTnetwork technology has plans to grow aswell. The next-generation standard, MOST50, has already been defined and offerstwice as much bandwidth as the original. Atthe time of this writing, the MOSTCooperative is planning a third-generationnetwork expected to reach data rates of 150
Mbps and beyond. These updates will even-tually increase available application band-width by more than an order of magnitudeand are expected to support both a copperand optical physical medium.
The Xilinx MOST NIC is availabletoday in CORE Generator™ software. Atsix block RAMs and about 2,600 slices, itwill fit in a mid-sized Spartan™-3E devicewith room to spare for an embeddedprocessor, peripherals, buffers, and yourown custom circuitry.
52 Xcell Journal Third Quarter 2007
• Read the MOST NIC data sheet for more details
• Contact your Xilinx FAE to test-drive the MOST NIC core
TAKE THE NEXT STEP (Digital Edition: www.xcellpublications.com/subscribe/)
I N T E L L E C T U A L P R O P E R T Y

by Stacey SecatchStaff Design EngineerXilinx, [email protected]
At only 2,600 slices, the Xilinx® MOST(Media Oriented Systems Transport) net-work interface controller (NIC) occupiesroughly half of a Spartan™-3E 500 device,which leaves plenty of room for the micro-processor and other peripherals. This full-featured embedded core provides easyaccess to data and network control as aslave or master node.
In this article, I’ll present a control mes-sage processing design case study and showhow the MOST NIC is able to autonomous-ly handle messages without any host softwareintervention. With careful planning, theminimal-resource PicoBlaze™ configurablestate machine can handle control messagescorrectly and efficiently.
Control Messages on a MOST NetworkMOST is an automotive infotainment-oriented network standard with a ringtopology. One of its strengths is that itsupports multiple simultaneous streams ofmedia intended for several nodes in thering. However, like any network, morethan just data is sent between nodes; con-trol communication is also required. Asimple MOST ring network is shown inFigure 1, with one network master andseveral slaves. Six different control messagetypes are available. Let’s focus on the threethat are most commonly used during oper-ation of a MOST network.
Normal MessagesNormal messages are distinct from othertypes in that they are intended for high-level application use in the host processor.All other messages are used for ring opera-tion and debugging. For example, as part ofthe boot sequence of the ring, the mastercould send a normal message to determinethe identification of slave B. Normal mes-sages may be combined in the applicationlayer when there is more information thanone message can hold.
Channel Allocation and DeallocationAllocation messages are sent to the masternode to gain access to the portion of theframe set aside for media data. The requestorindicates how many byte-wide channels aredesired and the responder (master) confirmsboth the status of the request (granted ordenied) and which channels have beengranted. Deallocation messages are similarto allocations, where the requestor indicateswhich channels to deallocate and the masterresponds with deallocation granted.
Third Quarter 2007 Xcell Journal 53
Making the Most of MOST Control MessagingThis case study presents the design of Xilinx LogiCORE MOST NIC control message processing.
I N T E L L E C T U A L P R O P E R T Y

Choosing the Hardware/Software PartitionEmbedded design involves choosing thebest boundary for the hardware/softwareinterface in terms of functionality andresources. Choosing to implement toomuch in hardware is costly because of theadditional resources required to implementthe design. Choosing to implement toomuch in software can result in an overbur-dened microprocessor and stalled logic,possibly even resulting in a non-functionaldesign if the processor drops events.
For the MOST LogiCORE™ solution,we found a clear boundary for dividing upcontrol message processing.
Delay Time RequirementsControl messages are broken across multi-ple frames. As messages travel around thering, specific handshaking is requiredbetween the communicating nodes, with aturnaround time of roughly one of thoseframes (about 23 µs). Message-responsegeneration usually requires calculations.For example, allocation responses dependon determining whether enough freechannels are available.
have decided to implement this in tradi-tional fashion as a custom state machine.Preliminary estimates placed the size of thestate machine at more than 1,000 slices,plus a block RAM to contain all of themessage buffers. Note that control mes-sages only use 2 bytes out of a 64-byteframe, yet processing just these two byteswould have accounted for more than athird of the core.
Instead, we chose to incorporate thePicoBlaze configurable state machine as thebackbone for control channel processingand minimize core resources. In our imple-mentation, this includes two block RAMs tohold the instruction memory, approximate-ly 100 slices for the PicoBlaze component,and 150 slices for peripherals, as well as theoriginal block RAM for message buffering.
Choosing a PicoBlaze controller offersyou similar opportunities for resource min-imization. You will probably also see thesame benefits that we did, namely a short-ened design cycle and easier code mainte-nance thanks to the simplicity of codingmessage processing procedurally.
Organizing Data StorageDetermining what kind of memory to usefor variables when designing an RTL statemachine is rather straightforward. In gen-eral, you use RAM for large buffers andstick everything else in a register. Whenusing a PicoBlaze controller, you need todo a bit more up-front planning to mini-mize resources while still providing accessto all of your data.
State Machine VariablesThe 64 “free” scratch pad registers areideal for storing variables that you willnever use outside of the PicoBlaze con-troller. For example, the accumulators tostore intermediate checksum results forMOST control messages are only neededby the state machine.
Larger BuffersBlock RAM is an ideal location for buffer-ing. Although the PicoBlaze controller onlyprovides direct access to 256 locations, it isprobably more efficient for you to use oneblock RAM than to instantiate distributed
Because this service requirement is sotight, it makes sense to place control mes-sage handling within the core as hardware,leaving the external processor available torun the network stack and media-orienteduser application.
Items to Leave to SoftwareAlthough nearly all control message typescan be handled completely by theLogiCORE system, normal control mes-sages must be passed on to the applica-tion. Therefore, the MOST NICLogiCORE solution provides interruptsto signal that a normal message has beenreceived and is available for processing.And because all messages are initiated bythe application, there are configurationregisters for the application to indicatethat a message is available for sending andinterrupts to alert the application that themessage sequence is complete.
Selecting the ImplementationThe next step after deciding to process con-trol messages in hardware was to choose themost efficient design possible. We could
Master
Slave ASlave C
Slave B
Figure 1 – A sample MOST ring
54 Xcell Journal Third Quarter 2007
I N T E L L E C T U A L P R O P E R T Y

Third Quarter 2007 Xcell Journal 55
memory for all of your buffers. Andbecause a PicoBlaze configurable statemachine executes sequentially, you willnever need to access more than one bufferat a time, which makes grouping togetherall of your memory easy. As a bonus, Xilinxblock RAM automatically converts datawidths, seamlessly allowing 32-bit accessfrom the host side and 8-bit access from thePicoBlaze controller side.
Shared VariablesSome configuration and status variableswill need to be continually available. Youcan map these variables into registers in thePicoBlaze controller external memoryspace for your state machine to access, justlike the memory in the MOST LogiCOREcontrol processing module (Figure 2). Inthe LogiCORE system, the PicoBlaze con-troller external memory port is mapped toa shared block RAM, with the exceptionthat the end of the memory range is mem-ory-mapped registers.
As an example, the currently pro-grammed addresses of the MOST node aremapped into a read-only “register” (a muxinput) to determine if a received message ismeant for this node. Status informationabout the current occupancy of the buffersis placed into a write-only register foraccess by the external host.
Ordering Your ProcessingComplex state machines are generally builtfrom smaller interlocking state machinesthat operate in parallel. PicoBlaze config-urable state machines execute sequentially,providing advantages in terms of conflict
avoidance and race conditions. You willneed to plan carefully, however, to ensurethat your event scheduling is correct andthat that no queued events get dropped.Here are some guidelines that might help indesigning your PicoBlaze application:
• Prioritize your event processing. If youhave events that are not important,choose to execute those last. For exam-ple, the value of buffer occupancycounts is changed by a MOST hostbuffer read. However, this update maybe deferred for several frames. Becauseresponding to a message must com-plete in one frame, the core servicesmessage responds first.
• Preserve event ordering. If your pro-cessing requires that one event com-plete before another, you will want toexecute the code for the first event,even if the second event may have atighter timing requirement. For exam-ple, control bytes must be sent outbefore the bytes in the current frame
are even received. Therefore, for a givenframe, transmit events are alwaysprocessed before receive events.
• Consider using a busy-wait loop. If youhave a very long event that cannot beprocessed in the time frame required byother events, you might consider plac-ing the long event in the main process-ing wait loop.
For example, preparing a MOST controlmessage for transmit can take multipleframes to complete. We could have setup multiple levels of interrupt servicingto ensure that we could still processframe data, but this type of task fits verywell into a busy-wait loop, which auto-matically gives it the lowest priority.
If you do choose to process data in themain loop, some additional care isneeded to ensure that you do not cor-rupt your main loop when servicinginterrupts. At the start of interrupt serv-icing, you should copy all registers thatmight get overwritten, and restore thoseregisters as interrupt servicing com-pletes. There are also PicoBlaze com-mands for disabling interrupts whenexecuting critical portions of your code.
ConclusionThe Xilinx MOST NIC has been shown toefficiently handle control message process-ing. It is ideal for automotive infotainmentsystems, as it provides similar efficiency instreaming data. With upcoming devicesupport for the Spartan-3A DSP family,this will allow even more efficient multime-dia processing for your design.
PicoBlaze 8-bitState Machine
Controller
Memory-MappedRegisters –
ContinuouslyAvailable
Data
Block RAM –Message
Buffers andLarge Amounts
of Data
Interrupt
Address
d Data
Strob
e Data Host
Interface
Node
Configuration/
Status
Strob
Scratch Pad –
State Machine Only
Variables
Registers –
Temporary
Computation Values
......
Figure 2 – Memory organization for Xilinx MOST NIC control message processing
• Get more information about embedded design using the Xilinx MOSTNIC LogiCORE solution in the MOST NIC lounge.
• The MOST NIC User Guide, available after generating a LogiCOREimplementation, provides more information about all MOST control message formats for the MOST link layer.
• Download the PicoBlaze microcontroller reference design, which includessupporting files such as the assembler and extensive documentation suchas the User Guide, with many coding examples and documentation forthe complete instruction set.
TAKE THE NEXT STEP (Digital Edition: www.xcellpublications.com/subscribe/)
I N T E L L E C T U A L P R O P E R T Y

by David Slogsnat Research AssociateUniversity of [email protected]
Alexander GieseResearch AssociateUniversity of [email protected]
Ulrich BrueningProfessorUniversity of [email protected]
FPGA-based devices are used widely instandard computing systems, either asreprogrammable coprocessors or as proto-typing devices. Usually, they are connectedto the system using peripheral buses likePCI Express.
AMD’s Opteron processors offer aunique opportunity to improve howdevices are connected to the system. Ratherthan using a proprietary front-side bus,there are three HyperTransport (HT) inter-faces per processor. The adoption of theHyperTransport Expansion Connector(HTX) specification and mainboards
equipped with this connector now make itpossible to directly connect devices to anOpteron processor.
The Computer Architecture Group at theUniversity of Mannheim researches networksand network interface controllers (NICs) forhigh-performance computing. For the con-struction of high-speed prototypes, we soughtto implement an efficient HyperTransport IPon an FPGA. Implemented on a Virtex-4 FXdevice, the IP is capable of running inHT400 mode, with a link clock of 400MHz. Of course, not only NICs benefitfrom a direct HyperTransport connec-tion. Any device with high bandwidth orlow latency requirements, like FPGAcoprocessors, will benefit from theincreased performance.
Advantages of HyperTransportBoth HyperTransport and its closest com-petitor, PCI Express, are very capable ofdelivering bandwidth. For example, the3.6-Gbps bi-directional bandwidth of ourHT400 core is also possible using a PCIExpress x8 device.
Besides bandwidth, there is a secondimportant criterion to specify the perform-ance of an interconnect: latency. Comparedto PCI Express, HyperTransport adds sig-nificantly less latency to the transfer of databetween a device and a host system com-prising processors and memory.
One reason for this is the protocol itself,which does not require steps like 8B/10Bcoding and high-speed serialization. (Adetailed latency analysis of both protocols
56 Xcell Journal Third Quarter 2007
Leveraging HyperTransport on Xilinx FPGAs An open-source HyperTransport IP core
allows FPGAs to directly connect to AMD Opteron processors.
I N T E L L E C T U A L P R O P E R T Y

can be found on www.hypertransport.org.)The main reduction in latency, however,stems from the fact that the HTX slot isdirectly connected to Opteron processorsinstead of having to go through one ormore I/O bridges, as depicted in Figure 1.This avoids time-consuming protocolconversions and usually saves one chip-to-chip hop.
Overview of HyperTransportHyperTransport is a packet-based com-munication protocol for data transfer.There are three versions: HT 1.05 wasdeveloped in 2001 and updated to HT2.0 in 2004. In April 2006, HT 3.0 wasdefined as the next successor. CurrentOpteron processors adhere to the HT2.0b specification; no HT 3.0 devices orsystems are currently available. Therefore,this article focuses on the implementationof an HT 2.0b device.
A HyperTransport link comprises twosets of unidirectional signals. Each set canbe distinguished into three signal types:CAD (command, address, and data), CTL(control), and CLK (clock signals). TheCAD lines are used to transport com-mand and data packets, while the CTLline distinguishes between command anddata packets on the CAD lines. TheHyperTransport protocol supports CADbuses with a width of 2, 4, 8, 16, or 32bit, as depicted in Table 1. The width ofthe CAD bus is usually known as thewidth of the HyperTransport link. If morethan eight CAD lines are used per linkand direction, every group of eight signalshas its own CLK signal. These groups ofsignals are synchronously transmittedwith the source-associated CLK signal.
The data transferred on the CAD bus is32-bit aligned independent of the buswidth. All transferred packets are at leastthe size of one doubleword (32 bit).HyperTransport allows clock frequenciesfrom 200 MHz to 1.4 GHz in HT 2.0 andup to 2.6 GHz in HT 3.0. On the CADbus, double-data-rate signaling is used.Current Opteron processors use 16-bit linkwidths and frequencies up to 1 GHz. InOpteron systems, all devices start at powerup of the system with 200-MHz and 8-bit-
that is sent on the link belongs to this pack-et. A data packet can have a maximum sizeof up to 64 bytes.
Sending other control packets during astream of data packets at every 32-bitboundary is allowed, but only if this con-trol packet would not be followed by data.Otherwise it could not be possible to deter-mine which control packet the databelongs to. This mechanism makes it possi-ble to send urgent control packets withhigh priority. Flow control on the link isimposed by a credit-based protocol.
Mastering Challenges in FPGA DesignThe HyperTransport core has two differentinterfaces: one is the HyperTransport sendand receive links, as specified in theHyperTransport protocol. On the otherside, there is the application interface,which allows FPGA designs to access theHyperTransport core. This interface con-sists of three queues in each direction, onefor every virtual channel. Applications canaccess these using a valid-stop synchroniza-tion mechanism. Control and attacheddata packets can be delivered simultaneous-ly over the 160-bit-wide interface (96 bit to
handle extended con-trol packets, 64 bit fordata packets).
Of course, our aimwas to build a corethat is as fast as possi-ble. One limiting fac-tor is the speed of theserial I/Os. In theXilinx® Virtex™-4 FX
devices we used, the speed is limited to400-MHz DDR, thus HT400. XilinxSERDES blocks can parallelize/serializethe link by a factor of four so that theclock frequency of the core is 200 MHz.The SERDES blocks are also controlledby a bitslip module to generate proper32-bit boundary alignment.
Our second challenge was to processthis data stream with the lowest number ofpipeline stages and reasonable resourcerequirements. The decode unit, responsi-ble for decoding the incoming packetstream and putting packets into the corre-sponding application interface queues or
wide links. The BIOS checks the capabili-ties of all devices by accessing the device’sHyperTransport register space and setsnew values for frequency and width forevery link according to the capabilities ofthe two devices that share the link. Afterthat, it forces a re-initialization of allHyperTransport devices to establish thenew parameters.
All transfers in HyperTransport arepacket-based. To decouple the transmission
response from the request, the packets aretransferred in a split phase transaction. Atransfer always starts with one of threekinds of control packets: information,request, or response. Information packetsare used for flow control and synchroniza-tion. Request packets are sent to write datato a receiver and are also used to initiatereads. Response packets contain the answerto a corresponding request.
Control packets have a size of 4 or 8bytes or, if they use addresses of 64 bitsinstead of 40-bit addresses, the extendedformat has a size of 12 bytes. If a transfercontains payload data, the next data packet
Third Quarter 2007 Xcell Journal 57
AMD Dual Opteron Processor
AMD64
CPU Core
AMD64
CPU Core
L1 D
Cache
L1 I
Cache
L1 D
Cache
L1 I
Cache
L2 Cache L2 Cache
System Request Queue
Crossbar
Memory HyperTransport
Memory Controller
HTX I/OBridge PCI-X
Figure 1 – Block diagram of an Opteron dual-core processor in a system with HTX and PCI-X slots
I N T E L L E C T U A L P R O P E R T Y
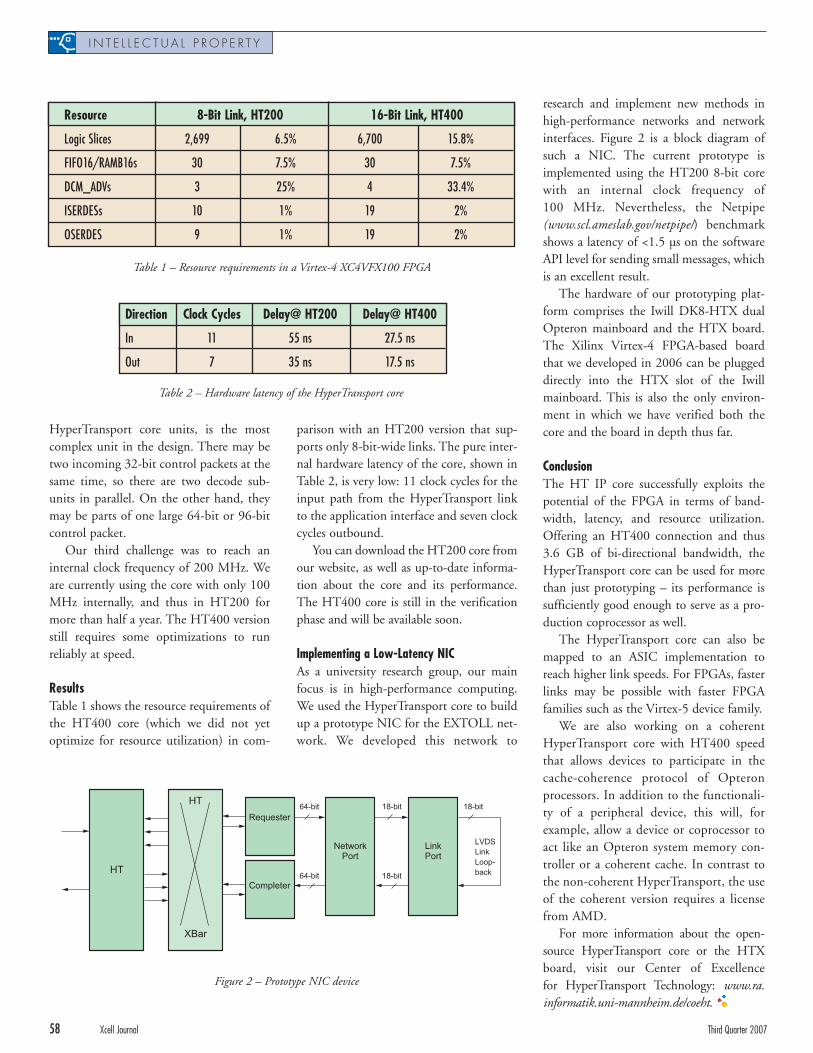
HyperTransport core units, is the mostcomplex unit in the design. There may betwo incoming 32-bit control packets at thesame time, so there are two decode sub-units in parallel. On the other hand, theymay be parts of one large 64-bit or 96-bitcontrol packet.
Our third challenge was to reach aninternal clock frequency of 200 MHz. Weare currently using the core with only 100MHz internally, and thus in HT200 formore than half a year. The HT400 versionstill requires some optimizations to runreliably at speed.
ResultsTable 1 shows the resource requirements ofthe HT400 core (which we did not yetoptimize for resource utilization) in com-
parison with an HT200 version that sup-ports only 8-bit-wide links. The pure inter-nal hardware latency of the core, shown inTable 2, is very low: 11 clock cycles for theinput path from the HyperTransport linkto the application interface and seven clockcycles outbound.
You can download the HT200 core fromour website, as well as up-to-date informa-tion about the core and its performance.The HT400 core is still in the verificationphase and will be available soon.
Implementing a Low-Latency NICAs a university research group, our mainfocus is in high-performance computing.We used the HyperTransport core to buildup a prototype NIC for the EXTOLL net-work. We developed this network to
research and implement new methods inhigh-performance networks and networkinterfaces. Figure 2 is a block diagram ofsuch a NIC. The current prototype isimplemented using the HT200 8-bit corewith an internal clock frequency of 100 MHz. Nevertheless, the Netpipe(www.scl.ameslab.gov/netpipe/) benchmarkshows a latency of <1.5 µs on the softwareAPI level for sending small messages, whichis an excellent result.
The hardware of our prototyping plat-form comprises the Iwill DK8-HTX dualOpteron mainboard and the HTX board.The Xilinx Virtex-4 FPGA-based boardthat we developed in 2006 can be pluggeddirectly into the HTX slot of the Iwillmainboard. This is also the only environ-ment in which we have verified both thecore and the board in depth thus far.
ConclusionThe HT IP core successfully exploits thepotential of the FPGA in terms of band-width, latency, and resource utilization.Offering an HT400 connection and thus3.6 GB of bi-directional bandwidth, theHyperTransport core can be used for morethan just prototyping – its performance issufficiently good enough to serve as a pro-duction coprocessor as well.
The HyperTransport core can also bemapped to an ASIC implementation toreach higher link speeds. For FPGAs, fasterlinks may be possible with faster FPGAfamilies such as the Virtex-5 device family.
We are also working on a coherentHyperTransport core with HT400 speedthat allows devices to participate in thecache-coherence protocol of Opteronprocessors. In addition to the functionali-ty of a peripheral device, this will, forexample, allow a device or coprocessor toact like an Opteron system memory con-troller or a coherent cache. In contrast tothe non-coherent HyperTransport, the useof the coherent version requires a licensefrom AMD.
For more information about the open-source HyperTransport core or the HTXboard, visit our Center of Excellence for HyperTransport Technology: www.ra.informatik.uni-mannheim.de/coeht.
58 Xcell Journal Third Quarter 2007
Resource 8-Bit Link, HT200 16-Bit Link, HT400
Logic Slices 2,699 6.5% 6,700 15.8%
FIFO16/RAMB16s 30 7.5% 30 7.5%
DCM_ADVs 3 25% 4 33.4%
ISERDESs 10 1% 19 2%
OSERDES 9 1% 19 2%
Direction Clock Cycles Delay@ HT200 Delay@ HT400
In 11 55 ns 27.5 ns
Out 7 35 ns 17.5 ns
HT
Requester
64-bit
NetworkPort
LinkPort
Completer
HT
XBar
18-bit
64-bit 18-bit
18-bit
LVDS
Link
Loop-
back
Table 1 – Resource requirements in a Virtex-4 XC4VFX100 FPGA
Table 2 – Hardware latency of the HyperTransport core
Figure 2 – Prototype NIC device
I N T E L L E C T U A L P R O P E R T Y


by Ando KiR&D DirectorDynalith [email protected]
Designing a hardware block does not sim-ply mean RTL coding and simulation; theprocess usually includes FPGA-based pro-totyping. To do this requires a huge effort– including the preparation of a PCBboard that implements your design andits surrounding functions in hardware –even though you probably only want tosee the functionality of your design andnot its surrounding components.
One possible solution around this hasactually existed for some time: convention-al emulation. This hardware-assisted accel-eration technique connects an HDLsimulator to programmable devices, allow-ing a design to run on real hardware whileits surrounding functions are simulated ontop of software.
In this article, I’ll describe DynalithSystems’s iNCITE USB-connected FPGAboard, supporting Xilinx® Spartan™-3FPGAs. The iNCITE board provides aUSB-based communication channelbetween software and an FPGA. Usingindustry-standard HDL simulator soft-ware, you can run your design in the FPGAunder software control.
iNCITEiNCITE is an FPGA-mounted PCB boardfeaturing various on-board memories, a
host computer interface using USB 2.0,and a board-to-board connector (seeFigure 1). For application-specific periph-erals, the iNCITE-AVREM applicationboard incorporates audio, video, RS-232C, Ethernet, MMC, and PS/2. Withboth boards, you can easily implement acomplete system-on-chip (SOC) orembedded system.
Design Flow for FPGA-Based SimulationAs shown in Figure 2, there are fourdesign steps. In the first step, the designunder test (DUT) and its test bench aredeveloped using a pure software simula-tor, such as the free ModelSim-XE HDLsimulator. When a synthesizable RTL ver-sion of the DUT is ready, the DUT issynthesized using an industry-standardFPGA synthesizer such as XST (XilinxSynthesis Technology), a proprietary syn-thesis engine in Xilinx ISE™ software.
The synthesis result EDIF is processedby iNSPIRE-Lite, which is the GUI-based integrated design environment foriNCITE (Xilinx place and route is usedinternally). During this step, two files aregenerated: an emulation information file(EIF) and a proxy module. The EIF con-tains the necessary data and bitstream toconfigure the FPGA. The proxy modulehandles communication between the sim-ulator and the FPGA through USB.
The test bench runs on top of the HDLsimulator while the DUT runs in theFPGA. During simulation with iNCITE,the EIF is automatically downloaded to theFPGA through the USB channel at thestart of simulation.
The channel between iNCITE andsoftware is a generic one; thus, you can useany programming language including C,C++, SystemC, and MATLAB/Simulink.Essentially, you can build a virtual system
60 Xcell Journal Third Quarter 2007
FPGA-Based Simulation for Rapid PrototypingYou can run an HDL simulator along with an FPGA through USB using iNCITE.
iNCITE iNCITE-AVREM
Host I/FBased onUSB 2.0
SDRAM SSRAM
JTAG Port Flash
Xilinx Spartan-3FPGA
Line Driver PS/2 Ethernet
MMCConnector
AudioCodec
VideoDAC
Board-to-Board ConnectorLED,
Button,GPIO
Figure 1 – Functional block diagram of iNCITE and iNCITE-AVREM
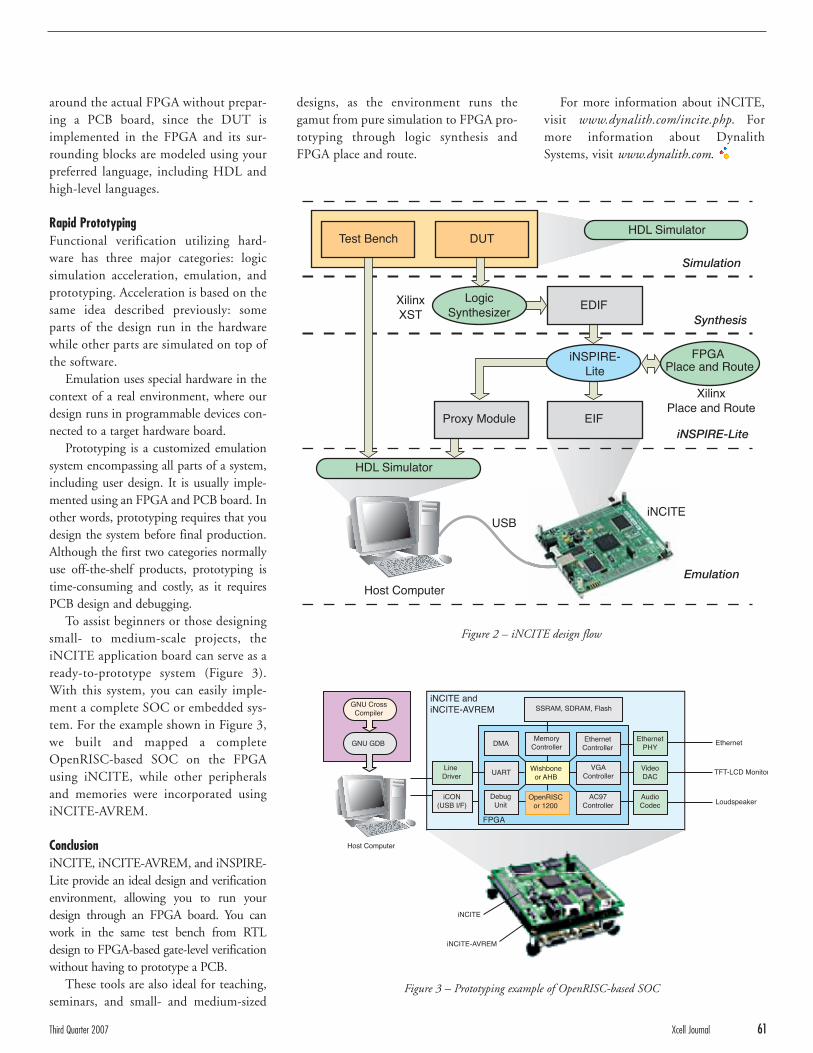
around the actual FPGA without prepar-ing a PCB board, since the DUT isimplemented in the FPGA and its sur-rounding blocks are modeled using yourpreferred language, including HDL andhigh-level languages.
Rapid PrototypingFunctional verification utilizing hard-ware has three major categories: logicsimulation acceleration, emulation, andprototyping. Acceleration is based on thesame idea described previously: someparts of the design run in the hardwarewhile other parts are simulated on top ofthe software.
Emulation uses special hardware in thecontext of a real environment, where ourdesign runs in programmable devices con-nected to a target hardware board.
Prototyping is a customized emulationsystem encompassing all parts of a system,including user design. It is usually imple-mented using an FPGA and PCB board. Inother words, prototyping requires that youdesign the system before final production.Although the first two categories normallyuse off-the-shelf products, prototyping istime-consuming and costly, as it requiresPCB design and debugging.
To assist beginners or those designingsmall- to medium-scale projects, theiNCITE application board can serve as aready-to-prototype system (Figure 3).With this system, you can easily imple-ment a complete SOC or embedded sys-tem. For the example shown in Figure 3,we built and mapped a completeOpenRISC-based SOC on the FPGAusing iNCITE, while other peripheralsand memories were incorporated usingiNCITE-AVREM.
ConclusioniNCITE, iNCITE-AVREM, and iNSPIRE-Lite provide an ideal design and verificationenvironment, allowing you to run yourdesign through an FPGA board. You canwork in the same test bench from RTLdesign to FPGA-based gate-level verificationwithout having to prototype a PCB.
These tools are also ideal for teaching,seminars, and small- and medium-sized
For more information about iNCITE,visit www.dynalith.com/incite.php. Formore information about DynalithSystems, visit www.dynalith.com.
designs, as the environment runs thegamut from pure simulation to FPGA pro-totyping through logic synthesis andFPGA place and route.
Third Quarter 2007 Xcell Journal 61
Test Bench DUTHDL Simulator
EDIF
EIFProxy Module
HDL Simulator
USB
XilinxXST
LogicSynthesizer
iNSPIRE-Lite
FPGA Place and Route
XilinxPlace and Route
Host Computer
iNCITE
Simulation
Synthesis
Emulation
iNSPIRE-Lite
GNU CrossCompiler
GNU GDB
Line Driver
iCON(USB I/F)
DMA
UART
DebugUnit
MemoryController
Wishboneor AHB
OpenRISCor 1200
EthernetController
VGAController
AC97Controller
EthernetPHY
VideoDAC
AudioCodec
Host Computer
iNCITE
iNCITE-AVREM
TFT-LCD Monitor
Ethernet
Loudspeaker
SSRAM, SDRAM, FlashiNCITE andiNCITE-AVREM
FPGA
Figure 2 – iNCITE design flow
Figure 3 – Prototyping example of OpenRISC-based SOC

Embedded Serial ATA Storage Systemwww.xilinx.com/bvdocs/appnotes/xapp716.pdf
This application note describes the designand implementation of an embedded SerialAdvanced Technology Attachment (SATA)storage system on a Xilinx® Virtex™-4platform. SATA is the successor of theprevalent Parallel Advanced TechnologyAttachment (PATA) interface. SATA over-comes many limitations of PATA and offersa maximum bandwidth of 150 Mbps.Combining SATA with a high-speed net-work interface, Gigabit Ethernet (1000Base-X) creates an ideal solution for manyhigh-performance storage applications suchas network attached storage (NAS), storagearea network (SAN), and redundant arrayof independent disks (RAID).
Audio/Video Connectivity Solutions for the Broadcast Industrywww.xilinx.com/bvdocs/appnotes/xapp514.pdf
This comprehensive reference designdescribes how to use Xilinx FPGAs to imple-ment serial digital video interfaces common-ly used in the professional video broadcastindustry. The serial video interfaces describedin this document are:
• SD-SDI (SMPTE-259M), used to trans-port uncompressed standard-definitiondigital video
• HD-SDI (SMPTE-292M), used totransport uncompressed high-definitiondigital video
• DVB-ASI, used to transport compresseddigital video
• AES, used to transport digital audio
Virtex-5 Embedded Tri-Mode Ethernet MACHardware Demonstration Platformwww.xilinx.com/bvdocs/appnotes/xapp957.pdf
This application note describes a system usingthe Virtex-5 embedded tri-mode EthernetMAC (Ethernet MAC) wrapper core on anML505 development board. The system pro-vides an example of how to integrate theembedded tri-mode Ethernet MAC andembedded tri-mode Ethernet MAC wrapper,using a hardware design to target the develop-ment board and a PC-based GUI to controlthe demonstration platform.
10 Gigabit Ethernet Hardware Demonstration Platformwww.xilinx.com/bvdocs/appnotes/xapp955.pdf
This application note describes the func-tionality of the LogiCORE™ 10 GigabitEthernet and XAUI cores in Xilinx FPGAhardware. Development board requirements,setup instructions, MAC core-specificdesign components, and a description ofthe GUI used to control the demonstra-tion platform are included.
62 Xcell Journal Third Quarter 2007
Featured Connectivity Application Notes
A P P L I C A T I O N N O T E S
Create a differentiated connectivity solution withproduct descriptions and associated design files.

Virtex-5 LXT ML505 Evaluation Platformwww.xilinx.com/xlnx/xebiz/designResources/ip_product_details.jsp?key=HW-V5-ML505-UNI-G
Create high-speed serial designs usingVirtex™-5 RocketIO™ GTP transceivers:
• Provides a feature-rich general-purposeevaluation and development platform
• Includes on-board memory and indus-try-standard connectivity interfaces
• Delivers a versatile development plat-form for embedded applications
Virtex-5 LXT ML52x RocketIOCharacterization Platformswww.xilinx.com/xlnx/xebiz/designResources/ip_product_details.jsp?key=HW-V5-ML52X-UNI-G
Xilinx ML52x platforms are ideal for char-acterization and evaluation of Virtex-5LXT RocketIO GTP transceivers. EachRocketIO GTP transceiver is accessiblethrough four SMA connectors. ML52xplatforms are available with XC5VLX50T-FF665 (ML521), XC5VLX110T-FF1136(ML523), and XC5VLX330T-FF1738FPGA devices.
Virtex-5 LXT ML555 FPGA Development Kit for PCI Express and PCIwww.xilinx.com/xlnx/xebiz/designResources/ip_product_details.jsp?key=HW-V5-ML555-G
The Virtex-5 LXT FPGA Developmentkit for PCI Express supports PCIe/PCI-X/PCI. This complete developmentkit passed PCI-SIG compliance for PCIExpress specification v1.1 and enablesyou to rapidly create and evaluatedesigns using PCI Express, PCI-X, andPCI interfaces.
Virtex-5 SXT ML506 Evaluation Platformwww.xilinx.com/xlnx/xebiz/designResources/ip_product_details.jsp?key=HW-V5-ML506-UNI-G
The ML506 is a feature-rich DSP gener-al-purpose evaluation and developmentplatform. Though economically priced,the ML506 offers you the ability to cre-ate DSP-based and high-speed serialdesigns using the Virtex-5 DSP48E slicesand RocketIO GTP transceivers. A vari-ety of on-board memories and industry-standard connectivity interfaces add tothe ML506’s ability to serve as a versatiledevelopment platform for embeddedapplications.
Third Quarter 2007 Xcell Journal 63
Connectivity Boards and Kits
Xilinx, together with distributors and partners, offers a complete line of development andexpansion boards to help you test and develop designs using Xilinx® devices. The follow-ing boards are specific to connectivity applications.
T H E B O A R D R O O M

by Craig WillertGlobal Training Solutions Communications ManagerXilinx, [email protected]
By learning advanced programmable logicdesign techniques and methodologies, youcan take full advantage of today’s advancedFPGA capabilities, including high-speedserial I/O. Equipped with this knowledge,you can better innovate when developingproducts for your market, reduce R&Dcosts through improved process efficiency,and lower production costs by using smallerdevices in a slower speed grade.
The Xilinx® Connectivity CurriculumPath offers a variety of classes to help youquickly understand how to build the mostoptimal system using one of the manyhigh-speed serial I/O protocols that Xilinxsupports. The curriculum path alsoincludes courses on the use of XilinxRocketIO™ GTP serial transceivers, signalintegrity, leading-edge programmable logictechnology, and Xilinx design flows.
Designing with Multi-Gigabit Serial I/OThe “Designing with Multi-Gigabit SerialI/O” course will teach you how to employRocketIO transceivers in your Virtex™-5LXT FPGA designs.
After completing this comprehensivetraining, you will have the skills to:
• Describe and utilize the ports andattributes of the RocketIO multi-gigabittransceiver in the Virtex-5 LXT FPGA
• Effectively use such features as:
• Comma detection, CRC, clock correction, and channel bonding
• 8B/10B encoding/decoding, program-mable termination, and pre-emphasis
• GTP primitive instantiation in adesign using the GTP wizard
• Reference material for board design issues
• Power supply, oscillators, and trace design
Designing a LogiCORE PCI Express SystemThe “Designing a LogiCORE™ PCIExpress System” course focuses on the keyPCI Express protocol subjects and targetshard and soft PCI Express cores in theVirtex-5 FPGA.
This course is ideal for:
• Hardware designers creating applica-tions using Xilinx IP cores for PCIExpress
• Software engineers creating APIs,GUIs, and driver software development
• System architects leveraging Xilinxperformance, latency, and bandwidth
After completing this training, you willhave the necessary skills to:
• Use Xilinx PCI Express cores in yourown design environments
• Select the appropriate PCIe solutionfor a specific application
• Identify how PCI Express specifica-tions apply to Xilinx PCI Express cores
Designing with Ethernet MAC ControllersThe “Designing with Ethernet MACControllers” course teaches the basics ofthe Ethernet standard, protocol, and OSImodel and related Xilinx solutions.
This course is ideal for:
• Engineers using Xilinx Ethernet con-nectivity solutions
After completing this training, you willhave the necessary skills to:
• Use various Ethernet cores alone or asa peripheral in processor-based designs
• Select the appropriate core for a specificdesign
• Develop software to drive the core andachieve desired functionality
ConclusionXilinx programs provide targeted, high-quality education products and servicesthat are designed by experts in programma-ble logic design and delivered by Xilinx-qualified trainers. We offer classes at allexpertise levels and create an engaginglearning environment by blending lectures,hands-on labs, interactive discussions, tips,and best practices.
Xilinx delivers training when and whereyou want it by leveraging our global net-work of authorized training providers(ATPs) and online learning systems.
64 Xcell Journal Third Quarter 2007
The Connectivity Curriculum PathXilinx Education Services is ready to help you use PCI Express, Gigabit Ethernet, or Rapid IO protocols in your next design.
• Register today for any of these courses.
• View the full Connectivity Curriculum Path.
• Contact your Xilinx sales representative.
TAKE THE NEXT STEP (Digital Edition: www.xcellpublications.com/subscribe/)
E D U C A T I O N


by Ivo BolsensCTOXilinx, [email protected]
Today’s college fresh-men will enter theworkforce in the 2010-2011 time frame. By
then, chip manufacturing will be at the 32-nm technology mode, allowing manufac-turers to build single chips that containtens of billions of transistors.
FPGAs will be the leading platformsleveraging this manufacturing technology,capable of implementing programmablesystems that will comprise nearly 100 mil-lion programmable logic gates. As such, theFPGA will become the heart of many elec-tronic products.
The main building blocks that willmake up a system in an FPGA will be softprocessors running complex embeddedsoftware; highly parallel or pipelined arith-metic functions executing real-time signal-processing algorithms; packet-processingengines securing embedded connectivity;and complex hierarchies of memories han-dling efficient data transfer and storagemechanisms. These programmable systemswill be adaptable and partially reconfig-urable in the field.
Triple play (the convergence of data,voice, and video over a peer-to-peer network)will be the driving force setting the require-ments for these platforms. The pace of thisevolution, however, leaves very little time toeducate today’s students so that they becometomorrow’s technical leaders. The challenge
and complexity of this task by far exceeds thecapacity and domain of a single professor.
Knowledge CommunitiesFor this reason, industry and academiahave come together to create “knowledgecommunities” around specific technologydomains. Universities seek to create a wideassociation of people with common tech-nology interests who wish to continuelearning, enhancing the skills of theirmembers and preserving lessons learned.The industry wants to be an active partner,educating those in academia in global sys-tem issues and creating a realistic agendathrough intensive dialogue between indus-try leaders and visionary academics.
As these knowledge communities takehold, students will be better prepared tobecome the team players and problemsolvers for future industry projects.Gradually, they will ascend the “knowl-edge value chain,” from reproducing text-book content to applying judgment callsin situational problems.
Xilinx is constantly deepening its part-nership with academia and is committedto jointly developing new ideas and oppor-tunities and solving key challenges.
Triple play will permit FPGA platformsto become the core infrastructure; however,there are challenges to solve. First is the fur-ther digitization and processing of signalswith growing resolutions, requiring anexponential growth in DSP compute capa-bility. Second is the secure and reliabletransport of this data with increasing band-
width over wireless and wired infrastruc-tures. And third is the need for high-per-formance computing to extract informationfrom large amounts of raw data.
For example, the RAMP research com-munity (http://ramp.eecs.berkeley.edu) isexploring a programming environmentbased on the BEE2 FPGA platform. TheNetFPGA platform (http://yuba.stanford.edu/nf2/) provides an open platform forresearch on high-bandwidth networkingapplications. And the WARP project(http://warp.rice.edu) has built a repositoryto support complex wireless DSP applica-tion designs.
These activities are part of the Xilinxuniversity outreach program, supportingcontinuing education and research based onour latest technology. The Xilinx UniversityProgram (XUP, www.xilinx.com/univ/) notonly allows easy access to Xilinx best-in-class tools but also provides free training,high-quality support, and curriculumdevelopment assistance. XUP donationstake many forms, from design software,FPGA devices, and IP cores to referencedesigns and student competitions.
As a business that is continually lookingglobally for new ideas and technologies,Xilinx has established relationships with alarge number of universities around theworld to allow their engineering studentsto receive hands-on experience with ourtechnology. These students will enter theworkforce with the necessary skills to bequickly productive in the fast-paced worldof semiconductors.
66 Xcell Journal Third Quarter 2007
Developing Technical Leaders through Knowledge CommunitiesKnowledge communities will better prepare students to become team players and problem solvers.
101010101001001 X P E C TAT I O N S


Complete PCI Express®
Development Kit
Low-Power TransceiversUltimate Connectivity . . .
Reduce serial I/O power, cost and complexity with the world’sfirst 65nm FPGAs.
With a unique combination of up to 24 low-power transceivers, and
built-in PCIe® and Ethernet MAC blocks, Virtex™-5 FPGAs get your
system running fast. Whether you are an expert or just starting out,
only Xilinx delivers everything you need to simplify high-speed
serial design, including protocol packs and development kits.
Lowest-power, most area-efficient serial I/O solutionRocketIO™ GTP transceivers deliver up to 3.2 Gbps connectivity
at less than 100 mW to help you beat your power budget. The
embedded PCI Express endpoint block saves 60% in power and
90% in area compared to other solutions. Virtex-5 chips and boards
are on the PCI-SIG® Integrators List. Plus our UNH-tested Ethernet
MAC blocks make connectivity easier than ever.
Visit our website to get the chips, boards, kits, and
documentation you need to start designing today.
www.xilinx.com/virtex5
The Ultimate System Integration Platform
©2007 Xilinx, Inc. All rights reserved. XILINX, the Xilinx logo, and other designated brands included herein are trademarks of Xilinx, Inc. All other trademarks are the property of their respective owners.
Optimized for logic, serial connectivity and DSP.
Delivering Benefits of 65nm FPGAs Since May 2006!
PN 0011035





























