Embed Size (px)
Citation preview

TALLINNA TEHNIKAÜLIKOOLInfotehnoloogia teaduskond
Arvutiteaduse instituutVõrgutarkvara õppetool
SKALEERUVA KOLLEKTIIVSE SOOVITUSSÜSTEEMI ARENDAMINE
Bakalaureusetöö
Üliõpilane: Marius Andra
Üliõpilaskood: 050552IAPB
Juhendaja: Innar Liiv, M.Sc.
Tallinn2008

AUTORIDEKLARATSIOON
Kinnitan, et olen koostanud antud lõputöö iseseisvalt ning seda ei ole kellegi teise poolt
varem kaitsmisele esitatud. Kõik töö koostamisel kasutatud teiste autorite tööd, olulised
seisukohad, kirjandusallikatest ja mujalt pärinevad andmed on töös viidatud.
________________ ________________
(kuupäev) (allkiri)
2

ANNOTATSIOON
Töö pealkirjaks on “Skaleeruva kollektiivse soovitussüsteemi arendamine”.
See bakalaureusetöö annab lühiülevaate soovitussüsteemide maailma. Töö eesmärgiks
oli luua väike, kuid kasvuvõimeline kollektiivne soovitussüsteem ning dokumenteerida
selle arendust. Süsteemi arendamisel võib eraldada nelja spetsiifilist osa:
1) süsteemi jaoks algandmete kogumine
2) algoritm, mis soovitusi jagab
3) kiiruse jaoks optimiseeritud serverirakendus, mis tulemusi väljastab
4) klientprogramm, mis serverirakendusega suhtleb ning tulemusi kuvab
Bakalaureusetöö vaatleb iga osa neist lähemalt ning kirjeldab meetodeid, mida neist iga
osa juures kasutati.
Töö käigus valmis soovitussüsteem, mis orkutist kogutud andmete abil suudab
kasutajatele soovitada nende poolt sisestatud filmidele, telesarjadele, raamatutele ning
muusikale sarnaseid elemente. Süsteem suudab ka kategooriatevaheselt töötada ning
pakkuda näiteks filme, mis võivad meeldida neile, kellele mõni teatud sari meeldib.
3

ANNOTATION
The title of this thesis is: “Development of a scalable collaborative filtering system”.
This bachelor's thesis gives a short introduction to the world of collaborative filtering.
The aim of this research was to develop a small and scalable recommendation system
and to document the process. There are four main distinctive elements in this
development:
1) gathering the test data
2) the algorithm used for recommendation
3) an optimised (for speed) server application to deliver the results
4) a client front-end to interact with the server and display the results
This thesis goes into depth with each one of those, describing specific methods which
were used in the development of each.
The end result of this work was the development of a simple recommendation system
that using input data gathered from the social networking site orkut can present the user
recommendations for entered movies, TV shows, books and music. The system even
knows how to work between categories, for example giving recommendations of
movies for people who like some specific TV show.
4

SISUKORD
AUTORIDEKLARATSIOON..........................................................................................2
ANNOTATSIOON............................................................................................................3
ANNOTATION.................................................................................................................4
SISUKORD.......................................................................................................................5
1. SISSEJUHATUS...........................................................................................................7
1.1. Mis on soovitussüsteemid?....................................................................................7
1.2. Töö eesmärk...........................................................................................................7
1.3. Nõuded loodavale programmile.............................................................................8
1.4. Arhitektuuri ülesehitus...........................................................................................9
2. ALGANDMETE KOGUMINE...................................................................................11
2.1. Algandmete allikad süsteemi erinevates faasides................................................11
2.2. Orkuti indekseerimine..........................................................................................11
2.3. Indekseerimisalgoritm..........................................................................................12
2.4. Indekseeritud andmete töötlemine.......................................................................13
3. SOOVITAMISE ALGORITM....................................................................................15
3.1. Nõuded algoritmile..............................................................................................15
3.2. Lühiülevaade association rule algoritmidest........................................................15
3.3. Usaldusreegel.......................................................................................................16
3.4. Millise algoritmi võtame?....................................................................................17
3.5. Müra andmebaasis...............................................................................................18
4. SERVERIPROGRAMMI KOOSTAMINE................................................................19
4.1. Eraldiseisva serveriprogrammi vajadus...............................................................19
4.2. Nõuded serveriprogrammile................................................................................20
4.3. Andmete laadimine..............................................................................................20
5

4.4. Usaldusreegli implementatsioon..........................................................................21
4.5. Automaatne andmete uuendamine.......................................................................22
4.6. Koormuse jaotamine Amazon EC2 süsteemis.....................................................23
5. KLIENTPROGRAMMI KOOSTAMINE...................................................................26
5.1. Nõuded klientprogrammile..................................................................................26
5.2. Suhtlus serveriprogrammiga................................................................................27
5.3. Andmete kogumine Amazonist............................................................................27
5.4. Filmiinfo kogumine IMDBst...............................................................................28
6. JÄRELDUSED JA JÄRGMISED SAMMUD............................................................29
7. KOKKUVÕTE............................................................................................................30
RESUME.........................................................................................................................31
LISAD.............................................................................................................................33
Lisa 1 – suhe kasutatud profiilide arvu ning unikaalsete elementide vahel................33
Lisa 2 – usaldusreegli implementatsioon serveriprogrammis.....................................34
Lisa 3 – ekraanitõmmis lõpptootest............................................................................36
KASUTATUD KIRJANDUS..........................................................................................37
6

1. SISSEJUHATUS
1.1. Mis on soovitussüsteemid?
Kollektiivsete soovitussüsteemide all mõistetakse süsteeme, mis pakuvad kasutaja poolt
antud sisendile vastuseks sarnaseid (või muule kriteeriumile vastavaid) objekte1.
Näitena võib tuua Amazon.com-i, mis soovitab kasutajatele uusi tooteid vastavalt nende
poolt juba vaadatud toodetele või last.fm muusikaportaali, mis vastavalt kasutaja poolt
sisestatud bändile sarnaste bändide poolt loodud muusikat mängima hakkab.
Soovitussüsteeme võib nende poolt kasutatava andmete kogumise liigi järgi jaotada
kaheks. Üks liik soovitussüsteeme kogub andmeid kasutajale teadmata ning kasutab
neid hiljem näiteks isiklike pakkumiste tegemiseks (eelmises näites Amazon.com), teine
liik kogub informatsiooni kasutajapoolsete konkreetsete toimingute järel ning kasutab
seda soovituste tegemiseks (eelmises näites last.fm).
1.2. Töö eesmärk
Selle bakalaureusetöö eesmärk oli luua üks kollektiivne soovitussüsteem ning
dokumenteerida selle arendustegevust.
Loodava soovitussüsteemi eesmärgiks oli pakkuda kasutajale filme, telesarju, muusikat
ning raamatuid, mis sarnanevad kasutaja poolt sisestatud päringutele. Kasutajapoolsed
1 http://en.wikipedia.org/wiki/Recommendation_system
7

päringud koosnevad loetelust filmidest, telesarjadest, muusikast ja/või raamatutest, mis
kasutajale endale meeldivad.
Näiteks kui kasutaja sisestab, et talle meeldivad sarjad “Heroes, Prison Break, Friends”
võiks ta vastuseks saada soovituse, et talle võiks ka veel meeldida sarjad “Lost,
Simpsons, CSI, Las Vegas”. Analoogiliselt toimiks soovitamine teiste meedialiikidega.
Süsteem peab olema ka piisavalt teadlik, et oskaks soovitada elemente
kategooriatevaheliselt, näiteks pakkudes millised filmid võivad meeldida inimestele,
kellele meeldib sari “Friends”.
1.3. Nõuded loodavale programmile
Loodav süsteem pidi olema kasutajatele võimalikult lihtsalt kasutatav.
See tähendab, et kasutaja ei peaks süsteemi kasutamiseks erilisi samme tegema.
Piisab vaid ühel lihtsal veebivormil enda lemmikute elementide sisestamisest
ning süsteem annab kohe vastused. Puudub vajadus mõnes portaalis konto
registreerida ning pikk ankeet ära täita.
Süsteemi kasutajaliides peab soosima kiiret otsingute tegemist ning laskma
kasutajatel teha seda mida nemad soovivad (st mitte segama ning eest ära
tulema).
Kasutajad peavad saama vastuse oma päringutele mitte rohkem kui poole sekundi
jooksul.
Google poolt läbiviidud test, mille jooksul tõsteti otsingutulemuste arvu lehel
10-lt 30-le ning mille tagajärjel suurenes keskmine lehe laadimise aeg 0.5
sekundit näitas, et isegi nii minimaalne laadimisaja tõus tõi kaasa
8

märkimisväärse külastuste vähenemise2. Seetõttu on oluline, et ka loodaval
süsteemil võtaks otsingutulemuste tagastamine minimaalset aega – mitte rohkem
kui 0.5 sekundit lehe kohta.
Süsteem peab olema skaleeruv ning võimaldama suurt arvu paralleelseid kasutajaid
suure andmebaasi pealt.
Süsteemi kiirus peaks kasvama lineaarselt või aeglasemalt sõltuvalt
sisendandmete ning paralleelsete kasutajate hulgast. Peab eksisteerima võimalus
paralleelsete kasutajate hulga suurenemisel koormust jaotada mitme serveri
vahel.
Süsteem peab omama võimalust iseseisvalt areneda ning uute algandmete lisamisel neid
koheselt kasutama hakkama.
Uute filmide jt objektide seoste lisamise järel peab süsteem võtma need
kasutusele otsingutulemuste serveerimiseks mitte rohkem kui 5 minuti jooksul.
1.4. Arhitektuuri ülesehitus
Loodava süsteemi juures võib vaadelda nelja erinevat osa:
Esiteks, et süsteem oleks kasutatav on vaja algmaterjali mille baasilt otsingutulemusi
kuvada.
Teiseks on oluline võtta kasutusele võimalikult täpseid tulemusi võimalikult kiirelt
väljastav algoritm.
2 http://www.freshbooks.com/blog/2006/11/17/how-google-does-it-with-speed/
9

Kolmanda komponendina on kasutusel serveriprogramm, mis eelnimetatud algoritmi
abil kogutud andmete seast tulemusi väljastab ning end iseseisvalt uute algandmetega
uuendab.
Neljanda ning viimase osana vaatleme klientprogrammi, mis esitab kasutajale lihtsalt
kasutatava liidese serveriprogrammiga suhtlemisel
Kõiki neid süsteemi osi vaatleme järgmiste peatükkide juures põhjalikumalt.
10

2. ALGANDMETE KOGUMINE
2.1. Algandmete allikad süsteemi erinevates faasides
Süsteemi lõppeesmärk on olla iseenesest uuenev. See tähendab, et kasutajate poolt
sagedamini teostatavad otsingud võetakse kasutusse kui uued algallikad andmebaasi
täiendamisel. Niiviisi tekiks web 2.03 ideoloogiaga kokkusobiv süsteem, kus kasutajate
arvu kasvamisel süsteemi andekus ning otsingutulemuste täpsus suureneb.
Ideoloogia teeb paradoksaalseks fakt, et kui kasutajatepoolne tegevus toob süsteemi
uusi algandmeid, siis üldiste algandmete puudumisel kaob kiirelt kasutajatepoolne huvi
süsteemi kasutada ning seega andmehulka täiendada. Seetõttu on oluline, et süsteem
oma algstaadiumis sisaldaks mingil hulgal algandmeid.
Algandmete kogumiseks on mitmeid erinevaid meetodeid. Neist kõige lihtsam on
koguda andmeid mõnelt juba olemasolevalt teenuselt, mis sellist informatsiooni jagab.
2.2. Orkuti indekseerimine
Orkut on Google poolt loodud sotsiaalvõrgustiku teenus, kus iga kasutaja võib endale
konto luua ning kõigile teistele orkuti kontot omavatele kasutajatele kättasaadaval kujul4
avaldada informatsiooni enda kohta.
3 http://en.wikipedia.org/wiki/Web_2.0
4 http://www.orkut.com/html/en-US/privacy.orkut.html?rev=4
11

Avaldatud informatsiooni hulgas sisalduvad kasutajatele meelepärased filmid,
telesarjad, raamatud ning muusika. Selle informatsiooni anonüümne kogumine ning
kasutamine annaks hea põhja soovitussüsteemi otsingutulemuste serveerimiseks.
Orkuti seadetes on võimalik sättida kellele on sinu profiilis leiduv informatsioon nähtav.
Valikute all on:
1. Ainult iseendale (0 taset)
2. Ainult minu sõpradele (1 tase)
3. Minu sõprade sõpradele (2 taset)
4. Kõigile
Valides “kõigile” lubad enda informatsiooni vabalt vaadata ning kasutada kõigil, kellel
on ligipääs orkutisse.
2.3. Indekseerimisalgoritm
Orkutis on iga kasutaja identifitseeritud unikaalse numbrilise ID koodiga.
Informatsiooni kogumiseks kasutatav algoritm on lihtne. Selle juures saame eraldada
kahte etappi: kasutaja ID koodide indekseerimine ning kasutajate profiilide
indekseerimine.
Vajadus etappide eraldamiseks tekkis sellest, et igal kasutajal on mitmeid sõpru, kelle
ID-sid pole veel andmebaasi lisatud. Kui indekseerida kasutaja profiil koos sõprade
nimekirjaga, siis kasvab sõprade loetelu ligikaudu eksponentsiaalselt indekseeritud
profiilide arvuga.
Näiteks kui igal kasutajal on 20 uut sõpra, kelle ID-d me varem näinud ei ole, siis uue
reaga profiilide tabelisse andmebaasis saame 20 uut rida sõprade tabelisse andmebaasis.
12

Nende 20 sõbra profiili indekseerimisel oleks kokku profiilide tabelis 21 rida, sõprade
tabelis 400 rida. Seetõttu tuleb mingis punktis tõmmata piir vahele kasutaja ID-de
kogumisele ning keskenduda profiilides leiduva informatsiooni kogumisele.
Algoritm kasutajate ID-de kogumiseks on lihtne:
1. Lae kasutajate tabelist esimene indekseerimata sõpradega ID.
2. Lae alla nimekiri selle ID-ga kasutaja sõprade ID-dest ning lisa sõprade tabelisse
need read, mis sealt veel puuduvad.
3. Märgi selle ID juures sõprade ID-de indekseeritus lõppenuks ning alusta uuesti
punktist 1.
Profiilide indekseerimise algoritm on veelgi lihtsam:
1. Leia kasutaja, kelle profiil on indekseerimata.
2. Lae alla selle kasutaja profiilis leiduv informatsioon filmide, telesarjade,
raamatute ning muusika kohta.
3. Märgi profiil indekseerituks ning alusta uuesti punktist 1.
2.4. Indekseeritud andmete töötlemine
Peale indekseerimist on kõik andmed salvestatud vabatekstina. Kuna iga kasutaja
loetleb enda filme jms erinevalt, tuleb leida mõni meetod kuidas neid andmeid edukalt
lugeda ning süsteemi jaoks optimaalsele kujule viia.
Mõned näited erinevatest loeteludest:
1. Red Hot Chili Peppers, Queen, VAST, Clawfinger, My Dying Bride, Nine Inch
Nails, Depeche Mode, Mozarti Requiem, Alo Mattiiseni isamaalised laulud
13

2. Nevermore<br>At the Gates<br>King
Diamond<br>Cemetary<br>Gorefest<br>In Flames<br>Dark Tranquillity
3. Heli Lääts ja Cannibal Corpse.<br>Eriti nende duetid.<br>ntx ´Stripped, raped
and strangled´
4. alternative/rock/indie/psychedelic
5. jne...
Paraku ei ole võimalik luua algoritmi, mis kõiki võimalikke kombinatsioone igal ajal
ideaalselt loeb, mistõttu peab arvestama mõningase informatsioonikaoga ning
ebainformatiivsete kirjete (näiteks “Eriti nende duetid”) tekkimisega andmebaasi.
Ebainformatiivsete sissekannete filtreerimiseks leiame arvu, millest vähem kordi
esinevaid kirjeid loeme müraks. Sellest lähemalt järgmises peatükis algoritmi kirjelduse
juures.
Peale elementide eraldamist ning “puhastamist” tuleb need lisada andmebaasi. Kogu
süsteemi kiiruse huvides kaardistame iga sõne peale ühe numbrilise ID koodi.
Informatsiooni elemendi liigis (film, raamat jne), elementide sõnede, sõnedele vastavate
ID-de ning elemendi esinemissagedusee kohta andmebaasis hoiame ühes tabelis.
Teises tabelis hoiame informatsiooni iga profiili kohta – komadega eraldatud loetelu
kõikide selles profiilis esinevate elementide ID koodidest. Kuidas kõiki neid andmeid
täpselt kasutame on kirjeldatud järgmistes peatükkides.
14

3. SOOVITAMISE ALGORITM
3.1. Nõuded algoritmile
Soovitussüsteemi tuumas hakkab töötama üks programm, mis kasutajaliideselt tulnud
päringute peale tagastab sobilikke tulemusi. Selleks, et see programm oma tööd
võimalikult efektiivselt täidaks, tuleb selle loogikaks valida antud tingimustes kõige
optimaalsem algoritm.
Kasutusele võtav algoritm peab täitma kolme põhilist tingimust:
1. Algoritm peab tagastama võimalikult häid tulemusi.
2. Algoritm peab tulemused tagastama võimalikult kiirelt. Tulemuste tagastamisele
kuluv aeg peab olema kõige rohkem lineaarselt sõltuv nii otsingutingimuste
hulgast kui ka andmebaasi suurusest.
3. Algoritmi mälukasutus peab olema võimalikult minimaalne antud tingimuste
juures. Tulemuste leidmisel kasutatav mälumaht ei tohi kasvada suurema kui
lineaarse sõltuvusega andmebaasi suurusest.
3.2. Lühiülevaade association rule algoritmidest
Andmekaevandamises kasutatakse association rule5 algoritme huvitavate
objektidevaheliste seoste leidmiseks andmebaasis.
5 http://en.wikipedia.org/wiki/Association_rule_learning
15

Tavaliselt opereerivad need andmebaasidel, millede tabelite read tähistavad erinevaid
tehinguid (näiteks ühe külastaja poolt poest ostetud kaupade loetelu) ning veerud
tõeväärtusi või koguseid, mis on seotud vastavate pakutavate elementidega (näiteks
mitu leiba, saia jne külastaja ostis).
Toome näite sellisest tabelist:
Tehingu ID Piim Sai Või Õlu
1 1 1 0 0
2 0 1 1 0
3 0 0 0 1
4 1 1 1 0
5 0 1 0 0
Tabel 1: Kujutletava poe ostuajalugu
Tabeli read tähistavad erinevaid poe külastuskäike, veergudel on märgitud milliseid
tooteid osteti. Tabeli veerge võib tähistada hulgaga I = {piim, sai, või, õlu}, tabeli ridu
hulgaga D = {t1, t2, t3, t4, t5}.
3.3. Usaldusreegel
Selliste andmete peal on defineeritud erinevad reeglid kujul X => Y, kus nii X kui ka Y
kuuluvad mõlemad tabeli elementide hulka I ega oma ühisosa. Näide sellisest reeglist
on {piim, sai} => {või}.
Elemendi tugi (ingl. support) andmebaasis supp(X) defineeritakse kui protsent
tabeliridadest, mis sisaldavad hulka X. Näiteks hulga {piim, sai} tugi on 2 / 5 = 0.4, sest
vaid kaks rida viiest (40%) sisaldavad nii piima kui ka saia.
16

Elemendi usaldus (ingl. confidence) conf(X => Y) on defineeritud kui protsent hulka X
sisaldavatest ridadest, mis sisaldavad ka hulka Y. Täpsemalt:
conf(X => Y) = supp(X ∪ Y) / supp(X)
Näiteks on reeglil {piim, sai} => {või} usaldus 0.2 / 0.4 = 0.5. See tähendab, et 50%
juhtudest, kui osteti nii piima kui ka saia osteti ka võid.
3.4. Millise algoritmi võtame?
On loodud mitmeid algoritme sagedaste seoste leidmiseks andmebaasist. Kõige tuntum
näide sellisest algoritmist on Apriori6, mis käib laiuti otsinguga läbi kõik võimalikud
hulgad X I suurusega 1, võtab neist kõige sagedamini esinevad, laiendab neid
elemendiga Y I ning vaatleb edasi kõiki võimalikke hulki (X ∪ Y) I suurusega 2.
Selline laienemine jätkub kuni on leitud kõik maksimaalse pikkusega alamhulgad, mille
tulemuste seas on rohkem kui elementi.
Loodaval soovitussüsteemil pole aga sellist keerukust vaja. Piisab kui võtta hulk
kõikidest otsinguparameetrina esitatud elementidest ning vaadelda milliste elementidega
esineb kõige suurem usaldusreegel.
Seega võib kasutatava algoritmi kirjeldada lihtsalt:
1. Koosta hulk otsingus päritud elementidest, mis oleks kõikide elementide
alamhulk.
2. Leia read andmebaasist, mis sisaldavad antud hulka
3. Iga sellise rea kohta pea arvet elementidest, mis samuti esinevad sellel real
6 http://en.wikipedia.org/wiki/Apriori_algorithm
17

4. Tagasta loetelu elementidest, mis esinesid kõige rohkem koos otsingus päritud
elementidega.
Edasi on klientprogrammi ülesanne saadud informatsiooni edastada kasutajale
atraktiivsel kujul.
3.5. Müra andmebaasis
Arvestades andmete kogumise taktikat on paratamatus, et andmebaasi tekib ridu, millel
puudub sisuline väärtus. Selliste filtreerimiseks võtame kasutusele mõned lihtsad
piirangud:
1. Reaalsete päringutena loevad vaid need elemendid, mida on andmebaasis
rohkem kui 35 tk
2. Reaalsete seostena loevad tulemustes vaid need elemendid, millega on
otsingupäringus esinevatel elementidel vähemalt 5 seost.
Antud arvud on leitud testimise käigus ning subjektiivse hinnanguna paistavad andvat
kõige paremaid tulemusi.
18

4. SERVERIPROGRAMMI KOOSTAMINE
4.1. Eraldiseisva serveriprogrammi vajadus
Vajadus eraldiseisva serveriprogrammi järele on lihtne: puhas PHP + MySQL
klientlahendus ei suudaks tagastada piisavalt hea kvaliteediga tulemusi piisavalt kiire
ajaga.
Kui võtta andmebaasiks algmaterjaliks 150 000 orkuti profiili, leidub neis kokku üle
300 000 erineva elemendi. Keskmine elementide arv profiili kohta on ligikaudu 6-7 tk.
1 000 000 profiili kohta on andmebaasis kirjeldatud täpselt 2 245 273 erinevat elementi.
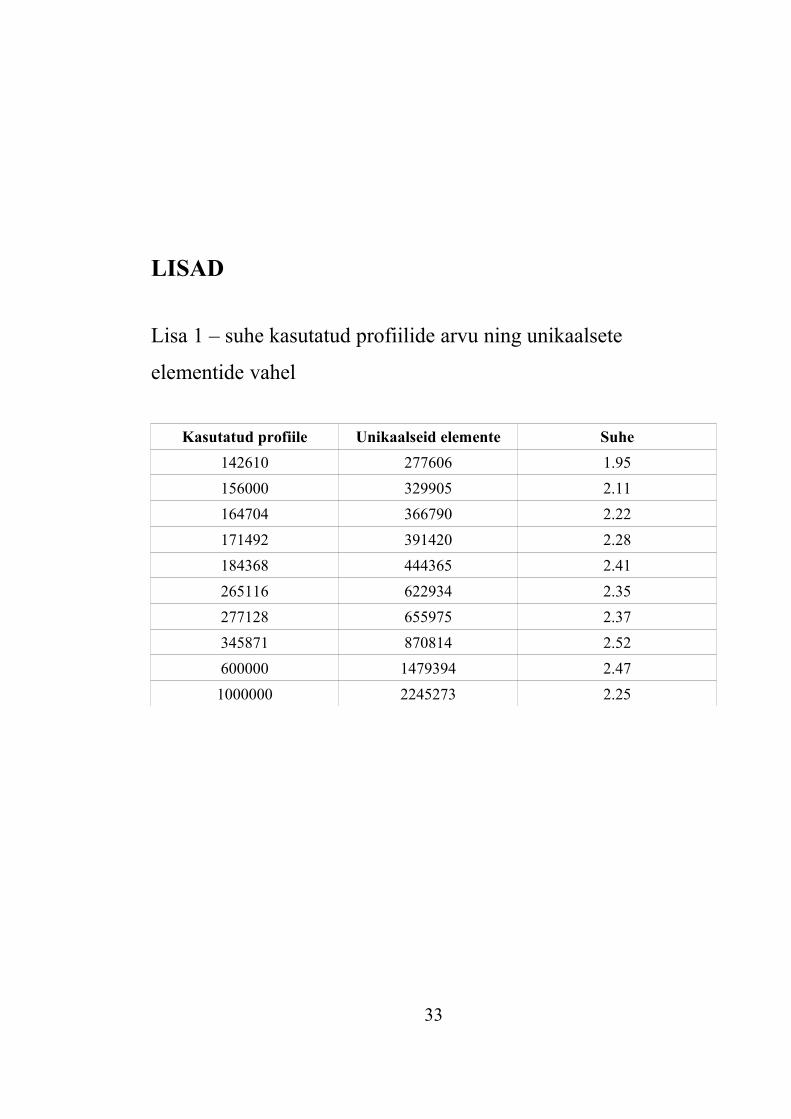
Parema ülevaate kasutatud profiilide ning erinevate elementide vahelistest suhetest
annab lisa 1.
Sellise andmebaasi sisse laadimine ning töötlemine klientrakenduse poolt eelmises
peatükis toodud algoritmi järgi on liialt aeganõudev. Kogu protsessi kiirust saab tõsta
kui kasutada veel ühte MySQL tabelit, mis sisaldab viiteid kõikide võimalike
elementide vahel ning viidete arvu (näiteks sarjad “Friends” ja “Joey” on seotud n
korral).
Paraku koosneb 150 000 rea ning 300 000 elemendi korral selline indekseeritud tabel 15
miljonist reast ning võtab ruumi ligikaudu 750MB. Kuigi ridade ning elementide
suurenedes kasvab tabeli suurus võrdlemisi lineaarselt, pole pikemas perspektiivis siiski
tegu hea lahendusega. Seda enam, et eksisteeriks vaid 1-1 seoste hulga leidmine ning
kaoks näiteks võimalus teha otsinguid reeglitele {piim, sai} => {?}.
19

Nendel põhjustel on kasulik luua iseseisev optimiseeritud serveriprogramm, mis tabelit
igal hetkel mälus hoiab ning sobilikke tulemusi päringu peale tagastab.
4.2. Nõuded serveriprogrammile
Vastav serveriprogramm peab olema võimalikult kiire ja optimiseeritud. Seega tuleb
valida programmeerimiskeel, mis kõige efektiivsemat koodi loob. See tähendab, et välja
jäävad erinevad skriptimiskeeled, mis on reeglina võrdlemisi aeglased. Kiiruse ning
mälukasutuse huvides otsustas autor kirjutada serveriprogrammi puhtas C keeles.
Serveriprogramm peab käivitudes automaatselt laadima mällu kõik andmebaasis
leiduvad profiilid. Lisaks peab serveriprogramm suutma ennast automaatselt uuendama
uute ridade lisamisel andmebaasi ega vajama pidevat restarti sellistel juhtudel.
Serveriprogramm peab olema skaleeruv. See tähendab, et vajadusel peab olema
võimalik programmi töö jaotada mitme programmi osa vahel. Kuigi selline vajadus ei
või hetkega ilmneda, siis peab olema programm vähemalt selliselt ehitatud, et vajaduse
ilmnemisel ei oleks skaleeruvust süsteemi raske lisada.
4.3. Andmete laadimine
Andmete laadimiseks on serveriprogrammil liides MySQL andmebaasile.
Programmi käivitamisel avab see ühenduse andmebaasiga, pärib sealt loetelu kõikidest
profiilidest ning saab ükshaaval vastuseks vastavad profiilid koos neis leiduvate
kirjetega. Kirjete loetelu on esitatud komaga eraldatud numbrilistest ID koodidest.
20

Kuna üks nõue süsteemi puhul oli andmebaasi automaatne uuendamine, salvestab see
andmebaasist saadud profiilid ühesuunalisse ahelasse (linked list). Niiviisi toimides on
lihtne uusi profiile hiljem mällu lisada.
Informatsioon iga profiili kohta käivatest elementidest salvestatakse sorteeritud kujul
nende jaoks dünaamiliselt loodud massiivi, et kokku hoida mälukasutuse pealt.
4.4. Usaldusreegli implementatsioon
Serveriprogramm rakendab eelmises peatükis kirjeldatud lihtsat usaldusreeglit.
Pärides programmilt tulemusi (näiteks “millised filmid sarnanevad filmile Gladiator”)
peab serveriprogramm läbi käima kõik seni sisse loetud read, märkima ära päritud
elementidega samadel ridadel asuvad teised elemendid ning nende esinemiste sageduse
klientprogrammile tagastama.
Selline tegevus on võrdlemisi lihtsalt implementeeritav. Arvestades, et kasutame
andmete mälus hoidmiseks ühesuunalist dünaamilist ahelat, on selle läbi käimine
triviaalne.
Ahela iga lüli sisaldab sorteeritud loetelu elementide ID koodidest. Selleks, et näha, kas
ahela lüli sisaldab mõnda kindlat koodi kasutame lihtsat binaarotsingut, mis tagastab
vastuse O(log2 n) ajaga, kus n on ahela lülis sisalduvate ID koodide arv. Seega on sellise
otsingu kiirus kokku O(m log2 n), kus m on ahela elementide arv.
Nendel juhtudel, kui ahela lüli vastab otsingutingimustele (sisaldab kõiki soovitud
elemente) tuleb pidada järge elementidest, mis lisaks otsingutingimustele nendel ridadel
esinevad.
21

Selleks kasutame kolme massiivi, millede pikkusteks on erinevate võimalike elementide
arv. Kohates uut elementi, mida pole seni veel otsingutulemustega samal real esinenud
määrame sellele elemendile uue ajutise koodi, mille salvestame massiivi
mapping[päris_id]. Kõik elemendid saavad endale uued koodid nende esinemise
järjekorras. See tähendab, et esimene element saab endale mapping[päris_id]
tabelis väärtuseks 1, järgmine 2 jne. mapping[päris_id] väärtus 0 tähistab, et seda
elementi pole veel esinenud.
Loome ka teistpidise massiivi realids, kust saame vastava järjekorranumbri 1, 2 jne abil
kätte elemendi päris_id. See tähendab: realids[mapping[päris_id]] =
päris_id. Massiiv count[mapping[päris_id]] sisaldab selle elemendi
esinemise sagedust koos otsingutingimustega. Selline lahendus on loodud kiiruse
huvides, sest lõpus tulemuste kuvamiseks piisab vaid tsüklist, mille pikkuseks on
erinevate esinenud elementide arv, mitte mitu suurusjärku suurem kõikide võimalike
elementide arv.
Protsessi lõpuks on meil loetelu otsingutingimustega koos esinevatest teistest
elementidest salvestatud koos nende esinemise sagedusega kolme massiivi. Lõplike
tulmeuste saamiseks need vaid klientprogrammile järjest saata.
Serveriprogrammi usaldusreegli implementatsiooni kood on lisatud lisana 2.
4.5. Automaatne andmete uuendamine
Kuna serveriprogramm salvestab andmeid ühesuunalise ahelana, on uute elementide
automaatne lisamine ahela lõppu kergelt implementeeritav.
Programmile on teada mitu rida andmeid igal hetkel sisse laetud on. Pärides teatud
ajavahemike järel andmebaasilt uusi seni lugemata andmeid saame tulemuste saabudes
need mällu lugeda ning ahela lõppu lisada.
22

Tähelepanu tuleb pöörata sellele, et tulemusi otsides kasutaksime igal hetkel vaid neid
ridasid, mis on kindlalt mällu loetud ega ole “poole peal”. Selleks kõige lihtsam on
edastada otsingufunktsioonile arv, millest rohkem ridu tulemuste edastamiseks ei
kasuta. Niiviisi jäävad küll tulemustest välja read, mis otsingu vältel mällu loetud said,
kuid teisest küljest hoiame ära võimalikke probleeme, mis poolikute andmete
lugemisega tekkida võivad.
4.6. Koormuse jaotamine Amazon EC2 süsteemis
Tüüpiline ressursimahukas serverirakendus vajab edukaks toimimiseks selle jaoks
eraldatud serverit, mistõttu selliste süsteemide arendamine nõuab võrdlemisi suurt
algkapitali.
Traditsiooniliste serverilahenduste puhul tekib alati laienemise vajadusel mure: uute
serverite lisamine on kulukas ning aeganõudev protsess (mõõdetakse päevades). Õnneks
on tänapäeval lahendused, mida kasutades võib kõik traditsioonilised mured riistvaraga
kõrvale jätta ning keskenduda vaid rakenduste loomise peale.
Üks sellistest teenustest on Amazon Elastic Compute Cloud7 (Amazon EC2). EC2
kujutab endast tasulist virtuaalmasinate rendi teenust.
Igale EC2 virtuaalmasinale saab paigaldada enda poolt soovitud tarkvara.
Virtuaalservereid on võimalik nupuvajutusega käivitada ning sulgeda. Loodud
konfiguratsioone saab tuleviku jaoks kettapiltidena salvestada ning vajaduse tekkimisel
minutitega käivitada.
7 http://www.amazon.com/ec2/
23

EC2 süsteemi on kasutatud erinevate rakenduste serveerimiseks, alates Facebooki
programmidest8 lõpetades miljonite PDF failide konverteermisega 24 tunni jooksul New
York Times'i poolt9.
Tuleb välja, et EC2 sobib loodava soovitussüsteemi põhjaks ideaalselt.
Kuna EC2 võimaldab uusi virtuaalmasinaid hetkega käivitada, jääb küsimuseks vaid
kuidas koormust jaotada. Variante on kolm:
1. Leides, et andmebaas kasvab liiga suureks, et üks server jõuaks seda mälus
hoida, võib jaotada selle kaheks või enamaks osaks, küsida tulemusi iga osa
käest ning tagastada kombineeritud tulemused.
2. Leides, et päringuid ajaühikus tekib rohkem kui server täita suudab võib sama
andmebaasi kasutada mitme paralleelselt töötava serveri poolt. Sel juhul jääb
klientprogrammi ülesandeks päringute tegemisel valida võrdse tõenäosusega
serveritest suvaline ning selle tulemusi kasutada.
3. Kombinatsioon mõlemast üleval toodud variandist, kus andmebaas on jaotatud
kahe või enama masina vahel, milledest kõigist on kaks või enam koopiat.
Kogu protsessi on võimalik ka automatiseerida. On võimalik paigaldada ühte
virtuaalmasinatest programm, mis jälgib kõigi masinate koormust. Leides, et mõnes
neist kasvab mälu ja muude ressursside kasutus üle teatud piiri saab automaatselt
käivitada uusi eelkonfigureeritud masinaid, mis teiste tööd abistavad.
Kõike ülaltoodut arvesse võttes pole skaleeruvus siiski probleem, millele rakenduse
algfaasis väga palju rõhku pöörata. Nagu soovitab 37signals'i raamat “Getting Real”10,
on kasulik kõigepealt ehitada suurepärane programm ning muretseda hiljem kui see
hästi edukaks muutub.
8 http://developer.amazonwebservices.com/connect/entry.jspa?entryID=1044
9 http://open.blogs.nytimes.com/2007/11/01/self-service-prorated-super-computing-fun/
10 http://gettingreal.37signals.com/ch04_Scale_Later.php
24

Iga rakenduse algfaasis ei ole probleemiks skaleeruvus vaid jõudmine punkti, kus on
vaja skaleerida. Siiski kord kui soovitussüsteem sellesse faasi jõuab, on see probleem
Amazon EC2 abil lihtsalt, kiirelt ning odavalt lahendatav.
25

5. KLIENTPROGRAMMI KOOSTAMINE
5.1. Nõuded klientprogrammile
Praeguseks on paigas kõik soovitussüsteemi loomiseks vajalikud elemendid peale selle
osa, millega kasutajad otseselt kokku puuutuvad.
Loodav klientprogramm peab olema võimalikult lihtsalt kasutatav. Arvestades, et see
võiks olla ka kõigile soovijatele igalt poolt kättesaadav, on üpris selge, et
klientprogrammiks saab olema tavalise brauseriga külastatav veebirakendus.
Lehekülg, mille abil kasutajad otsida saavad peab olema hästi lihtsalt kasutatav.
Külastajal peab olema võimalus sooritada oma päringuid vaid otsingutingimusi
sisestades. Puudub vajadus süsteemi kasutamiseks endale konto registreerida või teisi
sarnaseid tegevusi teha.
Süsteem peab toimima kiirelt. Kõik otsingutulemused peavad ilmuma vähem kui 0.5
sekundiga päringu sooritamisest.
Veebiliidese ülesehitus ning disain peab olema kasutaja jaoks sõbralik ning abistama
kasutaja poolt soovitud tegevuste tegemisel.
Lõplik kasutajaliides on nähtav lisas 3.
26

5.2. Suhtlus serveriprogrammiga
Peale päringu sooritamist on klientprogrammi ülesandeks seda analüüsida ning koostada
loetelu päringus esinenud elementide ID koodidest.
See loetelu saadetakse standartsete socket'ite kaudu edasi serveriprogrammile, mis
tulemuste valmimisel need kliendile edastab.
Klient sorteerib tulemused kahanevasse järjekorda ning sobitab iga saadud ID koodi
selle nime või pealkirjaga. Edasi on klientprogrammi ülesanne saadud informatsioon
edastada kasutajale võimalikult atraktiivsel viisil.
Selleks pärib klient elementide kohta andmeid Amazon.com11-ist ning IMDB-st12.
5.3. Andmete kogumine Amazonist
Amazon pakub informatsiooni oma toodete kohta kõigile soovijatele mugava REST
API13 abil.
Kohates otsingutulemustes elementi, mille kohta ei ole varem Amazonist infot päritud,
luuakse päring vastava elemendi Amazoni otsingule, kust võetakse kõige esimene
tulemus koos pildi ning pealkirjaga.
Saadud pilti kuvatakse otsingutulemuste kõrval klientprogrammi visuaalse külje
rikastamiseks. Esimest otsingutulemust ise kasutatakse viitena Amazoni veebipoodi,
kust kasutajad võivad seda elementi mugavalt osta.
11 http://www.amazon.com/
12 http://www.imdb.com/
13 http://en.wikipedia.org/wiki/Representational_State_Transfer
27

Kuna tooteid süsteemis on mitmeid ning Amazonist informatsiooni pärimine võtab
omajagu aega, on kasulik eelnevalt andmebaasis enimlevinud toodetele see
informatsioon koguda ning seega otsingutulemuste kuvamisele kuluvat aega kordades
vähendada.
5.4. Filmiinfo kogumine IMDBst
The Internet Movie Database (IMDB) pakub informatsiooni kõigi filmide ning
telesarjade kohta. Rakenduse seiukohalt on sellest informatsioonist kõige olulisem
elemendi väljalaskeaasta, kirjeldus, IMDB hinnang filmile ning IMDB viide, mida
külastades ülejäänud informatsiooni filmi või telesarja kohta koguda saab.
Paraku IMDB ei paku mugavat liidest selle informatsiooni hankimiseks, mistõttu tuleb
manuaalselt IMDB otsingutulemusi interpreteerida ning neist esimese kohta rohkem
informatsiooni pärida. Saadud informatsiooni seast leiab ka meid huvitavad väljad.
Nagu ka Amazoniga, on IMDBst informatsiooni küsimine aeglane tegevus ning kasulik
on enne otsingute tegemist see informatsioon enimlevinud filmide, telesarjade jne kohta
ära küsida ja andmebaasi salvestada.
28

6. JÄRELDUSED JA JÄRGMISED SAMMUD
Ülalkirjeldatud protsessi tulemusena valmis esimene versioon soovitussüsteemist
nimega SuggestANT. Siiski enne kui seda süsteemi maailmale terviklahendusena
tutvustada saab, vajab see mitmeid muudatusi.
Kuigi ühe miljoni orkuti profiili kasutamine annab hea alguse soovitussüsteemi arengus,
ei ole see väga perspektiivikas lahendus. Informatsioon filmide, sarjade ja muu kohta,
samuti ka inimeste arvamused nendest asjadest, muutub ajas väga kiirelt.
Seetõttu tuleb rakendada mehhanisme uue informatsiooni hankimiseks. Kõige lihtsam
on kasutada süsteemi päringuvälja ning sagedamini sooritatud otsinguid sisestada uute
seostena andmebaasi.
Süsteem praegusel kujul on hea sissejuhatusepunkt soovitussüsteemide maailma ning
omab perspektiivi õigete arendussuundade valimisel muutuda lihtsast hobiprojektist
paljukasutatud süsteemiks. Millal, kas ning kuidas see juhtub, selgub tulevikus.
29

7. KOKKUVÕTE
Bakalaureusetöö eesmärgiks oli luua kollektiivne soovitussüsteem ning dokumenteerida
selle arendust. Töö jaotus neljaks osaks:
1) algandmete kogumine
2) algoritmi valik
3) serveriprogrammi loomine
4) klientrakenduse implementatsioon
Nelja eraldi vaadatava, kuid üksteisega tugevalt seotud osa tulemusena valmis
soovitussüsteem, mis on võimalik juba kasutada huvitavate tulemuste saamiseks.
Kuigi tegu on hea algusega, tuleb süsteemi populaarseks ning kasutatavaks muutmiseks
veel suuri samme teha, kõige olulisem neist on andmete pidev uuendamine.
Üks töö varjatud eesmärkidest, mis ka täitus, oli see, et kasutades lihtsaid teadmisi
erinevatest tehnoloogiatest (PHP, C, MySQL, klient/server programmeerimine, erinevad
algoritmid, andmete kogumine) ning neid kokku pannes on võimalik luua midagi, mis
need tehnoloogiad ükshaaval mugavalt ei paku ja sealjuures luua midagi huvitavat ning
kasutatavat.
Süsteem oma praeguses staadiumis kättesaadav kõigile soovijatele aadressilt
http://suggestant.com/ant/ask.php .
30

RESUME
The aim of this thesis paper was to build a scalable collaborative filtering
recommendation system and to document its development. The system was supposed to
give adequate recommendations of movies, TV shows, books and music based on the
elements of the same categories entered into the search box.
The development of this system was broken into four steps:
1) Gathering of the test data.
For this we used data from the social networking site orkut. We developed a
crawler that would recursively fetch the ID-s of people on the site and if they
had made their profile information public to the world, also fetch the
information about their favourite books, movies, TV shows and music. This data
was used to make well-informed guesses that if you would like most or some of
the things most people liked, you might also like the other things these same
people liked.
2) The recommendation algorithm
The algorithm selected was a simple implementation of confidence association
rule learning. This algorithm gives a relevance ranking for each element that
appears in the same row of the entry data (transactions, or in this case orkut
profiles) as do the entered search terms. For example if the show “Joey” appears
in the database n times and the shows “Friends” and “Joey” appear together m
times, than the relevance for “Friends” as viewed from the point of “Joey” is m/
n. Calculating such relevance for each element (TV show, movie, etc) we can
31

rank them in decreasing order and find elements which are most similar to the
entered search terms.
3) The server application
A separate server application was built in C to keep the entered orkut profiles in
memory all time and develop fast results. Having done the same thing on the
PHP front-end side, it would have been many magnitudes slower.
4) The PHP front-end to the server
Finally a PHP front-end was developed which fetches the results from the server
and displays them in an attractive manner alongside descriptions and images
fetched from IMDB and Amazon respectively.
Combining these four steps a complete application was formed with relative ease.
Although the system is complete as of now, to be usable and self sustainable, an
automatic data update process needs to be implemented. This is most easily done by
using the most searched-for terms as new data entries.
The system in its current form is available for all interested parties at
http://suggestant.com/ant/ask.php .
32
LISAD
Lisa 1 – suhe kasutatud profiilide arvu ning unikaalsete
elementide vahel
Kasutatud profiile Unikaalseid elemente Suhe
142610 277606 1.95
156000 329905 2.11
164704 366790 2.22
171492 391420 2.28
184368 444365 2.41
265116 622934 2.35
277128 655975 2.37
345871 870814 2.52
600000 1479394 2.47
1000000 2245273 2.25
33

Lisa 2 – usaldusreegli implementatsioon serveriprogrammis
/* * exist_in_row – leiab, kas element ID-ga 'number' * eksisteerib reas 'rr' kasutades kahendotsingut */int exists_in_row(thing *rr, int number){
int a=0, b=0, c=rr->count;
�
if(c == 0) return false;
�
while(true){
if(c < a) return false;
�
b = (a+c)/2;
�
if(rr->names[b] > number){
c = b-1;}else if(rr->names[b] < number){
a = b+1;}else
return true;
�
}}
�
/* * find_similars – usaldusreegli implementatsioon * * rowcount – mitme rea pealt otsida * count, values - otsinguparameetrid * counts, realids, mapping – tulemuste massiivid * listcnt – counts massiivi järjehoidja */int find_similars(int rowcount, int count, int *values, int *counts, int *realids, int *mapping, int &listcnt){
int i=0, cnt=0, j=0, k, e, bad=0;listcnt = 0;
�
thing *next = rows;
34

�
for(next = rows;next != NULL && i<rowcount; next=next->next)
{bad = 0;for(k=0;k<count;k++){
if(!exists_in_row(next, values[k])){
bad = 1;break;
}}if(bad == 1) continue;
�
cnt++;for(j=0;j<next->count;j++){
bad = 0;e = next->names[j];
�
for(k=0;k<count;k++){
if(e == values[k]){
bad = 1;break;
}}if(bad == 1) continue;
�
if(mapping[e] > 0){
counts[mapping[e]]++;}else{
listcnt++;mapping[e] = listcnt;counts[listcnt]=1;realids[listcnt]=e;
}}i++;
}return cnt;
}
35
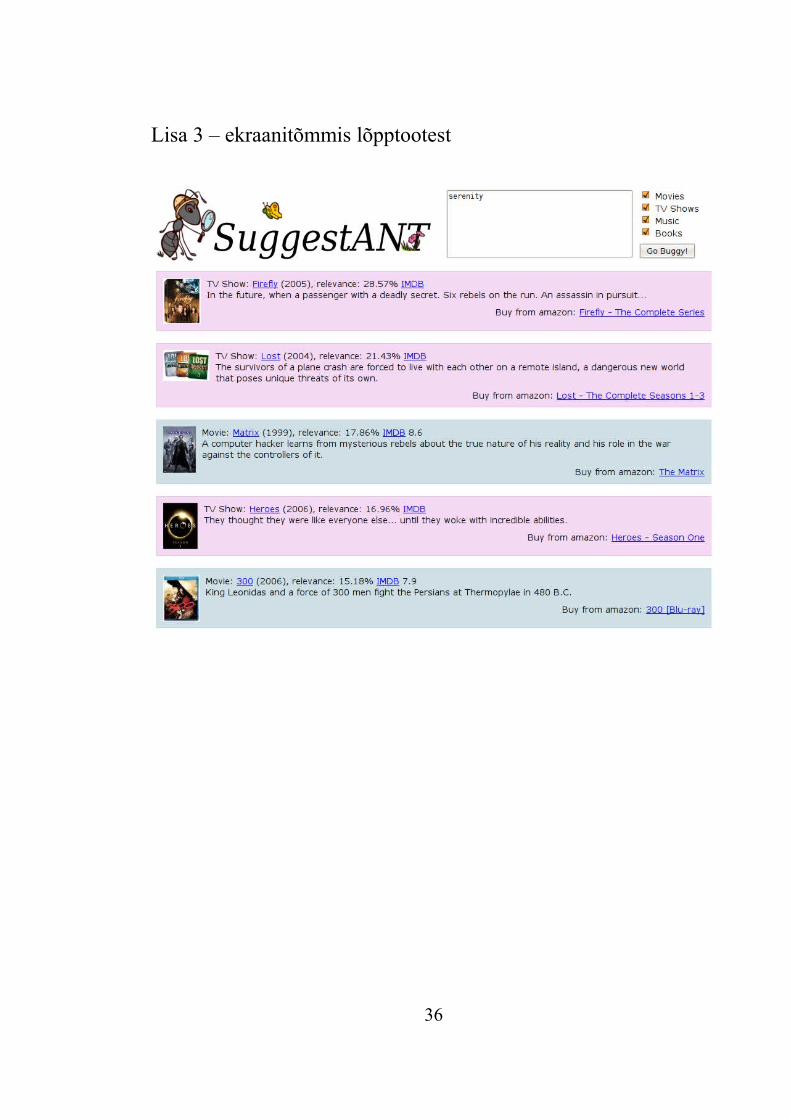
Lisa 3 – ekraanitõmmis lõpptootest
36

KASUTATUD KIRJANDUS
1. Amazon EC2 (vaadatud mai 2007)
http://www.amazon.com/ec2/
2. FreshBooks Blog: How Google Does It – With Speed (vaadatud mai 2007)
http://www.freshbooks.com/blog/2006/11/17/how-google-does-it-with-speed/
3. Getting Real: Scale Later (vaadatud mai 2007)
http://gettingreal.37signals.com/ch04_Scale_Later.php
4. NYT Blog: Self Service Prorated Super-Computing Fun (vaadatud mai 2007)
http://open.blogs.nytimes.com/2007/11/01/self-service-prorated-super-
computing-fun/
5. Orkut Privacy Notice (vaadatud mai 2007)
http://www.orkut.com/html/en-US/privacy.orkut.html?rev=4
6. Wikipedia – Apriori algorithm (vaadatud mai 2007)
http://en.wikipedia.org/wiki/Apriori_algorithm
7. Wikipedia – Association Rule Learning (vaadatud mai 2007)
http://en.wikipedia.org/wiki/Association_rule_learning
8. Wikipedia – Recommendation System (vaadatud mai 2007)
http://en.wikipedia.org/wiki/Recommendation_system
37





























