Embed Size (px)
DESCRIPTION
Sub-topic clustering on tweets and generating brief pseudo summaries, IIITH, Hyderabad. By Anil Kumar Sutrala, Raghav K, Dinesh Singla, Singdha Verma
Citation preview

Sub-topic clustering on tweets and generating brief pseudo summaries
Summarization

Team Members
Anil Sutrala Snigdha Verma Dinesh Singla Raghav K

Introduction
Summarizing twitter tweets can be viewed as an instance of the more general problem of automated text summarization.
A Twitter post or tweet is at most 140 characters long and in this study we only consider English posts.

Basic Idea
Identifying important entities from a cluster of tweets.
For each cluster we identify the most important entities from each type like Geographic location, Person etc using TF-IDF scores.
Finding most important tweets using these important entities.
Generate a brief pseudo summary for each cluster using the important entities and important tweets.

Dataset
Labelled tweets taken from Replab Dataset. RepLab is a competitive evaluation exercise for
Online Reputation Management systemsFinding most important tweets using these important entities.
In the dataset provided we have the set of tweets with the tweet id, author, entity id , text.
Labeled dataset contains the fields of tweet id, author, entity id, filtering, polarity, topic, topic priority.

MVP Model

Named Entity Recognition
Using labeled data we have generated Base tweet clusters, for further processing, using the tweet topic name.
Then use Aritter NLP tool for identifying named entities, attributes and attribute relations.
Generate TF-IDF Scores for these entities recognized.
Location (“geo-loc” named entity as per Aritter classification) has been taken as the most priority type among all named entities.

Generate Summary Per Cluster
Generate a map of named entity type vs named entities for the list of all tweets and call this map as NETYPE_MAP.
Tweet Summary is of three types broadly:– Case I : When the named entities with max
TF-IDF’s all are of location type– Case II : When no location type named entities
has maximum TF-IDF and only first the max TF-IDF named entity type is” important”
– Case III : Case III: When the max TF-IDF named entity types are of location and other types

Case 1
This case occurs when the named entities with max TF-IDF’s all are of location type.
In this case we print the summary as the collection of tweet texts which contains the named entities with max TF-IDF counts of location type.

Case 2
This case occurs When no location type named entities has maximum TF-IDF and only first the max TF-IDF named entity type is” important”.
A named entity type is marked as “important” only if its TF-IDF count is not less than half of the max TF-IDF count.
Max is the TF-IDF count for an NE type in cluster.

Case 3
When the max TF-IDF named entity types are of location and other types (Mixed case).
Becomes a subcase of case2. A named entity type is marked as “important” only if its TF-IDF count is not less than half of the max TF-IDF count.

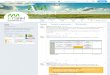
Web UI for summaries
We generate a web UI for the tweet cluster summary.
Clusters are provided in the alphabetical order and the summary is generated in following format.
Cluster Label: @ <Location> <List of Named entities> <Tweet Cluster Summary>

Results
We have generated pseudo summaries for tweet clusters and will analyze the summaries with that of text rank tool.
A sample screen shot is shown in the next slide.

Results