Embed Size (px)
DESCRIPTION
guia de estudos de estatística básica com exercícios resolvidos
Citation preview

Guia de estudos de Estatística

Guia de estudos de Estatística
UUNNIIDDAADDEE 11
IINNTTRROODDUUÇÇÃÃOO
1.1. O CONCEITO DE ESTATÍSTICA
Vamos buscar definir Estatística, e, para tanto, os dois conceitos a seguir são adequados.
Conceito 1.1. Estatística. Conjunto de técnicas que se ocupa com a coleta, organização, análise e
interpretação de dados, tendo um modelo por referência.
Conceito 1.2. Estatística. Conjunto de métodos de obtenção e utilização de informações, para
auxiliar a tomada de decisões em uma situação prática envolvendo incerteza.
Conforme se observa pelo conceito 1.1, para descrever um fenômeno ou um sistema, a
Estatística faz uso de dados (observações), os quais contêm as informações relevantes para a
elaboração e a validação de modelos.
Mais alguns conceitos básicos se fazem necessários:
Conceito 1.3. População. Corresponde ao sistema total, ou ao todo que se quer descrever, sem
generalizações para um universo maior, ou para o futuro. É sempre um conjunto de elementos com
características em comum.
A população pode ser um conjunto de peças de um lote, de anos, de pontos no solo de um
talhão, de animais, de plantas, entre outros. As populações podem ser classificadas em:
a) Finitas ou Reais;
b) Infinitas ou Conceituais.
Populações reais são, por exemplo, todas as árvores de um povoamento florestal, ou todo
o solo de um talhão de área. Por terem existência real, possuem número finito de elementos.
Quanto às populações conceituais são aquelas sem existência real, mas de concepção
bem definida, como o conjunto total de frangos que poderiam ser alimentados com uma certa

Guia de estudos de Estatística
ração, em condição de confinamento; ou ainda, todas as plantas de uma certa cultivar de milho
que foram, são ou poderão vir a ser plantadas em condições de cerrado. Pela própria definição,
tais populações só podem ser de tamanho infinito, porque nunca se disporá de todos os seus
elementos na prática.
É conveniente observar que, muitas vezes, as populações reais têm um número de
elementos tão grande, que são consideradas, sem maiores problemas, como sendo infinitas.
Alguns exemplos são: a população de todos os pés de eucalipto existentes numa grande fazenda
de reflorestamento ou, ainda, a população de todas as moléculas que compõe o volume de ar de
uma sala. Neste texto, o número total de elementos de uma população finita será simbolizado pela
letra maiúscula “N”.
Nos primórdios do conhecimento estatístico, a descrição era feita apenas para populações
reais, e por meio da observação de todos os seus elementos, conhecida como censo. Tais
levantamentos eram (e são) em geral dispendiosos, e, portanto, promovidos pelo Estado. A palavra
“Estatística” vem de “Estado”, por causa disso.
Felizmente, com o desenvolvimento da teoria de probabilidades, a partir do século XVIII,
verificou-se que as características populacionais poderiam ser obtidas (com grau variável de
confiança) a partir da observação de parte dos elementos da população, conhecida como amostra.
Conceito 1.4. Censo. Atividade de inspecionar (observar) todos os elementos de uma população
real, objetivando conhecer, com certeza, as suas características.
Conceito 1.5. Amostra. Um subconjunto ou parte da população. Ela sempre é finita.
O critério básico para diferenciar uma população de uma amostra é a seguinte questão:
“usarei minhas análises para extrapolar/generalizar os resultados para um universo maior, ou para
o futuro?”. Se a resposta for “sim”, os dados representam uma amostra, se “não”, representam
uma população. O número finito dos elementos da amostra será simbolizado pela letra minúscula
“n”.
O processo de coleta de uma ou mais amostras de uma população é conhecido como
amostragem. Como será visto ao longo do texto, existem maneiras adequadas de se proceder a
amostragem, de modo a garantir que as amostras guardem características mais próximas
possíveis da população, o que é chamado de representatividade.

Guia de estudos de Estatística
Conceito 1.6. Amostragem. Processo de obtenção ou coleta de amostras de uma população.
O objetivo último da Estatística é o de descrever e/ou tomar decisões a respeito da
população. Se isto é feito por meio de amostras, ao invés de censos, em razão da inviabilidade
destes últimos, então deve ficar claro que a descrição da amostra objetiva, em última instância,
descrever a população. Esse processo é chamado de inferência estatística, ou inferência indutiva,
porque induzir consiste em buscar generalização para um todo (população) a partir de parte do
todo (amostra).
Conceito 1.7. Inferência Estatística. Processo de se tirar conclusões ou tomar decisões acerca da
população com base em uma amostra dessa população.
Assim, didaticamente, o estudo da Estatística é dividido nos seguintes itens:
a) Estatística Descritiva: objetiva sintetizar a informação contida em um conjunto de dados, seja ele
referente a uma população finita ou a uma amostra.
b) Teoria de Probabilidades: objetiva descrever e prever as características de populações infinitas.
c) Teoria da Amostragem: é a formalização de um conjunto de técnicas para a coleta de amostras
em uma população.
d) Inferência Estatística: como já definida, trata da obtenção de informações a respeito da
população a partir de amostras, resultando na tomada de decisões a seu respeito. Como será visto
ao longo do texto, basicamente a inferência é praticada mediante: 1) a estimação de parâmetros
associados a modelos probabilísticos; e 2) testes de hipótese de interesse, sobre esses mesmos
modelos.
1.2. VARIÁVEIS E DADOS
De todas as características da população, sua descrição é feita por aquelas de maior
interesse do pesquisador. Por exemplo, as plantas de uma cultivar de milho definem uma
população, a qual é descrita por características de interesse econômico, tais como: produtividade
(t/ha), resistência a doenças, o ciclo cultural, arquitetura de planta, etc.
As características que descrevem a população são chamadas variáveis, e um valor
observado com relação a uma variável é chamado dado ou observação, sejam eles provenientes
de censos ou de amostras.

Guia de estudos de Estatística
Conceito 1.8. Variável. Característica pela qual deseja-se que a população seja descrita, ou pela
qual decisões acerca da população são tomadas.
Conceito 1.9. Dado. Observação ou realização referente a uma variável. Pode estar contido em um
censo ou em uma amostra.
Uma classificação possível quanto à natureza das variáveis está apresentada abaixo.
As variáveis qualitativas (também denominadas categóricas) correspondem a atributos,
categorias, e são oriundas da operação de classificação. Elas são nominais quando não são
passíveis de ordenação, como, por exemplo, a cultura predominante em propriedades de uma
região. As realizações dessa variável qualitativa nominal podem ser: milho, cana, soja, etc.
Quando os atributos são passíveis de ordenação, a variável qualitativa é dita ordinal; por
exemplo, esse é o caso quando usam notas para avaliar uma característica. Por exemplo, em um
laboratório de cultura de tecidos, esse critério por vezes é utilizado para classificar o grau de
regeneração no processo de micropropagação.
Quanto às variáveis quantitativas, estas correspondem a números resultantes das
operações de contagens ou medições, por isso também chamadas de numéricas. Quando se trata
de contagens, como o número de ovos ovipositados por um inseto, a variável é dita discreta, sendo
possível a separação em classes distintas (não há realização intermediária entre 2 e 3 ovos, por
exemplo) normalmente associadas aos números internos. Outros exemplos são: número de folhas
atacadas por certa praga; número de brotos germinados por tubérculo de batata, etc.
Nas variáveis quantitativas contínuas, as realizações resultam de medição, uma
mensuração, como a altura de pés de algodão ou o peso de novilhas, não havendo assim classes
distintas, mas antes um intervalo de números reais possíveis, só limitados pela precisão dos
aparelhos de medida empregados (balança, paquímetro, etc). Alguns autores ainda subdividem as
variáveis quantitativas contínuas em graduadas e proporcionais.
As graduadas (ou de razão) são aquelas onde intervalos são definidos (como em toda
variável quantitativa), mas o ponto de referência é arbitrário. Por exemplo, considere a escala
Celsius de temperatura. Suponha que um pesquisador descubra que uma técnica bioquímica é
mais eficiente a 15 0C do que a 10 0C. Nestes casos, deve-se tomar cuidado em afirmar que,
aumentando a quantidade de calor em 50%, a eficiência da técnica aumentou, porque o ponto de
referência (0 0C) foi escolhido arbitrariamente, como sendo aquele no ponto de congelamento da
água, sob uma pressão específica. Se o ponto de referência fosse deslocado, por exemplo, para o

Guia de estudos de Estatística
zero absoluto (escala Kelvin), o aumento de temperatura acima seria de apenas 5 / (273+10) =
1,8%.
As proporcionais são aquelas onde intervalos também são definidos, mas o ponto de
referência é absoluto. Por exemplo, dizer que o híbrido de milho A produz 10% mais que o híbrido
B (em t/ha) tem sentido, uma vez que o ponto de referência (a produção zero) é natural, absoluta;
não existe produção abaixo desse valor.
Por fim, observe como estamos rodeados de variáveis e dados “por todos os lados”: no
calendário abaixo, temos variáveis categóricas (o mês do ano, o dia da semana, a condição
climática do dia) e variáveis numéricas (o dia do mês). Poderíamos ter, em alguma estação
climatológica, os dados da variável numérica precipitação pluviométrica, temperatuta média do dia,
entre muitas outras.

Guia de estudos de Estatística
1.3. A NOTAÇÃO DE SOMATÓRIO
Apesar de existir vários tipos de variáveis, é muito frequente, em Estatística, trabalhar-se
com variáveis quantitativas. Essas variáveis são, em geral, simbolizadas por alguma letra latina
maiúscula, como X, Y, Z, etc. As observações ou dados, por sua vez, são representadas pelas
letras minúsculas correspondentes. Além disso, os dados são identificados por um índice, ou
contador, para indicar que trata-se da 1a observação, da 2a e assim por diante. Por exemplo, o
símbolo x1 representa a 1a observação do conjunto de dados (seja ele um censo ou uma amostra),
referente à variável quantitativa X.
Como também é muito comum o interesse no cálculo de somas, somas de termos ao
quadrado, cálculo de médias, entre outras, então é usual representar somas por um operador
chamado somatório, que é representado pela letra grega “sigma” maiúscula �. Assim, por
exemplo, a soma:
x1 + x2 + x3 + x4 ,
é representada em notação de somatório da seguinte forma:
∑=
4
1iix
,
ou seja, corresponde à soma dos termos “xi”, onde o índice i varia de 1 a 4. Esse operador é
também uma taquigrafia matemática.
Em função de sua própria definição, o operador somatório possui algumas regras, dadas a
seguir:
1) Se k é constante, então:
∑=
n
i
k1
= k + k + ... + k = n k .
2) Se k é constante e xi valores de uma variável quantitativa, então:
∑=
n
iikx
1
= k x1 + k x2 + ... + k xn = k (x1 + x2 + ... + xn) = k ∑=
n
iix
1
.
3) O somatório de uma soma de variáveis é igual à soma dos somatórios de cada variável:
( )∑=
++n
iiii zyx
1
= ∑=
n
iix
1
+ ∑=
n
iiy
1
+ ∑=
n
iiz
1
.
Em consequência das regras 1, 2 e 3, se “a” e “b” são constantes, então:

Guia de estudos de Estatística
4) ( )∑=
+n
iibxa
1
= ∑=
n
i
a1
+ ∑=
n
iibx
1
= n.a + b. ∑=
n
iix
1
.
1.4. EXERCÍCIOS RESOLVIDOS
1. Expresse as seguintes somas usando notação de somatório:
a. y 1 + y 2 + ... + y15 = i
15
1i
y∑=
b. x 21 + x 2
2 + ... + x 2n =
2i
n
1i
x∑=
c. z11 + z
23 + z
35 + ... + z
3059 = ∑
=−
30
1i
i1i2z
d. log x 1 + log x 2 + ... + log x 12 = ∑=
12
1iixlog
e. ( x1 - 1 ) + ( x22 - 2 2 ) 2 + ( x
33 - 3 3 ) 3 + ... + ( x n
n - n n ) n = ∑=
−n
1i
iiii )ix(
2. Sabendo que:
∑=
=4
1ii 16x , ∑
=
4
1i
2ix = 84 , ∑
==
4
1i
3i 496x , ∑
==
4
1ii 20y , ∑
==
4
1iii 100yx
Determine o valor numérico das expressões:
a) 39610049625x)25x(4
1i
4
1i
3i
4
1i
3i =−=−=− ∑∑∑
===
b) ∑∑==
=−+−=−4
1
234
1
3 )3375202540527()153(i
iiii
i xxxx
=−+− ∑ ∑∑ ∑= == =
4
1
4
1
4
1
4
1
23 3375202540527i i
ii i
ii xxx
∑ ∑ ∑= = =
=−+−4
1
4
1
4
1
23 )3375(4202540527i i i
iii xxx
172833754)162025()84405()49627( −=×−×+×−×

Guia de estudos de Estatística
1.5. EXERCÍCIOS PROPOSTOS
1. Desenvolva cada uma das seguintes expressões, colocando-as na sua forma mais simples
possível:
a) ∑=
5
1iix b) ∑
=
5
1i
2iixz c) ∑
=
6
1iiiyx d) ∑
=−
4
1ii xx
e) ∑=
−6
1i
2i )xx(
2. Escreva em notação sigma (somatório)
a) n21 x...xx +++
b) 2
n21 )x...xx( +++
c) 721 x...xx +++
d) 2n
22
21 x...xx +++
3. Sejam os conjuntos de dados: x= {4,3,0,1} e y={3,0,1,3}. Obtenha os seguintes somatórios:
a) ∑=
4
1iix b) ∑
=
4
1i
2ix c) ∑
=
4
1iiiyx
d) 2
4
1ii )x(∑
= e)
2
11
2
111
−
−
=
∑∑
∑∑∑
==
===
n
ii
n
ii
n
ii
n
ii
n
iii
xxn
yxyxn
b xbya −=

Guia de estudos de Estatística
UUNNIIDDAADDEE 22
EESSTTAATTÍÍSSTTIICCAA DDEESSCCRRIITTIIVVAA
2.1. INTRODUÇÃO
Neste capítulo serão abordados os conceitos elementares para a descrição de um conjunto
de dados, objetivando a retirada de informações que sejam pertinentes, interessantes, e úteis.
Duas situações devem ser ressaltadas: uma, onde os dados provêm de observações de uma
população finita, a qual é toda ela conhecida, sendo, assim, elementos de um censo, e outra,
quando os dados originam-se de uma amostra, recurso utilizado quando é impossível ou inviável
observar todos os elementos individuais da população. O conjunto de conceitos e métodos
estatísticos que operam sobre estes dois tipos de situação, populações finitas e amostras, é
denominado Estatística descritiva.
2.2. DESCRIÇÃO DE VARIÁVEIS CATEGÓRICAS
O conjunto de dados que se deseja descrever pode se referir a uma variável categórica
(também denominada qualitativa). A título de ilustração, seja o exemplo hipotético a seguir (Tabela
2.1), representando a atividade agropecuária predominante em 20 propriedades de um município.
Este conjunto de dados será tratado, como informamos, considerando-o como uma amostra,
proveniente de uma população das muitas propriedades de tal município. Como se observa, a
atividade predominante corresponde a uma variável categórica nominal, pois não é passível de
ordenação.
A maneira como os dados estão apresentados na Tabela 2.1 não deixa de ser uma
representação. No entanto, não é difícil perceber que se trata de uma disposição muito limitada
por exemplo, não se visualiza a atividade agropecuária predominante no município, e assim por
diante. Uma maneira de realçar esse tipo de informação é apresentando a frequência de cada
Tabela 2.1. Atividade predominante em 20 propriedades de um município.
Café Leite Leite Milho
Café Milho Soja Leite
Leite Café Milho Café
Olericultura Leite Café Laranja
Café Milho Café Café
atividade no município.

Guia de estudos de Estatística
Conceito 2.1. Frequência (de ocorrência) . Medida que quantifica, contando, a ocorrência dos
valores de uma variável em um dado conjunto de dados.
A frequência associada a uma variável X pode ser classificada em três tipos, conforme a
Figura 2.1:
Figura 2.1. Tipos de frequência de ocorrência.
A frequência absoluta, no caso de variáveis qualitativas, nada mais é do que o
número de observações ocorridos (contadas) em cada classe da variável em questão. É
representada por fa(x), ou simplesmente fa. A frequência relativa (fr) é obtida pela divisão da
frequência absoluta pelo número total de dados ou observações. A frequência percentual (ou
porcentual) (fp) é fornecida pela multiplicação da frequência relativa por 100%.
No exemplo das atividades agropecuárias predominantes em propriedades, as frequências
correspondentes da categoria ‘Café’ são:
fa(café) = 8 ;
fr(café) = 208
= 0,40 ;
fp(café) = 0,40 × 100% = 40%.
Assim, de forma geral, uma maneira informativa de descrever o conjunto de dados da Tabela 2.1 é
a de apresentar as frequências de cada categoria da variável ‘atividade agropecuária’, ou seja,
mostrar a sua distribuição de frequência.
Conceito 2.2. Distribuição de Frequência . Consiste em uma função que associa os valores que
uma variável assume com suas frequências de ocorrência, podendo ser elas absolutas, relativas
ou percentuais.
Frequência
Absoluta (fa) Relativa (fr) Percentual (fp)

Guia de estudos de Estatística
A distribuição de frequência de uma variável observada em população finitas e amostras,
pode ser apresentada mediante duas maneiras; a representação tabular ou a representação
gráfica. A representação tabular consiste em dispor a distribuição de frequência das categorias da
variável em tabelas. Para exemplificar, seja a Tabela 2.2 a seguir, representando a distribuição de
frequência absoluta da atividade agropecuária predominante em 20 propriedades de um município.
Tabela 2.2. Distribuição da frequência absoluta da atividade agropecuária predominante em 20
propriedades de um município.
Atividade predominante Frequência absoluta
Café 8
Milho 4
Leite 5
Olericultura 1
Soja 1
Laranja 1
Total 20
Fonte: dados fictícios.
Essa representação tabular poderia ter seu aspecto melhorado pela criação de uma nova
categoria, por exemplo, denominada ‘Outras’, que incluiria aquelas classes de menor frequência, a
saber, Olericultura, Soja e Laranja. Opções como estas são fortemente dependentes dos objetivos
e do bom senso do pesquisador. A nova representação da distribuição de frequência seria como a
da Tabela 2.3.
Outra observação pertinente é a seguinte: nesse exemplo, a variável é qualitativa nominal,
e, portanto, sem ordenação natural. Um critério sensato de ordenação, que facilita a interpretação
dos dados, é a de dispô-las de maneira que as frequências correspondentes estejam ordenadas,
como observado na Tabela 2.3. Além disso, a classe ‘Outras’, quando presente, deve
preferencialmente vir em último lugar, mesmo que sua frequência seja maior. Outrossim, quando a
variável for qualitativa ordinal como, por exemplo, o conjunto de notas:
{ótimo, bom, regular, ruim}
então, a distribuição de frequência deve ser disposta respeitando-se a ordem das categorias da
variável, crescente ou decrescente, mesmo que não seja obedecida a ordem de magnitude das
frequências.
Guia de estudos de Estatística
Tabela 2.3. Distribuição da frequência absoluta da atividade agropecuária predominante em 20
propriedades de um município.
Atividade predominante Frequência absoluta
Café 8
Leite 5
Milho 4
Outras 3
Total 20
Fonte: dados fictícios.
Quanto a sua estrutura, de maneira geral, as tabelas têm os seguintes componentes: título,
cabeçalho, coluna indicadora, corpo, linha de totais e rodapé (Figura 2.2). Estes são definidos
como:
- O título deve conter as informações relativas ao conteúdo da tabela, a(s) variável(eis) dispostas,
podendo ainda conter o local de coleta dos dados, e quando e como foi realizado o estudo. O título
deve responder, no mínimo, a 3 perguntas: “o quê?”, “onde?”, e “quando?”. O cabeçalho especifica
as variáveis e a frequência (ou outra característica) correspondente aos seus valores.
- O corpo é representado por uma série de colunas e subcolunas, dentro das quais são colocados
os dados apurados. Segundo o corpo, as tabelas podem ser de entrada simples, de dupla entrada,
e de múltipla entrada. A Tabela 2.3 é de entrada simples. A cada entrada corresponde uma linha
(ou coluna) de totais. Um exemplo de tabela de dupla entrada seria a classificação das
propriedades também segundo o nível de tecnologia utilizada (Tabela 2.4). Observe que há duas
totalizações marginais (totais de linhas e totais de colunas), e uma totalização geral.
- No rodapé, são colocadas a legenda e todas as observações que venham a esclarecer a
interpretação da tabela. Geralmente também é disposta a fonte dos dados (entidade que os
fornece), embora em alguns casos, seja colocada no título.

Guia de estudos de Estatística
Figura 2.2. Componentes de uma tabela.
Tabela 2.4. Distibuição de frequências absolutas das atividades predominantes e do nível de
tecnologia utilizada em propriedades de um município.
Nível de tecnologia utilizada
Atividade predominante Baixo Médio Alto Totais
Café 1 3 4 8
Leite 3 2 0 5
Milho 3 1 0 4
Olericultura 0 1 0 1
Soja 0 0 1 1
Laranja 0 0 1 1
Totais 7 7 6 20
Fonte: dados fictícios.
Traços horizontais para separar linhas são bastante utilizados. Quanto aos traços verticais, há a
tendência no meio científico de serem evitados, quando não houver prejuízo na qualidade de
apresentação.
Dependendo do contexto, alguns componentes podem estar ausentes. Nota-se que a
Tabela 2.1 é de natureza bastante simplificada, não tendo cabeçalho, coluna indicadora, linha de
totais ou rodapé. Pode-se dizer que o título e o corpo são os componentes mínimos de uma tabela.

Guia de estudos de Estatística
A idéia básica por trás de todas as regras de construção de uma tabela é que “uma tabela deve ser
autoexplicativa”, i.é, o leitor não deve precisar ter que recorrer ao texto para compreender um
tabela: ela se explica por si mesma (a mesma regra básica vale para figuras, cujos métodos de
construção serão vistos em seguida).
Além da representação tabular, a representação dos dados também pode ser feita
mediante gráficos. Para a representação de distribuições de frequência referentes a variáveis
qualitativas, existem três gráficos mais utilizados: o gráfico de linhas, o gráfico de barras, e o
setorgrama. O gráfico de linhas consiste em dois eixos, onde a frequência (absoluta, relativa ou
porcentual) é disposta no eixo vertical e as classes da variável no eixo horizontal, sendo a
identificação de cada par ordenado feita por uma linha vertical ligando o par ordenado ao eixo
horizontal. O gráfico de linhas referente ao exemplo das atividades agropecuárias predominantes
está apresentado na Figura 2.3.
Conceito 2.3. Gráfico . Diagrama ou figura para ilustração de fenômenos ou tendências, no qual
existem escalas definidas.
Café Leite Milho Outras0
0,1
0,2
0,3
0,4
0,5
Figura 2.3. Gráfico de linhas representando a distribuição de frequência relativa referente à
atividade agropecuária predominante em propriedades de um município fictício.
O gráfico de barras é bastante semelhante ao gráfico de linhas, com a diferença de que
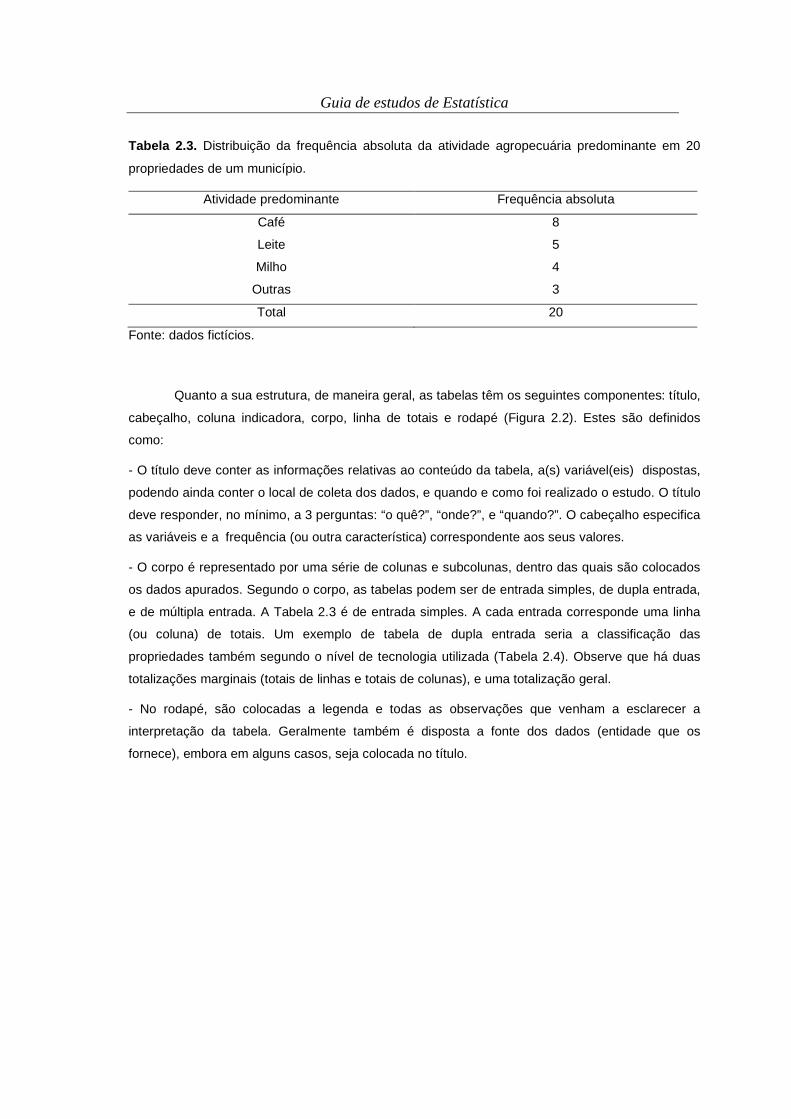
barras são utilizadas ao invés de linhas (Figura 2.4).
Guia de estudos de Estatística
Café Leite Milho Outras0
0,1
0,2
0,3
0,4
0,5
Figura 2.4 . Gráfico de barras verticais representando a distribuição de frequência relativa referente
à atividade agropecuária predominante em propriedades de um município fictício.
É importante salientar que, na disposição gráfica de variáveis qualitativas, devem ser padronizadas
as distâncias entre as categorias, bem como a largura das colunas, para que não cause falsas
impressões, em razão da escala desigual. Uma outra opção para o gráfico de barras é que estas
podem ainda ser horizontais (Figura 2.5). Outros recursos que algumas vezes são empregados em
gráficos de barras são a moldura e os traços. Estes últimos, em geral, são apenas traçados
paralelamente ao eixo x, para facilitar a visualização dos valores referentes às frequências (Figura
2.6).
O setorgrama (também chamado de gráfico circular, gráfico de setores ou gráfico de pizza)
consiste na figura de um círculo, cujos setores correspondem a categorias da variável em questão,
possuindo áreas proporcionais às frequências relativas ou porcentuais. Para a construção de um
setorgrama, basta obter o ângulo referente ao setor de uma dada categoria, pelo uso de uma regra
de três. Por exemplo, para a atividade agropecuária ‘Café’, do exemplo anterior, tem-se, para as
frequências porcentuais:
100% 360o
40% x
E assim, x = 144o. Os setores correspondentes podem ser então traçados. Hoje em dia, são
disponíveis muitos softwares que constroem esse tipo de representação gráfica, e outros.
Guia de estudos de Estatística
Café
Leite
Milho
Outras
0 0,1 0,2 0,3 0,4 0,5
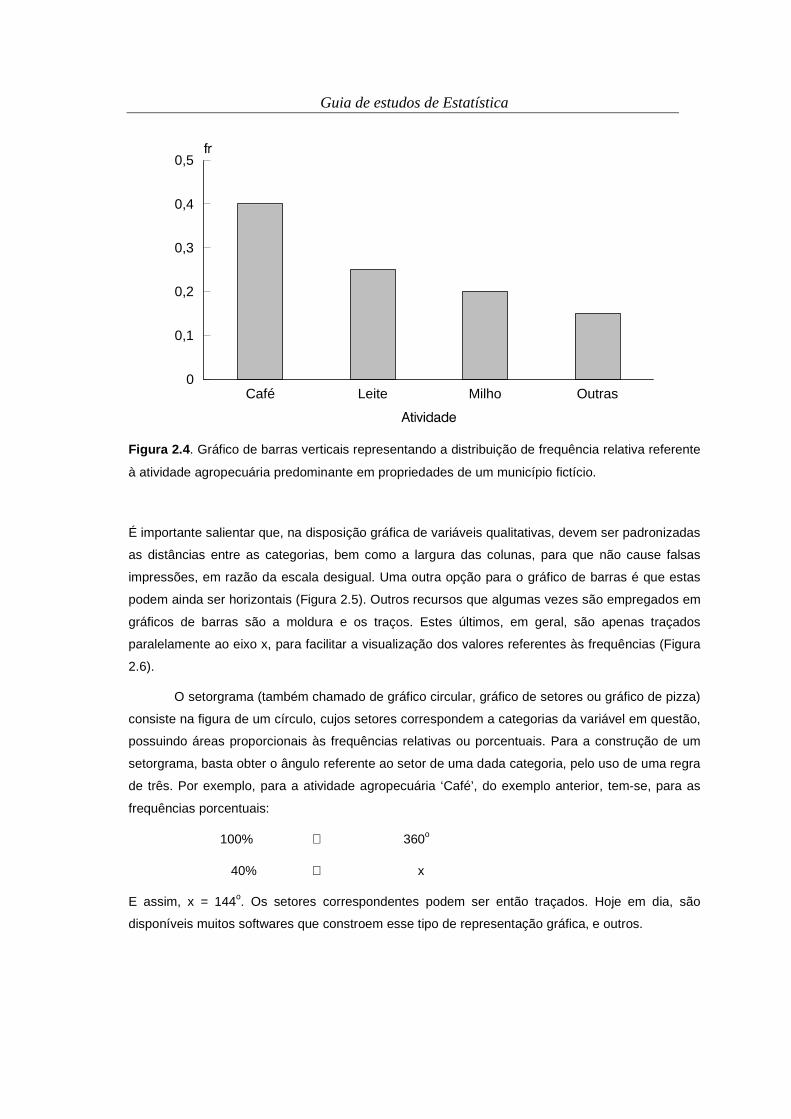
Figura 2.5. Gráfico de barras horizontais representando a distribuição de frequência relativa
referente à atividade agropecuária predominante em propriedades de um município fictício.
Café Leite Milho Outras0
0,1
0,2
0,3
0,4
0,5
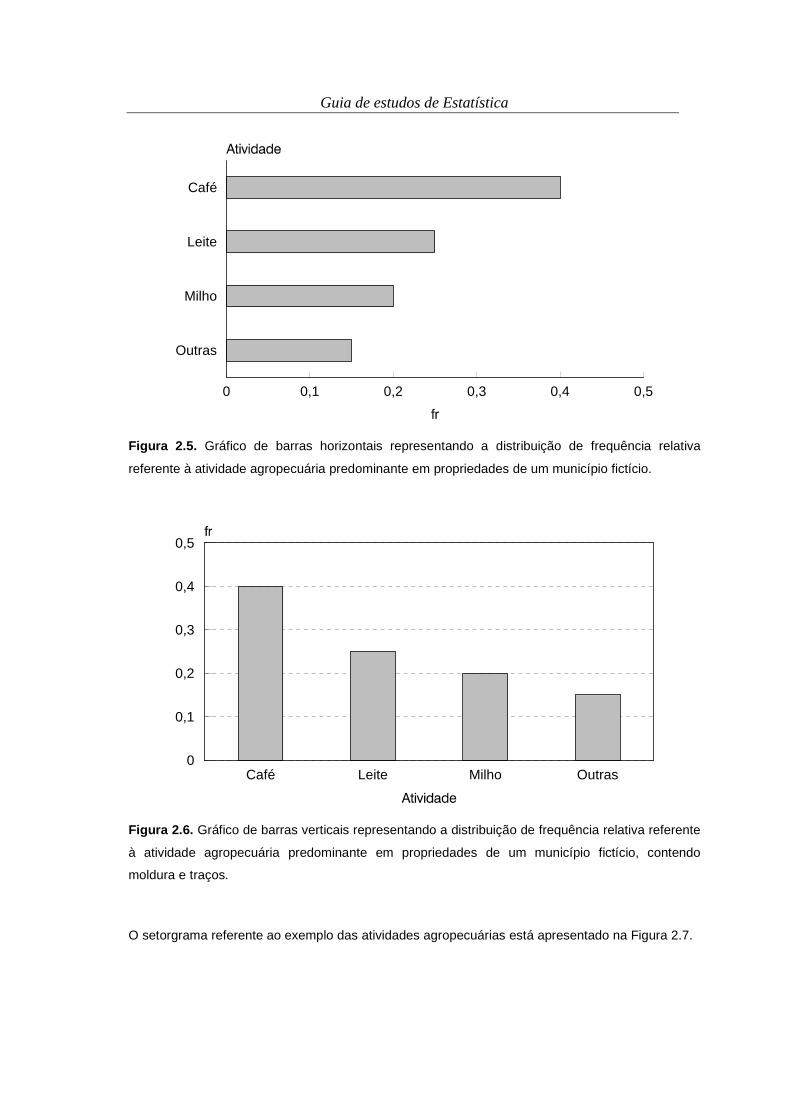
Figura 2.6. Gráfico de barras verticais representando a distribuição de frequência relativa referente
à atividade agropecuária predominante em propriedades de um município fictício, contendo
moldura e traços.
O setorgrama referente ao exemplo das atividades agropecuárias está apresentado na Figura 2.7.

Guia de estudos de Estatística
Café 40,0%
Leite 25,0%
Milho 20,0%
Outras 15,0%
Figura 2.7. Setorgrama representando a distribuição de frequência relativa referente à atividade
agropecuária predominante em propriedades de um município fictício.
Fonte: dados fictícios, apenas para efeito didático.
No caso de variáveis qualitativas ordinais, a representação gráfica é muito semelhante a
das nominais. Deve-se cuidar, contudo, para que a ordem das categorias da variável seja
respeitada ao longo do eixo referente à variável, ou qualquer outra disposição conjunta delas.
Observe também o local de colocação de títulos em tabelas e figuras: em tabelas o título
deve ficar em cima e em figuras o título deve ficar em baixo.
2.3. DESCRIÇÃO DE VARIÁVEIS NUMÉRICAS
Variáveis quantitativas (numéricas) podem ser classificadas em dois tipos: discretas e
contínuas. Conjuntos de dados referentes a variáveis quantitativas, de um modo geral, podem ser
descritos de três maneiras:
1) Distribuições de freqüência.
2) Medidas numéricas descritivas: medidas de posição (média, mediana, moda, e quantis)
e medidas de variabilidade (amplitude total, variância, desvio-padrão, coeficiente de
variação, entre outras).
3) Gráficos: histogramas, gráfico de barras, entre outros.
Frequentemente, as três maneiras são empregadas simultaneamente. Veremos o tratamento
destes modos de descrever separadamente, primeiro para distribuições de freqüência de variáveis
discretas e contínuas, e seus gráficos, e depois para medidas de posição e variabilidade, tanto
para discretas quanto para contínuas também.
Guia de estudos de Estatística
2.3.1. Distribuições de freqüência.
Nesta seção trataremos de mostrar como se faz distribuições de freqüência tanto para
variáveis contínuas quanto para variáveis discretas. Começando com as distribuições de
frequências para variáveis discretas, a representação de um conjunto de dados referentes a
realizações de uma variável quantitativa discreta é, em geral, bastante semelhante à das variáveis
qualitativas, pois os valores inteiros que a variável assume podem ser considerados como
“categorias”, ou “classes naturais”. Como exemplo, sejam dados referentes a um levantamento
onde observaram-se 91 plantas de café, numa pequena lavoura, nas quais contou-se o número de
folhas atacadas pela praga ‘bicho mineiro’, em cada planta. Como estabelecido, vamos considerar
tal massa de dados como uma amostra, proveniente de uma população constituída de todas as
plantas de café da lavoura de onde estas 91 plantas vieram (evidentemente a lavoura toda, que é a
população de onde esta amostra veio, possuía muito mais do 91 plantas – frequentemente
milhares de plantas!). A representação tabular da avaliação desse experimento está apresentada
na Tabela 2.5.
Observa-se que a disposição da variável ‘número de folhas lesionadas’ é semelhante a de
uma variável qualitativa ordinal com 11 categorias. A representação gráfica é, assim, igualmente
parecida, embora com a diferença de que a escala referente à variável possui uma interpretação
diferente, representando elementos do conjunto dos números inteiros. Exemplificando, o gráfico de
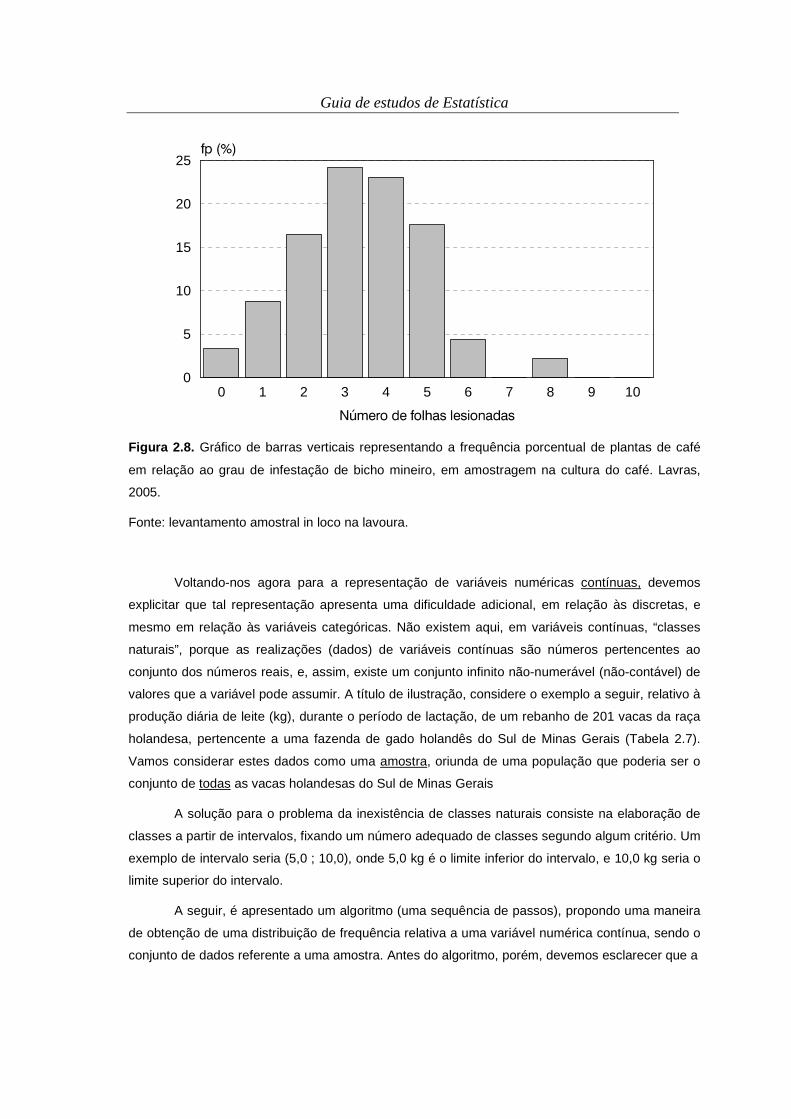
barras horizontais desse experimento está mostrado na Figura 2.8.
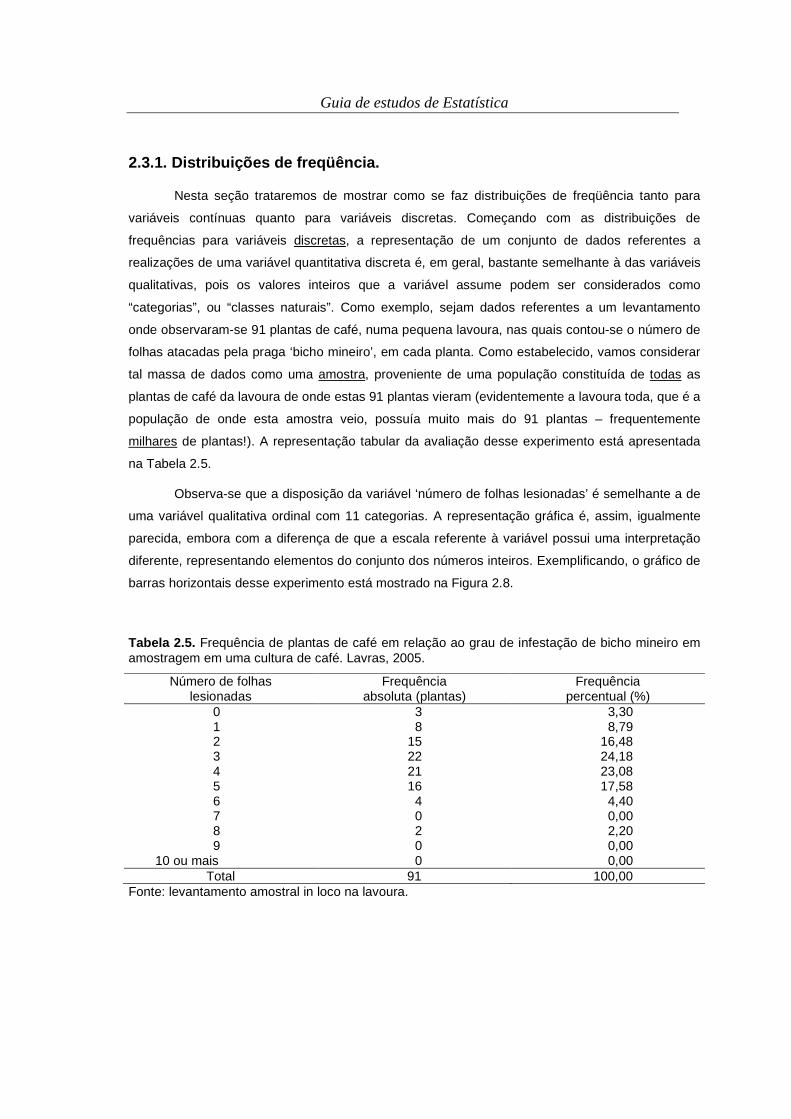
Tabela 2.5. Frequência de plantas de café em relação ao grau de infestação de bicho mineiro em amostragem em uma cultura de café. Lavras, 2005.
Número de folhas lesionadas
Frequência absoluta (plantas)
Frequência percentual (%)
0 3 3,30 1 8 8,79 2 15 16,48 3 22 24,18 4 21 23,08 5 16 17,58 6 4 4,40 7 0 0,00 8 2 2,20 9 0 0,00
10 ou mais 0 0,00 Total 91 100,00
Fonte: levantamento amostral in loco na lavoura.
Guia de estudos de Estatística
0 1 2 3 4 5 6 7 8 9 100
5
10
15
20
25
Figura 2.8. Gráfico de barras verticais representando a frequência porcentual de plantas de café
em relação ao grau de infestação de bicho mineiro, em amostragem na cultura do café. Lavras,
2005.
Fonte: levantamento amostral in loco na lavoura.
Voltando-nos agora para a representação de variáveis numéricas contínuas, devemos
explicitar que tal representação apresenta uma dificuldade adicional, em relação às discretas, e
mesmo em relação às variáveis categóricas. Não existem aqui, em variáveis contínuas, “classes
naturais”, porque as realizações (dados) de variáveis contínuas são números pertencentes ao
conjunto dos números reais, e, assim, existe um conjunto infinito não-numerável (não-contável) de
valores que a variável pode assumir. A título de ilustração, considere o exemplo a seguir, relativo à
produção diária de leite (kg), durante o período de lactação, de um rebanho de 201 vacas da raça
holandesa, pertencente a uma fazenda de gado holandês do Sul de Minas Gerais (Tabela 2.7).
Vamos considerar estes dados como uma amostra, oriunda de uma população que poderia ser o
conjunto de todas as vacas holandesas do Sul de Minas Gerais
A solução para o problema da inexistência de classes naturais consiste na elaboração de
classes a partir de intervalos, fixando um número adequado de classes segundo algum critério. Um
exemplo de intervalo seria (5,0 ; 10,0), onde 5,0 kg é o limite inferior do intervalo, e 10,0 kg seria o
limite superior do intervalo.
A seguir, é apresentado um algoritmo (uma sequência de passos), propondo uma maneira
de obtenção de uma distribuição de frequência relativa a uma variável numérica contínua, sendo o
conjunto de dados referente a uma amostra. Antes do algoritmo, porém, devemos esclarecer que a
Guia de estudos de Estatística
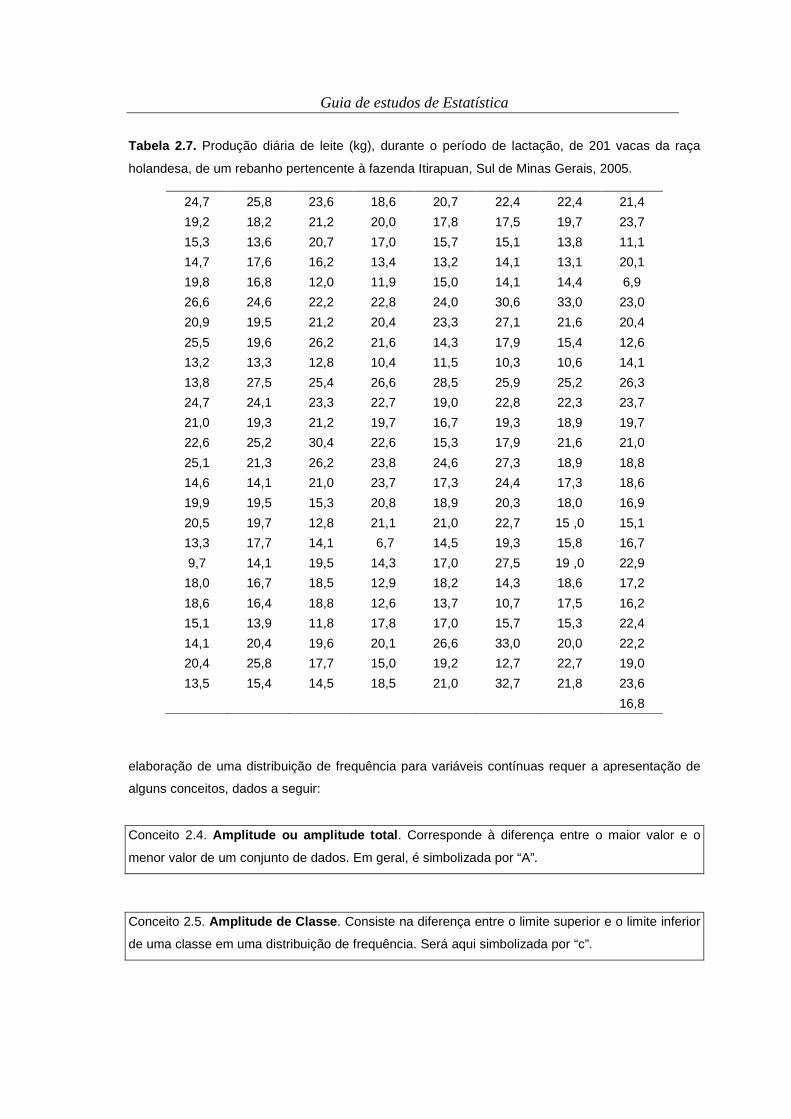
Tabela 2.7. Produção diária de leite (kg), durante o período de lactação, de 201 vacas da raça
holandesa, de um rebanho pertencente à fazenda Itirapuan, Sul de Minas Gerais, 2005.
24,7 25,8 23,6 18,6 20,7 22,4 22,4 21,4
19,2 18,2 21,2 20,0 17,8 17,5 19,7 23,7
15,3 13,6 20,7 17,0 15,7 15,1 13,8 11,1
14,7 17,6 16,2 13,4 13,2 14,1 13,1 20,1
19,8 16,8 12,0 11,9 15,0 14,1 14,4 6,9
26,6 24,6 22,2 22,8 24,0 30,6 33,0 23,0
20,9 19,5 21,2 20,4 23,3 27,1 21,6 20,4
25,5 19,6 26,2 21,6 14,3 17,9 15,4 12,6
13,2 13,3 12,8 10,4 11,5 10,3 10,6 14,1
13,8 27,5 25,4 26,6 28,5 25,9 25,2 26,3
24,7 24,1 23,3 22,7 19,0 22,8 22,3 23,7
21,0 19,3 21,2 19,7 16,7 19,3 18,9 19,7
22,6 25,2 30,4 22,6 15,3 17,9 21,6 21,0
25,1 21,3 26,2 23,8 24,6 27,3 18,9 18,8
14,6 14,1 21,0 23,7 17,3 24,4 17,3 18,6
19,9 19,5 15,3 20,8 18,9 20,3 18,0 16,9
20,5 19,7 12,8 21,1 21,0 22,7 15 ,0 15,1
13,3 17,7 14,1 6,7 14,5 19,3 15,8 16,7
9,7 14,1 19,5 14,3 17,0 27,5 19 ,0 22,9
18,0 16,7 18,5 12,9 18,2 14,3 18,6 17,2
18,6 16,4 18,8 12,6 13,7 10,7 17,5 16,2
15,1 13,9 11,8 17,8 17,0 15,7 15,3 22,4
14,1 20,4 19,6 20,1 26,6 33,0 20,0 22,2
20,4 25,8 17,7 15,0 19,2 12,7 22,7 19,0
13,5 15,4 14,5 18,5 21,0 32,7 21,8 23,6
16,8
elaboração de uma distribuição de frequência para variáveis contínuas requer a apresentação de
alguns conceitos, dados a seguir:
Conceito 2.4. Amplitude ou amplitude total . Corresponde à diferença entre o maior valor e o
menor valor de um conjunto de dados. Em geral, é simbolizada por “A”.
Conceito 2.5. Amplitude de Classe . Consiste na diferença entre o limite superior e o limite inferior
de uma classe em uma distribuição de frequência. Será aqui simbolizada por “c”.
Guia de estudos de Estatística
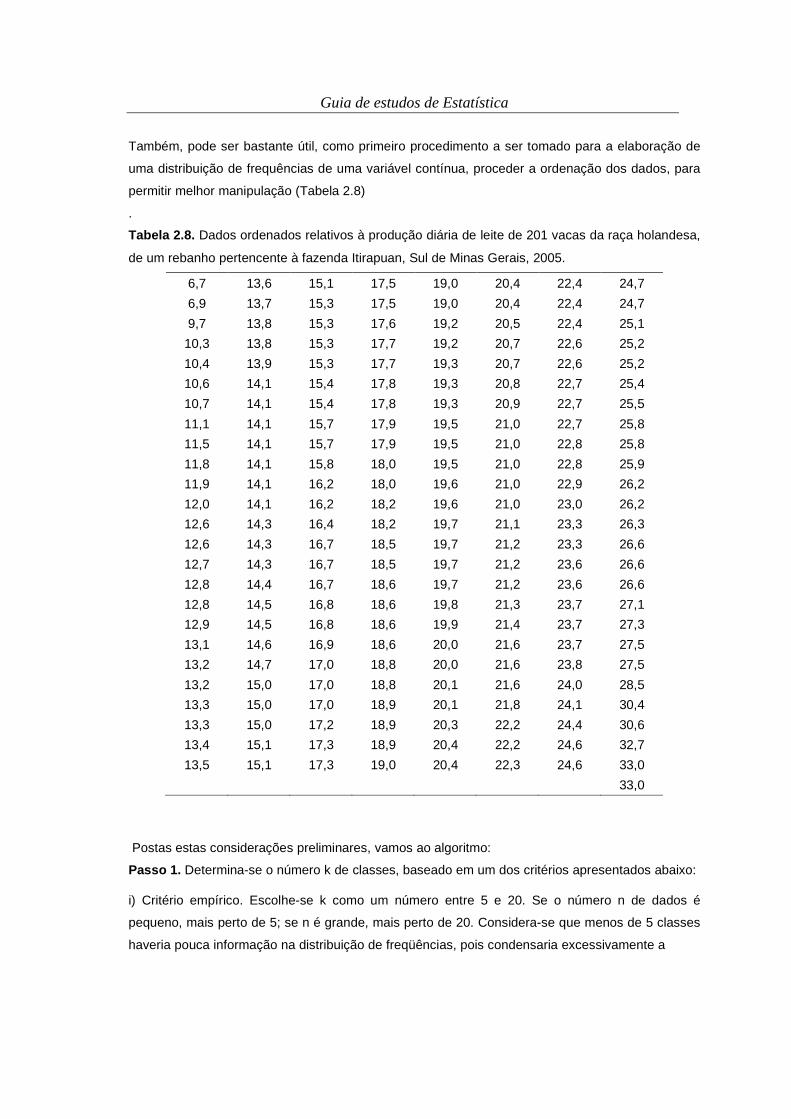
Também, pode ser bastante útil, como primeiro procedimento a ser tomado para a elaboração de
uma distribuição de frequências de uma variável contínua, proceder a ordenação dos dados, para
permitir melhor manipulação (Tabela 2.8)
.
Tabela 2.8. Dados ordenados relativos à produção diária de leite de 201 vacas da raça holandesa,
de um rebanho pertencente à fazenda Itirapuan, Sul de Minas Gerais, 2005.
6,7 13,6 15,1 17,5 19,0 20,4 22,4 24,7
6,9 13,7 15,3 17,5 19,0 20,4 22,4 24,7
9,7 13,8 15,3 17,6 19,2 20,5 22,4 25,1
10,3 13,8 15,3 17,7 19,2 20,7 22,6 25,2
10,4 13,9 15,3 17,7 19,3 20,7 22,6 25,2
10,6 14,1 15,4 17,8 19,3 20,8 22,7 25,4
10,7 14,1 15,4 17,8 19,3 20,9 22,7 25,5
11,1 14,1 15,7 17,9 19,5 21,0 22,7 25,8
11,5 14,1 15,7 17,9 19,5 21,0 22,8 25,8
11,8 14,1 15,8 18,0 19,5 21,0 22,8 25,9
11,9 14,1 16,2 18,0 19,6 21,0 22,9 26,2
12,0 14,1 16,2 18,2 19,6 21,0 23,0 26,2
12,6 14,3 16,4 18,2 19,7 21,1 23,3 26,3
12,6 14,3 16,7 18,5 19,7 21,2 23,3 26,6
12,7 14,3 16,7 18,5 19,7 21,2 23,6 26,6
12,8 14,4 16,7 18,6 19,7 21,2 23,6 26,6
12,8 14,5 16,8 18,6 19,8 21,3 23,7 27,1
12,9 14,5 16,8 18,6 19,9 21,4 23,7 27,3
13,1 14,6 16,9 18,6 20,0 21,6 23,7 27,5
13,2 14,7 17,0 18,8 20,0 21,6 23,8 27,5
13,2 15,0 17,0 18,8 20,1 21,6 24,0 28,5
13,3 15,0 17,0 18,9 20,1 21,8 24,1 30,4
13,3 15,0 17,2 18,9 20,3 22,2 24,4 30,6
13,4 15,1 17,3 18,9 20,4 22,2 24,6 32,7
13,5 15,1 17,3 19,0 20,4 22,3 24,6 33,0
33,0
Postas estas considerações preliminares, vamos ao algoritmo:
Passo 1. Determina-se o número k de classes, baseado em um dos critérios apresentados abaixo:
i) Critério empírico. Escolhe-se k como um número entre 5 e 20. Se o número n de dados é
pequeno, mais perto de 5; se n é grande, mais perto de 20. Considera-se que menos de 5 classes
haveria pouca informação na distribuição de freqüências, pois condensaria excessivamente a

Guia de estudos de Estatística
massa de dados, e que mais de 20 haveria excesso de classes, tornando a distribuição outra vez
pouco informativa. Para estes n = 201 dados, podemos utilizar 11 classes.
ii) Critério de Sturges. Escolhe-se k = 1 + log2 n = 1 + 3,32 nlog10 . Para o exemplo da Tabela 2.8:
=+= nlog.32,31k 10 ≅+ 201log.32,31 10 9 classes.
iii) Critério de Scott. Escolhe-se a amplitude de classe c como;
3
49,3..3.23
1
61
31
n
s
n
sc == π
Nota. No critério de Scott, s é o desvio-padrão da amostra, o qual será explicado mais adiante.
Para a massa de dados da Tabela 2.8, s = 3,94 kg, portanto, c = 3,73 kg. O número de classes k
será dado por
k = A / c = (33,0 – 6,7)/3,73 = 7,05, isto é, aproximadamente 7 classes.
iv) Critério prático. Escolhe-se o número k de classes segundo a Tabela 2.6 abaixo (esta tabela
constitui-se numa fusão prática dos critérios (ii) e (iii) acima):
Tabela 2.6. Critério para determinação do número k de classes na distribuição de frequência em
função do tamenho n da amostra.
Tamanho da Amostra (n) Número de Classes (k)
Até 100 Arredondamento de n
Mais de 100 Arredondamento de 5 n10log
Para n = 201 dados, por exemplo, teríamos k = Arredondamento de 5 201log10 = 12. Este critério
(iv) é especialmente recomendado, pela sua praticidade e bom desempenho.
Passo 2. Calcula-se a amplitude total A dos dados:
A = Max – Min = x(n) – x(1)
onde Max = maior valor observado (também simbolizado por x(n)) e Min = menor valor observado
(também simbolizado por x(1)). Na Estatística é convenção simbolizar dados em ordem crescente
com o índice da variável envolto por um parêntesis.
Passo 3. Se k foi calculado anteriormente (quando se usa ou o critério (i) ou (ii) ou (iv)), então
calcula-se a amplitude de classe c, por meio de:
c = 1k
A−

Guia de estudos de Estatística
Note que aqui o denominador do cálculo da amplitude de classe c corresponde a (k-1), em vez de
simplesmente k. Se em vez de k, foi dado o valor de c (quando se usa o critério (iii)), então calcula-
se o valor do número k de classes resolvendo-se a fórmula acima para k e arredondando-se para o
inteiro mais próximo.
Passo 4. O limite inferior LI1 da 1a classe é obtido por:
LI1 = Min - 2c
Observe que a subtração de c/2 do Passo 4, junto com o divisor k -1 do Passo 3, fazem com que
os limites de classe extremos (LI1 e LSk) fiquem menor e maior, respectivamente, do que o mínimo
e o máximo dos dados, ou seja, a distribuição fica mais “espichada”. A razão disto é a de que
existe uma grande chance de não se ter coletado valores extremos e pouco freqüentes, presentes
na população, fazendo com que a amplitude total A provavelmente tenha sido subestimada. Os
passos 3 e 4 buscam corrigir esta subestimação. Quando os valores calculados de LI1 ou LSk forem
incompatíveis com a variável estudada, pode-se ajustar tais valores. Uma ocorrência freqüente é,
por exemplo, o cálculo de LI1 entregar um valor negativo, num cenário em que a variável não pode
assumir valores negativos: neste caso, pode-se levar o valor de LI1 para zero.
Passo 5. O limite superior da 1a classe é obtido por:
LS1 = LI1 + c,
sendo que LS1 nada mais é que o limite inferior da 2a classe:
LI2 = LS1,
e assim, sucessivamente, as classes vão sendo construídas.
Nota 1. Deve-se observar que, sempre que possível, há conveniência em que se tenham todas as
classes de um histograma (e respectiva distribuição de freqüências) com mesma amplitude, isto é,
sejam todas de mesmo tamanho. Este algoritmo está construído para que tal igualdade de
tamanhos seja obtida.
Nota 2. Há duas alterações que podem ser necessárias neste algoritmo, relativamente as
instruções de seus passos:
(i) A primeira, que já foi pré-anunciada parcialmente no passo 4, é de que quando a variável
estudada tem valores mínimos e máximos naturais, como, por exemplo, notas em
avaliações escolares numa escala de 0 a 100, onde o mínimo naturalmente é zero
(não é possível uma nota negativa nesta escala) e o máximo naturalmente é 100 (não
é possível uma nota maior do que 100 nesta escala), pode se alterar os valores
calculados de k e/ou c para que LI1 seja igual ao mínimo natural e LSk seja igual ao
máximo natural. Tal alteração não é obrigatória, mas costuma fazer gráficos e
distribuições mais interpretáveis.

Guia de estudos de Estatística
(ii) A segunda é fundir várias classes numa só, ou alterar suas amplitudes de modo adequado
ao tipo de dados que se tem em mãos. Essa necessidade ocorre quando temos dados
com valores discrepantes (os outliers) ou quando a pesquisa transcorreu com
restrições no modo e/ou instrumento de coleta de dados. Neste caso, será quebrada a
convenção de que as classes tenham o mesmo tamanho, porém, este sacrifício será
necessário em favor da possibilidade tanto de construir o gráfico e distribuição, quanto
de interpretá-los. Um exemplo em que houve restrições está na Tabela A: para se
estudar a distribuição de frequência do consumo semanal Y (kg) de carne de frango,
em Antônio Dias (MG), foram entrevistadas 60 residências nos dias 20 e 21 de Julho
de 2001. Os resultados obtidos podem ser visualizados no quadro da distribuição de
frequência abaixo:
(iii)
Consumo Número de residências
Praticamente zero 5 (0, 1] 7 (1, 2] 22 (2, 3] 11 (3, 4] 6 (4, 5] 6
(5, 6] 3 Total 60
Um exemplo em que foi necessário alterar a amplitude das classes por causa de
valores discrepantes está na Tabela B: na implantação de um Sistema de Gestão
Ambiental (SGA) no modelo ISO 14.001 numa Pequena Central Hidrelétrica (PCH) a
variável X: “Volume de solo nas encostas marginais erodidos pela ocorrência de
processos erosivos” foi avaliada em vários pontos nas encostas do lago. Os dados
obtidos mostraram valores baixos para X, mas alguns poucos pontos tiveram valores
muito altos para X (estes são dados discrepantes). Estes outliers acarretaram a
junção de várias classes, conforme mostra a distribuição de freqüências abaixo.
Fonte: levantamento amostral na cidade, nos dias 20 e 21 de Julho de 2.009.
Tabela A . Distribuição de frequência do consumo (kg) de carne de frango, em Antônio Dias (MG), em Julho de 2.001.

Guia de estudos de Estatística
Tabela B. Volume de solo erodido nas encostas. PCH Jardim do Mato Grosso,
MS, Setembro de 2009.
X: Volume de solo erodido/carreado em m3. Número de ocorrências
(0; 5] 2.419
(5; 10] 759
(10;50] 356
(50; 100] 27
Mais de 100 0
Total 3.561 Fonte: Levantamento amostral in loco na PCH.
Um exemplo que mostra como a alteração da amplitude das classes afeta o histograma é
dado abaixo na Figura A:
Passo 6. Construídas as classes, são contados quantos dados estão contidos em cada classe
(frequências absolutas de cada classe).
Passo 7. Opcionalmente, são calculadas as frequências relativas e/ou percentuais de cada classe.
Passo 8. Para a construção de um histograma, que é o gráfico (ou representação gráfica) de uma
distribuição de freqüências de variável numérica contínua, é necessária calcular uma quantidade
denominada densidade de freqüência, definida como:
dfr(x)
50 100 150 200 250 300 350 400 x
0,0100 0,0075 0,0050 0,0025
Figura A. Histograma das áreas de 1.412 propriedades agropecuárias localizadas na região Sul do estado de Minas Gerais, 2006.
Fonte: dados simulados.

Guia de estudos de Estatística
densidade de frequência = frequência da classe / amplitude da classe,
df = f / c
Observe que cada classe tem a sua própria densidade de freqüência, que é calculada dividindo-se
a freqüência de ocorrência (ou absoluta, ou relativa, ou percentual) daquela classe pela amplitude
de classe daquela particular classe.
Como exemplo de aplicação do algoritmo acima, serão utilizados os dados referentes ao
rebanho de gado leiteiro da Tabela 2.8:
Passo 1 : Escolhe-se k = 10 classes neste exemplo, apenas porque este valor é a média de todos
os critérios acima (é claro, você pode escolher k segundo qualquer um dos 4 critérios
individualmente).
Passo 2 : A = 33,0 - 6,7 = 26,3 kg.
Passo 3 : c = 26,3 / 9 = 2,92 ⇒ c = 2,9 kg.
Passo 4 : LI1 = 6,7 - 2
9,2 = 5,25.
Passo 5 : LS1 = LI2 + c = 5,25 + 2,9 = 8,15;
LS2 = 8,15 + 2,9 = 11,05, e assim por diante, cumprindo os demais passos.
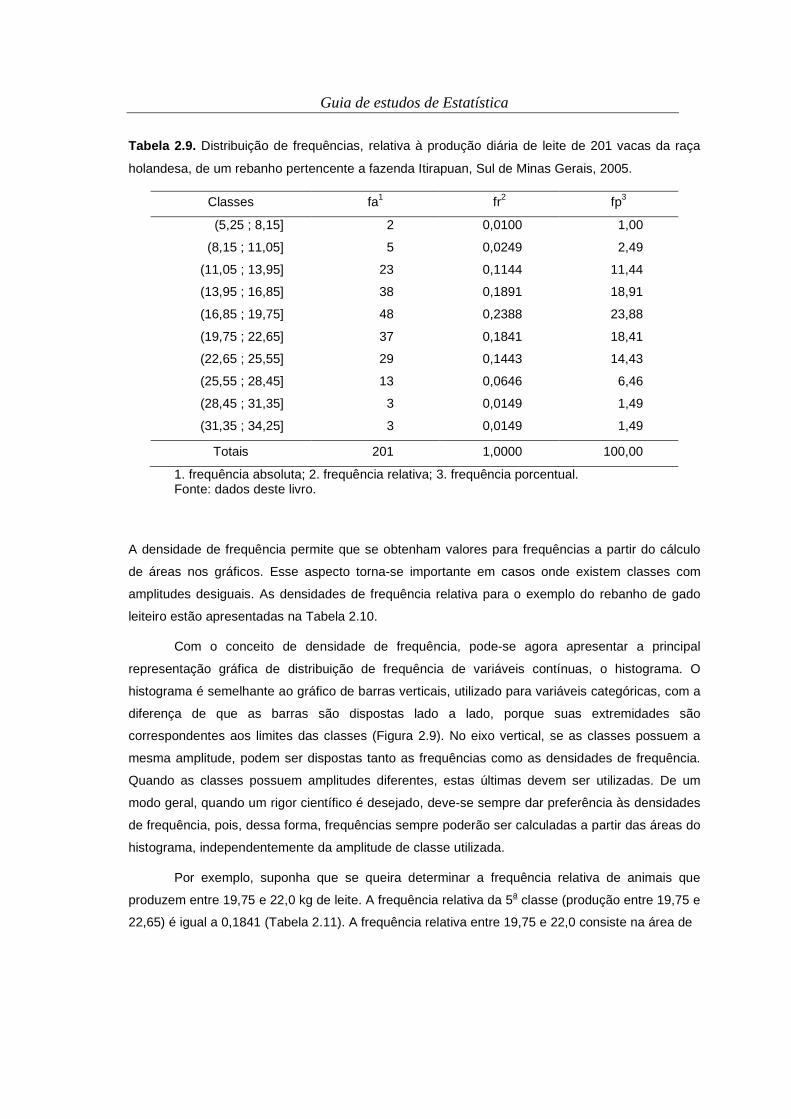
A representação tabular dessa distribuição de frequência está apresentada na Tabela 2.9. Para a
elaboração de gráficos referentes à distribuição de frequência, é necessário o cálculo da densidade
de frequência de cada classe, já dada como:
densidade de frequência = frequência da classe / amplitude da classe
Por essa definição de densidade, pode-se definir três tipos de densidade, sendo elas referentes à
frequência absoluta, relativa ou percentual. A densidade de frequência absoluta, por exemplo, é
simbolizada por dfa, e é dada por:
dfa(x) = ( )c
x fa
E assim, analogamente:
dfr(x) = ( )c
xfr e dfp(x) =
( )c
x fp
Guia de estudos de Estatística
Tabela 2.9. Distribuição de frequências, relativa à produção diária de leite de 201 vacas da raça
holandesa, de um rebanho pertencente a fazenda Itirapuan, Sul de Minas Gerais, 2005.
Classes fa1 fr2 fp3
(5,25 ; 8,15] 2 0,0100 1,00
(8,15 ; 11,05] 5 0,0249 2,49
(11,05 ; 13,95] 23 0,1144 11,44
(13,95 ; 16,85] 38 0,1891 18,91
(16,85 ; 19,75] 48 0,2388 23,88
(19,75 ; 22,65] 37 0,1841 18,41
(22,65 ; 25,55] 29 0,1443 14,43
(25,55 ; 28,45] 13 0,0646 6,46
(28,45 ; 31,35] 3 0,0149 1,49
(31,35 ; 34,25] 3 0,0149 1,49
Totais 201 1,0000 100,00
1. frequência absoluta; 2. frequência relativa; 3. frequência porcentual. Fonte: dados deste livro.
A densidade de frequência permite que se obtenham valores para frequências a partir do cálculo
de áreas nos gráficos. Esse aspecto torna-se importante em casos onde existem classes com
amplitudes desiguais. As densidades de frequência relativa para o exemplo do rebanho de gado
leiteiro estão apresentadas na Tabela 2.10.
Com o conceito de densidade de frequência, pode-se agora apresentar a principal
representação gráfica de distribuição de frequência de variáveis contínuas, o histograma. O
histograma é semelhante ao gráfico de barras verticais, utilizado para variáveis categóricas, com a
diferença de que as barras são dispostas lado a lado, porque suas extremidades são
correspondentes aos limites das classes (Figura 2.9). No eixo vertical, se as classes possuem a
mesma amplitude, podem ser dispostas tanto as frequências como as densidades de frequência.
Quando as classes possuem amplitudes diferentes, estas últimas devem ser utilizadas. De um
modo geral, quando um rigor científico é desejado, deve-se sempre dar preferência às densidades
de frequência, pois, dessa forma, frequências sempre poderão ser calculadas a partir das áreas do
histograma, independentemente da amplitude de classe utilizada.
Por exemplo, suponha que se queira determinar a frequência relativa de animais que
produzem entre 19,75 e 22,0 kg de leite. A frequência relativa da 5a classe (produção entre 19,75 e
22,65) é igual a 0,1841 (Tabela 2.11). A frequência relativa entre 19,75 e 22,0 consiste na área de
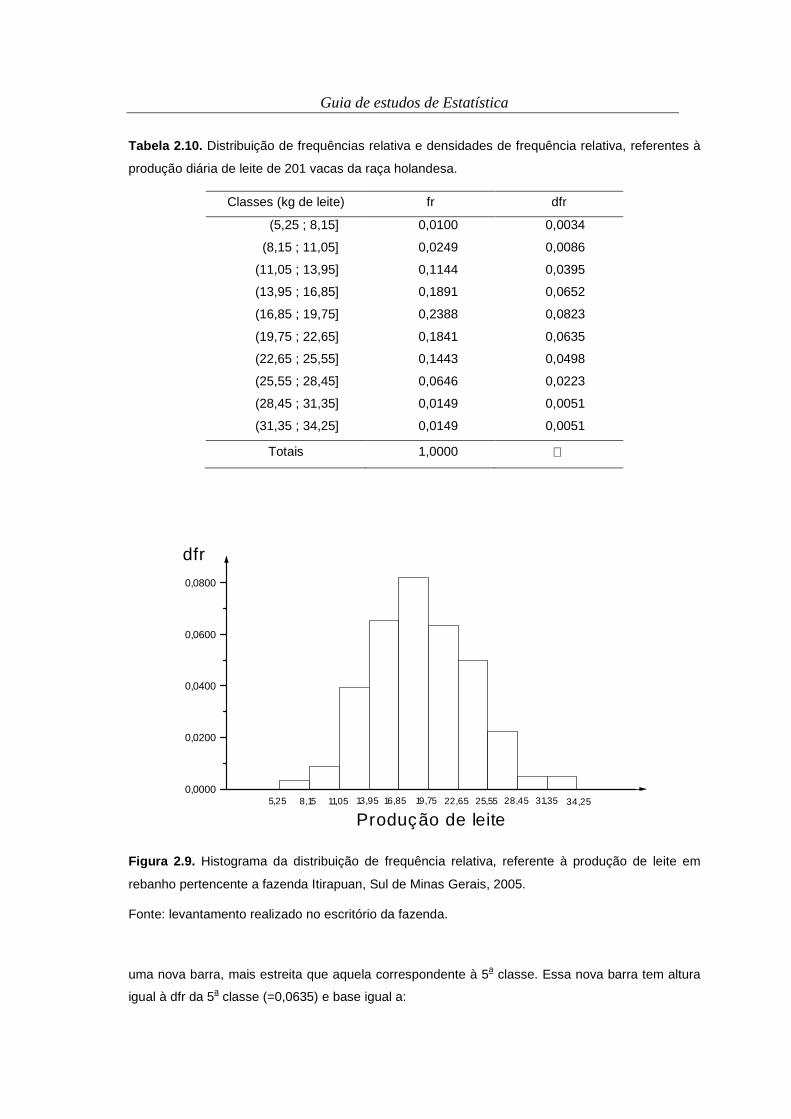
Guia de estudos de Estatística
Tabela 2.10. Distribuição de frequências relativa e densidades de frequência relativa, referentes à
produção diária de leite de 201 vacas da raça holandesa.
Classes (kg de leite) fr dfr
(5,25 ; 8,15] 0,0100 0,0034
(8,15 ; 11,05] 0,0249 0,0086
(11,05 ; 13,95] 0,1144 0,0395
(13,95 ; 16,85] 0,1891 0,0652
(16,85 ; 19,75] 0,2388 0,0823
(19,75 ; 22,65] 0,1841 0,0635
(22,65 ; 25,55] 0,1443 0,0498
(25,55 ; 28,45] 0,0646 0,0223
(28,45 ; 31,35] 0,0149 0,0051
(31,35 ; 34,25] 0,0149 0,0051
Totais 1,0000
0,0000
0,0200
0,0400
0,0600
0,0800
34,2531,3528,4525,5522,6519,7516,8513,9511,058,155,25
dfr
Produção de leite
Figura 2.9. Histograma da distribuição de frequência relativa, referente à produção de leite em
rebanho pertencente a fazenda Itirapuan, Sul de Minas Gerais, 2005.
Fonte: levantamento realizado no escritório da fazenda.
uma nova barra, mais estreita que aquela correspondente à 5a classe. Essa nova barra tem altura
igual à dfr da 5a classe (=0,0635) e base igual a:

Guia de estudos de Estatística
22,0 - 19,75 = 2,25.
Assim, a área dessa nova barra é calculada multiplicando-se sua base por sua altura, ou seja:
2,25 x 0,0635 = 0,1429 e
esse é o valor da frequência relativa entre 19,75 e 22,0. Podemos então dizer que há em torno de
14,29% de vacas que produziam entre 19,75 kg de leite e 22,0 kg de leite, na fazenda Itirapuan, no
ano de 2005. Essa porcentagem seria em torno de 29 vacas (0,1429 x 201).
2.3.2. Medidas de posição.
Na tentativa de se descrever um conjunto de dados por meio de grandezas numéricas,
talvez a noção mais imediata que ocorra seja a de um número que especifique a posição do
conjunto de dados na escala de valores possíveis da variável em questão. Tais grandezas são as
chamadas medidas de posição. As medidas de posição têm por objetivo definir o “centro” de uma
distribuição de frequências, o valor em torno da qual todos os dados “gravitam”, ou ainda, definir
“posições” de valores da variável sob estudo dentro da distribuição de frequências. Medidas de
posição só fazem sentido para variáveis numéricas. Dentre elas, serão abordadas primeiramente a
média, a mediana e a moda, as quais são as três principais medidas de posição. Existem outras,
conhecidas como quantis, que são consideradas medidas de posição por alguns autores, mas que
não têm por objetivo determinar o “centro” das distribuições de freqüências, mas apenas “posições”
dentro da distribuição de frequências. Oportunamente abordaremos os quantis.
Conceito 2.7. Medida de Posição . Grandeza numérica que descreve um conjunto de dados, pela
indicação da posição do conjunto na escala de valores possíveis que a variável em questão pode
assumir.
Média
A média aritmética (ou simplesmente média) amostral, calculada a partir de uma amostra,
e referente à característica (variável) X, é simbolizada por x e é definida como:
x = n
xn
ii∑
=1 ∑=
=n
iix
n 1
1
Para os dados de produção de leite da Tabela 2.8:

Guia de estudos de Estatística
x = leite/dia kg 04,19)8,33...9,63,5(201
1 =+++
Recorde que “n” refere-se ao número de elementos da amostra.
Muitas vezes, entretanto, há o interesse de associar a descrição por meio da distribuição
de frequências com a descrição por meio de medidas de posição. Quando se dispõe das
frequências relativas nas classes, a média aritmética pode ser obtida por:
x ∑=
≅k
iii xfr
1
.
onde fri é a frequência relativa da classe i, e ix é o ponto médio da classe i . Para a distribuição de
frequência da Tabela 2.10 temos a seguinte tabelinha auxiliar:
Produção (kg) ix ifr idfr
(5,25 ; 8,15] 6,70 0,0100 0,0034
(8,15 ; 11,05] 9,60 0,0249 0,0086
(11,05 ; 13,95] 12,50 0,1144 0,0395
(13,95 ; 16,85] 15,40 0,1891 0,0652
(16,85 ; 19,75] 18,30 0,2388 0,0823
(19,75 ; 22,65] 21,20 0,1841 0,0635
(22,65 ; 25,55] 24,10 0,1443 0,0498
(25,55 ; 28,45] 27,00 0,0646 0,0223
(28,45 ; 31,35] 29,90 0,0149 0,0051
(31,35 ; 34,25] 32,80 0,0149 0,0051
Totais 1,0000
x = 6,70 x 0,0100 + 9,60 x 0,0249 + ... + 32,80 x 0,0149 = 19,08 kg leite/dia
Outra tabelinha que pormenoriza estes cálculos é apresenta abaixo:
6,70 0,0100 0,0670
9,60 0,0249 0,2390
12,50 0,1144 1,4300
15,40 0,1891 2,9121
18,30 0,2388 4,3700
21,20 0,1841 3,9029
24,10 0,1443 3,4776
27,00 0,0646 1,7442
29,90 0,0149 0,4455
32,80 0,0149 0,4887

Guia de estudos de Estatística
19,0772 ≅ 19,08
Convém observar que o valor obtido por essa expressão (19,08) não coincide com o valor da
expressão que define a média (19,04). Esta diferença (19,08 – 19,04 = 0,04 kg leite/dia) é
chamada de erro de agrupamento. Apesar de que este erro é quase sempre pequeno, a expressão
da definição da média deve ser preferida, fazendo-se o cálculo diretamente sobre os dados
originais, apesar de ser mais trabalhoso. Atualmente, com a grande disponibilidade de softwares
específicos para Estatística, e mesmo planilhas de cálculos com poderes estatísticos, esse
trabalho deixou de ser um problema. O uso da expressão aproximada, que calcula a média
utilizando-se das frequências relativas das classes e de seus respectivos pontos médios, só deve
se utilizada quando não se dispõe dos dados originais.
A média possui algumas propriedades notáveis, como:
i) Somando-se a todas as observações uma constante k, a nova média fica acrescida de k.
ii) Multiplicando-se todas as observações por uma constante k, a média fica multiplicada por k.
iii) A soma dos desvios de cada observação em relação à média é igual a zero. O desvio da
observação i é dado por:
di = xi - x
e assim:
[ ]∑n
1=ii x - x = 0
1
=∑=
n
iid
iv) A média minimiza a soma dos quadrados dos desvios. Ou seja, a quantidade
[ ]∑n
1=i
2
i x - x ,
seria aumentada (ficaria maior) se colocássemos no lugar de x qualquer outro valor que não seja
x .
Mais duas observações são pertinentes:
i) A média é muito afetada por valores discrepantes, extremos.
ii) Trata-se da medida de posição mais amplamente utilizada.

Guia de estudos de Estatística
Mediana
A mediana é o valor que, no conjunto de dados ordenados, é precedido e seguido pelo
mesmo número de observações. É simbolizada por x~ . Por exemplo, considere o seguinte conjunto
de dados, com n = 5, referente a uma certa variável X:
x1 x2 x3 x4 x5
3 5 6 8 48
x = 14,0
Note que o valor da média, 14,0, influenciada pelo valor extremo 48, não corresponde a uma
medida de posição conveniente, uma vez que a maioria das observações possuem valores abaixo
de 10. A mediana x~ desses dados corresponde ao valor 6, pois é a observação, nos dados
ordenados, que possui um igual número de observações abaixo e acima dela, ou seja, 2 dados (3
e 5) são menores do que 6 e 2 dados (8 e 48) são maiores do que 6. Podemos considerar que 6,0
representaria os dados melhor do que 14,0, no sentido de não ser tão sensível a valores
discrepantes.
Quando o número de observações n é par, a mediana é definida como a média aritmética
dos dois valores centrais. Por exemplo, se no mesmo conjunto de dados eliminássemos a última
observação, a nova mediana seria dada por:
x~ = 5 6
2
+ = 5,5.
Podemos então propor as seguintes fórmulas para o cálculo da mediana:
x~
+=
+
+
par én se,2
ímpar én se,
122
2
1
nn
n
xx
x
Nota. x(i) é o i-ésimo valor da massa de dados em ordem crescente.
Observe que, se n é par, a mediana x~ é um valor que pode não aparecer na massa de dados.
Para a produção de leite apresentada na tabela 2.9, com n = 201 dados, n é ímpar e x~ = x(101) =
19,0 kg leite/dia pela fórmula acima, um valor que aparece na massa de dados. Para os dados da
duração das lâmpadas (tabela abaixo)

Guia de estudos de Estatística
Tabela. Dados ordenados para uma amostra de 50 lâmpadas (tempo de vida em horas).
712,7 714,1 715,1 716,7 718,2 719,8 720,5 721,8 723,0 724,6
712,8 714,3 715,3 717,3 718,5 719,9 720,8 722,2 723,6 725,1
713,8 714,4 715,7 717,5 718,6 720,1 721,0 722,4 723,6 725,2
713,9 714,6 715,7 717,7 718,8 720,4 721,2 722,7 723,7 725,9
714,1 715,0 716,2 717,8 719,0 720,4 721,6 722,8 723,8 728,5
a mediana seria a média de x(25) e de x(26):
x~ = 2
2,7188,717 += 718,0 horas
Este valor (718,0 horas) não aparece na massa de dados.
Em dados agrupados em uma distribuição de frequências, a mediana é obtida pelo valor
que divide o conjunto dos dados em dois grupos com igual frequência (50%). Para tanto, divide-se
o número de observações por dois (independente de ser par ou ímpar), e a seguir faz-se uma
interpolação na classe que contiver o resultado dessa divisão. No exemplo da produção de leite,
tem-se 201 observações organizadas numa distribuição de frequências (Tabela 2.9), obtendo-se
assim 201/2 = 100,5. Observando a distribuição de frequência absoluta nessa mesma Tabela 2.9,
verifica-se que esse valor (mesmo que não exista a posição 100,5) se encontra entre 16,85 e
19,75, ou seja, está contido na classe (16,85 , 19,75]. A interpolação é feita da seguinte maneira:
sabe-se que a amplitude de classe c corresponde a 2,9 , e que essa classe contém 48
observações (Tabela 2.9), a partir da 68a observação. A diferença entre 100,5 e 68 é igual a 32,5 ,
e assim:
48 2,9
32,5 x x = 1,96
Somando-se x ao limite inferior dessa classe, obtém-se a mediana, qual seja,
x~ = LIMd + x = 16,85 + 1,96 = 18,81;
onde LiMd é o limite inferior da classe que contem a mediana, isto é, a classe que acumula o dado
da posição n/2 em ordem cescente.
Esse raciocínio pode ser posto na forma de uma fórmula, a saber:
MdMd
Md
Md cf
Fn
LIx−−
+= 2~
,
onde:

Guia de estudos de Estatística
−MdF é a frequência absoluta acumulada até a classe imediatamente anterior à classe mediana;
Mdf é a frequência absoluta da classe mediana;
Mdc é a amplitude da classe mediana.
Se utilizamos frequência relativa nos cálculos, então a fórmula é dada por:
MdMd
MdMd c
fr
FrLIx −−
+=5,0~
;
onde:
−MdFr é a frequência relativa acumulada até a classe imediatamente anterior à classe mediana;
Mdfr é a frequência relativa da classe mediana;
Mdc é a amplitude da classe mediana.
Nota. Observe que essas fórmulas são aplicáveis apenas para variáveis contínuas, isto é, a
princípio, essas fórmulas são aplicáveis somente em variáveis numéricas oriundas de medições.
Lembre-se que não utilizamos, a principio, histogramas para representar variáveis discretas, e,
portanto, tais fórmulas (que precisam de quantidades tais como amplitude de classe e limite de
classe) não podem ser aplicadas no cálculos de mediana de variáveis discretas organizadas em
tabela de distribuição de freqüência.
A mediana é uma medida de posição apropriada para distribuições assimétricas. Nas
distribuições simétricas, mediana e média são iguais. Ela possui ainda as seguintes propriedades:
i) Somando-se a todas as observações uma constante k, a nova mediana fica acrescida de k.
ii) Multiplicando-se todas as observações por uma constante k, a mediana fica multiplicada por k.
iii) A mediana é o valor que minimiza a soma dos valores absolutos (módulos) dos desvios, isto é:
∑n
1=ii a - x é mínima se a = x~
Moda
A moda também foi idealizada visando descrever melhor aqueles conjuntos de dados com
distribuição assimétrica. Ela busca apresentar como medida de posição dos dados o valor típico de
ocorrência, isto é, por definição a moda é o valor mais frequente na massa de dados. Seu símbolo
é *x e não temos uma “fórmula matemática” para defini-la. Sua definição é simplesmente :

Guia de estudos de Estatística
*x : valor da variável que tem a maior frequência de ocorrência.
Assim como foi para média e mediana, apresentaremos seu cálculo para dados não-agrupados e
para dados agrupados.
Começando pelos dados não agrupados, a moda, sendo definida como sendo o valor mais
frequente, é calculada apenas buscando o valor que mais se repete na massa de dados. Por
exemplo, no conjunto de dados.
x1 x2 x3 x4 x5
1 2 2 3 4
a moda *x corresponde ao valor 2, que é o mais frequente, isto é, a moda é “calculada” como
sendo 2, pois o valor “2” para X ocorre com frequência absoluta 2, maior do que todos os outros
valores. Logo:
*x = 2.
Para os dados da produção leiteira do rebanho de n = 201 vacas:
*x = 14,1 kg leite/dia,
Observe que o valor 14,1 ocorreu 7 vezes, isto é, frequência absoluta de ocorrência igual 7, maior
que a frequência de ocorrência de todos os demais valores. Porém, é imediata a observação da
inconveniência de seu uso dessa maneira para o caso de variáveis contínuas, onde, na maioria
das vezes, é praticamente nula a chance de se encontrar valores exatamente iguais que se
repitam várias vezes. Esta característica de probabilidades infinitesimais para variáveis contínuas
leva alguns autores a declarar que “massa de dados brutos de variáveis contínuas não tem moda”,
porém, a rigor, mesmo tais massas de dados podem ter moda, e sua definição é como estamos
dando aqui.
Para contornar este imbróglio, convém-nos então, para variáveis contínuas, estimar a
moda como o valor que possui a maior densidade de frequência na distribuição de frequências,
obtida a partir do agrupamento dos dados. Para tanto, procede-se a construção de uma tabela de
distribuição de freqüência para os dados, buscando-se, então, em tal distribuição, o valor de maior
densidade de freqüência. Mais de um método poderia ser utilizado para este cálculo. Aqui
apresentarmos dois métodos:
(i) Método do ponto médio da classe de maior densidade de frequencia.
Neste método, considera-se a moda como sendo o ponto médio da classe de maior densidade
de freqüência, isto é, o ponto médio do retângulo de maior altura do histograma.
(ii) Método de Czuber.
Este método deriva-se de um raciocínio geométrico, que baseia-se no fato de que as classes
imediatamente anterior e posterior influenciam o comportamento modal. A moda é obtida pela
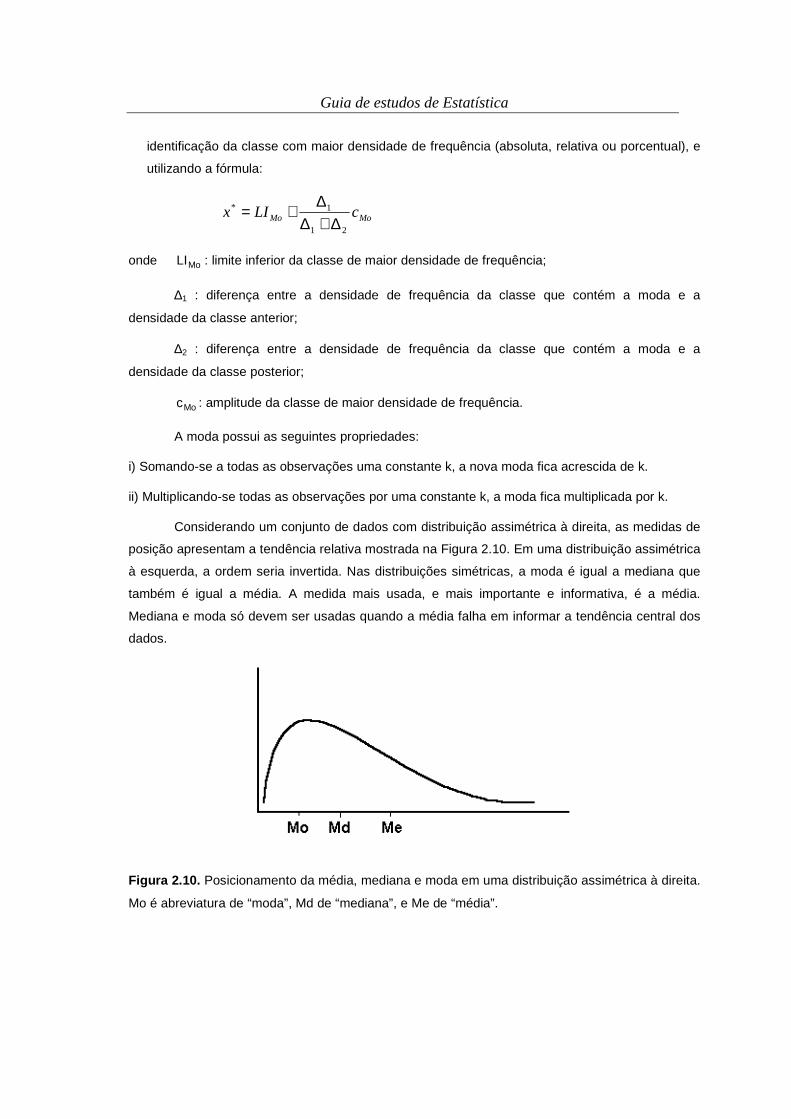
Guia de estudos de Estatística
identificação da classe com maior densidade de frequência (absoluta, relativa ou porcentual), e
utilizando a fórmula:
MoMo cLIx21
1*
∆+∆∆
+=
onde MoLI : limite inferior da classe de maior densidade de frequência;
∆1 : diferença entre a densidade de frequência da classe que contém a moda e a
densidade da classe anterior;
∆2 : diferença entre a densidade de frequência da classe que contém a moda e a
densidade da classe posterior;
Moc : amplitude da classe de maior densidade de frequência.
A moda possui as seguintes propriedades:
i) Somando-se a todas as observações uma constante k, a nova moda fica acrescida de k.
ii) Multiplicando-se todas as observações por uma constante k, a moda fica multiplicada por k.
Considerando um conjunto de dados com distribuição assimétrica à direita, as medidas de
posição apresentam a tendência relativa mostrada na Figura 2.10. Em uma distribuição assimétrica
à esquerda, a ordem seria invertida. Nas distribuições simétricas, a moda é igual a mediana que
também é igual a média. A medida mais usada, e mais importante e informativa, é a média.
Mediana e moda só devem ser usadas quando a média falha em informar a tendência central dos
dados.
Figura 2.10. Posicionamento da média, mediana e moda em uma distribuição assimétrica à direita.
Mo é abreviatura de “moda”, Md de “mediana”, e Me de “média”.

Guia de estudos de Estatística
2.3.3. Medidas de variabilidade.
Na descrição de uma massa de dados, apenas a utilização de medidas de posição é
insuficiente para explicitar o comportamento dos dados, pois tais medidas nada indicam a respeito
de sua variabilidade. Para ver isto, considere, por exemplo, os três conjuntos de dados na Tabela
2.11. Observa-se que as três regiões, apesar de apresentarem as mesmas medidas de posição,
são visivelmente diferentes, uma vez que a uniformidade dos dados decresce da região A para a
região C. Por isso, se faz necessária a elaboração de uma grandeza que quantifique a distribuição
dos dados (também chamada de dispersão ou variabilidade), as chamadas medidas de dispersão
ou de variabilidade. Estas medidas, do modo como apresentado aqui, só fazem sentido para
variáveis numéricas. Essas medidas constituem, junto com as medidas de posição, as medidas
estatísticas mais importantes. As principais são: variância, desvio-padrão, e coeficiente de
variação. Estudaremos essas principais mais a amplitude total.
Conceito 2.8. Medida de Dispersão . Grandeza numérica que descreve um conjunto de dados,
pela quantificação da variabilidade ou heterogeneidade neles presente.
Tabela 2.11. Estrutura fundiária como área (variável X) em 3 regiões agrícolas (medidas em ha).
i Região A Região B Região C
1 100 80 10
2 100 90 50
3 100 100 100
4 100 100 100
5 100 100 100
6 100 110 150
7 100 120 190
x 100 100 100
x~ 100 100 100
*x 100 100 100
Amplitude ou Amplitude total (A)
Anteriormente empregada na elaboração de distribuições de frequências, a amplitude total
corresponde à diferença do maior valor (máximo) para o menor valor (mínimo) do conjunto. Assim,
temos:
Região A: A = 0

Guia de estudos de Estatística
Região B: A = 40
Região C: A = 180
fornecendo-nos diferentes graus de variabilidade, como esperado.
A amplitude possui alguns inconvenientes. Trata-se de uma medida muito influenciada por
valores extremos, uma vez que é calculada somente a partir deles. Assim, sua interpretação
independe até certo ponto do número de observações do conjunto. Para ilustrar esse aspecto, no
exemplo do rebanho de gado holandês da fazenda Itirapuan, foram tomados subconjuntos de
diferentes números de animais, do total de 201 observações, sempre a partir dos primeiros dados
da Tabela 2.7 que estão fora de ordem, e, portanto, guardando uma certa “casualidade”. Foram
obtidos os seguintes valores para a amplitude:
Número de animais Min Max A
16 13,2 26,6 13,4
32 9,7 26,6 16,9
64 9,7 30,4 20,7
128 5,3 30,4 25,1
O primeiro conjunto de animais, possuindo um número relativamente satisfatório de
observações, deveria representar razoavelmente bem a dispersão total de todo o rebanho. No
entanto, observa-se que à medida que o número de observações aumenta, a chance do
aparecimento de valores extremos, acima ou abaixo da média, também aumenta, fazendo com que
os respectivos valores de amplitude aumentem, chegando quase a dobrar. Portanto, torna-se
evidente a necessidade de uma medida de dispersão que baseie-se em todas as observações, de
maneira a tornar-se menos sensível ao aparecimento de valores discrepantes. Isso pode ser
igualmente visto no exemplo:
Conjunto A 5 15 15 15 40
Conjunto B 5 10 20 30 40
Tais conjuntos possuem a mesma amplitude, 35, mas apresentam claramente diferentes
magnitudes de variabilidade, sendo esta magnitude inferior no conjunto A, pois este terá maior
uniformidade. Para resolver esse problema, foram concebidas duas medidas a partir de todas as
observações: a variância e o desvio padrão. São estas que estudaremos a seguir.

Guia de estudos de Estatística
Variância e Desvio-padrão
Trata-se de medidas de dispersão baseadas nos desvios dos dados em relação à média:
di = xi - x
Como quantificar a variabilidade de um conjunto de dados a partir dos desvios em relação à
média? Já que se sabe que o valor médio dos desvios em relação a média é zero, poder-se-ia
pensar então em se tomar a média dos módulos dos desvios:
n
xx
n
dn
ii
n
ii ∑∑
==
−= 11
Apesar desta medida ser uma possível medida de variabilidade, ela não tem boas propriedades
nem estatísticas e nem matemáticas. Por causa disso, razões estatísticas levam à considerar o
quadrado das diferenças (e não o módulo), e a divisão da soma dos quadrados dos desvios por n-
1 e não por n, definindo então a medida de variabilidade denominada variância:
s2 =
( )( ) ( ) ( )
1
...
1
222
211
2
−−+−+−
=−
−∑=
n
xxxxxx
n
xxn
n
ii
O desvio padrão é definido como a raiz quadrada da variância:
s =
( )
11
2
2
−
−=∑
=
n
xx
s
n
ii
O denominador (n - 1) é chamado de graus de liberdade. Para a amostra da Tabela 2.9, s=3,94 kg,
e s2 = 15,5442 kg2. Apesar do divisor n-1, a variância também pode ser denominada de “quadrado
médio”, visto ser uma espécie de média dos desvios ao quadrado. Algumas vezes autores de
textos sobre Estatística usam outra fórmula para a variância amostral, a saber,
s2 =
( )
n
xxn
ii∑
=
−1
2
e, consequentemente, também outra para desvio-padrão amostral,

Guia de estudos de Estatística
s =
( )
n
xxs
n
ii∑
=
−= 1
2
2
porém, devemos salientar que estas fórmulas levam a uma subestimação (isto é, apresenta um
viés) do valor real da variabilidade da variável em estudo, devendo serem, portanto, evitadas. As
fórmulas com divisor n-1 devem ser a utilizadas, pois permitem uma estimação exata (isto é, não
viesada) da variabilidade da variável de interesse.
Voltando ao exemplo dado para mostrar a insuficiência da amplitude, vamos calcular a
variância e o desvio-padrão dos conjuntos A e B:
Conjunto A 5 15 15 15 40
Conjunto B 5 10 20 30 40
onde sA = 13,04 e sB = 14,32
No conjunto de dados B do exemplo acima, tem-se:
Observação xi di di2
1 5 -16 256
2 10 -11 121
3 20 -1 1
4 30 9 81
5 40 19 361
Total 105 =>
=> x =21,00
0 820
E assim:
x = 105 / 5 = 21,00
s² = 820 / 4 = 205,0000
s = 14,32

Guia de estudos de Estatística
O conjunto A do exemplo possui uma variância igual a 170,0000, refletindo assim a menor
variabilidade nele existente, em relação ao conjunto B, que tem variância 205,0000.
O desvio padrão, ao tomar a raiz quadrada da variância, tem a vantagem de retornar à
escala original (por exemplo, passando de kg2 para kg), melhorando a compreensão do quanto os
dados se desviam em relação à média.
Para os dados da produção leiteira da Tabela 2.8:
( ) ( ) ( )[ ] 0007,2404,198,33...04,199,604,193,5200
1s² 222 =−++−+−=
0007,24=s kg de leite/dia = 4,90 kg de leite/dia
Nós podemos nos aproveitar do fato de que a soma de quadrados de desvios pode ser
expressada em uma forma simplificada, para criarmos uma fórmula alternativa para a variância (e
desvio-padrão), que é mais fácil para o cálculo, mesmo que pareça mais “complicada” para
escrever, qual seja:
( )
11
2
−
−∑=
n
xxn
ii
= 1
2
1
1
2
−
−∑
∑ =
=
n
n
x
x
n
iin
ii
Demonstração:
[ ]∑=
−n
ii xx
1
2 = [ ][ ]∑
=
+−n
iii xxxx
1
22 2 =
= [ ]∑∑∑=
+−==
nn
ii
n
ii
ixxxx
12 2
11
2 = [ ]2
1
1
1
2 2 xnxn
xx
n
ii
n
iin
ii +− ∑
∑∑
=
=
=
=
=
2
1
2
1
1
2 2
+
−∑∑
∑ ==
= n
x
nn
x
x
n
ii
n
iin
ii =
n
x
n
x
x
n
ii
n
iin
ii
2
1
2
1
1
2 2
+
−∑∑
∑ ==
=
=
= n
x
x
n
iin
ii
2
1
1
2
−∑
∑ =
=

Guia de estudos de Estatística
Para dados agrupados, a variância também pode ser calculada da seguinte forma
facilitada:
[ ]∑≅k
1j=j
2j
2 .fr - xxs
onde jx é o ponto médio da classe j. Essa expressão não fornece, na maioria das vezes, o
mesmo valor da expressão dada anteriormente, em razão do chamado erro de agrupamento,
sendo, portanto, uma fórmula aproximada para o verdadeiro valor de s2.
Demonstração:
( ) ( )( ) ( ) j
k
jj
jk
jj
k
jjj
n
ii
frxxn
faxx
n
xxfa
n
xxs .
111 1
2
1
21
2
1
2
2 ∑∑∑∑
==
== −≅−
−=−
−≅
−
−=
Nota. A aproximação final é tanto mais exata quanto maior for o valor de n, isto é:
jjn
j
n
j
nfrfrlim
n
falim
1n
falim ===
− ∞→∞→∞→
A variância e o desvio padrão possuem as seguintes propriedades:
i) Somando-se uma constante k a todas observações, nem a variância nem o desvio padrão se
alteram.
ii) Multiplicando-se uma constante k a todas as observações, a variância fica multiplicada por k2 e o
desvio padrão por k.
iii) O desvio padrão, em relação à média, ao invés de em relação a outro valor qualquer, é mínimo,
em razão do fato de a média ser o valor que torna mínima a soma de quadrados dos desvios.
Coeficiente de variação (cv)
Quando se deseja a comparação entre diferentes conjuntos de dados, mesmo a variância
e o desvio padrão podem não quantificar adequadamente, em certas situações, a variabilidade
presente em um conjunto de dados. Para ver isto, considere, a título de ilustração, os pesos dos
animais de dois rebanhos diferentes, dados a seguir:

Guia de estudos de Estatística
i Rebanho A Rebanho B
1 50 470
2 70 490
3 60 460
4 80 480
x 65 475
s 11,18 11,18
Obviamente, trata-se de rebanhos com animais em idades diferentes. Apesar de possuírem o
mesmo desvio padrão, é evidente que diferenças da ordem de 10 kg, por exemplo, possuem um
peso relativo muito maior no rebanho A do que no rebanho B. Assim, é razoável afirmar que a
variabilidade no rebanho A é bem superior; tornando-se necessária a elaboração de uma medida
apropriada nessas situações onde se deseja comparar conjuntos de dados com médias bem
discrepantes. Uma medida que reúne essas características é o chamado coeficiente de variação,
definido por:
cv = 100%s
x
Para os dados da produção diária de leite da Tabela 2.9:
25,7%100%19,04
4,89cv ==
Essa medida nos dá a magnitude da variabilidade, em relação à magnitude da média. No exemplo
acima, tem-se:
Rebanho A: cv = 17,2%
Rebanho B: cv = 2,4%
evidenciando que o rebanho A tem uma variabilidade maior que o rebanho B.
A necessidade da elaboração de uma medida apropriada nas situações onde se deseja
comparar conjuntos de dados com médias bem discrepantes não é a única demanda que justifica o
cv: também é verificada sua necessidade se o desejo é comparar variáveis medidas em unidades
diferentes. Observa-se que o coeficiente de variação é uma medida relativa, porcentual, sendo,
assim, adimensional, fazendo com que o cv seja útil não apenas na comparação entre conjuntos
de dados de mesma unidade, mas ainda útil na comparação da variabilidade entre conjuntos de
dados referentes a diferentes características, que são medidas em unidades diferentes.
Guia de estudos de Estatística
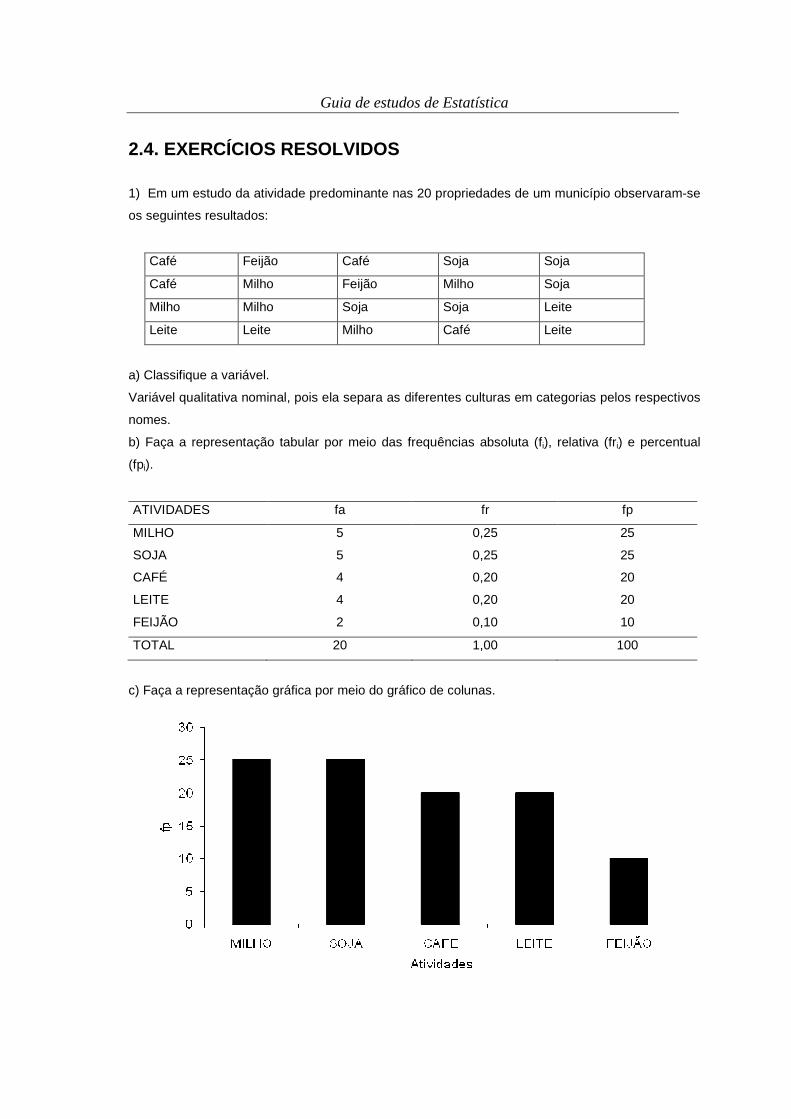
2.4. EXERCÍCIOS RESOLVIDOS
1) Em um estudo da atividade predominante nas 20 propriedades de um município observaram-se
os seguintes resultados:
Café Feijão Café Soja Soja
Café Milho Feijão Milho Soja
Milho Milho Soja Soja Leite
Leite Leite Milho Café Leite
a) Classifique a variável.
Variável qualitativa nominal, pois ela separa as diferentes culturas em categorias pelos respectivos
nomes.
b) Faça a representação tabular por meio das frequências absoluta (fi), relativa (fri) e percentual
(fpi).
ATIVIDADES fa fr fp
MILHO 5 0,25 25
SOJA 5 0,25 25
CAFÉ 4 0,20 20
LEITE 4 0,20 20
FEIJÃO 2 0,10 10
TOTAL 20 1,00 100
c) Faça a representação gráfica por meio do gráfico de colunas.

Guia de estudos de Estatística
2) Os dados abaixo referem-se às áreas (em ha) de 25 propriedades rurais que receberam
financiamento para pecuária de leite. Lavras, MG, de 1977 a 1982:
42 40 45 46 48
51 50 53 58 62
73 66 73 82 89
106 100 130 150 175
231 181 252 267 268
a) Reúna os dados em uma tabela de distribuição de frequências (use n k = )
1°- Calcula-se o número de classes (k) que comporão a distribuição:
classes 525nk === , sendo n é o número de propriedades que receberão
financiamento;
2°- Calcula-se a amplitude de classe (c):
hak
Ac 57
15
40268
1=
−−=
−= , onde A é a amplitude total, ou seja, o maior valor
observado menos o menor;
3°- Calcula-se o limite inferior (LI) da primeira classe que irá compor a distribuição:
hac
MinLI 5,112
5740
2=−=−= , onde Min é o menor valor observado.
4°- A tabela de distribuição de frequência:
Classes ix ifa ifr %fpi
(11,5;68,5] 40 11 0,44 44
(68,5;125,5] 97 6 0,24 24
(125,5;182,5] 154 4 0,16 16
(182,5;239,5] 211 1 0,04 4
(239,5;296,5] 268 3 0,12 12
Total - 25 1,00 100
b) Quantas propriedades na amostra têm área superior a 125,5 ha?
Nesta amostra, 8 propriedades possuem área superior a 125,5 ha.
c) Pode-se esperar encontrar propriedades com área entre 70,0 e 100,0 ha? Se sim, qual a sua
porcentagem de ocorrência?

Guia de estudos de Estatística
Sim, é possível encontrar propriedades com área entre 70,0 e 100,0 ha e para encontrar a
porcentagem de ocorrência, pode-se utilizar uma regra de três simples:
125,5 – 68,5 = 57,0 ha --------------------------------- 6 propriedades
110,0 – 70,0 = 40,0 ha --------------------------------- x
x = 4,2 propriedades => 4,2 / 25 = 16,8%
Assim, podemos inferir que 16,8% destas propriedades possuem área entre 70,0 e 110,0 ha.
3)Os pesos em Kg, de 6 suínos submetidos a uma ração de engorda foram:
184 193 204
204 196 207
a) Qual foi o desvio do 2° animal em relação à média? Explique o que ele significa.
Calculando a média: = + + += = =∑
x
ii 1
x184 193 ... 207
x 198 Kgn 6
O desvio do 2° animal em relação à média: = − = − = −i id x x 193 198 5 Kg
A média é uma medida de tendência central, ou seja, em torno dela se congregam valores abaixo
e acima da mesma. Assim, esse desvio negativo do 2° animal com relação à média se deve ao fato
de que ele esta 5 kg abaixo dela.
b) Mostre que a soma dos desvios com relação à média é nula.
0198)(207...198)(193198)(184)x(xn
1ii =−++−+−=−∑
=
c) Transforme os dados em arrobas. Qual é a constante de transformação? Encontre a média em
arrobas partindo daquela obtida no item a.
Como 1 arroba = 15 Kg, para transformar Kg em arrobas utilizamos:
15
x@Peso i=
Assim:
arrobas 13,206
13,8013,0713,6013,6012,8712,27n
x
x
6
1ii
=+++++==∑
=
d) Adicione 20 Kg a cada dado e encontre a média. Confronte o resultado com o obtido no item a.
Qual a propriedade esta envolvida?
Adicionando 20 Kg a cada dado, temos:
204 213 224
224 216 227
Calculando a nova média:

Guia de estudos de Estatística
kg 2186
227...213204n
x
x
6
1ii
=+++==∑
=
Confrontando a média obtida no item a com a obtida no item d:
kg 198xa = kg 218x d =
podemos perceber que a média se alterou na mesma proporção que cada observação foi
aumentada. A propriedade envolvida é a propriedade da soma, que diz que se somarmos a cada
observação uma constante “k” a média fica acrescida desta mesma constante “k”.
e) Calcule a Soma de Quadrados dos Desvios “SQD” em relação à média e em relação à
constante k = 196. Discuta os resultados.
Vejamos a SQD em relação à média:
∑=
=−++−+−=−=6
1i
2222i 378198)(207...198)(193198)(184)x(xSQD
E a SQD em relação à constante k = 196:
∑=
=−++−+−=−=6
1i
222i 402196)(207...196)(193196)(184k)(xSQD
Comparando os dois resultados podemos perceber que a SQD em relação à média é menor que a
SQD da constante k = 196. Confirma-se assim que a SQD em relação á média é o valor que torna
mínimo o valor dos desvios.
4) Para comparar 4 variedades de alfafa (A, B, C, D) foi conduzido um experimento em blocos
completos casualizados com seis repetições, usando parcelas de 32 m 2 (4m x 8m). Os
rendimentos em massa verde em Kg.parcela-1 foram os seguintes:
Tratamento
Blocos
1 2 3 4 5 6
A 56,8 57,2 57,5 55,4 56,0 57,9
B 53,5 54,3 53,8 54,7 53,3 52,6
C 54,0 53,5 52,8 54,2 53,6 54,1
D 54,5 54,5 54,5 54,5 54,5 54,5
a) Qual é a amplitude total do tratamento A? Que inconveniente tem esta medida para expressar
a variabilidade de uma amostra?
Amplitude Total(AT):
AT = Mvo – mvo sendo: Mvo = Maior valor observado e mvo = menor valor observado
Assim:

Guia de estudos de Estatística
AT = 57,9 – 55,4 = 2,5 Kg
O inconveniente de se usar a amplitude total para expressar a variabilidade de uma amostra é de
que utilizam-se apenas dois dados para fornecer esta estimativa.
b) Qual é a variância do tratamento D?
2222
6
1i
2i
2 Kg 016
54,5)...(54,554,5)(54,554,5)(54,51n
)x(x
1nSQD
s =−
−+−+−=−
−=
−=
∑=
c) Qual tratamento é mais variável: o B ou o C? Que medida estatística você usou para comparar
a variabilidade? Justifique.
Calculemos primeiro o desvio padrão para o tratamento B:
Kg 0,740,55ss
Kg 0,5616
53,7)(52,6...53,7)(54,353,7)(53,51n
)x(x
s
2BB
2222
6
1i
2i
2B
===
=−
−++−+−=−
−=∑
=
Agora para o tratamento C:
Kg 0,520,27ss
Kg 0,2716
53,7)(54,1...53,7)(53,553,7)(54,01n
)x(x
s
2CC
2222
6
1i
2i
2C
===
=−
−++−+−=−
−=∑=
Como o desvio padrão do tratamento B é maior do que o do tratamento C, podemos afirmar que o
B apresenta maior variabilidade entre seus dados. Neste foi possível utilizarmo-nos principalmente
do desvio padrão para comparar a variabilidade entre os tratamentos, pelo fato de os dois
tratamentos possuírem a mesma unidade de grandeza e a mesma média.
d) Calcule o desvio padrão do tratamento A . Interprete.
Kg 0,944460,88ss
Kg 0,8916
56,8)(57,9...56,8)(57,256,8)(56,81n
)x(x
s
2AA
2222
6
1i
2i
2A
===
=−
−++−+−=−
−=∑
=
A variabilidade do tratamento A medido pelo desvio padrão é maior do que a variabilidade dos
tratamentos B e C.
e) Multiplique os dados do tratamento A por 1000 e calcule o desvio padrão.
Multiplicando os dados do tratamento A por 1000 temos:
56800 57200 57500 55400 56000 57900
Calculando a nova média:
Kg 568006
57900...5720056800n
x
x
6
1ii
=+++==∑=
Calculando o novo desvio padrão:

Guia de estudos de Estatística
Kg 944,46892000ss
Kg 89200016
56800)(57900...56800)(5720056800)(568001n
)x(x
s
2AA
2222
6
1i
2i
2A
===
=−
−++−+−=−
−=∑=
f) Confronte o resultado do item d com o item e. Discuta.
Resultado item d: Resultado item e:
Kg 0,94446sA = Kg 944,46sA =
Essa diferença justifica-se por uma das propriedades do desvio padrão: Multiplicando-se ou
dividindo-se cada observação por uma mesma constante k ≠ 0, o desvio padrão fica multiplicado
ou dividido por esta mesma constante.
5) Temos, abaixo, informações climáticas mensais de uma determinada região:
Média Desvio padrão
Temperatura (ºC) 18 2,0
Precipitação (mm) 100 15,5
a) Qual das medidas (temperatura ou precipitação) possui maior variabilidade? Justifique.
Como as medidas estão em grandezas diferentes, para podermos comparar suas variabilidades
utilizaremos o coeficiente de variação (CV).
1º para a temperatura: % 11,11100182
100x
sCV ===
2º para a precipitação: % 15,510010015,5
100x
sCV ===
Quanto menor o CV, mais preciso é o experimento. A medida tem grande aplicação na
experimentação para avaliar a precisão dos ensaios. Nesse caso, a precipitação possui maior
variabilidade.
b) Se a temperatura fosse avaliada em ºF ,)932F
5C
(−= como ficaria a conclusão do item a?
Justifique.
Para a temperatura em ºF: % 5,5910064,43,6
100x
sCV ===
Assim, a conclusão do item 3.1. seria que a temperatura apresentaria menor variabilidade.

Guia de estudos de Estatística
2.5. EXERCÍCIOS PROPOSTOS
1) Um pesquisador necessita obter informações a respeito de uma determinada cultura no sul de
Minas Gerais. Para tanto, visita 50 propriedades e faz uma avaliação referente ao tamanho da área
plantada com a cultura (ha), a produção obtida (Kg), e as principais pragas e doenças.
Pergunta-se:
a) Qual é a população em estudo?
b) Utilizou-se de uma amostra para realizar o estudo? Por quê?
c) Quais foram as variáveis estudadas em cada caso?
d) Classifique as variáveis quanto a sua natureza.
2) Os ganhos de peso, em kg, de 80 novilhos nelore mantidos numa pastagem em determinado
período foram os seguintes:
36 45 60 39 57 32 39 40 63 37
42 42 44 30 47 39 15 39 25 39
57 48 44 37 44 38 21 56 52 50
41 37 39 28 43 39 29 45 48 46
31 34 36 38 43 24 38 41 46 42
33 30 36 23 39 35 33 35 47 39
28 31 32 49 39 19 49 39 42 43
20 58 34 56 35 50 27 36 40 37
a) Construa uma distribuição de frequência com as frequências absoluta, relativa e percentual;
b) Construa o histograma;
c) Calcule a média, mediana, moda, variância, desvio-padrão, e cv.
3) São contadas o número de lagartas tipo “rosca”(Agrotis ipisilon) em 25 canteiros de mudas de
eucalipto da Fazenda Experimental da UFLA. Encontrou-se o seguinte resultado:
1 1 3 3 1
4 2 0 4 4
1 1 3 2 3
4 0 2 0 3
1 1 2 1 2
a) Classifique a variável em questão;
b) Construa uma distribuição de frequência com as frequências absoluta, relativa e percentual;
c) Calcule a média, mediana, moda, variância, desvio-padrão, e cv.
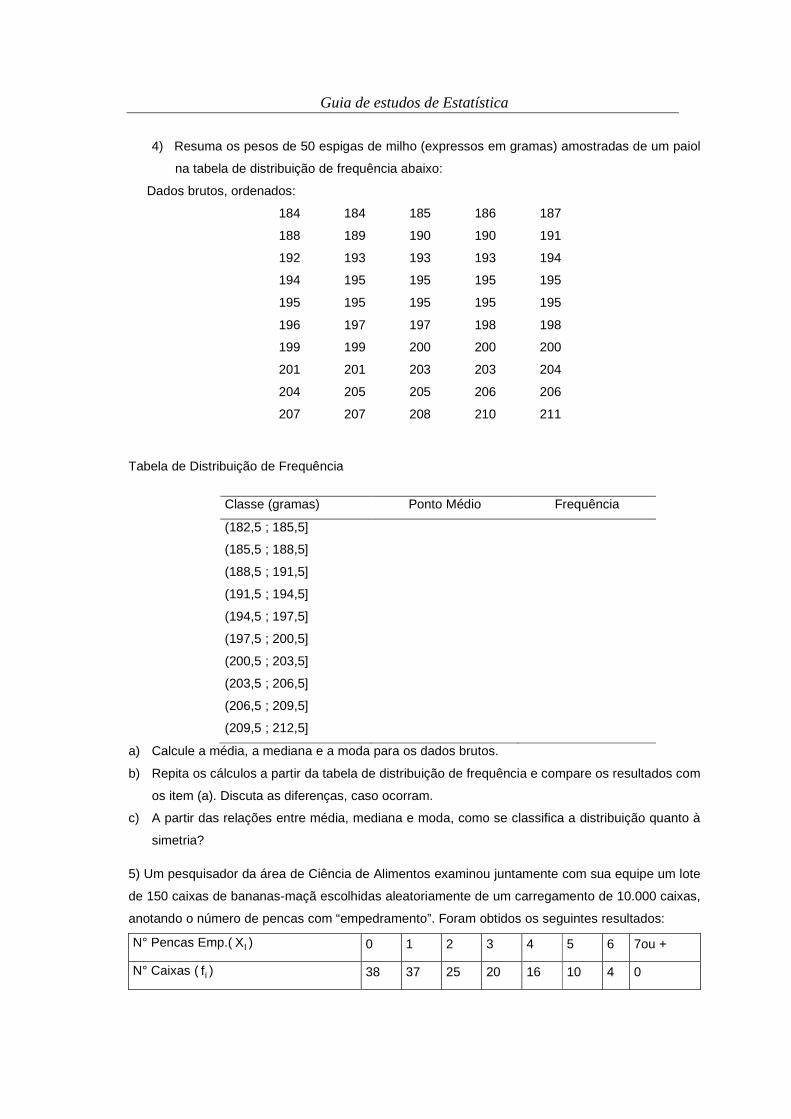
Guia de estudos de Estatística
4) Resuma os pesos de 50 espigas de milho (expressos em gramas) amostradas de um paiol
na tabela de distribuição de frequência abaixo:
Dados brutos, ordenados:
184 184 185 186 187
188 189 190 190 191
192 193 193 193 194
194 195 195 195 195
195 195 195 195 195
196 197 197 198 198
199 199 200 200 200
201 201 203 203 204
204 205 205 206 206
207 207 208 210 211
Tabela de Distribuição de Frequência
Classe (gramas) Ponto Médio Frequência
(182,5 ; 185,5]
(185,5 ; 188,5]
(188,5 ; 191,5]
(191,5 ; 194,5]
(194,5 ; 197,5]
(197,5 ; 200,5]
(200,5 ; 203,5]
(203,5 ; 206,5]
(206,5 ; 209,5]
(209,5 ; 212,5]
a) Calcule a média, a mediana e a moda para os dados brutos.
b) Repita os cálculos a partir da tabela de distribuição de frequência e compare os resultados com
os item (a). Discuta as diferenças, caso ocorram.
c) A partir das relações entre média, mediana e moda, como se classifica a distribuição quanto à
simetria?
5) Um pesquisador da área de Ciência de Alimentos examinou juntamente com sua equipe um lote
de 150 caixas de bananas-maçã escolhidas aleatoriamente de um carregamento de 10.000 caixas,
anotando o número de pencas com “empedramento”. Foram obtidos os seguintes resultados:
N° Pencas Emp.( IX ) 0 1 2 3 4 5 6 7ou +
N° Caixas ( if ) 38 37 25 20 16 10 4 0

Guia de estudos de Estatística
a) Qual é o número médio de pencas empedradas por caixa?
b) Qual é o número mediano de pencas empedradas por caixa?
c) Qual é o número modal de pencas empedradas por caixa?
d) Qual é o desvio-padrão do número de pencas empedradas por caixa?
e) Qual deverá ser a estimativa do número total de pencas empedradas no carregamento?
6) No Posto Agrometeorológico da seção de Climatologia Agrícola da EMBRAPA em Itaguaí, RJ,
foram registrados a evaporação e a insolação, durante o período de 1961 à 1996. As médias
mensais encontradas durante o período foram as seguintes:
Evaporação (mm)
97,9 94,1 77,4 71,3 73,4 75,5
86,2 105,9 99,2 93,6 79,6 87,3
Insolação (horas)
199,1 184,3 190,6 190,9 201,6 200,6
211,1 208,1 141,1 141,1 151,1 164,4
Qual atributo meteorológico é mais variável? Indique e justifique a medida estatística utilizada na
comparação.

Guia de estudos de Estatística
UUNNIIDDAADDEE 33
CCÁÁLLCCUULLOO DDEE PPRROOBBAABBIILLIIDDAADDEESS
3.1. O CONCEITO DE PROBABILIDADE
À princípio, poderíamos definir probabilidade como o limite de uma freqüência relativa:
[ ]N
)A(falimAPN ∞→
= ,
onde P[A] é a probabilidade de ocorrência do evento A. Essa definição, porém, padece de
dificuldades matemáticas, pois não se adequa à definição matemática de limite, baseada em
epsilons e deltas. Por causa disso, buscaremos uma definição de probabilidade alternativa que
seja, simplesmente, de que “probabilidade é a frequência relativa em infinitas repetições”.
Consideremos esta definição como sendo uma definição estatística, para diferenciar da definição
matemática, que usa uma teorização mais avançada que não será objeto deste curso.
Em outras palavras, podemos dizer que, estatisticamente, as frequências relativas em
populações infinitas são chamadas de probabilidades. Num exemplo ilustrativo, que considera a
segregação genética de gênero em seres humanos, se o interesse é descrever (prever) a taxa de
nascimento de homens ou mulheres, um modelo não-determinístico que explica o fato de um ser
humano nascer macho ou fêmea é aquele que estabelece que tanto um sexo quanto o outro
possuem chances iguais de acontecer. Ele procura explicar a frequência relativa de nascimentos
de infinitos seres humanos que existiram ou virão a existir, e daí se falar em probabilidade de
nascimento de machos ou fêmeas, que segundo esse modelo é igual a 1/2, 0,5, ou 50%.
Conceito 3.1. Probabilidade . Frequência relativa associada a uma variável descritora em infinitas
repetições.

Guia de estudos de Estatística
Portanto, pode-se denominar a distribuição de frequências relativas de uma população
infinita (o conjunto das infinitas repetições) como uma distribuição de probabilidade.
Conceito 3.2. Distribuição de Probabilidade . Distribuição de frequências relativas de uma
população infinita.
As variáveis descritoras de uma população infinita podem ser, qualitativas ou quantitativas.
Quando tais variáveis operam descrevendo valores de probabilidade, elas são chamadas de
variáveis aleatórias.
Conceito 3.3. Variável Aleatória . Variável a cujos valores são associadas probabilidades de
ocorrência.
Por convenção, as variáveis aleatórias são sempre quantitativas, mesmo se referindo a
qualidades. No exemplo do nascimento em mamíferos, às categorias ‘fêmea’ e ‘macho’ podem ser
associados os valores 0 e 1, respectivamente. Pode-se entender que X = 0 seja “zero macho”, e X
= 1 seja “um macho”, tornando a variável aleatória X realmente uma quantidade, e não apenas um
rótulo. Sendo assim, as variáveis aleatórias podem ser discretas ou contínuas.
3.2. DISTRIBUIÇÕES DE PROBABILIDADE
Uma distribuição de probabilidade corresponde a uma função que associa as realizações
de uma variável aleatória com suas respectivas probabilidades de ocorrência. As variáveis
aleatórias são denotadas por letras maiúsculas e suas realizações por letras minúsculas.
A probabilidade de que uma variável aleatória X assuma determinado valor é denotada por
P[X = x]. As variáveis aleatórias quantitativas podem ser discretas ou contínuas, sendo que para
cada qual podem ser construídos modelos matemáticos não-determinísticos que expressem as
distribuições de probabilidade correspondentes.
Além disso, sendo elas quantitativas, faz sentido falar-se em medidas de posição e
dispersão. Neste capítulo serão concentradas as atenções apenas na média, variância e desvio
padrão de uma variável aleatória quantitativa.

Guia de estudos de Estatística
A média de uma variável aleatória X também é chamada de esperança matemática da
variável aleatória X, ou valor esperado da variável aleatória X, e é denotada por E(X), ou ainda
Me(x).
Há dois tipos de distribuições de probabilidade: as discretas e as contínuas. Distribuições
discretas tratam da distribuição de probabilidade associada a variáveis aleatórias discretas. Por
exemplo, a função seguinte corresponde a uma distribuição de probabilidade discreta:
X 0 1 2 3 4
P[X = xi] 1/10 2/10 5/10 1/10 1/10
Observa-se que a soma de todas as probabilidades é um:
P[S] = P[X = 0] + P[X = 1] + P[X = 2] + P[X = 3] + P[X = 4] =
= 1/10 + 2/10 + 5/10 + 1/10 + 1/10 = 10/10 = 1
Essa característica é válida para toda distribuição de probabilidade discreta, assim como também
toda probabilidade é um número positivo. Ou seja, se a variável aleatória discreta assume k
valores, então:
[ ]∑=
=k
iixXP
1
= 1 e P[X=x] > 0.
O valor médio que uma variável aleatória assume é chamado, como já dito, além de média,
também de esperança matemática e de valor esperado. Para a obtenção do valor médio que uma
variável aleatória discreta assume, ou seja, sua esperança ou valor esperado, faz-se da mesma
maneira como foi feito para o cálculo da média para dados agrupados, substituindo fri por P[X = xi]:
E(X) = Me(X) = Xµ = µ = [ ]∑
=
=k
iii xXPx
1
No exemplo acima tem-se:
E(X) = Xµ = 0
101
+ 1102
+ 2105
+ 3101
+ 4101
= 1,9
O conceito de variância de uma variável aleatória também é semelhante àquele
apresentado para dados agrupados, trocando-se fri por P[X= xi]:
=σ=σ= 22x)X(Var ( )[ ] [ ]∑
=
=−k
iii xXPxMex
1
2
No exemplo tem-se:

Guia de estudos de Estatística
σ2 = (0 - 1,9)2
101
+ (1 - 1,9)2
102
+ (2 - 1,9)2
105
+ (3 - 1,9)2
101
+ (4 - 1,9)2
101
= 1,09
Existe uma série de distribuições de probabilidades discretas em Estatística. Duas das mais
importantes serão vistas a seguir. A distribuição contínua mais importante é a distribuição Normal,
e a estudaremos logo em seguida as discretas.
3.3. DISTRIBUIÇÃO BINOMIAL
Uma situação relativamente comum em pesquisas científicas ou levantamentos é aquela
onde apenas dois tipos de resultados são possíveis, como, por exemplo:
S = {macho, fêmea}.
S = {árvore doente, árvore não doente}.
S = {grande produtor, pequeno produtor}.
S = {talhão irrigado, talhão não irrigado}.
Uma distribuição de probabilidades que lida com tais situações é a chamada distribuição Binomial.
Em geral existe interesse maior em um dos 2 resultados possíveis, o qual é denominado
de sucesso, e o outro de insucesso ou fracasso. Para o desenvolvimento de seu modelo, considere
o exemplo de um suíno fêmea dando a luz a 5 leitões. Os eventos possíveis são ou o nascimento
de machos ou de fêmeas. Considere a variável aleatória número de machos, que obviamente é
discreta, podendo variar de 0 a 5. A probabilidade de que sejam 5 machos é igual à probabilidade
de que o primeiro leitão seja macho, e de que o segundo seja macho, e de que o terceiro também
o seja e assim por diante. Como os eventos são independentes, tem-se que:
P[X = 5] = (0,5).(0,5).(0,5).(0,5).(0,5) = (0,5)5
Considere agora o nascimento de 3 machos e 2 fêmeas. A probabilidade de uma
determinada combinação, por exemplo, a de que os 3 primeiros leitões, L1, L2, L3, sejam machos, e
os dois últimos, L4, L5, sejam fêmeas, é igual a:
P[M] × P[M] × P[M] × P[F] × P[F] = (0,5)5
No entanto, esta não é a única combinação possível para o nascimento de 3 machos,
existem várias, conforme mostrado abaixo:

Guia de estudos de Estatística
L1 L2 L3 L4 L5 Probabilidade
M M M F F (0,5)5
M M F M F (0,5)5
M F M M F (0,5)5
F M M M F (0,5)5
M M F F M (0,5)5
M F M F M (0,5)5
F M M F M (0,5)5
M F F M M (0,5)5
F M F M M (0,5)5
F F M M M (0,5)5
Na realidade, em vez de listar todas as possibilidades, como feito acima, pode-se calcular
diretamente o número total de combinações possíveis por meio de:
C5,3 = )!35(!3
!5−
= 10
Dessa forma, para calcular a probabilidade de nascimento de 3 machos, sem importar com
a ordem, tem-se que somar o valor (0,5)5 10 vezes. Portanto:
P[X = 3] = 10.(0,5)5 = 0,3125
Considerando agora qualquer número x de machos nascidos, em um total de 5 leitões,
tem-se que a probabilidade desse evento é:
P[X = x] = C5,x ( )[ ] ( )[ ] xx FPMP −5
Esse exemplo, justamente, ilustrou o desenvolvimento da distribuição binomial. O modelo geral
fornece a probabilidade de ocorrência de x sucessos, na observação de n eventos:
P[X = x] = Cn,x px q(n-x)
onde p é a probabilidade de sucesso (no exemplo, de nascimento de machos), e q a probabilidade
insucesso, igual a (1-p).
Observe, então, que a distribuição binomial é definida por dois números, ou parâmetros,
que diferenciam as mais diferentes situações, sem os quais não calculamos P[X = x]: p e n.

Guia de estudos de Estatística
Conceito 3.3. Parâmetro de uma Distribuição de Probabilidades . Uma Constante (conhecida ou
desconhecida) que define uma determinada distribuição de probabilidades.
Assim, uma notação comumente empregada para denotar que determinada variável aleatória
possui distribuição binomial com parâmetros p e n, é:
X ∩ B (n, p)
Pode-se demonstrar que a esperança e a variância de uma variável aleatória que segue
uma distribuição binomial são dadas por:
Me(X) = E(X) = = Xµ = µ = np
=σ=σ= 22x)X(Var npq
Ou seja, se avaliássemos todas as possíveis leitegadas de 5 leitões de infinitas porcas teríamos
um valor médio de 5.(0,5) = 2,5 machos, com variância entre leitegadas igual a 5.(0,5).(0,5) = 1,25
machos ao quadrado.
3.4. DISTRIBUIÇÃO DE POISSON
A distribuição de Poisson refere-se a uma variável também discreta, mas que pode assumir
qualquer número inteiro positivo, ou seja:
X = 0, 1, 2, ...
Essa distribuição é importante para descrever fenômenos de ocorrência rara, como certos
fenômenos meteorológicos e climáticos, eclosão de ovos de insetos submetidos a um inseticida,
porcentagem de plantas doentes em campos de produção de sementes, nº de chamadas
telefônicas num certo intervalo de tempo numa central telefônica, nº de pontos com defeito em
chapas de aço e em peças de tecido, entre muitos outros.
A distribuição de probabilidade é dada por:
P[X = x] = !x
e xλλ−
onde e = 2,718... (número de Euler), e λ é o parâmetro da distribuição, e que corresponde ao valor
médio que X assume.
Como exemplo, considere o número de chuvas por ano com intensidade acima de 50mm/h
que ocorrem em uma região. Essa variável pode ser importante no dimensionamento de drenos ou

Guia de estudos de Estatística
barragens. A população é constituída por todos os anos da região, e é infinita, pois abrange os
infinitos anos que ainda estão por vir. A variável aleatória é discreta, porque conta o número de
chuvas acima de 50 mm.h-1. Suponha que o número médio de chuvas por ano com essa
intensidade seja 1,5. Então, se o modelo de Poisson for um bom descritor, tem-se que:
P[X = 0] = !0
5,1 05,1−e = 0,2231
E assim, para outros valores de X:
X 0 1 2 etc.
P[X = xi] 0,2231 0,3347 0,2510 etc.
A probabilidade de que X seja maior do que 2 pode ser obtida pelo teorema 1 de
probabilidades:
P[X > 2] = 1 - P[X ≤ 2]
pois o evento (X ≤ 2) é o complemento do evento (X > 2). Como
P[X ≤ 2] = P[X = 0] + P[X = 1] + P[X = 2] = 0,8088
tem-se que:
P[X > 2] = 1 - 0,8088 = 0,1912
A distribuição de Poisson tem a particularidade de que sua média e sua variância são
ambas iguais a λ:
E(X) = Xµ = λ e σ2 = λ também.
Assim, no exemplo das chuvas, a variância associada ao número de precipitações com intensidade
acima de 50 mm.h-1 também é igual a 1,5.
A distribuição de Poisson pode também ser usada como uma aproximação da distribuição
Binomial, fazendo λ ser np. Esta aproximação é tanto melhor quanto mais n → ∞ e p → 0. Na
prática, quando n > 50 e p < 0,10, tal aproximação já pode ser usada. Como um exemplo, se no
caso dos leitões da seção anterior o número de leitões fosse n = 500 e estivéssemos interessados
em pesquisar uma doença com probabilidade de ocorrência de 8,2 %, então a probabilidade de
que encontremos pelo menos 1 leitão doente poderia ser calculada não somente pela Binomial
mas também pela Poisson:
N = 500 > 50 e p = 0,082 < 0,10, logo as condições para aproximar a Binomial pela Poisson estão
atendidas:

Guia de estudos de Estatística
X: número de leitões doentes entre os 500.
P (X ≥ 1 ) = 1 – P (X = 0) = 1 – e-500 x 0,082 . (500 x 0,082)0 ≅ 1
3.5. DISTRIBUIÇÃO NORMAL
A distribuição Normal corresponde a mais importante distribuição de variáveis aleatórias
contínuas, em razão da sua enorme aplicação nos mais variados campos do conhecimento, aí
incluída as ciências agrárias.
Sua função densidade de probabilidade é dada por:
f(x) = ( )
−−
π 2
2
2 b2
axexp
b2
1, -∞ < x < ∞
sendo π = 3,1416... Trata-se de um modelo que procura explicar o comportamento de uma variável
aleatória contínua X que pode variar desde -∞ até ∞, sem explicar as causas desse
comportamento. Por isso é que se trata de um modelo não-determinístico.
Conforme se observa, são necessários dois parâmetros para definir uma distribuição
normal, as constantes a e b. Na realidade, o primeiro corresponde à média (ou esperança) da
variável aleatória X, e o segundo corresponde à variância. Em outras palavras, a = µ e b = σ. Logo,
podemos escrever:
f(x) = ( )
−−
2
2
2 2exp
2
1
σµ
πσ
x, -∞ < x < ∞
A aparência dessa distribuição pode ser vista na Figura 3.1’ .
A distribuição Normal também é conhecida por distribuição gaussiana, curva normal ou
curva de Gauss, e possui as seguintes propriedades:
1) Ela é simétrica em relação a x = µ;
2) Forma campanular;
3) As medidas de posição Me(X), Md(X), Mo(X) confundem-se no mesmo ponto, e são
todas iguais a µ;
4) É definida simplesmente a partir dos parâmetros µ e σ2;
5) Possui dois pontos de inflexão correspondentes aos pontos x - σ e x + σ;
6) Assintótica em relação ao eixo da abscissa, ou seja, ela nunca corta o eixo X, mas cada
vez se aproxima mais dele;
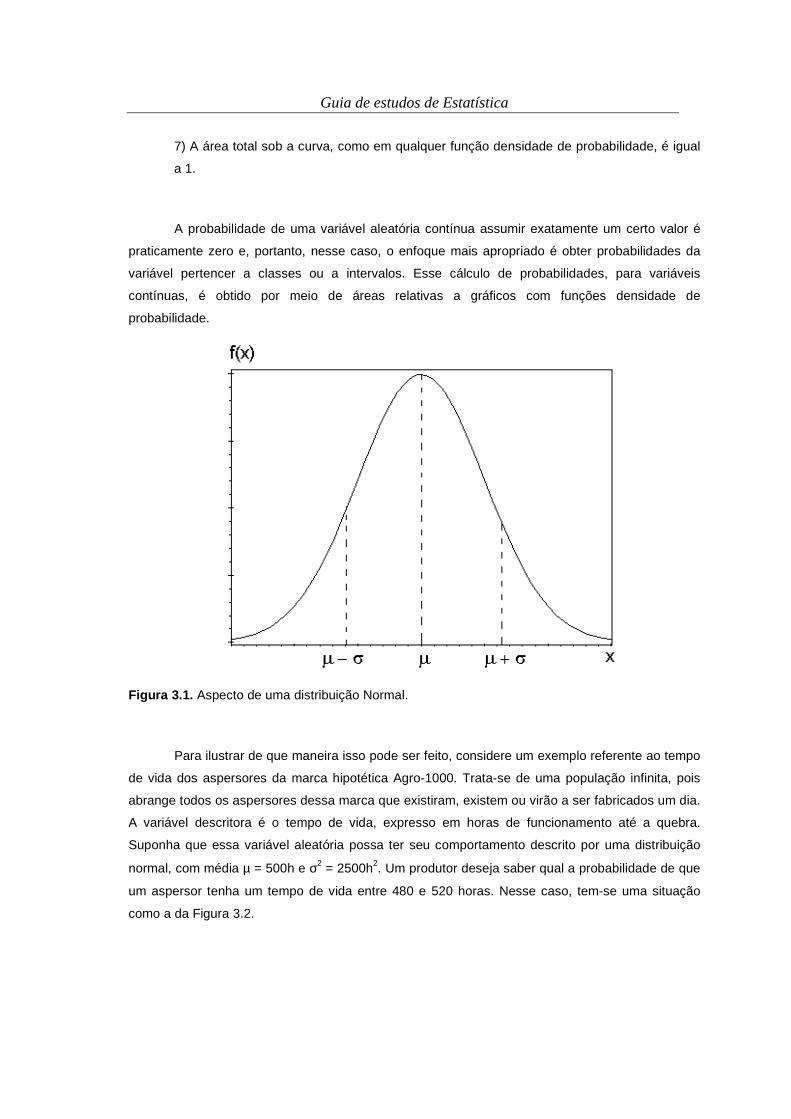
Guia de estudos de Estatística
7) A área total sob a curva, como em qualquer função densidade de probabilidade, é igual
a 1.
A probabilidade de uma variável aleatória contínua assumir exatamente um certo valor é
praticamente zero e, portanto, nesse caso, o enfoque mais apropriado é obter probabilidades da
variável pertencer a classes ou a intervalos. Esse cálculo de probabilidades, para variáveis
contínuas, é obtido por meio de áreas relativas a gráficos com funções densidade de
probabilidade.
Figura 3.1. Aspecto de uma distribuição Normal.
Para ilustrar de que maneira isso pode ser feito, considere um exemplo referente ao tempo
de vida dos aspersores da marca hipotética Agro-1000. Trata-se de uma população infinita, pois
abrange todos os aspersores dessa marca que existiram, existem ou virão a ser fabricados um dia.
A variável descritora é o tempo de vida, expresso em horas de funcionamento até a quebra.
Suponha que essa variável aleatória possa ter seu comportamento descrito por uma distribuição
normal, com média µ = 500h e σ2 = 2500h2. Um produtor deseja saber qual a probabilidade de que
um aspersor tenha um tempo de vida entre 480 e 520 horas. Nesse caso, tem-se uma situação
como a da Figura 3.2.
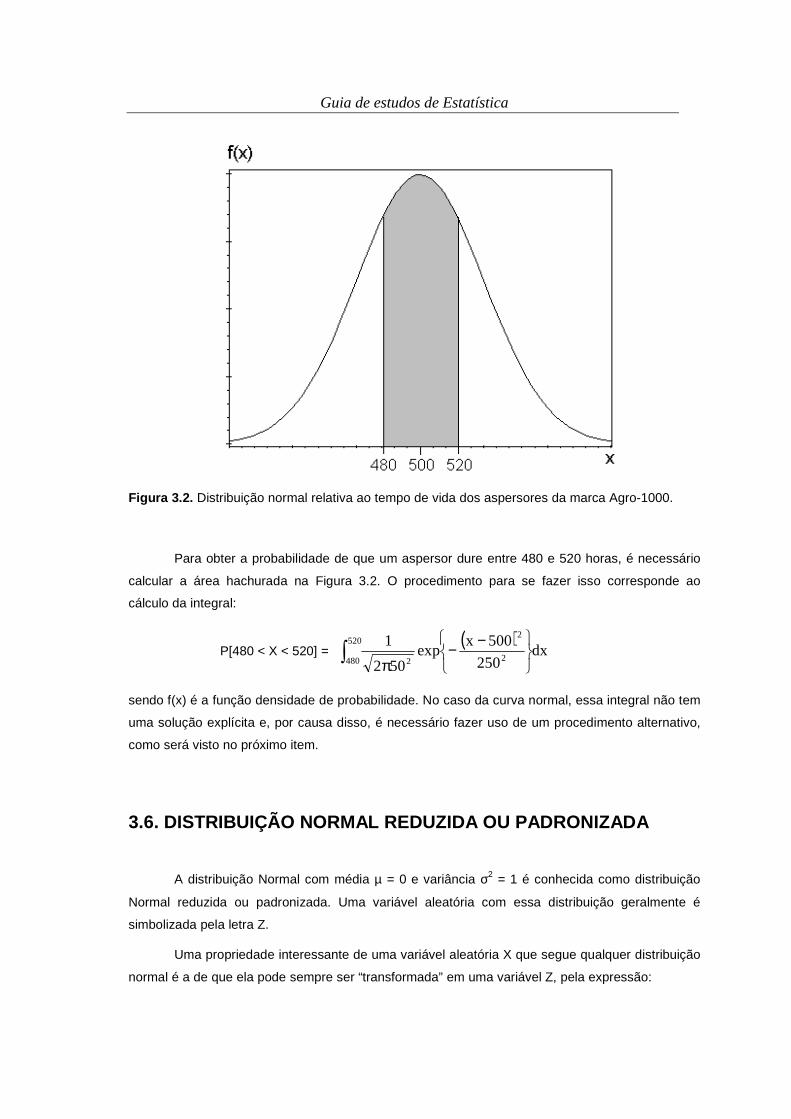
Guia de estudos de Estatística
Figura 3.2. Distribuição normal relativa ao tempo de vida dos aspersores da marca Agro-1000.
Para obter a probabilidade de que um aspersor dure entre 480 e 520 horas, é necessário
calcular a área hachurada na Figura 3.2. O procedimento para se fazer isso corresponde ao
cálculo da integral:
P[480 < X < 520] = ( )
dx250
500xexp
502
1520
480 2
2
2∫
−−
π
sendo f(x) é a função densidade de probabilidade. No caso da curva normal, essa integral não tem
uma solução explícita e, por causa disso, é necessário fazer uso de um procedimento alternativo,
como será visto no próximo item.
3.6. DISTRIBUIÇÃO NORMAL REDUZIDA OU PADRONIZADA
A distribuição Normal com média µ = 0 e variância σ2 = 1 é conhecida como distribuição
Normal reduzida ou padronizada. Uma variável aleatória com essa distribuição geralmente é
simbolizada pela letra Z.
Uma propriedade interessante de uma variável aleatória X que segue qualquer distribuição
normal é a de que ela pode sempre ser “transformada” em uma variável Z, pela expressão:

Guia de estudos de Estatística
z = σ
µ−x
A vantagem dessa transformação é a de que o valor de áreas (ou seja, probabilidades)
relativo à variável Z pode ser tabelado e, com isso, valores de áreas referentes a variáveis X com
quaisquer distribuições normais também podem ser calculadas.
As áreas referentes à variável Z que são geralmente tabeladas são do tipo:
P[ 0 < Z < z]
Existem tabelas próprias que contém os valores das áreas da distribuição Z. Para exemplificar seu
uso, considere que se queira calcular:
P[ 0 < Z < 0,46]
Na Tabela 1.1 do Apêndice, existe uma coluna indicadora e uma linha indicadora. Na coluna
existem valores de Z até a primeira casa decimal, e na linha a segunda casa decimal. Dessa
forma, para achar a probabilidade acima, basta buscar o valor 0,4 na coluna, e o valor 6 na linha.
Dessa forma, encontra-se o valor para a probabilidade como sendo igual a 0,1772. Essa área está
representada na Figura 3.3.
Agora é possível calcular a probabilidade de que um aspersor da marca Agro-1000 dure
entre 480 e 520 horas. Para tanto, serão calculadas:
P[500 < X < 520]
P[480 < X < 500]
as quais, somadas, fornecerão a probabilidade total P[480 < X < 520].
Como visto, a variável X pode ser transformada na Z. A distribuição de X é uma normal
com média 500 e variância 2500, ou seja:
µ = 500 σ2 = 2500 σ = 50
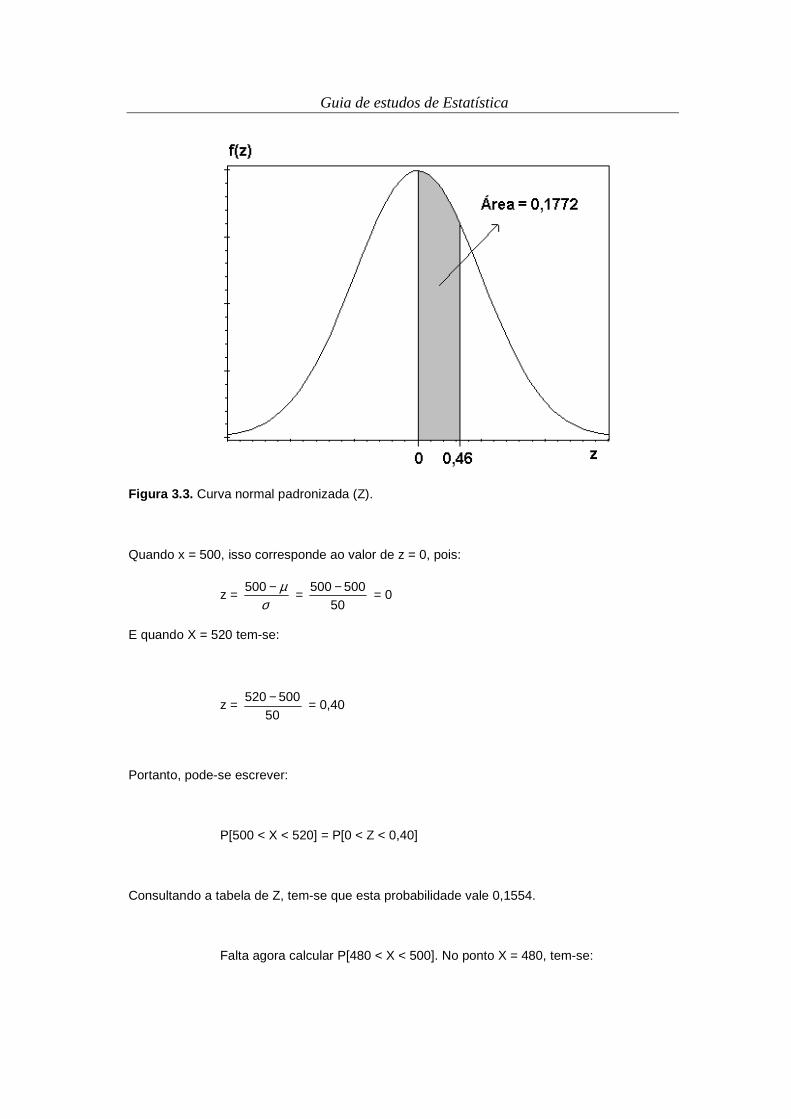
Guia de estudos de Estatística
Figura 3.3. Curva normal padronizada (Z).
Quando x = 500, isso corresponde ao valor de z = 0, pois:
z = σ
µ−500 =
50500500 −
= 0
E quando X = 520 tem-se:
z = 50
500520 − = 0,40
Portanto, pode-se escrever:
P[500 < X < 520] = P[0 < Z < 0,40]
Consultando a tabela de Z, tem-se que esta probabilidade vale 0,1554.
Falta agora calcular P[480 < X < 500]. No ponto X = 480, tem-se:

Guia de estudos de Estatística
z = 50
500480 − = -0,40
Na tabela de Z, não constam os valores negativos. Mas, como trata-se de uma distribuição
simétrica em torno do 0, tem-se que:
P[-0,40 < Z < 0] = P[0 < Z < 0,40]
E assim:
P[480 < X < 500] = P[0 < Z < 0,40] = 0,1554
Portanto, a probabilidade total P[480 < X < 520] vale:
P[480 < X < 520] = P[480 < X < 500] + P[500 < X < 520] = 0,1554 + 0,1554 = 0,3108
Outro aspecto importante da distribuição Normal padronizada é o de que, como se trata de
uma distribuição simétrica em torno de 0, e cuja área abaixo dela totaliza 1, então P[Z > 0] =
0,5000. Dessa forma, é possível calcular probabilidades de Z estar acima de quaisquer valores.
Por exemplo, suponha que se queira obter P[Z > 0,40]. Uma vez que P[Z > 0] = P[0 < Z < 0,40] +
P[Z > 0,40], tem-se:
0,5000 = 0,1554 + P[Z > 0,40]
E assim, P[Z > 0,40] = 0,3446.
Um aspecto interessante da distribuição Normal é o efeito que diferentes valores para a
variância provocam na aparência da curva (Figura 3.4).
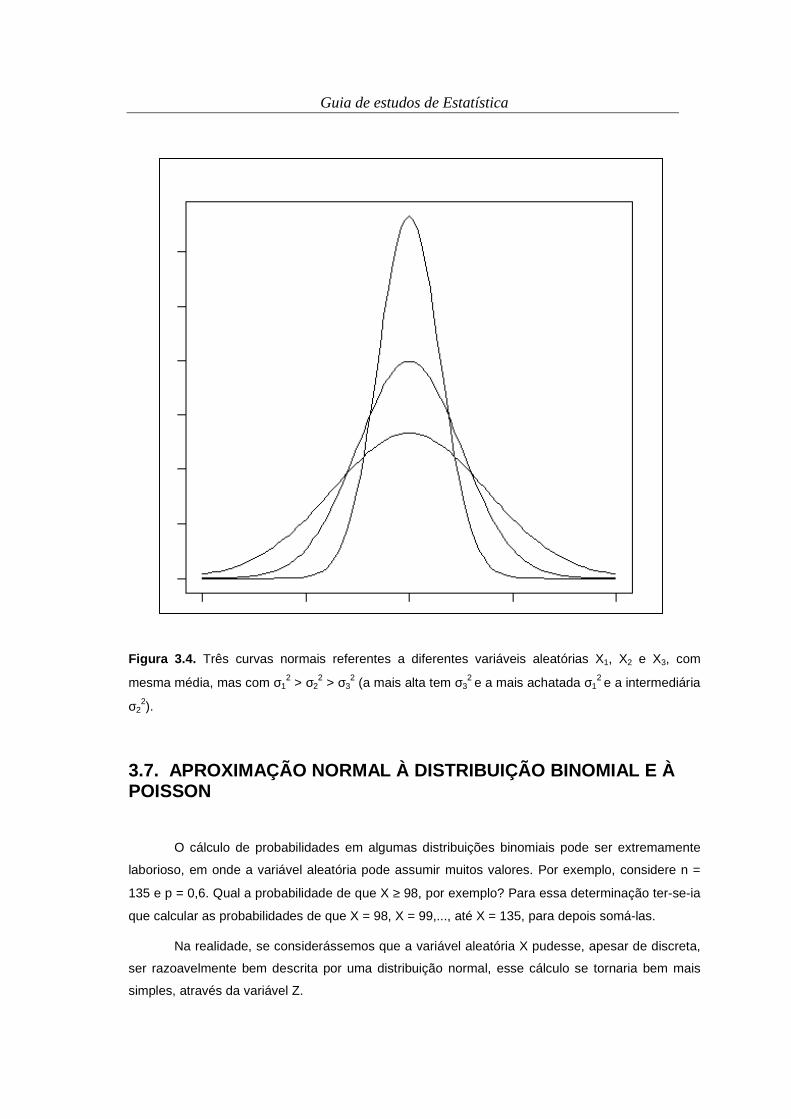
Guia de estudos de Estatística
σ
Figura 3.4. Três curvas normais referentes a diferentes variáveis aleatórias X1, X2 e X3, com
mesma média, mas com σ12 > σ2
2 > σ32 (a mais alta tem σ3
2 e a mais achatada σ12 e a intermediária
σ22).
3.7. APROXIMAÇÃO NORMAL À DISTRIBUIÇÃO BINOMIAL E À POISSON
O cálculo de probabilidades em algumas distribuições binomiais pode ser extremamente
laborioso, em onde a variável aleatória pode assumir muitos valores. Por exemplo, considere n =
135 e p = 0,6. Qual a probabilidade de que X ≥ 98, por exemplo? Para essa determinação ter-se-ia
que calcular as probabilidades de que X = 98, X = 99,..., até X = 135, para depois somá-las.
Na realidade, se considerássemos que a variável aleatória X pudesse, apesar de discreta,
ser razoavelmente bem descrita por uma distribuição normal, esse cálculo se tornaria bem mais
simples, através da variável Z.
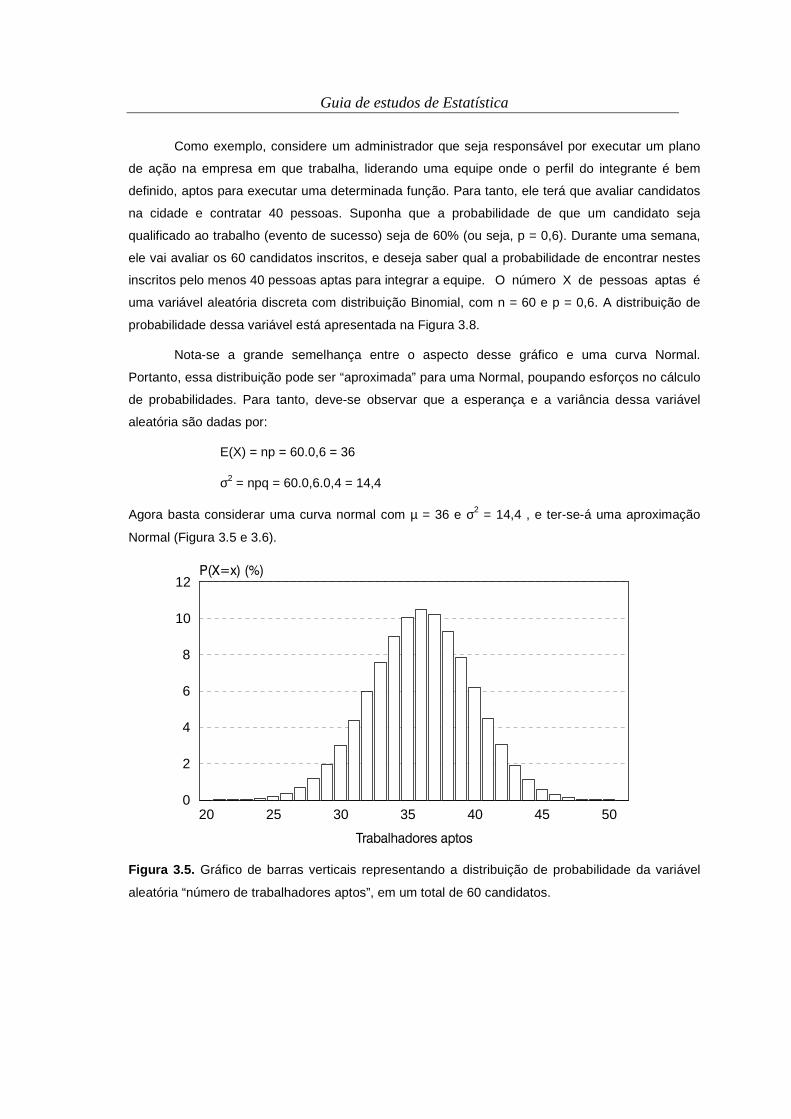
Guia de estudos de Estatística
Como exemplo, considere um administrador que seja responsável por executar um plano
de ação na empresa em que trabalha, liderando uma equipe onde o perfil do integrante é bem
definido, aptos para executar uma determinada função. Para tanto, ele terá que avaliar candidatos
na cidade e contratar 40 pessoas. Suponha que a probabilidade de que um candidato seja
qualificado ao trabalho (evento de sucesso) seja de 60% (ou seja, p = 0,6). Durante uma semana,
ele vai avaliar os 60 candidatos inscritos, e deseja saber qual a probabilidade de encontrar nestes
inscritos pelo menos 40 pessoas aptas para integrar a equipe. O número X de pessoas aptas é
uma variável aleatória discreta com distribuição Binomial, com n = 60 e p = 0,6. A distribuição de
probabilidade dessa variável está apresentada na Figura 3.8.
Nota-se a grande semelhança entre o aspecto desse gráfico e uma curva Normal.
Portanto, essa distribuição pode ser “aproximada” para uma Normal, poupando esforços no cálculo
de probabilidades. Para tanto, deve-se observar que a esperança e a variância dessa variável
aleatória são dadas por:
E(X) = np = 60.0,6 = 36
σ2 = npq = 60.0,6.0,4 = 14,4
Agora basta considerar uma curva normal com µ = 36 e σ2 = 14,4 , e ter-se-á uma aproximação
Normal (Figura 3.5 e 3.6).
20 25 30 35 40 45 500
2
4
6
8
10
12
Figura 3.5. Gráfico de barras verticais representando a distribuição de probabilidade da variável
aleatória “número de trabalhadores aptos”, em um total de 60 candidatos.
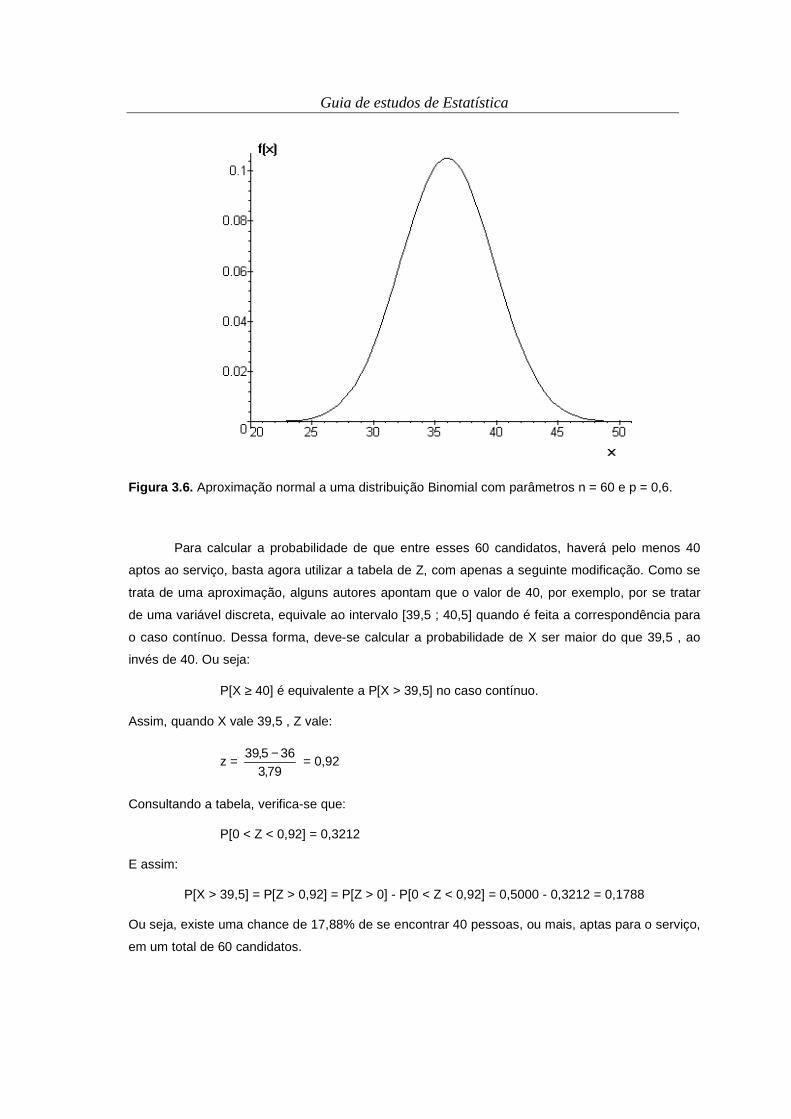
Guia de estudos de Estatística
Figura 3.6. Aproximação normal a uma distribuição Binomial com parâmetros n = 60 e p = 0,6.
Para calcular a probabilidade de que entre esses 60 candidatos, haverá pelo menos 40
aptos ao serviço, basta agora utilizar a tabela de Z, com apenas a seguinte modificação. Como se
trata de uma aproximação, alguns autores apontam que o valor de 40, por exemplo, por se tratar
de uma variável discreta, equivale ao intervalo [39,5 ; 40,5] quando é feita a correspondência para
o caso contínuo. Dessa forma, deve-se calcular a probabilidade de X ser maior do que 39,5 , ao
invés de 40. Ou seja:
P[X ≥ 40] é equivalente a P[X > 39,5] no caso contínuo.
Assim, quando X vale 39,5 , Z vale:
z = 79,3
365,39 − = 0,92
Consultando a tabela, verifica-se que:
P[0 < Z < 0,92] = 0,3212
E assim:
P[X > 39,5] = P[Z > 0,92] = P[Z > 0] - P[0 < Z < 0,92] = 0,5000 - 0,3212 = 0,1788
Ou seja, existe uma chance de 17,88% de se encontrar 40 pessoas, ou mais, aptas para o serviço,
em um total de 60 candidatos.

Guia de estudos de Estatística
Essa probabilidade, quando calculada da maneira exata e não pela aproximação normal,
fornece o valor 0,1786, evidenciando assim a qualidade da aproximação. Alguns autores observam
que são esperados bons resultados quando os produtos np e nq sejam ambos maiores que 5.
Caso contrário, o cálculo exato de probabilidades é recomendado.
Com argumentação semelhante, podemos justificar a aproximação da Poisson pela
Normal. Como exemplo, consideremos o cenário em que o nº de bactérias de uma certa espécie
por cm2 em uma lâmina está para ser contado. Este número de bactérias é uma variável aleatória
X, que assume valores 0,1,2,3,4.... O parâmetro λ desta Poisson é a média de bactérias
encontrada em lâminas semelhantes. Digamos que esta média é estimada como sendo 27,6 / cm2.
A probabilidade de que sejam encontradas mais de 35 bactérias por cm2 é calculada
exatamente como:
P(X > 35) = P(X = 36) + P(X = 37) + P(X = 38) + ... =
...!38
6,27!37
6,27!36
6,27 386,27
376,27
366,27 +++ −−− eee
ou como
1 - P(X > 35) = 1- P(X ≤ 35) = 1- [P(X = 0) + P(X = 1) + ... +P(X = 35)] =
1-
+++ −−−
!356,27
...! 16,27
!06,27 35
6,271
6,270
6,27 eee = 0,9292
A distribuição Normal pode ser usada para o cálculo aproximado de uma Poisson, trazendo
λµ = e λσ = , desde que, segundo estudos que analisam a quantidade da aproximação,
λ>15. O valor aproximado da mesma probabilidade é 0,4% (calcule você mesmo). Este erro
diminui à medida que λ aumenta.
3.8. EXERCÍCIOS RESOLVIDOS
1) Sabe-se que 5% de um rebanho bovino está com febre aftosa. Qual a probabilidade de que num
lote de 6 animais retirados deste rebanho, tenha-se:
Esse é um caso clássico de uma Distribuição Binomial, ou seja, os resultados estão condicionados
a sucesso ou insucesso. Como p = 0,05 e q = 1 - p, portanto q = 0,95. Observe que n = 6.
Sendo:
xnxxn, q p Cx)P(X −== sendo:
x)!(nx!n!
C xn, −=
a) Nenhum animal com febre aftosa.

Guia de estudos de Estatística
Para encontrar a probabilidade de que nenhum animal esteja infectado, teremos que achar esta
função.
Utilizamos então:
735,095,0 05,0 !6!0
!6)0( 60 ===XP
Portanto, a probabilidade de não encontrar nenhum animal infectado neste lote de seis animais é
de 73,5%.
b) Dois animais com febre aftosa
0304,095,0 05,0 !4!2
!6)2( 42 ===XP
Assim, a probabilidade de encontrarmos dois animais infectados neste lote de 6 animais é de
3,04%.
c) Mais de um animal com febre aftosa
Para facilitar o volume de cálculos, utilizamos o conceito de função acumulada, mas para isto é
necessário primeiro calcularmos a função para um animal infectado para o lote de seis animais.
232,095,0 05,0 !5! 1
!6)1( 51 ===XP
Como já se tem a probabilidade para nenhum animal e para um animal infectado para este lote,
podemos, enfim, calcular a probabilidade para mais de um animal infectado (P(X >1)).
033,0]232,0735,0[1)]1()0([1)1(
)6(...)3()2()1(
=+−==+=−=>=++=+==>
XPXPXP
XPXPXPXP
Portanto, a probabilidade de que, neste lote de 6 animais, tenha-se mais de um animal infectado é
de 3,7%.
2) Um jogador de basquete converte 90% dos lances livres. Qual a probabilidade de que este
jogador converta 4 de 6 lances livres de uma partida.
Este é um outro exemplo clássico da Distribuição Binomial. Temos p = 0,9 e q = 0,1 pois p + q = 1.
Sendo n = 6 e x = 4.
0984,01,0 9,0 !2!4
!6)4( 24 ===XP
Portanto, a probabilidade de que o jogador converta 4 de 6 lances livres é de 9,84%.
3) A probabilidade de que um indivíduo apresente reação alérgica após a aplicação de soro é de
0,2%. Esse mesmo soro foi aplicado a um grupo de 1800 pessoas. Qual a probabilidade de que:
a) Duas pessoas tenham reação alérgica?
Este exercício é um caso onde se aplica a Distribuição de Poisson como aproximação da Binomial.
Os dados:
n = 1800 p = 0,002 e q = 0,998
n ≥ 50 e p ≤ 0,10

Guia de estudos de Estatística
Então sua média será:
6,3002,0.1800 === npλ alérgicos
E a função de Poisson:
!)(
xexXP
xλλ−==
Assim, utilizando a função de Poisson:
1770,0!26,3
)2(2
6,3 === −eXP
Assim, a probabilidade de que duas pessoas apresentem reação alérgica ao soro é de 17,70%.
b) No máximo quatro pessoas tenham reação alérgica?
No máximo quatro pessoas significa dizer que podem ser: nenhuma pessoa tendo reação alérgica
ou uma ou duas ou três ou quatro pessoas apresentando a reação. Dessa forma, para encontrar a
probabilidade de no máximo quatro pessoas apresentar a reação, tem-se que calcular a
probabilidade para cada uma delas e posteriormente soma-las.
0273,0!0
6,3)0(
06,3 === −eXP 0984,0
! 16,3
)1(1
6,3 === −eXP 1770,0)2( ==XP
2125,0!3
6,3)3(
36,3 === −eXP 1912,0
!46,3
)4(4
6,3 === −eXP
Portanto:
7064,0)]4(...)1()0([)4( ==++=+==≤ XPXPXPXP
Assim, a probabilidade de que no máximo quatro pessoas apresentem reação alérgica é 70,64%.
c) Pelo menos duas pessoas apresentem reação alérgica?
Como já calculamos, as probabilidades para nenhuma e para uma pessoa apresentar reação
alérgica, podemos utilizar o conceito de função acumulada.
8743,0]0984,00273,0[1)]1()0([1)2( =+−==+=−=≥ XPXPXP
Assim, a probabilidade de que pelo menos duas pessoas apresentem reação alérgica é de
87,43%.
4) Numa lâmina verificou-se que existiam em média 3 bactérias.cm-2. A lâmina foi subdividida em
300 quadrados de 1 cm2 .
a) Em quantos desses quadrados você espera encontrar no máximo 1 bactéria?
Este exercício é um caso onde se aplica a Distribuição de Poisson diretamente.
%98,40498,0!0
3718,2
!)0(
03 ===== −−
xeXP
xλλ
%94,141494,0! 1
3718,2
!)1(
13 ===== −−
xeXP
xλλ
Assim, a probabilidade de se encontrar uma bactéria em qualquer um destes quadrados é de
14,94%.
Guia de estudos de Estatística
Para os 300 quadrados:
607659)9414984.(300 ≅=+ ,%,%,
Assim, espera-se encontrar no máximo 1 bactéria em cerca de 60 quadrados.
b) Qual é a probabilidade de se encontrar mais de 4 bactérias.cm-2?
Aqui utiliza-se o conceito de função acumulada, onde:
[ ])4()3()2()1()0(1)4( =+=+=+=+=−=> XPXPXPXPXPXP
Como as probabilidades para 0 e para 1 foram calculadas no item anterior, calcula-se para 2, 3 e 4.
224,0!2
3718,2
!)2(
23 ==== −−
xeXP
xλλ
224,0!3
3718,2
!)3(
33 ==== −−
xeXP
xλλ
168,0!4
3718,2
!)4(
43 ==== −−
xeXP
xλλ
[ ] 1848,0168,0224,0224,01494,00498,01)4( =++++−=>XP ou 18,48%
5) Usando a curva normal padronizada, determine as seguintes áreas com representação gráfica:
a) Entre 0,0 e 1,32:
Correspondendo à área de interesse a parte hachurada de azul. Assim, o valor correspondente na
tabela de z compreendido entre estes valores é de 0,4066.
0,4066
b) Entre 0,17 e 1,28:
Assim, a probabilidade compreendida entre estes valores será obtida pela diferença obtida de
0,397 – 0,0675 = 0,3322, pois, como sabemos, a probabilidade fornecida na tabela de z está
compreendida entre zero e o valor de interesse.
Guia de estudos de Estatística
0,3322
c) Entre –0,92 e 1,64
Somando as probabilidades para estes valores obteremos: 0,3212 + 0,4495 = 0,7707
d) Abaixo de 1,20.
A probabilidade será a soma de: 0,5 + 0,3849 = 0,8849
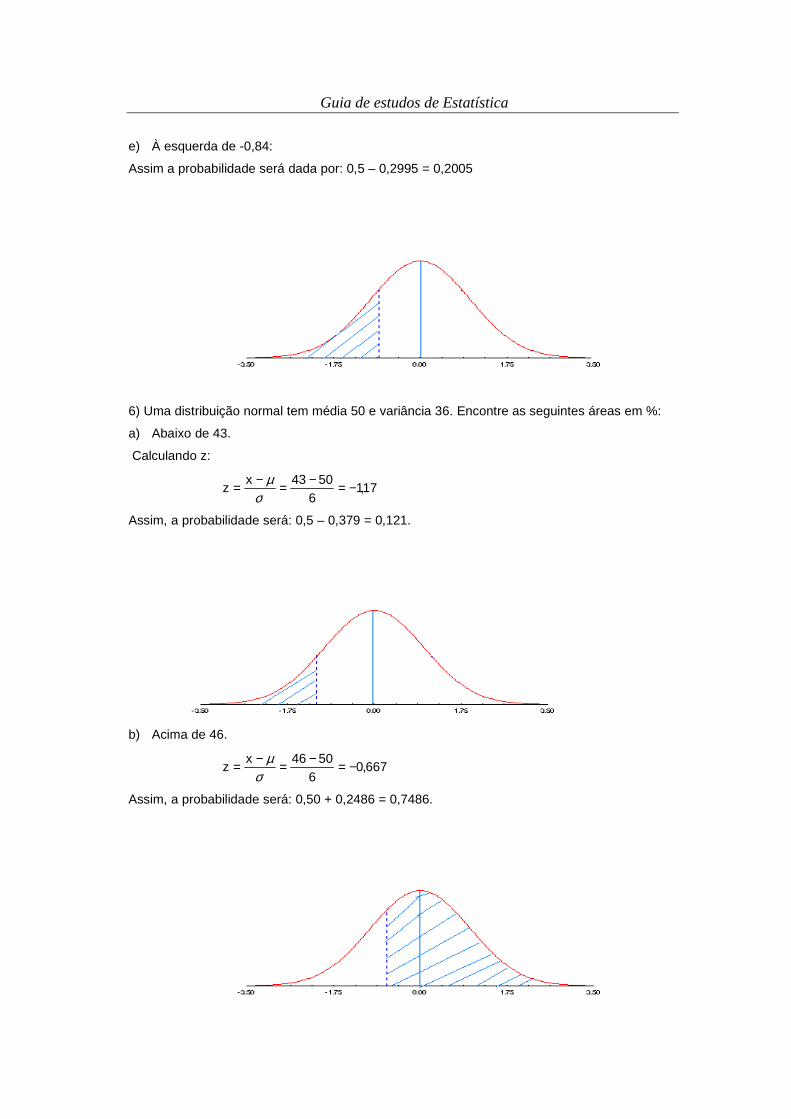
Guia de estudos de Estatística
e) À esquerda de -0,84:
Assim a probabilidade será dada por: 0,5 – 0,2995 = 0,2005
6) Uma distribuição normal tem média 50 e variância 36. Encontre as seguintes áreas em %:
a) Abaixo de 43.
Calculando z:
17,16
5043 −=−=−=σ
µxz
Assim, a probabilidade será: 0,5 – 0,379 = 0,121.
b) Acima de 46.
667,06
5046 −=−=−=σ
µxz
Assim, a probabilidade será: 0,50 + 0,2486 = 0,7486.
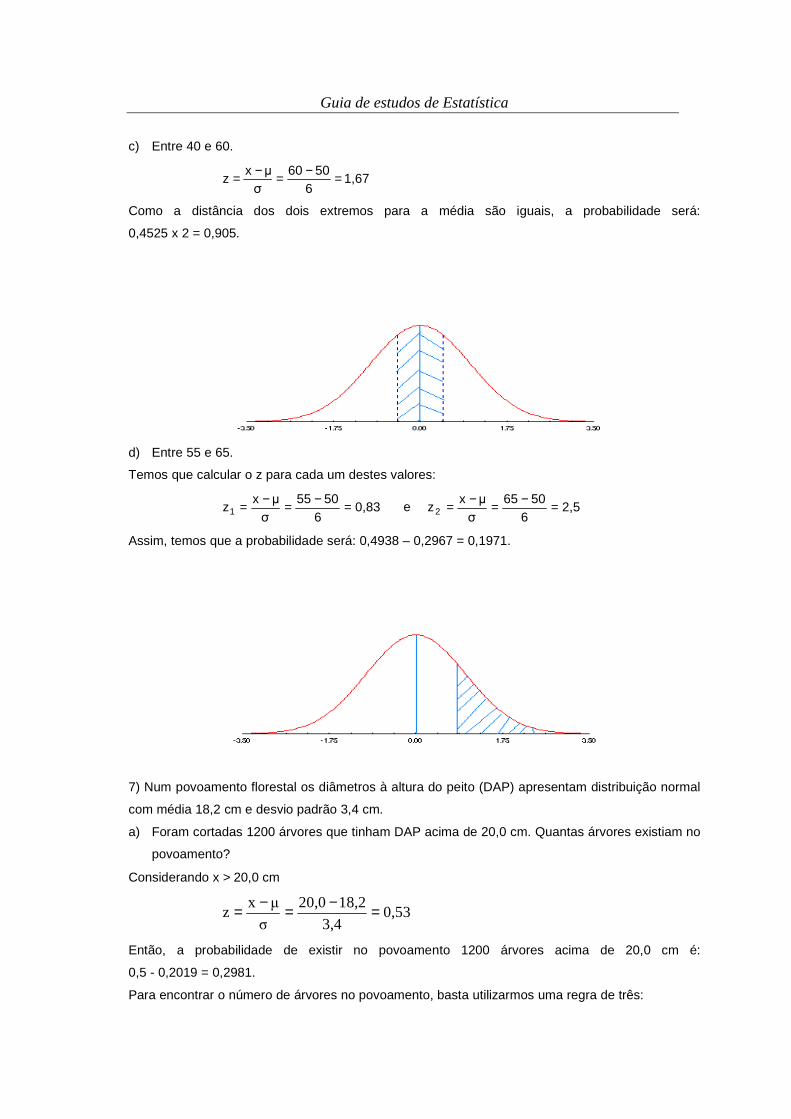
Guia de estudos de Estatística
c) Entre 40 e 60.
1,676
5060σ
µxz =−=−=
Como a distância dos dois extremos para a média são iguais, a probabilidade será:
0,4525 x 2 = 0,905.
d) Entre 55 e 65.
Temos que calcular o z para cada um destes valores:
0,836
5055σ
µxz1 =−=−= e 2,5
65065
σ
µxz2 =−=−=
Assim, temos que a probabilidade será: 0,4938 – 0,2967 = 0,1971.
7) Num povoamento florestal os diâmetros à altura do peito (DAP) apresentam distribuição normal
com média 18,2 cm e desvio padrão 3,4 cm.
a) Foram cortadas 1200 árvores que tinham DAP acima de 20,0 cm. Quantas árvores existiam no
povoamento?
Considerando x > 20,0 cm
0,533,4
18,220,0
σ
µxz =−=−=
Então, a probabilidade de existir no povoamento 1200 árvores acima de 20,0 cm é:
0,5 - 0,2019 = 0,2981.
Para encontrar o número de árvores no povoamento, basta utilizarmos uma regra de três:
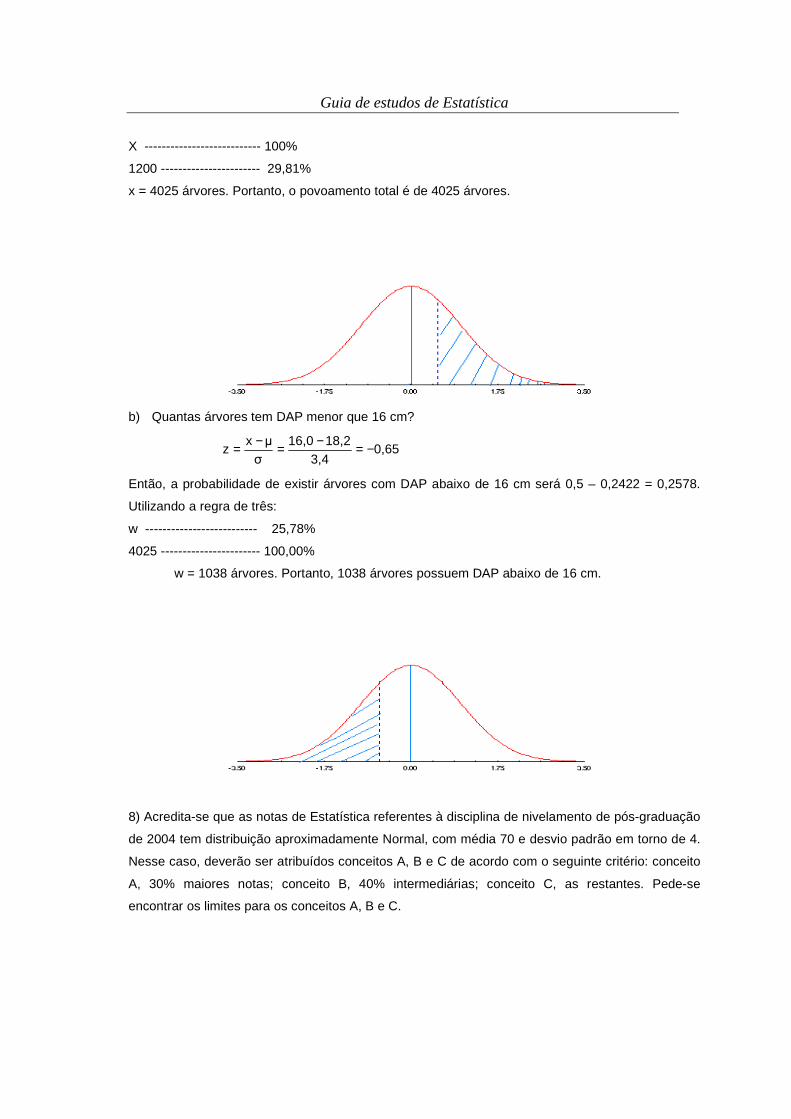
Guia de estudos de Estatística
X --------------------------- 100%
1200 ----------------------- 29,81%
x = 4025 árvores. Portanto, o povoamento total é de 4025 árvores.
b) Quantas árvores tem DAP menor que 16 cm?
0,653,4
18,216,0σ
µxz −=−=−=
Então, a probabilidade de existir árvores com DAP abaixo de 16 cm será 0,5 – 0,2422 = 0,2578.
Utilizando a regra de três:
w -------------------------- 25,78%
4025 ----------------------- 100,00%
w = 1038 árvores. Portanto, 1038 árvores possuem DAP abaixo de 16 cm.
8) Acredita-se que as notas de Estatística referentes à disciplina de nivelamento de pós-graduação
de 2004 tem distribuição aproximadamente Normal, com média 70 e desvio padrão em torno de 4.
Nesse caso, deverão ser atribuídos conceitos A, B e C de acordo com o seguinte critério: conceito
A, 30% maiores notas; conceito B, 40% intermediárias; conceito C, as restantes. Pede-se
encontrar os limites para os conceitos A, B e C.
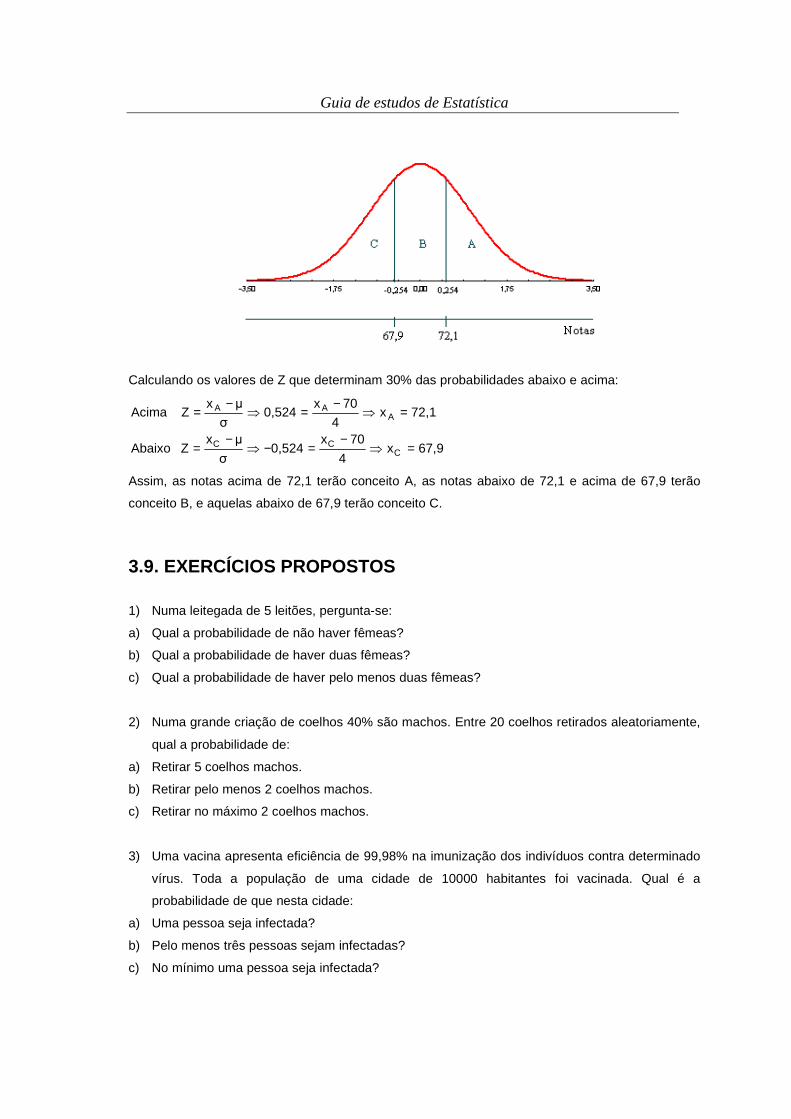
Guia de estudos de Estatística
Calculando os valores de Z que determinam 30% das probabilidades abaixo e acima:
67,94
700,524
σ
µZ Abaixo
72,14
700,524
σ
µZ Acima
=⇒−
=−⇒−
=
=⇒−
=⇒−
=
CCC
AAA
xxx
xxx
Assim, as notas acima de 72,1 terão conceito A, as notas abaixo de 72,1 e acima de 67,9 terão
conceito B, e aquelas abaixo de 67,9 terão conceito C.
3.9. EXERCÍCIOS PROPOSTOS
1) Numa leitegada de 5 leitões, pergunta-se:
a) Qual a probabilidade de não haver fêmeas?
b) Qual a probabilidade de haver duas fêmeas?
c) Qual a probabilidade de haver pelo menos duas fêmeas?
2) Numa grande criação de coelhos 40% são machos. Entre 20 coelhos retirados aleatoriamente,
qual a probabilidade de:
a) Retirar 5 coelhos machos.
b) Retirar pelo menos 2 coelhos machos.
c) Retirar no máximo 2 coelhos machos.
3) Uma vacina apresenta eficiência de 99,98% na imunização dos indivíduos contra determinado
vírus. Toda a população de uma cidade de 10000 habitantes foi vacinada. Qual é a
probabilidade de que nesta cidade:
a) Uma pessoa seja infectada?
b) Pelo menos três pessoas sejam infectadas?
c) No mínimo uma pessoa seja infectada?

Guia de estudos de Estatística
4) Um livro de 300 páginas tem 630 erros de impressão, distribuídos ao acaso por todas as
páginas do livro. Qual a probabilidade de que, abrindo o livro ao acaso em uma página, esta
página apresente 5 erros de impressão?
5) Uma certa viga de aço tem resistência média de 7.500 psi. Suponha que essa resistência tenha
distribuição normal com desvio padrão de 650 psi. Determine as probabilidades para as seguintes
capacidades de resistência:
a) Menor que 6.900 psi.
b) Maior que 7.000 psi.
c) Maior que 10.000 psi.
6) Na população humana é sabido que 30% das pessoas apresentam algum tipo de problema de
visão. Numa classe de 40 estudantes, qual a probabilidade de encontrar:
a) 8 alunos com problemas visuais.
b) Mais de 13 alunos com problemas visuais.
c) De 11 a 15 alunos com problemas visuais.
Obs: Neste exercício utilize a aproximação da Distribuição Binomial pela Normal.

UUNNIIDDAADDEE 44
AAMMOOSSTTRRAAGGEEMM
4.1. INTRODUÇÃO
Frequentemente não é possível ou viável a observação de todos os elementos de uma
população (ou seja, censos), e nesses casos tem-se que fazer uso de amostras.
A finalidade de uma amostra é a de descrever, indiretamente, a população. Portanto, é
necessário que as amostras coletadas guardem características as mais próximas possíveis da
população. Esta qualidade é denominada representatividade.
Conceito 4.1. Representatividade . Qualidade das amostras em possuirem ou reproduzirem as
mesmas propriedades da população.
Assim, é necessária a observação de alguns cuidados no momento da coleta de amostras,
caso contrário, problemas quanto à representatividade podem ocorrer. Por exemplo, se na
amostragem de um povoamento florestal forem observadas apenas árvores de um dos quadrantes
do talhão, pode acontecer de nesse quadrante ocorrer uma fertilidade de solo mais alta do que no
restante do talhão. Dessa forma, a quantidade de madeira no povoamento todo seria
superestimada.
O procedimento básico para garantir representatividade nas amostras é o sorteio.
Conceito 4.2. Sorteio . Procedimento pelo qual é conferida a todos os elementos de um conjunto a
mesma probabilidade de serem tomados.
O sorteio também é chamado de aleatorização ou casualização. Quando a obtenção de
uma amostra sofreu algum mecanismo de sorteio, ela é chamada de amostra aleatória. A coleta de
amostras aleatórias é chamada de amostragem aleatória.
Conceito 4.3. Amostra Aleatória . Amostra retirada por algum mecanismo de sorteio.

Guia de estudos de Estatística
O sorteio garante representatividade porque evita tendenciosidades no momento da coleta. A
amostragem pode ser classificada conforme a Figura 4.1.
Amostragem
aleatória
Figura 4.1. Classificação da amostragem aleatória.
Independente da natureza da amostragem (AAS, AAE, AAC ou AS), ela pode ainda ser
com reposição ou sem reposição:
Amostragem
Figura 4.2. Classificação da amostragem quanto à reposição.
Na amostragem com reposição, os elementos da população, à medida que são sorteados,
são devolvidos à população, e podem, eventualmente, ser sorteados de novo. Esse é o caso, por
exemplo, quando tilápias são amostradas em tanques de piscicultura, pesadas, e devolvidas aos
tanques. Quando a amostragem é sem reposição, os elementos são sorteados apenas uma única
vez. Tal é o caso onde, por exemplo, 50 animais são sorteados do rebanho com um total de 201
vacas.
Apesar de que a representatividade de uma amostra é construída utilizando-se do
expediente sorteio, que torna as amostras aleatórias, algumas vezes, na prática, procedimentos de
amostragem não aleatória são utilizados, admitindo-os como aproximadamente aleatórias.
Algumas destes procedimentos de amostragem não–probabilística são:
1. Amostragem a esmo: escolhem-se os elementos da população que foram parte da amostra
por algum mecanismo ou expediente “sem lógica”, ou “desgovernado”, ou “esforçando-se
para emular (imitar) um sorteio”.
2. Amostragem por conveniênia: escolhem-se os elementos da população para os quais se
tem maiores possibilidades de acesso.
Esses procedimentos não-probabilísticos, a rigor, não deveriam ser utilizados na Estatística,
portanto, seu uso, se necessário (como às vezes é) deve ser feito com cautela, procedendo
Simples (AAS)
Estratificada (AAE)
Por Conglomerado (AAC)
Sistemática (AS)
Sem reposição
Com reposição

Guia de estudos de Estatística
sempre o expurgo de qualquer tendência ou viés na escolha dos elementos e composição da
amostra. Quando se é forçado a utilizar amostragem não-aleatória, não se pode proibir de se
aplicar métodos estatísticos “como se a amostra fosse aleatória”, porém, caso alguém queira fazer
este desvio da teoria, deve fazer com toda cautela. Neste guia daremos enfoque apenas aos
procedimenos aleatórios.
4.2. AMOSTRAGEM ALEATÓRIA SIMPLES (AAS)
Este método de amostragem aleatória é o mais simples, e basicamente é tal que
todos os elementos da população tenham a mesma probabilidade de serem coletados. Assim, se a
população for finita com N elementos, cada um terá a probabilidade de 1/N de ser sorteado.
A amostra tem, como foi visto, n elementos. Se a AAS for feita com reposição em uma
população finita com N elementos, então o número total de amostras possíveis é dado por:
No de amostras possíveis = Nn
Por outro lado, se ela for feita sem reposição, então o número de amostras possíveis é:
No de amostras possíveis = AN,n
Obs. AN,n é arranjo de N elementos tomados n-a-n, dado por N! / (N – n)! .
Na prática, a realização do sorteio no processo de AAS é feita mediante várias
possibilidades. Pode-se, por exemplo, escrever em papeizinhos os N elementos da população,
colocá-los em uma caixa e sorteá-los. Pode-se ainda identificar os elementos com um número e
sorteá-los mediante tabelas de números aleatórios, ou funções randômicas na calculadora ou
computador. Ou ainda proceder métodos com apoio computacional. A figura abaixo é um exemplo.

Guia de estudos de Estatística
Será apresentado um exemplo, a seguir, para ilustrar o uso de tabelas aleatórias. Uma
tabela aleatória nada mais é que uma coleção de números contidos em um intervalo,
“bagunçados”, e com igual probabilidade de ocorrência. A Tabela 4.1 foi gerada a partir da função
randômica de uma calculadora eletrònica.
Tabela 4.1. 50 números aleatórios (x1000) entre 0 e 1000 gerados a partir da função randômica de
uma calculadora eletrônica.
237 464 533 282 623 592 074 481 613 874
602 269 678 269 273 346 355 110 211 113
200 417 046 914 201 628 549 704 707 295
847 615 452 454 129 643 552 975 441 091
486 197 153 541 802 980 798 603 373 156
Agora, suponha que se queira coletar uma amostra de tamanho n = 5, de uma população
com N = 10 elementos. Um procedimento de sorteio pode ser: associando um número que vai de 0
a 9, a todos os elementos da população, pode-se sorteá-los olhando-se o último algarismo dos
números da Tabela 4.1, a partir, por exemplo, do primeiro valor. Procedendo-se dessa forma, ter-
se-ia o seguinte sorteio:
1o elemento da amostra:
1o número aleatório = 237 ⇒ toma-se o elemento 7 da população
2o elemento da amostra:
2o número aleatório = 602 ⇒ toma-se o elemento 2 da população
3o elemento da amostra:
3o número aleatório = 200 ⇒ toma-se o elemento 0 da população
4o elemento da amostra:
4o número aleatório = 847. Como o elemento 7 da população já foi sorteado, passa-se para
o 5o número aleatório = 486 ⇒ toma-se o elemento 6 da população.
5o número aleatório = 486 ⇒ toma-se o elemento 6 da população.
6o número aleatório = 464 ⇒ toma-se o elemento 4 da população
Assim, a amostra coletada fica sendo o conjunto {7, 2, 0, 6, 4}.
Quando a população for infinita, não é possível identificar seus infinitos elementos com um
número. Nesse caso, pode-se proceder o mecanismo de sorteio com aqueles elementos que
estejam disponíveis. Por exemplo, em estudos sobre o número de chuvas com certa intensidade
em uma região, uma vez que se está querendo fazer previsões para anos futuros, trata-se de uma

Guia de estudos de Estatística
população de infinitos anos, compreendendo aqueles que passaram e os que ainda estão por vir.
Assim, suponha que se disponha de apenas dados de 80 anos passados. Uma amostra poderia
ser sorteada dentre esses dados. Aliás, mesmo que todos os 80 dados fossem analisados, este
conjunto continuaria sendo uma amostra com n = 80, da população infinita, porém, não aleatória,
mas, sim, por conveniência.
Mesmo quando o procedimento de sorteio for pouco viável, por exemplo, em uma
população finita com N muito grande, pode-se coletar a amostra “a esmo”, evitando ao máximo
qualquer favorecimento no processo. Tal é o caso, por exemplo, quando folhas de seringueira são
amostradas para verificação de ocorrência da doença ‘Mal das Folhas’. Obviamente, não teria
sentido dar-se ao enorme trabalho de numerar todas as folhas de cada árvore e sorteá-las em
seguida.
4.3. AMOSTRAGEM ALEATÓRIA ESTRATIFICADA (AAE)
Por vezes, a informação disponível sobre a estrutura da população a ser amostrada é tal
que permite melhorar a representatividade da amostra. Um caso onde isso ocorre é quando se
sabe que a população é dividida em estratos, isto é, quando a população se caracteriza por
subdivisões com características distintas. A figura abaixo é mais um exemplo.

Guia de estudos de Estatística
A título de ilustração, seja a Cooperativa dos Agricultores da Região de Orlândia Ltda
(CAROL), que representa cerca de 1500 agropecuaristas de 48 municípios do Norte de São Paulo
e 44 do Triângulo Mineiro. Suponha que a CAROL necessite de dados e informações atualizadas
sobre a sua área de atuação e sobre os seus associados para que possa atendê-los
convenientemente. A população de cooperados poderia ser dividida em 5 estratos, segundo o
tamanho da propriedade (Tabela 4.2).
Uma AAS desenvolvida sobre esta população pode produzir uma amostra não-
representativa. Por exemplo, se decidimos coletar uma amostra com n=156 propriedades,
poderemos ter uma AAS quase totalmente concentrada, ou totalmente concentrada nos estratos 1
e 2. Podemos até tê-la concentrada em um só estrato, o que, sem dúvida, comprometerá sua
representatividade, pois as características tecnológicas, capitalização, mão-de-obra, etc, devem
variar de estrato para estrato.
A solução consiste na realização de uma AAS dentro de cada estrato, de tal maneira que
todos os estratos fiquem representados. Tal delineamento amostral é chamado de amostragem
aleatória estratificada (AAE). É desejável para maximizar a representatividade da amostra, que os
estratos tenham a maior homogeneidade possível dentro de si.
Tabela 4.2. Estratificação dos cooperados da CAROL.
Estrato Área (alqueires) Número de Propriedades
1 1 a 34 873 873
2 34 a 73 386 386
3 73 a 126 246 246
4 126 a 282 186 186
5 282 ou mais 112 112
Tanto é possível estratificar populações finitas como infinitas. Um exemplo de estratificação
em populações infinitas são os experimentos montados para comparar características fitotécnicas
de certas variedades de uma cultura. Cada uma dessas variedades constitui um estrato da
população (infinita) formada pelo conjunto de todas estas variedades avaliadas.
Uma vez fixado um tamanho n para a amostra a ser coletada, via AAE, um critério de
ponderação (ou de proporcionalidade), para a determinação do tamanho da amostra em cada
estrato. Por este método, o número de elementos ni a serem observados no estrato i é proporcional
ao número de elementos Ni do estrato, de maneira que a precisão da avaliação em cada um deles
não seja desigual. Este critério é particularmente adequado quando a variabilidade presente em
cada estrato é relativamente homogênea. Determina-se, então ni por:

Guia de estudos de Estatística
ni = N
Ni
n
No exemplo da CAROL, se uma amostra de n = 100 elementos fosse coletada, ter-se-ia
uma situação como a da Tabela 4.3.
Tabela 4.3. Critério ponderado para dimensionamento do número de elementos a serem
amostrados em cada estrato dos cooperados da CAROL.
Estrato i
(i = 1, 2, ... 5)
Área da Propriedade Número de
Propriedades (Ni)
Número de
Elementos (ni)
1 1 a 34 873 48
2 34 a 73 386 21
3 73 a 126 246 14
4 126 a 282 186 10
5 282 ou mais 112 7
Total 1803 100
4.4. AMOSTRAGEM ALEATÓRIA POR CONGLOMERADO (AAC)
Não apenas por causa da representatividade pode se buscar delineamentos amostrais
alternativos a AAS. Também, a limitação de recursos para realizar a amostragem pode ser um
fator importante. Tal é a situação quando, por exemplo, uma agroindústria contrata um profissional
de marketing rural para analisar a viabilidade de lançamento de um novo produto, e para isso este
profissional tem que pesquisar características de agricultores da região sul de Minas Gerais, mas
deseja evitar percorrer municípios espalhados por toda a região (que poderia ser o caso se a
amostra fosse gerada por uma AAS).
Em vez disso, para diminuir os custos de locomoção (transporte), o profissional pode
concentrar suas entrevistas sobre um número limitado de sub-regiões ou municípios e usá-las
como uma amostra da população de agricultores do sul de Minas Gerais. Para não perder o
caráter aleatório que a amostragem deve ter, ele poderia enumerar os municípios da região e
sortear alguns deles (isto é, formar uma AAS de municípios) e em seguida sortear agricultores
dentro desses municípios.
O processo de subdividir a população em componentes (de mesmas características, ao
contrário dos estratos) com o objetivo único de facilitar o processo de coleta dos elementos da
amostra é denominado de amostragem aleatória por conglomerado.

Guia de estudos de Estatística
Deve-se observar que essa prática de amostragem não deve comprometer a
representatividade, em razão da não-observação dos outros conglomerados. Para tanto, é
necessário que cada conglomerado reproduza bem as características da população, sendo quase
que uma miniatura desta.
Se forem sorteados m conglomerados de uma população, dentro dos quais todos os
elementos são observados, esse processo é chamado de amostragem aleatória por conglomerado
em um estágio. Por outro lado, se dentro de cada conglomerado são sorteados outros tantos sub-
conglomerados, então a AAC é em dois estágios, três, etc. Essa hierarquização de sorteios de
amostragens aleatórias uma dentro da outra, pode ser desenvolvida em múltiplos estágios, tantos
quanto a necessidade exigir e a população suportar. A figura abaixo mostra uma amostragem por
conglomerado.

Guia de estudos de Estatística
4.5. AMOSTRAGEM ALEATÓRIA SISTEMÁTICA (AS)
Ainda objetivando facilitar o processo de amostragem, alguns autores também propõem
outro método, denominado de amostragem aleatória sistemática (AS), que pode vir a aumentar a
representatividade da amostra em algumas situações. Por esse sistema, os elementos da
população são considerados como dispostos em uma linha (como por exemplo, uma fileira de
árvores), e o primeiro elemento da amostra é sorteado. Em seguida, salta-se um determinado
número k de elementos (chamados ‘Passos de Amostragem’), e o segundo elemento é observado.
Salta-se novamente k passos, e esse processo é continuado até a coleta do último elemento da
amostra.
No caso de a população ser finita, a determinação do número k de passos é feita pela
seguinte razão, tomando-se o inteiro mais próximo:
k = nN
Por exemplo, se em um povoamento florestal existem 10.000 árvores, das quais serão amostradas
50, então k = 10.000 / 50 = 200. Em seguida, sorteia-se a primeira árvore dentre as 10.000.

Guia de estudos de Estatística
Supondo que a 1a árvore sorteada seja a de número 1.080, então somaremos e diminuiremos a
este valor a constante k=200. Assim, as árvores amostradas seriam:
80, 280, 480, 680, 880, 1080, 1280, 1480, 1680, 1880, 2080, 2280, ...., 9.880
Esse é um processo bastante simples de se implementar, e que pode aumentar a
representatividade da amostra pela melhor “cobertura” que o processo de amostragem faz da
população. Ou seja, na amostragem aleatória pode acontecer que, por puro acaso, os elementos
sorteados, em conjunto, não representem bem a população. No entanto, a amostragem
sistemática debve ser realizada com cuidado em situações onde os elementos sorteados podem
guardar algum tipo de relação entre si, ou periodicidade, decorrente do fato de serem coletados
sistematicamente.
Os enfoques da inferência estatística mais comumente utilizados pressupõem que a
amostragem seja aleatória simples, para validar, como será visto, os métodos de construção de
intervalos de confiança e testes de hipóteses. Apesar desta exigência, a utilização de
procedimentos de amostragem AAE, AAC, e AS são utilizados para gerar amostrasque, na prática,
sejam consideradas aleatórias.
4.6. EXERCÍCIOS RESOLVIDOS
1) O que é amostragem? Qual é a principal característica da amostragem probabilística? Quando
é possível empregar amostragem não probabilística?
Pode-se dizer que amostragem é o estudo das relações existentes entre a amostra (subconjunto
do universo em estudo) e a população (conjunto universo) de onde ela foi extraída. O principal
objetivo da amostra é estimar os parâmetros populacionais (média, variância, desvio padrão,
proporção, entre outros).
A principal característica de uma amostra probabilística é de que todos os indivíduos que
compõem a população têm a mesma probabilidade, diferente de zero, de pertencer à amostra.
Basicamente, pode-se utilizar uma amostragem não probabilística quando algum indivíduo que
pertence à população tem probabilidade zero de pertencer à amostra.
2) Deseja-se testar durante um mês um novo tipo de ração alimentícia em vacas leiteiras. O
objetivo é conhecer o incremento médio de produção de leite por vaca, quando é aplicada a nova
ração. Para isto, planejou-se determinar a diferença entre a produção do leite do mês em que foi

Guia de estudos de Estatística
fornecida a nova ração e a produção do mês anterior de cada vaca. Sabe-se que em qualquer
caso, antes e depois da ração, a produção de leite de vacas jovens é superior (ou pelo menos
diferente) à produção de vacas adultas, sendo esta diferença significativa. A granja conta
atualmente com 1000 vacas leiteiras e, após análise matemática e de custos, determinou-se
aplicar a ração em 30 animais.
a) Qual é a população em estudo?
As 1000 vacas leiteiras da granja em questão.
b) Qual é o tamanho da população e qual é o tamanho da amostra?
População = 1000 vacas leiteiras
Amostra = 30 vacas
c) A população é finita ou infinita? Por quê?
Finita, pois podemos enumerar cada um dos elementos que compõem a população.
d) Qual seria o parâmetro que se deseja conhecer? É possível conhecer o valor exato daquele
parâmetro?
O que deseja se conhecer é o aumento médio da produção de leite depois de aplicada à nova
ração.
Como estamos trabalhando com uma amostra não é possível saber exatamente o valor do
parâmetro.
e) Qual é o estimador que você utilizaria para estimar o parâmetro do item d?
O melhor estimador seria a média: n
x
x
n
ii∑
== 1
f) Para esse tipo de estudo, você recomendaria utilizar um processo de amostragem
probabilístico? Por quê? Qual seria este processo? Por quê?
Sem dúvida, o processo de amostragem probabilístico seria o mais indicado. Principalmente
porque todos os indivíduos têm uma mesma chance diferente de zero de pertencer à amostra.
O processo de amostragem mais indicado seria o proporcional estratificado, pois na população em
estudo percebe-se, claramente, dois subconjuntos, vacas jovens e vacas mais velhas que
apresentam diferenças significativas na produção de leite.
3) Para se obter a opinião dos brasileiros sobre a reforma agrária, entrevistaram-se 90% dos
associados de uma sociedade ruralista. Pergunta-se:
a) Qual é o tipo de amostragem empregado?
Basicamente poderíamos dizer que esta é uma amostra não probabilística, pois todos os
brasileiros, nesse caso, não possuem a mesma probabilidade de pertencer à amostra, uma vez
que somente 90% dos associados de uma sociedade ruralista serão os entrevistados.
b) Tal procedimento de amostragem é confiável? Justifique.

Guia de estudos de Estatística
Não, se o objetivo da pesquisa é saber a opinião de todos os brasileiros sobre a reforma agrária,
não é entre pessoas com interesse direto no fato que se terá a verdadeira opinião da população.
Esta amostra será realizada com um sério problema de viés ou tendenciosidade.
4) Uma empresa cafeeira do sul de Minas Gerais dispõe de 3200 funcionários distribuídos nas
diversas atividades, conforme o quadro abaixo. Deseja-se sortear uma amostra de 20 empregados
desta empresa, com o objetivo de conhecer alguns de seus aspectos sócioeconômicos e culturais.
A população em estudo se distribui dentro das seguintes categorias:
Atividade Nº Empregados
Campo 1600
Armazém 720
Indústria 480
Administração 240
Gerência 160
a) Na sua opinião, seria razoável levantar as informações desejadas por meio de uma
amostragem aleatória simples de n = 160 funcionários? Justifique.
Nessa situação a amostra aleatória simples não seria a mais indicada, pois ela não mostraria o
verdadeiro perfil dos empregados da empresa. O ideal seria utilizar uma amostra proporcional
estratificada.
b) Planeje uma amostragem proporcional estratificada n = 160 determinando o tamanho da
amostra para cada atividade.
A amostra proporcional estratificada deve ser composta de forma que o número de empregados de
cada setor seja proporcionalmente representado na amostra. Assim, pode-se calcular essa
amostra, usando inúmeros recursos matemáticos, como por exemplo:
Para os empregados do campo:
3200 --------------------- 100%
1600 ------------------------ x
%503200
160000x ==
Assim, os trabalhadores do campo compõem 50% do total de empregados da empresa de forma
que, 50% dos trabalhadores que comporão a amostra proporcional estratificada deverão pertencer
a esse grupo. Então, a amostra deverá ser de tamanho n = 160, 50% destes serão de
trabalhadores do campo, portanto 80 trabalhadores. Assim, deverá ser feito para todos os outros
setores, conforme resultados que podem ser melhor visualizados no quadro abaixo:
Guia de estudos de Estatística
Atividade Número de empregados
Amostra proporcional estratificadas
Campo 1600 80 Armazém 720 36 Indústria 480 24 Administração 240 12 Gerência 160 8 Total 3200 160
c) Usando a calculadora, ou a tabela de números aleatórios, sorteie os componentes da amostra
para os empregados que trabalham na gerência. Explique com detalhes como você realizaria o
sorteio.
Os empregados da gerência foram numerados de 1 a 160, ordenados quanto à data de admissão
na empresa, começando pelos mais velhos de casa. Utilizando o recurso de geração de números
aleatórios da calculadora, sortearemos os 8 trabalhadores que comporão a amostra. Com o auxílio
da calculadora obtemos os números:
47 153 144 27 102 125 121 61
Portanto, os trabalhadores que correspondem a esses números é que comporão a amostra.
5) Faça o sorteio de uma amostra sistemática n = 10, para estimar o volume de madeira de um
povoamento florestal de eucalipto com 2500 árvores dispostas em 25 fileiras com 100 plantas
em cada uma delas. Apresente um croqui identificando as plantas sortedas.
N = 2500 árvores n = 10 árvores
Para a amostra sistemática:
25010
2500 ===nN
K possíveis amostras.
Assim, sorteamos um número raiz ou ponto de partida e, a partir dele, conforme nossa escolha,
dependendo da sua grandeza, adicionamos ou retiramos dele 250. Por exemplo, para este caso, o
número raiz sorteado no gerador de números aleatórios da calculadora foi o número 3, assim, a
nossa amostra será composta pelas árvores correspondentes aos números:
3 253 503 753 1003 1253 1503 1753 2003 2253
No croqui, teremos a seguinte distribuição:

Guia de estudos de Estatística
Fileiras Plantas
1 2 3 . . . . . . . . . . . . . . . . . . . . . . .50 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .100
1
2
.
.
6
.
.
11
.
.
.
16
.
.
.
21
.
.
.
25
•
•
•
•
•
•
•
•
•
4.7. EXERCÍCIOS PROPOSTOS
1) Responda:
a) O que é população e o que é amostra?
b) O que é censo e processo de amostragem?
c) Em que condições é feito um censo e em quais é feita a amostragem?
d) Qual o objetivo da amostragem?
2) Critique os seguintes planos amostrais:
a) Para levantar a opinião dos brasileiros sobre a importância e necessidade da reforma agrária,
decidiu-se entrevistar os membros do MST de Campo do Meio, Minas Gerais.
b) Para diagnosticar a situação econômica da agropecuária mineira foram entrevistados os
produtores de café da cidade Lavras, Minas Gerais.

Guia de estudos de Estatística
c) Para se comparar duas rações de crescimento usam-se dez leitões nascidos da mesma mãe.
d) Para se comparar a percentagem de perda de grãos na debulha mecânica de duas variedades
de milho foram utilizadas setenta espigas de cada uma delas, utilizando duas máquinas
diferentes.
3) Como você selecionaria uma amostra representativa de:
a) Cem fichas com dados da produção de leite de vacas Girolandas, sabendo que as fichas estão
em cinco caixas contendo cada uma cem fichas.
b) Dez forrageiras do painel de forragicultura da UFLA para a avaliação do teor de proteína bruta.
c) Sessenta alunos de uma escola com mil alunos, onde setecentos estão na graduação e o
restante na pós-graduação.
d) Vinte folhas de uma laranjeira para avaliar o teor de cálcio.
4) Um indivíduo retirou três tomates da superfície de cada uma das caixas de tomates que
estavam no estoque de um supermercado, para caracterizá-lo quanto à qualidade. Isto é uma
amostra representativa? Justifique.
5) Proponha um plano de amostragem sistemática para avaliar a quantidade de alimento
desperdiçado nas bandejas devolvidas em um almoço no Refeitório Universítário. Para fixar
idéias, suponha que uma amostra de tamanho 40 deva ser extraída de uma população
estimada de 850 usuários nessa refeição. Com a ajuda da tabela de números aleatórios,
calcule inclusive quais bandejas deverão ser amostradas.
6) Desenvolva um planejamento completo para amostrar e avaliar várias características
socioeconômicas dos produtores de leite B associados à CAARG. A população tem uma
estrutura estratificada, segundo a produção, conforme quadro abaixo.
Produção em litros (dia) Número de cooperados Amostra
0 a 20 368
21 a 50 61
51 a 100 45
101 a 500 71
501 a 1.000 17
1.001 a 3.000 9
Um plano completo para um levantamento amostral deve conter:
a) Objetivo de pesquisa.
b) Definição da população a ser amostrada.

Guia de estudos de Estatística
c) Definição das variáveis a serem estudadas.
d) Definição do método de amostragem que será utilizado, em função das características da
população e da disponibilidade de recursos.
e) Dimensione uma amostra proporcional estratificada de tamanho 60 entre os produtores de leite
tipo B.
f) Orientações para a execução do levantamento no campo.

Guia de estudos de Estatística
UUNNIIDDAADDEE 55
EESSTTIIMMAAÇÇÃÃOO EESSTTAATTÍÍSSTTIICCAA
5.1. INTRODUÇÃO
Na atividade científica, quando tudo que se dispõe é de uma parte dos elementos de uma
população que se queira descrever (ou seja, como já definimos, uma amostra), então a obtenção
de conclusões a respeito da população estará presa à inerente incompleteza da amostra,
acarretando um certo grau de incerteza nestas conclusões. Lidar com esta incerteza, controlando-a
e medindo-a, é a tarefa da inferência estatística. Convém ressaltar que, sendo assim, deve ficar
claro que só tem sentido falar-se em inferência estatística quando não se conhece todos os
elementos da população. Quando temos conhecimento de toda a população (pois um censo foi
feito), então devemos falar em estatísticas descritivas.
A inferência estatística é definida como sendo o processo de obtenção de informações (ou
de descrições) sobre uma população a partir de amostras. A descrição populacional pode se dar,
como tem sido largamente comentado, mediante distribuições de frequência e por meio de
medidas descritoras, tais como média e desvio-padrão. Estas últimas são chamadas de
parâmetros populacionais.
Conceito 5.1. Parâmetro populacional . Valor que descreve uma população, em geral
desconhecido.
Alguns exemplos de parâmetros de interesse são dados a seguir.
Exemplo 1. Deseja-se ter uma idéia acerca da proporção (desconhecida) de produtores de
uma região que cultivam milho. O parâmetro em questão é a proporção p desejada.
Exemplo 2. Há o interesse no tempo médio de durabilidade dos aspersores da marca
Agro1000, bem como sua variância. Parâmetros: a média µ e a variância σ2.
Quando se dispõe apenas de uma parte dos elementos da população (uma amostra), o
máximo que se pode conseguir são valores aproximados para os parâmetros desconhecidos,
conhecidos como estimativas. Assim, definem-se os conceitos a seguir.

Guia de estudos de Estatística
Conceito 5.2. Estimativa . Valor aproximado de um parâmetro populacional desconhecido
calculado a partir de uma amostra.
Conceito 5.3. Estimação . O ato de obter uma estimativa.
Conceito 5.4. Estimador . Corresponde à expressão algébrica que permite obter uma estimativa,
ou, a variável aleatória que é usada no processo de estimação
Exemplificando, considere que se tenha calculado uma média amostral x , tendo sido
encontrado o valor 3,5. Esse valor é uma estimativa, ou seja, uma aproximação, para o parâmetro
populacional µ. A expressão que permitiu obter essa estimativa:
X = n
Xn
1ii∑
=
corresponde ao estimador da média populacional. Enquanto que para anotar a estimativa x
usamos letra minúscula, para o estimador X usamos letra maiúscula. Esta é uma convenção
universal, porém, pode-se também representar o estimador de um parâmetro pelo símbolo desse
parâmetro, com um “chapéu”. No exemplo do estimador da média populacional, ele poderia, além
da notação X , ser representado por $µ . A estimativa teria também o mesmo símbolo $µ .
5.2. PROPRIEDADES DESEJADAS DOS ESTIMADORES
Um fato que pode acontecer é o de se dispor de dois ou mais estimadores possíveis para
um mesmo parâmetro populacional. Como exemplo, considere o parâmetro µ de uma população
com distribuição Normal para uma variável X dada. Ora, µ é a média, a mediana, e a moda da
população, quando esta é Normal, como já vimos. Logo, podemos estimar µ tanto por X , quanto
por :
X , como também por *X , respectivamente a média, a mediana, e a moda de uma amostra.
Qual destes três estimadores é melhor?
Nessas situações, é conveniente que haja critérios que permitam selecionar algum deles,
com base em determinadas propriedades. Em Estatística, um procedimento geral para a geração
de tais critérios consiste na observação do comportamento dos estimadores, caso infinitas
amostras fossem tomadas da população. Obviamente, se diferentes amostras são coletadas da
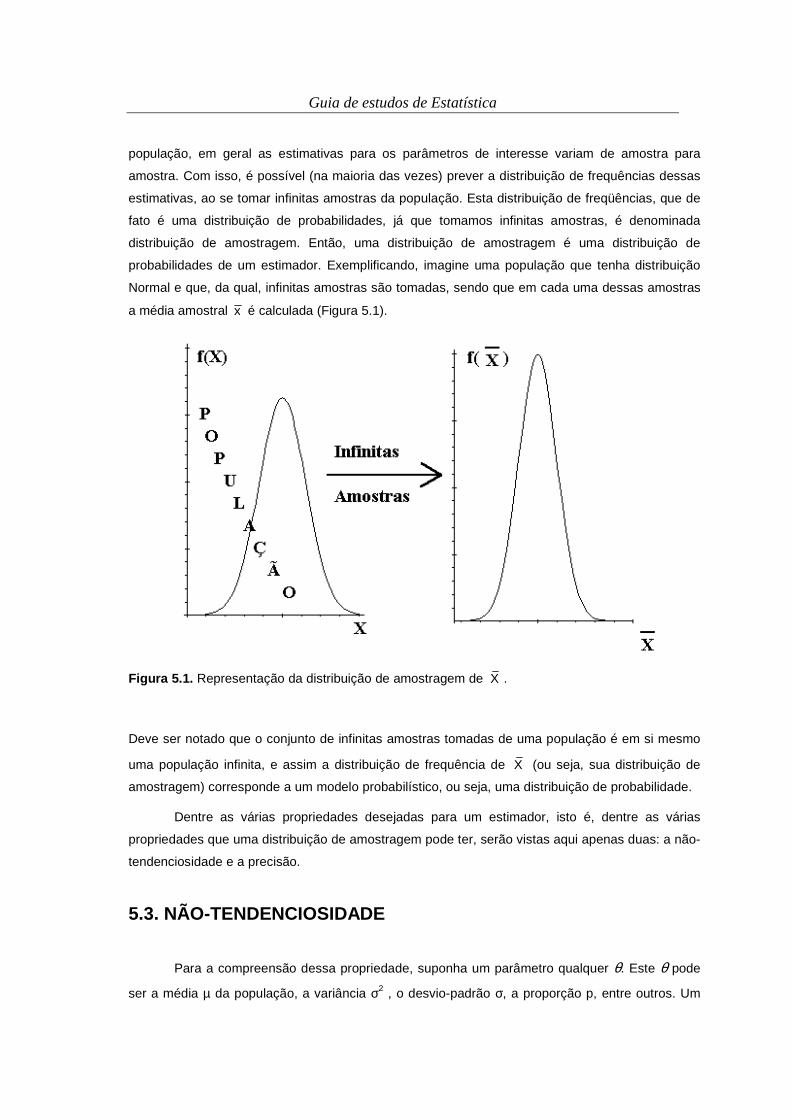
Guia de estudos de Estatística
população, em geral as estimativas para os parâmetros de interesse variam de amostra para
amostra. Com isso, é possível (na maioria das vezes) prever a distribuição de frequências dessas
estimativas, ao se tomar infinitas amostras da população. Esta distribuição de freqüências, que de
fato é uma distribuição de probabilidades, já que tomamos infinitas amostras, é denominada
distribuição de amostragem. Então, uma distribuição de amostragem é uma distribuição de
probabilidades de um estimador. Exemplificando, imagine uma população que tenha distribuição
Normal e que, da qual, infinitas amostras são tomadas, sendo que em cada uma dessas amostras
a média amostral x é calculada (Figura 5.1).
Figura 5.1. Representação da distribuição de amostragem de X .
Deve ser notado que o conjunto de infinitas amostras tomadas de uma população é em si mesmo
uma população infinita, e assim a distribuição de frequência de X (ou seja, sua distribuição de
amostragem) corresponde a um modelo probabilístico, ou seja, uma distribuição de probabilidade.
Dentre as várias propriedades desejadas para um estimador, isto é, dentre as várias
propriedades que uma distribuição de amostragem pode ter, serão vistas aqui apenas duas: a não-
tendenciosidade e a precisão.
5.3. NÃO-TENDENCIOSIDADE
Para a compreensão dessa propriedade, suponha um parâmetro qualquer θ. Este θ pode
ser a média µ da população, a variância σ2 , o desvio-padrão σ, a proporção p, entre outros. Um
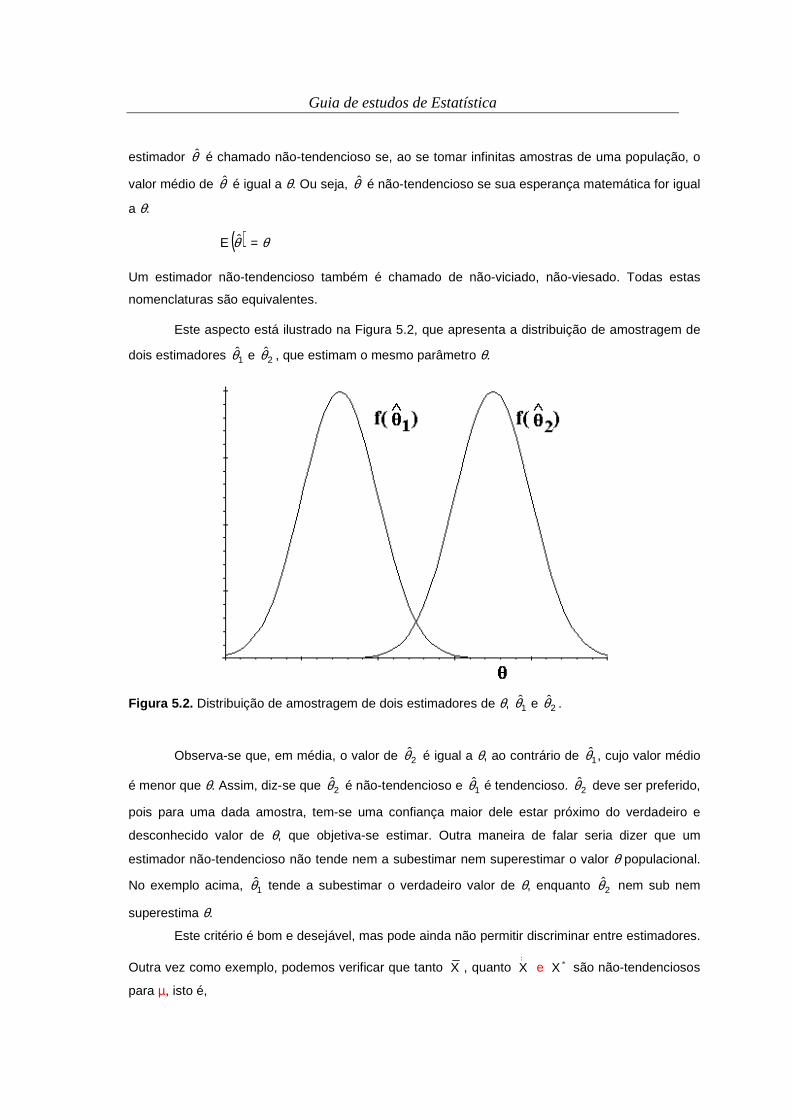
Guia de estudos de Estatística
estimador θ é chamado não-tendencioso se, ao se tomar infinitas amostras de uma população, o
valor médio de θ é igual a θ. Ou seja, θ é não-tendencioso se sua esperança matemática for igual
a θ:
E ( )θ = θ
Um estimador não-tendencioso também é chamado de não-viciado, não-viesado. Todas estas
nomenclaturas são equivalentes.
Este aspecto está ilustrado na Figura 5.2, que apresenta a distribuição de amostragem de
dois estimadores 1θ e 2θ , que estimam o mesmo parâmetro θ.
Figura 5.2. Distribuição de amostragem de dois estimadores de θ, 1θ e 2θ .
Observa-se que, em média, o valor de 2θ é igual a θ, ao contrário de 1θ , cujo valor médio
é menor que θ. Assim, diz-se que 2θ é não-tendencioso e 1θ é tendencioso. 2θ deve ser preferido,
pois para uma dada amostra, tem-se uma confiança maior dele estar próximo do verdadeiro e
desconhecido valor de θ, que objetiva-se estimar. Outra maneira de falar seria dizer que um
estimador não-tendencioso não tende nem a subestimar nem superestimar o valor θ populacional.
No exemplo acima, 1θ tende a subestimar o verdadeiro valor de θ, enquanto 2θ nem sub nem
superestima θ.
Este critério é bom e desejável, mas pode ainda não permitir discriminar entre estimadores.
Outra vez como exemplo, podemos verificar que tanto X , quanto :
X e *X são não-tendenciosos
para µ, isto é,
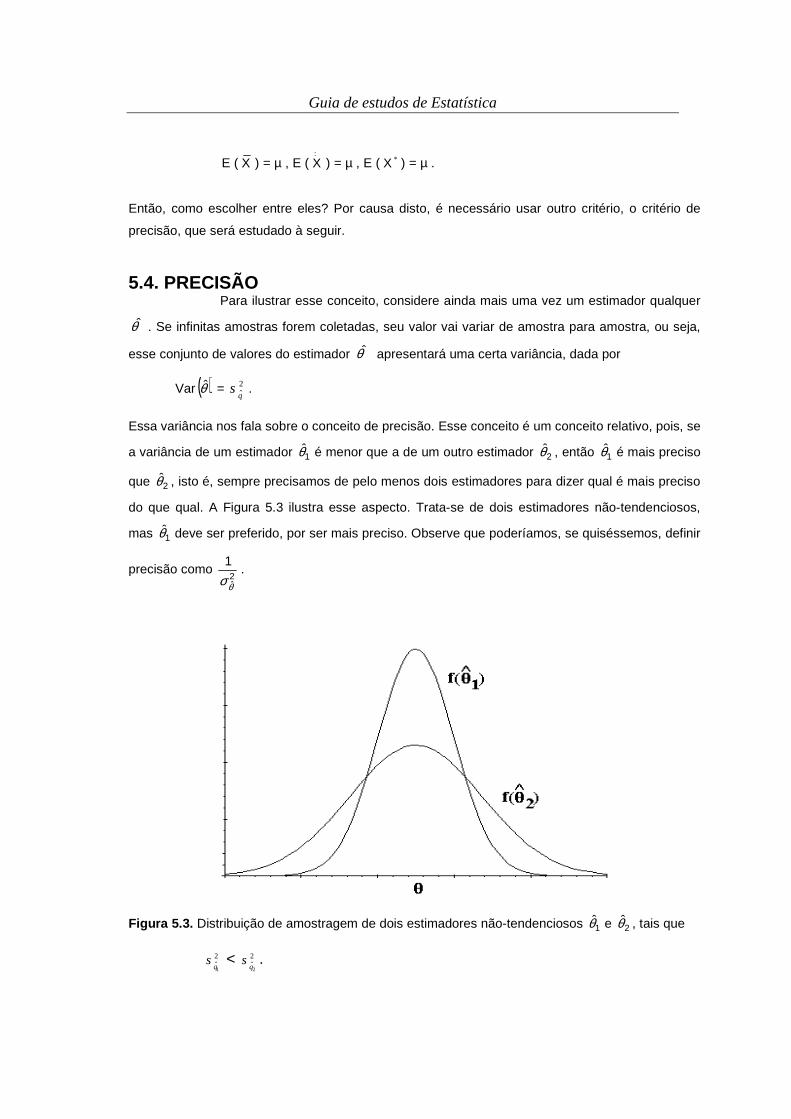
Guia de estudos de Estatística
E ( X ) = µ , E (:
X ) = µ , E ( *X ) = µ .
Então, como escolher entre eles? Por causa disto, é necessário usar outro critério, o critério de
precisão, que será estudado à seguir.
5.4. PRECISÃO Para ilustrar esse conceito, considere ainda mais uma vez um estimador qualquer
θˆ . Se infinitas amostras forem coletadas, seu valor vai variar de amostra para amostra, ou seja,
esse conjunto de valores do estimador θˆ apresentará uma certa variância, dada por
( )θVar = 2
qs .
Essa variância nos fala sobre o conceito de precisão. Esse conceito é um conceito relativo, pois, se
a variância de um estimador 1θ é menor que a de um outro estimador 2θ , então 1θ é mais preciso
que 2θ , isto é, sempre precisamos de pelo menos dois estimadores para dizer qual é mais preciso
do que qual. A Figura 5.3 ilustra esse aspecto. Trata-se de dois estimadores não-tendenciosos,
mas 1θ deve ser preferido, por ser mais preciso. Observe que poderíamos, se quiséssemos, definir
precisão como 2ˆ
1
θσ.
Figura 5.3. Distribuição de amostragem de dois estimadores não-tendenciosos 1θ e 2θ , tais que
1
2
qs <
2
2
qs .

Guia de estudos de Estatística
5.5. ESTIMADORES NÃO-TENDENCIOSOS E PRECISOS
A junção das duas propriedades, a de não-tenenciosidade e de precisão, é o ideal.
Estimadores θ com E( θ ) = θ e Var( θ ) pequena são os ideais. Estes são estimadores não-
tendenciosos com pequena variância. Quando encontramos um estimador não-tendencioso que
tem a menor variância possível dentre todos os estimadores não-tendenciosos, estes são
chamados MVUE, sigla em inglês para minimum variance unbiased estimator, estimadores não-
tendenciosos de variância mínima. Dada a média populacional µ, pode-se demonstrar que a média
amostral X é MVUE para µ. Em outras palavras, nada é melhor do que a média amostral X para
se estimar uma média populacional µ, mesmo que existam outros concorrentes (tais como a
mediana ou a moda). Nas próximas páginas, as figuras mostrarão de modo lúdico (ilustrando com
tiro-ao-alvo) o que seriam tais propriedades dos estimadores:
1. A “mosca” do alvo é o parâmetro populacional que se quer estimar, digamos a média µ
da população.
2. Cada “tiro” dado é uma estimativa feita, no caso o cálculo da média x . Observe que
estamos dando vários “tiros” para tentar acertar a “mosca”: isto equivale a retirar
muitas amostras de tamanho n de uma mesma população com média µ, e, em cada
uma, obtermos uma média x diferente. Cada uma dessas médias x serão diferentes
umas das outras (e todas quase certamente serão diferentes da média µ populacional).
Na prática, é claro, retiramos apenas uma amostra de tamanho n, e,
consequentemente, daremos um tiro somente, mas as figuras nos mostram o que
aconteceria se fizéssemos muitas amostragens, e como se comportariam as várias
estimativas. Obviamente, também, na prática, nunca sabemos onde está a “mosca”, já
que nunca conhecemos µ.
3. Há 6 figuras, sendo as 3 primeiras as mais desejadas, progressivamente, e as 3
últimas as indesejadas. Nestas 3 últimas figuras, vê-se como estimadores
tendenciosos podem ser muito inconvenientes, mesmo que sejam precisos.

Guia de estudos de Estatística
Estimador não-tendencioso, pouco preciso
Estimador não-tendencioso, médio preciso
Estimador não-tendencioso, muito preciso

Guia de estudos de Estatística
Estimador tendencioso, pouco preciso
Estimador tendencioso, médio preciso
Estimador tendencioso, muito preciso

Guia de estudos de Estatística
5.6. A NATUREZA DA ESTIMAÇÃO
A estimação por ponto, mesmo sendo feita por meio de um estimador não-tendencioso de
pequena variância (isto é, não-tendencioso e preciso), não resolve completamente o problema da
estimação. Ainda restam duas questões:
(i) Qual é o tamanho da confiança (probabilidade de estarmos certos) que podemos ter no
valor estimado quanto a ele ser igual ao valor do parâmetro? 90%? 10%? 95%? 99%?
Quanto?
(ii) Qual é o tamanho do erro cometido na estimação? (Este erro é medido por θ - θ ).
Podemos ajuntar essas duas questões em uma só questão: qual é a probabilidade de que
o erro absoluto de estimação | θ - θ | seja menor ou igual à um dado valor, digamos, c. Em
símbolos:
P (| θ - θ | ≤ c)
Como exemplo, considere o seguinte problema: uma amostra aleatória de n = 315 clientes
de uma provedora de Internet mostrou, que , em média, estes mantêm um uso de 118,1 MBytes de
memória ocupada com arquivos em sua caixa postal de emails, com um desvio-padrão amostral
igual à 189,7 MBytes. Qual seria o valor médio desta ocupação em todos os seus N = 114.337
clientes? A estimação por ponto dá o valor
µ = x = 118,1 MBytes
para a média desejada. Mas, além dessa estimativa pontual, gostaríamos de saber algo do tipo
abaixo:

Guia de estudos de Estatística
Valor do erro absoluto
| µ - µ |
Probabilidade do erro não superar
o valor ao lado
50 Mbytes
40 MBytes
30 MBytes
20 MBytes
10 MBytes
5 MBytes
1 MBytes
0,1 MBytes
? ? ? ? ? ? ? ?
Esse problema é resolvido, na Estatística, por meio do conceito de intervalos de confiança (IC), ou,
equivalentemente, estimação por intervalo.
Assim posto, vemos que existem, então, dois tipos de estimação: por ponto e por intervalo.
Quando simplesmente se obtém um só valor de estimativa para um parâmetro, diz-se que se trata
de uma estimação por ponto, ou pontual. No entanto, como temos dito, quase sempre a estimação
por ponto, sozinha, é pouco informativa, porque ela não fornece uma idéia do grau de erro e de
confiança que se comete ao assumir o valor da estimativa como sendo igual ao do parâmetro
desconhecido. Esse erro e confiança podem ser quantificados da seguinte forma. A partir da
distribuição de amostragem dos estimadores é possível elaborar um intervalo [a, b], de tal maneira
que a probabilidade de que uma dada amostra contenha o verdadeiro valor do parâmetro
desconhecido seja conhecida eestabelecida, ou seja:
P[a < θ < b] = α−1
onde θ é o parâmetro sendo estimado. A probabilidade α−1 mede o grau de confiança que se tem
na estimação de θ, e é, portanto, chamada de coeficiente de confiança. O intervalo [a, b] é
denominado intervalo (IC) de confiança, e a sua elaboração é chamada de estimação por intervalo.
Um intervalo de confiança pode ser interpretado segundo os seguintes argumentos:
(i) Se muitas e muitas amostras fossem coletadas, e, para cada uma dessas amostras
fosse constituído um IC, então uma proporção de ( α−1 ).100% destes IC conteriam o
verdadeiro valor θ do parâmetro sendo estimado.

Guia de estudos de Estatística
(ii) Um dado IC para o parâmetro desconhecido θ tem probabilidade ( α−1 ). 100% de
conter o verdadeiro valor de θ . Em outras palavras, um IC tem ( α−1 ). 100% de
probabilidade de estar “correto”.
Os tópicos que se seguem referem-se à estimação dos principais parâmetros de interesse.
5.7. ESTIMAÇÃO POR PONTO DE µµµµ E σσσσ2
O procedimento para se estimar a média e a variância populacionais varia conforme o tipo
de amostragem empregado. Nesse tópico será visto como proceder quando a amostragem é
aleatória simples. Neste caso, o parâmetro µ pode ser estimado pela média amostral, ou seja, pelo
estimador:
µ = X = n
xn
ii∑
=1
Pode-se demonstrar, como já dito, que esse estimador é não-tendencioso e, além disso, dentre os
não tendenciosos possíveis, é o de maior precisão (mínima variância). Este é o estimador
recomendado tanto para populações finitas como infinitas.
No tocante a σ2, seu estimador é dado por:
S2 = 1
1−n
. ( )∑=
−n
ii xx
1
2
Esse é o estimador para 2σ que vamos usar, seja a população finita ou infinita, pois S2 é não-
tendencioso e de variância mínima. Alguns autores, porém, advogam a possibilidade de uso de um
outro estimador, a saber:
D2 = n1
. ( )∑=
−n
ii xx
1
2
Esse estimador alternativo tem sua existência justificada pelo argumento de que ele é de máxima
verossimilhança, isto é, “de valor mais provável”. Porém, pode-se demonstrar que D2 é tendencioso
(não é exato), levando a subestimativas de 2σ . Essa deficiência de D2 é que nos faz escolher S2
para estimar 2σ .

Guia de estudos de Estatística
5.8. ESTIMAÇÃO POR INTERVALO PARA A MÉDIA µµµµ
Nesta seção será abordada a estimação por intervalo para µ, quando a amostra é do tipo
aleatória simples tomada em uma população infinita ou finita muito grande (que equivale, na
prática, a infinita). Utilizaremos o conceito de distribuição de amostragem, que é a distribuição de
probabilidade de uma variável aleatória definida sobre as amostras retiradas em uma dada
população.
Para a construção de um intervalo de confiança para µ é conveniente estudar distribuições
de amostragem associadas a seu estimador pontual X . Para tanto, existem alguns teoremas, para
casos onde a população pode ser descrita por uma distribuição Normal, que são úteis. Passemos à
conhecê-los.
Teorema 5.1
Seja uma população descrita por uma variável X com distribuição Normal N(µ, σ2). Se infinitas
amostras de tamanho n são coletadas nessa população, então a média X dessas amostras terá
distribuição Normal com média µ e variância σ2/n. Outra maneira de afirmar esta normalidade de
X é dizer que a variável Z =
n
Xσ
µ− tem distribuição Normal com média 0 e variância 1 (esta é a
Normal-padrão, vista no Capítulo 3).
Observe que, neste teorema acima, a variância populacional σ2 deve ser conhecida,
podendo-se então utilizar diretamente este teorema para calcular probabilidades associadas a X ,
pois, se:
X ∼ N
n
2
,σµ
então, sabe-se que a variável:
Z =
n
Xσ
µ− ∼ N ( )1,0 , isto é,
Z tem distribuição Normal com média 0 e variância 1, como já dito.
Entretanto, é muito pouco provável que, em uma situação real, σ2 seja conhecida. Assim,
faz-se necessário o uso do próximo teorema:
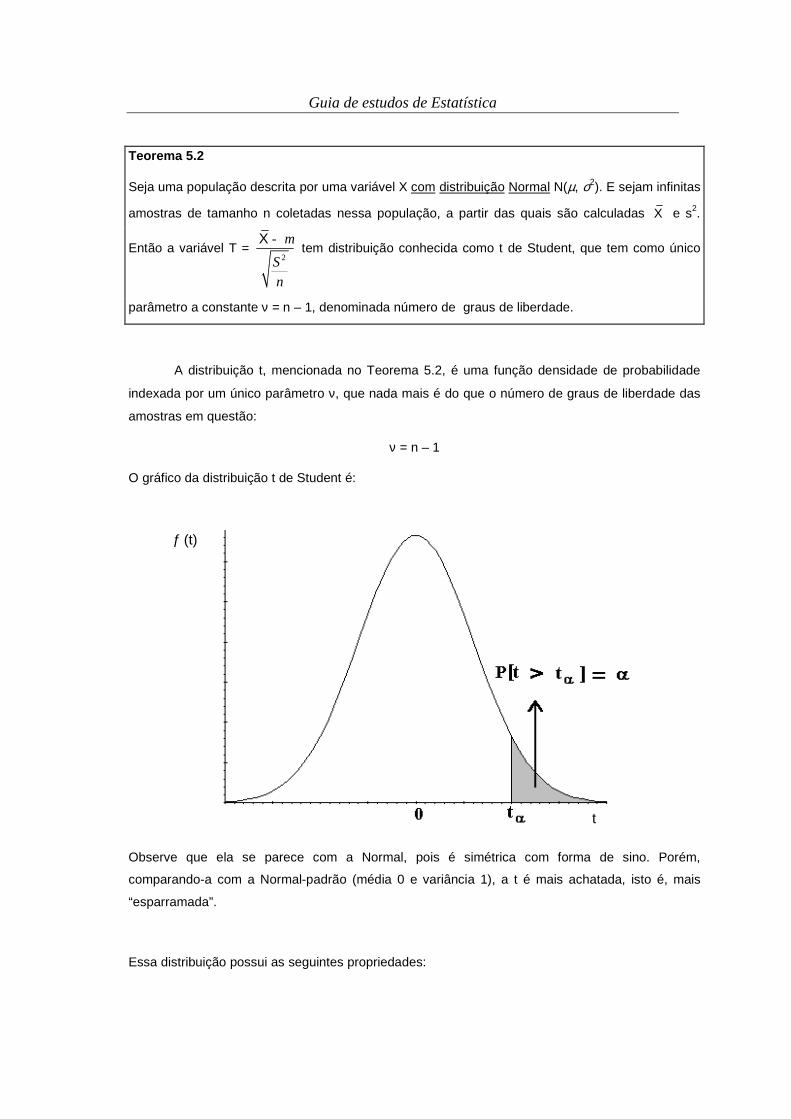
Guia de estudos de Estatística
Teorema 5.2
Seja uma população descrita por uma variável X com distribuição Normal N(µ, σ2). E sejam infinitas
amostras de tamanho n coletadas nessa população, a partir das quais são calculadas X e s2.
Então a variável T = 2S
n
m-X tem distribuição conhecida como t de Student, que tem como único
parâmetro a constante ν = n – 1, denominada número de graus de liberdade.
A distribuição t, mencionada no Teorema 5.2, é uma função densidade de probabilidade
indexada por um único parâmetro ν, que nada mais é do que o número de graus de liberdade das
amostras em questão:
ν = n – 1
O gráfico da distribuição t de Student é:
Observe que ela se parece com a Normal, pois é simétrica com forma de sino. Porém,
comparando-a com a Normal-padrão (média 0 e variância 1), a t é mais achatada, isto é, mais
“esparramada”.
Essa distribuição possui as seguintes propriedades:
ƒ (t)
t

Guia de estudos de Estatística
i) A média da variável T, ou seja, a esperança E(T), é igual a zero, da mesma forma que a
variável Z.
ii) É semelhante à distribuição Normal, pois é simétrica em relação à média e tem forma
campanular (sino).
iii) A distribuição t é definida a partir de um único parâmetro, o número ν de graus de
liberdade.
Na Tabela 2 do Apêndice, apresentam-se os valores tabelados para a distribuição t, para
valores fixos de probabilidade (simbolizados por α) e de maneira que:
P[T > tα] = a
onde tα corresponde a valores tabelados (ver Figura 5.4). Esses valores tα são chamados quantis
da distribuição t, e são correspondentes as áreas a . Para ficarmos com a notação conforme a
convenção universal, mudaremos a notação de α para α/2.
Deve-se notar que, da mesma maneira que a variável Z, a distribuição de t é simétrica e
assim teremos
P[T > tα] = P[T < - tα] =α
o que facilita sobremaneira o cálculo de probabilidades.
Finalmente, tendo definida a distribuição t, é possível agora construir um intervalo de
confiança para o parâmetro µ que não necessita do desvio-padrão σ populacional. Como visto, a
tais intervalos é associado um coeficiente de confiança γ = 1 - α tal que:
P[a < µ < b] = 1 - α = γ
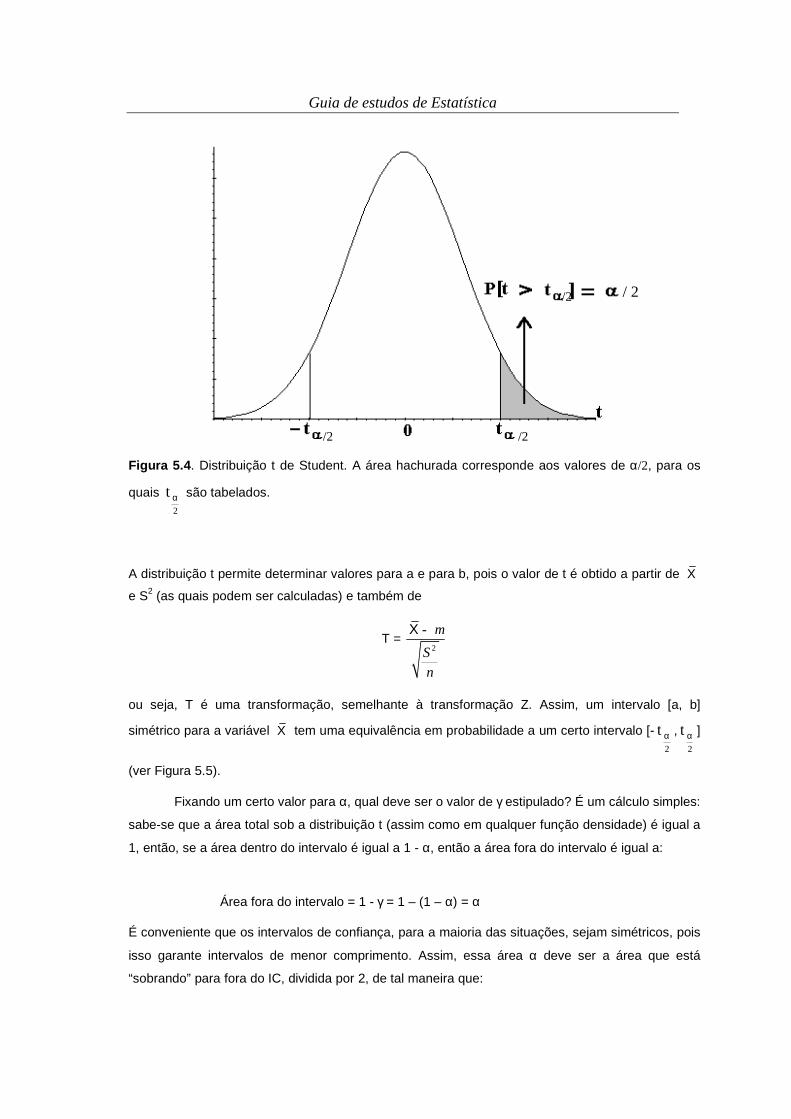
Guia de estudos de Estatística
Figura 5.4 . Distribuição t de Student. A área hachurada corresponde aos valores de α/2, para os
quais 2
t α são tabelados.
A distribuição t permite determinar valores para a e para b, pois o valor de t é obtido a partir de X
e S2 (as quais podem ser calculadas) e também de
T = 2S
n
m-X
ou seja, T é uma transformação, semelhante à transformação Z. Assim, um intervalo [a, b]
simétrico para a variável X tem uma equivalência em probabilidade a um certo intervalo [-2
t α ,2
t α ]
(ver Figura 5.5).
Fixando um certo valor para α, qual deve ser o valor de γ estipulado? É um cálculo simples:
sabe-se que a área total sob a distribuição t (assim como em qualquer função densidade) é igual a
1, então, se a área dentro do intervalo é igual a 1 - α, então a área fora do intervalo é igual a:
Área fora do intervalo = 1 - γ = 1 – (1 – α) = α
É conveniente que os intervalos de confiança, para a maioria das situações, sejam simétricos, pois
isso garante intervalos de menor comprimento. Assim, essa área α deve ser a área que está
“sobrando” para fora do IC, dividida por 2, de tal maneira que:
/2
/2
/2
/ 2
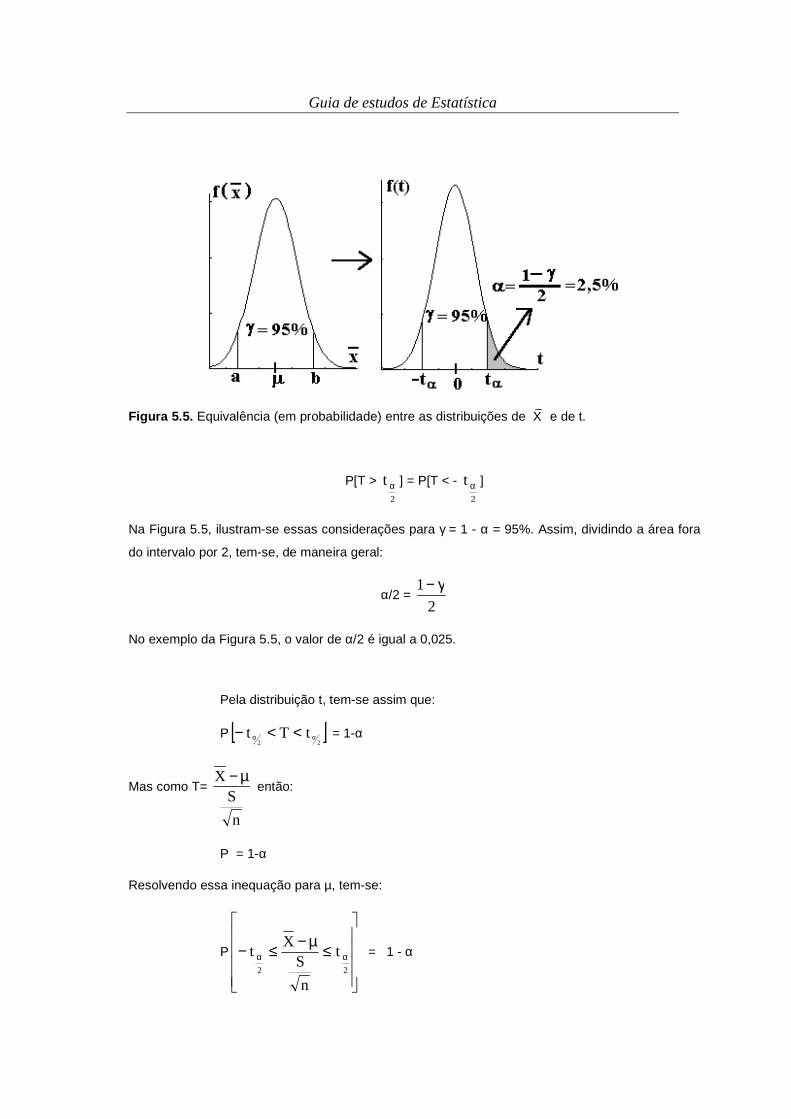
Guia de estudos de Estatística
Figura 5.5. Equivalência (em probabilidade) entre as distribuições de X e de t.
P[T > 2
t α ] = P[T < - 2
t α ]
Na Figura 5.5, ilustram-se essas considerações para γ = 1 - α = 95%. Assim, dividindo a área fora
do intervalo por 2, tem-se, de maneira geral:
α/2 = 2
1 γ−
No exemplo da Figura 5.5, o valor de α/2 é igual a 0,025.
Pela distribuição t, tem-se assim que:
P [ ]22
tTt αα <<− = 1-α
Mas como T=
n
SX µ−
então:
P = 1-α
Resolvendo essa inequação para µ, tem-se:
P
≤µ−≤− αα22
t
n
SX
t = 1 - α

Guia de estudos de Estatística
P
≤µ−≤− αα
n
StX
n
St
22
= 1 - α
P
+−≤µ−≤−− αα
n
StX
n
StX
22
= 1 - α
P
+≤µ≤− αα
n
StX
n
StX
22
= 1 - α
Como os intervalos de confiança para µ têm a forma geral:
P[a < µ < b] = 1 - α
tem-se então uma maneira de se determinar a e b, a partir da distribuição t, fazendo:
a = 2
2St
na-X b =
2
2St
na+X
Será apresentado a seguir um exemplo numérico. Suponha-se que um engenheiro agrícola
precisa determinar a velocidade de infiltração básica (VIB) de um solo de uma grande várzea, para
um projeto de irrigação. Para tanto, ele represa água em sulcos de comprimentos de 1m (este
método é conhecido como “Infiltrômetro de sulco”). Como se trata de uma grande várzea, para
representar bem a sua VIB, o engenheiro faz essa medição em 10 diferentes pontos de diferentes
sulcos tomados ao acaso na várzea utilizando uma Amostragem Aleatória Simples. Suponha-se
que os resultados (em cm.h-1) tenham sido os seguintes:
x1 = 0,8 x2 = 0,7 x3 = 0,8 x4 = 0,9 x5 = 1,0
x6 = 0,9 x7 = 0,8 x8 = 1,1 x9 = 0,8 x10 = 0,7
Esses dados correspondem a uma amostra com n = 10 elementos da população formada pelos
infinitos pontos no solo da várzea. Pressupondo que a VIB, nesses infinitos pontos, possa ser
descrita por uma distribuição Normal N(µ, σ2), onde µ e σ2 são desconhecidos, o objetivo do
engenheiro agrícola é o de estimar o parâmetro µ (ou seja, a VIB média do solo), para que se
possa determinar fatores importantes do projeto de irrigação, como vazão, turno de rega, entre
outros. Assim, a estimativa por ponto é feita pela média amostral, que é o estimador adequado
para µ:
$µ = x = 0,85 cm.h-1

Guia de estudos de Estatística
Como foi pressuposta uma distribuição Normal para a VIB, é possível construir um
intervalo de confiança para µ a partir da distribuição t. Inicialmente, é necessário calcular a
variância amostral:
s2 = 0,0161 (cm.h-1)2 = ( ) ( ) ( )
11085,07,0 ... 85,07,085,08,0 222
−−++−+−
E, assim, como:
P
+<µ<− αα
n
stx
n
stx
22
22 = 1-α
então:
P
+<<−
100161,0
85,0100161,0
85,022
αα µ tt = 1-α
Utilizando um coeficiente de confiança de 1 - α = 0,95, tem-se que:
2α
= 2
95,01− = 0,025
Consultando a tabela de t (ver Tabela 2 do Apêndice) para 2α
= 0,025 e com um número de graus
de liberdade igual a (10 - 1) = 9, tem-se o valor:
t0,025 = 2,262
e assim:
a = 100161,0
262,285,0 − = 0,85 - 0,0908 = 0,7592
b = 100161,0
262,285,0 + = 0,85 + 0,0908 = 0,9408
Portanto, o intervalo de confiança [0,7592 , 0,9408] é tal que:
P[0,7592 < µ < 0,9408] = 0,95 = 95%
A interpretação desse intervalo é:
(i) A média da VIB na várzea (µ) é um número desconhecido, pois não inspecionamos
todos os pontos da várzea, fazendo a medição em apenas uma amostra de n = 10
pontos, mas, estimamos que essa média, apesar de desconhecida, está entre 0,7592

Guia de estudos de Estatística
cm.h-1 e 0,9408 cm.h-1, com uma probabilidade de acerto de 95%, isto é, estamos
“95% certos” de que a VIB média não é menor do que 0,7592 cm.h-1 e não é maior do
que 0,9408 cm.h-1.
(ii) Se fizermos muitos e muitos intervalos nessa várzea (cada um baseado numa diferente
amostra de 10 pontos), então, aproximadamente 95% destes intervalos conterão a
verdadeira média VIB.
É pertinente agora uma observação: a grandeza
n
s 2
= n
s
utilizada na construção de intervalos de confiança para µ, a partir de amostras de tamanho n, dá
uma idéia da precisão com que o parâmetro é estimado. Ou seja, quanto menor essa grandeza,
menor será o comprimento do intervalo de confiança. Na realidade, ela corresponde a estimativa
do desvio padrão da variável X . Esse desvio padrão recebe o nome especial de erro-padrão da
média.
Conceito 5.5. Erro-padrão da Média . Desvio-padrão da variável X . O erro-padrão é o desvio-
padrão da média amostral e confere uma idéia acerca da precisão com que µ é estimada.
Esse erro-padrão da média é utilizado dentro de um IC como informação para o cálculo do
intervalo para a média, e fora do IC é utilizado como informação a respeito do grau de precisão
com que podemos confiar uma dada estimativa para a média.
5.9. ESTIMAÇÃO POR INTERVALO DA MÉDIA µµµµ PARA POPULAÇÕES NÃO-NORMAIS
O leitor deve ter percebido a importância de se assumir que a população amostrada tenha
distribuição Normal para a construção de intervalos de confiança, principalmente pelo Teorema
5.2, que torna possível a utilização da distribuição t. Mas, e se a população não for Normal? Nesse
caso, serão consideradas duas situações, a seguir apresentadas:
a) A amostra é grande (n elevado, acima de 30, adequado em muitas situações, ou mais ainda,
acima de 50).
Se a amostra possui um elevado número de elementos, então o seguinte teorema pode ser
utilizado:

Guia de estudos de Estatística
Teorema 5.3 (Teorema Central do Limite). Seja uma população qualquer, com média µ e variância
σ2. Se infinitas amostras grandes de tamanho n suficientemente grande são coletadas nessa
população, então a média X dessas amostras terá distribuição aproximadamente Normal, com
média µ e variância σ2/n, melhorando esta aproximação à medida que n tende ao infinito.
O teorema 5.3 acima, conhecido como o Teorema Central do Limite, poderia, se σ2 fosse
conhecido, ser diretamente empregado para a construção de intervalos de confiança, pois sabe-se
que:
Z =
n
Xσ
µ−
tem distribuição Normal N(0, 1) e com valores tabelados. Dessa maneira, pode-se fazer:
P
+<<−
nzx
nzx
22
22
σµσαα = 1-α
oriunda de uma manipulação algébrica muito semelhante à que foi vista para a distribuição t.
No entanto, quase sempre a variância populacional σ2 é desconhecida. Devemos então
substituir z por t, já que substituímos σ2 por s2. Resta ainda a questão: quando consideraremos n
como grande? Para responder a essa questão, consideraremos, aqui, o critério empírico de n ≥ 50.
Com isso, um intervalo de confiança aproximado é dado por:
P
+<<−
ns
txn
stx
22
22αα µ ≅ 1-α
b) A amostra é pequena e a população não é Normal.
Nesses casos, a distribuição t não fornece boa aproximação e, então, estudos sobre a
distribuição da população devem ser feitos, para se determinar modelos probabilísticos que
descrevam adequadamente a população. Em seguida, distribuições de amostragem exatas devem
ser obtidas e os intervalos de confiança devem ser baseados nelas.
Aqui não serão estudados tais casos, que são mais bem colocados em disciplinas
avançadas.

Guia de estudos de Estatística
5.10. ESTIMAÇÃO DE PROPORÇÕES
Um parâmetro para o qual frequentemente tem-se muito interesse é a proporção “p” dos
indivíduos de uma população que guardam alguma característica de interesse. Como exemplos,
tem-se a proporção de eleitores simpatizantes de um candidato, proporção de agricultores que
comprariam um novo insumo agrícola, de árvores doentes em um povoamento, de peças
defeituosas num pomar de produção, entre outros. Na realidade, a menos que se conheça toda a
população, em geral p não é conhecido. Nesse caso, uma amostra aleatória simples (AAS) poderia
ser coletada, de maneira a possibilitar a estimação de p. Supondo que, dos n indivíduos
amostrados, x deles apresentam a característica de interesse, então, o estimador por ponto de p é
igual a:
p = nx
E a estimação por intervalo? Uma solução consiste na construção de um intervalo de
confiança aproximado, utilizando a aproximação da distribuição Normal. Admitindo que a
aproximação Normal é satisfatória, intervalos de confiança aproximados podem ser construídos
mediante a distribuição de Z:
+<<−
nqp
zppnqp
zpPˆˆ
ˆˆˆ
ˆ 2/2/ αα = 1 - α
onde zα/2 é um valor da Tabela de Z tal que:
P[Z > zα/2] = α/2
Outro motivo pelo qual o intervalo acima seja apenas aproximado é o de que o termo:
( )pσ = npq
que corresponde ao erro padrão da proporção, está sendo estimado por:
( )pσ = nqp ˆˆ
Como exemplo, considere um exemplo de um administrador que tenha que selecionar
mão-de-obra para a safra de uma cultura cultivada em sua empresa rural e para tanto ele iria
avaliar 60 candidatos na região. Suponha que ele tenha, dentre os 60 candidatos, encontrado 38
aptos. A estimativa por ponto de verdadeira proporção p depessoas aptas em toda a região é:
p = nx
= 38
60 = 0,63

Guia de estudos de Estatística
e assim q = (1 - p ) = 1 - 0,63 = 0,37
O erro padrão da proporção é estimado como:
( )pσ = nqp ˆˆ
= 60
37,0.63,0 = 0,06
E assim o intervalo de confiança com 95% de confiança é dado por:
[ ]06,063,006,063,0 025,0025,0 zpzP +<<− = 0,95
O valor de z correspondente é igual a z0,025 = 1,960 (valor de z correspondente à probabilidade
0,475 na Tabela 1.1 do Apêndice). E assim:
[ ]12,063,012,063,0 +<<− pP = 0,95
[ ]75,051,0 << pP = 0,95
Ou seja, a proporção de candidatos, na região, aptos ao serviço está entre 0,51 e 0,75 , com 95%
de confiança.
5.11. DIMENSIONAMENTO DE AMOSTRAS
No dimensionamento do tamanho de amostras para estimação de proporções, utiliza-se o
termo
nqp
zˆˆ
2/α
Que fornece, no intervalo de confiança, a margem de erro (para cima ou para baixo) em relação ao
verdadeiro valor de p, desconhecido. Note-se que, se p fosse conhecido, a variância pq/n também
seria conhecida, e assim a margem de erro utilizando a variável Z seria ainda mais apropriada:
npq
z 2/α
admitindo, é claro, a aproximação Normal como satisfatória.
Pode-se facilmente demonstrar, utilizando o conceito de derivada, que o produto pq atinge
o valor máximo quando p = q = 0,5. Nesse caso, a margem de erro será máxima. Em pesquisas
eleitorais, por exemplo, é frequente a necessidade do conhecimento do tamanho da amostra n que
deve ser utilizado para que a margem de erro seja de, por exemplo, 2 pontos percentuais, ou 2% =
0,02. Para tanto, basta considerar a pior situação possível (quando p = q =0,5). Por exemplo,
utilizando um coeficiente de confiança de 95%, o valor de z0,025 é igual 1,96. Estipulando a margem
de erro como sendo 2%, então:

Guia de estudos de Estatística
npq
z 2/α = 0,02
1,96n
5,0.5,0 = 0,02
Resolvendo esta equação, tem-se:
(1,96)2
n25,0
= (0,02)2
E assim:
n = 2
2
)02,0(
25,0)96,1( = 2401
Ou seja, seria necessário entrevistar 2401 eleitores para uma pesquisa eleitoral com margem de
erro igual a 2%. Em geral, na divulgação dessas pesquisas, não se fala nada a respeito do
coeficiente de confiança, o que deveria ser feito.
No dimensionamento do tamanho de amostras para estimação de médias, será
considerado o caso de estimação da média por intervalo. Dessa forma:
+<<−
ns
txn
stxP
2
2/
2
2/ αα µ = 1 - α
O termo:
n
st
2
2/α = d
é a margem de erro da amostragem. Se uma estimativa preliminar s2 for disponível (por exemplo,
utilizando uma amostra-piloto), então o dimensionamento da amostra seria dado por:
n = 2
222/
d
stα
A título de ilustração, considere o exemplo do engenheiro agrícola que deseja estimar a
VIB de um solo de várzea. Suponha que ele deseja uma margem de erro igual a:
d = 0,07 cm.h-1 , isto é, ele não admite errar mais do que 0,07 cm.h-1 nesta estimação.
Tendo ele composto uma amostra-piloto com 5 elementos é possível obter uma estimativa
preliminar da variância igual a s2 = 0,0200 (cm.h-1)2. O tamanho de amostra adequado com 1 - α =
95% de não se ter uma margem de erro maior que 0,07 é dado por:

Guia de estudos de Estatística
n = ( )2
22/
07,0
0200,0αt = ( )2
2025,0
07,0
0200,0t
O valor de t consultado deve ser aquele correspondente à amostra-piloto, ou seja, com (5 - 1) = 4
graus de liberdade, e assim obtém-se t0,025 = 2,776. Com isso:
n = ( )2
2025,0
07,0
0200,0t ≅ 32 elementos
Isto quer dizer que o engenheiro deverá utilizar uma amostragem com 32 pontos na várzea. Com
estes 32 pontos, sua estimativa de média não diferirá da verdadeira média em mais de 0,07 cm.h-1:
( x - µ) ≤ 0,07 cm.h-1.
5.12. EXERCÍCIOS RESOLVIDOS 1) Foi feito um levantamento na região do sul de Minas Gerais por meio de uma amostra aleatória,
anotando-se as propriedades rurais onde os pecuaristas fazem a vacinação do rebanho para
prevenção da raiva bovina. Constatou-se que das 213 propriedades visitadas, 129 delas vacinaram
os seus rebanhos nos últimos dois anos.
a) Estime a proporção dos produtores da região que vacinam seus rebanhos contra a raiva.
Temos que n = 213 e x = 129, assim:
%606,0213129ˆ ====
nx
p
Portanto, a proporção dos produtores que vacinam seus rebanhos é de 60%.
b) Construa o intervalo de confiança de 95% para a proporção p da população.
IC (95%) ⇒ ep ± sendo que nqp
Ze α/2= , portanto:
IC (95%) ⇒ 213
4,0.6,096,16,0 ±
IC (95%) ⇒ 07,06,0 ±
IC (95%) ⇒ 0,53 < p < 0,67
c) Qual é o erro da estimativa para a estimação de p com 90% de confiança?
Com o valor tabelado de z para 90%(1,645) é só calcular o novo erro:
0,055213
0,4.0,61,645
nqp
ze α/2 ===
d) Quantas propriedades deverão ser visitadas no futuro para se estimar p com um erro de 3% e
confiança de 95%?
Aqui podemos utilizar uma fórmula com o “n” já isolado para facilitar os cálculos:

Guia de estudos de Estatística
102543,102403,0
4,0.6,096,1
ˆˆ2
22
22
≅=
=
×=
e
qpzn α
Portanto, para se estimar a proporção dos produtores rurais que vacinam seus rebanhos com erro
de 3% e nível de confiança de 95%, deveremos visitar 1025 propriedades.
2) Determine o intervalo com 90% de confiança para a seguinte situação.
Dados: 0,20x = 5,1sX = n = 25
0,513320,025
1,51,71120,0
n
stx Xα/2
±
±
±
Assim:
IC(90%)⇒ 19,487 < µ < 20,5133
3) Determine um intervalo de confiança de 98% para a verdadeira proporção populacional, se x =
50 e n = 200.
25,020050ˆ ===
nx
p
Construindo o intervalo:
0,070,25200
0,75.0,252,330,25
nqp
Zp α/2
±
±
±
IC(98%)⇒ 0,18 < p < 0,32
4) Numa Universidade, foi tomada uma amostra de 40 estudantes, anotando-se as suas alturas em
cm. Os resultados forneceram:
950.640
1
=∑=i
ix ∑=
=40
1
2 463.213.1i
ix
a) Encontre as estimativas por ponto de µ e de σ .
Calculando a média da amostra:
cm 1
73,75
40
6.950
n
xx
40
1ii
)===∑
= =

Guia de estudos de Estatística
Calculando o desvio padrão da amostra:
cms
n
x
xn
s ii
ii
30,12
cm 29,15140950.6
463.213.1140
11
1 22
240
140
1
22
=
=
−
−=
−−
=∑
∑ =
=
b) Construa o intervalo de confiança de 95% para a média da população. Interprete.
IC(µ )95%⇒ ex ±
Deveríamos usar a estatística t, pois estamos usando s, o desvio-padrão da amostra. Alguns
autores propõem que, para n>30, a estatística t pode ser aproximada pela estatística z. Usando
então esta aproximação:
3,81173,7540
12,301,96173,75
n
szx α/2
±
±
±
IC(µ )95%⇒ 169,94 < µ < 177,56
Com confiança de 95%, podemos afirmar que a verdadeira média da população se encontra
inserida entre 169,94 e 177,56.
Obs. Você mesmo pode fazer este IC com a t para 40-1 = 39 graus de liberdade, e verificar se há
grande diferença. Você verá que não há.
c) Construa o intervalo de confiança de 99% para a média da população. Interprete.
IC(µ )99%⇒ ex ±
Usando a aproximação da z:
0,575,17340
30,1252,57173,75
n
szx α/2
±
±
±
IC(µ )99%⇒ 168,75 < µ < 178,75
Com confiança de 99%, podemos afirmar que a verdadeira média da população se encontra
inserida entre 168,75 e 178,75.
d) Confronte os resultados de (a) e (b) e discuta as diferenças.
Observemos os dois intervalos:
IC(µ )95%⇒ 169,94 < µ < 177,56 ⇒ Amplitude intervalar de 7,62
IC(µ )99%⇒ 168,75 < µ < 178,75 ⇒ Amplitude intervalar de 10,00

Guia de estudos de Estatística
Pode-se perceber que quanto maior é a confiança exigida, maior a amplitude do intervalo de
confiança. Assim, grau de confiança e amplitude intervalar são diretamente proporcionais.
e) Quantos estudantes seriam necessários para num próximo estudo estimar a média da
população com 95% de confiança e um erro 10% menor que o do item (b).
O erro no item (b) é 3,81%, como queremos um erro 10% menor, temos que:
43,3)1,081,3(81,3 =×−=e
Agora com o erro 10% menor já definido, calculamos o tamanho da nova amostra:
5049,403,43
12,301,96e
szn
22α/2 ≅=
×=
×=
Portanto, para estimarmos a média da população com 95% de confiança e um erro 10% menor, o
tamanho da nova amostra deverá ser de 50 estudantes.
5.13. EXERCÍCIOS PROPOSTOS
1) Uma empresa responsável pelos pedágios de uma estrada fez recentemente uma pesquisa
sobre as velocidades desenvolvidas no período das 22 às 24 horas. No período de observação,
100 carros passaram por um aparelho de radar a velocidade média de 140 k.h-1, e desvio-padrão
de 30 k.h-1.
a) Estime a verdadeira média populacional
b) Construa um intervalo de confiança de 95% para a média populacional
2) Num concurso de produtividade de milho realizado na cidade de Lavras – MG, foram sorteadas
12 parcelas de 40m 2 na lavoura de um produtor local. Após a colheita, os fiscais pesaram as
produções das parcelas obtendo os seguintes resultados em kg:
24 26 25 27 33 32
27 26 24 23 25 27
a) O produtor em questão afirma que na sua lavoura, o rendimento médio é da ordem de 7,5
t.ha-1. Você concorda com a afirmação do produtor? Trabalhe com um coeficiente de confiança
de 95% e justifique sua resposta. Observe que os dados das parcelas estão expressos em
kg.40m-2 e a afirmativa do produtor é feita em t.ha-1. Para compará-las, é necessário que os
dados estejam na mesma grandeza. A sugestão é que os dados das produções das parcelas
sejam transformados para t.ha-1, utilizando o fator de correção:
1. 25,0004,0001,0 −= hat
hat

Guia de estudos de Estatística
b) Qual deverá ser o tamanho da amostra para se estimar o rendimento médio com um erro de
0,1 t.ha-1com confiança de 95%?
c) Qual deverá ser o tamanho da amostra para se estimar o rendimento médio com um erro de
0,1 t.ha-1 com coeficiente de confiança de 99%?
3) Um pecuarista se entusiasmou por nova ração amplamente divulgada pelos meios de
comunicação. Para verificar a eficiência da ração, ele selecionou uma AAS de 49 bois de seu
rebanho e os alimentou por 30 dias, obtendo um ganho de peso médio de 31,7 kg com um desvio-
padrão de 2,6 kg.
a) Construa o intervalo de confiança de 95% para a média e interprete.
b) Qual deverá ser o tamanho da amostra para que o erro não seja superior a 0,7 kg com
probabilidade de 95%.
4) Determine o intervalo de confiança com 95% para a seguinte situação:
0,15=x 0,2=Xs n = 16
5) Num levantamento amostral sobre hábitos de higiene e saúde envolvendo bairros da periferia da
cidade de Lavras – MG, foram obtidas as seguintes respostas à pergunta: “Com qual frequência
você lava sua caixa d’água?”
Resposta Frequência
Absoluta Relativa Percentual
Nunca De 3 em 3 meses De 6 em 6 meses
Anual Raramente
13 11 4
22 18
0,1912 0,1618 0,0588 0,3235 0,2647
19,12 16,18 5,88
32,35 26,47
Total 68 1,0000 100,00
Considerando que o ideal seria que as caixas d’água fossem lavadas exatamente de 6 em 6
meses, construa um intervalo com 95% de confiança para a proporção de residências que estão
fora da condição ideal de higiene para as caixas d’água.
6) Foi feita uma AAS de tamanho n=30 de um rebanho de Gado Holandês do sul de Minas Gerais,
com o objetivo de descrever a produção de leite. Os dados obtidos em kg na amostra foram:
17,7 20,7 19,3 19,3 18,0 16,9 19,7 20,1 21,0 21,2
23,3 15,3 23,7 18,8 25,2 18,0 22,8 21,1 18,8 25,9
19,3 19,6 26,6 14,3 19,7 32,7 14,1 16,8 19,7 19,3

Guia de estudos de Estatística
9,608x30
1ii =∑
= ∑
=
=30
1
2 07,787.12i
ix
a) Estime a média e variância da população
b) Estime a proporção dos animais que produzem menos que 20 kg de leite
c) Construa o intervalo de confiança para a média do rebanho com coeficiente de confiança de
95%.
7) Uma pesquisa realizada entre 218 eleitores escolhidos ao acaso indicou que 65 deles eram
favoráveis ao candidato A.
a) Construa um intervalo de confiança de 95% para a proporção de todos os votantes
favoráveis ao candidato A. Interprete.
b) Qual deve ser o tamanho da amostra para que o erro de estimação caia pela metade?

Guia de estudos de Estatística
UUNNIIDDAADDEE 66
TTEESSTTEESS EESSTTAATTÍÍSSTTIICCOOSS
6.1. INTRODUÇÃO
Por meio de amostragem, informações acerca de uma população de interesse são obtidas,
a partir de uma amostra. O passo seguinte é o de generalizar estas informações para a população.
Essa generalização é a inferência. Na unidade anterior foi vista uma maneira pela qual a inferência
estatística pode ser feita, qual seja, a estimação de parâmetros desconhecidos da população.
Algumas vezes, no entanto, o interesse do pesquisador reside na verificação da validade, ou não,
de uma determinada hipótese, frequentemente com a finalidade de tomar alguma decisão acerca
da população estudada.
Como exemplo, considere o cenário em que o gerente de produção de café em uma
agroindústria designa alguém para vistoriar a população de plantas de café com relação ao ataque
de uma praga, como, por exemplo, a broca do cafeeiro. Seu objetivo principal é o de saber se a
infestação desse inseto ultrapassa um nível de controle acima do qual ocorre prejuízo econômico.
Ele deseja, assim, verificar a validade, ou não, da seguinte hipótese:
HIPÓTESE: “A infestação da broca está abaixo do nível de controle”.
Se ele tiver razões para rejeitar essa hipótese, isso implicará em uma decisão, qual seja, por
exemplo, a de pulverizar a lavoura de café com algum inseticida. Por outro lado, se ele não rejeitar
essa hipótese, então sua outra decisão será a de não pulverizar a lavoura. Poderíamos tomar
como hipótese outra afirmação, a saber: “A infestação da broca é igual ou está acima do nível de
controle”, para a qual seguir-se-iam os mesmos tipos de considerações.
A verificação de uma hipótese de interesse, acerca da população, é chamada teste de
hipótese, ou, mais apropriadamente, teste estatístico. A teoria de testes faz parte de um conjunto
de conceitos e métodos chamado de teoria da decisão, pois frequentemente há rejeição, ou não,
de hipóteses, além de serem em si mesmas decisões (rejeitar é uma decisão e aceitar, isto é, não
rejeitar, também é uma decisão), tais testes de hipótese também se desdobram gerencialmente,
implicando em mais algumas outras decisões posteriores, como seria o caso anterior de pulverizar
com inseticida.

Guia de estudos de Estatística
Conceito 6.1. Teste estatístico . Verificação da validade, ou não, de hipóteses sobre a população,
mediante critérios estatísticos.
Conceito 6.2. Teoria da decisão . Em grande medida corresponde à teoria de testes, pois a
aceitação ou a rejeição de hipóteses frequentemente implica em alguma decisão acerca da
população.
Os testes podem se referir ao modelo utilizado para descrever a população de interesse,
ou ainda, admitindo que o modelo seja satisfatório, podem se referir aos parâmetros do modelo.
Como exemplo do primeiro caso, um engenheiro deseja saber se pode utilizar o modelo de
Poisson para descrever o número de chuvas por ano acima de determinada intensidade, com fins
de previsão, para a construção de um sistema de drenagem em barragem. Se o modelo de
Poisson não for adequado, sua previsão poderá ser falsa, e, consequentemente, seu projeto estará
errado, levando finalmente ao rompimento da barragem e consequentes perdas e prejuízos. Então
ele pode querer testar:
HIPÓTESE: “A distribuição de chuvas tem distribuição de Poisson”.
É claro que se ele, baseando em critérios estatísticos, rejeitar esta hipótese, será conveniente
procurar outro modelo probabilístico para descrever a distribuição de chuvas.
Por outro lado, as hipóteses podem se referir ao(s) parâmetro(s) do modelo probabilístico,
por sua vez tido como satisfatório. O exemplo da broca do café anterior mostra essa situação. A
probabilidade (ou a proporção) de frutos brocados é um parâmetro da distribuição Binomial e o
teste irá se referir a ela, admitindo o modelo probabilístico da distribuição Binomial como
satisfatório.
Um teste estatístico deve ser construído e avaliado segundo dois critérios de desempenho:
(i) Riscos (ou probabilidades) de decisões erradas.
(ii) Custo para a tomada de decisão.
Um terceiro critério poderia ser aventado, a saber o da utilidade da decisão tomada, mas tal critério
carrega uma medida grande de subjetividade, e não será considerado aqui. Simplesmente será
admitido aqui que toda e qualquer decisão tomada a partir de um teste estatístico é já previamente
considerada útil para o analista.

Guia de estudos de Estatística
6.2. ELEMENTOS DE UM TESTE Geralmente, os testes têm a seguinte estrutura: existe uma hipótese principal sob
julgamento, chamada de hipótese de nulidade ou hipótese nula, representada pela notação H0. Se
rejeitada, então uma outra hipótese candidata é considerada como verdadeira, a chamada
hipótese alternativa, representada por H1 ou Ha. No exemplo da broca do café, supondo que o nível
de controle acima do qual ocorre prejuízo seja a proporção p0 de frutos atacados, o teste
correspondente seria:
H0: a proporção p de frutos brocados é igual ou menor a p0
H1: a proporção p de frutos brocados é superior a p0
ou, simplesmente:
H0: p ≤ p0
H1: p > p0
Nota. Observe que a igualdade (p = p0 ) fica em H0.
Na prática, a aceitação ou rejeição de H0 (e, consequentemente, a aceitação de H1) são
feitas mediante uma amostra aleatória, da qual estimativas apropriadas são calculadas. Se a
distribuição de amostragem dos estimadores correspondentes for conhecida, então pode-se
calcular a probabilidade da estimativa observada ter ocorrido, admitindo a hipótese de nulidade H0
como verdadeira. Se esta probabilidade for baixa, então existem bons motivos para rejeitar essa
hipótese e aceitar H1.
Dessa forma, pode-se estipular um valor crítico para o estimador, de tal maneira que, se a
estimativa calculada na amostra for, por exemplo, maior que determinado valor, então rejeita-se H0.
Por exemplo, suponha que o nível de controle para a broca do café seja de p0 = 5% de frutos
brocados. Assim, o teste acima seria dado por:
H0: p ≤ 5%
H1: p > 5%
Uma amostra de n frutos é coletada, onde são contados o número x de frutos brocados. Em
seguida é então calculado a estimativa da proporção de frutos brocados:
nx
p =ˆ

Guia de estudos de Estatística
Digamos que, numa amostra de n = 400 frutos, conta-se 48 frutos brocados, totalizando então
40048ˆ =p = 0,12 = 12%.
A princípio, considerando que 12% é maior do que 5%, seríamos levados à rejeitar H0 e aceitar H1 .
Porém, surge a pergunta: sendo estes 12% a proporção da amostra, não deveríamos ser
cautelosos em decidir sobre a proporção da população (5% é da população) ? A resposta é,
obviamente, sim, e a cautela traduz-se por calcular a probabilidade de uma amostra de n = 400
frutos apresentar p = 12% se esta amostra é obtida aleatoriamente de uma população com
p = 5% (ou menos). Ora, na estimação de proporções já havíamos concluído que p ∼ N ( p, npq
), o
que nos leva a calcular esta probabilidade como:
z = (0,12-0,05)/0,010897 = 6,42.
Na tabela da Normal, o valor de área acima de 6,42 não está nem mesmo indicado (a tabela pára
no valor de 3,99), implicando que, com aproximação de 4 decimais, tal área acima é 0,0000. De
fato, tal área na é exatamente zero, pois a Normal é assintótica, e, teoricamente, nunca uma área
acima é zerada. Utilizando o Excel (poderia ser outro software estatístico, como o R, por exemplo,
veja o Capítulo 8), essa área com mais decimais seria de aproximadamente
0,00000000006813716258, ainda mais aproximadamente igual a 0,000000007%: um número
muito pequeno! Seria de aproximadamente 1 chance em 10.000.000.000 (dez trilhões)!
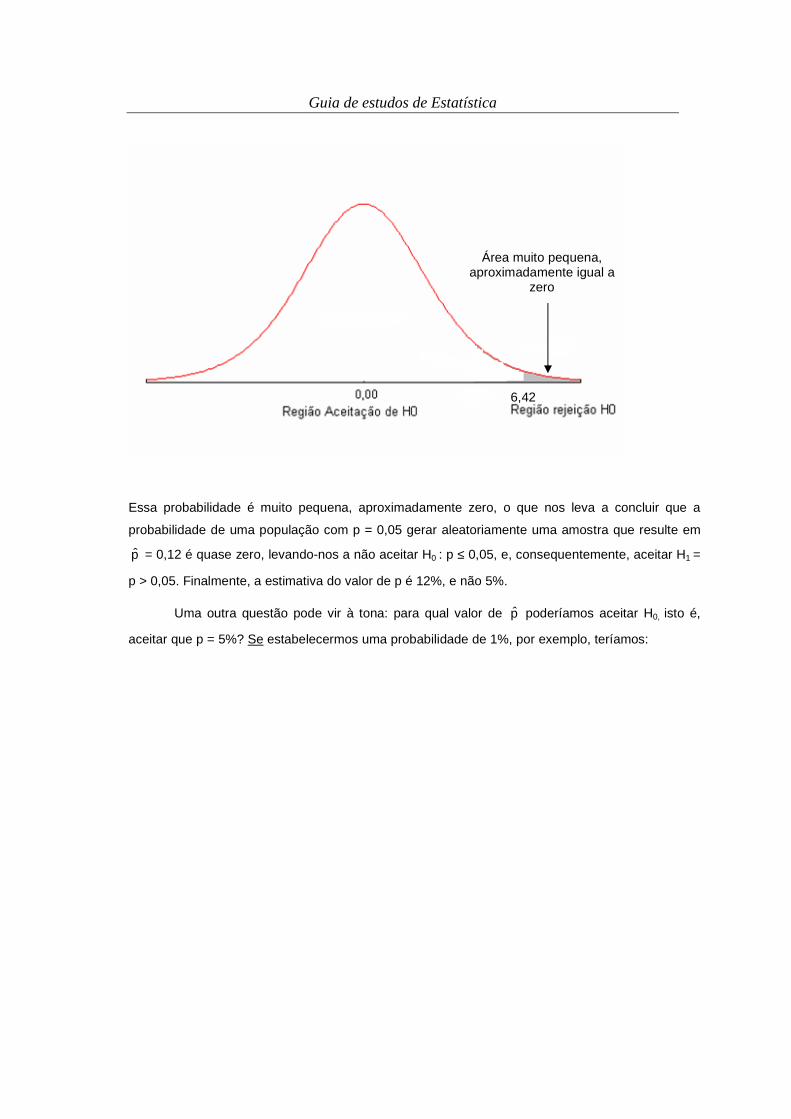
Guia de estudos de Estatística
Essa probabilidade é muito pequena, aproximadamente zero, o que nos leva a concluir que a
probabilidade de uma população com p = 0,05 gerar aleatoriamente uma amostra que resulte em
p = 0,12 é quase zero, levando-nos a não aceitar H0 : p ≤ 0,05, e, consequentemente, aceitar H1 =
p > 0,05. Finalmente, a estimativa do valor de p é 12%, e não 5%.
Uma outra questão pode vir à tona: para qual valor de p poderíamos aceitar H0, isto é,
aceitar que p = 5%? Se estabelecermos uma probabilidade de 1%, por exemplo, teríamos:
6,42
Área muito pequena, aproximadamente igual a
zero
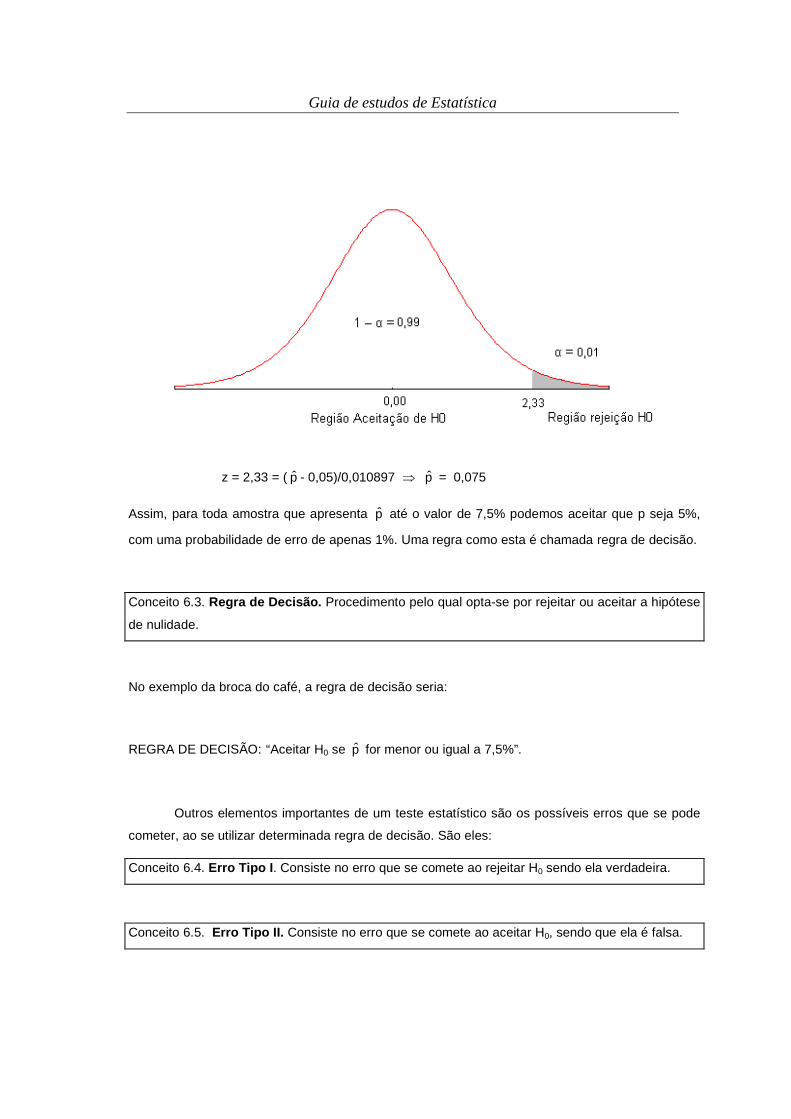
Guia de estudos de Estatística
z = 2,33 = ( p - 0,05)/0,010897 ⇒ p = 0,075
Assim, para toda amostra que apresenta p até o valor de 7,5% podemos aceitar que p seja 5%,
com uma probabilidade de erro de apenas 1%. Uma regra como esta é chamada regra de decisão.
Conceito 6.3. Regra de Decisão. Procedimento pelo qual opta-se por rejeitar ou aceitar a hipótese
de nulidade.
No exemplo da broca do café, a regra de decisão seria:
REGRA DE DECISÃO: “Aceitar H0 se p for menor ou igual a 7,5%”.
Outros elementos importantes de um teste estatístico são os possíveis erros que se pode
cometer, ao se utilizar determinada regra de decisão. São eles:
Conceito 6.4. Erro Tipo I . Consiste no erro que se comete ao rejeitar H0 sendo ela verdadeira.
Conceito 6.5. Erro Tipo II. Consiste no erro que se comete ao aceitar H0, sendo que ela é falsa.

Guia de estudos de Estatística
A probabilidade (ou risco) de se cometer o erro tipo I é, em geral, representada pela letra
grega α e comumente chamada de nível de significância do teste. A probabilidade (ou risco) de
ocorrência do erro tipo II é representada pela letra β, e não tem nome especial. Porém, quando se
aceita H0, e ela é verdadeira, ou quando se rejeita H0, e ela de fato é falsa, ambas consistem em
uma decisão correta. Esta última ocorre com probabilidade 1 - β, valor esse que por sua vez
recebe o nome de poder do teste. Já a probabilidade de se aceitar H0, quando ela é verdadeira,
corresponde ao valor 1 - α, que por sua vez também não recebe um nome especial. Esses
aspectos podem ser sumarizados como na Tabela 6.1.
Conceito 6.6. Nível de Significância. Consiste no valor da probabilidade α de se cometer o Erro
Tipo I.
Conceito 6.7. Poder do Teste. Consiste na probabilidade de rejeição de H0, quando de fato ela é
falsa.
Tabela 6.1. Resultados possíveis em um teste estatístico, e suas probabilidades de ocorrência.
A verdade na população
Decisão tomada H0 é verdadeira H0 é falsa
H0 é aceita
Decisão correta
Probabilidade = 1 - α
Decisão errada
(Erro Tipo II)
Probabilidade = β
H0 é rejeitada
Decisão errada
(Erro Tipo I)
Probabilidade = α
Decisão correta
Probabilidade = 1 - β
6.3. TESTES SOBRE A VALIDADE DE MODELOS
Comentou-se acima que os testes podem se referir a adequabilidade ou não de modelos
probabilísticos utilizados para descrever populações. Além do exemplo dado na Unidade 3 da

Guia de estudos de Estatística
distribuição de Poisson para descrever a distribuição de chuvas, deve-se citar também a grande
importância de testar se a população sob estudo pode ser considerada como tendo distribuição
(pelo menos aproximadamente) Normal, para que seja possível a utilização daqueles teoremas
para a construção de intervalos de confiança, utilizando a distribuição t, particularmente quando a
amostra é pequena. Se a população não tem distribuição Normal, e a amostra é pequena, então a
distribuição t não é adequada, e outros procedimentos, não abordados nesse curso, deverão ser
buscados.
Neste tópico, será visto como se pode testar se uma população em questão pode ser
considerada como tendo uma dada distribuição em particular. Esse tipo de teste é chamado teste
sobre a validade de modelos ou teste de aderência. Para exemplificar, imagine que um engenheiro
agrícola observou a ocorrência de chuvas por ano com intensidade acima de 30 mm.h-1 em uma
região nos 35 anos anteriores (compondo a sua amostra), tendo encontrado os seguintes valores
(Tabela 6.2):
Tabela 6.2. Número de chuvas ocorridas nos 35 anos passados em uma região com intensidade
acima de 30 mm.h-1.
1961: 2 1966: 1 1971: 0 1976: 2 1981: 3 1986:2 1991: 2
1962: 0 1967: 3 1972: 2 1977: 4 1982: 2 1987:2 1992: 6
1963: 3 1968: 2 1973: 4 1978: 5 1983: 0 1988: 1 1993: 5
1964: 2 1969: 3 1974: 2 1979: 2 1984: 6 1989: 3 1994: 3
1965: 1 1970: 1 1975: 3 1980: 0 1985: 2 1990: 4 1995: 1
A distribuição de frequência absoluta dessa variável descritora de natureza discreta está na Tabela
6.3 (a frequência fe apresentada na tabela é a frequência esperada e será logo em seguida
explicada).
Suponha que o engenheiro deseje verificar se a distribuição de frequência pode ser
descrita por uma distribuição de Poisson, para que possa fazer previsões futuras. Em outras
palavras, o problema consiste no teste:
H0: a ocorrência de chuvas acima de 30mm/h tem distribuição Poisson.
H1: a ocorrência de chuvas acima de 30mm/h não tem distribuição Poisson.

Guia de estudos de Estatística
Tabela 6.3. Distribuição de frequência absoluta observada (fo) da ocorrência de chuvas com
intensidade acima de 30 mm.h-1.
Número de chuvas por ano fo fe
0 4 3,17 1 5 7,62 2 12 9,15 3 7 7,32 4 3 4,39 5 2 2,11 6 2 0,84
7 ou mais 0 0,40 Total 35 35,00
Deve-se atentar que em H0 sempre fica a afirmação de “tem distribuição” e em H1 sempre a de
“não tem distribuição”.
A distribuição χ2 (qui-quadrado) fornece um meio (aproximado) de se testar a hipótese H0.
Para tanto, calcula-se, para cada número de chuvas, a frequência absoluta esperada (fe), caso os
dados da amostra tivessem exatamente distribuição de Poisson. Em seguida, são confrontadas
essas frequências esperadas fe com as observadas (fo). Se as diferenças puderem ser
consideradas como meramente casuais, então aceita-se H0. Para tanto, determina-se o valor de
qui-quadrado calculado 2Cχ pela expressão:
2Cχ =
( )∑
=
−k
i i
ii
fefofe
1
2
=( )
∑=
−k
i i
ii
fefefo
1
2
onde k é o número de classes. Este valor é comparado com o valor da tabela de qui-quadrado,
para determinado nível de significância α. Se o valor de χC2 for maior que esse valor da tabela,
então rejeita-se H0, pois então é muito pouco provável que a amostra em questão tenha acontecido
sob H0 verdadeira, pois a probabilidade das variações de fo em relação a fe terem acontecido por
puro acaso é baixa (igual ou menor que α). Para se saber o número de graus de liberdade v para a
consulta à tabela deve-se tomar:
v = (número de classes) – (número de parâmetros estimados) – 1
A distribuição de Poisson é, como foi visto, indexada por um único parâmetro λ, que nada
mais é do que a média (e também a variância) da população dos infinitos anos da região. Sendo λ
a média, tem-se como estimador para este parâmetro:
X=λ

Guia de estudos de Estatística
Voltando aos cálculos, tomando-se os dados da Tabela 6.2 e calculando-se essa média
tem-se:
x = ( )
3513302 +++++ L
= 3584
= 2,4
Esta média também poderia ser calculada pela distribuição de freqüências (Tabela 6.3):
x = ( ) =++++++
35
2.62.53.47.312.25.14.0 3584
= 2,4
Os cálculos serão feitos considerando x=λ = 84/35 = 2,4. Cada fe é calculada por P(X = x).35,
veja tabela auxiliar abaixo.
x P (X = x) P (X = x).35
0 e-2,4.2,40/0! = 0,0907 0,0907*35 = 3,18
1 e-2,4.2,41/1! = 0,2177 0,2177*35 = 7,62
2 e-2,4.2,42/2! = 0,2613 0,2613*35 = 9,14
3 e-2,4.2,43/3! = 0,2090 7,32
4 e-2,4.2,44/4! = 0,1254 4,39
5 e-2,4.2,45/5! = 0,0602 2,11
6 e-2,4.2,46/6! = 0,0241 0,84
7 ou mais 1 – (0,0907 + 0,2177 + 0,2613
+ 0,2090 + 0,1254 + 0,0602 +
0,0241) = 1-0,9884 = 0,0116
0,40
Por que a multiplicação da probabilidade P(X = x) por n = 35? Como comentado no
Capítulo 3, probabilidades são definidas como frequências relativas em populações infinitas. Assim
sendo, essas probabilidades, uma vez calculadas, se multiplicadas por 35, fornecerão as
frequências absolutas esperadas em cada classe. Isso pode ser entendido mais claramente se
atentarmos para o fato de que uma frequência relativa é uma proporção, e, como tal, obedece a
distribuição Binominal. Logo, a frequência esperada fe é o valor esperado de fo, pela Binominal.
Sabemos que um valor esperado é a média, e que a média na Binominal é dada pelo produto n.p:
µ = n.p = np

Guia de estudos de Estatística
Mas p é estimado pela probabilidade calculada. Logo:
fe = n. p = n.probabilidade estimada,
que fe é o número de elementos esperado para aquela classe que tem probabilidade calculada p
igual à p . Assim, temos que:
fe (classe) = n.probabilidade (classe).
A frequência absoluta na classe 0 será, então:
P(X = 0) = !0
4,2718,2 04,2−
= 0,0907
fe = 0,0907 x 35 = 3,18
A frequência absoluta na classe 1 será:
P(X = 1) = !1
4,2718,2 14,2−
= 0,2177
fe = 0,2177 x 35 = 7,62
Procedendo assim para as outras classes, tem-se:
P(X = 2) = !2
4,2718,2 24,2− = 0,2613 ⇒ fe = 9,14
P(X = 3) = !3
4,2718,2 34,2− = 0,2090 ⇒ fe = 7,32
e assim por diante, para as demais classes.
Alguns autores apontam que, como a distribuição qui-quadrado é um recurso aproximado
para a realização do teste, é necessário antes de tudo que as classes naturais da Tabela 6.3 (ou
seja, os diferentes números de chuvas) tenham frequência absoluta teórica de pelo menos 1
elemento, para que a aproximação seja satisfatória. Outros preconizam que nenhuma frequência
deve ser menor do que 5. A razão para isto é que freqüências teóricas menores do que 1 fariam a
parcela
( )i
ii
fe
fofe 2−
“explodir” para valores muito altos (observe que na fórmula do 2Cχ cada parcela é do tipo acima),
fazendo o valor final do 2Cχ ficar superestimado. Para alguns autores, aceitar fe < 5 em algumas
classes, mais do que possivelmente inflacionar exageradamente a parcela correspondente,
também prejudicaria a aproximação implícita no método. Como todos esses critérios são

Guia de estudos de Estatística
empíricos, usaremos o critério de frequências esperadas (teóricas) maiores ou iguais à 5, que nos
resguarda tanto da “explosão” do valor do 2Cχ quanto da aproximação ruim do método. Apenas
para comparação, vamos agrupar como se utilizássemos o critério fe > 1: fazendo assim, a Tabela
6.3 seria completada pelas frequências esperadas fe iguais à:
0 3,18 5 2,11
1 7,62 6 ou mais 1,24
2 9,14 Total 35,00
3 7,32
4 4,39
Veja que a tabela permaneceria quase como estava para a operação de teste de 2Cχ (somente as
2 últimas classes seriam agrupadas, pois têm fo menor do que 1). Porém, utilizando o critério fe >
5, teremos que agrupar várias classes. Assim, na Tabela 6.3 é necessário, em primeiro lugar,
agrupar aquelas classes com frequências esperadas menores do que 5. Isso conduz à distribuição
de frequências apresentadas na Tabela 6.4. Com esse procedimento, o número de classes k
diminuiu de 7 para 4 classes.
Tabela 6.4. Distribuição de frequência absoluta observada (fo) da ocorrência de chuvas,
agrupando as classes com menos de 5 elementos.
Número de chuvas por ano fo
fe
0 ou 1 9 10,80 = 3,18+7,62 2 12 9,14 3 7 7,32
4 ou mais 7 7,74 = 4,39+2,11+0,84+0,40 Total 35 35,00
Como fizemos, com base na estimativa do parâmetro λ pode-se calcular alternativamente a
frequência absoluta esperada em cada classe a partir das probabilidades, admitindo que os dados
da amostra tenham distribuição de Poisson. Para tanto, utilizamos a expressão conhecida
P(X = x) = !x
e xλλ−,
e assim, como já fizemos,
P(X = 0) = !0
4,2718,2 04,2− = 0,0907

Guia de estudos de Estatística
e P(X = 1) = !1
4,2718,2 14,2−
= 0,2177 , temos que,
portanto:
P(X = 0 ou X = 1) = 0,0907 + 0,2177 = 0,3084 e 0,3084.35 = 10,80, como seria se o valor fosse
calculado direto nas frequências esperadas (3,18+7,62). Para 4 ou mais o cálculo seria:
P(X ≥ 4) = 1 - P(X < 4) = 1 - 0,0907 - 0,2177 - 0,2613 - 0,2090 = 0,2213
o que dá uma frequência absoluta esperada de fe = 7,74.
Agora, só resta calcular o valor de qui-quadrado. Para facilitar o uso de sua expressão, os
passos estão apresentados na Tabela 6.5.
O valor de qui-quadrado é, portanto:
2Cχ =
( )∑
=
−4
1
2
i i
ii
fefofe
= 1,272
Para verificar se H0 é rejeitada ou não, deve-se consultar o valor da tabela de χ2. Para tanto, deve-
se observar que um parâmetro (λ) foi estimado, e o número de classes é igual a 4.
Tabela 6.5. Distribuição de frequência absoluta (observada e esperada) para a ocorrência de
chuvas, agrupando as classes com menos de 5 elementos.
Número de chuvas por ano foI feII ( )fo fe
fe
− 2
0 ou 1 9 10,80 0,297
2 12 9,15 0,890
3 7 7,32 0,014
4 ou mais 7 7,74 0,071
Total 35 35,00 1,272
I - frequência absoluta observada; II - frequência absoluta esperada.
Assim:
v = 4 - 1 - 1 = 2
Adotando-se um nível de significância de 0,05 (5%), tem-se que o valor tabelado é dado por
(Tabela 3.2 do Apêndice):
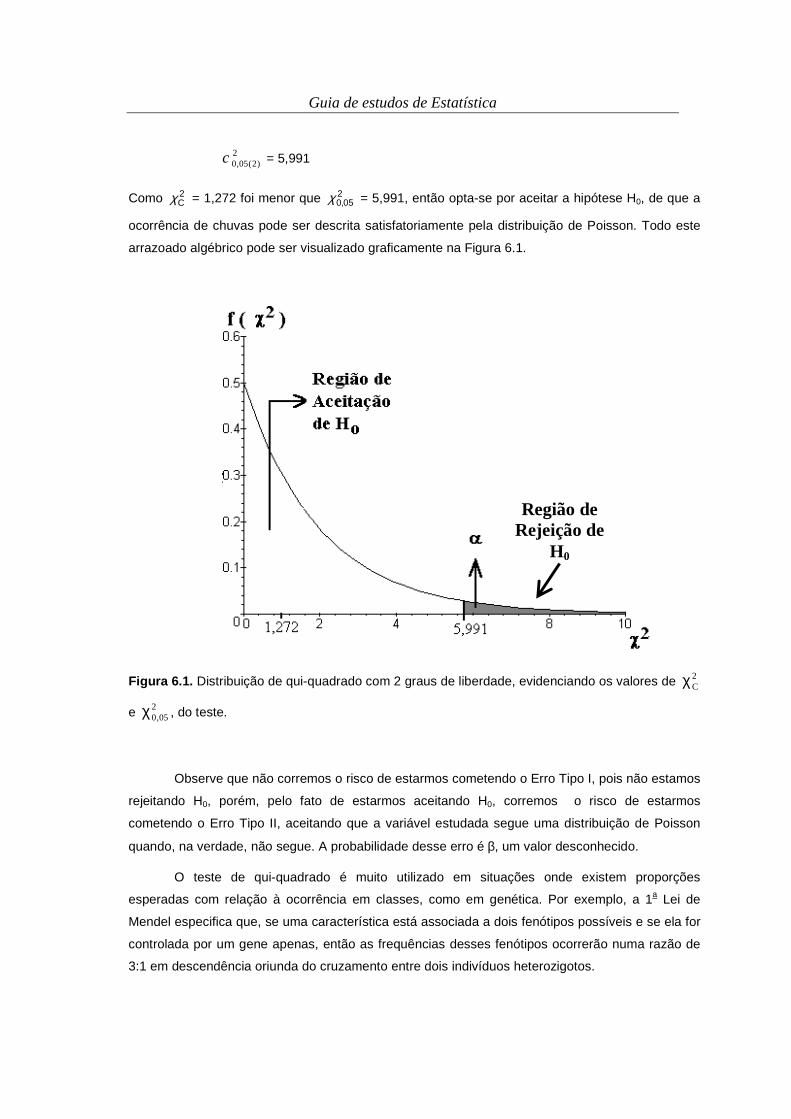
Guia de estudos de Estatística
20,05(2)c = 5,991
Como 2Cχ = 1,272 foi menor que 2
05,0χ = 5,991, então opta-se por aceitar a hipótese H0, de que a
ocorrência de chuvas pode ser descrita satisfatoriamente pela distribuição de Poisson. Todo este
arrazoado algébrico pode ser visualizado graficamente na Figura 6.1.
Figura 6.1. Distribuição de qui-quadrado com 2 graus de liberdade, evidenciando os valores de χC2
e χ0 052, , do teste.
Observe que não corremos o risco de estarmos cometendo o Erro Tipo I, pois não estamos
rejeitando H0, porém, pelo fato de estarmos aceitando H0, corremos o risco de estarmos
cometendo o Erro Tipo II, aceitando que a variável estudada segue uma distribuição de Poisson
quando, na verdade, não segue. A probabilidade desse erro é β, um valor desconhecido.
O teste de qui-quadrado é muito utilizado em situações onde existem proporções
esperadas com relação à ocorrência em classes, como em genética. Por exemplo, a 1a Lei de
Mendel especifica que, se uma característica está associada a dois fenótipos possíveis e se ela for
controlada por um gene apenas, então as frequências desses fenótipos ocorrerão numa razão de
3:1 em descendência oriunda do cruzamento entre dois indivíduos heterozigotos.
Região de Rejeição de
H0
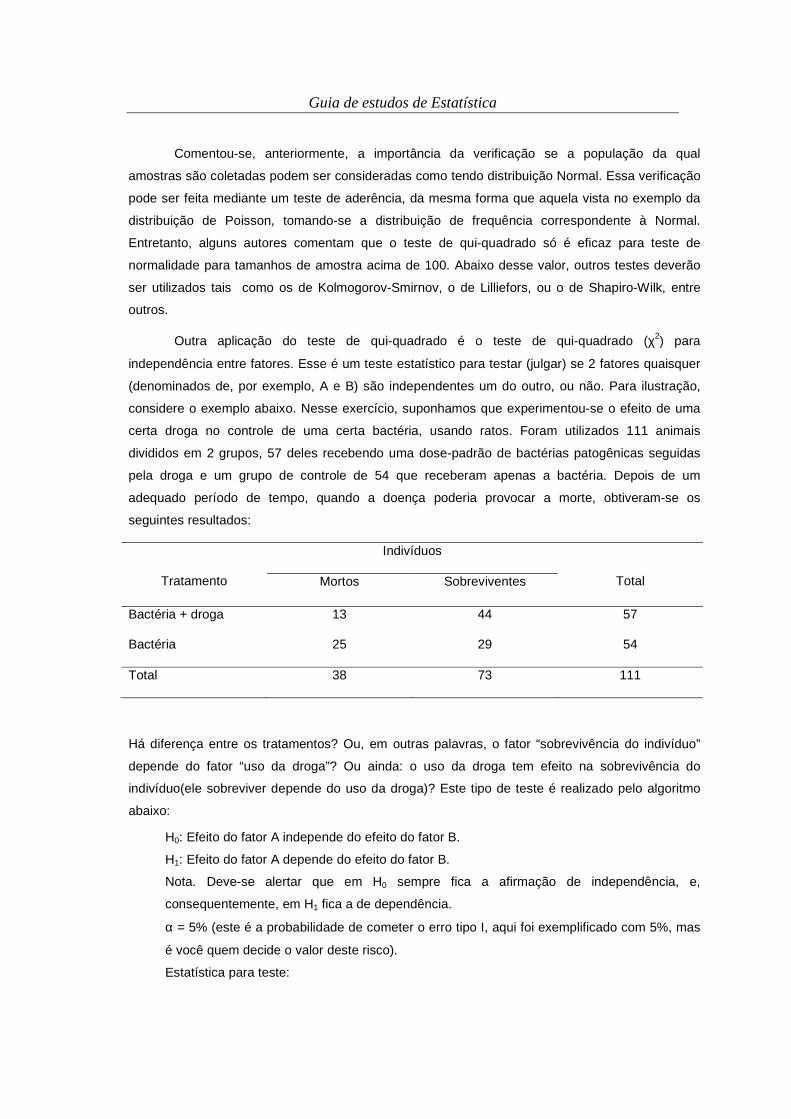
Guia de estudos de Estatística
Comentou-se, anteriormente, a importância da verificação se a população da qual
amostras são coletadas podem ser consideradas como tendo distribuição Normal. Essa verificação
pode ser feita mediante um teste de aderência, da mesma forma que aquela vista no exemplo da
distribuição de Poisson, tomando-se a distribuição de frequência correspondente à Normal.
Entretanto, alguns autores comentam que o teste de qui-quadrado só é eficaz para teste de
normalidade para tamanhos de amostra acima de 100. Abaixo desse valor, outros testes deverão
ser utilizados tais como os de Kolmogorov-Smirnov, o de Lilliefors, ou o de Shapiro-Wilk, entre
outros.
Outra aplicação do teste de qui-quadrado é o teste de qui-quadrado (χ2) para
independência entre fatores. Esse é um teste estatístico para testar (julgar) se 2 fatores quaisquer
(denominados de, por exemplo, A e B) são independentes um do outro, ou não. Para ilustração,
considere o exemplo abaixo. Nesse exercício, suponhamos que experimentou-se o efeito de uma
certa droga no controle de uma certa bactéria, usando ratos. Foram utilizados 111 animais
divididos em 2 grupos, 57 deles recebendo uma dose-padrão de bactérias patogênicas seguidas
pela droga e um grupo de controle de 54 que receberam apenas a bactéria. Depois de um
adequado período de tempo, quando a doença poderia provocar a morte, obtiveram-se os
seguintes resultados:
Tratamento
Indivíduos
Total Mortos Sobreviventes
Bactéria + droga
Bactéria
13
25
44
29
57
54
Total 38 73 111
Há diferença entre os tratamentos? Ou, em outras palavras, o fator “sobrevivência do indivíduo”
depende do fator “uso da droga”? Ou ainda: o uso da droga tem efeito na sobrevivência do
indivíduo(ele sobreviver depende do uso da droga)? Este tipo de teste é realizado pelo algoritmo
abaixo:
H0: Efeito do fator A independe do efeito do fator B.
H1: Efeito do fator A depende do efeito do fator B.
Nota. Deve-se alertar que em H0 sempre fica a afirmação de independência, e,
consequentemente, em H1 fica a de dependência.
α = 5% (este é a probabilidade de cometer o erro tipo I, aqui foi exemplificado com 5%, mas
é você quem decide o valor deste risco).
Estatística para teste:
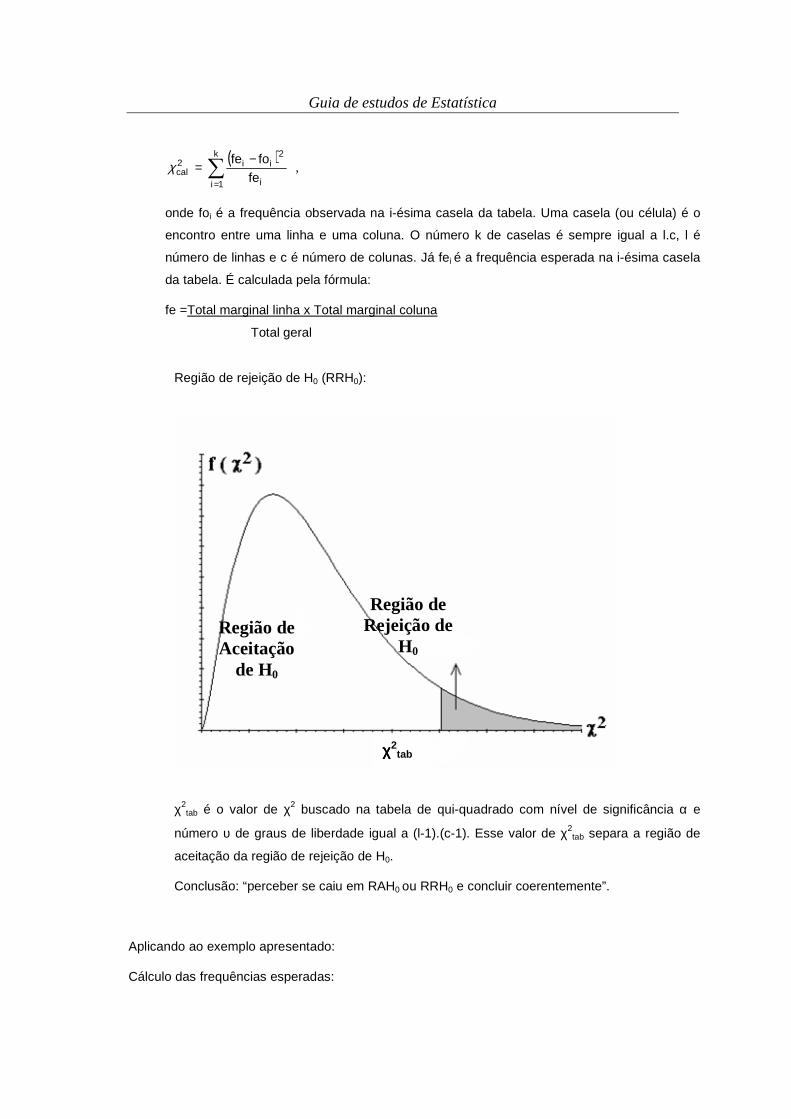
Guia de estudos de Estatística
2calχ =
( )∑
=
−k
i i
ii
fefofe
1
2
,
onde foi é a frequência observada na i-ésima casela da tabela. Uma casela (ou célula) é o
encontro entre uma linha e uma coluna. O número k de caselas é sempre igual a l.c, l é
número de linhas e c é número de colunas. Já fei é a frequência esperada na i-ésima casela
da tabela. É calculada pela fórmula:
fe =Total marginal linha x Total marginal coluna
Total geral
Região de rejeição de H0 (RRH0):
χ2tab é o valor de χ2 buscado na tabela de qui-quadrado com nível de significância α e
número υ de graus de liberdade igual a (l-1).(c-1). Esse valor de χ2tab separa a região de
aceitação da região de rejeição de H0.
Conclusão: “perceber se caiu em RAH0 ou RRH0 e concluir coerentemente”.
Aplicando ao exemplo apresentado:
Cálculo das frequências esperadas:
χχχχ2tab
Região de Rejeição de
H0
Região de Aceitação
de H0

Guia de estudos de Estatística
51,19111
3857.arg.arg).( =×=×=+×
TotalGeralColunaTotalMLinhaTotalM
DrogaBacMortesfe
49,18111
3854.arg.arg.)( =×=×=×
TotalGeralColunaTotalMLinhaTotalM
BacMortesfe
49,37111
7357.arg.arg)..( =×=×=+×
TotalGeralColunaTotalMLinhaTotalM
DrogaBacSobrevfe
51,35111
7354.arg.arg.).( =×=×=×
TotalGeralColunaTotalMLinhaTotalM
BacSobrevfe
Agora, passemos ao teste de hipótese:
1o) H0: Os efeitos da droga não influenciam na sobrevivência.
2o) HA: Os efeitos da droga influenciam na sobrevivência.
3o) α = 5%
4o) Estatística de Teste:
7882,651,35
)51,3529(49,37
)49,3744(49,18
)49,1825(51,19
)51,1913()( 22224
1
22 =−+−+−+−=−=∑
=ical fe
fofeχ
O valor de χ2tab tem υ = (2-1) x (2-1) = 1, onde 2 é o número de linhas, e 2 o número de colunas da
tabela acima. Assim χ2tab = 3,841.
5o)Como χ2cal > χ2
tab, rejeita-se H0
6o) Conclusão: os efeitos da droga influenciam na sobrevivência dos ratos expostos a essa
bactéria, pois não há independência entre os fatores.
6.4. TESTES SOBRE DIFERENÇA DE MÉDIAS µµµµ1 - µµµµ2 Frequentemente deseja-se comparar duas populações, com relação às suas médias, para
verificar simplesmente se são diferentes, sendo que a estimação dessa diferença é importante,
mas secundária. Nesse caso, é interessante perfazer um teste de hipóteses sobre µ1 - µ2.
A diferença, 1X - 2X , também relaciona-se com a distribuição t, o que permite compor
critérios de decisão para testes estatísticos. Admitindo que as variâncias de ambas as populações
sejam iguais, então a variável:
tc = ( ) ( )
+
−−−
22
2
1121
11nn
s
xx µµ

Guia de estudos de Estatística
tem distribuição t com n1 + n2 - 2 graus de liberdade. O leitor deve se lembrar que:
2s =
( ) ( )2
)1()1(2 21
222
211
21
2
1
222
1
1
211
−+−+−
=−+
−+− ∑∑==
nnsnsn
nn
xxxxn
jj
n
jj
Assim, os critérios de decisão para os testes unilaterais e bilaterais são:
a) Teste Unilateral do Tipo:
H0: µ1 - µ2 = d0 (ou µ1 - µ2 ≥ d0)
H1: µ1 - µ2 < d0
REGRA DE DECISÃO: rejeitar H0 se tc < -tα, onde tc = ( )
+
−−
21
2
021
11nn
s
dxx
b) Teste Unilateral do Tipo:
H0: µ1 - µ2 = d0 (ou µ1 - µ2 ≤ d0)
H1: µ1 - µ2 > d0
REGRA DE DECISÃO: rejeitar H0 se tc > tα, onde tc = ( )
+
−−
21
2
021
11nn
s
dxx
c) Teste Bilateral do Tipo:
H0: µ1 - µ2 = d0
H1: µ1 - µ2 ≠ d0
REGRA DE DECISÃO: rejeitar H0 se tc < -tα/2 ou tc > tα/2, onde tc = ( )
+
−−
21
2
021
11nn
s
dxx
Esse tipo de teste é empregado, por exemplo, quando uma empresa de reflorestamento,
que tradicionalmente cultiva um clone A de eucalipto, adquire numa instituição de pesquisa um
novo clone B. Assim, interessa saber se no plantio de novos talhões é justificável plantar o novo
clone B, ou seja, se ele é mais produtivo. Se µ1 - µ2 = 0, então não se justifica trocar o clone
cultivado na empresa. Se, por outro lado, µA - µB < 0, então o clone B é mais produtivo, e justifica-se
utilizá-lo. Assim, um teste de interesse seria:

Guia de estudos de Estatística
H0: µA - µB = 0 (ou µA - µB ≥ 0)
H1: µA - µB > 0
Suponha-se que, para a realização de tal teste, um experimento tenha sido conduzido com
25 parcelas de cada clone nas quais avaliou-se o DAP médio das árvores, tendo-se encontrado
AX = 18,61 cm, BX = 15,61, SA 2 = 1,70 cm2, e SB 2 = 1,90 cm2 . Assim, temos que S2 = 1,80 cm2,
e
tc = ( )
+
−−
251
251
80,1
061,1561,18 = 7,906
Utilizando a significância de α = 5%, tem-se que o valor tabelado de t para 48 graus de liberdade
deve ser obtido por interpolação: com 40 e 60 graus de liberdade, tem-se, respectivamente, 1,684
e 1,671 para os valores de t0,05, ou seja, diminuição de 0,013 ao se aumentar 20 graus de
liberdade. Assim:
20 ------------------0,013
8 ------------------- x x = 0,005
E, portanto, o valor t para 48 graus de liberdade é 1,684 - 0,005 = 1,679. Por nós mesmos
colocamos o sinal negativo, pois estamos vendo que o valor de t está do lado esquerdo da curva
de t: -1,679. Como 7,906 > -1,679 , aceita-se H0, isto é, não há evidências, neste teste, para
concluir que A e B sejam diferentes.
Observe que, nesse exemplo ilustrativo, consideramos, implicitamente, que as variâncias
σ2A e σ2
B das α populações de clones são iguais, justificando, assim, o uso da variância combinada
s2 = 1,8000 cm2. A maneira como deveríamos julgar essa pressuposição poderia ser como fizemos
no Capítulo 5: fazendo um intervalo de confiança para σ2A / σ
2B e, verificando se o número 1 está ,
ou não, no intervalo. Se estiver, as variâncias σ2A e σ2
B são iguais, se não estiver, não são. Outro
modo é proceder um teste para a razão de variâncias, que será visto adiante.
Outra observação importante é a coerência entre hipóteses H0 e H1 e evidências amostrais:
nossas amostras resultaram em AX - BX = 18,61 – 15,61 = 3 cm, um valor positivo. Logo, seria
mais razoável julgar H0: µA - µB = 0 contra H1: µA - µB > 0 , pois, se µA e µB não foram iguais (µA - µB
= 0, H0), então o mais razoável é admitir que µA será maior do que µB, porque as amostras sugerem
isto ( AX > BX ). Assim sendo, convém estabelecer como H1 aquilo que os dados sugerem, neste
caso, H1: µA - µB > 0. Façamos então o teste assim:
H0: µA - µB = 0
H1: µA - µB > 0 (por sugestão das amostras)

Guia de estudos de Estatística
α = 5%
Estatística para teste: tc = 7,906, e v = nA + nB – 2 = 25 + 25 – 2 = 48
Região de rejeição de H0: t5% = 1,679.
Conclusão: como 7,906 > 1,679, rejeita-se H0, a um nível de significância de 5%.
Observe que a conclusão mudou! Agora rejeitamos H0, isto é, estamos concluindo que a média de
DAP do clone A é maior do que a média de DAP do clone B. Observe como uma escolha mais
coerente da hipótese alternativa tornou o teste mais eficaz!
Vamos explorar mais um exemplo ilustrativo, onde as variâncias não são iguais: considere
uma provedora de internet que deseja saber se o espaço de memória no webmail utilizado por
seus clientes homens é, em média, diferente do que o espaço utilizado por suas clientes mulheres.
Para testar a hipótese de igualdade de média, tal provedora toma uma amostra de nH = 115
homens e nm = 134 mulheres, obtendo HX = 480,4 Mbytes e MX = 458,1 Mbytes, com sH = 111,8
Mbytes e sM = 75,5 Mbytes. Vamos consider que as variâncias populacionais são diferentes. O
teste para diferença entre duas médias, quando as variâncias são diferentes usa a estatística
tc = ( ) ( )
2
22
2
21
1121
n
s
n
s
xx
+
−−− µµ ,
a qual tem número de graus de liberdade igual à
v =
11 2
2
2
22
1
2
2
21
2
2
22
1
21
−
+−
+
n
n
s
n
n
s
n
s
n
s
(tome a parte inteira),
Esta é a já conhecida fórmula de Satterthwaite.
Então:
H0 : µH = µM
H1 : µH > µM (como sugerido pelos dados, já que HX > MX )
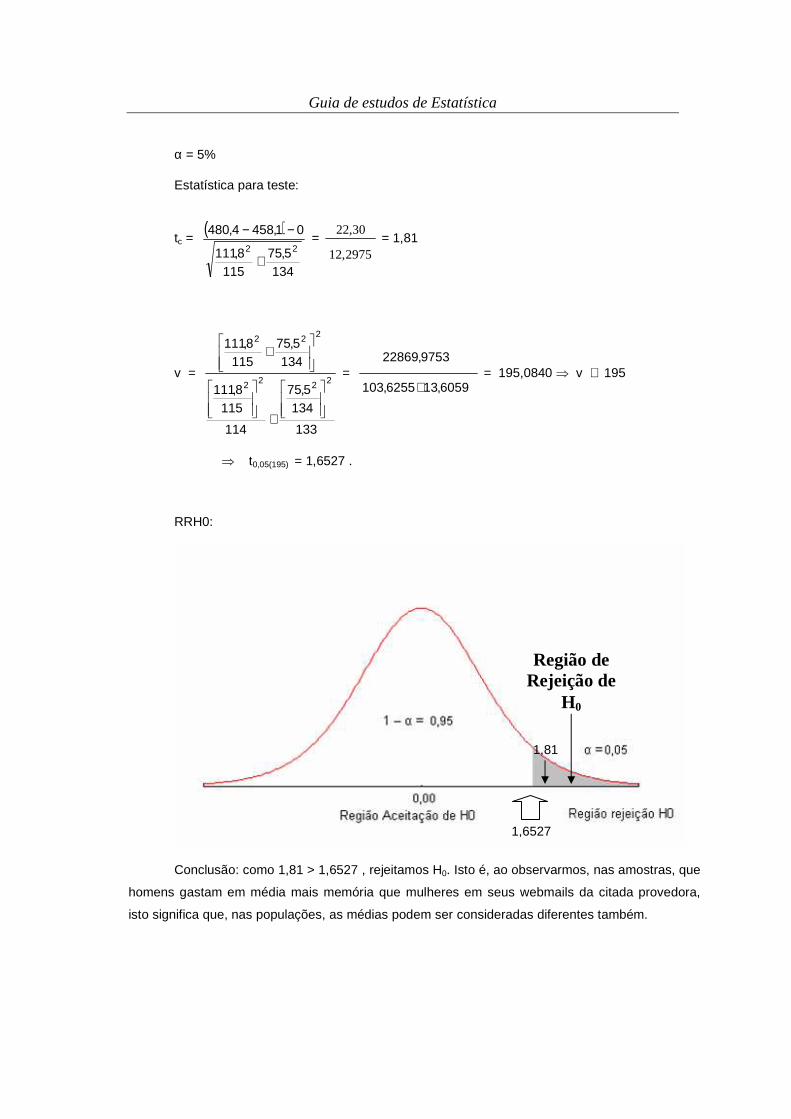
Guia de estudos de Estatística
α = 5%
Estatística para teste:
tc = ( )
1345,75
1158,111
01,4584,48022
+
−− =
2975,12
30,22 = 1,81
v =
133
1345,75
114
1158,111
1345,75
1158,111
2222
222
+
+
= 6059,136255,103
9753,22869
+ = 195,0840 ⇒ v ≅ 195
⇒ t0,05(195) = 1,6527 .
RRH0:
Conclusão: como 1,81 > 1,6527 , rejeitamos H0. Isto é, ao observarmos, nas amostras, que
homens gastam em média mais memória que mulheres em seus webmails da citada provedora,
isto significa que, nas populações, as médias podem ser consideradas diferentes também.
1,6527
Região de Rejeição de
H0
1,81

Guia de estudos de Estatística
6.5. TESTES SOBRE MÉDIA DA DIFERENÇA µµµµD
Testar µ1 - µ2 é testar sobre a diferença das médias, e é o que vimos na seção anterior. Já
testar µD é testar a média das diferenças, e é o que veremos agora. Você perceberá que isto não é
só um trocadilho – são situações diferentes! Vejamos um exemplo: considere um administrador
que deseja testar se um determinado programa de gestão da qualidade aumentou o retorno sobre
o investimento (ROI) de empresas de médio porte numa região dada. Para tal empreitada, ele
obteve os seguintes dados, antes e depois do programa ser aplicado, veja Tabela 6.6.
Tabela 6.6. Retorno sobre investimento (ROI) de 12 empresas, antes e depois de um certo
programa de gestão da qualidade ser aplicado.
ROI ROI
Empresa Antes Depois Empresa Antes Depois
A 0,101 0,123 G 0,126 0,119
B 0,097 0,106 H 0,111 0,122
C 0,131 0,119 I 0,091 0,122
D 0,088 0,091 J 0,085 0,117
E 0,157 0,158 K 0,100 0,127
F 0,099 0,099 L 0,095 0,108
Esse tipo de dados é chamado dados emparelhados, ou dados pareados, visto que cada
empresa gera um par de resultados, um antes e um depois – isto é, a mesma empresa (o mesmo
indivíduo) gera um par de dados correlacionados. Nesse tipo de dados, não se pode usar os testes
para diferença de médias µ1 - µ2 , exatamente porque tais dados são correlacionados, pois estão
vinculados, cada par, no mesmo indivíduo (empresa), Para este tipo de dados o teste é:
H0 : µD = d0 (na maioria das vezes d0 = 0, isto é, o antes é igual no depois)
H1 : µD > d0 ou µD < d0 ou µD ≠ d0
Estatística para teste:
tc = ns
dd
D /0−
, sendo d e Ds são a média e o desvio-padrão das diferenças par – à – par.
O número de graus de liberdade v é n -1.

Guia de estudos de Estatística
No exemplo acima:
Empresa Diferença D Empresa Diferença D
A 0,123 -0,101 = 0,022 G 0,119 – 0,126 = 0,007
B 0,106 – 0,097 = 0,009 H 0,122 – 0,111 = 0,011
C 0,119 – 0,131 = -0,012 I 0,122 – 0,091 = 0,031
D 0,091 – 0,088 = 0,003 J 0,117 – 0,085 = 0,032
E 0,158 – 0,157 = 0,001 K 0,127 – 0,100 = 0,027
F 0,099 – 0,099 = 0,000 L 0,108 – 0,095 = 0,013
d = ( 0,022 + 0,009 + (-0,012) + 0,003 + ... + 0,013) ⁄ 12 = 0,01275
sD = ( ) ( )
11201275,0013,0...01275,0022,0 22
−−++−
= 0,01238
H0 : µD =0
H1 : µD >0 (sugestão dos dados, já que d = 0,01275 > 0).
α = 5%
Estatística para teste:
tc =
12
01238,0001275,0 −
= 3,57
Conclusão: como tc = 3,57 > t5%(11) = 1,796, rejeitamos H0 ao nível de significância de 5%,
isto é, o programa de qualidade aumentou o ROI das empresas.
6.6. TESTES SOBRE RAZÕES DE VARIÂNCIAS 22
21
σσ
Como saber se duas populações podem ser consideradas como tendo variâncias iguais
ou diferentes? Isso corresponde a uma hipótese, dado que raramente as populações sob
comparação são conhecidas em sua totalidade. Assim, um teste de hipótese de interesse seria:
H0: 22
21
σσ
= 1

Guia de estudos de Estatística
H0: 22
21
σσ
≠ 1
onde 21σ é a variância da população 1 e 2
2σ é a variância da população 2.
De uma maneira geral, testes sobre razões de duas variâncias de populações diferentes,
nas quais pressupõe-se distribuição Normal, podem ser feitos mediante a distribuição F.
a) Teste Unilateral do Tipo:
H0: 22
21
σσ
= q0
H1: 22
21
σσ
< q0
REGRA DE DECISÃO: rejeitar H0 se fc < αf1
, onde fc = 0
22
21 1
qs
s
b) Teste Unilateral do Tipo:
H0: 22
21
σσ
= q0
H1: 22
21
σσ
> q0
REGRA DE DECISÃO: rejeitar H0 se fc > fα, onde fc = 0
22
21 1
qs
s
c) Teste Bilateral do Tipo:
H0: 22
21
σσ
= q0
H0: 22
21
σσ
≠ q0
REGRA DE DECISÃO: rejeitar H0 se fc < 2/
1
αf ou fc > fα/2, onde fc =
022
21 1
qs
s
Nota. Há 2 números de graus de liberdade para a distribuição F, como já vimos: v1 = n1 -1 é
relativo ao numerador e v2 = n2 -2 ao denominador.
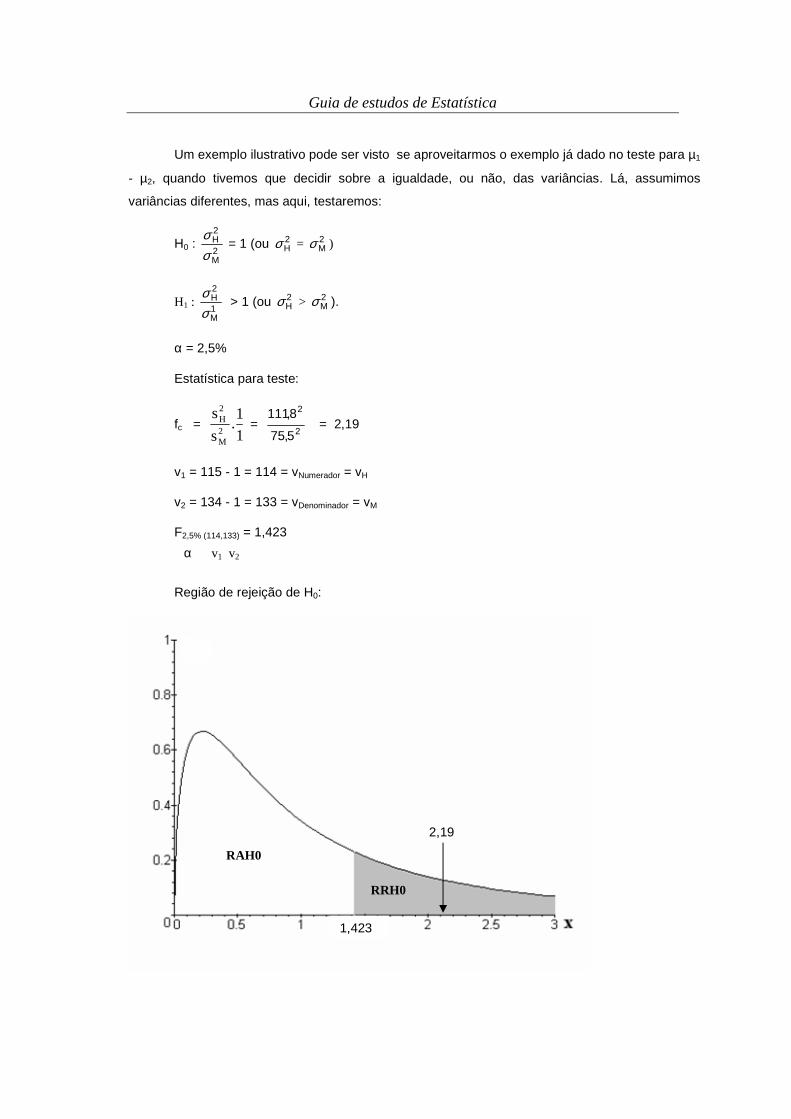
Guia de estudos de Estatística
Um exemplo ilustrativo pode ser visto se aproveitarmos o exemplo já dado no teste para µ1
- µ2, quando tivemos que decidir sobre a igualdade, ou não, das variâncias. Lá, assumimos
variâncias diferentes, mas aqui, testaremos:
H0 : 2
2
M
H
σσ
= 1 (ou 2Hσ = 2
Mσ )
H1 : 1
2
M
H
σσ
> 1 (ou 2Hσ > 2
Mσ ).
α = 2,5%
Estatística para teste:
fc = 1
1.
s
s2M
2H =
2
2
5,75
8,111= 2,19
v1 = 115 - 1 = 114 = vNumerador = vH
v2 = 134 - 1 = 133 = vDenominador = vM
F2,5% (114,133) = 1,423
Região de rejeição de H0:
2,19
RRH0
α v1 v2
RAH0
1,423

Guia de estudos de Estatística
Conclusão: 2Hσ > 2
Mσ , isto é, diferentes.
6.7. EXERCÍCIOS RESOLVIDOS
1) Em um experimento com ervilhas foram obtidos os seguintes resultados:
Cor Frequência
Verde 275
Amarela 156
Albino 28
Total 459
a) Teste a hipótese de que a segregação segue a proporção 9:6:1.
Teoria Mendeliana ⇒ 9 : 6 : 1
Proporção ⇒ 161
:166
:169
Tem-se a frequência observada, calcula-se então a frequência esperada (Total de observações
vezes a probabilidade dada pela Teoria Mendeliana).
Cor Freq. obs. (fo) Freq. esp. (fe)
Verde 275 258
Amarela 156 172
Albino 28 29
Total 459 459
Teste de Decisão:
1°) H0: Os dados seguem a proporção 9 : 6 : 1.
2°) HA: Ao dados não seguem a proporção 9 : 6 : 1.
3°) 5%α =
4°) Estatística de Teste: Distribuição de 2χ .
643,229
)2928(172
)172156(258
)258275()( 2223
1
22 =−+−+−=−=∑
=ical fe
fofeχ
O valor de 2χ tabelado com v = 2 GL: 991,52 =tabχ
Como: 2calχ < 2
tabχ
Aceita-se H0 , ou seja, os dados seguem a proporção 9 : 6 : 1.
b) Qual o erro que pode-se estar cometendo na decisão acima. Qual é a probabilidade desse erro
estar sendo cometido?

Guia de estudos de Estatística
O erro do Tipo II, ou seja, aquele que se comete quando aceita-se H0 sendo esta hipótese falsa. A
probabilidade de cometê-la é dada por:
95%0,950,051α1β ==−=−=
2) Suponhamos que experimentou-se o efeito de certa droga no controle de certa bactéria, usando
ratos. Foram utilizados 111 animais divididos em 2 grupos, 57 deles recebendo uma dose-padrão
de bactérias patogênicas seguidas pela droga e um grupo de controle de 54 que receberam
apenas a bactéria. Depois de um adequado período de tempo, quando a doença poderia provocar
a morte, obtiveram-se os seguintes resultados:
Tratamento Indivíduos
Total Mortos Sobreviventes
Bactéria +droga 13 44 57 Bactéria 25 29 54
Total 38 73 111
Há diferença entre os tratamentos?
Para a resolução será necessário o cálculo das frequências esperadas:
20111
3857.arg.arg).( =×=×=+×
TotalGeralColunaTotalMLinhaTotalM
DrogaBacMortesfe
18111
3854.arg.arg.)( =×=×=×
TotalGeralColunaTotalMLinhaTotalM
BacMortesfe
37111
7357.arg.arg)..( =×=×=+×
TotalGeralColunaTotalMLinhaTotalM
DrogaBacSobrevfe
36111
7354.arg.arg.).( =×=×=×
TotalGeralColunaTotalMLinhaTotalM
BacSobrevfe
Agora, passamos ao teste de decisão:
1°) H0: Os efeitos da droga não influenciam na sobrevivência.
2°) HA: Os efeitos da droga influenciam na sobrevivência
3°) 5%α =
4°) Estatística de Teste: Distribuição de 2χ .
85,736
)3629(
37
)3744(
18
)1825(
20
)2013(
fe
)fofe( 22223
1i
22cal =−+−+−+−=−=χ ∑
=
O valor de 2χ tabelado com v = (H-1).(K-1) = 1, onde H é o número de linhas, e K o número de
colunas da tabela acima,: Assim, 841,32 =tabχ
Como: 2calχ > 2
tabχ
Guia de estudos de Estatística
Rejeita-se H0 , ou seja, os efeitos da droga não influenciam na sobrevivência dos ratos expostos a
essa bactéria.
3) O número de chegadas de pacientes em determinado hospital foi anotado minuto a minuto para
uma amostra de 70 períodos (de um minuto). Os dados colhidos foram os seguintes:
N° Chegadas 0 1 2 3 4 5 6 7≥
Frequência 9 15 17 11 7 5 4 2
O modelo de Poisson foi proposto para modelar estes números de chegadas. Qual é sua opinião,
embase-a estatisticamente?
Primeiro, construamos as hipóteses a serem testadas:
H0: O número de chegadas tem distribuição de Poisson.
HA: O número de chegadas não tem distribuição de Poisson.
Calculemos a média, para os dados:
( ) ( ) ( )47,2
7027...15190 =×++×+×== ∑
n
fxX
ii
Agora, precisa-se de alguns cálculos auxiliares, que podem ser feitos em um quadro auxiliar:
X = n° Ch. fo fe = P(x) . n (fo –fe) (fo –fe)2 (fo –fe)2/fe
0 9 * 0,084 x 70 = 5,88 3,12 9,70 1,65
1 15 0,210 x 70 = 14,70 0,30 0,09 0,01
2 17 0,260 x 70 = 18,20 -1,20 1,44 0,08
3 11 0,210 x 70 = 14,70 -3,70 13,69 0,93
4 7 0,130 x 70 = 9,10 -2,10 4,41 0,48
5 5 0,063 x 70 = 4,53 0,47 0,22 0,05
6 4 0,030 x 70 = 2,10 3,11 9,67 3,35
7≥ 2 0,011 x 70 = 0,79
Total 70 6,55

Guia de estudos de Estatística
O cálculo das probabilidades para cada uma das chegadas será calculada assim:
084,0!0
47,2!
)0(0
47,2 =×=×== −− ex
eXPxλλ . Para as outras probabilidades seguem-se o mesmo
princípio.
Busca-se agora o 2χ tabelado:
Os graus de liberdade será obtido por, v = ( k – 1 ) – 1, onde k é o número de classes para o
número de chegadas, p é o número de parâmetros estimados (neste caso estimou-se λ, um
parâmetro estimado, portanto p = 1), e o “–1” fora do parêntese é um grau de liberdade perdido ao
se calcular a média apenas baseado nos dados amostrais :
v = ( k – 1 ) – 1 = ( 8 – 1 ) – 1 = 6
Utilizando α = 5%, 2χ tabelado com v = 6 GL é igual a 12,59.
Conclusão: Como 2calχ < 2
tabχ , aceita-se H0 com confiança de 95%, ou seja, o modelo de Poisson é
o mais adequado para modelar o número de chegadas. Há inúmeros usos gerenciais para esta
conclusão: por exemplo, se o gestor do hospital deseja dimensionar o número de atendentes que
devem ficar de prontidão na recepção do hospital, ele pode se valer do conhecimento de que o
número de chegadas segue a distribuição de Poisson para esse dimensionamento.
6.8. EXERCÍCIOS PROPOSTOS
1) Num cruzamento entre plantas de tomates altas e folhas normais, com plantas anãs e folhas tipo
batata, na geração F2 obteve-se:
Plantas altas folhas normais - 940
Plantas altas folhas batata - 290
Plantas anãs folhas normais - 282
Plantas anãs folhas batata - 88
Verifique concordância com a 2° Lei de Mendel (9:3:3:1) utilizando α = 5%.
2) Proceda ao teste de 2χ para decidir se o fator “ Tipo de Cooperativa” independe do fator
“Estado” com coeficiente de confiança de 95%.
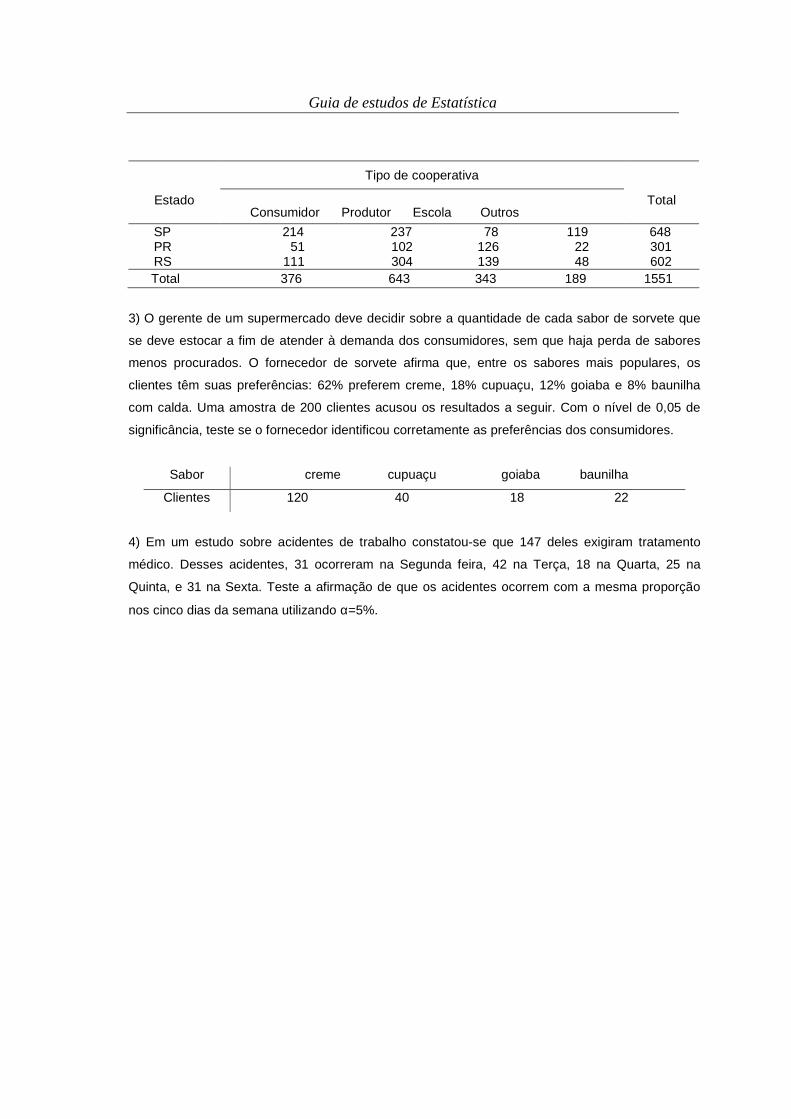
Guia de estudos de Estatística
Estado
Tipo de cooperativa
Total Consumidor Produtor Escola Outros
SP 214 237 78 119 648 PR 51 102 126 22 301 RS 111 304 139 48 602 Total 376 643 343 189 1551
3) O gerente de um supermercado deve decidir sobre a quantidade de cada sabor de sorvete que
se deve estocar a fim de atender à demanda dos consumidores, sem que haja perda de sabores
menos procurados. O fornecedor de sorvete afirma que, entre os sabores mais populares, os
clientes têm suas preferências: 62% preferem creme, 18% cupuaçu, 12% goiaba e 8% baunilha
com calda. Uma amostra de 200 clientes acusou os resultados a seguir. Com o nível de 0,05 de
significância, teste se o fornecedor identificou corretamente as preferências dos consumidores.
Sabor creme cupuaçu goiaba baunilha
Clientes 120 40 18 22
4) Em um estudo sobre acidentes de trabalho constatou-se que 147 deles exigiram tratamento
médico. Desses acidentes, 31 ocorreram na Segunda feira, 42 na Terça, 18 na Quarta, 25 na
Quinta, e 31 na Sexta. Teste a afirmação de que os acidentes ocorrem com a mesma proporção
nos cinco dias da semana utilizando α=5%.

Guia de estudos de Estatística
UUNNIIDDAADDEE 77
RREEGGRREESSSSÃÃOO EE CCOORRRREELLAAÇÇÃÃOO
7.1. INTRODUÇÃO
Correlação e Regressão são técnicas utilizadas em uma análise de dados amostrais para
medir o comportamento conjugado entre duas ou mais variáveis. Comecemos por definir
correlação e regressão:
Conceito 7.1. Correlação . É um número entre -1 e 1 que mede o grau de relacionamento ou de
associação entre duas variáveis.
Além de se calcular o grau de correlação entre duas variáveis, pode-se também fazer um estudo
para ajustar uma equação ao conjunto de dados, de forma que ele possa expressar uma relação
matemática entre as variáveis.
Conceito 7.2. Regressão . É o estudo que busca ajustar uma equação a um conjunto de dados de
forma que a relação entre as variáveis possa ser descrita matematicamente.
Encontramos na correlação um número que mede o grau de covariação entre duas
variáveis e na regressão uma tentativa para estabelecer uma equação matemática linear que
descreva a relação entre as variáveis. Basicamente, buscamos encontrar nestas equações de
regressão uma boa maneira de explicarmos o que ocorre com uma variável devido às variações
ocorridas nas outras variáveis a qual está associada. Existem vários tipos de relações entre as
variáveis. Neste estudo dar-se-á ênfase às regressões lineares.
7.2. O MODELO LINEAR
Um modelo linear é uma equação matemática da forma:
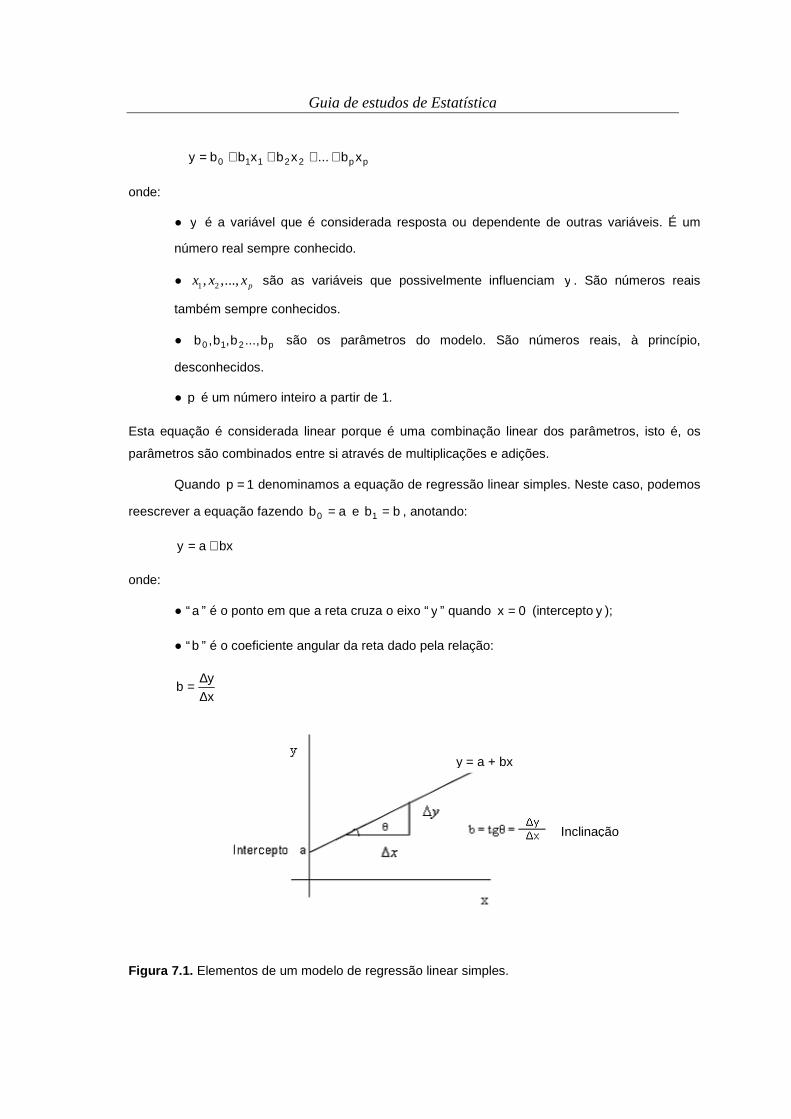
Guia de estudos de Estatística
pp22110 xb...xbxbby ++++=
onde:
● y é a variável que é considerada resposta ou dependente de outras variáveis. É um
número real sempre conhecido.
● 1 2, ,..., px x x são as variáveis que possivelmente influenciam y . São números reais
também sempre conhecidos.
● p210 b...,b,b,b são os parâmetros do modelo. São números reais, à princípio,
desconhecidos.
● p é um número inteiro a partir de 1.
Esta equação é considerada linear porque é uma combinação linear dos parâmetros, isto é, os
parâmetros são combinados entre si através de multiplicações e adições.
Quando 1p = denominamos a equação de regressão linear simples. Neste caso, podemos
reescrever a equação fazendo ab0 = e bb1 = , anotando:
bxay +=
onde:
● “ a ” é o ponto em que a reta cruza o eixo “ y ” quando 0x = (intercepto y );
● “ b ” é o coeficiente angular da reta dado pela relação:
xy
b∆∆
=
Figura 7.1. Elementos de um modelo de regressão linear simples.
y = a + bx
Inclinação
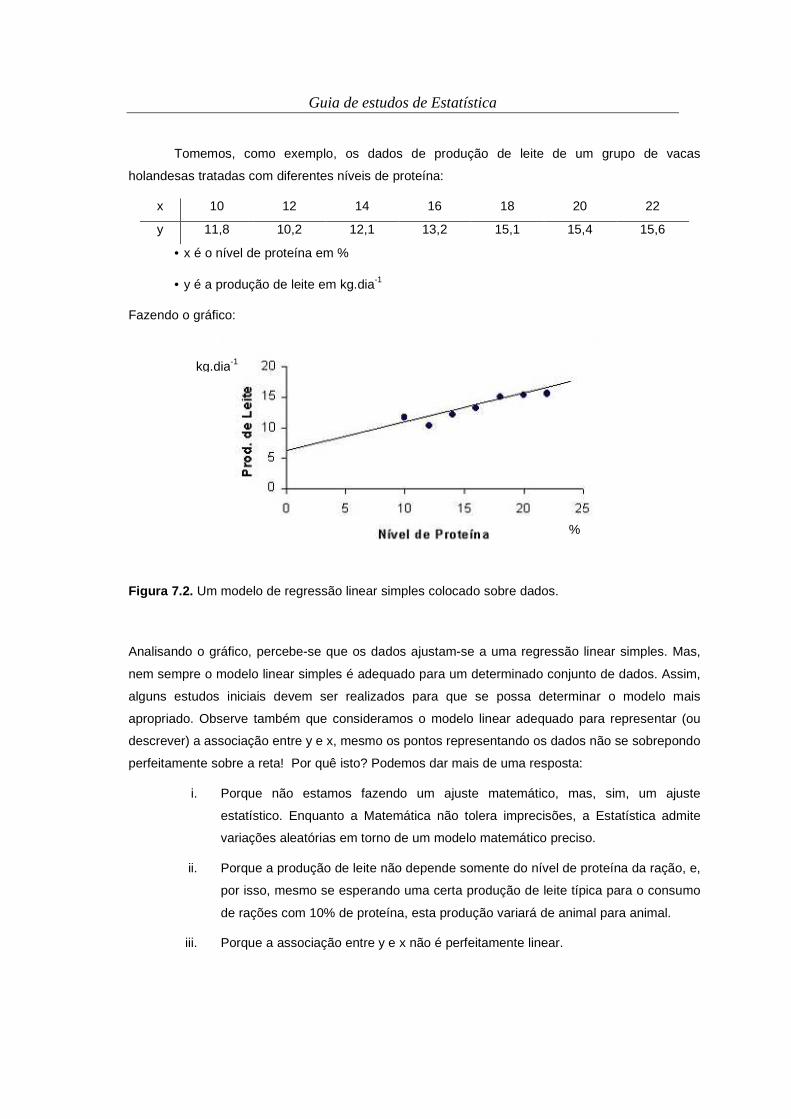
Guia de estudos de Estatística
Tomemos, como exemplo, os dados de produção de leite de um grupo de vacas
holandesas tratadas com diferentes níveis de proteína:
x 10 12 14 16 18 20 22
y 11,8 10,2 12,1 13,2 15,1 15,4 15,6
• x é o nível de proteína em %
• y é a produção de leite em kg.dia-1
Fazendo o gráfico:
Figura 7.2. Um modelo de regressão linear simples colocado sobre dados.
Analisando o gráfico, percebe-se que os dados ajustam-se a uma regressão linear simples. Mas,
nem sempre o modelo linear simples é adequado para um determinado conjunto de dados. Assim,
alguns estudos iniciais devem ser realizados para que se possa determinar o modelo mais
apropriado. Observe também que consideramos o modelo linear adequado para representar (ou
descrever) a associação entre y e x, mesmo os pontos representando os dados não se sobrepondo
perfeitamente sobre a reta! Por quê isto? Podemos dar mais de uma resposta:
i. Porque não estamos fazendo um ajuste matemático, mas, sim, um ajuste
estatístico. Enquanto a Matemática não tolera imprecisões, a Estatística admite
variações aleatórias em torno de um modelo matemático preciso.
ii. Porque a produção de leite não depende somente do nível de proteína da ração, e,
por isso, mesmo se esperando uma certa produção de leite típica para o consumo
de rações com 10% de proteína, esta produção variará de animal para animal.
iii. Porque a associação entre y e x não é perfeitamente linear.
%
kg.dia-1

Guia de estudos de Estatística
Todas estas respostas tem o seu lugar de ser, e estão mesmo relacionadas entre si. Para
acomodar tais argumentos, o modelo estatístico difere ligeiramente do modelo matemático
apresentado, tornando-se:
0 1 1 2 2 ... p py b b x b x b x e= + + + + +
onde:
● a parte matemática é como já apresentado acima.
● acrescenta-se a componente e , que é um número real sempre desconhecido (mas não é
um parâmetro), o qual abriga toda a variação encontrada nos dados que não é explicada
pelo modelo matemático.
No caso de regressão linear simples temos:
y a bx e= + +
A maneira mais simples para se determinar relação entre as variáveis é através da
representação gráfica dos pontos que representam a relação entre as variáveis no plano
cartesiano, como foi feito acima. Vejamos alguns exemplos de relação entre variáveis:
Os pontos dispostos em (b) e (d) apresentam relação linear entre as variáveis, o que não ocorre
em (a) e (c). O gráfico de (c) por exemplo, parece indicar relação quadrática entre y e x, pois há
aparência de um arco de parábola no gráfico:

Guia de estudos de Estatística
Uma relação assim seria uma equação do tipo 2cxbxay ++= com c>0 (“parábola com a boca
para baixo”). Apesar desta relação ser “quadrática”, nós a consideramos ainda linear, pois
permanece sendo uma combinação linear dos parâmetros a, b e c. Porém, não é linear simples.
Seria uma equação de regressão linear quadrática, ou simplesmente regressão quadrática. Já o
gráfico de (a), por exemplo, é do tipo que não poderia ser bem representado por nenhuma
regressão linear, nem simples, nem quadrática, nem polinomial com qualquer grau. Há uma
sugestão de uma relação exponencial do tipo cxbeay −+= , a qual não é uma combinação linear
dos parâmetros a, b e c. Este tipo de regressão é denominada não-linear. Aqui abordaremos
somente regressão linear simples.
Como já realçado, então, na Estatística, o modelo (matemático) linear simples incorpora as
variações devidas ao aleatório, tornando-se um modelo estatístico:
iii ebxay ++=
O termo ie está relacionado ao erro aleatório percebido em cada uma das i-ésimas observações.
A massa de dados que temos em mãos é do tipo:
x 1x 2x … nx
y 1y 2y … ny
7.3. ESTIMAÇÃO DA EQUAÇÃO MATEMÁTICA DA REGRESSÃO LINEAR
A partir do modelo de regressão linear, usando o método chamado método dos quadrados
mínimos, podemos determinar a equação da reta. Pode-se assim, obter a estimativa de regressão
por meio da equação:
ii xbay +=

Guia de estudos de Estatística
onde: a e b são as estimativas de a e b obtidas com os dados, e iy é a estimativa da i-ésima
observação.
Por meio desta equação, através dos valores dados de x (variável independente ou
variável resposta) é possível predizer os valores de y (variável dependente ou variável
regressora).
Por meio de operações algébricas, utilizando-se o método dos quadrados mínimos, é
possível determinar valores estimados para o intercepto ” a ” e para o coeficiente angular “ b ”, ou
seja, podemos estimar a equação de regressão.
∑∑
∑∑∑
=
=
=
==
−
−
=
n
i
n
ii
i
n
i
n
ii
n
ii
ii
n
x
x
n
yx
yx
b
1
2
12
1
11
ˆ
n
x
bn
y
a
n
ii
n
ii ∑∑
== −= 11 ˆˆ
Para os dados do exemplo das vacas holandesas, com o auxílio de um quadro auxiliar
para os cálculos, temos:
ix iy iiyx 2ix 2
iy
10 11,8 118,0 100,0 139,2
12 10,2 122,4 144,0 104,0
14 12,1 169,4 196,0 146,4
16 13,2 211,2 256,0 174,2
18 15,1 271,8 324,0 228,0
20 15,4 308,0 400,0 237,2
22 15,6 343,2 484,0 243,4
Totais: 112,00 93,40 1.544,00 1.904,00 1.272,46
Calculando “ a ” e “ b ”:

Guia de estudos de Estatística
44,0
7)0,112(
0,1904
7)4,93)(0,112(
0,1544b
2=
−
−=
30,6257,67
0,11244,0
74,93ˆ ≅=−=a
Logo, a equação estimada ou ajustada para a produção de leite em função do nível de proteína é
dada:
ii x44,030,6y +=
Esta equação pode ser interpretada da seguinte maneira: no intervalo estudado espera-se um
aumento médio de 0,44 kg.dia-1 na produção de leite das vacas a cada 1% (x variando de 10 a 22
% de proteína) de aumento no nível de proteína da ração. A interpretação está diretamente ligada
ao valor do coeficiente angular da reta (“b ”). Para o exemplo:
1
1
. 044,12)13(44,030,6ˆ%13
. 58,11)12(44,030,6ˆ%12−
−
=+=⇒=
=+=⇒=
diakgyx
diakgyx
%1x =∆ 1. 44,0 −=∆ diakgy
Deve-se ressaltar o perigo em extrapolar as conclusões além do alcance dos dados amostrais,
pois além do intervalo estudado, a relação existente entre as variáveis pode não se verificar.
7.4. VARIAÇÕES NO MODELO DE REGRESSÃO
Vejamos as variações admitidas no modelo de regressão e como calculá-las:
1º- A Variação Total ( SQTotal ) mede a variação dos pontos da reta de regressão em torno da
média da variável dependente ( y ):
n
y
ySQTotal
2n
1iin
1i
2i
−=∑
∑=
=
Para o exemplo: SQTotal mede toda a variação ocorrida na produção de leite.
24,267
)4,93(46,1272
2
=−=SQTotal

Guia de estudos de Estatística
2º- Variação na Regressão Linear ( SQRL ):
2
2
1
1
2
1
11
n
x
x
n
yx
yx
SQRLn
iin
ii
n
i
n
ii
n
ii
ii
−
−
=
∑∑
∑∑∑
=
=
=
==
Para o exemplo:
O desvio da regressão linear mede o valor da variação ocorrida na produção de leite devido à
variação nos diversos níveis de proteína na ração. Em termos percentuais da Variação Total, a
variação devida à Regressão Linear é denominada Coeficiente de Determinação ( 2r ):
%7,83%10024,2697,21
%100SQTOTAL
SQRL2 ===r
A interpretação é: 83,7 % da variação na produção de leite é explicada pela variação na
porcentagem de proteína na ração.
3º- Variação do acaso é a variação não explicada pela regressão (Soma de Quadrados do Desvio
( síduoReSQ )):
SQRLSQTotalSQResíduo −=
Nota. SQResíduo é também chamada SQDesvio .
Para o exemplo:
27,497,2124,26SQResíduo =−=
Mede a variação ocorrida na produção de leite que não foi devido à variação dos níveis de proteína
da ração. Em termos percentuais: %3,16%10024,2627,4 = da variação em y é explicada por x .
97,210,112)6,49( 2
==SQRL

Guia de estudos de Estatística
7.5. CORRELAÇÃO
A partir das evidências de que existe relacionamento entre as variáveis, existe a
necessidade de quantificação do grau de correlação entre elas. Isto já foi feito através das somas
de quadrados descritas acima, porém, é tradicional e conveniente fazer-se também, e
principalmente, esta quantificação calculando o chamado coeficiente de correlação (“ r ”):
−
−
−=
∑∑∑
∑
∑∑∑
=
==
=
=
==
n
y
yn
x
x
n
yx
yx
rn
iin
ii
n
i
n
ii
i
n
i
n
ii
n
ii
ii
2
1
1
2
1
2
12
1
11
Interpretação dos valores do coeficiente de correlação:
O valor do coeficiente de correlação pode variar de –1 até 1: os valores negativos indicam
associação inversa entre as variáveis e os positivos indicam associação direta. Se o coeficiente de
correlação for igual a zero, há indicação de que não existe relação entre as variáveis.
Calculando o coeficiente de correlação para o exemplo:
Interpretando o resultado: pode-se afirmar que existe alta associação direta (positiva) entre o nível
de proteína da ração e a produção de leite.
7.6. COEFICIENTE DE DETERMINAÇÃO (“ 2r ”)
O coeficiente de determinação, indica percentualmente a variação da variável dependente
(“ y ”) causada pela variação da variável independente (“ x ”). Isto já foi mostrado acima. Outro
modo de calcular ou medir esta associação é elevar o valor encontrado no coeficiente de
correlação ao quadrado. Tal quadrado é também o coeficiente de determinação, o 2r Para o
exemplo:
915,0)24,26)(0,112(
6,49 ==r

Guia de estudos de Estatística
%7,838372,0915,0 2 ===r
Interpreta-se que 83,7% da variação ocorrida na produção de leite se deve à variação do nível de
proteína na ração.
7.7. EXERCÍCIOS RESOLVIDOS
1) Qual é a equação da reta com as seguintes características?
a) Coeficiente angular 3,5 e intercepto -2;
Teremos a seguinte equação: y = -2 + 3,5 x
b) Coeficiente angular -5 e intercepto 6,3;
Teremos a seguinte equação: y = 6,3 -5 x
c) Coeficiente angular 0 e intercepto 3,8;
Teremos a seguinte equação: y = 3,8
2) Determine os coeficientes angulares e os interceptos das seguintes equações da reta:
a) y = -5 x
Coeficiente angular = –5 e intercepto = 0.
b) y = 3,8
Coeficiente angular = 0 e intercepto = 3,8.
c) y = 2 – 3x
Coeficiente angular = 3 e intercepto = 2.
3) Use os valores dados abaixo para estimar a equação de regressão e plote a reta de regressão:
∑=
=20
1
200i
x , ∑=
=20
1
300i
y , ∑=
=20
1
200.6i
xy , ∑=
=20
1
2 600.3i
x , n = 20
Calculando o coeficiente angular da reta:
( ) ( )( )( ) ( )
2200600.320
300200200.6202220
1
20
1
2
20
1
20
1
20
1 =−
−=
−
−
=
∑∑
∑∑∑
==
===
ii
iii
xxn
yxxyn
b
Calculando o intercepto da reta:
520
)200(2300
20
1
20
1 −=−=−
=∑∑
==
n
xby
a ii
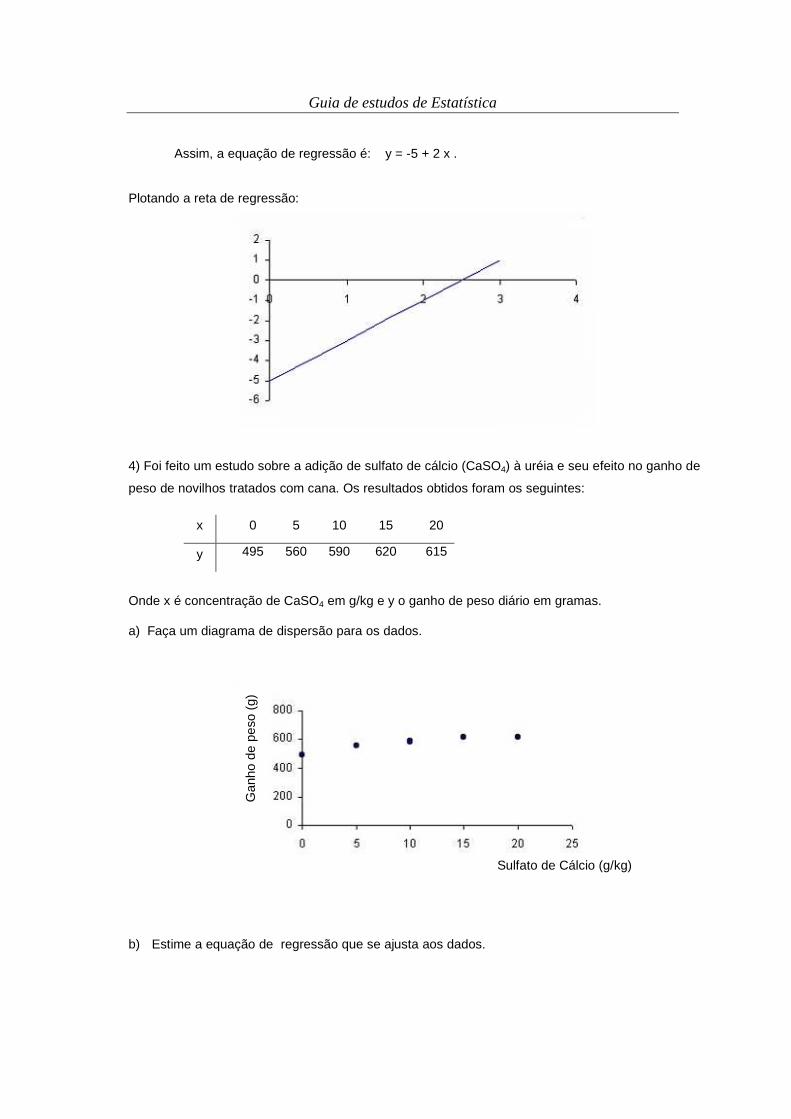
Guia de estudos de Estatística
Assim, a equação de regressão é: y = -5 + 2 x .
Plotando a reta de regressão:
4) Foi feito um estudo sobre a adição de sulfato de cálcio (CaSO4) à uréia e seu efeito no ganho de
peso de novilhos tratados com cana. Os resultados obtidos foram os seguintes:
Onde x é concentração de CaSO4 em g/kg e y o ganho de peso diário em gramas.
a) Faça um diagrama de dispersão para os dados.
b) Estime a equação de regressão que se ajusta aos dados.
x 0 5 10 15 20
y 495 560 590 620 615
Sulfato de Cálcio (g/kg)
Gan
ho d
e pe
so (
g)
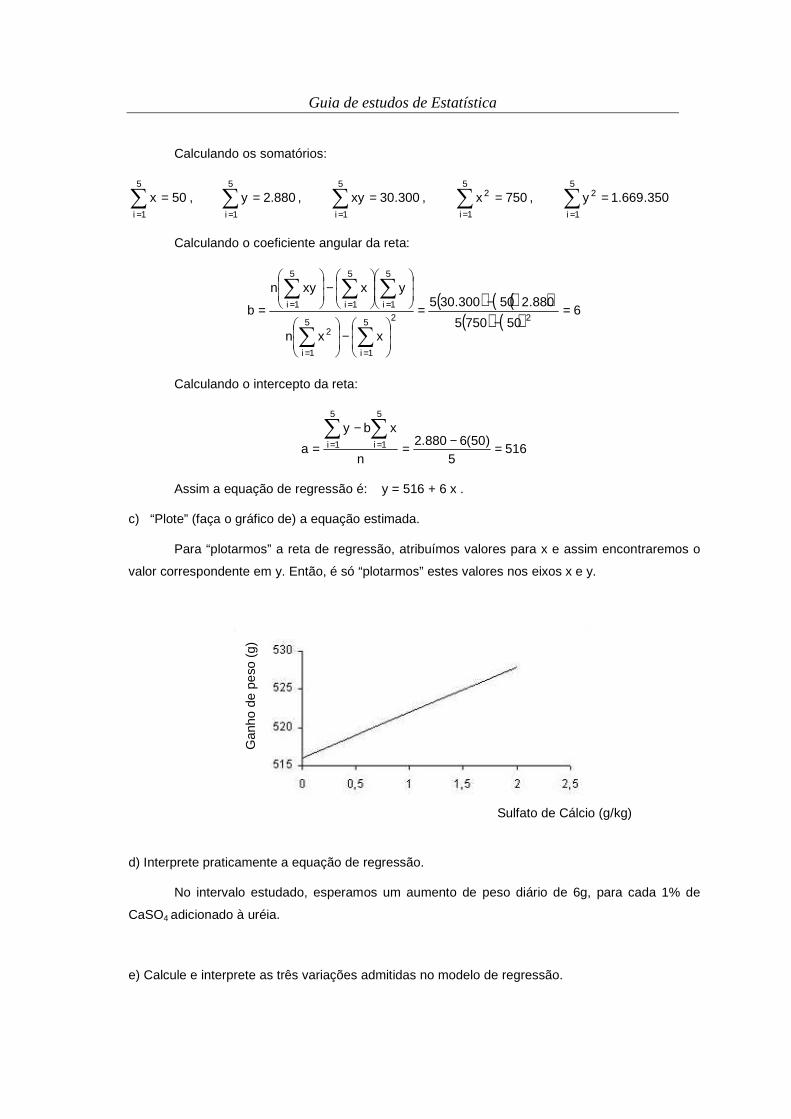
Guia de estudos de Estatística
Calculando os somatórios:
∑=
=5
1
50i
x , ∑=
=5
1
880.2i
y , ∑=
=5
1
300.30i
xy , 7505
1
2 =∑=i
x , ∑=
=5
1
2 350.669.1i
y
Calculando o coeficiente angular da reta:
( ) ( )( )( ) ( )
6507505
880.250300.305225
1
5
1
2
5
1
5
1
5
1 =−
−=
−
−
=
∑∑
∑∑∑
==
===
ii
iii
xxn
yxxyn
b
Calculando o intercepto da reta:
5165
)50(6880.2
5
1
5
1 =−=−
=∑∑
==
n
xby
a ii
Assim a equação de regressão é: y = 516 + 6 x .
c) “Plote” (faça o gráfico de) a equação estimada.
Para “plotarmos” a reta de regressão, atribuímos valores para x e assim encontraremos o
valor correspondente em y. Então, é só “plotarmos” estes valores nos eixos x e y.
d) Interprete praticamente a equação de regressão.
No intervalo estudado, esperamos um aumento de peso diário de 6g, para cada 1% de
CaSO4 adicionado à uréia.
e) Calcule e interprete as três variações admitidas no modelo de regressão.
Sulfato de Cálcio (g/kg)
Gan
ho d
e pe
so (
g)

Guia de estudos de Estatística
1°- Soma de Quadrados Total (SQTotal):
( )∑
∑
=
= =−=
−=5
1
2
25
12 470.105
880.2350.669.1
i
i
n
y
ySQTotal
Este valor encontrado para o SQTotal mede toda a variação ocorrida no peso dos novilhos.
2°- Soma de Quadrados de Regressão Linear (SQRL):
( )000.9
250500.1 2
25
15
1
2
25
1
5
15
1
==
−
−
=
∑∑
∑∑∑
=
=
==
=
n
x
x
n
yx
xy
SQRL
i
i
ii
i
Este valor encontrado para a SQRL mede a variação do peso dos novilhos devido à
variação do teor de sulfato de cálcio na uréia.
3°- Soma de Quadrados dos Desvios (SQDesvio): Pode ser encontrado pela diferença.
SQDesvio = SQTotal – SQRL = 10.470 – 9.000 = 1.470
Este valor encontrado mede a variação ocorrida no peso dos novilhos que não foi devido à
variação do teor de sulfato de cálcio na uréia.
g) Calcule o coeficiente de correlação e interprete.
93,0470.10250
500.1
5
1
25
12
25
1
5
1
2
5
1
5
1
5
1 =×
=
−
−
−
=
∑∑
∑∑
∑∑∑
=
=
==
===
i
i
ii
iii
n
y
yxxn
yxxyn
r
Portanto, r = 0,93 mostra que existe alta correlação positiva entre o teor de sulfato de
cálcio e o ganho de peso dos novilhos.

Guia de estudos de Estatística
h) Encontre o coeficiente de determinação (r2 ) e interprete.
r2 = 0,932
r2 = 0,8649
Portanto, 86,49% da variação ocorrida no ganho de peso dos novilhos se deve ao teor de
sulfato de cálcio na uréia.
7.9. EXERCÍCIOS PROPOSTOS
1) Qual é a equação da reta com as seguintes características? Esboce-as graficamente.
a) Coeficiente angular 10,2, e intercepto 5,0;
b) Coeficiente angular 55, e intercepto 0; .
c) Coeficiente angular 0, e intercepto 2,4;
2) Determine os coeficientes angulares e os interceptos-y das seguintes equações da reta:
a) y = 3 + 7x
b)y = 3x
c) y = -2 + x
3) Com os valores dados abaixo, estime a equação e plote a reta de regressão:
a) ∑=
=20
1
163i
x , ∑=
=20
1
150i
y , ∑=
=20
1
300.2i
xy e ∑=
=20
1
2 600.1i
x
b) ∑=
=6
1
37i
x , ∑=
=6
1
15i
y , ∑=
=6
1
230i
xy e ∑=
=6
1
2 560.1i
x
4) Numa pesquisa foram medidos os teores de alumínio em diversos solos onde é cultivado soja e
anotando-se suas respectivas produtividades. Foram obtidos os seguintes resultados:
Sendo:
- x teor de Al+++em mE/100 cc de solo;
- y a produtividade de soja em t/ha.
a) Faça um diagrama de dispersão para os dados.
b) Estime a equação de regressão que se ajusta aos dados.
x 0,9 1,1 1,2 1,5 1,6 1,8 2,0
y 1,0 0,9 0,8 0,9 0,6 0,5 0,5

Guia de estudos de Estatística
c) Plote a equação estimada.
d) Interprete de maneira prática a equação de regressão.
e) Calcule e interprete as três variações admitidas no modelo de regressão.
f) Calcule o coeficiente de correlação e interprete.
g) Encontre o coeficiente de determinação (r2 ) e interprete.
5) É necessário de tempos em tempos realizar estimativas do peso de ovelhas; por exemplo, para
predizer o efeito de certas drogas ou para predizer datas de disponibilização no mercado.
Infelizmente, pesar cada ovelha é difícil, então é necessário realizar estimativas do peso das
ovelhas de um modo mais fácil. Um estudo foi realizado para investigar a relação entre o peso vivo
da ovelha e a sua circunferência de tórax. A tabela mostra as medidas de uma amostra aleatória
de 66 ovelhas estudadas cuja circunferência de tórax encontra-se entre 60 cm e 90 cm.
Tabela 1. Peso vivo (LW) em kg e circunferência de tórax (CG) em cm de 66 ovelhas (dados de
Warriss e Edwards, 1995, com permissão.)
LW
(y)
CG
(x)
LW
(y)
CG
(x)
LW
(y)
CG
(x)
LW
(y)
CG
(x)
LW
(y)
CG
(x)
LW
(y)
CG
(x)
30 76 20 63 28 77 29 73 18 62 19 67
24 71 28 70 25 71 30 74 28 70 27 69
20 63 22 65 27 72 21 64 27 71 31 74
25 69 28 72 28 74 28 74 30 73 23 67
25 67 25 67 25 65 48 89 28 72 22 63
19 62 20 62 20 64 17 60 22 69 35 75
35 77 35 78 35 78 46 86 48 90 44 84
37 84 43 81 32 73 43 84 31 73 31 73
39 78 36 81 33 80 44 82 39 80 45 86
43 88 41 87 36 82 43 80 33 79 35 78
38 78 36 76 35 74 39 81 34 74 39 76
a) Faça um diagrama (gráfico) de dispersão para os dados.
b) Estime a equação de regressão que se ajusta aos dados.
c) Faça o gráfico da equação estimada. Faça-o sobreposto ao gráfico de dispersão.
d) Interprete praticamente a equação de regressão.
e) Calcule e interprete as três variações admitidas no modelo de regressão.
f) Calcule o coeficiente de correlação e interprete.
g) Encontre o coeficiente de determinação (r2 ) e interprete.
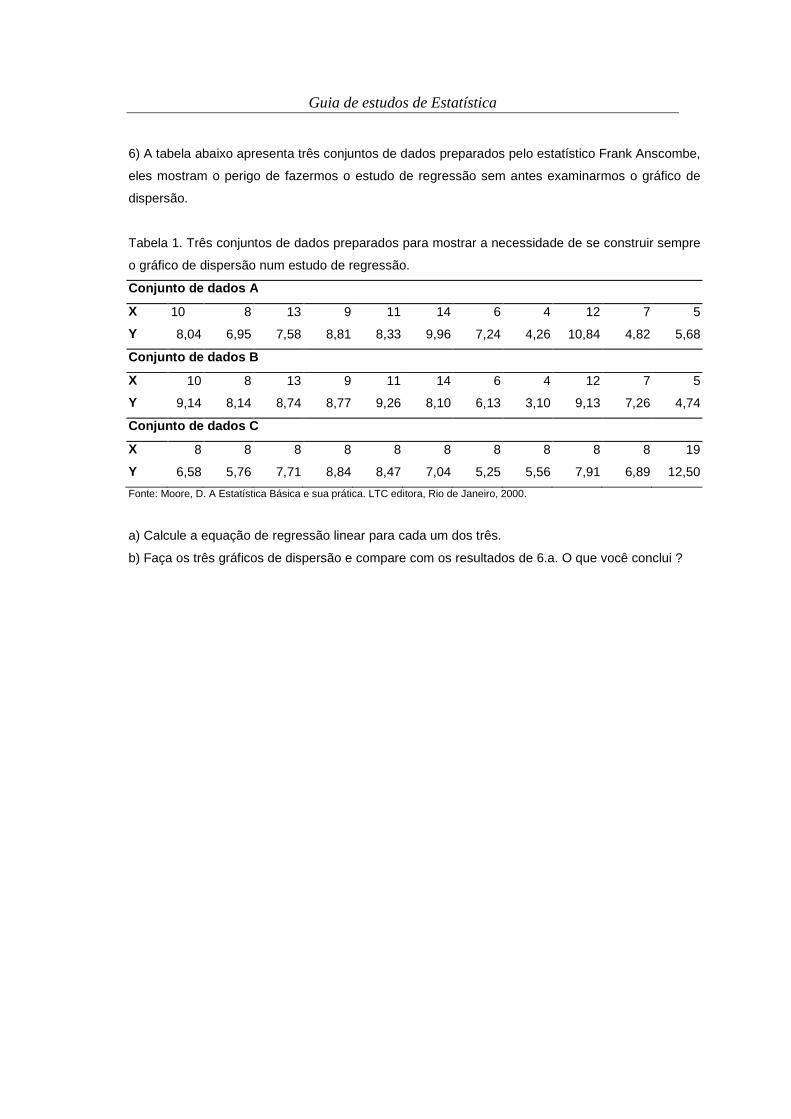
Guia de estudos de Estatística
6) A tabela abaixo apresenta três conjuntos de dados preparados pelo estatístico Frank Anscombe,
eles mostram o perigo de fazermos o estudo de regressão sem antes examinarmos o gráfico de
dispersão.
Tabela 1. Três conjuntos de dados preparados para mostrar a necessidade de se construir sempre
o gráfico de dispersão num estudo de regressão.
Conjunto de dados A
X 10 8 13 9 11 14 6 4 12 7 5
Y 8,04 6,95 7,58 8,81 8,33 9,96 7,24 4,26 10,84 4,82 5,68
Conjunto de dados B
X 10 8 13 9 11 14 6 4 12 7 5
Y 9,14 8,14 8,74 8,77 9,26 8,10 6,13 3,10 9,13 7,26 4,74
Conjunto de dados C
X 8 8 8 8 8 8 8 8 8 8 19
Y 6,58 5,76 7,71 8,84 8,47 7,04 5,25 5,56 7,91 6,89 12,50
Fonte: Moore, D. A Estatística Básica e sua prática. LTC editora, Rio de Janeiro, 2000.
a) Calcule a equação de regressão linear para cada um dos três.
b) Faça os três gráficos de dispersão e compare com os resultados de 6.a. O que você conclui ?

Guia de estudos de Estatística
Observação: as tabelas estatísticas estão em um arq uivo
separado.





























